
Abstract
Air overpressure is one of the most undesirable destructive effects induced by blasting operation. Hence, a precise prediction of AOp has vital importance to minimize or reduce the environmental effects. This paper presents the development of two artificial intelligence techniques, namely artificial neural network (ANN) and ANN based on genetic algorithm (GA) for prediction of AOp. For this purpose, a database was compiled from 97 blasting events in a granite quarry in Penang, Malaysia. The values of maximum charge per delay and the distance from the blast-face were set as model inputs to predict AOp. To verify the quality and reliability of the ANN and GA-ANN models, several statistical functions, i.e., root means square error (RMSE), coefficient of determination (R 2) and variance account for (VAF) were calculated. Based on the obtained results, the GA-ANN model is found to be better than ANN model in estimating AOp induced by blasting. Considering only testing datasets, values of 0.965, 0.857, 0.77 and 0.82 for R 2, 96.380, 84.257, 70.07 and 78.06 for VAF, and 0.049, 0.117, 8.62 and 6.54 for RMSE were obtained for GA-ANN, ANN, USBM and MLR models, respectively, which prove superiority of the GA-ANN in AOp prediction. It can be concluded that GA-ANN model can perform better compared to other implemented models in predicting AOp.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Blasting is one of the most important operations in opencast mines, civil and tunneling projects. The main goal of the blasting operation is rock fragmentation. Nevertheless, more than 85 % of energy released by blasting dissipates through the ground and leads to some undesirable effects, such as ground vibration, air overpressure (AOp) and flyrock [1–3]. As AOp is recognized/identified as a significant environmental issue, precise prediction of AOp is important to reduce/minimize the detrimental effects of blasting operations. In a blast, the pressure wave that causes AOp is generated by the displacement of air as a result of the movement of the rock from the face [4].
As highlighted in some studies, the level of AOp depends on different parameters divided into two main sets, i.e., controllable and uncontrollable (e.g., [5–7]). Controllable parameters, such as type of explosive material, total weight charge, maximum charge weight used per delay (MC), blast-hole diameter and depth, distance from the blast-face (DI), powder factor, delay interval in rows, burden, spacing, stemming and sub-drilling, can be changed by the blasting engineers, However, uncontrollable parameters, like rock mass properties, are out of control of blasting engineers. As mentioned by many researchers [5, 8], MC and DI are the most important factors effecting AOp. In the literature, it is tried to predict AOp using empirical models [9–13]. One of the most common empirical models is presented by the United States Bureau of Mines (USBM) [9]. The USBM equation has been extensively used as a generalized predictor equation for the prediction of AOp [5, 6, 8].
where MC and DI are maximum charge weight used per delay and distance from the blast-face in terms of kg and m, respectively. Moreover, K and n are site constant and can be calculated by regression analysis. As an example, Mohamad et al. [14] employed USBM model for AOp prediction in a quarry site, Malaysia.
Apart from empirical methods, the use of artificial intelligence (AI) methods for AOp prediction has recently been highlighted by various researchers. As AI methods demonstrate superior prediction ability/capability compared to empirical models, these methods have been widely used for problem solving in geotechnical and rock engineering fields [15–20].
ANN was proposed to predict AOp in the study conducted by Sawmliana et al. [21]. To test the ANN model, USBM empirical model was also utilized. In their study, datasets were collected from four different mines in India. Finally, they found that ANN model can predict AOp better than USBM models. Khandelwal and Kankar [6] proposed support vector machine (SVM) and empirical models for prediction of AOp. They used 75 datasets to construct the proposed models. They demonstrated that SVM can be performed for AOp prediction with a greater degree of confidence in comparison with empirical model. In the other study of AI methods, Mohamed [22] investigated the results of blast-induced AOp at Assiut Cement Company (ACC) plant and quarries, Egypt. They developed fuzzy logic, ANN and empirical models for AOp prediction. According to their result, fuzzy logic and ANN can estimate AOp with higher level of accuracy in comparison with empirical models. A comprehensive study to predict AOp in Miduk copper mine, Iran, was presented by Hasanipanah et al. [23] using empirical, fuzzy inference system (FIS), ANN, and adoptive neuro-fuzzy inference system (ANFIS) models. They concluded that the performance of ANFIS is better compared to other proposed models in this field.
