
Abstract
Coordination of overcurrent relays is a nonlinear and highly constrained optimization problem in a large distribution system where the operating time of all relays is to be minimized. Proper coordination of protective devices is a very crucial task for appropriate functioning of the electrical power system with distributed power generating stations. In order to solve this problem, various unconventional optimization techniques have been proposed. Random Walk Grey Wolf Optimizer (RW-GWO) is a recently developed algorithm based on improving the search ability of the leading wolves in classical GWO algorithm to overcome the issues of stagnation to local optima and premature convergence while solving nonlinear and complex optimization problems. Therefore, in the present work, RW-GWO algorithm is employed to find the optimal setting for directional overcurrent relay problem which is a highly complex problem. In the present paper, the results are also reported for classical GWO and the comparison is performed with several other optimization methods. The comparison of results demonstrates the strength of the RW-GWO in obtaining the optimal setting for the proper coordination of overcurrent relays as compared to other optimization methods.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In power systems, various generating stations run in parallel to feed a high voltage network. Many equipments are connected via these networks. The fault that occurs in power system may be very harmful. Therefore, securing network from these faults, protective relays are integrated into power systems and these protective relays detach the non-functioning components from a system by tripping the circuit. Overcurrent relays which are widely used protection devices [1] can sense the flow of current only in one direction. Directional overcurrent relay should operate for a fault which occurs in its zone for the functioning of the power system properly. Primary relays operate on the appearance of a fault and are backed up by secondary relays, and the secondary or backup relays operate when primary relay fails. Proper coordination of direction overcurrent relays is very crucial for the better performance of the power systems and to escape from the problem of equipment damages, and this relay coordination is very time-consuming and a tedious task. The protection of directional overcurrent relays consists of two types of settings—TS (Time Dial Setting) and PS (Plug Setting)—and by determining these optimal settings, an efficient coordination for overcurrent relays can be achieved. Earlier this has been done manually which was very tedious. The use of computer helps engineers with laborious efforts. Generally, there are two approaches that are used for directional overcurrent relay.
In conventional techniques, first the fault analysis is conducted and after that meshed networks are broken into radial form, then relay at far end is set, and in the last, setup of back relays is established and this process is repeated for all the relays. Final Time Dial Setting and Plug Setting depend on the selection of the initial relays which are known as breakpoints [2]. These breakpoints are selected by using graph theory. The number of iterations here depends on the selection of breakpoints. It has been observed that the values of Time Dial Setting and Plug Setting determined by conventional techniques are not optimal [3]. Coordination of overcurrent relays in a large distribution network with multi-source and multi-looped network by using deterministic optimization becomes infeasible [3]. Therefore, the unconventional parameter optimization techniques that are designed, especially for highly nonlinear or non-differentiable problems, are more effective for these types of problems. These techniques are called as nature-inspired optimization techniques or meta-heuristic techniques. These techniques are designed from the inspiration of nature.
In 1988 [4], first time the optimization theory has been utilized to deal coordination of directional overcurrent relay. The practical importance of these problems inspires to apply different optimization strategies to solve this type of problems. In [5], linear programming is also used to find the optimal setting of parameters in overcurrent relay.
In the literature, various nature-inspired optimization techniques are used to solve the relay coordination problem. For example, in [6,7,8,9,10], Genetic Algorithm (GA) and its modified variants are used to determine the optimal setting for the proper coordination of overcurrent relays. In [10,11,12,13,14], Differential Evolution (DE) and its modified variants are employed on the coordination of overcurrent relay problem to find the optimal setting of decision parameters called TS and PS. In [15, 16], mixed-integer nonlinear programming formulation is used and the relay coordination problem is solved using Particle Swarm Optimization (PSO). In [17,18,19], modified variants of PSO are introduced to solve relay coordination problem. In [20], Random Search Technique is applied to solve the coordination problem. Seeker Algorithm is applied in [21] with step length and adaptive search direction to find the decision parameters so that the operating time of all relays can be minimized.
Grey Wolf Optimizer Algorithm [22] is a recently developed optimization approach and is very efficient to approximate the optima of the optimization problem. This algorithm is designed from the inspiration of grey wolf pack where the dominant leadership behaviour can be observed which helps in the search process of prey. In [22], it has been suggested that GWO algorithm performs better than some state-of-the-art algorithms like Particle Swarm Optimization (PSO) [23], Gravitational Search Algorithm (GSA) [24], Fast Evolutionary Process (FEP) [25] and is very competitive as compared to the Differential Evolution (DE) [26]. However, similar to the other meta-heuristic search algorithms, GWO also faces the problem of getting trapped in sub-optimal solutions and premature convergence in some cases.
