
Abstract
This study presented herein compares the effect of the sampling strategies by means of landslide inventory on the landslide susceptibility mapping. The conditional probability (CP) and artificial neural networks (ANN) models were applied in Sebinkarahisar (Giresun–Turkey). Digital elevation model was first constructed using a geographical information system software and parameter maps affecting the slope stability such as geology, faults, drainage system, topographical elevation, slope angle, slope aspect, topographic wetness index, stream power index and normalized difference vegetation index were considered. In the last stage of the analyses, landslide susceptibility maps were produced applying different sampling strategies such as; scarp, seed cell and point. The maps elaborated were then compared by means of their validations. Scarp sampling strategy gave the best results than the point, whereas the scarp and seed cell methods can be evaluated relatively similar. Comparison of the landslide susceptibility maps with known landslide locations indicated that the higher accuracy was obtained for ANN model using the scarp sampling strategy. The results obtained in this study also showed that the CP model can be used as a simple tool in assessment of the landslide susceptibility, because input process, calculations and output process are very simple and can be readily understood.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Landslides are frequently responsible for considerable losses of money and lives. The severity of the landslide affects the urban development and land use. Landslides and related slope stability problems disturb many parts of the world. Experiences in recent years in understanding, recognition and treatment of landslide hazard showed that our knowledge is still fragmentary. A particular area requiring attention concerns the selection and design of appropriate, cost-effective remedial measures, which in turn require a clear understanding of the conditions and processes that caused the landslides. Much progress has been made in developing techniques to minimize the impact of landslides, although new, more efficient, quicker and cheaper methods could well emerge in the future. Landslides may be corrected or controlled by one or more combinations of four principle measures that are drainage, slope geometry modification, retaining structures and internal slope reinforcement.
As stated by Ercanoglu and Gokceoglu (2004), production of landslide susceptibility maps at the early stage of the landslide assessment has a crucial importance for safe and economic planning, such as urbanization activities and engineering structures, in particular. However, a standard procedure for the production of landslide susceptibility maps does not exist. For this reason, many researchers have used different techniques.
The landslide susceptibility maps are elaborated by means of deterministic and non-deterministic (probabilistic) models. The probabilistic ones are more frequently used, and hence a large number of methodologies have been developed (Rengers et al. 1998), based on the inventory of landslides, geomorphological analysis, qualitative and statistical bivariate analysis (Brabb et al. 1972; DeGraff and Romesburg 1980; Jade and Sarkar 1993; Chung and Fabbri 1999; Irigaray 1995; Fernández et al. 2003; Yilmaz and Yildirim 2006) and multivariate analysis (Carrara 1983; Carrara et al. 1991; Baeza 1994; Chung et al. 1995). Many researchers have used different techniques such as heuristic approach (Ives and Messerli 1981; Rupke et al. 1988; Barredo et al. 2000; Van Westen et al. 2000; Van Westen and Lulie 2003), deterministic models (Ward et al. 1982; Cascini et al. 1991; Gokceoglu and Aksoy 1996), statistical methods (Van Westen 1993; Chacón et al. 1994, 1996; Chung and Fabbri 1999; Dai et al. 2001; Lee and Min 2001; Carrara et al. 2003; Duman et al. 2006). Some new techniques such as; fuzzy-logic, artificial neural networks (ANN), neuro-fuzzy model, etc. (Pistocchi et al. 2002; Lee et al. 2003a, b; Ercanoglu and Gokceoglu 2004; Lee et al. 2004; Gomez and Kavzoglu 2005; Yesilnacar and Topal 2005; Yilmaz 2008b, etc.) were used to evaluate the landslide susceptibility.
A landslide inventory is a dataset presenting a single event, a regional event or multiple events. Landslide inventory map shows the locations and outlines of landslides. Small-scale maps may show only landslide locations whereas large-scale maps may distinguish landslide sources from deposits and classify different kinds of landslides and show other pertinent data.
The mandatory element of landslide hazard or risk assessment is reliable and accurate landslide inventory map. The importance of variables reflecting the prior landsliding conditions used in landslide susceptibility analyses was also stated by Atkinson and Massari (1998). However, the proper technique, quality, completeness, resolution and reliability of the landslide inventory maps are rarely ascertained. The lack of proper information on the quality of the inventory maps and on the reliability of the techniques used to complete the inventories may compromise the hazard or risk assessment.
However, there is no agreement on the technique for the preparation of landslide inventory map, researchers use the different inventory maps where the landslides are shown as point, scarp, seed cell, etc.
Nefeslioglu et al. (2008) quoted that the conceptual differentiation of different sampling strategies applied during susceptibility evaluations is commonly ignored and not stated anymore. Only a few study emphasized on this difference in literature. Dai and Lee (2003) used the source area in the analyses by separating the source area and run-out zone. The analysis of rupture zone only in landslide susceptibility mapping was also explained by Fernández et al. (2003). Landslide rupture hypothesis was suggested by Remondo et al. (2003) and Santacana et al. (2003) considered the rupture zone in landslide susceptibility evaluation. Suzen and Doyuran (2004) reported that the best un-disturbed morphological conditions would be extracted from the close vicinity of the landslide polygon itself. Reconstruction of pre-landslide hill slope was suggested by Van Den Eeckhaut et al. (2006). Clerici et al. (2006) have taken into account the selected factor cells that are defined on the upper edge of the main scarps of landslides during the susceptibility calculations (Nefeslioglu et al. 2008).
This paper presents the effect of the different sampling strategies (scarp, seed cells, point) on the landslide susceptibility maps prepared for landslide area in Sebinkarahisar (Giresun–Turkey) using the conditional probability (CP) and ANN models and their comparison. Comparison of the three landslide maps used in landslide susceptibility analyses will allow for a quantitative estimate of the differences between the three inventories. This paper will also add an extra value to the literature of the landslide susceptibility mapping as a comparative study of very basic technique (CP) with soft computing technique (ANN).
Study area and landslide characteristics
Geographical setting
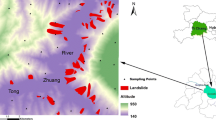
The study area is located 110 km south of Giresun (Turkey) (Fig. 1a). The main drainage system is dominated by the Avutmus creek that extends SW–NE. Topographical and morphological determinations using grid-based digital elevation model (DEM) derived by interpolating the contour lines of a topographic map at scale 1:25,000 (Fig. 1b) indicated that topographical elevations range from 788 m to 2,221 m and slope angle reaches to 85.4° in some locations in the study area.

