
Abstract
Accurately and effectively predicting the quantity of water inrush from the roof of coal mines is important for the safety of coal mine production. There is a complex and nonlinear relationship between the water inrush quantities from the coal roof and its influencing factors. To improve the precision and reliability in predicting the water inrush quantity, this paper establishes a water inrush quantity quantitative prediction model for coal seam roof aquifers based on the partial least squares regression (PLSR) and radial basis function (RBF) neural network coupling methods. First, the influencing factors of the coal roof water inrush quantity in the study area are determined, and then PLSR is used to reduce the dimensions of the original data by extracting the principal components with the best interpretation function for the system. The principal components are then used as input to the RBF neural network to model and predict the coal roof water inrush quantity, which effectively overcomes the multicollinearity problem between variables, optimizes the network structure, and improves the learning efficiency and robustness of the network. Finally, the reliability of the method is verified through simulation testing and comparison with other prediction methods. The results show that: compared with the PLSR model, the multiple linear regression (MLR) model, the RBF neural network model, the SVM model, and the FA-RBF neural network model, the fitting and prediction capabilities of the coal roof water inrush quantity prediction model based on the PLSR and the RBF neural network are better than the other models. The average absolute error of fitting of this model is 6.07E-4 m3/h, and the average relative error of fitting is 6.07E-3%; the average absolute error and the average relative error of prediction of this model for new samples are 1.9967 m3/h and 9.8730% respectively. The model combines the unique advantages of the PLSR and the RBF neural network and can deal with the correlation and nonlinear problems between variables, which is very practicable and provides a new way for predicting water inrush quantities from coal roofs.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
As China's main energy source, coal plays a crucial role in energy structure (Li et al. 2018; Zeng et al. 2018). In recent years, due to the application of comprehensive mechanized coal mining technology, as well as an increase in the scale of mining, mining depth, and mining intensity, the problem of water inrush from the roof of the coal mines has become ever more serious ( LaMoreaux et al. 2014; Xu et al. 2018; Yin et al. 2018, 2019). Roof water inrush accidents caused a large number of casualties and huge economic losses, which seriously affected and restricted safe production in the coal industry (Shi et al. 2017; Zhang and Yang 2018; Ju and Hu 2021). Effective water inrush prediction is an important tool to curb frequent water inrush accidents in coal mines by guiding the mine in taking preventive measures to ensure safe production and the safety of employees. It can also be used to accurately predict the water inrush quantity once a water inrush accident occurs in a mine (Qin et al. 2013). Fast and accurate methods for predicting the water inrush quantities in coal mines are therefore very important to mine safety.
The occurrence of water inrush from the roof and floor of the coal seam is the result of the joint action of multiple factors (Liu et al. 2021; Zhang and Yang 2021), and the factors that affect the water inrush quantity are complex, non-linear, and uncertain. The quantitative prediction of the water inrush quantities in mines is, therefore, a very complex and non-linear dynamic problem and there are certain difficulties in prediction (Xiao et al. 2012; Qin et al. 2013; Liu and Li 2019). At present, the prediction and analysis of mine water inrush are mostly limited to qualitative research, and finally, get the grade division of the water inrush quantity in mines. Most of these studies analyze water inrush from the coal floor, while there is limited quantitative research on the actual water inrush quantities from coal roofs (Cao and Zhao 2011). The methods for predicting water inrush from mine floor mainly include multiple linear regression (Gong et al. 2012), support vector machine (SVM) (Gao and Wang 2012; Ma et al. 2018), distance discriminant analysis theory (Chen et al. 2009), multiple information fusion methods (Han et al. 2009), and back propagation (BP) neural network prediction (Yang et al. 2013). Although the above methods have achieved good prediction results, due to the complexity and uncertainty of the mine water inrush problem, as well as the nonlinear and fuzzy relationship between the water inrush influencing factors and the water inrush quantity, these methods have certain limitations (Jiang and Liang 2005; Cheng et al. 2014). For example, the multiple linear regression model sometimes does not provide a satisfactory fit, resulting in low prediction accuracy (Chen et al. 2005). The blind selection of model parameters in the training process is problematic when the SVM model is used to predict the water inrush quantity alone (Gao and Wang 2012), and compared with neural network algorithms, there are no special advantages in its prediction accuracy (Wei et al. 2015). BP neural networks require more stringent modeling conditions, it is difficult to determine the network structure, it has parameters that must be adjusted, has a slow learning speed, and easily fall into local minimums and fail to obtain a globally optimal solution (Wu et al. 2017). The radial basis function (RBF) neural network is a typical forward modeling neural network (Liang et al. 2020). Because it has the characteristics of the only best approximation, no local minimum problem, simple structure, convenient training, and fast convergence speed of the learning process, it overcomes the above shortcomings of a BP network. It can approximate any nonlinear continuous function with high precision, and can better reveal the actual structure of a complex nonlinear system (Chen et al. 2010; Dai et al. 2014; Wu et al. 2017). It is therefore a suitable tool to analyze and predict water inrush quantities from the roof and floor of coal seams. In addition, the mine roof water inrush is affected by many factors such as geological structural conditions, hydrogeological conditions, and mining activities (Liu et al. 2021), and it is therefore almost impossible to comprehensively and accurately consider the impact of all the different factors. The multi-variable model proposed for some of the main influencing factors will inevitably be affected by overlapping information (Liu and Liang 2011) because there are often multicollinearity problems among the various factors, which will exaggerate the position of some factors in the system analysis. This will result in a less objective analysis, which is not conducive to the correct judgment of the model, and will affect the accuracy of prediction results. At the same time, due to the high-dimensional complexity brought about by multiple factors, the structure of the prediction model will be very large and the calculation process will be very complicated. To solve these problems, previous studies have introduced principal component analysis (PCA) and factor analysis (FA) methods with strong data compression capabilities (Liu and Liang 2011; Wen et al. 2017), but PCA and FA do not consider dependent variables at all during its component extraction, and only consider independent variables. Although the components obtained in this way have strong generalizability for the independent variable system, they lack the explanatory ability for the dependent variable. PLSR is superior to PCA and FA in this respect, in that it considers the influence of independent variables and dependent variables during principal component extraction. This method integrates the advantages of multiple linear regression, principal component analysis and canonical correlation analysis (Gong 2021). The best interpretation function for the system is extracted by decomposing and filtering data and information from the variable system to reduce the dimensions of the multidimensional data space, eliminate the noise interference in the system, and effectively solve the modeling problems such as serious multicollinearity between independent variables, the availability of a small number of samples, and model instability (Yan et al. 2021).
Given the above, to accurately and quantitatively predict the water inrush quantity of coal seam roof aquifer, this paper proposes a water inrush quantity quantitative prediction model based on the coupling of the PLSR and the RBF neural networks, explaining their respective advantages, aiming to improve the model prediction speed and accuracy while improving the generalizability of the model. Firstly, the influencing factors of the water inrush quantity from the coal seam roof were analyzed and selected, and the original data was reduced by PLSR to extract several components which can best describe the system. The extracted components were then used as input to the RBF neural network to model and predict water inrush quantities from the coal seam roof. Finally, the reliability of the method was verified by the simulation test and a comparison with various other prediction methods.
