
Abstract
Hybrid reliability analysis (HRA) with both random and interval variables is investigated in this paper. Firstly, it is figured out that a surrogate model just rightly predicting the sign of performance function can meet the requirement of HRA in accuracy. According to this idea, a methodology based on active learning Kriging (ALK) model named ALK-HRA is proposed. When constructing the Kriging model, the presented method only finely approximates the performance function in the region of interest: the region where the sign tends to be wrongly predicted. Based on the constructed Kriging model, Monte Carlo Simulation (MCS) is carried out to estimate both the lower and upper bounds of failure probability. ALK-HRA is accurate enough with calling the performance function as few times as possible. Four numerical examples and one engineering application are investigated to demonstrate the performance of the proposed method.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Probabilistic reliability analysis (PRA) requires precise probabilistic models of uncertain variables, which may be impossible for some uncertainties because of limited experimental data. Unwarranted assumptions during constructing a probabilistic model may bring about misleading results with PRA (Elishakoff 1995a; Elishakoff 1999). Thus, the non-probabilistic interval model was proposed to describe the uncertain variables with incomplete information. Compared with random variables, for an interval variable, nothing is known about it except that it lies within a certain interval. During the past decades, non-probabilistic approaches based on the interval model have been deeply investigated (Luo et al. 2009; Elishakoff 1995b; Wang et al. 2008; Qiu and Elishakoff 2001; Möller and Beer 2008), and they have provided alternative ways for reliability analysis.
In many engineering applications, a frequently encountered situation is that (Guo and Du 2009; Qiu and Wang 2010; Wang and Qiu 2010): some of the uncertainties can be characterized with precise probabilistic model and others have to be treated with interval model. HRA with both random variables and interval variables has attracted much attention in such circumstance. Guo and Lu (2002) proposed a probabilistic and non-probabilistic hybrid model. However, only the solution to linear performance function was proposed in this research. Qiu and Wang (2010), Wang and Qiu (2010) respectively developed a hybrid reliability model with interval arithmetic method. However, interval arithmetic is not applicable to black-box performance functions (Du 2007). Du (2007; 2008) advanced a sequential single-loop optimization method based on the first-order reliability method (FORM). It was named FORM-UUA. Guo and Du (2009) took advantage of this FORM-UUA method to carry out sensitivity analysis for hybrid reliability with both random and interval variables.
Compared with PRA, HRA is a nested procedure with interval analysis (IA) and PRA (Du 2007). IA is entailed to search for the extreme responses with respect to interval variables in the inner loop and PRA is needed to estimate the lower and upper bounds of failure probability in terms of random variables in the outer loop. Both the inner and outer loops can affect the accuracy of results. It is known that in PRA, FORM is very inaccurate for performance functions which are highly nonlinear or have multiple design points (Qin et al. 2006; Au et al. 1999). When the performance function is highly nonlinear or has multiple design points in terms of random variables, even if the extreme responses are exactly worked out in the inner loop, the results could be much too inaccurate in HRA. Therefore, FORM-UUA behaves very poorly in such cases. In addition, as FORM-UUA is a gradient-based optimization method, its efficiency depends upon the number of uncertain variables and the extent of nonlinearity of the performance function. That means, for a practical structure with a little many uncertain variables or a performance function which is highly nonlinear, FORM-UUA can also be inefficient. Moreover, to obtain the lower and upper bounds of failure probability, FORM-UUA entails to be respectively performed and thus the computational burden is doubled.
Jiang et al. (2012) proposed a new method based on FORM which can only estimate the upper bound of failure probability. This method is more robust and efficient while much less accurate than FORM-UUA as revealed from his paper. Xiao et al. (2012) proposed a mean value first order saddle-point approximation (MVFOSPA) method to analyze the hybrid reliability. In the inner loop, the performance function was linearized by the first order Taylor series, and then the interval arithmetic was employed to search for the maximum and minimum responses. In the outer loop, MVFOSPA was used to perform the PRA. When the performance function is nonlinear in terms of interval variables, the method with first order Taylor series and interval arithmetic cannot obtain the exact extreme responses and consequentially MVFOSPA cannot obtain accurate bounds of failure probability. Therefore, MVFOSPA is less accurate than FORM-UUA when the performance function is nonlinear as revealed from that paper.
Faced with a black-box function, it is available to use a surrogate model to approximate the unknown implicit function. In this field, the proposition of active learning Kriging (ALK) model is a major step forward. Active learning means that the Kriging model is iteratively updated by adding a new training point to the design of experiment (DoE), until the Kriging model satisfies necessary accuracy. In each iteration, the new point is selected because it is probably located in some region of interest. Therefore the ALK model focuses much attention on approximating the black-box function in the region of interest. Different kinds of ALK models have been proposed, and they have been applied to different fields, like the global optimization (Jones et al. 1998), the contour estimation (Ranjan et al. 2008), PRA (Bichon et al. 2008; Bichon et al. 2011; Echard et al. 2011), reliability-based design optimization (Dubourg et al. 2011) and the inspection of large surfaces (Dumasa et al. 2013). However, few studies have considered the application of surrogate model to HRA so far, let alone the ALK model.
