
Abstract
In recent years, distributed adaptive processing has received much attention from both theoretical and practical aspects. One of the efficient cooperation structures in distributed adaptive processing is the diffusion strategy, which provides a platform for the cooperation of nodes that run an adaptive algorithm, such as the least mean-squares (LMS) algorithm. Despite the studies that have been done on the diffusion-based LMS algorithm, the effect of deficient length on such structures has been overlooked. Accordingly, in this paper, we study the steady-state performance of the deficient length diffusion LMS algorithm. The results of this study show, in particular, that setting the tap length below its actual value leads to drastic degradation of the steady-state excess mean-square error (EMSE) and mean-square deviation (MSD) in diffusion adaptive networks. Furthermore, unlike the full-length case, where the steady-state MSD and EMSE decrease significantly with the step size reduction, this study shows that in the deficient-length scenario, there are no significant improvements in the steady-state performance by reducing the step size. Therefore, according to this study, the tap length plays a key role in diffusion adaptive networks since the performance deterioration due to deficient selection of tap length could not be compensated by an adjustment in the step size. Experiments exhibit a very good match between simulations and theory.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Distributed parameter estimation is gathered more increased interest in the wireless sensor networks (WSNs) application areas. It just relies on the local information exchange between neighbouring sensors. It, hence, eliminates the necessity of a powerful fusion center to collect and process the data from the entire sensor network and, as such, decreases the communications power and bandwidth of the conventional centralized approach while preserving similar performance. There are two widely considered topologies, diffusion and incremental, for distributed estimation over adaptive networks. [1]. However, amongst these structures, diffusion topologies show superior performance over incremental topologies in terms of robustness to the nodes and link failures and are manageable to distributed implementations [2]. As a result, diffusion-based adaptive networks are widely studied that can learn and adapt from consecutive data streaming and exhibit good tracking capability and fast convergence rates. Besides, based on the diffusion structure, different diffusion techniques have been presented, such as the diffusion recursive least squares (D-RLS) [3], diffusion least mean square (D-LMS) [4], diffusion Kalman filter [5], diffusion affine projection (D-APA) [6], and diffusion improved multiband-structured subband adaptive filter (D-IMSAF) [7]. The convex combination of two D-LMS algorithms is proposed in [8] to overcome the tradeoff between the convergence rate and steady-state error in the traditional D-LMS algorithm. Two D-LMS algorithms with different step sizes are combined in this algorithm, resulting in a lower steady-state error and faster convergence rate at the cost of increased computational complexity. Also, motivated by the idea of combining adaptive algorithms, [9] proposed an affine combination framework for diffusion topologies, where affine combination coefficients are adjusted based on the minimum mean-square-error (MSE) criterion. This combined diffusion structure enjoys the best characteristics of all component strategies. Since the conventional diffusion adaptive networks experience a significant performance degeneration in the presence of impulsive noise, robust D-RLS algorithms are developed in [10] to enhance the performance in such noisy scenarios. In another approach, to mitigate the performance deterioration experienced in diffusion adaptive networks in the presence of impulsive noise, [11] proposed a diffusion-based affine projection M-estimate algorithm, which employs a robust M-estimate based cost function. Paper [12] has studied the performance analysis of diffusion adaptive networks by considering the communication delays of the links between nodes. This paper presents the stability conditions in the mean and mean-square sense. This paper shows that the delayed D-LMS algorithm could converge under the same step-sizes limitation of the conventional D-LMS algorithm without considering delays. The transient performance of the D-LMS algorithm for the non-stationary systems has been studied in [13], where each node employs the different types of cyclostationary white non-Gaussian signals.
In [14], the authors have developed the zeroth-order (ZO)-diffusion algorithm by utilizing the gradient-free approach to the adaptation phase of the conventional diffusion structure. Furthermore, a modification of the stochastic variance reduced gradient (SVRG) named time-averaging SVRG (TA-SVRG) is provided in [14] for streaming data processing. Finally, the TA-SVRG algorithm has been applied in the ZO-diffusion to decrease the estimation variance and enhance the convergence rate.
