
Abstract
Feature selection is an important component of the machine learning domain, which selects the ideal subset of characteristics relative to the target data by omitting irrelevant data. For a given number of features, there are 2n possible feature subsets, making it challenging to select the optimal set of features from a dataset via conventional feature selection approaches. We opted to investigate glaucoma infection since the number of individuals with this disease is rising quickly around the world. The goal of this study is to use the feature set (features derived from fundus images of benchmark datasets) to classify images into two classes (infected and normal) and to select the fewest features (feature selection) to achieve the best performance on various efficiency measuring metrics. In light of this, the paper implements and recommends a metaheuristics-based technique for feature selection based on emperor penguin optimization, bacterial foraging optimization, and proposes their hybrid algorithm. From the retinal fundus benchmark images, a total of 36 features were extracted. The proposed technique for selecting features minimizes the number of features while improving classification accuracy. Six machine learning classifiers classify on the basis of a smaller subset of features provided by these three optimization techniques. In addition to the execution time, eight statistically based performance metrics are calculated. The hybrid optimization technique combined with random forest achieves the highest accuracy, up to 0.95410. Because the proposed medical decision support system is effective and ensures trustworthy decision-making for glaucoma screening, it might be utilized by medical practitioners as a second opinion tool, as well as assist overworked expert ophthalmologists and prevent individuals from losing their eyesight.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
A significant amount of high-dimensional data is being produced through the widespread use of social media and sensors. There are several features (characteristics) in the dataset; thus, feature extraction is essential in order to identify and extract the dataset's most usable data. Regression, classification, and clustering become less feasible due to the high-dimensional data's enormously increased space and temporal complexity. The high-dimensional dataset also includes numerous characteristics, some of which are superfluous or unimportant. A classifier's performance suffers as a result of duplicated and irrelevant features. Therefore, feature selection (FS) techniques that identify the optimal subset of features from large-dimensional datasets are often utilized to address this problem (Mafarja and Mirjalili 2017). FS is essential in order to identify and extract the dataset's most usable data. By reducing redundant and noisy data from the high-dimensional dataset, FS enhances the learning accuracy as well as the clarity of the results (Saraswat and Arya 2014). Using feature selection, the machine learning algorithm can be trained more quickly and easily. Additionally, it reduces the over-fitting issue and complexity of the classifier, making it simpler to understand (Wei et al. 2017). Thus, a proper mining technique must be used to fetch the necessary features from the dataset. To decrease the dimensionality of the feature space, several meta-heuristic techniques have been created and applied in the past as well. FS is an important stage in the design and development of data mining and machine learning algorithms. It facilitates faster calculation and increases classification accuracy. The performance of the classifiers may be hampered by feature spaces that include a significant number of duplicate or irrelevant characteristics. In order to boost the effectiveness of the classifiers, redundant features are removed from the original set using feature selection techniques to choose the best subset of features.
In computer-assisted diagnosis (CAD), FS chooses the relevant characteristics that have a deeper influence on classification accuracy and discards the features with a lower impact since they would negatively affect the performance of the classification subsystem. The classification of glaucoma is getting more difficult due to the absence of feature selection in computer-aided diagnostics. This is due to the fact that it must produce findings with more precision and that there must be more characteristics available for analysis. The location, few unpredictable development patterns, large dataset, and growing number of factors involved make it difficult to classify glaucoma disorders. The FS subsystem works to eliminate these duplicate features and only chooses the best subsets of features out of all the features in the dataset. Therefore, feature selection will significantly improve the accuracy and efficiency of the CAD system.
Glaucoma, also known as "silent theft of sight," was most likely identified as a disease in the early seventeenth century when the Greek word glaukEoma, which means obscurity of the lens or cataract and denotes ignorance of the condition, was coined. Glaucoma is the second most common cause of blindness worldwide. After cataracts, it is the second most frequent cause of permanent blindness, and if it goes undetected, it might overtake cataracts as the most prevalent cause. Globally, glaucoma affects around 60 million individuals, and by 2020, that figure is predicted to increase to 79.6 million (Singh and Khanna 2022a). The World Health Organization (WHO) reports that glaucoma is one of the main causes of blindness, which has already impacted more than 60 million people worldwide and might reach 80 million very soon. Additionally, 12 million Indians are thought to be affected. An abrupt visual disruption, excruciating eye discomfort, impaired vision, inflamed eyes, and haloes surrounding lights are some of its typical symptoms. People over the age of 40 are often affected by this condition. The brain visualizes the outside world as a consequence of receiving visual information from the retina through the optic nerve. The optic nerve is damaged as a result of a rise in intraocular pressure, which causes the disease to start. Sudden visual disruption, excruciating eye discomfort, hazy vision, inflamed eyes, and haloes surrounding lights are some of its typical symptoms (Singh et al. 2022b). The optic nerve head's structure, the thickness of the retinal nerve fiber layer, the ganglion cell, and the inner plexiform layers all alter as a consequence of the malfunctioning and loss of ganglion cells. Glaucoma may permanently damage the optic nerve if it is not treated, which would result in blindness. As a result, early detection of glaucoma in its early stages significantly reduces the risk of permanent blindness.
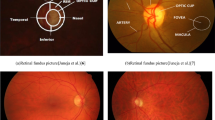
An image of the eye taken with a specialized fundus camera is called a fundus image (Fig. 1). A fundus camera, which comprises a microscope connected with a flash-enabled camera to capture the picture of the internal surface/back of an eye, is used to obtain the retinal fundus image. The fundus region's structural features include the fovea, macula, optic disc, and optic cup. It is a noninvasive method that has been shown to be a useful instrument for assessing a person's ocular health. The optic disc shows up as a bright yellowish area in colored fundus imaging, and it may be further split into two components, the optic cup (inner portion) and the neuroretinal rim (outer boundary). The optic nerve cup or the enlargement of the optic cup may be used to detect glaucoma in an eye. The cup-to-disc ratio (CDR), which is the ratio of the diameter of the optic cup to the diameter of the optic disc, is the best diagnostic for glaucoma identification. According to physicians, an eye with a CDR value of 0.65 or higher is classified as having glaucoma (Juneja et al. 2020a). However, the procedures used by the doctors are exceedingly laborious, time-consuming, and ineffective since they require manually separating the discs and cups from individual photographs. An experienced grader can measure, record, and ultimately determine whether a patient has glaucoma in roughly 8 min per eye on average. Additionally, glaucoma is also diagnosed by ophthalmologists using a variety of thorough retinal tests, including ophthalmoscopy, tonometry, perimetry, gonioscopy, and pachymetry. Ophthalmoscopy is the evaluation of the color and form of the optic nerve, while tonometry is the measurement of internal eye pressure. Perimetry is the examination of the visual field; gonioscopy is the measurement of the angle between the iris and cornea; and pachymetry is the measurement of corneal thickness. However, each of these methods necessitates human labor and takes time (Juneja et al. 2020b). All of these methods require human labor, take time, and might result in biased judgments from various experts (vulnerable to human error). In order to get beyond the restrictions of classical approaches, an automated glaucoma diagnostic system is required. Nowadays, computers are used in medical imaging as a noninvasive imaging modality to predict abnormalities. Therefore, automated techniques based on computer-aided detection and diagnosis (CADe/CADx) systems are preferable for solving the identification issue. In order to reduce the computational complexity, a computer-aided diagnostic system may act as a supportive measure for the first screening of glaucoma for diagnosis purposes. Consequently, a computer-aided diagnostic (CAD) system that may serve as a second opinion for clinicians is required to save valuable time for ophthalmologists. It has the potential to reduce the likelihood of misclassification, reduce the burden on physicians, and improve inter- and intra-observability. CAD systems can use images of the retinal fundus to predict glaucoma, pull out different kinds of features, and classify retinal images as "normal" or "abnormal."

Retinal fundus images
A number of individuals experience the retinal illness of glaucoma each year. Due to increasing intraocular pressure that damages the eye's optic nerve, glaucoma is the most common ocular condition that causes permanent blindness. An experienced ophthalmologist would often examine the dilated pupil in the eye to make a diagnosis of glaucoma progression. However, this method is time-consuming and difficult; thus, the problem may be handled using automation that would speed up diagnosis by using the idea of CAD (in the limelight of machine learning). The only way to stop it from progressing into irreversible blindness is through early identification. Treatment is often delayed by the need for onerous manual input from ophthalmologists, such as disc and cup size. Therefore, it is crucial to create quicker and more precise glaucoma diagnostic techniques. Automation offers a more practical and efficient answer to the glaucoma detection issue.
Any classification system that wants to get rid of extraneous or redundant features must first pick its best features. The classifier's ability to predict outcomes may be diminished by a feature collection that contains a significant number of irrelevant or undesirable features. Because of this, the best feature selection is crucial. This lowers the cost of computation and increases the classifier's predictive ability. The most crucial phase of glaucoma detection system design is feature selection. The primary goal of the suggested technique is to shrink the feature space in order to boost the classification system's performance. EPO, BFO, and their hybrid are the three algorithms used and employed in this study for the problem at hand. To the best of our knowledge, these algorithms have rarely been used in this way in the detection of any human disease. Six machine-learning classifiers that have been nominated for evaluation are used to assess the characteristics chosen by these three methods. Over fundus images from a different benchmark datasets, the suggested methodology's effectiveness is evaluated. There have been 24 tests in all. In many cases, the feature space is reduced to less than 50%. This reduction may be as high as 86.111% (5 features are returned from the original 36 features without significantly compromising accuracy).