Materials and methods
Overview of the study area
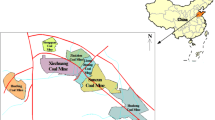
The Xuzhuang Coal Mine is located close to Datun Town, Pei County, Jiangsu Province, and Xiping Town, Weishan County, Shandong Province, China (see Fig. 1a). The mining area is about 10.0 km long from east to west and 3.84 km wide from north to south, with an area of about 38.4 km2. The coal-bearing strata in the mining area include the Taiyuan Formation, the Shanxi Formation, and the Xiashihezi Formation, which contains more than 20 layers of coal that has an average total thickness of about 13.43 m. There are four minable coal seams, of which No.7 coal seam with an average thickness of 4.87 m (variable between 1.13 m ~ 7.97 m) is the main coal seam in the Xuzhuang Coal Mine. At present, the No. 7 and No. 8 coal seams of the Shanxi Formation have been mined at the − 400 m level. In the eastern part, mining has begun at the − 750 m level, while the west is still being developed. The mine area is located in the central-southern part of the Tengpei synclinorium. Most of the area is a monoclinic structure with a strike 45°N ~ 70°E and a northwestern slope, with a dip angle of 10° ~ 36°. According to the actual measurement data revealed by exploration and mining, the fault structure in the mining area is relatively developed. There are more than 400 faults with a drop of ≥ 2 m, of which there are 209 faults with a drop of ≥ 5 m, 149 faults with a drop of 5 m ~ 20 m, and 60 faults with a drop of ≥ 20 m. Due to the influence of multiple tectonic movements, many folds have developed in the central and western parts of the mining area. The eastern part of the mining area is not well developed, with only a few obvious wide and gentle folds, small folds, and fault drag folds. The fold types are medium. The structural outline of the Xuzhuang Coal Mine is shown in Fig. 1b. From top to bottom, the main aquifers in the mining area include the pore aquifer of the bottom sand layer of the Quaternary system, the bottom conglomerate aquifer of the Lower Cretaceous-Upper Jurassic system, the bottom sandstone aquifer of the Lower Shihezi Formation of the lower Permian system, the sandstone aquifer of the coal seam roof of the Shanxi Formation of the lower Permian system (see Fig. 1c), the limestone of the Taiyuan Formation of the upper Carboniferous system and the karst limestone aquifer of the thick limestone of the Ordovician system. Among them, the No.7 coal seam roof sandstone aquifer is the direct source of water for the No.7 coal seam, which greatly impacts the safe mining of the No.7 coal seam. The comprehensive histogram of the roof of the No.7 coal seam is shown in Fig. 1d. Since the mine was put into operation, many roof water inrush accidents have occurred, and the high frequency of water inrushes into the No.7 coal seam roof has seriously threatened the safe production of the mine. It is very important to accurately predict the water inrush quantities of the No. 7 coal seam roof sandstone aquifer to ensure safe mining.

The location of the Xuzhuang Coal Mine, the outline of the geological structure, the profile of the exploration line and the comprehensive histogram of the roof of the No. 7 coal seam
Data source and index selection
Water inrush from the coal roof of a mine is a very complex systemic problem influenced by many factors, including hydrogeological conditions (such as aquifer thickness), geological conditions (such as faults, fold structures, and the development of cracks in the roof overlying rock), mining conditions (such as mining depth) and other aspects. Of them, the geological structure is the main factor controlling roof water inrush (Cheng et al. 2021). The geological fault structure not only destroys the integrity of the roof, but also reduces the strength of the rock mass, weakening the resistance of the roof aquiclude to deformation, and leading to the formation of fault fracture zones. The displacement of the upper and lower walls of the fault zone shortens the distance between the aquifer and the coal seam, which causes part of the aquifuge to lose its water resistance, causing water inrush accidents (Das et al. 2018; Wang et al. 2021). In the axial part of the fold (syncline or anticline), the stratum is subject to strong tensile or extrusion pressures, and the fractures are often quite developed, which not only means good aquifer storativity but also serves as pathways for water transport. The existence of an aquifer above the coal roof is a prerequisite for coal roof water inrush (Zhang and Yang 2018). A thick aquifer is usually water-rich and can store and transport large volumes of groundwater. The thicker the aquifer, the more water it can store leading to greater water inrush quantities once the coal roof is breached (Zeng et al. 2018; Zhang et al. 2021a). The sandstone-mudstone ratio mainly used to characterize the sedimentary facies of regional geological strata, and describes the relative content of sandstone and mudstone in the strata. If the sandstone content of the strata is large, the storativity and permeability of the aquifer are better, and the thinner the water barrier within the coal roof, the greater the risk of water inrush (Zeng et al. 2018). The drilling core recovery rate of the roof is an index reflecting the degree of rock fragmentation and the degree of rock fracture intersections (Zhang et al. 2021a). The lower the drilling core recovery rate of the roof, the poorer the rock integrity of the roof (Zeng et al. 2018). Coupled with the more sandstone fractures and larger storativity, this leads to greater water inrush quantities upon breaching of the roof (Wu et al. 2016; Ji 2019). Drilling fluid consumption is an important parameter reflecting the permeability of the rock formation (Liu and Li 2019). When the borehole passes through the aquifer, the drilling fluid will be consumed to a certain extent. If the drilling fluid consumption is large, it indicates that the degree of connectivity between fractures in the rock stratum is better, the permeability coefficient is larger, and the aquifer contains large volumes of water (Wu et al. 2016; Zeng et al. 2018). Mining depth plays an important role in the original stress state of the coal seam and its roof and floor strata. Within a certain range, mining depth has a great influence on the change in mine pressure and also has a certain influence on the development height of water flowing fractured zone (Hu et al. 2012; Gao et al. 2018), which affects the occurrence of water inrush accidents.
