
Abstract
This study aims to investigate the performances of different training algorithms used for an artificial neural network (ANN) method to produce landslide susceptibility maps. For this purpose, Ovacık region (southeast of Karabük Province), located in the Western Black Sea Region (Turkey), was selected as the study area. A total of 196 landslides were mapped, and a landslide database was prepared. Topographical elevation, slope angle, aspect, wetness index, lithology, and vegetation index parameters were taken into account for the landslide susceptibility analyses. Two different ANN structures, which were composed of single and double hidden layers, were applied to compare the effects of the ANN. Four different training algorithms, namely batch back-propagation, quick propagation, conjugate gradient descent (CGD), and Levenberg–Marquardt, were used for the training stage of the ANN models. Thus, eight different landslide susceptibility maps were produced for the study area using different ANN structures and algorithms. In order to assess the effects and spatial performances of the considered training algorithms on the ANN models, the relative operating characteristics (ROC) and relation value (rij) approaches were used. The susceptibility map produced by CGD1 has the highest AUC (0.817) and rij values (0.972). Comparison of the susceptibility maps indicated that CGD training algorithm is the slowest one among the other algorithms, but this algorithm showed the highest performance on the results.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Landslides are amongst the most damaging natural hazards, and the frequency of their occurrences seems to be on the rise throughout the world. The main reasons for the increase in landslide occurrences are growing instability as a result of the destruction of forests, urbanization due to population growth, and uncontrolled land use in addition to climatic changes and extreme weather conditions (Nadim et al. 2006). Based on the criticism raised by Nadim et al. (2006), the most striking regions with high landslide hazard South America, northwest United States and Canada, the Caucasus region, Iran, Turkey, the Himalayas, the Philippines, Indonesia, Japan, and New Zealand. It is clearly observed that the mountainous areas and northern region of Turkey, which also includes the study area, is located in high and very high landslide hazard regions according to Nadim et al.'s (2006) assessments. Considering these cases, use of landslide susceptibility maps for land use and regional planning purposes has been increased during recent decades by local authorities and governmental agencies. Landslide susceptibility maps are useful tools to specify regions with high potential to suffer from the possible damage from landslides (Ayalew et al. 2005; Begueira 2006; Guzzetti et al. 2006; Van Den Eeckhaut and Hervás 2012; Conforti et al. 2014). The process of landslide susceptibility mapping includes several qualitative and quantitative approaches (Sooters and Van Westen 1996; Aleotti and Chowdhury 1999; Fell et al. 2008). Qualitative methods are based on the subjective judgement of an expert opinion, conversely the quantitative methods reduce the subjectivity of the qualitative approaches. Quantitative methods involve some techniques such as statistical, deterministic, probabilistic, fuzzy logic, decision tree, and artificial neural network analyses. The landslide literature reveals that a quantitative ANN method has been succesfully used in a considerable number of landslide susceptibility mapping studies (Table 1) (e.g. Lee et al. 2003, 2004; Ermini et al. 2005; Ercanoglu 2005; Gomez and Kavzoglu 2005; Yesilnacar and Topal 2005; Kanungo et al. 2006; Pradhan and Lee 2007; Yilmaz 2009a, b; Kawabata and Bandidas 2009; Yilmaz 2010; Choi et al. 2012; Li et al. 2012; Bui et al. 2012; Das et al. 2013; Ramakrishnan et al. 2013; Park et al. 2013; Wu et al. 2013; Zare et al. 2013; Conforti et al. 2014; Alimohammadlou et al. 2014, Chen et al. 2015; Romer and Ferentinou 2016; Arnone et al. 2016). There are several ANN training algorithms in the literature, such as batch back-propagation (BBP), quick propagation (QP), conjugate gradient descent (CGD), Levenberg–Marquardt (LM), probabilistic neural network (PNN), multi-layered perception (MLP), error back-propagation (EBP), radial basic funcion (RBF). Of these, the BBP algorithm has more commonly been used for the training stage of ANN in landslide susceptibility mapping studies among scientists (see Table 1). The Levenberg–Marquardt (LM) algorithm takes the second place in terms of number of uses. In the literature, a single hidden layered ANN structure was mostly used in the susceptibility mapping studies, while on the other hand, two hidden layer network models and comparison of the training algorithms were rare in such studies. This issue can be considered one of the most important aspects of this study. The main purpose of this study is to assess the landslide susceptibility of the selected study area and to compare the different training algorithms of ANN approach such as batch back-propagation (BBP), quick propagation (QP), conjugate gradient descent (CGD), and Levenberg–Marquardt (LM) with different ANN structures.