Location map and digital elevation model of the study area
Rainfall is the main source of water in the study area and it is the most important element in the hydrologic cycle. Studied area receives an average annual rainfall of 590 mm. Most of the rainfall occurs during April, with a mean value of 86.6 mm. Meteorological records of 20 years (1985–2004) showed that the annual average maximum temperature is 20°C in August whereas the annual average minimum temperature is always recorded in January as −2.1°C.
Several times, moderately steep slope forming materials were failed after the periods of heavy rainfalls and affected the homes and farm buildings, etc. (Fig. 2). A long history of ground movements together with the river erosion at the toe and a change in the groundwater regime within the slope created the preconditions for landslide. Site investigations characterized the ground conditions and identified the active slip surface within the compound landslide terrain.

Photos from landslides
Stratigraphical and tectonic settings
The study area encompasses four units ranging in age from Oligo-miocene to Upper Cretaceous–Paleocene. From oldest to youngest, they are Dikmen volcanics, Sebinkarahisar formation and Kka5 (andesite and basalt) and Kka3 (dacite) which are the members of Altinoluk formation (Fig. 3).

Simplified geological map of the study area
In the study area, Altinoluk formation consists of two groups namely Kka3 and Kka5. Although Kka3 is formed of dacite, Kka5 is observed as andesite and basalt. This formation is densely jointed and crushed. Weathered, crushed and jointed, gray and black colored Dikmen volcanic crop out sparsely in the study area, although their basement rock characteristics. This unit consists of basalt. The age of this unit is Eocene (Yilmaz et al. 1985). Oligo-Miocene Şebinkarahisar formation is formed of red fissured clay and claystone, un-cemented loose sandstone, conglomerates and the little quantity of gypsum in some locations. This formation crops out most extensively in the study area as a cover unit, and overlies the volcanic with an unconformity. In the study area, lower part of the Sebinkarahisar formation is characterized with red clays derived from andesite-basalt. From down to up, very loose and un-cemented sandstone like sand, conglomerates are very distinctive.
Since it is well known, the neotectonic framework of Turkey is outlined and characterized by major intercontinental strike-slip faults, namely the dextral North Anatolian fault zone and the sinistral East Anatolian fault zone, between which the Anatolian block moves westward relative to the Eurasian plate in the north and the Arabian plate in the south due to the continued convergence of these plates since the middle Miocene (McKenzie 1972; Dewey and Şengör 1979; Şengör 1980; Barka and Gülen 1988; Koçyiğit 1989) (Fig. 4) (After Yilmaz and Bagci 2006; Yilmaz et al. 2006).

Tectonic map of Turkey
The other striking secondary faults are the left-lateral Central Anatolian Fault Zone (CAFZ), the right-lateral Salt Lake Fault Zone (SLFZ) and the Inönü–Eskişehir and Akşehir oblique-slip normal fault zones (Koçyigit and Özacar 2003). The area of neotectonic extensional tectonic regime is effective in the south-western part of Anatolia, partly covering the Central Anatolia region (Oral et al. 1995; Altiner et al. 1997; Reilenger 2002) (Akman and Tüfekçi 2004).
Landslides
It has been recognized that the study area is frequently subjected to landslides. Landslides have posed a significant hazard in Sebinkarahisar for many years. Geological and geotechnical studies were conducted on the landslide to gain a better understanding of the triggering mechanisms and failure process and to better prepare for future failures in the area. Velocity of the slope movements has been predicted by monitoring the relative building movements in 2 years and classified as slow rate (0.06 m/year to 1.5 m/month) using the movement scale of Varnes (1978). However, very high velocities of slope movements were recorded after heavy rainy seasons by increasing the water level of rivers and their erosive power.
Well-defined slip surface and ground conditions were satisfactorily characterized by subsurface investigations in the study area. Boreholes and trial pits on the slopes also revealed the presence of clayey soils at the contact of the slope-forming materials with the basement rock. In order to derive a geotechnical model for landslide area, exploratory drilling results were combined with geology and morphology.
Many daylights of rotational slides and ground movements through slope material and rock mass along particularly weak clayey soils that form a sliding plane reaching over the river bed were observed. The deep-seated elements of the landslide involve translational sliding with a sliding plane parallel to the basement rock. It means that first a translational slide started along the river bank and the removal of the lateral supports induced rotational slides upslope.
Landslides in the study area usually occur on the slopes above river/creek having very high discharge value and velocity in winter and are very destructive as seen in Fig. 2b. Landslides occupy slopes whose toes have been subjected to surface-water erosion, suggesting that undercutting of slopes by surface water is the primary cause of the landslides. Groundwater, stratigraphical conditions and precipitation are secondary causes. The presence of clays also contributes to the failure. A combination of the removal of lateral support by toe erosion and loading of slope by groundwater are thought to be the triggering mechanisms. As long as the landslide toe remains stable, further slope failure is unlikely to occur. It was concluded that the closeness to the river should be used as a main affecting factor of landslides.
The mechanism of landslides was illustrated on a model section in Fig. 5. Erosion of the toe of a slope causes a series of landslides and after the rainstorms saturated Sebinkarahisar formation flows over the andesite–basalts. Each slide leads to the removal of the lateral support of the main landslide blocks upslope, and progressively worsens the stability of the system. Each slope failure causes reduction of the lateral stress in its close vicinity, which in turn makes the red clay in the sliding surface mechanically expand and reduce its strength. Physical swelling is not possible in short term due to the low permeability of the clay. However, after a period of time, water flows into the area, reduces the clay shear strength and causes further failure.

Cross-section showing the landslide mechanism
Preparation of landslide inventory and landslide susceptibility mapping
In recent years, geographical information system (GIS) technologies have the potential to address a wide range of problems in disaster management and hazard mitigation, and are increasingly playing an important role in spatial planning and sustainable development (Yilmaz 2007, Yilmaz 2008a). Landslide susceptibility mapping before the landslide assessment is very important for safe planning. Several attempts have been made to understand the temporal-spatial distribution of landslides and thus minimize the possible impacts by means of predictive risk models. As indicated in Part I, a number of different models have been developed in order to assess the landslide susceptibility. Quantitative techniques have become very popular in the last decades depending on the developments in computer and GIS technology.
