
Abstract
Allocating resources for natural hazard risk management has high priority in development banks and international agencies working in developing countries. Global hazard and risk maps for landslides and avalanches were developed to identify the most exposed countries. Based on the global datasets of climate, lithology, earthquake activity, and topography, areas with the highest hazard, or “hotspots”, were identified. The applied model was based on classed values of all input data. The model output is a landslide and avalanche hazard index, which is globally scaled into nine levels. The model results were calibrated and validated in selected areas where good data on slide events exist. The results from the landslide and avalanche hazard model together with global population data were then used as input for the risk assessment. Regions with the highest risk can be found in Colombia, Tajikistan, India, and Nepal where the estimated number of people killed per year per 100 km2 was found to be greater than one. The model made a reasonable prediction of the landslide hazard in 240 of 249 countries. More and better input data could improve the model further. Future work will focus on selected areas to study the applicability of the model on national and regional scales.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Landslides and snow avalanches cause major disasters on a global scale every year, and the frequency of their occurrence seems to be on the rise. The main reasons for the observed increase in landslide disasters are a greater susceptibility of surface soil to instability as a result of overexploitation of natural resources and deforestation, and greater vulnerability of the exposed population as a result of growing urbanization and uncontrolled land-use. Furthermore, traditionally uninhabited areas such as mountains are increasingly used for recreational and transportation purposes, pushing the borders further into hazardous terrain.
Climate change and the potential for more extreme weather conditions may also be a contributing factor. Recent examples of major slide disasters are the debris floods and mudflows in Venezuela in December 1999, which caused over 20,000 fatalities; the El Salvador earthquake of January 2001, which caused 600 fatalities in just one landslide; and the debris flows and landslides on Hispaniola Island in May 2004, which caused over 2,500 fatalities in Haiti and the Dominican Republic.
Although slides and avalanches occur more frequently than other major natural hazards, in terms of the number of fatalities from different hazards, they rank rather low as seen from Table 1. Distribution of the casualties by continent, and economic damage due to landslides, are reported in Fig. 1. There is, however, reason to believe that the number of causalities due to landslides shown in the table is grossly underestimated. This is because the loss figures in the international databases are normally recorded by the primary triggering factor, and not by the hazard that causes the fatalities. For instance, the 1999 Venezuela disaster with more that 20,000 deaths is recorded as a flood, while most fatalities were caused by landslides in form of debris flows and mud flows.

Number of fatalities and cost of damage from landslides during 1903 to 2004, sorted by continents (Source: EM-DAT: The OFDA/CRED International Disaster database)
Information on natural hazards, vulnerabilities, and risks at an appropriate scale is of fundamental importance for the design and implementation of policies and programs for risk mitigation. Contingency planning, disaster preparedness, and early warning systems require the knowledge of what kind of losses could be expected from what type of hazard. Lack of such data on a global scale led to an initiative from the ProVention Consortium of the World Bank to launch a collaborative project on “Identification of Global Natural Disaster Hotspots” in 2001 – the “Hotspots Project”, for short. The aim of the Hotspots Project was to perform a global assessment of the risk of mortality and economic losses for six major natural hazards: droughts, floods, windstorms, earthquakes, landslides (including snow avalanches) and volcanoes. The results of the project are available in a World Bank publication (Dilley et al. 2005).
This paper describes the assessment of the global distribution of landslide hazard and risk, which was performed by the Norwegian Geotechnical Institute (NGI), (Nadim et al. 2004) in collaboration with the United Nations Environment Programme (UNEP) and Global Resource Information Database (GRID-Europe) for the Hotspots Project. The assessment of the hotspots for other natural hazards mentioned above was carried out by Columbia University (USA).
Model description
The general approach adopted in the present study for the evaluation of global landslide and snow avalanche hazard prone areas and risk hotspots is depicted in Fig. 2.

Approach for landslide hazard and risk evaluation
The study focused on slides with rapid mass movement, like rockslides, debris flows, snow avalanches, and rainfall- and earthquake-induced slides, which pose a threat to human life. Slow-moving slides have significant economic consequences for constructions and infrastructure, but rarely cause fatalities. The risk computation was calibrated according to past human losses recorded by various natural disaster impact databases. The estimation of expected losses was achieved by first combining frequency and population exposed, in order to provide the physical exposure, and then performing a regression analysis using different sets of uncorrelated socio-economical parameters in order to identify the indicators that were the best proxy for approaching human vulnerability to landslides in a given country. Details of the hazard and risk estimation models are provided below.
