
Abstract
With the time-consuming computations incurred by nested double-loop strategy and multiple performance functions, the enhancement of computational efficiency for the non-probabilistic reliability estimation and optimization is a challenging problem in the assessment of structural safety. In this study, a novel importance learning method (ILM) is proposed on the basis of active learning technique using Kriging metamodel, which builds the Kriging model accurately and efficiently by considering the influence of the most concerned point. To further accelerate the convergence rate of non-probabilistic reliability analysis, a new stopping criterion is constructed to ensure accuracy of the Kriging model. For solving the non-probabilistic reliability-based design optimization (NRBDO) problems with multiple non-probabilistic constraints, a new active learning function is further developed based upon the ILM for dealing with this problem efficiently. The proposed ILM is verified by two non-probabilistic reliability estimation examples and three NRBDO examples. Comparing with the existing active learning methods, the optimal results calculated by the proposed ILM show high performance in terms of efficiency and accuracy.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Structural design optimization plays a prominent role in practical engineering analysis, which aims to provide an optimal design within specified objective functions and constraints. However, the uncertainties stemming from its environment and incomplete knowledge about the examined system are unavoidable, and how to account for them is of great importance for optimization design (Li and Azarm 2008; Moon et al. 2018; Wang and Wang 2012). This can promote the development of non-deterministic structural optimization method, in which probabilistic approach and non-probabilistic approach are two representative methods (Huang et al. 2016b; Keshtegar and Lee 2016; Lee et al. 2013; Youn et al. 2005). The former is dedicated to performing the optimization design for uncertain structures, whose input random parameters can be described as the precise probabilistic distribution (Azarm and Mourelatos 2006; Du and Chen 2004; Rashki et al. 2014; Youn and Wang 2008). The latter focuses on handling the optimization design with uncertain-but-bounded variables (Jiang et al. 2007; Qiu et al. 2009). Unfortunately, it is commonly difficult to acquire enough experimental data in the complex engineering problems for constructing the probabilistic model, and thus non-probabilistic approach becomes a promising way to qualify the safety level of structures with inherent uncertain factors (Bae et al. 2018; Karuna and Manohar 2017; Moens and Vandepitte 2006). Until now, a variety of non-probabilistic models were proposed, which can be generally divided into two types, interval model (Elishakoff and Elettro 2014; Liu et al. 2016; Muscolino et al. 2016) and convex model (Ganzerli and Pantelides 2000; Jiang et al. 2014).
Currently, the research interests in the non-probabilistic theory can be traced to Ben-Haim and Elishakoff’s pioneering research (Ben-Haim 1994; Ben-Haim 1995; Ben-Haim and Elishakoff 1995), in which an effective tool for assessing structural safety level with limited sample information was developed. Qiu and Elishakoff (1998) introduced the interval analysis to carry out non-probabilistic reliability-based design optimization (NRBDO) successfully for a 6-bar plane truss. Majumder and Rao (2009) established a multi-objective optimization method for minimizing structural weight and energy required of aircraft wing structures with interval parameters. Moens and Vandepitte (2006) gave an exhaustive overview for non-deterministic method and pointed out that the non-probabilistic approach appears to be less sensitive to the effect of subjective data by comparing with the probabilistic approach. Additionally, the definition of non-probabilistic reliability index was also established, which is more conservative in comparison to the probabilistic model (Guo et al. 2013; Jiang et al. 2017; Kang and Luo 2010).
For complex engineering problems, the computations of the performance functions are always time-consuming; the pursuit of high efficiency for computing the non-probabilistic reliability indices is vital in real-life engineering problems. Until now, various advanced methods for non-probabilistic reliability analysis have been well introduced to improve the computational efficiency. Based on worst-case-scenario technique, Lombardi and Haftka (1998) utilized the inverse optimization technique to enhance the efficiency of optimization with load uncertainties. Kang et al. (2011) introduced a concerned performance approach to alleviate the unbearable computational burden, which was further extended to solve a topology optimization problem (Kang and Zhang 2016). Luo et al. (2011) established a sequential approximate programming method for solving the hybrid model involving the probabilistic and non-probabilistic uncertain parameters simultaneously. Moreover, Meng et al. (2015) developed a chaos control method to estimate the concerned point of ellipsoid convex model, and the computational efficiency was improved significantly for buckling analysis of stiffened shells. Hao et al. (2017) investigated the Wolfe-Powell criterion to select a suitable chaos control factor in chaos control method. Based upon a super parametric convex model, Meng and Zhou (2018) also created a new target performance approach to efficiently evaluate the non-probabilistic reliability of structures.
Recently, some approximate mathematical models, i.e., metamodels, are popular as surrogates for improving the efficiency of non-probabilistic reliability calculation through substituting into the actual performance functions. Jiang et al. (2008) presented a sequential computation method for handing the interval parameters, in which the Latin hypercube sampling (LHS) and response surface method (RSM) are combined together to evaluate the intervals of constraints. Based on the moving least square method with function data, Youn and Choi (2004) integrated the RSM to accelerate the convergence rate of performance function. Wang and Chen (2017) suggested an adaptive extreme RSM for solving time-variant reliability analysis problems. Bai et al. (2014) combined RSM with convex model to perform the correlation analysis technique. Zhang et al. (2017) employed RSM-based time-dependent reliability estimation technique, which can decrease the number of function calls to estimate the reliability of stochastic dynamic structures. Marelli and Sudret (2018) created an active learning method for polynomial chaos expansions based on bootstrap resampling.