Study area
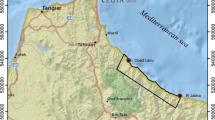
The study area is located in the southeast of Karabuk Province, the Western Black Sea region of Turkey between N4540000-4550000/E480000-500000 coordinates of 36. UTM zone (Fig. 1). It covers an area of 200 km2. The most important centre of population located in the study area is the Ovacık district. The area represents semi-mountainous characteristics with elevations ranging from 455 to 1447 m a.s.l. and the slope angles varying between 0° and 45° with an average approximate value of 17°. The most significant elevations in the study area are Kıraç Hill (1447 m), Aktaserenler Hill (1442 m), Nisancalisi Hill (1394 m), Ucoluk Hill (1378 m), Mantarlik Hill (1340 m), and Asarindoruk Hill (1328 m). The most important rivers coming from the north of the Ovacık district are the Bagirsak and Koltuk streams. Throughout the study area, slope aspect trends are generally in the southerly direction. Typical Black Sea climate with sudden and heavy rains is dominant in the study area and the land use of the study area mainly comprises forests and coverage of farmlands, orchards, and settlement areas. In the study area, different rock groups, ranging from Lower Cretaceous to Quaternary ages, are outcropped. Most of the study area was covered by sandstones, shale, conglomerates at the base and limestone alternations with flysch character. This unit is known in the region as Ulus Formation, which is weak and exposed to heavy weathering process. A detailed description of the lithological units observed in the study area was given in the “landslide conditioning parameters” section.

Location map of the study area
Database preparation
Preparation of the landslide inventory map and database is the crucial point of any landslide assessment. The necessary attention should be paid to this stage to produce reliable landslide susceptibility, hazard, or risk maps since this stage directly affects the results of the assessments. In addition, selection of the conditioning parameters is also a significant issue. This selection depends usually upon experience, size of the area, time, scale, landslide type, methodology to be applied, project budget, data availability, and reliability (Glade and Crozier 2005). As mentioned before, in this study, a total of six parameters (lithology, slope, aspect, topographical elevation, wetness index, and NDVI) were considered the conditioning parameters for the landslide susceptibility analyses. This procedure is mainly related to the regional characteristic(s) and mechanism(s) of the landslides and experience of the scientists. Thus, no parameter selection method was applied in this study, and these parameters were selected based on the relationship between the input parameters and landslide occurrences in the study area. In other words, the selected parameters in this study were considered more effective based on the field observations and our experience. All parameter maps were prepared in a GIS platform (ArcGIS version 10.3) with a raster format of 25 m × 25 m resolution, including a total of 3,20,000 pixels. Of these, 31,846 pixels (approximately 9.9% of the study area) were in the landslided areas, while the other 2,88,154 pixels were no landslided locations in the study area. Preparation of the landslide inventory and the other parameter maps are explained in the following sections.
Landslide inventory
Preparation of the landslide inventory map is a fundamental procedure for any landslide analysis based on a GIS environment (Lan et al. 2004). This stage is one of the most important evaluation criteria which includes the necessary basic information and landslide features for the production of landslide susceptibility, hazard, and risk maps. In the study area, a total of 196 landslides were mapped at 1:25,000 scale using detailed field works and aerial photography interpretations (Fig. 2). The smallest landslide covers an area of 12,210 m2, while the largest corresponds to an area of 8,01,902 m2. Additionally, the mean value of the landslide area for 196 failures in the study area is 1,01,500 m2. The landslides identified in the study area were classified as rotational earth slides and complex landslides (including at least two different types, namely earth flow and earth slide, in the study area) according to Varnes's (1978) landslide classification system. They frequently occur in the weathering zone of the rock units in the study area. The landslide inventory map is shown in Fig. 2. Some descriptive statistics of the considered parameters in landslided areas and in the overall study area are presented in Table 2. In addition, some landslide photographs taken from the study area are shown in Fig. 3a–d.

Landslide inventory map of the study area

a–d Field photos showing landslides and their sliding directions in the study area
In order to perform landslide susceptibility analyses, the landslide database was obtained with the aid of GIS applications for landslided and non-landslided pixels in the study area. In addition, 75% of the overall data (i.e. 2,40,000 pixels) were randomly extracted for the analysis stage, while the left part (i.e. 80,000 pixels) was used for the validation stage of the produced landslide susceptibility maps. In the landslide literature, there are some studies considering both the sampling strategies (e.g. seed cell, point, scarp sampling) and producing of landslide susceptibility maps together (e.g. Suzen and Doyuran 2004; Guzzetti et al. 2006; Gorum et al. 2008; Nefeslioglu et al. 2008; Yılmaz 2010; Hasekiogullari and Ercanoglu 2012; Dagdelenler et al. 2015; Ercanoglu et al. 2016). Of these, scarp sampling strategy was preferred to obtain landslide database (totally 392 points: 196 from landslide locations, 196 from no landslide locations).