Landslide hazard evaluation
Landslide hazard level depends on the combination of trigger and susceptibility. In the first-pass estimate of landslide hazard, the hazard level was estimated using a model similar to that suggested by Mora and Vahrson (1994) for regional analyses:
where H landslide is the relative landslide hazard level, S r the slope factor within a selected grid, S l is lithological (or geological) conditions factor, S h describes the soil moisture condition, T p the precipitation factor and T s describes the seismic conditions.
Slope factor S r
The slope factor represents the natural landscape ruggedness within a grid unit. In February 2000, NASA collected elevation data for much of the world using a radar instrument aboard the Space Shuttle. The raw data collected on the mission were processed over three years. NASA has now released a global elevation dataset called SRTM30, referring to the name of the mission and the resolution of the data, which is 30 arc-seconds, or approximately 1 km2 per data sample near the equator. The SRTM30 data set covers the globe from 60° south latitude to 60° north latitude. The vertical accuracy is estimated such that 90% of posts are within a 16-m tolerance of the actual position. Using the SRTM30 data set as the starting point and correcting the anomalies by using other datasets, Isciences (www.isciences.com) derived the grid of slope angles for this study. The slope data were reclassified on a geographical grid (WGS84) and the grid cells were categorized as shown in Table 2.
Note that S r was set equal to zero for slope angles less than 1°, i.e., for flat or nearly flat areas, because the resulting landslide hazard is null even if the other factors are favorable.
Lithology factor S l
This is probably the most difficult parameter to assess. Ideally, detailed geotechnical information should be used but, at the global scale, only a general geological description is available. Rock strength and fracturing are the most important factors to evaluate lithological characteristics, and these characteristics can vary greatly over short distances.
The dataset used in this study was the Geological map of the World at 1/25,000,000 scale published by the Commission for the Geological Map of the World and UNESCO (CGMW 2000). The map is available on CD-ROM. The grid Resolution is 2.5°×2.5° latitude/longitude. This map is the first geological dataset compiled at a global scale showing the geology of the whole planet, including continents and oceans. In the map, three main types of formation are identified: sedimentary rocks, extrusive volcanic rocks and endogenous rocks (plutonic or strongly metamorphosed). Usually old rocks are stronger than young rocks. Plutonic rocks will usually be strong and represent low risk. Strength of metamorphic rocks is variable, but these rocks often have planar structures such as foliation and therefore may represent higher risk than plutonic rocks. Lava rocks will usually be strong, but may be associated with tuff (weak material). Therefore, areas with recent volcanism are classified as high risk. Sedimentary rocks are often very weak, especially young ones. For the purpose of this study, five susceptibility classes were identified (Table 3).

Global soil moisture index: 1961–1990 (Willmott and Feddema 1992)
Soil moisture factor, S h
Sh is a soil moisture index, which indicates the mean humidity throughout the year and gives an indication of the state of the soil prior to heavy rainfall and possible destabilization. The data for this study were extracted from Willmott and Feddema's moisture index archive (Willmott and Feddema 1992). The data cover the standard meteorological period 1961–1990. Resolution of the grid is 0.5°×0.5°. Gridded mean monthly total potential evapotranspiration (Eo) and unadjusted (in respect to topography) total precipitation (P) are taken from:
-
Terrestrial Water Balance Data Archive: regridded monthly climatology, and
Fig. 4 
Expected monthly extreme precipitation values (mm) for a 100-year event (derived from statistics of monthly precipitation http://gpcc.dwd.de)
-
Terrestrial Air Temperature, monthly precipitation and annual climatology.

These data can be downloaded from the Internet (Centre for Climatic research, University of Delaware). Estimates of the average monthly moisture indices for Eo and P are only made for land-surface grid points (total of 85,794 points). The average monthly moisture indices are calculated according to Willmott and Feddema (1992) using the gridded average-monthly total Eo and P values, at the same resolution as the water-balance fields. For this study, five classes for soil moisture index were determined (Table 4). The map of the global soil moisture index is shown in Fig. 3.
Precipitation trigger factor T p
The categorization T p was based on the estimate of the 100-year extreme monthly rainfall (i.e., extreme monthly rainfall with 100 years return period). The source of data was the monthly precipitation time series (1986–2003) from the Global Precipitation Climatology Centre (GPCC) run by Germany's National Meteorological Service, DWD (Rudolf et al. 2005). The provided data are near real-time monitoring products based on the internationally exchanged meteorological data with gauge observations from 7,000 stations worldwide. The products contain precipitation totals, anomalies, number of gauges and systematic error correction factors. The grid resolution is 1.0°×1.0° latitude/longitude.
At the time of this study, the monthly values were available for 17 years, from 1986 to 2002. The maximum registered values per annum were used to calculate the expected 100-year monthly precipitation for every grid point assuming a Gumbel distribution. The results were divided into five susceptibility classes (Table 5).
