
Abstract
A new distribution is proposed for modeling lifetime data. It has better hazard rate properties than the gamma, lognormal and the Weibull distributions. A comprehensive account of the mathematical properties of the new distribution including estimation and simulation issues is presented. A real data example is discussed to illustrate its applicability.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
There are many distributions for modeling lifetime data. Among the known parametric models, the most popular are the gamma, lognormal and the Weibull distributions. The Weibull distribution is more popular than the gamma and lognormal distributions because the survival functions of the latter cannot be expressed in closed forms and one needs numerical integration. The Weibull distribution has closed form survival and hazard rate functions. We refer the readers to Murthy et al. (2004) for details about Weibull distributions.
Gupta and Kundu (1999) introduced the exponentiated exponential distribution as an alternative to the gamma distribution. The exponentiated exponential distribution has many properties similar to those of the gamma and yet has closed form survival and hazard rate functions. See Gupta and Kundu (2007) for a review and some developments on the exponentiated exponential distribution.
However, the above four distributions (gamma, lognormal, Weibull and exponentiated exponential) suffer from a number of drawbacks. Firstly, none of them exhibit bath tub shapes for their hazard rate functions. The four distributions exhibit only monotonically increasing, monotonically decreasing or constant hazard rates. This is a major weakness because most real-life systems exhibit bath tub shapes for their hazard rate functions. Secondly, at least three of the four distributions exhibit constant hazard rates. This is a very unrealistic feature because there are hardly any real-life systems that have constant hazard rates.
The aim of this paper is to introduce a two parameter alternative to the gamma, lognormal, Weibull and the exponentiated exponential distributions that overcomes these mentioned drawbacks. It is most conveniently specified in terms of the cumulative distribution function:
for x > 0, λ > 0 and α > 0. The corresponding probability density function is:
The corresponding hazard rate function is
where
Note that Eq. 2 has two parameters, α and λ, just like the gamma, lognormal, Weibull and exponentiated exponential distributions. Note also that Eq. 2 has closed form survival functions and hazard rate functions just like the Weibull and exponentiated exponential distributions. For α = 1, Eq. 2 reduces to the Lindley distribution (Lindley 1958). As we shall see later, Eq. 2 has the attractive feature of allowing for monotonically decreasing, monotonically increasing and bath tub shaped hazard rate functions while not allowing for constant hazard rate functions.
Another motivation for the new distribution in Eq. 1 can be described as follows. Consider the one parameter Lindley distribution (Lindley 1958) specified by the cumulative distribution function:
for x > 0 and λ > 0. This distribution is becoming increasing popular for modeling lifetime data, see Ghitany et al. (2008a, b) and Ghitany and Al-Mutairi (2009). Suppose X 1, X 2, ..., X α are independent random variables distributed according to Eq. 5 and represent the failure times of the components of a series system, assumed to be independent. Then the probability that the system will fail before time x is given by
So, Eq. 1 gives the distribution of the failure of a series system with independent components.
The contents of this paper are organized as follows. A comprehensive account of mathematical properties of the new distribution is provided in Sections 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 and 15. The properties studied include: relationship to other distributions, stochastic orderings, shapes of the probability density function and the hazard rate function, quantile function, raw moments, conditional moments, L moments, moment generating function, characteristic function, cumulant generating function, mean deviation about the mean, mean deviation about the median, Bonferroni curve, Lorenz curve, Bonferroni index, Gini index, Rényi entropy, Shannon entropy, cumulative residual entropy, order statistics and their moments, asymptotic distribution of the extreme values, and reliability measures. Estimation by the methods of moments and maximum likelihood—including the case of censoring—is presented in Section 16. Two simulation schemes are presented in Section 17. The performances of the two estimation methods are compared by simulation in Section 18. Finally, Section 19 illustrates an application by using a real data set. For additional properties of the new distribution including more details on the derived properties, we refer the readers to Nadarajah et al. (2011).
In the application section (Section 19), the lognormal distribution that we shall consider is a three parameter generalization (Chen 2006) of the usual one given by the probability density function:
for x > θ, σ > 0 and − ∞ < μ < ∞. We shall yet note that the proposed two parameter distribution provides better fits than Eq. 6.