This paper aims to develop an efficient and accurate method for HRA based on ALK model. When creating the Kriging model, we do not approximate the performance function in the whole uncertain space, but only in the region where the sign of the function tends to be wrongly predicted. That is based on the idea that a Kriging model only rightly predicting the sign of performance function can help to obtain the signs of its extrema and accurately estimate the bounds of failure probability. Then Monte Carlo Simulation (MCS) method can be effectively carried out based on the Kriging model. The proposed method is characterized with its local approximation to the performance function. Moreover, the single Kriging model can be employed to estimate both the lower and upper bounds of failure probability. ALK-HRA is accurate enough with calling the performance function as few times as possible.
This paper is outlined as follows. HRA with both random and interval variables is introduced in Section 2. MCS method is presented in Section 3. In Section 4 the proposed ALK-HRA methodology is elaborated. Five case studies are utilized to demonstrate the effectiveness of the proposed method in Section 5. Conclusions are made in the last section.
2 HRA with both random and interval variables
When only random variables appear in an uncertain structure, the reliability can be analyzed by traditional probabilistic reliability methods. The performance function is denoted as G(X), with \( X={\left[{x}_1,{x}_2,\cdots, {x}_{n_X}\right]}^T \) the vector of random variables. The failure probability P f is defined as
where P{•} denotes the probability of an event, f(•) is the joint probability density function (PDF).
When both random variables and interval variables are present, the performance function of an uncertain structure is expressed as G(X, Y), where \( Y={\left[{y}_1,{y}_2,\cdots, {y}_{n_Y}\right]}^T \) represents the vector of interval variables. The lower and upper bounds of Y are Y L and Y U respectively. The space defined by the interval variables is denoted by C = [Y L, Y U]. Because of the presence of interval variables, the failure probability is not a determinate value but an interval variable. The lower and upper bounds of P f are obtained by (Guo and Du 2009; Du 2008)
and
respectively, where \( \underset{Y\in C}{ \min }G\left(X,Y\right) \) and \( \underset{Y\in C}{ \max }G{\left(X,Y\right)}^{,} \) are the extreme responses of a structure in terms of interval variables. The main work of HRA is to calculate the bounds of P f , i.e. to solve Equations. (2) and (3). Each of them is a double-loop procedure: an optimization problem should be solved to find the maximum (minimum) response with respect to Y in the inner loop and PRA needs to be performed to estimate the failure probability with respect to X in the outer loop.
3 HRA with Monte Carlo simulation (MCS)
In this work, results obtained by MCS are considered as the references for other approaches. In addition, our proposed method is based on MCS. Therefore, HRA with MCS is offered in this section. Equation (2) can be rewritten as
where I U F (•) is the failure indicator function for the minimum response and it can be expressed as
In the same way, Equation (3) can be rewritten as
where I L F (•) is the failure indicator function for the maximum response and it can be expressed as
Then MCS can be used to estimate the bounds of failure probability through the following three steps:
-
(1)
Generate a large number of simulated samples for random variables according to their PDFs.
-
(2)
At each simulated sample, solve the optimization problems in Equations (5) and (7). Obtain the signs of extrema, and then the failure indicator functions at this sample can be obtained. To obtain the optimal solutions, global optimization algorithm is needed and in this paper the DIRECT algorithm (Gablonsky 1998) is adopted.
-
(3)
P max f and P min f can be respectively estimated by
$$ {P}_f^{\max }=\frac{1}{N}{\displaystyle \sum_{j=1}^N{I}_F^U\left({X}^{(j)}\right)} $$(8)and
$$ {P}_f^{\min }=\frac{1}{N}{\displaystyle \sum_{j=1}^N{I}_F^U\left({X}^{(j)}\right)} $$(9)where N is the total number of samples and X (j) is the j th sample.
4 ALK for HRA
4.1 Basic idea
It will become impossible to implement MCS when the performance function needs to be calculated with time-consuming simulation methods such as finite element (FE) analysis, computational fluid dynamics, etc. So Kriging model is employed to approximate the performance function, and then compute P max f and P min f with MCS based on the Kriging model. In this paper, our aim is to construct a Kriging model providing a right prediction for the sign of G(X, Y) rather than its true value. Therefore, the Kriging model only locally approximates the performance function rather than in the whole uncertain space.
Now we give the reason for which a Kriging model providing a right prediction for the sign of G(X, Y) can meet the demand of HRA in accuracy. Conveniently, the Kriging model is denoted as Ĝ(X, Y) and it satisfies the following two properties:
-
Property1
If sign(Ĝ(X, Y)) = sign(G(X, Y)), then \( \mathrm{sign}\left(\underset{Y\in C}{ \min }G\left(X,Y\right)\right)=\mathrm{sign}\left(\underset{Y\in C}{ \min}\widehat{G}\left(X,Y\right)\right) \), where sign(•) is the sign function.