Taking into account the adaptability, accuracy, conciseness, and desirability of the factor indicators, the drilling core recovery rate of the roof, the drilling fluid consumption, the aquifer thickness, the sandstone-mudstone ratio, the fault fractal dimension, the fold plane deformation coefficient, the fault strength, and the mining depth were selected as the main factors affecting the water inrush quantity from the roof aquifer of the No. 7 coal seam in Xuzhuang Coal Mine. They are represented by X1, X2, X3, X4, X5, X6, X7, X8, respectively. Based on the actual water inrush data of the mine, 24 groups of typical water inrush cases were selected to predict and analyze the water inrush quantity from the roof aquifer of No. 7 coal seam, and the training samples (No. 1–21) and simulation samples (No. 22–24) are randomly determined according to the principle of 7:1, as shown in Table 1
Research methods
Partial least squares regression analysis
The Partial least squares regression method is a widely applied multivariate statistical analysis method, similar to principal component analysis, canonical correlation analysis, and linear regression analysis. It can effectively solve the problem of multiple collinear variables (Gong 2021). PLSR adopts the method of component extraction but differs from the traditional PCA. The PLSR method reorganizes information instead of removing variables. When extracting variables, the linear relationship between the dependent variable and the independent variable is considered, the comprehensive variable with the strongest explanatory effect on the independent variable and the dependent variable is selected, and noise interference is eliminated. Therefore, it not only ensures the elimination of the multicollinearity problem but also ensures the stability of the model (Yan et al. 2021). The principle is as follows:
Suppose there are \(q\) dependent variables \(\left\{ {y_{1} ,y_{2} , \cdots ,y_{q} } \right\}\) and \(p\) independent variables \(\left\{ {x_{1} ,x_{2} , \cdots ,x_{p} } \right\}\). To study the statistical relationship between the dependent variable and the independent variable, \(n\) sample points are observed, which constitute the data tables \(X = \left\{ {x_{1} ,x_{2} , \cdots ,x_{p} } \right\}_{n \times p}\) and \(Y = \left\{ {y_{1} ,y_{2} , \cdots ,y_{q} } \right\}_{n \times q}\) of independent variables and dependent variables. PLSR extracts components \(t_{1}\) and \(u_{1}\) from X and Y respectively. To meet the needs of regression analysis, \(t_{1}\) and \(u_{1}\) should carry as much of the variation information in their respective data tables as possible and the correlation between \(t_{1}\) and \(u_{1}\) should be maximized. After the first component is extracted, PLSR implements the regression of X to \(t_{1}\) and the regression of Y to \(u_{1}\) respectively. If the regression equation has reached a satisfactory accuracy, the algorithm terminates; otherwise, the residual information after X that is explained by \(t_{1}\) and the residual information after Y that is explained by \(u_{1}\) will be used for the second round of component extraction. This process is repeated until a satisfactory accuracy is achieved.
If \(h\) components \(t_{1} ,t_{2} , \cdots ,t_{h}\) are finally extracted from X, PLSR will perform the regression of \(y_{k} (k = 1, \, 2, \, \cdots , \, q)\) on \(t_{1} ,t_{2} , \cdots ,t_{h}\), and then express it as the regression equation of \(y_{k}\) on the original independent variable \(x_{1} ,x_{2} , \cdots ,x_{p}\) (Shi et al. 2013; Wang et al. 2014). Based on the number of dependent variables, partial least squares regression analysis can be divided into multiple dependent variable partial least squares regression analysis and single dependent variable partial least squares regression analysis. In this study, only partial least squares regression analysis of single dependent variables is performed, and the specific modeling steps are as follows (Wang et al. 2014; Gong 2021):
-
(1)
To eliminate the influence of different dimensions of input parameters on the calculation results, the original data are standardized according to formula (1), and the standardized dependent variable matrix \(F_{0}\) and independent variable matrix \(E_{0}\) are obtained, which are recorded as, \(F_{0} = Y,E_{0} = X\) respectively.
$$ \hat{z}_{ij} = \frac{{z_{ij} - \overline{z}_{j} }}{{S_{j} }}(i = 1,2, \cdots ,n;j = 1,2, \cdots ,p) $$(1)where \(z_{ij}\) is the actual value of the sample;\(\overline{z}\) is the mean value of the sample \(z_{j}\); \(S_{j}\) is the standard deviation of the sample \(z_{j}\); \(\hat{z}\) is the standardized sample value.
-
(2)
Extraction of the first component \(t_{1}\)
It is known that \(F_{0}\) and \(E_{0}\) can be used to extract the first component \(t_{1}\),\(t_{1} = E_{0} W_{1}\), where \(W_{1}\) is the first axis of \(E_{0}\), which is the combination coefficient and \(\left\| {W_{1} } \right\| = 1\). At the same time, the first component \(u_{1}\) is extracted from \(F_{0}\) to meet \(u_{1} = F_{0} C_{1}\), where \(C_{1}\) is the first axis of \(F_{0}\) and \(\left\| {C_{1} } \right\| = 1\).
Here it is required that \(t_{1}\) and \(u_{1}\) should better express the data variation information in X and Y respectively, and \(t_{1}\) can better explain \(u_{1}\). In the principal component analysis and canonical correlation analysis, these conditions can be satisfied by taking \(W_{1} = E_{0}^{T} F_{0} /\left\| {E_{0}^{T} F_{0} } \right\|\). After \(W_{1}\) is obtained, the component \(t_{1}\) can be obtained, and the regression equations of \(E_{0}\) and \(F_{0}\) to \(t_{1}\) are respectively calculated as:
where \(p_{1} = E_{0}^{T} t_{1} /\left\| {t_{1} } \right\|^{2}\), vector \(r_{1} = F_{0}^{T} /\left\| {t_{1} } \right\|^{2}\), and \(E_{1}\) and \(F_{1}\) are the residual matrix of the regression equation.
-
(3)
Extraction of the second component \(t_{2}\)
Here \(E_{1}\) is substituted for \(E_{0}\) and \(F_{1}\) for \(F_{0}\). The above method is used to find the second axis \(W_{2}\) and the second component \(t_{2}\), then \(W_{2} = E_{1}^{T} F_{1} /\left\| {E_{1}^{T} F_{1} } \right\|,t_{2} = E_{1} W_{1}\). Similarly, \(E_{1}\) and \(F_{1}\) are regressed to \(t_{2}\) and \(E_{1} = t_{2} p_{2}^{T} + E_{2} ,F_{1} = t_{2} r_{2} + F_{2}\) are obtained.
The same applies to the extraction of the \(hth\) component. The number can be identified by the principle of cross-validity, and \(h\) is less than the rank of X.
-
(4) Cross-validity principle
The principle of cross validity is used to determine the number of extracted components \(h\) for modeling. Recorded as the original data as \(y_{i} (i = 1,2, \ldots ,n)\), \(\hat{y}_{hi}\) is the fitting value of the \(ith\) sample after modeling using all the samples and extracting the component \(t_{1}\), then the sum of squared fitting errors of \(\hat{y}_{hi}\) is \(SS_{h} = \sum\nolimits_{i = 1}^{n} {(y_{i} - \hat{y}_{hi} )^{2} }\). If \(\hat{y}_{h( - i)}\) is the fitting value of \(y_{i}\) calculated after deleting the sample point \(i\) during modeling and extracting the component \(t_{1}\) after regression modeling, then the sum of squared fitting errors \(y_{i}\) is \(PRESS_{h} = \sum\nolimits_{i = 1}^{n} {(y_{i} - \hat{y}_{h( - i)} )^{2} }\).