2 Related distributions
Note that the cumulative distribution function of a Lindley random variable given by Eq. 5 can be represented as
where θ = λ/(1 + λ), \(F_E (x) = 1 - \exp (-\lambda) x\), the cumulative distribution function of an exponential random variable with scale parameter λ, and \(F_{G2} (x) = 1 - \{ 1 + \lambda x \} \exp (-\lambda) x\), the cumulative distribution function of a gamma random variable with shape parameter 2 and scale parameter λ. It follows that the cumulative distribution function, Eq. 1, can be represented as
So, the proposed distribution can be viewed as an infinite mixture of the products of exponentiated gamma distributions. If α is an integer then the mixture is finite.
For x > 0, λ > m > 0 and β > 0, a gamma distribution has its cumulative distribution function and probability density function specified by
and
respectively, where \(\gamma (a, x) = \int_0^x t^{a - 1} \exp (-t) dt\) denotes the incomplete gamma function and \(\Gamma (a) = \int_0^\infty t^{a - 1} \exp (-t) dt\) denotes the gamma function. It is easy to see that
and
where
a finite constant for all 0 < m < λ.
For x > 0, m > 0, α > 0 and β > 0, an exponentiated gamma distribution has its cumulative distribution function and probability density function specified by
and
respectively. The properties of this distribution have been studied in detail by Nadarajah and Gupta (2007). The particular cases of Eqs. 9 and 10 for β = 2 are
and
respectively. It is easy to see that
for m = λ and m = λ/(1 + λ) and that F EG2 (x) is a decreasing function of m. If m = λ then
for α ≥ 1 and
for α < 1. If m = λ/(1 + λ) then
for α ≥ 1 and
for α < 1.
For x > 0, λ > 0 and β > 0, a Weibull distribution has its cumulative distribution function and probability density function specified by
and
respectively. It is easy to see that
and
where
a finite constant for all 0 < β < min(1, α).
3 Stochastic orders
Suppose X i is distributed according to Eqs. 1 and 2 with parameters λ i and α i for i = 1, 2. Let F i denote the cumulative distribution function of X i and let f i denote the probability density function of X i . If λ 1 = λ 2 then F 1(x) ≥ F 2(x) for all x > 0 and for all 0 < α 1 ≤ α 2, so X 2 is stochastically greater than or equal to X 1. If α 1 = α 2 then F 1(x) ≤ F 2(x) for all x > 0 and for all 0 < λ 1 ≤ λ 2, so X 1 is stochastically greater than or equal to X 2. The latter statement follows from the fact that \(1 - (1 + \lambda + \lambda x) \exp (-\lambda x)/(1 + \lambda)\) is an increasing function of λ.
We say that X 2 is stochastically greater than X 1 with respect to likelihood ratio if f 2(x)/f 1(x) is an increasing function of x (Shaked and Shanthikumar 1994). Note that
So, if λ 1 = λ 2 then X 2 is stochastically greater than X 1 with respect to likelihood ratio if and only if α 2 > α 1. If α 1 = α 2 = α then Eq. 13 reduces to
where
We can write
where
Note that
So, if α 1 = α 2 = α ≥ 1 then X 2 is stochastically greater than X 1 with respect to likelihood ratio if and only if λ 1 ≥ λ 2. If α 1 = α 2 = α < 1 then X 2 is stochastically greater than X 1 with respect to likelihood ratio if and only if λ 1 ≤ λ 2.
We say that X 2 is stochastically greater than X 1 with respect to reverse hazard rate if f 1(x) / F 1(x) ≤ f 2(x) / F 2 (x) for all x (Shaked and Shanthikumar 1994). Note that
where q(·) is as defined by Eq. 14. So, if λ 1 = λ 2 then X 2 is stochastically greater than X 1 with respect to reverse hazard ratio if and only if α 2 ≥ α 1. If α 1 = α 2 then X 2 is stochastically greater than X 1 with respect to reverse hazard ratio if and only if λ 2 ≤ λ 1. The latter statement follows from Eq. 15.
4 Shapes
It follows from Eq. 2 that
and
where V(·) is given by Eq. 4. If α ≥ 1 then, using the fact \(\exp (-\lambda x) > 1 - \lambda x\), we can see that d 2 log f(x)/dx 2 < 0 for all x. So, f is log-concave and has the increasing likelihood ratio property. Also d log f(x)/dx monotonically decreases from ∞ to − λ, so f must attain a unique maximum at x = x 0 for some 0 < x 0 < ∞. If α < 1 and λ ≥ 1 then d log f(x)/dx < 0 for all x, so f is monotonically decreasing for all x. If α < 1 and λ < 1 then f could attain a maximum, a minimum or a point of inflection according to whether d 2 log f(x)/dx 2 < 0, d 2 log f(x)/dx 2 > 0 or d 2 log f(x)/dx 2 = 0.