To the best of our knowledge, there is presently no report on glaucoma identification using EPO, BFO, and their hybrid. One of the objectives of our study is to close this gap. A hybrid algorithm that combines BFO and EPO for FS and classification in fundus images is implemented in order to strike a balance between global and local search, as well as between exploration and exploitation.
Our presented empirical study attempts to address all of these issues, beginning with the selection of the best, smallest, and most efficient features needed for the confirmation of this human eye-related, widespread disease, glaucoma, as a subject and ending with incredible performance and results. The primary contribution of this work may be summed up as follows:
-
Through an extensive literature survey, it is observed that there is a lot of room for feature optimization for glaucoma identification. Taking into account the benefits of BFO and EPO, a BFOEPO hybrid FS strategy is proposed. This strategy could get rid of redundant and unnecessary features from the feature space, improving classification accuracy and lowering the cost of computing. Finally, we get the best subset of attributes (features) from the combination of different standard datasets. To the best of our knowledge, we are the frontrunners in applying these algorithms for glaucoma identification, thus filling a large research gap.
-
When compared to recent state-of-the-art studies discussed in Table 17, our customized dataset is also one of the largest. Extensive experimentation has been conducted, which involves the implementation of 24 tests. In addition to demonstrating the applicability of the proposed method, a comprehensive study of a number of parameters is presented. Along with ROC curves, eight efficiency measurement parameters of six machine learning classifiers have been computed to indicate their efficient performance. This fivefold and tenfold approach implementation effort also shows the time taken by different processes.
-
We have also shown the extended results in the form of three tables depicting the best values generated for eight efficiency measurement parameters (using six machine learning classifiers) when the minimum number of features was selected (in the case of all three algorithms). This type of table is rarely observed in previous state-of-the-art studies.
-
Through this study, we provide the best features to researchers; an efficient and rapid support system for ophthalmologists (on which they can rely); and a software-based tool for the human race to slow down human eye sight loss by ensuring early, efficient, and effective identification of this infection. The tool can be tweaked to work with mobile and wearable medical equipment, and it can be used in places where there aren't enough experienced medical practitioners.
This research study is organized as follows: The review of the literature is presented in Sect. 2. Section 3 describes the datasets and algorithms, and Sect. 4 describes the results. Section 5 is dedicated to analysis of our work along with findings and comparison with recent state-of-the-art studies. Limitations and future directions are suggested in Sect. 6. Finally, the conclusion of the paper is illustrated in Sect. 7.
2 Prior studies
The prime goal of FS is to improve the accuracy of a classifier by minimizing the irrelevant information. Da Silva et al. (2011) transformed the many-objective fitness function into single-objective fitness by integrating classification accuracy and feature quantity. Yang and Honavar (1998) introduced a single target fitness function in that maximizes accuracy and lowers costs. Winkler et al. (2011) have also used several fitness functions to improve classification accuracy. By using the best characteristics, the data categorization problem may be solved with the greatest amount of accuracy (Pandey and Kulhari 2018). Since there are 2n alternative feature subsets for every n attributes, choosing a meaningful feature subset from the dataset is a difficult job (Emary et al. 2016). Consequently, it might be challenging to identify the optimum feature subset. It will get much harder as more features are introduced. It is sometimes hard to locate the ideal set of traits via exhaustive or brute-force search (Xue et al. 2015). Heuristic search, complete search, random search, and metaheuristic-based approaches are some alternative FS methods (Dash and Liu 1997; Liu et al. 2014). Admired metaheuristic methods like genetic algorithm (GA), differential evolution (DE), particle swarm optimization (PSO), ant colony optimization (ACO), and cuckoo search (CS) are often employed to find the best feature subset. Chen and Hsiao (2008) coupled actual GA with a support vector machine (SVM) classifier to choose the pertinent features. Derrac et al. (2009) used three distinct populations to introduce a GA-based cooperative co-evolutionary method for FS. The focus has been on FS and instance utilizing a single process. As a result, it shortens computation time. Used chaos theory and evolutionary algorithms to provide highly accurate and speedy patient information retrieval. Wu et al. (2018) produced an outcome for the grading of gliomas by using a semiautomatic segmentation technique. Additionally, genetic programming (GP) has been used to do FS (Muni et al. 2006). The majority of GP techniques use a tree-based representation where the properties of the leaf nodes are selected. A wrapper-based general purpose strategy that uses the naive Bayes algorithm for classification has been published by Neshatian and Zhang (2009). Additionally, PSO has been used for FS (continuous and binary). In binary PSO, bit strings 1 and 0 signify the selection and non-selection of respective features, respectively. The continuous PSO uses a threshold to determine whether or not to choose a certain feature (attribute). Lane et al. (2013) coupled the advantages of PSO with statistical clustering for FS. Later, they (Lane et al. 2013) enhanced the performance of the preexisting approach by allowing the selection of several features from the same group. Ke et al. (2008) used constrained pheromone values to choose relevant parameters while using ACO. O'Boyle et al. (2008) developed an ACO-based FS method and enhanced the SVM's parametric values to identify the best feature subset. The chance that a certain feature would be picked or not has also been determined using a weighted method. Khushaba et al. (2008) created a hybrid FS method where DE selects the ideal feature subset from the output of ACO. A combined ACO approach with two colonies for attribute selection has been given by Vieira et al. (2010), in which the first colony estimates the requisite number of features and the second colony selects particular features. Ke et al. (2010) proposed many-objective ACO to hasten the convergence of filter FS. Additionally, an adaptive DE was used for FS, with parameters that self-adapted to the difficulties (Ghosh et al. 2013). Rodrigues et al. (2014) introduced a novel FS method that is based on the binary version of the bat algorithm and the optimum-path forest. Using a memetic wrapper and Relief-F algorithm, a two-stage feature selection technique has graded each feature (Yang and Deb 2009). Furthermore, a memetic wrapper is used to choose the ideal combination of traits. Gu et al. (2018) selected the important features and dimensionality reduction with competitive swarm optimizer (CSO), a relatively recent PSO variant. A binary black hole algorithm (BBHA) was employed to solve the FS in biological data (Pashaei and Aydin 2017). Additionally, Emary et al. (2016) developed a binary variant of the grey wolf optimization (GWO) to increase the efficacy of the classifier. Mafarja and Mirjalili (2017) suggested a hybrid meta-heuristic FS strategy based on the whale optimization algorithm (WOA) and simulated annealing (SA), where SA method is implemented in WOA, in order to improve the exploitation process. Tang et al. (2016) devised two FS selection strategies, namely maximum discrimination (MD) and MD-2 techniques using Jefreys multi-hypothesis (JMH) divergence, to prevent the early convergence of BPSO-SVM FS. Kang et al. (2016) suggested an outlier-insensitive hybrid approach that both selects the suitable feature subset and recognizes outliers in data-driven diagnostics. Barani et al. (2017) used a binary-inspired gravitational search algorithm (bGSA) to solve the FS objective. Mafarja et al. (2018) used binary dragonfly optimization to choose the ideal subset of features using time-varying transfer functions. To address the problem of FS, a novel chaotic salp swarm approach has also been described (Sayed et al .2018). Shunmugapriya and Kanmani (2017) created a hybrid FS approach based on ACO and bee colony optimization (BCO) to stop ant stagnation behavior and choose the most excellent features subset. Jayaraman and Sultana (2019) created a unique hybrid metaheuristic strategy based on the efficiency of artificial gravitational cuckoo search and particle Bee optimized associative memory neural network in order to solve the FS dilemma. Ibrahim et al. (2019) developed a novel hybrid metaheuristic method named SSAPSO based on the slap swarm algorithm (SSA) and particle swarm optimization to extract the best subset of features from a high-dimensional dataset (PSO). Prabukumar et al. (2019) presented an excellent diagnostic model based on cuckoo search characteristics for the early detection of lung cancer. Sayed et al. (2019) introduced the chaotic crow search algorithm (CCSA), a novel metaheuristic optimization method, to extract the best features from a dataset. Mafarja et al. (2019) presented on a binary version of the grasshopper optimization approach based on sigmoid and V-shaped transfer functions for FS. Nematzadeh et al.'s (2019) frequency-based selection technique also uses mutual congestion to identify signals. The binary cuckoo search approach was developed by Rodrigues et al. (2013) to choose the ideal set of attributes. The Lévy fight is used in the binary cuckoo search method to explore the whole search space. Lévy fight produces a random walk and follows the heavy tailed probability distribution. As a consequence, more iterations result in larger step sizes, which affect the convergence accuracy. All metaheuristics-based FS strategies often suffer from stability issues since different sets of features are selected in different runs. It was shown that conventional and metaheuristic-based FS methods suffer from stability issues and are computationally expensive. The metaheuristic FS methods show premature convergence due to a lack of variance.
