
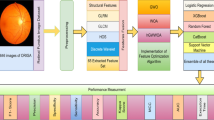
Abstract
Glaucoma is one of the leading causes of visual impairment worldwide. If diagnosed too late, the disease can irreversibly cause severe damage to the optic nerve, resulting in permanent loss of central vision and blindness. Therefore, early diagnosis of the disease is critical. Recent advancements in machine learning techniques have greatly aided ophthalmologists in timely and efficient diagnosis through the use of automated systems. Training the machine learning models with the most informative features can significantly enhance their performance. However, selecting the most informative feature subset is a real challenge because there are 2n potential feature subsets for a dataset with n features, and the conventional feature selection techniques are also not very efficient. Thus, extracting relevant features from medical images and selecting the most informative is a challenging task. Additionally, a considerable field of study has evolved around the discovery and selection of highly influential features (characteristics) from a large number of features. Through the inclusion of the most informative features, this method has the potential to improve machine learning classifiers by enhancing their classification performance, reducing training and testing time, and lowering system diagnostic costs by incorporating the most informative features. This work aims in the same direction to propose a unique, novel, and highly efficient feature selection (FS) approach using the Whale Optimization Algorithm (WOA), the Grey Wolf Optimization Algorithm (GWO), and a hybridized version of these two metaheuristics. To the best of our knowledge, the use of these two algorithms and their amalgamated version for FS in human disease prediction, particularly glaucoma prediction, has been rare in the past. The objective is to create a highly influential subset of characteristics using this approach. The suggested FS strategy seeks to maximize classification accuracy while reducing the total number of characteristics used. We evaluated the efficacy of the proposed approach in classifying eye-related glaucoma illnesses. In this study, we aim to assist professionals in identifying glaucoma by utilizing a proposed clinical decision support system that integrates image processing, soft-computing algorithms, and machine learning, and validates it on benchmark fundus images. Initially, we extract 65 features from the 646 retinal fundus images in the ORIGA benchmark dataset, from which a subset of features is created. For two-class classification, different machine learning classifiers receive the elected features. Employing 5-fold and 10-fold stratified cross-validation has enhanced the generalized performance of the proposed model. We assess performance using several well-established statistical criteria. The tests show that the suggested computer-aided diagnosis (CAD) model has an F1-score of 97.50%, an accuracy score of 96.50%, a precision score of 97%, a sensitivity score of 98.10%, a specificity score of 93.30%, and an AUC score of 94.2% on the ORIGA dataset. To demonstrate its excellence, we compared the suggested approach’s performance with other current state-of-the-art models. The suggested approach shows promising results in predicting glaucoma, potentially aiding in the early diagnosis and treatment of the disease. Furthermore, real-time applications showcase the proposed approach’s suitability, enabling its deployment in areas lacking expert medical practitioners. Overburdened expert ophthalmologists can use this approach as a second opinion, as it requires very little time for processing the retinal fundus images. The proposed model can also aid, after incorporating required modifications, in making clinical decisions for various diseases like lung infection and, diabetic retinopathy.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Over the last ten years, there has been a significant increase in interest in biomedical research. The significant amount of clinical and healthcare data generated as a result of technological advancements in medical research may help to explain this. Healthcare professionals who use this data to improve patient care are immensely intrigued by its potential. This information essentially promotes improved illness diagnosis and, as a result, better healthcare services. The biomedical data come from many different sources, are widely accessible, and include a large spectrum of information. However, it is often impractical to handle vast volumes of data manually. Therefore, people use data mining techniques to enhance existing data analysis methods and extract more profound and valuable insights from the data. Real-world datasets have a variety of traits or properties. It is possible that not all of these characteristics will be necessary to extract useful data from the databases. When certain machine learning or data mining approaches process the data, the presence of non-informative properties in the data does not enhance the learning algorithm’s effectiveness. In reality, these characteristics may sometimes make the learning algorithm perform worse while also lengthening the training period. As a result, it is crucial to carefully choose the ideal collection of characteristics for a methodical approach. Through the use of fewer features and lower training costs, this endeavor seeks to improve and maintain the performance of the underlying learning algorithm. Furthermore, the reduced proportions of the features would necessitate a lower quantity of storage space. Feature selection (FS) is one of the data pre-processing methods often used in data mining and machine learning applications [1]. The sizeable amount of high-dimensional data produced by modern technologies has made FS a crucial step in the data pre-processing process. Duplicate, irrelevant, and noisy properties in high-dimensional data can severely impact the accuracy of classification. Scholars use it when datasets may contain duplicated and unimportant data. By removing superfluous features, FS reduces dimensionality and improves classification accuracy. We can describe it as an optimization issue, aiming to enhance or sustain classification performance by selecting the optimal feature collection. Basically, there are three different feature selection approaches [2]: filter model, wrapper model, and embedded model. When there are more features (characteristics), it becomes computationally expensive to use exhaustive subset search techniques to find the right feature subset. This can be attributed to the exponential increase in the number of potential feature subsets. For the dataset with N features, there are a total of 2N possible feature subset options. The FS procedure is a challenging combinatorial issue. We must use an FS approach to select the subset that exhibits the best performance. Research has demonstrated that metaheuristic algorithms excel in combinatorial tasks [3]. In order to quickly locate the almost ideal feature subset, the metaheuristic algorithms have the capacity to investigate 2N possible feature subsets.
The Branch and Bound method use a monotonic evaluation function and has a low time complexity [4]. Because it is unable to handle large amounts of data, designing an evaluation function is very difficult. Other methods that may be used in this situation include scatter search and greedy search, according to [5, 6]. Many of these algorithms face challenges in avoiding local optima and incur significant computational burdens [7]. Because of their ability to efficiently find ideal solutions, FS methods based on evolutionary algorithms have gained popularity in recent years. In order to efficiently and reliably provide solutions for optimization issues, evolutionary algorithms make use of biological notions of evolution [8]. The term “chromosome” refers to each possible result. A chromosome contains a gene, a piece of structural DNA that determines the presence or absence of a certain characteristic. A gene’s value may be either 1 or 0, with 1 indicating the existence of a certain feature and 0 indicating its absence. We use the population to compile a complete list of viable solutions. A contender is a popular term for a chosen option. A candidate’s chosen fitness value from the population influences their performance. As the candidate’s fitness value rises, so does their performance. Through the use of genetic procedures like crossover and mutation, a small number of candidates increase population diversity [9].
Consequently, researchers have noted the use of evolutionary algorithms in diagnosing various ailments, with the aim of improving patient care through efficient and timely prediction. Researchers [12] used the augmented shuffled frog leaping algorithm to predict illnesses such as lung cancer and colon tumors, among others. Similar to [13, 14] covered the particle swarm optimization (PSO) technique for predicting lung cancer. Furthermore, [10] used the gravitational search-based algorithm (GSA) developed in [11] to forecast illnesses including breast cancer, heart disease, and dermatological problems. In recent years, the grasshopper optimization algorithm (GOA) [15], has become a very potent optimization tool. This technique replicates the natural foraging behaviour of a group of grasshoppers. The method is successful because it successfully strikes a good balance between exploration and exploitation, thereby limiting trapping in local optima. The experimental results presented in [15] provide additional proof that the GOA can either increase or decrease the average fitness of a population of randomly generated search agents over the course of iterations, depending on whether the goal is to maximize or minimize fitness. The researchers are also employing several widely recognized optimization algorithms, such as PSO [13], Bat Algorithm [16], States of Matter Search [17], Cuckoo Search [18], Flower Pollination Algorithm [19], Firefly Algorithm [20], GSA [10], and Genetic Algorithm [21, 22].
Meta-heuristic algorithms that draw their inspiration from nature have become well-known in recent years as effective answers to difficult real-world issues. These algorithms have shown astounding performance and efficacy. These algorithms may make use of the population’s vast knowledge in order to get the best results. These algorithms include the Elephant Herd Optimizer [23], Moth Search Algorithm [24], Cuckoo Search Algorithm [25], Monarch Butterfly Optimisation [26, 27], Elephant Herding optimization algorithm [28], Krill Herd [29] and Teaching learning-based algorithm [30]. Numerous optimisation issues, including complex design issues, node localization in wireless sensor networks, fault diagnosis, economic load dispatch, high-performance computing, high-dimension optimisation problems, image matching, and the knapsack problem, are commonly solved using these algorithms [31,32,33,34,35,36,37,38,39]. Various methods have been shown to be dependable and efficient in resolving various problems. Additionally, a number of academics have tried to use stochastic approaches to address feature selection problems. These techniques include genetic algorithms [21], simulated annealing [40], tabu search [41], bacterial foraging optimization algorithm [42], and artificial bee colonies [43]. Researchers [44, 45] have used a record-to-record trip approach based on fuzzy logic to address rough set attribute reduction issues. According to [46], the method entails thinking of attributes as graph nodes in order to build a graph model. To solve the feature selection issue, one can implement ant colony optimization approach to choose the nodes [47]. Proposed an FS method based on artificial bee colonies and differential evolution. Authors verified the method using fifteen datasets from the UCI collection. Previous research [48, 49] has used the Ant Lion Optimizer (ALO) as a feature selection model. The Flower Pollination Algorithm (FPA) [51], the Dragonfly Algorithm [52], and the Grey Wolf Optimizer (GWO) are modern algorithms that have effectively solved FS issues. Researchers have used a salp swarm algorithm (SSA) based on chaos to improve feature selection [50, 53]. The authors also employed a competent crossover strategy [55] to enhance the SSA’s ability to handle the FS difficulty. In order to find optimality, the authors’ work [51] presented a hybrid GWO-ALO algorithm that combines the global search powers of GWO with the exploitation capabilities of ALO. Recent research [54] employed the whale optimization approach (WOA) as a feature selection technique. Scholars have also combined the approaches of simulated annealing (SA) and WOA [52] to investigate feature subsets and choose the best feature set. The findings of this work contribute to the body of evidence showing that, when tested on benchmark image datasets, GWO, WOA, and their hybrid algorithms provide competitive results. These algorithms are good at locating key characteristics. These factors have led to the use of these three techniques in the field of feature selection for the classification of glaucoma, globally spreading an eye-related disease.
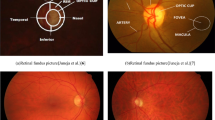
Glaucoma (Fig. 1) is a medical disorder that has the potential to harm the eye’s optic nerve. Over time, the issue gets worse. Experts believe a large buildup of pressure inside the eye is the main cause of the incident. The elevated intraocular pressure has harmed the optic nerve. The brain receives visual information from the optic nerve. Glaucoma’s increasing pressure over time can cause considerable damage that can lead to vision loss, including permanent impairment and the potential development of total blindness. Regaining lost vision might be difficult. Lowering intraocular pressure has the potential to help restore vision. In modern times, people in their 40s and older frequently suffer from this condition, but those aged 55 and above are the most commonly affected. Because glaucoma can take many different forms, it can be difficult to track how the disease is changing and could even advance undetected.

