
Abstract
In this study, pressuremeter modulus (Ep) and limit pressure (PL) were predicted using artificial intelligence methods through the available results of in situ and laboratory tests (the pressuremeter tests) obtained from the same place in Isfahan city metro line 2 in the east–west distance. In this regard, the results of pressuremeter experiments, standard penetration test, and downhole seismic geophysical test, as well as the results of laboratory tests such as grain size, density, and triaxial compression tests performed in fine-grained sediments (clay and silt), were used as training data. To predict the values of pressuremeter modulus and limit pressure for some other places close to the mentioned location, artificial neural network (ANN) and multi-adaptive neuro-fuzzy inference system (MANFIS) were trained using the available experimental data. It outperforms ANN predictive model where the values of R2, RMSE were 0.86% and 0.17, respectively. The values of correlation coefficient R2 and the root mean squares error (RMSE) in MANFIS model was equal to 0.94% and 0.05, respectively. Totally, the results implied that MANFIS model has the ability to provide more realistic outputs with higher accuracy compared to ANN. The most advantage of the method presented in this research is that since the cost of conducting in situ and lab tests is usually high, when the test values for some parts of a location are available, it is possible to estimate these values for a limited number of other close locations and/or in the range with a good accuracy without the need to perform extra tests.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Geotechnical studies and investigations of the location of the structure before performing any structural operations are very important and necessary (Cabalar et al. 2012). In site investigation in important geotechnical projects, in situ and laboratory experiments are used to obtain the soil characteristics of the project site. Because the conditions of field tests are most similar to the interactions of forces in the actual behavior of soil in the field and soil disturbance is much less, they provide more reliable results, in contrast to the fact that often in laboratory experiments If tampered with and performed on a very small scale relative to the ground, the results are less accurate. Therefore, the tendency to design the structure based on the parameters obtained from in situ experiments is more and more reliable (Wu et al. 2021).
The pressuremeter test (PMT) is an in situ test used to help design foundations for a variety of soils. In general, measuring the strength properties and deformation parameters of the soil done under overburden pressure. The parameters of limit pressure (PL) and pressuremeter modulus (Ep) obtained from the pressuremeter test are used to determine the amount of bearing capacity and settlement due to loading (Briaud 2019; ASTM D4719-20 2020; Wu et al. 2021). This test is relatively expensive, time consuming, and in some cases difficult to perform. As a result, for engineering projects to save time and money, indirect methods are sought for estimating the pressuremeter modulus and limit pressure (Cheshomi and Ghodrati 2015).
The use of software methods can provide a suitable solution to reduce costs and increase efficiency for the geotechnical studies of projects (Daneshvar et al. 2010). Therefore, due to the ability of artificial intelligence models such as artificial neural networks and fuzzy models in modeling and predicting geotechnical parameters, it has been widely used. (Cabalar et al. 2010; Aladag et al. 2013; Edincliler et al. 2013; Barzegari et al. 2019; Zaki et al. 2020). In addition to the required accuracy, artificial neural networks have high speed and ease of use. The analysis is based on artificial intelligence models by extracting the relationships between the factors affecting the limit pressure (PL) or the pressuremeter modulus (Ep) and their basic physical properties. Previous studies have been performed on the interpretation and application of artificial intelligence models to predict pressuremeter test data (Table 1). Prediction of pressuremeter parameters was performed through neural network using SPT number and some laboratory experiments (Aladag et al. 2013; Wu et al. 2021) or using CPT number (Zaki et al. 2020) with different neural network models, interpretation, and prediction of pressuremeter parameters (Fawaz et al. 2014). The shear modulus of sand with different mixtures using neural networks was anticipated (Cabalar and Cevik 2009; Edincliler et al. 2012).
There are numerous effective parameters on Ep and PL, such as soil depth, soil mechanical properties, grain size, density, cohesion, and internal friction angle as well as longitudinal and shear wave velocity and standard penetration number. As shown in Table 1, in the previous researches, a limited number of variables have been considered. But in this study, we have selected more number of variables as input, because all have effect on predict Ep and PL. This feature is accounted as a novelty of the present work.
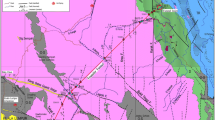
Also, in this research, in addition to solving the problems of previous projects, in order to increase the reliability, another prediction method was used alongside ANN method, which is a combination of neural network and fuzzy logic (MANFIS). Also, a model whose results can be generalized to other ongoing projects was provided. Therefore, for this purpose, the study area of the Isfahan’s metro line 2, route between the east–west borders was selected, which has suitable conditions in terms of the presence of fine silt and clay deposits, which are very common and similar to other alike projects. Figure 1 shows the study area and route of the metro line. To predict the Ep and PL in the study area, the artificial neural network modeling method was used and the results were compared with the results of the method of the adaptive neuro-fuzzy inference system model. In order to compare, the prediction factors have been studied using the results of common laboratory and in situ experiments that affect the pressuremeter parameters. Also, according to the ability of each artificial intelligence model, the combination of these models can take advantage of the simultaneous benefits of both models (Cevik et al. 2011; Umrao et al. 2018).

