
Abstract
The test points selection problem for analog fault dictionary is researched extensively in many literatures. Various test points selection strategies and criteria for Integer-Coded fault wise table are described and compared in this paper. Firstly, the construction method of Integer-Coded fault wise table for analog fault dictionary is described. Secondly, theory and algorithms associated with these strategies and criteria are reviewed. Thirdly, the time complexity and solution accuracy of existing algorithms are analyzed and compared. Then, a more accurate test points selection strategy is proposed based on the existing strategies. Finally, statistical experiments are carried out and the accuracy and efficiency of different strategies and criteria are compared in a set of comparative tables and figures. Theoretical analysis and statistical experimental results given in this paper can provide an instruction for coding an efficient and accurate test points selection algorithm easily.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
On the one hand, test points selection is very important task for design for testability (DFT). On the other hand, fault dictionary is an important method of simulation before test (SBT) and this technique is a popular choice for fault diagnosis [8]. So the test points selection problem for fault dictionary are researched extensively in many literatures [1, 3, 5, 6, 8–11, 13, 14–16, 18]. The global minimum set of test points can only be guaranteed by an exhaustive search which is computationally expensive [11, 14]. As pointed out by Augusto et al. [3], the exhaustive search algorithm is limited to small or medium size analog systems. For large or medium systems, such as the dictionaries with more than 40 faults and more than 40 test points, the exhaustive search is impractical. The tradeoff between the desired degree of fault diagnosis and computation cost is to select a near-minimum set (or a local minimum set).
Lin and Elcherif [8] proposed an Integer-Coded fault wise table (or dictionary) technique. This technique is proven to be an effective tool for the optimum test points selection. The later test points selection algorithms [3, 5, 9–11, 14, 18] are all based on the Integer-Coded fault wise table technique. This technique was used to solve test points selection problem for analog fault dictionary technique first. But this technique can be used not only in circuit level fault diagnosis but also in system level fault diagnosis. In fact, the dependency matrix proposed in Deb et al. [4] is a system level binary fault dictionary. Binary fault dictionary is just a special Integer-Coded fault wise table (dictionary) [12, 17]. Don’t take the possibility of fault happening and test cost into consideration; sequential fault diagnosis problem is just a test points selection problem. So the test points selection algorithms proposed in literatures [3, 5, 9–11, 14, 18] could be used not only in circuit level but also in board level and system level. Each of these algorithms consists of a test points selection strategy and a test points selection criterion. Although the latest literatures [9, 14, 18] have provide statistical experiments to illustrate their algorithms’ superiority, these new test points selection criteria do not always overmatch the previous test points selection criteria as discussed later.
The construction method of Integer-Coded fault wise table for analog fault dictionary is illustrated in this section. In Section 2, existing test points selection algorithms are summarized at first. The accuracy and efficiency of every test points selection strategy and test points selection criterion is summarized and compared in Section 3. A new easy-execute algorithm, which can efficiently and accurately find the minimum test points set, is proposed in this section also. Statistical experiments are carried out in Section 4. Finally, conclusions are given in Section 5.
In fault dictionary, rows represent different faults (including the nominal case) and columns show the available test points. Assume that the voltages shown in Table 1 are obtained when a given net work is analyzed for the nominal condition (f 0) as well as for eight faulty conditions (f 1 to f 8). Ambiguity group is defined that any two faulty conditions fall into the same ambiguity set if the gap between the voltage values produced by them is less than 0.7 V [6]. But it is necessary to point out that the voltage value span of an ambiguity group may be larger than 0.7 V. In column 2 of Table 1 for example, the voltage value gap produced by f 6 and f 4 is 0.4 V so they belong to one ambiguity set. Similarly, f 4 and f 5 belong to one ambiguity set also. Because f 6 f 4 are not distinguishable and f 4 f 5 are not distinguishable, so f 6 f 4 f 5 are not distinguishable and belong to one ambiguity set although the voltage value gap produced by f 6 and f 5 is 0.9 V, which is larger than 0.7 V. The reader is referred to references [6, 10] for details.
Table 2 indicates the ambiguity sets of Table 1. Lin and Elcherif [8] proposed an Integer-Coded fault wise table (or dictionary) for fault isolation phase. For each fault, a code is generated from the numbers of ambiguity sets of each test point. Considering test point n 1 in Table 2, fault f 4 is coded as “0”, faults {f 1, f 5, f 6} are coded as “1”, faults {f 0, f 2} are coded as “2”, {f 7, f 8} are coded as “3” and f 3 are coded as “4”. Then, Table 3 is derived.