Landslide conditioning parameters
In the susceptibility mapping analyses, it is very important to select the landslide conditioning parameters effectively. In this study, the conditioning parameters were considered under three main headings as suggested by Aleotti and Chowdhury (1999): (1) topographical parameters derived from DEM (such as topographical elevation, slope, aspect, and wetness index), (2) geological parameters (such as lithology), gathered from MTA (General Directorate of Mineral Research and Exploration) (2002), (3) environmental parameters (such as normalized difference vegetation index). Firstly, the digital elevation model (DEM) of the study area was produced by using ArcGIS 10.3 software with a spatial resolution of 25 m × 25 m pixel size. Topographical parameters were produced by using the Spatial Analyst Tool of the considered software. When the parameters derived from the DEM were examined, the topographical elevation values vary between 455.4 and 1447.4 m a.s.l. in the study area (Fig. 4a). It was clearly seen that the landslides in the study area tend to occur in the lower altitudes. The second considered parameter in this study was slope. The slope values change in the range from 0° to 45.8° (Fig. 4b). The third and the fourth parameters derived from DEM were aspect (Fig. 4c) and wetness index (Fig. 4d). The landslides were approximately occurred in the southeast-facing slopes in the study area. The wetness index values were extracted by using the equation below:

Input parameter maps of the study area: a topographical elevation; b slope; c aspect; d wetness index; e lithology; and f NDVI
where a is the local upslope area draining through a certain point per unit contour length and tanβ is the local slope) proposed by Beven and Kirkby (1979). The minimum and maximum values of wetness index were obtained as 0 and 20.5 in the study area, respectively.
The geological parameter taken into account in this study was the lithology. Although there are some other geological parameters used in the landslide literature such as distance to faults or lineaments, weathering conditions, and so on for producing landslide susceptibility maps, it was observed that there was no relationship between the landslide occurrence and any other geological parameter. Since the lithology is a very important parameter for landslide initiation and affects the mechanism of the landslides, this parameter was selected as an input for the analyses. According to the lithological map gathered from MTA (2002) with the scale of 1/25,000, there are nine different lithological units in the study area (Fig. 4e). Landslides in the study area were mostly located in the Ulus Formation (Ku) at which the landslides frequently occur in the Western Black Sea region of Turkey (Fig. 4e). Ulus Formation (Ku) is usually composed of a sandy limestone interlayer, grayish green, gray, and black colored sandstone, shale, marl, limestones, and conglomerates at the base. The Abant formation (ktab), covering a small portion of the study area in the southeast direction, consists of blocky conglomerate, sandstone, silt, and marble. The age of this formation is Upper Campanian-Lower Eocene (Timur and Aksay 2002). Another formation observed in the study area is Kışlaköy formation (tek). At the base of this formation consists of red, yellow, and green colored conglomerates. Claystone, siltstone, and marl units come gradually upon this level. Red colored sandstones, conglomerates, and mudstones are located at the top of this formation, as shown in (Fig. 4e). The Safranbolu formation (tes) begins with a very fine conglomerate-sandstone level at the bottom and passes through carbonated sandstone, sandy limestone, and limestone towards the upper level. The Çeçen member (tekaç) is composed of green conglomerate, sandstone, siltstone, and mudstone aggradation, while the Karabük formation (teka) mostly consists of marl, upward claystone, and sandstone aggradation. Middle Eocene thick-bedded limestones are defined as Soğanlı formation (Teso), and this unit is completely represented by limestones. The other formation observed in the study area is Akçapınar Formation (tea), and it is characterized by white, yellowish gray colored, clayey limestone, dolomitic limestone, and chert bands. Finally, alluviums observed in the river beds in the study area are composed of gravel, sand, and mud deposits. The last parameter used in this study was normalized difference vegetation index (NDVI). The NDVI parameter was selected to reflect the vegetation cover relation with the landslide occurrences. Many years before, most of the study area was covered by forests, but today and in the recent past it is mainly used for agricultural and settlement purposes. The NDVI map of the study area was created by using Landsat ETM + satellite image of the year 2000, which was the same date of the topographical maps used in data preparation stage. NDVI is an index derived from reflectance measurements in the red and near-infrared portions of the electromagnetic spectrum describing the relative amount of photosynthetically active green biomass present at the time of imagery. It is calculated by the equation below:
where IR infrared portion of the electromagnetic spectrum, R red portion of the electromagnetic spectrum. Thus, red and infrared bands of the Landsat ETM + satellite image of the study area was used to produce NDVI map (Fig. 4f). The minimum and the maximum ranges for this parameter were calculated as −0.49 and 0.65, which shows the negative values show no or low vegetation, while the higher values represent the healthy vegetation.
