
Abstract
Profust reliability analysis, in which the failure state of a load-bearing structure is assumed to be fuzzy, is investigated in this paper. A novel active learning method based on the Kriging model is proposed to minimize the number of function evaluations. The new method is termed ALK-Pfst. The sign of performance function at a given random threshold determines the profust failure probability. Therefore, the expected risk function at an arbitrary threshold is derived as the learning function of ALK-Pfst. By making full use of the prediction information of Kriging model, the prediction error of profust failure probability is carefully derived into a closed-form expression. Aided by the prediction error, the accuracy of Kriging model during the learning process can be monitored in real time. As a result, the learning process can be timely terminated with little loss of accuracy. Four examples are provided to demonstrate the advantages of the proposed method.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Uncertainties are unavoidable in a load-bearing structure, and it is crucial to conduct reliability analysis (RA) for the structure. In the conventional RA, a probability density function (PDF) is assigned to input variables and a performance function is defined to check whether the structure works or fails [1]. And then, the probability of failure, or the failure probability, is calculated. Practically, the performance function is frequently calculated by the finite element analysis and RA needs many function evaluations which is very time consuming. To minimize the number of function evaluations, quite a lot of methods have been proposed during the past decades.
Generally, those methods can be classified into three groups[2]. The first group includes the first-order and second-order reliability methods [3, 4]. Those methods are quite efficient while the accuracy is hard to be guaranteed if the performance function is highly nonlinear or has several failure regions. The second group comprises the crude Monte-Carlo simulation (MCS) method, the importance sampling (IS) methods [5,6,7] and the subset simulation (SS) method [8,9,10]. The main drawback of those methods is that they need quite a lot of function evaluations. The third group is the methods based on the surrogate models. The popularly used metamodels are the polynomial chaos expansion models [11, 12], the neural network models [13,14,15], and the Kriging model [16, 17].
State-of-the-art methods in the field of conventional RA are the active learning methods based on the Kriging (ALK) model [18,19,20]. By a learning function, optimal training points can be recognized and the prediction accuracy can be remarkably improved [2, 18, 21]. By a proper stopping condition, the learning process can be timely terminated without accuracy sacrifice [22,23,24]. The famous learning functions are U, the expected feasible function, and the expected risk function (ERF). The excellent works about the stopping conditions can be found in [22, 23, 25,26,27]. Abundant tests verify that ALK model can accurately estimate the failure probability with a pretty small number of function evaluations [27, 28].
Although great achievements have been obtained, one crucial issue exists in the conventional RA. As stated above, the binary state assumption is made to define the performance function. This means the state of a structure can only be eighter in the fully working state or complete failure state [29]. This assumption may violate the reality sometimes. For example, when evaluating the risk, it is often classified into several classes, such as no risk, weak risk, moderate risk, and large risk. And the threshold value between each pair of classes is subjectively set [30, 31]. For another example, the failure process of plastic materials often has four stages, i.e., elasticity, plasticity, necking, and fracture [32]. This means there is no distinct discrimination between success and failure and the boundary between them is quite ambiguous. In this context, the theory of profust RA is proposed [29, 33]. In profust RA, a membership function from the fuzzy set theory is assigned to the performance function [33]. The membership function measures the possibility that the state of a load-bearing structure belongs to the failure region. When compared with the traditional RA based on the binary-state assumption, the fuzzy-state assumption is introduced in profust RA that can reveal the degradation process of structure performance [34, 35]. In addition, the so-called nonprobabilistic RA with epistemic input uncertainties, described by convex set [21, 36], probability box [37], evidence theory [11], and fuzzy set [38,39,40], were also exploited by researchers. However, profust RA is different from the nonprobabilistic RA. In profust RA, epistemic uncertainty only exists in the output state of a structure. Contrarily, in nonprobabilistic RA, epistemic uncertainties are assumed in the input variables.
The introduction of fuzzy membership function makes the profust RA more complicated than the conventional RA. Primary studies on the evaluation of profust failure probability were conducted in [33, 41]. Those methods are based on the simple linear regression and numerical integral, which are not applicable to complicated problems [35]. The profust failure probability was transformed into the integration of failure probability at different thresholds of performance function. And then, it can be calculated by Gauss quadrature in conjunction with MCS or SS [35]. This is a double-layer process. The double-layer problem was transformed into a single layer problem and a more concise MCS method was presented in [42]. Considering the high efficiency of ALK model, the early exploration on how to adapt the ALK model to profust RA has been carried out. The active learning method combining Kriging model and MCS (AK-MCS), from the traditional RA, was integrated into the double-layer process and single-layer process in [31, 42, 43]. To make the ALK model applicable to estimate slightly small failure probability, the works of [44, 45] were extended to profust RA in [46] and a so-called dual-stage adaptive Kriging (DS-AK) method was proposed. Other works related to RA with fuzzy state can be seen from [47, 48].
This paper aims at proposing a more efficient method for profust RA based on the ALK model. The ERF given an arbitrary threshold of performance function is deduced and a new learning function is proposed for profust RA. The new learning function makes the learning process more robust than existing methods. The prediction error for profust failure probability is derived into a closed-form formula by making full use of the uncertain information of Kriging model and Central Limit Theorem. In this way, the learning process can be timely terminated compared with the existing methods. The proposed method is shorted as ALK-Pfst because it is an active learning method based on the Kriging model for the profust RA.
This paper is organized as follows. The theory of profust RA is briefly explained in Sect. 2. AK-MCS method is reviewed in Sect. 3. Section 4 is dedicated to our proposed method. The performance of the proposed method is demonstrated by four case studies in Sect. 5. Conclusions are made in the last section.
2 Profust reliability analysis
Denote the performance function of a structure as \(Y = G\left( {\mathbf{X}} \right)\), where \(\user2{X} = \left[ {X_{1} ,X_{2} , \ldots ,X_{{n_{X} }} } \right]\) is the vector of random variables. The joint PDF of random variables is \(f_{{\mathbf{X}}} \left( {\mathbf{x}} \right)\). In traditional RA, binary state is assumed and it is deemed that the structure belongs to the ‘fully working’ state or ‘completely failed’ state. The failure probability is defined as
in which \(I\left[ \cdot \right]\) is an indicator function of an event with value 1 if the event is true and 0 otherwise.