Compared with RSM surrogate model, the Kriging model not only can give predicted values for any input variables but also can estimate the local variance owing to its stochastic process property (Hawchar et al. 2018; Huang et al. 2016a). Based on this variance, the Kriging model can carry out the design of experiments (DoE) in an active learning manner, which can be considered as a major advantage of Kriging. The efficient global optimization and sequential Kriging-based optimization are considered as two distinguished representatives (Bichon et al. 2012; Huang et al. 2006; Jones et al. 1998). Inspired from the efficient global optimization and the contour assessment method of Ranjan et al. (2008), Bichon et al. (2012) developed a fully active learning method to implement the probabilistic reliability analysis, and then it was further extended to solve the system reliability problems with multiple failure modes (Bichon et al. 2011). Khodaparast et al. (2011) applied the Kriging for interval model updating, which was able to predict the regions of input and output uncertain parameters. Wang and Wang (2013) suggested a maximum confidence enhancement method, in which an ordinary Kriging model was employed to speed up the calculation process. Hu and Du (2015) applied the Kriging model to compute the reliability index of the time-variant problems. Lee and Jung (2008) constructed a constraint boundary sampling (CBS) criterion to sequentially add new points in the vicinity of the limit state function (LSF). Echard et al. (2011) suggested an active learning reliability method combining the Kriging model and Monte Carlo simulation, in which a new learning function U is created to efficiently predict the sign of performance functions (Echard et al. 2013). Moustapha et al. (2016) established a two stage procedure to enhance the local and global accuracies of function U. Chen et al. (2014) presented a local adaptive sampling strategy, which can generate new sample points around the design point to construct the Kriging model. Moreover, Yang et al. (2015) developed an expected risk function (ERF) by using expected improvement function to approximate the sign of performance functions, and then the failure probability can be easily calculated (Yang et al. 2014). Also, Li et al. (2006) utilized the Kriging variance for dealing with the multi-objective problems. All these active learning methods devoted to improving the computational efficiency of failure probability in probabilistic domain, but rare works can be found to solve the NRBDO problem. Besides, the existing active learning methods only consider the predicted value and variance, which means the samples on the LSF have the same opportunity to be selected. However, the most concerned point (MCP), i.e., the most important point on the LSF, is ignored during the learning process. Therefore, it requires a large amount of samples to approximate the entire LSF accurately. If the new samples are generated only in the local region around the MCP, the convergence rate can be significantly improved.
The purpose of this paper is to investigate the performance of the active learning methods in the non-probabilistic reliability estimation and NRBDO problems, and an importance learning method (ILM) is further developed to enhance the efficiency. By considering the influence of MCP during DOE, the task of predicted the entire LSF is degraded into the simple prediction of MCP. A Kriging model is first constructed with a rather small set of sample points and then is progressively rebuilt using the proposed importance learning function (ILF). In each iterative step, only the local region at the neighborhood of the MCP is approximated accurately. Then, the new sample points are adaptively added into DOE. Furthermore, a novel active learning function based on the ILF is established to solve the NRBDO problems with multiple LSFs. The outline of this paper is presented as follows: Sect. 2 reviews the basic theory of the non-probabilistic reliability estimation. Section 3 introduces fundamental of the Kriging model and several popular active learning functions. Then, the proposed method is described in detail in Sect. 4. Section 5 uses two non-probabilistic reliability estimation examples and two NRBDO examples to verify the accuracy and efficiency of the proposed method. In Sect. 5, some concluding remarks are drawn.
2 Review of non-probabilistic reliability analysis
2.1 Convex model
A n-dimensional interval model is one widely utilized non-probabilistic model, which can be described as a rectangle, as shown in Fig. 1a (Kang et al. 2011). The interval model is formulated as follows,
where n is the number of uncertain-but-bounded variables x. εi is the radius of interval, which can be determined by its upper bound \( {x}_{\mathrm{i}}^{\mathrm{L}} \) and lower bound \( {x}_{\mathrm{i}}^{\mathrm{U}} \). The value of εi can be computed by \( {\varepsilon}_{\mathrm{i}}=\frac{x_{\mathrm{i}}^{\mathrm{U}}-{x}_{\mathrm{i}}^{\mathrm{L}}}{2} \).

Two types non-probabilistic parameter models: a Interval model {‖qi‖ ≤ 1, i = 1, 2, 3}. b Ellipsoid model {‖q1, q2, q3‖ ≤ 1}
A n-dimensional ellipsoid model is another popular non-probabilistic to handle the uncertain-but-bounded parameters, as shown in Fig. 1b (Jiang et al. 2013). The ellipsoid model is described as follows,
where xC is a vector of the nominal values. The uncertain parameter vector contains n variables {x1, x2, …, xn}. W is a characteristic matrix of the ellipsoid model, which is a real symmetric positive definite matrix. ε is the radius of the ellipsoid model, which is similar to the interval model. The diagonal elements of W contain the information of the reference variation coefficients of uncertain variables, while non-diagonal elements represent the correlation relationship between different variables. In general, the matrix W and the number ε can be determined according to the instrument measurements, where the minimum volume method can be used to compute their values (Jiang et al. 2011; Kang and Zhang 2016). Especially, when the uncertain variables are independent, all the non-diagonal elements of W become 0. The radius of ith nominal value xi can be obtained by the following transformation: \( {x}_{\mathrm{i}}^{\mathrm{r}}=\frac{x_{\mathrm{i}}^{\mathrm{C}}}{\sqrt{W_{\mathrm{i}\mathrm{i}}}} \), where Wii is ith diagonal element of W.
There are various uncertain sources in practical engineering, and the ellipsoid model is another promising convex model. To implement the non-probabilistic reliability analysis conveniently, the uncertain-but-bounded vector x can be transformed into a dimensionless uncertain vector δ that can be expressed as,
When eigenvalue decomposition is implemented for the characteristic matrix W, an eigenvector Q and eigenvalue matrix Λ can be obtained accordingly. Then, the uncertain variables vector x can be easily converted into the normalized uncertain variables vector q using the following formula,
Through the above normalized transformation, the ellipsoid model in (2) can be rewritten as,
Thus, the ellipsoid is converted into spheres with unit radius in q-space. Similarly, the normalized uncertain variables vector q can be reversely transformed as uncertain-but-bounded variables vector x through the conversion formula, i.e., x = (1 + ε(Λ1/2QT)−1q) ⋅ xC.
2.2 Non-probabilistic reliability index
In the structural engineering, the safety level is determined by the non-probabilistic reliability index, which is defined as the max-min distance from the origin to corresponding LSF (G(q) = 0) in q-space. As mentioned in Sect. 2.1, the uncertain-but-bounded variables x are converted into the normalized uncertain variables q, and then the corresponding LSF g(x) is transformed as G(q). The LSF divides the uncertain domain into two parts, i.e., safety domain G(q) ≥ 0 and failure domain G(q) < 0. In the study of Kang et al. (2011), the non-probabilistic reliability index of interval model and ellipsoid model can be obtained by,
where non-probabilistic reliability index η is called as non-probabilistic reliability index, the optimal solution q∗ of (7) is defined as the MCP. sgn(⋅) represents the signum function. If G(0) > 0, sgn(G(0)) = 1, else if G(0) < 0, sgn(G(0)) = − 1 and if G(0) = 0, sgn(G(0)) = 0. When η = 1, it means the unit ellipsoid or interval set is tangent to the limit state surface, and then the critical state is reached. When η > 1, all combinations of uncertain variables are located in the safety domain, meaning the structure is reliable. When 0 ≤ η < 1, some failure events may occur, and the structure is unsafe.
