
Abstract
Climate time series may exhibit abrupt or gradual shift, due to non-climatic changes (e.g., the station relocation) or actual climate change of a region. This study presented a step-by-step methodology for detecting the climatic and non-climatic changes in annual precipitation (\(P\)) and maximum (\({T}_{x}\)) and minimum (\({T}_{n}\)) air temperature data related to 37 weather stations across Iran, using the statistical methods and stations metadata. All data cover the common period of 1961–2014. Abrupt changes in climate data were detected using the non-parametric Pettitt test and the piecewise linear regression model, the gradual changes using the non-parametric Mann–Kendall (MK) test, and the magnitude of trends using the Sen’s slope estimator. In addition, a two-sample t-test was used to consider whether means of the climate data have been significantly changed in the presence of change points recorded in stations metadata. Results indicated overall increasing trends in \({T}_{x}\) and\({T}_{n}\), with more increasing rate for \({T}_{n}\). In case of precipitation, most stations indicated non-significant decreasing/increasing trends while six of them showed significant decreasing trends. The detected breaking points, mainly in \({T}_{n} ,\) were concurrent with the years of change in the original locations of 6 out of 37 stations. It was specified that the unreliable stations’ data intensified the trend orientation and magnitude of climatic variables compared to the reliable ones. In addition, increasing rates in \({T}_{x}\) and \({T}_{n}\) (decreasing rate in\(P\)) for the stations located in the urban areas were larger (smaller) than those in the non-urban areas. This research revealed the necessity of metadata for accurate interpretation of results obtained from the statistical methods. The study suggests to the Iranian climate researchers to employ with caution a homogeneous length of series rather than total inhomogeneous length of series.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Due to an increase in anthropogenic greenhouse gas emissions, most regions of the world have experienced rapid warming since the mid-twentieth century, which in turn could potentially affect other climatic factors such as the global pattern of precipitation in the future (IPCC, 2014). In response to these global changes, the abrupt or gradual shifts (actual climatic changes) may appear in the regional or local climatic time series. However, changes in climate time series may also manifest due to changes in the location of the observing station, environment (exposure), instrumentation, or observation practices (Aguilar et al., 2003), which were termed as “spurious (i.e., non-climatic) changes” (Klein Tank & Zwiers, 2009). Such information that is accessible from the station history documents or metadata (Aguilar et al., 2003) allows researchers to accurately interpret the long-term or short-term changes detected in the climate time series and to reduce the uncertainties in climate change analyses.
A climate time series is defined as homogeneous where it is only affected by the climatic variations and regional trend information (Zhang et al., 2014). The climate time series of abrupt/gradual shifts related to actual climatic changes are thus homogeneous, whereas those related to non-climatic changes are inhomogeneous. Many research efforts were carried out to detect inhomogeneity in climate data (Bazgeer et al., 2019) and to investigate the effect of inhomogeneity on trend analysis for undocumented (Li & Dong, 2009) and documented (Feng et al., 2004; Kolendowicz et al., 2019; Li & Yan, 2010; Menne & Williams, 2009; Rahimzadeh & Nassaji Zavareh, 2014; Zhang et al., 2014) changes. In some studies, the stations with documented changes, especially relocation, were removed from the analyses of homogeneity and trend (Alizadeh-Choobari & Najafi, 2017; Rahimzadeh et al., 2009), and in some other studies, the effect of documented changes on the results of trend analysis were regarded (Bazrafshan, 2017; Feizi et al., 2014; Ghasemi, 2015; Kousari & Asadi Zarch, 2011; Rahimi & Fatemi, 2019), probably due to lack of access to metadata.
Over the last few decades, the maximum and minimum temperatures observed in weather stations have not been uniform (IPCC, 2014), but the warming rate of the minimum temperature has been mainly greater than that of the maximum temperature (Joanna & Bronislaw, 2002; Kruger & Shongwe, 2004; Vose et al., 2005). While nearly all regions of the globe have experienced a growing rise in air temperature, mean annual precipitation has risen in subpolar and tropical regions and decreased in subtropical regions (Feng et al., 2019). In fact, with increasing temperature in arid and semi-arid lands in the subtropical regions, the atmosphere needs a longer time to be saturated. Before precipitation being started, the atmospheric general circulation transports the accumulated water vapor to higher latitudes; thus, the amount of precipitation in the subtropical regions decreases (Alizadeh-Choobari & Najafi, 2017).