Distributed diffusion adaptive techniques are implemented in two phases: the combination phase, in which each sensor combines its neighbourhood information, and the adaptation phase, in which each sensor updates its estimate based on an adaptive rule. The performance of diffusion networks could be enhanced by developing combination policies that set the combination coefficients based on the data quality. Accordingly, the design of combination coefficients has been considered in the literature [15,16,17,18].
As discussed, the above-mentioned papers have been developed to estimate the elements of an unknown parameter vector of interest in a distributed manner. These cooperative methods utilize a simple assumption that the dimension of the unknown vector or the tap-length is known a priori. So, they overlook one crucial point: in some contexts, the optimal length of the desired parameter is also unknown, similar to its elements. On this basis, the tap-length estimation problem has been considered in the distributed context based on diffusion [19,20,21] and incremental strategies [22, 23].
However, in some cases, for reasons such as power storage (since power consumption is a critical concern in WSNs), such variable tap length approaches are not applicable. So a suppositional length for the unknown vector is considered at each sensor. Usually, the exact length of the filter is unknown in advance, so it is possible to apply in each sensor node a deficient tap-length adaptive filter, i.e., an adaptive filter whose tap-length is smaller than that of the unknown desired vector length.
In distributed adaptive filter settings, the steady-state study for deficient length scenarios has been conducted only in incremental-based adaptive networks [24]. Despite the importance of studying the deficient length scenario for diffusion LMS algorithm, in almost all diffusion adaptive networks theoretical analysis, it is supposed that the length of the adaptive filter is the same as that of the unknown desired vector. On the other hand, theoretical findings on sufficient tap-length diffusion adaptive algorithms could not necessarily apply to the practical deficient length cases. Accordingly, from practical aspects, it becomes very critical to analyze and quantify the statistical behavior of the deficient length diffusion adaptive algorithms.
On this basis, in this paper, we study the deficient length diffusion LMS adaptive networks’ performance in the steady state. More precisely, we derive closed-form expressions for the EMSE and MSD for each node to explain the efficiency of length deficiency on the steady-state performance of each node. This study shows that setting the tap length smaller than its actual value leads to drastic degradation of the steady-state EMSE and MSD in diffusion adaptive networks. Also, unlike the full-length case, where the steady-state MSD and EMSE decrease significantly with the step size reduction, this study shows that in the deficient-length scenario, there are no significant improvements in the steady-state performance by reducing the step size. Consequently, according to this study, the tap length plays a key role in diffusion adaptive networks since the performance deterioration due to deficient selection of tap length could not be compensated by an adjustment in the step size.
NotationAs a convenience to the reader, Tables 1 and 2 list the main acronyms and symbols used in this paper.
2 Background
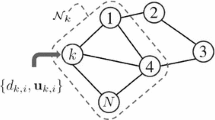
Consider a network of J sensors implemented in a diffusion structure to estimate the unknown vector \({\varvec{w}}_{{L_{opt}}}^o\) of length \({L_{opt}}\). It is supposed that the network nodes have no prior information about the length \({L_{opt}}\), and each node is equipped with a filter of length \( N\leqslant {L_{opt}}\). Considering the Combine-Then-Adapt (CTA) strategy, the filter coefficients update equation in diffusion adaptive networks would be as [2]:
where the \(N \times 1\) column vector \(\varvec{\psi }_k ^{(i)}\) represents the deficient-length local estimate of \({\varvec{w}}_{{L_{opt}}}^o\) at sensor k and time i, and where \( {\jmath _k}\) stands for the topologically connected nodes to node k (the neighborhood of sensor k, including itself). Note that, in (1), all vectors have length N. In (1), the positive constant \({\mu _k}\) is the step-size at sensor k, and the local combiners \(\{c_{k,\ell } \geqslant 0 \}\) meet the requirement \(\sum _{\ell =1}^{J} {{c_{k,\ell }}} = 1\). The combiners \(\{c_{k,\ell }\}\) are collected in a matrix \(C=[c_{k,\ell }]\) that reflects the network topology. In (1), the data are supposed to follow the linear model [25]:
In this equation, \({{v}_k}(i)\) represents white background noise with zero-mean and variance \(\sigma _{v,k}^2\), which is assumed to be independent of \( {{\varvec{u}}_{{L_{opt}}\ell ,j}}\) for all \(\ell ,j\).