It follows from Eq. 3 that
and
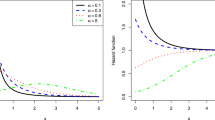
The modes of Eq. 3 are the points x = x 0 satisfying d log h(x)/dx = 0. These points correspond to a maximum, a minimum and a point of inflection if d 2 log h(x)/dx 2 < 0, d 2 log h(x)/dx 2 > 0 and d 2 log h(x)/dx 2 = 0, respectively. Plots of Eq. 3 presented in Nadarajah et al. (2011) show: the shape of Eq. 3 appears monotonically decreasing or to initially decrease and then increase, a bath-tub shape, if α < 1; the shape appears monotonically increasing if α ≥ 1. So, the proposed distribution allows for monotonically decreasing, monotonically increasing and bath-tub shapes for its hazard rate function. Note that a constant hazard rate is not allowed.
Note that
as x → ∞,
as x → 0,
as x → ∞,
as x → 0,
as x → ∞, and
as x → 0. So, the lower tail of the probability density function is polynomial while its upper tail decays exponentially. The lower tail of the hazard rate function is polynomial and allows for decreasing, increasing and constant hazard rates. In the upper tail, the hazard rate function approaches a constant.
5 Quantile function
Let X denote a random variable with the probability density function 2. The quantile function, say Q(p), defined by F(Q(p)) = p is the root of the equation
for 0 < p < 1. Substituting Z(p) = − 1 − λ − λQ(p), one can rewrite Eq. 18 as
for 0 < p < 1. So, the solution for Z(p) is
for 0 < p < 1, where W(·) is the Lambert W function, see Corless et al. (1996) for detailed properties. Inverting Eq. 19, one obtains
for 0 < p < 1. The particular case of Eq. 20 for α = 1 has been derived recently by Jodrá (2010). Our derivation of the general form here is independent.
A series expansion for Eq. 20 around p = 1 can be obtained as
where \(x = -(1 + \lambda) ( 1 - p^{1/\alpha} ) \exp (-1 - \lambda)\). However, these expansions may not be needed as in-built routines for computing W(·) are widely available, for example, ProductLog[·] in Mathematica.
6 Moments
Let X denote a random variable with the probability density function 2. Calculating moments of X requires the following lemma.
Lemma 1
Let
We have
Proof
Using the series expansion, Eq. 38, one can write
The result of the lemma follows by the definition of the gamma function. □
It follows from Lemma 1 that
In particular, the first four moments of X are
and
The variance, skewness and kurtosis of X can now be obtained. Plots of E(X), Var(X), Skewness(X) and Kurtosis(X) versus λ and α presented in Nadarajah et al. (2011) show: E(X) and Var(X) are decreasing functions of λ while Skewness(X) and Kurtosis(X) are increasing functions of λ for every fixed α; E(X) and Var(X) are increasing functions of α while Skewness(X) and Kurtosis(X) are decreasing functions of α for every fixed λ.
7 Conditional moments
For lifetime models, it is also of interest to know what E (X n | X > x) is. Calculating these moments requires the following lemma.
Lemma 2
Let
We have
where \(\Gamma (a, x) = \int_x^{\infty} t^{a - 1} \exp (-t) dt\) denotes the complementary incomplete gamma function. If c is an integer then Eq. 22 can be simplified to
Proof
The proof of Eq. 22 is similar to the proof of Lemma 1, but using the definition of the complementary incomplete gamma function. The final relation follows by using the fact
see http://functions.wolfram.com/GammaBetaErf/Gamma2/03/01/02/0007/. □
Using Lemma 2, it is easily seen that
where V(·) is given by Eq. 4. In particular,
and
The mean residual lifetime function is E (X | X > x) − x.
8 L moments
Some other important measures useful for lifetime models are the L moments due to Hoskings (1990). It can be shown using Lemma 1 that the kth L moment is
where
In particular,
and
where
and
The L moments have several advantages over ordinary moments: for example, they apply for any distribution having finite mean; no higher-order moments need be finite.