-
Proof1
Denote \( {\widehat{Y}}_1^{*}= \arg \underset{Y\in C}{ \min}\left(\widehat{G}\left(X,Y\right)\right) \) and \( {Y}_1^{*}= \arg \underset{Y\in C}{ \min}\left(G\left(X,Y\right)\right) \), namely \( \widehat{G}\left(X,{{\widehat{Y}}_1}^{*}\right)=\underset{Y\in C}{ \min}\left(\widehat{G}\left(X,Y\right)\right) \) and \( G\left(X,{Y}_1^{*}\right)=\underset{Y\in C}{ \min}\left(G\left(X,Y\right)\right) \). Note that Ŷ *1 is not equal to Y *1 definitely, because Ĝ(X, Y) can only rightly predict the sign of G(X, Y) rather than its true value. So it is hard to say that sign(Ĝ(X, Ŷ 1*)) = sign(G(X, Y 1*)). Then we will prove that even though Ŷ *1 is not surely equal to Y *1 , there is sign(Ĝ(X, Ŷ 1*)) = sign(G(X, Y 1*)).
If Ĝ(X, Ŷ *1 ) < 0, then G(X, Ŷ *1 ) < 0 because sign(Ĝ(X, Ŷ *1 )) = sign(G(X, Ŷ *1 )). Then G(X, Y *1 ) < 0 because G(X, Y *1 ) ≤ G(X, Ŷ *1 ) < 0. In the other case, if Ĝ(X, Ŷ *1 ) > 0, then Ĝ(X, Y *1 ) > 0 because Ĝ(X, Y *1 ) ≥ Ĝ(X, Ŷ *1 ) > 0. And then G(X, Y *1 ) > 0 because sign(Ĝ(X, Y *1 )) = sign(G(X, Y *1 )). That is sign(Ĝ(X, Ŷ 1*)) = sign(G(X, Y 1*)) or \( \mathrm{sign}\left(\underset{Y\in C}{ \max }G\left(X,Y\right)\right)=\mathrm{sign}\left(\underset{Y\in C}{ \max}\widehat{G}\left(X,Y\right)\right) \).
-
Property2
If sign(Ĝ(X, Y)) = sign(G(X, Y)), then \( \mathrm{sign}\left(\underset{Y\in C}{ \max }G\left(X,Y\right)\right)=\mathrm{sign}\left(\underset{Y\in C}{ \max}\widehat{G}\left(X,Y\right)\right) \)
-
Proof 2
Denote \( {\widehat{Y}}_2^{*}= \arg \underset{Y\in C}{ \max}\left(\widehat{G}\left(X,Y\right)\right) \) and \( {Y}_2^{*}= \arg \underset{Y\in C}{ \max}\left(G\left(X,Y\right)\right) \), namely \( \widehat{G}\left(X,{{\widehat{Y}}_2}^{*}\right)=\underset{Y\in C}{ \max}\left(\widehat{G}\left(X,Y\right)\right) \) and \( G\left(X,{Y}_2^{*}\right)=\underset{Y\in C}{ \max}\left(G\left(X,Y\right)\right) \). And also note that Ŷ *2 is not surely equal to Y *2 . If Ĝ(X, Ŷ *2 ) < 0, then Ĝ(X, Y *2 ) ≤ Ĝ(X, Ŷ *2 ) < 0. And then G(X, Y *2 ) < 0 because sign(Ĝ(X, Y *2 )) = sign(G(X, Y *2 )). In the other case, if Ĝ(X, Ŷ *2 ) > 0, then G(X, Ŷ *2 ) > 0 because sign(Ĝ(X, Ŷ *2 )) = sign(G(X, Ŷ *2 )). And then G(X, Y *2 ) > 0 because G(X, Y *2 ) ≥ G(X, Ŷ *2 ) > 0. That is \( \mathrm{sign}\left(\underset{Y\in C}{ \max }G\left(X,Y\right)\right)=\mathrm{sign}\left(\underset{Y\in C}{ \max}\widehat{G}\left(X,Y\right)\right) \)
Property 1 and 2 indicate that if the Kriging model can rightly predict the sign of performance function, the minimum (maximum) of the true performance function and that of the Kriging model will have the same sign even though their optimal solutions are different. Obtaining the signs of the extrema of the Kriging model, the signs of the extrema of the true performance function can be obtained. Therefore, constructing a Kriging model providing a right prediction for the sign of G(X, Y) can meet the demand of HRA in accuracy.
Then we will focus on constructing a Kriging model which can rightly predict the sign of G(X, Y). It should be noted that many ALK models have been proposed to improve the prediction for the sign of objective function until now. They have been well integrated with many sampling procedures like MCS (Echard et al. 2011), importance sampling methods (Echard et al. 2013; Balesdent et al. 2013), subset simulation (Dubourg et al. 2011) and largely improved the efficiency of PRA. However, as far as we know, all of them were proposed for PRA where there are no interval variables in the performance function and no searches for extreme responses at each simulated sample. And they may not be perfectly applicable to HRA. In this paper, we advance a new ALK model for HRA.
The general procedure to construct an ALK model is summarized as follows (Jones et al. 1998; Bichon et al. 2008; Ranjan et al. 2008):
-
(1)
Build an initial Kriging model by a DoE with a small number of training points.
-
(2)
Find a new point with a so-called learning function. The learning function is a function that judges whether a point is located in some region of interest. If the learning function satisfies some condition, stop.
