
Abstract
Prediction of ultimate pile bearing capacity with the aid of field experimental results through artificial intelligence (AI) techniques is one of the most significant and complicated problem in pile analysis and design. The aim of this research is to develop a new AI predictive models for predicting pile bearing capacity. The first predictive model was developed based on the combination of adaptive neuro-fuzzy inference system (ANFIS) and group method of data handling (GMDH) structure optimized by particle swarm optimization (PSO) algorithm called as ANFIS–GMDH–PSO model; the second model introduced as fuzzy polynomial neural network type group method of data handling (FPNN–GMDH) model. A database consists of different piles property and soil characteristics, collected from literature including CPT and pile loading test results which applied for training and testing process of developed models. Also a common artificial neural network (ANN) model was applied as a reference model for comparing and verifying among hybrid developed models for prediction. The modelling results indicated that improved ANFIS–GMDH model achieved relatively higher performance compared to ANN and FPNN–GMDH models in terms of accuracy and reliability level based on standard statistical performance indices such as coefficient of correlation (R), mean square error, root mean square error and error standard deviation values.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Taking into consideration the complex behavior associated with the soil along with soil-structure interaction, measuring the pile loading bearing capacity, is considered as one of the most challenging problems in geotechnics. Different researchers have proposed various methods for forecasting the piles bearing capacity [1,2,3]. In some of these methods such as pile static analysis, and pile empirical analysis relations due to the simplification is made, selection of a large safety factor is unavoidable which causes low accuracy and loss of resources [4]. In some other methods, like the pile loading test procedures despite the high percentage of reliability, application of these methods can make noneconomic, time-consuming, and cause high costs of setup [5, 6]. Cone penetration test (CPT) is one of the most common in situ field tests considered due to its simplicity, high speed, and relatively low cost. In addition, CPT could make an achievement a continuous output at soil depths; also since the similarity characteristics between penetrometer cone tip related to pile tip and cone sleeve related to pile friction surface, estimating the piles bearing capacity is one of common CPT applications [7]. There are two approaches to the use of CPT results in designing piles [8]. The direct approach calculates piles bearing capacity using CPT results and indirect approach which calculates pile bearing capacity using the soil specifications obtained from CPT results [9, 10]. The use of computational intelligence in estimating the bearing capacity of piles based on the CPT results classified as direct approaches [11, 12]. Despite the significant progress of soil mechanics and geotechnical engineering in recent decades, determination of pile bearing capacity is considered as a difficult issue. Mechanical properties and the physical behavior of the soils and also piles diversity lead to interaction between the pile and surrounding soils [13, 14]. Soil specifications could be varied due to nonhomogeneous, anisotropy, the presence of water and complex stress–strain behavior; also, sometimes due to various region conditions, the pile properties can be changeable such as the type, material, shape, construction and setups methods [15, 16]. With respect to the mentioned reasons, modeling such complex conditions including interaction among different parameters is not simply possible. Therefore, a large number of investigators [17, 18] have made incorporations over the past decades to provide theoretical or empirical relationships for determining the bearing capacity of the piles [6, 19]. However, each method using different input parameters associated with the laboratory conditions and the simplified assumptions may not be satisfactory for solving pile analysis and design in practice [20]. Therefore, the use of analytical and semi-experimental methods leads to an inaccurate determination of the bearing capacity of the piles [21]. Due to the high cost of laboratory and field tests of deep foundations as well as the need to optimally design pile structure, many researchers [22, 23] have been proposed to apply artificial intelligence (AI) techniques as complementary and alternative methods of the existing traditional methods for estimating the bearing capacity of piles [24,25,26,27].
Artificial neural networks (ANNs) and other AI algorithms inspired by the structure and function of the human brain which have been widely used in various field of science and engineering in recent years [28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63]. Many researchers have also used a wide range of these techniques for pile capacity prediction recently [64,65,66,67, 12, 68]. The results of this research reported the accuracy and reliability of AI and soft computing methods [9, 69] in predicting pile bearing capacity. Later on, another polynomial neural network [70] was developed known as group method of data handling (GMDH) which was used to predict axial pile bearing capacity in geotechnical engineering [71, 72]. Recently, the use of subset of the AI techniques such as the GMDH type neural network, genetic algorithm (GA) and the fuzzy logic theory and their parallel integration have led to the development of advanced hybrid computing algorithms [3, 73,74,75,76]. The hybrid synergies structure of these approaches had important significance for researchers [77,78,79,80]. Some degrees of success in the field of combining of these approaches have been reported to improve structure and tuning parameters of each specific algorithm during recent years [27, 50, 81]. The objective of this research is to achieve a novel hybrid neural network through combining GMDH type neural network by substituting structure of adaptive neuro-fuzzy inference system (ANFIS) in each partial description and finally to improve new hybrid ANFIS–GMDH network using particle swarm optimization (PSO) method to develop ANFIS–GMDH–PSO model for evaluation and prediction of the ultimate pile bearing capacity. Along with the development of ANFIS–GMDH–PSO, another model called as fuzzy polynomial neural network type GMDH (FPNN–GMDH) is extended for comparison purposes in terms of accuracy and overall performance against each developed model.