In this Integer-Coded fault wise table, the same integer number represents all the faults that belong to the same ambiguity group in a given column. Since each test point represents an independent measurement, ambiguity groups of each test point are independent and can be numbered using the same integers without confusion. The Integer-Coded table can also be regarded as an array of “N F ” elements. If all the elements of this array are different, it means that each fault has unique integer number. Hence all faults can be diagnosed. If an entry of this array repeats, it indicates that these faults cannot be separated, with the set of test points used for making this array.
2 Test Points Selection Method
Test points selection methods for faulty dictionary technique can be classified into two categories: inclusive and exclusive [16]. In the inclusive approaches, the optimum set of test points (S opt ) is initialized to be null, then an “ideal” test point based on a given criterion is added to it. The methods proposed in [6, 8–11, 14, 18] fall into inclusive category. While in exclusive methods, the desired optimum set is initialized to include all available test points at first. Then every test point will be checked one by one and will be deleted if it is redundant. The method proposed by Prasad and Babu [11] fall into exclusive method.
2.1 Inclusive Category
2.1.1 Algorithm 1[10]
-
Step 1:
Initialize S opt as null set and let S c consist of all candidate test points.
-
Step 2:
Draw out a test point n j with \(\mathop {Max}\limits_j \left( {N_{Aj} } \right)\) from S c and add to S opt .
-
Step 3:
Check whether the selected test points in S opt are enough to diagnose the given set of faults. If yes, stop.
-
Step 4:
If the size of any one ambiguity set determined by S opt is decreased after the inclusion of test point n j , go to Step 2. Else, discard n j from S opt and go to Step 2.
2.1.2 Algorithm 2[3]
-
Step 1:
Initialize S opt as null set and let S c consist of all candidate test points.
-
Step 2:
Draw out a test point n j with \(\mathop {Min}\limits_j \left( {\mathop {Max}\limits_i \left( {F_{ij} } \right)} \right)\) from S c and add to S opt .
-
Step 3:
Check whether the selected test points in S opt are enough to diagnose the given set of faults. If yes, stop.
-
Step 4:
If the size of any one ambiguity set determined by S opt is decreased after the inclusion of test point n j , go to Step 2. Else, discard n j from S opt and go to Step 2.
2.1.3 Algorithm 3[3]
-
Step 1:
Initialize S opt as null set and let S c consist of all candidate test points.
-
Step 2:
Draw out a test point n j with \(\mathop {Min}\limits_j \left( {s_j } \right)\) from S c and add to S opt , where
$$s_j = \sum\limits_{i = 1}^{N_{Aj} } {^{{{\left( {{{F_{ij} - N_F } \mathord{\left/ {\vphantom {{F_{ij} - N_F } {N_{Aj} }}} \right. \kern-\nulldelimiterspace} {N_{Aj} }}} \right)^2 } \mathord{\left/ {\vphantom {{\left( {{{F_{ij} - N_F } \mathord{\left/ {\vphantom {{F_{ij} - N_F } {N_{Aj} }}} \right. \kern-\nulldelimiterspace} {N_{Aj} }}} \right)^2 } {N_{Aj} }}} \right. \kern-\nulldelimiterspace} {N_{Aj} }}} } $$(1) -
Step 3:
Check whether the selected test points in S opt are enough to diagnose the given set of faults. If yes, stop.
-
Step 4:
If the size of any one ambiguity set determined by S opt is decreased after the inclusion of test point n j , go to Step 2. Else, discard n j from S opt and go to Step 2.
2.1.4 Algorithm 4[9]
-
Step 1:
Initialize S opt as null set and let S c consist of all candidate test points.
-
Step 2:
Draw out a test point n j with \(\mathop {Max}\limits_j \left( {q_j } \right)\) from S c and add to S opt .
-
Step 3:
Check whether the selected test points in S opt are enough to diagnose the given set of faults. If yes, stop.
-
Step 4:
In fault wise table (dictionary), eliminate rows that can be isolated by test points in S opt together.
-
Step 5:
Calculate q j for every test point n j in S c . Herein, q j is the number of faults that can be isolated by n j and test points in S opt together. Go to Step 2.
The second sentence in this Step 5 may be confusing. The following example is used to explain this operation.
-
Example 1:
Considering the test points selection problem of Table 11.