If the error of the regression equation is large, \(PRESS_{h}\) will be very sensitive to changes in the sample points, and its value will increase. Therefore, when \(PRESS_{h}\) reaches the minimum value, the corresponding \(h\) is the number of components. Generally, \(PRESS_{h}\) is greater than \(SS_{h}\), and \(SS_{h}\) is less than \(SS_{h - 1}\). Therefore, when extracting components, it is always hoped that the ratio \(PRESS_{h} /SS_{h}\) is as small as possible. Generally, the limit value can be set to 0.05, that is, when \(PRESS_{h} /SS_{h - 1} \le (1 - 0.05)^{2} = 0.95^{2}\), increasing the component \(t_{h}\) is beneficial and improves the accuracy of the model. The cross-validity of the component \(t_{h}\) is defined as \(Q_{h}^{2} = 1 - PRESS_{h} /SS_{h - 1}\) so that the cross-validity test is performed before the calculation of each step of PLSR modeling. If \(Q_{h}^{2} < (1 - 0.95^{2} ) = 0.0975\) in the \(hth\) step, the model has reached the accuracy requirement and the component extraction can be stopped. If \(Q_{h}^{2} \ge 0.0975\), it means that the marginal contribution of the component \(t_{h}\) extracted in step \(h\) is significant, and the calculation of the component extracted in step \(h + 1\) should be continued (Gong 2021).
-
(5) Establish a partial least squares regression model
Based on the above analysis, a partial least squares regression model can be obtained, as shown in formula (3).
Where \(W = \left[ {W_{1} ,W_{2} , \cdots ,W_{h} } \right],R = \left[ {r_{1} ,r_{2} , \cdots ,r_{h} } \right]\), \(F_{2}\) is the residual matrix.
Radial basis function neural network analysis
The Radial basis function neural network is an efficient feedforward neural network designed by using a multivariate interpolation radial basis function. It transforms the low-dimensional input vector into the high-dimensional space so that the linear inseparability in the low-dimensional space becomes linearly separable in the high-dimensional space. Therefore, it can approximate various nonlinear continuous functions with high precision and has the best approximation performance and global optimal characteristics compared to other forward networks (Kou and Zhang 2015; Su et al. 2020; Zhang et al. 2020; Tao et al. 2021). There is also no need for the data to conform to the normal distribution characteristics, and there are few prior knowledge requirements for the modeling of an object. Generally, it is not necessary to have knowledge about the structure, parameters, and dynamic characteristics of the object for it to be modeled in advance. Only input and output data of the object must be provided, and the input and output can be fully consistent through the self-learning function of the network itself, which avoids the complex algorithm to complete the calculation and prediction accurately (Tong et al. 2013; Zheng et al. 2013). This makes RBF suitable for the prediction of water inrush quantities from coal seam roofs.
The RBF neural network consists of three layers, and its network topology is shown in Fig. 2. The first layer is the input layer, which is composed of input nodes connected to the external environment and only transmits the input signal to the second linear layer, which is hidden. The second layer is composed of radial basis functions (such as Gaussian functions) to complete the nonlinear change from the input space to the hidden layer. In most applications, the hidden layer space is high-dimensional, and the entire RBF neural network has only one hidden layer. The third layer is the output layer and the nodes of the output layer are usually simple linear functions that respond to excitation patterns or signals added to the entire network (Peng et al. 2020; Montoya-Chairez et al. 2021; Yang et al. 2021).

Topological structure diagram of RBF neural network
The activation function of the hidden layer node in the RBF neural network is a radial basis function, and the distance between the input vector and the node center is used as an independent variable, and the input vector is directly mapped to the hidden layer. The action function of the output layer node is linear, and the output information of the hidden layer node is linearly weighted and then output is given. Because the Gaussian function has the advantages of rotational symmetry, good practicability, simple form, and existing any order derivative, and its local response characteristics are very consistent with the RBF neural network, the Gaussian function is often used as the basis function of the RBF neural network. The general expression of the Gaussian function is shown in formula (4) ( Peng et al. 2020).
where \(\left\| * \right\|\) is the European paradigm and \(\sigma\) is the variance of Gaussian function.
When the number of neurons in the hidden layer is large enough, it can approximate any n-element continuous function, and when the network is fully trained, a highly accurate fitting result can be obtained (Zhang et al. 2021b). During RBF neural network training, it is necessary to find the center vector and standardization constant of the Gaussian function according to the location distribution of the data. Finally, after the weight learning stage, the recursive least squares method is used to obtain the weight value matrix of the output layer after the hidden layer parameters are determined. The output function is shown in formula (5) (Guan et al. 2021).
where Y is the output variable; \(x_{i}\) is the input variable; \(c_{i}\) is the center of the Gaussian function; \(m\) is the number of variables; \(f(x_{i} - c_{i} )\) is the basis function; \(\varepsilon_{i}\) is the weight from the hidden layer node to the output layer.
Partial least squares regression- radial basis function neural network algorithm
Considering the relationship between multiple influencing factors, adopting appropriate forecasting methods is important for optimizing forecasting accuracy and operational efficiency. Based on the PLSR-RBF neural network coupling method, a data fusion model that integrates the PLSR and RBF neural networks are constructed to address the fact that the original data has many dimensions and is difficult to handle simultaneously. Firstly, PLSR is used to reduce the dimensionality of the original data. By refining and condensing the useful information in the original data, several components that best describe the system, are extracted. These components not only contain most of the useful information but also eliminate the noise and useless information in the original data. The extracted components are then used as the input data of the RBF neural network to establish a suitable neural network structure through learning and training and calculate the predicted result value.
PLSR reduces the dimensionality of the original data, eliminates the influence of multicollinearity between different factors, reduces the amount of data input into the RBF neural network, and also optimizes the structure of the determined neural network to ensure faster convergence speed, which increases the operability of the model simulation. The flow chart of the prediction model based on the PLSR-RBF neural network coupling method is shown in Fig. 3.

Flow chart of establishing PLSR-RBF neural network coupling model
Results and analysis
Correlation analysis
Selected water inrush data of 21 sets of training samples were used in the Origin 2021 software to analyze the correlation of the eight main control factors that affect the water inrush quantity, and draw the correlation heat map of the main controlling factors, as shown in Fig. 4. It can be seen from Fig. 3 that the Pearson correlation coefficients between the variables are not equal to 0, indicating that the variables have different degrees of correlation. For example, the correlations between X1 and X7, X8, between X3 and X4, between X7 and X4, between X6 and X5, and between X7 and X8 are all greater than 0.50. Among them, the maximum correlation coefficient between X3 and X4 is 0.93, indicating that there is a certain multicollinearity relationship between these variables, and the multicollinearity problem between independent variables may lead to instability of the prediction model (Yan et al. 2021). Therefore, to eliminate the mutual influence between the indicators, PLSR was used to eliminate the linear correlation between the variables.

Correlation heat map between main controlling factors
Extracting components using the PLSR method
After the original data of 21 sets of training samples were standardized according to formula (1), MATLAB software was used to carry out PLSR analysis on the calculation model \(Y = f(X_{1} ,X_{2} ,X_{3} ,X_{4} ,X_{5} ,X_{6} ,X_{7} ,X_{8} )\). Judging by the principle of cross-validity, when the two components are extracted, the accuracy requirements have been met at this time, that is, the two components \(t_{1}\) and \(t_{2}\) can be extracted. According to the aforementioned PLSR principle, \(t_{1}\) and \(t_{2}\) are orthogonal to each other, which eliminates the correlation or multicollinearity between the original data, and reduces the dimensionality of the independent variable from eight to two. At the same time, these two components also contain the information of the original data to the maximum extent. The expressions of the two components of \(t_{1}\) and \(t_{2}\) are shown in formula (6).
where \(\hat{X}_{1}\),\(\hat{X}_{2}\),\(\hat{X}_{3}\),\(\hat{X}_{4}\),\(\hat{X}_{5}\),\(\hat{X}_{6}\),\(\hat{X}_{7}\),\(\hat{X}_{8}\) are the standardized values of \(X_{1}\),\(X_{2}\),\(X_{3}\),\(X_{4}\),\(X_{5}\),\(X_{6}\),\(X_{7}\),\(X_{8}\) respectively.