Location of the subway route sites in Isfahan, Iran
The present study proposes a MANFIS (multi-ANFIS) model for estimating the Ep and PL in fine-grained sediments using samples collected from the study area. Furthermore, this study proposes alternative ANN and MANFIS models, to compare the accuracy of each model with one of the other soft computing methods.
Materials and methods
Database
Isfahan is a historical city in the central part of Iran. The initial study of Isfahan city train line 2 with a length of about 24 km along the east to west of Isfahan with 22 stations was conducted. A total of 44 machine boreholes 30 and 40 meters from the natural ground level have been drilled by the core barrel method and continuous sampling. The database used in this study examines in detail 36 of the 19 boreholes that are scattered throughout the route. Intact laboratory samples were sampled from a certain depth at which in-situ tests were performed. Assessment of soil properties with the help of laboratory tests simulates soil conditions on a small scale (Carter and Bentley 2016; Sharma et al. 2017b). The required laboratory tests are performed in accordance with the valid international standards (ASTM) on the samples taken. Some of the common laboratory experiments in most of the geotechnical studies used in this study include grain size, natural soil density үt, cohesion C, and internal friction angle Ф of soil obtained from the UU triaxial test, to identify the project site soil (da Fonseca et al. 2010).
In order to find out the physical and mechanical properties of the project site soil during drilling of boreholes, downhole geophysical tests have been performed to estimate the dynamic parameters of the soil for seismic analysis of the site. The velocities of longitudinal waves Vp and shear Vs inside the soil layers deep underground were obtained for this purpose.
N spt(60) (standard penetration number modified for energy ratio of 60%) obtained from the standard penetration test, which leads to the determination of resistance parameters of clay, sludge, and sandy soils (Yesiloglu-Gultekin 2021), and the pressuremeter modulus (Ep) and the limit pressure (PL) obtained from the pressuremeter test, were measured from in situ tests. Comparison of laboratory and in situ test results provides a comprehensive and accurate assessment of soil parameters. The samples consist of a variety of fine-grained soils including clay (CH, CL), silt (ML, MH), silty clay (CL-ML), and sandy silt to sandy clay. The data are given in Table 2.
Artificial intelligence methods: motivations and concepts
Artificial intelligence models were rapidly used in the engineering sciences because of their ability to recognize the behavior of complex nonlinear systems. Therefore, they have the ability to model and process geotechnical data (Barzegari et al. 2019). Artificial neural networks are algorithms that can be used to perform nonlinear statistical modeling and provide a new alternative to logistic regression, the most commonly used method for developing predictive models for estimation of geotechnical parameters (Hajian and Bayat 2022). Neural networks offer a number of advantages, including requiring less formal statistical training, ability to implicitly detect complex nonlinear relationships between dependent and independent variables, ability to detect all possible interactions between predictor variables, and the availability of multiple training algorithms (Tu 1996). Also, neural networks are more robust to noise that are available in the most of geotechnical lab or in situ tests, than common classical methods of estimations, i.e., model based or even statistical regressions (Kimiaefar et al. 2018). Furthermore, ANNs are able to learn from data, and therefore, there is no need to any pre-assumption about the geotechnical parameters, while other common methods try to fit a pre-assumed model to data and consequently the accuracy of the estimation is affected .Disadvantages include its “black box” nature that harden to interpret, proneness to overfitting, and the empirical nature of model development. To overcome black-box problem, one way is to combine fuzzy logic and neural networks yield to neuro-fuzzy system that not only have the mentioned advantages of ANNs but also is better interpretable due to the presence of fuzzy if-then rules (Mobara et al. 2013).
In this study, a multi-adaptive neuro-fuzzy inference system (MANFIS) was investigated to estimate the values related to the pressuremeter modulus and limit pressure obtained from the pressuremeter test of fine-grained soils. Its results are compared with the results of the artificial neural network model.
Network training
Normalization operations must be performed before many data mining algorithms, such as neural networks, so that the various dimensions are fairly examined by the algorithm and the effect of one is not greater than the others. Hence, the best data situation in teaching artificial intelligence networks is when the inputs and outputs are between zero and one. This normalization in terms of data value standardization helps the transfer functions to distinguish between very large numerical values and leads to easier network training (Nourani et al. 2008; Kanungo et al. 2014; Guha Roy and Singh 2020).
One of the common methods of data normalization used in this study is according to
where X is the value of the data should be normalized, XN is the normalized value of the data, and Xmin and Xmax are the minimum and maximum values in the data set, respectively.
Artificial neural network
Artificial neural network (ANN) is a type of artificial intelligence. This intelligent model consists of units called neurons that try to mimic the behavior of the human brain and nervous system (Shahin et al. 2001).
The basis of this network is a training-based algorithm that models the relationship between inputs and outputs. Neural networks were presented due to their high learning capability which can modify and improve their behavior while learning (Zaki et al. 2020).
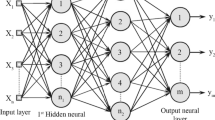
One of the most useful types of artificial neural networks to solve engineering and geotechnical problems are multilayer perceptron (MLP) networks. MLP networks consist of an input layer, one or more hidden layers, and an output layer (Emami and Yasrobi 2014).