Suppose that n 1 have already added to S opt viz. S opt ={n 1} and S c ={n 2,n 3,n 4,n 5}. Obviously, all faults can’t be isolated by n 1, so additional test points are needed. In Step 5, calculate q j for every test point n j in S c . There is no fault can be isolated by n 2 while n 3 can isolate f 3, n 4 can isolate f 2 and n 5 can isolate f 1. So one may get q 2=0, q 3=q 4=q 5=1 and draw that n 3,n 4 or n 5 is better than n 2. But when combined with test points in S opt (viz. n 1), all four faults can be isolated by n 2, n 3 can isolate {f 2 f 3}, n 4 can isolate {f 2 f 3}, also, n 5 can isolate {f 0 f 1}. So \(q\prime _2 = 4\), \(q\prime _3 = q\prime _4 = q\prime _5 = 2\). Obviously n 2 should be added to S opt according to Step 2. In Step 5, the q j value is \(q\prime \) value.
2.1.5 Algorithm 5[2]
-
Step 1:
Initialize S opt as null set and let S c consist of all candidate test points.
-
Step 2:
Draw out a test point n j with \(\mathop {Max}\limits_j \left( {I_j } \right)\) from S c and add to S opt , where
$$\begin{array}{*{20}c} {I_{j} = - {\left( {\frac{{F_{{1j}} }}{{N_{F} }}\ln \frac{{F_{{1j}} }}{{N_{F} }} + \frac{{F_{{2j}} }}{{N_{F} }}\ln \frac{{F_{{2j}} }}{{N_{F} }} + \cdots \frac{{F_{{N_{{Aj}} j}} }}{{N_{F} }}\ln \frac{{F_{{N_{{Aj}} j}} }}{{N_{F} }}} \right)}} \\ { = \frac{{\ln N_{F} }}{{N_{F} }}{\sum\limits_{i = 1}^{N_{{Aj}} } {F_{{ij}} } } - \frac{1}{{N_{F} }}{\sum\limits_{i = 1}^{N_{{Aj}} } {F_{{ij}} \ln } }F_{{ij}} } \\ { = \ln N_{F} - \frac{1}{{N_{F} }}{\sum\limits_{i = 1}^{N_{{Aj}} } {F_{{ij}} \ln } }F_{{ij}} } \\ \end{array} $$(2) -
Step 3:
Check whether the selected test points in S opt are enough to diagnose the given set of faults. If yes, stop.
-
Step 4:
Partition the rows of the dictionary according to the ambiguity sets of S opt and removing the rows that can be isolated by test points in S opt together.
-
Step 5:
Calculate I j for every test point in S c . Go to Step 2.
2.1.6 Algorithm 6[13]
In Yang et al. [18], a heuristic Depth-first graph search algorithm is developed to solve the test points selection problem. Root node S contain all faults that to be diagnosed. First, use all candidate test points to expand S and the new generated graph nodes belong to Level 1. Second, on Level 1, select a graph node with maximum fault discrimination power as the one to be expanded for the second iteration. Finally, expand the selected graph node with all the test points except those used on the path from this node to the root node S. The new generated graph nodes belong to Level 2. Execute these steps iteratively until all faults are isolated. An example is used to illustrate this method.
Figure 1 is the expanded graph for Table 3. In this figure, x i represents graph node and n j is the test point used on the graph path. Every intermediate graph node x i consists of two faults group. One group consists of isolated faults and the other consists of residual faults. Residual faults are subdivided into several ambiguity sets as shown in Fig. 1.

Expanded graph
Initially let the graph G consist of the root node S. All potential faults (f 0~f 8) are contained in node S and belong to one ambiguity set (viz. N AS =1). The root node S is expanded with all test points and the new four graph nodes (x 1~x 4) are shown on Level 1 in Fig. 1. Based on Level 1, Table 4 list the k i (number of graph node that can isolate fault f i ) value and information content of every fault, where information content is defined as:
Faults f 3 and f 4 are isolated by graph node x 1, so information content contained in x 1 is I(x 1)=I(f 3)+I(f 4). Information content for every graph node on Level 1 is shown in Table 5. Node x 2 has the maximum information content, so it should be expanded in next step. Because test point n 2 has been used on the path from root node to x 2, the residual three test points {n 1,n 3,n 4} are used to expand node x 2 on the second level of Fig. 1.
Test points used on the path from goal node x 8 to root node S make up of the final solution.
Obviously, each algorithm has its own test points selection criterion. One can call these criteria as fault discrimination power.
-
Criterion1
\(\mathop {Max}\limits_j \left( {N_{Aj} } \right)\)
-
Criterion2
\(\mathop {Min}\limits_j \left( {\mathop {Max}\limits_i \left( {F_{ij} } \right)} \right)\)
-
Criterion3
\(\mathop {Min}\limits_j \left( {s_j } \right)\)
-
Criterion4
\(\mathop {Max}\limits_j \left( {q_j } \right)\)
-
Criterion5
\(\mathop {Max}\limits_j \left( {I_j } \right)\)
-
Criterion6
\(\mathop {Max}\limits_j \left( {I\left( {x_j } \right)} \right)\)
2.2 Exclusive Category [3]
There are six candidate test points selection criteria for exclusive category also.
