
Abstract
In this paper, we introduce a new class of distributions generated by an integral transform of the probability density function of the Lindley distribution which results in a model that is more flexible in the sense that the derived model spans distributions with increasing failure rate, decreasing failure rate and upside down bathtub shaped hazard rate functions for different choices of parametric values. For this new model, various distributional properties including limiting distribution of extreme order statistics are established. Maximum likelihood estimators and the marginal confidence intervals of the parameters are obtained. The applicability of the proposed distribution is shown through application to real data sets. Through application to two real datasets, it is demonstrated that the proposed model fits better as compared to some other competing models. Further, the model is shown to be useful for analysing stress–strength model.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Lifetime distribution represents an attempt to describe, statistically, the length of the life of a system, a device, and in general, time-to-event data. Lifetime distributions are frequently used in fields like medicine, biology, engineering, insurance etc. Many parametric models such as exponential, gamma, weibull have been frequently used in statistical literature to analyse lifetime data.
Recently, one parameter Lindley distribution has attracted researchers for its potential in modelling lifetime data, and it has been observed that this distribution has performed excellently in many applications. The Lindley distribution was originally proposed by Lindley [19] in the context of Bayesian statistics, as a counter example to fiducial statistics. The distributon can also be derived as a mixture of exp(\(\theta \)) and gamma(2, \(\theta \)). More details on the Lindley distribution can be found in Ghitany et al. [7].
A random variable \(X\) is said to have the Lindley distribution with parameter \(\theta \) if its probability density is defined as:
The corresponding cumulative distribution function is
Ghitany et al. [6, 7] have introduced a two-parameter weighted Lindley distribution and have pointed out its usefulness, in particular, in modelling biological data from mortality studies. Bakouch et al. [4] have come up with extended Lindley (EL) distribution, Adamidis and Loukas [1] have introduced a new lifetime distribution with decreasing failure rate. Shanker et al. [23] have introduced a two-parameter Lindley distribution. Zakerzadeh and Mahmoudi [24] have proposed a new two parameter lifetime distribution: model and properties. Hassan [11] has introduced convolution of Lindley distribution. Ghitany et al. [8] worked on the estimation of the reliability of a stress-strength system from power lindley distribution. Elbatal et al. [5] has proposed a new generalized Lindley distribution by considering the mixture of two gamma distribution.
Ristić and Balakrishnan [22] have introduced a new family of distributions generated by gamma pdf with survival function given by
where \(G(x)\) is a chosen distribution function, called the parent distribution function (df).
In this paper, we introduce a new family of distribution generated by an integral transform of the pdf of a random variable \(T\) which follows one parameter Lindley distribution. The survival function of this new family is given as:
where \( \theta > 0 \) ,the corresponding probability density function (pdf) is given by
In this formation, we consider \(G(x)\) corresponding to exponential distribution with cdf \((1-e^{-\lambda x})\) which yields the survival function of the new distribution is as
with corresponding density
In this paper, we refer to random variable with survival function (4) as Lindley–Exponential (L–E) distribution with parameters \(\theta \) and \(\lambda \) and denote it by L–E(\(\theta ,\lambda \)). Motivation for this paper arose from the following observation.
In modelling time-to-event data arising from a new application, the monotonicity nature of the hazard rate function is uncertain and hence an a priori choice of a model becomes challenging. In such cases, one usually resorts to nonparametric methods in general. However, if a parametric model fits the particular application well, it is preferable to choose one such model. There is thus a need to develop a distributional model which would span various monotonicity properties of the hazard rate function, and this paper is an attempt to develop a new model with two parameters model ensuring flexibility of hazard function to posses increasing, decreasing and upside down shapes. Having developed one such distribution, we observe the following properties that connect the new model to known distributions.
-
1.
Let \( U \) be a random variable with the Log-lindley distribution \(LL(\theta ,1)\) proposed by Goméz et al. [10]. Then the random variable \(V= G^{-1}(U)\) has distribution with pdf as in (3).
-
2.
If \(U\) be Lindley distributed random variable, then the random variable \(X=G^{-1}(e^{-U})\) has pdf (3).
We now study properties of the L–E distribution and illustrate its applicability. The contents of the proposed work are organized as follows. Various distributional properties like shape of the pdf, quantile function, moment generating function, limiting distribution of sample statistics like maximum and minimum and entropy of L–E distribution are present in Sect. 2. The maximum likelihood estimation is presented in Sect. 3. Performance of the maximum likelihood estimators for small samples is assessed by simulation in Sect. 4. Applicability of the new distribution is shown in Sect. 5. Section 6, gives estimation of stress–strength parameter \((R)\) by using maximum likelihood estimation method.