The map of the estimated 100-year extreme monthly rainfall is shown in Fig. 4.
Seismic trigger factor T s
The data set used for the classification of the seismic trigger factor was the expected Peak Ground Acceleration (PGA) with 475-year return period (10% probability of exceedance in 50 years) from the Global Seismic Hazard Program, GSHAP (Giardini et al. 2003; Fig. 5).

Expected PGA with a return period of 475 years. Scale varies from 0 m/s2 (white) to 9 m/s2 (brown) (GSHAP results)
GSHAP was launched in 1992 by the International Lithosphere Program (ILP) with the support of the International Council of Scientific Unions (ICSU) and in the framework of the United Nations International Decade for Natural Disaster Reduction (UN/IDNDR). The primary goal of GSHAP was to create a global seismic hazard map in a harmonized and regionally coordinated fashion, based on advanced methods in probabilistic seismic hazard assessments (PSHA). Modern PSHA are made of four basic elements: earthquake catalogue, earthquake source characterization, strong seismic ground motion and computation of seismic hazard. For the purposes of this study, the Peak Ground Acceleration (PGA) with 475-year return period was used. The GSHAP PGA475 data were categorized into ten classes (Table 6).
Landslide hazard index H landslide
With the range of indices given above, the landslide hazard index computed from Eq. (1), varies between 0 and 1500. Based on the computed H landslide, each basic grid cell in the global analysis (30 arcsec × 30 arcsec latitude/longitude) was classified as shown in Table 7.
The annual frequency of serious landslides given on the last column was based on a crude calibration in few areas (mainly in Europe) where the authors have access to reliable data. The overlapping ranges in the annual frequencies reflect the uncertainty in the estimates.
Comparison of model prediction with actual inventories for slide events
The hotspots project included validation of predicted landslide hazard zones in a number of countries where data on geographical distribution of historical landslides were available. The countries where calibration was performed were Norway, Armenia, Georgia, Nepal, Sri Lanka, and Jamaica. In general, the prediction model was found to yield a good first-pass approximation.
An example for Armenia is shown here. Armenia (Fig. 6a) is one of the most disaster-prone countries in the world (earthquake, landslides, hailstorm, droughts, strong winds, and floods). The average value of direct damages that landslide processes cause to the social and economic infrastructure, approaches US $10 million/year (according to the national Emergency Management Administration). More than 3,000 large landslides have been reported for Armenia in the 20th century, and one-third of the country is exposed to high landslide hazard. Nearly 470,000 people (about 15% of the total population) live in the exposed areas. In the past 5 years, more than 2,000 families have been left homeless as a result of landslides.


a Map of Armenia. b Comparison of global landslide hazard mapping in Armenia using the first-pass model with the GEORISK (GEORISK, 2004) landslide inventory
Several landslide-prone areas in Armenia have been identified as being dangerous for the population. Nearly 300 of the largest landslides are in an active stage of development. They include an area of about 700 km2, involving 100 settlements, where nearly 400,000 people live. About 1,500 km, of a total of 8,000 km of transport corridors in Armenia, are located in landslide-prone terrain. A typical huge landslide area covers a few square kilometers. In some instances, a village with a population of a few hundred to a few thousand inhabitants is situated in an active landslide area. A typical landslide exhibits a slow, creeping movement, with a thickness between 10 and 100 m, and several, smaller, active creeping zones inside the area. The ground movements are horizontal and rotational, causing tension cracks in the ground, settlements, and rotational slip surfaces.
NGI produced a landslide hazard map for Armenia with support from the Armenian Scientific Research Company, GEORISK. GEORISK provided NGI with information on historical landslides as well as their interpretation of landslide-prone zones: regions where landslide processes develop, regions of creep motion of the ground, regions of intense landslide processes and regions of large seismic activity, which involve the most hazardous landslides.
Figure 6b presents the superposition of the GEORISK landslide inventory (hatched areas) on the global landslide hazard map obtained with the first-pass model developed in this study. The agreement between the model prediction and the GEORISK inventory is very good for the areas in the center of the mapped region. The first-pass model assigns landslide values between six and nine to all the landslide zones identified by GEORISK. The higher hazard zones correspond well to the areas characterized as most susceptible (values of eight and nine). However, the model does not predict the hazard area close to Yerevan, and only indicates high landslide activity in the southern periphery of the hazard zone identified by GEORISK close to Azerbaijan. Generally, the model prediction produces larger hazard zones than provided by the GEORISK mapping. This may lead to an overestimation on the global base. Such discrepancies should be expected when one applies a global model to a regional scale. Much better agreement could be achieved if the weighting of the indices (Eq. (1)) is calibrated for the local conditions.