In the literature, various efforts have been made to improve the search accuracy of classical GWO. Mittal et al. [27] have modified the parameters of GWO to maintain an appropriate balance between the operators’ exploration and exploitation. Malik et al. [28] have proposed a weighted position update mechanism to update the search agents. In [29], Levy flight search strategy is employed to enhance the search efficiency of wolf pack. In [30], evolutionary population dynamics (EPD) is applied to discard the worst fitted wolf from the pack and introduce a new wolf with the help of EPD. In [31], the crossover and mutation operators are introduced into classical GWO to enhance its performance. In [32], the GWO and PSO are hybridized to maintain an appropriate balance between exploitation and exploration in GWO. In [33, 34], the concept of opposition-based learning is introduced to avoid the problem of stagnation at local optima. In order to accelerate the convergence rate, chaos theory has been integrated in GWO [35, 36]. In [37], an adaptive bridging mechanism based on β-chaotic sequence is introduced to balance exploitation and exploration in the classical GWO. In [38, 39], random walk strategy based on Cauchy distribution is applied to the leading hunters of the grey wolf pack to reduce the problem of getting trapped in sub-optimal solutions and to enhance the search accuracy of classical GWO. In [40], exploration of search agents in GWO has been enhanced by proposing a new position update mechanism. In [41], a weighted grey wolf optimizer is introduced to enhance the performance of classical GWO and enhance the search around the best search agents. A brief literature review on GWO can be found in [42].
In the present work, the Random Walk Grey Wolf Optimizer (RW-GWO) [38, 39] is used to find the optimal setting of directional overcurrent relay problem which is nonlinear, highly complex, and highly constrained in nature. The experimental analysis conducted in the paper also verifies the ability of RW-GWO to avoid the stagnation problem of wolf pack in local optimums as compared to the classical GWO.
The rest of the paper is organized as follows: in Sect. 2, the problem of coordination of directional overcurrent relays is described briefly. Section 3 presents a framework of an efficient swarm intelligence-based optimization approach called Grey Wolf Optimizer (GWO). In Sect. 4, mechanism of RW-GWO algorithm is described briefly. In Sect. 5, experimental setup and obtained results on IEEE 4-bus system are presented. Finally, Sect. 6 concludes the work and suggests some future research directions.
2 Problem Description
The coordination problem of directional overcurrent relays is to minimize the sum of operating time of all relays corresponding to the maximum fault current [17, 43, 44]. A mathematical form of the problem can be stated as
where T is the objective function, \(t_{{i,{\text{op}}}}\) is the operating time of the ith relay, and N is the number of relays within the system. In Eq. (2), \(t_{{j,{\text{ob }}}}\) and \(t_{{i,{\text{op}}}}\) are the operating time of ith primary relay and its jth backup relay. In Eq. (3), \({\text{TS}}_{{i,{ \hbox{min} }}}\) and \({\text{TS}}_{{i,{ \hbox{max} }}}\) are the lower and upper limits for the decision variable TS. In Eq. (4), \({\text{PS}}_{{i,{ \hbox{min} }}}\) and \({\text{PS}}_{{i,{ \hbox{max} }}}\) are the lower and upper limits for the decision variable PS. In Eq. (5), \(t_{i,\hbox{min} }\) and \(t_{i,\hbox{max} }\) are the lower and upper limits on the operating time of ith relay.
The operating time of any relay can be obtained from its characteristic curve and is defined by IEEE/IEC as follows [45]:
where \(\mu , \alpha\), and L are the characteristic constants of the relays and \(I_{{{\text{f}},i}}\) is the fault current through ith relay. TS and PS are the decision parameters which are to be optimized. For standard inverse definite minimum time relays, \(\mu = 0.14, \alpha = 0.02\), and \(L = 0\) [45].