2 Distributional properties of L–E distribution
2.1 Shape of the density
Theorem 1
The probability density function of the L–E distribution is decreasing for \( 0<\theta <1 \) and uni-modal for \(\theta >1\). In the latter case, the mode is the root of the following equation:
Proof
The first order derivative of \( \log (f(x)) \) is
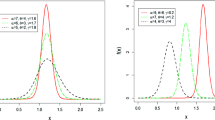
where, \(r(x)=\left( \theta e^{-\lambda x}+\left( 1-\theta e^{-\lambda x}\right) \log \left( 1-e^{-\lambda x}\right) -e^{-\lambda x}-1\right) \). For \(0<\theta <1\), the function \(r(x)\) is negative. So \(f'(x)<0\) for all \(x>0\). This implies that \(f\) is decreasing for \(0< \theta <1\). Also note that, \((\log f)'(0)=\infty \) and \((\log f)'(\infty )<0\). This implies that for \(\theta >1\), \( g(x) \) has a unique mode at \(x_0\) such that \(r(x) >0\) for \(x<x_0\) and \(r(x)<0\) for \(x>x_0\). So, \(g\) is uni-modal function with mode at \(x=x_0\). The pdf for various values of \(\lambda \) and \(\theta \) are plotted in Fig. 1. \(\square \)

PDF plot for various values of \(\lambda \) and \(\theta \)
Theorem 2
The hazard function of L–E distribution is decreasing, increasing or upside down according as \(0<\theta \le 1\), \(\theta >2\) and \(1<\theta <2\) respectively.
Proof
Considering the hazard rate function (hrf) of the L–E distribution given by
and using theorems of Glaser [9], we can discuss the shape characteristics of the hrf of L–E distribution. The function \( \eta (x) = -f^{'}(x)/f(x)\) for L–E distribution is given by
and
If \( 0 < \theta \le 1 \), then \(\eta ^{'} (x) < 0~ \forall ~ x > 0\). It follows from Theorem (b) of Glaser [9] that the failure rate is decreasing. Whereas, for \(\theta > 2, \eta ^{'} (x) > 0 \, \forall \, x > 0 \) which indicate increasing failure rate (see Theorem (b) of Glaser [9]. Furthermore, we note that the failure rate can be upside-down bathtub for \(1 < \theta < 2 \). Moreover, for \(\theta > 0\) the hazard rate function follows relation \(\lim \nolimits _{x \rightarrow \infty } h(x) = \lambda \). These different failure rate for different values of parameters \(\theta \) and \(\lambda \) are shown in Fig. 2. \(\square \)

Hazard function plot for various values of \(\lambda \) and \(\theta \)
2.2 The quantile function of L–E distribution
The cdf, \(F_X(x)=1-\bar{F}(x)\), can be obtained by using Eq. (4). Further, it can be noted that \(F_X\) is continuous and strictly increasing so that the quantile function of \( X \) is \(Q_X(\gamma )=F^{-1}_X(\gamma )\), \(0<\gamma <1\). In the following theorem, we give an explicit expression for \(Q_X\) in terms of the Lambert \( W \) function. For more details on Lambert \(W\) function we refer the reader to Joŕda [12] and also to Nair et al. [20] for discussion on quantile functions.
Theorem 3
For any \(\theta , \lambda >0\), the quantile function of the L–E distribution \( X \) is
where \(W_{-1}\) denotes the negative branch of the Lambert W function.
Proof
By assume \(p=1-e^{-\lambda x}\) the cdf can be written as
for fixed \(\theta , \lambda >0 \) and \(\gamma \in (0,1)\), the \(\gamma \)th quantile function is obtained by solving \(F_X(x)=\gamma \). By re-arranging the above, we obtain
it can be further written as
We see that \(-p^{-\theta } (1+\theta )\gamma \) is the Lambert-W function of real argument \(-(1+\theta )\gamma e^{-(1+\theta )}\) .
Thus, we have
Moreover, for any \(\theta \) and \(\lambda >0 \) it is immediate that \(p^{-\theta }(1+\theta )\gamma > 1 \), and it can also be checked that \((1+\theta )\gamma e^{-(1+\theta )} \in (-1/e,0)\) since \(\gamma \in (0,1)\). Therefore, by taking into account the properties of the negative branch of the Lambert W function, we deduce the following.
