
Abstract
After precipitation, reference evapotranspiration (ETO) plays a crucial role in the hydrological cycle as it quantifies water loss. ETO significantly impacts the water balance and holds great importance at the basin level because of the spatial distribution of managing water resources. Large scale teleconnection indices (LSTIs) play a vital role by influencing climatic variables and can be pivotal in determining ETO and its predictive variables. This study aimed to model and forecast annual ETO in Iran’s basins by utilizing LSTIs and employing various machine learning models (MLMs) such as least squares support vector machine, generalized regression neural network, multi-linear regression (MLR), and multi-layer perceptron (MLP). Initially, climate data from 122 synoptic stations covering six and 30, main and sub basins were collected, and annual ETO values were computed using the Food and Agriculture Organization 56 (PMF 56) Penman–Monteith equation. The correlations between these values and 37 LSTIs were examined within lead times ranging from 7 to 12 months. Through a stepwise approach, the most influential predictor indices (LSTIs) were selected as input datasets for the MLMs. The findings revealed the significant influence of factors such as carbon dioxide (CO2), Atlantic multidecadal oscillation, Atlantic Meridional Mode, and East Atlantic on annual ETO. Overall, all MLMs performed well in terms of the Scatter Index during both training and testing phases across all sub-basins. Furthermore, the MLP and MLR models displayed superior performance compared to other models in the training and testing evaluations based on various assessment metrics.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Shortage of water resources in the agricultural sector is widespread, especially in Iran is among the dry and semi-arid nations. Increasing water demand and limited access to water resources turned 75% of Iran into areas with water crisis (Hosseinzadeh Talaee et al. 2014). In the agricultural management, supplying the water requirements is essential to efficiently balance the water use, prevent its excessive consumption and access to maximum yield (Tabari et al. 2012a). The most important part of determining the water requirement of plants is references evapotranspiration (ETO). Another crucial element of the hydrological cycle is ETO that affects energy control between ecosystems and the atmosphere (Peterson et al. 1995; Shenbin et al. 2006). The significant role of ET in the global climate through the hydrological cycle is undeniable.
Accurate estimation of ETO has many applications in runoff and crop yield simulation, irrigation canal design and water distribution. ETO is an important factor in the hydrological cycle along with other climate factors such as relative humidity, wind speed, temperature, and radiation intensity (Allen et al. 1998). ETO as a climate factor, significantly affects energy and water exchange between ecosystem and atmosphere (Shenbin et al. 2006). Fluctuations in ETO are also important in water resources planning, management, irrigation scheduling, and crop yield (Allen et al. 1998; Lopez-Urrea et al. 2006; Wang et al. 2012).
Accurate predictions of evapotranspiration are essential in various fields, including irrigation design and planning, hydrology, determining crop water requirements, drainage design, and water resource allocation (Torres et al. 2011). These predictions are vital for effective agricultural water management, often necessitating ETO (Karbasi et al. 2023). Predicting ETo has proven to be challenging due to numerous unresolved critical issues in Earth System Science related to the complexity of ETo (Fisher et al. 2017). Failing to forecast evapotranspiration in a timely manner can lead to significant harm to crops, agricultural productivity, ecosystems, ecological balance, and the economy. The use of machine learning models for ETo forecasting remains one of the least examined hydrological variables in existing literature, and the development of machine learning approaches for predicting ETo has been relatively recent (Ali et al. 2023).
Intensity and rate of ETO are dependent not only to climatic variables (Roderick and Farquhar 2002; Xu et al. 2015; Cao and Zhou 2019) but also to other factors such as biophysical properties of plants and soils (Yuan et al. 2012) and the natural or abnormal oscillation of large-scale teleconnection indices (LSTIs) (Sabziparvar et al. 2011; Dong et al. 2021). Analysis of the fluctuations on ET in the 30-year period from 1982 to 2011 on a global scale and the effect of the ENSO phenomenon shows that there is an increasing linear relationship of 4.6 mm/decade in ET and a significant correlation between ENSO and its control variables. Besides, precipitation is an indicator of leaf area and potential evapotranspiration and the El Nino phase increased precipitation, and consequently, evapotranspiration (Yan et al. 2013).
On the other hand, LSTIs can also affect ET by affecting climatic components (Tabari et al. 2014a, b; Chai et al. 2018; Dong et al. 2021). Researchers believe that LSTIs have effects on ET through influencing climatic variables such as surface temperature (Thirumalai et al. 2017; Hejabi 2021), rainfall (Helali et al. 2020a, b; 2021a; 2022b; Dai and Wigley 2000), water content of soil (Nicolai-Shaw et al. 2016), wind speed and relative humidity (Hegerl et al. 2015; Hurrell et al. 2003). Numerous studies have attempted to investigate the effects of these indicators on meteorological and hydrological variables (Lyon and Camargo 2009; Nazemosadat and Cordery 2000; Helali et al. 2020a), crop yield (Heino et al. 2020), evaporation (Martens et al. 2018) and evapotranspiration (Tabari et al. 2014a, b; Helali and Asadi Oskouei 2021).
Sabziparvar et al. (2011) studied the correlation and effect of different phases of ENSO on changing ETO in warm climates of Iran by considering the correlation scenarios with delay and without delay. They showed that in more than 54% of the studied stations, there is a significant correlation between ENSO (SOI) and seasonal ETO fluctuations. Tabari et al. (2014a) examined the statistical relationship between Arctic Oscillation index (AO) with monthly and annual ETO revealed a noteworthy link in several areas of their study area specifically in the areas with a delay of 5 months. In another study in Iran (Tabari et al. 2014b), the winter ETO of most of the regions showed an inverse relationship with the North Atlantic Oscillation (NAO).
Chai et al. (2018) in China showed that seasonal and annual ETO always has significant correlations with AO, NAO, PDO, and ENSO indices with different lag times. According to Chen et al. (2018), the main factor affecting the ET of evergreen needle leaf forests in North America varies in different climates. For example, temperature and concentration of carbon dioxide are the most important factors in all climates, while radiation in Mediterranean/subarctic climates and soil temperature in hot summer climates of continental regions are the most dominant. Fang et al. (2018) proposed ENSO and Nino1.2 as suitable predictive indices of regional ET. The results of Dong et al. (2021) show that ETO in China in the period 1961–2017 has experienced three different trends, and in the third period from 1997 onward, it was significantly increasing. Also, they examined the correlation between ETO and large-scale teleconnection indices concluding high potential of predicting annual ETO by AO, AMO, and South China Sea summer indices. The authors mentioned that the effect of those indices on ETO arises from their effects on climatic factors.
Le and Bae (2020) investigated the global evaporation response to the main climatic patterns in the base and future climates of CMIP5. They found that the ENSO, IOD, and NAO were the main drivers of evaporation in the tropical Pacific, western part of the tropical Indian Ocean, and near North Atlantic Europe, respectively. Furthermore, land evaporation was less sensitive to LSTIs than oceanic regions. They also showed that the spatial effect of LSTIs on global evaporation in 1906–2000 compared to 2006–2100 was less significant for ENSO and more so for IOD and NAO. According to the literature review, it has been found that the relationship between LSTIs and ET was conducted for limited stations (Tabari et al. 2014a), specific climates (Sabziparvar et al. 2011) and with limited LSTIs (Dong et al. 2021). Helali and Asadi Oskouei (2021) showed that the widest spatial distribution of significant correlation frequency of Monthly ETO with LSTIs belongs to the CO2 for every lag period and every month that was examined up until November and December. Additionally, their study’s findings showed that, for lag durations ranging from 0 to 12 months of monthly ETO, LSTIs and CO2 can exhibit a strong association.