The extraction of wavelet features was implemented in this research (Singh et al. 2016), and then genetic feature optimization, many learning methods, and different parameter settings were included. This research uses feature extraction from the segmented, blood vessel-free optic disc to increase identification accuracy. They justified that wavelet characteristics of the segmented optic disc image are clinically more relevant in comparison with features of the full or sub-fundus image. In this article (Khan et al. 2022), authors suggested method takes advantage of image denoising of digital fundus pictures by minimize the statistics of wavelet coefficients of glaucoma images using a non-Gaussian bivariate probability distribution function. The least square support vector machine classifier, which uses a variety of kernel functions, is then fed the chosen features. This study makes use of nonparametric GIST descriptor and optic disc (Raghavendra et al. 2018). After revolutionary area-based optic disc segmentation, the Radon transformation was proposed in the approach (RT). Modified census transformation was used to account for changes in the light levels of the Radon-converted picture (MCT). The spatial envelope energy spectrum was then extracted from the MCT pictures using the GIST descriptor. Utilizing locality-sensitive discriminant analysis (LSDA), the resultant GIST descriptor dimension was lowered, and then, different FS and ranking algorithms are used. In this study (Maheshwari et al. 2017), practitioners provide an innovative technique for an automated glaucoma diagnosis using digital fundus pictures. The iterative variational mode decomposition (VMD) approach is used for picture decomposition. From VMD components, a number of properties were retrieved, including fractal dimensions, Yager entropy, Renyi entropy, and Kapoor entropy. The discriminating features were chosen using the ReliefF method, and the least square-SVM uses these features to classify the data. The approach described in the study uses information from higher-order spectra (HOS), trace transform (TT), and discrete wavelet transform (DWT) (Krishnan and Faust 2013). In this study, the SVM classifier with a polynomial order 2 kernel function performed well in differentiating between glaucoma and healthy pictures.
The automated glaucoma diagnosis approach presented in this work uses quasi-bivariate variational mode decomposition (QB-VMD) (Agrawal et al. 2019). This approach is employed to deconstruct 505 fundus pictures altogether, yielding band-limited sub-band images (SBIs) centered on a certain frequency. These SBIs are fault-free and have no issues with mode mixing. The most helpful elements that effectively acquired the necessary data are what determine how accurately glaucoma is detected. QB-VMD SBIs are used to extract 70 features. The ReliefF approach selects the extracted features. The dimensionality of selected characteristics is then decreased by feeding them through singular value decomposition. The least square SVM classifier is then used to classify the reduced features. Glaucoma detection is performed using time-invariant feature cup-to-disc ratio and anisotropic dual-tree complex wavelet transform features (Kausu et al. 2018). Fuzzy C-Means clustering is employed for optic disc segmentation, while Otsu’s thresholding is used for optic cup segmentation. The extraction of GIST and PHOG characteristics from preprocessed fundus pictures was the main emphasis of this paper (Gour and Khanna 2020). To choose relevant characteristics, the extracted features are sorted and chosen using principal component analysis (PCA).
Super-pixel sorting for glaucoma screening has been done using center-surround data and histograms (Cheng et al. 2013). Fractal dimensions (FDs) and power spectral characteristics were combined with a SVM by Kolar and Jan (2008). Pixel intensities and the fast Fourier transform (FFT) were employed by Nyul (2009). Raja and Gangatharan (2013) employed complicated wavelet transform and higher-order spectra. They employed wavelet packet decomposition (WPD) together with entropy and energy geographies as a feature. The DWT and histogram functions have been proposed by Kirar and Agrawal (2018) for this infection identification. 2D-DWT has been suggested by Kirar and Agrawal (2019) to separate glaucoma from healthy pictures, and classification has been carried out using histogram-based features. Glaucoma fundus pictures were employed by Yadav et al. (2014) for texture-based feature extraction and categorization. Maheshwari et al. (2016) used empirical wavelet transform (EWT) to deconstruct fundus pictures. The least square-SVM has been shown to be useful for applying on fundus pictures in two categories in the newly published research on glaucoma diagnosis using fundus images (Martins et al. 2020; Parashar and Agrawal 2020). The dimensions of the optic disc and optic cup were calculated and used to estimate the CDR (cup-to-disc ratio) using fundus images in this study (Shanmugam et al. 2021). The initial step was to segment the optic disc (OD) and optic cup (OC). The second goal of the study was to reduce the number of features and errors, which are two conflicting objectives. Phases such as contrast amplification, picture collection, feature extraction, and glaucoma assessment are included in the suggested identification system. During the feature extraction phase, the OD and OC borders were segmented. In order to evaluate glaucoma in the images, the CDR ratio of an overused image is then determined. The glaucomatous photos have then been categorized using a random forest classifier according to the CDR values. Different versions of U-Net that have been tweaked have been used to assess the performance of the suggested technique. Deformable U-Net, Full-Deformable U-Net, and Original U-Net have all been used to assess the performance of the suggested approach. In this study (Mrad et al. 2022), the authors reported an automated technique for Smartphone Captured Fundus Images (SCFIs) glaucoma screening. The installation of an optical lens for retinal image capture results in a mobile-assisted glaucoma screening system. The central idea was based on vessel displacement inside the optic disk (OD), where the vessel tree is adequately represented using SCFIs. Within this aim, the most significant contribution consists of proposing: (1) a robust method for finding vessel centroids in order to accurately model vessel distribution and (2) a feature vector that reflects two prominent glaucoma biomarkers in terms of vessel displacement. In this work (Deperlioglu et al. 2022), explainable artificial intelligence (XAI) was used to provide a hybrid solution with image processing and deep learning for Glaucoma screening. Enhancing colored fundus imaging data were performed using histogram equalization (HE) and contrast-limited adaptive HE (CLAHE). An explainable CNN utilized the augmented image data for the diagnosis. The XAI was accomplished by Class Activation Mapping (CAM), which enabled heat map-based explanations for the CNN's picture interpretation. Using three public retinal image datasets, the performance of the hybrid approach was examined. The optic cup (OC) borders in retinal fundus pictures are not very clear (Haider et al. 2022); as a result, correct segmentation of the OC is extremely difficult, and the OD segmentation performance must also be enhanced. For precise pixel-wise segmentation of the OC and OD, researchers suggested new networks: separable linked segmentation network (SLS-Net) and separable linked segmentation residual network (SLSR-Net). In SLS-Net and SLSR-Net, it is possible to preserve a big final feature map, which improves the performance of OC and OD segmentation by limiting spatial information loss. SLSR-Net uses external residual connections to enable features. Both suggested networks have a detachable convolutional connection to increase computational performance and decrease network cost. On four publicly accessible retinal fundus image datasets, the segmentation abilities of the proposed networks were examined.
In this glaucoma detection approach, Elmoufidi et al. 2022, the Regions of Interest (ROI) were divided into components (BIMFs + residue) using the Bi-dimensional Empirical Mode Decomposition (BEMD) technique. To extract features from deconstructed BEMD components, VGG19 was applied. The same ROI features are combined into a bag of features, and principal component analysis (PCA) are used to reduce the feature dimension. To SVM, this condensed subset of characteristics is sent. ACRIMA and REFUGE were used for training, while RIM-ONE, ORIGA-light, Drishti-GS1, and sjchoi86-HRF were used for testing together with a portion of ACRIMA and REFUGE. An strategy based on the wrapper method employing soft-computing methods and a Kernel-Extreme Learning Machine (KELM) classifier were recommended for glaucoma diagnosis in this study by Balasubramanian and Ananthamoorthy (2022). The nature-inspired algorithms use a correlation-based feature selection (CFS) method to extract three feature sub-sets from the preprocessed fundus pictures. The salp-swarm optimization-based KELM, which determines the ideal parameters of the KELM classifier network, was trained using the chosen features. The objective of this study was to develop machine learning (ML) models with high predictive power and interpretability for glaucoma diagnosis based on multiple candidate features extracted from the examination retinal nerve fiber layer (RNFL) thickness and visual field (VF) (Kim et al. 2017). Using a process of feature evaluation, they then chose the optimal characteristics for classification (diagnosis). Authors considered C5.0, random forest (RF), support vector machine (SVM), and k-nearest neighbor as ML algorithms (KNN). Using multiple metrics, we analyzed the models' quality. They utilized 100 data cases as the test dataset and 399 data cases as the training and validation datasets. The random forest model performs the best. Clinicians may use the prediction findings to make more informed recommendations. This article examines the many problems involved with multi-objective optimization and the current efforts made to overcome these obstacles. It also describes how the current methodologies and body of knowledge have been used to meet the many multi-objective situations in the actual world. The paper concludes by highlighting future research prospects associated with multi-objective optimization. In this article, the authors describe what is often used, whether it algorithms or test issues, so that the reader is aware of the benchmarks and other possibilities.