Again,solving for \(x\) by using \(p=1-e^{-\lambda x}\), we get
\(\square \)
Further the first three quantiles can be obtained by substituting \(\gamma =\frac{1}{4},\frac{1}{2},\frac{3}{4} \) in (11).
2.3 Moments
The Moment Generating function of L–E random variable is given as
where, \(\psi ^{(n)}(z)=\frac{d^n \psi (z)}{dz^n}\) and \(\psi (z)=\frac{\Gamma '(z)}{\Gamma (z)}\) known as digamma function.
Hence the first and second raw moments can be obtained by differentiating the MGF \(\left( \frac{d\mathbb {M}_X(t)}{dt}\right) _{t=0}\) and \(\left( \frac{d^2\mathbb {M}_X(t)}{dt^2}\right) _{t=0}\) respectively.
where \(\upgamma \) is Eulergamma constant \(=\) 0.577216.
Table 1 displays the mode, mean and median for L–E distribution for different choices of parameter \(\lambda \) and \(\theta \). It can be noted from the table that all three measures of central tendency decrease as \(\lambda \) increases, and the measures increase as \(\theta \) increase. Also for any choice of \(\lambda \) and \(\theta \) Mean \( > \) Median \( > \) Mode which is an indication of positive skewness.
2.4 Limiting distribution of sample minimum and maximum
We can derive the asymptotic distribution of the sample minima \(X_{1:n}\) by using Theorem 8.3.6 of Arnold et al. [3], it follows that the asymptotic distribution of \(X_{1:n}\) is Weibull type with shape parameter \(\theta >0\) if
From (4), \(F(X)=1-\bar{F}(X)\), using the identities
and
Thus,we get
Similarly, using the following identity
and
It can be seen that
by using L-Hópitals rule,
Hence, it follows from Theorem 1.6.2 in Leadbetter et al. [17] that there must be norming constants \(a_n>0\), \( b_n, c_n>0\) and \(d_n\) such that
and
as \(n \rightarrow \infty \). By following Corollary 1.6.3 in Leadbetter et al. [17], we can determine the form of the norming constants. As an illustration, one can see that \(a_n = \theta \) and \(b_n=F^{-1}(1-1/n)\), where \( F^{-1}(.) \) denotes the inverse function of \(F(.)\).
2.5 Entropy
In many fields of science such as communication, physics and probability, entropy is an important concept to measure the amount of uncertainty associated with a random variable \(X\). Several entropy measures and information indices are available but among them the most popular entropy called Rényi entropy defined as
In our case
substituting \(x=-\frac{1}{\lambda }\log (1-e^{-u})\) and using power series expansion \((1-z)^\alpha =\sum \nolimits _{j=0}^{\infty }(-1)^j \left( {\begin{array}{c}\alpha \\ j\end{array}}\right) z^j\), the above expression reduces to
where \(E_n(z)=\int _1^{\infty }e^{-zt} t^{-n} dt\) known as exponential integral function. For more details see http://functions.wolfram.com/06.34.02.0001.01.
Thus according to (18) the Rényi entropy of L–E\((\theta ,\lambda )\) distribution given as
Moreover, The Shannon entropy defined by \(E[\log (f(x))]\) is a special case derived from \(\lim \nolimits _{\zeta \rightarrow 1}\mathfrak {J}(\zeta )\)
3 Maximum likelihood estimators
In this section we shall discuss the point and interval estimation of the parameters of L–E\( (\theta ,\lambda ) \). The log-likelihood function \(\nonumber l(\Theta )\) of single observation (say \(x_i\)) for the vector of parameter \(\Theta =(\theta , \lambda )^\top \) is
The associated score function is given by \(U_n= \left( \frac{\partial l_n}{\partial \theta }, \frac{\partial l_n}{\partial \lambda } \right) ^\top \), where
As we know th expected value of score function equals zero, i.e. \(\mathbb {E}(U(\Theta ))\), which implies \(\mathbb {E}\left( \log \left( 1-e^{-\lambda x}\right) \right) = \frac{1}{\theta +1}-\frac{2}{\theta }\).