The average annual temperature in Iran has increased significantly by 0.3 \(^\circ{\rm C}\) per decade over the last 50 years (Rahimi et al., 2019). The warming rates of the homogenized annual mean minimum and maximum temperature data were determined 0.4––0.5 and 0.2–0.3 \(^\circ{\rm C}\) per decade over the country (Rahimzadeh & Nassaji Zavareh, 2014). On an intra-annual basis, the winter season became warm at a higher rate than other seasons (Ahmadi et al., 2018). However, the warm seasons (summer and spring) showed a more definite warming trend than the cold seasons (winter and autumn). Moreover, Iran’s warm climate regions have experienced warming at a higher rate than the cold climate regions (Ghasemi, 2015). Annual mean precipitation over the country has decreased by about − 7 mm per decade (Bazrafshan, 2017; Rahimi et al., 2019). Decreasing trends in the annual mean precipitation have been observed mainly in the northern and northwestern parts of Iran (Modarres & Sarhadi, 2009). However, extreme precipitation has increased over the last few decades (Balling et al., 2016; Soltani et al., 2016), particularly in the arid and semi-arid regions of the country (Modarres & Sarhadi, 2009). Similar to extreme precipitation, significant increasing trends in extreme temperature indices have also been reported (Soltani et al., 2016).
Various statistical approaches were used to analyze trends and to identify breakpoints in the climate time series. The Mann–Kendall statistic (Kendall, 1970; Mann, 1945) has been used as the most common statistical test for trend analysis and the Pettitt test (Pettitt, 1979) and the piecewise linear regression model (Li et al., 2017; Toms & Lesperance, 2003) for breakpoint detection. Following the detection of temporal trends and breakpoints in the climate time series, it is necessary to consider their validity with respect to the station history metadata (Klein Tank & Zwiers, 2009). Unfortunately, most studies performed in Iran (Ahmadi et al., 2018; Balling et al., 2016; Feizi et al., 2014; Kousari & Asadi Zarch, 2011; Soltani et al., 2016) only reported the findings of the change detection statistical tests without checking the validity of the detected changes relative to metadata. In addition, the impact of the time and type of changes documented in stations metadata on the statistical measures (e.g., mean) of climate data has not been clearly addressed by the previous studies done in the country. In order to address these issues, main objectives of this study were described as follows:
-
i)
Detection of abrupt and gradual shifts in annual Iranian air temperature and precipitation data using a variety of statistical tests
-
ii)
Validation of significant abrupt or gradual shifts, detected by the statistical tests, in the climate time series regarding stations metadata
-
iii)
Evaluation of the changes documented in stations metadata for the significant shifts in the means of climate data
This paper is organized as follows. The “Study area and datasets” section describes the study area and the datasets. The “Methodology” section introduces the general methodology and the methods used in this study to identify inhomogeneity in data. The “Results and discussion” section presents the results obtained from analyzing data by using several statistical techniques. Last, the “Conclusion” section presents our conclusions.
Study area and datasets
Study area
The study area, Iran, is located between 25° and 39° north latitude and 44° and 63° east longitude. Diversity in climate of Iran is very high due to existing the high lands stretched from the west to the east (Alborz Mountains) and from the northwest to the southwest (Zagros Mountains), the vast latitude, and the proximity of the land to the seas (Caspian Sea in the north and Persian Gulf in the south) and the other near/far water bodies (Khalili & Rahimi, 2018). According to the extended De Martonne classification (Rahimi et al., 2013), Iran’s climates ranges from per-humid to extra arid, in terms of an aridity index, and from very cold to warm, in terms of a thermal index. Most of the country area is located in arid and semi-arid climates.
Meteorological data
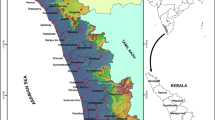
In this study, the annual precipitation and air temperature datasets of 376 weather stations across Iran were collected from IR of Iranian Meteorological Organization (IRIMO). Most stations were established in recent years; therefore, lengths of their data were so short that can be used in this study. The missing values for each of 376 stations were counted during three record periods including 1951–2014, 1961–2014, and 1971–2014. For an acceptable threshold of 10% or less of the missing values over the record periods (Aguilar et al., 2003), there were 27, 37, and 38 stations corresponding to the three record periods. It is observed that, in terms of the number of stations, the difference between the first and both of the other two record periods is high; however, there is a small difference between the second and third periods. Therefore, 37 stations covering mainly the record period of 1961–2014 were chosen for further analyses in this study. Our investigations showed that 18 out of 37 stations had no missing values during the selected period. Missing values were filled using a regression model between the target station and the neighboring station of complete data that was strongly correlated with the target station (Sattari et al., 2017). The geographical locations of the weather stations chosen for this study are presented in Fig. 1.

Situations of the selected weather stations over the study area, Iran. The names of stations corresponding to stations’ numbers are presented in Table 1
Metadata
According to Aguilar et al. (2003), the metadata or the station’s documentation is information about the data measured at the station; therefore, metadata is data about the data. It provides information about site/location, instrumentation, observation practices, site exposure, station location changes etc. Knowledge of non-climatic changes in the station history allows us to accurately judge the results of the statistical techniques on changing climate elements in a region and to ensure that variations in the climate time series are only due to actual climate variability and change.
Table 1 presents the metadata of the 37 selected weather stations used in this study. As per the table, there have not been reported any non-climatic changes at 9 out of 37 stations over the record period. Many stations experienced relocation mainly due to urban development, war-induced damages to the station’s original location, and the nonstandard platform. Most of the historical changes in location of stations have been happened over the 1990s. Furthermore, 23 out of 37 stations were within the urban areas. Ten (19) stations reported two (one) change points according to their metadata. Change in the station’s location was reported at 23 stations, with one station (Saghez) that its location has been changed two times over the record period. The other two changes recorded in the stations metadata were the change in the exposure and type of station.