Snow avalanche hazard evaluation
Any model for snow avalanche hazard should include parameters describing the terrain and the amount of snow. Steep terrain is a necessary condition for avalanches to occur. Snow cover conditions during the winter, snow precipitation, wind conditions and temperature development during a storm, can result in snow avalanches. The magnitude of these different parameters controls the avalanche size, run-out distance and return period (probability of occurrence). It is difficult to produce a global snow avalanche hazard map based on all these factors, so simplifications have to be made.
The probability of a given amount of precipitation can be related to the return period through analysis of long-term data from weather stations. However, due to the paucity of global data from weather stations, this is not feasible. Available information is restricted to average annual precipitation, monthly precipitation, and maximum daily precipitation. These data are insufficient for the estimation of return periods and probabilities of avalanche occurrence. The calculation of probability can be avoided through calibration of a susceptibility map in countries where the avalanche history has been known for many centuries. Therefore, it is possible to combine some of the susceptibility grid values to the known consequences and return periods. The estimated return periods for a number of locations in a country with long-term records may then be used to estimate the probability for avalanches in other areas.
A specific weight was assigned to each factor in the avalanche model. Multiplying and summing these indices determines a relative avalanche hazard level H avalanche, given by:
Where S r is the slope factor, T pw is a factor depending on precipitation for four winter months, T t is the temperature factor, and F is a factor that depends on average temperature in winter months (F=0 if average monthly temperature in winter months >2.5°C, F=1 otherwise).
The slope factor S r is already discussed for landslides. For evaluation of snow avalanche hazard, Sr was categorized into nine classes (instead of five for landslides).
The winter month's precipitation factor, Tp, was based on the mean monthly precipitation data from the International Institute for Applied System Analyses (IIASA) Climate Database (see Internet data resources, in the references). The grid resolution for the precipitation data is 0.5°×0.5° latitude/longitude. Since the amount of snow during the winter months greatly affects the number and size of avalanches, the sum of the precipitation values for the four “winter months” (December through March in the northern hemisphere and June through September in the southern hemisphere) was used in the analysis. The classification of T pw is shown in Table 8.
The temperature factor T t was based on the mean monthly temperature data from the IIASA Climate Database (see web data sources in the references). The global temperature map, with a resolution of 0.5°×0.5° latitude/longitude, constrains the avalanche areas to colder regions. Areas with temperature in one winter month (e.g., January in the northern hemisphere) with different temperature ranges {+5°C → 0°C}, {−0°C → −2°C}, and {<−2°C} were studied. In mountain areas above 1,000 m, precipitation occurs as snow when the temperature at sea level is less than +5°C. The model implies that the areas with longer, cold periods have a greater potential to produce avalanches. The classification of T t is shown in Table 9.

Global hotspot landslide hazard zonation for the world
With the range of indices given above, the value of avalanche hazard level H avalanche obtained from Eq. (2) varies between 0.8 and 9. Similar to the landslide hazard, the avalanche hazard was also divided into nine classes (Table 10).
The annual frequencies of (major) avalanche events corresponding to these classes are similar to the corresponding classes for landslide hazard.
The combined annual frequency of landslide and avalanche events is approximately the sum of the frequencies for each event. The approximation is valid because the probability numbers are very small:
where P[L] is the annual probability of a major landslide event and P[A] is the annual probability of a major avalanche event with a grid pixel (0.5°×0.5° latitude/longitude).
Global hotspots for landslide and avalanche hazard
The main regions of the world with moderate to very high landslide hazards were found to include: Central America, northwestern South America, northwestern USA and Canada, the Caucasus region, the Alborz and Zagros mountain ranges in Iran, Turkey, Tajikistan, Kyrgyzstan, the Himalayan belt, Taiwan, Philippines, Indonesia, New Guinea, New Zealand, Italy and Japan. The locations are marked on the world map in Fig. 7.
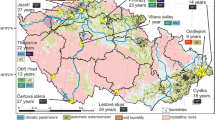
A more detailed mapping for Central Asia and the Middle East is shown in Fig. 8, see also Pusch (2004). Countries, in this region, with medium to high, high, and very high landslide hazard include: Georgia, Armenia, Turkey, Iran, a small part of southern Russia, Tajikistan, Kyrgyzstan, Afghanistan, Nepal, northern India and southern China.

Global hotspot landslide hazard zonation for Central Asia and Middle East
The map for the Central American and Caribbean countries is shown in Fig. 9. The most exposed countries in this region include Guatemala, Mexico, El Salvador, Honduras, Nicaragua, Costa Rica, Panama, Columbia, Ecuador, and Peru.

