
Abstract
The historical data on water intake into the reservoir is collected and used within the framework of a deterministic optimization method to determine the best operating parameters for the dam. The principles that have been used to extract the best values of the flow release from the dam may no longer be accurate in the coming years when the inflow to dams will be changing, and the results will differ greatly from what was predicted. This represents this method’s main drawback. The objective of this study is to provide a framework that can be used to guarantee that the dam is running as efficiently as possible in real time. Because of the way this structure is created, if the dam’s inflows change in the future, the optimization process does not need to be repeated. In this case, deep learning techniques may be used to restore the ideal values of the dam’s outflow in the shortest amount of time. This is achieved by accounting for the environment’s changing conditions. The water evaluation and planning system simulator model and the MOPSO multi-objective algorithm are combined in this study to derive the reservoir’s optimal flow release parameters. The most effective flow discharge will be made feasible as a result. The generalized structure of the group method of data handling (GSGMDH), which is predicated on the results of the MOPSO algorithm, is then used to build a new model. This model determines the downstream needs and ideal release values from the reservoir in real time by accounting for specific reservoir water budget factors, such as inflows and storage changes in the reservoir. Next, a comparison is drawn between this model’s performance and other machine learning techniques, such as ORELM and SAELM, among others. The results indicate that, when compared to the ORELM and SAELM models, the GSGMDH model performs best in the test stage when the RMSE, NRMSE, NASH, and R evaluation indices are taken into account. These indices have values of 1.08, 0.088, 0.969, and 0.972, in that order. It is therefore offered as the best model for figuring out the largest dam rule curve pattern in real time. The structure developed in this study can quickly provide the best operating rules in accordance with the new inflows to the dam by using the GSGMDH model. This is done in a way that makes it possible to manage the system optimally in real time.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
One of the most important components of water resource planning and management is the responsible operation of reservoirs and dams for a range of economic, social, and cultural reasons. This is due to the significant rule it plays in the availability of water. Many of the optimization problems that arise in engineering sciences are inherently complicated and demanding, making conventional optimization methodologies, like mathematical programming methods, inadequate for handling them. In this regard, several scholars have built a collection of evolutionary algorithms. To put it simply, these researchers are trying to find an efficient and successful operation method within the search space by integrating the basic concepts of operation techniques. These methods are currently frequently called exploratory technologies (Blum and Roli 2003; Nicklow et al. 2010). Among evolutionary algorithms, the genetic algorithm is thought to be the most widely used technique (Chang et al. 2005; Momtahen and Dariane 2007).
Multi-objective metaheuristic algorithms are a practical tool for system optimization in the field of water resources (Zarei et al. 2022; Karamian et al. 2023; Rezaei and Safavi 2020).
The non-dominated sorting genetic algorithm (NSGA-II), which is essentially a kind of multi-objective genetic algorithm, uses a population of possible solutions to go through each step of the solution process. Compared to the standard genetic algorithm model, this approach converges more quickly (Deb et al. 2002; Azari et al. 2018; Zeinali et al. 2020). This is because the model chooses solutions that are not dominated each time the equations are repeated and has an appropriate structure. This approach is used in this study to carry out the optimization procedure. This is because there are many choice factors involved, the problem is complex, and the structure is multi-objective. Multi-objective genetic algorithm was used by Jian et al. (2005) in their study on programming of multi-reservoir systems. Despite the fact that the evolutionary algorithm adds more variables and lengthens the program’s execution time, they found that it has a great potential for handling issues with few inputs and complex circumstances. Goorani and Shabanlou (2021) used NSGA-II to extract the optimal rule curve and establish the optimal operation of the Marun dam in order to meet both quantitative and qualitative goals.
As was previously indicated in this debate, a great deal of research has been done on the topic of enhancing reservoir operation through deterministic optimization. In many researches, the structure of multi-objective optimization (deterministic optimization) based on recorded historical inputs has been used to optimize the operation of water resources systems. This type of optimization takes into account a specific sequence of inflows into the reservoir across the operation period, and the release from the reservoir is optimized to supply the downstream uses under these conditions. The issue with these models is that the best answers are not transferable to other potential reservoir inflow scenarios. Moreover, the acquired optimal solutions are probably not going to work if the inflow to the reservoirs changes, so the system’s operation should be improved again using an optimization method. One solution to this kind of problem, according to Bayesteh and Azari (2021) and Jalilian et al. (2022), is to use stochastic optimization to take advantage of random inflows. However, in order to avoid extending the solution time due to the variety of the inflow series, this strategy necessitates a large reduction in the number of decision factors. This will lead to issues with the system’s real-time functionality. Using intelligent techniques is another option for implementing the results of system optimization in real time.
In recent research, along with statistical methods (Ebtehaj et al. 2020; Zeynoddin et al. 2020; Azari et al. 2021), in some studies, machine learning-based methods and hybrid methods are used to predict hydroclimatological data, river flow and changes in groundwater storage have been used (Nourmohammadi Dehbalaei et al. 2023; Soltani et al. 2021; Esmaeili et al. 2021).
The support vector machine, which served as the foundation for the development of regression vector machine technology, has been applied in several researches to predict time series. Lin et al. (2006) discovered that support vector machines outperformed ARMA and artificial neural network models in the forecasting of flow rate time series. Support vector machines and particle swarm algorithms were two of the many methods used by Du et al. (2017) to anticipate the three-hour rainfall at a meteorological station in Nanjing, China. Su et al. (2014) used GA-SVM in their work to predict the monthly storage volume of China’s Miyun Reservoir. Lei et al. (2021) stated that the combined GA-SVM model has been used in several researches to improve the accuracy of the hydrological parameter analysis.