2 Theoretical concepts
2.1 Framework of group method of data handling (GMDH) type neural network structure
The idea associated with ANNs stimulation through modeling structure of the complex human brain, known as a non-linear, parallel performing approach [82]. GMDH type neural network structure is the self-organizing method by which a behavior system identified by assessment of their performances over a provided set of multi-input single output dataset \((x_{i} ,\,x_{j} )\,,\,(i = 1,2, \ldots ,M)\). The concept of the GMDH network is to make an analytic function within a feed-forward network determined by a polynomial transfer function in which coefficients attained applying the particular regression process [71]. By applying the GMDH algorithm, a model displayed as a set of neurons through which various sets in every single layer usually interconnected through a quadratic polynomial, creating new neurons inside the subsequent layer. These types of representation employed to map inputs space to outputs space. The basic description of the identification issue is to uncover a function \((\hat{f})\) utilized as opposed to the desired function \((f)\) as a way to predict output result \((\hat{y})\) for any provided input vector \(X = \left( {x_{1} ,\,x_{2} ,\,x_{3} , \ldots ,\,x_{n} } \right)\) as close as possible towards the target value (y). For that reason, provided M observations involving multivariable input–single variable output dataset:
It could be practical to train a GMDH type of ANN to estimate predicted values \((\hat{y}_{i} )\) considered to be for each provided input vector (X):
The main issue is to specify a GMDH type neural network to ensure the square of the differences between observed and expected output values minimized as follows:
An elaborate discrete type of the Volterra functional series, referred to as Kolmogorov-Gabor polynomial can present the general relationship among input and output parameters space. As a result:
This specific full form of mathematically description typically exhibited using a solution of partial quadratic polynomials made from simply two variables (neurons) by applying Eq. (5) as follow:
Using this approach, the description of a partial quadratic is recursively applied to interconnected neurons network to develop the standard mathematical relation concerning inputs and output provided in Eq. (4). The ai coefficients in Eq. (5), computed by applying the regression method to decrease the main difference between observed output values (y) and predicted the output ones \((\hat{y})\) for each pair input parameters \((x_{i} ,\,x_{j} )\). Clearly, a tree of polynomials developed by utilizing the quadratic type provided in Eq. (5) whose coefficients achieved by the least squares method. The coefficients of each quadratic function Gi obtained for an optimum fitting for that output associated with the total pairs of input–output data sets based on minimizing Eq. (6) criteria:
For the standard form of GMDH type neural network formula, all possibilities of two independent variables from the total n input variables are taken into account to construct the regression polynomial by the use of Eq. (5) that most closely fit the dependent observations \((y_{i} \,,\,\,\,i = 1,\,2, \ldots ,\,M)\,\) based on the least squares perspective.
Therefore, \(\left( \begin{aligned} n \hfill \\ 2 \hfill \\ \end{aligned} \right) = \frac{n(n - 2)}{2}\) neurons established within the first hidden layer from the feedforward network using the observations \(\left\{ {(y_{i} ,\,x_{ip} ,\,x_{iq} );\,(i = 1,2,3, \ldots ,M)} \right\}\) using \(p,q \in \,\left\{ {1,\,2,\,3, \ldots ,\,n} \right\}\) in the form of Eq. (7):
From the quadratic sub-expression, using Eq. (5) per each row of M data triples, the below matrix formulation achieved through Eq. (8) to Eq. (11), respectively:
The least squares technique from the multiple regression analysis leads to a solution of the characteristic equations, in the following form:
The solution determines the coefficients vector of Eq. (5) for all range of M dataset triples. It observed that this process repeated for every neuron of any succeeding hidden layer as outlined by the interconnection topology in this network.
2.2 Framework of fuzzy polynomial neural network GMDH (FPNN–GMDH) structure
In FPNN–GMDH structure, partial descriptions are in the form of RBF networks. In each network, this partial description that each of which has two inputs introduced, and network structure created as a hierarchy of these blocks. If M describes the number of partial descriptions in each layer and P is the number of layers of the network, output calculation procedure in the network as follows:
If \(A_{ki} (x_{i} )\) represents the membership function for the kth fuzzy rule in the domain of ith input variable, then its membership function calculated with Eq. (13):
In which L could adopt the values of 1 and 2. The inference part of fuzzy inference engine to conclude y value, presented by a coefficient such as \(w_{i}\) coefficient. For mth partial description in pth layer, the output calculated as follows Eq. (14):
In which the membership function is chosen as Eq. (15):
In which Eq. (14) known as RBF network. In the end, FPNN–GMDH model output calculated as follow according to Eq. (16):
Figure 1 represents a sample of this network that has three layers and, in each layer, has assigned three partial descriptions. The researchers introduced different methods to train FPNN model. Most common methods are gradient descent method, structural learning with forgetting (SLF) [83], MSLF [84]. Also, other various intelligence optimization methods proposed by researchers in recent years including evolutionary algorithms [85], and meta-heuristics methods such as PSO [86, 87].

Structure of FPNN–GMDH with six input variables
2.3 Framework of adaptive network based-fuzzy inference system (ANFIS) structure
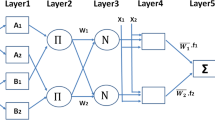
In this article, an overview of Takagi–Sugeno type Adaptive Neuro-Fuzzy Inference System (ANFIS) network discussed. ANFIS structure takes advantage from two main fields of the fuzzy logic and neural network concepts [88]. If two approaches combined with each other, the better results will achieve the best performance regarding quality and quantity due to fuzzy wisdom and neural networks computational ability [89]. Like other types of fuzzy-neural systems, ANFIS framework consists of two parts. The primary section is an antecedent, and the subsequent section is a consequence part so that these two parts connected to each other by a set of rules. Five layers observed in ANFIS structure considered as a multi-layer network. A sample of ANFIS structure is shown in Fig. 2. The 1st layer performs fuzzification, the 2nd layer completes fuzzy (AND/OR) operations and developing fuzzy rules; the 3rd layer performed the membership functions normalization; the 4th layer carries out fuzzy rules inference, and at last, the 5th layer calculates the output of the network (system predicted output).

ANFIS architecture including two inputs, four rules, and one output
Formulated equations regarding ANFIS network are listed as follows:
ANFIS network uses fuzzy membership functions, and most important membership functions are Bell-shaped functions having minimum and maximum values of zero and one, respectively, as follows:
In which \(\left\{ {x_{i} ,b_{i} ,\sigma_{i} } \right\}\), the parameters associated with a membership function shape.