Karbasi et al. (2023) employed the time-varying filter-based empirical mode decomposition (TVF-EMD) technique alongside four machine learning models: bidirectional recurrent neural network (Bi-RNN), multi-layer perceptron (MLP), random forest (RF), and extreme gradient boosting (XGBoost), to forecast weekly ETO. The results showed that the TVF-BiRNN model provided the highest accuracy at both the Redcliffe and Gold Coast stations, achieving correlation coefficients (R) of 0.9281 (RMSE = 3.8793 mm/week, MAPE = 9.20%) and 0.8717 (RMSE = 4.1169 mm/week, MAPE = 11.54%), respectively. Mandal and Chanda (2023) identified LSTM as the best model for real-time predictions, achieving an R2 of 0.847 and a mean absolute error (MAE) of 0.474 mm/day for 28-day ahead forecasting. Following LSTM, the random forest (RF) model showed the next best performance, attaining an R2 of 0.722 and an MAE of 0.635 mm/day, using ERA5 datasets as input.
Granata et al. (2024) employed innovative algorithms, namely the Multilayer Perceptron-Random Forest (MLP-RF) Stacked Model and the Correlated Nystrom Views (XNV), to predict ETo. The MLP-RF Stacked Model achieved excellent performance for the 60-day forecasting horizon, with a Kling-Gupta Efficiency (KGE) of 0.98 and a Mean Absolute Percentage Error (MAPE) of 8.36%. Lee et al. (2024) utilized a hybrid system combining K-Best selection (KBest), multivariate variational mode decomposition (MVMD), and machine learning (ML) models for forecasting daily evapotranspiration (ETo) at twelve stations in California, covering 1-, 3-, 7-, and 10-day horizons. The results demonstrated that the hybrid models significantly outperformed standalone models.
Major studies on evapotranspiration has been focused on the trend (Tabari et al. 2012a,b; Dinpashoh et al. 2011; Nouri and Bannayan 2019; Rahman et al. 2019; Cao and Zhou 2019) and the impact of LSTIs with limited stations and specific climates of Iran (Tabari et al. 2014a,b; Sabziparvar et al. 2011). It has also been shown that there is a kind of relationship between LSTIs and the evaporative component in Iran and the world, which is mainly at station (Sabziparvar et al. 2011; Miralles et al. 2013; Dong et al. 2021) and basin (Helali and Asadi Oskouei 2021) scales. Meanwhile, the study and simulation of evapotranspiration based on LSTIs using MLMs can be an important and vital decision in water resources planning, especially at the basin scale as a method of decision support system (Helali and Asadi Oskouei 2021). The MLMs have been used to predict precipitation in a number of studies based on LSTIs (Cayan et al. 1999; Kim et al. 2020; Lee and Julien 2016; Hartman et al. 2016), some of them obtained satisfactory results (Helali et al. 2021b). Previous studies suggested that the use of LSTIs as precipitation predictor variables for machine learning models (MLMs) had a good performance (Hartman et al. 2016; Helali et al. 2021a, 2023; Li et al. 2017; Helali and Asadi Oskouei 2021), in most of which neural network models led to more reliable results. Within the field of artificial intelligence, machine learning provides in-depth understanding of intricate nonlinear data structures (Helali et al. 2023). The literature on hydro climatology and weather forecasting is quickly utilizing machine learning (Adnan et al. 2017; Granata 2019; Helali et al. 2022b; Kalu et al. 2023). Lately, machine learning approaches have been used to predict evapotranspiration (Zhao et al. 2019; Adnan et al. 2017) and evapotranspiration based on teleconnection signals (Liu et al. 2018; Xu et al. 2019). However, no studies have been conducted on the use of LSTIs as a predictor of evapotranspiration with different MLMs. Thus, the efficiency of different MLMs in predicting and modeling the annual ETO in Iran was evaluated. Since the allocation of water resources to different sectors of agricultural, industrial and drinking water consumption is conducted at basin scale, it is necessary to discuss water resources from the perspective of the basin with different spatial scales (Hosseinzadeh Talaee et al. 2014). Hence, the study was conducted in the basin and sub-basin scales.
The purpose of this investigation is threefold. First, we aim to develop and apply machine learning models to forecast ETO using a meteorological dataset and large-scale teleconnection indices. This will involve utilizing input data from 1990 to 2010 and testing the models on data from 2011 to 2019. The second objective is to identify the most effective LSTIs on ETO within the study basins. Lastly, the third objective involves conducting a thorough statistical analysis of model performance through key statistical parameters.
Data and methodology
Study area
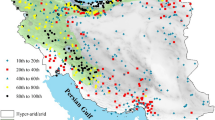
Iran, spanning an area of 1,648,000 km2, is situated of southwest Asia (Fig. 1). It comprises six and 30 main and sub-basins with average precipitation below global annual (Biabanaki et al. 2013; Salehi et al. 2019). Characterized as one of the most mountainous nations worldwide, Iran features rough mountain ranges in the west and north, such as the Alborz and Zagros, respectively, which divide various basins or plateaus (Hoseinzadeh Talaee et al., 2014). The strategic locations of these mountain ranges have led to the formation of extensive deserts, such as the Lut and Kavir deserts, significantly influencing Iran’s climate. While the north experiences a Mediterranean and humid climate, the majority of the country witnesses arid or semi-arid conditions (Tabari et al. 2012a, b), with a notable annual potential evapotranspiration rate.

Geographical location of the study area (Iran), synoptic stations, and the basins and sub-basins
To prepare the data for this study, we first collected all data from synoptic stations across Iran through the Iranian Meteorological Organization (https://data.irimo.ir/). Many of these stations were established in recent years, resulting in relatively short data records suitable for analysis. We assessed the number of missing values for each station during the recording periods, ensuring they adhered to an acceptable threshold of 10% or less (Aguilar et al. 2003; Bazrafshan and Cheraghalizadeh 2021). We then selected the stations with the longest data records and the lowest levels of missing data, ensuring they provided good spatial coverage for the case study. Based on these criteria, we utilized meteorological data from 122 synoptic stations with consistent records from 1990 to 2019 to calculate annual ETO for six main basins and 30 sub-basins in Iran (Fig. 1).
The highest and lowest annual ETO are 2272.3 and 851.5 mm per year in the Hamoon-Hirmand (HAH) and Haraz-Sefidroud (HAS) sub-basins, respectively (Table 1) (Helali et al. 2022b).
Using the meteorological data acquired from the synoptic stations (i.e., the average daily temperature data, wind speed, saturated vapor pressure, actual vapor pressure, and sunshine hours), ETO at 2 m above the ground surface were calculated by Food and Agriculture Organization 56 (PMF-56) Penman–Monteith equation (Allen et al. 1998):
where, G and Rn are the soil heat flux density and net radiation (MJ/m2/day), respectively. Ta denotes the average daily temperature (ºC) and U2 represents the wind speed (m/s). es and ea specify the saturated and actual vapor pressure (kPa), respectively. ∆ (kPa) is the slope of the vapor pressure curve and γ (kPa) is the Psychrometric constant. In this study, G was assumed to be negligible due to its small size over annual period and was considered as zero. Rn was estimated by FAO-56 method (Allen 2000) using minimum and maximum temperatures, sunshine hours, and vapor pressure for all stations. It worth noting that a double-mass curve analysis (a graphical method) was used to control the quality of climate data showing the homogeneity amongst the datasets (Kohler 1949).
