
Abstract
In twin support vector regression (TSVR), one can notice that the samples are having the same importance even they are laying above the up-bound and below the down-bound on the estimation function for regression problem. Instead of giving the same emphasis to the samples, a novel approach Asymmetric ν-twin support vector regression (Asy-ν-TSVR) is suggested in this context where samples are having different influences with the estimation function based on samples distribution. Inspired by this concept, in this paper, we propose a new approach as improved regularization based Lagrangian asymmetric ν-twin support vector regression using pinball loss function (LAsy-ν-TSVR) which is more effective and efficient to deal with the outliers and noise. The solution is obtained by solving the simple linearly convergent approach which reduces the computational complexity of the proposed LAsy-ν-TSVR. Also, the structural risk minimization principle is implemented to make the problem strongly convex and more stable by adding the regularization term in their objective functions. The superiority of proposed LAsy-ν-TSVR is justified by performing the various numerical experiments on artificial generated datasets with symmetric and heteroscedastic structure noise as well as standard real-world datasets. The results of LAsy-ν-TSVR compares with support vector regression (SVR), TSVR, TSVR with Huber loss (HN-TSVR) and Asy-ν-TSVR, regularization on Lagrangian TSVR (RLTSVR) for the linear and Gaussian kernel which clearly demonstrates the efficacy and efficiency of the proposed algorithm LAsy-ν-TSVR.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In the machine learning computational world, support vector machine (SVM) is a very popular and safe algorithm for binary classification [1]. Later, it is extended for regression problem also that is known as support vector regression (SVR) [2]. According to statistical learning theory, SVM follows the structural risk minimization (SRM) principle that solves a single large size quadratic programming problem (QPP) to get the optimal solution. SRM principle is basically for model selections which broadly explains the details of capacity control of model and maintain balance between VC dimension of function and empirical error.
SVM for regression is globally accepted due to superior forecasting performance in many research fields such as predict the popularity of online video [3], productiveness of higher education system [4], energy utilization in heat equalization [5], software enhancement effort [6], electric load [7], velocity of wind [8], flow of river [9], snow depth [10], neutral profiles from laser induced fluorescence data [11] and stock price [12]. The disadvantage of SVM is high training cost i.e. O(m3). So many significant improvements have been done by the researchers to lessen the training cost and complexity of SVM such as ν-SVR [13], SVMTorch [14], Bayesian SVR [15], geometric approach to SVR [16], active set SVR [17], heuristic training for SVR [18], smooth ε-SVR [19], fuzzy weighted support vector regression with fuzzy partition [20] etc.
A remarkable enhancement has been done in standard SVM by Jayadeva et al. [21] to propose a novel approach termed as twin support vector machine (TWSVM) which finds two non-parallel hyperplanes that are nearer to one of the class either positive or negative and also sustains unit difference between each other. In comparison to SVM, TWSVM has shown good generalization ability and lesser computation time. Motivated by the concept of TWSVM, a non-parallel twin support vector regression (TSVR) is proposed by Peng [22] in which two unknown optimal regression such as ε−insensitive down- and up- bound functions are determined. TSVR has better prediction performance and accelerated training speed over the SVR [22]. Many other variants of TSVR have been suggested such as reduced TSVR [23] which applied the concept of rectangle kernels to obtain significant improvement in learning time on TSVR, weighted TSVR [24] reduces the problem of overfitting by assigned different penalties to each sample. Twin least square SVR [25] takes the concept of TSVR and least square SVR [26] to improve the prediction performance with training speed. Linearly convergent based Lagrangian TSVR [27] has been proposed to improve the generalization performance and learning speed. Unconstrained based Lagrangian TSVR [28] has been suggested to reduce the complexity of model and improve the learning speed via solving the unconstrained minimization problems. Niu et al. [29] has combined the TSVR with Huber loss function (HN-TSVR) for handling the Gaussian noise. Tanveer & Shubham [30] has proposed a new algorithm termed as regularization on Lagrangian twin support vector regression (RLTSVR) which solves the regression problem very effectively. There are many variants of SVM exists in the literature based on pinball loss function for the classification problems like Huang has applied pin ball loss function in SVM and suggested an approach as pin-SVM [31] to handle the noisy data; Huang et al. [32] has proposed sequential minimization optimization for SVM with truncated pinball loss along with its sparse version that enhances the generalization efficiency of pin-SVM; Pin-M3HM [33] has improved the twin hyper-sphere SVM (THSVM) [34] using pin ball loss that avoids noise and error in very effective manner; Xu et al. [35] has proposed a new approach TWSVM with pin ball loss that indulge with quantile distance which is performed well for noisy data and related to this for more study, see [36,37,38,39,40,41,42,43,44]. It actually gives the active research direction in forward way.
