
Abstract
In this paper, we introduce a generalized mixture distribution, so-called the binomial mixture Lindley distribution (BMLD). The density function of this distribution is obtained by mixing binomial probabilities with gamma distribution. BMLD have various distributions as its special cases and posses various shapes for its hazard rate function including increasing, decreasing, bathtub shape and upside down bathtub shape depending on its parameters. Several mathematical, structural and statistical properties of the new distribution is presented such as moments, moment generating function, hazard rate function, vitality function, mean residual life function, inequality measures, entropy and extropy etc. The parameters of the model are estimated using the method of maximum likelihood and finally real life data sets are considered to illustrate the relevance of the new model by comparing it with some other lifetime models.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Numerous probability distributions are introduced in the literature by mixing, extending and modifying well known distributions and hence provide more flexible hazard rate function for modelling lifetime data. These distributions will then be more suitable for fitting appropriate real data than the base models. Knowledge of the appropriate distribution plays an important role in improving the efficiency of any statistical inference related to data sets. Hence the researchers are more keen to develop new distributions by extending classical distributions to increase model flexibility and adaptability in various aspects of modelling data.
Lindley (1958) introduced in the literature one of the most discussed lifetime distribution, the Lindley distribution, in the context of the Bayesian statistics as a counter example of the fiducial statistics. Lindley distribution (LD) have the probability density function (pdf),
which is a mixture of exponential \((\theta )\) and gamma \((2,\theta )\) distributions. The corresponding cumulative distribution function (cdf) has been obtained as,
where \(\theta\) is the scale parameter.
Mixture models provide a mathematical based, flexible and meaningful approach for the wide variety of classification requirements. There are numerous fields in which mixture models have practical applicability. Lindley itself being a mixture model, it has gained momentum in the theoretical perspective as well as in terms of its applications. Ghitany et al. (2008) have studied various properties of this distribution and showed that (1.1) provides a better model for some applications than the exponential distribution. Mazucheli and Achcar (2011) applied the Lindley distribution to competing risk life time data. A discrete version of this distribution has been suggested by Deniz and Ojeda (2011) having its applications in count data related to insurance. Al-Mutairi et al. (2013) developed the inferential procedure of the stress-strength parameter, when both stress and strength variables follow Lindley distribution. The applicability of Lindley distribution in solving lifetime modelling problems and modelling stress strength model made researchers to develop many generalizations, modifications and extensions of this distribution. Shanker et al. (2013) introduced a two parameter Lindley distribution (\(LD_2\)) for modelling waiting and survival times data with pdf,
where \(f_2(x; \alpha , \theta )\) is a mixture of exponential \((\theta )\) and gamma \((2,\theta )\) with mixing probabilities \(\frac{\theta }{\theta +\alpha }\) and \(\frac{\alpha }{\theta +\alpha }\) respectively. Even though one parameter and two parameter Lindley distributions are mixture of \(E(\theta )\) and \(G(2,\theta )\), most of the further generalizations are based on two gamma models with suitable mixtures. The generalizations that we aware of are:
Zakerzadeh and Dolati (2009) introduced a generalized Lindley distribution (GLD) with pdf,
\(f_3(x; \alpha , \theta , \gamma )\) is a mixture of gamma \((\alpha ,\theta )\) and gamma \((\alpha +1, \theta )\) with mixing probabilities \(\frac{\theta }{\gamma +\theta }\) and \(\frac{\gamma }{\gamma +\theta }\) respectively.
Ghitany et al. (2011) introduced a weighted Lindley distribution (WLD) with pdf,
\(f_4(x;\theta ,\alpha )\) can also be expressed as a two component mixture such that
where \(p=\frac{\theta }{\theta +\alpha }\) and \(g_i(x)=\frac{\theta ^{\alpha +j-1}}{\Gamma (\alpha +j-1)}x^{\alpha +j-2}e^{-\theta x}, \alpha ,\theta ,x>0, j=1, 2\), is the pdf of the gamma distribution with the shape parameter \(\alpha +j-1\) and scale parameter \(\theta , j=1, 2.\)
Elbatal et al. (2013) proposed a new generalized Lindley distribution (NGLD) with pdf,
where \(f_5(x; \alpha , \theta )\) is a mixture of gamma \((\alpha ,\theta )\) and gamma \((\beta , \theta )\) with mixing probabilities \(\frac{\theta }{\theta +1}\) and \(\frac{1}{\theta +1}\) respectively.
Abouammoh et al. (2015) defined another new generalized Lindley distribution (\(NGLD_1\)) with pdf,
where \(f_6(x; \alpha , \theta )\) is a mixture of gamma \((\alpha ,\theta )\) and gamma \((\alpha -1, \theta )\) with mixing probabilities \(\frac{1}{\theta +1}\) and \(\frac{\theta }{\theta +1}\) respectively.
All these generalizations play various roles in the literature both in theoretical and applied perspectives. It can be perceived that most of the further developments are based on these six models, which immensely motivates to propose a generalized family, which generalizes the afore mentioned Lindley models. Hence in this work we introduce a wider class of Lindley distribution by mixing binomial probabilities with gamma distribution and name the distribution as binomial mixture Lindley distribution (BMLD).
One of the main peculiarity of the LD is its shape of hazard rate (increasing hazard rate) function compared to the well known exponential distribution. By scrutinizing the flexibility of various variants of Lindley model in terms of the hazard rate function, Lindley-Exponential distribution (Bhati et al. 2015) possess decreasing hazard rate function, GLD possess bathtub shape hazard rate function and inverse Lindley distribution (Sharma et al. 2015) possess upside down bathtub shape hazard rate function. Hence another motivation of this work is to propose a flexible extension of Lindley model which possess all the available shapes of hazard rate function. During the initial stage of this work, we came across several recent articles based on Lindley models. Several authors claim that their model possess bathtub shaped hazard rate but not even a single author attempted to fit a bathtub shaped data. Hence one motivation of this work is to propose a model and successfully apply a well known bathtub shaped data of Aarset (1987). In addition to Aarset data, to prove the superiority of BMLD we also took two other data sets, viz., strength of glass fiber data (see, Smith and Naylor 1987) and survival times of 72 guinea pigs data (see, Bjerkedal 1960) both having increasing hazard rate function.