2.3 Non-probabilistic reliability-based design optimization
In NRBDO, the reliability index is selected as the constraint condition. Without loss of generality, the mathematical formulas of NRBDO are typically expressed as,
where d and x represent the deterministic and uncertain design variables, and p is a vector of the uncertain parameters. xC is the nominal values of x and can be considered as the design variables vector. d(L) and xC(L) are the low bounds of d and xC, while d(U) and xC(U) are the corresponding upper bounds. ηj denotes the jth non-probabilistic reliability index, which is estimated by (7). Evidently, the solution of the NRBDO problems consists of double loops, i.e., the inner loop seeks the non-probabilistic reliability constraint at the current design point, while the outer loop updates the design variables based on the results of inner loop. Herein, the sequential quadratic programming technique can be applied to solve the NRBDO problems.
3 Active learning method for Kriging model
3.1 Basic of the Kriging model
For the sake of convenience, the uncertain parameters y are denoted as the input parameters of Kriging. In the Kriging model, the real responses Y = [g(x1), g(x2), …, g(xk)]T for the kth sample point can be replaced by the approximate response g(x), and it is consisted by a regression part fT(x)β and a Gaussian process z(x),
where f(x) = [f1(x), f2(x), …, fm(x)]T is the vector of basis functions. β = [β1, β2, …, βm]T is the vector of regression coefficients. z(x) is stationary Gaussian process with means zero, and the covariance function for any two sample points xi and xj are defined as follows,
where R(xi, xj) is the correlation function that can be assumed following Gaussian distribution. By using the generalized least square regression, the regression coefficients and the process variance can be assessed by,
where F is a matrix with Fij = fj(xi), i = 1, 2, …, k, j = 1, 2, …, m.
Once the Kriging model is built successfully, a best linear unbiased predictor and Kriging variance for any unknown point x0 can be evaluated using the following formulas,
where r0 = [R(x0, x1), R(x0, x2), …, R(x0, xk)]T and u = FTR−1r0 − f(x0).
The Kriging Toolbox DACE (Lophaven et al. 2002) is used to build the Kriging model in this study, which can provide the important predicted values \( {\widehat{\sigma}}_{\widehat{g}}^2\left({\mathbf{x}}_0\right) \) for \( \widehat{g}\left({\mathbf{x}}_0\right) \). Benefiting from the advantage of the Kriging variance, the active learning technique is widely developed to alleviate the heavy computational burden in probabilistic domain.
3.2 Expected feasibility function
In reliability analysis, the prediction of the LSF is crucial. An expected feasibility function (EFF) can be applied to give an indication for the actual values of the performance functions, which is expected to satisfy the equality constraints g(x) = a in efficient reliability analysis method (Bichon et al. 2008). The EFF makes a trade-off between exploiting the random space with good results and exploring the random space with higher variance of the Kriging model for the LSF. It can be formulated as follows,
where Φ(⋅) and ϕ(⋅) are the cumulative distribution function and probability density function, respectively. \( \overline{z} \) is proportional to the standard deviation, and the value of \( \overline{z} \) is set as \( 2{\widehat{\sigma}}_{\widehat{g}}^2\left(\mathbf{x}\right) \), which refers to the relevant literature (Echard et al. 2011). Similar to the expected improvement function, the points that the expected performance function value is close to the threshold and points with a large predicted uncertainty \( {\widehat{\sigma}}_{\widehat{g}}^2\left(\mathbf{x}\right) \) should be sequentially selected as new points. In the case of non-probabilistic reliability estimation, the threshold value of a is 0, which aims to predict the LSF.
3.3 Expected risk function
Yang et al. (2014) suggested an ERF to improve the predicted accuracy of the LSF by picking out the wrongly predicted point with the largest risk. Then, the efficiency of reliability estimation is improved, and the formulation of ERF is expressed as follows,
where ERF(·) can give the risk degree of the sign of the constraint for any point. Thus, this point is expected to be wrongly predicted by the Kriging model. The larger value of the ERF is, the higher risk of this point will be wrongly predicted. Based on the active learning method, the LSF can be predicted accurately; therefore, the computational cost of reliability analysis will be reduced significantly.
3.4 Learning function U of AK-MCS
Echard et al. (2011) constructed a learning function U to judge which point has the largest probability to be wrongly predicted. The definition is as
This function U gives more opportunities in the vicinity of predicted LSF rather than those with high Kriging variance \( {\widehat{\sigma}}_{\widehat{g}}\left(\mathbf{x}\right) \). The failure probability using function U is assessed slower than that using EFF, and this function converges toward the actual failure probability more quickly for solving probabilistic problems.
3.5 Constraint boundary sampling
The CBS uses the normal probability density function to perform reliability analysis with multiple probabilistic constraints, i.e., gi(x), i = 1, 2, …, m, in which m is the number of performance functions. The values of the learning function will become large when the sample points are located near the LSF or corresponding predicted values with a large error. The formulation is given as,
where D denotes the minimum distance from the existing sample points, which is used to make the samples consecutively located on the LSF. In the CBS, when the predicted points are located in the infeasible region, the value of sampling criterion becomes 0. For this reason, the computational efficiency can be further improved by ignoring sample points to construct the LSF in the infeasible region. Meanwhile, the minimum distance D is maximized to ensure the sample uniformly distribution. Although these active learning methods are successfully utilized for assessing the failure probability, the accuracy and efficiency in the non-probabilistic domain remain unknown.