One can notice that very few literatures are available on SVR with pinball loss function for the regression problems. In spite of considering ε-insensitive loss function, Huang has proposed a novel approach termed as asymmetric ν-tube support vector regression (Asy-ν-SVR) [45] based on ν-SVR with pinball loss function to divide the outliers asymmetrically over above and below of the tube and improved the computational complexity. Similarly, one can observe that we have assigned same penalties to every point above the up-bound and below the down-bound in TSVR. But each sample may not give same effect in order to determine the regression function. So, asymmetric ν-twin support vector regression (Asy-ν-TSVR) [35] has been suggested to give different effects on the regression function by using the pin-ball loss function. Motivated by the above studies, we propose a new approach as improved regularization based Lagrangian asymmetric ν-twin support vector regression (LAsy-ν-TSVR) using pinball loss function in this paper where the end regression function is determined by solving the linearly convergent iterative approach unlike solve the QPPs in case of SVR, TSVR, HN-TSVR and Asy-ν-TSVR. This approach reduces the computational cost of the model. Another advantage of our proposed LAsy-ν-TSVR is that it follows the SRM principle which yields the existence of global solution and improves the generalization ability. The characteristics of proposed LAsy-ν-TSVR are as follows:
-
To make the problem strongly convex and find the unique global solution, 2-norm of vector of slack variables is included in the objective functions of proposed LAsy-ν-TSVR.
-
Regularization terms are added in the objective functions of LAsy-ν-TSVR to implement the SRM principle which makes the model well pose.
-
The solution of proposed LAsy-ν-TSVR is obtained by using the linearly convergent iterative schemes which improve the computational cost.
Further, to check the effectiveness and applicability of proposed LAsy-ν-TSVR, numerical experiments are conducted on artificial generated datasets having symmetric and asymmetric structure of noise and also on real-world benchmark datasets. The experimental results of proposed LAsy-ν-TSVR are compared with SVR, TSVR, HN-TSVR, Asy-ν-TSVR and RLTSVR in this paper.
This paper is organised as follows. Section 2 outlines briefly about SVR, TSVR, HN-TSVR, Asy-ν-TSVR and RLTSVR. The formulation of proposed LAsy-ν-TSVR is described in Section 3. In Section 4, the numerical experiments are performed on artificially generated and real-world datasets in detail. At last, conclusion and future work is presented in Section 5.
2 Background
In this paper, consider the training data as \( {\left\{\left({x}_i,{y}_i\right)\right\}}_{i=1}^m \) where ith -input data sample is shown as xi = (xi1, ..., xin) ∈ Rn and yi ∈ R is the observed outcome of corresponding input sample. Let consider A is a m × n matrix in which m is the number of input samples and n is the number of attributes in such a way that A = (x1, ..., xm)t ∈ Rm × n and y= (y1, ..., ym)t ∈ Rm. The 2-norm of a vector x will be represented by ‖x‖. The plus function x+ is given by max{0, xi} for i = 1, ..., m.
2.1 Support vector regression (SVR)
In the linear regression [2], the main aim is to find the optimal linear regression estimating function of the form as
where, w ∈ Rn, b ∈ R.
The formulation of linear SVR as constrained minimization problem [46] is given as
subject to
where, the vectors of slack variables ξ1 ≥ (ξ11, ..., ξ1m)t and ξ2 ≥ (ξ21, ..., ξ2m)t; C > 0, ε > 0 are the input parameters and e ∈ Rm is the vector of one’s.
Now introduce the Lagrangian multipliers α1 = (α11, ..., α1m)t,β1 = (β11, ..., β1m)t and further apply the Karush–Kuhn–Tucker (KKT) conditions, the dual QPP of (1) is given as:
subject to
The decision function f(.) will be obtained from (2) [46] for any test data x ∈ Rn as
For nonlinear SVR, we assume the nonlinear function of the given form as.
f(x) = wtϕ(x) + b
where, ϕ(.) is a nonlinear mapping which consider the input space into feature space in the high dimension. The formulation of nonlinear constrained QPP [2, 46] is considered as
subject to
Now, the dual QPP of the primal problem (3) is determined by using the Lagrangian multipliersα1, β1 and further apply the KKT conditions. We get
subject to
where, the kernel function k(xi, xj) = ϕ(xi)tϕ(xj). The decision function f(.) will be obtained [46] for any test data x ∈ Rn from (4) as
2.2 Twin support vector regression (TSVR)
Twin support vector regression (TSVR) [22] is an effective approach which is influenced from TWSVM [21] to predict the two nonparallel ε-insensitive down-bound function \( {f}_1(x)={w}_1^tx+{b}_1 \) and ε-insensitive up-bound function \( {f}_2(x)={w}_2^tx+{b}_2 \). Here, w1, w2 ∈ Rn and b1, b2 ∈ R are unknowns. In linear TSVR, the regression functions are determined by solving the following QPPs in such a way:
subject to
and
subject to
where, input parameters are C1, C2 > 0 and ε1, ε2 > 0; the vectors of slack variables are ξ1 and ξ2.
Now introduce the Lagrangian multipliers in the above problems (5) and (6) is shown as
and
where, α1 = (α11, ..., α1m)t, α2 = (α21, ..., α2m)t are the vectors of Lagrangian multipliers. After, we get the Wolfe dual QPPs of the above primal problems by using the KKT conditions as
subject to
and
subject to
where, S = [A e] is the augmented matrix.
After solving the above pair of dual QPPs (7) and (8) for α1 and α2, one can derive the values as:
and
Then, the final estimated regression function is obtained as
In nonlinear case of TSVR, the kernel generating regression functions f1(x) = K(xt, At)w1 + b1 and f2(x) = K(xt, At)w2 + b2 are determined by the following QPPs as
subject to
and
subject to
Similarly as the linear TSVR, we get the dual QPP from the Eqs. (10) and (11)
subject to
and
subject to
where, \( T=\left[K\left(A,{A}^t\right)\kern0.5em e\right] \) is the augmented matrix; α1 and α2 are Lagrangian multipliers.