Methodology
The process of this study, as shown in Fig. 2, begins with the compilation of the available air temperature and precipitation data and the metadata of the selected weather stations across Iran. Each time series is subjected to the Pettitt test (Pettitt, 1979) (and the piecewise linear regression model (Li et al., 2017; Toms & Lesperance, 2003) as a comparative method with the Pettitt test) to detect the most probable breakpoint over the record period. If a statistically non-significant breakpoint is detected by the test during the record period, homogeneity of the time series is confirmed and the process goes ahead for temporal trend analysis; otherwise, the detected breakpoint is compared to the change point(s) recorded in the station history metadata. If both the detected breakpoint and the observed change point have happened at the same time, i.e., the outcome is “Yes,” a non-climatic factor has led to inhomogeneity in the time series and that time series is unreliable for trend analysis. For the outcome “No,” the breakpoint detected by the Pettitt test is assumed to have occurred as a result of actual climate change in the region and the next step asks for any changes that may be recorded in the metadata. Conditioned to existing change point(s) in the station metadata, another statistical test, i.e., the t-test, is carried out to determine whether the means of the subseries prior to and after the change time are significantly different from each other. If the observed change is statistically significant, the abrupt change in the time series may be due to non-climatic change, and therefore, the series should be modified for that change (Feng et al., 2004). Otherwise, the time series is homogeneous and can be taken into consideration for trend analysis. More details on the methods used in this study are presented as follows.

Flowchart of the methodology used in this study
The Pettitt statistical test
The non-parametric Pettitt test (Pettitt, 1979) is used to find the most probable breakpoint (i.e. abrupt change point) in a time series. Assuming the occurrence of the break point at any time \(t\), the \({U}_{t,n}\) statistic is calculated using the sign function:
where \(\mathit{sgn}({x}_{i}-{x}_{j})\) is the sign function and takes values + 1, 0, -1 if \(({x}_{i}-{x}_{j})\) is positive, zero, and negative, respectively; \(n\) is size of the data; \(t\) is the assumed breakpoint time and takes values \(1, \dots , n\); \({x}_{i}\) and \({x}_{j}\) are the data at times \(i\) and \(j\). The Pettitt statistic (\(K\)) is calculated using the following formula:
The \(p-value\) corresponding to the \(K\)-value is calculated as follows:
The null hypothesis of no breakpoint (H0) is rejected if \(p value\) is less than the significance level of α (i.e., the probability of incorrectly rejecting H0, here 5 percent).
The piecewise linear regression model
The piecewise linear regression (PLR) model (Li et al., 2017; Toms & Lesperance, 2003), in addition to the Pettitt test, is used to detect the most probable breakpoint in climate data. The PLR model used in this study breaks a climate series into two segments at the breakpoint \(c\) as follows:
where \({\beta }_{0}\), \({\beta }_{1}\), and \({\beta }_{2}\) are the regression parameters; \(\delta =0\) if \(x\le c,\) and \(\delta =1\) if \(x>c\); \(x\) is the time variable (here, the year); y is the climate variable (\(P\), \({T}_{n}\), or \({T}_{x}\)). The breakpoint \(c\) is determined using the iterative search procedure described by Crawley (2012). It is the value of \(x\) for which the slope of the linear regression changes and Eq. (4) is estimated with the lowest value of mean square error (MSE). All parameters are estimated using the least square error method.
The two-sample t-test
The two-sample t-test (Snedecor & Cochran, 1989) is used to determine if two population means are equal. As a history change (recorded in the station metadata) splits the time series into two subseries (one relates to before and the other relates to after the change point), the t-test is applied to compare the two subseries means in this study. Assuming two independent populations, the t-test statistic for testing the null hypothesis H0 (\({\mu }_{1}={\mu }_{2})\) against H1 (\({\mu }_{1}\ne {\mu }_{2})\) is defined as follows:
in which \({\stackrel{-}{X}}_{1}\) and \({\stackrel{-}{X}}_{2}\) are the means of subseries 1 and 2, respectively; \({n}_{1}\) and \({n}_{2}\) are the subseries sizes used to compute \({\stackrel{-}{X}}_{1}\) and \({\stackrel{-}{X}}_{2}\), respectively; t is the value of a random variable having t-distribution with degrees of freedom of \(df={n}_{1}+{n}_{2}-2\); and \({S}_{p}\) is the square root of the pooled variance that is given by:
in which \({S}_{1}^{2}\) and \({S}_{2}^{2}\) are the variances of the subseries 1 and 2, respectively. Note that the t-test statistic assumes that the variances of two subseries in their populations are equal, but unknown. The null hypothesis is rejected if \(\left|t\right|>\left|{t}_{\alpha /2}\right|\) (\(\alpha\) is the significance level, here 5%). Under condition of rejection of H0, the data are inhomogeneous and unreliable for trend analysis.