Large-scale teleconnection indicators
Previous researches across Iran have investigated the effect of LSTIs, including indicators related to Sea Surface Temperatures (SSTs), North Atlantic Oscillation (NAO), El Nino Southern Oscillation (ENSO) and Arctic Oscillation (AO) on climate variables (Ahmadi et al. 2015; Helali et al., 2023; Ahmadi et al. 2019) and ETO (Sabziparvar et al. 2011; Tabari et al. 2014a). From the National Oceanic and Atmospheric Administration of the United States (NCEP/NCAR) website, 37 different types of LSTIs were downloaded for the current research. The information about these indices has been presented in Table 2. These indices were used as predictors for annual ETO modeling.
Selection of predictive indices and performance metrics
In large-scale applications that involve vast datasets, the need for efficient methods is paramount. As a result, optimizing predictive variables has become crucial to eliminate redundant and less impactful data, thus boosting performance speed and accuracy. To achieve this, the correlation matrix and Pearson correlation approach were applied to assess the relationships among the 37 factors (namely, the teleconnection indices and ETO) in order to identify and rank the most important indices in the research field. The formulation of the Pearson correlation coefficient (R) is explained by Eq. (2).
In this context, xi represents the independent values (observations), while yi signifies the dependent variables (predictions), where the means of the independent and dependent variables are denoted by x̄ and ȳ, respectively. The R ranges between − 1 (reflecting a perfect negative correlation) and 1 (indicating a perfect positive correlation between the variables). The datasets, comprising 37 indices with lead times of 7–12 months, were input into the model using the step-by-step approach. This methodology enabled us to establish the significant relationship between predictive indices and the likelihood of precipitation events. Based on the stepwise process, the three variables with the highest R2, were subsequently determined to be the most influential indices for the annual ETO.
In assessing the precision of the modeling and forecasting, four evaluation metrics were employed the of determination’s coefficient (R2), root mean square error (RMSE), mean absolute error (MAE), and scatter index (SI) during both the training and testing stages, as detailed below (Ma and Iqbal 1984; Willmott and Matsuura 2006; Li et al. 2013; Behar et al. 2015):
In the equations above, M represents the estimated data, O signifies the observation, n refers to number of data, and O̅ denotes the average of the observation data. According to the metrics, ideal models exhibit R2 values approaching 1, while low MAE and RMSE values are close to zero. The effectiveness of the SI statistic in modeling is categorized as follows (Li et al. 2013):
Prediction models
Machine learning models (MLMs) are advanced methods known for their capacity in data mining and training for prediction. The prediction process in MLMs involves training and testing phases. In this study, four different MLMs including multi linear regression (MLR), least squares support vector machine (LSSVM), multi-layer perceptron (MLP), and generalized regression neural network (GRNN) were used to predict annual ETO in Iran’s sub-basins.
Three key reasons for selecting these methods are: (1) Simplicity and User-Friendliness: These methods are accessible and easy for researchers to implement, (2) Hardware Requirements: They do not demand high-performance hardware, promoting broader usability, and (3) Previous Applications: Many studies have effectively used these methods in various contexts, especially in ETO forecasting, enabling easier comparison with other research results.
To identify key predictive indices, the datasets were split randomly into 70% training samples and 30% testing samples, along with relevant predictive indices for input into the four MLM algorithms. Each model produced three final outputs from 30 iterations. Brief descriptions of the models follow below.
Generalized regression neural network
Within the realm of MLM models, artificial neural networks (ANN) aim to replicate the structures and functions of biological neural networks, mirroring the information processing abilities of the human brain (Seyedzadeh et al. 2020; Duan et al. 2013). Neurons in an ANN consist of two components, weights and activation functions. Input variables are weighted upon reaching neurons, and the result is fed into the activation function to generate the final output. Generalized regression neural network (GRNN), probabilistic structure and radial basis function (RBF), serves as a NN algorithm for modeling dependent variables in regression functions, avoiding the local minima issue encountered by other models (Cigizoglu 2005). Unlike traditional ANNs, GRNN operates as a 3-layer NN with the matching the dimensions of input and output vectors in input and output layers, respectively. Unlike ANNs, the middle layer neuron count in GRNN is determined by the measured data during modeling steps (Araghinejad 2014). Equation (3) defines the Gaussian function in the neural network’s middle layer.
where, \(\left\| {X_{r} - X_{t} } \right\|\) calculates Euclidean distance between the real time vector of predictors (Xr) and the observed vector of predictors for the tth neuron (Xt). h is the spread parameter representing the spread of radial basis function and adjust function for the best fitness. Generally, h value is equal to 1.0. The larger h will result in the smoother approximate function while, the smaller h will closely fit the adjust function (Araghinejad 2014).
The value (Yr) of GRNN model (forecasted annual ETO) for the vector of predictors (Xr) is measured based on a kernel function of the normal performance function outputs [f (Xr,t)] depicted in Eq. (4) (Modaresi et al. 2018a):
in which, Tt and n are the measured data of forecasted variables and the number of data, respectively.
Multi-layer perceptron
Multi-layer perceptron (MLP) is a popular type of artificial neural network characterized by a feed-forward network structure comprising at least three layers—the input layer, hidden layer, and output layer (Gholami Rostam et al. 2020). Within the hidden layer, the neurons are configured based on the weights and biases, aiming to minimize the root mean square error (RMSE) to enhance the model’s performance (Widiasari et al. 2018). Equations 5 and 6 (Araghinejad 2014) show that the neurons in the intermediate and output layers use linear and sigmoid functions, respectively:
The Weight (w) and bias (b) are computed as the inputs of the neurons through wjxj + bj, where j = 1, 2, …, m, by setting the optimal values in each neuron and by the calibration of the model. The network was trained and calibrated using the Feed Forward Back Propagation (FFBP) technique to produce the best prediction. Every iteration (epoch) involves the minimization of the error function (Araghinejad 2014):
The simulation error for the ith training pair is indicated by ei in the error function of E, while the total number of training pairs is defined by nc.
Least squares support vector machine
Structural risk minimization is used by machine learning techniques such as LSSVM to lower model errors (Dibike et al. 2001; Cristianini and Shawe-Taylor 2000), while alternative approaches such as artificial neural networks (ANN) rely on principles of risk (Seyedzadeh et al. 2020). The LSSVM strategy utilizes linear equations within its prediction algorithm (Suykens and Osipov 2008), enhancing performance through the utilization of proper kernel functions (Seyedzadeh et al. 2020; Modaresi et al. 2018b). In LSSVM, for the feature space of Xt ∈ Rm, a nonlinear function of ϕ (predictors) and Y(Xt) ∈ R (target) is defined as specified by Suykens et al. (2002).
where, w is the weight and b are the bias of the regression function which are determined by minimization of the following function:
here, e and γ are error and the regularization parameter, respectively, to fit the approximation function.