One can derive the values of w1, w2, b1, b2 from the Eqs. (12) and (13) as follows:
and
One can notice that σI is added as extra term in the matrix (TtT)−1 to make the matrix positive definite, where σ > 0 is the small real positive value. Finally, end regression function is obtained from (9).
2.3 Twin support vector regression with Huber loss (HN-TSVR)
TSVR [22] is based on ε-insensitive loss function but fail to deal for data having Gaussian noise. Motivated by the work of [47, 48], TSVR with Huber loss function (HN-TSVR) [29] has been suggested in order to improve the generalization ability by suppress a variety of noise and outliers. Here, Huber loss function is given by
The nonlinear HN-TSVR QPPs are as follows:
subject to
where, U1 = {i| 0 ≤ ξ1i < ε}, U2 = {i| ξ1i ≥ ε}.and
subject to
where, V1 = {i| 0 ≤ ξ2i < ε}, V2 = {i| ξ2i ≥ ε};ξ1 = (ξ11, ...ξ1m)t and ξ2 = (ξ21, ...ξ2m)t are the slack variables; C1, C2 > 0, ε1, ε2 > 0 are parameters.
By applying the Lagrange’s multipliers α1 = (α11, ..., α1m)t, α2 = (α21, ..., α2m)t, the dual formulation of problem (14) and (15) are determined as
subject to:
and
subject to:
where, \( S=\left[K\left(A,{A}^t\right)\kern0.5em e\right]. \)
The value of corresponding w1, w2, b1, b2 are
Finally, the end regression function can be obtained as similar to (9).
2.4 Asymmetric ν-twin support vector regression (Asy-ν-TSVR)
Asymmetric v-twin support vector regression with pinball loss function (Asy-ν-TSVR) [35] has been proposed in order to pursue the asymmetric tube where the different penalties are assigned to the above the up-bound and below the down-bound. Asy-ν-TSVR is highly influenced from Huang et al. [45] whereε-insensitive loss is replaced by pinball loss [40] where points having the different penalties based on their different position. Here, pinball loss function is defined as:
where p is the asymmetric penalty parameter. One can be degraded into ε-insensitive loss by choosing the value p = 0.5..
In linear Asy-ν-TSVR case, two nonparallel ε1-insensitive down-bound \( {f}_1(x)={w}_1^tx+{b}_1 \) and up-bound \( {f}_2(x)={w}_2^tx+{b}_2 \) functions are generated by solving the pair of QPPs in the following manner:
subject to
and
subject to
where, ξ1, ξ2 are the slack variables; C1, C2 > 0; ε1, ε2 > 0, ν1, ν2 are the input parameters.
Apply Lagrangian multipliers α1, α2 > 0 ∈ Rm and KKT conditions, we get the dual QPP of Asy-ν-TSVR from the Eqs. (19) and (20)
subject to
and
subject to
where, \( S=\left[A\kern0.5em e\right] \).
After solving the Eqs. (21) and (22), one can compute the values of w1, w2, b1, b2 in the following manner:
and
Finally, the end regression function is obtained as similar to (9).
In the nonlinear case, kernel generating regression functions are f1(x) = K(xt, At)w1 + b1 and f2(x) = K(xt, At)w2 + b2 by solving the pair of QPPs in such a way:
subject to
and
subject to
Apply Lagrangian multipliers α1, α2and KKT necessary conditions, the dual formation of (23) and (24) can be derived as follows:
subject to
and
subject to
where, \( T=\left[K\left(A,{A}^t\right)\kern0.5em e\right] \).
After solving the Eqs. (27) and (28) for α1 and α2, we can obtain the augmented vectors as
and
Finally, the end regression estimation function is given as similar to the linear case for any test samplex ∈ Rn.
2.5 A regularization on Lagrangian twin support vector regression (RLTSVR)
By considering the principle of structural risk minimization instead of usual empirical risk in ε-TSVR, recently Tanveer & Shubham [30] proposed a new algorithm termed as regularization on Lagrangian twin support vector regression (RLTSVR) whose solution is obtained by simple linearly convergent iterative approach. The two nonparallel functions f1(x) = K(xt, At)w1 + b1 and f2(x) = K(xt, At)w2 + b2 are determined by using the following constrained minimization problems:
subject to
and
subject to
where, input parameters are C1, C2, C3, C4 > 0 and ε1, ε2 > 0; ξ1, ξ2 are slack variables.
Now introduce the Lagrangian multipliers α1 = (α11, ..., α1m)t and α2 = (α21, ..., α2m)t, the dual form of the QPP of (27) and (28) can be written as:
and
where, \( S=\left[K\left(A,{A}^t\right)\kern0.5em e\right] \) is the augmented matrix.
After solving the above pair of dual QPPs (29) and (30) for α1 and α2, one can derive the values as:
and
Finally, the end regression function is obtained as similar to (9). For more details, one can see [30].