From the objective function defined in Eq. (1), it is clear that the operative time of primary relay is minimized without any restrictions on operating time of its backup relays. Therefore, in [46, 47], a new objective function is introduced which minimizes the operating time of primary and backup relays simultaneously. Mathematically, the objective function is defined as follows:
where M is total number of relay pairs. \(\beta_{1}\) and \(\beta_{2}\) are the positive weights corresponding to primary and backup relays, and \(\beta_{1} + \beta_{2} = 1\). The values of weighting factors \(\beta_{1}\) and \(\beta_{2}\) provide a conciliation between the operating times of backup and primary relays [46]. In the present work, the value of CTI is fixed as 0.2. The minimum and maximum limits on the operating times of primary relays are fixed in the range [0.1, 4]. The values of TS have been considered in the range [0.1, 1.1]. In the present paper, the values of \(\beta_{1}\) and \(\beta_{2}\) are taken as 0.73 and 0.27, respectively. This parameter selection is adopted from [47]. The description of the Grey Wolf Optimizer (GWO) along with their working steps is describes as follows:
3 Classical Grey Wolf Optimizer Algorithm
Grey Wolf Optimizer [22] is designed from the inspiration of leadership and social behaviour present in a pack or group of grey wolves. Grey wolves are considered as apex predators, and they are on the top of food chain. Their pack is about 5–11 wolves, and within the pack, discipline and leadership behaviour are maintained by dividing pack into 4 types of wolf—alpha (the dominant wolf of the pack which is responsible for all the important and major decisions regarding the various activities of wolves within pack), beta (these are the subordinate wolf to the alpha and act as a leading wolf if the alpha wolf passes away), delta (the sentinels, caretakers, and elder wolves belong to this category), and omega (all the remaining wolves of the pack that are allowed to eat in the end). The wolf alpha, beta, and delta are known as leading wolves of the pack, and the hunting process of prey is totally depending on these wolves. According to Muro et al. [48], grey wolves perform their hunting process in 3 steps that can be expressed as:
- 1.
Tracking and pursuing of prey,
- 2.
Encircling of prey, and
- 3.
The attack on prey to complete the hunting process.
All these characteristics of grey wolves are modelled in mathematical form by Mirjalili et al. [22] to find their food (prey). Briefly, the mathematical model can be summarized as:
3.1 Mathematical Modelling of GWO
In this section, mathematical equations that are designed from the simulation of grey wolves’ activities, while searching prey, are presented to demonstrate the ability of wolf pack. The stepwise description of hunting strategies that grey wolves follow is described as follows:
3.1.1 Leadership Hierarchy
In a wolf pack, wolves are divided into several categories based on their leadership characteristics. To simulate this, the top three fittest solutions to the problem are elected as dominant hunters for the pack. These leading solutions are called as alpha, beta, and delta. The rest of the solutions are called omega solutions to the problem. These omega solutions update their position according to the position of leading hunters based on exploitation and exploration operators.
3.1.2 Encircling Prey
It is obvious that the prey is hunted by wolves when it stops moving, and to hunt the prey first wolves encircle the prey in a group. The encircling mathematical equations that are designed from the inspiration of encircling behaviour of grey wolves are given as follows:
where \(y_{t} , y_{t + 1 }\) are the states of the grey wolf at tth and \((t + 1){\text{th}}\) iteration, respectively; \(y_{p,t}\) represents the state of prey at tth iteration. d represents the difference vector, a and c are coefficient vectors, and b is a vector that decreases linearly over the course of iterations and can be formulated as:
and \(r_{1} ,r_{2}\) are random vectors whose components are generated within the interval (0, 1) and are uniformly distributed.
3.1.3 Hunting
Grey wolves have the ability to recognize the position of prey and encircle them. Generally, the hunting procedure is guided by alpha wolves, but occasionally, beta and delta wolves also participate in hunting process with the assumption that they have enough information about the prey. Therefore, these leading wolves are gathered in each iteration of algorithm and updated when the better location is achieved. Having the useful information about prey, these leading wolves of pack help to estimate the prey location with the help of the following mathematical equations:
where \(y_{\alpha ,t}\), \(y_{\beta ,t}\), and \(y_{\delta ,t}\) are the locations of leading wolves (alpha, beta, and delta) at tth iteration, respectively. \(c_{\alpha } , c_{\beta }\), and \(c_{\delta }\) are the random vectors as defined in Eq. (9). With the help of difference vectors \(d_{\alpha } , d_{\beta }\) and \(d_{\delta }\), the states of wolves for \((t + 1){\text{th}}\) iteration can be updated as:
Therefore, the leading wolves alpha, beta, and delta estimate the state of prey and omega wolves update their states around the prey. In this way, on repeating the process of encircling and hunting activity of grey wolves in mathematical form the optima can be found for any optimization problem.
3.1.4 Exploration (Search for Prey) and Exploitation (Attack on Prey) in GWO
In GWO algorithm, the search process of prey stops when wolf pack chases the prey and prey stops moving. In order to simulate the behaviour of chasing the prey, the value of b is linearly decreased as the iteration proceeds. In the algorithm, the exploration of a search space by grey wolves is controlled by vectors A and C. When \(\left| A \right| > 1\) or \(\left| C \right| > 1\), the new search regions are discovered by wolves in order to explore the unvisited regions of search space that helps in preventing the pack from stagnation in local optima and this situation refers the process of searching prey within search space.
When \(\left| A \right| < 1\) or \(\left| C \right| < 1\), the search spaces are exploited locally by grey wolves in order to discover the better positions around the explored regions and this situation demonstrates the attacking behaviour by wolves on prey.