-
(3)
Evaluate the response at the chosen point and add the point to the DoE. Update the Kriging model and go to Stage (2).
In each iteration, the new point is chosen because it is probably situated in some region of interest. Therefore ALK model can only finely approximate the objective function in the specific region of interest. During this procedure, the learning function plays the key role for an ALK model. It judges which point should be added into the DoE and when the iterative process should be stopped. In this paper we propose a new learning function called expected risk function (ERF). Based on ERF, ALK-HRA is constructed.
4.2 Kriging theory reminder
For the sake of convenience, we use the vector x to denote all the uncertain variables, i.e. x = (X, Y), and then the performance function becomes G(x). Note that x is an n-dimensional vector and there is n = n X + n Y . With a Kriging model, G(x) is generally expressed as
where \( \widehat{\beta} \) is the overall mean and z(x) is a Gaussian process with the following statistical characteristics:
where E[•] is the expectation operator, σ 2 is the variance of z(x), a and b are two arbitrary points in the real space, ℜ(θ, a, b) is a correlation function with parameter θ which reads:
Kriging model needs a DoE to determine its parameters. Then predictions for the objective function can be made at unknown points. Given a DoE: [x (1), x (2), ⋯, x (m)]T with x (j) the j th training point, and the vector of corresponding responses g = [G(x (1)), G(x (2)), ⋯, G(x (m))]T, at any unknown point x, the predicted value Ĝ(x) for G(x) is
The corresponding predicted variance s 2(x) is given as
In Equation (13), 1 is an m-dimensional unit vector, r(x) is the correlation vector between x and each training point which is defined as
In Equations (13) and (14), R is the correlation matrix between each pair of training points which is defined as
The parameters \( \widehat{\beta} \) and σ 2 can be respectively estimated as
The parameter θ is determined with maximum likelihood estimation. Thus the following optimization problem should be solved:
The ALK models in Echard et al. (2011), Dumasa et al. (2013) and Balesdent et al. (2013) were all performed with the MATLAB toolbox DACE (Lophaven 2002). In DACE, a pattern search method was employed to search for the optimal parameter θ*. Nevertheless, this method is easily trapped in local minima (Luo et al. 2012). As revealed in Kaymaz (2005), θ has the largest effect on the accuracy of a Kriging model. Only the Kriging model with the optimal parameter θ* can give the best predictions in Equations (13) and (14). Therefore, θ* in Equation (19) is explored by global optimization strategy and again the DIRECT algorithm (Gablonsky 1998) is adopted.
4.3 ALK-HRA
4.3.1 Expected risk function
To improve the prediction for the sign of objective function, the point at which the sign of objective function has the largest risk being wrongly predicted should be picked out. Add this point into the DoE, and then the prediction for the sign of objective function will be largely improved. To identify such a point, a learning function is entailed in ALK-HRA and we propose the ERF in this paper. ERF is elaborated inspired by the so-called expected improvement function for global optimization in Jones et al. (1998) At a point x, Kriging model provides a predicted value Ĝ(x) for G(x), whereas Ĝ(x) is not the true value of G(x). And thus there is a risk that the sign of G(x) is wrongly predicted.Consider the case that the predicted value is negative, i.e. Ĝ(x) < 0. Even though Ĝ(x) < 0, there exists some extent of risk that G(x) > 0, because G(x) is uncertain and G(x) ~ N(Ĝ(x), s(x)) (Jones et al. 1998; Ranjan et al. 2008). We define an indicator to measure such risk as
R(x) measures the extent that G(x) is larger than zero when Ĝ(x) < 0. Obviously, as illustrated in Fig. 1a, the larger R(x) is, the more likely the sign of G(x) is to be wrongly predicted. However, R(x) is a random variable because G(x) is a random variable. Therefore, R(x) is averaged throughout the real space inspired by Jones et al. (1998) and the expected risk that the sign of G(x) is wrongly predicted for the case Ĝ(x) < 0 is obtained as
In the same way, as depicted in Fig. 1b, we define the indicator of risk in the case Ĝ(x) > 0 as
And the expected risk in the case Ĝ(x) > 0 is derived as
Equations (21) and (23) can be uniformly written into an equation as
where ϕ(•) and Φ(•) are the PDF and cumulative distribution function (CDF) of the standard normal distribution, respectively. Equation (24) is called ERF in this study. ERF indicates the extent of risk that the sign of objective function at a point is expected to be wrongly predicted by a Kriging model. When a point maximizes ERF, the sign of response at this point has the largest expectation to be wrongly predicted. So the point should be added to the set of training points.Note that different kinds of learning functions have been proposed to improve the prediction for the sign of objective function with a Kriging model (Ranjan et al. 2008; Bichon et al. 2008; Picheny et al. 2010; Dubourg et al. 2011; Echard et al. 2011; Balesdent et al. 2013). However, they were all employed in PRA. A comparison of different learning functions used in PRA can be found in Bect et al. (2012). ERF provides an alternative way to identify the point enriching the DoE and improve the prediction for the sign of objective function. ERF is proposed for HRA and the comparison of ERF to other learning functions used in PRA has been beyond our scope.