PLSR is introduced in this study because the independent variables extracted by PLSR are those that best correlate with dependent variable Y. PLSR is also more accurate and stable than other principal component analysis methods when processing multicollinear, high redundancy, and multi-noise data. Therefore, PLSR is the first choice in dimension reduction (Chen et al. 2015). In this study, two independent variable components were extracted from eight factors that affect the water inrush quantity through PLSR analysis, and these two-component inputs were used to replace eight independent variable inputs in the subsequent RBF neural network model to achieve the optimized network.
Establishment of PLS-RBF neural network prediction model
Determine the network and training
The two components \(t_{1}\) and \(t_{2}\) extracted by PLSR were used as the input of the RBF neural network, expressed by the vector \(T = \left\{ {t_{1} ,t_{2} } \right\}\), \(\hat{Y}\) (standardized value of Y) as the output. An RBF neural network with two input neurons and one output neuron was established and the network was trained by using 21 groups of training samples. The radial basis function network is designed with newrb function by using MATLAB. When it is used as a function approximation, the hidden layer neurons of the radial basis function network can automatically be increased until the requirement of mean square error is reached (Chen et al. 2010). The format is shown in Eq. (7).
where \(net\) is the radial basis function network object; \(newrb\) is the radial basis function; \(input\) is the network input sample vector; \(output\) is the target vector; \(GOAL\) is the mean square error; \(SPREAD\) is the radial basis function distribution density; \(MN\) is the maximum number of neurons; and \(DF\) is the display frequency of the training process.
In this network training, \(GOAL\) is set to 0; \(MN\) is set to 30;\(DF\) is set to 2. After continuous experiments, when \(SPREAD\) is 0.20, the RBF neural network has the smallest error and the best approximation effect. The obtained RBF network training error curve is shown in Fig. 5. The mean square error of the target setting is 0, and the mean square error of actual network training is 8.03388e-33, and it is considered that the network error has reached the ideal requirements. At this time, after neural network training and testing, the predicted values of 21 groups of training samples are obtained. After de-standardization, the comparison between the measured values and the predicted values is made, as shown in Fig. 6. It can be seen from Fig. 6 that the predicted values of water inrush in the 21 groups of training sample data are very close to the actual values, and the errors between them are very small. The average relative error of the training set sample is 6.07E-3%, and the correlation coefficient of the linear fitting line between them is 1, which indicates that the fitting accuracy of the water inrush quantity prediction model based on the PLSR-RBF neural network is very high.

Trend of mean square error with the increase of the number of neurons

Comparison between the predicted value and the actual value of the training sample
Simulation test
To verify the prediction ability of the water inrush quantity prediction model of coal seam roof aquifer based on PLS and RBF neural network for new samples, the reserved three groups of test sample data were processed according to the principle of standardized processing of training sample data, and then substituted the standardized data into formula (6) to obtain two PLSR components \(\left\{ {t_{1} ,t_{2} } \right\}\) of each test sample, which were substituted into the trained PLSR-RBF neural network model for simulation prediction. Finally, the network output value of each test sample was de-standardized to obtain the water inrush quantity prediction value of the test sample. The results are shown in Table 2. It can be seen from Table 2 that the relative errors between the simulation sample data prediction results and the actual values are small, and the average relative error is 9.8730%, which is less than 10%, indicating that the model has a good prediction effect for new sample inputs.
Comparison among different prediction models
Comparison with other models' fitting ability
To further verify the model fitting accuracy of the water inrush quantity prediction model of coal seam roof aquifer based on the coupled PLS and RBF neural networks, based on 21 groups of training samples data, the multiple linear regression(MLR) model, the PLSR prediction model, the RBF neural network prediction model, the SVM prediction model and the FA-RBF neural network model were developed, and their model fitting results were compared with that of the PLS-RBF neural network prediction model. Among them, SVM is a machine learning method based on statistical learning theory. It realizes the minimization of empirical risk and confidence range, so as to obtain good statistical laws and generalization ability in the case of a small number of samples. For nonlinear mapping problems, it can be mapped to a high-dimensional feature space through a kernel function, and linear regression is performed on this nonlinear relationship in the high-dimensional feature space (Roushangar and Koosheh 2015; Dhiman et al. 2019). Because SVM has unique advantages in solving problems such as small samples, nonlinear and high-dimensional data analysis, they have been widely used in various prediction problems in many fields (Zhao and Wu 2018) and some scholars have used this method to predict the water inrush from coal seam floor (Qin et al. 2013; Ma et al. 2018). The results of various models are shown in Fig. 7. When evaluating the fitting of the prediction model, this study mainly considers the three indicators—the coefficient of determination (R2), the average absolute error, and the average relative error, as shown in Table 3. The absolute error is the difference between the predicted value and the true value. For the convenience of analysis, this study takes the absolute value of the difference between the predicted value and the true value.

Comparison of fitting results of the different models on training samples
It can be seen from Fig. 7 and Table 3 that between the six models, the PLSR prediction model and the multiple linear regression prediction model have the worst fit. Although the PLSR model can solve the multicollinearity problem between independent variables, like the linear analysis method used in the multiple linear regression analysis, it has a poor ability to deal with nonlinear problems. The SVM and the RBF neural network can effectively deal with nonlinear problems and have shown a better fit for nonlinear problems. The fit of the RBF neural network model is better than that of the SVM model, which reflects the advantages of the RBF neural network compared with the SVM. After implementing FA or PLSR analysis to reduce the dimensions of the original data, the redundant information between variables is eliminated, and the structure of the neural network is optimized, so that the fit of the FA-RBF neural network prediction model and PLSR-RBF neural network prediction model is better than that of the RBF neural network prediction model alone. The fitting accuracy of the FA-RBF neural network prediction model is further improved compared to that of the RBF neural network model alone, but the PLSR-RBF neural network prediction model is not further improved compared to the RBF neural network model in terms of fitting accuracy.