4 The proposed method
4.1 Importance learning method
As above-mentioned, the Kriging model can speed up the reliability estimation and optimization process by replacing the actual performance function, in which the DoE of Kriging model is the key. A series of active learning techniques were developed to predict the LSF, such as the CBS, EFF, and ERF. However, these methods ignore the importance degree of different points on LSF. According to the definition in (7), once the MCP near the LSF is obtained, we can directly compute the non-probabilistic reliability index other than predicting the entire LSF. Therefore, it is more rational to consider the importance degree of the points for an active learning function. As plotted in Fig. 2, when the value of non-probabilistic reliability index of the point q1 is smaller than that of the q2, it means the point q1 is closer to the MCP and more important than the point q2. Following this concept, the prediction of the LSF is converted to search the MCP, and thus only a small number of samples are required to find this point. This new active learning function is called the ILF, and the formulation is defined as,
where η(x) is the value of non-probabilistic reliability index at the current point, and it can be computed by,
where F(·) denotes the transformation from the uncertain-but-bounded variables x into normalized uncertain variables q, which is computed by the mentioned methods in Sect. 2.1. The proposed ILF considers three different factors, i.e., the predicted value of performance function, Kriging variance and importance degree. The term \( \phi \left(\frac{\widehat{g}\left(\mathbf{x}\right)}{\widehat{\sigma}\left(\mathbf{x}\right)}\right) \) is employed to ensure the new points generating near the LSF with large Kriging variance, while the non-probabilistic reliability index η(x) contains the information of the importance degree. Evidently, the smaller value of η(x) is, the more important of the point becomes (Fig. 2). By considering the importance degree, the new samples generated using the proposed ILF move toward the MCP gradually, which results in the improving both the computational efficiency and accuracy of reliability analysis. To fully exploit the potential of ILF, we add one point each time into the DOE, so it may require a large number of iterations for high dimensional problems. However, it should be emphasized that the calculation of predicted performance function by Kriging is very cheap, and thus ILF is very efficient, especially for complex engineering systems.

The iterative process of the proposed ILM
It is well-known that a terminated criterion needs to provide for metamodeling-based reliability analysis technique. Herein, a new relative error is proposed as the terminated criterion to guarantee the accuracy of the Kriging model, in which the information of the predicted performance functions and non-probabilistic reliability index are used. Assume a new sample point x′ is obtained in the kth iterative step using the proposed ILF, the proposed termination criterion can be defined as follows,
where \( \widehat{g}\left(\cdot \right) \) and g(⋅) denote the Kriging performance function and actual performance function, respectively. The point set {x1, x2, …, xn} represents the existing training sample points in the design domain. And δ1 represents the maximum value of relative error between the predicted values and actual performance function values, while δ2 represents the relative error of the non-probabilistic reliability index between the previous and current iterative steps. Thus, the proposed non-probabilistic reliability estimation method is considered as convergent when the relative error is less than a small enough value Δ, where Δ is set as 10−5 in the procedure.
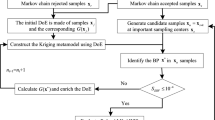
A flowchart of the proposed method is given in Fig. 4a. Firstly, the initial DOE is generated uniformly according to the dimension and computational cost, then a Kriging model is built using the initial DOE. Secondly, a new point xk is generated using the proposed ILF in (19), in which the particle swarm optimization algorithm is used (Birge 2003). Besides, the actual value of performance function is calculated at this point. Thirdly, the DOE is updated by adding a new point into the training sample points set. Finally, a new Kriging model is reconstructed based on all training samples and relative errors are calculated based on the newly-established Kriging model. This process is carried out until the terminated criterion is satisfied.
4.2 NRBDO based on the proposed ILM
NRBDO always need to deal with the multiple non-probabilistic reliability index constraints simultaneously, which means the MCPs of all constraints should be calculated. To this end, the proposed ILM is extended to solve the NRBDO problems with multiple performance functions and constraints. A two-dimensional example with three non-probabilistic reliability constraints is shown in Fig. 3. When the constraint functions g1(x) and g2(x) are active (Fig. 3a), the ILF values of performance functions g1(x) and g2(x) are larger than that of performance function g3(x); this is due to η3(x) > η1(x) and η3(x) > η2(x). Similarly, when the constraint functions g1(x) and g3(x) are active (Fig. 3b), the ILF values of performance functions g1(x) and g3(x) are larger than that of performance function g2(x). Hence, we maximize the ILF values of all constraints to obtain the MCPs, i.e., the minimum non-probabilistic reliability index value from LSFs to the current optimum point. Note that the points located in the infeasible region are useless for solving NRBDO problems. The proposed ILF for NRBDO problems can be redefined as,

A sketch of the ILM for NRBDO problem
According to (19), the computational cost can be greatly decreased. For NRBDO model with multiple non-probabilistic reliability constraints, the proposed ILM only focuses on the active constraints; on the contrary, the inactive constraints are ignored during the optimization process. Therefore, we only need to validate the accuracy of the active constraints. As mentioned above, the proposed ILM first adds the sample point located near the active LSF, which means that the accuracy of the active constraints is always higher than that of the inactive constraints. Similar with ILM in reliability assessment, we also update one point each time. It should be noted that the active checking condition \( {\widehat{g}}_{\mathrm{i}}\left(\mathbf{x}\right)\ge -{\varepsilon}_{\mathrm{g}} \) is established based on Kriging performance functions. εg is a small value to improve the robustness for highly nonlinear problems, and it is set to be 10−3 in this study. It should be noted that the active checking condition may produce some errors during the initial iterative process. However, as the increase of iterations, the error is gradually decreased until it is vanished.
During each iterative step of the NRBDO, enough samples should be generated to guarantee the accuracy of MCP and movement of design variables. Therefore, the terminated criterion for NRBDO problems is necessary by considering the reliability system with multiple constraints.
where \( {\widehat{g}}_{\mathrm{j}}\left(\cdot \right) \) and gj(⋅) are the values of jth Kriging model and actual performance function, respectively.
4.3 Procedures and flowcharts
A flowchart of the proposed ILM for NRBDO problems is given in Fig. 4b, and the procedures are generalized as follows,
-
(a)
Initialize the sample set s0, the design variables d(0), and xC(0) for NRBDO problems.
-
(b)
Build a Kriging model based on the initial sample set. Then, the NRBDO approach is carried out based on the Kriging model.
-
(c)
Select new sample points using the proposed ILF and add these points to the initial sample set sk. Then, a new Kriging model is rebuilt for the objective functions and constraints based on the new sample points and corresponding responses.
-
(d)
Based on the new Kriging model in step (3), the NRBDO approach is performed to update the design variables.
-
(e)
Calculate the relative error according to (23)
-
(f)
If the convergence condition is satisfied, then stop the iteration. Otherwise, set k = k + 1, back to step (3) to update the Kriging model.