In this study, perceptron network with two hidden layers was used. In these networks, the number of hidden layers, the number of neurons in the hidden layers, and the number of educational data are the most important factors influencing the network performance. The neurons are connected to the next layers by weights (W) and the biases (b) in the middle layer and output neurons are responsible for modulating the values. Transfer functions (f) are also responsible for processing neurons in the middle layer, which can include a wide range of functions (Fig. 2). In this research, in the first and second hidden layers, Log–Sigmoid function and hyperbolic tangent Sigmoid function have been used as activation functions, as mentioned in Eqs. (2) and (3), respectively (Hagan et al. 1966; Hajian and Styles 2018).
where x is the weighted sum of the input of each neuron and y is its output.

A typical structure of ANN processing elements (Shahin et al. 2001)
Network training is either supervised or unsupervised. In the monitored algorithms, by increasing and decreasing weights and biases, the network parameters are adjusted so that the network output is as close as possible to the desired response and produces less error. Next, the network can provide a closer output to the target in the face of an untrained input (Nadiri et al. 2014; Ghorbani et al. 2020).
In contrast, unsupervised education is based on internal compulsions and restrictions. It only produces impressive results if there is some kind of redundancy and abundance in the input data. Without this increase in input data, it is impossible to detect any pattern in the input data.
In artificial neural networks, various optimization algorithms training and modulate the network by creating repetitive changes in weights and biases. (In fact, the value of network weights is determined when learning the network.) The backpropagation of errors algorithm is one of the most widely used for supervised network training. The main application of the law of learning is the backpropagation of errors algorithm in multilayer feedforward neural networks. The basis of this method is to minimize the error function (Nalbant et al. 2007).
In this study, designed networks of three-layer perceptron feedforward backpropagation training algorithm have been used. The final optimal model is optimized after trial and error cycles, and its output has a relatively low error compared to other designed models.
Fuzzy logic
A fuzzy set, as its name implies, is a set with vague boundaries and has a special structure for analyzing and modeling approximate arguments. In fact, in this type of collections, the transition from inclusion to non-inclusion is gradual. This gradual and smooth transition is organized by the membership function. The membership function is a curve that defines how to map each point of the input space to a membership value (membership grade) between 0 and 1. The MFs has different shapes such as Gaussian, triangular, trapezoidal, bell-shaped, and Sigmoid, which are shown in Fig. 3. These various MFs are in custom design fuzzy control software tools. For example, where the neural network is operated to adjust and implement the fuzzy system, the Sigmoid MF was used (Horikawa et al. 1990; Zhao and Bose 2002). In triangular MFs, distribution of membership grades is so that the maximum membership occurs at one point and the function has a height of unity. But, when it is in a domain range, trapezoidal functions are used. Gaussian or bell-shaped MFs are the most common MFs used for non-linear problems and systems with complex behavior (Ilkhchi et al. 2006; Hajian and Styles 2018).

Different types of common membership functions: a triangular, b trapezoidal, c Gaussian, d generalized bell, and f sigmoidal
The fuzzy system consists of three main parts: (1) fuzzification data, (2) fuzzy inference system (fuzzy rules), and (3) defuzzification data. In fuzzification, the inputs are changed to the appropriate fuzzy set through the corresponding membership function. Fuzzy results are obtained through a fuzzy inference system or fuzzy if–then rules. In most applications of fuzzy logic, such as what humans do when making decisions, they design appropriate structures to analyze and solve equations using experience. These fuzzy rules can also select the appropriate number of fuzzy sets and language patterns for a particular purpose. Solve uncertainties and interpret the relationship between input and output (Ahmadi-Nedushan 2012). In the last stage, the final results are obtained from the community of outputs and their defuzzification. Based on the type of membership functions, the fuzzy model is divided into two types: Mamdani and Takagi Sugeno. In Mamdani method, the output membership functions are fuzzy sets. But, in the Takagi Sugeno model, the output is constant or linear, which is obtained by the classification method. In this research, fuzzy logic has been used by Takagi Sugeno TS-FL method (Yang and Yang 2014).
Neuro-fuzzy inference system
The adaptive neuro-fuzzy inference system developed by Jung in 1993 is a combination of the FIS model, which has the ability to extract fuzzy rules by data, and the ANNs model, with network training capability (Jang 1993). In this way, it can overcome the disadvantages of each of these models. ANFIS can provide better results with less limitations than ANNs and FIS models in various fields, including geotechnical data, which often have inherent heterogeneity. Therefore, with this intelligent method, the accuracy of obtaining these parameters can be increased and the error rate the observation of the prediction error will be reduced and will make the modeling more accurate and improve the soil resistance parameters (Hajian et al. 2011).
Fuzzy inference systems are different in terms of the principles governing the result part, but they are all similar in terms of the hypothetical part. Therefore, there are different methods for dividing the entrance space; this is done in order to provide appropriate assumptions in fuzzy rules and are applicable to all fuzzy inference systems. Grid partitioning is one of the separation methods in 2D input space (Jang et al. 1997; Ahmadi-Nedushan 2012). This segmentation method requires only a small number of membership functions per input, and in the case of systems with a large number of inputs, the fuzzy if–then rule increases too much. This problem is commonly referred to as curse of dimensionality. In contrast, models made with subtractive clustering method lead to low network efficiency due to their very small number of rules (Yusefzadeh and Nadiri 2021).