Figure depicting normal eye and glaucomatous eye
The eye contains the fluid known as aqueous humor. It normally comes out of a mesh-like duct in a typical person. The blockage in the duct causes the eye to continuously produce fluid, which accumulates over time. The medical community is still researching the cause of the channel obstruction, making it a hereditary problem. Inappropriate use of the drainage angle. The accumulation of fluid causes the pressure inside the eye to rise. We refer to the pressure within the eye as intraocular pressure (IOP) damage to the optic nerve. Millions of incredibly tiny nerve fibers make up the optic nerve. In many aspects, it is similar to various electric cables made up of countless tiny wires. Any human will become more prone to developing blind spots that impair vision when these nerve fibers start to deteriorate over time. These blind zones are rarely noticeable unless a person has lost a significant amount of their visual nerve fibers. Simple causes of glaucoma include a minor wound, an infection, or any other type of damage that causes obstruction of blood vessels in an average person’s eye. Although it is extremely rare, there are situations when eye surgery may be used to treat another issue.
Glaucoma, the second most common cause of blindness worldwide (after cataract), is a common chronic disorder that poses a serious risk to ocular health [56]. The World Health Organization (WHO) estimates that glaucoma affects 65 million people globally [57]. People sometimes refer to glaucoma as the “silent theft of sight” [58] due to its irreversible nature and the absence of symptoms in its early stages. Even though there is no known cure for glaucoma at this time, early detection and the right care may greatly help patients avoid visual loss and lower their risk of becoming blind. Clinical settings commonly use the measurement of intraocular pressure (IOP) to detect glaucoma. IOP is a well-known glaucoma symptom. This disorder has the potential to have negative consequences such as optic nerve injury, abnormalities in the visual field, and eventually blindness [59]. Therefore, glaucoma evaluation considers IOP as a crucial signal. The IOP of certain people with glaucoma, however, may decrease within the normal range, making this technique ineffective [60]. As a result, relying solely on IOP measurement may result in missed detection of these specific situations. Conducting optic nerve head (ONH) tests, which require clinical ophthalmologists to evaluate glaucoma using retinal pictures, is another frequently used technique for glaucoma screening [61]. Ophthalmologists routinely manually improve the retinal picture throughout the glaucoma screening procedure and make diagnoses based on their experience and domain-specific knowledge. The ineffectiveness and length of the diagnostic procedure render the two approaches listed above unsuitable for population screening. As a result, the development of an automated glaucoma screening system is both very advantageous and necessary for a broad and early diagnosis of the problem. However, the development of digital retinal image processing and artificial intelligence has made it feasible to perform automated glaucoma screening. Large-scale screening can benefit from this method due to its reliable accuracy and efficiency. Pathological signs of glaucoma often include an expanded optic cup and degradation of the retinal nerve margin [62, 63]. The ONH is the primary cause of these abnormal symptoms. As a result, the ONH evaluation is an important method for glaucoma screening. Clinical measurement analysis and image-based feature analysis are the two main groups of automated glaucoma diagnostic techniques that use fundus pictures. The term “clinical measurement analysis” refers to the evaluation of certain geometric features related to glaucoma, such as the ratio of the optic cup to disc (CDR) [64], the diameter of the optic disc [65], and the area of the optic cup. The most important of these traits, as recognized by clinical ophthalmologists, is the CDR, which shows a substantial link with glaucoma screening. An observer may quickly recognize the optic disc (OD) in a color retinal picture because of its distinctive appearance as a bright yellow oval area. It may be challenging to see the optic cup (OC), located in the middle of the OD and distinguished by its brilliant oval or circular shape. The remaining peripheral portion of the optic disc is referred to as the neuroretinal rim, with the exception of the optic cup area. A bigger CDR indicates a higher possibility of developing glaucoma, and conversely, a smaller CDR predicts a lower probability, as shown in Fig. 1. This observation is based on clinical experience and domain knowledge. Researchers have developed numerous automated glaucoma diagnosis techniques, many of which rely on clinical traits such as the CDR. A few recent state-of-the-art research and the most current methods that academics have developed for glaucoma prediction are shown in Table 1 below.
Examining fundus images requires the time-consuming and computationally complex processing of large amounts of data. Expert ophthalmologists analyze the subject’s fundus images to confirm the disease. The observation takes time and is subject to error due to its intra-observability. Moreover, there is always a scarcity of expert medical practitioners. Hence, an artificial intelligence-based computer-aided diagnosis (CAD) system is today’s need. To achieve better results from CAD systems, effective approaches necessitate feature collection, selection, and organization as critical components of comprehensive data analysis. Glaucoma is a complex illness, and various features have to be analyzed from the patient’s retinal fundus image, which makes the confirmation of this disease and distinguishing between healthy and glaucomatous eyes a very challenging task. The hybrid approach improves the accuracy and usefulness of finding glaucoma in fundus pictures by combining Grey Wolf Optimization (GWO) and the Whale Optimization Algorithm (WOA). This makes it possible to create reliable and highly efficient CAD system.
If this chronic illness is not found in its early stages, it might cause permanent blindness. There are several manual scanning techniques, but they are costly, time-consuming, and require the assistance of specialists in these fields. It’s critical to use image processing, feature selection, and machine learning-based classification models to identify the illness sooner in order to prevent such detrimental effects. All of these procedures have been used in this work to classify images from the ORIGA benchmark dataset. Three nature-inspired metaheuristic algorithms—GWO, WOA, and integration of these two—are used in the fundamental process of selecting the most important features (the hybrid model presented from our side is the original scientific contribution). The empirical study presented the research that identifies the optimal and most effective features required for the diagnosis of a prevalent eye disease glaucoma. The study concludes by demonstrating exceptional performance and outcomes.
Using the most recent artificial intelligence techniques, researchers have attempted to develop a very effective diagnosis system for eye-related disorders [104,105,106,107]. This recent article presents the Fundus-DeepNet system [104] where the proposed approach uses deep learning to classify many eye illnesses by merging feature representations from two fundus images. The intricate dataset Ophthalmic Image Analysis-Ocular Disease Intelligent Recognition (OIA-ODIR), which includes numerous fundus images displaying eight different eye illnesses, has undergone extensive testing. Ophthalmologists and other eye experts can diagnose and determine the appropriate course of treatment for a range of retinal disorders by using the author’s suggested approach for segmenting and extracting clinically meaningful information from the retinal blood vessels [105]. Next study rigorously evaluates and categorizes approaches for identifying veins and arteries in fundus images as either automatic or semi-automatic [106]. In the subsequent study rigorously evaluates and categorizes approaches for identifying veins and arteries in fundus images as either automatic or semi-automatic [107].
1.1 Motivation and the novelty in the work
This study introduces a novel hybrid FS algorithm, termed GWOWOA, which combines the Grey Wolf Optimization Algorithm (GWO) with the Whale Optimization Algorithm (WOA). The study comprehensively investigates three FS algorithms—GWO, WOA, and GWOWOA—for glaucoma classification tasks using fundus retinal images belonging to the ORIGA benchmark dataset. Multiple experiments were conducted on this well-established glaucoma dataset. The objective is to enhance glaucoma classification accuracy, robustness, and scalability using a fundus image dataset. Initially, 65 features belonging to five vital categories were extracted using self-created, handcrafted coding scripts. Additionally, the study evaluates six classifiers: support vector machine, random forest, logistic regression, XGBoost, catboost, and ensemble of all five. Evaluation metrics include accuracy, precision, sensitivity, specificity, F1-score, Kappa score, MCC, and ROC analysis. Our approach is compared against recent FS brave-new-ideas based approaches, showing improvements in feature selection process, classification accuracy, and other performance measuring parameters. Our suggested approach offers an exploration-exploitation balance that enhances the algorithms’ ability to identify relevant features while optimizing computational efficiency. By leveraging optimization capabilities alongside feature importance estimation, the hybrid approach can yield robust and generalizable FS results. The objective of combining the algorithms for FS in glaucoma classification using a fundus image dataset is to identify the most relevant features associated with this disease. These algorithms aim to improve the accuracy of glaucoma classification by selecting a subset of informative features while reducing dimensionality and removing irrelevant or redundant genes from the dataset. The goal is to enhance the performance of ML classifiers by focusing on the most discriminative features for accurate glaucoma diagnosis and prognosis. The novelty of this paper stems from the introduction of a three-phase hybrid classification model, combining feature extraction, feature selection, and finally two-class classification using machine learning classifiers that are trained on these selected features. This hybrid approach offers a unique solution to the challenge of FS in glaucoma classification using a fundus image dataset. This novel algorithm addresses the limitations of existing methods and aims to improve the accuracy and efficiency of glaucoma classification models. The GWOWOA algorithm introduces a novel approach for determining feature importance in glaucoma classification. Its utilization marks a departure from traditional methods and promises improved performance in identifying relevant features from the ORIGA dataset. These three algorithms, while not previously employed in the realm of glaucoma detection using fundus image datasets, present a promising avenue for optimizing FS. Its novel approach to optimization offers potential improvements in the efficiency and accuracy of FS processes. Additionally, the incorporation of these algorithms underscores the importance of exploring innovative techniques to enhance cancer classification models and advance research in the field. We have implemented 5-fold and 10-fold cross-validation approaches in this work. Convergence curves and the effect of population size are some of the characteristics of the in-depth analysis performed in this work, which are rarely observed in recent state-of-the-art articles. The novelty of this research stems from several key contributions aimed at advancing glaucoma classification from the fundus image dataset. The results generated from our approach are highly auspicious; our proposed clinical decision support system requires less human intervention, has a robust nature, high reliability, and is fast-responding in nature.
In a nutshell, highlighting points of this work are as follows:
-
After conducting a thorough analysis of the current literature, it is evident that there is vast potential for improving features and features count in the field of glaucoma detection. This study presents a new feature selection technique called the hybrid GWOWOA, which combines the strengths of the GWO and the WOA. This technique has the ability to remove irrelevant features from the feature space, thereby improving classification accuracy and reducing computing costs. This proposed algorithm represents a significant innovation and scientific contribution from the author. With our current understanding, we are pioneering the use of these algorithms to detect glaucoma, effectively addressing a major research gap in the field.
-
This work presents a novelty by applying three feature selection algorithms to select the most influential features, along with highly in-depth experimentation and analysis. We have conducted a comprehensive set of experiments using the ORIGA benchmark dataset, covering various tests. In addition, this research provides a comprehensive analysis of various characteristics to demonstrate the effectiveness of the proposed methodology. By including the analysis of confusion measures and ROC curves, we have thoroughly evaluated the performance of six machine learning classifiers. The current assessment involved calculating eight metrics used to measure efficiency. These metrics are important for assessing the effectiveness of the classifiers’ performance. This study highlights the importance of timing in the development of a soft-computing approach and the training and testing of a machine learning model, as demonstrated by the execution of a 5- and 10-fold cross-validation method.
-
In this work thorough experimentation and analysis accompany the selection process, showcasing a highly professional approach. This study aims to showcase the researchers the most informative features required for the screening of this disease along with a highly reliable and effective clinical decision support system for professionals specializing in ophthalmology. Furthermore, our main objective is to offer a software-driven solution that can assist in addressing the decrease in human visual acuity by enabling quick, effective, and accurate identification of ocular infections. The tool demonstrates a high level of professionalism by allowing for customization to connect with mobile and wearable medical devices. This makes it suitable for use in environments where there may be a shortage of skilled medical professionals.
The rest of the paper is organized as follows: Section 2 is dedicated to proposed approach mentioning dataset, methodology along with the algorithms applied; Section 3 depicts the computed results in tabular format and graphical format in detailed fashion along with discussion on the results and the comparison of the suggested approach with recent state-of-the-art published studies. Finally, section 4 concludes the work.
2 Proposed approach
2.1 Dataset and the details about features extracted
The dataset used in this empirical study is ORIGA_ALL_FEATURES dataset. The Table 2 given below provides the information about the dataset.
The dataset created by extracting 65 features (Table 2) from ORIGA images [103] contains 646 instances i.e., 646 rows of data. The dataset contains 66 columns, out of which the 65 columns are features and the last column is the classification column. The last column is the column with heading (glaucoma) which contains discrete data. The data is either 0 or 1. Here, 0 represents the person does not have glaucoma while 1 represents that the person has glaucoma. In 646 instances of data, we have 166 instances containing 1 s while the other 480 instances contain 0 s. Table 3 present the list and Table 4 depicts short description about extracted features.
2.1.1 Structural features (cup diameter, disk diameter, cup to disk ratio, RIM, DDLS)
Prior to determining the cup-to-disc ratio, it is necessary to segment the optic disc and optic cup. In this procedure, the area of interest (ROI) is extracted from the input fundus image. The ROI is further subdivided into Red, Green, and Blue channels. The Red component is suitable for optic disc segmentation because to the abundance of information for disc area in the red channel, whereas the Green component is appropriate for optic cup segmentation due to the presence of the appropriate optic cup region in the green channel. Thus, the entire procedure is described with the assistance of Fig. 2, which itself is self-explanatory.