In profust RA, a fuzzy state is introduced to describe the gradual transition from fully working state to completely failed state. A membership function \(\mu _{{\tilde{F}}} \left( Y \right)\) is used to measure the possibility of a structure belongs to the failure state. \(\mu _{{\tilde{F}}} \left( Y \right)\) monotonically decreases from 1 to 0 with respect to \(Y\). A larger \(\mu _{{\tilde{F}}} \left( Y \right)\) means a larger possibility that the structure belongs to the failure state. \(\mu _{{\tilde{F}}} \left( Y \right) = 0\) indicates that the structure is totally safe while \(\mu _{{\tilde{F}}} \left( Y \right) = 1\) means the structure completely fails. Several kinds of membership functions have been proposed so far. The most widely used ones are the linear membership function, the normal membership function, and the Cauchy membership function [43]. They are mathematically given in Eqs. (2)–(4).
-
1.
Linear membership function
$$\mu _{{\tilde{F}}} \left( Y \right) = \left\{ \begin{gathered} 1{\text{ }}Y \le a_{{\text{1}}} \hfill \\ {{\left( {y - a_{2} } \right)} \mathord{\left/ {\vphantom {{\left( {y - a_{2} } \right)} {\left( {a_{1} - a_{2} } \right)}}} \right. \kern-\nulldelimiterspace} {\left( {a_{1} - a_{2} } \right)}}{\text{ }}a_{{\text{1}}} < Y < a_{{\text{2}}} \hfill \\ 0{\text{ }}Y \ge a_{{\text{2}}} \hfill \\ \end{gathered} \right.$$(2) -
2.
Normal membership function
$$\mu _{{\tilde{F}}} \left( Y \right) = \left\{ \begin{gathered} 1{\text{ }}Y \le b_{{\text{1}}} \hfill \\ \exp \left( { - \left( {Y - b_{1} } \right)^{2} /b_{2} } \right){\text{ }}Y{\text{ > }}b_{{\text{1}}} \hfill \\ \end{gathered} \right.$$(3) -
3.
Cauchy membership function
$$\mu _{{\tilde{F}}} \left( Y \right) = \left\{ \begin{gathered} 1{\text{ }}Y \le c_{1} \hfill \\ {{c_{2} } \mathord{\left/ {\vphantom {{c_{2} } {\left[ {c_{2} + 10\left( {Y - c_{1} } \right)^{2} } \right]}}} \right. \kern-\nulldelimiterspace} {\left[ {c_{2} + 10\left( {Y - c_{1} } \right)^{2} } \right]}}{\text{ }}Y{\text{ > }}c_{1} \hfill \\ \end{gathered} \right.$$(4)
where \(\left[ {a_{1} ,a_{2} } \right]\), \(\left[ {b_{1} ,b_{2} } \right]\), and \(\left[ {c_{1} ,c_{2} } \right]\) are parameters. The profust failure probability is defined as
Introduce an index variable \(\lambda\) with \(\lambda \in \left[ {0,1} \right]\), then it can be proved that [33, 43]
Because \(\mu _{{\tilde{F}}} \left( Y \right)\) is a monotonical function, it can be easily obtained that
where \(\mu _{{\tilde{F}}}^{{ - 1}} \left( \lambda \right)\) is the inverse function of \(\mu _{{\tilde{F}}} \left( Y \right)\). Substituting Eq. (7) into Eq. (5), there is
In Refs. [35, 43, 46], the inner integration was put outside, i.e.,
Then, the outer one-dimensional integral can be solved by Gauss quadrature.
where l is the number of Gauss points; \(\lambda _{k}\) and \(\omega _{k}\) are the kth quadrature point and weight. With MCS, one can obtain the first estimator of \(P_{{\tilde{F}}}\), i.e.,
in which \({\mathbf{x}}^{{\left( i \right)}}\) is the ith simulated sample of MCS.
However, the utilization of Gauss quadrature makes the calculation as a double-stage process. One must calculate the failure probability at \(l\) different thresholds. Moreover, the performance functions with \(l\) different thresholds are totally correlated which is detrimental for us to estimate the prediction error of \(\hat{P}_{{\tilde{F}}}\) according to the predication information of Kriging model.
Actually, Eq. (8) can be calculated in an integrated way by treating \(\lambda\) as a uniformly distributed variable in [0,1], i.e.,
in which \(f_{\Lambda } \left( \lambda \right)\) is the PDF of \(\lambda\). Then, another unbiased estimator can be obtained as [31, 42]
in which \(\lambda ^{{\left( i \right)}}\) is the ith simulated sample of \(\lambda\). This estimator is quite direct and the calculation is a single stage process.
3 Reminder of AK-MCS
To reduce the number of function evaluations, AK-MCS was investigated in [31, 42, 43], and is briefly presented in this section. AK-MCS was firstly proposed in the field of traditional RA. It can be easily adapted to the profust RA by modifying its learning function.
In Kriging model, \(G\left( {\mathbf{x}} \right)\) is expressed by a prior Gaussian process. Given a design of experiments (DoE), parameters of the Gaussian process can be updated and the posterior Gaussian process can be utilized to make predictions at unknown positions. At an unknown point, the prediction is given as \(G_{P} \left( {\mathbf{x}} \right) \sim N\left( {\mu _{G} \left( {\mathbf{x}} \right),\sigma _{G} \left( {\mathbf{x}} \right)} \right)\), in which \(\mu _{G} \left( {\mathbf{x}} \right)\) is the predicted mean and \(\sigma _{G}^{2} \left( {\mathbf{x}} \right)\) is the predicted variance.