Global hotspot landslide hazard zonation for Central America and Caribbean countries
The global snow avalanche hazard maps were developed in the same manner as the landslide maps. Figure 10 illustrates such global results obtained for Central Asia with the simple snow avalanche prediction model described in this paper.

Global hotspot snow avalanche hazard zonation for Central Asia
The more susceptible areas/countries in this region (those with highest avalanche hazard value) include the border of Georgia and Russia, Tajikistan, Afghanistan and Kyrgyzstan.
Vulnerability and risk assessment
The landslide vulnerability and risk assessment followed the approach developed by UNEP/GRID-Europe and applied to floods, cyclones, earthquakes and drought for the UNDP report: “Reducing Disaster Risk” (Peduzzi et al. 2002; UNDP 2004; Dao and Peduzzi 2004).
Based on the UN definition (UNDRO 1979), risk is determined by three components: hazard (occurrence probability), elements at risk, and vulnerability. For this study, risk refers to the expected loss of human lives following landslides, while vulnerability reflects “the degree of loss to each element should a hazard of a given severity occur” (Coburn et al. 1991). The expected economic losses due to landslides were not considered in the study because the global datasets on economical losses are of variable quality. Risk, as defined by UNDRO (1979), is computed by the following equation:
where R is the risk, H the Hazard, Pop the population exposed to risk from landslides, Vul the vulnerability of the exposed population.
Equation (4a) could be rewritten as:
where
Therefore, to create a risk map three computations are needed:
-
Computation of physical exposure
-
Computation of a proxy for vulnerability
-
Computation of the spatial distribution of risk
Computation of physical exposure
In broad term, the physical exposure was estimated by multiplying the hazard (frequency of landslides) by the population living in the exposed area. The derivation of hazard was described earlier in the paper. The physical exposure was computed as:
where PhExpnat is the physical exposure at national level, F i the annual frequency of landslide or avalanche event in one spatial unit. Popi the total population living in the spatial unit divided by 10.
It was assumed that a typical serious landslide or avalanche event affects, on average, 10% of the population living in the spatial unit used for the analyses (about 1 km2 at the equator). The annual frequency F i used in the calculations was based on the computed hazard as described earlier and summarized in Table 11.
The data on population were derived from Center for International Earth Science Information Network (CIESIN), the International Food Policy Research Institute (IFPRI), the World Resources Institute (WRI), and Gridded Population of the World (GPW, Deichmann et al. 2001). The data were further supplemented with Human Population and Administrative Boundaries Database for Asia (UNEP 1987). Since GPW is based on a spatial resolution of 2.5° (about 5×5 km at the equator) and the resolution of hazard model was based on a raster with cells of 1×1 km, an algorithm was developed to compute population inside the grid cell used in the calculations. The algorithm recomputed the population of the new cell in proportion of the terrestrial area of the GPW cell. For example, a 5×5 km cell contains 25 1×1 km cells. If they are all located over land, the population of the 1×1 km cell will be 1/25 of the larger cell. However, on coastal area, suppose only 18 of the smaller cell are over land, the assigned population will be 1/18 of the bigger cell. The algorithm allows automatic computation of the population.
Once the population density was estimated, the physical exposure (PhExp) was computed by multiplying it by the average hazard frequency listed in Table 11. A preliminary analysis was made using killed on one side of the equation and then tested with different PhExp on the other side, (e.g., PhExp to magnitude classes 1–9, 2–9, 3–9, …) in order to select the threshold from which the magnitude start to have significant impact. The choice of magnitude classes 2–9 demonstrated the best correlation with past human losses.
To take into account the increase of population (hence the increase of physical exposure) since the event in the database took place, the average physical exposure was weighted by the actual population density at the time of the event to better reflect the situation when the events occurred. The formula is similar to the one use to transform socio-economical values.
where PhExpav is the average physical exposure, K ic the killed from landslides for the year “i” and the country “c”, PhExpic the physical exposure for the year “i” and the country “c”, K tot the total number of killed from landslides for the selected country.
Finally, the Physical Exposure was aggregated at national level (PhExpnat), by summing all the values of the cells included within the national boundaries. Territories were treated separately from the main land (e.g., Martinique Island was not aggregated with mainland France).
Computation of vulnerability proxy
Figure 11 shows the average of number fatalities caused by landslides annually versus the exposed population in selected countries. If one assumes that the number of casualties increases when the physical exposure increases, then the difference observed in casualty for similar physical exposures can be explained by the difference in vulnerability.