As the iterations increase, the value of b decreases, and therefore, the value of A decreases, and when \(t \to {\text{maximum}} \,{\text{no}}. \,{\text{of}}\,{\text{iterations}}\), the value of \(A \to 0\), and therefore, the vector C is accountable for the exploration of search space at this state.
4 Random Walk Grey Wolf Optimizer
This algorithm was proposed by the authors [38, 39] for unconstraint and constraint optimization problem to enhance the search ability of leading wolves alpha, beta, and delta of the pack. It has been observed experimentally that the classical GWO faces the problem of premature convergence in local optimum as the algorithm is completely dependent on the leading guidance of alpha, beta, and delta wolves, and if they trapped in sub-optimal solutions, then the whole wolf pack trapped in local optima due to the absence of optimum leading guidance. Another reason of proposing this modified GWO (RW-GWO) is to update the states of leading hunters, alpha, beta and delta of the pack. Because, in the classical GWO, it has been observed that these leading wolves were updating their states with the guidance of low fitted wolf. For example, alpha wolf was updating with the guidance of beta and delta. Similarly, beta wolf was updating with the help of delta wolf. Therefore, a proper optimum guidance should be there so that the leaders can improve their states to find prey. With the motivation of improvement in leaders with optimum direction, authors proposed a novel search strategy for leading wolves based on the Cauchy random walk.
4.1 Cauchy Random Walk Search Strategy for Leading Wolves
The random walk [48] is a random search process in which search proceeds with consecutive random steps. Mathematically the random walk can be defined as:
where \(s_{t}\) is a step length that can follow any random distribution. Mathematically a relation can be established between any two successive random walks as:
From this relation, it can be observed that next position depends only on current state and selected step length from current state to next state. In a random walk, the step can be fixed or can be varied. For our algorithm, assume that the current state of the wolf is \(y_{0}\) and the final state after N steps by a random walk is \(y_{N}\), i.e.
where \(a_{j}\) is a parameter used to control the step length. In our proposed algorithm Random Walk GWO, random steps \(y_{j}\) follow the Cauchy distribution. The reason behind choosing Cauchy distribution is the variance of Cauchy distribution which is infinite and which helps the leaders to explore the search space with the exploitation of search regions which are already explored as the parameter \(y_{j}\) sometimes takes a higher value which helps in taking a long jump when the leaders are trapped in local solution, and the small value of \(y_{j}\) that is obtained from distribution helps in discovering the optimum states in a neighbourhood of already explored states. Thus, the Cauchy-distributed random steps help in local as well as a global search of search space. In this strategy, parameter \(a_{j}\) is considered as a vector that is decreased linearly from 2 to 0 as the iterations proceed to converge the wolf pack (population of solutions). The framework of the algorithm Random Walk Grey Wolf Optimizer is presented in Algorithm 1.

4.2 Computational Complexity of Random Walk Grey Wolf Optimizer
Since the algorithm complexity plays an important role to analyse the complexity of algorithms, the user always prefers less complex algorithm. Therefore, in the present section, the worst time complexity of classical GWO and the RW-GWO algorithms has been calculated in terms of big O notation. The pseudocode of the algorithms presented in Algorithm 1 can be used to evaluate the complexity. Therefore, the complexity of algorithm for classical GWO and Random Walk Grey Wolf Optimizer is calculated as:
Similarly, for RW-GWO,
where T is the total number of iterations and N is the size of wolf pack and D represents the dimension of the problem under consideration. Hence, it can be concluded that in terms of computational complexity, both the algorithms classical GWO and the RW-GWO are same.
4.3 Constraint Handling
A majority of the meta-heuristic algorithms are designed initially to obtain an efficient result of unconstraint optimization problems. However, in real life, most of the problems are constrained optimization problem. In the present study, the considered coordination of overcurrent relay problem is highly complex and highly constrained. Therefore, to deal with the constraints a static penalty approach [49] is used to obtain a solution of the problem in which the objective function is defined as
where the value of \(\alpha\) can be 1 or 2 and \(c_{j}\)\(\left( {j = 1,2, \ldots ,m} \right)\) are the penalty parameters. The equality constraint \(h\) can be transformed easily into inequality constraint by the simple transformation
where \(\in\) is predefined tolerance parameter and \(h\left( x \right)\) is the equality constraint.
