
Abstract
This paper proposes an efficient Kriging-based subset simulation (KSS) method for hybrid reliability analysis under random and interval variables (HRA-RI) with small failure probability. In this method, Kriging metamodel is employed to replace the true performance function, and it is smartly updated based on the samples in the first and last levels of subset simulation (SS). To achieve the smart update, a new update strategy is developed to search out samples located around the projection outlines on the limit-state surface. Meanwhile, the number of samples in each level of SS is adaptively adjusted according to the coefficients of variation of estimated failure probabilities. Besides, to quantify the Kriging metamodel uncertainty in the estimation of the upper and lower bounds of the small failure probability, two uncertainty functions are defined and the corresponding termination conditions are developed to control Kriging update. The performance of KSS is tested by four examples. Results indicate that KSS is accurate and efficient for HRA-RI with small failure probability.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Hybrid reliability analysis under both aleatory and epistemic uncertainties has attracted great attention over the past two decades (Zhang and Huang 2010; Liu et al. 2017; Brevault et al. 2016; Jiang et al. 2018; Alvarez et al. 2018; Wang et al. 2018a, b). Generally, the classical probability theory is often employed to quantify aleatory uncertainty while epistemic uncertainty is described by some other methods, such as possibility theory (Mourelatos and Zhou 2005), probability box (Jiang et al. 2012), evidence theory (Jiang et al. 2013; Li et al. 2013; Xiao et al. 2015; Zhang et al. 2015, 2018b), and interval theory (Du et al. 2005; Guo and Du 2009; Wu et al. 2013; Wang et al. 2016, 2017; Jiang et al. 2018). In practical engineering, a structure is fortunately designed with codified rules leading to a large safety margin, which means that failure is a small probability event (Echard et al. 2013). In reliability analysis with small failure probability, the sample populations generated by the simulation methods, such as Monte Carlo simulation (MCS), need to be very large, which leads to huge computational burden in terms of the evaluations of true performance functions, especially when the true performance functions involve expensive and time-consuming computer simulation codes. Therefore, assessing small failure probabilities (lower than 10−3) (Balesdent et al. 2013) is quite a challenging task (Lelièvre et al. 2018). In this paper, hybrid reliability analysis under both aleatory and epistemic uncertainties with small failure probability is investigated, in which aleatory and epistemic uncertainties are quantified by probability theory and interval theory, respectively.
Specifically, in hybrid reliability analysis under random and interval variables (HRA-RI), the failure probability Pf is an interval value due to the existence of interval variables. The upper and lower bounds of Pf can be respectively estimated by Du (2008):
where G(X,Y) is the performance function with a vector of random variables \( X={\left[{x}_1,{x}_2,...,{x}_{n_x}\right]}^{\mathrm{T}} \) and a vector of interval variables \( Y={\left[{y}_1,{y}_2,...,{y}_{n_y}\right]}^{\mathrm{T}} \). P(∙) represents the probability of an event. \( {P}_f^U \) is the upper bound of the failure probability related to the minimum value of the performance function in terms of interval variables. \( {P}_f^L \) is the lower bound of the failure probability corresponding to the maximum value of the performance function in terms of interval variables. YL and YU are the lower and upper bounds of interval variables, respectively.
For HRA-RI, some methods have been developed to estimate the upper and lower bounds of the failure probability. MCS is a basic sampling method and easy to implement. However, a large number of calls to the actual performance function are required when MCS is utilized to deal with reliability analysis problems, especially in cases with small failure probabilities. Unified uncertainty analysis (UUA) method based on the first-order reliability method (FORM), termed as the FORM-UUA method (Du 2008), can be employed to evaluate the upper and lower bounds of the failure probability in HRA-RI. In terms of calculation efficiency, FORM-UUA shows greater advantages in cases with small failure probabilities compared with MCS. However, the application of FORM-UUA is limited by FORM, which may generate unstable and unacceptable results for reliability analysis problems with highly nonlinear performance functions or multiple design points (Yang et al. 2015).
To alleviate the computational burden in reliability analysis by MCS, advanced variance reduction-based simulation methods, such as importance sampling (IS) and subset simulation (SS), are adopted to reduce the total number of samples involved in MCS for accurate estimation of the upper and lower bounds of the failure probability. SS is a well-known and efficient method for reliability analysis, especially for estimating small failure probabilities. Alvarez et al. (2018) developed a combination method of SS and random set theory to estimate the upper and lower bounds of the failure probability. However, this method still needs a large computational effort when handling practical problems with time-consuming performance functions.
Up to now, metamodel techniques have been extensively employed in reliability analysis to reduce the computational cost (Shan and Wang 2006; Basudhar and Missoum 2010; Picheny et al. 2010; Zhu and Du 2016; Sadoughi et al. 2018). However, a majority of metamodel-assisted techniques handle reliability analysis only with random variables and their applications to HRA-RI are few. For HRA-RI, Yang et al. (2015) proposed an efficient method based on an active learning Kriging metamodel and MCS, in which Kriging metamodel is built to replace the performance function with locally refining the limit-state surface by adding update training points in its vicinity. To refine the limit-state surface in HRA-RI, Brevault et al. (2016) developed a modification of the generalized max–min method to search out update points for refining Kriging metamodel. Though well approximating the limit-state surface can obtain accurate estimation of the upper and lower bounds of failure probability, it is determined that projection outlines on the limit-state surface are crucial rather than the whole limit-state surface in HRA-RI (Zhang et al. 2018a). Compared with the whole limit-state surface, the region of projection outlines is much smaller. Hence, refining the whole limit-state surface may cause unnecessary computational cost. With refining the projection outlines, an efficient projection outline-based active learning method combined with Kriging and MCS is proposed for HRA-RI. Though this method is successfully employed in HRA-RI and the computational cost can be reduced, a large number of samples are involved in MCS to estimate the upper and lower bounds of failure probability, which could provoke computer memory problems. Especially, in cases with small failure probabilities, the sample populations need to be very large (Lelièvre et al. 2018), which will incur greater computational burden. This drawback of the method limits its applications in the cases with small failure probabilities.