Various methods have been proposed to train ANFIS network. The most common approach among them is gradient descent method that can minimize the output error. Other hybrid methods were introduced for training this network as training consequence part by gradient descent method and training antecedent part by PSO [24]. Training of both the antecedent and consequence parts of ANFIS structure using evolutionary optimization techniques, for instance, GA or meta-heuristic optimization methods e.g., PSO and gravitational search algorithm are among the other intelligence optimization methods [90,91,92].
2.4 MLP–ANNs framework
Artificial neural networks (ANNs) which have developed by McCulloch and Pitts [93], are information processing patterns made by mimicking the neural network of the human brain. ANN consists of input, hidden, and output layers. In each layer, there is a set of interconnected processor components (neurons) whose output is the input layer of the next layer. The output signal from one layer will be connected to the next layer by means of weight factors through an intermediate that amplifies or weakens the signals [94]. An active function such as the linear or sigmoid function will be used to calculate the outputs of neurons in the hidden and output layers. The number of neurons in the input and output layers is determined by the number of input and output variables. Given the number of neurons in the hidden layer, there is no specific way; however, the number of hidden layers is determined by the number of neurons according to the complexity of the problem and the trial and error method [95]. There are several neural networks with different training algorithms, but a review of the articles shows that forward training with back-propagation (BP) algorithm is commonly used in different areas such as mining and geotechnical engineering [96,97,98,99,100]. The ANN modeling process can be summarized in two main parts: (1) assigning network structure and (2) adjusting the weight of connections between neurons. In the BP algorithm, weights will be determined by minimizing the error between the outputs and the value predicted by the ANN and the error returns to the input layer. Finally, the network response will be obtained as the model output [95]. In the next step, if the response is different from the target value, the bias correction will start to reduce the error rate. Therefore, the BP algorithm was used in this study [101]. However, the feedforward back propagation suffers from convergence problems and is trapped in the local minimum. Figure 3 illustrates the architecture of common ANN used in this study as a benchmark model for comparative purposes with other models [101].

Traditional ANN structure
3 Pile and soil information
A compiled dataset collected from published paper based on CPT results and PLT results to develop and running different predictor hybrid models related to pile capacity evaluation. Databank compiled from various sources: The most provided by those found in literature together with the experimental field test reported in past years in some southern area of Iran. An ongoing database consisted of soil characteristics, pile properties (pile embedded length, pile cross-section shape, pile material), CPT results including the resistance of cone tip and the sleeve friction of cone and ultimate pile capacity (Qt) derived from in situ pile loading tests (PLT). Two important types of parameters influence Qt; a group associated with the measured soil properties, and other groups relevant to pile characteristics. Typically, soil characteristics close to embedded piles could be assumed described by CPT output results including the resistance of cone tip (QC) and cone sleeve friction resistance (FS) in most cases. Therefore, CPT results utilized as the representation of soil parameters which influencing Qt values. Pile geometry specifications (length and diameter) involving pile characteristics which effecting on Qt. Additionally, unmodified CPT results were applied through modeling process since they are seldom included the pore pressure measurement using CPT due to the cone device limitation in the past; also pile load tests were performed by different researchers over 72 piles collected in literature reviews used in this study shown in Table 1. Pile setup and establishment installed by hammer and jack driving tools; Some of which are concrete piles while remaining ones are steel piles [69]. Limited offset load adopted as the standard reference for piles bearing capacity calculations derived from PLT results [102].
In the following section, new AI hybrid models were developed to evaluate the ultimate pile bearing capacity using the collected database according to Table 1 for training and testing stage of proposed AI models; finally, the performance of developed models were compared to each other with the aid of applying conventional ANN as a reference model based on statistical indices criterion. The methodology flowchart of this study is briefly described in Fig. 4 and in Sect. 4.

The flowchart of this study
4 Methods
In this section, the researchers intend to combine the structure of two soft computing approaches called as ANFIS algorithm and GMDH algorithm to develop new hybrid network model called as ANFIS–GMDH. Furthermore, to optimize the structure of developed ANFIS–GMDH network model for pile bearing capacity prediction, first a brief description of particle swarm optimization algorithm was described; then, through applying PSO method over topology of desired ANFIS–GMDH model, the membership function parameters and network structure was improved to achieve better performance model (ANFIS–GMDH–PSO) compared to another model (FPNN–GMDH). Finally, the prediction and regression results of applied two developed models compared to each other based on some common statistical criteria. The result was shown graphically by charts and tabulated by tables for each developed model to verify the precision and performance in training and testing stages for each predictor model in predicting pile bearing capacity.
4.1 Development of hybrid ANFIS–GMDH structure
In this part, the new structure of GMDH type neural network has discussed in which partial descriptions (PD’s) are ANFIS networks having two inputs in place of RBF structure. Each partial description is an ANFIS network with two inputs in which the number selection of membership functions per each input is changeable. Accordingly, the output of each partial description (PD) defined as follows in Eq. (23) through Eq. (24):
In which m is partial description number in the pth layer, n is the selected number of membership functions intended for inputs and q coefficients are real numbers. In this case, the network output achieved based on Eq. (25):
The notation M refers to the number of partial descriptions in the last layer.
4.2 Description and development of PSO algorithm on ANFIS–GMDH topology
The ANFIS–GMDH network model has different components which could be optimized by common meta-heuristic algorithms such as PSO method; the PSO algorithm has been employed for improving the structure of ANFIS–GMDH network model through optimizing the membership functions and tuning associated parameters in PDs. The PSO algorithm was proposed by Kennedy and Ebertman which inspired by the social behavior of animals such as fish, insects, and birds [91]. Each member in a bunch acts like a particle that these particles make massive batches and each particle is like a potential solution for optimization problem; for instance, the ith particle with tth iteration has the \(X_{i}^{t}\) position vector and \(V_{i}^{t}\) velocity vector, as follow in Eq. (26) and (27):
where D indicates solution space dimension.
