
Abstract
Landslide susceptibility and hazard assessments are the most important steps in landslide risk mapping. The main objective of this study was to investigate and compare the results of two artificial neural network (ANN) algorithms, i.e., multilayer perceptron (MLP) and radial basic function (RBF) for spatial prediction of landslide susceptibility in Vaz Watershed, Iran. At first, landslide locations were identified by aerial photographs and field surveys, and a total of 136 landside locations were constructed from various sources. Then the landslide inventory map was randomly split into a training dataset 70 % (95 landslide locations) for training the ANN model and the remaining 30 % (41 landslides locations) was used for validation purpose. Nine landslide conditioning factors such as slope, slope aspect, altitude, land use, lithology, distance from rivers, distance from roads, distance from faults, and rainfall were constructed in geographical information system. In this study, both MLP and RBF algorithms were used in artificial neural network model. The results showed that MLP with Broyden–Fletcher–Goldfarb–Shanno learning algorithm is more efficient than RBF in landslide susceptibility mapping for the study area. Finally the landslide susceptibility maps were validated using the validation data (i.e., 30 % landslide location data that was not used during the model construction) using area under the curve (AUC) method. The success rate curve showed that the area under the curve for RBF and MLP was 0.9085 (90.85 %) and 0.9193 (91.93 %) accuracy, respectively. Similarly, the validation result showed that the area under the curve for MLP and RBF models were 0.881 (88.1 %) and 0.8724 (87.24 %), respectively. The results of this study showed that landslide susceptibility mapping in the Vaz Watershed of Iran using the ANN approach is viable and can be used for land use planning.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Landslides represents approximately 9 % of the natural disasters occurred during the 1990s worldwide (Gomez and Kavzoglu 2005). This trend is expected to continue in the coming decades due to increasing urbanization and development, continuing deforestation and an increase in regional precipitation in landslide-prone areas due to changing climatic patterns (Yilmaz 2009a). Several factors play role in the occurrence of landslides. Primary causes of landslides could include a wide range of factors like slope, lithology, distance from roads (Dahal et al. 2008), land use and human activity (Zêzere et al. 1999). The identification of landslide-prone areas is essential for safer strategic planning for future developmental activities in the region. Therefore, landslide hazard assessment of an area is extremely important (Varnes 1984). Over the decades, landslide susceptibility and hazard assessment are in use (Fell et al. 2008). The landslide susceptibility modeling broadly falls into two main groups: qualitative and quantitative approaches. Generally, a qualitative approach is based on the subjective judgment of an expert or a group of experts, whereas the quantitative approach is based on mathematically rigorous objective methodologies (Neaupane and Achet 2004). During the recent decades, the use of landslide susceptibility and hazard maps for land use planning has increased significantly. These maps rank different sections of land surface according to the degree of actual or potential landslide hazard; thus, planners are able to choose favorable sites for urban and rural development. In recent years, the use of geographical information system (GIS) for landslide susceptibility modeling has been increasingly used. It is because of the development of commercial systems and the quick access to data obtained through global positioning systems and remote sensing techniques. Moreover, GIS is an excellent and useful tool for the spatial analysis of a multidimensional phenomenon such as landslide susceptibility mapping (Van Westen et al. 2003). Over the last decades, a number of different methods for landslide susceptibility mapping have been used and suggested. The process of creating these maps includes several qualitative or quantitative approaches (Soeters and Van Wsten 1994; Aleotti and Chowdhury 1999). Early attempts defined susceptibility classes by overlaying lithological and morphological slope attributes on landslide inventories (Nilsen et al. 1979). Many studies have been carried out on landslide hazard evaluation using GIS; for example, Guzzetti et al. (1999) summarized several landslide hazard evaluation studies. Recently, there have been studies on landslide susceptibility mapping using GIS, and many of these studies have applied probabilistic-based models (Gokceoglu et al. 2005; Lee and Sambath 2006; Akgun and Bulut 2007; Akgun et al. 2008; Akgun and Turk 2010; Pradhan et al. 2010; Pradhan and Youssef 2010; Yilmaz 2010a; Akgun 2011; Pourghasemi et al. 2012a, b, e). Logistic regression model, one of the most widely used statistical models, has also been employed for the purpose of landslide susceptibility mapping (Can et al. 2005; Duman et al. 2006; Gorsevski et al. 2006; Lee and Evangelista 2006; Nefeslioglu et al. 2008; Yilmaz 2009b; 2010b; Pradhan 2010; Chauhan et al. 2010; Bai et al. 2010; Pradhan 2011a, b; Akgun et al. 2011; Felicisimo et al. 2012; Lee et al. 2012; Oh et al. 2012). Data mining using fuzzy logic (Ercanoglu and Gokceoglu 2002, 2004; Champati Ray et al. 2007; Kanungo et al. 2008; Pradhan 2010; Akgun et al. 2012; Pourghasemi et al. 2012c), artificial neural networks (Ermini et al. 2005; Yilmaz 2009a; 2010a; Pradhan and Pirasteh 2010; Caniani et al. 2008; Pradhan and Lee 2010a, b, c; Pradhan and Buchroithner 2010; Akgun et al. 2011b; Song et al. 2012; Lee et al. 2012; Bui et al. 2012a), decision tree (Wan 2009; Saito et al. 2009; Akgun and Turk 2010; Nefeslioglu et al. 2010; Yeon et al. 2010; Gorsevski and Jankowski 2010), spatial multicriteria evaluation (Pourghasemi et al. 2012d), evidential belief functions (Althuwaynee et al. 2012; Bui et al. 2012b), support vector machine (Yao et al. 2008; Yilmaz 2010b; Marjanovic et al. 2011; Xu et al. 2012) and neuro-fuzzy (Kanungo et al. 2006; Lee et al. 2009; Pradhan and Lee 2010a; Vahidnia et al. 2010; Oh and Pradhan 2011; Sezer et al. 2011; Bui et al. 2011) models have also been applied using GIS. Preparation of landslide hazard assessment maps requires an evaluation of the relationships between various terrain conditions and landslide inventories. Therefore, an objective procedure is often desired to quantitatively support the landslide studies (Chauhan et al. 2010).