Contour plot of log-likelihood surface for different values of \(\theta \) and \(\lambda \)
The total log-likelihood of the random sample \(x=\left( x_1,\ldots , x_n\right) ^\top \) of size \( n \) from \( X \) is given by \(l_n= \sum \nolimits _{1}^{n}l^{(i)}\) and th total score function is given by \(U_n=\sum \nolimits _{i=1}^{n}U^{(i)}\), where \(\nonumber l^{(i)}\) is the log-likelihood of \(i\)th observation and \( U^{(i)} \) as given above. The maximum likelihood estimator \(\hat{\Theta }\) of \(\Theta \) is obtained by solving Eqs. (21) and (22) numerically or this can also obtained easily by using nlm() function in R. The initial guess for the estimators were obtained from the inner region of 3D contour plot of log-likelihood function for a given sample. For example, in Fig. 3, the contour plot of log-likelihood function for different \(\theta \) and \(\lambda \), the initial estimates were taken from interior. The associated Fisher information matrix is given by
where
The above expressions depend on some expectations which can be easily computed using numerical integration. Under the usual regularity conditions, the asymptotic distribution of
where \(\lim \nolimits _{n \rightarrow \infty } K_n(\Theta )^{-1}=K(\Theta )^{-1}\). The asymptotic multivariate normal \(N_2(0,K(\Theta )^{-1})\) distribution of \(\hat{\Theta }\) can be used to construct approximate confidence intervals. An asymptotic confidence interval with significance level \( \alpha \) for each parameter \( \theta \) and \( \lambda \) is
where \(z_{1-\alpha /2}\) denotes \(1-\alpha /2\) quantile of standard normal random variable.
4 Simulation
In this section, we investigate the behaviour of the ML estimators in finite sample sizes through a simulation study based on different L–E\((\theta ,\lambda )\). The observations are generated using cdf technique presented in Sect. 4 from L–E\((\theta ,\lambda )\) and in the following Sects. 4.1 and 4.2, we investigate the performance of maximum likelihood estimators \((\hat{\theta },\hat{\lambda })\) for various combinations of parameters \((\theta ,\lambda )\) and also with respect to sample size \( n \) respectively.
4.1 Performance of estimators for different parametric values
A simulation study consisting of following steps is carried out for each triplet \((\theta ,\lambda ,n)\), where \(\theta = 0.5, 1, 2, \lambda = 0.5, 1, 2 ,3\) and \(n= 25, 50, 75, 100\).
-
1.
Choose the values \( \theta _\circ ,\lambda _\circ \) for the corresponding elements of the parameter vector \(\Theta =(\theta ,\lambda )\), to specify L–E\((\theta ,\lambda )\) distribution;
-
2.
choose sample size \( n \);
-
3.
generate \( N \) independent samples of size \( n \) from L–E\((\theta ,\lambda )\);
-
4.
compute the ML estimate \(\hat{\Theta _n}\) of \(\Theta _\circ \) for each of the \( N \) samples;
-
5.
compute the average bias \(= \frac{1}{N} \sum \nolimits _{i=1}^{N}(\Theta _i-\Theta _\circ ) \), the average mean square error MSE \((\Theta )= \frac{1}{N} \sum \nolimits _{i=1}^{N}(\Theta _i-\Theta _\circ )^2\) and average width (AW) of 95 % of confidence limit of the obtained estimates over all \( N \) samples.
In all three Tables, Tables 2, 3 and 4, it can be clear seen that the value of average bias, MSE and average width decreases with increase in sample size \(n\).
4.2 Performance of estimators with respect to sample size \(n\)
In this subsection, we assess the performance of ML estimators of \(\hat{\theta }\) and \(\hat{\lambda }\) as sample size \(n\), varies from \(n = 10, 11,\ldots , 100\), for \(\theta =1\) and \(\alpha =0.5\). For each of these sample sizes, we generate one thousand samples by using inversion method discussed in Sect. 4 and obtain maximum likelihood estimators and standard errors of ML estimates, \((\hat{\theta }, \hat{\lambda })\) and \((s_{i,\hat{\theta }}, s_{i,\hat{\lambda }})\) for \(i=1, 2, \ldots , 1{,}000\) respectively. For each repetition we comput bias, mean squared error and Coverage Lengths (CL):
The coverage probabilities (CP) are given by
for \(\Theta =(\theta , \lambda )\) and \(\mathbb {I}\) is an indicator function.