To predict the landslide locations, it is necessary to assume that landslide occurrence is determined by landslide-related factors and that future landslides will occur under the same conditions as past landslides (Lee and Talib 2005). In order to construct the landslide susceptibility map quantitatively, the CP and ANN models were used by means of GIS.
In this study, GIS software, ArcGIS 9.1 was used as a basic tool for spatial management and data manipulation. The cell size of landslide and parameters maps were chosen as 20 × 20 m as the working scale was 1:25,000. These maps consist of 524 rows and 689 columns, and totally 361,036 cells.
A map of existing landslides serves as the basic data source for understanding conditions contributing to landslide occurrence. The map may be prepared at different sampling strategies concerning existing landslides. A simple inventory should identify the definite and probable areas of existing landslides. There are several considerations to keep in mind when gathering data on existing landslides. First, the time and effort required to conduct an inventory varies with (1) geologic and topographic complexity; (2) size of an area; and (3) desired level of inventory detail (Varnes 1978). Second, more detailed inventories will require larger map scales to reveal the small features of this added detail. Third, additional data gathering can add detail to an existing inventory. This enables a previously completed simple inventory to be transformed into an intermediate inventory with less time and effort than producing the intermediate inventory solely from field work and aerial photography.
The study area has experienced many landslides over a long period and 92 landslides have been mapped in the study area (Fig. 1b). In order to prepare an inventory map, landslide locations were plotted on 1:25,000 scaled topographic map using the Landsat TM satellite images and 1:35,000 aerial photographs, then information was completed and confirmed by the field surveys.
In this study, three landslide inventory maps were prepared by the following different techniques:
-
The first map (Map A) (Fig. 6) was prepared through the drawing of main scarp distinguished from the accumulation/depletion zone or rupture zone as polygon feature.
Fig. 6 
Sampling strategies used in the models
-
The second map (Map B) (Fig. 6) was obtained using the seed-cell proposed by Suzen and Doyuran (2004). Detail of this method can be read from the paper written by (Suzen and Doyuran 2004).
-
The third map (Map C) (Fig. 6) was prepared using the locations plotted as point selected at the upper part of the scar.

As known, many factors influence the occurrence of landslides, such as; geological, morphological, hydrogeological and meteorological conditions, vegetation and land use. The intensity of precipitation was ignored in this study, because it was almost the same throughout the area. This means that the effect of rainfall is negligible, because relative effect on the landslide occurrence in each cell will be the same in the susceptibility analyses.
Lithology and structural elements are very important parameters in the analyses of landslide susceptibility. There are four types of geological units in the study area, and Sebinkarahisar formation was found to be the most susceptible geological formation. Lineaments in the study area were drawn by the use of field observations, 1:35,000 scaled aerial photographs and satellite images. Proximity to the structural elements is a very important contributing parameter in the evaluation of landslide susceptibility. That is why distances to faults were calculated at 250 m intervals by buffering. It was obtained that regions having higher landslide occurrence probability were distributed in the area closer to the faults (Fig. 7a).

Parameter maps used in the analyses
In the susceptibility analyses, topographical parameters such as, drainage system, topographical elevation, slope angle, slope aspect and topographic wetness index (TWI) were considered and produced from the DEM of the study area. First, DEM was constructed by implementation of 1:25,000 scaled topographical map contours using ArcMap of ArcGIS 9.1 software (ArcGIS (Version 9.1) 2005). In order to assess the influence of drainage on the landslide occurrence, distance from drainage was calculated from topographical database.
Distance to drainage is an important contributing factor, because failure mechanism of landslides in the study area is mainly based on the erosion at the toe. Distances to drainage were calculated at 150 m intervals (Fig. 7b). At the distance closer to the drainage system, a high probability of landslide occurrence was found.
Analyses showed that slope angle in a range of 10°–30° (Fig. 7c) indicate high probability of landslide occurrence. Slope aspect analyses (Fig. 7d) showed that landslides were most abundant in E, W, S, SE, SW, NW facing slopes. Relationships between elevation and landslide occurrence indicated that landslides generally occur at the elevation range of 1,000–1,300 m. It can be seen from the Figs. 1 and 7e that landslides are also very rare at higher elevation than 1,300 m having a low-CP (Table 1). This sparseness is sourced from very thin soil cover and rocky characteristics of the areas at higher elevations (Fig. 7e).
As a general aspect, shear stresses on the slope material increase with the increasing slope degree, it is expected that landslides will occur on the steepest slopes. On the other hand, very low shear stresses are expected at gentle slopes. As a result of the analyses related to slope as a contributing factor showed that the low probability of landslide occurrence obtained in the areas having a steeper slope more than 30°. Because, steeper slopes are generally not susceptible to shallow landslides due to the bedrock outcrops and their eroded characteristics.
Topography first controls the spatial variation of hydrological conditions and slope stabilities. It affects the spatial distribution of soil moisture, and groundwater flow often follows surface topography (Burt and Butcher 1986; Seibert et al. 1997; Rodhe and Seibert 1999; Zinko et al. 2005). Topographic indices have therefore been used to describe the spatial soil moisture patterns (Burt and Butcher 1986; Moore et al. 1991). One such index is the TWI developed by Beven and Kirkby (1979) within the runoff model. It is defined as:
where a is the local upslope area draining through a certain point per unit contour length and tanβ is the local slope. The TWI has been used to study spatial scale effects on hydrological processes. Water infiltration to slope material cause pore water pressures and decreases the soil strength. In this study, TWI (Fig. 7f) was taken under consideration as a contributing factor. In the analysis, a transmissivity value of 1 was used constant for the whole catchments area.
Higher TWI values, distributed in higher elevations, point out the infiltration of surface water into the slope forming materials, and pore water pressures increase with decreasing shear strength. It was observed that landslides were very abundant at the lower elevations than locations having high TWI values at higher locations.
As another topographical index, the stream power index (SPI) (Fig. 7g), which is a measure of erosive power of the stream, was computed for the study area. SPI can be defined by the following equation
where A s is the specific catchment area and β is the local slope gradient in degrees.
The normalized difference vegetation index (NDVI) is a measure of surface reflectance and gives a quantitative estimate of the vegetation growth and biomass (Hall et al. 1995). Satellite maps of vegetation show the density of plant growth over the entire globe. The most common measurement is NDVI. Very low values of NDVI (0.1 and below) correspond to barren areas, sand or snow. Moderate values represent shrub and grassland (0.2–0.3), while high values indicate temperate and tropical rainforests (0.6–0.8) (Weier and Herring 2005).