Risk of sign of response wrongly predicted by a Kriging model: a the sign is predicted to be negative b the sign is predicted to be positive
4.3.2 Summary of ALK-HRA
-
(1)
Define the initial DoE.
-
(a)
The number of training points in the initial DoE should be a little small. According to the experience in Echard et al. (2011) and Dubourg et al. (2011), 12 is chosen as the number in this study.
-
(b)
Latin hypercube sampling (LHS) is employed to generate points uniformly distributed in the uncertain space. For random variables, the bounds are chosen as F i − 1(Φ(±5))(i = 1, 2, ⋯, n X ), where F i − 1(•) is the inverse CDF of x i . For interval variables, the lower and upper bounds are chosen as Y L and Y U respectively.
-
(c)
Evaluate the performance function at all those points and construct a Kriging model with the DoE.
-
(a)
-
(2)
Generate a large number of candidate points.
-
(a)
The set of candidate points is denoted as Ω. For random variables, Monte Carlo sampling is employed to generate samples according to their PDFs. For interval variables, LHS is used to generate samples uniformly covering the space between their lower and upper bounds.
-
(b)
The number of samples in Ω is denoted as N Ω . N Ω should be sufficiently large so that the points can fill the whole uncertain space. We make N Ω = 105 in this paper.
-
(c)
It should be stressed that the performance function is not evaluated in this stage. All the points are treated as candidates and the new training points in the next few stages will be chosen among them.
-
(a)
-
(3)
Identify the new training point in Ω
The point in Ω with maximum ERF value will be chosen as a new point. Denote the point as (X (*), Y (*)).
-
(4)
Stopping condition.
If the maximum of ERF is less than a very small tolerance, the Kriging model has been accurate enough to predict the sign of performance function. Go to Stage (6). Obviously, ERF is a dimensional function and the dimension could impact the convergence of iteration. To eliminate this influence, ERF is scaled by the absolute nominal value of performance function. The stopping condition used here is \( E\left[R\left({X}^{\left(*\right)},{Y}^{\left(*\right)}\right)\right]/\left(\left|G\left(\overline{X},\overline{Y}\right)\right|+\varepsilon \right)\le {10}^{-4} \) in which \( \overline{X} \) is the mean of X, \( \overline{Y} \) is the nominal value of Y defined by \( \overline{Y}=\frac{1}{2}\left({Y}^L+{Y}^U\right) \) and ε is a small positive constant (like 10−6) to prevent the denominator from being 0.
-
(5)
Update the DoE and construct a new Kriging model.
If the stopping condition in Stage (4) is not satisfied, compute the true performance function at (X (*), Y (*)). Add (X (*), Y (*)) into the DoE and update the Kriging model with the updated DoE. And then go to Stage (3).
-
(6)
This Kriging model is accurate enough to estimate both the lower and upper bounds of failure probability. Carry out MCS presented in Section 3 based on the Kriging model. Note that searching for the extreme responses at a large number of simulated samples with DIRECT algorithm can be a little time-consuming. Actually, there is no need to search for both the minimum and maximum responses at all simulated samples. At a sample X (j), if \( \underset{Y\in C}{ \min}\widehat{G}\left({X}^{(j)},Y\right)>0 \), obviously there is \( \underset{Y\in C}{ \max}\widehat{G}\left({X}^{(j)},Y\right)>0 \). And then there is no need to search for the maximum response. In addition, the parfor-loop in MATLAB which means executing loop iterations in parallel is recommended in this stage (Sharma and Martin 2009).
5 Numerical examples and discussions
In this section, five examples are researched to demonstrate the efficiency and accuracy of the proposed method. In the first four examples, MCS is implemented to independently examine the results obtained by other methods. The performance of ALK-HRA is illustrated through comparison with FORM-UUA. The last example is a practical engineering case to demonstrate the application of the proposed method to black-box performance functions.
5.1 A mathematical problem
The first example is a mathematical problem modified from Bichon et al. (2008). The performance function is defined as
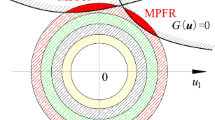
where x 1 and x 2 are independent normal distributed random variables and x 1 ~ N(μ = 1.5, σ = 1), x 2 ~ N(μ = 2.5, σ = 1); y is an interval variable and y ∈ [2, 2.5].To estimate the bounds of failure probability for this problem with ALK-HRA, a Kriging model should be constructed to rightly predict the sign of G(X, Y). 12 training points are selected, and then the iterative process starts to enrich the DoE. In each iteration, the point at which the sign of G(X, Y) has the largest risk being wrongly predicted is added into the DoE. Then the prediction of the sign is improved. After 39 iterations, the stopping criterion is satisfied and 39 training points are added into the DoE. The obtained DoE is illustrated in Fig. 2. It is observed that some of the added points are far from the limit state G(X, Y) = 0 while more points are located in the vicinity. That is ALK-HRA only locally approximates the performance function rather than in the whole uncertain space.The reason why more points are located in the vicinity of the limit state is that even very low uncertainty may result in the sign of objective function being wrongly predicted in this region. Therefore more training points should be added into this region to decrease the uncertainty. As for other region, even large uncertainty may not affect the prediction for the sign of objective function. Consequently, only a small part of training points are located in the region far away from the limit state.After the Kriging model is constructed, MCS can be effectively implemented based on the Kriging model. 105 samples are generated and the extreme responses are repeatedly explored at every sample. The sign of minimal response at each sample predicted by ALK-HRA is depicted in Fig. 3. It is seen that only 5 signs are wrongly predicted in this example. That demonstrates the accuracy of the proposed method.Table 1 lists the results with all methods. It is seen that very large errors occur with FORM-UUA. For this highly nonlinear problem, ALK-HRA provides much more accurate results with errors less than 1 %. Moreover, only 51 function calls are needed with the proposed method, which are much fewer than FORM-UUA.

