
Abstract
Object tracking is the process of locating objects of interest in video frames. Challenges still exist in handling appearance changes in object tracking for robotic vision. In this paper, we propose a novel Dirichlet process-based appearance model (DPAM) for tracking. By explicitly introducing a new model variable into the traditional Dirichlet process, we model the negative and positive target instances as the combination of multiple appearance models. Within each model, target instances are dynamically clustered based on their visual similarity. DPAM provides an infinite nonparametric mixture of distributions that can grow automatically with the complexity of the appearance data. In addition, prior off-line training or specifying the number of mixture components (clusters or parameters) is not required. We build a tracking system in which DPAM is applied to cluster negative and positive target samples and detect the new target location. Our experimental results on real-world videos show that our system achieves superior performance when compared with several state-of-the-art trackers.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Object tracking is the process of locating objects of interest in video frames. Tracking systems are increasingly used in various applications such as surveillance, security and robotic vision. Tracking in robotic vision (i.e., with moving cameras) is considered more difficult than tracking with static camera videos as segmenting the foreground objects by background subtraction methods is not applicable. Although numerous approaches have been proposed for tracking a specific type of objects (e.g., humans [1], faces [2], rigid objects [3], mice [4]), robust tracking of a generic object is still a challenging problem in robotic vision research. Specifically, one of the major challenges comes from handling appearance variations caused by changes in scale, pose, illumination and occlusion during tracking [5].
Current tracking methods can be grouped in two main categories: discriminative and generative approaches [6–15]. Discriminative approaches deal with object tracking as a binary classification problem by finding the best location that separates the target from the background. The classifier can be built using off-line training. For example, Avidan [16] trained support vector machine off-line and Lepetit et al. [17] trained randomized trees. The main problem with these methods is that a comprehensive training dataset that covers all appearance variations and different backgrounds is required beforehand. Other approaches applied adaptive classifiers where tracking results are used for classifier adaptation. To this end, Lim et al. [18] employed incremental subspace learning; Avidan [19] applied adaptive ensembles classifiers by constructed a feature vector for main frame pixels. Grabner and Bischof [20] used online boosting and Kalal et al. [21] applied bootstrapping binary classifiers. Babenko et al. [22] used online multiple instance learning and Williams et al. [23] sparse Bayesian learning. However, adaptive discriminative methods suffer from drifting caused by the accumulation of updating errors.
Generative approaches search in a video frame for the most similar location based on a target appearance model [24–27]. The previously observed target instances are used to learn the appearance model before adopting it to the current frame. Many generative methods employ static appearance models (e.g., randomized trees [3]). The training sets of static appearance models are collected manually or from the first frame only [1, 3, 28–31]. Generally, they are unable to cope with the sudden appearance changes, especially when prior knowledge about the target is limited. Subsequently, adaptive appearance models are proposed where a model is constantly updated during tracking [32–34]. Similar to the adaptive discriminative methods, adaptive generative approaches suffer from drifting.

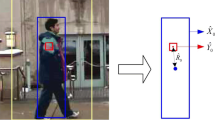
Our system distributes target instances to positive and negative samples. Each group instance is clustered dynamically based on visual similarity
In order to characterize appearance variations and handle drifting and occlusion problems, an appearance model should have the following desired properties. First, the capacity of the model should be adaptive to the appearance complexity. Second, the model should be built based on both initial target instances and online tracking results as complete off-line training is only applicable to very limited scenarios. Finally, for robust tracking, the performance of the model should not heavily rely on parameter tuning for each video.
In this paper, we propose a novel multiple appearance model based on Dirichlet process (DP) to address the aforementioned challenges. Our method differs from the traditional DP by explicitly introducing a new model variable v, which categorizes the negative and positive target instances into different models. Within each model, target instances are dynamically clustered based on their visual similarity (see Fig. 1 for an illustrative example). DPAM provides an infinite nonparametric mixture of distributions that can grow automatically with the complexity of the appearance data. In addition, prior off-line training or specifying the number of mixture components (clusters or parameters) is not required. We build a tracking system in which DPAM is applied to cluster negative and positive target samples and detect the new target location. In our tracker, the target object can be arbitrarily chosen with no prior knowledge except its initial location in the first frame. Our experimental results on real-world videos show that our system can provide stable, robust tracking in complex scenes (e.g., with occlusions, illumination and pose variations) and achieve superior performance when compared with several state-of-the-art tracking systems.