Artificial neural network (ANN) analyses
After the first modelling of neurons was devised by McCulloch and Pitts (1943) and the first training algorithm was proposed by Rosenblatt (1958), artificial neural networks have been widely used for pattern recognition and classification problems. For training the ANN, the most suitable algorithm must be chosen for the right type of the problem. Since it was shown that the error back-propagation algorithm proposed by Rumelhart et al. (1985) trained the neural networks effectively, many training algorithms have been developed. Batch back-propagation (BBP), quick Propagation (QP), conjugate gradient descent (CGD), and Levenberg–Marquardt (LM) training algorithms, the most common approaches used in the training stage of multi-layered networks, were considered in this study. The batch back-propagation (BBP) algorithm is one of the most commonly used training techniques (see Table 1) that guarantees convergence only to a local minimum of the error function to train the ANN (Hagan et al. 1996). In general, the purpose of a BBP algorithm is to learn the specific relationship between the input (w) and output (u) pairs by setting the weights (Ding and Matthews, 2009). These weights are set with the “gradient descent” rule and the error (E) is minimized. In the BBP algorithm, each network is evaluated to obtain a derivative and summed to obtain the total derivative (Table 3). In order to save space, only the simple network weight calculation equations of the considered algorithms are presented in Table 3. The details can be found in the literature mentioned in this section. The quick propagation (QP) algorithm is a variation of the back propagation (BP) algorithm developed by Fahlman (1988). Because the QP algorithm is defined as an intuitive modification of the BP algorithm in the literature, many researchers prefer the BBP training algorithm rather than using QP. The QP algorithm calculates the value of \(\partial {\text{E }}/\partial {\text{w}}\) at the update of the weights as in the case of the BP algorithm, but the QP uses a second-order equation associated with the Newtonian method instead of the simple “gradient descent”. The QP algorithm is one of the best algorithms for solving the scale problem of the BP algorithm and also it is faster than BP in solving many problems (Rumelhart et al. 1985; Sejnowski and Rosenberg 1987). The other training algorithm used in this study was the conjugate gradient descent (CGD) algorithm. It was developed by Hestenes and Stiefel (1952). In the CGD algorithm, the weights are updated by the optimal distance (learning rate; αk) during the current search direction (Ding and Matthews 2009) (Table 3). The reason some researchers choose this algorithm in their studies is that it gives more accurate and reliable results than BBP and also it is very efficient in the training of large scale neural networks (Shanthi et al. 2009). The Levenberg–Marquardt (LM) algorithm developed by Kenneth Levenberg and Donald Marquardt, is a combination of the features of gradient descent found in back propagation and the Newton method (Hagan and Menhaj 1994). It is a nonlinear optimization algorithm based on the usage of second-order derivatives. The LM algorithm goes between Gauss–Newton and steepest-descent algorithms during network training. Gauss–Newton is used when μ is close to zero, and steepest-descent is used when μ is large. When the coupling coefficient μ is too large, it can be interpreted as the learning coefficient in the steepest-descent algorithm. The Jacobian matrix is used to reduce the base of the calculation process and is helpful for simplifying the equation in the calculation phase of the algorithm. The Levenberg–Marquardt algorithm does not take into account the learning rate and the momentum factor (Kanungo et al. 2006). Although it provides good and fast performance in terms of training time, it cannot always be preferred because it can only be used for multi-layered neural networks.
BBP, QP, CGD, and LM algorithm applications were performed by using Alyuda Neuro Intelligence 2.3 computer code in this study.
Landslide susceptibility maps of the study area were created by using these four ANN training algorithms, which were structured by one and two hidden layers. Afterwards, the performance of the susceptibility maps created by one and two hidden layered training ANN algorithms were compared. Considering these ANN structures and training algorithms, landslide susceptibility maps were produced. The aim was to evaluate the best ANN structure and training algorithm that represents the best performance with respect to landslide susceptibility analyses. In line with this purpose, the steps of this stage of the study can be summarized as (1) the preparation of the parameter maps, (2) the creation of the data sets, (3) the creation of the ANN models, (4) the production of the final susceptibility maps, and (5) the validation of the so produced landslide susceptibility maps.
Design of ANN
In the ANN design stage, first, the ratio of training, testing, and validating data sets, number of neurons in the hidden layer, activation function, learning rate, momentum rate, iteration number, and mean square error (MSE) values should be determined. In the first step of ANN design, it is necessary to prepare data sets for training the network. The data sets representing landslided and non-landslided areas contain six inputs, namely topographical elevation, slope, aspect, lithology, wetness index, and NDVI. As mentioned before, 196 points taken from the scarp zone of the mapped landslides corresponding to the same number of points were randomly selected from non-landslided areas, and a total of 392 points were obtained. In this study, training, testing, and validation data sets were randomly selected from the data sets used in the susceptibility analyses by using Alyuda Neuro Intelligence (2.3). Sixty-eight percent of the parent database was separated as a training data set, 16% as a testing data set, and 16% as a validating data set for testing network performance. At the beginning of ANN design, the number of hidden layers and the number of neurons per layer were determined. Generally, in the literature it has been pointed out that networks designed by one or two hidden layers perform well, but use of more than two hidden layers may cause overestimation of the results and can be considered a time consuming process (Lippmann 1987; Rumelhart et al. 1985; Yesilnacar and Topal 2005). In other words, the increase in the number of hidden layers can lead to incorrect estimation of the network and calculation period. For this reason, ANN structures used in the study were limited to two hidden layers. To determine the best ANN structure with one hidden layer, the network structure was proposed as 6-13-1 with the lowest error values, AIC (Akaike Information Criterion), etc. by the program (Fig. 5a). Likewise, for the two hidden layers, the best ANN structure emerged as 6-11-6-1 for the data sets (Fig. 5b).