Using the satellite image of Landsat Thematic Mapper (TM), the NDVI (Fig. 7h) was taken into consideration as a landslide-related factor. The NDVI was calculated from the following formula:
where IR infrared portion of the electromagnetic spectrum, R red portion of the electromagnetic spectrum.
The results showed that the landslides focused into the grassland areas and afforested areas having the respective NDVI values of 0.1–0.6.
Conditional probability model
As stated by Duman et al. (2005), one such limitation is the necessity to introduce a limited number of factors subdivided into a limited number of classes into the analysis. Otherwise, a high number of pixels of small dimensions, and so of less statistical significance, could result from the crossing of the data layers. However, probably the most limiting aspect is that an eventual change of the factors or simply their reclassification, implies restarting the entire procedure which, however conceptually simple it may be, is nevertheless complicated to execute. To overcome this difficulty, Clerici et al. (2002) have produced a shell program (or shell script) that executes the procedure automatically making it, therefore, possible to repeat it quickly and with limited user involvement.
Each specific combination represents a pixel. Subsequently, the landslide spatial frequency, usually represented by the landslide density, is determined within each pixel. Assuming the already mentioned principle that slope failure in the future will be more likely to occur under those conditions which led to the past instability and working on the statistical concept whereby the frequency of an event, the density of an event, equals the probability that the same event will occur, the resulting landslide density equals the landslide susceptibility (Clerici et al. 2002). Conditional probability is denoted mathematically as p(AIB) (Eq. 4) (Negnevitsky 2002; Duman et al. 2005).
The number of times A and B can occur or the probability that both A and B will occur, is also called “joint probability” of A and B. It represents mathematically as P(A ∩ B). The number of ways B can occur is the probability of B, P(B);
Bayesian rule is given in Eqs. 9, and 10 and can be written as event A being dependent on a number of mutually exclusive events B1, B2,…, Bn.
Landslide susceptibility maps were produced using Eq. 10 for three different sampling strategies of scarp, seed cell and point (Fig. 8). The p(A|B), p(A) and p(B) values are tabulated in Table 1.

Landslide susceptibility maps produced from the two models for three sampling strategies
Artificial neural networks model
Neural networks may be used as a direct substitute for multivariable regression, linear regression, trigonometric and other statistical analysis and techniques (Singh et al. 2003). Neural networks, with their remarkable ability to derive rules from complicated or imprecise data, can be used to extract patterns and detect trends that are too complex to be noticed by either humans or other computer techniques. The main characteristics of ANN include large-scale parallel distributed processing, continuous nonlinear dynamics, collective computation, high fault tolerance, self-organization, self-learning and real-time treatment. A trained neural network can be thought of as an “expert” in the category of information it has been given to analyze.
When a dataset is analyzed using neural networks, it is possible to detect important predictive patterns that are not previously apparent to a non-expert. Thus, the neural networks can act as an expert. The particular network can be defined using three fundamental components: transfer function, network architecture and learning law (Simpson 1990). It is essential to define these components, to solve the problem satisfactorily.
As stated by Gomez and Kavzoglu (2005); an alternative method for landslide risk zonation is the use of ANNs. ANNs are an attempt, in the simplest way, to imitate the neural system of the human brain.
Artifıcial neural networks have the ability to handle imprecise and fuzzy data, so they can work with continuous, categorical and binary data without violating any assumptions. As assessment of probability for landsliding is performed through the forecast of future events from experience of past landslides, it may be considered as an ideal application for ANNs (Jain et al. 1996; Yesilnacar and Hunter 2004; Gomez and Kavzoglu 2005).
Feed-forward back propagation learning algorithm as ANNs was also applied to the study area. More than one layer of neurons was included in the perceptron in order to cope with nonlinearly separable problems, and a multilayer perceptron (MLP) was obtained.
Neural networks consist of a large class of different architectures. In many cases, the issue is approximating a static nonlinear, mapping f(x) with a neural network f (x) NN , where x ∈ R K. There are many kinds of ANN models, among which the back propagation (BP) model is the most widely used, and it is an instructive training model. It is accepted that the most useful neural networks in prediction and decision algorithm are back propagation and radial basis function (RBF) networks. In this paper, back propagation algorithm, created by generalizing the Widrow–Hoff learning rule to multiple layer networks and nonlinear differentiable transfer function, is used. A back propagation consists of an input layer, several hidden layers and outputs layers. All of those layers may contain multiple nodes (After Yilmaz and Yüksek 2008, 2009).
The inputs x n , n = 1,…, n to the neuron are multiplied by weights w ni and summed up together with the constant bias term Q i . The resulting n i is the input to the activation function y. The activation function was originally chosen to be a relay function, but for mathematical convenience a hyperbolic tangent (tan h) or a sigmoid function are most commonly used. Hyperbolic tangent is defined as
The output of node i become
Connecting several nodes in parallel and series, an MLP network is formed. A typical network is shown in Fig. 9. The following equations explain mathematical notation of back propagation algorithm.

Neural network structure used in the study
The learning is done using the following procedure;
-
1.
Selection of random and small sized (between 0 and 1) numbers for all weight and bias.
-
2.
Calculation of network output and comparison with the destination output.
-
3.
If the network output is approximately equal to the desired output, then continue with step 1, and if not weights are corrected according to the correction rule and then continue with step 1.
MatLab 7.0 was used to training and testing for neural networks. A three-layer feed-forward network that consists of an input layer (9 neurons), one hidden layer (19 neurons) and one output layer was used as a network structure of 9–19–1 (Fig. 9). MLPs can have more than one hidden layer. However, there is rarely an advantage in using more than one hidden layer (Lippmann 1987; Rumelhart et al. 1986). It has been shown that an MLP with one hidden layer has the capability to approximate any function with an acceptable degree of accuracy if there are enough hidden nodes. In cases where the optimum number of hidden nodes on a single hidden layer is large, two hidden layers with a small number of nodes on each layer could be more appropriate. In this study, one hidden layer having 19 nodes (as proposed by Hecht-Nielsen 1987) were used. Initial weight range is also an important parameter influencing the convergence of learning rule. In this study, weights were randomly initialized in a small range of [−0.25–0.25] as proposed by Kavzoglu (2001). Kavzoglu (2001) had also suggested that the minimum number of training samples should be more than 30 × N i × (N i + 1) where N i is the number of input nodes.