In the recent years, genetic programming (GP) and gene expression programming (GEP) techniques have been examined for estimating the blasting side effects. Dindarloo [2] employed GEP and ANN methods to estimate blast-induced ground vibration. In his study, the blast-hole diameter, No. of holes, hole depth, burden, spacing, stemming, maximum charge per delay, horizontal distance and radial distance were utilized as the model inputs. The results showed that GEP can be introduced as a reliable tool to predict blast-induced ground vibration and its results were more precise than ANN model. In the other study, GEP was used to predict peak particle velocity by Shirani Faradonbeh et al. [3]. They used nonlinear multiple regression (NLMR) to check the performance of the GEP. Finally, it was demonstrated that the GEP is more suitable for peak particle velocity estimation in comparison to the NLMR model.
Although ANN is a powerful tool for approximating many engineering problems, it has some drawbacks such as slow learning rate and getting trapped in local minima (e.g., [24, 25]). To overcome these difficulties, evolutionary algorithms (EA) such as imperialist competitive algorithm (ICA), particle swarm optimization (PSO) and genetic algorithm (GA) can be used to optimize weights and biases of ANN. For instance, ICA was used to optimize the ANN in the study conducted by Jahed Armaghani et al. [13]. They showed that the performance prediction of ICA-ANN model was better than ANN. Among the mentioned EAs, GA is the one which has been widely studied and applied to solve geotechnical engineering problems [14, 19, 25]. Therefore, in the present study, ANN and a hybrid ANN-GA are used to develop an accurate and applicable model for predicting the AOp values gathered from a granite quarry in Penang, Malaysia. In fact, the GA algorithm is used to optimize the weights of ANN.
2 Materials and methods
2.1 Artificial neural network
Artificial neural network (ANN) imitates the process of transferring information in the human brain. ANN is generally a function approximation tool that is applicable in the situations in which the contact nature between output(s) and input(s) is complicated and nonlinear [26]. Among ANN types, the most widely employed is multilayer feed forward ANN that consists of a number of layers (output layers, hidden layers, and input layers). Three are a connection between these layers through several hidden nodes via various connection weights [27]. For the achievement of a pleasing outcome, some learning algorithms should be used to train ANNs. There are many types of learning algorithms; among them, back-propagation (BP) algorithm is the most commonly used one [28]. The basis of BP is a gradient descendent optimization procedure, where often there is a minimized root mean squared error (RMSE) between the desired and predicted values. RMSE is generally described as the average root mean squared error between the desired and predicted outputs. Essentially, the input layer, in BP ANN, receives raw data, and then it passes the data to the hidden nodes via the connection weights. Each hidden node’s output is identified after performing a transfer function, commonly the sigmoidal function, to the hidden node’s net input. Each hidden node’s net input is formed by addition of the connection weights received by the node to the bias (a threshold value). For other layers and hidden nodes, a parallel process continues till the output is produced. Then, the error is calculated through making a comparison between the generated output (predicted output) and the desired output (targets). In cases where RMSE is less than the calculated error, the network must back-propagate and adjust the connection weights till it can meet the stopping criteria.
2.2 Genetic algorithm (GA)
Genetic algorithm (GA) which was introduced by Holland [29] can be employed as a technique for stochastic search and optimization [14]. GA imitates the evolution process of biological species and the mechanism of natural selection [14]. The stochastic optimization is referred to a technique, wherein solution space is searched by producing potential solutions through a random number generator. For the purpose of advancement, GA only should evaluate the value of objective function in case of each decision variable. The reason is that GA needs no definite information to guide the search [30]. However, similar to other artificial intelligence (AI) techniques, GA is not able to ensure constant times for the optimization response. Furthermore, the difference between the longest and the shortest time of response for the optimization is larger in comparison with that of the traditional gradient methods. As a result, GA is limited to being used in real-time application [31].