Sample for extraction optic cup and optic disc from Retinal fundus image
2.1.2 GLCM features
The gray-level co-occurrence matrix (GLCM), also known as the gray-level spatial dependency matrix, is a mathematical process of analyzing texture that recognizes the spatial association of pixels. The GLCM functions describe an image’s texture by measuring how frequently pairs of pixels with unique values and in a given spatial relationship appear in an image, generating a GLCM, and extracting statistical measures from this matrix. The size of matrix Mk × Mk, which describes the second-order joint likelihood of a mask-bound image field defined a.
(x(l, n), λ, θ). The (l, n) th element of matrix represents number of times the combined levels l and m occurs in two pixels within the image separated by distance λ along angle θ.Now,let ℑ be a small positive num x(l, n) is the co-occurrence matrix for λ=1 and angle θ. \({x}_p(l)=\sum \limits_{n=1}^{M_k}x\left(l,n\right)\) is marginal row probability. \({x}_q(n)=\sum \limits_{n=1}^{M_k}x\left(l,n\right)\) is marginal row probability. ηp is the grey level intensity of xp. ηq is the grey level intensity of xq. σp and σq are the standard deviation of xp and xq.For each degree, the GLCM final value is calculated, and the mean of these values is returned. Horizontally the values of θ are 0∘,the diagonally it represent 45∘ and 90∘ in vertical direction. Finally, the resulting matrix is calculated with the functionality described below. Table 5 presents the shortlisted GLCM features.
2.1.3 Gray level run length matrix (GLRM)
The GLRM is a matrix that provides details regarding textural features for analyzing an object’s texture. It’s known as a line of pixels in a specific direction with the same intensity values. The sum of such pixels is referred to as the grey level run length, and the number of times it occurs is referred to as the run length value. In GLRM, x(l, n| θ) the (l, n)th element defines the number of runs with gray level l and n in the image along θ. Now let Mk be the discrete value of intensity in the image. Mr be the discrete run lengths in the image. Mp be the voxels number in the image. Mr(θ) is the number of runs along angle θ. Table 6 presents the shortlisted GLRM features.
2.1.4 First order statistical (FoS) features
FoS features can often used to evaluate an image’s texture by the computation of an image histogram showing the likelihood of a pixel appearing in an image. These characteristics rely only on individual pixel values and not on the relationship with the pixels nearby. The first order histogram estimate is given by \(p(c)=\frac{N(c)}{K}\).Here c represents the grey level in the image, K is the total number of pixels in the neighbourhood window centered around the expected pixel and N(c) is the number of pixels of gray value c in the window 0 ≤ c ≤ M − 1.
The FoS characteristics are widely used as described below: mean, standard variation, variance, curtosis, skewness and entropy. Table 7 presents the shortlisted FoS features.
2.1.5 Discrete wavelet transforms (DWT) features
The transformation of wavelets is the division of data, operators or functions into different frequency components and the analysis of each with a resolution corresponding to a scale. Here, Wavelet transforms the picture into four distinct elements, i.e. approximation, horizontal, diagonal and vertical. Approximation variable is used for scaling and three for localization. For images, separate wavelet Transform with One-Dimension filter bank is added to rows and columns of each channel. Here for p rows and q columns, we have suppose the scaling function ℑm, p, q(r, s) and for translation function \({\wp}_{m,p,q}^l\left(r,s\right)\) in Equation () and ().The Horizontal high-pass channels, vertical high-pass channels and diagonals high pass channels are ζH(r, s), ζV(r, s), ζD(r, s).All these important channels are extracted from ℑm, p, q(r, s) scaling function.
Here the three main components of wavelets are diagonal (D), horizontal (H) and vertical (V).
For the image f(r, s) of the size p,q, The discrete wavelet transform is as follows:
j 0 is an arbitrary starting scale and Wℑ(j0, p, q) coefficient define an approximation of f(r, s) at scale j0.The \({W}_{\wp}^l\left(m,p,q\right)\) coefficients add horizontal, vertical and diagonal details for scales m ≥ j0.We normally let j0 =0 and select p=q=2m so that m = 0,1,2,….m-1.
Below is a short mathematical representation of the traits that were retrieved.
-
1.
CDR (Cup Disc Ratio) –The eye is considered normal. The formula to calculate CDR is:
-
2.
GLCM (Grey Level Co-occurrence Matrix) –Grey level Co-occurrence Matrix S(o, t):
-
3.
SRE (Short Run Emphasis) –
Here p(l, m), (l, m)th element define the number of run with grey level l and length m in the image.
-
4.
GLU (Grey Level Uniformity) –
-
5.
where gmax and gmin correspond to the maximum and minimum gray levels respectively and the whole range of gray levels is 255–0.
-
6.
DDLS (Disc Damage Likelihood Scale)-
-
7.
Bicoherence-
|X(w1, w2)| is a magnitude feature and \({e}^{j\phi \left(X\left({w}_1,{w}_2\right)\right)}\) is a phase feature.
-
8.
Energy-
-
9.
Homogenity–
-
10.
Correlation-
-
11.
Contrast-
-
12.
Dissimilarity (dissi)-
-
13.
Entropy-
2.2 Methodology implemented in this work
Using the ORIGA_ALL_FEATURES dataset, the suggested approach here assists in determining if an individual has glaucoma or is healthy. This dataset includes information from 646 cases that was retrieved from snapshots in both the glaucomatous and normal conditions. There are 65 characteristics in the provided ORIGA dataset. The presented dataset has to be normalized since it contains several characteristics with different values. Some characteristics have values that are less than 0 while others have values that are larger than 50 k. The dataset must be normalized as a result. A sklearn pre-processing module called Standard Scaler was used to normalize the dataset. Normalization is a criterion that machine learning estimators must often meet. The estimators could perform poorly if the data are not normalized. After normalizing the dataset, we provide the specified optimizer list the dataset’s dimensions, population size, and number of iterations. Then, after carrying out their tasks, these optimizers provide us the fitness value at each iteration along with a list of features they’ve chosen from among all the features in the dataset. Following the return of a list of chosen features, machine learning analysis is conducted utilizing a variety of machine learning estimators on the supplied list of chosen features from the dataset. These numerous estimators pick up on new dataset characteristics, making predictions that are then measured by a variety of performance criteria. The outcomes are documented for further analysis.
2.2.1 Objective function
The objective Function used for the Grey Wolf Optimizer is Rastrigin Function.
Mathematical implementation of Rastrigin Function-:
The Rastrigin function is mainly used as a performance test problem for optimization algorithms. It is basically a non-linear multimodal function was first proposed in 1974. The Rastrigin function has many local minima it is because the optimization algorithms have to be run from multiple starting points Rastrigin function has only one global minimum, and all other local minimums have value greater than global minimum.
2.3 Recent advances in optimization
In this research [93], a binary version of the Coyote Optimisation Algorithm (COA) called Binary COA (BCOA) was suggested. It was used to choose the best feature subset for classification by utilising a wrapper model’s hyperbolic transfer function. In this manner, a classification algorithm’s performance evaluation was used to determine which features to include. Lévy Arithmetic Algorithm is an improved metaheuristic optimisation method that uses the Lévy random step [94]. Arithmetic operators solve many optimisation problems in Arithmetic Optimisation Algorithm. Its linear search capabilities may prevent ideal solutions, causing stagnation. This paper introduces the Lévy Arithmetic Algorithm by merging the Arithmetic Optimisation Algorithm and the Lévy random step to improve search capabilities and reduce processing demands. Ten CEC2019 benchmark functions, four real-world engineering issues, and microgrids with renewable energy integration Economic Load Dispatch were evaluated. Next study introduces an optimisation method for plate-fin heat exchangers (PFHEs) that aims to minimise the entropy generating units. The method used is Adaptive Differential Evolution with Optional External Archive (JADE) and a modified version called Tsallis JADE (TJADE) [95]. Plate-fin heat exchangers possess significant attributes, including elevated thermal conductivity and efficiency, as well as a substantial heat transfer surface area relative to their volume. These characteristics result in reduced space and energy requirements, weight, and cost. Additionally, the design of plate-fin heat exchangers can consider various geometric and operational parameters.
GPOA, which integrates GOA and POA, is used to segment lesions and train U-Net to identify different types of lesions [96]. The image and vector-based features of fundus images are extracted after flipping, rotation, shearing, cropping, and translating fundus images. Exponential Gannet Pelican Optimisation Algorithm-trained Deep Q Network (DQN) detects diabetic retinopathy. Equivalently Weighted Moving Average (EWMA), Gannet Optimisation Algorithm (GOA), and Firefly Optimisation Algorithm (FFA) form the EGFOA. This study presents a new and enhanced firefly algorithm (IFA) that utilises a Gaussian distribution function for the optimal chiller loading design [97]. The study demonstrates the effectiveness of the proposed method by conducting two case studies. These studies compare the results of the developed model using IFA with those of traditional firefly algorithm and other optimisation methods found in literature. The study focuses on the optimisation problem of minimising energy consumption in multi-chiller systems. The objective function is to reduce energy consumption, and the optimum parameter to achieve this is the partial loading ratio of each chiller. Chiller loading optimisation strategies have been presented recently [98]. In general, the optimisation problem minimises chiller energy use while meeting cooling demand. Continuous parameters optimisation problems can be solved efficiently with the CSA (cuckoo search algorithm). CSA relies on cuckoo species’ obligate brood-parasitic behaviour and birds’ and fruit flies’ Lévy flying. Its early studies suggest it could outperform existing algorithms. This research presents a differential operator (DCSA) CSA technique for optimal chiller loading design [98]. Next study proposes a modified grasshopper optimisation technique for non-linear wireless channel equalisation [99]. Although grasshopper optimisation algorithm (GOA) is efficient, it gets caught in local optima after some iterations due to swarm diversity loss. GOA includes no provision to maintain elite grasshoppers detected at each index, which weakens its exploitation and convergence rate. This research modifies GOA in three ways to overcome its limitations. Inefficient search regions are detected by a threshold setting. Lévy Flight is combined with the basic GOA to increase grasshopper swarm diversity, and the greedy selection operator preserves exceptional grasshoppers at every index. The modified grasshopper optimisation algorithm (MGOA) outperforms metaheuristic methods. This study introduces a cheetah-based optimisation algorithm (CBA) that incorporates the social behaviour of these animals [100]. The proposed CBA is tested against seven well-known optimizers using three diverse benchmark problems. Lastly, the study provides insights into research issues and directions in the CBA design. In [101] scholars proposed a beta distribution and natural gradient local search-based modified social spider optimisation (SSO) (MSSO) to improve SSO performance. The MSSO’s performance is tested using Loney’s solenoid benchmark and a brushless direct current motor benchmark to compare the SSO with the proposed MSSO. In the next study, authors presented a meerkat optimisation algorithm (MOA) by mimicking their natural behaviour [102]. Meerkat survival techniques, whose sentinel system allows them to switch behaviour patterns, inspired MOA. Some mathematical aspects of meerkat optimisation algorithm were proven, and classical optimisation test functions verify MOA’s advantages. MOA solves real-world engineering issues with constraints, proving its efficacy and excellence.
2.4 Rationale behind selecting GWO and WOA
The Grey Wolf Optimization (GWO) algorithm is an optimization algorithm that draws inspiration from the social behaviour of grey wolves. It is a population-based approach that aims to find optimal solutions. A wide range of optimization problems, including feature selection in machine learning tasks, have utilized it. Researchers widely regard this method as the preferred choice for selecting features from a large set of retinal fundus images for glaucoma diagnosis. Its key properties include exploration and exploitation, efficiency, a population-based approach, adaptability, robustness to noise, and parallelizability. In summary, the GWO algorithm shows great potential for selecting features from retinal fundus images for glaucoma diagnosis. Its ability to balance exploration and exploitation, along with its efficiency, adaptability, robustness, and parallelizability, make it a highly professional choice. These dynamic characteristics (Leader-Follower Hierarchy, Exploration and Exploitation, Dynamic Search Intensity, Encouragement of variation and Local and Global Search) of the GWO allow for effective feature selection from a sizable set of original features in the context of diagnosing human diseases. In order to efficiently uncover pertinent features for illness detection while managing the complexity of high-dimensional feature spaces, GWO combines local and global search algorithms, encourages diversity, and strikes a balance between exploration and exploitation.
The Whale Optimization Algorithm (WOA) is an optimization algorithm that draws inspiration from the social behaviour of humpback whales. It has been utilized for a wide range of optimization problems, including feature selection. Practitioners widely recognize this method as the best option for selecting features from a large set of retinal fundus images, which is crucial for diagnosing human diseases like glaucoma. Its notable features include thorough exploration and exploitation, a population-based approach, a dynamic search strategy, high efficiency, and the ability to perform both global and local searches. In general, the WOA shows great potential for feature selection from a large feature set extracted from retinal fundus images for human disease, such as glaucoma diagnosis. Its exploration-exploitation balance, population-based approach, dynamic search strategy, efficiency, global and local search capabilities, and robustness to noise all contribute to its promise. The WOA’s various dynamic properties, such as its ability to balance exploration and exploitation, update encircling prey dynamically, establish a leader-follower hierarchy, adapt the search space dynamically, and maintain diversity, all contribute to its effectiveness in selecting features for human disease diagnosis from large sets of original features. WOA possesses several characteristics that allow it to efficiently traverse the complex feature space, detect significant features, and enable precise diagnosis of human diseases.
2.5 GWO-WOA hybrid
The hybrid algorithm comprising the two implemented soft-computing algorithms (GWO and WOA) is proposed with an intention that the properties of these two algorithms may enhance the performance, then the individual case, overall, in a joint venture by collaborating each other [81, 82, 83, 84]. GWO-WOA is predicted to increase the WOA Algorithm’s performance. The given method applies the GWO leadership ranking to the WOA’s bubble net attacking strategy. The proposed algorithm selects three best candidate solutions from the entire search agents, the first level alpha(α), the second and third levels in the group beta(β) and delta(δ), and the other search agents will adjust their positions in accordance with the positions of the best search agents to improve the performance of the WOA algorithm. Overall, for the purpose of screening human diseases, the hybrid algorithm that combines WOA and GWO’s dynamic qualities allow for effective feature selection from sizable original feature sets. The hybrid algorithm dynamically adjusts search intensity, incorporates efficient convergence mechanisms, and uses a variety of exploration and exploitation strategies to efficiently navigate the high-dimensional feature space and identify relevant features with high accuracy and efficiency.
Table 8 illustrates the parameters and their corresponding values applied in this hybridized algorithm. Humpback whales use two ways to swim around their prey, as previously indicated. The mathematical model that has been proposed for updating whale positions and the following mathematical representation of this during optimization utilising GWO’s leadership hierarchy is shown below using various equations. Using a bubble-net attack strategy, they use of the hierarchy to update the position of whales.
GWO Equations:
Whale Equations
The following is a formula for GWO leadership: Humpback whales have a shrinking encircling mechanism utilising to update their position using Eq. (29).
Mathematical model and algorithm for optimization
Spiral updating position: To update the position of humpback whales on a spiral path, use the formula below.
And now
2.5.1 Pseudo code
The pseudo code for the proposed HWGO algorithm can be built in the following steps:
Step 1: Create the search agent’s initial population.
Step 2: Determine the value of the objective function for each search agent.
Step 3: ηα= The most suitable candidate.
Step 4: ηβ= The second possible solution.
Step 5: ηδ= The Third candidate solution.
Step 6: While (m < Max number of iterations).
Step 7: for i = 1 to number of each search agent.
Step 8: Make a change to control parameter (κ, N, ψ,l and q).
Step 9: If1i = (q< 0.5),
Step 10: if2 (∣κ ∣ < 1).
Step 11: Update the search agent’s position by (24).
Step 12: else If2 (∣κ ∣ > 1).
Step 13: Pick a search agent at random (ηrand).
Step 14: Update the search agent’s position by (29).
Step 15: end if2.
Step 16: else if1 (q> = 0.5).
Step 17: Update the position of the search agent by (32).
Step 18: end if1.
Step 19: end for.
Step 20: Check to see whether any search agents have left the search space.
Step 21: Calculate the value of each search agent’s objective function.
Step 22: Update the position of ηα,ηβ andηδ.
Step 23 m = m + 1
Step 24: end while
Step 25: return ηα.
Variables used in the algorithm
ηα: The best candidate solution.
ηβ: The second candidate solution.
ηδ: The Third candidate solution.
q: random number in [0,1].
φ: random number in [−1,1].
χ:The shape of the logarithmic spiral is defined by this constant.
η: Humpback whale position vector.
m: used for iterations.
2.5.2 Flowchart
Figure 3 depicts the hybrid algorithm and Fig. 4 represents the diagrammatic representation of the whole suggested process for efficient glaucoma classification.