The rest of this paper is organized as follows. We start with reviewing relevant works in Sect. 2. Section 3 describes DPAM, the model structure and the Bayesian decision in detail. Section 4 gives our tracking system. Section 5 presents the experiment results. Finally, Sect. 6 concludes.
2 Related works
Appearance modeling has been widely used in object tracking. In this section, we review related work in two categories: single appearance models and multiple appearance models.
In single appearance models, previously observed target instances are used to train the model and then the model is adapted to the current frame. Collins and Liu [25] utilized target instances to learn the discriminative color features that distinguish the target from the background. Aeschliman et al. [24] proposed a probabilistic framework for joint segmentation and tracking. In [16, 19], the target is represented by a binary classifier that is learned by support vector machine and AdaBoost, respectively. Later on, Kalal et al. [21] used randomized trees. Grabner and Bischof [20] proposed an online boosting method to update an appearance model. Babenko et al. [22] applied online multiple instance learning to build a discriminative tracker. Zhou et al. [35] used SIFT features and mean shift. Godec et al. [36] built a tracking system by integrating hough forests with voting-based detection, back-projection and rough segmentation. He et al. [37] employed locality sensitive histogram to update the appearance model. Sevilla and Miller [38] used distribution fields to represent targets and images in tracking. However, due to the limitation of building only one appearance model that covers all target appearance changes, these methods update the model from subsets of the previous target instances [16, 19, 25] or the most recent ones [20, 22]. Therefore, they are intolerant of sudden appearance changes.
Multiple appearance models overcome the limitation by establishing several models and allowing each one to represent a specific target situation [39]. Kwon and Lee [40] decomposed the target appearance and motion into several models and assigned a tracker for each one. Kim et al. [41] trained and updated multiple classifiers to capture the changes of the appearance. Liu et al. [42] used the sparse representation to extract samples from the training set with minimal reconstruction errors. Avidan [19] combined multiple weak classifiers into a strong one. Han et al. [43] applied Kalman and Particle filters to evaluate the collected features from color and gradient orientation histograms. However, the performance of such models generally depends on the availability of comprehensive training sets and fine tuning of the model parameters for each video.
In this paper, we propose Dirichlet process-based appearance model (DPAM) for object tracking, which is different from the aforementioned methods in several ways. First, the number of mixture components (clusters or parameters) is automatically determined based on the complexity of the appearance data. Thus, DPAM can be used to model various amounts of appearance changes and is widely applicable in object tracking. Second, DPAM is an online learning model that can handle significant and abrupt appearance variations during tracking. Finally, DPAM is a nonparametric method. Its performance does not depend on hand tuning of system parameters.
3 Dirichlet process-based appearance model
In this section, we introduce DPAM in details. We begin with an overview of Dirichlet process (DP) and our contribution and modification to the traditional DP model in Sect. 3.1, the DPAM model structure in Sect. 3.2 and finally the Bayesian decision in Sect. 3.3.
3.1 Dirichlet process
Our goal is to learn a target appearance model during real-time object tracking. Since the target data are unknown in advance, the capacity of the model should adapt to the appearance complexity. So, we need a multiple appearance model. According to De Finetti’s theorem, the probability distribution of infinite exchangeable observations \(\{x_1,x_2,\ldots ,x_n\}\) is a mixture of probability distributions of these observations. That is [44],
where \({\varTheta }\) is an infinite-dimensional mixture space of probability measures and \({\hbox {d}\theta }\) defines a probability measure over distributions.