3 Proposed improved regularization based Lagrangian asymmetric ν-twin support vector regression using pinball loss (LAsy-ν-TSVR)
Recently, Xu et al., [35] has suggested a novel approach termed as asymmetric ν-twin support vector regression using pinball loss function to handle the asymmetric noise and outliers in challenging real-world problems. In order to further improvement of generalization ability and reduction of computation cost, we propose another approach termed as improved regularization based Lagrangian asymmetric ν-twin support vector regression using pinball loss function (LAsy-ν-TSVR) whose solution is obtained by solving the linearly convergent iterative method in place of solving QPPs. To formulate our proposed LAsy-ν-TSVR formulation, we replace the 1-norm of vector of slack variables ξ1 and ξ2, by the square of the vector of slack variables in 2-norm which makes the problem strongly convex and yields the existence of global unique solution. In order to follow the SRM principle unlike in case of TSVR and Asy-ν-TSVR, the regularization terms \( \frac{C_3}{2}\left({\left\Vert {w}_1\right\Vert}^2+{b}_1^2\right) \) and \( \frac{C_4}{2}\left({\left\Vert {w}_2\right\Vert}^2+{b}_2^2\right) \) are also added in the objective functions of (19) and (20) respectively that improves the stability in the dual formulations as well as makes the model well-posed. In the formulations of linear proposed LAsy-ν-TSVR, the regression functions \( {f}_1(x)={w}_1^tx+{b}_1 \) and \( {f}_2(x)={w}_2^tx+{b}_2 \) are obtained by solving the modified QPPs as
subject to
and
subject to
where C1, C2, C3, C4 > 0, and ν1, ν2 are input parameters; ξ1 = (ξ11, ...ξ1m)t, ξ2 = (ξ21, ...ξ2m)t are the slack variables. Here, the non-negative constraints of the slack variables are dropped in (31) and (32). The Lagrangian functions of (31) and (32) are obtained by using the Lagrangian multipliers α1, α2 > 0 ∈ Rm as
and
Further, apply the KKT conditions in (41), we get
By combining the Eqs. (35) and (36), we get
where \( S=\left[A\kern0.5em e\right] \) is an augmented matrix.
By using the Eqs. (33), (36), (37) and (38), the dual QPP of primal problem (33) is given as
Similarly, we get the following dual QPP of the primal problem (34) as
The values of α1 and α2 are determined by solving the QPPs (40) and (41). The end regression function f(.) is determined by taking the mean of f1(x) and f2(x) for any test sample x ∈ Rn:
and
In the formulation of non-linear LAsy-ν-TSVR, the kernel generated functions f1(x) = K(xt, At)w1 + b1 and f2(x) = K(xt, At)w2 + b2 are determined by the following QPPs as
subject to
and
subject to
respectively, where C1, C2, C3, C4 > 0; and ν1, ν2 are input parameters.
Using the Lagrangian multipliers α1, α2 > 0 ∈ Rm, the Lagrangian functions of (44) and (45) are given by
and
Further, apply the KKT conditions, the dual QPP of primal problems (46) & (47) are given as
and
where \( T=\left[K\left(A,{A}^t\right)\kern0.5em e\right] \) is an augmented matrix.
After computing the values of α1 and α2 from (48) and (49), the final estimation function f(.) is determined for non-linear kernel by taking the mean of the following non-linear functions f1(x) and f2(x) as
and
One can rewrite the problems (48) and (49) in the following form:
and
respectively, where
\( {D}_1=\left(T{\left({T}^tT+{C}_3I\right)}^{-1}{T}^t+\frac{4m{\left(1-p\right)}^2}{C_1}+\frac{e{e}^t}{2{C}_1{\nu}_1}\right) \), \( {D}_2=\left(T{\left({T}^tT+{C}_4I\right)}^{-1}{T}^t+\frac{4m{p}^2}{C_2}+\frac{e{e}^t}{2{C}_2{\nu}_2}\right) \), r1 = T(TtT + C3I)−1Tty − y and r2 = − T(TtT + C4I)−1Tty + y.
The KKT optimality conditions [49] is applied on the QPPs (50) and (51) which lead to the following pair of classical complementary problems as
and
respectively. By using the identity 0 ≤ x ⊥ y ≥ 0 if and only if x = (x − ψy)+ for any vectors x, y and parameter ψ > 0, the equivalent pair of problems [50] of (52) and (53) are rewritten in the following fixed point theorems: for any ψ1, ψ2 > 0, the relations
and
To solve the above problems (50) and (51), one can propose the following simple iterative approach in the following form:
and
i.e.
and
Remark 1
One may notice that we have to compute the inverse of the matrices \( \left(T{\left({T}^tT+{C}_3I\right)}^{-1}{T}^t+\frac{4m{\left(1-p\right)}^2}{C_1}+\frac{e{e}^t}{2{C}_1{\nu}_1}\right) \) and \( \left(T{\left({T}^tT+{C}_4I\right)}^{-1}{T}^t+\frac{4m{p}^2}{C_2}+\frac{e{e}^t}{2{C}_2{\nu}_2}\right) \) in the above iterative schemes (58) and (59) to find the solution of our proposed LAsy-ν-TSVR. Unlike the Asy-ν-TSVR and TSVR, these matrices are positive definite which can be compute at the very beginning of the algorithm.
Remark 2
Unlike the TSVR and Asy-ν-TSVR, there is not any required additions of extra term δ I to make the matrix positive definite where δ is very small positive number and I is the identity matrix. Our proposed LAsy-ν-TSVR always gives unique global solution since \( \left(T{\left({T}^tT+{C}_3I\right)}^{-1}{T}^t+\frac{4m{\left(1-p\right)}^2}{C_1}+\frac{e{e}^t}{2{C}_1{\nu}_1}\right) \) and \( \left(T{\left({T}^tT+{C}_4I\right)}^{-1}{T}^t+\frac{4m{p}^2}{C_2}+\frac{e{e}^t}{2{C}_2{\nu}_2}\right) \) both are positive definite matrices.