As it can be seen in the aforementioned literature, artificial neural networks have been widely used in landslide susceptibility assessment. An artificial neural network (ANN) is composed of a set of nodes and a number of interconnected processing elements. ANNs use learning algorithms to model knowledge and save this knowledge in weighted connections, mimicking the function of a human brain (Pradhan and Lee 2010b). They are considered as heuristic algorithms in the sense that they can learn from experience via samples and are subsequently applied to recognize new unseen data (Kavzoglu and Mather 2000). The parallel distribution of information within the ANNs provides the capacity to model complicated, nonlinear, interrelated processes. This ultimately allows ANNs to model environmental systems without prior specification of the algebraic relationships between variables (Lek et al. 1999). The main difference between the present study and the approaches described in the aforementioned publications is that multilayer perceptron (MLP) and radial basic function (RBF) algorithms were applied and their results were compared for landslide susceptibility at Vaz Watershed of Mazandaran Province, Iran.
Study area characteristics
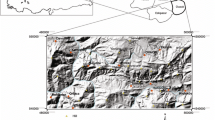
Vaz Watershed is located in the south of Mazandaran Province, northern Iran where most landslides have occurred, in the mountainous and forest region. The area is located between 52° 01′ to 53° 12′ E longitude and latitude 36° 25′ to 36° 14′ N covering with an area of 1,420 km2. The general topography of the area is highlands with elevations ranging from 240 to 3,590 m a.s.l and slopes varying between flat and >60° (Fig. 1). The bedrock in this region mainly consists of limestone with dolomite, siltstone, sandstone, marl and conglomerate (source: geology survey of Iran, (GSI)). The majority of the area is covered by \( R_e^2 \) (thick bedded to massive dolomitic limestone, dolomite and limestone) and R 3 J S (shale, sandstone, siltstone, carbonaceous shale and quartzite) lithological units (85.91 %). The land use of the study area mainly comprises forest with variant range of coverage from low to dense, poor range, medium range, good range, orchard and settlement areas. The climate in the study area is Mediterranean with a mean annual precipitation of 968 mm and occurs in the form of snow during the winter. The climate is mostly affected by altitude with amount of precipitation decreasing with an increasing altitude.

Location map of the study area (landslide location map with hill shaded map of the study area)
There are 136 landslide locations in the study area. Some of the landslides are presumably very old in age. Most of the landslides are shallow rotational with a few translational. However, during the analyses performed in the present study, only rotational failure is considered and translational slides were eliminated because its occurrence is rare. The minimum and maximum size of landslides is 20 and 3,000 m2, respectively. Some field photographs showing some recent landslides are shown in Fig. 2. Very old landslides are mostly relict or dormant and are partially concealed by forest and the intensive farming activity. In addition to the landslides, it is possible to observe various types of erosional features (i.e., rill erosion, bank erosion, gully erosion and surface erosion) in the study area. The Vaz River which is the main river system in the study area consists of alluvial fans and terraces, alluvial sheets and locally undivided lake deposits.

Field photographs showing some recent landslides in Vaz Watershed area: a this picture is taken at 1,915 m a.s.l. at X, 604459 and Y, 4016165 near to a river; b taken at 1,375 m a.s.l. at X, 598280 and Y, 4019760in the forest area and away from the road; c taken at 729 m a.s.l. at X, 598859 and Y, 4023650 showing very steep slope between the river and road
Thematic data preparation
Various thematic data layers representing landslide conditioning factors, such as slope, slope aspect, altitude, land use, lithology, distance from rivers, distance from roads, distance from fault and rainfall, were prepared. A total of 136 landslides were mapped in the study area at 1:25,000 scale (Fig. 1). The modes of failure for the landslides identified in the study area were determined according to the landslide classification system proposed by Varnes (1978). In order to develop a method for the assessment of landslide susceptibility, determination of the conditioning factors for the landslides is crucial (Ercanoglu and Gokceoglu 2002). In fact, the regional landslide assessments should be practical and applicable for the study area. For that reason, the input parameters should be representative, reliable and obtained easily. The landslide conditioning factors were transformed into a vector-type spatial database using the GIS. For the digital elevation model (DEM) creation, 20 m interval contours and survey base points showing the elevation values was extracted from the 1:50,000-scale topographic maps. Using this DEM, slope, slope aspect and altitude were produced (Fig. 3a–c). In the present study, substantial attention has been given for slope conditions. Slope configuration and steepness play an important role in conjunction with lithology. The slope map was reclassified into five classes: (1) <5 %, (2) 5–15 %, (3) 15–30 %, (4) 30-60 % and (5) >60 % (Fig. 3a). The slope aspects are grouped into nine classes (Fig. 3b): flat (−1°), north (337.5–360°, 0–22.5°), north–east (22.5–67.5°), east (67.5–112.5°), south–east (112.5–157.5°), south (157.5–202.5°), south–west (202.5–247.5°), west (247.5–292.5°) and north–west (292.5–337.5°). Altitude is also a significant landslide conditioning factor because it is controlled by several geologic and geomorphological processes (Gritzner et al. 2001; Dai and Lee 2002; Ayalew et al. 2005). The altitude map is prepared from the 20 × 20 m digital elevation model and grouped into 12 classes (Fig. 2c).

Topographical parameter maps of the study area: a slope; b slope aspect; c altitude
In addition, the distance from rivers and roads was calculated using the topographic database. The river and road buffer was calculated at 100 m intervals as shown in Fig. 4a, b, respectively. Using the geology database, the types of lithology were extracted, and the distances of faults were calculated. The lithology map was obtained from a 1:100,000-scale geological map (Fig. 5), and distance from faults map was calculated in 100 m intervals (Fig. 6). The land use data were classified by using a Landsat Enhanced Thematic Mapper satellite image acquired on 2006 was used employing a supervised classification method and was verified by field survey. There are six land use classes identified, such as poor range, medium range, good range, orchard, forest and settlement area extracted for land use mapping (Fig. 7). All the above-mentioned landslide conditioning factors were converted to a raster grid with 20 × 20 m pixel for application of artificial neural network models. Finally, the precipitation map was prepared using the rainfall data (Fig. 8) using the data received from four rainfall stations for the years 1975 to 2010 (annual mean rainfall).

