
Abstract
Test point selection is an important stage in analog circuits fault diagnosis. In this paper, a test point selection method is proposed that is suitable for large numbers of predefined faults in DC analog circuits using the technique of constructing a fault dictionary for each component. Main idea is selecting a test point set with minimum amount of overlap between fault and no-fault regions for each component. A combined exclusive-inclusive algorithm is applied on each fault dictionary and using the achieved information, a grade is given to each test point. Then the test points with grades lower than a threshold value are eliminated and a decision guide is provided for tester to select final test point set. Applying this method on a benchmark circuit is eliminating 22% of test points and the accuracy metrics of proposed approach is comparable with using all of the test points. The results show that by eliminating 56% of the test points, the accuracy metrics just drops about 4%.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Methods for fault diagnosis of analog circuits fall in two categories called simulation before test (SBT) and simulation after test (SAT) [1]. SBT methods require minimum computation during the test and most of the computational effort are performed off-line. Fault dictionary is an important method of SBT approach, especially in diagnosing catastrophic faults [1]. A fault dictionary is a set of measurements of the circuit under test (CUT) simulated under potentially faulty conditions (including no-fault case) and constructed before the test. There are three important phases in the fault dictionary approach. At first, the circuit is simulated for each of the predefined faults and the resulting responses are stored. Next phase is selection of test points. The last phase is designing classifier to isolate the predefined faults. During the test, the faulty circuit is excited by the same stimuli that were used in simulations, and measurements are made at the preselected nodes. Finally, they are classified using the designed classifier to diagnose the fault.
Test points may be nodes at which the measurements are performed. In practice, it may not be possible to make measurements at every point of the circuit. Test point selection is process of selecting optimum set of points with maximum degrees of fault isolation.
Generally, test point selection methods fall in two categories: inclusive and exclusive approaches [2]. In inclusive approaches, the desired optimum set of test points is initialized to be null, then a new test point is added to it if needed. For the exclusive approaches, the desired optimum set is initialized to include all available test points. Then a test point will be deleted if its exclusion does not degrade the degree of fault diagnosis. Various criterions were used in contributions to include or exclude a test point. Ambiguity set (AS) and integer-coded table were used in [2] to define the criterion. Entropy index (EI) of test points is the criterion used in [3]. The work in [4] uses a fault-pair Boolean table technique instead of integer-coded table to increase its accuracy. The method in [5] used the line’s slope of voltage equation between two nodes to select optimum test point set in linear time-invariant circuits. Probability density of node voltages is another approach used to define the criterion [6, 7]. The work in [6] introduced a fault-pair isolation table constructed by calculating the area of non-overlapping part of the distribution curves, and the work in [7] used fault-pair similarity coefficients calculated by Cauchy–Schwarz inequality. Combined inclusion–exclusion approach was also proposed in some contributions [8,9,10]. To take into consideration the component tolerances, a new integer-coded fault dictionary called extended fault dictionary (EFD) was used in [11]. A novel entropy measure was used as the criterion in this work. Some works have been done which cannot be classified into inclusion or exclusion group, such as graph based algorithm [12, 13], greedy randomized adaptive search procedure (GRASP) [14], genetic algorithm [15], multidimensional fitness function discrete particle swarm optimization (MDFDPSO) [16], Quantum-inspired evolutionary algorithm [17], binary bat algorithm (BBA) [18], and depth first search (DFS) algorithm [19].
In all of these works, whole fault classes are investigated during search for optimum test points. The works are based on exhaustive or local search which select optimum set for isolating predefined faults. It was pointed out in [3, 15] that exhaustive search is NP-hard. Also, time complexity of local search approaches is in direct proportion to the number of predefined faults. Therefore, these approaches are not applicable when the number of predefined faults is enlarged.
To deal with the problem of large numbers of predefined faults, the idea of designing a classifier for each of the circuit components rather than one classifier for the whole circuit was proposed in [20]. However, the method suffers from randomness effect of the used classifiers. Two overcome this problem, there is a new idea in designing approach of classifiers. In this way, classifiers are designed in two stages. At first, Support Vector Data Description (SVDD) technique is used to detect the fault regions in data space of each component. Afterward, classification among various classes included in fault regions are performed based on a clustering approach by using Improved Kernel Fuzzy C-Means (IKFCM) algorithm. The main idea of this paper is to find a test point set for each component by which the fault regions have minimum overlap with no-fault region. This leads to best isolation of fault and no-fault states. Since there are a few specified number of fault types that a component may be encountered with, this process has low complexity even if the number of circuit faults is large. Details about this approach are given in following sections.