5 Experimental Setup and Results
In the present work, Random Walk Grey Wolf Optimizer is applied to solve the complex nonlinear coordination overcurrent relay problem. The population size is a very crucial parameter for any meta-heuristic algorithm. As very small size of the population fails to explore the search space of the problem, very large population size may fail to determine an efficient solution. Therefore, a suitable population size for algorithm should be chosen. In the present study, the population size is fixed as 30 for each algorithm, and the 30 runs of each algorithm are executed on each case of bus system to analyse the search efficiency of applied algorithms. In order to compare the performance of the RW-GWO algorithm, the recent optimization methods such as classical GWO [22], improved Grey Wolf Optimizer (mGWO) [27], Exploration Enhanced Grey Wolf Optimizer (EEGWO) [40], Weighted Grey Wolf Optimizer (wGWO) [41], Salp Swarm Algorithm (SSA) [50], Chaotic Salp Swarm Algorithm (cSSA) [51], and Sine Cosine Algorithm (SCA) [52] are used. For fair comparison, the maximum number of iterations are fixed as 100 for each algorithm. Since each search agent is evaluated once in an iteration of each algorithm, the total number of function evaluations which are utilized to solve the problem is 3 × 103. The 4-bus system which is used to evaluate the search efficiency of RW-GWO algorithm is described as follows:
5.1 Test Model
To evaluate the performance of the RW-GWO algorithm, a 4-bus distribution network (DN) with distributed energy resources (DERs) is considered which is shown in Fig. 1. The DN consists of three DERs such as synchronous-based DER (SBDER) and inverter-based DERs (IBDERs) connected at buses B2, B3, and B4, respectively. The capacity of SBDER and IBDER is 3MVA and 2 MW, respectively. The current transformer (CT) ratio is calculated based on maximum load current (ILmax) flowing through each relay and is given in Table 1. Three phase-to-ground faults (F1–F3) are considered at midpoint of all three feeders to determine fault currents flowing through primary and backup relays. The DN with DERs fault logic is developed using real-time digital simulator (RTDS) [53]. The three phase-to-ground fault and line-to-line fault are considered as maximum and minimum faults, respectively.

4-Bus system
The RW-GWO algorithm is tested for three different operating modes (cases) of 4-bus DN with DERs and is given as:
- 1.
Grid-connected mode (GCM).
- 2.
Islanded mode (IM).
- 3.
Disconnection of DERs (DCDERs).
5.1.1 Grid-Connected Mode (GCM) of Operation
The DN is operated in grid-connected mode when switches S1, S2, S3, and S4 are closed as shown in Fig. 1. In this mode of operation, whenever fault occurs, the fault current is contributed by both main grid and DERs connected to the DN. The maximum load current, minimum fault current, and maximum fault current flowing through all the relays (R1–R6) are provided in Table 2. The fault current flowing through all primary and backup relays is shown in Table 3. The obtained setting of decision variables TS and PS by RW-GWO and classical GWO algorithms is shown in Table 4. The value of the obtained relay operating time is also presented in Table 11. In the same tables, the results are also compared with several optimization methods such as improved Grey Wolf Optimizer (mGWO) [27], Exploration Enhanced Grey Wolf Optimizer (EEGWO) [40], Weighted Grey Wolf Optimizer (wGWO) [41], Salp Swarm Algorithm (SSA) [50], Chaotic Salp Swarm Algorithm (cSSA) [51], and Sine Cosine Algorithm (SCA) [52].
5.1.2 Islanded Mode (IM) of Operation
The DN is operated in islanded mode when switches S2, S3, and S4 are closed as shown in Fig. 1. In this mode of operation, whenever fault occurs, the fault current is contributed by only DERs connected to the DN. The maximum load current, minimum fault current, and maximum fault current flowing through all the relays are provided in Table 5. The fault current flowing through all primary and backup relays is shown in Table 6. The obtained value of decision variables TS and PS by RW-GWO and classical GWO algorithms is shown in Table 7. The value of the obtained relay operating time is also presented in Table 11. In the same tables, the results are also compared with several optimization methods as similar to case 1.
5.1.3 Disconnection of DERs (DCDERs)
The DN is operated in disconnection of DERs mode when only the switch S1 is closed as shown in Fig. 1. In this mode of operation, whenever fault occurs, the fault current is contributed by only main grid. The maximum load current, minimum fault current, and maximum fault current flowing through all the relays are provided in Table 8. The fault current flowing through all primary and backup relays is shown in Table 9. The obtained value of decision variables TS and PS by RW-GWO and classical GWO algorithms is shown in Table 10. The value of the obtained relay operating time is also presented in Table 11. In the same tables, the results are also compared with several optimization methods as similar to cases 1 and 2.
From Table 11, where the operating time for each case of 4-bus system is presented, it can be observed that the RW-GWO algorithm determines the minimum operative time and optimal setting for overcurrent relays as compared to the other comparative algorithms.