Topographical parameter maps of the study area: a distances from rivers; b distances from roads

The lithology map of the study area

Distances from faults

The land use map of the study area

The rainfall map of the study area
Artificial neural networks
ANNs are generic nonlinear function approximation algorithms s that has been extensively used for problems like pattern recognition and classification (Palani et al. 2008; Kawabata and Bandibas 2009). The categorization of a terrain into ordinal zones of landslide susceptibility may also be regarded as a classification problem. Thus, the ANN outputs may be considered as the degree of the membership of each terrain unit with regard to the occurrence of landslide (Ermini et al. 2005). The higher the membership value indicates the more susceptible is the terrain unit to the occurrence of landslide and vice versa. Moreover, since ANN can process input data at varied measurement scales and units, such as continuous, categorical and binary data, it appears to be an appropriate approach for landslide susceptibility assessment mapping (Garrett 1994).
The backpropagation artificial neural networks are the most widely used type of networks (Negnevitsky 2002) because of their flexibility and adaptability in modeling a wide spectrum of problems in many application areas (Basheer and Hajmeer 2000). When developing an artificial neural network, the data are commonly partitioned into at least two subsets such as training and test data. It is expected that the training data include all the data belonging to the problem domain. Certainly, this subset is used in the training stage of the model development to update the weights of the network. On the other hand, the test data should be different from those used in the training stage. The main purpose of this subset is to check the network performance using untrained data, and to confirm its accuracy. No exact mathematical rule to determine the required minimum size of these subsets exists. However, some suggestions for the portions of these samplings are encountered in the literature (Basheer and Hajmeer 2000). Considering these suggestions, it is revealed that approximately 80 % of whole data are commonly enough to train the network, and the rest of it is usually handled to test the final architecture of the model (Baum and Haussler 1989; Nelson and Illingworth 1990; Haykin 1994; Masters 1994; Dowla and Rogers 1995; Looney 1996; Swingler 1996). In a paper, Looney (1996) recommends 65 % of the parent database be used for training, 25 % for testing and 10 % for validation, whereas Swingler (1996) proposed 20 % for testing and Nelson and Illingworth (1990) suggested 20–30 % data for training.
The MLP was trained with the backpropagation algorithm (BPA), the most frequently used neural network method, and was adopted in this study (Fig. 9). The MLP with the BPA was trained using a set of examples of associated input and output values (Pradhan and Lee 2010b).

Architecture of neural network model for Vaz Watershed
MLP is perhaps the most popular and most widely used ANN, which consists of two layers, input and output, and one or more hidden layers between these two layers. The hidden layers are introduced to increase the network’s ability to model complex functions (Paola and Schowengerdt 1995). Each layer in a network contains sufficient number of neurons depending upon the application. The input layer is passive and merely receives the data (e.g., the data pertaining to various causative factors). Unlike the input layer, both hidden and output layers actively process the data. The output layer produces the neural network’s results.
Thus, the number of neurons in the input and output layers are typically fixed by the type of application. The number of hidden layers and their neurons are typically determined by trial and error (Gong 1996). There are three stages involved in ANN data processing for a classification problem: the training stage, the weight determination stage, and the classification stage. The training process is initiated by assigning arbitrary initial connection weights which are constantly updated until an acceptable training accuracy is reached. The adjusted weights obtained from the trained network were subsequently used to process the testing data in order to evaluate the generalization capability and accuracy of the network. The performance of the networks is evaluated by determining both training and testing data accuracies in terms of percent correct and overall classification accuracy (Congalton 1991). Training data from input neurons are processed through hidden neurons to generate an output in the output neuron. The input that a single neuron j in the first hidden layer (HA), received from the neurons (i) in its preceding input layer, may be expressed as (Pradhan and Lee 2010a, b):
Where w ij represents the connection weight between input neuron i and hidden neuron j, p i is the data at the input neuron i and t is the number of input neurons. The output value produced at the hidden neuron j, p j , is the transfer function, f, evaluated as the sum produced within neuron j, net j . So, the transfer function f can be expressed as (Pradhan and Lee 2010a, b):
The function f is usually a nonlinear sigmoid function that is applied to the weighted sum of the input data before the data are processed to the next layer. Similarly, the neural network output value, p j , at the output neuron o, is obtained using Eqs. (1) and (2).
Similarly, another algorithm is RBF which emerged as a variant of artificial neural network in late 1980s. However, their roots are entrenched in much older pattern recognition techniques, as for example, potential functions, clustering, functional approximation, strict interpolation and mixture models. RBFs are embedded in a two-layer neural network, where each hidden unit implements a radial-activated function. The output units implement a weighted sum of hidden unit outputs. The input into an RBF network is nonlinear while the output is linear. Their excellent approximation capabilities have been studied in. Due to their nonlinear approximation properties, RBF networks are able to model complex mappings, which perceptron neural networks can model by means of multiple intermediary layers (Haykin 1994).
On the other hand, the Broyden–Fletcher–Goldfarb–Shanno (BFGS) algorithm is a quasi-Newton algorithm for numerical optimization. Quasi-Newton algorithms compute an approximation for Hessian matrix as a function of the gradient. Hence, the computation complexity is lesser than the direct Newton’s method for numerical optimization. BFGS algorithm is the most successful quasi-Newton algorithm found so far. Even though it requires more computation in each iteration than simple gradient descent method, it generally converges in less iteration (Wijesinghe and Dias 2008).