Fatalities caused by landslides annually versus the exposed population in selected countries
Estimating human vulnerability to natural disasters is a difficult task. The degree of loss following a single event is the result of a complex interaction of factors ranging from time of occurrence (during day, night, day off) quality of building, level of education, political status, and so on. The discrepancy between the losses from two events of similar severity is usually quite significant. However, the aim of analyses described here was to highlight the trends, rather than come up with exact estimates. The past human losses were derived from EM-DAT (EM-DAT, 2003). According to previous studies (Peduzzi et al. 2002; Dao and Peduzzi 2004) the period of the study was set from 1980 to 2000, where the access to information was proved to be stable during this period but not for previous years. A database was created for associating the number of persons killed by slide events, with the year and the country population for each year.
A proxy for vulnerability was computed by using the ratio of past casualties and physical exposure:
where Vulproxy the proxy of vulnerability, K the past casualties (killed between 1980 and 2000), PhExpnat the Physical Exposure weighted by level of population at the date of the casualties recorded and aggregated by country.
Computation of risk
Once the vulnerability proxy was computed, it was multiplied by the Physical Exposure to produce a risk map on a pixel-by-pixel basis.
The multiple regression analysis results showed strong correlation (R=0.852) between high risk and three factors: physical exposure, Human Development Index (HDI) as determined by United Nations Development Program (UNDP) and percentage of forest cover. This shows that the risk is higher when more persons are exposed and when poorer populations are exposed, which is what was expected. However, surprisingly, it shows that the higher the national percentage of forest cover, the higher the risk. This might reflect the fact that the countries with the highest forest coverage might also be the ones with the highest degree of deforestation. Deforestation is an important factor that needs to be addressed in more detail (World Disaster Report 2004), but the parameter is difficult to determine on the global basis with the existing data sets. The percentage “arable land” also showed a strong correlation with landslide risk. This indicates that rural population is more vulnerable to landslides than urban population. However, the model used in the study is not capable of accounting for the significant vulnerability differences between rural and urban populations. This limitation can only be overcome through the use of sub-national datasets on socio-economic factors and on geo-referenced information on the number of casualties. Such an analysis would also require more records than the analysis of average vulnerability derived from the national level values.
Some of the major findings from risk mapping were:
-
The annual number of expected fatalities due to major landslides worldwide, as predicted by the model, was found to be in excess of 4,300. This number is somewhat higher, but of the same order of magnitude as the reported average number of people killed per year (about 1,700) during the period 1980–2000 as reported in the CRED EM-DAT database. Since CRED includes mean to large events, a higher number of victims is not surprising, as it is expected that numerous landslides would killed less than ten (CRED records an event if it has a minimum of ten killed, or 100 wounded).
-
98% of the recorded victims lived within areas predicted by the model to fall in landslide hazard zones 5 and above.
-
Localized areas of pixel size 1 km2, with highest mortality risk, were found to be in Colombia, Tajikistan, India and Nepal where the predicted risk for number of people killed per year per 1 km2 was found to be greater that 0.01.
-
In countries like Guatemala, El Salvador, Honduras, Panama, Costa Rica, Mexico, Columbia, Afghanistan, and Iran, the model predicted large areas with risk for number of people killed per year per 1 km2 between 0.001 and 0.01.
Global hotspots for landslide and avalanche risk
The result of the regression analysis for landslide risk is shown on Fig. 12. It should be mentioned that out of the 249 countries, 11 could not be processed due to missing data; these countries are: Afghanistan, Bosnia, Democratic People Republic of Korea, Georgia, Kyrgyzstan, Lebanon, Liberia, Puerto Rico, Taiwan, Tajikistan, Vanuatu. Four other countries were rejected by the model (outliers): Egypt, Ethiopia, Guyana, and Sri Lanka. Except for Ethiopia, all the others have low frequency of 1–4. Ethiopia and Egypt do not fit in the model due to low forested areas.

Proxy of vulnerability expressed in killed versus exposed population in landslide fatalities
A major aim of the Hotspots Project was the prediction of the geographical distribution of landslide risk expressed as the expected number of people killed per year per km2. Figures 13 and 14 show typical results for Central Asia and Central America, respectively.

Hotspot landslide risk zonation for Central Asia

Hotspot landslide risk zonation for Central America and Jamaica
Discussion
The model used in the study to establish the global hazard and risk hotspots is to be considered as a first pass analysis. There are, however, many promising trends in the results:
The model delineates that high risk of human loss has a strong correlation (r=0.852, R 2=0.727) with high physical exposure, combined with low human development index (HDI) and in countries which are both high in arable land and in forest coverage. The connection with arable land and high forest coverage could be seen as profile of countries where forest conversion is significant. Countries largely covered by forest have wetter climatic conditions and should be seen as a proxy of high rural population, more vulnerable than the urban population, as expressed in Equation 8 which is the multiple logarithmic regression model for landslides
where K is the number killed from landslides, PhExp_all the physical exposure including all the classes, FCpc the transformed percentage of forest in the country, HDI the transformed human development index, Ar_Land the percentage of arable land.