a Non-probabilistic reliability analysis using the ILF. b The ILF for NRBDO
5 Numerical examples
In this section, five numerical examples are applied to verify the efficiency and accuracy of the proposed ILM by comparing with LHS method and other four popular active learning methods from probabilistic domain (i.e., EFF, ERF, function U, and CBS). The results calculated using the analytical (Anal.) method are considered as a benchmark solution, in which the actual LSFs and objective functions are used. Meanwhile, the Kriging-based learning methods are compared with the analytical method to validate their effectiveness. For NRBDO problems, the relative errors of calculated results between the analytical method and Kriging-based methods are calculated by \( \frac{\left\Vert \mathbf{d}-{\mathbf{d}}^{\ast}\right\Vert }{\left\Vert {\mathbf{d}}^{\ast}\right\Vert}\times 100\% \), where d∗ denotes the values of design variables computed using the analytical method at the optimum point. In addition, the non-probabilistic reliability analysis and NRBDO approach are performed based on the advanced nominal value method (Meng et al. 2018) to further test the accuracy of the proposed method. The finite difference method is used to calculate the sensitivities of objective and performance functions during the NRBDO process.
5.1 Mathematical example 1
The first example is a two-dimensional nonlinear function, which is modified from the reference (Bichon et al. 2008).
where both of two uncertain variables x1 and x2 are assumed to lie within the range of [5, 15].
The results computed using the analytical method are shown in Fig. 5, in which the nominal values of x1 and x2 are set as (10.0, 10.0). The location is denoted as black “*.” The black curve denotes the actual LSF, and the red curve denotes the Kriging model-based LSF. The red “×” denote the locations of sample points during the Kriging model-based non-probabilistic reliability analysis. To compare the accuracy of different active learning methods in a fair way, nine initial sample points are generated by the grid sampling with three-level full factorial design to construct the initial Kriging model. The relative errors ∣η − η∗ ∣ / ∣ η∗ ∣ × 100% between different methods are used to compare the accuracy, where η and η∗ denote the actual and Kriging non-probabilistic reliability indices, respectively. Besides, the number of sample size and CPU time are also given to demonstrate the efficiency. The unit of the CPU time is second.

Non-probabilistic reliability analysis of different methods for example 1. a LHS, b EFF, c ERF, d function U, e CBS, f ILM
The results computed using the analytical method are listed in Table 1. The actual non-probabilistic reliability index is 1.5840. The LHS method with 60 sample points is shown in Fig. 5a, and dotted square denotes the geometric figure of non-probabilistic model. Since the samples are evenly distributed in the entire uncertain space, the relative error between the LHS method and the analytical method is quite small. Since the calculation of performance function is very cheap, a small amount of CPU time is required.
The reliability analysis results computed using the EFF, ERF, function U, and CBS methods are illustrated in Fig. 5b–e, respectively. Comparing with LHS, EFF generates most of sample points near the LSF despite of few samples locating at the top right corner. Thus, the number of samples of EFF is far less than that of LHS, while the accuracy is also accordingly increased. ERF is slightly better than EFF; this may be because EFF requires considering an additional parameter \( \overline{z} \). Function U in AK-MCS generates the samples near the LSF with the large value of Kriging variance, so the LSF is predicted accurately. CBS considers the minimum distance between the existing samples, so the samples more evenly than that generated by function U. It is also very efficient and accurate. But all these active learning methods approximate the LSF in entire design space, it needs a large number of sample points. The sampling process of the proposed ILM is illustrated in Fig. 5f, which indicates that the sample points move toward the CPF gradually. Besides, the CPU time are also given in Table 1; the CPU time of these active learning methods is higher than that of LHS, because it needs constantly solving optimization problem. However, since the prediction by Kriging model is efficient, the sampling process is also very fast. The CPU time of these active learning methods has a same trend with the sample numbers of these methods, and the proposed ILM is the most effective method. For complex engineering problem, the DoE of Kriging-based method occupies most of CPU time, so the proposed method has a great potential for reducing the CPU time for complex engineering systems.
The compared results of all methods are shown in Table 1. “Sample size” represents the number of function calls for different Kriging model-based non-probabilistic reliability analysis methods. The efficiency of the active learning methods, i.e., EFF, ERF, function U, and CBS, is much improved compared with the LHS method. In terms of the computational accuracy, the relative error between the proposed ILM and analytical method is 0 as shown in Table 1, which is more accurate than other methods provided in this study. In addition, the sample size of the proposed method is only 16, which is the least among all the methods; in other words, the number of function calls is nearly 1/2 of that of ERF and function U. It also needs to point out that the proposed ILM only generates the sample points on the LSF in the vicinity of the MCP, which is an obvious improvement by comparing with the provided reference methods.
5.2 Mathematical example 2
The second example is a highly nonlinear mathematical example, which is modified from reference (Bichon et al. 2008). The performance function is given as follows,
where the nominal values of uncertain variables x1 and x2 are 1.5 and 2.5, and the radii of x1 and x2 are assumed as 1. Thus, the mathematical expression of the ellipsoid model is formulated as \( {\left(\frac{\mathbf{x}-{\mathbf{x}}^{\mathrm{C}}}{{\mathbf{x}}^{\mathrm{C}}}\right)}^{\mathrm{T}}\left[\begin{array}{l}2.25\kern1em 0\\ {}0\kern2em 6.25\end{array}\right]\left(\frac{\mathbf{x}-{\mathbf{x}}^{\mathrm{C}}}{{\mathbf{x}}^{\mathrm{C}}}\right)\le 1 \).
The performance function is highly nonlinear, as shown in Fig. 6. The coordinate of the MCP computed using the analytical method is (1.9406, 3.5924). Nine initial sample points are also generated by the grid sampling with 3-level full factorial design to construct the initial Kriging model for the EFF, ERF, function U, CBS, and ILM. The reliability analysis results of the LHS method are shown in Fig. 6b, there are totally 120 sample points evenly generated in the entire uncertain space. However, many sample points are located far from the MCP, which results in the approximate LSF is inaccurate. The results computed using the EFF, ERF, and CBS methods are illustrated in Fig. 6c–e, respectively. It is observed that most of sample points generated using three active learning methods are located near the LSF; thus, both the efficiency and accuracy are improved remarkably. Among these three active learning methods, EFF shows the most accuracy, but it also needs more sample points.