Flowchart of the GWOWOA hybrid algorithm

Diagrammatic representation of the proposed framework for efficient glaucoma classification
3 Implementation, results and comparison
3.1 Hardware and software
All the experiments have been performed on a machine with Intel Core i5-8250U (8 Gen) at 1.60–1.80 GHz, 8 GB RAM and 64-bit Operating System. Language and the platform used was Python (version 3.7) and Jupyter Notebook. NumPy, Pandas, Seaborn, Matplotlib, Time, Random, Sklearn, and Math libraries were used. Within the python programming language used for coding, different libraries used are NumPy (Version 1.24.1) and Pandas (Version 2.0.3). In this work, normalization have been performed (using min-max approach) during data processing phase.
3.2 Performance measuring indicators and evaluation metrics
The machine learning models, trained using the features identified by soft-computing feature selection methods, present their results and findings in this subsection. The objective of this training was to classify benchmark fundus images into two categories: healthy individuals and those with glaucoma. The confusion matrix, as shown in Table 9 and Fig. 5, is a performance metric used in machine learning classification tasks with multiple potential outputs. The table displays four unique combinations of actual and forecasted values. The confusion matrices measure roughly two by two. People often use this chart to demonstrate a specific classification network’s performance. The confusion matrix includes four values: true positive (TP), false positive (FP), true negative (TN), and false negative (FN). We have some confusion matrices that provide insights into the binary classification task of identifying positive cases of glaucoma. This empirical study includes a range of performance assessment metrics, including F1-score, specificity, accuracy, precision, sensitivity, Kappa, MCC, and AUC. We primarily use TP, TN, FP, and FN. False positive, or FP, occurs when a test result indicates the presence of a condition in people who do not actually have it. Based on the results, it appears that the individual is in excellent health. Regrettably, this prediction proves to be inaccurate and resembles a false alarm, a result that falls short of our initial expectations. Conversely, TP, or true positive, signifies that the individual indeed has glaucoma, which is the desired result. Similarly, FN represents a patient who shows signs of a specific illness, but the diagnostic test produces a negative result. It is evident that the patient has tested positive for glaucoma, which is a very serious condition. On the other hand, TN refers to individuals who do not have an infection and therefore receive a negative test result. Figure 5 displays the confusion matrix for the proposed work, with “negative” (0) indicating normal and “positive” (1) indicating glaucoma.