Application of ANN to landslide susceptibility mapping
When developing an artificial neural network, the data are commonly partitioned into at least two subsets such as training and validation data. Before running the artificial neural network program, the training site should be selected (Nefeslioglu et al. 2008; Caniani et al. 2008). In this study, the landslide-prone (occurrence) area and the landslide-not-prone area were selected as training sites. Cells from each of the two classes were randomly selected as training cells, with 136 cells denoting areas where landslide occurred. Among the 136 cases of landslide occurrences, 95 cases (70 %) were selected for calibrating the ANN and the remaining 41 cases (30 %) were used for validation testing. Data normalization as one of frequently standard data preprocess in the development of ANN models. It is recommended to linearly scale each attribute to the range [0.1, 0.9], [−1, +1], or [0, 1]. In the modeling process, the data set of nine variables was scaled to the range between 0.1 and 0.9 by following Eq. 3:
where, N i is the normalized value, X i is the original data and X min and X max, respectively, the minimum and maximum value of X i (Pradhan and Lee 2010b).
Subsequently, after normalizing the data for nine landslide conditioning factors, the presence or absence of landslides is defined with codes 0 and 1. The distribution of the training pixels is shown in Table 1. Once the ANN, MLP and RBF models were successfully trained in the training phase, the connection weights of the two models were used to calculate the landslide susceptibility indexes (LSI) for all the pixels in the study area as shown in Figs. 10 and 11.

Landslide susceptibility map using MLP-ANN model

Landslide susceptibility map using RBF-ANN model
In order to obtain landslide susceptibility map, the LSI values were reclassified into different susceptibility classes. There are many classification methods available such as quantiles, natural breaks, equal intervals and standard deviations (Ayalew and Yamagishi 2005). Generally, the selection of classification methods may depend on the histogram of landslide susceptibility indexes. The LSIs were classified (Falaschi et al. 2009; Bednarik et al. 2010; Constantin et al. 2010; Erner et al. 2010; Pourghasemi et al. 2012c) into five classes based on natural break classification scheme (None, low, moderate, high and very high) (Figs. 10 and 11).
Results and discussion
Landslides are natural phenomena which often have detrimental consequences. Landslide hazards can be systematically assessed by using different factors and methods. In this study, landslide susceptibility maps have been constructed using the relationship between landslide locations and causative factors. The artificial neural network model was applied by employing both MLP and RBF algorithms to study the influence of different factors on landslide occurrence, and subsequently landslide susceptibility maps were constructed. In this study, both MLP and RBF methods results showed a total of five artificial neural networks, among which four related to the MPL method and the fifth one is related to the RBF. The distributions of the training samples are given in Table 1. The first MLP was used by employing 9 input layers, 14 hidden layers and 1 output layer; the second used 9 input layers, 3 hidden layers and 1 output layer; the third used 9 input layers, 10 hidden layers and 1 output layer; and the fourth used 9 input layers, 6 hidden layers and 1output layer. Table 2 shows (train perfect) 9 input layers, 14 hidden layers and 1 output layer that has been used during the training phase. Further, to compare the performance of the BFGS function and gradient descent using various learning rate (0.1 to 0.9), it was found that landslide susceptibility assessment using gradient descent learning rate of 0.9 is a better approach in landslide susceptibility assessment. The neural network analysis was performed using the gradient descent by employing nine input layers, eight hidden layers and one output layer (Table 3).
According to the landslide susceptibility map produced from the gradient descent 0.9 function methods, 2.61 and 5.31 % of the total area are found under no and low landslide susceptibility classes. Areas covering moderate, high and very high susceptibility zones represent 22.77, 39.15 and 30.16 % of the total area, respectively. Based on the landslide susceptibility map produced by the MLP function method, 38.65 % of the total area is found under no (0.39) and low (38.26) landslide susceptibility classes. Similarly, areas encompassing moderate, high and very high susceptibility zones represent 47.48, 11.28 and 2.59 % of the total area, respectively.
Relationship between landslide and landslide conditioning factors
The results of spatial relationship between landslide and conditioning factors using frequency ratio model is shown in Table 1. In Table 1, slope percentage classes showed that >60 % of the classes have higher frequency ratio value. As the slope increases, the shear stress in the soil or other unconsolidated material generally increases. Gentle slopes are expected to have a low frequency of landslides because of the generally lower shear stresses associated with low gradients. Steep natural slopes resulting from outcropping bedrock, however, may not be susceptible to shallow landslides. In the case of slope aspect, most of the landslides occurred in east and south–east facing. In the case of altitude, both 900–1,200 m classes have 29.67 % of landslide probability and frequency ratio value of 2.70. Results showed that the frequency ratio values decreased with the altitude addition in the study area (Table 1). Assessment of distance from rivers and roads showed that distance of >400 m of rivers and 0–100 m of roads have high correlation with landslide occurrence. Investigation of lithological conditions showed that \( R_e^1 \) consisting of thin bedded marly limestone with worm traces, calcareous shale has higher value of frequency ratio (2.02). In the case distance to faults, the distance >400 m has weight of 1.07. In the case of land use, higher frequency ratio value was for settlement area (1.89). This result referred to anthropogenic (human-caused) interferences such as land use change. In the case of rainfall, we observed frequency ratio increased with the rainfall addition.
Validation of landslide susceptibility maps
Using the success rate- and prediction rate methods, the results of the two landslide susceptibility maps were validated by comparing them with the existing landslide locations (Chung and Fabbri 2003). The success rate results were obtained based on a comparison of the landslide grid cells in the training dataset (95 landslide grid cells) with the two landslide susceptibility maps. The success rate measures how the landslide analysis results fit the training dataset. This method first divides the area of landslide susceptibility map in equal classes, ranging from the highest to the lowest LSI values. Then, the numbers of landslide grid cells occurred in each class were calculated and a cumulative curve was plotted. The success rate curves of the two landslide susceptibility map obtained from MLP and RBF models are shown in Fig. 12. The result shows that MLP has the slightly highest area under the curve (AUC) value (0.9193), followed by RBF (0.9085). It indicates that the capabilities for correctly classifying the areas with existing landslides are slightly better for the MLP model than the RBF model.