This paper has been organized in five sections. Section 2 describes the fault diagnosis method. The new test point selection method is described in Sect. 3. Experimental results are discussed in Sect. 4 and finally, Sect. 5 concludes the paper.
2 Fault diagnosis method for large numbers of predefined faults
The proposed test point selection method is comprised of two phases: off-line process which is done before starting the test, and on-line process during the test process. These processes are described in following.
2.1 Off-line process
Figure 1 shows the diagram of off-line process. First, the predefined fault list is provided for the CUT, which usually includes all of single hard/soft faults, or all of double hard/soft faults. Here, hard fault means short-circuit and open-circuit, and soft fault means deviation from the specified tolerance ranges. Single fault means one component is faulty, and double fault means two components are faulty simultaneously. Single and double faults are most probable faults in analog circuits [1]. The circuit is simulated in each fault mode and no-fault mode to store measured responses in the fault dictionary.

Diagram of constructing the fault dictionary with off-line process
The collected data of fault list are divided into the train and test sets and normalization is done by the Z-Score method with respect to the mean and standard deviation of the train set part. The normalized data are classified based on various fault types of each component. Table 1 shows the predefined single hard fault list for a typical circuit with three resistors, R1 to R3, and the fault types of each component. In this table, O, S, and “–” mean open-circuit, short-circuit and no-fault respectively. This categorization forms the required fault dictionary for each component.
Then, the fault regions in data space of each fault dictionary are recognized by the SVDD algorithm. The SVDD is a popular kernel-based technique to construct a flexible description of the input data [21]. This process has been shown for a typical component in Fig. 2 with two detected fault regions in which no-fault area are separated from fault regions.

Detecting the fault regions for a typical component by the SVDD algorithm
For each component, the accurate diagnosing fault states are more importance than no-fault state, so the fault regions are tightened by t% when finding the samples of no-fault class that is located in the fault regions. Therefore, some of no-fault samples located in the fault regions are disregarded and the overlap between fault and no-fault samples is decreased with the penalty of misclassifying the disregarded no-fault samples. The value of t should be selected so that misclassification rate of no-fault class does not increase too much. This process is shown in Fig. 3. The left is a fault region containing the fault and no-fault samples. In the right, some of the no-fault samples that are located in the fault region disregarded with tightening the fault region.

Tightening fault region for no-fault samples; (left) fault region including fault and no-fault samples, (right) the tightened fault region
The detected fault regions include the data from various fault classes and a part of no-fault class. The data of various classes in fault regions are clustered using IKFCM algorithm [20]. Thereby, some cluster centers are achieved which are used for classifying new data during the test (in on-line process).
2.2 On-line process
The on-line process is performed during the test to classify a new measured data. Figure 4 shows the on-line process for a typical component. If data is located in fault regions, then the sample belongs to the no-fault class and so the component is non-faulty. Otherwise, classification is made in the fault region which includes this sample. For this purpose, distance of the sample to each cluster center included in this fault region is found. The data belongs to the cluster with minimum distance, and the class of samples in this cluster determines the fault type of the related component.

The on-line process of classifying a new data
3 A novel approach for test point selection
The more no-fault samples in fault regions leads to the more probability of misdiagnosing faulty components which is more destructive than misdiagnosing non-faulty components.
Main idea used in this paper is finding a test point set by which there are minimum amount of overlap between faults and no-fault classes. A solution to this problem is exhaustive search among test points using evolutionary algorithms. The fitness function may be the number of no-fault samples that are located in fault regions. Therefore, all of no-fault samples in each fault dictionary should be examined to find those located in fault regions.
In a circuit with \({\text{n}}_{\text{c}}\) components and \({\text{n}}_{\text{f}}\) fault modes for each component, the number of \({\text{m}}\)-fold faults (\({\text{N}}_{\text{F}}\)) is achieved by Eq. 1. No-fault class, in which all of components are non-faulty, should be added to \({\text{N}}_{\text{F}}\). Among these \({\text{N}}_{\text{F}} + 1\) classes, \({\text{N}}_{\text{fault}}\) classes fall in each fault class and \({\text{N}}_{\text{no-fault}}\) classes fall in no-fault class for every component (Eqs. 2–3).