As mentioned above, relatively fewer samples are involved in reliability analysis to estimate small failure probabilities by SS compared with MCS; meanwhile, the metamodel-assisted techniques can alleviate the computational burden by substituting easy-to-evaluate mathematical functions for expensive simulation-based models. Thus, an efficient Kriging-based subset simulation (KSS) method is proposed in this paper. In KSS, the performance function is replaced by Kriging metamodel, which is constructed by using initial design of experiments (DoE) and then smartly refined based on the samples in the first and last levels of SS. Because candidate samples in the first level of SS are distributed in the whole random variable space, Kriging update based on these samples has high contribution to the exploration of failure domain. On the other hand, samples in the last level of SS are located around the separation surface between the failure and safety domains. Hence, the Kriging update based on these samples benefits the exploitation of failure domain. To achieve the above update, a new update strategy is developed to search out samples located around the projection outlines on the limit-state surface from those in the first and last levels of SS. Meanwhile, the number of samples in each level of SS is adaptively adjusted according to the coefficients of variation of estimated \( {P}_f^U \) and \( {P}_f^L \). Besides, in consideration of the influence of metamodel uncertainty (Apley et al. 2006; An and Choi 2012; Zhang et al. 2013; Wang and Wang 2014) on estimation of \( {P}_f^U \) and \( {P}_f^L \), two uncertainty functions are defined and new termination conditions are developed for Kriging update. Four examples are presented to test the performance of KSS.
The remainder of this paper is outlined as follows. The subset simulation method is introduced in Section 2. In Section 3, a new update strategy, termination conditions of Kriging update, and the proposed KSS method for HRA-RI with small failure probability are elaborated. Four examples are employed to test the proposed KSS method in Section 4. Section 5 provides the conclusions and future work.
2 Subset simulation method
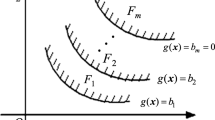
In HRA-RI, for the upper bound of the failure probability, the failure domain can be described as \( {F}^U=\left\{\mathbf{X}|\underline{g}\left(\mathbf{X}\right)\le 0\right\} \) and the safe domain is \( {S}^U=\left\{\mathbf{X}|\underline{g}\left(\mathbf{X}\right)>0\right\} \), where \( \underline{g}\left(\mathbf{X}\right) \) is calculated by (3). The separation surface between FU and SU can be represented by \( \underline{g}\left(\mathbf{X}\right)=0 \). Similarly, for the lower bound of the failure probability, the failure and safe domains are \( {F}^L=\left\{\mathbf{X}|\overline{g}\left(\mathbf{X}\right)\le 0\right\} \) and \( {S}^L=\left\{\mathbf{X}|\overline{g}\left(\mathbf{X}\right)>0\right\} \), where \( \overline{g}\left(\mathbf{X}\right) \) is evaluated by (4). The separation surface between FL and SL is \( \overline{g}\left(\mathbf{X}\right)=0 \). Figure 1 schematically displays the failure domains for the upper and lower bounds of the failure probability.

Failure regions in the design space of two random variables
The basic idea of SS is that a rare failure event with a small probability is expressed as a sequence of multiple intermediate failure events with larger probabilities. Taking the upper bound of the failure probability in HRA-RI as an example, the application of SS will be introduced in the following sections.
2.1 Principle of SS
In SS, the failure event EU is expressed as a sequence of multiple intermediate failure events \( {E}_i^U\left(i=1,2,\dots, \overline{m}\right) \), where \( \overline{m} \) denotes the number of simulation levels in SS. These intermediate failure events \( {E}_i^U \) are defined by a series of threshold values \( {b}_i^U \), which are formulated as:
These threshold values and intermediate failure events should satisfy the following conditions:
where \( {b}_i^U\left(i=1,2,\dots, \overline{m}-1\right) \) are adaptively determined in SS.
Then, the upper bound of the failure probability can be estimated by using the product of conditional probabilities \( P\left({E}_i^U|{E}_{i-1}^U\right) \) and \( P\left({E}_1^U\right) \) in (8).
Define \( {P}_1^U=P\left({E}_1^U\right) \) and \( {P}_i^U=P\left({E}_i^U|{E}_{i-1}^U\right) \) (i = 2, 3,…,\( \overline{m} \)). The upper bound of the failure probability in (8) can be rewritten as:
\( {P}_1^U \) in the first level of SS is evaluated by MCS, i.e.,
where \( {\mathbf{X}}_k^{(1)}\ \left(k=1,2,\dots, {N}_1^U\right) \) are independent and identically distributed samples generated based on the joint probability density function (PDF). \( {I}_1^U\left({\mathbf{X}}_k^{(1)}\right) \) is the intermediate failure indicator function as:
To assess the conditional probability \( {P}_i^U\left(i=2,3,\dots, \overline{m}\right) \) in the ith level of SS, Markov chain Monte Carlo (MCMC) can be employed. In this study, modified Metropolis-Hastings (MMH) (Au and Wang 2014) is used to implement the MCMC. The \( {P}_i^U\left(i=2,3,\dots, \overline{m}\right) \) can be calculated by:
where \( {\mathbf{X}}_k^{(i)}\ \left(k=1,2,\dots, {N}_i^U,i=2,3,\dots, \overline{m}\right) \) are MCMC samples obtained according to the conditional PDF \( q\left(\mathbf{X}|{F}_{i-1}^U\right)={I}_{i-1}^U\left(\mathbf{X}\right)f\left(\mathbf{X}\right)/P\left({F}_{i-1}^U\right) \). The indicator function \( {I}_i^U\left({\mathbf{X}}_k^{(i)}\right) \) is represented as:
In practice, the value of \( {P}_i^U\left(i=1,2,\dots, \overline{m}-1\right) \) is usually set as a fixed conditional probability p0. It is demonstrated that choosing any p0∈[0.1, 0.3] will have the similar computational efficiency (Zuev et al. 2012). Thus, in this paper, p0 is set to 0.1. Then, the conditional probability \( {\widehat{P}}_{\overline{m}}^U \) is not less than 0.1. Thresholds \( {b}_i^U\left(i=1,2,\dots, \overline{m}-1\right) \) will be adaptively evaluated based on the fixed p0. The upper bound of the failure probability in (9) can be rewritten as:
2.2 Statistical property of SS
According to the reference Au and Beck (2001), the coefficient of variation of \( {P}_1^U=P\left({E}_1^U\right) \) in the first level of SS is calculated by \( {\delta}_1^U=\sqrt{\left(1-{P}_1^U\right)/{P}_1^U{N}_1^U} \). The coefficient of variation of \( {P}_i^U \) in the ith level of SS (i = 2, 3,…,\( \overline{m} \)) is evaluated by:
in which \( {N}_{ci}^U \) is the number of initial samples in MCMC, and \( {\rho}_i^U(k) \) is the correlation coefficient. The coefficient of variation of \( {P}_f^U \) can be calculated by:
Similarly, when the lower bound of the failure probability \( {P}_f^L \) is estimated by SS, the corresponding coefficient of variation can be evaluated by:
where \( \underline{m} \) is the number of simulation levels in SS for estimation of \( {P}_f^L \). \( {\delta}_i^L \) is the coefficient of variation of the conditional probability \( {P}_i^L \) in the ith simulation level of SS.