Success rate curve for the landslide susceptibility maps produced by a MLP and b RBF models
Because the success rate method used the training dataset that has already been used for training the neural network models, therefore strictly speaking, the success rate method may not be a suitable method for the prediction capacity assessment of the landslide models (Lee et al. 2007; Pourghasemi et al. 2012c). The prediction rate can explain how well the landslide models and landslide conditioning factors predict landslides (Pradhan and Lee 2010a; Chung and Fabbri 2003). In this study, the prediction rate results were obtained by using the receiver operating characteristics (ROC) method; the results of the two landslide susceptibility maps (produced by MLP and RBF models) were validated by comparing them with the landslide locations (41 landslide grid cells) which were not used during the training of the models (Chung and Fabbri 2003). The AUC of the two landslide susceptibility map obtained from MLP and RBF models are shown in Fig. 13. If the AUC is equal to 1, it indicates perfect prediction accuracy (Pradhan and Lee 2010a). ROC plot assessment results show that in the susceptibility map using MLP model, the AUC was 0.881 and the prediction accuracy was 88.10 %. In the susceptibility map using RBF model, the AUC was 0.8724 and the prediction accuracy was 87.24 %.

ROC curve for the landslide susceptibility maps produced by a MLP and b RBF models
Conclusions
The preparation of landslide susceptibility maps is one of great interest to planning agencies for preliminary hazard studies, especially when a regulatory planning policy is to be implemented. In the present study, artificial neural network approach by MLP and RBF algorithms were applied for the landslide susceptibility mapping at Vaz area in Iran. A landslide inventory map was created through multiple field investigations and aerial photo interpretation. Among the landslide-related factors, slope percentage, slope aspect, altitude, distance from rivers, distance from roads, lithology, distance from faults, land use and rainfall were used for landslide susceptibility mapping. In order to verify the results, the success rate and prediction rate were used. The susceptibility maps produced by MLP and RBF models are shown in Figs. 10 and 11 and comprise five landslide susceptibility classes, such as no, low, moderate, high and very high. The areal extents of these sub-classes for MLP model were found to be 0.39, 38.26, 47.48, 11.28 and 2.59 %, respectively, whereas in landslide susceptibility map produced based on RBF, 2.61 % of the study area has no susceptibility and the low, moderate, high and very high susceptibility zones from 5.31, 22.77, 39.15 and 30.16 % of the study area, respectively.
The validation results show that the MLP and BFGS function with 9 input layers, 14 hidden layer and 1 output layers has slightly better predication accuracy of 0.86 % (88.10–87.24 %) than the RBF model. The most commonly used algorithms are multilayer feed-forward artificial neural network (MLP) and radial basis function network (RBFN). The RBFN is traditionally used for strict interpolation problem in multidimensional space and has similar capabilities with MLP neural network which solves any function approximation problem (Park and Sandberg 1993; Yilmaz et al. 2011). Yilmaz et al. (2011) presented the potential benefits of soft computing models extend beyond the high computation rates. Higher performances of the soft computing models were sourced from greater degree of robustness and fault tolerance than traditional statistical models because there are many more processing neurons, each with primarily local connections. The performance comparison also showed that the soft computing techniques are good tools for minimizing the uncertainties, and their use will also may provide new approaches and methodologies and minimize the potential inconsistency of correlations. For the conclusion, the authors can conclude that the results of these models have shown reasonable prediction accuracy in landslide susceptibility mapping in the study area.
References
Akgun A (2011) A comparison of landslide susceptibility maps produced by logistic regression, multi-criteria decision, and likelihood ratio methods: a case study at İzmir, Turkey. Landslides, doi:10.1007/s10346-011-0283-7
Akgun A, Bulut F (2007) GIS-based landslide susceptibility for Arsin-Yomra (Trabzon, North Turkey) region. Environ Geol 51(8):1377–1387
Akgun A, Turk N (2010) Landslide susceptibility mapping for Ayvalik (Western Turkey) and its vicinity by multi-criteria decision analysis. Environ Earth Sci 61(3):595–611
Akgun A, Dag S, Bulut F (2008) Landslide susceptibility mapping for a landslide-prone area (Findikli, NE of Turkey) by likelihood frequency ratio and weighted linear combination models. Environ Geol 54(6):1127–1143
Akgun A, Kıncal C, Pradhan B (2011) Application of remote sensing data and GIS for landslide risk assessment as an environmental threat to Izmir city (west Turkey). Environ Monit Assess. doi:10.1007/s10661-011-2352-8
Akgun A, Sezer EA, Nefeslioglu HA, Gokceoglu C, Pradhan B (2012) An easy-to-use MATLAB program (MamLand) for the assessment of landslide susceptibility using a Mamdani fuzzy algorithm. Comput Geosci 38(1):23–34
Aleotti P, Chowdhury R (1999) Landslide hazard assessment: summary review and new perspectives. Bull Eng Geol Environ 58:21–44
Althuwaynee OF, Pradhan B, Lee S (2012) Application of an evidential belief function model in landslide susceptibility mapping. Comput Geosci. doi:10.1016/j.cageo.2012.03.003
Ayalew L, Yamagishi H (2005) The application of GIS-based logistic regression for landslide susceptibility mapping in the Kakuda-Yahiko Mountains, Central Japan. Geomorphology 65:15–31