The rest of the paper is outlined as follows. In Sect. 2 binomial mixture Lindley distribution is defined along with its moments, model identifiability, mean, variance, a recursive relationship for moments and moment generating function. Some of the reliability properties of the model such as hazard rate function, vitality function, mean residual life function, inequality measures and some uncertainty measures are presented in Sect. 3. In Sect. 4, the parameters of the distribution are estimated using method of maximum likelihood and thus obtained observed Fisher information matrix and asymptotic confidence intervals. A simulation study is presented in Sect. 5. Finally in Sect. 6, experimental results of the proposed distribution based on real data sets are illustrated.
2 Binomial Mixture Lindley Distribution
In this section, we present definition and some important properties of the binomial mixture Lindley distribution . Here after we use the short form BMLD for binomial mixture Lindley distribution.
Definition 2.1
A continuous random variable X is said to follow BMLD if its pdf f(x) has the following form,
where
for \(\theta >0\), \(\alpha _i > 0\) for \(i=0,1,\cdots ,g\). We define the mixing weights \(p_i\) such that
for \(i=0,1,\cdots ,g\) and \(\displaystyle \sum _{i=0}^{g}p_i=1\), \(\beta > 0\), \(\theta > 0\) .
Special cases
-
(1)
If g=1, \(\alpha _0\)=1 and \(\alpha _1\)=1, then BMLD becomes the exponential distribution (ED).
-
(2)
If g=1, \(\beta\)=1 and \(\alpha _0\)=\(\alpha _1\)=\(\alpha\), then BMLD becomes the gamma distribution (GD).
-
(3)
If g=1, \(\beta\)=1, \(\alpha _0\)=2 and \(\alpha _1\)=1, then BMLD becomes the Lindley distribution (LD).
-
(4)
If g=1, \(\alpha _0\)=2 and \(\alpha _1\)=1, then BMLD becomes the two parameter Lindley distribution [\(LD_{2}\) (Shanker et al. 2013)].
-
(5)
If g=1, \(\alpha _0\)=\(\alpha +1\) and \(\alpha _1\)=\(\alpha\), then BMLD becomes the generalized Lindley distribution [GLD (Zakerzadeh and Dolati 2009)].
-
(6)
If g=1 \(\alpha _0=\alpha +1\), \(\alpha _1=\alpha\) and \(\beta =\alpha\), then BMLD becomes the weighted Lindley distribution [\(WLD\,\)(Ghitany et al. 2011)].
-
(7)
If g=1 and \(\beta\)=1, then BMLD becomes the new generalized Lindley distribution [\(NGLD\,\)(Elbatal et al. 2013)].
-
(8)
If g=1, \(\beta\)=1, \(\alpha _{0}\)=\(\alpha\) and \(\alpha _{2}\)=\(\alpha -1\), then BMLD becomes new generalized Lindley distribution [\(NGLD_{1}\,\)(Abouammoh et al. 2015)].
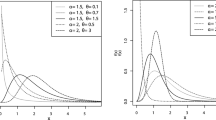
The pdf of the distribution, for different values of parameters, is plotted in Fig. 1.

The pdf of BMLD for g=2 and different values of \(\theta\), \(\beta\), \(\alpha _{0}\), \(\alpha _{1}\), \(\alpha _{2}\)
2.1 Identifiability
A set of parameters for a particular model is said to be identifiable if not any two sets of the parameters gives same distribution for the given x.
Result 2.1
The identifiability condition for BMLD with pdf as given in (2.1) is \(\alpha _{i} \ne \alpha _{j}\) for each \(i,j \in {0,1,2,...,g}\) such that \(i\ne j\) .