The particle can move across the position vector and its position varies with its speed. The best position of a particle is called (pbest) and the best global position is (gbest) and the bunch experience them in its first iteration.
where \(r_{1}\) and \(r_{2}\) = two uniform random values sequences generated from interval [0 1], \(c_{1}\) and \(c_{2}\) = cognitive and social scaling parameters, respectively.
PSO is very sensitive to the inertial weight (w) parameter which has an inverse relationship with the number of iterations.
where \(w_{ \rm{max} }\) and \(w_{ \rm{min} }\) = maximum and minimum values of w, respectively, and \(t_{ \rm{max} }\) = limit numbers of optimization iteration.
We can combine the PSO algorithm with the ANFIS–GMDH model and get into the ANFIS–GMDH–PSO model that generates three PD in the first layer. The second layer is created using the PD form of the first layer and finally, the ANFIS–GMDH–PSO model is optimized with three layers.
The particles, P, are initialized with random positions and velocities, then the population is evaluated. Initialize the \(p{\text{best}}_{i}^{k}\) with a copy of the position for each particle such as \(X_{i}^{k}\). If the final condition is satisfactory, the flowchart reaches to \(g{\text{best}}_{i}^{k}\) and if not, the updating process of velocities and the positions will be performed; then evaluating the population again parallel to updating \(p{\text{best}}_{i}^{k}\) and \(g{\text{best}}_{i}^{k}\). Eventually, k = k + 1 is gained; the flowchart of PSO algorithm and the flowchart process of combining PSO topology on developed ANFIS–GMDH model were shown in Fig. 5a, b, respectively.

a Flowchart of the PSO algorithm. b Flowchart of ANFIS–GMDH model optimized by PSO algorithm

Results of performance indices of the ANN model for training and testing stages in predicting pile bearing capacity

Predicted vs. measured values plot for ANN model in train and test stages

Results of performance indices of FPNN–GMDH model in pile bearing capacity prediction
5 Predictive AI models evaluation
In this research, to verify best-fitted models for predicting pile capacity, some statistical parameters such as coefficient of correlation (R), mean square error (MSE), root mean square error (RMSE) were calculated to evaluate the performance prediction of the developed models as in following equations:
in which \(y_{{i({\text{Model}})}}\) implies predicted value (model output) for each observation (i = 1,2,…, M), \(y_{{i({\text{Actual}})}}\) is target value (measured value), M is the number of observations and E indicate the error value between measured actual values and model outputs for each observation within the dataset.
For comparative purposes, the same training and test datasets were used for all estimator AI models, respectively, while above quantitative performance evaluation criteria were applied to evaluate different models’ performance. The degree of accuracy and reliability of predicted output values (Pile Capacity) determined using R, MSE and RMSE known as statistical indications. Theoretically, a predictive model could be perfect if R = 1, MSE/RMSE = 0 obtaining lower error mean parallel with minimum error standard deviation (error StD) in some cases depends on scattering and outlier nature of datasets. The results of the model performance indices for the best ANN, FPNN–GMDH and ANFIS–GMDH–PSO models for data training and testing stages presented in Table 2.
As illustrated in Figs. 9 and 11 respectively, it was determined that the ANFIS–GMDH–PSO model’ performance were relatively higher than the FPNN–GMDH model’ performance in train and test stages. The results of the integrated FPNN–GMDH approach based on R values are 0.93 and 0.92, respectively, shown Fig. 8 for train and test datasets, while hybrid ANFIS–GMDH–PSO model achieves the values of 0.94 and 0.96 for R values for train and test stages, respectively, according to Fig. 10. Moreover, RMSE values of 0.048 and 0.069 for training and testing stages of ANFIS–GMDH–PSO model show that the proposed hybrid model could be introduced in pile bearing capacity calculation as the more effective accurate model in comparison to other developed models according to Figs. 6, 7 and 8. It was observed from Table 1 that two developed hybrid AI models (FPNN–GMDH and ANFIS–GMDH–PSO) perform well during training and testing phase compared to traditional ANN’s; and also these methods shown better performance rather than ANN benchmark model utilized in this study for all mentioned statistical criteria. To estimate the bearing capacity of the piles, in the training stage, the ANFIS–GMDH–PSO model achieved the best R, MSE, RMSE, and Error StD of 0.94, 0.002, 0.048 and 0.048, respectively, based on Fig. 10; while according to Figs. 6 and 8, it was shown that the FPNN–GMDH model obtained better results than ANN model. By analyzing the results during the testing stage, it was determined that the optimized ANFIS–GMDH model performs better than all the other models overall based on Fig. 10. The relation between the best-fitted ANN, FPNN–GMDH, ANFIS–GMDH–PSO models and measured actual values in pile bearing capacity prediction for train and test datasets are shown in Figs. 7, 9 and 11, respectively. Also there is a significant difference among the results of a new developed model (ANFIS–GMDH–PSO) and other developed models (ANN, FPNN–GMDH). This can be justified by the use of PSO algorithm to adjust the weights and bias of the hybrid network structure during the learning process. As indicated in Table 2, the performance indices demonstrate that the results derived from ANFIS–GMDH–PSO model are much correlated in pile bearing capacity forecast and have demonstrated that this model can estimate pile capacity with a high level of precision. In addition, the plots of predicted versus measured ultimate pile bearing capacity for ANFIS–GMDH–PSO model performance were shown through Fig. 11 for train and test phases. The RMSE estimates the residual between the observed and the predicted values. R evaluates the linear correlation between the observed and calculated values while E evaluates the model’s ability to predict mean values. According to the statistics presented in Table 2, it can be concluded that the best performance of all the methods of artificial intelligence developed in this paper differs in terms of different statistical criteria. It is noted that during the modelling procedure, there is no significant limitation on running developed hybrid algorithms, however, it should be taken into account that due to the limitation of the existing datasets (72 datasets) introduced to the optimum model it is not possible to further train the network to achieve best model performance over test dataset; therefore it is valuable to consider big datasets for AI network training stage if expects to get a better degree of accurate results from optimum models.