Remark 3
For any arbitrary vectors \( {\alpha}_1^0\in {R}^m \) and \( {\alpha}_2^0\in {R}^m \), the iterate \( {\alpha}_1^i\in {R}^m \) and \( {\alpha}_2^i\in {R}^m \) of iterative schemes (58) and (59) converge to the unique solution \( {\alpha}_1^{\ast}\in {R}^m \) and \( {\alpha}_2^{\ast}\in {R}^m \) respectively and also satisfying the following conditions as
and
One can follow the proof of convergence of above from [50].
4 Numerical experiments
To measure the effectiveness of the proposed LAsy-ν-TSVR, several numerical experiments have been performed on standard benchmark real-world datasets for SVR, TSVR, HN-TSVR, Asy-ν-TSVR and RLTSVR. To conduct these numerical experiments, MATLAB software version2008b is used. In the formulations of SVR, TSVR, HN-TSVR, Asy-ν-TSVR, the QPPs are solved by using the external MOSEK optimization toolbox [51]. The number of interesting datasets are used in these numerical experiments such as Pollution, Space Ga [52]; Kin900, Demo [53]; the inverse dynamics of a Flexible robot arm [54]; S&P500, IBM, RedHat, Google, Intel, Microsoft [55]; Concrete CS, Boston, Auto-MPG, Parkinson, Gas furnace, Winequality from ([56]), Mg17 from [57]. In this paper, we consider both linear and non-linear case where Gaussian kernel function is taken in case of non-linear as
where, kernel parameter μ > 0.
Here, the user input parameter values are described in Table 1. Finally, root mean square error (RMSE) is calculated based on optimal values for measuring the prediction accuracy by using the following formula:
where, yi are the observed values, \( {\tilde{y}}_i \) are the predicted values respectively and N is the number of test data samples.
4.1 Artificial datasets
In this subsection, we have performed numerical experiments on 8 artificial generated datasets which are mentioned in Table 2 with their function definitions. In order to check the applicability of proposed LAsy-ν-TSVR for outliers and noise, we added two types of noise level in artificial datasets i.e. symmetric noise and asymmetric noise structure. Function 1 to Function 6 are having symmetric noise to generate artificial datasets in which variability of noise is proceeded from symmetric distribution and Function 7 and Function 8 are using the asymmetric noise such as heteroscedastic noise structure to generate the artificial dataset i.e. the noise is directly dependent on the value of input samples. Further, we use uniform probability distribution Ω ∈ U (a, b) with interval (a, b) for uniform noise and normal distribution Ω ∈ N (μ, σ2) where μ and σ2 are the mean and variance respectively for Gaussian noise. Here, artificial dataset is generated by using 200 training samples with the additive noise and 500 testing samples without any addition of noise. To test the efficacy of proposed LAsy-ν-TSVR along with reported algorithms in this paper, a comparative analysis of their corresponding prediction errors for all artificial datasets are presented in Table 3 using linear kernel and Table 5 using Gaussian kernel. One can conclude from Tables 3 and 5 that our proposed LAsy-ν-TSVR performs better or comparable generalization performance in comparison to other methods. Further, Tables 4 and 6 are consisted the average ranks of SVR, TSVR, HN-TSVR, Asy-ν-TSVR, RLTSVR and LAsy-ν-TSVR based on RMSE values for artificial datasets using linear and Gaussian kernel respectively. One can notice that proposed LAsy-ν-TSVR is having lowest rank among SVR, TSVR, HN-TSVR, Asy-ν-TSVR and RLTSVR in both linear and nonlinear case which shows the usability and effectiveness of proposed LAsy-ν-TSVR.
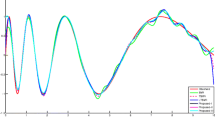
To check the performance for symmetric noise structure, the prediction values are plotted for SVR, TSVR, HN-TSVR, Asy-ν-TSVR, RLTSVR and LAsy-ν-TSVR using Gaussian kernel of Function 5 in Fig. 1 with uniform noise. Similarly, for Function 6 with Gaussian noise, we depict the prediction plots in Fig. 2 respectively. It is easily noticeable that our proposed LAsy-ν-TSVR is having better agreement with final target values in comparison to SVR, TSVR, HN-TSVR, Asy-ν-TSVR and RLTSVR for symmetric noise structure having both uniform and Gaussian noise.

Accuracy plot over the test set by SVR, TSVR, HN-TSVR, Asy-v-TSVR, RLTSVR and LAsy-v-TSVR using Gaussian kernel for Function 5 with uniform noise

Accuracy plot over the test set by SVR, TSVR, HN-TSVR, Asy-v-TSVR, RLTSVR and LAsy-v-TSVR using Gaussian kernel for Function 6 with Gaussian noise
Further, to test the applicability of proposed LAsy-ν-TSVR on datasets having asymmetric noise structure i.e. heteroscedastic noise, the prediction plots are drawn in Fig. 3 for Function 7 using uniform noise. Similarly, for Function 8, we depict the prediction plots in Fig. 4 having Gaussian noise. One can observe from these results that LAsy-ν-TSVR is more effective to handle the asymmetric noise structure for both uniform and Gaussian noise.