Researchers, Maheshwari et al. (2019), present a novel approach for glaucoma diagnosis based on bit-plane slicing (BPS) and local binary patterns (LBP). Initially, the method divides the red (R), green (G), and blue (B) channels of the input color fundus picture into bit planes. Then, they extracted LBP-based statistical features from each of the individual channels' bit planes. Then, the characteristics of the individual channels are supplied independently to three distinct SVMs for categorization. Finally, the decisions from the individual SVMs are combined at the decision level in order to classify the input fundus image as either normal or glaucoma. Using tenfold cross validation, the experimental findings indicate that the suggested method can distinguish between normal and infected cases with an accuracy of 99.30%. This paper presents a model for glaucoma diagnosis that employs multiple features (such as inferior, superior, nasal, and temporal region areas and cup-to-disc ratio) to detect glaucoma in retinal fundus images (Singh et al. 2021). Using support vector machine (SVM), the proposed model provides a maximum classification accuracy of 98.60%. In contrast to other existing models such as SVM, K-nearest neighbors (KNN), and Naive Bayes, the proposed model combines four machine learning techniques to achieve a classification accuracy of 98.60%. CAD system utilizing machine learning (ML) algorithms (for classification) and nature-inspired computing (for feature selection/reduction) resolved glaucoma detection problems (Singh et al. 2022c). Two novel two-layered techniques (BA-BCS, BCS-PSO) based on Particle Swarm Optimization (PSO), Binary Cuckoo Search (BCS), and the Bat Algorithm (BA) were presented in this recommended empirical study. In addition, they have independently examined the performances of BA, BCS, and PSO. These five (single- and two-layered) approaches are used to generate subsets of reduced features that, when given to three machine learning (ML) classifiers, provide the maximum accuracy. Using benchmark publicly accessible datasets, ORIGA and REFUGE, as well as their combinations, the proposed method is validated. In addition, the researcher's community is provided with a multitude of different possibilities, including trade-offs.
Following this extensive survey of prior premium studies, we conclude that there is still a large scope for working on effective feature selection through soft-computing approaches for glaucoma screening, as very little work has been implemented in this direction and newly proposed algorithms are rarely used for this work. Furthermore, our work is novel in that we extracted features from different classes while also satisfying the subject image count (selected for training and testing). The subject images are a combination of different public datasets and private images taken from the internet and hospitals located near the authors' home. This study implements innovative BFO and EPO techniques and provides a hybrid method to solve the drawbacks of metaheuristics and other transformation-based FS techniques. The performance of the proposed approach is assessed using widely established benchmark fundus pictures. The proposed method is used to discover the optimal collection of features (characteristics), with the main objective of enhancing classification accuracy while limiting the number of features chosen and the error rate. The best subset of features from different benchmark datasets is created using specified and hybrid data transformation procedures. We provide the best qualities to researchers through this study: an efficient and quick support system for ophthalmologists (that they can rely on) and a software-based tool for the human race to slow down human eye sight loss by ensuring early, efficient, and effective diagnosis of this illness. The tool may be modified to function with mobile and wearable medical equipment, and it can be utilized in areas where there aren't enough skilled medical practitioners.
3 Materials and methods
In this section, we have discussed about the datasets selected for our study and the required details about three implemented soft-computing-based FS algorithms.
3.1 Dataset
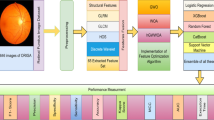
Our dataset consists of mixture of images from 4 standard benchmark publically available dataset and one private dataset collected from hospitals located in nearby cities. The total images considered are 3112 (1226 Glaucomatic images and 1886 healthy images). These 3112 images are collected from ACRIMA (396 glaucomatous and 309 healthy images), DRISHTI (16 glaucomatous images), HRF (15 glaucomatous and 15 healthy images), ORIGA (168 glaucomatous and 482 healthy images) and PRIVATE 631 glaucomatous images and 1080 healthy images. From these images, 36 features are retrieved whose list is shown using Table1. Figure 2 displays the framework of this glaucoma identification study.

Framework of the suggested study for glaucoma identification
The brief description about these features is given below:
-
1.
CDR (Cup-to-Disc Ratio): The cup-to-disc ratio features are defined as ratio of cup diameter and disc diameter of fundus images.
-
2.
GLCM (Grey Level Co-occurrence Matrix)—It is used to determine image texture by calculating the presence of paired pixels with certain values in spatial relationship inside an image.
-
3.
GLRM (grey-level run length matrix)—It can be described as a row of identically intense pixels arranged in a particular orientation. The quantity of these pixels is known as the grey level run length, and the occurrences of these pixels are regarded as the run length value.
-
4.
SRE (Short-Run Emphasis)—It is a measure of the distribution of short-run lengths. In this case, a higher SRE score suggests fine texture.
-
5.
LRE (Long-Run Emphasis)—It is a measure of the distribution of long-run lengths, with greater values suggesting a coarse texture.
-
6.
GLU (Grey-Level Uniformity)—When determining the true value of full length uniformity, we must greatly expand the scale.
-
7.
RLU (Run-Level Uniformity)—In this, we will first convert the image to grayscale and then determine its uniformity and the amount to which the entire grey section is stretched. It will show us where we have the lightest intensity and where we need less light density.
-
8.
RPC (Rational polynomial coefficient)—It is utilized to calculate the ratio of items preserved in space with changes in the regions that appear in other objects, allowing us to discriminate between them.
-
9.
Mat 0—It is a correlation feature matrix that is used to extract the greatest degree, which is zero degree, of the GLCM image's features.
-
10.
Mat 45—The goal of this feature is the same as the last one, but there are some differences. For example, we are now looking at a GLCM image of glaucoma at a 45-degree angle from the origin and on an axis that is directly opposite the origin.
-
11.
Mat 0_avg—In the feature, we have a correlation matrix including all the features shared by all the images.
-
12.
Mat 45_avg—This feature is utilized to determine the correlation matrix coefficients of the glaucoma image characteristics. Each image following 45-degree rotation of both matrices.
-
13.
Mat90_avg—This is the average used to determine the GLCM and correlation matrix characteristics of each image following 90-degree rotation of both matrices.
-
14.
Mat135_avg—All of the matrices in our possession will be rotated by 135 degrees at this place. When rotate the matrices, the changes that happen will have an effect on each image.
-
15.
HOS (Higher Order Spectral) —HOS characteristics are also employed to analyze picture attributes that are non-stationary, non-linear, or non-Gaussian.
-
16.
NRR (Neuro Retinal Rim)—The rim that surrounds the eye is the neuroretinal rim. We discovered that the rim of a glaucoma-affected eye is somewhat larger than the rim of a glaucoma-free eye.
-
17.
DDLS (Disc Damage Likelihood Scale)—The ratio of the disc's diameter to its Rim width, or the DDLS, is used to predict the development of glaucoma.
-
18.
HOC (Higher-Order Cumulant)—Higher-order statistics based on a picture's moments and correlation moments are specific weights that are applied to the pixels or intensities of a picture and assessed by a function.
-
19.
DWT (Discrete Wavelet Transform)—The separation of data, operators, or functions into discrete frequency components and analysis of each with a resolution proportional to scale are both carried out using wavelet transformations.
-
20.
FOS (First-Order Statistical)—These traits are used to compute an image's histogram, which shows the likelihood of an individual pixel occurring in an image, and use it to analyze the texture of the picture.
-
21.
Cum2est—Cum2est is an eye feature in which we minimize the area and concentrate on the optic disc region.
-
22.
Biocoherence—Biocoherence is the bispectrum that has been normalized. It is the moment spectrum of the third order.
-
23.
Energy—Energy is a way to measure the size of voxels in an image. In this case, a higher value of energy means that the sum of the squares is higher.
-
24.
Homogeneity—It is used for analysis the homogeneity of image.
-
25.
Correlation—Correlation is a way to figure out how much the grey levels of the pixels at certain positions depend on each other.
-
26.
Contrast—Contrast is a measure of intensity and variation. The greater the contrast value, the greater the discrepancy in image intensity values.
-
27.
Dissimilarity—It is a measure of the relationship between pairs of similar and dissimilar intensities.
-
28.
Entropy—Low first-order entropy is found in homogeneous scenes, while high entropy is found in heterogeneous scenes.
3.2 Preprocessing
The optic disc and optic cup regions in retinal fundus pictures are a key area for the diagnosis of glaucoma. In the retinal fundus image, the optic disc—where the location of the optic cup is in the centre of the optic disc—is the main area of concern. The picture of the retinal fundus has been reduced by 230 × 230x3 to allow for additional processing at the outset. In a picture of a section of the retina, the optic disc is typically in the centre of the disc. The colors of red, green, and blue (RGB)—commonly known as red, blue, and green display formats for three networks—are shown in fundus images in Fig. 4(a). It could be challenging to perform a variety of operations on the blue pattern. The grey image in Fig. 4(c) is used to symbolize the vital part of our eyes, which houses a vast quantity of information. Initially, fundus imaging converts a person's eye scan into a "gray-green" color box. Equalization is the transformation or conversion feature that is only used to produce an output picture with a consistent histogram. Changing the brightness of the input picture's histogram's equalization procedure is a highly effective method. The input image's amplitude is evenly spread over the updated image. The main focus of this approach is applying strength in a way that is comparable to the overall image. This provides the linear trend for the cumulative probability function (cdf).