For example, in a typical circuits with 10 components, the number of double hard faults is \({\text{N}}_{\text{F}}\) = 180 (\({\text{m}}\) = 2 and \({\text{n}}_{\text{f}}\) = 2, including short-circuit and open-circuit). These fault classes, as well as the no-fault class are divided into three classes for each component including short-circuit (\({\text{n}}_{\text{fault}}\) = 18 classes), open-circuit (\({\text{N}}_{\text{fault}}\) = 18 classes), and no-fault (\({\text{N}}_{\text{no - fault}}\) = 145 classes). By performing Monte Carlo analysis with 50 iterations in each simulation, there would be 900 samples in short-circuit (18 × 50 = 900), 900 samples in open-circuit class and 145 × 50 = 7250 samples in no-fault class. Based on our experiments, dealing with this large number of no-fault samples to calculate fitness function in exhaustive search for each component, may take several days to be performed. Although this process is performed before starting real test, but the long time vesting may affect marketing parameters like time-to-market.
Alternative method has been shown in Fig. 5. This is a combined exclusive-inclusive method. The percentage of no-fault samples located in fault regions is the criterion \((C(\% ))\) to be minimized (Eq. 4).
where \(Ns_{nfr}\) is the number of no-fault samples located in the fault regions, and \(Ns_{nf}\) is the number of total no-fault samples. Steps of this algorithm are as follows.

Test point selection process
3.1 Exclusion
After constructing the fault dictionaries by the measured DC node voltages at all of the accessible test points, the value of C is calculated for each test points in single-dimensional space. The test points are sorted with respect to the values of C in ascending order. Then, redundant test points are eliminated by exclusive method. In this way, the test point set is initialized to include all accessible test points and starting from last one (maximum to minimum value of C), a test point is eliminated in each iteration if two following conditions are met.
First, its elimination should not increase the value of C more than 1%. By this manner, the test points which do not create significant improvement in the value of C are eliminated.
The second condition is related to tighten the fault regions for no-fault samples (Sect. 3.1). No-fault samples located outside the tightened fault regions do not affect diagnosing accuracy of fault samples. However, those located inside the tightened regions may cause misclassifications in fault samples.
Typically, let’s consider the two fault regions in Fig. 6. The samples of the fault regions are achieved from different test points. The right-sided fault region contains fewer no-fault samples than the left-sided fault region, but it contains more no-fault samples located in tightened fault region. Since the no-fault samples located out of the tightened regions are disregarded, the accuracy of diagnosing fault samples in the left-sided fault region is higher than the left fault region. To consider this effect, percentage of no-fault samples located in tightened fault regions \((C_{t} (\% ))\) is calculated (Eq. 5).

Two fault regions in two different two-dimensional spaces
In which, \(Ns_{nft}\) is the number of no-fault samples located in the tightened fault regions. The second condition is that by excluding test point, the \(C_{t}\) should not increase more than 1%.
3.2 Inclusion
The effectiveness of selected test points is verified by inclusive method. In this way, the test point set is initialized to be null. Starting from the first test point in the selected set at the previous step, a test point is selected in each iteration if two conditions are met. First, including that test point should decrease the value of C more than 1%. The second condition is that including the test point should not increase the \(C_{t}\).
Performing exclusive method before inclusive method speeds up the test point selection process. The reason is that inclusive algorithm is started with one node and may include most of test points to gradually improve \(C\) and \(C_{t}\). However, exclusive algorithm is started with all nodes, that probably have better value of \(C\) and \(C_{t}\) than one node in inclusive algorithm. Therefore, it is more probable that redundant test points are eliminated in next iterations, and performing the inclusive algorithm with this reduced test point set take less time.
3.3 Decision making
Previous processes are performed for every component to find effective test point set for each of them. Thereafter, a grade is given to each test point that is equal to the number of components whose selected test point set include that test point.
The grades are sorted in descending order and cumulative sum of them are calculated by partially summing the grades. Let \(\left\{ {{\text{g}}_{1} , \ldots ,{\text{g}}_{\text{N}} } \right\}\) be the cumulative sum of grades, where \({\text{N}}\) is the number of test points and \({\text{g}}_{\text{N}}\) is sum of all grades. Then they are manipulated as follows:
Values of \({\text{g}}^{ *}_{\text{i}}\) (\(i = 1, \ldots ,{\text{N}}\)) are in interval [0,1]. Let \({\text{g}}^{ *}_{\text{t}}\) be first grade equal to or greater than 0.9. This means that test points related to grades \({\text{g}}^{ *}_{1}\) to \({\text{g}}^{ *}_{\text{t}}\) are adequate to diagnose at least 90% of components. Therefore, other ones are omitted and selected test points make the optimum test point set (\({\text{S}}_{\text{opt}}\)).