Accuracy plot over the test set by SVR, TSVR, HN-TSVR, Asy-v-TSVR, RLTSVR and LAsy-v-TSVR using Gaussian kernel for Function 7 with uniform noise

Accuracy plot over the test set by SVR, TSVR, HN-TSVR, Asy-v-TSVR, RLTSVR and LAsy-v-TSVR using Gaussian kernel for Function 8 with Gaussian noise
4.2 Real world datasets
In this paper, we have shown comparative analysis of our proposed LAsy-ν-TSVR with SVR, TSVR, HN-TSVR, Asy-ν-TSVR, RLTSVR using real world datasets for linear and non-linear case that are tabulated in Tables 7 and 9 respectively. One can notice that the prediction accuracy of proposed LAsy-ν-TSVR is better or equal in 8 out of 18 standard benchmark real world datasets for linear kernel and 11 out of 18 standard real world datasets for Gaussian kernel which justified the applicability and usability. In order to show the performance graphically, we plot prediction values for Auto-MPG, Gas furnace and Intel datasets in Figs. 5, 7 and 9 respectively. Similarity, prediction error of Auto-MPG, Gas furnace and Intel are shown in Figs. 6, 8 and 10 respectively. One can conclude from these results that the prediction values of our proposed LAsy-ν-TSVR is very close to target values in comparison to SVR, TSVR, HN-TSVR, Asy-ν-TSVR, RLTSVR which justify the existence and usability of our approach. Further, to justify the performance statistically of our proposed LAsy-ν-TSVR, the average ranks are depicted based on RMSE values in Tables 8 and 10 for all reported methods using both linear and nonlinear kernel respectively. It is clear form Tables 8 and 10 that proposed LAsy-ν-TSVR is having lowest rank among all in both cases.

Prediction over the testing dataset by SVR, TSVR, HN-TSVR, Asy-v-TSVR, RLTSVR and LAsy-v-TSVR on the Auto-MPG dataset. Gaussian kernel was used

Prediction error over the testing dataset by SVR, TSVR, HN-TSVR, Asy-v-TSVR, RLTSVR and LAsy-v-TSVR on the Auto-MPG dataset. Gaussian kernel was used

Prediction over the testing dataset by SVR, TSVR, HN-TSVR, Asy-v-TSVR, RLTSVR and LAsy-v-TSVR on the Gas furnace dataset. Gaussian kernel was used

Prediction error over the testing dataset by SVR, TSVR, HN-TSVR, Asy-v-TSVR, RLTSVR and LAsy-v-TSVR on the Gas furnace dataset. Gaussian kernel was used

Prediction over the testing dataset by SVR, TSVR, HN-TSVR, Asy-v-TSVR, RLTSVR and LAsy-v-TSVR on the Intel dataset. Gaussian kernel was used

Prediction error over the testing dataset by SVR, TSVR, HN-TSVR, Asy-v-TSVR, RLTSVR and LAsy-v-TSVR on the Intel dataset. Gaussian kernel was used
Now, non-parametric Friedman test is conducted with the corresponding post hoc test [58] on 6 algorithms and 18 datasets in which it is used to detect differences in ranking of RMSE across multiple algorithms.
This test is mainly used for one-way repeated measures analysis of variance by ranks of different algorithms. Let us consider, all methods are equivalent under null hypothesis, the Friedman statistic is determined for linear cases from Table 8 as follows.
According to Fisher–Snedecor F distribution, Friedman expression FF is distributed with degree of freedom (6 − 1, (6 − 1) ∗ (18 − 1)) = (5, 85) degree of freedom. The critical value of F(5, 85) is 2.321 for α = 0.05. Since FF > 2.321, we reject the null hypothesis i.e. all algorithms are not equivalent. Now, Nemenyi post hoc test is conducted for pair wise comparison of all methods. This test is applied after Friedman test if it rejects the null hypothesis, for comparison of pair wise performance. For this, we calculate the critical difference (CD) with qα = 2.589 as
where, the value of qα is decided on the basis of number of concerned algorithms and the value of θ from Demsar,[58].
The difference of average rank between SVR and proposed LAsy-ν-TSVR (5.055556 − 2.527778 = 2.527778) which is greater than CD i.e. (1.6145). This result assures that the prediction performance of proposed algorithm LAsy-ν-TSVR is better than SVR. Further, the differences of average rank of proposed LAsy-ν-TSVR with TSVR, HN-TSVR, Asy-ν-TSVR and RLTSVR are not more than the CD, so there is not any significant differences among them.
Secondly, to apply Friedman test in non linear case for standard real world bench mark datasets on the average ranks of SVR, TSVR, HN-TSVR, Asy-ν-TSVR, RLTSVR and proposed LAsy-ν-TSVR from Table 10 as follows:
The critical value of F(5, 85) is 2.321 forα = 0.05. Since FF > 2.321, we reject the null hypothesis. Now, we perform the Nemenyi test to compare the methods pair-wise. Here, critical difference (CD) is 1.6145.
-
i.
The differences between the average rank of SVR and proposed LAsy-ν-TSVR (4.888889 − 1.555556 = 3.333333) is greater than CD ( 1.6145) thus proposed LAsy-ν-TSVR is better than SVR.
-
ii.
Further, check the dissimilarity between the proposed LAsy-ν-TSVR with TSVR, the difference between the average ranks i.e. (4.166667 − 1.555556 = 2.611111) is larger than( 1.6145), thus the prediction performance of proposed LAsy-ν-TSVR is much effective in comparison to TSVR.
-
iii.