Representation of the Confusion Matrix used in proposed work
The main metrics for assessing diagnostic accuracy are recall and sensitivity. We determine recall by dividing the number of true positives by the sum of true positives and false negatives, and we represent the true positive rate with sensitivity. The assessment evaluates machine learning’s accuracy in predicting the occurrence of glaucoma infection. The proportion of correct rejections to the overall number of evaluations is equivalent to the combination of sensitivity and the occurrence of incorrect rejections. We calculate accuracy by dividing the number of true negatives by the sum of true negatives and false positives. The measure of specificity determines the ratio of correctly predicted negative cases, while the measure of sensitivity calculates the ratio of correctly predicted positive cases. Studies have shown that machine learning algorithms can provide accurate medical reports for individuals without glaucoma infections. We define recall as a count of precise results. How closely a sample matches the target determines its accuracy. The F1-score is a method that takes into account both the accuracy and recall of the model to calculate a single number, known as the harmonic mean. The precision level of a measurement determines its accuracy in relation to the final result. Precision can be calculated by determining the ratio of true positives to the total of true positives and false positives. Precision is the most crucial measure for assessing the accuracy of the classifier model. The technique calculates the proportion of accurately defined images to the overall number of images in the dataset [108]. The scores for sensitivity and specificity are reliable indicators of performance accuracy. We use the Matthews correlation coefficient (MCC) as a metric to evaluate the accuracy of binary classifications. It provides a fair assessment by considering TP, TN, FP, and FN, even when the classes have different sizes. It plays a vital role in predicting human diseases using machine learning. It offers a comprehensive evaluation measure that considers the balance between sensitivity and specificity in a meticulous manner. This facilitates model selection and optimisation while also ensuring their clinical applicability. The kappa score, also known as Cohen’s kappa coefficient, serves as another statistical measure to evaluate the performance of machine learning models. This is particularly advantageous for assessing models used in classification tasks with categorical outcomes. The calculation determines the level of agreement between the anticipated and observed categories, taking into consideration the possibility of coincidental agreement. The kappa score is crucial in machine learning for predicting human diseases. The kappa score is a valuable indicator for predicting human diseases using machine learning techniques. It enables comparisons between models in terms of their performance and clinical utility. Furthermore, it serves as a measure of agreement that considers the potential for random concurrence.
The ROC curve is a visual representation of how well a classification model performs when it comes to adjusting classification thresholds. A ROC curve illustrates the correlation between the rates of true positive, false positive, and true negative at various classification thresholds. ROC analysis is a reliable method for accurately categorising glaucoma. The ROC curve is a visual representation of the classification’s characteristics, showing the relationship between sensitivity and 1-specificity. It provides valuable information about the measurement’s sensitivity. A partially independent vector refers to the field that exists below the curve. The ROC curve is a visual representation that illustrates the relationship between the true positive rate and the false positive rate. The ROC quantifies the level of distinction among various groups, demonstrating the model’s ability to accurately categorize and examine these groupings. As the true positive rate increases, both the true positive and false positive rates will also increase in proportion. We evaluate the model’s performance by computing the area under the receiver operating characteristic curve, which is a two-dimensional area that extends from the point (0,0) to (1,1). The model used to classify different groups is known as the area under the curve (AUC), indicating a higher level of excellence [109]. We expect the AUC to be 1.0, signifying flawless performance. A value of 0 would indicate a lack of predictive power, while a value of 0.5 would suggest that the model performs no better than random guessing. This is an all-encompassing measure of achievement at every level of acknowledgement.
Parameters values for implemented machine learning models
The following values are finalized for different parameters belonging to various ML classifiers which have shortlisted for this work.
Random Forest Classifier:
n_estimators = 100, max_depth:None, min_samples_split:2, min_samples_leaf:1,max_features:“auto “, max_leaf_nodes: None,max_sample:None.
Logistic Regression:
Penalty = l2, C = 1.0, fit_intercept_scaling = 1, class_weight = None, random_state = None, solver = ‘lbfgs’, max_iter = 100, multi_class = ‘auto’ verbose = 0 warm_start = False n_jobs = None.
Decision Tree Classifier:
Criterion = ‘gini’ splitter = ‘best’ Max_depth = None,min_samples_leaf = 1, min_weight_fraction = 0.0, max_features = None,random_state = None, max_leaf_nodes = None, min_impurity_decrease = 0.0, class_weight = None.
KNN:
N_neighbors = 5,weights = ‘uniform’,algorithm = ‘auto’,leaf_size = 30,metric = ‘minkowski’,metric_rarams = None,n_jobs = None.
Support Vector Machine:
C = 1.0,kernel = ‘rbf’,degree = 3, gamma = ‘scale’, coef0 = 0.0, shrinking = True probability = False, tol = 0.001,cache_size = 200,class_weight = None, verbose = False,max_iter = −1,decision_function = ‘ovr’,break_ties = False,random_state = None.
3.3 Results
We have compressed all of the GWO and WOA results into one comparative table ( Table 10), which shows the overall best results of the entire experimental process. We have compressed all the results of GWO and WOA into a single comparative table due to space constraints and the large number of results we can display. If any reader is interested in seeing these results in detail, we can share them via email (Table 10).
3.3.1 Results of hybrid GWOWOA algorithm
Here are the results of the hybrid GWOWOA algorithm when we have provided the dataset ORIGA_ALL_FEATURES to the particular code. We have performed the experiment on population size (5, 10, 15, 20) and recorded fitness values on iterations (100, 200, 300, 400, and 500). Due to space constraints, we have shown convergence curves for population sizes 10 and 20 only. Tables 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22 show the results generated through the features selected through the hybrid algorithm. Table 23 compiles all previous tables to present the overall best results of the experimentation process. We present the confusion matrix and convergence curve related to these experiments in Figs. 6, 7, 8, 9, 10, 11, 12, 13, 14, 15.

Confusion matrix of best classifier and the combined ROC curves for hybrid algorithm population size was 5 and cross validation was 5-fold

Confusion matrix of best classifier and the combined ROC curves for hybrid algorithm population size was 5 and cross validation was 10-fold

Convergence curves for WOA algorithm when population size was 15

Confusion matrix of best classifier and the combined ROC curves for hybrid algorithm population size was 10 and cross validation was 5 fold

Confusion matrix of best classifier and the combined ROC curves for hybrid algorithm population size was 10 and cross validation was 10-fold

Confusion matrix of best classifier and the combined ROC curves for hybrid algorithm population size was 15 and cross validation was 5-fold

Confusion matrix of best classifier and the combined ROC curves for hybrid algorithm population size was 15 and cross validation was 10-fold

Convergence curves for hybrid algorithm when population size was 20

Confusion matrix of best classifier and the combined ROC curves for hybrid algorithm population size was 20 and cross validation was 5-fold