GA comprises individuals who are candidate solutions that mature steadily in a way to be converged to an optimal solution. There are two terms in GA: the population size that is the total number of solutions and generation that refers to each iteration of the optimization process. Termination of the optimization process in GA is done by the definition of some stopping criteria, e.g., meeting the desired fitness or achieving the maximum number of generations.
In GA, reproduction, cross-over, and mutation are three basic genetic operators that should be performed to form the next generation. Through the reproduction operator, the best chromosomes are chosen, on the basis of their scaled values regarding the given criteria of fitness, and then the chosen chromosomes are transferred directly to the next generation. In the cross-over operator, offspring (i.e., new individuals) are created by the combination of definite parts of the individuals (parent). This operator is of several types; two of them are two-point cross-over and single-point cross-over. Through the cross-over procedure, the algorithm selects two parents and a random cross-over point. Then, an inverse process needs to be done for the formation of the second offspring [24]. Through the mutation operator, a random change is appeared in a chromosome’s elements (allele). In the binary system, mutation refers to flipping a bit’s values where 0 becomes 1 and 1 becomes 0. Those small random changes occurred in a chromosome’s allele cause genetic diversity and make GA capable of searching a wider space.
2.3 Hybrid GA-based ANN
Literature suggests that GA can efficiently increase the ANN performance and minimize its drawbacks as well [32–35]. According to Chambers [36], the most considerable benefit of GA is its capability in avoiding being trapped in local optima, and using GA or a hybrid GA offers the chance of freely selecting the most suitable objective functions.
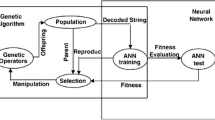
Owing to the multidirectional search in GA, the ANN models can be converted to a global minimum, hence improving the ANNs’ prediction capability [37]. In fact, an ANN model that is based on GA is trained with GA algorithm rather than the BP algorithm. Therefore, instead of random generation, the biases and network connection weights are optimized using GA. Algorithm of a combination GA-ANN model is shown in Fig. 1. For better understanding of GA incorporated in ANN, it is recommended to find more related studies in the literature (e.g., [25, 33, 38, 39]).

Combination of GA-ANN [39]
3 Study area and data collection
The purpose of this research is to predict precisely the blast-induced AOp at a granite quarry in Penang state, Malaysia (see Fig. 2). The mentioned site is coated by two main granite pluton, including Pluton Penang south and north. Generally, granite is the main rock type observed in the studied site. In the north Pluton Penang, granite Tanjung Bunga, granite Feringgi and mikrogranit are three main units. While, muscovite-biotite granite is the main unit in the south Pluton Penang. Weathering zones of III, IV and V with strength range of (50–70 MPa) were observed in the studied site. Rock mass rating (RMR) ranging from 40 to 65 was observed generally in different places of the studied site. Moreover, mean values of 0.5 and 1.5 m were measured for joint spacing and joint trace length, respectively.

A view of study area
The aim of the blasting operation in these sites is to produce aggregates for various construction works with capacity range of 500,000–700,000 tons per year. Ammonium nitrate fuel oil (ANFO), dynamite, and fine gravel were used as the main explosive material, initiation and stemming material, respectively. In the drilling process, the blast-holes diameters were 76 and 89 mm.