The average rank difference between HN-TSVR and proposed LAsy-ν-TSVR is (4.194444 − 1.555556 = 2.638889) which is greater than ( 1.6145), it implies that LAsy-ν-TSVR is better than HN-TSVR.
-
iv.
Since the dissimilarity of average rank between Asy-ν-TSVR and proposed LAsy-ν-TSVR (3.861111 − 1.555556 = 2.305556) is larger than ( 1.6145) which validates the existence and applicability of proposed algorithm LAsy-ν-TSVR in comparison to Asy-ν-TSVR.
5 Conclusions and future work
In this paper, we propose a new approach as improved regularization based Lagrangian asymmetric ν-twin support vector regression (LAsy-ν-TSVR) using pinball loss function that follows the gist of statistical learning theory i.e. SRM principle effectively. The solution of LAsy-ν-TSVR is determined by solving the linearly convergent iterative approach unlike solving the QPPs as used in SVR, TSVR, HN-TSVR and Asy-ν-TSVR. Thus, no external optimization toolbox is required in our case. Another advantage of proposed LAsy-ν-TSVR is that proposed LAsy-ν-TSVR is more effective and usable to handle both symmetric and asymmetric structure having two types uniform and Gaussian noise in comparison to SVR, TSVR, HN-TSVR, Asy-ν-TSVR and RLTSVR. In order to justify numerically, proposed LAsy-ν-TSVR is tested and validated on various artificial generated datasets having symmetric and heteroscedastic structure of uniform and Gaussian noise. One can conclude that proposed LAsy-ν-TSVR is much more effective to handle the noise in comparison to SVR, TSVR, HN-TSVR, Asy-ν-TSVR and RLTSVR. On the basis of experimental results for real world datasets, it can be stated that proposed LAsy-ν-TSVR are far better than SVR, TSVR, HN-TSVR, Asy-ν-TSVR and RLTSVR in terms of generalization ability as well as the faster learning ability clearly illustrate its efficacy and applicability. In future, one can apply the heuristic approach to select the optimum parameters and another, a sparse model can be proposed based on asymmetric pinball loss function.
References
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20(3):273–297
Drucker H, Burges CJC, Kaufman L, Smola AJ, Vapnik V (1997) Support vector regression machines." In Advances in neural information processing systems, pp. 155–161
Trzciński T, Rokita P (2017) Predicting popularity of online videos using support vector regression. IEEE Trans Multimedia 19(11):2561–2570
López-Martín C, Ulloa-Cazarez RL, García-Floriano A (2017) Support vector regression for predicting the productivity of higher education graduate students from individually developed software projects. IET Softw 11(5):265–270
Golkarnarenji G, Naebe M, Badii K, Milani AS, Jazar RN, Khayyam H (2018) Support vector regression modelling and optimization of energy consumption in carbon fiber production line. Comput Chem Eng 109:276–288
García-Floriano A, López-Martín C, Yáñez-Márquez C, Abran A (2018) Support vector regression for predicting software enhancement effort. Inf Softw Technol 97:99–109
Dong Y, Zhang Z, Hong W-C (2018) A hybrid seasonal mechanism with a chaotic cuckoo search algorithm with a support vector regression model for electric load forecasting. Energies 11(4):1009
Khosravi A, Koury RNN, Machado L, Pabon JJG (2018) Prediction of wind speed and wind direction using artificial neural network, support vector regression and adaptive neuro-fuzzy inference system. Sustainable Energy Technol Assess 25:146–160
Baydaroğlu Ö, Koçak K, Duran K (2018) River flow prediction using hybrid models of support vector regression with the wavelet transform, singular spectrum analysis and chaotic approach. Meteorog Atmos Phys 130(3):349–359
Xiao X, Zhang T, Zhong X, Shao W, Li X (2018) Support vector regression snow-depth retrieval algorithm using passive microwave remote sensing data. Remote Sens Environ 210:48–64
Fisher DM, Kelly RF, Patel DR, Gilmore M (2018) A support vector regression method for efficiently determining neutral profiles from laser induced fluorescence data. Rev Sci Instrum 89(10):10C104
Zhang J, Teng Y-F, Chen W (2018) Support vector regression with modified firefly algorithm for stock price forecasting. Appl Intell:1–17
Schölkopf B, Smola AJ, Williamson RC, Bartlett PL (2000) New support vector algorithms. Neural Comput 12(5):1207–1245
Collobert R, Bengio S (2001) SVMTorch: support vector machines for large-scale regression problems. J Mach Learn Res 1:143–160
Law MHC, Kwok JT-Y (2001) Bayesian Support Vector Regression. AISTATS
Bi J, Bennett KP (2003) A geometric approach to support vector regression. Neurocomputing 55(1–2):79–108
Musicant DR, Feinberg A (2004) Active set support vector regression. IEEE Trans Neural Netw 15(2):268–275
Wang W, Xu Z (2004) A heuristic training for support vector regression. Neurocomputing 61:259–275
Lee Y-J, Hsieh W-F, Huang C-M (2005) ε-SSVR: a smooth support vector machine for ε-insensitive regression. IEEE Trans Knowl Data Eng 17(5):678–685
Chuang C-C (2007) Fuzzy weighted support vector regression with a fuzzy partition. IEEE Trans Syst Man Cybern B 37(3):630–640