Zeynoddin et al. (2020), Azari et al. (2021), Poursaeid et al. (2020, 2021, 2022), Yosefvand and Shabanlou (2020), Malekzadeh et al. (2019a, b), Azimi et al., (2020), Azizpour et al. (2021, 2022), Mazraeh et al. (2023, 2024), Fallahi et al., (2023), Mohammad et al. (2023), Azizi et al., (2023), Amiri et al, (2023) and Soltani and Azari (2023) stated that using artificial intelligence technologies and stochastic models to predict changes in groundwater storage and meteorological and hydrological parameters is one of the most widely used strategies in water resources planning (Soltani and Azari, 2022; Zeynoddin et al. 2018; Nourmohammadi Dehbalaei et al. 2023; Esmaeili et al. 2021). Hybrid models and machine learning-based techniques like GMDH, ORELM, and ELM have been extensively utilized recently to forecast hydroclimatological parameters including discharge and precipitation in diverse basins. Among these techniques were hybrid models. Group method of data handling (GMDH) has been used to simulate different problems such as discharge coefficient (Gharib et al. 2020; Moghadam et al. 2022; Shabanlou Saeid 2018; Khani and Shabanlou 2022; Shahbazbeygi et al. 2021) and hydraulic jump (Azimi et al. 2018).
The current research is based on a combination of the MOPSO multi-objective algorithm with innovative machine learning techniques, like GSGMDH, SAELM, and ORELM. This is done to make sure that the dam can be run as effectively as feasible in the present. In this example, real recorded data is used for system optimization instead of randomly generated data. Then, based on the operational conditions, the optimal rules that were produced throughout the optimization process are updated in real time. Deep learning techniques are employed to achieve this goal. In this specific scenario, there is a significant relationship between the optimal release rate variable (as a dependent variable) and the monthly inflows to the reservoir, the volume of water stored in the reservoir, changes in the volume of the reservoir, and downstream needs (as independent variables). Once the procedure is completed and the optimal variables are extracted, this association is established. Therefore, the main goal of this research is to effectively integrate the MOPSO optimization algorithm with deep learning techniques like GSGMDH, SAELM, and ORELM in order to achieve the most efficient operation of the dam in real time. In this scenario, real-time calculations of the first four parameters at the beginning of each month will be used to determine the ideal amount of release from the dam, accounting for variations in inflows over the next few years. But with this structure, understanding the optimal parameters does not require running optimization again. This is due to the fact that, with the anticipated change in the reservoir’s intake over the next several years, the optimization procedure needs to be carried out again in the shared structure and using the deterministic optimization approach. Rather, deep learning techniques can be used to obtain the optimal release quantity in real time. This is dependent on the reservoir’s inflows and initial water storage level, as well as changes in the reservoir’s storage over the course of the month and downstream demands. The innovation of the current research is the combined use of the MOPSO algorithm and the new machine learning model (GSGMDH) for the optimal exploitation of water resources systems in real time. Based on this innovation, the rules for the operation of the dam command curve in the future time are based on the data new ones can be extracted instantly and there is no need to run the optimizer algorithm again.
Methods and materials
Study area
In particular, the Ilam dam, located in the semi-arid and desert region of western Iran, would be the site of this investigation. The three sub-basins that comprise the base of the basin area of this dam are Gol-Gol, Chaviz, and Emma. The main river that pours into the dam, the Konjancham River, is split into two smaller rivers, Chaviz and Gol-Gol, as Fig. 1 illustrates. The Ilam dam provides drinking water to the city of Ilam and the agricultural areas of Amirabad and Konjancham. River data and maps, exact locations of hydrometric stations and dams, and a range of applications are defined in the WEAP model (Fig. 1). The amount of water entering the system is equal to the discharge values that have been observed upstream of the Ilam dam and at the dam location over 30 years, or 366 months.

Location of study area, dam, and rivers and schematic of WEAP model
The simulation of the system
Using available resources and adhering to basic GIS maps, the WEAP model digitizes various types of information, including the course of rivers, locations of hydrometric stations, dam sites, water withdrawal channels, nodes linked to cities and uses, and other data. The model also includes irrigation data time series, agricultural, drinking, and environmental use quantities, reservoir management parameters, water withdrawal sites, and any other relevant data. The Tennant (1976) method, which is one of the hydrological grading methods, is utilized to approximate the minimum downstream environmental flow based on the natural flow of the river. In Tennant method, 30 and 10% of the average annual flow, respectively, is considered as the minimum environmental flow in the first and second six months of the year. Table 1 lists the most important operational characteristics for the Ilam dam.
The values of the inflows that are deposited into the reservoir of the Ilam dam are computed using the model-defined flow rate values of the rivers that are situated upstream of the dam at the Chaviz, Gol-Gol, and Emma hydrometric stations. The average amount of precipitation that fell in these areas over the course of the machine’s simulation period is shown in Fig. 2a. The model specifies the environmental requirements for the downstream areas as well as the water demands of the areas immediately downstream of the Ilam dam, which include the plains of Amirabad and Konjancham. It also specifies a portion of the drinking water requirements of the city of Ilam. The monthly usage statistics are shown for your review in Fig. 2b.

a Average monthly discharge at hydrometric stations upstream the dam b monthly agricultural, drinking, and environmental demand values downstream the dam (MCM)
Simulator model structure
The WEAP model was used to simulate system performance. This model is used in many researches to simulate surface and groundwater systems (Karamian et al. 2023; Goorani and Shabanlou 2021). In WEAP model, the simulation period was considered to be about 30 years. The other parameters in the WEAP model included time series parameters of hydrologically recorded data and information on monthly demands (agricultural, drinking, and environmental demands), information on reservoirs and places of withdrawal, coefficients and required parameters, etc., which are mostly in the form of text files (CSV file) and according to the instructions for setting the input files were prepared and introduced to the model using the auto-call feature in the model functions section.
The proposed multi-objective operation model’s structure
The MOPSO multi-objective approach is used in the context of this inquiry to optimize the system. A multi-objective function is used to evaluate the quality of the solutions at each iteration of the optimization process. First, the goal is to meet as many system requirements as possible in percentage terms. Secondly, the goal is to minimize the amount of penalty that results from exceeding the reservoir’s permissible capacity during the whole operation period.
Objective functions
-
1.