In the considered blasting events in these sites, some of the controllable blasting parameters, including spacing, total charge, MC, stemming, blast-hole diameter, burden, blast-hole depth, number of blast-hole, powder factor and DI, were measured. Additionally, Vibra ZEB seismograph was installed to measure the AOp values. The minimum distance between blast points and surrounding residential area was 400 m. Hence, the distances between the blast points and utilized seismograph were ranging from 250 to 579 m. It is worth noting that all AOp values were recorded in front of the quarry bench and approximately perpendicular to it. In total, more than 120 blasting operations were investigated and several outlier data were removed to establish a good database consisting of 97 datasets before performing the analyses.
To propose a predictive model for prediction of AOp, a suitable database with the most effective model inputs is required. For this purpose, most of the previous investigations into the field of AOp prediction were reviewed [5, 6, 9–11, 22, 40, 41] and it was found that the factors with the deepest impact on AOp are MC and DI. Hence, they were selected as model inputs to estimate AOp values. Table 1 summarizes the range of measured parameters to predict AOp in this study. In addition, Fig. 3 shows the graphical summary of input and output data utilized for this research. In the following section, an attempt is conducted to predict AOp proposing both ANN and GA-ANN models.

A graphical summary of input and output data
4 Model development for AOp estimation
4.1 ANN
This part describes modeling procedure of ANN technique in approximating air overpressure resulting from blasting. As an initial stage, as stated by Khamesi et al. [42], the prepared database should be normalized to make the analysis easier. Normalization can be performed using the following formula:
where X and X norm are the measured and normalized values, respectively. X max and X min are the maximum and minimum values of the X.
In the next stage, all datasets should be divided into training and testing. Various percentages ranging from 20 to 30 % of whole datasets have been suggested by previous researchers for testing datasets [43–45]. Hence, in the present study, 19 datasets or 20 % of whole datasets were utilized for model evaluation. Obviously, another 78 datasets were used for developing the predictive models. Designing network architecture and selecting an ANN training algorithm are considered as the most important factors in ANN modeling [46]. In this study, Levenberg–Marquardt (LM) was chosen for ANN training as recommended by some investigators (e.g., [47]). In addition, many researchers such as Hornik et al. [48] reported that any complex problem can be solved using only one hidden layer. Consequently, one hidden layer was used in the modeling of all ANN models in the current paper. Sonmez et al. [49] highlighted the high impact on the number of hidden node (N h) on the ANN performance. Previous researchers introduced equations to determine N h as shown in Table 2. As it can be seen in this table, the upper limitation for the number of hidden node is 2N i + 1, where N i is the number of input parameters. With N i equal to 2 and No equal to 1 and also equations of Table 2, ranging from 1 to 5, can be considered for N h. Through a trial-and-error procedure, several ANN models were built and their results based on the coefficient of determination (R 2) are presented in Table 3. Note that the ultimate modeling aim is to obtain higher values of R 2 for a specific ANN model. R 2 of 0.871 and 0.857 were obtained for training and testing datasets of the model No. 5. So, an architecture of (\(2 \times 5 \times 1\)) was selected for predicting AOp by ANN model. Evaluation of ANN model No. 5 will be given later.
4.2 GA-ANN
For approximating AOp in this study, several parametric investigations were carried out to find optimum GA parameters. In hybrid systems, as recommended by Momeni et al. [25], the mutation probability was set to 25 % of the population size. Moreover, recombination percentage was used as 9 and 1 % of the population size. The single-point cross-over was used with 70 % possibility. Although there are various techniques to choose cross-over operations, the tournament selection technique was performed to create two offsprings from two parents [25]. To determine the best population size, several GA-ANN models were constructed with population sizes (S pop) ranging from 25 to 600 as presented in Table 4. In Table 4, generally, increment in S pop causes the increase in R 2 values. Based on obtained results from training and testing datasets (0.935 and 0.948, respectively), model No. 9 with S pop = 350 can provide higher performance capacity compared with other models.