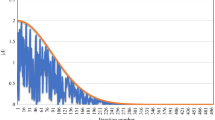
The diversity plot in terms of average distance between the solutions in each generation is plotted in Fig. 2. The Euclidean distance ||.|| between two solutions \(X = \left( {x_{1} , x_{2} , \ldots ,x_{d} } \right)\) and \(Y = \left( {y_{1} , y_{2} , \ldots ,y_{d} } \right)\) is calculated as follows:
From the diversity curves, it can be analysed that the average distance between the search agents in RW-GWO is less as compared to classical GWO which shows the better balance between the exploration and exploitation in RW-GWO. From these curves, it can be also observed that the leading hunters which are improved through random walk provide a better guidance as compared to classical GWO because RW-GWO provides better solution to the problem and the average distance between the search agents is less as compared to classical GWO.

Diversity plot 4-bus system
6 Conclusion and Future Scope
Coordination of directional overcurrent relays is a very trending and complex nonlinear problem in the field of electrical engineering. The problem consists of a large number of constraints which makes the problem more difficult to solve compared to unconstrained problems. In the present work, to find the optimal setting for overcurrent relays, a Novel Random Walk Grey Wolf Optimizer is employed. In the paper, three cases of 4-bus system are used. The performance comparison of RW-GWO algorithm is conducted with classical GWO, improved Grey Wolf Optimizer (mGWO), Exploration Enhanced Grey Wolf Optimizer (EEGWO), Weighted Grey Wolf Optimizer (wGWO), Salp Swarm Algorithm (SSA), Chaotic Salp Swarm Algorithm (cSSA), and Sine Cosine Algorithm (SCA). The experimental analysis and performance comparison with algorithms indicate the better quality of solution accuracy of RW-GWO algorithm to solve the coordination problem. Analysing the comparative performance, it can be recommended to use Random Walk Grey Wolf Optimizer to find the efficient optimal setting for the coordination of overcurrent relays.
In future, another complex bus model can be considered for the evaluation of search ability of Grey wolf optimizer and Random Walk Grey Wolf Optimizer. The other constraint-handling mechanisms can also be integrated in the RW-GWO to develop a constrained RW-GWO.
References
Blackburn, J.L.; Domin, T.J.: Protective Relaying: Principles and Applications. CRC Press, Boca Raton (2014)
Damborg, M.J.; Ramaswami, R.; Venkata, S.S.; Postforoosh, J.M.: Computer aided transmission protection system design part I: algorithms. IEEE Trans. Power Appar. Syst. 1, 51–59 (1984)
Abyaneh, H.A.; Al-Daddagh, M.; Karegar, H.K.; Sadeghi, S.H.H.; Khan, R.J.: A new optimal approach for coordination of overcurrent relays in interconnected power system. IEEE Trans. Power Deliv. 15(2), 430–435 (2003)
Fuller, J.F.; Fuchs, E.F.; Roesler, D.J.: Influence of harmonics on power distribution system protection. IEEE Trans. Power Deliv. 3(2), 549–557 (1988)
Bedekar, P.P.; Bhide, S.R.; Kale, V.S.: Determining optimum TMS and PS of overcurrent relays using linear programming technique. In: 8th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), IEEE, pp. 700–703 (2011)
Singh, D.K.; Gupta, S.: Use of genetic algorithms (GA) for optimal coordination of directional over current relays. In: Students Conference on Engineering and Systems (SCES), IEEE, pp. 1–5 (2012)
Uthitsunthorn, D.; Kulworawanichpong, T.: Optimal overcurrent relay coordination using genetic algorithms. In: International Conference on Advances in Energy Engineering (ICAEE), IEEE, pp. 162–165 (2010)
Razavi, F.; Abyaneh, H.A.; Al-Dabbagh, M.; Mohammadi, R.; Torkaman, H.: A new comprehensive genetic algorithm method for optimal overcurrent relays coordination. Electric Power Syst. Res. 78(4), 713–720 (2008)
Thakur, M.; Kumar, A.: Optimal coordination of directional over current relays using a modified real coded genetic algorithm: a comparative study. Int. J. Electr. Power Energy Syst. 82, 484–495 (2016)