Bias for \(\hat{\theta }\) and \(\hat{\lambda }\) versus \( n \)

MSE for \(\hat{\theta }\) and \(\hat{\lambda }\) versus \( n \)

Converge length for \(\hat{\theta }\) and \(\hat{\lambda }\) versus \( n \)

Converge probabilities for \(\hat{\theta }\) and \(\hat{\lambda }\) versus \(n\)
Figures 4, 5, 6 and 7 shows behaviour of bias, mean squared error, coverage length and coverage probability of parameter \((\theta \) and \(\lambda )\) as one varies vary \( n \). The horizontal lines in Fig. 7 correspond to the coverage probabilities being 0.95.
The following observations can be drawn from the figures: the biases for both the parameter appear generally positive and approach to zero with increasing \(n\); the mean squared errors and coverage lengths of \((\theta \) and \(\lambda )\) decrease with \(n\). The coverage probabilities for \(\lambda \) appear generally less than the nominal level but reach the nominal level as sample size increases whereas the coverage probabilities for \(\theta \) appear generally closer than the nominal level. These observations are for \(\theta = 1\) and \(\alpha = 0.5\) and similar observations were noted for other values of parameters.
5 Application to real datasets
In this section, we illustrate, the applicability of L–E Distribution by considering two different datasets used by different researchers. We also fit L–E distribution, Power–Lindley distribution [8], New Generalized Lindley Distribution [5], Lindley Distribution [19], and Exponential distribution. Namely
(i) Power–Lindley distribution (PL\((\alpha ,\beta )\)):
(ii) New Generalized Lindley distribution (NGLD(\(\alpha ,\beta ,\theta \))):
(iii) Lindley Distribution (L\((\theta )\))
For each of these distributions, the parameters are estimated by using the maximum likelihood method, and for comparison we use Negative LogLikelihood values (\(-LL\)), the Akaike information criterion (AIC) and Bayesian information criterion (BIC) which are defined by \(-2LL+2q\) and \(-2LL+q\log (n)\), respectively, where \(q\) is the number of parameters estimated and \(n\) is the sample size. Further Kolmogorov–Smirnov test (K–S) = \( \sup _x|F_n(x)-F(x)|\), where \(F_n(x)=\frac{1}{n} \sum \nolimits _{i=1}^{n}\mathbb {I}_{x_i\le x}\) is empirical distribution function and \(F(x)\) is cumulative distribution function is calculated and shown for all the datasets.
5.1 Illustration 1: Application to bladder cancer patients
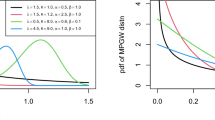
We consider an uncensored data set corresponding to remission times (in months) of a random sample of 128 bladder cancer patients (Lee and Wang [18]) as presented in Appendix A.1 in Table 9. The results for these data are presented in Table 5. We observe that the L–E distribution is a competitive distribution compared with other distributions. In fact, based on the values of the AIC and BIC criteria and K–S test statistic, we observe that the L–E distribution provides the best for these data among all the models considered. The probability density function and empirical distribution function are presented in Fig. 8 for all considered distributions for these data.

PDF plot for various values of \(\lambda \) and \(\theta \)
5.2 Illustration 2: Application to waiting times in a queue
As second example, we consider 100 observations on waiting time (in minutes) before the customer received service in a bank (see Ghitany et al. [7]). The data sets are presented in Appendix A.2 as Table 10. The results for these data are presented in Table 6. From these results we can observe that L–E distribution provide smallest AIC and BIC values as compare to Power lindley, new generalized Lindley distribution, Lindley and exponential and hence best fits the data among all the models considered. The results are presented in Table 6 and probability density function and empirical distribution function are shown in Fig. 9.

PDF plot for various values of \(\lambda \) and \(\theta \)
6 Estimation of the reliability of a stress–strength system
The stress–strength parameter \((R)\), defined as \(R=P\left( X>Y\right) \), plays an important role in the reliability analysis as it measures the system performance. Some of the significant work on the stress–strength model can be seen in Kundu and Gupta [14, 15], Raqab and Kundu [21], Kundu and Raqab [16], Krishnamoorthy et al. [13], and the references cited therein. Recently Al-Mutairi et al. [2] have presented the estimation of the stress–strength parameter where both strength and stress of the system follow lindley distribution with different shape parameters. In this section, we consider a situation where \( X\sim \) L–E\((\theta _1,\lambda )\) and \(Y\sim \)L–E\((\theta _2,\lambda )\) and are independent of each other. In our case, the stress–strength parameter \( R \) is given by
Remarks:
-
(i)
R is independent of \( \lambda \)
-
(ii)
When \(\theta _1=\theta _2\), R \(=\) 0.5. This is intuitive that \(X\) and \(Y\) are i.i.d. and there is an equal chance that \(X\) is bigger than \(Y\).