Finally, it is useful to provide a decision guide for testing. For this purpose, starting from the first test point in \({\text{S}}_{\text{opt}}\) and adding next test points in each iteration, parameters \(C\) and \(C_{t}\) are calculated for each component. Then, the parameters are averaged over components. The tester can decide which set is appropriate for the circuit. According to our previous experiences, a good choice is a set using which averaged \(C\) and averaged \(C_{t}\) is as follows:
where \(C_{av}\) and \(C_{tav}\) are averaged \(C\) and averaged \(C_{t}\) over components respectively. By this choice, according to Eq. 7, on average, at most 20% of no-fault samples are located in fault regions. Therefore, average accuracy of 80% in diagnosing no-fault samples is guaranteed. Also, according to Eq. 8, the average number of no-fault samples located in tightened fault regions is half the number of fault samples which is reasonable choice to dominate the fault samples in fault regions. The test point selection method is more described in the next section using a benchmark circuit.
4 Experimental results
4.1 DC transistor circuit
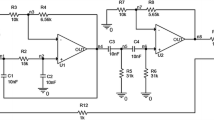
Figure 7 shows an analog DC transistor circuit. In [22] only 6 predefined faults were considered for this circuit but here all the double hard faults are selected as predefined faults. There are two possible hard faults for resistors (short-circuit and open-circuit) and six hard faults for each transistor (three short-circuits in junctions and three open-circuits in leads). By considering all the related faults in a transistor, each transistor can be assumed as 6 components as base–emitter, base–collector, collector–emitter junctions (with no-fault and short-circuit fault), and base, collector, emitter leads (with no-fault and open-circuit fault). Therefore, there are 33 components in Fig. 7, including 9 resistors and 24 transistor components.

Benchmark circuit used in this paper
According to above discussion for Fig. 7, we don’t have same number of faults for each component and Eq. 1 is not applicable for fault calculation. If we want to use Eq. 1 for number of faults in Fig. 7, we should imaginary consider same number of faults for each component. To do this, we add open-circuit fault to each junction and short-circuit fault to each lead to reach \({\text{n}}_{\text{f}} = 2\) for all components. Now, using Eq. 1 we get 2112 faults for this circuit that 1259 of them are not real. Therefore, the number of double hard faults in Fig. 7 is 853, and adding no-fault mode to this list, the number of predefined faults and no-fault mode is 854.
According to other works, we consider 5% tolerance for the resistors. Open- and short-circuit faults were modeled by connecting a 100 MΩ resistor in series and paralleling a 0.01 Ω resistor, respectively.
Circuit simulations are done by HSPICE and classifiers are implemented with MATLAB. The Monte-Carlo analysis with 50 iterations is done for each of 854 predefined faults to measure DC voltage at all nodes. The fault dictionary for each component is constructed by the achieved data from simulations according to the discussion in Sect. 2.
Table 2 shows the sorted values of \(C\) for each component. In this table, B, C, E, BE, CE, and CB stand for Base, Collector, Emitter, Base–Emitter, Collector–Emitter and Collector–Base respectively.
In the next step, exclusive and inclusive algorithms should be performed for every component. Tables 3 and 4 show these processes for BE1. In these tables, \(acc_{nf}\) is rate of truly classified samples of no-fault class, and \(acc_{f}\) is rate of non-misclassified samples of fault classes in no-fault class that are defined as follows:
where \(Ni_{fnf}\) is the number of fault samples incorrectly classified in no-fault class, \(Ns_{f}\) is total number of fault samples, \(Nc_{nf}\) is the number of correctly classified no-fault samples, and \(Ns_{nf}\) is the total number of no-fault samples.
Typically, by excluding node 7 in the first row of Table 3, the value of \(C\) is unchanged and increment of \(C_{t}\) less than 1%, so it could be discarded from the test point list. Continuing this exclusion process, finally just nodes 2, 9, and 4 are remained for inclusion process. According to Table 4, by inclusive process, the effectiveness of the selected nodes is verified. Because of significant improvement in \(C\) and \(C_{t}\) values by adding nodes 9 and 4, all of these nodes are selected for fault diagnosis of BE1 component.