The profust failure probability is mainly determined by \(I\left( {G\left( {\mathbf{x}} \right) < \mu _{{\tilde{F}}}^{{ - 1}} \left( \lambda \right)} \right)\), i.e., the sign of \(G\left( {\mathbf{x}} \right) - \mu _{{\tilde{F}}}^{{ - 1}} \left( \lambda \right)\). Learning function U was modified in [31, 42, 43] to find the point at which the sign of \(G\left( {\mathbf{x}} \right) - \mu _{{\tilde{F}}}^{{ - 1}} \left( \lambda \right)\) has the largest probability to be wrongly predicted according to the information \(G_{P} \left( {\mathbf{x}} \right) \sim N\left( {\mu _{G} \left( {\mathbf{x}} \right),\sigma _{G} \left( {\mathbf{x}} \right)} \right)\). The modified U is given as
Then, AK-MCS can be adapted to profust RA in the framework of double-stage MCS or single-stage MCS. For simplicity, AK-MCS in the framework of single-stage MCS is termed as AK-MCS#1 and in the framework of double-stage MCS is termed AK-MCS#2.
However, learning function U is very local [45, 49]. If the boundary between failure and working state has multiple branches, the ALK model based on the learning function U tends to sequentially approximate those branches. This generates potential risk that the learning process is terminated when only several branches are finely approximated. Moreover, because there is no estimation technique on the prediction error of \(P_{{\tilde{F}}}\), the stopping condition of AK-MCS must be defined very conservative. The learning process is not stopped until the minimum value of \({\text{U}}\left( {\user2{x}\left| \lambda \right.} \right)\) among the samples of MCS is larger than 2. As a result, quite a lot of training points are wasted by AK-MCS.
4 ALK-Profust
To overcome the drawbacks of AK-MCS, ALK-Profust is developed in this section. When compared with AK-MCS, twofold improvements exist in ALK-Profust. A learning criterion modified from ERF, which is more robust than U, is put forward. A new stopping criterion measuring the prediction error of \(\hat{P}_{{\tilde{F}}}\) is derived and the learning process can be timely terminated with little accuracy sacrifice.
4.1 Learning criterion
In this paper, ERF [21] is modified as the acquisition function. The profust failure probability is mainly determined by \(I\left( {G\left( {\mathbf{x}} \right) < \mu _{{\tilde{F}}}^{{ - 1}} \left( \lambda \right)} \right)\). The predicted mean \(\mu _{G} \left( {\mathbf{x}} \right)\) is frequently utilized to replace \(G_{P} \left( {\mathbf{x}} \right)\) and a determinate prediction for \(I\left[ {G_{P} \left( {\mathbf{x}} \right) < \mu _{{\tilde{F}}}^{{ - 1}} \left( \lambda \right)} \right]\) is obtained. Actually, the prediction is uncertain because \(G_{P} \left( {\mathbf{x}} \right)\) is uncertain. Our goal is to find the point with the largest expectation of risk that \(I\left[ {\mu _{G} \left( {\mathbf{x}} \right) < \mu _{{\tilde{F}}}^{{ - 1}} \left( \lambda \right)} \right]\) violates \(I\left[ {G_{P} \left( {\mathbf{x}} \right) < \mu _{{\tilde{F}}}^{{ - 1}} \left( \lambda \right)} \right]\).
If \(\mu _{G} \left( {\mathbf{x}} \right) - \mu _{{\tilde{F}}}^{{ - 1}} \left( \lambda \right) < 0\), we define a risk indicator function to measure the risk that \(G_{P} \left( {\mathbf{x}} \right) - \mu _{{\tilde{F}}}^{{ - 1}} \left( \lambda \right) > 0\) as
Because \(R\left( {\user2{x}\left| \lambda \right.} \right)\) is also an uncertain variable, its expectation is calculated as follows.
in which \(f_{{G_{P} }} \left( {G_{P} \left( \user2{x} \right)} \right)\) is the PDF of \(G_{P} \left( \user2{x} \right)\). Let \(g = \frac{{G_{P} \left( \user2{x} \right) - \mu _{G} \left( \user2{x} \right)}}{{\sigma _{G} \left( \user2{x} \right)}}\), and we have
in which \(\phi \left( \cdot \right)\) and \(\Phi \left( \cdot \right)\) are the PDF and cumulative distribution function (CDF) of standard normal distribution. If \(\mu _{G} \left( {\mathbf{x}} \right) - \mu _{{\tilde{F}}}^{{ - 1}} \left( \lambda \right) > 0\), the risk that \(G_{P} \left( {\mathbf{x}} \right) - \mu _{{\tilde{F}}}^{{ - 1}} \left( \lambda \right) < 0\) is defined as
and the expected risk is obtained as
Combining Eqs. (16) and (19), the uniform expression of modified ERF can be obtained as:
in which \(\mu _{{\tilde{G}}} \left( \user2{x} \right) = \mu _{G} \left( \user2{x} \right) - \mu _{{\tilde{F}}}^{{ - 1}} \left( \lambda \right)\).
The modified ERF reveals the expected risk that the sign of \(G\left( {\mathbf{x}} \right)\) given an arbitrary threshold predicted by \(\mu _{G} \left( {\mathbf{x}} \right)\) violates that predicted by \(G_{P} \left( {\mathbf{x}} \right)\). The point at which the modified ERF is maximized should be added into the DoE. Among the candidate points \(\left( {{\mathbf{x}}^{{\left( i \right)}} ,\lambda ^{{\left( i \right)}} } \right)\left( {i = 1, \ldots ,N_{{{\text{MC}}}} } \right)\), the best next training point is obtained by
4.2 Stopping criterion
Denote the profust failure probability obtained from \(G_{P} \left( {\mathbf{x}} \right)\) as \(\hat{P}_{{\tilde{F}}}\) and that from \(\mu _{G} \left( {\mathbf{x}} \right)\) as \(\hat{P^{\prime}}_{{\tilde{F}}}\). Apparently, \(\hat{P}_{{\tilde{F}}}\) fully considers the prediction information of Kriging model, while \(\hat{P^{\prime}}_{{\tilde{F}}}\) only considers the predicted mean. The discrepancy between them can measure the prediction accuracy of profust failure probability. The prediction (relative) error of the profust failure probability can be given as
in which \(N_{{\tilde{F}}}\) is the predicted number of failure samples considering prediction uncertainty of Kriging model and \(N^{\prime}_{{\tilde{F}}}\) is that without such consideration. They are given as
and
The numerator in Eq. (22) has an upper bound which is given as
in which \(N_{{{\text{WSP}}}}^{{}}\) is the number of points at which the signs of \(G_{P} \left( {\mathbf{x}} \right) - \mu _{{\tilde{F}}}^{{ - 1}} \left( \lambda \right)\) and \(\mu _{G} \left( {\mathbf{x}} \right) - \mu _{{\tilde{F}}}^{{ - 1}} \left( \lambda \right)\) are different, i.e., the number of points with wrong sign prediction (WSP).