Proof
For mathematical simplicity, first we consider the case of \(g=2\) and let
where \(b_{0}\), \(b_{1}\) and \(b_{2}\) are real numbers, \(B_{0}(x)=\int \limits _{u=0}^{x} f(u) d u\), \(B_{1}(x)=\int \limits _{u=0}^{x} g(u) d u\) and \(B_{2}(x)=\int \limits _{u=0}^{x} h(u) d u\) with \(x>0\). Also g(u) and h(u) can be obtained from f(u) by replacing \(\alpha _{i}\) by \(\rho _{i}\) and \(\alpha _{i}\) by \(\mu _{i}\) respectively. Assume that for each \(i=0,1,2\), \(\alpha _{i}\ne \rho _{i}\ne \mu _{i}\),
and
Putting the values of \(B_{0}(x)\), \(B_{1}(x)\) and \(B_{2}(x)\) in (2.3) , we obtain the following,
and
On combining Eqs. (2.7), (2.8) and (2.9), we get
in which, F= \(\begin{bmatrix} f_{\alpha _{0}} &{} f_{\rho _{0}} &{} f_{\mu _{0}} \\ f_{\alpha _{1}} &{} f_{\rho _{1}} &{} f_{\mu _{1}} \\ f_{\alpha _{2}} &{} f_{\rho _{2}} &{} f_{\mu _{2}} \\ \end{bmatrix}\), b= \(\begin{bmatrix} b_{0}\\ b_{1}\\ b_{2} \end{bmatrix}\) and 0= \(\begin{bmatrix} 0\\ 0\\ 0 \end{bmatrix}\) and we define \(f_{\alpha _{i}}=\frac{\theta ^{\alpha _{i}}}{\Gamma \alpha _{i}} \int \limits _{0}^{x} t^{\alpha _{i}-1} e^{-\theta t} d t\), \(f_{\rho _{i}}=\frac{\theta ^{\rho _{i}}}{\Gamma \rho _{i}} \int \limits _{0}^{x} t^{\rho _{i}-1} e^{-\theta t} d t\) and \(f_{\mu _{i}}=\frac{\theta ^{\mu _{i}}}{\Gamma \mu _{i}} \int \limits _{0}^{x} t^{\mu _{i}-1} e^{-\theta t} d t\) for \(i=0,1,2\). Obviously det \(F\ne 0\) shows that \(b=0\) and thereby we conclude that the distribution functions \(B_{0}\), \(B_{1}\) and \(B_{2}\) are linearly independent over the set of real numbers ( see, Titterington et al. 1985). In a similar way, the argument can be extended to the case of any positive integer \(g(\ge 3)\) and thus the result follows. \(\square\)
Result 2.2
The cumulative distribution function (cdf) of the BMLD given in (2.1) has the following form,
Proof
We have
where \(\gamma (s,t)=\int \limits _0^t x^{s-1}e^{-x}dx\) is the lower incomplete gamma function and \(\gamma _{s}(t)=\frac{\gamma (s,t)}{\Gamma (s)}\). \(\square\)
Remark 2.1
The survival function of the BMLD is obtained as
Result 2.3
The \(r^{th}\) raw moment about origin of the BMLD has been obtained as
Proof
By definition, we have
\(\square\)
Remark 2.2
Mean and variance of BMLD is given by
and
Result 2.4
The moments of the BMLD can be calculated recursively through the relationship
Proof
From (2.13), we have
and
By rearranging the above equation, we get (2.16). \(\square\)
Result 2.5
If X has BMLD, then the moment generating function \(M_X(t)\) has the following form,
Proof
We have
\(\square\)
Remark 2.3
The characteristic function of the BMLD is \(\Phi _X(t)=M_X(it)\), where \(i=\sqrt{-1}\) is the unit imaginary number.
3 Certain Measures of Reliability, Inequality, Entropy and Extropy
In this section we derived expressions for some reliability measures such as hazard rate function, reversed hazard rate function, cumulative hazard rate function, vitality function and mean residual life function associated with BMLD. Certain inequality measures, entropy and extropy measures are also obtained.
3.1 Reliability Properties
3.1.1 Hazard Rate Function
Let X denote a lifetime variable with cdf \(F(x)=Pr(X\le x)\) and pdf f(x). Then the hazard rate function(hrf) is given by,
where \({\overline{F}}(x)=1-F(x)\) is the survival function of X. That is, h(x)dx represents the instantaneous chance that an individual will die in the interval \((x,x+dx)\) given that this individual is alive at age x.
3.1.2 Reversed Hazard Rate Function
Let X be a non-negative random variable representing lifetimes of individuals having absolutely continuous distribution function F(x) and pdf f(x). Then the reversed hazard rate function is given by
3.1.3 Cumulative Hazard Rate Function
Cumulative hazard rate function is the total number of failure or deaths over an interval of time, and it is defined as
Clearly R(x) is a non-decreasing function of x satisfying; (a) \(R(0)=0\) and (b) \(\mathop {\lim }\limits _{x \rightarrow \infty }R(x)=\infty\).
Result 3.1
If X has the BMLD with density function, cumulative distribution function and survival function given in Eqs. (2.1), (2.11) and (2.12) respectively, then
- (a):
-
Hazard rate function,
$$\begin{aligned} h(x)=\frac{\sum \limits _{i=0}^{g}\left( {\begin{array}{c}g\\ i\end{array}}\right) \left( \frac{\theta }{\theta +\beta }\right) ^i \left( \frac{\beta }{\theta +\beta }\right) ^{g-i}\frac{\theta ^{\alpha _i}}{\Gamma (\alpha _i)}x^{\alpha _i-1}e^{-\theta x}}{1-\sum \limits _{i=0}^{g}\left( {\begin{array}{c}g\\ i\end{array}}\right) \left( \frac{\theta }{\theta +\beta }\right) ^i \left( \frac{\beta }{\theta +\beta }\right) ^{g-i}\gamma _{\alpha _i}(\theta x)}. \end{aligned}$$(3.4) - (b):
-
Cumulative hazard rate function,
$$\begin{aligned} R(x)=-\log \left[ 1-\sum \limits _{i=0}^{g}\left( {\begin{array}{c}g\\ i\end{array}}\right) \left( \frac{\theta }{\theta +\beta }\right) ^i \left( \frac{\beta }{\theta +\beta }\right) ^{g-i}\gamma _{\alpha _i} (\theta x)\right] . \end{aligned}$$(3.5) - (c):
-
Reversed hazard rate function,
$$\begin{aligned} r(x)=\frac{\sum \limits _{i=0}^{g}\left( {\begin{array}{c}g\\ i\end{array}}\right) \left( \frac{\theta }{\theta +\beta } \right) ^i \left( \frac{\beta }{\theta +\beta }\right) ^{g-i}\frac{\theta ^{\alpha _i}}{\Gamma (\alpha _i)}x^{\alpha _i-1}e^{-\theta x}}{\sum \limits _{i=0}^{g}\left( {\begin{array}{c}g\\ i\end{array}}\right) \left( \frac{\theta }{\theta +\beta }\right) ^i \left( \frac{\beta }{\theta +\beta }\right) ^{g-i}\gamma _{\alpha _i}(\theta x)}. \end{aligned}$$(3.6)
Proof
By using (2.1), (2.11) and (2.12) in the equations, \(h(x)=\frac{f(x)}{{{\overline{F}}}(x)}\), \(r(x)=\frac{f(x)}{ F(x)}\) and \(R(x)= -\log {{\overline{F}}} (x),\) the hazard rate function, reversed hazard rate function and cumulative hazard rate function are easily obtained.