-
Criterion7
\(\mathop {Min}\limits_j \left( {N_{Aj} } \right)\)
-
Criterion8
\(\mathop {Max}\limits_j \left( {\mathop {Max}\limits_i \left( {F_{ij} } \right)} \right)\)
-
Criterion9
\(\mathop {Max}\limits_j \left( {s_j } \right)\)
-
Criterion10
\(\mathop {Min}\limits_j \left( {q_j } \right)\)
-
Criterion11
\(\mathop {Min}\limits_j \left( {I_j } \right)\)
-
Criterion12
\(\mathop {Min}\limits_j \left( {I\left( {x_j } \right)} \right)\)
-
Step 1:
Let S opt consist of all candidate test points.
-
Step 2:
Draw out a test point n j from S opt by using any one of the exclusive criteria.
-
Step 3:
Check whether the residual test points in S opt are enough to diagnose the given set of faults. If yes, go to Step 2. Else, add n j to S opt .
-
Step 4:
Repeat Step 2 to Step 3, till all test points are examined.
3 Algorithm Analysis and Statistical Experiments
3.1 Accuracy Analysis
Before the accuracy analysis, an example is considered at first.
-
Example 2:
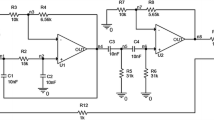
A band pass filter circuit example
Figure 2 is a band pass filter circuit, which is cited by literatures [3, 5, 9–11, 14, 18] as a benchmark circuit. The excitation signal is a 1 kHz, 4 V sinusoidal wave. Totally, there are eighteen potential catastrophic faults f 1~f 18 and eleven test points n 1~n 11. Voltage values at all nodes for different faulty conditions are obtained by simulation and the Integer-Coded fault wise table is constructed by procedures introduced in Section 1. The results are shown in Table 6. All seven strategies mentioned in Section 2 (six inclusive strategies and an exclusive strategy) are used to select optimum test points respectively. All the simulations are done by using Visual C+ + 6.0 codes. The results are listed in Table 7.

A band pass filter circuit
The global minimum test points set is found by Algorithm 5, Algorithm 6 and Exclusive category. By using Algorithm 4, the final solution contains a redundant test point n 7. Algorithm 1, Algorithm 2 and Algorithm 3 are even worse, since about three redundant test points are contained in the final solution. Obviously, the latter three inclusive strategies (and exclusive category) can more accurately find the optimum solution than the former three strategies. This conclusion was also proved by statistical experiments in literatures [9, 14, 18].
Because each algorithm (except for Exclusive category) has its own test points selection criterion, one may naturally conclude that the later three criteria (4~6) is better than the former criteria (1~3) based on the statistical experiment results. But this is not the fact as discussed in the following text.
3.1.1 Inclusive Category
As pointed out in Section 2, in the inclusive approaches, the optimum set of test points (S opt ) is initialized to be null, then an “ideal” test points based on a given criterion is added to it. So test points selection criterion is an essential ingredient of inclusive algorithm. All the inclusive algorithms are greedy heuristic algorithms. Although each criterion evaluates the fault discrimination power of a test point from different point of view, but they are all just greedy heuristic functions and there is no theoretical proof can be offered to demonstrate a specific criterion’s optimality.
Besides test points selection criterion, test points selection strategy is another important ingredient of inclusive algorithm. A good test points selection strategy can improve the accuracy of a searching algorithm. For Algorithms 1, 2 and 3 mentioned in Section 2, the most important strategy lies in Step 4 and is called as Strategy 1 in this paper. According to Strategy 1, although a test point is evaluated as the best one in S c , it will not be added to S opt if it can not subdivide ambiguity sets determined by S opt . In Example 2, after n 8, n 11, n 7 and n 5 are added to S opt , n 6 has the maximum fault discrimination power among the test points in S c . By using Criterion 1, n 6 is concluded as the best one and added to S opt . Table 8 is the ambiguity sets information decided by the test points n 8, n 11, n 7 and n 5 together. Table 9 is the ambiguity sets information decided by test points n 8, n 11, n 7, n 5 and n 6 together. Obviously, Table 8 and Table 9 have the same ambiguity sets information, say the new selected test point n 6 has no contribution to S opt . In other words, n 6 is redundant test point for S opt . By using Strategy 1, n 6 will be eliminated from S opt , so Strategy 1 can reduce the number of redundant test points of final solution set.