The MK statistical test
In this study, the nonparametric Mann–Kendall (MK) statistical test (Kendall, 1970; Mann, 1945) was used to assess trend orientation in the annual and seasonal precipitation and temperature time series. Taking into account the serially independent data \({x}_{i},i=\mathrm{1,2},...,n\), in which \(n\) is the size of data, the \(S\) statistic of the MK test is defined as the sum of the sign function values as follows:
The statistic \(S\) is approximately normally distributed if the size of data is greater than 8 (Kendall, 1970; Mann, 1945). The MK test statistic \(Z\) is then given by:
where \(Var(S)\) is the variance of \(S\), expressed as:
in which, \(g\) is the number of tied groups; and \({t}_{p}\) is the number of observations in the \(p\) th group. The null hypothesis H0 (no trend or trend-free) is rejected if \(\left|Z\right|>{Z}_{1-\alpha /2}\), where \({Z}_{1-\alpha /2}\) is the standard normal variate at the significance level of α. Under alternative hypothesis H1 (existing trend), a positive (negative) value of \(Z\) specifies an upward (downward) monotonic trend. Note that all series were subjected to testing for the serial dependencies (lag-1 autocorrelations) and such dependencies were removed from the time series (i.e., the series were pre-whitened) before they were further analyzed for trend detection. The approach used to pre-whitening the time series has been presented in Hamed and Ramachandra Rao (1998) and Yue et al. (2002).
The Sen’s slope estimator
The Sen’s slope estimator, which was developed by Sen (1968), is used to estimate the magnitude of trend in the climate time series. It estimates the median of the slopes between any two time points of data by the following formula:
Results and discussion
Detection of the most probable breakpoints in the climate time series
Results of the Pettitt test applied to the annual mean maximum (\({T}_{x}\)) and minimum (\({T}_{n}\)) air temperature and the annual total precipitation (\(P\)) data are presented in Table 2. As per the table, at most stations, the test detected significant breakpoints in the temperature variables \({T}_{x}\) and \({T}_{n}\) at the 5% significance level, with more cases for \({T}_{n}\) (35 stations) than \({T}_{x}\) (30 stations). In case of the variable \(P\), only eight stations showed significant abrupt change at the 5% significance level. This means that air temperature compared with precipitation is more responsive to climatic or non-climatic changes in the stations of interest. It was also indicated that only for five stations (Kermanshah, Khoy, Sanandaj, Tabriz, and Zabol) the Pettitt test detected the significant breakpoints in all three variables \({T}_{n}\), \({T}_{x}\), and \(P\). However, the variables were not the same in terms of the year corresponding to the most probable breakpoint. Most of the estimated breakpoints concentrated on the 1980s and 1990s, which is consistent with the results of Bazgeer et al. (2019) and Ghasemi (2015).
As presented in Table 2 and shown in Fig. 3, the Pettitt test identified totally six significant breakpoints in the annual time series that were consistent with the change points recorded in the stations metadata. Five of the six significant breakpoints mentioned above were observed in \({T}_{n}\) (Abadan, Ahwaz, Bam, Shahrekord, and Mashhad) and the remaining one in \(P\) (Khoy). In addition, the significant breakpoints detected in Abadan, Ahwaz, Bam, Shahrekord, and Khoy can be attributed to change in the location of stations, and the significant breakpoint detected in Mashhad can be triggered by change in the station’s exposure. None of the breakpoints detected in \({T}_{x}\) were compatible with the changes recorded in the stations metadata. This result is consistent with the results of other researches, e.g., Bazgeer et al. (2019) and Rahimzadeh and Nassaji Zavareh (2014), conducted in Iran. The PLR also found four significant breakpoints in \({T}_{n}\) and \(P\), like the Pettitt test, which accorded with the metadata change points, as represented in Table 2. Two out of four breakpoints (for \(P\) in the Khoy station and \({T}_{n}\) in the Shahrekord station) obtained from the PLR were similar to those obtained from the Pettitt test. The remainder two breakpoints were recorded at different stations. The PLR model generated breakpoints which were similar to those generated by the Pettitt test in 18, 7, and 11 cases for \({T}_{n}\), \({T}_{x}\) and \(P\), respectively. The piecewise regressions fitted to the left hand and the right hand of the breakpoints detected by the iterative search procedure were represented in Fig. 4. As a result, the Pettitt test was more reliable than the PLR because it identified more breakpoints that consistent with the metadata change points.