Ayalew L, Yamagishi H, Marui H, Kanno T (2005) Landslide in Sado Island of Japan: Part II. GIS-based susceptibility mapping with comparison of results from two methods and verifications. Eng Geol 81:432–445
Bai S, Lu G, Wang J, Zhou P, Ding L (2010) GIS-based rare events logistic regression for landslide-susceptibility mapping of Lianyungang, China. Environ Earth Sci 62(1):139–149
Basheer IA, Hajmeer M (2000) Artificial neural networks: fundamentals, computing, design and application. J Microb Meth 43:3–31
Baum E, Haussler D (1989) What size net gives valid generalization? Neural Comput 1:151–160
Bednarik M, Magulova B, Matys M, Marschalko M (2010) Landslide susceptibility assessment of the Kralovany–Liptovsky Mikulaš railway case study. Phys Chem Earth 35:162–171
Bui DT, Pradhan B, Lofman O, Revhaug I, Dick OB (2011) Landslide susceptibility mapping at Hoa Binh Province (Vietnam) using an adaptive neuro-fuzzy inference system and GIS. Comput Geosci. doi:10.1016/j.cageo.2011.10.031
Bui DT, Pradhan B, Lofman O, Revhaug I, Dick OB (2012a) Landslide susceptibility assessment in the Hoa Binh Province of Vietnam: A comparison of the Levenberg-Marquardt and Bayesian regularized neural networks. Geomorphology. doi:10.1016/j.geomorph.2012.04.023
Bui DT, Pradhan B, Lofman O, Revhaug I, Dick OB (2012b) Spatial prediction of landslide hazards in Hoa Binh province (Vietnam): a comparative assessment of the efficacy of evidential belief functions and fuzzy logic models. Catena 96:28–40
Can T, Nefeslioglu HA, Gokceoglu C, Snomez H, Duman TY (2005) Susceptibility assessment of shallow earth flows triggered by heavy rainfall at three sub catchments by logistic regression analyses. Geomorphology 72:250–271
Caniani D, Pascale S, Sado F, Sole A (2008) Neural networks and landslide susceptibility: a case study of the urban area of Potenza. Nat Hazards 45:55–72
Champati Ray DP, Dimri S, Lakhera RC, Sati S (2007) Fuzzy-based method for landslide hazard assessment in active seismic zone of Himalaya. Landslides 4:101–111
Chauhan S, Sharma M, Arora M, Gupta N (2010) Landslide susceptibility zonation through ratings derived from artificial neural network. Intl J Appl Earth Observ Geoinf 12:340–350
Chung CJF, Fabbri AG (2003) Validation of spatial prediction models for landslide hazard mapping. Nat Hazards 30:451–472
Congalton RG (1991) A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens Environ 37:35–46
Constantin M, Bednarik M, Jurchescu MC, Vlaicu M (2010) Landslide susceptibility assessment using the bivariate statistical analysis and the index of entropy in the Sibiciu Basin (Romania). Environ Earth Sci. doi:10.1007/s12665-010-0724-y
Dahal RK, Hasegawa S, Nonomura S, Yamanaka M, Masuda T, Nishino K (2008) GIS-based weights-of-evidence modelling of rainfall-induced landslides in small catchments for landslide susceptibility mapping. Environ Geol 54(2):314–324
Dai FC, Lee CF (2002) Landslide characteristics and slope instability modeling using GIS, Lantau Island, Hong Kong. Geomorphology 42:213–228
Dowla FU, Rogers LL (1995) Solving problems in environmental engineering and geosciences with artificial neural networks. MIT, Cambridge
Duman TY, Can T, Gokceoglu C, Nefeslioglu HA, Sonmez H (2006) Application of logistic regression for landslide susceptibility zoning of Cekmece Area, Istanbul, Turkey. Environ Geol 51:241–256
Ercanoglu M, Gokceoglu C (2002) Assessment of landslide susceptibility for a landslide-prone area (north of Yenice, NW Turkey) by fuzzy approach. Environ Geol 41:720–730
Ercanoglu M, Gokceoglu C (2004) Use of fuzzy relation to produce landslide susceptibility map of a landslide prone area (West Black Sea Region, Turkey). Eng Geol 75:229–250
Ermini L, Catani F, Casagli N (2005) Artificial neural networks applied to landslide susceptibility assessment. Geomorphology 66:327–343
Erner A, Sebnem H, Duzgun B (2010) Improvement of statistical landslide susceptibility mapping by using spatial and global regression methods in the case of More and Romsdal (Norway). Landslides 7:55–68
Falaschi F, Giacomelli F, Federici PR, Puccinelli A, D’Amato Avanzi G, Pochini A, Ribolini A (2009) Logistic regression versus artificial neural networks: landslide susceptibility evaluation in a sample area of the Serchio River valley, Italy. Nat Hazards 50:551–569
Felicisimo A, Cuartero A, Remondo J, Quiros E (2012) Mapping landslide susceptibility with logistic regression, multiple adaptive regression splines, classification and regression trees, and maximum entropy methods: a comparative study. Landslides. doi:10.1007/s10346-012-0320-1
Fell R, Corominas J, Bonnard C, Cascini L, Leroi E, Savage P (2008) Guidelines for landslide susceptibility, hazard and risk zonation for land-use planning. Eng Geol 102:99–111
Garrett J (1994) Where and why artificial neural networks are applicable in civil engineering. Civil Eng 8:129–130
Gokceoglu C, Sonmez H, Nefeslioglu HA, Duman TY, Can T (2005) The 17 March 2005 Kuzulu landslide (Sivas, Turkey) and landslide susceptibility map of its near vicinity. Eng Geol 81:65–83
Gomez H, Kavzoglu T (2005) Assessment of shallow landslide susceptibility using artificial neural networks in Jabonosa River Basin, Venezuela. Eng Geol 78:11–27
Gong P (1996) Integrated analysis of spatial data for multiple sources: using evidential reasoning and artificial neural network techniques for geological mapping. Photogram Eng Rem Sens 62:513–523
Gorsevski PV, Jankowski P (2010) An optimized solution of multi-criteria evaluation analysis of landslide susceptibility using fuzzy sets and Kalman filter. Comput Geosci 36:1005–1020
Gorsevski PV, Gessler PE, Foltz RB, Elliot WJ (2006) Spatial prediction of landslide hazard using logistic regression and ROC analysis. Trans GIS 10(3):395–415