ANN structures used in the study: a one hidden layer and b two hidden layers
In the design of ANN, several activation functions, namely linear, threshold, sinusoidal, hyperbolic tangent, and sigmoid are used as the activation function in the literature. In this study, a sigmoid (logistic) function was chosen, which produces a value between zero and one for each of the input values.
The learning rate, which is an important parameter influencing the convergence of the model, was chosen as 0.1 in the BBP and QP training algorithms. In the CGD and LM training algorithms, this rate was not taken into consideration. In fact, there is not a general rule to choose a correct or suitable learning rate, and it is selected experimentally for each particular problem (Yesilnacar and Topal 2005). The learning rate must be small to avoid skipping gaps and for oscillation problems (Nauck et al. 1997). The completion process of the ANN learning phase is determined by iteration number and MSE value. In this study, several iterations were tested, and 30,000 iterations were found to be the best for each training algorithms. The last parameter that plays an important role in ANN design is a mean square error (MSE) value. The closeness of the MSE value to zero indicates a good relationship between the targeted and predicted values. Until the specified value of MSE is obtained, the network’s training phase continues. By using the current MSE equation in the literature, the MSE value was selected as 0.001 in this study.
Landslide susceptibility mapping using training algorithms
In this study, which aims to evaluate the performance of four different training algorithms and two different ANN structures, a total of eight ANN models were created for each training algorithm. According to the number of hidden layers and training algorithms, these ANN models were named BBP1, QP1, CGD1, LM1 for the one hidden layer model, and BBP2, QP2, CGD2, and LM2 for the two hidden layer model. Using these four training algorithms in two different network structures (one and two hidden layers), final landslide susceptibility maps were obtained from a total of eight different ANN models (Fig. 6). These eight susceptibility maps were classified individually into five susceptibility classes as “very low”, “low”, “medium”, “high”, and “very high” based on equal intervals between maximum and minimum values (Fig. 6).

Landslide susceptibility maps of BBP, QP, CGD, and LM training algorithms with one and two hidden layers
Validation of landslide susceptibility maps
The landslide susceptibility maps of four different training algorithms were validated using the ROC curve method. This method is a very functional method for measuring the quality of deterministic and probabilistic detection and forecast systems (Sweet 1988). ROC curves plot the sensitivity counter to the specificity, where the specificity is the proportion of grid cells outside a mapped landslide that are correctly classified as stable, and the sensitivity is the proportion of correctly classified known landslide grid cells that are unstable (Sweet 1988; Lasko et al. 2005; Begueira 2006). The area under the curve (AUC) value is one of the most commonly used indicators for predicting models in natural hazard assessments (Begueira 2006). The maximum value of AUC is 1, meaning perfect prediction, while the minimum value is 0.5, meaning that the relationship is a random assignment and/or gathered by chance. AUC values are calculated with the following formula:
where n is the number of threshold value; for i threshold value xi is the proportion of false positive values of pixels showing landslide presence in landslide areas; yi value is the proportion of true positivity values of landslide areas showing landslide presence. ROC analyses for each ANN model were performed in the SPSS (ver. 20) computer code. ROC curves of each ANN model were plotted, and area under the curve (AUC) values were determined for eight ANN models (Table 4). AUC values seen in Table 4 showed that the ROC curve estimated for the CGD algorithm with one hidden layer was higher than the other training algorithms (AUC value of CGD1 is 0.817, and the QP algorithm with one single hidden layer took the second place following the value of CGD1 (see Table 4). As a second approach to evaluate the performance of ANN models, the rij values, which express the relationship between the existing and predicted values used in binary data comparison in fuzzy logic, were calculated. The relation value rij is calculated by evaluating the binary memberships (xi and xj) in the m = 2 dimensional space of the cosine-amplitude function (Ercanoglu 2005). The range of these values varies from 0 to 1 (0 ≤ rij ≤ 1), and the values close to 0 indicate that relationship between the two groups of data is weak, while close values to 1 express a good relationship (Ross 1995). The rij values of the models were calculated by the equation below and summarized in Table 4.