3 The proposed method: Kriging-based subset simulation
The concept of projection outlines on the limit-state surface is first proposed in reliability analysis by Zhang et al. (2018a), which can be respectively represented by point sets shown as follows:
The relationship between projection outlines and the failure probability in HRA-RI has been illustrated in Zhang et al. (2018a). Namely, if the projection outlines in (19) and (20) are accurately approximated by a metamodel, the upper and lower bounds of the failure probability can be accurately assessed. The detailed introduction can be referred to (Zhang et al. 2018a).
In this paper, the Kriging metamodel is employed to approximate the actual performance function. A new update strategy is developed for refining Kriging. Meanwhile, two uncertainty functions are defined to quantify the influence of Kriging metamodel uncertainty on the estimation of the upper and lower bounds of failure probability by SS. Accordingly, the new termination conditions of Kriging update are developed. Based on the new update strategy and termination conditions, a Kriging-based subset simulation method, termed as KSS, is proposed to evaluate the upper and lower bounds of small failure probability in HRA-RI.
3.1 Update strategy of Kriging metamodel
With the substitution of the performance function by a Kriging metamodel, the upper bound of the failure probability in (1) can be represented as:
where \( {\widehat{I}}_F^U\left(\mathbf{X}\right) \) is the failure indicator function associated with the minimum response of the approximate performance function by the Kriging metamodel. It can be expressed by:
Given a set ΩU with a large number of random variable samples \( {\mathbf{X}}_i^U \) (i = 1, 2,…, NU), the value of \( \widehat{G}\left({\mathbf{X}}_i^U,{\mathbf{Y}}_i^U\right) \) requires to be evaluated in order to calculate the value of \( {\widehat{I}}_F^U\left({\mathbf{X}}_i^U\right) \), where \( {\mathbf{Y}}_i^U \) can be solved by:
The above minimization problem can be solved by some alternative methods, such as the vertex method, the interior-point algorithm, and the sampling method (Alvarez et al. 2018). The vertex method is efficient for linear performance functions, while calculation error will be caused by the vertex method for highly nonlinear performance functions. The interior-point algorithm may be easily trapped into a local optimal solution. Furthermore, it may be time-consuming if a constrained optimization problem is solved for each random variable sample. In this paper, the sampling method is employed to solve (23) by uniformly sampling 200 points within the range of interval variables.
Using the Kriging metamodel, the probability of making a wrong prediction about the actual sign of \( G\left({\mathbf{X}}_i^U,{\mathbf{Y}}_i^U\right) \) is \( \varPhi \left(-U\left({\mathbf{X}}_i^U,{\mathbf{Y}}_i^U\right)\right) \), in which Φ(⋅) is the cumulative distribution function of a standard normal distribution. U(⋅) is a learning function formulated as (Echard et al. 2011):
where \( {\sigma}_{\widehat{G}}\left(\mathbf{X},\mathbf{Y}\right) \) is the prediction variance of the Kriging metamodel. It can be seen that the smaller \( U\left({\mathbf{X}}_i^U,{\mathbf{Y}}_i^U\right) \) is, the larger the probability of making a wrong prediction about the sign of \( G\left({\mathbf{X}}_i^U,{\mathbf{Y}}_i^U\right) \). Hence, in this study, an update point is chosen by minimizing \( U\left({\mathbf{X}}_i^U,{\mathbf{Y}}_i^U\right) \). Namely, the update point is defined as:
Based on (24) and (25), the point, which is closer to the approximate limit-state surface \( \widehat{G}\left(\mathbf{X},\mathbf{Y}\right)=0 \) and has a larger prediction variance, will have more chance to be selected as the update one. Note that the chosen update point satisfies (23). According to the projection outlines described in (19) and (20), the selection of an update point based on (25) actually focuses on the region in the vicinity of the approximate projection outlines on the limit-state surface.
Similarly, the lower bound of the failure probability in (2) can be rewritten as:
where \( {\widehat{I}}_F^L\left(\mathbf{X}\right) \) is the failure indicator function related to the maximum response of the approximate performance function by the Kriging metamodel. It is depicted as:
Given a set ΩL with a large number of random variable samples \( {\mathbf{X}}_i^L \) (i = 1, 2,…, NL), it requires to estimate the value of \( \widehat{G}\left({\mathbf{X}}_i^L,{\mathbf{Y}}_i^L\right) \) in order to evaluate \( {\widehat{I}}_F^L\left({\mathbf{X}}_i^L\right) \), where \( {\mathbf{Y}}_i^L \) is calculated by:
Then, a design point with the minimization of \( U\left({\mathbf{X}}_i^L,{\mathbf{Y}}_i^L\right) \) can be chosen as an update one to improve the approximation accuracy of projection outlines on the limit-state surface. The update point is searched out by:
3.2 Termination conditions of Kriging update
In HRA-RI, the conditional probabilities \( {P}_{\overline{m}}^U \) and \( {P}_{\underline{m}}^L \) in the last level of SS need to be computed and the others are set as the fixed value p0. When the performance function is substituted by the Kriging metamodel, the influence of metamodel uncertainty on the calculation of the two conditional probabilities needs to be considered. To quantify this influence, two uncertainty functions under random and interval variables are developed for the estimation of the upper and lower bounds of the failure probability by SS.