ANFIS works by approximating the functional relations between responses and input variables, by gradually fine-tuning the parameters at the adaptive nodes of ANFIS for the process under study. A typical layer structure of an ANFIS network is depicted in Fig. 4. Relationship between the two input variables (x, y) and one output (f) parameters through hybrid learning for the determination of the membership function distribution can be simulated by ANFIS. The ANFIS utilizes a hybrid-learning rule as it is easy to use. It is comprised of five layers in the inference system, and each layer includes several nodes, which are defined by the node function (Jahed Armaghani et al. 2015).

Schematic diagram of the layers of an ANFIS (Jahed Armaghani et al. 2015)
For simplicity, we assume the fuzzy inference system under consideration has two inputs x and y and one output z with f membership function. Suppose that the rule base contains two fuzzy if–then rules of Takagi and Sugeno’s. Therefore, these rules are of the form: (Takagi and Sugenu 1983, Hajian and Styles 2018)
where A and B are fuzzy variables and {p, q, r} is the set parameters.
In order to train the network, there is a forward pass which propagates the input vector through the network, layer by layer, and a backward pass where the error is sent back through the network (backpropagation).
Layer 1: the output of each node is
where x is the input to node i, and A is the linguistic label (small, large, etc.) associated with this node function and the O1,i(x) is essentially the membership grade for x and y. n. In other words, O1,i is the membership function of Ai and it specifies the degree to which the given x satisfies the quantifier Ai and for all equations 6 to 8, μ denotes the membership degree. The membership functions can have broad definitions but here we have used the bell-shaped function. The membership functions can have broad definitions but here we have used the bell-shaped function:
where ai, bi, and ci are parameters to be learnt and are known as the premise parameters.
Layer 2: each node in this layer is fixed and the t-norm is used to perform the operator ‘AND’ on the membership grades (for example the product):
where wi denotes for the weight of the firing of each rule in layer 2.
Layer 3: layer 3 contains fixed nodes which calculate the ratio of the firing strengths of the rules:
Layer 4: the nodes in this layer are adaptive and output the consequence of applying the rules:
The parameters in this layer (pi, qi, ri) to be determined are known as the consequent parameters.
Layer 5: there is a single node here that computes the overall output:
This is typically how the input vector is fed through the network, layer by layer. The type of fuzzy model used in the ANFIS structure to estimate the pressuremeter modulus and limit pressure is of the Sugeno type, which is often used by the ANFIS systems using the Takagi Sugeno fuzzy system. There are a number of possible training approaches but here the hybrid learning algorithm method was used to optimize the network training, which combines the least square estimation (LSE) method with the steepest descent gradient algorithm. For this model, a generalized Gaussian function is used to create membership functions for 7 input data. Then, each input is fuzzified based on the membership function according to the if–then rules, and finally, based on the type of input data, the output membership function is displayed as a constant (Tayfur et al. 2014; Hajian and Styles 2018).
In this study, the MANFIS model uses the advantages of simultaneous neural network and fuzzy logic to predict the pressuremeter modulus and soil limit pressure and provides better results than any of the individual models.
Network validation
After training the network, the validity of the results should be weighed. The predicted quantity validation dataset is given to the network and the network responses are compared with the actual values measured with the instrument. The more similar these two data sets (real and predicted), the greater the power of network generalization and its efficiency. There are usually two ways to evaluate the difference between two data sets: correlation coefficient R2 and root mean squared error (RMSE) (Basarir et al. 2014; Jahed Armaghani et al. 2015; Fattahi 2016). These values are determined by the following equations:
where the values of t, o, and p, j are the target value (actual observation), model output, and the number of observations, counter of samples in the summations, respectively. It is clear that the best value for R2 is 1 and for RMSE is zero (Nalbant et al. 2007).
Results and discussion
In this study, in order to estimate the pressuremeter modulus and limit pressure of fine-grained soils in Isfahan’s metro line 2, two types of artificial intelligence methods including MANFIS and ANN were used and their results were compared with each other. Execution of models was done through MATLAB software. Information and data from laboratory tests and in situ studies conducted by the Urban Train Organization were collected and analyzed. 36 data including natural soil density values үt, cohesion C and internal friction angle Ф, longitudinal wave velocity Vp and shear wave velocity Vs, N spt(60), and depth tested D were prepared.
Based on the classification of experimental models, neural network models are completely closed (black box); it means the relationship between input and output and the network operation process is unknown and unimaginable to the user. It should be noted that the neural network is not so accurate in extrapolation problems. The data used in this research have the same type soil (fine-grained), and the ANN model cannot be expected to be accurate for different range of data specially when the distance of the understudy points from the new points is far and consequently the inputs range might be so different with the trained range. While ANNs are black box type, the neuro-fuzzy networks are of the type gray box as they have a base of fuzzy optimized rules and therefore their efficiency is generally higher than ANNs.