Comparison with other models' predictive ability
Because the established prediction model may have over the fitting phenomenon, that is, the prediction accuracy of the model near the training samples is very high, but the prediction accuracy of new samples is very low. Such a prediction model is not a good model that can be applied to solve practical problems. Therefore, judging the quality of a prediction model mainly depends on the prediction ability of the model for new samples (Chu et al. 2021). The ability of the coupled PLSR-RBF neural network model of the coal seam roof aquifer to predict water inrush quantities for new samples were further verified by processing the three reserved groups of simulation sample data according to the principle of training sample data standardization. Thereafter, the processed sample data were substituted into both the MLR prediction model, the PLSR prediction model, the RBF neural network prediction model, the SVM prediction model, and the FA-RBF neural network model. To further analyze the applicability and rationality of different methods, the prediction effects of the PLSR-RBF neural network model were compared with the other five models (see Table 4 and Fig. 8). This study mainly considered four indicators for evaluating the predictive ability of the PLSR-RBF neural network model, including the maximum absolute error, the average absolute error, the maximum relative error, and the average relative error(see Table 4).

Comparison of fitting results of the different models based on simulation samples
The prediction effect of the PLSR prediction model and the MLR prediction model are the worst of the six models (see Fig. 8, Table 4), which indicates that both of these methods are used as methods to deal with linear problems, and their predictive ability and fitting ability for non-linear problems are both poor. The RBF neural network model and the SVM model have almost the same predictive capabilities for new sample data, and both are significantly better than the PLSR prediction model and the MLR prediction model. This means that the RBF neural network model and the SVM model have better generalizability, but their predictive accuracy must still be improved compared with the FA-RBF neural network prediction model and the PLSR-RBF neural network prediction model after dimension reduction. The PLSR-RBF neural network prediction model has the highest prediction accuracy for new samples among the six models and this indicates that the PLSR-RBF neural network model has a strong generalization ability and high prediction accuracy, and it can be more practicable and accurate to predict the water inrush quantities of coal seam roof aquifers.
Discussion
Compared with other models, the PLSR-RBF neural network prediction model proposed in this paper has a good fitting ability for training samples, and more importantly, it shows better prediction accuracy for new samples. The reasons for this result may be due to three factors. First, the RBF neural network can approximate arbitrary nonlinear continuous functions with high precision, and can better reveal the actual structure of complex nonlinear systems. Second, the PLSR not only considers the generalizability of the independent variable system but also focuses on explaining dependent variables and the components that were extracted using the PLSR can better explain the whole system than the principal components that were extracted by FA. The application of PLSR effectively realizes the dimensionality reduction processing of high-dimensional data, eliminates noise interference, and effectively solves the problems of serious multicollinearity between independent variables. Third, the prediction model based on PLSR-RBF neural network proposed in this paper integrates the unique advantages of these two methods and it can not only eliminate the influence of repeated information among various influencing factors on the prediction results but also simplify the structure of the neural network model, which greatly improves the convergence speed, learning ability and prediction ability of the model. Therefore, from the perspective of obtaining a good model fit and the ability to make accurate predictions, the PLSR-RBF neural network model can reasonably effectively model water inrush quantities of coal seam roof aquifers and is very practicable.
In addition, although the PLSR-RBF neural network model can effectively handle the complex nonlinear coupling system required to model coal seam roof water inrushes, where water inrushes are affected by many factors (Liu and Li 2019), including hydrogeological conditions, geological structure, and mining conditions (Xiao et al. 2012; Qin et al. 2013; Liu et al. 2021). Therefore, it is necessary to comprehensively consider the various factors that affect the coal roof water inrush and their interrelationships, effectively use the existing geological and hydrological parameters, and analyze the potential changes in depth (Chen et al. 2021). This study was limited in that it only considered eight of these variables, and the number of modeling samples is relatively small. For the prediction accuracy of the model, the number of influencing factors selected and the richness and reliability of data resources will have impact on the accuracy of the prediction results. As many variables as possible and more sample data would be considered in the future to further improve the prediction ability of the PLSR-RBF model, so that it can predict coal seam roof water inrush quantities more accurately.
Conclusions
Based on the geological and hydrogeological conditions of the Xuzhuang Coal Mine, a quantitative prediction model of the water inrush quantities from the coal seam roof based on PLSR and RBF neural network was proposed in this study. Through this study, the following conclusions can be obtained:
-
(1)
Water inrushes from coal seam roofs are the result of many complex and nonlinear factors. In this study, the drilling core recovery rate of the roof, the drilling fluid consumption, the aquifer thickness, the sandstone-mudstone ratio, the fault fractal dimension, the fold plane deformation coefficient, the fault strength, and the mining depth were the main factors that controlled the water inrush quantity from the roof aquifer of the No. 7 coal seam in the Xuzhuang Coal Mine. Correlation analysis showed that there is certain multicollinearity among the independent variables which will make prediction models unstable.
-
(2)
The PLSR and RBF neural networks were used to develop a prediction model of the water inrush quantities from coal seam roof. PLSR was used to extract two main variables from the eight independent variables which strongly explain the water inrush quantities. These two variables were then used as an input layer to the RBF neural network, which reduced the input dimensions of the RBF neural network and optimized the network structure.
-
(3)
Compared with the PLSR model, the MLR model, the RBF neural network model, the SVM model, and the FA-RBF neural network model, the coupled PLSR-RBF neural network prediction model of coal seam roof water inrush has better fitting accuracy and the best prediction accuracy. The average absolute error of fitting of this model is 6.07E-4 m3/h, and the average relative error of fitting is 6.07E-3%; while the average absolute error of prediction of this model for new samples is 1.9967 m3/h, and the average relative error of prediction for new samples is 9.873%, which is less than 10%.
-
(4)
This model not only solves the multicollinearity problem among multiple variables but also improves the stability and prediction accuracy of the model while avoiding the phenomenon of overfitting. It has good engineering application value and can meet the needs of the water inrush quantity quantitative prediction of coal seam roof aquifer.