To investigate the number of generation (G max), a series of analyses were carried out. In these analyses, a value of 1000 was fixed for the number of generation. Several models were built in this regard on the GA-ANN network (see Table 4). The results showed that the best G max for all models was obtained as 400. Hence, a value of 400 was used as G max of hybrid GA-ANN model to predict AOp. It is worth mentioning that the analysis of this part was conducted based on the results of RMSE. The last step of modeling is related to constructing 5 GA-ANN models based on 5 randomly selected datasets. R 2 values of 0.955, 0.944, 0.940, 0.961 and 0.960 were obtained for trains 1–5, respectively, while these values were 0.960, 0.951, 0.948, 0.965, and 0.963 for tests 1–5, respectively. These values indicate that run number 4 is the best one among these five constructed models in estimating AOp. More explanation/evaluation in this regard will be given in the next section.
5 Prediction of AOp using USBM and MR models
5.1 Prediction of AOp using USBM
In the present paper, the USBM as one of the most common empirical models is applied for predicting the AOp. For this work, datasets were classified into training and testing datasets, in ratio 80–20 %, in order. In the other words, 78 and 19 datasets were used to develop the USBM and to test the developed USBM model. It should be noted that in USBM developing model, the same datasets were applied in the analyses of ANN and Ga-ANN. Based on training datasets, the developed USBM model is formulated as follows:
where AOp, DI and MC are in terms of dB, m and kg, in order. Considering Eq. 3 and testing datasets, the accuracy of the developed USBM model can be determined. More information regarding the performance of the developed USBM model will be given in Sect. 6.
5.2 Prediction of AOp using MLR model
Multiple linear regression (MLR) is one of the common statistical tools to fit a linear equation between two or more independent variables and a dependent variable. This model is extensively utilized for solving different engineering problems by many researchers [57, 58].
In the presented paper, the accuracy of the ANN, GA-ANN and USBM models was also compared with the MLR model. Generally, the MLR can be described as follows:
where \(X_{i} \left( {i = 1, \ldots ,n} \right)\) and Y are independent and dependent variables, respectively. Also, \(P_{i} \left( {i = 0,1, \ldots , n} \right)\) present regression coefficients. Like USBM model, 78 and 19 datasets were used to develop the MLR and to test the developed MLR model, in order. It should be noted that in MLR developing model, the same datasets performed in the analyses of ANN, GA-ANN and USBM were applied. In the first step, 78 datasets were considered and the MLR was constructed using SPSS v16 software [59] as follows:
Considering Eq. 5 and testing datasets, the accuracy of the developed MLR equation can be determined. More information regarding the performance of the MLR equation will be given in Sect. 6.
6 Discussion and conclusion
As mentioned above, blast-induced AOp is one of the most undesirable by-products of blasting operation, so precise prediction of AOp is crucial. This article adopts two AI models, i.e., ANN and ANN-based GA models for prediction of AOp at a granite quarry in Penang state, Malaysia. In this regard, 97 blasting events were monitored to measure the input and output parameters and then to construct the ANN and GA-ANN models. In modeling, MC and DI were set as two input parameters, while AOp was set as the output parameter. Moreover, in these models, 80 and 20 % of whole datasets were randomly selected as training and testing datasets, respectively. In other words, 78 datasets were used to construct the ANN and GA-ANN models, while the remained 19 datasets were used to verify and test the models. Trial-and-error method was utilized to select the best ANN and GA-ANN models. Based on obtained results, \(2 \times 5 \times 1\) architecture was selected as the best ANN model. Also, In GA-ANN model, the values of 350 and 400 were selected for the S pop and G max, respectively. The performance of the models has been compared using several statistical indexes, i.e., variance account for (VAF), R 2 and RMSE.