Optimizing the overall coverage percentage for every demand in the system
$$ F_{1} = {\text{Maximize}}\left( {\mathop \sum \limits_{z = 1}^{m} \mathop \sum \limits_{d = 1}^{k} \mathop \sum \limits_{t = 1}^{n} \left( {{\text{COV}}_{zdt} } \right)} \right) = {\text{Maximize}}\left( {\mathop \sum \limits_{z = 1}^{m} \mathop \sum \limits_{d = 1}^{k} \mathop \sum \limits_{t = 1}^{n} \left( {\frac{{{\text{TDW}}_{zdt} }}{{{\text{MD}}_{zdt} }}} \right)} \right) $$(1)
This study extends the structure of the MOPSO algorithm for determining the goal functions’ minimum values. Consequently, Eq. (1) is recast as Eq. (2):
where COVzdt is the percentage of each time t that the demand d in the zone z is supplied. TDWzdt: The total amount of water provided for each time t in relation to demand d in zone z. MDzdt: The volume of water needed at each moment t to meet demand d in zone z.
-
2.The second aim function is to minimize the quantity of violations of the reservoir’s permitted operating capabilities.
$$ F_{2} = {\text{Minimize}}\left( {\mathop \sum \limits_{R = 1}^{k} \mathop \sum \limits_{t = 1}^{n} {\text{Max}}\left( {\left( {1 - \frac{{S_{tR} }}{{S_{{\min_{R} }} }}} \right),0} \right)} \right) $$(3)where \({S}_{tR}\): the amount of water stored at any one time t in the dam reservoir R, \({S}_{{min}_{R}}\):the amount of water stored in reservoir R at the dam while it is operating at its lowest capacity.
Limitations:
\({\text{RS}}_{tzs}\): The total amount of water allotted by zone z to sector s at each time t, \(nz\): the total number of demand areas, \(ns\): the number of various water consumers in each demand area, \(m\): the number of months, \(y\): the number of operation years
\({\text{ARS}}_{tzs}\): the entire volume of surface water from zone z that is allotted to sector s in time z (taking demand priority of consumptions into consideration)
\({\text{TDF}}_{tzs}\):The amount of water scarcity experienced by customers in zone z during each time interval t
\(Tb1\): The Ilam dam’s hedging level (m), \(M1\): operation dead level (m), \(N1\): the operation maximum level of the Ilam dam (m).
The MOPSO algorithm’s main body consists of twenty-four decision criteria. Twelve variables are linked to the capacity of the reservoir at the hedging level, and twelve variables are linked to the hedging factor—which is defined in the system on a monthly basis.
Machine learning methods (ML)
The results of the optimization method enable the determination of the ideal rule curve or dam release rate using the observed inflows as a base. When they are really running the reservoir system, the operators usually adhere to the rule curves. They can then use this information to make reasonably accurate decisions about how to run the reservoirs in a range of scenarios. The duty curve is an illustration of the amount of storage or discharge that the reservoir needs to have during a given time of the year (often a month). Because the operation rule curves provide a set of specific and rigid guidelines, operators are thus able to make appropriate decisions about releases in real time, taking it into account and anticipating future flows. In order to update the optimization rules for real-time settings, this inquiry makes use of the generalized structure of group method of data handling (GSGMDH). Next, a comparison is drawn between this model’s performance and other machine learning techniques, such ORELM and SAELM, among others.
Generalized structure of group method of data handling (GSGMDH)
These straightforward structures are gradually combined to create a complicated system with good performance (Elkurdy et al. 2021; Naderpour et al. 2020). One modeling and linear regression technique that is employed is the GMDH. Rather than creating estimation models all at once, an incremental and iterative technique is employed. This approach is used to build estimating models and involves the creation and addition of very basic structures called polynomial neurons. The GMDH neural network, according to Zaji et al. (2018), Miri et al. (2021), and Ahmadi et al. (2019), is composed of a group of neurons that are formed by connecting different pairs of neurons with a polynomial of the second degree. A collection of inputs is used to characterize the estimated function \(\hat{f}\) with the output \(\hat{y}\)
with the fewest errors in relation to the actual output, y. That being said, the connection for M laboratory data, which consists of n inputs and one output, presents the real results as follows:
We are trying to find a network that can figure out the output value for every vector X that is present in the input:
The following should be noted in order to lower the mean square error (MSE) between the actual values and the predicted values:
The following polynomial function can be used to define the form of link between the input and output variables (Dag and Yozgatligil 2016; Mallick et al. 2020; Elkurdy et al. 2021).
The following relationship is one of the many real-world scenarios in which the quadratic and two-variable form of this polynomial is employed:
Using regression techniques, the unknown coefficients ai derived in the following relationship are constructed in order to minimize the difference between the actual output y and the calculated values for each pair of the input variables xi and yi. Equation 12 is used to generate a set of polynomials, and all of the unknown coefficients can be determined using the least squares method (LSM). The coefficients of each neuron’s equations are found to minimize the neuron’s total error for each Gi function, which stands in for each produced neuron. The goal of doing this is to match inputs as closely as possible across all potential pairs of input–output sets.
One of the core techniques of the GMDH algorithm, the least squares approach, can be used to obtain the unknown coefficients of every neuron. Using n input variables, all binary combinations—also referred to as neurons—are built. Next,
The following equation can be used to represent the second layer, which is where neurons are built:
We use the function expressed in Eq. 14’s quadratic form to determine the value of each M triple row. These equations can be written as the following relation when put in matrix form:
The following is the equation for the quadratic equation given in Eq. 13, where A is the vector of unknown coefficients:
It is evident from the function’s form and the values of the input vectors that:
The equations’ solution in the following form is provided by the least squares method of multiple regression analysis:
The vector of coefficients for each of the M sets of three that are accessible is computed by this equation. The coefficients of neurons in the hidden and output layers during the training phase are also determined by the researcher’s intended confidence interval and the program’s initial specification of the degree of significance. This is also where the data screening mechanism—which entails removing variables that exhibit poor correlation at this phase—and the optimization of the neuronal coefficients and equations are completed.