As the results of the networks showed, the correlation between the actual data and the predicted values of Ep and PL for the neural network is 0.86, and in the neural-fuzzy network is 0.94. Also, a comparative diagram of observational and computational values for each of the models is prepared and shown in Figs. 5 and 6 for the ANN and 9 and 10 for the ANFIS.

Neural network architecture used in this study

Comparison of the normalized predicted and the measured for ANN model EP(OPT)
Neural network modeling
In order to construct an artificial neural network model using the perceptron multilayer network method, 36 data obtained from the Isfahan’s metro line 2 project with the help of 7 parameters have been used as input using MATLAB software, so that first the input and output parameters must be specify the network. Final input parameters included natural soil density үt, cohesion C and internal friction angle Ф, longitudinal wave velocity Vp and shear wave velocity Vs, N spt (60), and depth tested D. The output or target parameter was the pressuremeter modulus (Ep) and the limit pressure (PL) obtained from the pressuremeter test. Geological information has been extracted from geotechnical boreholes drilled along the route. 70% of the available data were randomly selected for education and 30% of the available data were randomly selected and used as test data (15% for testing and 15% for validation). In order to understand that ANN correctly predicted, experimental data that were not previously provided to the network are used.
The purpose of neural network training is to determine the optimal network parameters including weights and biases. In this study, 2 hidden middle layers and 1 output layer, the number of neurons in the middle layers were 35 and 10, respectively, and in the output layer, 2 neurons were trained and tested (Fig. 5). These values were determined by trial and error. Different algorithms have been used in the modeling to achieve the optimal network (Nalbant et al. 2007; Sarmadian and Keshavarzi 2010; Edincliler et al. 2012; Emami and Yasrobi 2014; Zaki et al. 2020). The best result was shown by perceptron algorithm with LOGSIG and TANSIG transfer functions in the first and second hidden layers and PURELIN transfer function in the output layer, respectively. The actual and predicted data of the pressuremeter modulus and limit pressure at the yield point are 0.86 (Figs. 6 and 7, Table 3) (Taşan and Demir 2020).

Comparison of the normalized predicted and the measured for ANN model PL(OPT)
Adaptive neuro-fuzzy inference system modeling
The comparative neuro-fuzzy inference system (ANFIS) has been used to predict the limit pressure and pressuremeter modulus obtained from the pressuremeter test in Isfahan’s metro line 2. A network with 7 input variables, including natural soil density үt, adhesion C and internal friction angle Ф, longitudinal wave velocity Vp and shear wave velocity Vs, N spt(60), and depth tested D, was selected. The output of the model is the pressuremeter modulus (Ep) and the limit pressure (PL) resulting from the pressuremeter test, for each of these outputs a separate interface network is trained. As it is shown in Fig. 8, the structure of the network under study includes a parallel combination of two ANFISes, namely, MANFIS.

Architecture of multiple adaptive neuro-fuzzy inference system
The data are divided into three categories: educational, experimental, and validation with a certain number. As a result, a total of 36 normalized data, 21 data for training, 9 data for testing, and 6 data for neural-fuzzy network validation were randomly selected.
The next step is to determine the initial fuzzy inference system for ANFIS training; here, the system is of the Takagi–Sugeno type. Hybrid optimization method has been used for ANFIS training; the criterion for stopping the training is zero error and the training has been done in 40 epoch. The grid partitioning method has also been used to create the structure of the fuzzy inference system automatically (Sihag et al. 2019; Jalal et al. 2021).
In the optimal model, considering to have 7 inputs, in order to avoid facing the problem of dimensions, 2 gaussmf membership functions have been determined for each of the inputs. The output membership function is constant. The best structure of ANFIS model was selected as the optimal model due to high data correlation and limited error (Fig. 9) (Zhang et al. 2020).

The schematic of multi adaptive neuro-fuzzy inference system architecture used in this study (the structures of the two models are parallel).
To evaluate the efficiency and accuracy of the optimal ANFIS model used, first the scatter plot of the observed values versus the computational values related to each of the parameters of pressuremeter modulus (Ep) and limit pressure (PL) was drawn (Figs. 10 and 11) and Pearson coefficient (R2) was calculated. The root mean squares error (RMSE) were calculated for each of the training, testing, and checking steps (Table 4) (Umrao et al. 2018; Taşan and Demir 2020; Jalal et al. 2021). Quantitative results show that this model has a lower RMSE value than the ANN model, which indicates a high correlation between the predicted values and the actual values of both parameters.