Predicted vs. measured values plot for FPNN–GMDH model in train and test stages

Results of performance indices of ANFIS–GMDH–PSO model in pile bearing capacity prediction

Predicted vs. measured values plot for ANFIS–GMDH–PSO model in train and test stages
6 Conclusions
In this study, one of the most significant problems related to predicting ultimate pile bearing capacity of deep foundations has been solved with the aid of in situ field CPT and PLT results through utilizing new developed AI models. An experimental database was collected from existing literature review including cone penetration test (CPT) and pile loading tests (PLT) results were applied for constructing and developing different AI models. Two new hybrid AI methods (FPNN–GMDH, ANFIS–GMDH–PSO) were developed simultaneously with applying ANN model for comparing and validating best-fitted predictive model among developed ones in terms of the degree of accuracy and performance indices based on standard statistical parameters. According to the derived modeling results for different mentioned AI models, the following conclusions would present:
-
Based on results derived from two different hybrid neural models under consideration, it was concluded that model based on optimized ANFIS–GMDH–PSO network model shown better performance than FPNN–GMDH and also ANN models due to having lowest value of RMSE and highest value of R. It observed that two developed models could employ as a form of new hybrid soft computing tool which showing acceptable degree of precision in the field of geotechnical engineering problems. In this respect, the new alternative approaches possibly could substitute instead of using in situ field experimental tests and semi-empirical regression based-equations methods related to ultimate pile bearing capacity assessment that lead to high cost-time consuming, unreliability and uncertainty in case of complicated executive conditions.
-
It can be concluded to extend furthermore improving the hybrid structure network while developing hybrid ANFIS–GMDH by applying other intelligent meta-heuristics optimization technique such as GA, and imperialism competitive algorithms for future investigation.
-
For simplicity reason, in constructing of structure network with lower complex structure, both ANFIS-GMD-PSO and FPNN–GMDH topology have been created based on assumed setting parameters by the user that leads to algorithm running time as faster as possible in MATLAB programming language.
-
Statistical indices such as R, MSE, RMSE, and Error StD were used as model structure evaluation criterion associated with the various models developed. During the modeling and testing process, it was found that the developed ANFIS–GMDH–PSO model had a relatively high level of accuracy and precision for estimating the bearing capacity of the piles compared to the other developed models so that the predicted values had a relatively high correlation with the measured values. Relative error estimation shows relatively good performance in the hybrid models developed in the test process.
References
Mayerhof GG (1976) Bearing capacity and settlemtn of pile foundations. J Geotech Geoenvironmental Eng 102 ASCE# 11962
Maizir H, Suryanita R, Jingga H (2016) Estimation of pile bearing capacity of single driven pile in sandy soil using finite element and artificial neural network methods. Int J Appl Phys Sci 2:45–50
Armaghani DJ, Bin Raja RSNS, Faizi K, Rashid ASA (2017) Developing a hybrid PSO–ANN model for estimating the ultimate bearing capacity of rock-socketed piles. Neural Comput Appl 28:391–405
Shahin MA (2013) Artificial intelligence in geotechnical engineering: applications, modeling aspects, and future directions. In: Yang X, Gandomi AH, Talatahari S, Alavi AH (eds) Metaheuristics water, geotechnical and transport engineering. Elsevier Inc, London, pp 169–204
Zhang L (2004) Reliability verification using proof pile load tests. J Geotech Geoenvironmental Eng 130:1203–1213
Kondner RL (1963) Hyperbolic stress-strain response: cohesive soils. J Soil Mech Found Div 89:115–144
Kordjazi A, Nejad FP, Jaksa MB (2014) Prediction of ultimate axial load-carrying capacity of piles using a support vector machine based on CPT data. Comput Geotech 55:91–102
Cai G, Liu S, Tong L, Du G (2009) Assessment of direct CPT and CPTU methods for predicting the ultimate bearing capacity of single piles. Eng Geol 104:211–222
Shahin MA, Jaksa MB, Maier HR (2009) Recent advances and future challenges for artificial neural systems in geotechnical engineering applications. Adv Artif Neural Syst 2009:1–9. https://doi.org/10.1155/2009/308239
Schneider JA, Xu X, Lehane BM (2008) Database assessment of CPT-based design methods for axial capacity of driven piles in siliceous sands. J Geotech Geoenviron Eng 134:1227–1244
Shahin MA (2010) Intelligent computing for modeling axial capacity of pile foundations. Can Geotech J 47:230–243
Alkroosh I, Nikraz H (2012) Predicting axial capacity of driven piles in cohesive soils using intelligent computing. Eng Appl Artif Intell 25:618–627
Shahin MA (2016) State-of-the-art review of some artificial intelligence applications in pile foundations. Geosci Front. https://doi.org/10.1016/j.gsf.2014.10.002