To further balance the signal, we used an adaptive median filter. Pulse noise has the potential to alter the image of the fundus. Impulsive noise is produced as a result of electromagnetic interference. The adaptive median filter is a useful filtering technique to minimize the noise of the impulse in the spatial domain. It compares each pixel with its immediate neighbors in order to identify the noisy pixels. The adaptive median filter performs spatial analysis to determine which pixels in a picture have been impacted by impulsive noise. The adaptive median filter categorizes pixels as noise by comparing each pixel in the image to its immediate neighbors (Fig. 3). Both the reference criterion and the neighborhood's size may be altered. A pixel is referred to as "impulse noise" because it differs from any of its neighbors and is architecturally inconsistent with the pixels. The median pixel value of the nearby pixels that passed the noise marking test will subsequently be used to replace these noise pixels. Figure 4a–f displays the preprocessed glaucoma picture, whereas (g)–(l) displays the preprocessed healthy image. The whole process diagram of this preprocessing stage is shown below with the help of Fig. 3.

Layout of the preprocessing of the images

a–f Preprocessing of Glaucoma image and g–l preprocessing of healthy image
3.3 Feature selection algorithms
Three algorithms BFO, EPO and their hybrid are shortlisted for this study, whose details are given below. Table 2 depicts the various parameters and their values assigned during the implementation of these three algorithms.
The Bacteria Foraging Optimization Algorithm (BFO) is a novel addition to the family of nature-inspired optimization algorithms (Das et al. 2009). A set of tensile flagella propels the genuine bacterium while foraging. Flagella assist an E.coli bacterium in its foraging activities by allowing it to tumble or swim. Each flagellum tugs on the cell as they spin the flagella clockwise. As a consequence, the flagella move independently, and the bacteria tumbles with fewer tumblings, while in a hazardous environment, it tumbles often to locate a nutritional gradient. Moving the flagella counterclockwise allows the bacteria to move extremely quickly. In the algorithm described above, bacteria engage in chemotaxis, in which they choose to travel toward a food gradient while avoiding unpleasant environments. In general, germs migrate further in a welcoming environment. When they obtain enough nourishment, they grow in length and, in the presence of an appropriate temperature; they break in the centre to form an identical clone of themselves. This phenomenon prompted Passino to include a reproduction event in BFO algorithm. Because of unexpected environmental changes or an assault, chemotactic development may be disrupted, and a group of bacteria may travel to other locations or be incorporated into the swarm of concern. This is an example of an elimination-dispersal event in a genuine bacterial population, in which all of the bacteria in an area are killed or a group is dispersed into a different portion of the environment (Das et al. 2009; Chen et al. 2017). Table 2 displays the list of parameters used in this algorithm.
The steps of BFO algorithms are as follows.

The mathematical equations used in the algorithms are as follows
The emperor penguin is one of the biggest penguins, with male and female having about the same size. An emperor penguin has a black back, a white belly, golden ear patches, and grayish-yellow breasts. The emperor penguin's wings serve as a fin while swimming. Emperor penguins move similarly like humans. Their whole existence is spent in Antarctica, and they are famous for their capacity to procreate through the brutal Antarctic winter, which may reach minus 60 °C. Although their unique feathers and body fat protect them from chilly winds, they must cluster together to stay warm in severe cold. During mating season, each female penguin lays a single egg, which is then passed on to one of the males. Females will go up to 80 km in the open sea to hunt after the egg transfer. Male penguins utilize their brood pouches to keep the eggs warm until they hatch, allowing the eggs to survive until they hatch. A female emperor penguin normally returns to the nest after spending approximately two months in the ocean with food in her stomach, which she vomits up for the chicks to ingest and take over care of. Emperor penguins are excellent divers in addition to being excellent swimmers. They often go foraging and hunting together. They are the only species that huddle to live through the Antarctic winter. After dissecting the huddling behavior of emperor penguins into four stages, a mathematical model was built. To begin, emperor penguins form their huddle boundaries at random. Second, they calculate the temperature profile around them. Third, they use this approach to compute penguin distances in order to simplify exploring and exploiting emperor penguins. Finally, they choose the effective mover as the best option and update the emperor penguin placements to recalculate the huddle's boundaries. This mathematical process's main purpose is to discover the most effective mover. The huddle is considered to be on a 2D polygonal surface with a L shape. In reaction to this huddling behavior, the EPO algorithm was created. Figure 5 depicts the flowchart of huddling process of EPO algorithm and complete EPO algorithm.

a Flowchart of huddling progress b Flowchart of the standard EPO algorithm
The steps of EPO algorithms are as follows.
Step 01: Generate the Emperor Penguins Population.
Step 02: Set Initial Parameters such as Maximum Iterations, Temperature, A,C
Step 03: Calculate the fitness values for all search agent.
Step 04: Determine the Huddle Boundary for Emperor Penguins Using:
Step 05: Calculate temperature profile (\({\text{Temp}}^{\prime}\)) around the Huddle using:
Step 06: Compute the distance between the emperor penguins using:
Step 07: Update the position of Emperor Penguins
Step 08: If any emperor penguin goes beyond the Huddle Boundary improve its position.
Step 09: Calculate the fitness values for each search agent and update new optimal solution position.
Step 10: If Stopping Criteria met STOP else Goto Step 05.
Step 11: Return Best Emperor Penguins/Optimal Solutions.
The mathematical equations applied in the algorithm are as follows: Let \(\gamma\) define the wind velocity and \(\Im\) be the gradient of \(\gamma\).
Vector \(\Re\) is combined with \(\gamma\) to generate the complex potential
where \(j\) denotes the imaginary constant and \({\text{AF}}\) is an analytical function on the polygon plane.
The temperature profile around the huddle \(A^{\prime}\) is computed as follows:
Here \(y\) define the current iteration,\({\text{Maximum}}_{{{\text{iteration}}}}\) represents the maximum number of iteration. \(A\) is the time for finding best optimal solution in a search space.
where \(\overrightarrow {{{\text{Dis}}_{{{\text{epn}}}} }}\) shows the distance between the emperor penguin and best fittest search agent. \(y\) shows the current iteration. \(\overrightarrow {A1}\) and \(\overrightarrow {c1}\) are used to avoid the collision between neighbors. \(k()\) defines the social forces of emperor penguins.
\({\text{Poly}}\_{\text{grid}}({\text{Acc}})\) defines the polygon grid accuracy by comparing difference between emperor penguins and random function \({\text{Random}}()\).
where \(e\) defines the expression function. \(f\) and \(l\) are control parameters for better exploration.
Table 3 depicts the parameters and their corresponding values used in the algorithms. The objective function for all the optimization algorithms is according to Eq. (21).
Here, Eq. (21) is basically a sphere function, one of many benchmark optimization functions used for solving optimization in single variable (Tang et al. 2007). So in the proposed work we have used single variable sphere function for updating the cost on different set of population. The function is suitable for single objective optimization. This means that it presents one mode and has a single global optimum. In our case, our objective is to finding the minimum fitness value and after that pass, we have forwarded set of features retrieved on minimum fitness value.
The operating system used is Windows 7 Professional. System type is 64-bit operating system with Intel(R) Core ((TM) i3-4150 CPU @ 3.50 GHz GHz processor and Python 3.7.15 is the programming language used.
The pseudocode of the hybrid BFOAEPO algorithm is given below:

4 Results
Tables 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, and 15 assemble the calculated results in tabular style. Tables 4 and 5 are devoted to presenting the findings of the EPO algorithm. Similarly, Tables 8 and 9 are devoted to presenting the results created by the BFO algorithm, while Tables 12 and 13 are dedicated to presenting the results obtained by the hybrid method. Apart from this, we have also created two small tables (per algorithm) depicting vital information such as what were the values of different performance measuring metrics (like sensitivity, specificity, accuracy,F1-score etc.) when the number of features was at a minimal during the whole experimentation phase. When the features were minimal, researchers rarely showed this type of data (values of various performance measuring measures) in previous studies. These traits are shown in the table along with the outcomes they produced (Tables 7, 11, and 15). If one does not have the time to calculate and extract all the features, they may still utilize these features without making too many sacrifices in terms of getting the best results. The results are quite satisfying, even with a relatively small number of features. The best value for each algorithm created throughout the course of all eight tests with each algorithm is shown in the second table (Tables 8, 12, and 16). Figures 6, 7, and 8 display the collection of ROC graphs for various experiments performed. Figure 9 depicts the convergence graphs (iteration vs. fitness) of 12 experiments (out of 24 experiments performed) due to space constraints. Along with this, hypothesis testing was also performed in the experiments. To determine statistically whether one model has a substantially different AUC from another, we applied DeLong's test to provide a p-value (DeLong et al. 1988; Sun and Xu 2014). In our study, the hypothesis was set up so that, assuming the two models performed as expected, H0: AUC1 = AUC2. The alternative hypothesis, H1: AUC1 ≠ AUC2, states that the two models' AUCs differ. We computed the z-value and associated p-value. The overall ML model's p-values were less than 0.05 for all comparisons. After getting the Z-score, we use the "two-tailed test" to see whether the AUC of model A is different from the AUC of model B. A brief description of the terms used in the remainder of the paper is shown in Table 4.