Comparison of the normalized predicted and the measured for ANFIS model E(OPT)

Comparison of the normalized predicted and the measured for ANFIS model PL (OPT)
Conclusion
The purpose of this study was to demonstrate and evaluate the ability to learn and predict the values of the pressuremeter modulus and the limit pressure obtained from the pressuremeter test by computational models, especially ANN and MANFIS. Geotechnical experimental methods, including laboratory and in situ experiments, usually require special equipment and take more time than computational methods. The results of this study include the pressuremeter modulus and the limit pressure predicted by the pressuremeter test (PMT), using the information of boreholes drilled in Isfahan’s metro line 2, the results of artificial neural network (ANN) model and multi-adaptive neuro-fuzzy inference system (MANFIS). The MANFIS model, which is a combination of the ANN and FIS models, uses the artificial neural network training capability and the classification capability in the fuzzy system. Accordingly, MANFIS demonstrated a practical approach to minimizing uncertainties compared to artificial neural networks. To select the best type of model that can accurately estimate the pressuremeter modulus and limit pressure in Isfahan’s metro line 2, a comparison between evaluation criteria was performed. Examining the R2 and RMSE values for each of the models used in this study, it was observed that the R2 values for all data sets in the ANN, ANFIS models are 86% and 94%, respectively, and the RMSE values for the ANN and ANFIS prediction models are equal to 0.17 and 0.05, respectively. Although the neural network provided good results, the MANFIS model is more accurate in estimating the pressuremeter modulus and soil limit pressure because its RMSE is less than one-third of ANN and also its R2 is 10 percent more than that of ANN. Pressuremeter modulus and limit pressure are the most widely used soil deformation parameters that was resulted from in-situ tests. In the previous studies, the pressure meter test parameters have been estimated through non-linear regression methods. But in this research, these parameters were predicted using MANFIS. Therefore, the models obtained from this method can be used to develop other data centers in similar researches. In order to improve the present study, it is suggested to use finite element methods, 3D modeling software and other machine learning algorithms to compare the methods performed in this research to better evaluate and validate the efficiency of intelligent methods in estimating pressuremeter parameters in Isfahan’s metro line 2 and other similar projects.
References
Ahmadi-Nedushan B (2012) Prediction of elastic modulus of normal and high strength concrete using ANFIS and optimal nonlinear regression models. Constr Build Mater 36:665–673. https://doi.org/10.1016/j.conbuildmat.2012.06.002
Aladag CH, Kayabasi A, Gokceoglu C (2013) Estimation of pressuremeter modulus and limit pressure of clayey soils by various artificial neural network models. Neural Comput Appl 23:333–339. https://doi.org/10.1007/s00521-012-0900-y
ASTM D4719-20 (2020) Standard test methods for prebored pressuremeter testing in soils. ASTM International, West Conshohocken, PA. i. https://doi.org/10.1520/D4719-07.2
Barzegari G, Nadiri AA, Javid H (2019) Prediction of maximum settlement in EPB mechanized twin tunneling using supervised combined artificial intelligence model. Adv Appl Geo 9:256–271. https://doi.org/10.22055/aag.2019.28287.1929
Basarir H, Tutluoglu L, Karpuz C (2014) Penetration rate prediction for diamond bit drilling by adaptive neuro-fuzzy inference system and multiple regressions. Eng Geol 173:1–9. https://doi.org/10.1016/j.enggeo.2014.02.006
Briaud J-L (2019) The pressuremeter, 1st edn. Routledge, London
Cabalar AF, Cevik A (2009) Modelling damping ratio and shear modulus of sand-mica mixtures using neural networks. Eng Geol 104:31–40. https://doi.org/10.1016/j.enggeo.2008.08.005
Cabalar AF, Cevik A, Gokceoglu C (2012) Some applications of adaptive neuro-fuzzy inference system (ANFIS) in geotechnical engineering. Comput Geotech 40:14–33. https://doi.org/10.1016/j.compgeo.2011.09.008
Cabalar AF, Cevik A, Guzelbey IH (2010) Constitutive modeling of Leighton Buzzard Sands using genetic programming. Neural Comput Appl 19:657–665. https://doi.org/10.1007/s00521-009-0317-4
Carter M, Bentley SP (2016) Soil properties and their correlations. Wiley, Chichester, UK
Cevik A, Sezer EA, Cabalar AF, Gokceoglu C (2011) Modeling of the uniaxial compressive strength of some clay-bearing rocks using neural network. Appl Soft Comput J 11:2587–2594. https://doi.org/10.1016/j.asoc.2010.10.008