Multi-linear regression
The reliability of a regression model may diminish when only a limited number of variables are selected. This study used the multi-linear regression (MLR) method to forecasting ETO by developing a regression function (Kim et al. 2020). Utilizing 28 years of data to model and forecast for the current investigation, seasonal datasets were employed along with a regression function (Y) featuring three independent variables, as outlined below:
where Y is the response (annual ETO), α0, α1, α2, α3 represent the coefficients, Xi are the highly correlated predictors (LSTIs), and ε determines the residual of models.
The structural characteristics of the four MLMs are presented in Table 3 and their schematic views are shown in Fig. 2A, 2B, 2C, and 2D, respectively.

The MLMs flowchart used for the study (A: GRNN; B: MLP; C: LSSVM; D: MLR)
Results
The most important LSTIs affecting annual ETO
The most effective LSTIs on ETO in the basins are listed in Table 4. According to the results, in most main basin and sub-basins, the CO2 index was the best indicator for predicting the annual ETO, followed by the AMO, AMM and EA with lead-times of 7–12 months. The results were mainly in agreement with the study by Helali and Asadi Oskouei (2021) examining the correlation of LSTIs and ETO on a monthly scale. However, some other indices have considerable influence on ETO in some other basins.
Evaluation of MLMs for ETO modeling
Average of all basins
The correlation between observed and modeled annual ETO is presented in Fig. 3. It showed the appropriate scattering of the observed and modeled ETO around the 1:1 line by all MLMs with R2 equal to 0.95, 0.99, 0.62 and 0.78 for MLR, MLP, GRNN and LSSVM, respectively. The results indicate the superiority and accuracy of the two MLP and MLR models. In the train and test phases of the evaluation (Table 5), the RMSE and MAE values in the MLR and MLP models were lower than other models. Table 5 also show that R2 of the MLP model had the highest value in the train and test phases (0.9 and 0.64, respectively). According to NSE criteria, MLP and LSSVM models performed more accurately in train and test phases. The SI criterion indicated that the performances of all models were excellent. In general, MLP and MLR models exhibited a high accuracy in annual ETO prediction.

Correlation between observed and modeled ETO (average of basins) for four machine learning models
Main basins
The correlation between the modeled and observed annual ETO in the main basins are presented in Fig. 4. The evaluation metrics also are provided in Table 6. Analyzing the real and modeled data time series reveals a reasonable scattering around the 1:1 line, although it is less for the main basins of Central Plateau (CP) and Urmia Lake (UL). This result can be considered due to climatic diversity and geographical distribution of the basins and also the high amount of annual ETO in these basins. Evaluation metrics in Caspian Sea (CS) basin show the lowest value for RMSE and MAE and highest value of NSE by MLP in training phase (27.6, 19.8 and 0.88 mm, respectively) and by MLR in testing step (45.9, 37.5 and 0.5 mm, respectively). The highest values of R2 belong to LSSVM for both training and testing phases. The value of SI (less than 0.1) demonstrates the excellent quality of all models. According to these results, MLP and MLR models can be considered as the best model in predicting the annual ETO of the Caspian Sea basin (CS) (Table 6). In the Persian Gulf-Oman Sea (PG), the metrics prove that both MLP and MLR models have appropriate performance. The minimum MAE and RMSE’s values in the training and testing obtained by these two models. The highest R2 values in the training and testing phases belong to the MLP model (0.91 and 0.63, respectively), and the highest NSE index in the training and testing phases belong to the MLP and MLR. In terms of the SI, the excellent performance of all models was confirmed in the two phases. In summary, in the Persian Gulf-Oman Sea (PG) basin, the MLP and MLR have the best performance for ETO modeling. In the Urmia Lake (UL) basin, the lowest values of RMSE and MAE obtained for MLP and MLR models, while based on R2 and NSE indices, the LSSVM model is more accurate than others. On the other hand, the SI indicates the excellent performance of all models for both training and testing phases. The overall result shows the superiority of the LSSVM model over other models. The results obtained in the Central Plateau (CP) basin highlighted that the lowest values of RMSE and MAE in the training phase belong to the GRNN model and in the testing phase belongs to the MLR and GRNN models; however, based on the R2 and NSE indices, the MLP model has a better performance. The SI index also shows the excellent quality of all models. In general, the MLP model performs better in the CP basin than other models. In the East Boundary (EB) basin, the results are similar to Caspian Sea (CS) basin, except for highest R2 which have seen for MLP model (0.90 for training phase and 0.62 for testing phase) The SI index shows the excellent quality of all models, and in general the output of both MLP and MLR models is better than the other two models. In the Qara Qom (QQ) basin, the accuracy of GRNN model in training and testing phases was better than other models. It shows the lowest values of RMSE and MAE and the highest values of R2 and NSE. According to SI criteria, excellent performance of all models used in the training and testing phases have also been proven.

Modeled and observed annual ETO at the basin scale for different MLMs
Summarizing the results obtained in the main basin shows that the annual ETO modeling based on LSTIs with the help of different MLMs is reliable. However, depending on the basins, the models perform differently. Due to the high climatic and geographical diversity in the main basins, it is necessary to examine the efficiency of MLMs in the sub-basin scale, which is discussed in the next section.
Sub-basins
Comparison between observed and modeled ETO based on four MLMs are shown in Fig. 5. The data scattering around the 1:1 line is appropriate in all models. However, the variability of the data around the line varies in different sub-basins, as lower variabilities have observed in the ARZ, HAS, SFR, TLS, BDA, HLL, JAZ, KRK, WSB, URL, CTD and STL. The results of evaluation metrics of the MLMs in training and testing phases are shown in Fig. 6. Based on these results, the MLMs perform differently in sub-basins. Unlike more efficient and less error-prone models of more complex models in the training phase, models with a simpler structure such as MLR show less error in the testing phase. Based the R2, it can be concluded that the best models are MLP and LSSVM models. Besides, based on NSE index, MLP and LSSVM models have the best performance. The SI index also shows the reliable performance of all models used in the train and test phases in all sub-basins.

Modeled and observed ETO at sub-basin scale four different MLMs

Values of different evaluation metrics to ETO forecasting
It should be noted that the effect of LSTIs on annual ETO can be due to their effect on important evaporative stimuli such as surface temperature, rainfall, water content of soil, relative humidity and wind speed (Sun et al. 2016; Thirumalai et al. 2017; Hejabi 2021; Dai and Wigley 2000; Nicolai-Shaw et al. 2016; Hegerl et al. 2015; Hurrell et al. 2003). However, more studies are needed from dynamic and synoptic meteorology point of views (Helali et al. 2021a). One of the advantages of using LSTIs as predictor variables of annual ETO is being predictable and having timely data available and linking it to future time steps.
Discussion
Trends and investigation of evapotranspiration have been studied in various regions of the world based on different views and models (Brutsaert and Parlange 1998; Roderick and Farquhar 2002; Zhang et al. 2011; Liu et al. 2011; Tabari et al. 2012a,b; Yang et al. 2017; Dinpashoh et al. 2018; Nouri and Bannayan 2019; Le and Bae 2020). Generally, the significant increases or decrease in ETo dominated in the different regions of the world (Hobbins et al. 2004; Shenbin et al. 2006; Dinpashoh et al. 2011, 2018; Tabari et al. 2012a; Hosseinzadeh Talaee et al. 2014; Xu et al. 2015; Rahman et al. 2019; Le and Bae 2020). Therefore, investigating, modeling and predicting evapotranspiration in historical and future periods is very important (Yan et al. 2013; Liu et al. 2018; Chai et al. 2018).