Fault discrimination power of S opt is determined by the all test points contained in it together. So simply adding a test point with best C i to S opt a maximum information increment of S opt is not guaranteed and then global minimum test points set is less likely to be obtained. To overcome this shortcoming, Algorithm 4 provides another strategy in Step5 called as Strategy 2 in this paper. By using Strategy 2, fault discrimination power of a test point n j is determined not by itself but by n j and all test points in S opt together. So if a test point n j is to be added to S opt , a maximum fault discrimination power increase of S opt is guaranteed. In fact, Strategy 2 is also included in Algorithm 5 and Algorithm 6. In Algorithm 5, step 4 is the embodiment of Strategy 2. In Algorithm 6, graph node expanding process is based on the ambiguity sets information determined by S opt , where S opt consists of test points used on the path from current graph node to root node. So the selected node guarantees the maximum information increase to S opt . Besides Strategy 2, Algorithms 4, 5 and 6 remove the faults that can be isolated by S opt in each iteration. This can reduce these algorithms’ time and space complexities and is called as Strategy 3. Strategy 2 can further reduce redundant test points and in turn improve the solution accuracy. If Algorithms 1, 2 and 3 adopt Strategy 2 and 3, they can also more accurately find the optimum test point set. In Example 2, the new results are listed in Table 10. Compared to Table 7, improved algorithms (with Strategy 2 and Strategy 3) can more accurately find the optimum test point set.
Although Strategy 2 can reduce the number of redundant test points, but the final solution may still have redundant test points. For example, there are still one or two redundant test points in final solutions in Table 10. As mentioned above, in the inclusive approaches, the optimum set of test points (S opt ) is initialized to be null, then test point is added to it one by one. Although the new selected test point is not redundant for those selected test points, it cannot be guaranteed that one or more former selected test points is not redundant for the new set S opt . In Table 10 for example, the final solution found by improved Algorithm 1 is {n 1,n 5,n 8,n 9,n 11}. The selected order is n 8→n 9→n 5→n 1→n 11. At first S opt is initialized to be null, then test point n 8 is added to S opt . Obviously n 8 is not redundant. But after n 9,n 5,n 1,n 11 are added to S opt , n 8 is a redundant test point for S opt because that all faults can be isolated by n 9,n 5,n 1,n 11 without n 8. So if only an algorithm belong to inclusive category, it cannot guarantee that there is no redundant test point contained in the final solution.
3.1.2 Exclusive Category
As mentioned in Section 2, exclusive algorithms examine all test points. Anyone redundant will be eliminated from S opt . So the final solution found by exclusive category must have no redundant test points. It is needed to point out that a set without redundant test points does not mean that this set is a minimum set. An example is used to illustrate this viewpoint. Table 11 is a simple fault wise table. Both set S opt 1={n 1,n 2} and set S opt 2={n 3,n 4,n 5} can isolate all faults and each set contains no redundant test points. Obviously, S opt 2 is not the minimum set.
For a practical complex system, there are many candidate test points (N T ) in the design stage, but only a few physical test points (m) can be set, normally N T > 2 m. As discussed above, exclusive method takes more time when N T > 2m.
3.1.3 Combined Category
Based on the former discussion, considering test points set selection problem for a large-scale system, inclusive method is more efficient than exclusive method while exclusive method is more accurate than inclusive method.
To efficiently and accurately find the optimum test points set, an inclusive algorithm is executed at first, then exclusive algorithm is used to eliminate redundant test points in S opt . This method is called as combined category. Table 12 lists the final solutions found by inclusive algorithms (Strategy 2 and Strategy 3 is adopted by every algorithm) and combined algorithms.
From Table 12, it can be seen that no matter which inclusive algorithm is executed, if only exclusive method is appended, the final solution contains no redundant test points. The combined method found the minimum set in this example.
3.2 Time Complexity
The complexities of Algorithm 1, Algorithm 2 and Algorithm 3 are dominated by Strategy 1. They all have the complexity of \(O\left( {N_F p\log N_F } \right)\) [11], where p is the number of test points examined and \(\begin{array}{*{20}l} {{m \leqslant p \leqslant N_{T} } \hfill} & {{{\left( {m = {\left| {S_{{opt}} } \right|}} \right)}} \hfill} \\ \end{array} \).