Confusion matrix of best classifier and the combined ROC curves for hybrid algorithm population size was 20 and cross validation was 10-fold
The column features selected shows the number of features that have been selected from the total features in the dataset at each individual iteration and the fitness value calculated at that iteration.
The column features selected shows the number of features that have been selected from the total features in the dataset at each individual iteration and the fitness value calculated at that iteration.
Convergence evaluation for population 10
The convergence behaviour of Hybrid Grey Wolf Optimizer and Whale Optimization Algorithm is evaluated over the objective function (Rastrigin Function) with population 10 for iterations (100, 200, 300, 400, and 500) and the curves are given below.
The column features selected shows the number of features that have been selected from the total features in the dataset at each individual iteration and the fitness value calculated at that iteration.
The column features selected shows the number of features that have been selected from the total features in the dataset at each individual iteration and the fitness value calculated at that iteration.
Convergence evaluation for population 20
The convergence behaviour of Hybrid Grey Wolf Optimizer and Whale Optimization Algorithm is evaluated over the objective function (Rastrigin Function) with population 20 for iterations (100, 200, 300, 400, and 500) and the curves are given below.
3.4 Discussion
The WOA’s convergence curves indicate stepwise fluctuation in the early iterations, but very modest variability after a specific number of iterations. The WOA’s convergence curves converge swiftly, and we are now exploiting the search space’s dimensions to obtain the optimal result. The switching continues until they have exploited the entire search space. As the iteration progresses to the termination condition, the falling trend of these convergence curves illustrates a population of whales working together to improve results by updating their positions to a much better one. The WOA algorithm features a better balance between exploration and exploitation, which leads to improved convergence. Because the WOA is optimized for a multimodal function, it has similar convergence behavior. As a result, the convergence behavior is consistent across populations.
The GWO’s convergence curves show high fluctuations in the first iteration and very low variations after a certain number of iterations. The convergence curves of the GWO converge quickly as they have explored the whole search space and then started exploitation in the dimensions of the search space, finding the best result. The cycle continues until the search space yields the optimal feature set. The descending trend of these convergence curves depicts the population of wolves that are in collaboration, improving results by updating their positions to a much better one as the iteration moves to the termination condition. The descending trend of these convergence curves depicts the population of wolves that are in collaboration, improving results by updating their positions to a much better one as the iteration moves to the termination condition. The GWO algorithm exhibits superior convergence, suggesting a superior equilibrium between exploration and exploitation. Hence, the convergence behavior is similar for different populations.
The convergence curves of the hybrid of GWO and WOA are much better than those of the Grey Wolf Optimizer and the Whale Optimizer because the hybrid’s convergence curves do not converge as quickly as those of the Whale Optimizer, indicating that it has a good exploration capability, but it exploits the data using the Whale Optimizer’s bubble net attacking method. The curves are the finest compromise between exploration and exploitation. The curves of the hybridized version algorithm are asymptotic due to the use of an objective function. The algorithm updates the search agents’ placements, calculates their fitness values, and selects the best search agent based on the falling trend of these convergence curves. The Grey Wolf Optimizer’s wolves, primarily the Alpha, Beta, and Delta, serve as search agents in the hybrid version of GWO and WOA, providing excellent exploration capabilities, while the whale’s bubble net attacking style enhances prey exploitation.
The proposed approach uses three different algorithms—GWO, WOA, and a hybrid approach that incorporates the traits of both algorithms. The three implemented soft-computing algorithms perform the optimization on the dataset ORIGA_ALL_FEATURES, selecting the most informative features out of a total of 65 features. The primary aim of these methods is to narrow down the initial feature set, which serves as the input for various machine learning classifiers. The key goal is to correctly divide the two distinct types of subject-fundus photographs. We administered multiple distinct tests as part of a comprehensive investigation, using all three methods. Every experiment shares a similar objective function. The experimental framework shows a population size ranging from 5 to 20, with increments occurring at regular intervals of 5. We evaluate the population’s performance by gradually altering the number of iterations, which ranges from 100 to 500 with increments of 100. The classifier then receives the attributes (features) of the instance exhibiting the smallest value of the objective function, without examining or accounting for the remaining four incidences in the research. The tables above indicate that we must gather a minimum of 23 features and a maximum of 40. As a result, the degree of feature reduction is highly variable, ranging from 65% (equal to 23 out of 65) to a maximum of 40 obtained after the evaluation, which is 35% of the maximum possible score of 65 features. In order to determine the execution’s time, a precise inspection of two different perspectives is required. The demonstration also includes the temporal element of iteration in soft computing techniques. After that, an investigation into the temporal specifications for the development and assessment of machine learning models will take place. For this current work, we select and implement six machine learning classifiers. The first five ML classifiers are classical, and the sixth one is the ensemble of all five. We assess the effectiveness of classifiers using a variety of metrics, including accuracy, sensitivity, specificity, and precision. Additionally, the F1-Score, Kappa-Score, Matthews Correlation Coefficient (MCC), and Area under the Curve (AUC) are used. According to the examination of medical images, each of these metrics is essential to the prognosis of human disorders. Research investigations rarely examine all of these calculations simultaneously.
We assess the model’s performance by calculating the percentage of accurate predictions compared to the total number of predictions made. We obtain the accuracy rate by dividing the total number of predictions by the number of accurate forecasts. One of the most important performance indicators is the measure of accuracy, and our findings in this particular area deserve attention. The accuracy has significantly increased in the hybrid algorithm’s integration with the Ensemble classifier, rising to an auspicious rate of 96.55%. The GWO case has an accuracy of 95.6%, the WOA case has an accuracy of 95.2%, and the hybrid case has the lowest accuracy rate at 93.1%, which is also very satisfactory. The hybrid algorithm selected features that achieved an accuracy rate of more than 90% in all situations. Therefore, we can conclude that this study’s strategy exhibits a significant level of accuracy. Sensitivity is a key concept in the measuring field, particularly in terms of a test’s capacity to correctly identify people who actually have the ailment. In clinical contexts, we refer to the “detection rate” as the percentage of individuals who receive a positive test result for a specific illness among those who actually have the condition. A diagnostic test with 100% sensitivity will reliably identify and label every patient with the specific illness as positive. According to the results of the GWO study’s sensitivity findings, the SVM model has the highest score, 0.981. In a situation like this, WOA records the highest sensitivity score, up to 0.974. Using a ML classifier allows the hybrid models to achieve their highest sensitivity score, precisely 0.973.
The idea of specificity has to do with how well a diagnostic test can distinguish between those who are in excellent health and don’t exhibit any symptoms. The term “specificity” refers to the proportion of people who test negative for a particular ailment even when they do not have the disease. A positive outcome suggests a higher probability of the disease being present. A test with the highest level of specificity would correctly identify healthy people by returning a negative result. On the other hand, a test with less than full specificity would unambiguously rule out the existence of the condition. Because individuality is so important, it is imperative to carefully evaluate the factors that lead to its development. When implementing the SVM model, WOA has the highest value of 0.933. The best GWO value is 0.921. The hybrid technique’s finding, which also uses these classifiers, reveals a maximum value of 0.903. We use the harmonic mean of accuracy and recall to derive the F1-score, which offers a fair evaluation of the classifier. The F1 score is a well-known performance statistic for assessing the effectiveness of classification models. We specifically designed the evaluation to assess accuracy, taking into account both the potential negative and positive effects of incorrect results. The maximum F1-score for the integration of the GWO-CatBoost classifier and Hybrid-Ensemble is 0.975; also, the maximum F1-score for the WOA is equivalent to 0.967. Precision, a quantitative measurement, assesses the proportion of correctly identified positive cases compared to the total number of instances classified as positive. It is possible to accurately determine the prevalence of glaucoma in a population using a number of viable methods. Furthermore, the degree of precision closely correlates with the quantity of pertinent data points. When starting medication for a patient who, according to our theoretical framework, has glaucoma-like symptoms but not the actual clinical condition, it is crucial to exercise caution. When integrating GWO with RF at their respective maximum values, the optimal combination for precision values is 0.976. Our proposed hybrid algorithm achieves superior accuracy and F1-Score compared to other benchmark approaches. When it comes to measuring precision, sensitivity, F1-score, kappa score, and MCC performance, GWO even slightly outperforms the proposed hybrid algorithm.
There are equivalent sets of sensitivity and specificity values for each diagnostic threshold. We generated a Receiver Operating Characteristic (ROC) curve, a graphic depiction of paired data points, using the dataset. The x-axis represented specificity, while the y-axis represented sensitivity. Both the AUC calculation and the receiver operating characteristic (ROC) curve analysis can assess a test’s capacity to discriminate between groups. The test shows increasing discriminating ability in differentiating between impacted and unaffected scenarios as the curve slowly approaches the top left corner and the region beneath it grows. The integral of the curve ranges from 0 to 1, which is a valid indicator of the test’s effectiveness. An ideal diagnostic test has an AUC of 1, while an area of 0.50 describes a non-selective zone of the test. The AUC is a regularly used metric for assessing a test’s diagnostic accuracy. Additionally, we have calculated the AUC values, which serve as indicators of successful outcomes in the specific study setting. As the number gets closer to 1.000, the overall quality of the output shows a discernible improvement. The combination of the SVM classifier and the GWO achieved the best AUC value of 0.943, which was also the best result of the WOA algorithm. The hybrid strategy showed the highest AUC score of 0.938. The AUC metric shows that the SVM classifier performs admirably. The findings include numerous important metrics, including receiver operating characteristic (ROC) curves for each instance, confusion matrices, and estimates of the Matthews correlation coefficient (MCC) and Kappa scores for each experiment. We also compute and show execution time, along with other key performance measurement parameters.