For the condition probability \( {\widehat{P}}_{\overline{m}}^U \) in the estimation of \( {P}_f^U \), the uncertainty function is defined as:
where \( q\left(\mathbf{X}|{E}_{\overline{m}-1}^U\right) \) is the conditional PDF of the intermediate failure event \( {E}_{\overline{m}-1}^U \). When U(X, YU) > 2, the probability of making a wrong prediction on the sign of G(X, YU) will be less than Φ(− 2) = 0.0228. Hence, within the domain of {X| U(X, YU) > 2}, a high prediction accuracy of the sign of G(X, YU) can be ensured (Echard et al. 2011). Then, UFU can be approximated as:
where R(·) is evaluated by
Based on samples in the last level of SS, UFUcan be calculated by:
The variance of \( {\widehat{\mathrm{UF}}}^U \) is estimated by:
Hence,
According to the central limit theorem (Sun et al. 2017), the following condition will be satisfied, namely:
The influence of metamodel uncertainty on the estimation of \( {\widehat{P}}_{\overline{m}}^U \) is defined as:
Considering the influence of Kriging uncertainty on the estimation of \( {\widehat{P}}_{\overline{m}}^U \), a termination condition of Kriging update is set as:
where tu is a prescribed convergence value of \( {\widehat{\mathrm{UF}}}^U/{\widehat{P}}_{\overline{m}}^U \).
Based on (35)–(38), it can be derived that:
Then, (40) can be derived from (36) and (39).
Because the conditional probability \( {\widehat{P}}_m^U \) ≥ 0.1, when \( {N}_{\overline{m}}^U \) in the last level of SS is not less than 104 and stopping condition in (38) is satisfied, (40) can be rewritten as:
When tu is set to 0.05, (41) can be written as (42). It can be observed that a narrow interval can be determined under 95% confidence value when tu is set to 0.05. Thus, tu is set to 0.05 in this paper.
Similarly, the uncertainty function for the condition probability \( {\widehat{P}}_{\underset{\_}{m}}^L \) is defined as:
where \( q\left(\mathbf{X}|{E}_{\underline{m}-1}^L\right) \) is the conditional PDF of the intermediate failure event \( {E}_{\underline{m}-1}^U \). After setting a prescribed convergence value tl, a stopping condition of Kriging update during calculating \( {\widehat{P}}_{\underline{m}}^L \) in the estimation of \( {P}_f^L \) is set as:
In this paper, tl is also set to 0.05.
3.3 The KSS method
Based on the update strategy and termination conditions for Kriging metamodel, an efficient KSS method is proposed for HRA-RI with small failure probability. In KSS, the Kriging metamodel is first built by using initial design of experiments (DoE) and then smartly updated based on the samples in the first and last levels of SS. In this paper, the toolbox DACE (Lophaven et al. 2002) is employed to build the Kriging metamodel and the first-order polynomial regression model is selected for the Kriging construction. To take the estimation of the upper bound of the small failure probability as an example, the flowchart of KSS is given in Fig. 2, and the procedure is elaborated as follows:
-
1.
Generate MU initial samples in the first level of SS in random variable space. These samples are simulated by MCS according to the joint PDF of random variables. The set of these samples is denoted as \( {\varOmega}_{mc}^U \). The number of samples in the first level of SS in random variable space is adaptively added during the procedure. Hence, it is not necessary to assign a very large value to MU. In this paper, MU is set to 104.
-
2.
Define the initial DoE. Some alternative techniques, such as random sampling and Latin Hypercube Sampling (LHS), can be employed. For random variables, the bounds of the sampling domain are defined as \( {F}_i^{-1}\left(\varPhi \left(\pm 5\right)\right)\ \left(i=1,2,...,{n}_x\right) \), where \( {F}_i^{-1}\left(\cdot \right) \) is the inverse cumulative distribution function of random variable xi and nx is the number of random variables. For interval variables, their intervals are taken as the sampling domain. According to the experience in Echard et al. (2011), the number of points Ni in the initial DoE is set to the maximum value between nx + ny + 2 and 12 to build an initial Kriging, where nx is the number of random variables and ny is the number of interval variables. The response of the actual performance function is then calculated for each of these points. The iteration information iter is set to 1.
-
3.
Establish an initial Kriging metamodel based on the DoE.
-
4.
Search out an update point \( \left({\mathbf{X}}_{\ast}^U,{\mathbf{Y}}_{\ast}^U\right) \) based on \( {\varOmega}_{mc}^U \) and the update strategy in (23)–(25).
-
5.
Judge the stopping condition of Kriging update. In consideration of the uncertainty of current Kriging metamodel, based on (38), the stopping condition is defined as:

KSS flowchart
where \( {\widehat{\mathrm{UF}}}_{mc}^U \) and \( {\widehat{P}}_f^U \) are respectively calculated by:
\( {\mathbf{X}}_k^U \) (k = 1, 2, …, \( {N}_{mc}^U \)) denotes the samples in \( {\varOmega}_{mc}^U \). \( {N}_{mc}^U \) is the total number of samples in \( {\varOmega}_{mc}^U \). Note that the above Kriging update is based on the samples in the first level of SS and the \( {\widehat{P}}_f^U \) in (47) is not the ultimate output result of KSS. If the condition in (45) is not satisfied, go to the next step; otherwise, go to step 7.
-
6.
Rebuild Kriging. The response of the performance function is calculated for the update point \( \left({\mathbf{X}}_{\ast}^U,{\mathbf{Y}}_{\ast}^U\right) \) and then DoE is augmented with the data of this update point. Kriging metamodel is rebuilt by using the updated DoE. After that, the procedure goes back to step 4.
-
7.
Implement the ith (i = 2, 3,…, \( \overline{m} \)) level of SS. The current Kriging metamodel is denoted by \( {\widehat{G}}^{(0)} \). Because each level of SS has the same number of samples and the number of samples in the first level of SS is \( {N}_{mc}^U \), the number of samples \( {N}_i^U \) in the ith (i = 2, 3, …, \( \overline{m} \)) level of SS is equal to \( {N}_{mc}^U \). The first threshold b1 is determined based on all samples in \( {\varOmega}_{mc}^U \). Then, the ith (i = 2, 3, …, \( \overline{m} \)) level of SS is performed based on \( {\widehat{G}}^{(0)} \), and the thresholds \( {b}_i^U \) (i = 1, 2, …, \( \overline{m} \)) are recorded. In addition, the set of samples \( {\mathbf{X}}_k^{\left(\overline{m}\right)} \) (k = 1, 2, …,\( {N}_{\overline{m}}^U \)) in the last level of SS is denoted as \( {\varOmega}_{SS}^U \). The coefficient of variation of \( {\widehat{P}}_i^U \) in the ith level of SS (i = 2, 3,…,\( \overline{m} \)) is evaluated by (15) and (16), and then the coefficient of variation \( \delta \left({\widehat{P}}_f^U\right) \) is estimated by (17).