9 MGF, CHF and CGF
Let X denote a random variable with the probability density function 2. It follows from Lemma 1 that the moment generating function of X, \(M (t) = E [\exp (tX)]\), is given by
for t < λ. So, the characteristic function of X, \(\phi (t) = E [\exp ({\rm i} tX)]\), and the cumulant generating function of X, K (t) = log ϕ(t), are given by
and
respectively, where \({\rm i} = \sqrt{-1}\).
10 Mean deviations
The amount of scatter in a population is evidently measured to some extent by the totality of deviations from the mean and median. These are known as the mean deviation about the mean and the mean deviation about the median—defined by
and
respectively, where μ = E(X) and M = Median(X) denotes the median. The measures δ 1(X) and δ 2(X) can be calculated using the relationships
and
By Lemma 2,
and
so it follows that
and
11 Bonferroni and Lorenz curves
The Bonferroni and Lorenz curves (Bonferroni 1930) and the Bonferroni and Gini indices have applications not only in economics to study income and poverty, but also in other fields like reliability, demography, insurance and medicine. The Bonferroni and Lorenz curves are defined by
and
respectively, or equivalently by
and
respectively, where μ = E (X) and q = F − 1 (p). The Bonferroni and Gini indices are defined by
and
respectively.
If X has the probability density function, Eq. 2, then, by Lemma 2, one can calculate Eqs. 23 and 24 as
and
respectively. Alternatively, by using Eq. 21, one can calculate Eqs. 25 and 26 as
and
respectively. Integrating Eqs. 31 and 32 with respect to p, one can calculate the Bonferroni and Gini indices given by Eqs. 27 and 28, respectively, as
and
respectively. Plots of the Bonferroni curve given by Eq. 29 and the Lorenz curve given by Eq. 30 presented in Nadarajah et al. (2011) show that the variability of X—as measured by the area between Bonferroni curve and B (p) = 1 or the area between the Lorenz curve and L(p) = p—decreases as α increases. The area between a Bonferroni curve and B (p) = 1 is the Bonferroni index given by Eq. 33. The area between a Lorenz curve and L(p) = p is known as the area of concentration. The Gini index given by Eq. 34 is twice this area.
12 Entropies
An entropy of a random variable X is a measure of variation of the uncertainty. A popular entropy measure is Rényi entropy (Rényi 1961). If X has the probability density function f(·) then Rényi entropy is defined by
where γ > 0 and γ ≠ 1. Suppose X has the probability density function 2. Then, one can calculate
where V(·) is given by Eq. 4 and the final step follows by the definition of the complementary incomplete gamma function. So, one obtains the Rényi entropy as
Shannon entropy (Shannon 1951) defined by E[ − log f(X)] is the the particular case of Eq. 35 for γ ↑ 1. Limiting γ ↑ 1 in Eq. 36 and using L’Hospital’s rule, one obtains after considerable algebraic manipulation that
where K( ⋯ ) is as defined by Lemma 1.
Finally, consider the cumulative residual entropy (Rao et al. 2004) defined by
Using the series expansions,
and
one can calculate Eq. 37 as
where the final step follows by an application of Lemma 1.
13 Order statistics
Suppose X 1, X 2, ..., X n is a random sample from Eq. 2. Let X 1: n < X 2: n < ⋯ < X n: n denote the corresponding order statistics. It is well known that the probability density function and the cumulative distribution function of the kth order statistic, say Y = X k: n , are given by
and
respectively, for k = 1, 2, ..., n. It follows from Eqs. 1 and 2 that
and
where V(·) is given by Eq. 4. Using Lemma 1, the qth moment of Y can be expressed as
for q ≥ 1.
14 Extreme values
If \(\overline{X} = (X_1 + \cdots + x_n)/n\) denotes the sample mean then by the usual central limit theorem \(\sqrt{n} (\overline{X} - E (X))/\sqrt{Var (X)}\) approaches the standard normal distribution as n → ∞. Sometimes one would be interested in the asymptotics of the extreme values M n = max(X 1, ..., X n ) and m n = min(X 1, ..., X n ).
Let g (t) = 1/λ. Take the cumulative distribution function and the probability density function as specified by Eqs. 1 and 2, respectively. Note from Eqs. 16 and 17 that
as t → ∞ and
as t → 0. Hence, it follows from Theorem 1.6.2 in Leadbetter et al. (1987) that there must be norming constants a n > 0, b n , c n > 0 and d n such that
and
as n → ∞. The form of the norming constants can also be determined. For instance, using Corollary 1.6.3 in Leadbetter et al. (1987), one can see that \(b_n = F^{-1} (1 - 1/n)\) and a n = λ, where F − 1(·) denotes the inverse function of F(·).