Alam, M.N.; Das, B.; Pant, V.: A comparative study of metaheuristic optimization approaches for directional overcurrent relays coordination. Electric Power Syst. Res. 128, 39–52 (2015)
Thangaraj, R.; Pant, M.; Abraham, A.: New mutation schemes for differential evolution algorithm and their application to the optimization of directional over-current relay settings. Appl. Math. Comput. 216(2), 532–544 (2010)
Thangaraj, R.; Pant, M.; Deep, K.: Optimal coordination of over-current relays using modified differential evolution algorithms. Eng. Appl. Artif. Intell. 23(5), 820–829 (2010)
Chelliah, T.R.; Thangaraj, R.; Allamsetty, S.; Pant, M.: Coordination of directional overcurrent relays using opposition based chaotic differential evolution algorithm. Int. J. Electr. Power Energy Syst. 55, 341–350 (2014)
Moirangthem, J.; Krishnanand, K.R.; Dash, S.S.; Ramaswami, R.: Adaptive differential evolution algorithm for solving non-linear coordination problem of directional overcurrent relays. IET Gener. Transm. Distrib. 7(4), 329–336 (2013)
Zeineldin, H.; El-Saadany, E.F.; Salama, M.A.: Optimal coordination of directional overcurrent relay coordination. In: Power Engineering Society General Meeting, IEEE, pp. 1101–1106 (2005)
Zeineldin, H.H.; El-Saadany, E.F.; Salama, M.M.A.: Optimal coordination of overcurrent relays using a modified particle swarm optimization. Electric Power Syst. Res. 76(11), 988–995 (2006)
Mansour, M.M.; Mekhamer, S.F.; El-Kharbawe, N.: A modified particle swarm optimizer for the coordination of directional overcurrent relays. IEEE Trans. Power Deliv. 22(3), 1400–1410 (2007)
Deep, K.; Bansal, J.C.: Optimization of directional overcurrent relay times using Laplace Crossover Particle Swarm Optimization (LXPSO). In: World Congress on Nature and Biologically Inspired Computing, NaBIC 2009, IEEE, pp. 288–293 (2009)
Yang, M.T.; Liu, A.: Applying hybrid PSO to optimize directional overcurrent relay coordination in variable network topologies. J. Appl. Math. 2013, 879078 (2013). https://doi.org/10.1155/2013/879078
Birla, D., Maheshwari, R.P., Gupta, H.O., Deep, K., Thakur, M.: Application of random search technique in directional overcurrent relay coordination. Int. J. Emerg. Electr. Power Syst. (2006). https://doi.org/10.2202/1553-779X.1271
Amraee, T.: Coordination of directional overcurrent relays using seeker algorithm. IEEE Trans. Power Deliv. 27(3), 1415–1422 (2012)
Mirjalili, S.; Mirjalili, S.M.; Lewis, A.: Grey wolf optimizer. Adv. Eng. Softw. 69, 46–61 (2014)
Eberhart, R.; Kennedy, J.: A new optimizer using particle swarm theory. In: MHS’95: Proceedings of the Sixth International Symposium on Micro Machine and Human Science, IEEE, pp. 39–43 (1995)
Rashedi, E.; Nezamabadi-Pour, H.; Saryazdi, S.: GSA: a gravitational search algorithm. Inf. Sci. 179(13), 2232–2248 (2009)
Yao, X.; Liu, Y.; Lin, G.: Evolutionary programming made faster. IEEE Trans. Evolut. Comput. 3(2), 82–102 (1999)
Storn, R.; Price, K.: Differential evolution–a simple and efficient heuristic for global optimization over continuous spaces. J. Global Optim. 11(4), 341–359 (1997)
Mittal, N., Singh, U., Sohi, B.S.: Modified grey wolf optimizer for global engineering optimization. Appl. Comput. Intell. Soft Comput. (2016). https://doi.org/10.1155/2016/7950348
Malik, M.R.S.; Mohideen, E.R.; Ali, L.: Weighted distance grey wolf optimizer for global optimization problems. In: International Conference on Computational Intelligence and Computing Research (ICCIC), IEEE, pp. 1–6 (2015)
Heidari, A.A.; Pahlavani, P.: An efficient modified grey wolf optimizer with Lévy flight for optimization tasks. Appl. Soft Comput. 60, 115–134 (2017)
Saremi, S.; Mirjalili, S.Z.; Mirjalili, S.M.: Evolutionary population dynamics and Grey Wolf Optimizer. Neural Comput. Appl. 26(5), 1257–1263 (2015)
Jayabarathi, T.; Raghunathan, T.; Adarsh, B.R.; Suganthan, P.N.: Economic dispatch using hybrid grey wolf optimizer. Energy 111, 630–641 (2016)
Kamboj, V.K.: A novel hybrid PSO–GWO approach for unit commitment problem. Neural Comput. Appl. 27(6), 1643–1655 (2016)