References
Cao QK, Zhao F (2011) Forecast of water inrush quantity from coal floor based on genetic algorithm-support vector regression. J Chin Coal Soc 36(12):2097–2101. https://doi.org/10.13225/j.cnki.jccs.2011.12.026
Chen JP, Wang CL, Wang XD (2021) Coal mine floor water inrush prediction based on CNN neural network. Chin J Geol Hazard Control 32(01):50–57. https://doi.org/10.16031/j.cnki.issn.1003-8035.2021.01.07
Chen G, Yang ZQ, Liu BQ (2015) A probabilistitic neural network classification algorithm based PLS. Microelectron Comput 32(05):73–78. https://doi.org/10.19304/j.cnki.issn1000-7180.2015.05.016
Chen NX, Cao LH, Li M, Huang Q (2005) Forecasting water yield of mine with the partial least square method and neural network. J Jilin Univ (eArth Sci Ed) 35(06):88–92. https://doi.org/10.13278/j.cnki.jjuese.2005.06.015
Chen HJ, Li XB, Liu AH, Dong LJ, Liu ZX (2009) Forecast method of water inrush quantity from coal floor based on distance discriminant analysis theory. J Chin Coal Soc 34(04):487–491. https://doi.org/10.13225/j.cnki.jccs.2009.04.014
Chen CH, Tan J, Yin JK, Zhang F, Yao J (2010) Prediction for soil moisture in tobacco fields based on PCA and RBF neural network. Trans Chin Soc Agric Eng 26(08):85–90. https://doi.org/10.3969/j.issn.1002-6819.2010.08.014
Cheng AP, Gao YT, Ji MW (2014) Wu P (2014) Forecast of water inrush from coal floor based on unascertained measure theory. Metal Mine 08:157–161. https://doi.org/10.3969/j.issn.1001-1250.2014.08.037
Cheng XG, Qiao W, Li GF, Yu ZQ (2021) Risk assessment of roof water disaster due to multi-seam mining at Wulunshan Coal Mine in China. Arab J Geosci 14(12):1116. https://doi.org/10.16031/10.1007/S12517-021-07491-8
Chu JC, Liu XY, Zhang ZW, Zhang YL, He MG (2021) A novel method overcomeing overfitting of artificial neural network for accurate prediction: application on thermophysical property of natural gas. Case Stud Thermal Eng 28:101406. https://doi.org/10.1016/j.csite.2021.101406
Dai QW, Jiang FP, Dong L (2014) RBFNN inversion for electrical resistivity tomography based on Hannan-Quinn criterion. Chin J Geophys 57(04):1335–1344. https://doi.org/10.6038/cjg20140430
Das AJ, Mandal PK, Sahu SP, Kushwaha A, Bhattacharjee R, Tewari S (2018) Evaluation of the effect of fault on the stability of underground workings of coal mine through DEM and statistical analysis. J Geol Soc India 92(6):732–742. https://doi.org/10.1007/s12594-018-1096-2
Dhiman HS, Deb D, Guerrero JM (2019) Hybrid machine intelligent SVR variants for wind forecasting and ramp events. Renew Sustain Energy Rev 108:369–379. https://doi.org/10.1016/j.rser.2019.04.002
Gao WD, Wang ZS (2012) Forecast of inrushed water volume grade from coal floor based on support vector machine with particle swarm optimization. Coal Geol Explor 40(06):44–47. https://doi.org/10.3969/j.issn.1001-1986.2012.06.010
Gao R, Yan H, Ju F, Mei XC, Wang XL (2018) Influential factors and control of water inrush in a coal seam as the main aquifer. Int J Min Sci Techno 28(02):187–193. https://doi.org/10.1016/j.ijmst.2017.12.017
Gong YW, Jiang CL, Wu AJ (2012) Prediction of mine water inrush based on multiple linear regression. Coal Technol 31(03):112–114. https://doi.org/10.3969/j.issn.1008-8725.2012.03.049
Gong B (2021) Study of PLSR-BP model for stability assessment of loess slope based on particle swarm optimization. Sci Rep-UK 11(1):17888. https://doi.org/10.1038/s41598-021-97484-0
Guan P, Jiao YY, Duan XS (2021) Non-liner prediction of soil thermal conductivity based on RBF neural network. Acta Energiae Solaris Sinica 42(03):171–178
Han J, Shi LQ, Zhai PH, Li SC, Yu XG (2009) Application of multi-attribute decision and D-S evidence theory to water-inrush decision of floor in mining. Chin J Rock Mech Eng 28(S2):3727–3732. https://doi.org/10.3321/j.issn:1000-6915.2009.z2.062
Hu XJ, Li WP, Cao DT, Liu MC (2012) Index of multiple factors and expected height of fully mechanized water flowing fractured zone. J Chin Coal Soc 37(04):613–620
Ji YD (2019) The risk assessment of roof water inrush based on cluster analysis and fuzzy comprehensive evaluation. Mining Saf Environ Protection 46(04):68–72. https://doi.org/10.3969/j.issn.1008-4495.2019.04.015
Jiang AN, Liang B (2005) Forecast of water inrush from coal floor based on least square support vector machine. J Chin Coal Soc 30(05):71–75. https://doi.org/10.3321/j.issn:0253-9993.2005.05.016
Ju QD, Hu YB (2021) Source identification of mine water inrush based on principal component analysis and grey situation decision. Environ Eartn Sci 80:157. https://doi.org/10.1007/s12665-021-09459-z
Kou JQ, Zhang WW (2015) Research on the effects of function widths of aerodynamic modeling based on recursive RBF neural network. Adv Aeronaut Sci Eng 6(3):261–270
Liu BZ, Liang B (2011) Prediction of seamfloor water inrush based on combining principal component analysis and support vector regression. Coal Geol Explor 39(01):28–30. https://doi.org/10.3969/j.issn.1001-1986.2011.01.007
LaMoreaux JW, Wu Q, Zhou WF (2014) New development in theory and practice in mine water control in China. Carbonates Evaporites 29:141–145. https://doi.org/10.1007/s13146-014-0204-7
Li HJ, Chen QT, Shu ZY, Li L, Zhang YC (2018) On prevention and mechanism of bed separation water inrush for thick coal seams: a case study in China. Environ Earth Sci 77(22):759. https://doi.org/10.1007/s12665-018-7952-y
Liu SL, Li WP (2019) Fuzzy comprehensive risk evaluation of roof water inrush based on catastrophe theory in the Jurassic coalfield of northwest China. J Intell & Fuzzy Syst 37(2):2101–2111. https://doi.org/10.3233/JIFS-171157
Liang Z, Wang YY, Yue YT, Wei FL, Jiang H, Li SC (2020) A coupling model of genetic algorithm and RBF neural network for the prediction of PM2.5 concentration. China Environ Sci 40(02):523–529
Liu WT, Zheng QS, Pang LF, Dou WM, Meng XX (2021) Study of roof water inrush forecasting based on EM-FAHP two-factor model. Math Biosci Eng 18(5):4987–5005. https://doi.org/10.3934/MBE.2021254
Ma D, Duan HY, Cai X, Li ZH, Li Q, Zhang Q (2018) A global optimization-based method for the prediction of water inrush hazard from mining floor. Water 10(11):1618. https://doi.org/10.3390/w10111618
Montoya-Chairez J, Rossomando FG, Carelli R, Santibanez V, Moreno-Valenzuela J (2021) Adaptive RBF neural network-based control of an underactuated control moment gyroscope. Neural Comput Appl 33(12):6805–6818. https://doi.org/10.1007/s00521-020-05456-8
Peng BB, Yan XG, Du J (2020) Surface quality prediction based on BP and RBF neural networks. Surface Technol 49(10):324–328. https://doi.org/10.16490/j.cnki.issn.1001-3660.2020.10.038