The hazard rate function for BMLD is plotted for different values of parameters is given in Fig. 2. \(\square\)

The hrf of BMLD for g = 2 and different values of \(\theta\), \(\beta\), \(\alpha _{0}\), \(\alpha _{1}\), \(\alpha _{2}\)
The graphs of the hazard function for various combination of parameters show various shapes including increasing, decreasing, bathtub shape (decreasing -stable-increasing) and upside down bathtub shape. This attractive flexibility of the BMLD hazard rate function highly suitable for non-monotone empirical hazard behaviours which are more likely to be encountered in real life situations.
3.1.4 Vitality Function
If X is a non-negative random variable having an absolutely continuous distribution function F(x) with pdf f(x). The vitality function associated with the random variable X is defined as,
In the reliability context (3.7) can be interpreted as the average life span of components whose age exceeds x. It may be noted that the hazard rate reflects the risk of sudden death within a life span, where as the vitality function provides a more direct measure to describe the failure pattern in the sense that it is expressed in terms of increased average life span.
Result 3.2
The vitality function of BMLD has the following form,
Proof
The Eq. (3.7) can also be written as,
Now
where \(\Gamma (s,t)=\int \limits _x^\infty x^{s-1}e^{-x}dx\) is the upper incomplete gamma function and \(\Gamma _{s}(t)=\frac{\Gamma (s,t)}{\Gamma (s)}.\) Substituting (3.10) and (2.12) in (3.9), we get the required result. \(\square\)
3.1.5 Mean Residual Life Function
Mean residual life function or remaining life expectancy function at age x is defined to be the expected remaining life given survival to age x. For a continuous random variable X, with \(E(X)<\infty\), then the mean residual life function (MRLF) is defined as the Borel measurable function,
MRLF is sometimes considered as a superior measure to describe the failure pattern as compared to hazard rate function since the former focuses attention on the average lifetime over a period of time while the latter on instantaneous failure at a point of time. Also MRLF can be expressed in terms of vitality function. That is, Eq. (3.9) can also be written as
Result 3.3
The mean residual life function of BMLD has the following form,
Proof
Substituting (3.8) in (3.12), we get (3.13). \(\square\)
3.2 Inequality Measures
Lorenz and Bonferroni curves are income inequality measures that are widely useful and applicable to some other areas including reliability, demography, medicine and insurance (see, Bonferroni 1930). Also Zenga curve introduced by Zenga (2007) is another widely used inequality measure. In this section, we will derive Lorenz, Bonferroni and Zenga curves for the BMLD. The Lorenz, Bonferroni and Zenga curves are respectively given as
\(L_{F}(x) = \frac{\int \limits _{0}^x t f(t) dt }{E(X)}\), \(B_{F}(x) = \frac{\int \limits _{0}^x t f(t) dt }{ F(X)E(X)}\) and \(A_{F}(x)=1-\frac{\mu ^{-}(x)}{\mu ^{+}(x)}\), where \(\mu ^{-}(x)=\frac{\int \limits _{0}^x t f(t) dt }{ F(X)}\) and \(\mu ^{+}(x)=\frac{\int \limits _{x}^\infty t f(t) dt }{ {{\overline{F}}}(X)}.\)
Result 3.4
If X has the BMLD with density function, cumulative distribution function and survival function given in Eqs. (2.1), (2.11) and (2.12) respectively, then
- (a):
-
Lorenz curve,
$$\begin{aligned} L_F(x)=\frac{\sum \limits _{i=0}^{g}\left( {\begin{array}{c}g\\ i\end{array}}\right) \left( \frac{\theta }{\theta +\beta }\right) ^i \left( \frac{\beta }{\theta +\beta }\right) ^{g-i}\alpha _i\gamma _{\alpha _i+1}(\theta x)}{\sum \limits _{i=0}^{g}\left( {\begin{array}{c}g\\ i\end{array}}\right) \left( \frac{\theta }{\theta +\beta }\right) ^i \left( \frac{\beta }{\theta +\beta }\right) ^{g-i}\alpha _i}. \end{aligned}$$(3.14) - (b):
-
Bonferroni curve,
$$\begin{aligned} \begin{aligned} B_{F}(x)&=\frac{\sum \limits _{i=0}^{g}\left( {\begin{array}{c}g\\ i\end{array}}\right) \left( \frac{\theta }{\theta +\beta }\right) ^i \left( \frac{\beta }{\theta +\beta }\right) ^{g-i}\alpha _i\gamma _{\alpha _i+1}(\theta x)}{\left\{ \sum \limits _{i=0}^{g}\left( {\begin{array}{c}g\\ i\end{array}}\right) \left( \frac{\theta }{\theta +\beta }\right) ^i \left( \frac{\beta }{\theta +\beta }\right) ^{g-i}\alpha _i \right\} \left\{ \sum \limits _{i=0}^{g}\left( {\begin{array}{c}g\\ i\end{array}}\right) \left( \frac{\theta }{\theta +\beta }\right) ^i \left( \frac{\beta }{\theta +\beta }\right) ^{g-i} \gamma _{\alpha _i}(\theta x)\right\} }. \end{aligned} \end{aligned}$$(3.15) - (c):
-
Zenga curve,