In (2), \( {{\varvec{u}}_{{L_{opt}}k,i}}\) is a vector of length \({L_{opt}}\), and \({{\varvec{u}}_{k,i}}\) consists of N first elements of \( {{\varvec{u}}_{{L_{opt}}k,i}}\). In this regard, \({\varvec{u}}_{L_{opt}k,i}\) could be written as \({\varvec{u}}_{L_{opt}k,i}=\left[ {\varvec{u}}_{k,i},\ {\bar{{\varvec{u}}}}_{k,i}\right] \), where \({\varvec{u}}_{k,i}=\left[ u_k\left( i\right) ,u_k\left( i-1\right) ,...,u_k\left( i-N+1\right) \right] \) and \({\bar{{\varvec{u}}}}_{k,i}=\left[ u_k\left( i-N\right) ,...,u_k\left( i-L_{opt}+1\right) \right] \), with \(u_k\left( i\right) \) representing the ith element of \({\varvec{u}}_{k,i}\).
3 Steady-state analysis of deficient tap-length CTA diffusion LMS algorithm
Now, we intend to analyze the steady-state behavior of the CTA diffusion LMS algorithm when a conjectural deficient length is applied for the unknown parameter. In this regard, the unknown vector is treated as the composition of two vectors stacked on top of each other as \(\left[ \begin{matrix}{\varvec{w}}_N^{\left( 1\right) }\\ {\varvec{w}}_{L_{opt}-N}^{\left( 2\right) }\\ \end{matrix}\right] \), where \({\varvec{w}}_N^{\left( 1\right) }\) consists of the first N entries of \({\varvec{w}}_{{L_{opt}}}^o\), and \({\varvec{w}}_{L_{opt}-N}^{\left( 2\right) }\) consists of the \( {L_{opt}-N}\) final elements.
To assess the steady-state performance, we analyze the MSD and EMSE measures for each sensor k, which are defined as [2]:
where \({\overline{{\varvec{\psi }}}}^{\left( i-1\right) }_{L_{opt},k}\) is defined as:
where \({\overline{{\varvec{\psi }}}}^{\left( i-1\right) }_{N,k}={{\varvec{\psi }}}^{\left( i-1\right) }_k-{{{\varvec{w}}}}^{\left( 1\right) }_N\). With the definition of \({\overline{{\varvec{\psi }}}}^{\left( i-1\right) }_{L_{opt},k}\), (3) could be rewritten as:
where \(R_{{{{\varvec{u}}}}_k}=E\left\{ {{{\varvec{u}}}}^*_{k,i}{{{\varvec{u}}}}_{k,i}\right\} \) and \(R_{{\overline{{{\varvec{u}}}}}_k}=E\left\{ {\overline{{{\varvec{u}}}}}^*_{k,i}{\overline{{{\varvec{u}}}}}_{k,i}\right\} \). The components of the regressors are assumed to be uncorrelated zero-mean Gaussian processes with variance \({\sigma }^2_{u,k}\). It is also assumed that \({\varvec{u}}_{{L_{opt}}k,i}\) is independent of \({\varvec{u}}_{{L_{opt}}\ell ,j}\) for \( k\ne \ell \) and \(i\ne j\). This assumption will imply the independence of \({\varvec{u}}_{k,i}\) from \({\overline{{\varvec{\psi }}}}^{\left( i-1\right) }_{N,k}\). To proceed, we rewrite (1) as:
where the condition \({\sum _{\ell \in {\jmath }_k}{c_{k,\ell }}=1}\) is imposed. Let us subtract \({{{\varvec{w}}}}^{\left( 1\right) }_N\) from both sides of (6):
For ease of analysis, we define some quantities:
Let \(C=\{c_{k,\ell } \}\) represents the combination coefficient matrix; we also define \({G=C\bigotimes I_N}\), where \(\bigotimes \) represents the standard Kronecker product.