The use of more complex models such as machine learning models in modeling of hydrological and climatic variables (Amirmoradi et al. 2015; Modaresi et al. 2018a,b; Kim et al. 2020) such as evapotranspiration has also been the subject of many studies (Adnan et al. 2017; Fang et al. 2018; Zhao et al. 2019; Granata 2019; Kalu et al. 2023). The results of these studies have shown the efficiency of these models in accurate modeling with less uncertainty. Large scale teleconnection indices fluctuations and their correlation with hydrological and climatic variables offer a viable strategy for forecasting precipitation (Cayan et al. 1999; Skeeter et al. 2019; Ahmadi et al. 2019; Gholami Rostam et al. 2020; Irannezhad et al. 2021), evapotranspiration (Dong et al. 2021; Sabziparvar et al. 2011; Miralles et al. 2013; Yan et al. 2013; Tabari et al. 2014a,b; Fang et al. 2018; Xu et al. 2019; Helali and Asadi Oskuei, 2021), frost (Muller et al. 2000; Scaife et al. 2008; Maryanaji et al. 2019; Helali et al. 2022a) and Wood Decay Hazard (Helali et al. 2021c) amounts and anomalies.
The use of large-scale teleconnection indices as predicting variables of evapotranspiration through machine learning models will be a new aspect in climatic and hydrological studies (Dai and Wigley 2000; Nicolai-Shaw et al. 2016; Helali et al. 2020a, b, 2021a, 2023; Kalu et al. 2023). Most of the studies conducted in this case have focused on station data (Sabziparvar et al. 2011; Biabanaki et al. 2013; Yan et al. 2013; Tabari et al. 2014a,b; Lee and Julien 2016; Modaresi et al. 2018a,b; Fang et al. 2018; Ahmadi et al. 2019; Xu et al. 2019; Gholami Rostam et al. 2020; Kim et al. 2020). The importance of hydrological studies is mainly focused on the catchment area (Helali et al. 2020a, 2021a, b; 2022b). Therefore, in the present study, the connection between indices of large-scale teleconnection and evapotranspiration were analyzed using different machine learning models at the basin and sub-basin scales of Iran. Previous studies show that in different parts of the world, the influence of large scale teleconnection indices on evapotranspiration is diverse according to the region. In some warm climates in Iran, Sabziparvar et al. (2011) demonstrated a substantial link between ETo and ENSO. Xu et al. (2019) showed that within the three change patterns of annual ETo and climate oscillations in China, there were only a few discontinuous lower timeframe bands. Tabari et al. (2014a) showed that significant correlations between annual ETo and the corresponding AO index are quite rare, and the differences between the ETo values during the extreme AO phases and the long-term average ETo values were found to be significant only at three out of the 41 study stations. Tabari et al. (2014b) found that the winter ETo had negative correlations with the NAO index, with a time lag from 0 to 6 months. Helali and Asadi Oskouei (2021) show that the highest positive correlation monthly ETo and large scale teleconnection indices belongs to the indices TSA, NTA, CO2, TNA, and AMO while the indices MEI and SST3.4 have the largest negative correlation at varying lag durations. The results show that at the basin and sub-basin scales are significant correlations between annual ETo with carbon dioxide (CO2), Atlantic Multidecadal Oscillation (AMO), Atlantic Meridional Mode (AMM) and East Atlantic (EA). The reason for the difference between the results obtained in this study and the previous studies can be due to the different spatial scales (station-based vs basin-based). Helali et al. (2020a; 2021a, b; 2022b) indicated that the influence of large scale teleconnection indices on precipitation fluctuations on basin scale had different results compared to station-based studies. According to research by Modaresi et al. (2018a) on monthly streamflow forecasting in linear and nonlinear situations, ANN performs best in linear conditions, with LS-SVR, GRNN, and KNN ranking next, in that order. However, under nonlinear situations, KNN, ANN, and GRNN models trail LS-SVR in terms of performance. The results obtained in the current study indicated that both complex and simple models had very accurate in modeling annual ETo. These results can be justified considering the geographical and climatic diversity of the studied basins (Helali et al. 2021a, b; 2022b). Moreover, MLP and MLR models were mainly superior to other models in the training and testing phases based on different evaluation metrics.
Satellite images are highly effective for modeling, as they produce vast amounts of data that can be transformed into valuable information when processed correctly. To manage large data volumes (big data), it is essential to use robust models that can effectively analyze the variable of interest within this data set. Currently, machine learning algorithms are becoming increasingly significant due to their ability to make faster predictions with lower errors when handling big data (Shang et al. 2023). These algorithms consist of mathematical rules and procedures that enable computer systems to learn from data and enhance their performance on specific tasks without explicit programming (dos Santos et al. 2024). In related study, the findings from dos Santos et al. (2024) revealed that the Bayesian regularized neural networks (BRNN) model achieved R2 and RMSE values of 0.73 and 1.10, respectively, while the XgbLinear (extreme gradient boosting—linear method) model had values of 0.74 and 1.25 for these metrics, showing the best overall performance.
Conclusions
In this study, an attempt has been made to evaluate the relationship between LSTIs on the annual ETO across Iran. To achieve this aim, different MLMs have been used for ETO modeling by applying the LSTIs as predictor variables. The results showed that the most important predictors of annual ETO belong to CO2 index, followed by AMO, AMM, and EA indices with lead-times of 7–12 months, which are somewhat consistent with obtained results by Helali and Asadi Oskouei (2021). The results showed that the efficiency of different MLMs varies in training and testing phases at different spatial scales. The scattering plots of the observed and modeled data illustrated that all MLMs in all spatial basin scales perform well. However, the evaluation of statistical criteria in the training and testing phases is different. Generally, at the main basin scale, the performance of MLP, MLR and LSSVM is better than GRNN. However, it should be noted that the performance of ETO modeling at the main basin scale due to high climatic and geographical diversity cannot be reliable. Therefore, it is necessary to examine the modeling at the sub-basin scale. The results showed that the ETO modeling using the MLMs have led to more reliable results in the ARZ, HAS, SFR, TLS, BDA, HLL, JAZ, KRK, WSB, URL, CTD and STL sub-basins. The evaluation metrics indicated that the MLMs perform differently in each sub-basins; thus, a certain model cannot be suggested for all sub-basins. For future studies, it is suggested that in order to analyze the dynamics and physics of the effect of LSTIs on ETO, limited indices with a physical-based are used. It is also necessary to link LSTIs with ETO on seasonal and monthly scales as well as the stages in which the most evapotranspiration occurs in order to evaluate the long-term performance of these indices. In this case the effect of short-term and long-term LSTIs on ETO can be analyzed. It seems that the clustering of the stations based on ETo regime and examining its relationship with the large-scale teleconnection indices can provide useful results (Helali et al. 2023).