$$\begin{aligned} \begin{aligned} A_{F}(x)=1-&\left\{ \frac{\sum \limits _{i=0}^{g}\left( {\begin{array}{c}g\\ i\end{array}}\right) \left( \frac{\theta }{\theta +\beta }\right) ^i \left( \frac{\beta }{\theta +\beta }\right) ^{g-i}\alpha _i\gamma _{\alpha _i+1}(\theta x)}{\sum \limits _{i=0}^{g}\left( {\begin{array}{c}g\\ i\end{array}}\right) \left( \frac{\theta }{\theta +\beta }\right) ^i \left( \frac{\beta }{\theta +\beta }\right) ^{g-i} \gamma _{\alpha _i}(\theta x)}\right. \\&\quad \times \left. \frac{\Big (1-\sum \limits _{i=0}^{g}\left( {\begin{array}{c}g\\ i\end{array}}\right) \left( \frac{\theta }{\theta +\beta }\right) ^i \left( \frac{\beta }{\theta +\beta }\right) ^{g-i} \gamma _{\alpha _i}(\theta x)\Big )}{\sum \limits _{i=0}^{g}\left( {\begin{array}{c}g\\ i\end{array}}\right) \left( \frac{\theta }{\theta +\beta }\right) ^i \left( \frac{\beta }{\theta +\beta }\right) ^{g-i}\alpha _i\Gamma _{\alpha _i+1}(\theta x)}\right\} . \end{aligned} \end{aligned}$$(3.16)
Proof
-
(a)
By definition
$$\begin{aligned} \begin{aligned} L_{F}(x)&= \frac{\int \limits _{0}^x t f(t) dt }{E(X)}. \end{aligned} \end{aligned}$$(3.17)Now
$$\begin{aligned} \begin{aligned} \int \limits _{ 0 }^x t f(t) dt&= \frac{1}{\theta }\sum \limits _{i=0}^{g} \frac{p_{i}}{\Gamma (\alpha _{i})} \gamma ({\alpha _{i}+1},\theta x)\\&=\frac{1}{\theta }\sum \limits _{i=0}^{g}\left( {\begin{array}{c}g\\ i\end{array}}\right) \left( \frac{\theta }{\theta +\beta }\right) ^i \left( \frac{\beta }{\theta +\beta }\right) ^{g-i}\alpha _i\gamma _{\alpha _i+1}(\theta x) . \end{aligned} \end{aligned}$$(3.18) -
(b)
By definition
$$\begin{aligned} \begin{aligned} B_{F}(x) = \frac{\int \limits _{0}^x t f(t) dt }{ F(X)E(X)}. \end{aligned} \end{aligned}$$ -
(c)
By definition
$$\begin{aligned} \begin{aligned} A(x)&=1-\frac{\mu ^{-}(x)}{\mu ^{+}(x)}.\\ \end{aligned} \end{aligned}$$(3.19)
By using (3.18) and (2.11), we get \(\mu ^{-}(x)\) and by definition \(\mu ^{+}(x)=\frac{\int \limits _{x}^\infty t f(t) dt }{ {{\overline{F}}}(X)}=\nu (x).\) which is given in (3.8). Substituting \(\mu ^{-}(x)\) and \(\mu ^{+}(x)\) in (3.19), we get (3.16). \(\square\)
3.3 Entropy
Here we derive the expressions for Rényi Entropy and Havrda-Charv\(\acute{a}\)t-Tsallis (HCT) entropy. We are also deriving the expression for a recently developed uncertainty measure, namely extropy and its residual version. For mathematical simplicity these results are derived for \(g=2\).
The concept of entropy was introduced and extensively studied by Shannon (1948). Let X be a non-negative random variable admitting an absolutely continuous cdf F(x) and with pdf f(x). Then the Shannon’s entropy associated with X is defined as \(H(X) = - \int \limits _0^\infty {f(x)\ \log f(x)\ dx}.\) It gives the expected uncertainty contained in f(x) about the predictability of an outcome of X.
Several generalizations of Shannon’s entropy have been put forward by researchers. A generalization which has received much attention subsequently is due to Rényi (1959). The Rényi’s entropy of order \(\nu\) is defined as
Another important generalization of Shannon’s entropy is the Havrda-Charv\(\acute{a}\)t-Tsallis (HCT) entropy. It was introduced by Havrda and Charv\(\acute{a}\)t (1967) and further developed by Tsallis (1988) and is given by,
Result 3.5
The R\(\acute{e}\)nyi entropy function for BMLD has the following form,
Proof
Using the definition of Rényi entropy, we have
\(\square\)
Remark 3.1
When \(\nu \rightarrow 1\) in (3.20), it reduces to Shannon entropy.
Result 3.6
The Havrda-Charv\(\acute{a}\)t-Tsallis entropy of order \(\rho\), for BMLD has the following form,
Proof
Proof is similar to that of Result 3.5 and hence omitted. \(\square\)
3.4 Extropy
Recently, Lad et al. (2015) defined statistically the term extropy as a potential measure of uncertainty, an alternative measure of Shannon entropy. For a random variable X, its extropy is defined as
In statistical point of view, the term extropy is used to score the forecasting distributions under the total log scoring rule.
A serious difficulty involved in the application of Shannon’s entropy is that, it is not applicable to a system which has survived for some units of time. In this situation, Ebrahimi (1996) proposed the concept of residual entropy. As in the scenario of introducing the concept of residual entropy, Qiu and Jia (2018) introduced residual extropy to measure the residual uncertainty of a random variable. For a random variable X, its residual extropy is defined as (see, Qiu and Jia 2018)
Result 3.7
The extropy function for BMLD has the following form,
Proof
By definition of J(X),
By simplifying (3.25), we get (3.24).\(\square\)
Result 3.8
The residual extropy function for BMLD has the following form,
Proof
Proof is similar to that of Result 3.7 and hence omitted. \(\square\)
4 Estimation and Ιnference
Estimation of unknown parameters of a distribution is essential in all areas of statistics. In this section, first we obtain the maximum likelihood estimates (MLEs) of the parameters of BMLD for a given random sample. The Fisher information matrix is also computed in this section for the interval estimation. For mathematical simplicity all these inferences are made for \(g=2\).