15 Reliability
In the context of reliability, the stress-strength model describes the life of a component which has a random strength X 1 that is subjected to a random stress X 2. The component fails at the instant that the stress applied to it exceeds the strength, and the component will function satisfactorily whenever X 1 > X 2. So, \(R = \Pr(X_2 < X_1)\) is a measure of component reliability. It has many applications especially in engineering concepts such as structures, deterioration of rocket motors, static fatigue of ceramic components, fatigue failure of aircraft structures, and the aging of concrete pressure vessels. In the area of stress-strength models there has been a large amount of work as regards estimation of the reliability R when X 1 and X 2 are independent random variables belonging to the same univariate family of distributions and its algebraic form has been worked out for the majority of the well-known standard distributions. However, there are still many other distributions (including generalizations of the well-known distributions) for which the form of R has not been investigated. Here, we derive the reliability R when X 1 and X 2 are independent random variables distributed according to Eq. 2 with parameters (α 1, λ 1) and (α 2, λ 2), respectively.
Several representations can be derived for the reliability R. Firstly, note from Eqs. 1 and 2 that
Applying the series expansion, Eq. 37, for both the terms within square brackets in Eq. 38, one obtains the representation
where the final step follows by the definition of the gamma function. Applying series expansion, Eq. 38, for only the first term within square brackets in Eq. 39, one obtains the representation
where the final step follows by an application of Lemma 1. Applying series expansion, Eq. 38, for only the second term within square brackets in Eq. 39, one obtains the representation
where the final step follows by an application of Lemma 1. Finally, if λ 1 = λ 2 = λ then
which follows by an application of Lemma 1. If in addition α 1 = α 2 then R = 1/2. Contours of the Eq. 39 presented in Nadarajah et al. (2011) show that they appear symmetric around the 45° diagonal when λ 1 and λ 2 are equal. They become more skewed towards the vertical axis (respectively, the horizontal axis) as the magnitude of λ 2 − λ 1 (respectively, λ 1 − λ 2) increases.
16 Estimation
Here, we consider estimation by the methods of moments and maximum likelihood and provide expressions for the associated Fisher information matrix. We also consider estimation issues for censored data.
Suppose x 1, ..., x n is a random sample from Eq. 2. For the moments estimation, let \(m_1 = (1/n) \sum_{j = 1}^n x_j\) and \(m_2 = (1/n) \sum_{j = 1}^n x_j^2\). By equating the theoretical moments of Eq. 2 with the sample moments, one obtains the equations:
and
The method of moments estimators are the simultaneous solutions of these two equations.
Now consider estimation by the method of maximum likelihood. The log likelihood function of the two parameters is:
where V(·) is given by Eq. 4. It follows that the maximum likelihood estimators, say \(\widehat{\alpha}\) and \(\widehat{\lambda}\), are the simultaneous solutions of the equations:
and
For interval estimation of (α, λ) and tests of hypothesis, one requires the Fisher information matrix:
The elements of this matrix for Eq. 42 can be worked out as:
and
where K( ⋯ ) is as defined by Lemma 1. Under regularity conditions, the asymptotic distribution of \((\widehat{\alpha}, \widehat{\lambda})\) as n → ∞ is bivariate normal with zero means and variance co-variance matrix I − 1.
Often with lifetime data, one encounters censored data. There are different forms of censoring: type I censoring, type II censoring, etc. Here, we consider the general case of multicensored data: there are n subjects of which
-
n 0 are known to have failed at the times \(X_1, \ldots, X_{n_0}\).
-
n 1 are known to have failed in the interval [S i − 1, S i ], i = 1, ..., n 1.
-
n 2 survived to a time R i , i = 1, ..., n 2 but not observed any longer.
Note that n = n 0 + n 1 + n 2. Note too that type I censoring and type II censoring are contained as particular cases of multicensoring. The log likelihood function of the two parameters for this multicensoring data is:
It follows that the maximum likelihood estimators are the simultaneous solutions of the equations:
and
where U (x) = V α(x) log V (x) and \(W (x) = (1 + \lambda)^{-2} V^{\alpha - 1} (x) \exp (-\lambda x) \{ \lambda (1 + \lambda) (1 + \lambda + \lambda x) - x \}\). The Fisher information matrix corresponding to Eq. 45 is too complicated to be presented here.