ROC curve of different classifiers on k-fold cross-validation, a For minimum cost 0.89409 (population size 5), b For minimum cost 0.97123 (population size 5), c For minimum cost 0.00798 (population size 10), d For minimum cost 0.00855 (population size 10), e For minimum cost 0.00790 (population size 15), f For minimum cost 0.00792(population size 15), g For minimum cost 0.00715(population size 20), h For minimum cost 0.83086(population size 20)

Combined ROC curve of different classifiers including ensemble based on k-fold approach, a For minimum cost 0.00841 (population size 5), b For minimum cost 0.00991 (population size 5), c For minimum cost 0.00910 (population size 10), d For minimum cost 0.00863 (population size 10), e For minimum cost 0.00857 (population size 15), f For minimum cost 0.00853 (population size 15), g For minimum cost 0.00815 (population size 20), h For minimum cost 0.00786 (population size 20)

Combined ROC curve of different classifier including Ensemble based on 70:30 splitting approach, a For minimum cost 0.82956 (population size 5), b For minimum cost 0.83156 (population size 5), c For minimum cost 0.88324 (population size 10), d For minimum cost 0.69869 (population size 10), e For minimum cost 0.76739 (population size 15), f For minimum cost 0.74174 (population size 15), g For minimum cost 0.86435 (population size 20), h For minimum cost 0.76353 (population size 20)


Fitness Vs Iterations graphs of 12 experiments
4.1 Experiment based on the Emperor penguin optimization (FS using EPO)
4.2 Experiment based on the bacterial foraging optimization algorithm using K-fold approach (FS using BFO)
4.3 Experiment based on the hybrid of BFO and EPO using K-fold approach (FS using Hybrid approach)
The following convergence graphs (figures) of 12 experiments have been shown here (out of 24 experiments performed), due to space constraints.
5 Discussion and comparison with prior studies
This section is divided into two subsections. The first is dedicated to a discussion and findings of our work. In the later half, we have focused on comparison of our work with prior state-of-the-art studies.
5.1 Discussion
Three algorithms have been implemented in this proposed approach: BFO, EPO, and an amalgamation of these two. The goal of these methods is to divide the set of original images into two classes. The extracted features were forwarded to various machine learning classifiers for categorization of the subject fundus images. Twenty-four trials on these three algorithms were conducted (eight individually). All of the experiments have a common objective function. During a specific experiment, the population size remains constant, and the performance of this population is evaluated by varying the number of iterations from 100 to 500 (with a gap of 100). The case in which we find the minimum value of the objective function is chosen, and the features returned by this case are forwarded to the classifier; the remaining four cases are discarded and will not be considered further. The population size is then varied in fivefold increments from 5 to 20. According to the above tables, the minimum number of features returned is 5, and the maximum number of features returned is 26. Thus, the feature reduction scale ranges from 86.11% (the highest) to 27.77% (the lowest). The execution time is also computed in two ways: first, we show the iteration time of soft-computing algorithms; second, we show the training and testing time of machine learning classifiers. Six machine learning classifiers were chosen and put into action. The first five are classical, while the last is an ensemble of these five. Accuracy, sensitivity, specificity, precision, the F1-Score, the Kappa-Score, the MCC, and the AUC are all used to evaluate the performance of these classifiers. All of these criteria are important in predicting human diseases using medical pictures. All of these indicators are rarely computed in a single study.
We know that accuracy is a vital indicator of performance, and our findings on this parameter are remarkable; we were able to get the best accuracy of 0.9541 in the combination of a hybrid algorithm and a random forest classifier. In the hybrid example, the least accuracy generated is 0.8094; similarly, in the BFO scenario, the least accuracy generated is 0.8035 (and a maximum of 0.9264(with DT)); and finally, in the EPO case, the least accuracy generated is 0.8030 (and a maximum of 0.9194 (with DT)). As a result, we can conclude that we were never able to obtain an accuracy of less than 0.80 in any of the cases, despite using a few selections of features; this demonstrates that the suggested method is satisfactory. Another important measurement aspect is sensitivity; a 100% sensitive test will identify all people with the illness by testing positive. When generated with an ensemble, the maximum sensitivity for EPO is 0.88589. For BFO, the best match was BFO-ensemble, which had a maximum value of 0.89906. Finally, the maximum value for hybrid is 0.93431 when generated with random forest.
Specificity refers to a test's capacity to correctly exclude healthy people who are free of a problem. A positive test result would unequivocally confirm the existence of the sickness, because a test with 100% specificity would identify all people who do not have the ailment by testing negative. The range of results demonstrates the success of this strategy. The next essential factor that is computed is specificity. The range for EPO is 0.88378 to 0.97899 (with LR), the range for BFO is 0.81552 to 0.98447 (with SVM), and the range for the hybrid method is 0.82739 to 0.97347 (with DT). As a result, we were able to achieve at least 81% specificity in all situations. Because the F1-score is the harmonic mean of accuracy and recall, it keeps the classifier in balance. The maximum value of 0.88635 is determined when using the EPO-DT combination, 0.90638 when using the BFO-RF combination, and 0.90749 when using the hybrid-RF combination. Precision is defined as the ratio of true positives to all positives. It is critical that we do not start treating a patient who does not have a true glaucoma issue but does according to our model. When we computed precision, we got the highest value of 0.95043 in EPO, the highest value of 0.96398 in BFO, and the highest value of 0.94491 in the hybrid algorithm.
There is a set of diagnostic sensitivity and specificity values for each cutoff. To make a ROC graph, we plotted these pairs of values on a graph with specificity on the x-axis and sensitivity on the y-axis. The area under the curve (AUC) and the shape of the ROC curve both contribute to establishing a test's discriminative capacity. As the curve approaches the upper-left hand corner and the area under the curve increases, the test performs better at distinguishing between sick and non-sick situations. The area under the curve, a trustworthy indicator of how well the test was performed, can have any value between 0 and 1. The area of a non-discriminatory test is 0.5, whereas the AUC of a perfect diagnostic test is 1.0. Finally, we generated AUC scores, and the approach performed admirably in this situation as well, with a range of 0.80138 to 0.90698 in the EPO algorithm case, 0.80300 to 0.97542 (with LR) in the BFO algorithm case, and 0.80701 to 0.91567 in the hybrid scenario (with RF classifier). The closer the value is to 1.000, the better the outcome. We can see that the EPO has the best range (up to 0.97542). The results are also shown to include ROC curves for all cases, selected confusion metrics, and the computation of MCC and Kappa scores for all experiments.
The created glaucoma assessment pipeline should be tested, performed offline on mobile devices as well, and the findings presented in a short amount of time. This is one of the limitations of this effort. The proposed method must still be tested on large-scale clinical imaging before it can be used in real-world circumstances worldwide. Future studies could include training the proposed model on a large number of varieties of images in order to improve its performance on other datasets and generalize it to all fundus images. Furthermore, as researchers are constantly proposing new optimization algorithms, in the future we will try to implement and analyze the performance of these algorithms on our problem. The same ideology can be applied to the diagnosis of various disorders such as diabetes, retinopathy, fatty liver disease, thyroid cancer, and ovarian cancer, among others.
5.2 Comparison with prior published literature
A comparison of the suggested approach to the existing state-of-the-art glaucoma prediction methods is shown in Table 17. The comparative table suggests the effectiveness of the implemented approach in glaucoma identification as compared to previous studies. This table provides irrefutable evidence that the proposed novel approach is robust and efficient in categorizing fundus images with an accuracy of up to 95.410%. The sensitivity and specificity of the performance are both high, as with other metrics. Our method (which relies on soft computing and machine learning) has been shown to outperform deep learning methods in a few scenarios. However, there may be a few instances when the datasets on which the other methods were evaluated are different from ours. We have worked on several datasets to further investigate the performance of the technique we created, as previously described, which indicates the generalizability of our suggested approach.
6 Limitations and future work directions
7 Conclusion
The key to preventing this visual degradation is early identification, which, if left untreated, might go further and result in irreversible vision loss. Early identification and diagnosis of this illness are substantially hampered by standard diagnostic techniques' laborious and lengthy approach. Moreover, the most crucial phase in the development of a glaucoma detection system is the selection of the most appropriate features. The primary purpose of the suggested approach is to reduce the size of the feature space in order to enhance the classification system's performance. This article implements three algorithms: EPO, BFO, and a hybrid of these two algorithms. To the best of our knowledge, these algorithms have only rarely been employed in this way for the detection of glaucoma. The characteristics (features) chosen by these three methods are assessed using six machine learning classifiers that have been shortlisted. The performance of the proposed technique is evaluated using benchmark fundus image datasets. In total, twelve experiments have been conducted. Typically, more than 50% of the characteristics are decreased most of the time. This decrease gets up to 86.11% (five features are restored from the original 36 features without a significant compromise in accuracy). In addition to being computationally efficient, the suggested method requires relatively little time to process and analyze high-resolution retinal pictures. Expert ophthalmologists may use the proposed method as a second opinion when diagnosing glaucoma. Consequently, the suggested method might be highly valuable for glaucoma patients' first screening. The proposed solution yields trustworthy results and is simple to implement in medical departments for successful prediction.
Data availability
The datasets analyzed during the current study are easily and publically available in the internet’s repository. We also confirm that data will be available on demand.