4.1 Maximum Likelihood Estimation
The method of maximum likelihood is the most frequently used technique for parameter estimation. It’s success stems from its many desirable properties including consistency, asymptotic efficiency, invariance property as well as intuitive appeal.
Let \(X_1, X_2,..., X_n\) be observed values from the BMLD with unknown parameter vector \({\textcircled {{H}}}= \Big (\theta , \beta , \alpha _{0}, \alpha _{1}, \alpha _{2}\Big )\). The likelihood function is given by
The partial derivatives of \(\log l\big ({\textcircled { {H}}}\big )\) with respect to the parameters are given by
and
where \(A_{i}=\frac{\beta ^{2}\theta ^{\alpha _0}x_{i}^{\alpha _0-1}}{\Gamma (\alpha _{0})}\), \(B_{i}=\frac{2\beta \theta ^{\alpha _1+1}x_{i}^{\alpha _1-1}}{\Gamma (\alpha _{1})}\) and \(C_{i}=\frac{\theta ^{\alpha _2+2}x_{i}^{\alpha _2-1}}{\Gamma (\alpha _{2})}.\)
The MLE of the parameters \({\textcircled { {H}}}= \Big (\theta , \beta , \alpha _{0}, \alpha _{1}, \alpha _{2}\Big )\) are obtained by solving the equations \(\frac{\partial \log l}{\partial \theta }=0\), \(\frac{\partial \log l}{\partial \beta }=0\), \(\frac{\partial \log l}{\partial \alpha _{0}}=0\), \(\frac{\partial \log l}{\partial \alpha _{1}}=0\), \(\frac{\partial \log l}{\partial \alpha _{2}}=0\) simultaneously. This can only be achieved by numerical optimization technique such as the Newton-Raphson method and Fisher’s scoring algorithm using mathematical packages like R, Mathematica etc. To avoid local minima problem, we first obtain the moment estimators of the parameters of BMLD and setting these estimators as the initial values to obtain MLEs of the parameters of BMLD.
4.2 Fisher Information Matrix
In order to determine the confidence interval for the parameters of BMLD, we need to find the expected Fisher information matrix \(I({\textcircled { {H}}})\). The expected Fisher information matrix of BMLD is given by,
The expected Fisher information can be approximated by the observed Fisher information matrix \(J\widehat{({\textcircled { {H}}})}\) given by,
That is,
For large n, the following approximation can be used,
The elements of \(J\widehat{({\textcircled { {H}}})}\) are given in APPENDIX.
4.3 Asymptotic Confidence Interval
Here we present the asymptotic confidence intervals for the parameters of BMLD. Let \(\widehat{{\textcircled { {H}}}}=\Big ({\widehat{\theta }}, {\widehat{\beta }}, \widehat{\alpha _0}, \widehat{\alpha _1}, \widehat{\alpha _2}\Big )\) be the maximum likelihood estimator of \({\textcircled { {H}}}=\Big (\theta , \beta , \alpha _0, \alpha _1, \alpha _2\Big )\). Under the usual regularity conditions and that the parameters are in the interior of the parameter space, but not on the boundary, we have \(\sqrt{n} ({\textcircled { {H}}} - \widehat{{\textcircled { {H}}}}) \mathop \rightarrow \limits ^d N_{2}({\underline{0}},I^{-1}({\textcircled { {H}}}))\), where \(I({\textcircled { {H}}})\) is the expected Fisher information matrix. The asymptotic behaviour is still valid if \(I({\textcircled { {H}}})\) is replaced by the observed Fisher information matrix \(J\widehat{({\textcircled { {H}}})}\). The multivariate normal distribution, \(N_{5}\Big ({\underline{0}},I^{-1}({\textcircled { {H}}}) \Big )\) with mean vector \({\underline{0}}=\Big (0, 0, 0, 0, 0\Big )^{\tau }\) can be used to construct confidence interval for the parameters. The approximate \(100(1-\varphi )\%\) two-sided confidence intervals for \(\theta , \beta , \alpha _0, \alpha _1,\) and \(\alpha _2\) are respectively given by, \({\widehat{\theta }} \pm Z_{\frac{\varphi }{2}}\sqrt{I_{\theta \theta }^{-1}({\hat{\theta }}) }\), \({\widehat{\beta }} \pm Z_{\frac{\varphi }{2}}\sqrt{I_{\beta \beta }^{-1}({\hat{\beta }}) },\) \(\widehat{\alpha _0} \pm Z_{\frac{\varphi }{2}}\sqrt{I_{\alpha _{0} \alpha _{0}}^{-1}({\hat{\alpha }}_{0}) },\) \(\widehat{\alpha _1} \pm Z_{\frac{\varphi }{2}}\sqrt{I_{\alpha _{1} \alpha _{1}}^{-1}({\hat{\alpha }}_{1})}\) and \(\widehat{\alpha _2} \pm Z_{\frac{\varphi }{2}}\sqrt{I_{\alpha _{2} \alpha _{2}}^{-1}({\hat{\alpha }}_{2})}\) , where \(I_{\theta \theta }^{-1}({\hat{\theta }})\), \(I_{\beta \beta }^{-1}({\hat{\beta }})\), \(I_{\alpha _{0} \alpha _{0}}^{-1}({\hat{\alpha }}_{0})\), \(I_{\alpha _{1} \alpha _{1}}^{-1}({\hat{\alpha }}_{1})\), \(I_{\alpha _{2} \alpha _{2}}^{-1}({\hat{\alpha }}_{2})\) are diagonal elements of \(J^{-1}\widehat{({\textcircled { {H}}})}\) and \(Z_{\frac{\varphi }{2}}\) is the upper \(\frac{\varphi }{2}^{th}\) percentile of a standard normal distribution.