Gritzner ML, Marcus WA, Aspinall R, Custer SG (2001) Assessing landslide potential using GIS, soil wetness modeling and topographic attributes, Payette River, Idaho. Geomorphology 37:149–165
Guzzeti F, Carrara A, Cardinalli M, Reichenbach P (1999) Landslide hazard evaluation: a review of current techniques and their application in a multi-case study, central Italy. Geomorphology 31:181–216
Haykin S (1994) Neural networks: a comprehensive foundation. Macmillan, New York
Kanungo DP, Arora MK, Sarkar S, Gupta RP (2006) A comparative study of conventional, ANN black box, fuzzy and combined neural and fuzzy weighting procedures for landslide susceptibility zonation in Darjeeling Himalayas. Eng Geol 85:347–366
Kanungo DP, Arora MK, Gupta RP, Sarkar S (2008) Landslide risk assessment using concepts of danger pixels and fuzzy set theory in Darjeeling Himalayas. Landslides 5:407–416
Kavzoglu T, Mather PM (2000) Using feature selection techniques to produce smaller neural networks with better generalization capabilities. Proc IEEE 2000 Int Geosci Rem Sens Symp, Hawaii 3:3069–3071
Kawabata D, Bandibas J (2009) Landslide susceptibility mapping using geological data, a DEM from ASTER images and an artificial neural network (ANN). Geomorphology 113:97–109
Lee S, Evangelista DG (2006) Earthquake-induced landslide-susceptibility mapping using an artificial neural network. Nat Hazards Earth Syst Sci 6:687–695
Lee S, Sambath T (2006) Landslide susceptibility mapping in the Damrei Romel area, Cambodia using frequency ratio and logistic regression models. Environ Geol 50(6):847–855
Lee S, Ryu JH, Kim IS (2007) Landslide susceptibility analysis and its verification using likelihood ratio, logistic regression, and artificial neural network models: case study of Youngin, Korea. Landslides 4(4):327–338
Lee S, Choi J, Oh H (2009) Landslide susceptibility mapping using a neuro-fuzzy. Abstract presented at American Geophysical Union, Fall Meeting 2009, abstract #NH53A-1075
Lee MJ, Choi JW, Oh HJ, Won JS, Park I, Lee, S (2012) Ensemble-based landslide susceptibility maps in Jinbu area, Korea. Environ Earth Sci (article in press)
Lek S, Guiresse M, Giraudel JL (1999) Predicting stream nitrogen concentration from watershed features using neural network. Wat Res 33(16):3469–3478
Looney CG (1996) Advances in feed forward neural networks: demystifying knowledge acquiring black boxes. IEEE Trans Knowl Data Eng 8(2):211–226
Marjanović M, Kovačević M, Bajat B, Voženílek V (2011) Landslide susceptibility assessment using SVM machine learning algorithm. Eng Geol 123:225–234
Masters T (1994) Practical neural network recipes in C++. Academic, Boston
Neaupane KM, Achet SH (2004) Use of back propagation neural network for landslide monitoring: a case study in the higher Himalaya. Eng Geol 74(3–4):213–226
Nefeslioglu HA, Gokceoglu C, Sonmez H (2008) An assessment on the use of logistic regression and artificial neural networks with different sampling strategies for the preparation of landslide susceptibility maps. Eng Geol 97:171–191
Nefeslioglu HA, Sezer E, Gokceoglu C, Bozkir AS, Duman TY (2010) Assessment of landslide susceptibility by decision trees in the metropolitan area of Istanbul, Turkey. Math Probl Eng. doi:10.1155/2010/901095, Article ID 901095
Negnevitsky M (2002) Artificial intelligence—a guide to intelligent systems. Addison-Wesley Co, Great Britain
Nelson M, Illingworth WT (1990) A practical guide to neural nets. Addison-Wesley, Reading
Nilsen TH, Wrigth RH, Vlasic TC, Spangle WE (1979) Relative slope stability and land-use planning in the San Francisco Bay region, California. US Geological Survey Professional Paper 944
Oh HJ, Pradhan B (2011) Application of a neuro-fuzzy model to landslide-susceptibility mapping for shallow landslides in a tropical hilly area. Comput Geosci 37:1264–1276
Oh HJ, Park NW, Lee SS, Lee S (2012) Extraction of landslide-related factors from ASTER imagery and its application to landslide susceptibility mapping. Int J Rem Sens 33(10):3211–3231
Palani S, Liong S, Tkalich P (2008) An ANN application for water quality forecasting. Mar Poll Bull 56:1586–1597
Paola JD, Schowengerdt RA (1995) A review and analysis of back propagation neural networks for classification of remotely sensed multi-spectral imagery. Int J Rem Sens 16:3033–3058
Park J, Sandberg IW (1993) Approximation and radial basis function networks. Neural Comput 5:305–316
Pourghasemi HR, Pradhan B, Gokceoglu C, Mohammadi M, Moradi HR (2012a) Application of weights-of-evidence and certainty factor models and their comparison in landslide susceptibility mapping at Haraz watershed, Iran. Arab J Geosci. doi:10.1007/s12517-012-0532-7
Pourghasemi HR, Pradhan B, Gokceoglu C, Deylami Moezzi K (2012b) A comparative assessment of prediction capabilities of Dempster-Shafer and weights-of-evidence models in landslide susceptibility mapping using GIS. Geomat, Nat Hazards Risk. doi:10.1080/19475705.2012.662915
Pourghasemi HR, Pradhan B, Gokceoglu C (2012c) Application of fuzzy logic and analytical hierarchy process (AHP) to landslide susceptibility mapping at Haraz watershed, Iran. Nat Hazard. doi:10.1007/s11069-012-0217-2
Pourghasemi HR, Gokceoglu C, Pradhan B, Deylami Moezzi K (2012d) Landslide susceptibility mapping using a spatial multi criteria evaluation model at Haraz Watershed. In: Pradhan IB, Buchroithner M (eds) Terrigenous mass movements. Springer, Berlin, pp 23–49. doi:10.1007/978-3-642-25495-6-2
Pourghasemi HR, Mohammady M, Pradhan B (2012e) Landslide susceptibility mapping using index of entropy and conditional probability models in GIS: Safarood Basin, Iran. Catena. doi:10.1016/j.catena.2012.05.005
Pradhan B (2010) Application of an advanced fuzzy logic model for landslide susceptibility analysis. Int J Comput Intel Syst 3(3):370–381