In Eqs. 6–8, N denotes the number of datasets, \(y^{{\prime }}\) and y denote the predicted and measured PPV values, respectively. The R 2, RMSE and VAF equal to 1, 0 and 100 (%) indicate the best approximation, respectively. Table 5 gives the results of the statistical indices for GA-ANN, ANN, USBM and MLR models. It should be mentioned that values of USBM and MLR models are not normalized values and are the original one. Comparison results demonstrate that the GA-ANN model performs better than the ANN model. Considering only testing datasets, values of 0.965, 0.857, 0.77 and 0.82 for R 2, 96.380, 84.257, 70.07 and 78.06 for VAF, and 0.049, 0.117, 8.62 and 6.54 for RMSE were obtained for GA-ANN, ANN, USBM and MLR models, respectively, which prove superiority of the GA-ANN in AOp prediction. Figures 4, 5, 6 and 7 show the measured versus predicted values of AOp by USBM, MLR, ANN and GA-ANN models, respectively. From these figures, it can be seen that GA-ANN model simulated the AOp more reliably than ANN model. As a conclusion, GA-ANN model with R 2 of 0.961 and 0.965 for training and testing datasets is sufficient enough to solve such problems like AOp resulting from blasting. Considering the controllable parameters, i.e., DI and MC and using the developed GA-ANN model of this study, damage(s) due to AOp in the studied site can be controlled/minimized.

R 2 values of the developed USBM model

R 2 values of the developed MLR model

R 2 values of the developed ANN model

R 2 values of the developed GA-ANN model
References
Khandelwal M, Singh TN (2007) Evaluation of blast-induced ground vibration predictors. Soil Dyn Earthq Eng 27:116–125
Dindarloo SR (2015) Prediction of blast-induced ground vibrations via genetic programming. Int J Min Sci Technol 25:1011–1015
Shirani Faradonbeh R, Jahed Armaghani D, Abd Majid MZ, Tahir MMD, Ramesh Murlidhar B, Monjezi M, Wong HM (2016) Prediction of ground vibration due to quarry blasting based on gene expression programming: a new model for peak particle velocity prediction. Int J Environ Sci Technol. doi:10.1007/s13762-016-0979-2
Singh PK, Sinha A (2013) Rock fragmentation by blasting, Fragblast 10. Taylor & Francis Group, London, p 427
Khandelwal M, Singh TN (2005) Prediction of blast induced air overpressure in opencast mine. Noise Vib Control Worldw 36:7–16
Khandelwal M, Kankar PK (2011) Prediction of blast-induced air overpressure using support vector machine. Arab J Geosci 4:427–433
Dindarloo SR (2015) Peak particle velocity prediction using support vector machines: a surface blasting case study. J South Afr Inst Min Metall 115:637–643
Amiri M, Bakhshandeh Amnieh H, Hasanipanah M, Mohammad Khanli L (2016) A new combination of artificial neural network and K-nearest neighbors models to predict blast-induced ground vibration and air-overpressure. Eng Comput. doi:10.1007/s00366-016-0442-5
Siskind DE, Stachura VJ, Stagg MS, Koop JW (1980) Structure response and damage produced by airblast from surface mining. Report of investigations, vol 8485. United States Bureau of Mines, Washington, DC
Hustrulid WA (1999) Blasting principles for open pit mining: general design concepts. Balkema, Amsterdam
Kuzu C, Fisne A, Ercelebi SG (2009) Operational and geological parameters in the assessing blast induced airblast-overpressure in quarries. Appl Acoust 70:404–411
Jahed Armaghani D, Hajihassani M, Sohaei H, Mohamad ET, Marto A, Motaghedi H, Moghaddam MR (2015) Neuro-fuzzy technique to predict air-overpressure induced by blasting. Arab J Geosci 8(12):10937–10950
Jahed Armaghani D, Hasanipanah M, Mohamad ET (2016) A combination of the ICA-ANN model to predict air-overpressure resulting from blasting. Eng Comput 32(1):155–171