The quality of the regression was assessed by looking at both R 2 value, 0.727 meaning that 72.7% of the variance is explained and the p-value. A significant variable should have a p-value smaller than 0.05, this is the case with p-value smaller than 10−4.
The model for risk assessment gave somewhat surprising results regarding the positive correlation between landslide risk and forest cover, indicating that countries with high forest cover have the highest landslide risk. This result needs to be investigated in more detail. Reliable data on forest cover is difficult to assess and the parameter itself is not precisely defined. The problem with the changes in forest cover, which in some countries changes very rapidly over the years, also causes complications. These changes might not necessarily be reflected in the reported figures.
Unfortunately, loss data on mortality due to slides and avalanches is incomplete in the international databases. For further improvement of the model, it might be necessary to investigate the availability of better data on a national and regional level, especially in the most hazard-prone areas of the world. Investment in keeping proper landslide inventories is getting more and more attention in many countries around the world. Such data are instrumental for at least two major purposes (i) they are vital for both hazard and risk predictions, and (ii) loss data on mortality and materiel losses will often serve the basis and documentation for setting national priorities on needed mitigation measures.
Conclusions
The probability of landslide and avalanche occurrence was estimated by modeling the physical processes and combining the results with statistics from past experience. The main input data used in the hazard assessment were topography and slope angles, extreme monthly precipitation, seismic activity, lithology, mean temperature in winter months (for snow avalanches) and hydrological conditions. The first-pass analyses presented in the paper were done with relatively simple models. We have shown that a fairly good first-pass estimate of landslide hazard can be made by using the global data sets on slope, lithology, soil moisture, precipitation and seismicity. Validation of the global hazard prediction, which was carried out for six countries (namely Georgia, Armenia, Sri Lanka, Nepal, Jamaica and Norway), showed fair agreement between the boundaries of the known slide-prone areas and the hazard zones predicted by the global model. However, the analyses suffered from significant shortcomings in the quality and resolution of the available global data sets.
Working in a smaller area, it should be possible to refine the analyses using better resolution in the input data, as well as adding supplementary parameters such as land cover, deforestation, and effects of long-term climatic change. With use of a more comprehensive set of site-specific data, it should also be possible to make a prediction of economic losses with the model, and not only fatalities, as was done in the present study.
For the estimation of risk, the computations were based on human losses as recorded in various natural disaster impact databases. The estimation of expected losses was achieved by first combining the landslide frequency and the population exposed, in order to estimate the physical exposure, and then doing a regression analysis using different sets of uncorrelated socio-economical parameters. The study identified the socio-economic parameters that seem to have the strongest correlation with expected fatality due to landslides. Improved data quality, adding new types of data sets to the model, and having loss data from the landslide-prone countries that are presently missing, are important for better understanding and identification of the most relevant socio-economic parameters that affect landslide risk.
The study clearly shows that the following countries and geographical areas are among the landslide hazard hotspots:
-
Central America
-
North-western South America
-
The Caucasus region
-
The Himalayan belt
-
Taiwan
-
Philippines
-
Indonesia
-
Italy
-
Japan
The conclusions of this study are all based on a global model, which does have shortcomings when applied at a local level. Use or interpretation of the results for specific national conditions is not recommended without further investigations. Several factors contribute to uncertainties in the predictions presented in the paper, the major one being the scarcity of high-quality, high-resolution data at a global scale. The paper discusses additional factors that could lead to improved predictions and provides a list of suggestions for further studies.