With the expressed notation, we rewrite (7) as:
Also, with the expressed notation, the local MSD and EMSE at sensor k can be rewritten as:
Also, to characterize the network performance, the network MSD and EMSE could be considered as:
where \( R_{\varvec{U}} = E\left\{ {{\varvec{U}}_{i}^{*} {\varvec{U}}_{i} } \right\} = {\text{diag}}\left\{ {{\text{R}}_{{{{{\varvec{u}}}}_{{{1}}} }} , \ldots ,{\text{R}}_{{{{{\varvec{u}}}}_{{\text{J}}} }} } \right\} \) and \({R_{\overline{{{\varvec{U}}}}}=E\left\{ {\overline{{{\varvec{U}}}}}^*_i{\overline{{{\varvec{U}}}}}_i\right\} ={{\text {diag}}}\left\{ R_{{\overline{{{\varvec{u}}}}}_1},\dots ,R_{{\overline{{{\varvec{u}}}}}_J}\right\} }\).
What all these measures have in common is the weighted norm \({{\left\| {\overline{{\varvec{\varPsi }}}}^{\left( i-1\right) }_N\right\| }^2_{\sum }}\). On this basis, evaluating the weighted norm on both sides of (8) and then taking expectations yields the following relation:
where
The term \({{{\mathcal {W}}}}^{*\left( O\right) }_{L_{opt}-N}E\left\{ {\overline{{{\varvec{U}}}}}^*_i{{{\varvec{U}}}}_iD\sum D{{{\varvec{U}}}}^*_i{\overline{{{\varvec{U}}}}}_i\right\} {{{\mathcal {W}}}}^{\left( O\right) }_{L_{opt}-N}\) on the right-hand side of (11) is due to the deficient length adaptive filter application at each node. This term, which contains all the omitted entries of the unknown vector, does not appear in the sufficient length scenario.
To proceed, we calculate the moments in the relations (11) and (12). First, \(E\left\{ {{{\varvec{V}}}}^*_i{{{\varvec{U}}}}_iD\sum D{{{\varvec{U}}}}^*_i{{{\varvec{V}}}}_i\right\} \) could be evaluated as [25]:
where \({R_{{{\varvec{V}}}}=E\left\{ {{{\varvec{V}}}}_i{{{\varvec{V}}}}^*_i\right\} ={{\text {diag}}}\left\{ \sigma ^2_{v,1},\dots ,\sigma ^2_{v,J}\right\} }\)
To evaluate \({{{\mathcal {W}}}}^{*\left( O\right) }_{L_{opt}-N}E\left\{ {\overline{{{\varvec{U}}}}}^*_i{{{\varvec{U}}}}_iD\sum D{{{\varvec{U}}}}^*_i{\overline{{{\varvec{U}}}}}_i\right\} {{{\mathcal {W}}}}^{\left( O\right) }_{L_{opt}-N}\), we start by assessing \({\varUpsilon \mathrm{=}E\left\{ {\overline{{{\varvec{U}}}}}^*_i{{{\varvec{U}}}}_i\sum {{{\varvec{U}}}}^*_i{\overline{{{\varvec{U}}}}}_i\right\} }\) as:
where \({\varUpsilon }_{k\ell }\) is the \(k\ell \)-block of \({\varUpsilon }\). Therefore, \({{{\mathcal {W}}}}^{*\left( O\right) }_{L_{opt}-N}E\left\{ {\overline{{{\varvec{U}}}}}^*_i{{{\varvec{U}}}}_iD\sum D{{{\varvec{U}}}}^*_i{\overline{{{\varvec{U}}}}}_i\right\} {{{\mathcal {W}}}}^{\left( O\right) }_{L_{opt}-N}\) could be calculated as:
We could express \({\text{bvec}}\{\varUpsilon \}\) as \({b{{vec}}}\left\{ \varUpsilon \right\} =\text {col}\left\{ {{\varvec{\gamma }}}_1,\dots ,{{\varvec{\gamma }}}_J\right\} \), where:
where \(\sigma _{kk}=\text {vec}\left\{ {\sum }_{kk}\right\} \), \({{{\varvec{r}}}}_k=\text {vec}\left\{ R_{{{{\varvec{u}}}}_k}\right\} \), and \({\overline{{{\varvec{r}}}}}_k=\text {vec}\{R_{{\overline{{{\varvec{u}}}}}_k}\}\). It follows that
where \({\sigma _k=\text {col}\left\{ \sigma _{1k},\ \sigma _{2k},\dots ,\sigma _{Jk}\right\} }\). So, \({\text{bvec}}\{\varUpsilon \}\) could be rewritten as:
Consequently, we find that:
Also, applying the block vectorization operator bvec to \(\widetilde{\sum }\) in (12) will result in [25]:
where \({{\mathcal {B}}}={\text {diag}}\left\{ {\mathfrak {B}}_1,{\mathfrak {B}}_2,\dots ,{\mathfrak {B}}_J\right\} \), and
where \(\mathfrak {b}^{\left( \ell \right) }_k\) is given by
where \(\beta =2\) for real regressors and \(\beta =1\) for complex data.
Substituting the resulting moments in (11) and (12) leads to the following relation for deficient length diffusion LMS adaptive networks.
where
and
In steady-state, (24) yields to
Therefore, the network and local MSD and EMSE could be evaluated as:
4 Simulation results
This section compares the theoretical derivations with the computer experiments. All simulations are performed in MATLAB© software and examined in the HP laptop with Windows 10 Pro 64-bit, with Processor Intel®-coreTM i5-3340M CPU @ 2.70GHz and 8GB of RAM. All expectations are resulted from averaging over 100 independent runs. We consider a network with \(J=10\) sensors where each sensor runs a local filter with N taps to estimate the unknown vector \(w_{{L_{opt}}}^o=col\{1, 1, ..., 1 \} / \sqrt{L_{opt}}\) with length \({L_{opt}=10}\). The zero-mean Gaussian noise and regressors are independent in space, and i.i.d. in time. Their statistics profile and the network topology are illustrated in Fig. 1. The step size at each sensor is set to \(\mu _k=0.01\). Also, for the local combiners \(\{c_{k,\ell } \geqslant 0 \}\), the Metropolis rule is utilized as [25]:
where \({j_k}\) Indicates the degree of node k, i.e., \(j_k = | {\jmath _k}|\).

Network topology a, and statistical settings b for \(J=10\) sensors
Figure 2 shows the steady-state MSD per node, where every node runs an adaptive filter of lengths \(N=5\), \(N=8\) (to model the deficient length scenario), and \(N=10\) (which implies the sufficient length scenario). As can be seen from this figure, there is a good match between simulation and theoretical results. Also, this figure confirms that by decreasing the tap-length from its actual value, the steady-state MSD deteriorates drastically, such that, for only two units of length reduction (\(N=8\)), the steady-state MSD in node \(\#1\) decreases from −51.49 to −6.98 dB.