Mohamad ET, Jahed Armaghani D, Hasanipanah M, Ramesh Murlidhar B, Asmawisham Alel MN (2016) Estimation of air-overpressure produced by blasting operation through a neuro-genetic technique. Environ Earth Sci 75:174. doi:10.1007/s12665-015-4983-5
Verma AK, Singh TN (2009) A Neuro-Genetic approach for prediction of compressional wave velocity of rock and its sensitivity analysis. Int J Earth Sci Eng 2(2):81–94
Verma AK, Singh TN, Monjezi M (2010) Intelligent prediction of heating value of coal. Iran J Earth Sci 2:32–38
Singh TN, Verma AK (2010) Sensitivity of total charge and maximum charge per delay on ground vibration. Geomat Nat Hazards Risk 1(3):259–272
Singh R, Vishal V, Singh TN (2012) Soft computing method for assessment of compressional wave velocity. Sci Iran 19(4):1018–1024
Verma AK, Singh TN (2012) Comparative analysis of intelligent algorithms to correlate strength and petrographic properties of some schistose rocks. Eng Comput 28:1–12
Singh R, Vishal V, Singh TN, Ranjith PG (2013) A comparative study of generalized regression neural network approach and adaptive neuro-fuzzy inference systems for prediction of unconfined compressive strength of rocks. Neural Comput Appl 23(2):499–506
Sawmliana C, Roy PP, Singh RK, Singh TN (2007) Blast induced air overpressure and its prediction using artificial neural network. Min Technol 116(2):41–48
Mohamed MT (2011) Performance of fuzzy logic and artificial neural network in prediction of ground and air vibrations. Int J Rock Mech Min Sci 48:845–851
Hasanipanah M, Jahed Armaghani D, Khamesi H, Bakhshandeh Amnieh H, Ghoraba S (2015) Several nonlinear models in estimating air-overpressure resulting from mine blasting. Eng Comput. doi:10.1007/s00366-015-0425-y
Jadav K, Panchal M (2012) Optimizing weights of artificial neural networks using genetic algorithms. Int J Adv Res Comput Sci Electron Eng 1:47–51
Momeni E, Nazir R, Jahed Armaghani D, Maizir H (2014) Prediction of pile bearing capacity using a hybrid genetic algorithm-based ANN. Measurement 57:122–131
Garrett J (1994) Where and why artificial neural networks are applicable in civil engineering. J Comput Civ Eng 8:129–130
Simpson P (1990) Artificial neural system: foundation, paradigms, applications and implementations. Pergamon, New York
Dreyfus G (2005) Neural networks: methodology and application. Springer, Berlin
Holland J (1975) Adaptation in natural and artificial systems. The University of Michigan Press, Ann Arbor
Chipperfield A, Fleming P, Pohlheim H (2006) Genetic algorithm toolbox for use with MATLAB User’s guide, version 1.2. University of Sheffield, Sheffield
Simpson AR, Dandy GC, Murphy LJ (1994) Genetic algorithms compared to other techniques for pipe optimization. J Water Res PL-ASCE 120:423–443
Lee Y, Oh S-H, Kim MW (1991) The effect of initial weights on premature saturation in back-propagation learning. In: Proceedings of the Seattle international joint conference on neural networks (IJCNN-91), vol 1. IEEE, pp 765–770
Majdi A, Beiki M (2010) Evolving neural network using a genetic algorithm for predicting the deformation modulus of rock masses. Int J Rock Mech Min Sci 47:246–253
TingXiang L, ShuWen Z, QuanYuan W et al. (2012) Research of agricultural land classification and evaluation based on genetic algorithm optimized neural network model. In: Wu Y (ed) Software engineering and knowledge engineering: theory and practice. Springer, Berlin, pp 465–471
Rashidian V, Hassanlourad M (2013) Predicting the shear behavior of cemented and uncemented carbonate sands using a genetic algorithm-based artificial neural network. Geotech Geol Eng 2:1–18
Chambers LD (2010) Practical handbook of genetic algorithms: complex coding systems. CRC Press, Boca Raton