-
8.
Identify an update point \( \left({\mathbf{X}}_{\ast}^U,{\mathbf{Y}}_{\ast}^U\right) \) based on \( {\varOmega}_{SS}^U \) and the update strategy in (23)–(25).
-
9.
Judge the stopping condition of Kriging update. To control the influence of metamodel uncertainty on estimation of \( {P}_{\overline{m}}^U \), the stopping condition in (38) is employed. If the stopping condition is not satisfied, go to step 10; otherwise, the current Kriging metamodel is denoted as \( {\widehat{G}}^{(1)} \), and go to step 11.
-
10.
Rebuilt Kriging. The response of the performance function is calculated for the update point \( \left({\mathbf{X}}_{\ast}^U,{\mathbf{Y}}_{\ast}^U\right) \) and DoE is augmented with the data of update point. Then, the Kriging metamodel is rebuilt by using the updated DoE. After that, the procedure goes back to step 8.
-
11.
Calculate the upper bound of the failure probability and the corresponding coefficient of variation based on sample \( {\mathbf{X}}_k^{\left(\overline{m}\right)} \) (k = 1, 2, …, \( {N}_{\overline{m}}^U \)) and \( {\widehat{G}}^{(1)} \). The response of \( {\widehat{G}}^{(1)} \) at each \( {\mathbf{X}}_k^{\left(\overline{m}\right)} \) is estimated. Then, the upper bound of the failure probability \( {P}_f^{U(iter)} \) is calculated by:
where p0 is fixed conditional probability and set to 0.1 in this work. The coefficient of variation of \( {\widehat{P}}_{\overline{m}}^U \) is recalculated based on responses of \( {\widehat{G}}^{(1)} \) at \( {\mathbf{X}}_k^{\left(\overline{m}\right)} \) (k = 1, 2, …, \( {N}_{\overline{m}}^U \)), and hence, the coefficient of variation \( \delta \left({\widehat{P}}_f^U\right) \) is also recalculated.
-
12.
Judge the validity of \( {\widehat{P}}_f^U \). Based on the rule of SS, the condition probability \( {\widehat{P}}_f^U \) needs to be larger than p0. In addition, an intermediate failure event should include its latter intermediate failure events. Thus, it is necessary to determine whether \( {E}_{\overline{m}}^U=\left\{{\underset{\_}{g}}^{(1)}\left(\mathbf{X}\right)\le {b}_{\overline{m}}^U\right\} \) is included in \( {E}_{\overline{m}-1}^U=\left\{{\underset{\_}{g}}^{(0)}\left(\mathbf{X}\right)\le {b}_{\overline{m}-1}^U\right\} \), where:
To implement the judgment, MCMC is employed to generate \( {N}_{\overline{m}}^U \) samples in \( {E}_{\overline{m}}^U \) based on \( {\widehat{G}}^{(1)} \). Then, the responses of \( {\widehat{G}}^{(0)} \) at these samples are calculated. If all responses are less than \( {b}_{\overline{m}-1}^U \), and \( {\widehat{P}}_{\overline{m}}^U \) is not less than p0, \( {\widehat{P}}_f^{U(iter)} \) is taken as a valid value, and then the procedure goes to step 13. Otherwise, the procedure goes back to step 4.
-
13.
Judge the termination condition of the procedure. If the condition in (51) is satisfied and iter is not equal to 1, the procedure will go to step 15; otherwise, go to step 14.
where \( {\delta}_{\ast}^U \) is the prescribed convergence value of the coefficient of variation of \( {\widehat{P}}_f^U \). It is used to ensure whether the number of samples in SS is sufficiently large to obtain a small coefficient of variation. Based on the experience in Echard et al. (2011), \( {\delta}_{\ast}^U \) is set to 0.05 in this study.
-
14.
Generate MU new random variable samples and add them into \( {\varOmega}_{MC}^U \) in the first level of SS. Then, iter = iter + 1, and the procedure goes back to step 4.
-
15.
Terminate the procedure and output \( {P}_f^{U(iter)} \).
Note that when the lower bound of the failure probability \( {\widehat{P}}_f^L \) is estimated by KSS, all MCS samples in \( {\varOmega}_{MC}^U \) are chosen as the samples in the first level of SS in the first iteration, and all sample points in DoE during estimating \( {\widehat{P}}_f^U \) is used to build the initial Kriging. The other steps in estimating \( {\widehat{P}}_f^L \) are similar to those in the estimation of \( {\widehat{P}}_f^U \). Hence, the detail procedure of estimating \( {\widehat{P}}_f^L \) by KSS is not introduced. In this paper, tu and tl are set to 0.05.
4 Test examples
In this section, four examples are employed to validate the efficiency and accuracy of KSS for HRA-RI with small failure probability. In example 1 for a nonlinear mathematical problem, the performance function is highly nonlinear, which is used to validate the performance of the proposed method in the case with nonlinear performance functions. In examples 2 and 3 for a roof structure and a 23-bar planar truss, traditional civil engineering structures are tested. In example 4, a piezoelectric energy harvester is presented to test the proposed method in real-world mechanical engineering applications.
4.1 Example 1: a nonlinear mathematical example
A mathematical example with small failure probability is modified from Yang et al. (2015), in which the nonlinear performance function is formulated as:
where x1 and x2 are two random variables obeying independent standard normal distribution. y is an interval variable bounded in [3, 4].