5 Simulation Study
Here we perform a simulation study to investigate the performance of maximum likelihood estimators of parameters of BMLD. As the model is a general model, we take \(g=2\) in (2.1) and do the Monte Carlo Simulation. The estimates were calculated for true values of parameters (\(\theta =1.5\), \(\beta =3\), \(\alpha _{0}=0.6\), \(\alpha _{1}=1.9\) and \(\alpha _{2}= 1.7\)) and (\(\theta =0.5\), \(\beta =0.01\), \(\alpha _{0}=1.5\), \(\alpha _{1}=1.3\) and \(\alpha _{2}= 1\)) for N = 1000 samples of sizes 25,50,100,200,400 and 800 and the following quantities are computed.
-
1.
Mean of the MLEs, \(\widehat{{\textcircled { {H}}}}\) of parameters \({\textcircled { {H}}}=\Big (\theta , \beta , \alpha _0, \alpha _1, \alpha _2\Big )\) ,
$$\begin{aligned} \widehat{{\textcircled { {H}}}} =\frac{1}{N}\sum \limits _{i=1}^{N}{\widehat{{\textcircled { {H}}}}_{i}}. \end{aligned}$$ -
2.
Average absolute bias of MLEs of parameters,
$$\begin{aligned} Bias({\textcircled { {H}}}) = \frac{1}{N}\sum \limits _{i=1}^{N}(\widehat{{\textcircled { {H}}}}_{i}-{\textcircled { {H}}}). \end{aligned}$$ -
3.
Root Mean Square Error (RMSE) of MLEs of parameters:
$$\begin{aligned} RMSE({\textcircled { {H}}}) =\sqrt{\frac{1}{N}\sum \limits _{i=1}^{N}(\widehat{ {\textcircled { {H}}}}_{i}-{\textcircled { {H}}})^{2}}. \end{aligned}$$
The simulation results are presented in Table 1. From Table 1, one can infer that estimates are quite stable and more precisely close to the true parameter values. Also the estimated biases, MSEs and RMSEs are decreasing when the sample size n is increasing. These results reveal the consistency property of the MLEs.
6 Data Analysis
In this section we illustrate the superiority of BMLD as compared to some other distributions using three real data sets. The first one is the lifetimes of 50 devices provided by Aarset (1987). Second one is the strength of glass fibres of length 1.5 cm from the National Physical Laboratory in England (see, Smith and Naylor 1987). And the final one is the survival times (in days) of 72 guinea pigs infected with virulent tubercle bacilli, observed and reported by Bjerkedal (1960). A graphical method based on Total Time on Test (TTT) (see, Aarset 1987) is used here to determine the shape of hazard rate function of the datasets we considered. The empirical TTT plot is,
where \(X_{(i)}\) denote the ith order statistic of the sample. Figure 3 depicts the empirical TTT plots of the three data sets that we have considered here.

Empirical TTT plots of datas of a Lifetimes of 50 devices, b Strength of glass fibres and c Survival times of 72 guinea pigs
For the data set, lifetimes of 50 devices provided by Aarset (1987), the empirical TTT transform is convex then concave, so the hazard function is bathtub shaped. For the other two data sets, the empirical TTT transform is concave, therefore both have increasing hazard function.
For the three data sets we compute model adequacy measures and goodness of fit statistic of BMLD, and compare it with that of classical distributions such as Modified Weibull (MW) (see, Lai et al. 2003), Additive Weibull (AW) (see, Lemonte et al. 2014), Exponentiated Lindley (EL) (see, Nadarajah et al. (2011), Weighted Lindley (WL) (see, Ghitany et al. 2011), Generalized Lindley (GL) (see, Zakerzadeh and Dolati 2009), Lindley Exponential (LE) (see, Bhati et al. 2015), New Generalized Lindley (NGL) (see, Abouammoh et al. 2015), Extended Generalized Lindley (EGL) (see,Ranjbar et al. 2019) and Exponentiated Weibull (EW) (see, Pal et al. 2006).
The estimates of the parameters, -Log Likelihood (− log L), Akaike information criterion (AIC), Bayesian information criterion (BIC), Corrected Akaike information criterion (AICc), Kolmogorov Smirnov (KS) statistic values along with the p value are calculated for these datasets and are given in Tables 2, 3 and 4 respectively. The plots of fitted densities and cumulative densities with respective to the given data sets are also plotted.
The best model is the one with lowest AIC, BIC, AICc and KS statistic with largest p value. From the Tables 2,3 and 4 we can clearly observe that BMLD has the smallest value for its model adequacy measures such as AIC, BIC and AICc. Thus one can conclude that BMLD has the better performance compared to the other competing models. Further the Kolmogorv Smirnov (KS) statistic is computed to check the goodness of fit for the data set to BMLD as well as the other models. The value of KS statistic indicates that the BMLD has high fitting ability compared to other models considered here.
The plots of fitted densities and cumulative densities with respective to the datasets are given in Figs. 3, 4 and 5 respectively.

Fitted densities (a) and cumulative densities (b) of data of lifetimes of 50 devices

Fitted densities (a) and cumulative densities (b) of data of strength of glass fibres

Fitted densities (a) and cumulative densities (b) of data of survival times of 72 guinea pigs
Figures 4a, 5a and 6a depicts the empirical histograms of the real data and the fitted densities of the BMLD and other distributions considered here. The fit of BMLD seems to be closer to the histogram of real data sets than other distributions. Also Figs. 4b, 5b and 6b shows the empirical and fitted cumulative density functions of BMLD and other distributions with the real data set. From these plots it is clear that BMLD will give consistently better fits than other competitive models.