Because \(G_{P} \left( {{\mathbf{x}}^{{\left( i \right)}} } \right)\) is a random variable, \(I\left\{ {\left[ {G_{P} \left( {{\mathbf{x}}^{{\left( i \right)}} } \right) - \mu _{{\tilde{F}}}^{{ - 1}} \left( {\lambda ^{{\left( i \right)}} } \right)} \right]\left[ {\mu _{G} \left( {{\mathbf{x}}^{{\left( i \right)}} } \right) - \mu _{{\tilde{F}}}^{{ - 1}} \left( {\lambda ^{{\left( i \right)}} } \right)} \right] < 0} \right\}\) is also random. Specifically, \(I\left\{ {\left[ {G_{P} \left( {{\mathbf{x}}^{{\left( i \right)}} } \right) - \mu _{{\tilde{F}}}^{{ - 1}} \left( {\lambda ^{{\left( i \right)}} } \right)} \right]\left[ {\mu _{G} \left( {{\mathbf{x}}^{{\left( i \right)}} } \right) - \mu _{{\tilde{F}}}^{{ - 1}} \left( {\lambda ^{{\left( i \right)}} } \right)} \right] < 0} \right\}\) follows the Bernoulli distribution.
According to the prediction information that \(G_{P} \left( {\mathbf{x}} \right) \sim N\left( {\mu _{G} \left( {\mathbf{x}} \right),\sigma _{G} \left( {\mathbf{x}} \right)} \right)\), the probability of a point with WSP can be obtained as [22]
Then, the expectation and variance of \(I\left[ {\left( {G_{P} \left( {{\mathbf{x}}^{{\left( i \right)}} } \right) - \mu _{{\tilde{F}}}^{{ - 1}} \left( {\lambda ^{{\left( i \right)}} } \right)} \right)\left( {\mu _{G} \left( {{\mathbf{x}}^{{\left( i \right)}} } \right) - \mu _{{\tilde{F}}}^{{ - 1}} \left( {\lambda ^{{\left( i \right)}} } \right)} \right) < 0} \right]\) can be obtained as:
Recall that \(N_{{{\text{WSP}}}}^{{}}\) is the summation of \(N_{{{\text{MC}}}}\) random variables obeying the Bernoulli distribution. According to the Central Limit Theorem [50], if \(N_{{{\text{MC}}}} \to \infty\) and \(G_{P} \left( {{\mathbf{x}}^{{\left( i \right)}} } \right)\left( {i = 1,2, \ldots ,N_{{{\text{MC}}}} } \right)\) are mutually independent, \(N_{{{\text{WSP}}}}^{{}}\) in distribution converges to such a normal distribution as
with the mean and variance
Similarly, if \(N_{{{\text{MC}}}} \to \infty\) and \(G_{P} \left( {{\mathbf{x}}^{{\left( i \right)}} } \right)\left( {i = 1,2, \ldots ,N_{{{\text{MC}}}} } \right)\) are totally independent,\(N_{{\tilde{F}}}^{{}}\) in distribution will also converges to such a normal distribution as:
with the mean and variance
in which \(P_{{{\text{fail}}}}^{{}} \left( {{\mathbf{x}}\left| \lambda \right.} \right)\) is the probability of \(G_{P} \left( {\mathbf{x}} \right) < \mu _{{\tilde{F}}}^{{ - 1}} \left( \lambda \right)\), which is given as:
In summary, the upper bound of Eq. (22) is obtained as:
and the error limit \(\hat{\varepsilon }_{{\tilde{F}}}\) on the right hand has two normal variables. At a confidence level \(1 - \alpha\), the confidence interval is given as:
in which \(F^{{ - 1}} \left( \cdot \right)\) is the inverse CDF of \(\hat{\varepsilon }_{{\tilde{F}}}\). It is hard to obtain the confidence interval in an analytic way. MCS can be utilized instead. The upper bound of \(\hat{\varepsilon }_{{\tilde{F}}}\) can be estimated by the following procedures [51].
(A1) Generate \(N_{\varepsilon }\) independently and identically distributed samples for \(N_{{{\text{WSP}}}}^{{}}\) and \(N_{{\tilde{F}}}^{{}}\).
(A2) Calculate \(\hat{\varepsilon }_{{\tilde{F}}}^{{\left( i \right)}}\) \(\left( {i = 1, \ldots ,N_{\varepsilon } } \right)\) at the samples of \(N_{{{\text{WSP}}}}^{{}}\) and \(N_{{\tilde{F}}}^{{}}\).
(A3) Sort \(\hat{\varepsilon }_{{\tilde{F}}}^{{\left( i \right)}}\) from the smallest to the largest. Let \(\hat{\varepsilon }_{{s:l}}^{{\left( i \right)}}\) \(\left( {i = 1, \ldots ,N_{\varepsilon } } \right)\) be the sorted values. And the upper bound of confidence interval can be estimated as
and there is
in which \(\left\lfloor \cdot \right\rfloor\) is the ceiling (or round-up) function.