Since R in Eq. (27) is a function of stress–strength parameters \(\theta _1\) and \(\theta _2\), we need to obtain the maximum likelihood estimators (MLEs) of \(\theta _1\) and \(\theta _2\) to compute the MLE of R under invariance property of the MLE. Suppose that \( X_1,X_2,\ldots ,X_n \) and \(Y_1,Y_2,\ldots ,Y_m\) are independent random samples from L–E \((\theta _1, \lambda )\) and L–E \((\theta _2,\lambda )\) respectively, then likelihood function is given by
The log-likelihood function is given by
where \(s_1(\lambda )=- \sum \nolimits _{i=1}^{n} \log \left( 1-e^{-\lambda x_i}\right) \) and \( s_2(\lambda )=-\sum \nolimits _{j=1}^{m}\log \left( 1-e^{-\lambda y_j}\right) \).
The MLE of \(\hat{\Theta }\) of \(\Theta \) is solution of the following non linear equations:
from above equations, it follows that
where \(\hat{\lambda }\) is the solution of the non-linear equation:
The value of \(\hat{\lambda }\) can be substituted in (29) to get \(\hat{\theta _1}\) and \(\hat{\theta _2}\).
Hence, using the invariance property of the MLE, the maximum likelihood estimator \(\hat{R}_{mle}\) of \( R \) can be obtained by substituting \(\hat{\theta }_k\) for \(k\) \(=\) 1,2 in Eq. (27).
6.1 Asymptotic confidence interval
For an estimator \(\hat{\theta }_k\) to be asymptotically efficient for estimating \(\theta _k\) for large sample, we should have \(\sqrt{n_k} \big ( \hat{\theta }_k-\theta _k\big ) \xrightarrow {\textit{D}} N\left( 0,I(\theta _k)^{-1}\right) \)
where \(n_1 = n\) and \(n_2= m\).
Therefore, as easily follows it \(n\rightarrow \infty \) and \(m \rightarrow \infty \)
where
Interval Using the asymptotic distribution of \(\hat{R}\), 100\((1-\alpha )\) % confidence interval for R can be easily obtained as
6.2 Illustration 3: Application to stress–strength data
In illustration 3, we present the results obtained from estimation methods of \(R\) proposed in Sect. 6, we consider two datasets, reported in Ghitany et al. [7], Al-Mutairi et al. [2], represents the waiting times (in minutes) before customer service in two different banks having 100(n) and 60(m) number of observations respectively. Q–Q plot in Fig. 10 and KS value in Table 7 indicate that LE Distribution fits better than Lindley Distribution (L). Thus, \(\hat{R}_{MLE}\) and 95 % confidence interval were computed and presented in Table 8. It is clear that, from the Table 8 that the estimated value of stress–strength parameter obtained from L–E distribution is lower than the one obtained from Lindley distribution. Moreover, standard error of \(R\) is also lower for LE distribution compared to Lindley distribution. Hence we recommend, LE distribution for stress-strength analysis also.

Q–Q plot of the fitted LE and Lindley distribution for Bank A and Bank B data set
7 Conclusion
We have proposed a new two parameter class of distribution called Lindley–Exponential (L–E) distribution generated by Lindley distribution possess increasing, decreasing or upside down hazard function for different choices of the parameters. We have derived important properties of the L–E distribution like moments, entropy, asymptotic distribution of sample maximum and sample Minimum. Maximum likelihood of the parameters are obtained which can be used to get asymptotic confidence intervals. We have also illustrated the application of L–E distribution to two real data sets used by researchers earlier and compare it with other popular models. Further the stress–strength analysis were carried out and compared with that of Lindley distribution. Our application to real data set indicate that L–E distribution performs satisfactorily or better than its competitors and can be recommended for lifetime modelling the encountered in engineering, medical science, biological science and other applied sciences.