Maizir H, Suryanita R (2018) Evaluation of axial pile bearing capacity based on pile driving analyzer (PDA) test using Neural Network. In: IOP conference series: earth and environmental science. IOP, p 12037
Momeni E, Armaghani DJ, Hajihassani M, Amin MFM (2015) Prediction of uniaxial compressive strength of rock samples using hybrid particle swarm optimization-based artificial neural networks. Measurement 60:50–63
Lima DC de, Tumay MT (1991) Scale effects in cone penetration tests. In: Geotechnical engineering congress—1991. ASCE, pp 38–51
Liu L, Moayedi H, Rashid ASA et al (2019) Optimizing an ANN model with genetic algorithm (GA) predicting load-settlement behaviours of eco-friendly raft-pile foundation (ERP) system. Eng Comput. https://doi.org/10.1007/s00366-019-00767-4
Moayedi H, Moatamediyan A, Nguyen H et al (2019) Prediction of ultimate bearing capacity through various novel evolutionary and neural network models. Eng Comput. https://doi.org/10.1007/s00366-019-00723-2
Semple RM, Rigden WJ (1984) Shaft capacity of driven pipe piles in clay. In: Analysis and design of pile foundations. ASCE, pp 59–79
Randolph MF (2003) Science and empiricism in pile foundation design. Géotechnique 53:847–875
Ghorbani B, Sadrossadat E, Bazaz JB, Oskooei PR (2018) Numerical ANFIS-based formulation for prediction of the ultimate axial load bearing capacity of piles through CPT data. Geotech Geol Eng 36:2057–2076
Shaik S, Krishna KSR, Abbas M et al (2018) Applying several soft computing techniques for prediction of bearing capacity of driven piles. Eng Comput. https://doi.org/10.1007/s00366-018-0674-7
Sulewska MJ (2017) Applying artificial neural networks for analysis of geotechnical problems. Comput Assist Methods Eng Sci 18:231–241
Moayedi H, Armaghani DJ (2018) Optimizing an ANN model with ICA for estimating bearing capacity of driven pile in cohesionless soil. Eng Comput 34:347–356
Nawari NO, Liang R, Nusairat J (1999) Artificial intelligence techniques for the design and analysis of deep foundations. Electron J Geotech Eng 4:1–21
Momeni E, Nazir R, Jahed Armaghani D, Maizir H (2014) Prediction of pile bearing capacity using a hybrid genetic algorithm-based ANN. Meas J Int Meas Confed. https://doi.org/10.1016/j.measurement.2014.08.007
Momeni E, Nazir R, Armaghani DJ, Maizir H (2015) Application of artificial neural network for predicting shaft and tip resistances of concrete piles. Earth Sci Res J 19:85–93
Yang Y, Rosenbaum MS (2002) The artificial neural network as a tool for assessing geotechnical properties. Geotech Geol Eng 20:149–168
Asteris PG, Plevris V (2017) Anisotropic masonry failure criterion using artificial neural networks. Neural Comput Appl 28:2207–2229
Zhou J, Li E, Yang S et al (2019) Slope stability prediction for circular mode failure using gradient boosting machine approach based on an updated database of case histories. Saf Sci 118:505–518
Toghroli A, Suhatril M, Ibrahim Z, Safa M, Shariati M, Shamshirband S (2018) Potential of soft computing approach for evaluating the factors affecting the capacity of steel–concrete composite beam. J Intell Manuf 29(8):1793–1801
Chen C, Shi L, Shariati M et al (2019) Behavior of steel storage pallet racking connection—a review. 30:457–469
Koopialipoor M, Nikouei SS, Marto A et al (2018) Predicting tunnel boring machine performance through a new model based on the group method of data handling. Bull Eng Geol Environ 78:3799–3813
Koopialipoor M, Jahed Armaghani D, Hedayat A et al (2018) Applying various hybrid intelligent systems to evaluate and predict slope stability under static and dynamic conditions. Soft Comput. https://doi.org/10.1007/s00500-018-3253-3
Koopialipoor M, Jahed Armaghani D, Haghighi M, Ghaleini EN (2017) A neuro-genetic predictive model to approximate overbreak induced by drilling and blasting operation in tunnels. Bull Eng Geol Environ. https://doi.org/10.1007/s10064-017-1116-2
Zhao Y, Noorbakhsh A, Koopialipoor M et al (2019) A new methodology for optimization and prediction of rate of penetration during drilling operations. Eng Comput. https://doi.org/10.1007/s00366-019-00715-2
Koopialipoor M, Fahimifar A, Ghaleini EN et al (2019) Development of a new hybrid ANN for solving a geotechnical problem related to tunnel boring machine performance. Eng Comput. https://doi.org/10.1007/s00366-019-00701-8
Hasanipanah M, Noorian-Bidgoli M, Jahed Armaghani D, Khamesi H (2016) Feasibility of PSO-ANN model for predicting surface settlement caused by tunneling. Eng Comput. https://doi.org/10.1007/s00366-016-0447-0
Khandelwal M, Mahdiyar A, Armaghani DJ et al (2017) An expert system based on hybrid ICA-ANN technique to estimate macerals contents of Indian coals. Environ Earth Sci 76:399. https://doi.org/10.1007/s12665-017-6726-2
Asteris PG, Nikoo M (2019) Artificial bee colony-based neural network for the prediction of the fundamental period of infilled frame structures. Neural Comput Appl. https://doi.org/10.1007/s00521-018-03965-1
Asteris PG, Nozhati S, Nikoo M, Cavaleri L, Nikoo M (2019) Krill herd algorithm-based neural network in structural seismic reliability evaluation. Mech Adv Mater Struct 26(13):1146–1153
Sarir P, Chen J, Asteris PG et al (2019) Developing GEP tree-based, neuro-swarm, and whale optimization models for evaluation of bearing capacity of concrete-filled steel tube columns. Eng Comput. https://doi.org/10.1007/s00366-019-00808-y