The complexity of Algorithms 4, 5 and 6 are dominated by Strategy 2. The process of calculating fault discriminate power q j for every test point in S c is the same with the process of checking whether a number repeats or not. There exist several efficient sequential algorithms such as quick sort, heap sort etc. [2][7] with time complexity of \(O\left( {N_F \log N_F } \right)\) for calculating faulty discriminate power for one test point. Algorithms 4, 5 and 6 examine every test point in S c for each iteration, so these algorithms have the time complexity of \(O\left( {N_F p\prime \log N_F } \right)\), where \(p\prime = N_T + \left( {N_T - 1} \right) + \cdots \left( {N_T - m + 1} \right)\). Because the case of N T >2m is considered in this paper, there will be \(p\prime > > m\). So the total time complexity of Algorithms 4, 5 and 6 is \(O\left( {N_F mN_T \log N_F } \right)\).
Exclusive category has the complexity of \(O\left( {N_F \left( {p + m} \right)\log N_F } \right)\), where m is the number of test points contained in S opt . As pointed out in Prasad et al. [11],
As discussed above, the time complexity of inclusive algorithm is \(O\left( {N_F p\log N_F } \right)\) or \(O\left( {N_F p\prime \log N_F } \right)\). Suppose that the final solution found by an inclusive algorithm contains m test points, using exclusive method to examine all test points in S opt will take \(O\left( {N_F m\log N_F } \right)\) complexity. So the time complexity of combined method is
Because \(p\prime > > m\) and p >> m, the total time complexity of combined algorithm is still \(O\left( {N_F p\log N_F } \right)\) or \(O\left( {N_F p\prime \log N_F } \right)\).
The following three conclusions can be drawn according to the theoretical analysis in this Section.
-
Conclusion 1:
Every test points selection criterion is just greedy heuristic function and there is no theoretical proof can be offered to demonstrate a specific criterion’s optimality. Any specific criterion has no superior in the final solution to others.
-
Conclusion 2:
Strategy 2 is superior in the accuracy to Strategy 1 while Strategy 1 is more efficient than Strategy 2.
-
Conclusion 3:
When combined with exclusive strategy, either Strategy 1 or Strategy 2 can improve the accuracy of the final solution and do not increase the time complexity.
Besides the theoretical proof, the statistical experiments are also provided to prove the above conclusions in Section 4.
4 Statistical Experiments
Statistical experiments are carried out on the randomly computer-generated Integer-Coded dictionaries by using the inclusive category (adopting six criteria, Strategy 1 and Strategy 2 respectively) and combined category respectively. All the simulations are done by using Visual C++ 6.0 codes. All the execution times in this paper are obtained using an Intel 1.6 GHz processor, 512 M RAM and Microsoft Windows XP operating system.
-
Experiment 1:
Totally, there are 100 Integer-Coded fault wise tables and each table has 1,000 simulated faults, 100 test points, and six ambiguity sets per test point.
Table 13 lists the results of Strategy 1 by using six different criteria respectively. It can be seen that by using Strategy 1 and Criterion 1 (the second column of Table 13), 17 simulated fault wise tables (17% of the simulated cases) need seven test points to isolated all faults, 61 simulated fault wise tables need eight test points to isolated all faults, 22 simulated fault wise tables need nine test points to isolated all faults. Comparing different columns of Table 13, one can see that the size of final solutions found by six different criteria are all varying between seven and nine. In about 14–19% of the simulated fault wise tables, the size of final solutions is seven. In most (about 60–71%) of the simulated cases, the final solutions consist of eight test points. In the rest (about 15–22%) of the simulated cases, the size of the final solutions is nine. So it can be drawn that if the same strategy is adopted, the accuracy of final solutions found by different criteria have no dramatic differences (viz. in the accuracy of finding final solution, no one specific criterion is superior to others). Besides the accuracy, the computation time of different criterion has no notable difference also. This gives that in the time efficiency, no one specific criterion is superior to the others. This conclusion can also be drawn according to Tables 14, 15 and 16.
By comparing column 2 of Table 14 to column 2 of Table 13, it can be seen that the combined category improves the accuracy of final solutions substantially. By using combined category and Criterion 1, the size of final solutions is no more than 8. While if inclusive category and the same criterion are adopted, one will draw that there are 22 simulated cases need nine test points to isolate all faults as shown in Table 13. Additionally, to isolate all faults, 83% of the simulated dictionaries only need seven test points by using combined category while 83% (61%+22%) of the simulated dictionaries need eight or nine test points by using inclusive category. In Fig. 3, Criterion 3 is the common criterion adopted by Strategy 1 and Combined category. In 66% of the simulated cases, it is concluded that eight test points are necessary by using strategy 1. However in most (90%) of the simulated cases, it is concluded that only seven test points are enough to isolate all faults. Additionally, in 17% of the simulated cases the size of final solution found by Strategy 1 is 9 while the size of final solution is no more than 8 if the Combined category is used.