3.5 Comparison with the current best practices
A comparison of the suggested method to the most cutting-edge glaucoma prediction methods is shown in Table 24. The comparison table that is shown demonstrates how well the methods used in this study performed in terms of detecting glaucoma when compared to earlier research. With an accuracy of up to 96.5% efficacy in recognising glaucoma when compared to earlier research, the offered table provides strong evidence that the suggested approach is reliable and proficient in categorising fundus pictures. The performance’s sensitivity and specificity are encouraging, as are other metrics. When compared to the other 18 techniques indicated in Table 24 that were published in or after 2018, our performance shows exceptional results. Our approach, which makes use of machine learning and soft computing techniques, has proven to be more successful than deep learning approaches in a few situations. It is important to keep in mind that in certain cases, the datasets used to evaluate the other approaches may be different.
4 Conclusion
It is commonly acknowledged that feature selection (FS) is a crucial pre-processing step in modelling. FS main goal is to get rid of pointless features so that the learning model performs better by using the right number of features. This is important in the field of biomedical research, particularly in illness databases, where it has been noted that patients’ various characteristics are captured, and a wrong diagnosis might have serious repercussions. To address this issue, we have proposed a pioneering method for FS. Our approach employs three algorithms derived from nature to identify the most significant traits. The suggested approach selects limited features while maintaining a high degree of classification accuracy. We have applied this approach to the ORIGA collection of glaucoma images, accessible to the general public. This investigation focuses on glaucoma, the second most common cause of vision loss in people. The only way for people to protect themselves from the negative effects of glaucoma is through timely identification to reduce the risk of vision loss as well as initiating the treatment. Using both 5-fold cross-validation and 10-fold cross-validation procedures, several machine learning classifiers were trained and tested on the features selected through soft-computing computing. To fully explore the occurrence of glaucoma, we extract a mix of several classes of features, such as clinical measurement features and image-based features (e.g., statistical features). This strategy seeks to greatly improve the glaucoma screening classifier’s accuracy by accumulating extensive evidence for glaucoma discrimination. Our glaucoma screening approach surpasses other available recent approaches in terms of accuracy, sensitivity, and specificity, according to experimental results derived from the ORIGA dataset. The soft-computing algorithms’ accuracy rate was 95%, while the hybrid method’s accuracy rate exceeded that of the individual algorithms by more than 96%. In contrast to many other current approaches taken into consideration in this comparison, the acquired findings show greater performance. Therefore, we can regard the suggested novel methodology as an appropriate and reliable technique for automated glaucoma screening in a variety of clinical scenarios. To illustrate our strategy’s resilience, we want to use high-dimensional datasets in the future. In our future endeavors, we want to use the suggested technique in a variety of clinical and real-world situations. As a result, we will be able to improve classification accuracy and get more exact results. We can observe, formulate, and analyze this two-class classification problem as a mutiobjective problem, where the two conflicting objectives aim to maximize accuracy while minimizing the number of features. Similarly, we can add more objectives and transform the problem into multiple objective problems, each with more than two objectives. We can compute and suggest multiple solutions using Pareto fronts, enabling researchers and those in need to select the ones that best suit their needs.
The extremely favourable outcome shows that hospitals in remote locations with a shortage of expert medical practitioners can deploy the proposed system. Additionally, it serves as a second opinion, alleviating the burden on overworked, experienced, and senior ophthalmologists. The approach, which is highly efficient and affordable, aids humanity by successfully classifying images of humans as healthy or infected, thereby initiating the best treatment as soon as possible, mitigating (slowing down) the spread of the disease, and preventing humans from losing their visibility permanently. The suggested system can seamlessly integrate with the Internet of Things, providing the human race with Internet of Medical Things functionalities. From patient images, the suggested method can also predict the presence of other diseases like skin cancer, breast cancer, and diabetic retinopathy.
This empirical study’s validation of the proposed approach on a medium-sized dataset is one of its major limitations. Validation on multiple datasets, or a combination of different medium- or small-size datasets, will increase confidence in the suggested approach. We could have extracted a larger number of features from this fundus image dataset. Extracting more features might impact the performance of the approach.
Data availability
“The datasets analyzed during the current study are easily and publically available in the internet’s repository,” We also confirm that data will be available on demand.
References
Ghosh KK, Singh PK, Hong J, Geem ZW, Sarkar R (2020) Binary social mimic optimization algorithm with x-shaped transfer function for feature selection. IEEE Access 8:97890–97906
Kira, K., & Rendell, L. A. (1992). The feature selection problem: traditional methods and a new algorithm. In proceedings of the tenth national conference on artificial intelligence (pp. 129-134).
Talbi EG (2009) Metaheuristics: from design to implementation. John Wiley & Sons
Yagiura M, Ibaraki T (2001) On metaheuristic algorithms for combinatorial optimization problems. Syst Comput Japan 32(3):33–55
Wilt, C., Thayer, J., & Ruml, W. (2010). A comparison of greedy search algorithms. In proceedings of the international symposium on combinatorial search (Vol. 1, no. 1, pp. 129-136).
López FG, Torres MG, Batista BM, Pérez JAM, Moreno-Vega JM (2006) Solving feature subset selection problem by a parallel scatter search. Eur J Oper Res 169(2):477–489. https://doi.org/10.1016/j.ejor.2004.08.010
Xue B, Zhang M, Browne WN, Yao X (2015) A survey on evolutionary computation approaches to feature selection. IEEE Trans Evol Comput 20(4):606–626
Tabakhi S, Moradi P, Akhlaghian F (2014) An unsupervised feature selection algorithm based on ant colony optimization. Eng Appl Artif Intell 32:112–123
Eiben AE (2003) Multiparent recombination in evolutionary computing. In: Advances in evolutionary computing: theory and applications. Springer Berlin Heidelberg, Berlin, Heidelberg, pp 175–192
Rashedi E, Nezamabadi-Pour H, Saryazdi S (2009) GSA: a gravitational search algorithm. Inf Sci 179(13):2232–2248
Nagpal S, Arora S, Dey S (2017) Feature selection using gravitational search algorithm for biomedical data. Proc Comput Sci 115:258–265
Hu B, Dai Y, Su Y, Moore P, Zhang X, Mao C, … Xu L (2016) Feature selection for optimized high-dimensional biomedical data using an improved shuffled frog leaping algorithm. IEEE/ACM Trans Comput Biol Bioinform 15(6):1765–1773
Eberhart R, Kennedy J (1995) A new optimizer using particle swarm theory. In: MHS'95. Proceedings of the sixth international symposium on micro machine and human science. Ieee, pp 39–43
Chen, Y., Wang, Y., Cao, L., & Jin, Q. (2018). An effective feature selection scheme for healthcare data classification using binary particle swarm optimization. In 2018 9th international conference on information technology in medicine and education (ITME) (pp. 703-707). IEEE.
Saremi S, Mirjalili S, Lewis A (2017) Grasshopper optimisation algorithm: theory and application. Adv Eng Softw 105:30–47
Yang XS (2010) A new metaheuristic bat-inspired algorithm. In: Nature inspired cooperative strategies for optimization (NICSO 2010). Springer Berlin Heidelberg, Berlin, Heidelberg, pp 65–74
Cuevas E, Echavarría A, Zaldívar D, Pérez-Cisneros M (2013) A novel evolutionary algorithm inspired by the states of matter for template matching. Expert Syst Appl 40(16):6359–6373. https://doi.org/10.1016/j.eswa.2013.05.055
Yang XS, Deb S (2009) Cuckoo search via Lévy flights. In: 2009 world congress on nature & biologically inspired computing (NaBIC). Ieee, pp 210–214
Yang XS (2012) Flower pollination algorithm for global optimization. In: International conference on unconventional computing and natural computation. Springer Berlin Heidelberg, Berlin, Heidelberg, pp 240–249
Yang XS (2010) Firefly algorithm, stochastic test functions and design optimisation. Int J Bio-Inspir Com 2(2):78–84
Kabir MM, Shahjahan M, Murase K (2011) A new local search based hybrid genetic algorithm for feature selection. Neurocomputing 74(17):2914–2928
Sikora R, Piramuthu S (2007) Framework for efficient feature selection in genetic algorithm based data mining. Eur J Oper Res 180(2):723–737
Wang GG, Deb S, Gao XZ, Coelho LDS (2016) A new metaheuristic optimisation algorithm motivated by elephant herding behaviour. Int J Bio-Inspir Com 8(6):394–409
Wang GG (2018) Moth search algorithm: a bio-inspired metaheuristic algorithm for global optimization problems. Memetic Comput 10(2):151–164
Wang GG, Deb S, Gandomi AH, Zhang Z, Alavi AH (2016) Chaotic cuckoo search. Soft Comput 20:3349–3362
Wang GG, Deb S, Cui Z (2019) Monarch butterfly optimization. Neural Comput & Applic 31:1995–2014
Wang GG, Deb S, Zhao X, Cui Z (2018) A new monarch butterfly optimization with an improved crossover operator. Oper Res 18:731–755
Singh LK, Shrivastava K (2024) An enhanced efficient approach for feature selection for chronic human disease prediction: A breast cancer study. Heliyon.
Wang GG, Gandomi AH, Alavi AH (2014) Stud krill herd algorithm. Neurocomputing 128:363–370
Singh LK, Khanna M, Monga H, Pandey G (2024) Nature-inspired algorithms-based optimal features selection strategy for COVID-19 detection using medical images. N Gener Comput 1–64
Arora S, Singh S (2017) Node localization in wireless sensor networks using butterfly optimization algorithm. Arab J Sci Eng 42:3325–3335
Yi JH, Wang J, Wang GG (2016) Improved probabilistic neural networks with self-adaptive strategies for transformer fault diagnosis problem. Adv Mech Eng 8(1):1687814015624832
Rizk-Allah RM, El-Sehiemy RA, Wang GG (2018) A novel parallel hurricane optimization algorithm for secure emission/economic load dispatch solution. Appl Soft Comput 63:206–222
Wang GG, Cai X, Cui Z, Min G, Chen J (2017) High performance computing for cyber physical social systems by using evolutionary multi-objective optimization algorithm. IEEE Trans Emerg Top Comput 8(1):20–30
Cui Z, Sun B, Wang G, Xue Y, Chen J (2017) A novel oriented cuckoo search algorithm to improve DV-hop performance for cyber–physical systems. J Parallel Distr Com 103:42–52
Wang GG, Chu HE, Mirjalili S (2016) Three-dimensional path planning for UCAV using an improved bat algorithm. Aerosp Sci Technol 49:231–238
Zhang JW, Wang GG (2012) Image matching using a bat algorithm with mutation. Appl Mech Mater 203:88–93
Feng YH, Wang GG (2018) Binary moth search algorithm for discounted {0-1} knapsack problem. IEEE Access 6:10708–10719
Feng Y, Wang GG, Deb S, Lu M, Zhao XJ (2017) Solving 0–1 knapsack problem by a novel binary monarch butterfly optimization. Neural Comput & Applic 28:1619–1634
Jensen R, Shen Q (2004) Semantics-preserving dimensionality reduction: rough and fuzzy-rough-based approaches. IEEE Trans Knowl Data Eng 16(12):1457–1471
Hedar AR, Wang J, Fukushima M (2008) Tabu search for attribute reduction in rough set theory. Soft Comput 12:909–918
Singh LK, Khanna M, Singh R (2024) Feature subset selection through nature inspired computing for efficient glaucoma classification from fundus images. Multimed Tools Appl. https://doi.org/10.1007/s11042-024-18624-y
Wang J, Li T, Ren R (2010) A real time IDSs based on artificial bee colony-support vector machine algorithm. In: Third international workshop on advanced computational intelligence. IEEE, pp 91–96