Large-scale calculations are practically solvable, allowing the system of normal equations to be set under adequate and solvable conditions (Naderpour et al. 2020; Park et al. 2020; Ahmadi et al. 2019). The main benefit of the GMDH above conventional neural networks is the ability to develop and provide a mathematical model for the process under study using polynomials (Madala and Ivakhenko 1994). The GMDH’s great capability for multi-parameter data set analysis is an additional benefit (Dodangeh et al. 2020). It can also automatically determine the model’s structure and parameters (Stepashko et al. 2017), as well as exclude inputs that have a negligible impact on the output value computation (Dag et al. 2016; Park et al. 2020).
Furthermore, even though classical GMDH has many advantages—for example, automatically choosing the most efficient input variables, automatically determining the model’s structure, and taking into account both simplicity and accuracy at the same time to prevent overfitting-it also has several drawbacks that make it challenging to use. (1) The polynomial degree is limited to two; (2) each neuron’s input is limited to two; and (3) each neuron’s input is limited to the neurons in the layer adjacent to it. These are the principal issues that are related to this approach. The MATLAB software is being used to program a new computer program. The three main limitations of the conventional group management data technique are addressed by this software, which is called the generalized structure of the group management data method (GSGMDH). By resolving the current issues, this program seeks to provide a straightforward and highly accurate model. In the GSGMDH, polynomials of degrees of two or three are conceivable. Furthermore, the inputs of the model are not limited to the layer next to it; that is, a neuron can receive two or three inputs at most. According to the description that was given, each virtual variable has one of the following classes as its structure:
1. A polynomial of the second order with two variables as inputs is represented by Eq. (21).
2. A polynomial of the second order with three variables as inputs is represented by Eq. (22).
3. A polynomial of the third order with two variables as inputs is represented by Eq. (23).
4. With three variables as inputs, the polynomial in Eq. (24) is of the third order.
In general, the GSGMDH is a robust and flexible technique and provides a set of equations in order to estimate the target function. The GSGMDH approach is quite more accurate than the classical GMDH method since this model can input from non-adjacent layers.
Outlier robust extreme learning machine (ORELM)
The concept for the extreme learning machine (ELM), a multilayer feedforward neural network, was developed by Huang et al. (2004, 2006). While the output weights are established analytically, the input weights are determined arbitrarily by ELM. The general layout of this method is shown in the diagram designated Fig. 2a. The primary distinction between an ELM and a single-layer feedforward neural network (SLFFNN) is that the latter does not apply any bias at all at the output neuron. It is feasible to create connections between each and every neuron in the hidden layer and the input layer. While the activation function of the neuron in the output layer is linear, it may take the shape of a piecewise continuous function within the hidden neurons. The utilization of many methods for weight and bias calculation by the ELM model results in a noteworthy decrease in the training duration of the network. This mathematical description can be applied to a single-layer feedforward neural network with n number of hidden nodes according to the following description:
The weight between the ith hidden node and the output node is represented by the variable βi. The training factors for the hidden nodes are represented by the variables (ai) and bi. The output of the ith node, given the input x, is designated by the variable G(ai, bi, x). The activation function g(x) can be recast as follows at the additive hidden node G(ai, bi, x). This rule might take many different shapes.
Activation functions are used to ascertain the response output of neurons. In an ELM network with j hidden layer neurons, i input neuron, and k training instances, the activation of neurons in the hidden layer for each training example is calculated using the following equation:
where g(.) can be any continuous nonlinear activation function, Xik is the input neuron for the kth training sample, Hik is the activation matrix of the jth hidden layer neuron for the kth training example, and Wji is the weight of the ith input neuron and the jth hidden layer neuron, Bj is the bias of the jth hidden layer neuron. This matrix provides the activation of all the hidden layer neurons for the examples used in training. This matrix indicates that j stands for the column and k for the row. The matrix H is written as the hidden layer of the neural network’s output matrix. The weights between the neurons of the hidden and output layers are applied by using the least squares fitting for the target values in the train mode versus the outputs of the hidden layer neurons for each training example. The following is the equivalent mathematical expression for this fitting, which is as follows:
Now let us look at this equation: Eq. (30): where T is the vector representing the target values for training samples, and β is the weight that denotes the association between the neurons of the hidden layer and the neurons of the output layer.
Equation (31) eventually makes it possible to calculate weights:
where
here \(\tilde{a} = a_{1} , \ldots ,a_{L} ;\tilde{b} = b_{1} , \ldots ,b_{L} ;\tilde{x} = x_{1} , \ldots x_{L}\) and the weight vector between the neurons of the hidden layer and the input layer is denoted by the symbol β, and H′ represents the Moore–Penrose pseudo-inverse of the matrix H. The symbol T symbolizes the vector that refers to the vector that is between the training samples.
ELM training, based on the explanations, can be divided into two phases: the first involves randomly allocating weights and biases to the hidden layer neurons and computing the matrix H′s hidden layer output; the second phase computes the weight outputs by utilizing the Moore–Penrose pseudo-inverse of the matrix H and target values for various training samples. The hidden layer matrix (H) is found by a quick training process, which makes it faster than conventional iteration-based algorithms like Lundberg–Marquardt, which do not use a nonlinear optimization method. As a result, the time needed for network training is significantly decreased.
When employing artificial intelligence-based algorithms for modeling, outlier data is unavoidably present. This outlier data cannot be eliminated because the nature of the issue is often correlated with their occurrence. Consequently, it has a part that is a percentage of the total training error (e). Handling such data requires having sparsity as a distinguishing feature of the presence of outliers. Zhang and Luo (2015) are aware that using the l0-norm rather than the l2-norm can provide a sparser representation. An alternate method to using the l2-norm is to compute the output weight matrix (β) by treating the training error (e) in a sparse manner.