References
Adnan M, Latif MA, Nazir M (2017) Estimating evapotranspiration using machine learning techniques. Int J Adv Comput Sci Appl 8(9):108–113
Aguilar E, Auer I, Brunet M, Peterson TC, Wieringa J (2003) Guidance on metadata and homogenization. Wmo Td 1186:1–53
Ahmadi M, Fathniya A, Abkharabat S (2015) Trend analysis of Iran’s precipitation and its relation to the teleconnection forces. J Clim Res 23:19–32 ((In Persian))
Ahmadi M, Salimi S, Hosseini SA, Poorantiyosh HA, Bayat A (2019) Iran’s precipitation analysis using synoptic modeling of major teleconnection forces (MTF). Dyn Atmos Oceans 85:41–56
Ali M, Jamei M, Prasad R, Karbasi M, Xiang Y, Cai B, Abdulla S, Farooque AA, Labban AH (2023) New achievements on daily reference evapotranspiration forecasting: potential assessment of multivariate signal decomposition schemes. Ecol Ind 155:111030
Allen RG (2000) REF-ET: reference evapotranspiration calculation software for FAO and ASCE standardized equations. Version 2 for windows [Computer Software]. Univ. of Idaho research and extension center, Kimberly, ID. http://www.kimberly.uidaho.edu/ref-et
Allen RG, Periera LS, Raes D, Smith M (1998) Crop evapotranspiration: guideline for computing crop water requirement. FAO irrigation and drainage paper no. 56. FAO: Rome, Italy
Amirmoradi K, Sabziparvar AA, Deihimi A (2015) Analysis of the relationship between seasonal streamflow variations and some teleconnection indices by wavelet analysis method (case study: northwest rivers). Water Soil Science J 4(1):269–284
Araghinejad S (2014) Data-driven modeling: using MATLAB in water resources and environmental engineering. Springer, water science and technology library, Volume 67
Bazrafshan J, Cheraghalizadeh M (2021) Verification of abrupt and gradual shifts in Iranian precipitation and temperature data with statistical methods and stations metadata. Environ Monit Assess 193(3):139
Behar O, Khellaf A, Mohammedi K (2015) Comparison of solar radiation models and their validation under Algerian climate–the case of direct irradiance. Energy Convers Manage 98:236–251
Biabanaki M, Eslamian SS, Koupai JA, Cañón J, Boni G, Gheysari M (2013) A principal components/singular spectrum analysis approach to ENSO and PDO influences on rainfall in western Iran. Hydrol Res 45:250–262
Brutsaert W, Parlange MB (1998) Hydrologic cycle explains the evaporation paradox. Nature 396(6706):30–30
Cao L, Zhou Z (2019) Variations of the reference evapotranspiration and aridity index over Northeast China: changing properties and possible causes. Adv Meteorol 7692871:1–13
Cayan DR, Redmond KT, Riddle LG (1999) ENSO and hydrologic extremes in the western United States. J Clim 12:2881–2893
Chai R, Sun S, Chen H, Zhou S (2018) Changes in reference evapotranspiration over China during 1960–2012: attributions and relationships with atmospheric circulation. Hydrol Process 32(19):3032–3048
Chen Y, Xue Y, Hu Y (2018) How multiple factors control evapotranspiration in North America evergreen needle leaf forests. Sci Total Environ 622–623:1217–1224
Cigizoglu HK (2005) Generalized regression neural network in monthly flow forecasting. Civ Eng Environ Syst 22(2):71–81
Cristianini N, Shawe-Taylor J (2000) An introduction to support vector machines and other Kernel-based learning methods. Cambridge University Press, 189 pages.
Dai A, Wigley TML (2000) Global patterns of ENSO-induced precipitation. Geophys Res Lett 27:1283–1286
Dibike YB, Velickov S, Solomatine D, Abbott MB (2001) Model induction with support vector machines: introduction and applications. J Comput Civ Eng 15:208–216
Dinpashoh Y, Jhajharia D, Fakheri-Fard A, Singh VP, Kahya E (2011) Trends in reference crop evapotranspiration over Iran. J Hydrol 399:422–433
Dinpashoh Y, Jahanbakhsh-Asl S, Rasouli AA, Foroughi M, Singh VP (2018) Impact of climate change on potential evapotranspiration (case study: west and NW of Ian). Theor Appl Climatol 136:185–201
Dong Y, Zhao Y, Zhai J, Zhao J, Han J, Wang Q, He G, Chang H (2021) Changes in reference evapotranspiration over the non-monsoon region of China during 1961–2017: relationships with atmospheric circulation and attributions. Int J Climatol 41:734–751
dos Santos RA, Mantovani EC, Bufon VB, Fernandes-Filho EI (2024) Improving actual evapotranspiration estimates through an integrated remote sensing and cutting-edge machine learning approach. Comput Electron Agric 225:109258
Duan ZH, Kou SC, Poon CS (2013) Prediction of compressive strength of recycled aggregate concrete using artificial neural networks. Constr Build Mater 40:1200–1206
Fang W, Huang S, Huang Q, Huang G, Meng E, Luan J (2018) Reference evapotranspiration forecasting based on local meteorological and global climate information screened by partial mutual information. J Hydrol 561:764–779
Fisher JB, Melton F, Middleton E, Hain C, Anderson M, Allen R, McCabe MF, Hook S, Baldocchi D, Townsend PA, Kilic A (2017) The future of evapotranspiration: global requirements for ecosystem functioning, carbon and climate feedbacks, agricultural management, and water resources. Water Resour Res 53(4):2618–2626
Gholami Rostam M, Sadatinejad SJ, Malekian A (2020) Precipitation forecasting by large-scale climate indices and machine learning techniques. J Arid Land 12:854–864
Granata F (2019) Evapotranspiration evaluation models based on machine learning algorithms—A comparative study. Agric Water Manag 217:303–315
Granata F, Di Nunno F, de Marinis G (2024) Advanced evapotranspiration forecasting in Central Italy: Stacked MLP-RF algorithm and correlated Nystrom views with feature selection strategies. Comput Electron Agric 220:108887
Hartman H, Snow JA, Stein S, Su B, Zhai J, Jiang T, Valentina K, Zbigniew W (2016) Predictors of precipitation for improved water resources management in the Tarim river basin creating a seasonal forecast model. J Arid Environ 125:31–42
Hegerl GC, Black E, Allan RP, Ingram WJ, Polson D, Trenberth KE, Chadwick RS, Arkin PA, Sarojini BB, Becker A, Dai A, Durack PJ, Easterling D, Fowler HJ, Kendon EJ, Huffman GJ, Liu C, Marsh R, New M, Osborn TJ, Skliris N, Stott PA, Vidale P-L, Wijffels SE, Wilcox LJ, Willett KM, Zhang X (2015) Challenges in quantifying changes in the global water cycle. B Am Meteorol Soc 96:1097–1115
Heino M, Guillaume JHA, Müller C, Iizumi T, Kummu M (2020) A multi-model analysis of teleconnected crop yield variability in a range of cropping systems. Earth Syst Dynam 11:113–128
Hejabi S (2021) Estimation of the reference evapotranspiration using the projections of CORDEX project and investigation of the meteorological variables contribution in its changes (Case Study: Lake Urmia Basin). Iran J Irrig Drain 6(14):1920–1938