The steady-state local MSD vs. node for \(N=5\) a, \(N=8\) b, and \(N=10\) c
A similar achievement is observed for the EMSE evaluation criterion, illustrated in Fig. 3. This figure confirms the close match between simulation and theoretical results of the EMSE measure. According to Fig. 3, similar to MSD, by decreasing the tap length from its actual value, the performance from the steady-state EMSE point of view degrades considerably. For example, for node \(\#7\), as indicated in Fig. 3, for tap lengths \(N=3\), \(N =7\), and \(N =10\), the steady-state EMSE is −3.75, −7.54, and −53.55 dB, respectively.
It is evident from Figs. 2 and 3 that the steady-state MSD and EMSE are sensitive to the sensor statistics in both sufficient and deficient length scenarios.

The steady-state local EMSE vs. node for \(N=3\) a, \(N=7\) b, and \(N=10\) c
The dependency of the steady-state MSD and EMSE on the filter tap-length is seen clearly in Fig. 4. According to this figure, the steady-state measures are improved as the tap length tends to its actual value. However, this improvement occurs slowly for \(N<{L_{opt}}\), changing the length from 9 to 10 improves the value of the steady-state measures by about 41 dB.

Network MSD a, and Network EMSE b per N
Figures 5 and 6 show another interesting finding concerning deficient length diffusion LMS adaptive networks: in the case of deficient length, the steady-state MSD and EMSE curves continue to grow at a slower rate as \(\mu \) increases. These figures also reveal the acceptable matching between simulation and theoretical findings. Also, we can see from these figures that, by tending the tap length to its optimum value, the performance increases as expected. As can be seen from Fig. 5, by decreasing the step size from 0.01 to 0.001, the network MSD is improved by about 10.483 dB in the case of sufficient length, but this improvement is about 0.006 dB in the case of deficient length N = 6.

Network MSD vs. \(\mu \) for deficient length aand full length b scenarios

Network EMSE vs. \(\mu \) for deficient length a and full length b scenarios
5 Concluding remarks
In this paper, we studied the steady-state behavior of the deficient length diffusion LMS algorithm. We provided a closed-form expression for the EMSE and MSD of each node to clarify the efficiency of length deficiency on the steady-state performance of each sensor. The results verified the dependency of the steady-state MSD and EMSE on the filter tap length. It was concluded that the performance of diffusion adaptive networks is considerably affected in the deficient length scenario, or equivalently, the steady-state measures are improved as the tap length tends to its actual value. Unlike the full-length case, where the steady-state MSD and EMSE decrease significantly with the step size reduction, this research showed that in the deficient-length scenario, there are no considerable improvements in the steady-state performance by reducing the step size, or equivalently, in the case of deficient length, the steady-state MSD and EMSE curves continue to grow at a slower rate as step-size increases. Therefore, it can be concluded that the tap length plays a critical role in diffusion adaptive networks since the performance deterioration due to the deficient selection of tap length could not be compensated by an adjustment in the step size.