(β) denotes the matrix of output weights (\({w}_{{\text{o}}}\) or the same \({w}_{{\text{output}}}\)):
The equation that was just displayed is an illustration of a non-convex programming problem. Formulating this issue in the tractable convex relaxation form without removing the sparsity characteristic is one of the easiest ways to solve it. This is among the easiest approaches to handle this issue. The l1-norm is used to obtain the sparse term. In addition to producing a convex minimization, or a decrease in the error function, replacing l0-norm with l1-norm also guarantees the existence of limit events, or unusual data, or sparsity features.
To fully tune the proper domain of the augmented Lagrangian (AL) multiplier, the above-mentioned formula is a restricted convex problem.
The penalty parameter and the Lagrangian multiplier vector are represented by the symbol \(\mu = = 2N/\left\| {\mathbf{y}} \right\|_{1}\) in this context. Using the data from Yang and Zhang (2011), the following function is minimized iteratively to arrive at the best solution (e, β) and the Lagrangian multiplier vector (λ).
Self-adaptive extreme learning machine
The differential evolution algorithm can be used in the form of self-adaptiveness to get over current limitations, such as control parameters inside the algorithm and the choice of trial vector approach. Consequently, the self-adaptive extreme learning machine (SAELM) algorithm was introduced by Cao et al. (2012) to optimize hidden node biases and network input weights. To get the intended outcomes, this was done. The activation function g(K), L hidden nodes, and training data sets are required to develop the SAELM method.
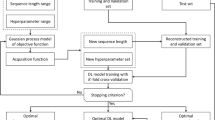
The integration of the SAELM and ORELM models with the MOPSO optimization approach is the last stage of this inquiry that will successfully extract the rules of operation of dams in real time. The ideal release volume in real time is determined using four parameters: monthly inflows, the amount of water held in the reservoir the month before, fluctuations in reservoir capacity at the start of each month, and the downstream need in the current month. After the MOPSO algorithm has determined the ideal dam release parameters, this is carried out throughout the ensuing years. In the upcoming years, the MOPSO algorithm's outputs and deep learning approaches will be used to help with the operation. The process flowchart is located in Fig. 3, which is accessible at this link.

Combination of MOPSO algorithm with deep learning methods
Results
Results acquired from optimization method
The MOPSO algorithm is run through a total of 1000 iterations while accounting for the 48 particles in order to optimize the system. Other parameters such as c1r1 and c2r2 coefficients were considered equal to 1.5 and 2, respectively, for better convergence of the algorithm. In the final iteration of the procedure, the set of optimal solutions is achieved. These solutions are shown between the goals \(F_{1}\) and \(F_{2}\) on the Pareto graph, which is also called the optimal exchange curve of goals (Fig. 4). The MOPSO algorithm uses the crowding distance function to select the best solutions for each iteration, much to the NSGA-II approach. Then, in order to move on to the next optimization stage, these solutions are saved under the Pareto front name. The points that are shown on the Pareto front are a collection of the twenty-four optimal solutions that the approach was able to extract. The axes of the Pareto graph reflect the objective functions \(F_{1}\) and \(F_{2}\).

Pareto graph (Pareto front) at the last optimization iteration
The solution that has the most favorable value for both of the desired objective functions \(F_{1}\) and \(F_{2}\) is chosen as the optimal solution in contrast to alternative solutions based on the values of the objective functions, and answer 16 is thought to be the best appropriate response in this research because the Pareto graph showed that it exhibits this attribute. The best choice variables are incorporated into the WEAP model once solution number 16 is put into practice, and the system’s behavior is examined in light of this solution. Figure 5 shows the values of the percentage of meeting the requirements of each of the numerous uses after the system optimization is complete.

Coverage of demand sites following system improvement
The results show that system optimization during the 360-month planning period results in better and more principled management of the reservoir during severe drought circumstances. Furthermore, for the entire duration, the needs are met in the best possible way. The application of water hedging policy with the aid of the optimization algorithm in arid and semi-arid regions not only achieves the desired and acceptable level of reliability, but also reduces the number of months of failure as well as the severity of failure during these months. This is especially helpful at those crucial times when we are facing a severe water deficit. In September and October, the average percentage of supply to demand has a minimal value of 81.1 and 81.4%, respectively. This is a decent statistic. Moreover, during the 360-month planning period, the ideal release values from the dam reservoir are determined once the system has been optimized. Therefore, we try to create a structure based on the output of the MOPSO method for the fresh data of the reservoir’s inflow by using the GSGMDH model. Real-time calculations are made to determine the ideal reservoir outflow values based on this structure. As was previously said, these figures may not be ideal for the sequence of upcoming inflows into the reservoir because they are derived from historical data on the inflow to the reservoir. In order to ensure the accuracy of the GSGMDH model, its performance is compared with that of the ORELM and SAELM models.
The outcomes of using the ORELM and SAELM models in comparison with the GSGMDH model
To take advantage of real-time optimization results, the GSGMDH model is used in this study and compared to the ORELM and SAELM models. The first 288 months of training are dedicated to training these models with the output of the MOPSO algorithm. After that, the data that was not used during the training phase is validated for a further 72 months. The amount of water pumped into the reservoir at the beginning of each month, the volume of water stored in the reservoir at the beginning of the month, changes in the reservoir’s storage, and the demands of downstream users are all taken into consideration when determining the ideal release amount for this duration of time based on these models.
The output of the optimization method is being compared with the outcomes during both the training and testing phases. Based on the inputs mentioned, the best artificial intelligence model needs to be able to predict the ideal dam release values, and its conclusions ought to differ as little as possible from the outcomes that the optimization algorithm has generated and attained. Table 2 presents the outcomes of these models’ predictions of the dam’s outflow based on the optimization algorithm’s findings. During the training and testing phases, these outcomes are contrasted with the output of the optimization technique.
The GSGMDH model is thought to be the most accurate model when compared to the ORELM and SAELM models in the two training and testing phases since it has the lowest values of the RMSE and NRMSE evaluation indices and the greatest values of the NASH and R indices overall. Table illustrates this (2).
Figure 6 illustrates how well the GSGMDH model’s trained structure predicts the ideal dam release in a range of months for both the train and test stages. This graphic also shows the relative error rate of the built model in terms of figuring out the optimal amount of discharge from the dam based on fresh data.