DoE of the mathematical problem obtained with ALK-HRA

Predicted sign of minimum response at each sample with ALK-HRA
5.2 A roof structure
A roof truss structure modified from Wei et al. (2012) and Wang et al. (2013) is investigated in this section. As shown in Fig. 4, the bottom boom and the tension bars are made of steel while the top boom and the compression bars are reinforced by concrete. The roof is subjected to a uniformly distributed load q which can be equivalently transformed into the nodal load P = ql/4. The vertical deflection at node C can be obtained by

A roof truss structure (Wang et al. 2013)
in which A C and A S respectively denote the sectional areas of the concrete and steel bars; E C and E S respectively denote the Young’s moduli of them. The vertical deflection at node C should be less than 0.025 m, so the performance function is constructed as G(X, Y) = 0.025 − Δ C . The random and interval variables of the roof structure are listed in Table 2.
Results of this problem obtained by different methods are listed in Table 3. It is seen that FORM-UUA behaves well in accuracy for this simple example. However, ALK-HRA performs much better than FORM-UUA no matter in efficiency or accuracy. ALK-HRA obtains very accurate bounds of failure probability with calling the performance function only 50 times. The DoE obtained by ALK-HRA is illustrated in Fig. 5. It is seen that many training points are located in the vicinity of G(X, Y) = 0. Therefore ALK-HRA only finely approximates the performance function in the region of interest. Moreover, when the Kriging model is constructed, it can be used to obtain both the lower and upper bounds of failure probability. However, to obtain the two bounds of failure probability, FORM-UUA entails to be respectively performed: it needs 173 function calls for P max f and 176 function calls for P min f . Consequently, the proposed method can be so efficient compared to FORM-UUA.

DoE of the roof truss structure obtained with ALK-HRA
5.3 A cantilever tube
The third example is a cantilever tube, as shown in Fig. 6, which was presented in Du (2007; 2008). The performance function is created as

A cantilever tube (Du 2007)
where S y is the yield strength of the tube and σ max is the maximum Von Mises stress which can be computed by
in which the torsional stress τ zx is calculated by
The normal stress σ x is expressed as
where
Random and interval variables of the cantilever tube are given in Table 4. There are more uncertain variables than the numerical example in Section 5.2 and there exist several non-normal random variables. The performance function is nonlinear and it is not monotonic in terms of the interval variables θ 1 and θ 2 (Du 2007). Therefore, the extreme values of performance function should be obtained with optimization strategy.
Results of this problem are summarized in Table 5. It can be seen that FORM-UUA shows very poor performance for this problem. It obtains the bounds of failure probability with very large errors. That results from the nonlinearity of the performance function. The nonlinearity comes from two sources: the nonlinearity of the performance function itself and the transformation of the non-normal random variables into standard normal random variables. Additionally, as FORM-UUA is a gradient-based optimization method, its efficiency is affected by the number of uncertain variables and the nonlinearity of the performance function. Hence the efficiency of FORM-UUA for this problem is very low: it needs 260 function calls for the upper bound of failure probability and 221 function calls for the lower bound.
However, ALK-HRA keeps very well both in accuracy and efficiency. For this complicated problem, ALK-HRA accurately obtains both bounds of failure probability with calling the performance function only 82 times. The DoE obtained by ALK-HRA is illustrated in Fig. 7. It is demonstrated that ALK-HRA only locally approximates the performance function in the region of interest. In addition, the accuracy of ALK-HRA verifies the properties that the maximum (minimum) of the Kriging model in terms of the interval variables will have the same sign with that of the true performance function if the Kriging model is able to rightly predict the sign of the true performance function.

DoE of the cantilever tube with ALK-HRA
5.4 A composite beam
A composite beam (Huang and Du 2008), as shown in Fig. 8, is considered in this section to certify the application of ALK-HRA to high-dimensional problems. 20 uncertain variables exist in this problem and details of them are listed in Table 6. The performance function is defined as
in which σ max is the maximum stress of the beam which occurs in the M-M cross-section. σ max can be computed by
where Δ is defined as
Different methods are employed to solve this complicated problem and the results are listed in Table 7. The DoE obtained by ALK-HRA is illustrated in Fig. 9. It can be seen that only 93 training points are chosen for a Kriging model to predict the sign of G(X, Y). With only 93 function calls, the proposed method obtains very accurate bounds of failure probability. No matter in accuracy or efficiency, the proposed method behaves much better than FORM-UUA.