Results of exclusion and inclusion processes for all of the components are shown in Table 5. According to this table, now node grading is done to determine the importance of each node in circuit fault diagnosis process (Table 6). According to the second row of Table 6, there are 23 components that require node 6, and 2 components which require node 5. The third row shows the cumulative sum of grades. Finally, the normalized grade of each node is determined in the last row. On the base of normalized grades of the nodes, node 3 is the first node with the grade of more than 0.9 and by adding nodes 4 and 5 there is not any significant improvement in the grade values. Consequently, nodes 4 and 5 can be discarded from the test point set. Therefore, nodes 6, 8, 2, 7, 9, 1, and 3 are most effective nodes for diagnosing almost all of components.
If access to all the selected test points is not possible, it is useful to recommend a decision guide for testing. This guide is shown in Table 7. The parameters in this table are averaged over the components. According to this table, we can see the fault diagnosis accuracy using the specified nodes. The average of \(C\) is decreased and so \(acc_{nf}\) is increased by including more nodes. The slow falling trend of \(acc_{f}\) in this table is because of rising trend of averaged \(C_{t}\).
With reference to the criteria equations (Eqs. 7, 8), and regarding that \(\frac{{\frac{{Ns_{f} }}{2}}}{{Ns_{nf} }} \times 100\% = 5\%\) in this circuit, the set \(\left\{ {6,8,2,7} \right\}\) is appropriate test node set since the average \(C\) of this set is almost equal to 20% and average \(C_{t}\) is less than 5%.
If all of the nine test points are used, then average \(acc_{nf}\) and average \(acc_{f}\) are 85.2% and 92.9% respectively. Therefore, using \(\left\{ {6,8,2,9} \right\}\) test point set, there are about 56% reduction in the number of test points with just 3.9% reduction in \(acc_{nf}\) and 3.1% increment in \(acc_{f}\). If the set in the last row of Table 7 is selected, the accuracy parameters will be same as when using all of the nine nodes, with about 22% reduction in the number of test points.
To verify the effectiveness of the selected test point set, one can discard any of the selected node to see its importance. This process is shown in Table 8 and degradation of diagnosis capability is demonstrated in it. Although some sets have higher \(acc_{f}\), but decreasing of \(acc_{nf}\) is much more than increasing of \(acc_{f}\) for them.
4.2 Comparison with other methods
The previous works in this field are on the base of searching the best node set so that maximum number of predefined faults can be isolated. The number of predefined faults in those works cannot be very large, since the accuracy of isolating may be too low. For instance, the test point selection method proposed in [6] is examined on a band-pass filter with 11 nodes, 16 components, and 32 potential single hard faults (short-circuit and open-circuit for each component) from which 23 faults were selected as predefined faults. Its simulation results, lead to selecting 5 nodes from 11 nodes by which only 14 faults could be classified (60.9% diagnostic accuracy).
Table 9 shows the comparison results of the proposed method with the references [6, 7, 22] which are works in DC domain. The proposed method can classify very large number of predefined faults with highest accuracy using only 4 nodes that shows the efficiency of the proposed method specifically when the number of predefined faults is very large.
The process time for our method is about 35 min that is very faster than using exhaustive search that needs multiple days for best test point selection.
5 Conclusion and future work
A test point selection method using combined exclusive-inclusive algorithm was introduced for analog circuits with large numbers of predefined faults. In this method it is supposed that a classifier is designed for each of circuit components, and most effective test points that make significant improvement in accuracy of every classifier are selected. Based on the experimental results 4 nodes from 9 circuit nodes were selected using which average \(acc_{f}\) and \(acc_{nf}\) of the components are 96% and 81.3% respectively. These nodes are used for diagnosing 854 predefined faults (as well as no-fault mode) containing all of double hard faults.
Due to computational burden of calculating the criterions, exhaustive search was not used in this paper. Therefore, it is not claimed that the proposed method can find global optimum solution. However, the method aimed to find most effective test points that make significant improvement in circuit diagnosing. Test points that have little impact on the criterions are eliminated to reduce the number of required test points.
Finally, it is worth noting that although the proposed method was used for a DC analog circuit, it has the potential of being used for time or frequency domains. Steps of the algorithm may be applied on time samples or frequency points of circuit’s frequency response to select the optimum set. This idea will be examined in future works.