Predicted values of the outflow by the GSGMDH model in the train and test phases compared to the output of the MOPSO algorithm
Figure 7 shows the value of the correlation coefficient between the data predicted by GSGMDH and the output data of the MOPSO algorithm during the two training and testing phases. It is also discussed how these spots are distributed around the y = x line. This figure’s high R value indicates that the support vector machine model does a good job of predicting the dam’s ideal output given the current time.

The distribution of the output points of the MOPSO algorithm and predicted by the GSGMDH model around the y = x line in the train and test phases
Conclusions
The results showed that the model built by connecting the WEAP simulation model with the MOPSO multi-objective algorithm has the proper capacity and efficiency to tackle challenging, fully nonlinear problems and to yield optimal solutions. The outcomes provided evidence of this. In the last algorithm iteration, 24 distinct solutions that fell inside the optimal Pareto front value were used to build the goal exchange curve. The optimal solution among these possibilities was determined to be the one with the lowest value of the objective functions. The assessment of the relevant objective functions served as the basis for this conclusion. The application of the optimal release values from the dam, when the optimal policy is taken into account, produced findings that demonstrate that the percentage of meeting the needs of most users is appropriate and acceptable, and that it is more than 90% in most months. The optimal release values or the optimal rule curve were produced as a result of using the MOPSO algorithm on a specific sequence of inflows to the reservoir throughout the operating time. In addition, given these circumstances, the reservoir's discharge was tailored to support downstream usage. The issue with these models is that the best answers are not transferable to other potential inflows into the reservoir in the upcoming years. It is possible that the found optimal solutions will not hold true when the inflow to the reservoirs varies, and an optimizer method should be used to optimize the system once more. This is the issue with these kinds of models. After that, in order to benefit from the real-time optimization results, the GSGMDH model was used instead of the ORELM and SAELM models. The results indicated that the GSGMDH model performed the best when compared to the ORELM and SAELM models. The RMSE, NRMSE, NASH, and R evaluation indices were used to calculate this; their respective values during the test stage were 1.08, 0.088, 0.969, and 0.972. The results showed that in the superior GSGMDH model, about 90% of the predictions had errors of less than 4%. While in other models (ORELM and SAELM) about 60% of noses had this amount of error. It is therefore offered as the best model for figuring out the largest dam rule curve pattern in real time. The structure that was created as a result of this research can be used to identify the ideal release quantity in real time. This structure accounts for the monthly inflow into the reservoir, the reservoir's initial water storage volume, variations in the reservoir’s storage, and the demands of users downstream during the course of the current month. To put it another way, the GSGMDH model that was developed possesses the ability to quickly provide optimal operating policies in line with the new dam inflows in a way that permits optimal system management at all times. It is suggested to use the model developed in this research to plan and manage the operation of dam and aquifer systems for the coming years. It is suggested to use artificial intelligence models that have multiple output layers in multi-dam systems where each dam has a separate command curve, but the release of each of these dams is affected by each other. These models can be developed in the MATLAB environment for new conditions. Also, part of the information needed for such models can be obtained from online databases that are received from different satellites. This is especially important in areas without statistics.
Availability of data and materials
The total data and materials are available for applicants if needed.
References
Amiri S, Rajabi A, Shabanlou S et al (2023) Prediction of groundwater level variations using deep learning methods and GMS numerical model. Earth Sci Inform. https://doi.org/10.1007/s12145-023-01052-1
Ahmadi MH, SadeghzadehM RAH, ChauKW, (2019) Applying GMDH neural network to estimate the thermal resistance and thermal conductivity of pulsating heat pipes. Eng Appl Comput Fluid Mech 13:327–336. https://doi.org/10.1080/19942060.2019.1582109
Azari A, Hamzeh S, Naderi S (2018) Multi-objective optimization of the reservoir system operation by using the hedging policy. Water Resour Manag 32(6):2061–2078
Azari A, Zeynoddin M, Ebtehaj I, Sattar AMA, Gharabaghi B, Bonakdari H (2021) Integrated preprocessing techniques with linear stochastic approaches in groundwater level forecasting. Acta Geophys 69:1395–1411. https://doi.org/10.1007/s11600-021-00617-2
Azimi AH, Shabanlou S, Yosefvand F et al (2020) Estimation of scour depth around cross-vane structures using a novel non-tuned high-accuracy machine learning approach. Sādhanā 45:152
Azimi H, Bonakdari H, Ebtehaj I, Khoshbin F (2018) Evolutionary design of generalized group method of data handling-type neural network for estimating hydraulic jump roller length. Acta Mech 229(3):1197–1214
Azizi E, Yosefvand F, Yaghoubi B, Izadbakhsh MA, Shabanlou S (2023) Modelling and prediction of groundwater level using wavelet transform and machine learning methods: a case study for the Sahneh Plain Iran. Irrig Drain 72(3):747–762
Azizpour A, Izadbakhsh MA, Shabanlou S, Yosefvand F, Rajabi A (2021) Estimation of water level fluctuations in groundwater through a hybrid learning machine. Groundw Sustain Dev 15:100687. https://doi.org/10.1016/j.gsd.2021.100687