References
Abad PF, Coronado-Gutierrez D, Lopez C, Burgos-Artizzu XP (2021) Glaucoma patient screening from online retinal fundus images via Artificial Intelligence. medRxiv
Acharya UR, Bhat S, Koh JE, Bhandary SV, Adeli H (2017) A novel algorithm to detect glaucoma risk using texton and local configuration pattern features extracted from fundus images. Comput Biol Med 88:72–83
Agrawal DK, Kirar BS, Pachori RB (2019) Automated glaucoma detection using quasi-bivariate variational mode decomposition from fundus images. IET Image Proc 13(13):2401–2408
Balasubramanian K, Ananthamoorthy NP (2022) Correlation-based feature selection using bio-inspired algorithms and optimized KELM classifier for glaucoma diagnosis. Appl Soft Comput 128:109432
Barani F, Mirhosseini M, Nezamabadi-Pour H (2017) Application of binary quantum-inspired gravitational search algorithm in feature subset selection. Appl Intell 47(2):304–318
Cheng J, Liu J, Xu Y, Yin F, Wong DWK, Tan NM, Tao D, Cheng CY, Aung T, Wong TY (2013) Superpixel classification based optic disc and optic cup segmentation for glaucoma screening. IEEE Trans Med Imaging 32(6):1019–1032
Chen YP, Li Y, Wang G, Zheng YF, Xu Q, Fan JH, Cui XT (2017) A novel bacterial foraging optimization algorithm for feature selection. Expert Syst Appl 83:1–17
Chen LH, Hsiao HD (2008) Feature selection to diagnose a business crisis by using a real GA-based support vector machine: an empirical study. Expert Syst Appl 35(3):1145–1155
Da Silva SF, Ribeiro MX, Neto JDEB, Traina-Jr C, Traina AJ (2011) Improving the ranking quality of medical image retrieval using a genetic feature selection method. Decis Support Syst 51(4):810–820
Dash M, Liu H (1997) Feature selection for classification. Intell Data Anal 1(1–4):131–156
Das P, Nirmala SR, Medhi JP (2016) Diagnosis of glaucoma using CDR and NRR area in retina images. Netw Model Anal Health Inform Bioinform 5(1):1–14
Das S, Biswas A, Dasgupta S, Abraham A (2009) Bacterial foraging optimization algorithm: theoretical foundations, analysis, and applications. Foundations of computational intelligence, vol 3. Springer, Berlin, Heidelberg, pp 23–55
DeLong ER, DeLong DM, Clarke-Pearson DL (1988) Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics, 837–845
Deperlioglu O, Kose U, Gupta D, Khanna A, Giampaolo F, Fortino G (2022) Explainable framework for Glaucoma diagnosis by image processing and convolutional neural network synergy: analysis with doctor evaluation. Futur Gener Comput Syst 129:152–169
Derrac J, García S, Herrera F (2009) A first study on the use of coevolutionary algorithms for instance and feature selection. In: International conference on hybrid artificial intelligence systems. Springer, Berlin, Heidelberg. 557–564
Elangovan P, Nath MK (2021) Glaucoma assessment from color fundus images using convolutional neural network. Int J Imaging Syst Technol 31(2):955–971
Elmoufidi A, Skouta A, Jai-Andaloussi S, Ouchetto O (2022) CNN with multiple inputs for automatic glaucoma assessment using fundus images. Int J Image Graph, 2350012
Emary E, Zawbaa HM, Hassanien AE (2016) Binary grey wolf optimization approaches for feature selection. Neurocomputing 172:371–381
Fu H, Cheng J, Xu Y, Liu J (2019) Glaucoma detection based on deep learning network in fundus image. In: Deep learning and convolutional neural networks for medical imaging and clinical informatics. Springer, Cham. 119–137
Ghosh A, Datta A, Ghosh S (2013) Self-adaptive differential evolution for feature selection in hyperspectral image data. Appl Soft Comput 13(4):1969–1977
Gour N, Khanna P (2020) Automated glaucoma detection using GIST and pyramid histogram of oriented gradients (PHOG) descriptors. Pattern Recogn Lett 137:3–11
Gu S, Cheng R, Jin Y (2018) Feature selection for high-dimensional classification using a competitive swarm optimizer. Soft Comput 22(3):811–822
Guo F, Mai Y, Zhao X, Duan X, Fan Z, Zou B, Xie B (2018) Yanbao: a mobile app using the measurement of clinical parameters for glaucoma screening. IEEE Access 6:77414–77428
Guo F, Li W, Tang J, Zou B, Fan Z (2020) Automated glaucoma screening method based on image segmentation and feature extraction. Med Biol Eng Comput 58(10):2567–2586
Haider A, Arsalan M, Lee MB, Owais M, Mahmood T, Sultan H, Park KR (2022) Artificial Intelligence-based computer-aided diagnosis of glaucoma using retinal fundus images. Expert Syst Appl 207:117968
Ibrahim RA, Ewees AA, Oliva D (2019) Improved salp swarm algorithm based on particle swarm optimization for feature selection. J Ambient Intell Humaniz Comput 10:3155–3169
Jayaraman V, Sultana HP (2019) Artificial gravitational cuckoo search algorithm along with particle bee optimized associative memory neural network for feature selection in heart disease classification. J Ambient Intell Human Comput, 1–10
Jerith GG, Kumar PN (2020) Recognition of Glaucoma by means of gray wolf optimized neural network. Multimed Tools Appl 79(15):10341–10361
Juneja M, Thakur S, Wani A, Uniyal A, Thakur N, Jindal P (2020) DC-Gnet for detection of glaucoma in retinal fundus imaging. Mach Vis Appl 31(5):1–14
Juneja M, Thakur N, Thakur S, Uniyal A, Wani A, Jindal P (2020) GC-NET for classification of glaucoma in the retinal fundus image. Mach Vis Appl 31(5):1–18
Kang M, Islam MR, Kim J, Kim JM, Pecht M (2016) A hybrid feature selection scheme for reducing diagnostic performance deterioration caused by outliers in data-driven diagnostics. IEEE Trans Ind Electron 63(5):3299–3310
Kausu TR, Gopi VP, Wahid KA, Doma W, Niwas SI (2018) Combination of clinical and multiresolution features for glaucoma detection and its classification using fundus images. Biocybern Biomed Eng 38(2):329–341
Ke L, Feng Z, Ren Z (2008) An efficient ant colony optimization approach to attribute reduction in rough set theory. Pattern Recogn Lett 29(9):1351–1357
Ke L, Feng Z, Xu Z, Shang K, Wang Y (2010) A multiobjective ACO algorithm for rough feature selection. In: 2010 second pacific-Asia conference on circuits, communications and system, IEEE Vol. 1, pp 207–210
Khan SI, Choubey SB, Choubey A, Bhatt A, Naishadhkumar PV, Basha MM (2022) Automated glaucoma detection from fundus images using wavelet-based denoising and machine learning. Concurr Eng 30(1):103–115
Khushaba RN, Al-Ani A, AlSukker A, Al-Jumaily A (2008) A combined ant colony and differential evolution feature selection algorithm. In: International Conference on ant colony optimization and swarm intelligence. Springer, Berlin, Heidelberg. pp 1–12
Kim SJ, Cho KJ, Oh S (2017) Development of machine learning models for diagnosis of glaucoma. PLoS One 12(5):e0177726
Kirar BS, Agrawal DK, Kirar S (2020) Glaucoma detection using image channels and discrete wavelet transform. IETE J Res, 1–8
Kirar BS, Agrawal DK (2018) Glaucoma diagnosis using discrete wavelet transform and histogram features from fundus image. Int J Eng Technol 7(4):2546–2551
Kirar BS, Agrawal DK (2019) Computer aided diagnosis of glaucoma using discrete and empirical wavelet transform from fundus images. IET Image Proc 13(1):73–82
Kolář R, Jan J (2008) Detection of glaucomatous eye via color fundus images using fractal dimensions. Radioengineering 17(3):109–114
Krishnan MMR, Faust O (2013) Automated glaucoma detection using hybrid feature extraction in retinal fundus images. J Mech Med Biol 13(01):1350011
Lane MC, Xue B, Liu I, Zhang M (2013) Particle swarm optimisation and statistical clustering for feature selection. In: Australasian Joint Conference on Artificial Intelligence. Springer, Cham. pp 214–220
Liu Y, Tang F, Zeng Z (2014) Feature selection based on dependency margin. IEEE Trans Cybern 45(6):1209–1221
Liu S, Hong J, Lu X, Jia X, Lin Z, Zhou Y, Liu Y, Zhang H (2019) Joint optic disc and cup segmentation using semi-supervised conditional GANs. Comput Biol Med 115:103485
Mafarja MM, Mirjalili S (2017) Hybrid whale optimization algorithm with simulated annealing for feature selection. Neurocomputing 260:302–312
Mafarja M, Aljarah I, Heidari AA, Faris H, Fournier-Viger P, Li X, Mirjalili S (2018) Binary dragonfly optimization for feature selection using time-varying transfer functions. Knowl-Based Syst 161:185–204
Mafarja M, Aljarah I, Faris H, Hammouri AI, AlaM AZ, Mirjalili S (2019) Binary grasshopper optimisation algorithm approaches for feature selection problems. Expert Syst Appl 117:267–286
Maheshwari S, Pachori RB, Acharya UR (2016) Automated diagnosis of glaucoma using empirical wavelet transform and correntropy features extracted from fundus images. IEEE J Biomed Health Inform 21(3):803–813