17 Simulation
Here, we consider simulating values of a random variable X with the probability density function 2. Let U denote a uniform random variable on the interval (0, 1). One way to simulate values of X is to set
and solve for X, i.e. use the inversion method. Using Eq. 20, we obtain X as
where W(·) denotes the Lambert W function. Another way to simulate values of X is by the rejection method with envelope g(·) chosen to be either the gamma probability density function in Eq. 7 or the Weibull probability density function in Eq. 11. It is well known that the rejection scheme for simulating is given by:
-
1.
Simulate X = x from the probability density function g(·).
-
2.
If g(·) is given by Eq. 7 then simulate Y = U M g(x), where U is an independent uniform random variable on (0, 1) and M is given by Eq. 8; if g(·) is given by Eq. 11 then simulate Y = U M * g(x), where U is an independent uniform random variable on (0, 1) and M * is given by Eq. 12.
-
3.
Accept X = x as a realization of a random variable with the probability density function 2 if Y < f(x). If Y ≥ f(x) return to step 2.
Routines are widely available for simulating from gamma and Weibull distributions (step 1).
18 Maximum likelihood versus moments estimation
In this section, we compare the performances of the two estimation methods presented in Section 16. For this purpose, we generated samples of size n = 10, 20, ..., 50 from Eq. 2 for λ = 1, 2, ..., 6, α = 1, 2, ..., 6 by following the inversion method described in Section 17. For each sample, we computed the moments estimates and the maximum likelihood estimates, by solving the Eqs. 40, 41, 43 and 44 in Section 16. We repeated this process thousand times and computed the bias of the estimates and the mean squared error (MSE). The computer programs NEQNF and GAMIC in IMSL and the computer package R were used for the calculations. The results for n = 20 are reported in Table 1. Those for n = 10, 30, 40, 50 are reported in Nadarajah et al. (2011). logl
The following observations can be made:
-
for n = 10, the moments estimator is generally superior in terms of bias and mean squared error,
-
for n = 20, 30, 40, 50, the moments estimator is generally superior in terms of bias and the maximum likelihood estimator is generally superior in terms of mean squared error,
-
the bias of \(\widehat{\lambda}\) decreases with increasing n for both maximum likelihood and moments estimators,
-
the bias of \(\widehat{\alpha}\) decreases with increasing n for both maximum likelihood and moments estimators,
-
the mean squared error of \(\widehat{\lambda}\) decreases with increasing n for both maximum likelihood and moments estimators,
-
the mean squared error of \(\widehat{\alpha}\) decreases with increasing n for both maximum likelihood and moments estimators,
-
the bias of \(\widehat{\lambda}\) generally decreases with increasing α for any given λ and n and for both maximum likelihood and moments estimators,
-
the bias of \(\widehat{\lambda}\) generally increases with increasing λ for any given α and n and for both maximum likelihood and moments estimators,
-
the bias of \(\widehat{\alpha}\) generally increases with increasing α for any given λ and n and for both maximum likelihood and moments estimators,
-
the mean squared error of \(\widehat{\lambda}\) generally decreases with increasing α for any given λ and n and for both maximum likelihood and moments estimators,
-
the mean squared error of \(\widehat{\lambda}\) generally increases with increasing λ for any given α and n and for both maximum likelihood and moments estimators,
-
the mean squared error of \(\widehat{\alpha}\) generally increases with increasing α for any given λ and n and for both maximum likelihood and moments estimators.
Because of space limitations, we have only considered n = 10, 20, ..., 50. But the above observations hold also for sample sizes greater than 50.
19 Data analysis
In this section, we illustrate that the new distribution given by Eq. 2 can be a better model than those based on the gamma, lognormal and the Weibull distributions. We use the lifetime data set given by Table 2. This data set is taken from Gross and Clark (1975, p. 105). It shows the relief times of twenty patients receiving an analgesic. We would like to emphasize that the aim here is not to provide a complete statistical modeling or inferences for the data set involved.
We fitted the models given by Eqs. 2, 7, 6 and 11 to the lifetime data set. The maximum likelihood procedure described by Eqs. 43 and 44 was used. The fitted estimates are given in Table 3. The numbers given within brackets are the standard errors of parameter estimates obtained by the delta method (Rao 1973, pp. 387–389). Also given in the table are the Kolmogorov Smirnov statistics of the fits and the associated p values.