Azizpour A, Izadbakhsh MA, Shabanlou S, Yosefvand F, Rajabi A (2022) Simulation of time-series groundwater parameters using a hybrid metaheuristic neuro-fuzzy model. Environ Sci Pollut Res 29:28414–28430
Bayesteh M, Azari A (2021) Stochastic optimization of reservoir operation by applying hedging rules. J Water Resour Plan Manag 147(2):04020099
Blum C, Roli A (2003) Metaheuristics in combinational optimization: overview and conceptual comparison. ACM Comput Surv 35(3):268–308
Cao J, Lin Z, Huang GB (2012) Self-adaptive evolutionary extreme learning machine. Neural Proc Lett 36(3):285–305
Chang JF, Chen L, Chang CL (2005) Optimizing reservoir operating rule curves by genetic algorithms. Hydrol Process 19:2277–2289
Dag O, Yozgatligil C (2016) GMDH: an R package for short term forecasting via GMDH-type neural network algorithms. R J 8:379
Deb K, Pratap A, Agarwal S, Meyarivan T (2002) A fast and elitist multi-objective genetic algorithm: NSGA-II. IEEE Trans Evol Comput, Indian 6(2):182–197
Dodangeh E, Panahi M, Rezaie F, Lee S, Bui DT, Lee CW, Pradhan B (2020) Novel hybrid intelligence models for flood-susceptibility prediction: meta optimization of the GMDH and SVR models with the genetic algorithm and harmony search. J Hydrol 590:125423
Du J, Liu Y, Yu Y, Yan W (2017) A prediction of precipitation data based on support vector machine and particle swarm optimization (PSO-SVM) algorithms. Algorithms 10(57):1–15
Ebtehaj I, Bonakdari H, Zeynoddin M et al (2020) Evaluation of preprocessing techniques for improving the accuracy of stochastic rainfall forecast models. Int J Environ Sci Technol 17:505–524. https://doi.org/10.1007/s13762-019-02361-z
Elkurdy M, Binns AD, Bonakdari H, Gharabaghi B, McBean E (2021) Early detection of riverine flooding events using the group method of data handling for the Bow River, Alberta. Canada. Int. J. River Basin Manag 20(4):1–35. https://doi.org/10.1080/15715124.2021.1906261
Esmaeili F, Shabanlou S, Saadat M (2021) A wavelet-outlier robust extreme learning machine for rainfall forecasting in Ardabil City Iran. Earth Sci Inform 14:2087–2100
Fallahi MM, Shabanlou S, Rajabi A et al (2023) Effects of climate change on groundwater level variations affected by uncertainty (case study: Razan aquifer). Appl Water Sci 13:143
Gharib R, Heydari M, Kardar S et al (2020) Simulation of discharge coefficient of side weirs placed on convergent canals using modern self-adaptive extreme learning machine. Appl Water Sci 10:50
Goorani Z, Shabanlou S (2021) Multi-objective optimization of quantitative–qualitative operation of water resources systems with approach of supplying environmental demands of Shadegan Wetland. J Environ Manag 292(6):112769
Huang GB, Siew CK (2004) Extreme learning machine: RBF network case, In: Proceedings of the eighth international conference on control, automation, robotics and vision (ICARCV 2004), Kunming, China, 6–9 December, 2004
Huang GB, Zhu QY, Siew CK (2006) Extreme learning machine: theory and applications. Neurocomputing 70(1–3):489–501
Jalilian A, Heydari M, Azari A, Shabanlou S (2022) Extracting optimal rule curve of dam reservoir base on stochastic inflow. Water Resour Manag 36:1763–1782
Jian C, Qiang H, Min W (2005) Genetic algorithm for optimal dispatching. Water Resour Plan Manag 19:321–331
Kalita HM, Sarma AK, Bhattacharjya PK (2007) Evaluation of optimal river training work using GA based linked simulation-optimization approach. Water Resour Manag 28:2077–2092
Karamian F, Mirakzadeh AA, Azari A (2023) Application of multi-objective genetic algorithm for optimal combination of resources to achieve sustainable agriculture based on the water-energy-food nexus framework. Sci Total Environ 860:160419
Khani MC, Shabanlou S (2022) A robust evolutionary design of generalized structure group method of data handling to estimate discharge coefficient of side weir in trapezoidal channels. Iran J Sci Technol Trans Civ Eng 46:585–602. https://doi.org/10.1007/s40996-021-00594-y
Lei J, Quan Q, Li P, Yan D (2021) Research on monthly precipitation prediction based on the least square support vector machine with multi-factor integration. Atmosphere 12(8):1076
Lin JY, Cheng CT, Chau KW (2006) Using support vector machines for long-term discharge prediction. Hydrol Sci j Sci Hydrol 51(4):599–612
Madala HR, Ivakhenko AG (1994) Inductive learning algorithms for complex systems modeling. CRC Press Inc., Boca Raton
Malekzadeh M et al (2019a) A novel approach for prediction of monthly ground water level using a hybrid wavelet and non-tuned self-adaptive machine learning model. Water Resour Manag 33:1609–1628
Malekzadeh M, Kardar S, Shabanlou S (2019b) Simulation of groundwater level using MODFLOW, extreme learning machine and wavelet-extreme learning machine models. Groundw Sustain Dev 9:100279. https://doi.org/10.1016/j.gsd.2019.100279
Mallick M, Mohanta A, Kumar A, Charan Patra K (2020) Prediction of wind-induced mean pressure coefficients using GMDH neural network. J Aerosp Eng 33:04019104
Mazraeh A, Bagherifar M, Shabanlou S, Ekhlasmand R (2023) A hybrid machine learning model for modeling nitrate concentration in water sources. Water Air Soil Pollut 234(11):1–22
Mazraeh A, Bagherifar M, Shabanlou S, Ekhlasmand R (2024) A novel committee-based framework for modeling groundwater level fluctuations: a combination of mathematical and machine learning models using the weighted multi-model ensemble mean algorithm. Groundw Sustain Dev 24:101062. https://doi.org/10.1016/j.gsd.2023.101062
Miri S, Davoodi SM, Darvanjooghi MHK, Brar SK, Rouissi T, Martel R (2021) Precision modelling of co-metabolic biodegradation of recalcitrant aromatic hydrocarbons in conjunction with experimental data. Process Biochem. https://doi.org/10.1016/j.procbio.2021.03.026
Moghadam RG, Yaghoubi B, Rajabi A et al (2022) Evaluation of discharge coefficient of triangular side orifices by using regularized extreme learning machine. Appl Water Sci 12:145
Mohammed KS, Shabanlou S, Rajabi A et al (2023) Prediction of groundwater level fluctuations using artificial intelligence-based models and GMS. Appl Water Sci 13:54. https://doi.org/10.1007/s13201-022-01861-7