Helali J, Asadi Oskouei E (2021) Correlation analysis of large-scale teleconnection indices with monthly reference evapotranspiration of Iran synoptic stations. Iran J Soil Water Res 52(6):1629–1644
Helali J, Pishdad E, Alidadi M, Loukzadeh S, Asadi Oskoei E, Norooz Valashedi R (2020a) Investigating the relationship between climate teleconnection indices and autumnal rainfall in Iran Watersheds. Iran J Soil Water Res 51(8):1921–1936
Helali J, Salimi S, Lotfi M, Hosseini SA, Bayat A, Ahmadi M, Naderizarneh S (2020b) Investigation of the effect of large-scale atmospheric signals at different time lags on the autumn precipitation of Iran’s watersheds. Arab J Geosci 13(18):1–24
Helali J, Hosseinzadeh T, Cheraghalizadeh M, Mohammadi Ghaleni M (2021a) Feasibility study of using climate teleconnection indices in prediction of spring precipitation in Iran Basins. Iran J Soil Water Res 52(3):749–769
Helali J, Momenzadeh H, Saeidi V, Brischke C, Ebrahimi G, Lotfi M (2021b) Decadal variations of Wood Decay Hazard and El Nino Southern Oscillation Phases in Iran. Front For Glob Change 4:693833
Helali J, Momenzadeh H, Salimi S, Hosseini SA, Lotfi M, Mohamadi SM, Maghami MG, Pazhoh F, Ahmadi M (2021c) Synoptic-dynamic analysis of precipitation anomalies over Iran in different phases of ENSO. Arab J Geosci 14(22):2322
Helali J, Asadi Oskouei E, Hosseini SA, Saeidi V, Modirian R (2022a) Projection of changes in late spring frost based on CMIP6 models and SSP scenarios over cold regions of Iran. Theoret Appl Climatol 149:1405–1418
Helali J, Ghaleni MM, Hosseini SA, Siraei AL, Saeidi V, Safarpour F, Mirzaei M, Lotfi M (2022b) Assessment of machine learning model performance for seasonal precipitation simulation based on teleconnection indices in Iran. Arab J Geosci 15(15):1343
Helali J, Nouri M, Mohammadi Ghaleni M, Hosseni SA, Safarpour F, Shirdeli A, Paymard P, Kalantari Z (2023) Forecasting precipitation based on teleconnections using machine learning approaches across different precipitation regimes. Environ Earth Sci 82:495
Hobbins MT, Ramírez JA, Brown TC (2004) Trends in pan evaporation and actual evapotranspiration across the conterminous U.S.: paradoxical or complementary? Geophys Res Lett 31(13):L13503
Hosseinzadeh Talaee P, Shifteh Some’e B, Sobhan Ardakani S (2014) Time trend and change point of reference evapotranspiration over Iran. Theor Appl Climatol 116:639–647
Hurrell JW, Kushnir Y, Ottersen G, Visbeck M (2003) An overview of the North Atlantic oscillation. Geophys Monogr-Ame Geophys Union 134:1–36
Irannezhad M, Liu J, Chen D (2021) Extreme precipitation variability across the Lancang-Mekong River Basin during 1952–2015 in relation to teleconnections and summer monsoons. Int J Climatol 42:2614–2638
Kalu I, Ndehedehe CE, Okwuashi O, Eyoh AE, Ferreira VG (2023) Identifying impacts of global climate teleconnection patterns on land water storage using machine learning. J Hydrol: Reg Stud 46:101346
Karbasi M, Jamei M, Ali M, Malik A, Chu X, Farooque AA, Yaseen ZM (2023) Development of an enhanced bidirectional recurrent neural network combined with time-varying filter-based empirical mode decomposition to forecast weekly reference evapotranspiration. Agric Water Manag 290:108604
Kim CG, Lee J, Lee JE, Kim NW, Kim H (2020) Monthly precipitation forecasting in the Han River Basin, South Korea, using large-scale teleconnections and multiple regression models. Water 12:1590
Kohler MA (1949) Double-mass analysis for testing the consistency of records and for making adjustments. Bull Am Meteorol Soc 30:188–189
Le T, Bae DH (2020) Response of global evaporation to major climate models in historical and future Coupled Model Intercomparison Project Phase 5 simulations. Hydrol Earth Syst Sci 24:1131–1143
Lee JH, Julien PY (2016) Teleconnections of the ENSO and South Korean precipitation patterns. J Hydrol 534:237–250
Lee J, Bateni SM, Jun C, Heggy E, Jamei M, Kim D, Ghafouri HR, Deenik JL (2024) Hybrid machine learning system based on multivariate data decomposition and feature selection for improved multitemporal evapotranspiration forecasting. Eng Appl Artif Intell 135:108744
Li MF, Tang XP, Wu W, Liu HB (2013) General models for estimating daily global solar radiation for different solar radiation zones in mainland China. Energy Convers Manag 70:139–148
Li G, Xie SP, He C, Chen Z (2017) Western Pacific emergent constraint lowers projected increase in Indian summer monsoon rainfall. Nat Clim Chang 7(10):708–712
Liu X, Luo Y, Zhang D, Zhang M, Liu C (2011) Recent changes in pan-evaporation dynamics in China. Geophys Res Lett 38(13):L13404
Liu B, Chen X, Li Y, Chen X (2018) Long-term change of potential evapotranspiration over southwest China and teleconnections with large-scale climate anomalies. Int J Climatol 38(4):1964–1975
Lopez-Urrea R, de Santa M, Olalla F, Fabeiro C, Moratalla A (2006) Testing evapotranspiration equations using lysimeter observations in a semiarid climate. Agric Water Manag 85:15–26
Lyon BV, Camargo SJ (2009) The seasonally-varying influence of ENSO on rainfall and tropical cyclone activity in the Philippines. Clim Dyn 32:125–141
Ma C, Iqbal M (1984) Statistical comparison of solar radiation correlations monthly average global and diffuse radiation on horizontal surfaces. Sol Energy 33:143–148
Mandal N, Chanda K (2023) Performance of machine learning algorithms for multi-step ahead prediction of reference evapotranspiration across various agro-climatic zones and cropping seasons. J Hydrol 620:129418
Martens B, Waegeman W, Dorigo WA, Verhoest NEC, Miralles DG (2018) Terrestrial evaporation response to modes of climate variability, npj Clim. Atmos Sci 1:43
Maryanaji Z, Tapak L, Hamidi O (2019) Climatic and atmospheric indices teleconnection impact on the characteristics of frost season in western Iran. J Water Clim Change 10(2):391–401
Miralles DG, van den Berg MJ, Gash JH, Parinussa RM, de Jeu RAM, Beck HE, Holmes TRH, Jiménez C, Verhoest NEC, Dorigo WA, Teuling AJ, Johannes Dolman A (2013) El Niño-La Niña cycle and recent trends in continental evaporation. Nat Clim Chang 4:1–5
Modaresi F, Araghinejad S, Ebrahimi K (2018a) A Comparative assessment of artificial neural network, generalized regression neural network, least-square support vector regression, and k-nearest neighbor regression for monthly streamflow forecasting in linear and nonlinear conditions. Water Resour Manage 32:243–258
Modaresi F, Araghinejad S, Ebrahimi K (2018b) Selected model fusion: an approach for improving the accuracy of monthly streamflow forecasting. J Hydroinf 20(4):917–933
Muller GV, Nunez MN, Seluchi ME (2000) Relationship between ENSO cycles and frost events within the Pampa Humeda region. Int J Climatol 20:1619–1637