The important design parameters for network generalization are (1) number of hidden nodes, (2) size of training and test datasets, (3) initial weight range, (4) learning rate, (5) the momentum term, and (6) number of training cycles. Extreme values of these parameters cause some severe effects on training convergence and network generalization. For example, too high learning parameter speeds up the convergence however unstable NN (weights) oscillates about the optimal solution, and too low values causes slow training and a greater likelihood of becoming trapped in a local minimum. Too high momentum parameter reduces risk of local minima, speeds up training and causes unstable learning, but too low value suppresses effect of momentum leading to increased risk of potential entrapment in local minima and causes slow training (Basheer and Hajmeer 2000; Yesilnacar and Hunter 2004).
In this study 4,800 training samples were used, and parameters were then adjusted as below:
-
Learning parameters 0.1
-
Momentum parameters 0.9
-
Networks training function: variable learning rate with momentum (traing dx)
-
Activation (transfer) function for all layers: tansig
As in many other network training methods, models and parameters were used to be able to reach minimum RMSE values. After the network goal was reached, study area was fed into the network in order to estimate the landslide susceptibility. The set of susceptibility values obtained in each grid was then converted to raster file in GIS medium, and landslide susceptibility map was produced applying different sampling strategies such as; scarp, seed cell and point (Fig. 8).
Validation of the maps
The landslide susceptibility maps can be tested using the known landslide locations. The AUC is a good indicator to check the prediction performance of the model and the largest AUC, varying from 0.5 to 1.0, is the most ideal model. By the use of the 100 subdivisions of LSI values of all cells in the study area and cumulative percentage of landslide occurrence in the classes, curves were drawn to calculate AUC (Fig. 10). The obtained values of AUC from the two models for different sampling strategies are tabulated in Table 2. The AUC values showed that the map obtained from ANN model looks like more accurate than the other model, while scarp sampling was obtained as the most appropriate sampling strategy in preparation of the landslide susceptibility map. However, the AUC values for scarp and seed cells sampling can be evaluated relatively similar.

AUC representing the quality of the two models for three sampling strategies
Moreover, the validation by field investigations was also performed by comparing the known landslide location data with the classes of landslide susceptibility in maps. The results obtained from field observation were also found to be harmonious with results of AUC.
Results and discussions
The study area in Sebinkarahisar is located in the North Anatolian Fault Zone, and has been recognized that the study area and environment are frequently subjected to landslides. Recently, numerous landslides in different masses were occurred in the study area. Landslides in the studied area were first characterized by means of field and laboratory measurements, monitoring and remote sensing data. As known, reoccurrence potential in this area and understanding of the failure mechanism is very important in order to select the remediation measures; therefore, landslide mechanism was first explained.
Landslide susceptibility can be assessed using different methods based on the GIS technology. Especially in the last 20 years, many research papers were published in order to solve the deficiencies and difficulties in the susceptibility assessment. It should be aimed that the procedure for preparing landslide susceptibility map must be simple and have a higher accuracy.
Landslide events in Sebinkarahisar (Giresun–Turkey) are strongly correlated to many factors. The quantitative relationship between affecting factors and landslide occurrence was achieved and powerful relationships were found with geology, faults, drainage system, topographical elevation, slope angle, slope aspect, TWI, SPI and NDVI. In the susceptibility analyses, DEM was first constructed using ArcGIS 9.1 GIS software and parameters affecting slope stability were considered. In order to show the effect of the different sampling strategies on the landslide susceptibility, maps of scarp, seed cells and point sampling strategies were prepared. In the last stage of the analyses, landslide susceptibility maps were produced for each sampling strategy using the CP and neural networks models, and results were then compared by means of their validation.
Validations of the obtained maps indicated that the more realistic results obtained from the analyses where the scarp sampling strategy was used, however, it was relatively similar with the seed cells strategy. It can be evaluated that the two strategies such as scarp and seed cells considered have relatively similar accuracy. Because the areas due to the proposed strategies included in the analyses are very closer. On the other hand, the worst performances of the validations were obtained from the analyses depending on the point sampling strategy using the both model CP and ANNs. Nefeslioglu et al. (2008) had also reported that the susceptibility map based on the samplings in which the presence of data taken from a zone that almost represents prefailure conditions constituted more realistic susceptibility evaluations.
As reported by Yilmaz (2008c); point data in GIS can be described by a single X, Y coordinate and does not reflect the landslide affected area, and this type of feature may be used when the area extend of a small landslide cannot be drawn due to the scale of the map. However, the logic way is to reveal the landslide responsible pixels. In landslide inventory mapping, for each landslide, the main scarp distinguished from the accumulation/depletion zone or rupture zone as polygon feature or seed cells should be used to obtain an accurate and realistic susceptibility map.
As another result of this study, higher accuracies of susceptibility mapping for the two models were obtained. AUC values showed that the map obtained from ANN model looks like having a better accuracy than the other model. However, neural networks method was found to be more realistic, in CP model, input process, calculations and output process were very simple and can be readily understood.
Yesilnacar and Topal (2005) stated that several investigators have compared neural network models with logistic regression using different data sets, with some researchers finding superior performance for the neural networks and other authors finding no differences in overall predictive performance (Tu 1996; Schumacher et al. 1996; Manel et al. 1999; Ottenbacher et al. 2001; Mahiny and Turner 2003). They had also indicated that the susceptibility map produced using the neural networks method is found to be more realistic. Aleotti et al. (1998) and Gomez (2002) applied ANN approach for landslide susceptibility mapping and found it out-performed traditional statistical methods.