Non-probabilistic reliability analysis of different methods for example 2. a LHS, b EFF, c ERF, d function U, e CBS, f ILM
The compared results of all methods are shown in Table 2. Unlike the EFF, ERF, and CBS methods, most of sample points generated using the proposed ILM are located in the local region around the MCP, and thus, the LSF near the neighborhood of the MCP can provide enough accuracy. As shown in Fig. 6, the ILM is more accurate than the LHS, EFF, ERF, function U, and CBS methods, while the computational cost of the ILM is greatly reduced by considering the influence of non-probabilistic reliability index during the active learning process. Also, the CPU time of the proposed method is significantly reduced compared to other active learning methods.
5.3 NRBDO mathematical example
There are three performance functions and two uncertain variables in this NRBDO example (Meng et al. 2016). The design variables are selected as the nominal values, and the reference variation coefficients of nominal values are assumed as 10%. The NRBDO model is defined as follows,
The compared optimization results and NRBDO solutions of different methods for example 3 are listed in Table 3 and Fig. 7. To compare the optimal results of different methods, the non-probabilistic reliability index at the optimum is tested by ANVM. The optimal results are identical to those in reference (Meng et al. 2016). The initial sample sizes of different Kriging model-based NRBDO approaches are equal to nine, which is also generated using grid sampling with three-level full factorial design.

NRBDO solutions of different methods for example 2. a LHS, b EFF, c ERF, d function U, e CBS, f ILM
From Table 3 and Fig. 7, it can be observed that the samples generated by the LHS method are evenly distributed in the design space, which requires a large number of sample points to find the optimum. As shown in Fig. 7b, c, the EFF and ERF methods generate new sample points near the LSF, so they are more efficient than the LHS method. For function U, the samples located on the LSF g3 are more than those located on the LSFs g1 and g2, so it is less accurate than EFF and ERF. But the number of samples of function U is less than that of EFF and ERF. For CBS, the samples are evenly distributed on LSF in the feasible region, whose efficiency is further improved to a certain extent than function U. Compared with the EFF, ERF, and CBS methods, the proposed ILM only adds the sample points on the LSFs at the neighborhood of the MCP, while the inactive constraint g3 is ignored owing to the large value of non-probabilistic reliability constraint. Therefore, it is a more efficient and accurate approach than other prevalent active learning methods for solving the NRBDO problems in terms of the number of function calls and CPU time.
5.4 A speed reducer
A speed reducer contains seven uncertain variables and 11 non-probabilistic reliability constraints, as shown in Fig. 8. The objective functions are the structural weight, while physical quantities, involving bending stress, contact stress, longitudinal displacement, stress of the shaft, and geometry constraints, are deemed as the constraints. All uncertain parameters are considered as the uncertain-but-bounded variables, and the reference coefficients of variation of nominal values are assumed as 1%. The deterministic optimum solution is selected as the initial design and the NBRDO model is formulated as follows,

A speed reducer
The compared results for the speed reducer are listed in Table 4, while the non-probabilistic reliability index at the optimum is validated by the ANVM, as shown in Table 5. The abbreviation “inact.” denotes this non-probabilistic reliability constraint is inactive in Table 5. The numbers of initial sample point for the EFF, ERF, function U, CBS, and ILM are 36, which is sampled by the LHS method. It can be seen that the efficiency of the LHS method is low. EFF, function U, and ERF are more efficient than the LHS. However, the minimum non-probabilistic reliability index calculated using the EFF, function U, and ERF methods are 0.9948, 0.8810, and 0.9924, respectively. The CBS method is more efficient than the LHS, ERF, function U, and EFF methods, and the corresponding minimum non-probabilistic reliability index at the optimum is 0.9938. The minimum non-probabilistic reliability index of the proposed ILM is 1.0000, and thus, it is obviously more accurate than other active learning functions. In addition, the number of sample size is less than other comparative methods. Also, the CPU time of the proposed method is less than that of other active learning methods. Therefore, it can be concluded that the proposed ILM shows a high performance in terms of accuracy and efficiency.
5.5 A welded beam
As shown in Fig. 9, the weight of weld beam is minimized, while the non-probabilistic reliability constraints are related to shear stress, bending stress, buckling and displacement (Meng et al. 2016). There are four uncertain-but-bounded variables, and their nominal values are selected as design variables. The reference coefficients of variation of nominal values are selected as 5%. The deterministic optimum results are selected as the initial design, and the NBRDO model is formulated as follows,

A welded beam
The compared results for the welded beam design are shown in Table 6. The non-probabilistic reliability index at the optimum is listed in Table 7, which is validated by the ANVM. The numbers of initial sample points for the EFF, ERF, function U, CBS, and ILM are 24, which are sampled by the LHS method.
For the LHS method, 360 samples are generated in the entire design space, and the optimum converges to (10.1555, 175.8606, 112.7095, and 12.3325). It is obviously found that the accuracy of the NRBDO results computed by the LHS method is poor. The EFF method improves the accuracy of Kriging model to a certain extent through adding the sample points near the LSF; however, the minimum non-probabilistic reliability index at the optimum is far less than 1. Thus, the optimal results computed by EFF have the risk of failure. Other three active learning methods, including ERF, function U, and CBS methods, exhibit similar behavior for this highly nonlinear problem. The approximate difficulty of the proposed ILM is significantly decreased because of only approximating the MCP in the local region, and thus, the accuracy is significantly improved. Also, the number of function calls and CPU time are about half of any other comparative methods.
6 Conclusions
This study investigates the active learning methods for the non-probabilistic reliability analysis and optimization and develops an ILM for improving the computational efficiency and accuracy. Considering the importance degree of non-probabilistic reliability index during the active learning process, an ILF is proposed to accurately predict the MCP in the vicinity of LSF. Then, the proposed ILM is further extended to solve the NRBDO problems with multiple performance functions accurately and efficiently by constructing the system ILF. In addition, in order to ensure the accuracy, two new stopping criterions are proposed to distinguish the convergence condition of the non-probabilistic reliability analysis and optimization, which is also an innovation point of the proposed algorithm.
The efficiency and accuracy of the proposed ILM are validated through two non-probabilistic reliability analysis examples and three NRBDO examples. The compared results with one typical sampling method (LHS) and four popular active learning methods (EFF, ERF, function U, and CBS) indicated that the proposed ILM is more efficient and accurate. The results validated by the advanced nominal value method are almost identical to the results computed by the actual performance functions, which verifies that the proposed ILM is more accurate than other comparative methods. In the future, the application of the ILM for large-scale engineering systems will be reinforced.