In theory, if \(\bar{\varepsilon }_{{\tilde{F}}}^{{}}\) is smaller than a prescribed threshold \(\gamma\), i.e., \(\bar{\varepsilon }_{{\tilde{F}}}^{{}} \le \gamma\), the learning process can be stopped. However, it should be reminded that the correlation among \(G_{P} \left( {{\mathbf{x}}^{{\left( i \right)}} } \right)\left( {i = 1,2, \ldots ,N_{{{\text{MC}}}} } \right)\) is neglected. If the correlation is considered, \(N_{{{\text{WSP}}}}^{{}}\) and \(N_{{\tilde{F}}}^{{}}\) in distribution “asymptotically” converge to normal distribution as \(N_{{{\text{MC}}}} \to \infty\) [10, 52]. This means the estimator in Eq. (36) is a little biased. Therefore, a more conservative criterion is utilized in this paper. At the kth iteration, the stopping condition is given as:
in which \(N_{r}\) is a constant and \(k \ge N_{r}\); \(\bar{\varepsilon }_{{\tilde{F}}}^{{\left( l \right)}}\) is the value of \(\bar{\varepsilon }_{{\tilde{F}}}^{{}}\) in the lth iteration. If Eq. (38) is satisfied, it means \(\bar{\varepsilon }_{{\tilde{F}}}^{{}}\) has been consistently smaller than \(\gamma\) during the last \(N_{r}\) iterations and the estimated error is very stable. In this paper, \(\gamma = 2\%\) and \(N_{r} = 5\) are used.
5 Summary of ALK-Pfst
The flowchart of the proposed method is shown in Fig. 1, and the concrete procedures are explained as follows.
-
(B1)
Generate \(N_{{{\text{MC}}}}\) samples for \({\mathbf{x}}\) and \(\lambda\).
-
(B2)
Define the initial DoE.
-
1.
The number of initial training points is defined 12. The number should be enlarged for high-dimensional problems.
-
2.
Latin hypercube sampling is utilized to generate those training points. The lower and upper bounds are chosen as \(\left[ {\varvec{\mu }}_{X} - 5{\varvec{\sigma }}_{X} {\text{, }}{\varvec{\mu} }_{X} + 5{\varvec{\sigma }}_{X} \right]\) with \({\varvec{\mu }}_{X}\) and \({\varvec{\sigma }}_{X}\) the mean and standard variation of \({\mathbf{x}}\).
-
3.
Evaluate the performance function at those points and construct an initial Kriging model with the DoE.
-
1.
-
(B3)
Obtain the optimal training point by Eq. (21).
-
(B4)
According to the prediction information of Kriging model, obtain the distributions of \(N_{{{\text{WSP}}}}^{{}}\) and \(N_{{\tilde{F}}}^{{}}\).
-
(B5)
Based on the procedures in (A1)– (A3), obtain the upper bound of \(\hat{\varepsilon }_{{\tilde{F}}}\) in the current stage.
-
(B6)
If the stopping condition in Eq. (38) is satisfied, continue to Step (B8). Otherwise, evaluate the performance function at \({\mathbf{x}}^{{\left( * \right)}}\). Add \({\mathbf{x}}^{{\left( * \right)}}\) into the DoE and update the Kriging model. Go to Step (B3).
-
(B7)
Estimate the profust failure probability based on the Kriging model.

Flowchart of ALK-Pfst
6 Numerical examples
6.1 A mathematical problem
The first example has four unconnected failure regions and it is employed to demonstrate the performance of ALK-Pfst for problems with multiple failure regions. The performance function is defined as
in which \({\mathbf{x}} = \left[ {x_{1} ,x_{2} } \right]\) are two independent random variables obeying the standard normal distribution. Fuzzy failure state is assumed and is described by a linear membership function (as shown in Eq. (2)) with parameters a1 = − 0.1, a2 = 0.
The results of different methods are given in Table 1. The results of DS-AK and AK-MCS are duplicated from [46]. The proposed method is performed 20 times and the data are averaged results. It can be seen that the proposed method is more efficient than other methods. Note that the number of candidate points of the proposed method is kept the same as MCS. The Cov of ALK-Pfst (3.28%) is a little larger than DS-AK and AK-MCS while it is acceptable in practice.
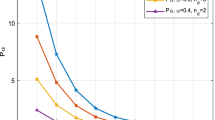
To demonstrate the robustness of ALK-Pfst, the efficiency and accuracy varying with the prescribed error threshold \(\gamma\) is illustrated by boxplots (Fig. 2). At each value of \(\gamma\), ALK-Pfst is tested 20 independent times. The best, mean, and worst performances of the proposed method can be clearly seen in the figure. Generally, along with the decreasing of \(\gamma\), the number of function evaluations increases and the accuracy becomes higher. The proposed method is quite robust if \(\gamma\) is set as 2%.

Boxplots of true relative error and Ncall VS error threshold γ (Example 5.1)
Also note that learning function U can also be utilized in ALK-Pfst. However, U is not robust which may cause the early stop of learning process. In one test, learning function U is utilized in the ALK-Pfst method and the comparison of training points obtained by U and ERF is given in Fig. 3. It can be seen that the boundary of failure and safety has four branches and the upper left one is coarsely approximated by U. This may be because rare initial training points are placed around the upper left branch. U is too local which tends to find new training points around existing training points. In contrast, all the four branches are finely approximated by the modified ERF in this test. The modified ERF is more robust than U and is more proper to ALK-Pfst.

DoE of training points obtained by U and modified ERF in an extreme situation
According to the membership function, the region in which \(G\left( {\mathbf{x}} \right) > 0\) is the totally safe region, the region in which \(G\left( {\mathbf{x}} \right) < - 0.1\) is the complete failure region and the region where \(- 0.1 \le G\left( {\mathbf{x}} \right) \le 0\) is the fuzzy failure region. As shown in Fig. 3, the region bounded by \(G\left( {\mathbf{x}} \right) + 0.1 = 0\) and \(G\left( {\mathbf{x}} \right) = 0\) is the fuzzy failure region. The existence of fuzzy failure region is the main difference between the profust RA and the traditional RA. If the fuzzy failure region is ignored and treated as the failure region, the failure probability of \(G\left( {\mathbf{x}} \right) < 0\) calculated by MCS will be 0.0022. That is larger than the profust failure probability.
6.2 A nonlinear oscillator
The second example is a nonlinear oscillator taken from [46, 53]. Several methods have been used to solve this problem. The performance of the proposed method is compared with other methods to show its advantage. The performance function is defined as:
where \(\omega _{0} = \sqrt {\left( {w_{1} + w_{2} } \right)/m}\). Six variables exist in this example and they are given in Table 2. The membership function of the failure state is assumed as the Cauchy form with parameters \(c_{1} = - 0.1\) and \(c_{2} = 0.001\).