Dirichlet process (DP) [45] is a Bayesian nonparametric probabilistic model comes under De Finetti’s theorem where a Dirichlet random variable \({\theta }\) with k-dimensionality has the property: \({\theta _{i}\ge 0,\sum _{i=1}^{k}\theta _{i}=1}\). DP describes the distribution of \({\theta }\) with the following probability density:
where the parameter \({\alpha }\) is a k-vector with components \({\alpha _{i}>1}\) and \({{\varGamma }}\) is the Gamma function.
As the number of clusters generally grows with the number of target instances, which is unknown in advance, an infinite DP is required where \({k \rightarrow \infty }\). The equations for the infinite DP are:
where \({G_0}\) is the base distribution and \({\alpha }\) is the concentration parameter.
The advantage of using the infinite DP for target instance clustering over traditional clustering methods lies on the number of repetitions required to infer the number of clusters. The infinite DP automatically infers the number of clusters with a single repetition, while the traditional clustering methods need multiple repetitions to compare different hypotheses on the number clusters before determining the best one. Moreover, during testing, DP has the flexibility of allowing previously unseen data to form a new cluster.
The distribution over data partitions induced by DP is known as a Chinese Restaurant Process (CRP) [46]. CRP can potentially model an infinite number of mixture clusters regarding the input data, where each cluster can have infinite target’s instances. If the target’s instances \(\{x_1,x_2,\ldots ,x_n\}\) have occupied the clusters \(\{\theta _1,\ldots ,\theta _m\}\), when a new target’s instance \(x_{n+1}\) comes, the probability of joining or creating a new cluster is given as:
where n is the total number of target instances, \({L_k}\) is the number of target instances in cluster k and \({\alpha }\) the concentration parameter.
When used in tracking, CRP has the nice property where neither the number of clusters nor the number of target instances needs to be known in advance. It can dynamically increase the number of clusters as data grows. In this paper, we propose a novel appearance model based on CRP to cluster the target instances and handle the appearance changes during tracking.

Dirichlet process-based appearance model (DPAM)
Generally, in order to detect the new location of the target, we need to model the appearance of both the target and its surrounding background. Thus, the proposed model, DPAM, includes two CRPs, one for positive samples and the other one for negative samples. Since DPAM could have more than one CRP model, Eq. 6 is rewritten as follows:
where v is a model variable that will be explained with details in the next section, \({n^v}\) is the total number of target instances in model v, \({\{\theta _1,\ldots ,\theta ^v_m\}}\) are the clusters of model v, and \({L^v_k}\) is the number of target instances in cluster k. When a new target instance comes, Eq. 7 determines the order of the evaluation (joining an existing cluster or creating a new cluster). Specifically, it chooses the cluster with the highest number of images first. If the similarity is lower than the preset threshold, we move to the next highest cluster. The hyperparameter \(\alpha \) is set to 1 to enforce our system to check all the existing clusters before creating a new one.
3.2 The model structure
Our appearance model is created based on CRP proposed by Aldous [46]. We differ from the traditional CRP by explicitly introducing a new model variable v to categorize data into different models. Here, we use v to indicate the positive (target) and negative (surrounding background) categories, while in general, v can represent any desired categorization of the target. For example, we can build a model for each different object in multiple object tracking.
As shown in Fig. 2, a feature vector x represents the target instance that is used as a base for clustering. A collection of N instances for the same tracked target is denoted by \({}X = \{x_1, x_2,\ldots , x_n\}\). Note that both x and v are shaded to indicate that they are observed variables.
In our model, the generative process of creating an object instance x is given in the following steps:
-
1.
Choose the model variable label \({v\,\sim\, p(v|\beta )}\) for each instance, where \({v=\{1,\ldots ,V\}}\), V is the total number of model variables and \({\beta }\) is a dimensional vector of a multinomial distribution with length V.
-
2.
Given the model variable label v, we draw a distribution by choosing \({\theta ^v \,{\sim}\, p(\theta |v,\alpha )}\) for each instance, where \({\theta }\) is the parameter of a multinomial distribution for choosing the clusters; \({\alpha }\) is a \({V\times Z}\) matrix where V is the total number of model variables and Z is the total number of clusters under the model variables.
-
3.