Results and conclusions
In this study, a total of 196 landslides were mapped through field studies and aerial photograph interpretations, and thus a landslide inventory map of the study area was created. The mapped landslides covered approximately 9.9% of the 200 km2 study area. Landslide susceptibility maps of the study area were prepared by using four different training algorithms (BBP, QP, CGD, and LM) with two different structures for ANN analyses. In landslide susceptibility analyses, topographical elevation, slope, aspect, wetness index, lithology, and NDVI parameters were used as input parameters. It was determined that landslides in the study area mostly occurred in the Ulus formation, in the lower elevations and slopes, in the southeastern-facing slopes, in the range of 0–0.3 NDVI value, and the wetness index value ranged from 4 to 8. In order to compare the effects of the ANN models trained by using four different training algorithms on the final resultant maps, firstly, characterization of the appropriate artificial neural network was conducted, and two different structured networks with one and two hidden layers were designed. A total of eight ANN models were created by using four different training algorithms. The results used to compare the performances of these training algorithms in the ANN models were summarized in Tables 4 and 5. In Table 5, it can be concluded that the Levenberg–Marquardt (LM) algorithm is the fastest performing algorithm with respect to the training duration. On the other hand, the slowest algorithm in terms of training duration is the CGD1 algorithm. In addition, models with two hidden layer network structure except for CGD2, the training duration depending on the decrease in training rates was observed to increase. This was because the CGD2 model reached the desired MSE value in a short time.
A total of eight different landslide susceptibility maps were obtained from single hidden and two hidden layer ANN models. The maps were classified into five different landslide susceptibility classes as “very low”, “low”, “medium”, “high”, and “very high”. In order to compare the performances of the maps produced by the ANN method with four different training algorithms, AUC and rij values were calculated. According to the results, it is concluded that AUC and rij values of all models were very close to each other. If comparisons are made according to AUC values, the BBP1 was better than the BBP2, QP2 was better than QP1, CGD1 was better than CGD2, and LM1 was better than LM2. Likewise, if rij values are compared, models with a single hidden layer network for all algorithms performed better than network models with two hidden layers. As a result, taking into consideration all these performance indicators, it was determined that the map with the highest performance representing the existing landslides is the landslide susceptibility map generated by the CGD1 model. Although CGD algorithm is slower than the others, it was interpreted as an algorithm that produces the best results in terms of prediction success. LM algorithm is the fastest ANN algorithm among the other tested algorithms and its prediction performance was as good as the BBP and QP algorithms. In line with this conclusion, the LM algorithm is preferred for the training stage of ANN in producing landslide susceptibility maps in order to save time.
References
Aleotti P, Chowdhury R (1999) Landslide hazard assessment: summery review and new perspective. Bull Eng Geol Env 58(1):28–44
Alimohammadlou Y, Najafi A, Gokceoglu C (2014) Estimation of rainfall-induced landslides using ANN and fuzzy clustering methods: a case study in Saeen Slope, Azerbaijan province, Iran. Catena 120:149–162
Arnone E, Francipane A, Scarbaci A, Puglisi C, Noto LV (2016) Effect of raster resolution and polygon-conversion algorithm on landslide susceptibility mapping. Env Model and Software 84:467–481
Ayalew L, Yamagishi H, Marui H, Kanno T (2005) Landslides in Sado Island of Japan: part II. GIS-based susceptibility mapping with comparisons of results from two methods and verifications. Eng Geol 81(4):432–445
Begueira S (2006) Validation and evaluation of predictive models in hazard assessment and risk management. Nat Haz 37:315–329
Beven KJ, Kirkby MJ (1979) A physically based, variable contributing area model of basin hydrology. Hydrol Sci Bull 24:43–69
Bui DT, Pradhan B, Lofman O, Revhaug I, Dick OB (2012) Landslide susceptibility assessment in the Hoa Binh province of Vietnam: a comparison of the Levenberg–Marquardt and Bayesian regularized neural networks. Geomorphology 171–172:12–29
Chen J, Zenga Z, Jiang P, Tang H (2015) Deformation prediction of landslide based on functional network. Neurocomputing 149:151–157
Choi J, Oh H, Won J, Lee S (2010) Validation of an artificial neural network model for landslide susceptibility mapping. Env Earth Sci 60:473–483
Choi J, Oh H-J, Lee H-J, Lee C, Lee S (2012) Combining landslide susceptibility maps obtained from frequency ratio, logistic regression, and artificial neural network models using ASTER images and GIS. Eng Geol 124:12–23