The fitted models given by Eqs. 2, 7, 6 and 11 are not nested. So, their comparison should be based on criteria such as the Akaike’s information criterion or the Bayesian information criterion. Table 3 also gives values of these criteria. Note however that if the models have the same number of parameters then these criteria reduce to the usual likelihood ratio test.
Comparing the likelihood values, p values based on the Kolmogorov Smirnov test, AIC and BIC, we see that Eq. 2 provides a significantly better fit than the other three models. We also note from Table 3 that the new model generally yields smaller standard errors than the gamma, lognormal and the Weibull models. This suggests that the new model provides more accurate estimates as well as better fits.
References
Bonferroni, C.E. 1930. Elementi di statistica generale. Seeber, Firenze.
Chen, C. 2006. Tests of fit for the three-parameter lognormal distribution. Computational Statistics and Data Analysis 50:1418–1440.
Corless, R.M., Gonnet, G.H., Hare, D.E.G., Jeffrey, D.J., and D.E. Knuth. 1996. On the Lambert W function. Advances in Computational Mathematics 5:329–359.
Ghitany, M.E., and D.K. Al-Mutairi. 2009. Estimation methods for the discrete Poisson-Lindley distribution. Journal of Statistical Computation and Simulation 79:1–9.
Ghitany, M.E., Al-Mutairi, D.K., and S. Nadarajah. 2008a. Zero-truncated Poisson-Lindley distribution and its application. Mathematics and Computers in Simulation 79:279–287.
Ghitany, M.E., Atieh, B., and S. Nadarajah. 2008b. Lindley distribution and its application. Mathematics and Computers in Simulation 78:493–506.
Gross, A.J., and V.A. Clark. 1975. Survival distributions: Reliability applications in the biomedical sciences. New York: John Wiley and Sons.
Gupta, R.D., and D. Kundu. 1999. Generalized exponential distributions. Australian and New Zealand Journal of Statistics 41:173–188.
Gupta, R.D., and D. Kundu. 2007. Generalized exponential distribution: Existing results and some recent developments. Journal of Statistical Planning and Inference 137:3537–3547.
Hoskings, J.R.M. 1990. L-moments: analysis and estimation of distribution using linear combinations of order statistics. Journal of the Royal Statistical Society B, 52:105–124.
Jodrá, J. 2010. Computer generation of random variables with Lindley or Poisson–Lindley distribution via the Lambert W function. Mathematics and Computers in Simulation 81:851–859.
Leadbetter, M.R., Lindgren, G., and H. Rootzén 1987. Extremes and related properties of random sequences and processes. New York: Springer Verlag.
Lindley, D.V. 1958. Fiducial distributions and Bayes’ theorem. Journal of the Royal Statistical Society B, 20:102–107.
Murthy, D.N.P., Xie, M., and R. Jiang. 2004. Weibull models. New York: John Wiley and Sons.
Nadarajah, S., Bakouch, H.S., and R. Tahmasbi. 2011. A generalized Lindley distribution. Technical Report, School of Mathematics, University of Manchester, UK.
Nadarajah, S., and A.K. Gupta. 2007. The exponentiated gamma distribution with application to drought data. Calcutta Statistical Association Bulletin 59:233–234.
Rao, C.R. 1973. Linear statistical inference and its applications, 2nd edn. New York: John Wiley and Sons.
Rao, M., Chen, Y., Vemuri, B.C., and F. Wang. 2004. Cumulative residual entropy: A new measure of information. IEEE Transactions on Information Theory 50:1220–1228.
Rényi, A. 1961. On measures of entropy and information. In Proceedings of the 4th berkeley symposium on mathematical statistics and probability, vol. 1, 547–561. Berkeley: University of California Press.
Shaked, M., and J.G. Shanthikumar. 1994. Stochastic orders and their applications. Boston: Academic Press.
Shannon, C.E. 1951. Prediction and entropy of printed English. The Bell System Technical Journal 30:50–64.
Acknowledgements
The authors would like to thank the Editor-in-Chief and the referee for careful reading and for their comments which greatly improved the paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Nadarajah, S., Bakouch, H.S. & Tahmasbi, R. A generalized Lindley distribution. Sankhya B 73, 331–359 (2011). https://doi.org/10.1007/s13571-011-0025-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13571-011-0025-9