References
Azarm S, Mourelatos ZP (2006) Robust and reliability-based design. J Mech Des 128(4):829–831
Bae S, Kim NH, Jang SG (2018) Reliability-based design optimization under sampling uncertainty: shifting design versus shaping uncertainty. Struct Multidiscip Optim 57(5):1845–1855
Bai YC, Han X, Jiang C, Bi RG (2014) A response-surface-based structural reliability analysis method by using non-probability convex model. Appl Math Model 38(15–16):3834–3847
Ben-Haim Y (1994) A non-probabilistic concept of reliability. Struct Saf 14(4):227–245
Ben-Haim Y (1995) A non-probabilistic measure of reliability of linear systems based on expansion of convex models. Struct Saf 17(2):91–109
Ben-Haim Y, Elishakoff I (1995) Discussion on: a non-probabilistic concept of reliability. Struct Saf 17(3):195–199
Bichon BJ, Eldred MS, Swiler LP, Mahadevan S, McFarland JM (2008) Efficient global reliability analysis for nonlinear implicit performance functions. AIAA J 46(10):2459–2468
Bichon BJ, McFarland JM, Mahadevan S (2011) Efficient surrogate models for reliability analysis of systems with multiple failure modes. Reliab Eng Syst Saf 96(10):1386–1395
Bichon BJ, Eldred MS, Mahadevan S, McFarland JM (2012) Efficient global surrogate modeling for reliability-based design optimization. J Mech Des 135(1):011009
Birge B (2003) PSOt-a particle swarm optimization toolbox for use with Matlab. In: Swarm Intelligence Symposium, 2003. SIS'03. Proceedings of the 2003 IEEE. IEEE, pp 182–186
Chen ZZ, Qiu HB, Gao L, Li XK, Li PG (2014) A local adaptive sampling method for reliability-based design optimization using Kriging model. Struct Multidiscip Optim 49(3):401–416
Du X, Chen W (2004) Sequential optimization and reliability assessment method for efficient probabilistic design. J Mech Des 126(2):225–233
Echard B, Gayton N, Lemaire M (2011) AK-MCS: an active learning reliability method combining Kriging and Monte Carlo simulation. Struct Saf 33(2):145–154
Echard B, Gayton N, Lemaire M, Relun N (2013) A combined importance sampling and Kriging reliability method for small failure probabilities with time-demanding numerical models. Reliab Eng Syst Saf 111:232–240
Elishakoff I, Elettro F (2014) Interval, ellipsoidal, and super-ellipsoidal calculi for experimental and theoretical treatment of uncertainty: which one ought to be preferred? Int J Solids Struct 51(7–8):1576–1586
Ganzerli S, Pantelides CP (2000) Optimum structural design via convex model superposition. Comput Struct 74(6):639–647
Guo X, Zhang W, Zhang L (2013) Robust structural topology optimization considering boundary uncertainties. Comput Methods Appl Mech Eng 253:356–368
Hao P, Wang YT, Liu C, Wang B, Wu H (2017) A novel non-probabilistic reliability-based design optimization algorithm using enhanced chaos control method. Comput Methods Appl Mech Eng 318:572–593
Hawchar L, El Soueidy C-P, Schoefs F (2018) Global Kriging surrogate modeling for general time-variant reliability-based design optimization problems. Struct Multidiscip Optim 58(3):955–968. https://doi.org/10.1007/s00158-018-1938-y
Hu Z, Du XP (2015) First order reliability method for time-variant problems using series expansions. Struct Multidiscip Optim 51(1):1–21
Huang D, Allen TT, Notz WI, Zeng N (2006) Global optimization of stochastic black-box systems via sequential Kriging meta-models. J Glob Optim 34(3):441–466
Huang X, Chen J, Zhu H (2016a) Assessing small failure probabilities by AK–SS: an active learning method combining Kriging and subset simulation. Struct Saf 59:86–95
Huang ZL, Jiang C, Zhou YS, Zheng J, Long XY (2016b) Reliability-based design optimization for problems with interval distribution parameters. Struct Multidiscip Optim 55(2):513–528
Jiang C, Han X, Liu GR (2007) Optimization of structures with uncertain constraints based on convex model and satisfaction degree of interval. Comput Methods Appl Mech Eng 196(49–52):4791–4800
Jiang C, Han X, Liu GP (2008) A sequential nonlinear interval number programming method for uncertain structures. Comput Methods Appl Mech Eng 197(49–50):4250–4265
Jiang C, Han X, Lu GY, Liu J, Zhang Z, Bai YC (2011) Correlation analysis of non-probabilistic convex model and corresponding structural reliability technique. Comput Methods Appl Mech Eng 200:2528–2546
Jiang C, Bi RG, Lu GY, Han X (2013) Structural reliability analysis using non-probabilistic convex model. Comput Methods Appl Mech Eng 254:83–98
Jiang C, Ni BY, Han X, Tao YR (2014) Non-probabilistic convex model process: a new method of time-variant uncertainty analysis and its application to structural dynamic reliability problems. Comput Methods Appl Mech Eng 268(0):656–676
Jiang C, Qiu HB, Gao L, Cai XW, Li PG (2017) An adaptive hybrid single-loop method for reliability-based design optimization using iterative control strategy. Struct Multidiscip Optim 56(6):1271–1286
Jones DR, Schonlau M, Welch WJ (1998) Efficient global optimization of expensive black-box functions. J Glob Optim 13(4):455–492
Kang Z, Luo Y (2010) Reliability-based structural optimization with probability and convex set hybrid models. Struct Multidiscip Optim 42(1):89–102
Kang Z, Zhang W (2016) Construction and application of an ellipsoidal convex model using a semi-definite programming formulation from measured data. Comput Methods Appl Mech Eng 300:461–489
Kang Z, Luo Y, Li A (2011) On non-probabilistic reliability-based design optimization of structures with uncertain-but-bounded parameters. Struct Saf 33(3):196–205
Karuna K, Manohar CS (2017) Inverse problems in structural safety analysis with combined probabilistic and non-probabilistic uncertainty models. Eng Struct 150:166–175
Keshtegar B, Lee I (2016) Relaxed performance measure approach for reliability-based design optimization. Struct Multidiscip Optim 54(6):1439–1454
Khodaparast HH, Mottershead JE, Badcock KJ (2011) Interval model updating with irreducible uncertainty using the Kriging predictor. Mech Syst Signal Process 25(4):1204–1226