Internet data sources
Moisture index data
Center for Climatic Research, Department of Geography, University of Delaware Newark, USA, http://climate.geog.udel.edu/∼climate/html_pages/README.im2.html
Precipitation data
Global Precipitation Climatology Centre, Deutscher Wetterdienst, Offenbach, Germany, http://gpcc.dwd.de
Seismic trigger factor
Global Seismic Hazard Assessment Program (GSHAP), Geo Forschungs Zentrum Potsdam, Potzdam Germany, http://www.gfz-potsdam.de/pb5/pb53/projects/en/gshap/menue_gshap_e.html http://seismo.ethz.ch/GSHAP/index.html
Winter precipitation and temperature
International Institute for Applied Systems Analysis (IIASA), Laxenburg, Austria, http://www.grid.unep.ch/data/index.php
Population data
Gridded Population of the World (GPW), Columbia University, New York, USA, http://sedac.ciesin.org/plue/gpw
Human Population and Administrative Boundaries Database for Asia
UNESCO, through UNEP/GRID-Geneva, Switzerland http://www.grid.unep.ch/data/index.php
International disaster database
EM-DAT: The OFDA/CRED International Disaster Database, Université catholique de Louvain, Brussels, Belgium, http://www.em-dat.net/
References
CGMW (2000) Geological map of the world. Commission for the Geological Map of the World. UNESCO Publishing
Coburn AW, Spence RJS, Pomonis A (1991) Vulnerability and risk assessment. UNDP Disaster Management Training Program: 57
Dao H, Peduzzi P (2004) Global evaluation of human risk and vulnerability to natural hazards. Enviro-info 2004, Sh@ring, Editions du Tricorne, Genève, ISBN 282930275-3 (1):435–446
Deichmann U, Balk D, Yetman G (2001) Transforming population data for interdisciplinary usages: from census to grid. Available at http://sedac.ciesin.columbia.edu/plue/gpw/GPWdocumentation.pdf
Dilley M, Chen RS, Deichmann U, Lerner-Lam AL, Arnold M et al. (2005) Natural disaster hotspots – a global risk analysis. Report of the International Bank for Reconstruction and Development/The World Bank and Columbia University: 132
EM-DAT (2003) The OFDA/CRED International Disaster Database - www.em-dat.net - Université Catholique de Louvain - Brussels - Belgium
GEORISK (2004) Communications through The World Bank study
Giardini D, Grünthal G, Shedlock K, Zhang P (2003) The GSHAP Global Seismic Hazard Map. In: Lee W, Kanamori H, Jennings P (eds) International handbook of earthquake and engineering seismology. IASPEI
Mora S, Vahrson W (1994) Macrozonation methodology for landslide hazard determination. Bull Assoc Eng Geol 31(1):49–58
Nadim F, Kjekstad O, Gregoire AS, Rodriguez C, Peduzzi P (2004) First-order identification of global slide and avalanche hotspots. NGI report 20021613-1, 31 March 2004. Norwegian Geotechnical Institute, Oslo, Norway
Peduzzi P, Dao H, Herold C, Mouton F (2002) Global risk and vulnerability index trends per year (GRAVITY), phase II: development, analysis and results. 56 http://www.grid.unep.ch/product/publication/download/ew_gravity2.pdf
Pusch C (2004) A comprehensive risk management framework for Europe and Central Asia. Disaster Risk Management Working Paper Series No. 9. The World Bank, October 2004
Rudolf B, Beck C, Grieser J, Schneider U (2005) Global precipitation analysis products, Deutscher Wetterdienst, Offenbach a. M., Germany
UNDP (2004) Reducing disaster risk. United Nations Development Programme, Bureau for Crisis Prevention and Recovery, New York, USA
UNDRO (United Nations Disaster Relief Coordinator) (1979) Natural disasters and vulnerability analysis. Report of expert group meeting (9–12 July 1979). Geneva: UNDRO. 49 pp
UNEP (1987) Global data sets for atmosphere, biosphere, and human related data. UNEP/GRID-Geneva
Willmott CJ, Feddema JJ (1992) A more rational climatic moisture index. Prof Geogr 44(1):84–88
World Disaster Report (2004) International Federation of Red Cross and Red Crescent Societies, IFRC, Geneva; http://ifrc.org
Acknowledgements
This paper is based on a study conducted under the ProVention Consortium initiative on Natural Disaster Hotspots. The overall study is published by the World Bank in two volumes. The first volume, Natural Disaster Risk Hotspots: A Global Risk Analysis (Dilley et al. 2005), presents the global findings. Volume 2, which presents a number of case studies (including this one on landslide risk) is forthcoming. The study was initiated by the World Bank's Hazard Management Unit (HMU), headed by Margaret Arnold, under the umbrella of the ProVention Consortium. The study was conducted as part of the ProVention activity on Natural Disaster Hotspots: A Global Risk Analysis. A major part of the funding was provided by the United Kingdom's Department for International Development (DFID) and The Norwegian Ministry of Foreign Affairs. Margaret Arnold's support and encouragement throughout the work are gratefully appreciated. The support of Christopher Pusch of the World Bank for the landslide hazard study in Armenia is also gratefully acknowledged. The authors acknowledge close cooperation with Columbia University, especially Robert Chen and Max Dilley. A number of NGI personnel participated actively in the project, among them Ulrik Domaas, Ramez Rafat and Frode Sandersen. The authors are grateful to these individuals for their active participation and support.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Nadim, F., Kjekstad, O., Peduzzi, P. et al. Global landslide and avalanche hotspots. Landslides 3, 159–173 (2006). https://doi.org/10.1007/s10346-006-0036-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10346-006-0036-1