Qin J, Li C, Li Z, Zhao Y (2013) Prediction of mine water inrush quantity based on support vector regression. China Saf Sci J 23(05):114–119. https://doi.org/10.16265/j.cnki.issn1003-3033.2013.05.022
Roushangar K, Koosheh A (2015) Evaluation of GA-SVR method for modeling bed load transport in gravel-bed rivers. J Hydrol 527:1142–1152. https://doi.org/10.1016/j.jhydrol.2015.06.006
Shi XZ, Wu YM, Tang LZ, Huang XD (2013) Application of neural network model with partial least-square regression in prediction of peak velocity of blasting vibration. J Vib Shock 32(12):45–49. https://doi.org/10.13465/j.cnki.jvs.2013.12.008
Shi WH, Yang TH, Yu QL, Li Y, Liu HL, Zhao YC (2017) A study of water-inrush mechanisms based on geo-mechanical analysis and an in-situ groundwater investigation in the Zhongguan Iron Mine, China. Mine Water Environ 36(3):409–417. https://doi.org/10.1007/s10230-017-0429-5
Su KX, Zhang JW, Li X, Zhang JX, Zhu SD, Yi KJ (2020) Prediction of fatigue life and residual stress relaxation behavior of shot-peened 25CrMo axle steel based on neural network. Rare Metal Mater Eng 49(08):2697–2705
Tong ZH, Liu WY, Han CH, Qi ZF (2013) Research on the evaluation of enterprise knowledge integration capability based on Fussy-RBF. Info Stud Theory Appl 36(08):51–56
Tao JL, Yu Z, Zhang RD, Guo FR (2021) RBF neural network modeling approach using PCA based LM-GA optimization for coke furnace system. Appl Soft Comput. https://doi.org/10.1016/j.asoc.2021.107691
Wang KL, Xiong HG, Zhang F (2014) PLSR-BP complex model-based hyper-spectrum retrieval of oasis soil pH. Arid Zone Res 31(06):1005–1009
Wei DZ, Chen FJ, Zheng XX (2015) Internet public opinion chaotic prediction based on chaos theory and the improved radial basis function in neural networks. Acta Physica Sinica 64(11):52–59. https://doi.org/10.7498/aps.64.110503
Wu Q, Xu K, Zhang W (2016) Further research on “three maps-two predictions” method for prediction on coal seam roof water bursting risk. J Chin Coal Soc 41(06):1341–1347. https://doi.org/10.13225/j.cnki.jccs.2015.1210
Wu Q, Shen JJ, Liu WT, Wang Y (2017) A RBFNN-based method for the prediction of the developed height of a water-conductive fractured zone for fully mechanized mining with sublevel caving. Arab J Geosci 10(7):1–9. https://doi.org/10.1007/s12517-017-2959-3
Wen TX, Sun X, Tian HB, Kong XB (2017) Prediction of the water inrush from the coal seam based on PCA-Fuzzy-RF model. J Saf Environ 17(3):855–858. https://doi.org/10.13637/j.issn.1009-6094.2017.03.009
Wang XH, Zhu SY, Yu HT, Liu YX (2021) Comprehensive analysis control effect of faults on the height of fractured water-conducting zone in longwall mining. Nat Hazards 108(2):2143–2165. https://doi.org/10.1007/s11069-021-04772-z
Xiao JY, Tong MM, Jiang CL (2012) Prediction of water inrush quantity from coal floor based on fuzzy evidence theory. J Chin Coal Soc 37(S1):131–137. https://doi.org/10.13225/j.cnki.jccs.2012.s1.032
Xu ZM, Sun YJ, Gao S, Zhao XM, Duan RQ, Yao MH, Liu Q (2018) Groundwater source discrimination and proportion determination of mine inflow using ion analyses: a case study from the Longmen Coal Mine, Henan Province, China. Mine Water Environ 37:385–392. https://doi.org/10.1007/s10230-018-0512-6
Yan CB, Wang HJ, Yang JH, Chen K, Zhou JJ, Guo WX (2021) Predicting TBM penetration rate with the coupled model of partial least squares regression and deep neural network. Rock Soil Mech 42(02):519–528. https://doi.org/10.16285/j.rsm.2020.0164
Yang ZL, Meng XR, Wang XQ, Wang KY (2013) Nonlinear prediction and evaluation of coal mine floor water inrush based on GA-BP neural network model. Saf Coal Mines 44(02):36–39. https://doi.org/10.13347/j.cnki.mkaq.2013.02.024
Yang Q, Ye ZF, Li XZ, Wei DZ, Chen SH, Li ZR (2021) Prediction of flight status of logistics UAVs based on an information entropy radial basis function neural network. Sensors 21(11):3651. https://doi.org/10.3390/s21113651
Yin HY, Shi YL, Niu HG, Xie DL, Wei JC, Lefticariu L, Xu SX (2018) A GIS-based model of potential groundwater yield zonation for a sandstone aquifer in the Juye Coalfield, Shangdong, China. J Hydrol 557:434–447. https://doi.org/10.1016/j.jhydrol.2017.12.043
Yin HY, Zhao H, Xie DL, Sang SZ, Shi YL, Tian MH (2019) Mechanism of mine water inrush from overlying porous aquifer in Quaternary: a case study in Xinhe Coal Mine of Shandong Province. China Arab J Geosci 12(05):163. https://doi.org/10.1007/s12517-019-4325-0
Zeng YF, Wu Q, Liu SQ, Zhai YL, Lian HQ, Zhang W (2018) Evaluation of a coal seam roof water inrush: case study in the Wangjialing coal mine, China. Mine Water Environ 1(37):174–184. https://doi.org/10.1007/s10230-017-0459-z
Zhang J, Yang T (2018) Study of a roof water inrush prediction model in shallow seam mining based on an analytic hierarchy process using a grey relational analysis method. Arab J Geosci 11(7):153. https://doi.org/10.1007/s12517-018-3498-2
Zhang YG, Yang LN (2021) A novel dynamic predictive method of water inrush from coal floor based on gated recurrent unit model. Nat Hazards 105(02):2027–2043. https://doi.org/10.1007/S11069-020-04388-9
Zhang P, Zhang JX, Zhang ZH (2020) Design of RBFNN-based adaptive sliding mode control strategy for active rehabilitation robot. IEEE Access 8:155538–155547. https://doi.org/10.1109/ACCESS.2020.3018737
Zhang YW, Zhang LL, Li HJ, Chi BM (2021a) Evaluation of the water yield of coal roof aquifers based on the FDAHP-Entropy method: A case study in the Donghuantuo Coal Mine. China Geofluids 2021:5512729. https://doi.org/10.1155/2021/5512729
Zhang ZC, Gao TY, Zhang L, Tuo SF (2021b) Aeroheating agent model based on radial basis function neural network. Acta Aeronautica Et Astronautica Sinica 42(04):303–312. https://doi.org/10.7527/S1000-6893.2020.24167
Zhao DK, Wu Q (2018) An approach to predict the height of fractured water-conducting zone of coal roof strata using random forest regression. Sci Rep-UK 8(1):10986. https://doi.org/10.1038/s41598-018-29418-2
Zheng K, Jia XY, Liao WH (2013) Wear loss prediction model of denture material based on radial basis function neural network. J Nanjing Univ Sci Technol 37(06):922–925. https://doi.org/10.14177/j.cnki.32-1397n.2013.06.020
Funding
The study was supported by the National Natural Science Foundation of China (Grant No. 41272278) and the Scientific Research Platform Innovation Team Construction Project in Universities of Anhui (Grant No. 2016-2018-24).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Bi, Y., Wu, J. & Zhai, X. Quantitative prediction model of water inrush quantities from coal mine roofs based on multi-factor analysis. Environ Earth Sci 81, 314 (2022). https://doi.org/10.1007/s12665-022-10432-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12665-022-10432-7