References
Akman AÜ, Tüfekçi K (2004) Determination and characterization of fault systems and geomorphological features by Rs and Gis techniques in the WSW part of Turkey. XXth ISPRS Congress, Istanbul, pp 899–904
Aleotti P, Baldelli P, Polloni G, Puma F (1998) Keynote paper: different approaches to landslide hazard assessment. In: Proceedings of the second conference environment management (ICEM-2), Wollongong (Australia), 1:3–10
Altıner Y, Habrich H, Kahveci M, Kurt M, Salk M, Seeger H (1997) GPS measurements in western Turkey from 1992 to 1994. International Symposium on GIS/GPS, Istanbul
ArcGIS (Version 9.1) (2005) Integrated Geographical information system software, ESRI
Atkinson PM, Massari R (1998) Generalised linear modelling of susceptibility to landsliding in the Central Appenines Italy. Comput Geosci 24(4):373–385. doi:10.1016/S0098-3004(97)00117-9
Baeza C (1994) Evaluación de las condiciones de rotura y la movilidad de los deslizamientos superficiales mediante el uso de técnicas de análisis multivariante. Tesis Univ. Pol, Catalunya
Barka AA, Gülen L (1988) New constraints on age and total offset of the North Anatolian Fault Zone: implications for tectonics of the eastern Mediterranean region. METU J Pure Appl Sci 21(1–3):39–63
Barredo JJ, Benavides A, Hervas J, Van Westen CJ (2000) Comparing heuristic landslide hazard assessment techniques using GIS in the Trijana basin, Gran Canaria Island, Spain. JAG 2(1):9–23
Basheer IA, Hajmeer M (2000) Artificial neural networks: fundamentals, computing, design, and application. J Microbiol Methods 43:3–31. doi:10.1016/S0167-7012(00)00201-3
Beven KJ, Kirkby MJ (1979) A physically based, variable contributing area model of basin hydrology. Hydrol Sci Bull 24:43–69
Brabb EE, Pampeyan EH, Bonilla M (1972) Landslide susceptibility in the San Mateo County, California, scale 1 : 62.500, US Geol Survey Misc Field Studies Map MF344
Burt T, Butcher D (1986) Stimulation from simulation—a teaching model of hillslope hydrology for use on microcomputers. J Geography Higher Educ 10:23–39. doi:10.1080/03098268608708953
Carrara A (1983) Multivariate models for landslide hazard evaluation. Math Geol 15(3):403–426. doi:10.1007/BF01031290
Carrara A, Cardinalli M, Detti R, Guzzetti F, Pasqui V, Reichenbach P (1991) GIS techniques and statitistical models in evaluating landslide hazards. Earth Surf Proc Land 16:427–445. doi:10.1002/esp.3290160505
Carrara A, Crosta G, Frattini P (2003) Geomorphological and historical data in assessing landslide hazard. Eart Surf Processes Landf 28:1125–1142. doi:10.1002/esp.545
Cascini L, Critelli S, Gulla G, Di Nocera S (1991) A methodological approach to landslide hazard assessment: a case history. In: Proceedings 16th international landslide conference, Balkema, Rotterdam, pp 899–904
Chacón J, Irigaray C, Fernández T (1994) Large to middle scale landslide inventory, analysis and mapping with modelling and assessment of derived susceptibility, hazards and risks in a GIS. In: Proceedings of 7th IAEG Congress, Balkema, Rotterdam, Holland, pp 4669–4678
Chacón J, Irigaray C, Fernández T (1996) From the inventory to the risk analysis: improvements to a large scale GIS method. In: Chacón J, Irigaray C, Fernández T (eds) Proceedings of 8th International conference and field workshop on landslides. Balkema, Rotterdam, Holland, pp 335–342
Chung CF, Fabbri AG (1999) Probabilistic prediction models for landslide hazard mapping. Photogrammetric Eng Remote Sens 65(12):1389–1399
Chung CF, Fabbri AG, van Westen CJ (1995) Multivariate regression analiysis for landslide hazard zonalition. In: Carrara A, Guzetti F (eds) Geographical information’s systems in assessing natural hazards. Kluwer, Dordrecht
Clerici A, Perego S, Tellini C, Vescovi P (2002) A procedure for landslide susceptibility zonation by the conditional analysis method. Geomorphology 48:349–364. doi:10.1016/S0169-555X(02)00079-X
Clerici A, Perego S, Tellini C, Vescovi P (2006) A GIS-based automated procedure for landslide susceptibility mapping by the conditional analysis method: the Baganza valley case study (Italian Northern Apennines). Environ Geol 50(7):941–961. doi:10.1007/s00254-006-0264-7
Dai FC, Lee CF (2003) A spatiotemporal probabilistic modelling of storm induced shallow landsliding using aerial photographs and logistic regression. Earth Surf Proc Land 28:527–545. doi:10.1002/esp.456
Dai FC, Lee CF, Zhang XH (2001) GIS-based geo-environmental evaluation for urban land-use planning: a case study. Eng Geol 61:257–271. doi:10.1016/S0013-7952(01)00028-X
DeGraff J, Romesburg H (1980) Regional landslide-susceptibility assessment for wildland management: a matrix approach. In: Coates D, Vitek J (eds) Thresholds in geomorphology. George Allen and Unwin, London, pp 401–414
Dewey JF, Şengör AMC (1979) Aegean and surroundings regions: complex multiple and continuum tectonics in a convergent zone. Geol Soc Am Bull 90:84–92. doi:10.1130/0016-7606(1979)90<84:AASRCM>2.0.CO;2
Duman TY, Can T, Gokceoglu C, Nefeslioglu HA (2005) Landslide susceptibility mapping of Cekmece Area (Istanbul, Turkey) by conditional probability. Hydrol Earth Syst Sci Discuss 2:155–208
Duman TY, Can T, Gokceoglu C, Nefeslioglu HA, Sonmez H (2006) Application of logistic regression for landslide susceptibility zoning of Cekmece Area, Istanbul, Turkey. Environ Geol 51(2):241–256. doi:10.1007/s00254-006-0322-1
Ercanoglu M, Gokceoglu C (2004) Use of fuzzy relations to produce landslide susceptibility map of a landslide prone area (West lack Sea Region, Turkey). Eng Geol 75:229–250. doi:10.1016/j.enggeo.2004.06.001
Fernández T, Irigaray C, Hamdouni RE, Chacón J (2003) Methodology for landslide susceptibility mapping by means of a GIS. Application to the Contraviesa Area (Granada, Spain). Nat Hazards 30:297–308. doi:10.1023/B:NHAZ.0000007092.51910.3f
Gokceoglu C, Aksoy H (1996) Landslide susceptibility mapping of the slopes in the residual soils of the Mengen region (Turkey) by deterministic stability analyses and image processing technique. Eng Geol 44:147–161. doi:10.1016/S0013-7952(97)81260-4