The left panels: the most probable breakpoints (vertical dotted red lines) resulted from the Pettitt test related to the minimum temperature of five stations and the precipitation of one station whose breaking years are in accordance with the years of the changes recorded in those stations’ metadata. The parallel dotted lines before and after breakpoints show the mean values. The right panels: the Pettit statistic along with the 10% (light pink color) and 5% (dark pink color) significance levels

The left panels: the most probable breakpoints (vertical dotted red lines) based on the PLR method over the six climatic series specified in Fig. 3, along with the piecewise regressions and their corresponding 95% confidence levels. The right panels: the MSE variations and the position of breakpoint having the lowest value of MSE for each climate series
As indicated by the Pettitt test in Fig. 5, less than 50% of the most probable breakpoints happened at the same time as or after the first change points recorded in metadata. This implies that the most probable up or down abrupt changes in time series, identified by the test, might have started from the first change point reported in metadata. For the most significant abrupt changes that occurred prior to the change points recorded in metadata, the natural or unrecorded human factors may be responsible for the changes. For the stations with no change points in their metadata (i.e., nine stations, as mentioned earlier in Table 1), the Pettitt test detected the abrupt shifts in \({T}_{n}\) at all nine stations, in \({T}_{x}\) at seven out of the nine stations, and in \(P\) at one out of the nine stations. Note that all nine stations are located in urban development areas (Table 1).

Displaying the 5% significant breakpoints detected by the Pettitt test and the metadata’s change points for a maximum temperature, b minimum temperature, and c precipitation across the stations of interest
Testing the significance of documented change points
In addition to determining the most probable change point in a time series, considerations were done to be determined whether the change points recorded in the station history metadata generate significant abrupt shifts in the three annual time series related to the stations of interest. As stated earlier, based on the situation of each observed change point in metadata, each time series was broken into two subseries, including the subseries prior to the change point (the first subseries) and the subseries after the change point (the second subseries). Then, difference between the subseries means was examined using the two-sample t-test. Results of the test for the first change point recorded in the stations metadata have been presented in Table 3. As shown in the table, the first change points for 20, 16, and 6 stations significantly affected means of the subseries \({T}_{x}\), \({T}_{n}\), and P, respectively. The second change points (results not shown) also significantly changed the means of the subseries of air temperature compared with those of precipitation.
The change points recorded in the metadata of Kerman, Sanandaj, and Tabriz stations significantly changed the means of all three climate variables used in this study. At the Sanandaj and Tabriz stations, each of which with two historic change points, the means of the three climate variables were significantly affected by both historic change points. It is notable that all five change points mentioned above were due to the change in the stations’ exposure.
Trend analysis of the climate time series
When a station’s time series is marked as inhomogeneous (due to a non-climatic change), the data series of that station is unreliable for the analysis of trend and variability (Feng et al., 2004; Menne & Williams, 2009). In order to consider this issue, trend analysis was carried out for both reliable and unreliable stations’ data and the results of trend analysis for the two mentioned groups were compared together. Note that the significant serial dependencies in all three climate variables were eliminated from the original series before the series were analyzed for trend orientation and magnitude. In the following, the issue of trend analysis is considered under two below states:
-
• Aggregation of the unreliable and reliable stations’ data: Table 4 shows the results of the MK statistical test and the Sen’s slope estimator for analysis of trend orientation and magnitude, respectively, in the climate variables \({T}_{x}\), \({T}_{n}\), and \(P\) at all stations of interest. The reliable stations’ data have been distinguished with grey color from the unreliable ones. As shown in Table 4, the MK test mainly detected the significant increasing trends in air temperature data and the significant decreasing trends in precipitation data at the 5% significance level. Of 28 stations with change points recorded in their metadata, 17 stations detected the significant positive/negative gradual changes in \({T}_{x}\) (one station was negative and the remaining ones were positive), 23 stations in \({T}_{n}\) (two cases were negative and the remaining ones were positive), and 7 stations in \(P\) (one station was positive and the remaining ones were negative). For the stations without any change points in metadata, 3, 6, and 1 station indicated gradual shifts in \({T}_{x}\), \({T}_{n}\), and \(P\), respectively, with the positive significant trends for \({T}_{x}\) and \({T}_{n}\) and the negative significant trend for \(P\). Table 4 also shows the trend magnitudes for all stations of interest. As shown in the table, for the stations with (without) change points recorded in metadata the trend magnitudes for \({T}_{x}\) ranged between − 0.02 and 0.05°\(^\circ{\rm C}\) per year (− 0.01–0.06°\(^\circ{\rm C}\) per year). Likewise, the magnitudes varied from − 0.04 to 0.09°\(^\circ{\rm C}\) per year (0.01–0.07°\(^\circ{\rm C}\) per year) for \({T}_{n}\), and varied from − 3.58 to 0.99 mm per year (− 2.08–0.35 mm per year) for \(P\). In general, at most stations, the magnitudes of the increasing rates for both \({T}_{x}\) and \({T}_{n}\) were greater than the decreasing rates and \({T}_{n}\) increased with the rates higher than \({T}_{x}\). Also, the decreasing rates in \(P\) were higher than the increasing rates.