The results of different methods are given in Table 3. Again, it can be seen that the proposed method is apparently more efficient than other methods in this example. Only about 35 function evaluations are cost while very accurate results are obtained by ALK-Pfst. Although the performance function is very simple, DS-AK and AK-MCS#2 need quite a lot of function calls. That is because they should approximate the boundary of failure and safety at different thresholds. With the same size of candidate points, about 20 more function evaluations are needed by AK-MCS#1 than ALK-Pfst. That is because the stopping condition of AK-MCS#1 is very conservative.
The learning processes of ALK-Pfst and AK-MCS#1 are given in Fig. 4. It can be seen that along with the absorption of new training points, the prediction accuracy of both methods is improved. However, after absorbing 20 ones, little improvement occurs. However, AK-MCS#1 continues learning and a quantity of training points are added. The prediction error estimated by Eq. (36) during the learning process is given in Fig. 4. It can be seen that the proposed technique properly estimates the error of Kriging model. Aided by the error estimated technique, the proposed method timely terminates the learning process and only several additional points are added.

Evolution of predicted failure probability and estimated error (Example 5.2)
Also note that randomness exists in the proposed method. In addition, the parameter of prescribed error threshold γ will influent the accuracy and efficiency of the proposed method. To demonstrate the robustness and variation, the performance variation of 20 runs along with different error thresholds is offered in Fig. 5. In this figure, the information on the mean and worst accuracy (efficiency) can be obtained. It can be seen that, the efficiency will degenerate if the stopping condition becomes stricter. In general, the estimated error is smaller than the true error. However, the fact reverses sometimes in the worst case. Therefore, it is recommended to set the error threshold as a little small for conservation.

Boxplots of true relative error and Ncall VS error threshold γ (Example 5.2)
6.3 A creep–fatigue failure problem
The third example is obtained from [42]. The proposed method is compared with methods in [42] in efficiency and accuracy. The performance function in this example describes the creep- and fatigue behaviors of a material. It is obtained from fitting the experimental data which is given as[42, 54]
where \(D_{{\text{c}}}\) is the amount of creep damage and \(D_{{\text{f}}}\) is that of fatigue damage; \(\theta _{1}\) and \(\theta _{2}\) are parameters which can be obtained by experimental data. Only one level of creep and fatigue loading is assumed in this example. Therefore, the damage can be computed by
in which \(n_{{\text{c}}}\) is the number of creep loading cycles and \(N_{{\text{c}}}\) is the total number of cycles to creep failure at the creep loading level. Similarly, the fatigue damage can be obtained by
in which \(n_{{\text{f}}}\) is the number of fatigue loading cycles and \(N_{{\text{f}}}\) is the total number of cycles to fatigue failure at the fatigue loading level. Six random variables exist in this example, and they are given in Table 4. The failure state is assumed to be fuzzy. Three kinds of membership functions are considered, as shown in Table 5.
The results of different methods are given in Table 5. ALK-Pfst is performed 10 times and average results are listed in this table. Advanced sampling methods, i.e., SS and IS, offers very accurate results with fewer function evaluations than MCS. In addition, the proposed method is remarkably more efficient than other methods. Especially, ALK-Pfst saves 60–150 function evaluations than AK-MCS#1.
In one test of Case 3, ALK-Pfst and AK-MCS#1 are implemented with the same candidate points and initial training points. The varying processes of the predicted \(\tilde{P}_{{\tilde{F}}}\) are given in Fig. 6. It can be seen that both methods in accuracy can converge to the true value along with the involvement of new training points. However, in AK-MCS#1, after the predicted accuracy has been very high, a very large number of redundant training points are involved. In contrast, only several additional training points are added by the proposed method. The evolutionary process of estimated error in the proposed method is also given in the figure. The estimated error gradually becomes smaller and smaller during the process. By monitoring the prediction error of \(\tilde{P}_{{\tilde{F}}}\), the learning process can be timely terminated and a large quantity of function calls can be saved without loss of accuracy.

Evolution of predicted \(\tilde{P}_{{\tilde{F}}}\) and estimated error (Example 5.3)
6.4 Engineering application: a missile wing
A missile wing[49], comprising ribs, spars, and skins, is investigated in this example. The performance function is implicit and the finite element software is required to solve it. The application of the proposed method to practical engineering problems can be verified in this example. The detailed geometry and finite element model of the wing are shown in Fig. 7. The Young’s modulus of the skins is 70 GPa and that of the ribs and spars is 120 GPa. The wing is fixed on the main boy of missile by a mount. During cruise of the missile, the upper skin of the wing is subject to a uniform air pressure P. The thicknesses of the skins, the ribs from No. 3 to 5, and the spars are denoted as si (i = 1, 2), ri(i = 3, 4, 5, 6), and ti(i = 1, 2,⋯, 5).

Geometry model and finite element model of the missile wing [49]
To maintain the flight accuracy of the missile, the maximum deflection of the wing should not exceed 11 mm according to the design requirement. Therefore, the performance function of this problem is defined as
in which \(\user2{x = }\left[ {s_{1} ,s_{2} ,r_{3} , \ldots ,r_{6} ,t_{1} , \ldots ,t_{5} ,P} \right]\) is the vector of random variables and \(\Delta\) is the maximum deflection of the wing. Considering that the design requirement—the deflection should not exceed 11 mm—is subjectively prescribed, fuzzy failure state is assumed in this problem. A linear membership functions with parameters a1 = 0 and a2 = 0.1 are used here to describe the failure state. The distributions of the twelve random variables are listed in Table 6.
The results of different methods are given in Table 7. Note that, one time of finite element analysis needs about 27 s on a workstation with an Intel® Xeon E5-2650 v4 CPU and 32 GB RAM. Therefore, it is very hard to obtain the true \(\tilde{P}_{{\tilde{F}}}\) by MCS. Therefore, 500 training points uniformly distributed throughout a rather large space are generated and a “global” Kriging model is built to approximate the true performance function. MCS with 105 samples is used to estimate \(\tilde{P}_{{\tilde{F}}}\) based on the global Kriging model. In addition, the solution is regarded as the benchmark of other methods. AK-MCS#1 and ALK-Pfst are run ten independent times, and the average results are outlined in the table. Table 7 shows that both methods have very high accuracy while ALK-Pfst doubles the efficiency compared with AK-MCS#1.