Statistical results of strategy 1 and combined category
So it can be drawn that combined category has superiority in the final solutions’ accuracy to inclusive category. Comparing the other corresponding columns of Tables 13 and 14 (viz. the other five criteria are adopted respectively), the same conclusion can be drawn.
Computation time per dictionary is averagely about 195 ms by using inclusive category and 218 ms by using combined category. So the combined category need little more time than inclusive category. This conclusion is consistent with the former time complexity analysis given in Section 3.2. So it can be drawn that the combined category is superior to the inclusive categories. This conclusion can also be drawn by comparing Table 15 to Table 16.
From Table 15 it can be seen that the size of final solutions found by Strategy 2 is no more than seven while more than 80% of simulated cases need eight or nine test points by using Strategy 1 in Table 13. So Strategy 2 can improve the solutions’ accuracy dramatically and this conclusion is consistent with the former accuracy analysis given in Section 3.1.2. Figure 4 is used to illustrate this conclusion.

Statistical results of strategy 1 and strategy 2
The size (number of selected test points) of the final solutions found by Strategy 2 is no more than 7 while the the size of the final solutions found by Strategy 1 is no less than 7. Obviously, Strategy 2 can improve the accuracy of final solution substantially. The same conclusion can be drawn when the other criteria are adopted respectively (by comparing other corresponding columns of Tables 13 and 15).
At the same time the computation time of Strategy 2 is about six times as much as that of Strategy 1. The same conclusion can also be drawn by comparing Table 14 to Table 15. This is consistent with former theoretical analysis. So Strategy 2 is superior in solution accuracy to Strategy 1 while Strategy 1 is superior in time efficiency to Strategy 2.
It can be argued that the ambiguity sets number of a fault wise table is seldom a constant. For example, the ambiguity sets contained in each test points in Table 6 vary in number from 3 to 9. So to validate former conclusions, another set of simulations are carried out in this paper.
-
Experiment 2:
Totally, there are 100 Integer-Coded fault wise tables and each table has 1,000 simulated faults, 40 test points. Ambiguity sets number per test point can vary form 1 to 10 randomly.
Table 17 lists the results of inclusive category by using six different criteria respectively. Comparing the different columns of this table, one cannot say which specific criterion is better than the others. This proves the conclusion that no one specific criterion is superior to the others again.
By comparing Table 17 with Table 18 or by comparing Table 19 with Table 20, it can be drawn that the combined category can improve the solution accuracy without taking too much additional computation time. Similarly, conclusion that Strategy 2 is superior to Strategy 1 in solution accuracy can also be drawn by comparing Table 17 with Table 19 or by comparing Table 18 with Table 20.
5 Conclusion
Heuristic test points selection methods for faulty dictionary technique can be classified into two categories: inclusive and exclusive. Either in inclusive category or in exclusive category, every greedy search algorithm consists of a test points selection strategy and a test points selection criterion. The time complexity and solution accuracy of these algorithms, strategies and criteria are analyzed and compared extensively in this paper. Theoretical analysis and statistical experimental results give the following three conclusions.
-
Conclusion 1:
In the accuracy and efficiency of finding final solution, no one specific criterion is superior to the others.
-
Conclusion 2:
Strategy 2 is superior in the accuracy to Strategy 1 while Strategy 1 is more time efficient than Strategy 2.
-
Conclusion 3:
When combined with exclusive strategy, either Strategy 1 or Strategy 2 can improve the accuracy of the final solution and does not increase the time complexity.
Above conclusions provide an instruction for coding a test points selection algorithm. Conclusion 1 shows that any criterion can be adopted without affecting the accuracy and the efficiency of an algorithm. So a criterion that can be calculated easily, such as Criterion 1, is suggested to be chosen. Based on Conclusion 2 and Conclusion 3, if an efficient algorithm is required, Strategy 1 plus exclusive strategy is a good choice. If the solution’s accuracy is required, Strategy 2 plus exclusive strategy should be adopted. No matter Strategy 1 or Strategy 2 are adopted, the combined strategy proposed in this paper can guaranty that the final solution contain no redundant test points.
Additionally, conclusions drawn in this paper show that a new strategy rather than a new criterion should be focused on in future work.
Abbreviations
- S opt :
-
Desired test points set.
- S c :
-
Candidate test points set.
- n j :
-
Test point j.
- N T :
-
Number of candidate test points.
- f i :
-
Fault i.
- N F :
-
Number of all potential faults (including the nominal case).
- k i :
-
Number of test point (or graph node) that can isolate fault f i .
- q j :
-
Number of faults that can be isolated by n j .