In this example, the comparison among MCS, SS, FORM-UUA, and KSS is performed. Meanwhile, to analyze the influence of Ni (i.e., the number of points in the initial DoE) on the performance of the proposed KSS method, different cases under Ni = 6, 12, 20, and 30 are tested. The results of MCS are gained with 200 × 106 performance function evaluations, where 106 random variable samples are simulated based on the joint PDF of random variables, and 200 interval variable samples are selected to evaluate the maximum and minimum values of the performance function over the range of interval variables. The upper and lower bounds of the failure probability assessed by MCS are considered as reference values. For MCS, SS, and KSS, 10 independent runs of each of them for this example are conducted. The average results of each method are obtained. Comparative results are listed in Table 1. In Table 1, Ncall is the total number of the true performance function evaluations. \( {\widehat{P}}_f^{\mathrm{max}} \) and \( {\widehat{P}}_f^{\mathrm{min}} \) denote the estimated values of the upper and lower bounds of failure probability, respectively. \( \varepsilon \left({\widehat{P}}_f^{\mathrm{max}}\right) \) and \( \varepsilon \left({\widehat{P}}_f^{\mathrm{min}}\right) \) are the relative errors of \( {\widehat{P}}_f^{\mathrm{max}} \) and \( {\widehat{P}}_f^{\mathrm{min}} \) compared with the references obtained by MCS, respectively. \( ci\left({\widehat{P}}_f^{\mathrm{max}}\right) \) and \( ci\left({\widehat{P}}_f^{\mathrm{min}}\right) \) stand for the 95% confidence intervals of \( {\widehat{P}}_f^{\mathrm{max}} \) and \( {\widehat{P}}_f^{\mathrm{min}} \) over 10 independent runs for MCS, SS, and KSS.
As shown in Table 1, for the estimated values of the upper and lower bounds of the failure probability, the relative errors of FORM-UUA are the largest. The relative errors of SS and KSS in each case are smaller. Besides, the confidence interval of KSS in each case is narrower than that of SS. As Ni increases, the number of update points in KSS decreases while Ncall increases. The reason is that the sample points in the initial DoE are usually scattered in the uncertain design space while the update points are located around the projection outlines. Thus, more sample points in the initial DoE may not be beneficial to cut down the total number of performance function evaluations. However, from Table 1, it can be observed that KSS in each case needs much fewer performance function evaluations than the other methods. Hence, KSS is an accurate and efficient method for HRA-RI with small failure probability.
Figure 3 respectively presents the update samples during estimating \( {\widehat{P}}_f^U \) by KSS under Ni = 12, samples in the last level of SS at the last iteration of KSS, the true separation surface \( \underset{\_}{g}=0 \), and the approximate separation surface by Kriging metamodel. As shown in Fig. 3, it can be seen that the true separation surface is well approximated in the region where the random variables have a high probability density. Besides, a majority of update samples are located in the vicinity of the true separation surface, which indicates that the update strategy in KSS can well search out update samples to refine the approximate separation surface. To estimate the lower bound of the failure probability, 4 update points are added into the initial DoE. Figure 4 respectively shows these update points, samples in the last level of SS at the last iteration of KSS, the true separation surface \( \overline{g}=0 \), and the approximate separation surface by Kriging metamodel. It can be also found that the true separation surface is well approximated in the region where the random variables have a high probability density, and the update points are close to the true separation surface. Figure 5 displays the iterative curves of estimating \( {\widehat{P}}_f^U \) and \( {\widehat{P}}_f^L \) by KSS under Ni = 12 in one independent run. It can be seen that \( {\widehat{P}}_f^U \) and \( {\widehat{P}}_f^L \) are very close to the reference values at the end of iterations. Therefore, it is illustrated that KSS is an accurate and efficient method for HRA-RI with small failure probability.

Update points during estimating \( {\widehat{P}}_f^U \) by KSS under Ni = 12 in example 1

Update points during estimating \( {\widehat{P}}_f^L \) by KSS under Ni = 12 in example 1

Iterative curves of estimating \( {\widehat{P}}_f^U \) and \( {\widehat{P}}_f^L \) by KSS under Ni = 12 in example 1
4.2 Example 2: a roof structure
This example is associated with a roof structure with small failure probability (Yang et al. 2015) shown in Fig. 6. The tension bars and the bottom boom are made by steel while the top boom and compression bars are reinforced by concrete. A uniformly distributed load q is imposed on this roof structure. It can be equivalently transformed into the nodal load P = ql/4. At node C, the vertical deflection can be calculated by:
where EC and ES respectively denote the Young’s moduli of the concrete and steel bars. AC and AS respectively represent their cross-sectional areas. The allowable value of the vertical deflection at node C is 0.027 m. In this example, the performance function is formulated as G(X, Y) = 0.027 − ΔC. The random and interval variables in this example are given in Table 2.

Schematic view of the roof structure
For MCS, SS, and KSS with 12 sample points in initial DoE, 10 independent runs of each method for this example are conducted. The average results of each method are obtained. Comparative results of MCS, SS, FORM-UUA, and KSS are presented in Table 3. As shown in Table 3, FORM-UUA shows the largest relative errors for the upper and lower bounds of the failure probability, while the relative errors of SS and KSS are smaller and KSS has the smallest relative errors. Furthermore, the 95% confidence intervals of KSS are narrower than those of SS. In terms of Ncall, about 38 evaluations of the actual performance function are required in KSS to obtain the final \( {\widehat{P}}_f^U \) and \( {\widehat{P}}_f^L \), which is the fewest among the comparative methods. Figure 7 presents the iterative curves of estimating \( {\widehat{P}}_f^U \) and \( {\widehat{P}}_f^L \) by KSS in one independent run. It can be seen that the estimated values of \( {\widehat{P}}_f^U \) and \( {\widehat{P}}_f^L \) by KSS are very close to the reference values at the end of iterations. Accordingly, KSS can accurately and efficiently estimate the upper and lower bounds of the failure probability in HRA-RI with small failure probabilities.

Iterative curves of estimating \( {\widehat{P}}_f^U \) and \( {\widehat{P}}_f^L \) by KSS in example 2
4.3 Example 3: 23-bar planar truss
A planar 23-bar truss structure shown in Fig. 8 with small failure probability (Dai et al. 2014) is selected. The six loads are taken as random variables. The cross-sectional areas of the main members and diagonal members, and Young’s modulus E are taken as interval variables. All uncertain variables are introduced in Table 4. The performance function of the 23-bar planar truss is formulated by:
where v1 represents the vertical deflection at node 1, which is computed through finite element analysis. The response of the truss is assumed to be linear elastic. va is the allowable deflection, which is set to 0.08 m.