Conforti M, Pascale S, Robustelli G, Sdao F (2014) Evaluation of prediction capability of the artificial neural networks for mapping landslide susceptibility in the Turbolo River catchment (northern Calabria, Italy). CATENA 113:236–250
Dagdelenler G, Nefeslioglı HA, Gokceoglu C (2015) Modification of seed cell sampling strategy for landslide susceptibility mapping: an application from the Eastern part of the Gallipoli Peninsula (Canakkale, Turkey). Bull Eng Geol Env 75:575–590
Das HO, Sonmez H, Gokceoglu C, Nefeslioglu HA (2013) Influence of seismic acceleration on landslide susceptibility maps: a case study from NE Turkey (the Kelkit Valley). Landslides 10:433–454
Ding L, Matthews J (2009) A contemporary study into the application of neural network techniques employed to automate CAD/CAM integration for 130 die manufacture. Comput Ind Eng 57:1457–1471
Ercanoglu M (2005) Landslide susceptibility assessment of SE Bartin (West Black Sea region, Turkey) by artificial neural networks. Nat Haz Earth Sys Sci 5:979–992
Ercanoglu M, Dagdelenler G, Ozsayın E, Alkevli T, Sonmez H, Ozyurt NN, Kahraman B, Ucar İ, Cetinkaya S (2016) Application of Chebyshev theorem to data preparation in landslide susceptibility mapping studies: an example from Yenice (Karabuk, Turkey) region. J Mt Sci 13(11):1923–1940
Ermini L, Catani F, Casagli N (2005) Artificial Neural Networks applied to landslide susceptibility assessment. Geomorphology 66:327–343
Fahlman SE (1988) Faster-Learning Variations on Back-Propagation: An Empirical Study. In Proceedings of the 1988 Connectionist Models Summer School, Morgan Kaufmann, pp 1–17
Fell R, Corominas J, Bonnard C, Cascini L, Leroi E, Savage WZ (2008) Guidelines for landslide susceptibility, hazard and risk zoning for land-use planning. Eng Geol 102:99–111
García-Rodríguez MJ, Malpica JA (2010) Assessment of earthquake-triggered landslide susceptibility in El Salvador based on an artificial neural network model. Nat Haz Earth Sys Sci 10:1307–1315
Glade T, Crozier MJ (2005) Landslide hazard and risk—Concluding comment and perspectives. In: Glade T, Anderson M, Crozier M (eds) Landslide hazard and risk. Wiley, Chichester, pp 767–774
Gomez H, Kavzoglu T (2005) Assessment of shallow landslide susceptibility using artificial neural networks in Jabonosa River Basin, Venezuela. Eng Geol 78:11–27
Gorum T, Gonencgil B, Gokceoglu C, Nefeslioglu H (2008) Implementation of reconstructed geomorphologic units in landslide susceptibility mapping: the Melen Gorge (NW Turkey). Nat Haz 46(3):323–351
Guzzetti F, Reichenbach P, Ardizzonne F, Cardinali M, Galli M (2006) Estimating the quality of landslide susceptibility models. Geomorphology 81:166–184
Hagan MT, Menhaj MB (1994) Training feedforward networks with the Marquardt algorithm. IEEE Trans Neural Netw 5:989–993
Hagan MT, Demuth HB, Beale MH (1996) Neural network design. PWS, Boston
Hasekiogullari GD, Ercanoglu M (2012) A new approach to use AHP in landslide susceptibility mapping: a case study at Yenice (Karabuk, NW Turkey). Nat Haz 63:1157–1179
Hestenes MR, Stiefel E (1952) Methods of conjugate gradients for solving linear systems. J Res Natl Bur Stand 49:2379
Kanungo D, Arora M, Sarkar S, Gupta R (2006) A comparative study of conventional, ANN black box, fuzzy and combined neural and fuzzy weighting procedures for landslide susceptibility zonation in Darjeeling. Eng Geol 85:347–366
Kawabata D, Bandidas J (2009) Landslide susceptibility mapping using geological data, a DEM from ASTER images and an Artificial Neural Network (ANN). Geomorphology 113:97–109
Lan HX, Zhou CH, Wang LJ, Zhang HY, Li RH (2004) Landslide hazard spatial analysis and prediction using GIS in the Xiaojiang watershed, Yunnan, China. Engineering Geology 76(1–2):109–128
Lasko TA, Bhagwat JG, Zou KH, Ohno-Machado L (2005) The use of receiver operating characteristic curves in biomedical informatics. J Biomed Inform 38(5):404–415
Lee CF, Ye H, Yeung MR, Shan X, Chen G (2001) AIGIS-based methodology for natural terrain landslide susceptibility mapping in Hong Kong. Episodes 24(3)
Lee S, Ryu J-H, Min K, Won J-S (2003) Landslide susceptibility analysis using GIS and artificial neural network. Earth Surf Proc Landf 28:1361–1376
Lee S, Ryu J-H, Min K, Won J-S, Park H-J (2004) Determination and application of the weights for landslide susceptibility mapping using an artificial neural network. Eng Geol 71:289–302
Li Y, Chen G, Zhou G, Zheng I (2012) Rainfall and earthquake-induced landslide susceptibility assessment using GIS and Artificial Neural Network. Nat Haz Earth Syst Sci 12:2719–2729
Lippmann R (1987) An introduction to computing with neural nets. ASSP Mag, IEEE
McCulloch WS, Pitts W (1990) A logical calculus of the ideas immanent in nervous activity. Bull Math Biol 52(1/2):99–115
MTA (2002) Geological map of Turkey. General directorate of mineral research and exploration, Ankara
Nadim F, Kjekstad O, Peduzzi P, Herold C, Jaedicke C (2006) Global landslide and avalanche hotspots. Landslides 3(2):159–174