Asteris PG, Tsaris AK, Cavaleri L et al (2016) Prediction of the fundamental period of infilled RC frame structures using artificial neural networks. Comput Intell Neurosci 2016:20
Plevris V, Asteris PG (2014) Modeling of masonry failure surface under biaxial compressive stress using Neural Networks. Constr Build Mater 55:447–461
Cavaleri L, Asteris PG, Psyllaki PP et al (2019) Prediction of surface treatment effects on the tribological performance of tool steels using artificial neural networks. Appl Sci 9:2788
Xu C, Gordan B, Koopialipoor M et al (2019) Improving performance of retaining walls under dynamic conditions developing an optimized ANN based on ant colony optimization technique. IEEE Access 7:94692–94700
Shao Z, Armaghani DJ, Bejarbaneh BY et al (2019) Estimating the friction angle of black shale core specimens with hybrid-ANN approaches. Measurement. https://doi.org/10.1016/j.measurement.2019.06.007
Khari M, Dehghanbandaki A, Motamedi S, Armaghani DJ (2019) Computational estimation of lateral pile displacement in layered sand using experimental data. Measurement 146:110–118
Mohamad ET, Li D, Murlidhar BR et al (2019) The effects of ABC, ICA, and PSO optimization techniques on prediction of ripping production. Eng Comput. https://doi.org/10.1007/s00366-019-00770-9
Chen W, Sarir P, Bui X-N et al (2019) Neuro-genetic, neuro-imperialism and genetic programing models in predicting ultimate bearing capacity of pile. Eng Comput. https://doi.org/10.1007/s00366-019-00752-x
Asteris PG, Kolovos KG (2019) Self-compacting concrete strength prediction using surrogate models. Neural Comput Appl 31:409–424
Armaghani DJ, Hasanipanah M, Amnieh HB, Mohamad ET (2018) Feasibility of ICA in approximating ground vibration resulting from mine blasting. Neural Comput Appl 29:457–465
Yang H, Liu J, Liu B (2018) Investigation on the cracking character of jointed rock mass beneath TBM disc cutter. Rock Mech Rock Eng 51:1263–1277
Yang H, Wang H, Zhou X (2016) Analysis on the damage behavior of mixed ground during TBM cutting process. Tunn Undergr Sp Technol 57:55–65
Yang HQ, Li Z, Jie TQ, Zhang ZQ (2018) Effects of joints on the cutting behavior of disc cutter running on the jointed rock mass. Tunn Undergr Sp Technol 81:112–120
Yang H, Koopialipoor M, Armaghani DJ et al (2019) Intelligent design of retaining wall structures under dynamic conditions. Steel Compos Struct 31:629–640
Yang HQ, Lan YF, Lu L, Zhou XP (2015) A quasi-three-dimensional spring-deformable-block model for runout analysis of rapid landslide motion. Eng Geol 185:20–32
Asteris P, Roussis P, Douvika M (2017) Feed-forward neural network prediction of the mechanical properties of sandcrete materials. Sensors 17:1344
Chen H, Asteris PG, Jahed Armaghani D et al (2019) Assessing dynamic conditions of the retaining wall: developing two hybrid intelligent models. Appl Sci 9:1042
Zhou J, Li X, Shi X (2012) Long-term prediction model of rockburst in underground openings using heuristic algorithms and support vector machines. Saf Sci 50:629–644
Zhou J, Li X, Mitri HS (2016) Classification of rockburst in underground projects: comparison of ten supervised learning methods. J Comput Civ Eng 30:4016003
Zhou J, Shi X, Du K et al (2016) Feasibility of random-forest approach for prediction of ground settlements induced by the construction of a shield-driven tunnel. Int J Geomech 17:4016129
Shi X, Jian Z, Wu B et al (2012) Support vector machines approach to mean particle size of rock fragmentation due to bench blasting prediction. Trans Nonferrous Met Soc China 22:432–441
Kordjazi A, Pooya Nejad F, Jaksa MB (2015) Prediction of load-carrying capacity of piles using a support vector machine and improved data collection. In: Ramsay G (ed) Proceedings of the 12th Australia New Zealand conference on geomechanics: the changing face of the earth - geomechanics & human influence, pp 1–8
Armaghani DJ, Faradonbeh RS, Rezaei H et al (2016) Settlement prediction of the rock-socketed piles through a new technique based on gene expression programming. Neural Comput Appl. https://doi.org/10.1007/s00521-016-2618-8
Guo H, Zhou J, Koopialipoor M et al (2019) Deep neural network and whale optimization algorithm to assess flyrock induced by blasting. Eng Comput. https://doi.org/10.1007/s00366-019-00816-y
Zhou J, Koopialipoor M, Murlidhar BR et al (2019) Use of intelligent methods to design effective pattern parameters of mine blasting to minimize flyrock distance. Nat Resour Res. https://doi.org/10.1007/s11053-019-09519-z
Moayedi H, Raftari M, Sharifi A et al (2019) Optimization of ANFIS with GA and PSO estimating α ratio in driven piles. Eng Comput. https://doi.org/10.1007/s00366-018-00694-w
Ebrahimian B, Movahed V (2017) Application of an evolutionary-based approach in evaluating pile bearing capacity using CPT results. Ships Offshore Struct 12:937–953
Kurnaz TF, Kaya Y (2019) A novel ensemble model based on GMDH-type neural network for the prediction of CPT-based soil liquefaction. Environ Earth Sci 78:339
Ivakhnenko AG, Ivakhnenko GA, Muller JA (1994) Self-organization of neural networks with active neurons. Pattern Recognit Image Anal 4:185–196
Lawal IA, Auta TA (2012) Applicability of GMDH-based abducitve network for predicting pile bearing capacity. In: automation. IntechOpen
Najafzadeh M, Azamathulla HM (2013) Neuro-fuzzy GMDH to predict the scour pile groups due to waves. J Comput Civ Eng 29:4014068