Gomez HR (2002) Modeling landslide potential in the Venezuelan Andes. PhD Thesis, The University of Nottingham, School of Geography, 272 p (unpublished)
Gomez H, Kavzoglu T (2005) Assessment of shallow landslide susceptibility using artificial neural networks in Jabonosa River Basin, Venezuela. Eng Geol 78(1–2):11–27. doi:10.1016/j.enggeo.2004.10.004
Hall FG, Townshend JR, Engman ET (1995) Status of remote sensing algorithms for estimation of land surface state parameters. Remote Sens Environ 51:138–156. doi:10.1016/0034-4257(94)00071-T
Hecht-Nielsen R (1987) Kolmogorov’s mapping neural network existence theorem. In: Proceedings of the first IEEE international conference on neural networks. San Diego, CA, USA, pp 11–14
Irigaray C (1995) Movimientos de ladera: inventoria, analisis y cartografaa de susceptibilidad mediante un Sistema de Informacion Geografica. Aplicacion a las zonas de Colmenar (Ma), Rute (Co) y Montefrio (Gr). Thesis Doctoral, University Granada
Ives JD, Messerli B (1981) Mountain hazard mapping in Nepal: introduction to an applied mountain research project. Mt Res Dev 1(3–4):223–230. doi:10.2307/3673059
Jade S, Sarkar S (1993) Statistical models for slope instability classification. Eng Geol 36:91–98. doi:10.1016/0013-7952(93)90021-4
Jain AK, Mao J, Mohiuddin KM (1996) Artificial neural networks: a tutorial. Comput IEEE March 3:1–44
Kavzoglu T (2001) An investigation of the design and use of feed-forward artificial neural networks in the classification of remotely sensed images. PhD Thesis, University of Nottingham, School of Geography, 306 pp
Koçyiğit A (1989) Suşehri basin: an activa fault-wedge basin on the North Anatolian Fault Zone, Turkey. Tectonophysics 167:13–29. doi:10.1016/0040-1951(89)90291-6
Koçyiğit A, Özacar AA (2003) Extensional neotectonic regime through the NE edge of the outer Isparta Angle, SW Turkey: new field and seismic data. Turkish J Earth Sci 12:67–90
Lee S, Min K (2001) Statistical analyses of landslide susceptibility at Yongin. Korea Environ Geol 40:1095–1113. doi:10.1007/s002540100310
Lee S, Talib JA (2005) Probabilistic landslide susceptibility and factor effect analysis. Environ Geol 47:982–990. doi:10.1007/s00254-005-1228-z
Lee S, Ryu JH, Min K, Won JS (2003a) Landslide susceptibility analysis using GIS and artificial neural network. Earth Surf Process Landf 27:1361–1376. doi:10.1002/esp.593
Lee S, Ryu JH, Lee MJ, Won JS (2003b) Landslide susceptibility analysis using artificial neural network at Boun, Korea. Environ Geol 44:820–833. doi:10.1007/s00254-003-0825-y
Lee S, Ryu JH, Won JS, Park HJ (2004) Determination and application of the weights for landslide susceptibility mapping: using an artificial neural network. Eng Geol 71:289–302. doi:10.1016/S0013-7952(03)00142-X
Lippmann RP (1987) An introduction to computing with neural nets. IEEE ASSP Magazine, 4–22. doi:10.1109/MASSP.1987.1165576
Mahiny AS, Turner BJ (2003) Modeling past vegetation change through remote sensing and GIS: a comparison of neural networks and logistic regression methods. In: Proceedings of the 7th international conference on geocomputation. University of Southampton, UK
Manel S, Dias JM, Ormerod SJ (1999) Comparing discriminant analysis, neural networks and logistic regression for predicting species distributions: a case study with Himalayan river bird. Ecol Model 120:337–347. doi:10.1016/S0304-3800(99)00113-1
McKenzie D (1972) Active tectonics of the Mediterranean region. Geophys J R Astr Soc 30:109–185
Moore ID, Grayson RB, Ladson AR (1991) Digital terrain modeling—a review of hydro- hydrological, geomorphological, and biological applications. Hydrol Processes 5:3–30. doi:10.1002/hyp.3360050103
Nefeslioglu HA, Gokceoglu C, Sonmez H (2008) An assessment on the use of logistic regression and artificial neural networks with different sampling strategies for the preparation of landslide susceptibility maps. Eng Geol 97:171–191. doi:10.1016/j.enggeo.2008.01.004
Negnevitsky M (2002) Artificial intelligence: a guide to intelligent systems. Addison-Wesley, Great Britain, 394 p
Oral B, Reilenger R, Toksöz NM, King R, Barka A, Kınık I, Lenk O (1995) Coherent plate motion in the eastern Mediterranean continental collision zone. EOS, January, 1–3
Ottenbacher KJ, Smith PM, Illig SB, Linn RT, Fiedler RC, Granger CV (2001) Comparison of logistic regression and neural networks to predict rehospitalization in patients with stroke. J Clin Epidemiol 54:1159–1165. doi:10.1016/S0895-4356(01)00395-X
Pistocchi A, Luzi L, Napolitano P (2002) The use of predictive modeling techniques for optimal exploitation of spatial databases: a case study in landslide hazard mapping with expert system-like methods. Environ Geol 41:765–775. doi:10.1007/s002540100440
Reilenger R (2002) GPS applications to earthquake mechanics and seismic hazard studies: The 1999, M7,6 İzmit Earthquake. 4th international Turkish geological symposium abstracts, 338, Adana
Remondo J, Gonzalez-Diez A, Teran JRD, Cendrero A (2003) Landslide susceptibility models utilising spatial data analysis techniques: a case study from the lower Deba Valley, Guipúzcoa (Spain). Nat Hazards 30:267–279. doi:10.1023/B:NHAZ.0000007202.12543.3a
Rengers N, van Westen CJ, Chacón J, Irigaray C (1998) Draft for the chapter on the application of digital techniques for natural hazard zonation. Report on mapping of natural hazards, international association of engineering geology. Commission No. 1 on engineering geological mapping
Rodhe A, Seibert J (1999) Wetland occurrence in relation to topography: a test of topographic indices as moisture indicators. Agric For Meteorol 98–99:325–340. doi:10.1016/S0168-1923(99)00104-5
Rumelhart DE, Hinton GE, Williams RJ (1986) Learning internal representations by error propagation. In: Rumelhart DE, McClelland JL (eds) Parallel distributed processing. vol 1. pp 318–362