The traditional RA is also performed based on the global Kriging model. If the epistemic uncertainty in the failure state is ignored, the failure probability will be 0.0107 which is smaller than \(\tilde{P}_{{\tilde{F}}}\) in this example. If the epistemic uncertainty exists while the wing is designed according to the traditional RA, the design may be a little ideal which may not satisfy the requirement of profust RA.
7 Conclusion
Profust RA is researched and a new method based on the ALK model is proposed in this paper. The new method is termed ALK-Pfst. In ALK-Pfst, two main contributions are made: (1) a modified ERF is proposed as the learning function. The new learning function measures the expected risk that Kriging model wrongly predicts the sign of performance function given an arbitrary threshold. The new learning function makes the learning process more robust. (2) The prediction error of profuse failure probability is deduced based on the Kriging prediction information and the Central Limit Theorem. With the prediction error, the accuracy of Kriging model can be monitored in real time and the learning process can be timely stopped.
Four examples are utilized to investigate the performance of the proposed method and other state-of-the-art methods. The results validate the efficiency and robustness of ALK-Pfst outperform other methods with little loss of accuracy. However, it should be noted that high-dimensional problems and problems with small failure probabilities are not tested in this paper. For high-dimensional problems, exploring the optimal parameters of Kriging model by a global optimization algorithm will take a long time [55]. For problems with small failure probabilities, Kriging model should make predictions at a large population of candidate samples [49], which is also pretty time demanding. To overcome those problems, the fusion of the ALK model with dimensionality reduction techniques [55] and importance sampling methods [49] will be our future research emphases.
Availability of data and material
The simulation data within this submission is available based on the request.
Code availability
Implementation codes are available upon request.
Abbreviations
- RA:
-
Reliability analysis
- PDF:
-
Probability density function
- MCS:
-
Monte Carlo simulation
- IS:
-
Importance sampling
- SS:
-
Subset simulation
- ALK:
-
Active learning methods based on the Kriging
- ERF:
-
Expected risk function
- AK-MCS:
-
Active learning method combining Kriging model and MCS
- DS-AK:
-
Dual-stage adaptive Kriging
- ALK-Pfst:
-
Active learning method based on the Kriging model for the profust RA
- DoE:
-
Design of experiments
- CDF:
-
Cumulative distribution function
- WSP:
-
Wrong sign prediction
References
Du X, Chen W (2004) Sequential optimization and reliability assessment method for efficient probabilistic design. J Mech Des 126:225–233
Bichon BJ, Eldred MS, Swiler LP et al (2008) Efficient global reliability analysis for nonlinear implicit performance functions. AIAA J 46:2459–2468
Der Kiureghian A, Dakessian T (1998) Multiple design points in first and second-order reliability. Struct Saf 20:37–49
Du X (2008) Unified uncertainty analysis by the first order reliability method. J Mech Des 130:091401
Au S, Beck JL (1999) A new adaptive importance sampling scheme for reliability calculations. Struct Saf 21:135–158
Yang X, Cheng X, Wang T et al (2020) System reliability analysis with small failure probability based on active learning Kriging model and multimodal adaptive importance sampling. Struct Multidiscip Optim 62:581–596
Yang X, Liu Y, Mi C et al (2018) Active learning Kriging model combining with kernel-density-estimation-based importance sampling method for the estimation of low failure probability. J Mech Des 140:051402
Li H-S, Cao Z-J (2016) Matlab codes of subset simulation for reliability analysis and structural optimization. Struct Multidiscip Optim 54:391–410
Xiao M, Zhang J, Gao L et al (2019) An efficient Kriging-based subset simulation method for hybrid reliability analysis under random and interval variables with small failure probability. Struct Multidiscip Optim 59:2077–2092
Au S-K, Beck JL (2001) Estimation of small failure probabilities in high dimensions by subset simulation. Probab Eng Mech 16:263–277
Wang C, Matthies HG (2019) Epistemic uncertainty-based reliability analysis for engineering system with hybrid evidence and fuzzy variables. Comput Methods Appl Mech Eng 355:438–455
Pan Q, Dias D (2017) Sliced inverse regression-based sparse polynomial chaos expansions for reliability analysis in high dimensions. Reliab Eng Syst Saf 167:484–493
Papadopoulos V, Giovanis DG, Lagaros ND et al (2012) Accelerated subset simulation with neural networks for reliability analysis. Comput Methods Appl Mech Eng 223:70–80
Dai H, Xue G, Wang W (2014) An adaptive wavelet frame neural network method for efficient reliability analysis. Comput Aid Civ Infrastruct Eng 29:801–814
Fei C-W, Lu C, Liem RP (2019) Decomposed-coordinated surrogate modeling strategy for compound function approximation in a turbine-blisk reliability evaluation. Aerosp Sci Technol 95:105466
Yang X, Wang T, Li J et al (2020) Bounds approximation of limit-state surface based on active learning Kriging model with truncated candidate region for random-interval hybrid reliability analysis. Int J Numer Meth Eng 121:1345–1366
Qian J, Yi J, Cheng Y et al (2020) A sequential constraints updating approach for Kriging surrogate model-assisted engineering optimization design problem. Eng Comput 36:993–1009
Echard B, Gayton N, Lemaire M (2011) AK-MCS: an active learning reliability method combining Kriging and Monte Carlo simulation. Struct Saf 33:145–154
Wang Z, Shafieezadeh A (2019) REAK: reliability analysis through error rate-based adaptive kriging. Reliab Eng Syst Saf 182:33–45
Zhang J, Xiao M, Gao L (2020) A new local update-based method for reliability-based design optimization. Eng Comput