7 Conclusion
In this article, we proposed a wider class of Lindley distribution called the binomial mixture Lindley distribution (BMLD), which generalizes ED, GD, LD, \(LD_2\), WLD, GLD, NGLD and \(NGLD_1\). Its flexibility allows increasing, decreasing, bathtub shaped and upside-down bathtub shaped hazard rates. Owing to the attractive feature of hazard rate function of BMLD it can be used to model any type of failure data sets. The estimation of parameters was explored by MLE method and the statistical properties of the estimators are investigated using a simulation study. Finally to establish the potentiality of this model, we use three real data sets in which one among them has bathtub shaped hazard rate and the other two have increasing hazard rate. For all these data sets BMLD performs better when compared to other competing models. Summing up, the BMLD provides a better model for fitting the wide spectrum of positive data sets arising in engineering, survival analysis, hydrology, economics, physics as well as numerous other fields of scientific investigation.
References
Aarset MV (1987) How to identify a bathtub hazard rate. IEEE Trans Reliab 36(1):106–108
Abouammoh AM, Alshangiti AM, Ragab IE (2015) A new generalized Lindley distribution. J Stat Comput Simul 85(18):3662–3678
Al-Mutairi DK, Ghitany ME, Kundu D (2013) Inferences on stress-strength reliability from Lindley distributions. Commun Stat Theory Methods 42(8):1443–1463
Bjerkedal T (1960) Acquisition of resistance in guinea pies infected with different doses of virulent tubercle bacilli. Am J Hyg 72:130–148
Bhati D, Malik MA, Vaman HJ (2015) Lindley-exponential distribution. Properties and applications. METRON 73(3):335–357
Bonferroni CE (1930) Elementi di statistica generale. Seeber, Firenze
Deniz EG, Ojeda EC (2011) The discrete Lindley distribution properties and applications. J Stat Comput Simul 81:1405–1416
Ebrahimi N (1996) How to measure uncertainty in the residual life time distribution. SankhyÄ Indian J Stat Ser 5:48–56
Elbatal I, Merovci F, Elgarhy M (2013) A new generalized Lindley distribution. Math Theory Model 3(13):30–47
Ghitany ME, Alqallaf F, Al-Mutairi DK, Husain HA (2011) A two-parameter weighted Lindley distribution and its applications to survival data. Math Comput Simul 81(6):1190–1201
Ghitany ME, Atieh B, Nadarajah S (2008) Lindley distribution and its applications. Math Comput Simul 78:493–506
Havrda J, Charvát F (1967) Quantification method of classification processes. Concept of structural a-entropy. Kybernetika 3(1):30–35
Lad F, Sanfilippo G, Agro G (2015) Extropy. Complementary dual of entropy. Stat Sci 30(1):40–58
Lai CD, Xie M, Murthy DNP (2003) A modified Weibull distribution. IEEE Trans Reliab 52(1):33–37
Lemonte AJ, Cordeiro GM, Ortega EM (2014) On the additive Weibull distribution. Commun Stat Theory Methods 43(10–12):2066–2080
Lindley DV (1958) Fiducial distributions and Baye’s theorem. J Roy Stat Soc B 20:102–107
Mazucheli J, Achcar JA (2011) The Lindley distribution applied to competing risks lifetime data. Comput Methods Programs Biomed 104(2):188–192
Nadarajah S, Bakouch HS, Tahmasbi R (2011) A generalized Lindley distribution. Sankhya B 73(2):331–359
Pal M, Ali MM, Woo J (2006) Exponentiated weibull distribution. Statistica 66(2):139–147
Qiu G, Jia K (2018) The residual extropy of order statistics. Stat Probabil Lett 133:15–22
Ranjbar V, Alizadeh M, Altun E (2019) Extended Generalized Lindley distribution: properties and applications. J Math Ext 13:117–142
Rényi A (1961) On measures of entropy and information. Proc Fourth Berkeley Symp Math Stat Probabil 1:547–561
Shanker R, Sharma S, Shanker R (2013) A two-parameter Lindley distribution for modeling waiting and survival times data. Appl Math 4(2):363–368
Sharma VK, Singh SK, Singh U, Agiwal V (2015) The inverse Lindley distribution: a stress-strength reliability model with application to head and neck cancer data. J Ind Prod Eng 32(3):162–173
Shannon CE (1948) A mathematical theory of communication. Bell Syst Tech J 27(3):379–423
Smith RL, Naylor JC (1987) A comparison of maximum likelihood and Bayesian estimators for the three parameter Weibull distribution. J R Stat Soc Ser C 36(3):358–369
Titterington DM, Smith AFM, Markov UE (1985) Statistical analysis of finite mixture distributions. Wiley, New York
Tsallis C (1988) Possible generalization of Boltzmann-Gibbs statistics. J Stat Phys 52(1–2):479–487
Zakerzadeh H, Dolati A (2009) Generalized Lindley distribution. J Math Exten 3:13–25
Zenga M (2007) Inequality curve and inequality index based on the ratios between lower and upper arithmetic means. Statistica Applicazioni 4:3–27
Acknowledgements
The authors express their gratefulness to the learned referee for many of the constructive comments and suggestions, which lead the way to improvements and thus procure current version of the paper. First author acknowledge the Cochin University of Science and Technology for providing financial support in the form of seed money for new research initiatives (No.PL.(UGC)I/SPG/SMNRI/2018-2019).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
The second partial and cross derivatives with respect to the parameters are derived as,
and
Rights and permissions
About this article

Cite this article
Irshad, M.R., Shibu, D.S., Maya, R. et al. Binominal Mixture Lindley Distribution: Properties and Applications. J Indian Soc Probab Stat 21, 437–469 (2020). https://doi.org/10.1007/s41096-020-00090-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41096-020-00090-y