References
Adamidis, K., Loukas, S.: A lifetime distribution with decreasing failure rate. Stat. Probab. Lett. 39, 35–42 (1998)
Al-Mutairi, D.K., Ghitany, M.E., Kundu, D.: Inference on stress–strength reliability from Lindley distribution. Commun. Stat. Theory Methods 42, 1443–1463 (2013)
Arnold, B.C., Balakrishnan, N., Nagaraja, H.N.: A First Course in Order Statistics. Wiley, New York (2013)
Bakouch, H.S., Al-Zahrani, B.M., Al-Shomrani, A.A., Marchi, V.A., Louzada, F.: An extended Lindley distribution. J. Korean Stat. Soc. 41, 75–85 (2012)
Elbatal I., Merovci F., Elgarhy M.: A new generalized Lindley distribution. Math. Theory Model. 3(13) (2013)
Ghitany, M.E., Alqallaf, F., Al-Mutairi, D.K., Husain, H.A.: A two-parameter weighted Lindley distribution and its applications to survival data. Math. Comput. Simul. 81(6), 1190–1201 (2011)
Ghitany, M.E., Atieh, B., Nadarajah, S.: Lindley distribution and its application. Math. Comput. Simul. 78, 493–506 (2008)
Ghitany, M.E., Al-Mutairi, D.K., Aboukhamseen, S.M.: Estimation of the reliability of a stress–strength system from power lindley distributions. Commun. Stat.-Simul. Comput. 44(1), 118–136 (2015)
Glaser, R.E.: Bathtub and related failure rate characterizations. J. Am. Stat. Assoc. 75, 667–672 (1980)
Gómez, E.D., Sordo, M.A., Calderín, E.O.: The LogLindley distribution as an alternative to the beta regression model with applications in insurance. Insur. Math. Econ. 54, 49–57 (2014)
Hassan, M.K.: On the convolution of Lindley distribution. Columbia Int. Publ. Contemp. Math. Stat. 2(1), 47–54 (2014)
Joŕda, P.: Computer generation of random variables with Lindley or Poisson–Lindley distribution via the Lambert W function. Math. Comput. Simul. 81, 851–859 (2010)
Krishnamoorthy, K., Mukherjee, S., Guo, H.: Inference on reliability in two parameter exponential stress–strength model. Metrika 65, 261–273 (2007)
Kundu, D., Gupta, R.D.: Estimation of \( R = P\left( {Y < X} \right) \) for generalized exponential distributions. Metrika 61, 291–380 (2005)
Kundu, D., Gupta, R.D.: Estimation of \( R = P\left( {Y < X} \right) \) for Weibull distributions. IEEE Trans. Reliab. 55, 270–280 (2006)
Kundu, D., Raqab, M.Z.: Estimation of \( R = P\left( {Y < X} \right) \) for three-parameter Weibull distribution. Stat. Probab. Lett. 79, 1839–1846 (2009)
Leadbetter, M.R., Lindgren, G., Rootzn, H.: Extremes and Related Properties of Random Sequences and Processes. Springer Statist. Ser. Springer, Berlin (1983)
Lee, E.T., Wang, J.W.: Statistical Methods for Survival Data Analysis, 3rd edn. Wiley, Hoboken (2003)
Lindley, D.V.: Fiducial distributions and Bayes theorem. J. R. Stat. Soc. Ser. B (Methodological). 20(1), 102–107 (1958)
Nair, N., Nair, N.U., Sankaran, P.G., Balakrishnan, N.: Quantile-Based Reliability Analysis. Springer, Berlin (2013)
Raqab, M.Z., Kundu, D.: Comparison of different estimators of \(P(Y < X)\) for a scaled Burr type X distribution. Commun. Stat. Simul. Comput. 34, 465–483 (2005)
Ristić, M.M., Balakrishnan, N.: The gamma exponentiated exponential distribution. J. Stat. Comput. Simul. 82(8), 1191–1206 (2012)
Shanker, R., Sharma, S., Shanker, R.: A two-parameter Lindley distribution for modeling waiting and survival times data. Appl. Math. 4, 363–368 (2013)
Zakerzadeh, H., Mahmoudi, E.: A new two parameter lifetime distribution: model and properties. arXiv:1204.4248v1 [stat.CO], 2012 (1998)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Bhati, D., Malik, M.A. & Vaman, H.J. Lindley–Exponential distribution: properties and applications. METRON 73, 335–357 (2015). https://doi.org/10.1007/s40300-015-0060-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40300-015-0060-9
Keywords
- Lindley distribution
- Integral transform
- IFR
- DFR
- Upside down bath-tub shaped hazard
- Entropy
- Stress–strength reliability model
- Maximum likelihood estimator