Nauck D, Klawonn F, Kruse R (1997) Foundations of neuro-fuzzy systems. Wiley, New York. ISBN 0471971510
Nefeslioglu HA, Gokceoglu C, Sonmez H (2008) An assessment on the use of logistic regression and artificial neural networks with different sampling strategies for the preparation of landslide susceptibility maps. Eng Geol 97(3/4):171–191
Park S, Choi C, Kim B, Kim J (2013) Landslide susceptibility mapping using frequency ratio, analytic hierarchy process, logistic regression, and artificial neural network methods at the Inje area, Korea. Env Earth Sci 68:1443–1464
Pradhan B, Lee S (2007) Utilization of optical remote sensing data and GIS tools for regional landslide hazard analysis by using an artificial neural network model. Earth Sci Front 14(6):143–152
Pradhan B, Lee S, Buchroithnera MF (2010) A GIS-based back-propagation neural network model and its cross-application and validation for landslide susceptibility analyses. Comput Environ Urban Syst 34:216–235
Ramakrishnan D, Singh TN, Verma AK, Gulati A, Tiwari KC (2013) Soft computing and GIS for landslide susceptibility assessment in Tawaghat area, Kumaon Himalaya, India. Nat Haz 65:315–330
Romer C, Ferentinou M (2016) Shallow landslide susceptibility assessment in a semiarid environment- A Quaternary catchment of KwaZulu-Natal, South Africa. Eng Geol 201:29–44
Rosenblatt F (1958) Theperceptron: aprobabilistic model for information storage and organization in the brain. Psychol Rev 6:386–408
Ross TJ (1995) Fuzzy logic with engineering applications. Mc-Graw-Hill, New Mexico
Rumelhart D, Hinton G, Williams R (1985) Learning internal representations by error propagation. ICS Report 8506
Sejnowski T, Rosenberg C (1987) Parallel networks that learn to pronounce English text. Comp Syst 1(1):145–168
Shanthi D, Sahoo G, Saravanan N (2009) Evolving connection weights of artificial neural networks using genetic algorithm with application to the prediction of stroke disease. Int J Soft Comput 4:95–102
Sooters R, Van Westen CJ (1996) Slope stability recognition analysis and zonation. In: Turner AK, Schuster RI (eds) Landslides: investigation and mitigation, transportation research board special report 247. National Academy Press Washington DC 129–177 pp
Suzen ML, Doyuran V (2004) Data driven bivariate landslide susceptibility assessment using geographical information systems: a method and application to Asarsuyu catchment, Turkey. Eng Geol 71:303–321
Sweet JA (1988) Measuring the accuracy of diagnostic systems. Science 240:1285–1293
Timur E, Aksay A (2002) 1/100.000 scaled geological maps of Turkey, Zonguldak F29 Quadrangle. MTA Institution Publication
Van Den Eeckhaut M, Hervás J (2012) State of the art of national landslide databases in Europe and their potential for assessing landslide susceptibility, hazard and risk. Geomorphology 139–140:545–558
Varnes DJ (1978) Slope movement, types and processes. In: Schuster RL, Krizek RJ (eds) Landslides, analysis and control, special report 176: Transportaion research board. National Academy of Sciences, Washington DC, pp 11–33
Wu X, Niu R, Ren F, Peng L (2013) Landslide susceptibility mapping using rough sets and backpropagation neural networks in the Three Gorges, China. Env Earth Sci 70:1307–1318
Yesilnacar E, Topal T (2005) Landslide susceptibility mapping: a comparison of logistic regression and neural networks methods in a medium scale study, Hendek region (Turkey). Eng Geol 79:251–266
Yilmaz I (2009a) Landslide susceptibility mapping using frequency ratio, logistic regression, artificial neural networks and their comparison: a case study from Kat landslides (Tokat-Turkey). Comp and Geosci 35:1125–1138
Yilmaz I (2009b) Comparison of landslide susceptibility mapping methodologies for Koyulhisar, Turkey: conditional probability, logistic regression, artificial neural networks, and support vector machine. Env Earth Sci 61:821–883
Yilmaz I (2010) The effect of the sampling strategies on the landslide susceptibility mapping by conditional probability and artificial neural networks. Env Earth Sci 60:505–519
Zare M, Pourghasemi HR, Vafakhah M, Pradhan B (2013) Landslide susceptibility mapping at Vaz Watershed (Iran) using an artificial neural network model: a comparison between multilayer perceptron (MLP) and radial basic function (RBF) algorithms. Arab J Geosci 6:2873–2888
Acknowledgements
This research was supported by Hacettepe University Scientific Researches Coordination Section (Project No: 735). The authors would also like to thank Mr. Alphan Haktanır and Mr. Arda Öncü for their logistic support during the field studies.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Can, A., Dagdelenler, G., Ercanoglu, M. et al. Landslide susceptibility mapping at Ovacık-Karabük (Turkey) using different artificial neural network models: comparison of training algorithms. Bull Eng Geol Environ 78, 89–102 (2019). https://doi.org/10.1007/s10064-017-1034-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10064-017-1034-3