References
Bandler, J. W., & Salama, A. E. (1985). Fault diagnosis of analog circuits. Proceedings of the IEEE,73, 1279–1325.
Prasad, V. C., & Babu, N. S. C. (2000). Selection of test nodes for analog fault diagnosis in dictionary approach. IEEE Transaction on Instrumentation and Measurement,49, 1289–1297.
Starzyk, J. A., Liu, D., Liu, Z.-H., Nelson, D. E., & Rutkowski, J. O. (2004). Entropy-based optimum test points selection for analog fault dictionary techniques. IEEE Transaction on Instrumentation and Measurement,53(3), 754–761.
Yang, C., Tian, S., Long, B., & Chen, F. (2010). A novel test point selection method for analog fault dictionary techniques. Journal of Electronic Testing,26(5), 523–534.
Yang, C., Tian, S., Long, B., & Chen, F. (2011). Methods of handling the tolerance and test-point selection problem for analog-circuit fault diagnosis. IEEE Transaction on Instrumentation and Measurement,60(1), 176–185.
Zhao, D., & He, Y. (2015). A new test point selection method for analog circuit. Journal of Electronic Testing,31, 53–66.
Ma, Q., He, Y., Zhou, F., & Song, P. (2018). Test point selection method for analog circuit fault diagnosis based on similarity coefficient. Mathematical Problems in Engineering,2018, 1–11.
Yang, C., Tian, S., & Long, B. (2009). Test points selection for analog fault dictionary techniques. Journal of Electronic Testing,25, 157–168.
Zhao, D., & He, Y. (2015). A new test points selection method for analog fault dictionary techniques. Analog Integrated Circuits and Signal Processing,82, 435–448.
Saeedi, S., Pishgar, S. H., & Eslami, M. (2019). Optimum test point selection method for analog fault dictionary techniques. Analog Integrated Circuits and Signal Processing,100(1), 167–179.
Cui, Y., Shi, J., & Wang, Z. (2016). Analog circuit test point selection incorporating discretization-based fuzzification and extended fault dictionary to handle component tolerances. Journal of Electronic Testing,32, 661–679.
Huang, J. L., & Cheng, K. T. (1997). Analog fault diagnosis for unpowered circuit boards. In International test conference, Washington.
Huang, J. L., & Cheng, K. T. (2000). Test point selection for analog fault diagnosis of unpowered circuit boards. IEEE Transaction on Circuits and Systems II,47(10), 977–987.
Lei, H., & Qin, K. (2014). Greedy randomized adaptive search procedure for analog test point selection. Analog Integrated Circuits and Signal Processing,79, 371–383.
Golonek, T., & Rutkowski, J. (2007). Genetic-algorithm-based method for optimal analog test points selection. IEEE Transaction on Circuits and Systems II,54(2), 117–121.
Jiang, R., Wang, H., Tian, S., & Long, B. (2010). Multidimensional fitness function DPSO algorithm for analog test point selection. IEEE Transaction on Instrumentation and Measurement,59(6), 1634–1641.
Lei, H., & Qin, K. (2013). Quantum-inspired evolutionary algorithm for analog test point selection. Analog Integrated Circuits and Signal Processing,75, 491–498.
Zhao, D., & He, Y. (2015). Chaotic binary bat algorithm for analog test point selection. Analog Integrated Circuits and Sigal Processing,84(2), 201–214.
Luo, H., Lu, W., Wang, Y., & Wang, L. (2017). A new test point selection method for analog continuous parameter fault. Journal of Electronic Testing,33(3), 339–352.
Khanlari, M., & Ehsanian, M. (2017). An improved KFCM clustering method used for multiple fault diagnosis of analog circuits. Circuits Systems and Signal Processing,36, 3491–3513.
Tax, D., & Duin, R. (2004). Support vector data description. Machine Learning,54, 45–66.
Tan, Y., He, Y., Cui, C., & Qiu, G. (2008). A novel method for analog fault diagnosis based on neural networks and genetic algorithms. IEEE Transactions on Instrumentation and Measurement,57(11), 2631–2639.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Khanlari, M., Ehsanian, M. A test point selection approach for DC analog circuits with large number of predefined faults. Analog Integr Circ Sig Process 102, 225–235 (2020). https://doi.org/10.1007/s10470-019-01550-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10470-019-01550-7