Schematic view of the planar 23-bar truss structure
For MCS, SS, and KSS with 12 sample points in initial DoE, 10 independent runs of each method for this example are performed. The average results of each method are gained. Comparative results of MCS, SS, FORM-UUA, and KSS are listed in Table 5. As seen in Table 5, for the estimation of upper and lower bounds of the failure probability, large relative errors are caused by FORM-UUA. However, the relative errors of SS and KSS are smaller and KSS has the smallest relative errors. In addition, the 95% confidence interval of \( {\widehat{P}}_f^U \) in KSS is similar to that in SS, while the 95% confidence interval of \( {\widehat{P}}_f^L \) in KSS is narrower than that in SS. In terms of Ncall, it can be observed that KSS requires the fewest true performance function evaluations. Figure 9 shows the iterative curves of estimating \( {\widehat{P}}_f^U \) and \( {\widehat{P}}_f^L \) by KSS in one independent run. As seen in Fig. 9, it can be seen that the final \( {\widehat{P}}_f^U \) and \( {\widehat{P}}_f^L \) obtained by KSS are very close to the reference values. Overall, it is illustrated that KSS is accurate and efficient for HRA-RI with small failure probability.

Iterative curves of estimating \( {\widehat{P}}_f^U \) and \( {\widehat{P}}_f^L \) by KSS in example 3
4.4 Example 4: a piezoelectric energy harvester
The structural reliability of a piezoelectric energy harvester (Sadoughi et al. 2018; Seong et al. 2017) is assessed in this example. As shown in Fig. 10, it consists of a tip mass attached at one end and a shim laminated by piezoelectric materials at the other end. The shim and tip mass are constructed from blue steel and tungsten/nickel alloy, respectively. Mechanical strain is transferred into voltage or current with the piezoelectric effect. Thirty-one modes are taken into account in this example, where higher longitudinal strain is allowed when the energy harvester is subject to small input forces. Voltage is produced along the thickness direction with longitudinal stress/strain. The piezoelectric energy harvester can be modeled by a transformer circuit. According to the Kirchhoff’s voltage Law, the circuit can be represented by the coupled differential equations that characterize the transformation from mechanical stress/strain to voltage. The conversion process can be simulated by Matlab Simulink. The details of this piezoelectric energy harvester can be found in Sadoughi et al. (2018).

A piezoelectric energy harvester
In this example, the length of shim lb, piezoelectric strain coefficient v, Young’s modulus for PZT-5A E1, Young’s modulus for the shim E2, the length of tip mass lm, and the height of tip mass hm are uncertain variables. The distributions of lb, v, E1, and E2 are known while only bounds can be obtained for lm and hm. Table 6 provides all these variables. The performance function is expressed as:
where P is the harvester output power, and P0 is the minimum required power, which is set to 28 mW.
In this example, the number of sample points in initial DoE in KSS is set to 12 since 6 uncertain variables exist. The performance function evaluation in this example is expensive and time-consuming. Meanwhile, a large number of true performance function evaluations are required by MCS for reliability analysis with small failure probability. Thus, the lower and upper bounds of failure probability estimated by SS with 3 × 104 random samples in each level are taken as reference values in this real-world example. Table 7 shows the comparative results between SS and KSS. As shown in Table 7, the relative errors of KSS are small and it needs much fewer evaluations of the true performance function compared with KSS. Hence, KSS is accurate and efficient in support of HRA-RI with small failure probability.
5 Conclusions and future work
In this paper, an efficient KSS method is proposed for HRA-RI with small failure probability. In this method, the number of samples in each level of SS is adaptively adjusted according to the coefficients of variation of estimated failure probability. Kriging metamodel is first built by using initial DoE to replace the actual performance function and then smartly updated based on the samples in the first and last levels of SS, in which a new update strategy is developed to refine Kriging by searching out the samples around the approximate projection outlines on the limit-state surface. Because the candidate samples in the first level of SS are distributed in the whole random variable space and samples in the last level of SS are located around the separation surface between the failure and safety domains, the Kriging update based on these samples can benefit from the exploration and exploitation of the failure domain. In addition, to control the influence of Kriging metamodel uncertainty on the estimation of the upper and lower bounds of the small failure probability, two uncertainty functions are defined and corresponding termination conditions are developed for Kriging update. Finally, four examples are provided to validate the advantages of the proposed KSS method. The prominent performance of KSS is illustrated by comparative results in terms of accuracy and efficiency for HRA-RI with small failure probability.
Kriging metamodels may show the poor approximation efficiency for high-dimensional functions, i.e., large-scale problems. When high-dimensional performance functions are involved in HRA-RI with small failure probability, the proposed method will be unsuitable. The applications of other kinds of surrogate models (such as support vector machine) in HRA-RI with small failure probability for large-scale problems can be investigated in the future.