Momtahen Sh, Dariane AB (2007) Direct search approaches using genetic algorithms for optimization of water reservoir operating policies. Water Resour Plan Manag, ASCE 133(3):202–209
Naderpour H, Eidgahee DR, Fakharian P, Rafiean AH, Kalantari SM (2020) A new proposed approach for moment capacity estimation of ferrocement members using group method of data handling. Eng Sci Technol Int J 23(2):382–391. https://doi.org/10.1016/j.jestch.2019.05.013
Nicklow J, Reed P, Savic D, Dessalegne T, Harrell L, Chan-Hilton A, Karamouz M, Minsker B, Ostfeld A, Singh A, Zechman E (2010) State of the art for genetic algorithms and beyond in water resources planning and management. J Water Resour Plan Manag 136:412–432
NourmohammadiDehbalaei F, Azari A, Akhtari AA (2023) Development of a linear–nonlinear hybrid special model to predict monthly runof in a catchment area and evaluate its performance with novel machine learning methods. Appl Water Sci 13(5):1–23
Park D, Cha J, Kim M, Go JS (2020) Multi-objective optimization and comparison of surrogate models for separation performances of cyclone separator based on CFD, RSM, GMDH-neural network, back propagation-ANN and genetic algorithm. Eng Appl Comput Fluid Mech 14:180–201
Poursaeid M, Mastouri R, Shabanlou S, Najarchi M (2020) Estimation of total dissolved solids, electrical conductivity, salinity and groundwater levels using novel learning machines. Environ Earth Sci 79:453
Poursaeid M, Mastouri R, Shabanlou S, Najarchi M (2021) Modelling qualitative and quantitative parameters of groundwater using a new wavelet conjunction heuristic method: wavelet extreme learning machine versus wavelet neural networks. Water Environ 35:67–83
Poursaeid M, Poursaeid AH, Shabanlou SA (2022) comparative study of artificial intelligence models and a statistical method for groundwater level prediction. Water Resour Manag. https://doi.org/10.1007/s11269-022-03070-y
Rayegani F, Onwubolu GC (2014) Fused deposition modelling (FDM) process parameter prediction and optimization using group method for data handling (GMDH) and differential evolution (DE). Int J Adv Manuf Technol 23:509–519
Rezaei F, Safavi HR (2020) f-MOPSO/Div: an improved extreme-point-based multi-objective PSO algorithm applied to a socio-economic-environmental conjunctive water use problem. Environ Monit Assess 192(12):767
Shabanlou S (2018) Improvement of extreme learning machine using self-adaptive evolutionary algorithm for estimating discharge capacity of sharp-crested weirs located on the end of circular channels. Flow Meas Instrum 59:63–71
Shahbazbeygi E, Yosefvand F, Yaghoubi B et al (2021) Generalized structure of group method of data handling to prognosticate scour around various cross-vane structures. Arab J Geosci 14:1121
Soltani K, Azari A (2022) Forecasting groundwater anomaly in the future using satellite information and machine learning. J Hydrol 612(2):128052
Soltani K, Azari A (2023) Terrestrial water storage anomaly estimating using machine learning techniques and satellite-based data (a case study of Lake Urmia Basin). Irrig Drain 72(4):215–229
Soltani K, Ebtehaj I, Amiri A, Azari A, Gharabaghi B, Bonakdari H (2021) Mapping the spatial and temporal variability of flood susceptibility using remotely sensed normalized difference vegetation index and the forecasted changes in the future. Sci Total Environ 770:145288
Stepashko V, Bulgakova O, Zosimov V (2017) Construction and research of the generalized iterative GMDH algorithm with active neurons. In: Conference on computer science and information technologies (pp 492–510). Springer, Cham
Su J, Wang X, Liang Y, Chen B (2014) GA-based support vector machine model for the prediction of monthly reservoir storage. J Hydrol Eng 19(7):1430–1437
Tennant DL (1976) Instream flow regimens for fish, wildlife, recreation and related environmental resources. Fisheries 1(4):6–10
Yang J, Zhang Y (2011) Alternating approximation algorithms for l1-problems in compress sensing. SIAM J Sci Comput 33(1):250–278
Yosefvand F, Shabanlou S (2020) Forecasting of groundwater level using ensemble hybrid wavelet—self-adaptive extreme learning machine-based models. Nat Resour Res 29:3215–3232
Zaji AH, Bonakdari H, Gharabaghi B (2018) Reservoir water level forecasting using group method of data handling. Acta Geophys 66:717–730
Zarei N, Azari A, Heidari MM (2022) Improvement of the performance of NSGA-II and MOPSO algorithms in multi-objective optimization of urban water distribution networks based on modification of decision space. Appl Water Sci 12(133):1–12
Zeinali M, Azari A, Heidari M (2020) Multiobjective optimization for water resource management in low-flow areas based on a coupled surface water-groundwater model. J Water Resour Plan Manag (ASCE) 146(5):04020020
Zeynoddin M, Bonakdari H, Azari A, Ebtehaj I, Gharabaghi B, Madavar HR (2018) Novel hybrid linear stochastic with non-linear extreme learning machine methods for forecasting monthly rainfall a tropical climate. J Environ Manag 222:190–206
Zeynoddin M, Bonakdari H, Ebtehaj I, Azari A, Gharabaghi B (2020) A generalized linear stochastic model for lake level prediction. Sci Total Environ 723:138015. https://doi.org/10.1016/j.scitotenv.2020.138015
Zhang K, Luo M (2015) Outlier-robust extreme learning machine for regression problems. Neurocomputing 151:1
Funding
The authors received no specific funding for this work.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection, and analysis were performed by SM, HF, ANS, MA, and AA. The first draft of the manuscript was written by HF and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
All authors approve principles of ethical and professional conduct.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mansouri, S., Fathian, H., Nikbakht Shahbazi, A. et al. Optimal operation of the dam reservoir in real time based on generalized structure of group method of data handling and optimization technique. Appl Water Sci 14, 105 (2024). https://doi.org/10.1007/s13201-024-02159-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13201-024-02159-6