Cheshomi A, Ghodrati M (2015) Estimating Menard pressuremeter modulus and limit pressure from SPT in silty sand and silty clay soils. A case study in Mashhad, Iran. Geomech Geoengin 10:194–202. https://doi.org/10.1080/17486025.2014.933894
da Fonseca AV, Silva SR, Cruz N (2010) Geotechnical characterization by in situ and lab tests to the back-analysis of a supported excavation in metro do porto. Geotech Geol Eng 28:251–264. https://doi.org/10.1007/s10706-008-9183-6
Daneshvar M, Asghari E, Ghanbari A, Shahbazi M (2010) Geotechnical and geological aspects of Amir Kabir tunnel of Tehran, pp 26–28
Edincliler A, Cabalar AF, Cagatay A, Cevik A (2012) Triaxial compression behavior of sand and tire wastes using neural networks. Neural Comput Appl 21:441–452. https://doi.org/10.1007/s00521-010-0430-4
Edincliler A, Cabalar AF, Cevik A (2013) Modelling dynamic behaviour of sand-waste tires mixtures using neural networks and neuro-fuzzy. Eur J Environ Civ Eng 17:720–741. https://doi.org/10.1080/19648189.2013.814552
Emami M, Yasrobi SS (2014) Modeling and interpretation of pressuremeter test results with artificial neural networks. Geotech Geol Eng 32:375–389. https://doi.org/10.1007/s10706-013-9720-9
Fattahi H (2016) Adaptive neuro fuzzy inference system based on fuzzy C-means clustering algorithm, a technique for estimation of TBM penetration rate. Int J Optim Civ Eng Int J Optim Civ Eng 6:159–171
Fawaz A, Hagechehade F, Farah E (2014) A study of the pressuremeter modulus and its comparison to the elastic modulus of soil. Study Civ Eng Archit 3:7–15
Ghorbani B, Arulrajah A, Narsilio G, Horpibulsuk S (2020) Experimental and ANN analysis of temperature effects on the permanent deformation properties of demolition wastes. Transp Geotech 24:100365. https://doi.org/10.1016/j.trgeo.2020.100365
Guha Roy D, Singh TN (2020) Predicting deformational properties of Indian coal: soft computing and regression analysis approach. Meas J Int Meas Confed 149:106975. https://doi.org/10.1016/j.measurement.2019.106975
Hagan MT, Demuth HB, Jesús ODE (1966) Scientific immigrants in the United States. Endeavour 25:58. https://doi.org/10.1016/0160-9327(66)90069-X
Hajian A, Bayat M (2022) Prediction of maximum shear modulus (Gmax) of granular soil using empirical, neural network and adaptive neuro fuzzy, inference system models. Geomech Eng 31(3):291–304. https://doi.org/10.12989/gae.2022.31.3.291
Hajian A, Styles P (2018) Application of soft computing and intelligent methods in geophysics. Springer International Publishing, Cham
Hajian A, Styles P, Zomorrodian H (2011) Depth estimation of cavities from microgravity data through multi adaptive neuro fuzzy interference system. In: Near Surf 2011 - 17th Eur Meet Environ Eng Geophys, pp 12–14. https://doi.org/10.3997/2214-4609.20144374
Horikawa Sichi, Furuhashi T, Okuma S, Uchikawa Y (1990) Composition methods of fuzzy neural networks. IECON Proceedings (Industrial Electronics Conference). pp. 1253–1258.
Ilkhchi AK, Rezaee M, Moallemi SA (2006) A fuzzy logic approach for estimation of permeability and rock type from conventional well log data: an example from the Kangan reservoir in the Iran Offshore Gas Field. J Geophys Eng 3:356–369. https://doi.org/10.1088/1742-2132/3/4/007
Jahed Armaghani D, Tonnizam Mohamad E, Momeni E et al (2015) An adaptive neuro-fuzzy inference system for predicting unconfined compressive strength and Young’s modulus: a study on Main Range granite. Bull Eng Geol Environ 74:1301–1319. https://doi.org/10.1007/s10064-014-0687-4
Jalal FE, Xu Y, Iqbal M et al (2021) Predictive modeling of swell-strength of expansive soils using artificial intelligence approaches: ANN, ANFIS and GEP. J Environ Manage 289:112420. https://doi.org/10.1016/j.jenvman.2021.112420
Jang J-SR (1993) ANFIS architecture. IEEE Trans. Syst. Man Cybern. 23:665–685
Jang JSR, Sun CT, Mizutani E (1997) Neuro-fuzzy and soft computing-a computational approach to learning and machine intelligence [book review]. IEEE Trans Automat Contr 42:1482–1484. https://doi.org/10.1109/TAC.1997.633847
Kanungo DP, Sharma S, Pain A (2014) Artificial neural network (ANN) and regression tree (CART) applications for the indirect estimation of unsaturated soil shear strength parameters. Front Earth Sci 8:439–456. https://doi.org/10.1007/s11707-014-0416-0
Kayabasi A (2012) Prediction of pressuremeter modulus and limit pressure of clayey soils by simple and non-linear multiple regression techniques: a case study from Mersin, Turkey. Environ Earth Sci 66:2171–2183. https://doi.org/10.1007/s12665-011-1439-4
Kimiaefar R. Siahkoohi HR, Hajian A., Kalhor A.,(2018) Random noise attenuation by Wiener-ANFIS filtering, J App Geophy,159,453-459.