References
Alvarez DA, Uribe F, Hurtado JE (2018) Estimation of the lower and upper bounds on the probability of failure using subset simulation and random set theory. Mech Syst Signal Process 100:782–801
An D, Choi JH (2012) Efficient reliability analysis based on Bayesian framework under input variable and metamodel uncertainties. Struct Multidiscip Optim 46(4):533–547
Apley DW, Liu J, Chen W (2006) Understanding the effects of model uncertainty in robust design with computer experiments. AMSE J Mech Des 128(4):945–958
Au SK, Beck JL (2001) Estimation of small failure probabilities in high dimensions by subset simulation. Probab Eng Mech 16(4):263–277
Au SK, Wang Y (2014) Engineering risk assessment with subset simulation. Wiley, Hoboken
Balesdent M, Morio J, Marzat J (2013) Kriging-based adaptive importance sampling algorithms for rare event estimation. Struct Saf 44:1–10
Basudhar A, Missoum S (2010) An improved adaptive sampling scheme for the construction of explicit boundaries. Struct Multidiscip Optim 42(4):517–529
Brevault L, Lacaze S, Balesdent M, Missoum S (2016) Reliability analysis in the presence of aleatory and epistemic uncertainties, application to the prediction of a launch vehicle fallout zone. AMSE J Mech Des 138(11):11401
Dai H, Xue G, Wang W (2014) An adaptive wavelet frame neural network method for efficient reliability analysis. Comput Aided Civ Inf Eng 29(10):801–814
Du X (2008) Unified uncertainty analysis by the first order reliability method. AMSE J Mech Des 130(9):091401
Du X, Sudjianto A, Huang B (2005) Reliability-based design with the mixture of random and interval variables. ASME J Mech Des 127(6):1068–1076
Echard B, Gayton N, Lemaire M (2011) AK-MCS: an active learning reliability method combining Kriging and Monte Carlo Simulation. Struct Saf 33(2):145–154
Echard B, Gayton N, Lemaire M, Relun N (2013) A combined importance sampling and Kriging reliability method for small failure probabilities with time-demanding numerical models. Reliab Eng Syst Saf 111(2):232–240
Guo J, Du X (2009) Reliability sensitivity analysis with random and interval variables. Int J Numer Methods Eng 78:1585–1617
Jiang C, Han X, Liu W, Liu J, Zhang Z (2012) A hybrid reliability approach based on probability and interval for uncertain structures. AMSE J Mech Des 134(3):031001
Jiang C, Zhang Z, Han X, Liu J (2013) A novel evidence-theory-based reliability analysis method for structures with epistemic uncertainty. Comput Struct 129:1–12
Jiang C, Zheng J, Han X (2018) Probability-interval hybrid uncertainty analysis for structures with both aleatory and epistemic uncertainties: a review. Struct Multidiscip Optim. https://doi.org/10.1007/s00158-017-1864-4
Lelièvre N, Beaurepaire P, Mattrand C, Gayton N (2018) AK-MCSi: a Kriging-based method to deal with small failure probabilities and time-consuming models. Struct Saf 73:1–11
Li F, Luo Z, Rong J, Zhang N (2013) Interval multi-objective optimization of structures using adaptive kriging approximations. Comput Struct 119(4):68–84
Liu X, Kuang Z, Yin L, Hu L (2017) Structural reliability analysis based on probability and probability box hybrid model. Struct Saf 6:73–84
Lophaven SN, Nielsen HB, Sondergaard J (2002) DACE, a matlab Kriging toolbox, version 2.0. Tech. Rep. IMM-TR-2002-12; Technical University of Denmark; http://www2.imm.dtu.dk/hbn/dace/
Mourelatos ZP, Zhou J (2005) Reliability estimation with insufficient data based on possibility theory. AIAA J 43(8):1696–1705
Picheny V, Ginsbourger D, Roustant O, Haftka RT, Kim NH (2010) Adaptive designs of experiments for accurate approximation of a target region. AMSE J Mech Des 132(7):461–471
Sadoughi M, Li M, Hu C, Mackenzie C, Lee S, Eshghi AT (2018) A high-dimensional reliability analysis method for simulation-based design under uncertainty. AMSE J Mech Des 140(7):071401
Seong S, Hu C, Lee S (2017) Design under uncertainty for reliable power generation of piezoelectric energy harvester. J Intell Mater Syst Struct 28(17):2437–2449
Shan S, Wang GG (2006) Failure surface frontier for reliability assessment on expensive performance function. AMSE J Mech Des 128(6):1227–1235
Sun Z, Wang J, Li R, Tong C (2017) LIF: a new Kriging based learning function and its application to structural reliability analysis. Reliab Eng Syst Saf 157:152–165
Wang ZQ, Wang PF (2014) A maximum confidence enhancement based sequential sampling scheme for simulation-based design. AMSE J Mech Des 136(2):021006
Wang L, Wang X, Wang R, Chen X (2016) Reliability-based design optimization under mixture of random, interval and convex uncertainties. Arch Appl Mech 86(7):1341–1367
Wang L, Wang X, Su H, Lin G (2017) Reliability estimation of fatigue crack growth prediction via limited measured data. Int J Mech Sci 121:44–57
Wang L, Xiong C, Wang X, Li Y, Xu M (2018a) Hybrid time-variant reliability estimation for active control structures under aleatory and epistemic uncertainties. J Sound Vib 419:469–492
Wang L, Xiong C, Yang Y (2018b) A novel methodology of reliability-based multidisciplinary design optimization under hybrid interval and fuzzy uncertainties. Comput Methods Appl Mech Eng 337:439–457
Wu J, Luo Z, Zhang Y, Zhang N, Chen L (2013) Interval uncertain method for multibody mechanical systems using Chebyshev inclusion functions. Int J Numer Methods Eng 95(7):608–630
Xiao M, Gao L, Xiong H, Luo Z (2015) An efficient method for reliability analysis under epistemic uncertainty based on evidence theory and support vector regression. J Eng Des 26(10–12):1–25
Yang XF, Liu YS, Gao Y, Zhang YS, Gao ZZ (2015) An active learning kriging model for hybrid reliability analysis with both random and interval variables. Struct Multidiscip Optim 51(5):1003–1016
Zhang X, Huang H (2010) Sequential optimization and reliability assessment for multidisciplinary design optimization under aleatory and epistemic uncertainties. Struct Multidiscip Optim 40(1):165–175
Zhang SL, Zhu P, Chen W, Arendt P (2013) Concurrent treatment of parametric uncertainty and metamodeling uncertainty in robust design. Struct Multidiscip Optim 47(1):63–76
Zhang Z, Jiang C, Wang GG, Han X (2015) First and second order approximate reliability analysis methods using evidence theory. Reliab Eng Syst Saf 137:40–49
Zhang JH, Xiao M, Gao L, Fu JJ (2018a) A novel projection outline based active learning method and its combination with Kriging metamodel for hybrid reliability analysis with random and interval variables. Comput Methods Appl Mech Eng 341:32–52
Zhang JH, Xiao M, Gao L, Qiu HB, Yang Z (2018b) An improved two-stage framework of evidence-based design optimization. Struct Multidiscip Optim 58(4):1673–1693
Zhu Z, Du X (2016) Reliability analysis with Monte Carlo simulation and dependent kriging predictions. AMSE J Mech Des 138(12):121403
Zuev KM, Beck JL, Au SK, Katafygiotis LS (2012) Bayesian post-processor and other enhancements of subset simulation for estimating failure probabilities in high dimensions. Comput Struct 92:283–296
Funding
This research was financially supported by the National Natural Science Foundation of China [grant numbers 51675196 and 51721092] and the Program for HUST Academic Frontier Youth Team.
Author information
Authors and Affiliations
Corresponding author
Additional information
Responsible Editor: Hai Huang
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Xiao, M., Zhang, J., Gao, L. et al. An efficient Kriging-based subset simulation method for hybrid reliability analysis under random and interval variables with small failure probability. Struct Multidisc Optim 59, 2077–2092 (2019). https://doi.org/10.1007/s00158-018-2176-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00158-018-2176-z