Pradhan B (2011a) Use of GIS-based fuzzy logic relations and its cross application to produce landslide susceptibility maps in three test areas in Malaysia. Environ Earth Sci 63(2):329–349
Pradhan B (2011b) Manifestation of an advanced fuzzy logic model coupled with geoinformation techniques for landslide susceptibility analysis. Environ Ecol Stat 18(3):471–493
Pradhan B, Buchroithner MF (2010) Comparison and validation of landslide susceptibility maps using an artificial neural network model for three test areas in Malaysia. Environ Eng Geosci 16(2):107–126. doi:10.2113/gseegeosci.16.2.107
Pradhan B, Lee S (2010a) Delineation of landslide hazard areas on Penang Island, Malaysia, by using frequency ratio, logistic regression, and artificial neural network models. Environ Earth Sci 60(5):1037–1054
Pradhan B, Lee S (2010b) Landslide susceptibility assessment and factor effect analysis: back-propagation artificial neural networks and their comparison with frequency ratio and bivariate logistic regression modeling. Environ Modell Softw 25(6):747–759
Pradhan B, Lee S (2010c) Regional landslide susceptibility analysis using back-propagation neural network model at Cameron Highland, Malaysia. Landslides 7(1):13–30
Pradhan B, Pirasteh S (2010) Comparison between prediction capabilities of neural network and fuzzy logic techniques for landslide susceptibility mapping. Disaster Adv 3(2):26–34
Pradhan B, Youssef AM (2010) Manifestation of remote sensing data and GIS on landslide hazard analysis using spatial-based statistical models. Arab J Geosci 3(3):319–326
Pradhan B, Oh HJ, Buchroithner MF (2010) Weights-of-evidence model applied to landslide susceptibility mapping in a tropical hilly area. Geomat, Nat Hazards Risk 1(3):199–223
Saito H, Nakayama D, Matsuyama H (2009) Comparison of landslide susceptibility based on a decision-tree model and actual landslide occurrence: the Akaishi Mountains, Japan. Geomorphology 109:108–121
Sezer EA, Pradhan B, Gokceoglu C (2011) Manifestation of an adaptive neuro-fuzzy model on landslide susceptibility mapping: Klang Valley, Malaysia. Exp Syst Appl 38:8208–8219
Soeters R, Van Westen CJ (1994) Slope stability: recognition, analysis and zonation. In: Turner AK, Shuster RL (eds) “Landslides: investigation and mitigation”. Transportation research Board–National Research Council. Special Report 247:129–177
Song KY, Oh HJ, Choi J, Park I, Lee C, Lee S (2012) Prediction of landslide using ASTER imagery and data mining models. Adv Space Res 49:978–993
Swingler K (1996) Applying neural networks: a practical guide. Academic, New York
Vahidnia MH, Alesheikh AA, Alimohammadi A, Hosseinali F (2010) A GIS-based neuro-fuzzy procedure for integrating knowledge and data in landslide susceptibility mapping. Comput Geosci 36:1101–1114
Van Westen CJ, Rengers N, Soeters R (2003) Use of geomorphological information in indirect landslide susceptibility assessment. Nat Hazards 30:399–419
Varnes DJ (1978) Slope movement types and processes. In: Schuster RL, Krizek RJ (eds) Landslides analysis and control. Special Report, vol 176. Transportation Research Board, National Academy of Sciences, New York, pp 12–33
Varnes DJ (1984) Landslide hazard zonation—a review of principles and practice. IAEG Commission on Landslides. UNESCO, Paris
Wan S (2009) A spatial decision support system for extracting the core factors and thresholds for landslide susceptibility map. Eng Geol 108:237–251
Wijesinghe P, Dias D (2008) Novel approach for RSS calibration in DCM-based mobile positioning using propagation models. 978-1-4244-2900-4/08/$25.00 c 2008 IEEE. 6pp
Xu C, Dai F, Xu X, Lee YH (2012) GIS-based support vector machine modeling of earthquake-triggered landslide susceptibility in the Jianjiang River watershed, China. Geomorphology. doi:10.1016/j.geomorph.2011.12.040
Yao X, Tham LG, Dai FC (2008) Landslide susceptibility mapping based on support vector machine: a case study on natural slopes of Hong Kong, China. Geomorphology 101:572–582
Yeon YK, Han JG, Ryu KH (2010) Landslide susceptibility mapping in Injae, Korea, using a decision tree. Eng Geol 116:274–283
Yilmaz I (2009) A case study from Koyulhisar (Sivas-Turkey) for landslide susceptibility mapping by artificial neural networks. Bull Eng Geol Environ 68(3):297–306
Yılmaz I (2009) Landslide susceptibility mapping using frequency ratio, logistic regression, artificial neural networks and their comparison: a case study from Kat landslides (Tokat-Turkey). Comput Geosci 35(6):1125–1138
Yilmaz I (2010a) The effect of the sampling strategies on the landslide susceptibility mapping by conditional probability (CP) and artificial neural network (ANN). Environ Earth Sci 60:505–519
Yilmaz I (2010b) Comparison of landslide susceptibility mapping methodologies for Koyulhisar, Turkey: conditional probability, logistic regression, artificial neural networks, and support vector machine. Environ Earth Sci 61:821–836
Yilmaz I, Marschalko M, Bednarik M, Kaynar O, Fojtova L (2011) Neural computing models for prediction of permeability coefficient of coarse grained soils. Neural Comput Appl. doi:10.1007/s00521-011-0535-4
Zêzere J, Ferreira A, Rodrigues M (1999) The role of conditioning and triggering factors in the occurrence of landslide: a case study in the area north of Lisbon. Geomorphology 30:133–146
Acknowledgments
Authors would like to thank two anonymous reviewers for their helpful comments on the previous version of the manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Zare, M., Pourghasemi, H.R., Vafakhah, M. et al. Landslide susceptibility mapping at Vaz Watershed (Iran) using an artificial neural network model: a comparison between multilayer perceptron (MLP) and radial basic function (RBF) algorithms. Arab J Geosci 6, 2873–2888 (2013). https://doi.org/10.1007/s12517-012-0610-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12517-012-0610-x