Rupke J, Cammeraat E, Seijmonsbergen AC, Van Westen CJ (1988) Engineering geomorphology of the Widentobel catchment, Switzerland: a geomorphological inventory system applied to geotechnical appraisal of the slope stability. Eng Geol 26:33–68. doi:10.1016/0013-7952(88)90005-1
Santacana N, Baeza B, Corominas J, Paz A, Marturia J (2003) A GIS based multivariate statistical analysis for shallow landslide susceptibility mapping in la pobla de lillet area (Eastern Pyrenees, Spain). Nat Hazards 30:281–295. doi:10.1023/B:NHAZ.0000007169.28860.80
Schumacher M, Robner R, Vach W (1996) Neural networks and logistic regression: part I. Comput Stat Data Anal 21:661–682. doi:10.1016/0167-9473(95)00032-1
Seibert J, Bishop KH, Nyberg L (1997) A test of TOPMODEL’s ability to predict spatially distributed groundwater levels. Hydrol Processes 11:1131–1144. doi:10.1002/(SICI)1099-1085(199707)11:9<1131::AID-HYP549>3.0.CO;2-#
Şengör AMC (1980) Mesozoic-Cenozoic tectonic evolution of Anatolia and surrounding regions, Abstract. Bull Bur Rech Geol Minieres France 11:5–137
Simpson PK (1990) Artificial neural system-foundation, paradigm, application and implementation. Pergamon Press, New York
Singh TN, Kanchan R, Verma AK, Singh S (2003) An intelligent approach for prediction of triaxial properties using unconfined uniaxial strength. Min Eng J 5(4):12–16
Suzen ML, Doyuran V (2004) Data driven bivariate landslide susceptibility assessment using geographical information systems: a method and application to Asarsuyu catchment, Turkey. Eng Geol 71:303–321. doi:10.1016/S0013-7952(03)00143-1
Tu JV (1996) Advantages and disadvantages of using artificial neural networks versus logistic regression for predicting medical outcomes. J Clin Epidemiol 49(11):1225–1231. doi:10.1016/S0895-4356(96)00002-9
Van Den Eeckhaut M, Vanwalleghem T, Poesen J, Govers G, Verstraeten G,Vandekerckhove L (2006) Prediction of landslide susceptibility using rare events logistic regression: a case-study in the Flemish Ardennes (Belgium). Geomorphology 76:392–410
Van Westen CJ (1993) Application of geographic information systems to landslide hazard zonation. PhD Dissertation Technical University Delft. ITCPublication Number 15, ITC, Enschede, The Netherlands, 245 p
Van Westen CJ, Lulie GF (2003) Analyzing the evolution of the Tessina landslide using aerial photographs and digital elevation models. Geomorphology 54(1–2):77–89. doi:10.1016/S0169-555X(03)00057-6
Van Westen CJ, Soeters R, Sijmons K (2000) Digital geomorphological landslide hazard mapping of the Alpago area, Italy. Int J Appl Earth Observ Geoinform 2(1):51–59. doi:10.1016/S0303-2434(00)85026-6
Varnes DJ (1978) Slope movement, types and processes. In: Schuster RL, Krizek, RJ (eds) Landslides, analyses and control. National Academy of Science, Report 176, Washington DC, pp 11–35
Ward T, Ruh-Ming L, Simons D (1982) Mapping landslide hazard in forest watershed. J Geotech Eng Div 108(2):319–324
Weier J, Herring D (2005) Measuring vegetation (NDVI and EVI). Earth Observatory Library of NASA, http://earthobservatory.nasa.gov/Library/MeasuringVegetation/
Yesilnacar E, Hunter GJ (2004) Application of neural networks for landslide susceptibility mapping in Turkey. İn: van Leeuwen JP, Timmermans HJP (eds) Recent advances in design and decision support systems in architecture and urban planning, pp 3–18
Yesilnacar E, Topal T (2005) Landslide susceptibility mapping: a comparison of logistic regression and neural networks methods in a medium scale study, Hendek region (Turkey). Eng Geol 79:251–266. doi:10.1016/j.enggeo.2005.02.002
Yilmaz I (2007) GIS based susceptibility mapping of karst depression in gypsum: a case study from Sivas basin (Turkey). Eng Geol 90(1–2):89–103. doi:10.1016/j.enggeo.2006.12.004
Yilmaz I (2008a) A case study for mapping of spatial distribution of free surface heave in alluvial soils (Yalova, Turkey) by using GIS software. Comput Geosci 34(8):993–1004. doi:10.1016/j.cageo.2007.06.008
Yilmaz I (2008b) A case study from Koyulhisar (Sivas–Turkey) for landslide susceptibility mapping by artificial neural networks. Bull Eng Geol Environ. doi:10.1007/s10064-009-0185-2
Yilmaz I (2008c) Landslide susceptibility mapping using frequency ratio, logistic regression, artificial neural networks and their comparison: a case study from Kat landslides (Tokat–Turkey). Comput Geosci 35(6):1125–1138
Yilmaz I, Bagci A (2006) Soil liquefaction susceptibility and hazard mapping in the residential area of Kütahya (Turkey). Environ Geol 49(5):708–719. doi:10.1007/s00254-005-0112-1
Yilmaz I, Yildirim M (2006) Structural and geomorphological aspects of the Kat landslides (Tokat-Turkey), and susceptibility mapping by means of GIS. Environ Geol 50(4):461–472. doi:10.1007/s00254-005-0107-y
Yilmaz I, Yüksek AG (2008) An example of artificial neural network application for indirect estimation of rock parameters. Rock Mech Rock Eng 41(5):781–795. doi:10.1007/s00603-007-0138-7
Yilmaz I, Yüksek AG (2009) Prediction of the strength and elasticity modulus of gypsum using multiple regression, ANN, ANFIS models and their comparison. Int J Rock Mech Min Sci 46(4):803–810. doi:10.1016/j.ijrmms.2008.09.002
Yilmaz A, Oral A, Bilgiç T (1985) Yukarı Kelkit çayı yöresi ve güneyinin temel jeoloji özellikleri ve sonuçları. MTA Report (in Turkish)
Yilmaz I, Ekemen T, Yildirim M, Keskin I, Özdemir G (2006) Failure and flow development of a collapse induced complex landslide: the 2005 Kuzulu (Koyulhisar–Turkey) landslide hazard. Environ Geol 49(3):467–476. doi:10.1007/s00254-005-0113-0
Zinko U, Seibert J, Dynesius M, Nilsson C (2005) Plant species numbers predicted by a topography based groundwater-flow index. Ecosystems 8:430–441. doi:10.1007/s10021-003-0125-0
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Yilmaz, I. The effect of the sampling strategies on the landslide susceptibility mapping by conditional probability and artificial neural networks. Environ Earth Sci 60, 505–519 (2010). https://doi.org/10.1007/s12665-009-0191-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12665-009-0191-5