-
• Disaggregation of the unreliable and reliable stations’ data: The results of the MK test and Sen’s slope estimator disaggregated for the reliable and unreliable stations’ data of the climate variables \({T}_{x}\), \({T}_{n}\), and \(P\) have been displayed as boxplots in Fig. 6. As shown in the figure, the unreliable stations’ data, compared with the reliable ones, increased the absolute values of the median of the MK statistic for all three climate variables. While the median of the MK statistic for the reliable stations’ data of the variables \({T}_{x}\) and \(P\) were insignificant in the 5% level, the median of the MK statistic for the unreliable stations’ data of the same variables were significant. In case of the variable \({T}_{n}\), although medians of both reliable and unreliable data were significant at the 5% level, the level of median for unreliable data were higher than that for reliable data. Therefore, the percentage of stations with positive significant trends in \({T}_{x}\) and \({T}_{n}\) and negative significant trends in \(P\) were very greater for unreliable data than reliable ones. According to Fig. 6, the same results can be attributed to the trend magnitudes of the climate variables used in this study. The unreliable stations’ data raised the median rates of increasing (decreasing) in \({T}_{x}\) and \({T}_{n}\) (\(P\)), in comparison with the reliable ones. As a result, the unreliable stations’ data introduced unrealistically increasing trends in \({T}_{x}\) and \({T}_{n}\) and decreasing trend in \(P\), which, in turn, can produce concerns about the rate of warming and its impact on precipitation over the study area.

Comparison of the Mann–Kendall statistic (a‒c) and Sen’s slope (e, f) between the reliable and unreliable stations’ data for a and d maximum temperature, b and e minimum temperature, and c and f precipitation. The dotted lines display the 95% confidence interval
Effect of urbanization on the trend magnitudes of time series
Effect of the presence/no presence of the stations in urban area on the trend magnitudes of the climate variables \({T}_{x}\), \({T}_{n}\), and \(P\) has been presented in Table 5. The results in this table have been also further grouped based on the reliable/unreliable stations’ data. As shown in this table, the presence in urban area compared to the no presence in urban area has had an increasing effect on the average of trend magnitudes of all three climate variables \({T}_{x}\) and \({T}_{n}\) and a less decreasing effect on \(P\) under both reliable and unreliable stations’ data. Therefore, in the following, we discuss on the results obtained from the reliable data. Moving from the stations located outside the urban area to those inside the urban area increased the average of trend magnitudes for \({T}_{x}\) from 0.010 to 0.015 \(^\circ{\rm C}\) per year, for \({T}_{n}\) from 0.013 to 0.042°\(^\circ{\rm C}\) per year, and for \(P\) from − 0.941 to − 0.769 mm per year.
Table 5 also shows that, considering the areas under development of urbanization, the minimum temperature heating rate was higher than that of the maximum temperature (Alizadeh-Choobari & Najafi, 2017; Ghasemi, 2015). The faster increase in the minimum temperature is attributed to the blocking of outgoing long-wave radiation, and the lower increase in the maximum temperature is related to the reduction of incoming short-wave radiation to the Earth’s surface due to urban air pollution. As a result, the diurnal temperature range in urban areas is decreasing (Alizadeh-Choobari & Najafi, 2017).
As shown in Table 5, the precipitation in urban areas has been decreased to a lesser rate than in non-urban ones. It means that amount of precipitation in urban stations is greater than non-urban ones (Rahimpour Golroudbary et al., 2018). Three causatives factors including urban heat island, higher aerosol concentration, and large surface roughness have been expressed in literatures for explaining the urban impacts on precipitation (Han et al., 2014). The first two factors in the presence of enough air moisture increase precipitation and the latter through disrupting or bifurcating precipitating convective systems formed outside cities while passing over the cities may increase or decrease the urban precipitation (Han et al., 2014).
Conclusion
In this study, three annual climate data series from 37 Iranian weather stations were explored to detect probable abrupt and gradual shifts using a variety of statistical methods. A methodology was proposed to verify the results obtained from statistical methods using the stations history metadata. The key findings of this study are as follows:
-
• The most probable breakpoints (MPBs) detected by the statistical methods mainly differed from the change points recorded in the stations metadata. Such dissimilarities might be due to a climatic or unrecorded non-climatic change that had an effect on climate elements stronger than the effect of the recorded change (s) in metadata.
-
• The two-sample t-test showed that the changes recorded in the stations metadata significantly affected the means of the three climate variables used in this study.
-
• There were substantial differences between the results of trend analysis based on the unreliable and reliable data of the climate variables used in this study. This issue was more critical for maximum temperature and precipitation than minimum temperature. Therefore, researchers must be cautious when interpreting the results of the trend analysis, because both magnitude and orientation of trend may be remarkably affected by the historical changes occurred in the station environment.
-
• Effect of the urban areas on minimum temperature was considerably larger than that on maximum temperature. In addition, the average of trend magnitudes of precipitation was higher for the urban areas than the non-urban ones, though both mentioned areas mainly experienced decreasing trends in precipitation.
This study attempted to state the issues of three widely used climate variables in 37 popular weather stations with longest records across the country. It suggests to researchers to employ with caution a homogeneous length of series or carefully homogenize data before using them in any applications, especially in climate change impact assessments, due to much non-climatic factors that have unhomogenized the climate data measured in Iran.