Maheshwari S, Pachori RB, Kanhangad V, Bhandary SV, Acharya UR (2017) Iterative variational mode decomposition based automated detection of glaucoma using fundus images. Comput Biol Med 88:142–149
Maheshwari S, Kanhangad V, Pachori RB, Bhandary SV, Acharya UR (2019) Automated glaucoma diagnosis using bit-plane slicing and local binary pattern techniques. Comput Biol Med 105:72–80
Mrad Y, Elloumi Y, Akil M, Bedoui MH (2022) A fast and accurate method for glaucoma screening from smartphone-captured fundus images. IRBM 43(4):279–289
Martins J, Cardoso JS, Soares F (2020) Offline computer-aided diagnosis for Glaucoma detection using fundus images targeted at mobile devices. Comput Methods Programs Biomed 192:105341
Muni DP, Pal NR, Das J (2006) Genetic programming for simultaneous feature selection and classifier design. IEEE Trans Syst Man Cybern Part B (Cybern) 36(1):106–117
Nematzadeh H, Enayatifar R, Mahmud M, Akbari E (2019) Frequency based feature selection method using whale algorithm. Genomics 111(6):1946–1955. https://doi.org/10.1016/j.ygeno.2019.01.006
Neshatian K, Zhang M (2009) Dimensionality reduction in face detection: a genetic programming approach. In: 2009 24th International Conference Image and Vision Computing New Zealand. IEEE. pp 391–396
Nyúl LG (2009) Retinal image analysis for automated glaucoma risk evaluation. In: MIPPR 2009: medical imaging, parallel processing of images, and optimization techniques. SPIE. Vol. 7497, pp 332–340
O’Boyle NM, Palmer DS, Nigsch F, Mitchell JB (2008) Simultaneous feature selection and parameter optimisation using an artificial ant colony: case study of melting point prediction. Chem Cent J 2(1):1–15
Orlando JI, Fu H, Breda JB, van Keer K, Bathula DR, Diaz-Pinto A et al (2019) REFUGE Challenge: a unified framework for evaluating automated methods for glaucoma assessment from fundus photographs. Med Image Anal 2020(59):101570
Pandey AC, Kulhari A (2018) Semi-supervised spatiotemporal classification and trend analysis of satellite images. In: Advances in Computer and Computational Sciences. Springer, Singapore. pp 353–363
Parashar D, Agrawal DK (2020) Automated classification of glaucoma stages using flexible analytic wavelet transform from retinal fundus images. IEEE Sens J 20(21):12885–12894
Pashaei E, Aydin N (2017) Binary black hole algorithm for feature selection and classification on biological data. Appl Soft Comput 56:94–106
Prabukumar M, Agilandeeswari L, Ganesan K (2019) An intelligent lung cancer diagnosis system using cuckoo search optimization and support vector machine classifier. J Ambient Intell Humaniz Comput 10(1):267–293
Raghavendra U, Bhandary SV, Gudigar A, Acharya UR (2018) Novel expert system for glaucoma identification using non-parametric spatial envelope energy spectrum with fundus images. Biocybern Biomed Eng 38(1):170–180
Raja C, Gangatharan N (2013) Glaucoma detection in fundal retinal images using trispectrum and complex wavelet-based features. Eur J Sci Res 97(1):159–171
Rodrigues D, Pereira LA, Nakamura RY, Costa KA, Yang XS, Souza AN, Papa JP (2014) A wrapper approach for feature selection based on bat algorithm and optimum-path forest. Expert Syst Appl 41(5):2250–2258
Rodrigues D, Pereira LA, Almeida TNS, Papa JP, Souza AN, Ramos CC, Yang XS (2013) BCS: a binary cuckoo search algorithm for feature selection. In: 2013 IEEE International symposium on circuits and systems (ISCAS). IEEE. pp 465–468
Saraswat M, Arya KV (2014) Feature selection and classification of leukocytes using random forest. Med Biol Eng Compu 52(12):1041–1052
Sayed GI, Khoriba G, Haggag MH (2018) A novel chaotic salp swarm algorithm for global optimization and feature selection. Appl Intell 48(10):3462–3481
Sayed GI, Hassanien AE, Azar AT (2019) Feature selection via a novel chaotic crow search algorithm. Neural Comput Appl 31(1):171–188
Shanmugam P, Raja J, Pitchai R (2021) An automatic recognition of glaucoma in fundus images using deep learning and random forest classifier. Appl Soft Comput 109:107512
Shunmugapriya P, Kanmani S (2017) A hybrid algorithm using ant and bee colony optimization for feature selection and classification (AC-ABC Hybrid). Swarm Evol Comput 36:27–36
Singh A, Dutta MK, ParthaSarathi M, Uher V, Burget R (2016) Image processing based automatic diagnosis of glaucoma using wavelet features of segmented optic disc from fundus image. Comput Methods Programs Biomed 124:108–120
Singh LK, Garg H, Khanna M, Bhadoria RS (2021) An enhanced deep image model for glaucoma diagnosis using feature-based detection in retinal fundus. Med Biol Eng Comput 59(2):333–353
Singh LK, Khanna M, Thawkar S, Singh R (2022) Collaboration of features optimization techniques for the effective diagnosis of glaucoma in retinal fundus images. Adv Eng Softw 173:103283
Singh LK, Khanna M (2022) A novel multimodality based dual fusion integrated approach for efficient and early prediction of glaucoma. Biomed Signal Process Control 73:103468
Singh LK, Khanna M, Thawkar S (2022) A novel hybrid robust architecture for automatic screening of glaucoma using fundus photos, built on feature selection and machine learning-nature driven computing. Expert Syst 39:e13069
Sreng S, Maneerat N, Hamamoto K, Win KY (2020) Deep learning for optic disc segmentation and glaucoma diagnosis on retinal images. Appl Sci 10(14):4916
Sun X, Xu W (2014) Fast implementation of DeLong’s algorithm for comparing the areas under correlated receiver operating characteristic curves. IEEE Signal Process Lett 21(11):1389–1393
Tang B, Kay S, He H (2016) Toward optimal feature selection in naive Bayes for text categorization. IEEE Trans Knowl Data Eng 28(9):2508–2521
Tang K, Yáo X, Suganthan PN, MacNish C, Chen YP, Chen CM, Yang Z (2007) Benchmark functions for the CEC’2008 special session and competition on large scale global optimization. Nat Inspired Comput Appl Lab USTC China 24:1–18
Tulsani A, Kumar P, Pathan S (2021) Automated segmentation of optic disc and optic cup for glaucoma assessment using improved UNET++ architecture. Biocybern Biomed Eng 41:819–832
Vieira SM, Sousa JM, Runkler TA (2010) Two cooperative ant colonies for feature selection using fuzzy models. Expert Syst Appl 37(4):2714–2723
Wei J, Zhang R, Yu Z, Hu R, Tang J, Gui C, Yuan Y (2017) A BPSO-SVM algorithm based on memory renewal and enhanced mutation mechanisms for feature selection. Appl Soft Comput 58:176–192
Winkler SM, Affenzeller M, Jacak W, Stekel H (2011) Identification of cancer diagnosis estimation models using evolutionary algorithms: a case study for breast cancer, melanoma, and cancer in the respiratory system. In: Proceedings of the 13th annual conference companion on Genetic and evolutionary computation pp 503–510
Wu Y, Liu B, Wu W, Lin Y, Yang C, Wang M (2018) Grading glioma by radiomics with feature selection based on mutual information. J Ambient Intell Humaniz Comput 9(5):1671–1682
Xue B, Zhang M, Browne WN, Yao X (2015) A survey on evolutionary computation approaches to feature selection. IEEE Trans Evol Comput 20(4):606–626
Yadav D, Sarathi MP, Dutta MK (2014) Classification of glaucoma based on texture features using neural networks. In: 2014 seventh international conference on contemporary computing (IC3). IEEE. pp 109–112
Yang J, Honavar V (1998) Feature subset selection using a genetic algorithm. In: Feature extraction, construction and selection. Springer, Boston, MA. pp 117–136
Yang XS, Deb S (2009) Cuckoo search via Lévy flights. In: 2009 World congress on nature & biologically inspired computing (NaBIC). IEEE. pp 210–214
Zilly J, Buhmann JM, Mahapatra D (2017) Glaucoma detection using entropy sampling and ensemble learning for automatic optic cup and disc segmentation. Comput Med Imaging Graph 55:28–41
Funding
The authors declare that no funds, grants, or other support were received during the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
All authors contributed equally to the study conception, design and coding. Material preparation, data collection and analysis were performed by [LKS], [MK], [HG] and [RS]. All authors read and approved the final submitted manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Ethical approval
No ethical approval required.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Singh, L.K., Khanna, M., Garg, H. et al. Emperor penguin optimization algorithm- and bacterial foraging optimization algorithm-based novel feature selection approach for glaucoma classification from fundus images. Soft Comput 28, 2431–2467 (2024). https://doi.org/10.1007/s00500-023-08449-6
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-023-08449-6