Nazemosadat MJ, Cordery I (2000) On the relationships between ENSO and autumn rainfall in Iran. Int J Climatol 20:47–61
Nicolai-Shaw N, Gudmundsson L, Hirschi M, Seneviratne SI (2016) Long-term predictability of soil moisture dynamics at the global scale: persistence versus large-scale drivers. Geophys Res Lett 43:8554–8562
Nouri M, Bannayan M (2019) Spatiotemporal changes in aridity index and reference evapotranspiration over semi-arid and humid regions of Iran: trend, cause, and sensitivity analyses. Theoret Appl Climatol 136:1073–1084
Peterson TC, Golubev VS, Groisman PY (1995) Evaporation losing its strength. Nature 377(6551):687–688
Rahman MA, Yunsheng L, Sultana N, Ongoma V (2019) Analysis of reference evapotranspiration (ETO) trends under climate change in Bangladesh using observed and CMIP5 data sets. Meteorol Atmos Phys 131:639–655
Roderick ML, Farquhar GD (2002) The cause of decreased pan evaporation over the past 50 years. Science 298(5597):1410–1411
Sabziparvar AA, Mirmasoudi SH, Tabari H, Nazemosadat MJ, Maryanaji Z (2011) ENSO teleconnection impacts on reference evapotranspiration variability in some warm climates of Iran. Int J Climatol 31(11):1710–1723
Salehi S, Dehghani M, Mortazavi SM, Singh VP (2019) Trend analysis and change point detection of seasonal and annual precipitation in Iran. Int J Climatol 40(1):308–323
Scaife AA, Folland CK, Alexander LA, Moberg A, Knight JR (2008) European climate extremes and the North Atlantic Oscillation. J Clim 21:72–83
Seyedzadeh A, Maroufpoor S, Maroufpoor S, Shiri J, Bozorg-Haddad O, Gavazi F (2020) Artificial intelligence approach to estimate discharge of drip tape irrigation based on temperature and pressure. Agric Water Manag 228:105905
Shang K, Yao Y, Di Z, Jia K, Zhang X, Fisher JB, Chen J, Guo X, Yang J, Yu R, Xie Z (2023) Coupling physical constraints with machine learning for satellite-derived evapotranspiration of the Tibetan Plateau. Remote Sens Environ 289:113519
Shenbin C, Yunfeng L, Thomas A (2006) Climatic change on the Tibetan Plateau: potential evapotranspiration trends from 1961–2000. Clim Chang 76:291–319
Skeeter WJ, Senkbeil JC, Keellings DJ (2019) Spatial and temporal changes in the frequency and magnitude of intense precipitation events in the southeastern United States. Int J Climatol 39:768–782
Sun C, Li J, Ding R (2016) Strengthening relationship between ENSO and western Russian summer surface temperature. Geophys Res Lett 43:843–851
Suykens JA, Osipov GV (2008) Introduction to focus issue: synchronization in complex networks. Chaos. https://doi.org/10.1063/12985139
Suykens JAK, De Brabanter J, Lukas L, Vandewalle J (2002) Weighted least squares support vector machines: Robustness and sparse approximation. Neural Comput (Spec Issue Fundam Inf Process Asp Neurocomp) 48(1–4):85–105
Tabari H, Aeini A, Hosseinzadeh Talaee P, Shifteh Some’e B (2012a) Spatial distribution and temporal variation of reference evapotranspiration in arid and semi-arid regions of Iran. Hydrol Prossecc 26(4):500–512
Tabari H, Nikbakht J, Hosseinzadeh Talaee P (2012b) Identification of trend in reference evapotranspiration series with serial dependence in Iran. Water Resour Manage 26:2219–2232
Tabari H, Hosseinzadeh Talaee P, Willems P (2014a) Links between Arctic Oscillation (AO) and inter-annual variability of Iranian evapotranspiration. Quatern Int 345:148–157
Tabari H, Hosseinzadeh Talaee P, Shifteh Some’e B, Willems P (2014b) Possible influences of North Atlantic Oscillation on winter reference evapotranspiration in Iran. Glob Planet Change 117:28–39
Thirumalai K, DInezio PN, Okumura Y, Deser C (2017) Extreme temperatures in Southeast Asia caused by El Ninõ and worsened by global warming. Nat. Commun. 8:1–8
Torres AF, Walker WR, McKee M (2011) Forecasting daily potential evapotranspiration using machine learning and limited climatic data. Agric Water Manag 98(4):553–562
Wang P, Yamanaka T, Qiu GY (2012) Causes of decreased reference evapotranspiration and pan evaporation in the Jinghe River catchment, northern China. Environmentalist 32:1–10
Widiasari IR, Nugroho LE, Widyawan (2018) Deep learning multilayer perceptron (MLP) for flood prediction model using wireless sensor network based hydrology time series data mining. In: Proceedings-2017 international conference on innovative and creative information technology: computational intelligence and IoT, ICITech 2017, 2018-January, 1–5
Willmott CJ, Matsuura K (2006) On the use of dimensioned measures of error to evaluate the performance of spatial interpolators. Int J Geogr Inf Sci 20:89–102
Xu L, Shi Z, Wang Y, Zhang S, Chu X, Yu P, Xiong W, Zuo H, Wang Y (2015) Spatiotemporal variation and driving forces of reference evapotranspiration in Jing River basin, northwest China. Hydrol Process 29(23):4846–4862
Xu Y, Wu Y, Xu G (2019) Variation of reference evapotranspiration and its teleconnection with multiple large-scale climate oscillations in the Yangtze River Delta. China Int J Climatol 39(5):2630–2645
Yan H, Yu Q, Zhu ZC, Myneni RB, Yan HM, Wang SQ, Shugart HH (2013) Diagnostic analysis of interannual variation of global land evapotranspiration over 1982–2011: assessing the impact of ENSO. J Geophys Res Atmos 118:8969–8983
Yang Q, Ma Z, Zheng Z, Duan Y (2017) Sensitivity of potential evapotranspiration estimation to the Thornthwaite and Penman—Monteith methods in the study of global drylands. Adv Atmos Sci 34:1381–1394
Yuan W, Liu S, Liang S, Tan Z, Liu H, Young C (2012) Estimations of evapotranspiration and water balance with uncertainty over the Yukon River basin. Water Resour Manag 26:2147–2157
Zhang Q, Xu CY, Chen X (2011) Reference evapotranspiration changes in China: natural processes or human influences? Theoret Appl Climatol 103:479–488
Zhao WL, Gentine P, Reichstein M, Zhang Y, Zhou S, Wen Y, Lin C, Li X, Qiu GY (2019) Physics-constrained machine learning of evapotranspiration. Geophys Res Lett 46(24):14496–14507
Acknowledgements
The Iranian Meteorological Organization (IRIMO) is to be thanked by the authors for supplying the necessary data.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Author information
Authors and Affiliations
Contributions
All authors were involved in the conceptualization and design of the study. The final manuscript was reviewed and approved by all authors.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Helali, J., Mohammadi Ghaleni, M., Mianabadi, A. et al. Enhancing references evapotranspiration forecasting with teleconnection indices and advanced machine learning techniques. Appl Water Sci 14, 219 (2024). https://doi.org/10.1007/s13201-024-02289-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13201-024-02289-x