References
Aguilar E, Auer I, Brunet M, Peterson TC, Wieringa J (2003) Guidelines on climate metadata and homogenization. WMO-TD No.1186, WCDMP No.53, . Geneva, Switzerland
Ahmadi, F., Nazeri Tahroudi, M., Mirabbasi, R., Khalili, K., & Jhajharia, D. (2018). Spatiotemporal trend and abrupt change analysis of temperature in Iran. Meteorological Applications, 25, 314–321. https://doi.org/10.1002/met.1694
Alizadeh-Choobari, O., & Najafi, M. S. (2017). Trends and changes in air temperature and precipitation over different regions of Iran. Journal of the Earth and Space Physics, 43, 569–584. https://doi.org/10.22059/jesphys.2017.60300
Balling RC, Keikhosravi Kiany MS, Sen Roy S, Khoshhal J (2016) Trends in Extreme Precipitation Indices in Iran: 1951–2007 Advances in Meteorology 2016:1–8. https://doi.org/10.1155/2016/2456809
Bazgeer, S., Abbasi, F., Asadi Oskoue, E., Haghighat, M., & Rezazadeh, P. (2019). Assessing the Homogeneity of Temperature and Precipitation Data in Iran with Climatic Approach. Journal of Spatial Analysis Environmental Hazarts, 6, 51–70. https://doi.org/10.29252/jsaeh.6.1.4
Bazrafshan, J. (2017). Effect of air temperature on historical trend of long-term droughts in different climates of Iran. Water Resources Management, 31, 4683–4698. https://doi.org/10.1007/s11269-017-1773-8
Crawley MJ (2012) Regression. In: The R Book. 2 edn. John Wiley & Sons, Ltd, pp 449–497. https://doi.org/10.1002/9781118448908.ch10
Feizi, V., Mollashahi, M., Farajzadeh, M., & Azizi, G. (2014). Spatial and temporal trend analysis of temperature and precipitation in Iran. Ecopersia, 2(4), 727–742.
Feng, S., Hu, Q., & Qian, W. (2004). Quality control of daily meteorological data in China, 1951–2000: a new dataset. International Journal of Climatology, 24, 853–870. https://doi.org/10.1002/joc.1047
Feng, X., Liu, C., Xie, F., Lu, J., Chiu, L. S., Tintera, G., & Chen, B. (2019). Precipitation characteristic changes due to global warming in a high-resolution (16 km) ECMWF simulation. Q J R Meteorol Soc, 145, 303–317. https://doi.org/10.1002/qj.3432
Ghasemi, A. R. (2015). Changes and trends in maximum, minimum and mean temperature series in Iran. Atmospheric Science Letters, 16, 366–372. https://doi.org/10.1002/asl2.569
Hamed, K. H., & Ramachandra Rao, A. (1998). A modified Mann-Kendall trend test for autocorrelated data. Journal of Hydrology, 204, 182–196. https://doi.org/10.1016/S0022-1694(97)00125-X
Han, J.-Y., Baik, J.-J., & Lee, H. (2014). Urban impacts on precipitation Asia-Pacific. Journal of Atmospheric Sciences, 50, 17–30. https://doi.org/10.1007/s13143-014-0016-7
IPCC (2014) Climate Change 2014: Synthesis Report. Contribution of Working Groups I, II and III to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change [Core Writing Team, R.K. Pachauri and L.A. Meyer (eds.)]. IPCC, Geneva, Switzerland, 151 pp.
Joanna, W., & Bronislaw, G. (2002). Trends of minimum and maximum temperature in Poland. Climate Research, 20, 123–133.
Kendall, M. G. (1970). Rank Correlation Methods. London: Griffin.
Khalili A, Rahimi J (2018) Climate. In: Roozitalab MH, Siadat H, Farshad A (eds) The Soils of Iran. Springer International Publishing, Cham, pp 19–33. https://doi.org/10.1007/978-3-319-69048-3_3
Klein Tank AMG, Zwiers FW (2009) Guidelines on analysis of extremes in a changing climate in support of informed decisions for adaptation. WCDMP- No. 72, WMO.