A composite beam (Huang and Du 2008)

DoE of the composite beam with ALK-HRA
5.5 Engineering application
A missile wing structure, as shown in Fig. 10, is investigated here to demonstrate the performance of the proposed method when dealing with practical engineering problem. The wing structure comprises four wing spars, five wing ribs, and the upper and lower skins. Partial of the upper skin is hidden to illustrate inner details of the wing in Fig. 10. The wing is fixed on the missile body through a connector. The spars and ribs are made of titanium alloy. The Young’s modulus is E 1, the Poisson’s ratio is 0.3 and the density is 4.5 × 103 Kg/m3. The skins are made of some kind of composite material. The Young’s modulus is E 2, the Poisson’s ratio is 0.3 and the density is 2.0 × 103 Kg/m3. The thicknesses of the skins are denoted as s 1 and s 2; those of the ribs are denoted as t i (i = 1, 2, ⋯, 5); those of the spars are represented by t i (i = 6, 7, 8, 9). A uniform air pressure P is exerted on the upper skin during flight.

A missile wing structure
The uncertain variables are listed in Table 8. To guarantee the accuracy of missile flight path, the vertical deformation of the wing should not exceed 10.5 mm. Hence the performance function is defined as
where X and Y denote the vector of random variables and that of interval variables, respectively; Δ(•) is the maximum vertical deformation of the wing. The performance function is a black-box function which needs to be calculated by FE analysis.
ALK-HRA is employed to solve this complicated engineering problem. MSC. Nastran is used to calculate the vertical deformation of the wing structure and the FE model is shown in Fig. 11. The wing is meshed by 4,063 shell elements and 840 solid elements. 80 MPC elements are created to connect the shell elements and the solid elements. The interval of the failure probability is [0.00585, 0.00932]. For this complicated engineering problem, ALK-HRA obtains this result with only 80 times of FE analysis. The DoE obtained with ALK-HRA is shown in Fig. 12. Again it is observed that ALK-HRA focuses much attention on the region of G(X, Y) = 0. That is why the proposed method can be so efficient. From this example, it is demonstrated that ALK-HRA is suitable to cope with many complex engineering problems with black-box performance functions.

FE model of the missile wing structure

DoE of the missile wing structure
6 Conclusion
This paper develops an ALK model for HRA with both random and interval variables. Firstly, it is figured out that a surrogate model just rightly predicting the sign of performance function can satisfy the accuracy demand of HRA. Based on this idea, ALK-HRA is proposed to iteratively construct a Kriging model only finely approximating the performance function in the region where the sign is prone to be wrongly predicted. Thus ALK-HRA is able to meet the demand of HRA in accuracy with calling the performance function only a few times.
The performance of the proposed method is tested with four numerical examples and one engineering example. Compared with FORM-UUA, no matter in efficiency or accuracy, ALK-HRA behaves very well revealed from four numerical examples. ALK-HRA is able to obtain very accurate bounds of failure probability even when the performance function is highly nonlinear. Moreover, the single Kriging model can be used to obtain both the lower and upper bounds of failure probability. Therefore ALK-HRA is generally more efficient than FORM-UUA. From the last engineering application, it is seen that ALK-HRA is an efficient technique that is capable of dealing with complex engineering problems with black-box performance functions.
However, it should be pointed out that the proposed method has its own limitations. As revealed from the numerical examples, the efficiency of the proposed method decreases as the number of uncertain variables increases. When there are too many uncertain variables, like 50 or100, much more training points and iterations are needed to construct the Kriging model. And then the proposed strategy loses its numerical efficiency. This limitation requires further investigation. In addition, ALK-HRA is not applicable to estimating small probability of failure. When the bounds of failure probability are very small, a very large number of samples are necessary and so many searches for the extreme responses by global optimization algorithm need to be performed based on the Kriging model. Although there is no need to call the performance function in this process, it can also become very time-consuming in practice. To overcome this curse, two solutions will be researched in our future work: (1) combining ALK model with importance sampling to reduce the simulated samples; (2) introducing Karush-Kuhn-Tucker conditions like Du (2007) did so that many searches of extreme responses can be skipped.