Yang X, Liu Y, Gao Y et al (2015) An active learning Kriging model for hybrid reliability analysis with both random and interval variables. Struct Multidiscip Optim 51:1003–1016
Wang J, Sun Z, Yang Q et al (2017) Two accuracy measures of the Kriging model for structural reliability analysis. Reliab Eng Syst Saf 167:494–505
Wang Z, Shafieezadeh A (2020) On confidence intervals for failure probability estimates in Kriging-based reliability analysis. Reliabil Eng Syst Saf 196:106758
Zhang J, Xiao M, Gao L (2019) An active learning reliability method combining Kriging constructed with exploration and exploitation of failure region and subset simulation. Reliab Eng Syst Saf 188:90–102
Yang X, Mi C, Deng D et al (2019) A system reliability analysis method combining active learning Kriging model with adaptive size of candidate points. Struct Multidiscip Optim 60:137–150
Lelièvre N, Beaurepaire P, Mattrand C et al (2018) AK-MCSi: A Kriging-based method to deal with small failure probabilities and time-consuming models. Struct Saf 73:1–11
Hu Z, Mahadevan S (2016) Global sensitivity analysis-enhanced surrogate (GSAS) modeling for reliability analysis. Struct Multidiscip Optim 53:501–521
Haeri A, Fadaee MJ (2016) Efficient reliability analysis of laminated composites using advanced Kriging surrogate model. Compos Struct 149:26–32
Cai K-Y, Wen C-Y, Zhang M-L (1993) Fuzzy states as a basis for a theory of fuzzy reliability. Microelectron Reliab 33:2253–2263
Feng K, Lu Z, Yun W (2019) Aircraft icing severity analysis considering three uncertainty types. AIAA J 57:1514–1522
Zhang X, Lu Z, Feng K et al (2019) Reliability sensitivity based on profust model: an application to aircraft icing analysis. AIAA J 57:5390–5402
Wu FF, Zhang ZF, Mao SX (2009) Size-dependent shear fracture and global tensile plasticity of metallic glasses. Acta Mater 57:257–266
Jiang Q, Chen C-H (2003) A numerical algorithm of fuzzy reliability. Reliab Eng Syst Saf 80:299–307
Pandey D, Tyagi SK (2007) Profust reliability of a gracefully degradable system. Fuzzy Sets Syst 158:794–803
Feng K, Lu Z, Pang C et al (2018) Efficient numerical algorithm of profust reliability analysis: an application to wing box structure. Aerosp Sci Technol 80:203–211
Zhang J, Xiao M, Gao L et al (2018) A novel projection outline based active learning method and its combination with Kriging metamodel for hybrid reliability analysis with random and interval variables. Comput Methods Appl Mech Eng 341:32–52
Wei P, Song J, Bi S et al (2019) Non-intrusive stochastic analysis with parameterized imprecise probability models: II. Reliability and rare events analysis. Mech Syst Signal Process 126:227–247
Jahani E, Muhanna RL, Shayanfar MA et al (2014) Reliability assessment with fuzzy random variables using interval Monte Carlo simulation. Comput Aid Civ Infrastruct Eng 29:208–220
Wang C, Matthies HG (2021) Coupled fuzzy-interval model and method for structural response analysis with non-probabilistic hybrid uncertainties. Fuzzy Sets Syst 417:171–189
Wang C, Qiu Z, Xu M et al (2017) Novel reliability-based optimization method for thermal structure with hybrid random, interval and fuzzy parameters. Appl Math Model 47:573–586
Bing L, Meilin Z, Kai X (2000) A practical engineering method for fuzzy reliability analysis of mechanical structures. Reliab Eng Syst Saf 67:311–315
Zhang X, Lyu Z, Feng K et al (2019) An efficient algorithm for calculating Profust failure probability. Chin J Aeronaut 32:1657–1666
Ling C, Lu Z, Sun B et al (2020) An efficient method combining active learning Kriging and Monte Carlo simulation for profust failure probability. Fuzzy Sets Syst 387:89–107
Dubourg V, Sudret B, Deheeger F (2013) Metamodel-based importance sampling for structural reliability analysis. Probab Eng Mech 33:47–57
Razaaly N, Congedo PM (2018) Novel algorithm using active metamodel learning and importance sampling: application to multiple failure regions of low probability. J Comput Phys 368:92–114
Feng K, Lu Z, Wang L (2020) A novel dual-stage adaptive Kriging method for profust reliability analysis. J Comput Phys 419:109701
Ling C, Lu Z, Zhang X et al (2020) Safety analysis for the posfust reliability model under possibilistic input and fuzzy state. Aerosp Sci Technol 99:105739
Zhao Z, Quan Q, Cai K (2014) A Profust reliability based approach to prognostics and health management. IEEE Trans Reliab 63:26–41
Yang X, Cheng X (2020) Active learning method combining Kriging model and multimodal-optimization-based importance sampling for the estimation of small failure probability. Int J Numer Meth Eng 121:4843–4864
Johnson O (2004) Information theory and the central limit theorem. World Scientific, Singapore
Dong H, Nakayama MK (2020) A tutorial on quantile estimation via Monte Carlo. Springer, Cham, pp 3–30
Wassily H, Robbins H (1948) The central limit theorem for dependent random variables. Duke Math J 15:773–780
Yang X, Liu Y, Fang X et al (2018) Estimation of low failure probability based on active learning Kriging model with a concentric ring approaching strategy. Struct Multidiscip Optim 58:1175–1186
Mao H, Mahadevan S (2000) Reliability analysis of creep–fatigue failure. Int J Fatigue 22:789–797
Bouhlel MA, Bartoli N, Otsmane A et al (2016) Improving kriging surrogates of high-dimensional design models by Partial Least Squares dimension reduction. Struct Multidiscip Optim 53:935–952
Acknowledgements
This work is supported by the National Natural Science Foundation of China (Grant no. 51705433), the Fundamental Research Funds for the Central Universities (Grant no. 2682017CX028).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflicts of interest.
Rights and permissions
About this article

Cite this article
Yang, X., Cheng, X., Liu, Z. et al. A novel active learning method for profust reliability analysis based on the Kriging model. Engineering with Computers 38 (Suppl 4), 3111–3124 (2022). https://doi.org/10.1007/s00366-021-01447-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00366-021-01447-y