Kolendowicz, L., Czernecki, B., Półrolniczak, M., Taszarek, M., Tomczyk, A. M., & Szyga-Pluga, K. (2019). Homogenization of air temperature and its long-term trends in Poznań (Poland) for the period 1848–2016. Theoretical and Applied Climatology, 136, 1357–1370. https://doi.org/10.1007/s00704-018-2560-z
Kousari, M. R., & Asadi Zarch, M. A. (2011). Minimum, maximum, and mean annual temperatures, relative humidity, and precipitation trends in arid and semi-arid regions of Iran. Arabian Journal of Geosciences, 4, 907–914. https://doi.org/10.1007/s12517-009-0113-6
Kruger, A. C., & Shongwe, S. (2004). Temperature trends in South Africa: 1960–2003. International Journal of Climatology, 24, 1929–1945. https://doi.org/10.1002/joc.1096
Li, Q., & Dong, W. (2009). Detection and adjustment of undocumented discontinuities in Chinese temperature series using a composite approach. Advances in Atmospheric Sciences, 26(1), 143–153. https://doi.org/10.1007/s00376-009-0143-8
Li, X., Fu, W., Shen, H., Huang, C., & Zhang, L. (2017). Monitoring snow cover variability (2000–2014) in the Hengduan Mountains based on cloud-removed MODIS products with an adaptive spatio-temporal weighted method. Journal of Hydrology, 551, 314–327. https://doi.org/10.1016/j.jhydrol.2017.05.049
Li, Z., & Yan, Z. (2010). Application of Multiple Analysis of Series for Homogenization to Beijing daily temperature series (1960–2006). Advances in Atmospheric Sciences, 27, 777–787. https://doi.org/10.1007/s00376-009-9052-0
Mann, H. B. (1945). Nonparametric Tests Against Trend Econometrica, 13, 245–259. https://doi.org/10.2307/1907187
Menne, M. J., & Williams, C. N., Jr. (2009). Homogenization of Temperature Series via Pairwise Comparisons. Journal of Climate, 22, 1700–1717. https://doi.org/10.1175/2008jcli2263.1
Modarres R, Sarhadi A (2009) Rainfall trends analysis of Iran in the last half of the twentieth century. Journal of Geophysical Research: Atmospheres 114. https://doi.org/10.1029/2008JD010707
Pettitt, A. N. (1979). A Non-Parametric Approach to the Change-Point Problem Journal of the Royal Statistical Society Series C (Applied Statistics), 28, 126–135. https://doi.org/10.2307/2346729
Rahimi, J., Ebrahimpour, M., & Khalili, A. (2013). Spatial changes of Extended De Martonne climatic zones affected by climate change in Iran. Theoretical and Applied Climatology, 112, 409–418. https://doi.org/10.1007/s00704-012-0741-8
Rahimi, J., Malekian, A., & Khalili, A. (2019). Climate change impacts in Iran: assessing our current knowledge. Theoretical and Applied Climatology, 135, 545–564. https://doi.org/10.1007/s00704-018-2395-7
Rahimi, M., & Fatemi, S. S. (2019). Mean versus Extreme Precipitation Trends in Iran over the Period 1960–2017. Pure and Applied Geophysics, 176, 3717–3735. https://doi.org/10.1007/s00024-019-02165-9
Rahimpour Golroudbary, V., Zeng, Y., Mannaerts, C. M., & Su, Z. (2018). Urban impacts on air temperature and precipitation over The Netherlands. Climate Research, 75, 95–109.
Rahimzadeh, F., Asgari, A., & Fattahi, E. (2009). Variability of extreme temperature and precipitation in Iran during recent decades. International Journal of Climatology, 29, 329–343. https://doi.org/10.1002/joc.1739
Rahimzadeh, F., & Nassaji Zavareh, M. (2014). Effects of adjustment for non-climatic discontinuities on determination of temperature trends and variability over Iran. International Journal of Climatology, 34, 2079–2096. https://doi.org/10.1002/joc.3823
Sattari, M.-T., Rezazadeh-Joudi, A., & Kusiak, A. (2017). Assessment of different methods for estimation of missing data in precipitation studies. Hydrology Research, 48, 1032–1044. https://doi.org/10.2166/nh.2016.364
Sen, P. K. (1968). Estimates of the regression coefficient based on Kendall’s tau. Journal of the American Statistical Association, 63, 1379–1389. https://doi.org/10.2307/2285891
Snedecor, G. W., & Cochran, W. G. (1989). Statistical Methods. Eighth Edition edn: Iowa State University Press.
Soltani, M., et al. (2016). Assessment of climate variations in temperature and precipitation extreme events over Iran. Theoretical and Applied Climatology, 126, 775–795. https://doi.org/10.1007/s00704-015-1609-5
Toms, J. D., & Lesperance, M. L. (2003). Piecewise regression: A tool for identifying ecological thresholds. Ecology, 84, 2034–2041. https://doi.org/10.1890/02-0472
Vose RS, Easterling DR, Gleason B (2005) Maximum and minimum temperature trends for the globe: An update through 2004. Geophysical Research Letters 32. https://doi.org/10.1029/2005gl024379
Yue, S., Pilon, P., Phinney, B., & Cavadias, G. (2002). The influence of autocorrelation on the ability to detect trend in hydrological series. Hydrological Processes, 16, 1807–1829. https://doi.org/10.1002/hyp.1095
Zhang, L., Ren, G.-Y., Ren, Y.-Y., Zhang, A.-Y., Chu, Z.-Y., & Zhou, Y.-Q. (2014). Effect of data homogenization on estimate of temperature trend: a case of Huairou station in Beijing Municipality. Theoretical and Applied Climatology, 115, 365–373. https://doi.org/10.1007/s00704-013-0894-0
Funding
The authors would like to thank the Iran National Science Foundation (INSF) for funding this research under Grant Number 96010915.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Bazrafshan, J., Cheraghalizadeh, M. Verification of abrupt and gradual shifts in Iranian precipitation and temperature data with statistical methods and stations metadata. Environ Monit Assess 193, 139 (2021). https://doi.org/10.1007/s10661-021-08925-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10661-021-08925-2