Jayadeva, Khemchandani R, Chandra S (2007) Twin support vector machines for pattern classification. IEEE Trans Pattern Anal Mach Intell 29(5):905–910
Peng X (2010) TSVR: an efficient twin support vector machine for regression. Neural Netw 23(3):365–372
Singh M, Chadha J, Ahuja P, Chandra S (2011) Reduced twin support vector regression. Neurocomputing 74(9):1474–1477
Xu Y, Wang L (2012) A weighted twin support vector regression. Knowl-Based Syst 33:92–101
Zhao Y-P, Zhao J, Zhao M (2013) Twin least squares support vector regression. Neurocomputing 118:225–236
Suykens JAK, Vandewalle J (1999) Least squares support vector machine classifiers. Neural Process Lett 9(3):293–300
Balasundaram S, Tanveer M (2013) On Lagrangian twin support vector regression. Neural Comput & Applic 22(1):257–267
Balasundaram S, Gupta D (2014) Training Lagrangian twin support vector regression via unconstrained convex minimization. Knowl-Based Syst 59:85–96
Niu J, Chen J, Xu Y (2017) Twin support vector regression with Huber loss. J Intell Fuzzy Syst 32(6):4247–4258
Tanveer M, Shubham K (2017) A regularization on Lagrangian twin support vector regression. Int J Mach Learn Cybern 8(3):807–821
Huang X, Shi L, Suykens JAK (2014a) Support vector machine classifier with pinball loss.". IEEE Trans Pattern Anal Mach Intell 36(5):984–997
Huang X, Shi L, Suykens JAK (2015) Sequential minimal optimization for SVM with pinball loss. Neurocomputing 149:1596–1603
Xu Y, Yang Z, Zhang Y, Pan X, Wang L (2016) A maximum margin and minimum volume hyper-spheres machine with pinball loss for imbalanced data classification. Knowl-Based Syst 95:75–85
Peng X, Xu D (2013) A twin-hypersphere support vector machine classifier and the fast learning algorithm. Inf Sci 221:12–27
Xu Y, Yang Z, Pan X (2017) A novel twin support-vector machine with pinball loss. IEEE Transactions on Neural Networks and Learning Systems 28(2):359–370
Nandan Sengupta R (2008) Use of asymmetric loss functions in sequential estimation problems for multiple linear regression. J Appl Stat 35(3):245–261
Reed C, Yu K (2009) A partially collapsed Gibbs sampler for Bayesian quantile regression
Le Masne Q, Pothier H, Birge NO, Urbina C, Esteve D (2009) Asymmetric noise probed with a Josephson junction. Phys Rev Lett 102(6):067002
Hao P-Y (2010) New support vector algorithms with parametric insensitive/margin model. Neural Netw 23(1):60–73
Steinwart I, Christmann A (2011) Estimating conditional quantiles with the help of the pinball loss. Bernoulli 17(1):211–225
Xu Y, Guo R (2014) An improved ν-twin support vector machine. Appl Intell 41(1):42–54
Rastogi R, Anand P, Chandra S (2017) A ν-twin support vector machine based regression with automatic accuracy control. Appl Intell 46(3):670–683
Demšar J (2006) Statistical comparisons of classifiers over multiple data sets. J Mach Learn Res 7:1–30
Xu Y, Li X, Pan X, Yang Z (2018) Asymmetric ν-twin support vector regression. Neural Comput & Applic 30(12):3799–3814
Huang X, Shi L, Pelckmans K, Suykens JAK (2014b) Asymmetric ν-tube support vector regression. Comput Stat Data Anal 77:371–382
Cristianini N, Shawe-Taylor J (2000) An introduction to support vector machines and other kernel-based learning methods. Cambridge university press, Cambridge
Huber PJ (1964) Robust estimation of a location parameter. Ann Math Stat 35(1):73–101
Mangasarian OL, Musicant DR (2000) Robust linear and support vector regression. IEEE Trans Pattern Anal Mach Intell 22(9):950–955
Mangasarian OL (1994) Nonlinear programming. SIAM, Philadelphia
Mangasarian OL, Musicant DR (2001) Lagrangian support vector machines. J Mach Learn Res 1:161–177
Mosek.com (2018) ‘MOSEK optimization software for solving QPPs.’[online]. Available: https://www.mosek.com
StatLib (2018) ‘StatLib, Carnegie Mellon University.’ [online]. Available: http://lib.stat.cmu.edu/datasets
DELVE (2018) ‘DELVE, University of California.’ [online]. Available: https://www.cs.toronto.edu/~delve/
DaISy (2018) ‘DaISY: Database for the Identification of Systems, Department of Electrical Engineering, ESAT/STADIUS, KU Leuven, Belgium.’ [online]. Available: http://homes.esat.kuleuven.be/~smc/daisydata.html
Yahoo Finance (2018) ‘Yahoo Finance.’ [online] Available: http://finance.yahoo.com/
Lichman M (2018) “UCI Machine Learning Repository. Irvine, University of California, Irvine, School of Information and Computer Sciences. (2013). 02–14. Available: https://archive.ics.uci.edu/ml/
Casdagli M (1989) Nonlinear prediction of chaotic time series. Physica D 35(3):335–356
Xu Y (2012) A rough margin-based linear ν support vector regression. Statistics & Probability Letters 82(3):528–534
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Gupta, U., Gupta, D. An improved regularization based Lagrangian asymmetric ν-twin support vector regression using pinball loss function. Appl Intell 49, 3606–3627 (2019). https://doi.org/10.1007/s10489-019-01465-w
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-019-01465-w