Gupta, S.; Deep, K.: An opposition-based chaotic Grey Wolf Optimizer for global optimisation tasks. J. Exp. Theor. Artif. Intell. (2018). https://doi.org/10.1080/0952813X.2018.1554712
Zhang, S.; Luo, Q.; Zhou, Y.: Hybrid grey wolf optimizer using elite opposition-based learning strategy and simplex method. Int. J. Comput. Intell. Appl. 16(02), 1750012 (2017)
Oliveira, J.; Oliveira, P.M.; Boaventura-Cunha, J.; Pinho, T.: Chaos-based grey wolf optimizer for higher order sliding mode position control of a robotic manipulator. Nonlinear Dyn. 90(2), 1353–1362 (2017)
Teng, Z.J.; Lv, J.L.; Guo, L.W.: An improved hybrid grey wolf optimization algorithm. Soft Comput. (2018). https://doi.org/10.1007/s00500-018-3310-y
Saxena, A.; Kumar, R.; Das, S.: β-Chaotic map enabled Grey Wolf Optimizer. Appl. Soft Comput. 75, 84–105 (2019)
Gupta, S.; Deep, K.: A novel Random Walk Grey Wolf Optimizer. Swarm Evolut. Comput. 44, 101–112 (2019)
Gupta, S.; Deep, K.: Random walk grey wolf optimizer for constrained engineering optimization problems. Comput. Intell. 34(4), 1025–1045 (2018)
Long, W.; Jiao, J.; Liang, X.; Tang, M.: An exploration-enhanced grey wolf optimizer to solve high-dimensional numerical optimization. Eng. Appl. Artif. Intell. 68, 63–80 (2018)
Rodríguez, L.; Castillo, O.; Soria, J.; Melin, P.; Valdez, F.; Gonzalez, C.I.; Soto, J.: A fuzzy hierarchical operator in the grey wolf optimizer algorithm. Appl. Soft Comput. 57, 315–328 (2017)
Mirjalili, S.; Aljarah, I.; Mafarja, M.; Heidari, A.A.; Faris, H.: Grey Wolf Optimizer: theory, literature review, and application in computational fluid dynamics problems. In: Nature-Inspired Optimizers, Springer, Cham, pp. 87–105 (2020)
Chattopadhyay, B.; Sachdev, M.S.; Sidhu, T.S.: An on-line relay coordination algorithm for adaptive protection using linear programming technique. IEEE Trans. Power Deliv. 11(1), 165–173 (1996)
Gers, J.; Holmes, E.: Protection of Electricity Distribution Networks, 3rd edn. IET Power and Energy SeriesInstitution of Engineering and Technology, Stevenage (2011)
Alam, M.N.; Das, B.; Pant, V.: An interior point method based protection coordination scheme for directional overcurrent relays in meshed networks. Int. J. Electr. Power Energy Syst. 81, 153–164 (2016)
Alam, M.N.: Adaptive protection coordination scheme using numerical directional overcurrent relays. IEEE Trans. Ind. Inform. 15(1), 64–73 (2019)
Muro, C.; Escobedo, R.; Spector, L.; Coppinger, R.P.: Wolf-pack (Canis lupus) hunting strategies emerge from simple rules in computational simulations. Behav. Process. 88(3), 192–197 (2011)
Yang, X.S.: Nature-Inspired Metaheuristic Algorithms. Luniver Press, Bristol (2010)
Coello, C.A.C.: Theoretical and numerical constraint-handling techniques used with evolutionary algorithms: a survey of the state of the art. Comput. Methods Appl. Mech. Eng. 191(11–12), 1245–1287 (2002)
Mirjalili, S.; Gandomi, A.H.; Mirjalili, S.Z.; Saremi, S.; Faris, H.; Mirjalili, S.M.: Salp Swarm Algorithm: a bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 114, 163–191 (2017)
Sayed, G.I.; Khoriba, G.; Haggag, M.H.: A novel chaotic salp swarm algorithm for global optimization and feature selection. Appl. Intell. 48(10), 3462–3481 (2018)
Mirjalili, S.: SCA: a sine cosine algorithm for solving optimization problems. Knowl. Based Syst. 96, 120–133 (2016)
Almas, M.S.; Leelaruji, R.; Vanfretti, L.: Over-current relay model implementation for real time simulation and Hardware-in-the-Loop (HIL) validation. In: IECON 2012-38th Annual Conference on IEEE Industrial Electronics Society IEEE, pp. 4789–4 (2012)
Acknowledgements
The first author is thankful to the Ministry of Human Resource Development (Grand No. MHR-02-41-113-429) Government of India for financial support in pursuing this research.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Gupta, S., Deep, K. Optimal Coordination of Overcurrent Relays Using Improved Leadership-Based Grey Wolf Optimizer. Arab J Sci Eng 45, 2081–2091 (2020). https://doi.org/10.1007/s13369-019-04025-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13369-019-04025-z