- \(S_i^j \) :
-
Ambiguity set i in test point n j , defined as:
- \(S_i^j = \left\{ {f_m \left| {a_{mj} = i,0 < m < N_F } \right.} \right\}\), where a mj :
-
is element of fault dictionary corresponding to the m th fault (row) and j th test point (column).
- F ij :
-
Number of faults in ambiguity set \(S_i^j \).
- N Aj :
-
Number of ambiguity sets in n j or in graph node j.
References
Abderrahman A, Cerny E, Kaminska B (1996) Optimization-based multifrequency test generation for analog circuits. J. Journal of Electronic Testing: Theory and Applications 9:59–73 doi:10.1007/BF00137565
Aho A, Hopcroft J, Ullman J (1974) The design and analysis of computer algorithms. Reading, MA, Addison-Wesley
Augusto JS, Almeida C (2006) A tool for test points selection and single fault diagnosis in linear analog circuits. In Proc XXI Intl Conf On Design of Systems and Integrated Systems DCIS′06, Barcelona, Spain
Deb S, Pattipati KR, Raghavan V, Shakeri M, & Shrestha R (1995) Multi-signal flow graphs : A novel approach for system testability analysis and fault diagnosis. IEEE Aerospace and Electronics Magazine
Golonek T, Rutkowski J (2007) Genetic-algorithm-based method for optimal analog test points selection. IEEE Transactions on Circuits and Systems—II. Express Briefs 54(2):117–121 doi:10.1109/TCSII.2006.884112
Hochwald W, Bastian JD (1979) A dc approach for analog fault dictionary determination. IEEE Transactions on Circuits and Systems CAS-26:523–529 doi:10.1109/TCS.1979.1084665
Horowitz E, Sahni S (1978) Fundamentals of computer algorithms. Potomac, MD, Computer Science
Lin PM, Elcherif YS (1985) Analogue circuits fault dictionary—New approaches and implementation. Inl J Circuit Theory Appl 13:149–172 doi:10.1002/cta.4490130205
Pinjala KK, Kim BC (2003) An approach for selection of test nodes for analog fault diagnosis. Proceedings of the 18th IEEE International Symposium on Defect and Fault Tolerance in VLSI Systems 3:278–294
Prasad VC, Rao Pinjala SN (1995) Fast algorithms for selection of test nodes of an analog circuit using a generalized fault dictionary approach. Circuits Syst Signal Process 14(6):707–724 doi:10.1007/BF01204680
Prasad VC, Babu NSC (2000) Selection of test nodes for analog fault diagnosis in dictionary approach. IEEE Transactions on Instrumentation and Measurement 49:1289–1297 doi:10.1109/19.893273
Shakeri M, Raghavan V, Pattipati KR, Patterson-Hine A (2000) Sequential testing algorithms for multiple fault diagnosis. IEEE Trans SMC Part A: systems humans 30:1–14 doi:10.1109/3468.823474
Spaandonk J, & Kevenaar T (1996) Iterative test-point selection for analog circuits. in Proc. 14th VLSI Test Symp 66–71
Starzyk JA, Liu D, Liu Z-H, Nelson DE, Rutkowski JO (2004) Entropy-based optimum test nodes selection for analog fault dictionary techniques. IEEE Transactions on Instrumentation and Measurement 53:754–761 doi:10.1109/TIM.2004.827085
Stenbakken GN, Souders TM (1987) Test points selection and testability measure via QR factorization of linear models. IEEE Transactions on Instrumentation and Measurement 36(6):406–410
Varghese X, Williams JH, Towill DR (1978) Computer-aided feature selection for enhanced analog system fault location. Pattern Recognition 10:265–280 doi:10.1016/0031-3203(78)90036-5
Wang W, Hu QH, & Yu D (2007) Application of Multivalued Test Sequencing to fault diagnosis. ICEMI
Yang CL, Tian SL, & Long B Application of Heuristic Graph Search to Test Points Selection for Analog Fault Dictionary Techniques. To be published in IEEE Trans Instrum Meas in June 2009
Acknowledgments
This work was supported in part by Commission of Science Technology and Industry for National Defense of China (No.A1420061264), and by RFDP(The Research Fund for the Doctoral Program of Higher Education)(No. 20070614018).
Author information
Authors and Affiliations
Corresponding author
Additional information
Responsible Editor: J. W. Sheppard
Rights and permissions
About this article
Cite this article
Yang, C., Tian, S. & Long, B. Test Points Selection for Analog Fault Dictionary Techniques. J Electron Test 25, 157–168 (2009). https://doi.org/10.1007/s10836-008-5097-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10836-008-5097-8