Mobarra M, Hajian A, Rahgozar M (2013) Application of artificial neural networks to the prediction of TBM penetration rate in TBM-driven Golab water transfer tunnel. In: International Conference on Civil Engineering Architecture & Urban Sustainable Development 27&28 November 2013, Tabriz, Iran
Nadiri AA, Chitsazan N, Tsai FT-C, Moghaddam AA (2014) Bayesian artificial intelligence model averaging for hydraulic conductivity estimation. J Hydrol Eng 19:520–532. https://doi.org/10.1061/(asce)he.1943-5584.0000824
Nalbant M, Gokkaya H, Toktaş İ (2007) Comparison of regression and artificial neural network models for surface roughness prediction with the cutting parameters in CNC turning. Model Simul Eng 2007:1–14. https://doi.org/10.1155/2007/92717
Nourani V, Mogaddam AA, Nadiri AO (2008) An ANN-based model for spatiotemporal groundwater level forecasting. Hydrol Process 22:5054–5066. https://doi.org/10.1002/hyp.7129
Sarmadian F, Keshavarzi A (2010) Developing pedotransfer functions for estimating some soil properties using artificial neural network and multivariate regression approaches. World Acad Sci Eng Technol 72:501–507
Shahin MA, Jaksa MB, Maier HR (2001) Artificial neural network applications in geotechnical engineering. Aust Geomech J 36:49–62
Sharma LK, Singh R, Umrao RK et al (2017a) Evaluating the modulus of elasticity of soil using soft computing system. Eng Comput 33:497–507. https://doi.org/10.1007/s00366-016-0486-6
Sharma LK, Vishal V, Singh TN (2017b) Developing novel models using neural networks and fuzzy systems for the prediction of strength of rocks from key geomechanical properties. Meas J Int Meas Confed 102:158–169. https://doi.org/10.1016/j.measurement.2017.01.043
Sihag P, Tiwari NK, Ranjan S (2019) Prediction of unsaturated hydraulic conductivity using adaptive neuro- fuzzy inference system (ANFIS). ISH J Hydraul Eng 25:132–142. https://doi.org/10.1080/09715010.2017.1381861
Takagi T, Sugeno M (1983) Derivation of fuzzy control rules from human operator’s control actions. IFAC Proc 16:55–60. https://doi.org/10.1016/S1474-6670(17)62005-6
Taşan S, Demir Y (2020) Comparative analysis of MLR, ANN, and ANFIS models for prediction of field capacity and permanent wilting point for Bafra plain soils. Commun Soil Sci Plant Anal 51:604–621. https://doi.org/10.1080/00103624.2020.1729374
Tayfur G, Nadiri AA, Moghaddam AA (2014) Supervised intelligent committee machine method for hydraulic conductivity estimation. Water Resour Manag 28:1173–1184. https://doi.org/10.1007/s11269-014-0553-y
Tu JV (1996) Advantages and disadvantages of using artificial neural networks versus logistic regression for predicting medical outcomes. J Clin Epidemiol 49(11):1225–1231. https://doi.org/10.1016/S0895-4356(96)00002-9
Umrao RK, Sharma LK, Singh R, Singh TN (2018) Determination of strength and modulus of elasticity of heterogenous sedimentary rocks: an ANFIS predictive technique. Meas J Int Meas Confed 126:194–201. https://doi.org/10.1016/j.measurement.2018.05.064
Wu M, Congress SSC, Liu L et al (2021) Prediction of limit pressure and pressuremeter modulus using artificial neural network analysis based on CPTU data. Arab J Geosci 14. https://doi.org/10.1007/s12517-020-06324-4
Yang ZR, Yang Z (2014) Artificial neural networks. Compr Biomed Phys 6:1–17. https://doi.org/10.1016/B978-0-444-53632-7.01101-1
Yesiloglu-Gultekin N (2021) Performance prediction modeling of standard penetration blow count of clayey soils by two non-linear tools. Arab J Geosci 14. https://doi.org/10.1007/s12517-021-06649-8
Yusefzadeh S, Nadiri AA (2021) Estimation hydraulic conductivity via intelligent models using geophysical data. Adv App Geo 11:382–404. https://doi.org/10.22055/AAG.2020.29223.1970
Zaki MFM, Ismail MAM, Govindasamy D, Leong FCP (2020) Prediction of pressuremeter modulus (E M) using GMDH neural network: a case study of Kenny Hill Formation. Arab J Geosci 13. https://doi.org/10.1007/s12517-020-05336-4
Zhang W, Zhang R, Wu C et al (2020) State-of-the-art review of soft computing applications in underground excavations. Geosci Front 11:1095–1106. https://doi.org/10.1016/j.gsf.2019.12.003
Zhao J, Bose BK (2002) Evaluation of membership functions for fuzzy logic controlled induction motor drive. In: IECON Proceedings (Industrial Electronics Conference), pp 229–234
Ziaie Moayed R, Kordnaeij A, Mola-Abasi H (2018) Pressuremeter modulus and limit pressure of clayey soils using GMDH-type neural network and genetic algorithms. Geotech Geol Eng 36:165–178. https://doi.org/10.1007/s10706-017-0314-9
Author information
Authors and Affiliations
Contributions
Asieh Alidousti: conceptualization, methodology, visualization, investigation, and writing—reviewing and editing. Rassoul Ajalloeian: investigation, resources, supervision, and reviewing and editing. Alireza Hajian: methodology, validation, supervision, and reviewing and editing.
Corresponding author
Ethics declarations
Competing interest
The authors declare no competing interests.
Additional information
Responsible Editor: Zeynal Abiddin Erguler
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Alidousti Shahraki, A., Ajalloeian, R. & Hajian, A. ANN and MANFIS to predict pressuremeter modulus and limit pressure, case study: Isfahan metro line 2. Arab J Geosci 16, 104 (2023). https://doi.org/10.1007/s12517-022-11170-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12517-022-11170-7