Mafarja M, Abdullah S (2013) Investigating memetic algorithm in solving rough set attribute reduction. Int J Comput Appl Technol 48(3):195–202
Mafarja M, Abdullah S (2015) A fuzzy record-to-record travel algorithm for solving rough set attribute reduction. Int J Syst Sci 46(3):503–512
Kashef S, Nezamabadi-pour H (2015) An advanced ACO algorithm for feature subset selection. Neurocomputing 147:271–279
Zorarpacı E, Özel SA (2016) A hybrid approach of differential evolution and artificial bee colony for feature selection. Expert Syst Appl 62:91–103
MunishKhanna S, L. K., & Garg, H. (2024) A novel approach for human diseases prediction using nature inspired computing & machine learning approach. Multimed Tools Appl 83(6):17773–17809
Emary E, Zawbaa HM (2019) Feature selection via Lèvy antlion optimization. Pattern Anal Applic 22:857–876
Emary E, Zawbaa HM, Hassanien AE (2016) Binary grey wolf optimization approaches for feature selection. Neurocomputing 172:371–381
Zawbaa HM, Emary E, Grosan C, Snasel V (2018) Large-dimensionality small-instance set feature selection: a hybrid bio-inspired heuristic approach. Swarm Evol Comput 42:29–42
Mafarja, M. M., Eleyan, D., Jaber, I., Hammouri, A., & Mirjalili, S. (2017). Binary dragonfly algorithm for feature selection. In 2017 international conference on new trends in computing sciences (ICTCS) (pp. 12-17). IEEE.
Sayed GI, Khoriba G, Haggag MH (2018) A novel chaotic salp swarm algorithm for global optimization and feature selection. Appl Intell 48:3462–3481
Ahmed, S., Mafarja, M., Faris, H., & Aljarah, I. (2018). Feature selection using salp swarm algorithm with chaos. In proceedings of the 2nd international conference on intelligent systems, metaheuristics & swarm intelligence (pp. 65-69).
Faris H, Mafarja MM, Heidari AA, Aljarah I, Ala’m AZ, Mirjalili S, Fujita H (2018) An efficient binary salp swarm algorithm with crossover scheme for feature selection problems. Knowl-Based Syst 154:43–67
Tham YC, Li X, Wong TY, Quigley HA, Aung T, Cheng CY (2014) Global prevalence of glaucoma and projections of glaucoma burden through 2040: a systematic review and meta-analysis. Ophthalmology 121(11):2081–2090
Bourne RRA (2006) Worldwide glaucoma through the looking glass. Br J Ophthalmol 90(3):253–254
Shen SY, Wong TY, Foster PJ, Loo JL, Rosman M, Loon SC, … Aung T (2008) The prevalence and types of glaucoma in Malay people: the Singapore Malay eye study. Invest Ophthalmol Vis Sci 49(9):3846–3851
Raghavendra U, Gudigar A, Bhandary SV, Rao TN, Ciaccio EJ, Acharya UR (2019) A two layer sparse autoencoder for glaucoma identification with fundus images. J Med Syst 43:1–9
Zhao X, Guo F, Mai Y, Tang J, Duan X, Zou B, Jiang L (2019) Glaucoma screening pipeline based on clinical measurements and hidden features. IET Image Process 13(12):2213–2223
Garway-Heath DF, Hitchings RA (1998) Quantitative evaluation of the optic nerve head in early glaucoma. Br J Ophthalmol 82(4):352–361
Budenz DL, Barton K, Whiteside-de Vos J, Schiffman J, Bandi J, Nolan W, … Tema Eye Survey Study Group (2013) Prevalence of glaucoma in an urban west African population: the Tema eye survey. JAMA Ophthalmol 131(5):651–658
Derick RJ, Pasquale LR, Pease ME, Quigley HA (1994) A clinical study of peripapillary crescents of the optic disc in chronic experimental glaucoma in monkey eyes. Arch Ophthalmol 112(6):846–850
Jonas JB, Bergua A, Schmitz–Valckenberg, P., Papastathopoulos, K. I., & Budde, W. M. (2000) Ranking of optic disc variables for detection of glaucomatous optic nerve damage. Invest Ophthalmol Vis Sci 41(7):1764–1773
Hancox MD (1999) Optic disc size, an important consideration in the glaucoma evaluation. Clin Eye Vision Care 11(2):59–62
Guo F, Mai Y, Zhao X, Duan X, Fan Z, Zou B, Xie B (2018) Yanbao: a mobile app using the measurement of clinical parameters for glaucoma screening. IEEE Access 6:77414–77428
Liu S, Hong J, Lu X, Jia X, Lin Z, Zhou Y, … Zhang H (2019) Joint optic disc and cup segmentation using semi-supervised conditional GANs. Comput Biol Med 115:103485
Fu H, Cheng J, Xu Y, Liu J (2019) Glaucoma detection based on deep learning network in fundus image. In: Deep learning and convolutional neural networks for medical imaging and clinical informatics. Springer, Cham, pp 119–137
Martins J, Cardoso JS, Soares F (2020) Offline computer-aided diagnosis for Glaucoma detection using fundus images targeted at mobile devices. Comput Methods Prog Biomed 192:105341
Sreng S, Maneerat N, Hamamoto K, Win KY (2020) Deep learning for optic disc segmentation and glaucoma diagnosis on retinal images. Appl Sci 10(14):4916
Orlando JI, Fu H, Breda JB, van Keer K, Bathula DR, Diaz-Pinto A et al (2020) REFUGE challenge: a unified framework for evaluating automated methods for glaucoma assessment from fundus photographs. Med Image Anal 59:101570
Guo F, Li W, Tang J, Zou B, Fan Z (2020) Automated glaucoma screening method based on image segmentation and feature extraction. Med Biol Eng Comput 58(10):2567–2586
Abad PF, Coronado-Gutierrez D, Lopez C, Burgos-Artizzu XP (2021) Glaucoma patient screening from online retinal fundus images via Artificial Intelligence. medRxiv
Elangovan P, Nath MK (2021) Glaucoma assessment from color fundus images using convolutional neural network. Int J Imaging Syst Technol 31(2):955–971
Tulsani A, Kumar P, Pathan S (2021) Automated segmentation of optic disc and optic cup for glaucoma assessment using improved UNET++ architecture. Biocybern Biomed Eng 41(2):819–832
Juneja M, Singh S, Agarwal N, Bali S, Gupta S, Thakur N, Jindal P (2020) Automated detection of Glaucoma using deep learning convolution network (G-net). Multimed Tools Appl 79(21):15531–15553
Jerith GG, Kumar PN (2020) Recognition of Glaucoma by means of gray wolf optimized neural network. Multimed Tools Appl 79(15):10341–10361
Kirar BS, Agrawal DK, Kirar S (2022) Glaucoma detection using image channels and discrete wavelet transform. IETE J Res 68(6):4421–4428
Parashar D, Agrawal DK (2020) Automated classification of glaucoma stages using flexible analytic wavelet transform from retinal fundus images. IEEE Sensors J 20(21):12885–12894
Gour N, Khanna P (2020) Automated glaucoma detection using GIST and pyramid histogram of oriented gradients (PHOG) descriptors. Pattern Recogn Lett 137:3–11
Mirjalili S, Mirjalili SM, Lewis A (2014) Grey wolf optimizer. Adv Eng Softw 69:46–61
Mirjalili S, Lewis A (2016) The whale optimization algorithm. Adv Eng Softw 95:51–67
Singh LK, Khanna M (2023) A novel enhanced hybrid clinical decision support system for accurate breast cancer prediction. Measurement 221:113525
Singh LK, Khanna M, Garg H, Singh R (2024) Emperor penguin optimization algorithm-and bacterial foraging optimization algorithm-based novel feature selection approach for glaucoma classification from fundus images. Soft Comp 28(3):2431–2467
Balasubramanian K, Ananthamoorthy NP (2022) Correlation-based feature selection using bio-inspired algorithms and optimized KELM classifier for glaucoma diagnosis. Appl Soft Comput 128:109432
Pathan S, Kumar P, Pai RM, Bhandary SV (2023) An automated classification framework for glaucoma detection in fundus images using ensemble of dynamic selection methods. Prog Artif Intell 12(3):287–301
Patel RK, Kashyap M (2023) Automated screening of glaucoma stages from retinal fundus images using BPS and LBP based GLCM features. Int J Imaging Syst Technol 33(1):246–261
Sharma SK, Muduli D, Rath A, Dash S, Panda G (2023) Discrete ripplet-II transform feature extraction and metaheuristic-optimized feature selection for enhanced glaucoma detection in fundus images using LS-SVM.
Chaudhary PK, Pachori RB (2021) Automatic diagnosis of glaucoma using two-dimensional Fourier-Bessel series expansion based empirical wavelet transform. Biomed Signal Process Control 64:102237
Fu H, Cheng J, Xu Y, Zhang C, Wong DWK, Liu J, Cao X (2018) Disc-aware ensemble network for glaucoma screening from fundus image. IEEE Trans Med Imaging 37(11):2493–2501
Singh LK, Khanna M, Garg H, Singh R (2024) Efficient feature selection based novel clinical decision support system for glaucoma prediction from retinal fundus images. Med Eng Phys 123:104077
Singh LK, Khanna M, Garg H et al (2024) Emperor penguin optimization algorithm- and bacterial foraging optimization algorithm-based novel feature selection approach for glaucoma classification from fundus images. Soft Comput 28:2431–2467. https://doi.org/10.1007/s00500-023-08449-6
de Souza RCT, de Macedo CA, dos Santos Coelho L, Pierezan J, Mariani VC (2020) Binary coyote optimization algorithm for feature selection. Pattern Recogn 107:107470
Barua S, Merabet A (2024) Lévy arithmetic algorithm: an enhanced metaheuristic algorithm and its application to engineering optimization. Expert Syst Appl 241:122335
de Vasconcelos Segundo EH, Amoroso AL, Mariani VC, dos Santos Coelho L (2017) Thermodynamic optimization design for plate-fin heat exchangers by Tsallis JADE. Int J Therm Sci 113:136–144
Prabhakar T, Rao TM, Maram B, Chigurukota D (2024) Exponential gannet firefly optimization algorithm enabled deep learning for diabetic retinopathy detection. Biomed Signal Process Control 87:105376
dos Santos Coelho L, Mariani VC (2013) Improved firefly algorithm approach applied to chiller loading for energy conservation. Energy Build 59:273–278
dos Santos Coelho L, Klein CE, Sabat SL, Mariani VC (2014) Optimal chiller loading for energy conservation using a new differential cuckoo search approach. Energy 75:237–243
Ingle KK, Jatoth RK (2024) Non-Linear Channel equalization using modified grasshopper optimization algorithm. Appl Soft Comput 153:110091
Klein, C. E., Mariani, V. C., & dos Santos Coelho, L. (2018). Cheetah based optimization algorithm: a novel swarm intelligence paradigm. In ESANN (pp. 685-690).
Klein CE, Segundo EH, Mariani VC, Coelho LDS (2015) Modified social-spider optimization algorithm applied to electromagnetic optimization. IEEE Trans Magn 52(3):1–4
Xian S, Feng X (2023) Meerkat optimization algorithm: a new meta-heuristic optimization algorithm for solving constrained engineering problems. Expert Syst Appl 231:120482
Zhang, Z., Yin, F. S., Liu, J., Wong, W. K., Tan, N. M., Lee, B. H., … & Wong, T. Y. (2010). Origa-light: an online retinal fundus image database for glaucoma analysis and research. In 2010 annual international conference of the IEEE engineering in medicine and biology (pp. 3065-3068). IEEE.
Al-Fahdawi S, Al-Waisy AS, Zeebaree DQ, Qahwaji R, Natiq H, Mohammed MA, … Deveci M (2024) Fundus-deepnet: multi-label deep learning classification system for enhanced detection of multiple ocular diseases through data fusion of fundus images. Inf Fusion 102:102059
Abdulsahib AA, Mahmoud MA, Aris H, Gunasekaran SS, Mohammed MA (2022) An automated image segmentation and useful feature extraction algorithm for retinal blood vessels in fundus images. Electronics 11(9):1295
Abdulsahib AA, Mahmoud MA, Mohammed MA, Rasheed HH, Mostafa SA, Maashi MS (2021) Comprehensive review of retinal blood vessel segmentation and classification techniques: intelligent solutions for green computing in medical images, current challenges, open issues, and knowledge gaps in fundus medical images. Netw Model Anal Health Inform Bioinform 10:1–32
Lal S, Rehman SU, Shah JH, Meraj T, Rauf HT, Damaševičius R, … Abdulkareem KH (2021) Adversarial attack and defence through adversarial training and feature fusion for diabetic retinopathy recognition. Sensors 21(11):3922
Thawkar S, Sharma S, Khanna M, kumar Singh, L. (2021) Breast cancer prediction using a hybrid method based on butterfly optimization algorithm and ant lion optimizer. Comput Biol Med 139:104968
Thawkar S, Katta V, Parashar AR, Singh LK, Khanna M (2023) Breast cancer: a hybrid method for feature selection and classification in digital mammography. Int J Imaging Syst Technol 33(5):1696–1712
Funding
“The authors declare that no funds, grants, or other support were received during the preparation of this manuscript.”
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
“The authors have no relevant financial or non-financial interests to disclose. The authors declare that they have no known competing financial or personal relationships that could be viewed as influencing the work reported in this paper”.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Singh, L.K., Khanna, M., Garg, H. et al. A three-stage novel framework for efficient and automatic glaucoma classification from retinal fundus images. Multimed Tools Appl (2024). https://doi.org/10.1007/s11042-024-19603-z
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11042-024-19603-z