Harandizadeh H, Toufigh MM, Toufigh V (2018) Different neural networks and modal tree method for predicting ultimate bearing capacity of piles. Iran Univ Sci Technol 8:311–328
Najafzadeh M, Tafarojnoruz A, Lim SY (2017) Prediction of local scour depth downstream of sluice gates using data-driven models. ISH J Hydraul Eng 23:195–202
Najafzadeh M, Saberi-Movahed F, Sarkamaryan S (2018) NF-GMDH-Based self-organized systems to predict bridge pier scour depth under debris flow effects. Mar Georesour Geotechnol 36:589–602
Suman S, Das SK, Mohanty R (2016) Prediction of friction capacity of driven piles in clay using artificial intelligence techniques. Int J Geotech Eng 10:469–475
Najafzadeh M, Lim SY (2015) Application of improved neuro-fuzzy GMDH to predict scour depth at sluice gates. Earth Sci Inform 8:187–196
Najafzadeh M, Bonakdari H (2016) Application of a neuro-fuzzy GMDH model for predicting the velocity at limit of deposition in storm sewers. J Pipeline Syst Eng Pract 8:6016003
Harandizadeh H, Toufigh MM, Toufigh V (2018) Application of improved ANFIS approaches to estimate bearing capacity of piles. Soft Comput. https://doi.org/10.1007/s00500-018-3517-y
Momeni E, Armaghani DJ, Fatemi SA, Nazir R (2018) Prediction of bearing capacity of thin-walled foundation: a simulation approach. Eng Comput 34:319–327
Kordnaeij A, Kalantary F, Kordtabar B, Mola-Abasi H (2015) Prediction of recompression index using GMDH-type neural network based on geotechnical soil properties. Soils Found 55:1335–1345
Ishikawa M (1996) Structural learning with forgetting. Neural Netw 9:509–521
Ohtani T, Ichihashi H, Miyoshi T, Nagasaka K (1998) Structural learning with M-apoptosis in neurofuzzy GMDH. In: 1998 IEEE international conference on fuzzy systems proceedings. IEEE world congress on computational intelligence (Cat. No. 98CH36228). IEEE, pp 1265–1270
Sharifi A, Teshnehlab M (2007) Simultaneously structural learning and training of Neurofuzzy GMDH using GA. In: 2007 Mediterranean conference on control & automation. IEEE, pp 1–5
Wang B, Moayedi H, Nguyen H et al (2019) Feasibility of a novel predictive technique based on artificial neural network optimized with particle swarm optimization estimating pullout bearing capacity of helical piles. Eng Comput. https://doi.org/10.1007/s00366-019-00764-7
Ghomsheh VS, Shoorehdeli MA, Teshnehlab M (2007) Training ANFIS structure with modified PSO algorithm. In: 2007 Mediterranean conference on control & automation. IEEE, pp 1–6
Abraham A (2001) Neuro fuzzy systems: State-of-the-art modeling techniques. In: International work-conference on artificial neural networks. Springer, pp 269–276
Akcayol MA (2004) Application of adaptive neuro-fuzzy controller for SRM. Adv Eng Softw 35:129–137
Davis L (ed) (1991) Handbook of genetic algorithms. Van Nostrand Reinhold, New York
Kennedy J (2011) Particle swarm optimization. In: Encyclopedia of machine learning. Springer, pp 760–766
Rashedi E, Nezamabadi-Pour H, Saryazdi S (2009) GSA: a gravitational search algorithm. Inf Sci (Ny) 179:2232–2248
McCulloch WS, Pitts W (1943) A logical calculus of the ideas immanent in nervous activity. Bull Math Biophys 5:115–133
Tonnizam Mohamad E, Hajihassani M, Jahed Armaghani D, Marto A (2012) Simulation of blasting-induced air overpressure by means of Artificial Neural Networks. Int Rev Model Simul 5:2501–2506
Armaghani DJ, Mohamad ET, Narayanasamy MS et al (2017) Development of hybrid intelligent models for predicting TBM penetration rate in hard rock condition. Tunn Undergr Sp Technol 63:29–43. https://doi.org/10.1016/j.tust.2016.12.009
Jahed Armaghani D, Hasanipanah M, Mahdiyar A et al (2016) Airblast prediction through a hybrid genetic algorithm-ANN model. Neural Comput Appl. https://doi.org/10.1007/s00521-016-2598-8
Khandelwal M, Armaghani DJ (2016) Prediction of drillability of rocks with strength properties using a hybrid GA-ANN technique. Geotech Geol Eng 34:605–620. https://doi.org/10.1007/s10706-015-9970-9
Jahed Armaghani D, Hajihassani M, Marto A et al (2015) Prediction of blast-induced air overpressure: a hybrid AI-based predictive model. Environ Monit Assess. https://doi.org/10.1007/s10661-015-4895-6
Jahed Armaghani D, Hajihassani M, Monjezi M et al (2015) Application of two intelligent systems in predicting environmental impacts of quarry blasting. Arab J Geosci. https://doi.org/10.1007/s12517-015-1908-2
Jahed Armaghani D, Mohd Amin MF, Yagiz S et al (2016) Prediction of the uniaxial compressive strength of sandstone using various modeling techniques. Int J Rock Mech Min Sci. https://doi.org/10.1016/j.ijrmms.2016.03.018
Mohamad ET, Faradonbeh RS, Armaghani DJ et al (2017) An optimized ANN model based on genetic algorithm for predicting ripping production. Neural Comput Appl 28:393–406
Davisson MT (1972) High capacity piles. In: Proceedings of the lecture series on Innovation in Foundation Construction, ASCE, NY, pp 81–112
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Harandizadeh, H., Jahed Armaghani, D. & Khari, M. A new development of ANFIS–GMDH optimized by PSO to predict pile bearing capacity based on experimental datasets. Engineering with Computers 37, 685–700 (2021). https://doi.org/10.1007/s00366-019-00849-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00366-019-00849-3