Lee TH, Jung JJ (2008) A sampling technique enhancing accuracy and efficiency of metamodel-based RBDO: constraint boundary sampling. Comput Struct 86(13–14):1463–1476
Lee I, Choi KK, Gorsich D (2013) System reliability-based design optimization using mpp-based dimension reduction method. Struct Multidiscip Optim 41(6):823–839
Li M, Azarm S (2008) Multiobjective collaborative robust optimization with interval uncertainty and interdisciplinary uncertainty propagation. J Mech Des 130(8):081402
Li M, Li G, Azarm S (2006) A Kriging metamodel assisted multi-objective genetic algorithm for design optimization. J Mech Des 130(3):405–414
Liu Y, Jeong HK, Collette M (2016) Efficient optimization of reliability-constrained structural design problems including interval uncertainty. Comput Struct 177:1–11
Lombardi M, Haftka RT (1998) Anti-optimization technique for structural design under load uncertainties. Comput Methods Appl Mech Eng 157(1–2):19–31
Lophaven SN, Nielsen HB, Søndergaard J (2002) DACE-A Matlab Kriging toolbox, version 2.0
Luo YJ, Li A, Kang Z (2011) Reliability-based design optimization of adhesive bonded steel-concrete composite beams with probabilistic and non-probabilistic uncertainties. Eng Struct 33(7):2110–2119
Majumder L, Rao SS (2009) Interval-based multi-objective optimization of aircraft wings under gust loads. AIAA J 47(3):563–575
Marelli S, Sudret B (2018) An active-learning algorithm that combines sparse polynomial chaos expansions and bootstrap for structural reliability analysis. Struct Saf 75:67–74
Meng Z, Zhou H (2018) New target performance approach for a super parametric convex model of non-probabilistic reliability-based design optimization. Comput Methods Appl Mech Eng 339:644–662
Meng Z, Hao P, Li G, Wang B, Zhang K (2015) Non-probabilistic reliability-based design optimization of stiffened shells under buckling constraint. Thin-Walled Struct 94(9):325–333
Meng Z, Zhou H, Li G, Yang D (2016) A decoupled approach for non-probabilistic reliability-based design optimization. Comput Struct 175(10):65–73
Meng Z, Hu H, Zhou H (2018) Super parametric convex model and its application for non-probabilistic reliability-based design optimization. Appl Math Model 55(3):354–370
Moens D, Vandepitte D (2006) Recent advances in non-probabilistic approaches for non-deterministic dynamic finite element analysis. Arch Comput Meth Eng 13(3):389–464
Moon MY, Cho H, Choi KK, Gaul N, Lamb D, Gorsich D (2018) Confidence-based reliability assessment considering limited numbers of both input and output test data. Struct Multidiscip Optim 57(5):2027–2043
Moustapha M, Sudret B, Bourinet JM, Guillaume B (2016) Quantile-based optimization under uncertainties using adaptive Kriging surrogate models. Struct Multidiscip Optim 54(6):1403–1421
Muscolino G, Santoro R, Sofi A (2016) Reliability analysis of structures with interval uncertainties under stationary stochastic excitations. Comput Methods Appl Mech Eng 300:47–69
Qiu Z, Elishakoff I (1998) Antioptimization of structures with large uncertain-but-non-random parameters via interval analysis. Comput Methods Appl Mech Eng 152(3):361–372
Qiu Z, Wang X, Li Z (2009) Post-buckling analysis of a thin stiffened plate with uncertain initial deflection via interval analysis. Int J Non Linear Mech 44(10):1031–1038
Ranjan P, Bingham D, Michailidis G (2008) Sequential experiment design for contour estimation from complex computer codes. Technometrics 50(4):527–541
Rashki M, Miri M, Moghaddam MA (2014) A simulation-based method for reliability based design optimization problems with highly nonlinear constraints. Autom Constr 47(11):24–36
Wang Z, Chen W (2017) Confidence-based adaptive extreme response surface for time-variant reliability analysis under random excitation. Struct Saf 64:76–86
Wang Z, Wang P (2012) A nested extreme response surface approach for time-dependent reliability-based design optimization. J Mech Des 134(12):12100701–12100714
Wang Z, Wang P (2013) A maximum confidence enhancement based sequential sampling scheme for simulation-based design. J Mech Des 136(2):021006
Yang X, Liu Y, Gao Y, Zhang Y, Gao Z (2014) An active learning Kriging model for hybrid reliability analysis with both random and interval variables. Struct Multidiscip Optim 51(5):1003–1016
Yang X, Liu Y, Zhang Y, Yue Z (2015) Probability and convex set hybrid reliability analysis based on active learning Kriging model. Appl Math Model 39(14):3954–3971
Youn BD, Choi KK (2004) A new response surface methodology for reliability-based design optimization. Comput Struct 82(2–3):241–256
Youn BD, Wang P (2008) Bayesian reliability-based design optimization using eigenvector dimension reduction (EDR) method. Struct Multidiscip Optim 36(2):107–123
Youn BD, Choi KK, Du L (2005) Adaptive probability analysis using an enhanced hybrid mean value method. Struct Multidiscip Optim 29(2):134–148
Zhang D, Han X, Jiang C, Liu J, Li Q (2017) Time-dependent reliability analysis through response surface method. J Mech Des 139(4):041404
Funding
The supports of the National Natural Science Foundation of China (Grant Nos. 11602076 and 11502063), the Natural Science Foundation of Anhui Province (Grant No. 1708085QA06), the Foundation of State Key Laboratory of Structural Analysis for Industrial Equipment from Dalian University of Technology (Grant No. GZ1702), and the Fundamental Research Funds for the Central Universities of China (Grant No. JZ2018HGTB0231) are much appreciated.
Author information
Authors and Affiliations
Corresponding author
Additional information
Responsible Editor: Byeng D Youn
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Meng, Z., Zhang, D., Li, G. et al. An importance learning method for non-probabilistic reliability analysis and optimization. Struct Multidisc Optim 59, 1255–1271 (2019). https://doi.org/10.1007/s00158-018-2128-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00158-018-2128-7