References
Azarnia G, Tinati MA, Sharifi AA, Shiri H (2020) Incremental and diffusion compressive sensing strategies over distributed networks. Digital Signal Process 101:102732
Cattivelli FS, Sayed AH (2010) Diffusion LMS strategies for distributed estimation. IEEE Trans Signal Process 58(3):1035–1048
Gao W, Chen J, Richard C (2021) Transient theoretical analysis of diffusion RLS algorithm for cyclostationary colored inputs. IEEE Signal Process Lett 28:1160–1164
Zayyani H (2021) Robust minimum disturbance diffusion LMS for distributed estimation. IEEE Trans Circuits Syst II Express Briefs 68(1):521–525
Khalili A, Vahidpour V, Rastegarnia A, Bazzi WM, Sanei S (2021) Partial diffusion kalman filter with adaptive combiners. IEEE Trans Aerosp Electron Syst 57(3):1972–1980
Song P, Zhao H, Zhu Y (2021) Robust multitask diffusion affine projection algorithm for distributed estimation. IEEE Trans Circuits Syst II Express Briefs 69(3):1892–6
Abadi MSE, Ahmadi MJ (2018) Diffusion improved multiband-structured subband adaptive filter algorithm with dynamic selection of nodes over distributed networks. IEEE Trans Circuits Syst II Express Briefs 66(3):507–511
Abadi MSE, Adabi AP (2019) Convex combination of two diffusion LMS for distributed estimation. In: 2019 27th Iranian conference on electrical engineering (ICEE), , IEEE, pp 1715–1719
Jin D, Chen J, Richard C, Chen J, Sayed AH (2020) Affine combination of diffusion strategies over networks. IEEE Trans Signal Process 68:2087–2104
Yu Y, Zhao H, de Lamare RC, Zakharov Y, Lu L (2019) Robust distributed diffusion recursive least squares algorithms with side information for adaptive networks. IEEE Trans Signal Process 67(6):1566–1581
Song P, Zhao H, Zeng X (2019) Robust diffusion affine projection algorithm with variable step-size over distributed networks. IEEE Access 7:150484–150491
Hua F, Nassif R, Richard C, Wang H, Sayed AH (2020) Diffusion LMS with communication delays: stability and performance analysis. IEEE Signal Process Lett 27:730–734
Gao W, Chen J (2019) Performance analysis of diffusion LMS for cyclostationary white non-gaussian inputs. IEEE Access 7:91243–91252
Zhang M, Jin D, Chen J, Ni J (2021) Zeroth-order diffusion adaptive filter over networks. IEEE Trans Signal Process 69:589–602
Khalili A, Vahidpour V, Rastegarnia A, Bazzi WM, Sanei S (2020) Partial diffusion kalman filter with adaptive combiners. IEEE Trans Aerosp Electron Syst 57(3):1972–1980
Ijeoma CA, Hossin MA, Bemnet HA, Tesfaye AA, Hailu AH, Chiamaka CN (2020) “Exploration of diffusion LMS over static and adaptive combination policy,” In: 2020 17th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), pp. 424–427, IEEE
Merched R, Vlaski S, Sayed AH (2019) Enhanced diffusion learning over networks. In: 2019 27th European signal processing conference (EUSIPCO), IEEE, pp 1–5
Erginbas YE, Vlaski S, Sayed AH (2021) Gramian-based adaptive combination policies for diffusion learning over networks. In: ICASSP 2021-2021 IEEE international conference on acoustics, speech and signal processing (ICASSP), IEEE, pp 5215–5219
Li L, Feng J, He J, Chambers JA (2013) A distributed variable tap-length algorithm within diffusion adaptive networks. AASRI Procedia 5:77–84
Zhang Y, Wang C, Zhao L, Chambers JA (2015) A spatial diffusion strategy for tap-length estimation over adaptive networks. IEEE Trans Signal Process 63(17):4487–4501
Azarnia G (2021) Diffusion fractional tap-length algorithm with adaptive error width and step-size. Circuits, Syst Signal Process 41(1):321–45
Li L, Zhang Y, Chambers JA (2008) Variable length adaptive filtering within incremental learning algorithms for distributed networks. In: 2008 42nd Asilomar conference on signals, systems and computers, IEEE, pp 225–229
Azarnia G, Hassanlou M (2021) A variable tap-length dilms algorithm with variable parameters for wireless sensor networks. Int J Sensor Netw 36(2):97–107
Azarnia G, Tinati MA (2015) Steady-state analysis of the deficient length incremental LMS adaptive networks. Circuits Syst Signal Process 34(9):2893–2910
Lopes CG, Sayed AH (2008) Diffusion least-mean squares over adaptive networks: formulation and performance analysis. IEEE Trans Signal Process 56(7):3122–3136
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Azarnia, G. Steady-state analysis of diffusion least-mean squares with deficient length over wireless sensor networks. Computing 105, 2443–2458 (2023). https://doi.org/10.1007/s00607-023-01187-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00607-023-01187-5