References
Au S, Papadimitriou C, Beck J (1999) Reliability of uncertain dynamical systems with multiple design points. Struct Saf 21:113–133
Balesdent M, Morio J, Marzat J (2013) Kriging-based adaptive importance sampling algorithms for rare event estimation. Struct Saf 44:1–10
Bect J, Ginsbourger D, Li L et al (2012) Sequential design of computer experiments for the estimation of a probability of failure. Stat Comput 22:773–793
Bichon B, Eldred M, Swiler L et al (2008) Efficient global reliability analysis for nonlinear implicit performance functions. AIAA J 46:2459–2468
Bichon B, McFarland J, Mahadevan S (2011) Efficient surrogate models for reliability analysis of systems with multiple failure modes. Reliab Eng Syst Saf 96:1386–1395
Du X (2007) Interval reliability analysis. In: Proceedings of the ASME 2007 Design Engineering Technical Conference and Computers and Information in Engineering Conference, Las Vegas, Nevada, USA
Du X (2008) Unified uncertainty analysis by the first order reliability method. J Mech Design (ASME) 130:1401–1410
Dubourg V, Sudret B, Bourinet J-M (2011) Reliability-based design optimization using kriging surrogates and subset simulation. Struct Multidiscip Optim 44:673–690
Dumasa A, Echard B, Gaytona N et al (2013) AK-ILS: an active learning method based on kriging for the inspection of large surfaces. Precis Eng 37:1–9
Echard B, Gayton N, Lemaire M (2011) AK-MCS: an active learning reliability method combining kriging and Monte Carlo simulation. Struct Saf 33:145–154
Echard B, Gayton N, Lemaire M et al (2013) A combined importance sampling and kriging reliability method for small failure probabilities with time-demanding numerical models. Reliab Eng Syst Saf 111:232–240
Elishakoff I (1995a) Essay on uncertainties in elastic and viscoelastic structures: from A M. Freudenthal’s criticisms to modern convex modeling. Comput Struct 56:871–895
Elishakoff I (1995b) Discussion on: a non-probabilistic concept of reliability. Struct Saf 17:195–199
Elishakoff I (1999) Are probabilistic and anti-optimization approaches compatible? whys and hows in uncertainty modelling: probability, fuzziness and antioptimization. Springer, New York
Gablonsky J (1998) Implementation of the DIRECT Algorithm. Center for Research in Scientific Computation, Technical Rept. CRSC-TR98-29, North Carolina State Univ, Raleigh, NC, Aug
Guo J, Du X (2009) Reliability sensitivity analysis with random and interval variables. Int J Numer Methods Eng 78:1585–1617
Guo S, Lu Z (2002) Hybrid probabilistic and non-probabilistic model of structural reliability. Chinese J Mech Strength 24:524–526
Huang B, Du X (2008) Probabilistic uncertainty analysis by mean-value first order saddlepoint approximation. Reliab Eng Syst Saf 93:325–336
Jiang C, Lu G, Han X et al (2012) A new reliability analysis method for uncertain structures with random and interval variables. Int J Mech Mater Des 8:169–182
Jones DR, Schonlau M, Welch WJ (1998) Efficient global optimization of expensive black-box functions. J Global Optim 13:455–492
Kaymaz I (2005) Application of kriging method to structural reliability problems. Struct Saf 27:133–151
Lophaven S, Nielsen H, Sondergaard J (2002) DACE, a matlab Kriging toolbox, version 2.0. Tech. Rep. IMM-TR-2002-12; Technical University of Denmark.
Luo Y, Kang Z, Alex L (2009) Structural reliability assessment based on probability and convex set mixed model. Comput Struct 87:1408–1415
Luo X, Li X, Zhou J et al (2012) A Kriging-based hybrid optimization algorithm for slope reliability analysis. Struct Saf 34:401–406
Möller B, Beer M (2008) Engineering computation under uncertainty - capabilities of non-traditional models. Comput Struct 86:1024–41
Picheny V, Ginsbourger D, Roustant O et al (2010) Adaptive designs of experiments for accurate approximation of a target region. J Mech Design 132:071008
Qin Q, Lin D, Mei G et al (2006) Effects of variable transformations on errors in FORM results. Reliab Eng Syst Safe 91:112–118
Qiu Z, Elishakoff I (2001) Anti-optimization technique-a generalization of interval analysis for nonprobabilistic treatment of uncertainty. Chaos Soliton Fract 12:1747–1759
Qiu Z, Wang J (2010) The interval estimation of reliability for probabilistic and non-probabilistic hybrid structural system. Eng Fail Anal 17:1142–1154
Ranjan P, Bingham D, Michailidis G (2008) Sequential experiment design for contour estimation from complex computer codes. Technometrics 50:527–541
Sharma G, Martin J (2009) MATLAB®: a language for parallel computing. Int J Parallel Prog 37(1):3–36
Wang J, Qiu Z (2010) The reliability analysis of probabilistic and interval hybrid structural system. Appl Math Model 34:3648–3658
Wang X, Qiu Z, Elishakoff I (2008) Non-probabilistic set-theoretic model for structural safety measure. Acta Mech 198:51–64
Wang P, Lu Z, Tang Z (2013) An application of the Kriging method in global sensitivity analysis with parameter uncertainty. Appl Math Model 37:6543–6555
Wei P, Lu Z, Hao W et al (2012) Efficient sampling methods for global reliability sensitivity analysis. Comput Phys Commun 183:1728–1743
Xiao N, Huang H, Wang Z et al (2012) Unified uncertainty analysis by the mean value first order saddlepoint approximation. Struct Multidisc Optim 46:803–812
Acknowledgments
This work is supported by the Aerospace Support Fund (NBXW0001) and Foundation Research Funds of Northwestern Polytechnical University (JCY20130123).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Yang, X., Liu, Y., Gao, Y. et al. An active learning kriging model for hybrid reliability analysis with both random and interval variables. Struct Multidisc Optim 51, 1003–1016 (2015). https://doi.org/10.1007/s00158-014-1189-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00158-014-1189-5