Rajasekaran S, Vijayalakshmi Pai GA (2007) Neural networks, fuzzy logic, and genetic algorithms, synthesis and applications. Prentice-Hall of India, New Delhi
Hagan MT, Menhaj MB (1994) Training feed forward networks with the Marquardt algorithm. IEEE Trans Neural Networks 5:861–867
Saemi M, Ahmadi M, Varjani AY (2007) Design of neural networks using genetic algorithm for the permeability estimation of the reservoir. J Pet Sci Eng 59:97–105
Hopler RB (1998) Blasters’ handbook. International Society of Explosives Engineers, Cleveland, OH
Jahed Armaghani D, Hajihassani M, Monjezi M, Mohamad ET, Marto A, Moghaddam MR (2015) Application of two intelligent systems in predicting environmental impacts of quarry blasting. Arab J Geosci. doi:10.1007/s12517-015-1908-2
Khamesi H, Torabi S, Mirzaei-Nasirabad H, Ghadiri Z (2015) Improving the performance of intelligent back analysis for tunneling using optimized fuzzy systems: case study of the Karaj Subway Line 2 in Iran. J Comput Civ Eng 29(6):05014010
Swingler K (1996) Applying neural networks: a practical guide. Academic Press, New York
Looney CG (1996) Advances in feed-forward neural networks: demystifying knowledge acquiring black boxes. IEEE Trans Knowl Data Eng 8(2):211–226
Nelson M, Illingworth WT (1990) A practical guide to neural nets. Addison-Wesley, Reading MA
Hush DR (1989) Classification with neural networks: a performance analysis. In: Proceedings of the IEEE international conference on systems engineering, Dayton, pp 277–280
Maulenkamp F, Grima MA (1999) Application of neural networks for the prediction of the unconfined compressive strength (UCS) from Equotip hardness. Int J Rock Mech Min Sci 36:29–39
Hornik K, Stinchcombe M, White H (1989) Multilayer feedforward networks are universal approximators. Neural Netw 2:359–366
Sonmez H, Gokceoglu C, Nefeslioglu HA, Kayabasi A (2006) Estimation of rock modulus: for intact rocks with an artificial neural network and for rock masses with a new empirical equation. Int J Rock Mech Min Sci 43:224–235
Hecht-Nielsen R (1987) Kolmogorov’s mapping neural network existence theorem. In: Proceedings of the first IEEE international conference on neural networks, San Diego, pp 11–14
Ripley BD (1993) Statistical aspects of neural networks. In: Barndoff-Neilsen OE, Jensen JL, Kendall WS (eds) Networks and chaos-statistical and probabilistic aspects. Chapman & Hall, London, pp 40–123
Paola JD (1994) Neural network classification of multispectral imagery, M.Sc. thesis. The University of Arizona
Wang C (1994) A theory of generalization in learning machines with neural application, Ph.D. thesis. The University of Pennsylvania
Masters T (1994) Practical neural network recipes in C++. Academic Press, Boston
Kaastra I, Boyd M (1996) Designing a neural network for forecasting financial and economic time series. Neurocomputing 10:215–236
Kanellopoulas I, Wilkinson GG (1997) Strategies and best practice for neural network image classification. Int J Remote Sens 18:711–725
Rezaei M, Monjezi M, Yazdian Varjani A (2011) Development of a fuzzy model to predict flyrock in surface mining. Saf Sci 49:298–305
Tripathy A, Singh TN, Kundu J (2015) Prediction of abrasiveness index of some Indian rocks using soft computing methods. Measurement 68:302–309
SPSS Inc (2007) SPSS for Windows (version 16.0). SPSS Inc, Chicago
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Rights and permissions
About this article

Cite this article
Jahed Armaghani, D., Hasanipanah, M., Mahdiyar, A. et al. Airblast prediction through a hybrid genetic algorithm-ANN model. Neural Comput & Applic 29, 619–629 (2018). https://doi.org/10.1007/s00521-016-2598-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-016-2598-8