For each target instance:
-
(a)
choose cluster assignment \(\theta _c \,\sim\, \hbox {Mult}(\theta ^v)\)
-
(b)
choose a target instance \({x \,\sim\, p(x|\theta _c)}\).
-
(a)
Given the parameters \({\alpha }\) and \({\beta }\), the generative equation can be known. The joint probability of an instance mixture \({\theta }\), a set of N instances x and a model variable v is:
3.3 Bayesian decision
In tracking, DPAM is employed to recognize a given target instance x. Specifically, the probability of the model variable v is computed as follows:
where \({p(v|\alpha )}\) is the probability of choosing a certain CRP, \({p(x|v,\alpha )}\) is the probability of choosing a certain cluster in that CRP, and \({\alpha }\) and \({\beta }\) are parameters learned from the target’s previously observed instance set. For convenience, the distribution of \({p(v|\beta )}\) is assumed to be a fixed uniform distribution: \({p(v)=1/V}\), where V is the number of models. So, Eq. 11 could be rewritten as,
The target recognition problem is solved by computing the maximal likelihood of (x) given the model variable v: \({\max _{v}p(x|v,\alpha )}\cdot {p(x|v,\alpha )}\) is obtained by,
where D is the number of clusters in v, \({y_d}\) is the cluster centroid feature vector of cluster \({d \in D}\), and BD is the Bhattacharyya distance that is computed as:
where N is the dimension of the feature vectors.
4 Tracking system
In this section, we introduce how DPAM is used to build the appearance model for positive and negative samples and track the target. The pipeline of our tracker is illustrated in Fig. 1, and the tracking procedure is summarized in Algorithm 1.

4.1 Target tracking
The performance of the tracking system depends mainly on the effectiveness of the appearance model. In this paper, we build two models using DPAM, P-DPAM for positive samples and N-DPAM for the negative samples. In addition to the importance of choosing an effective appearance model, the method of choosing positive and negative samples when updating the appearance model is also important. In our system, we applied the most common technique for choosing positive and negative samples, in which the patch at the current tracker location is selected as the positive sample and the neighborhood samples around the current tracker location are considered as negative ones. Then, the positive sample is used to update P-DPAM and the negative ones are used to update N-DPAM.
Before tracking starts, a user first chooses the target of interest \(\ell (x)^*_t\). The system extracts the positive samples \(x \in X^P\) within an integer radius \(\eta \) from the given target location \(X^P=\{x|||\ell (x)_t^*-\ell (x)_t||<\eta \}\). \(\eta =1\) gives only one positive sample, while setting \(\eta > 1\) provides multiple positive samples. For negative samples \(x \in X^N\), the system extracts patches from an annular region surrounding the target location, defined by \(X^N=\{x|\psi>||\ell (x)_t^*-\ell (x)_t||>\omega \}\), \(\psi \) and \(\omega \) are parameters to control the size of the region. The patches \(X^P\) and \(X^N\) are used to update P-DPAM and N-DPAM, respectively.
In tracking, our system finds the target location \(\ell (x)_t^*\) in frame t by extracting and evaluating all patches \(X=\{x| ||\ell (x)^*_{t-1}-\ell (x)_{t}|| < \gamma \}\) that are within a search radius from the previous target location \(\ell (x)_{t-1}^*\) in frame \(t-1\). Based on Eq. 13, the appearance tracker first identifies the candidate patches that have high probability belonging to the positive cluster \(p(x|s=\hbox{P-DPAM})\) (higher than a threshold \(\zeta \)). Second, from the P-DPAM candidates patches, N-DPAM chooses a candidate that has lowest probability to belong to the negative appearance model \(p(x|s=\hbox{N-DPAM})\) to consider it as the new target location \(\ell (x)^*_t\). If no patch is classified as positive patch in the first step, the target is considered fully occluded. In full occlusion, the entire frame will be used as the searching area. The detailed steps of tracking are given in Algorithm 1.
After the system detects the new tracker location, the system extracts the positive and negative samples. The positive samples are extracted according to \(X^P=\{x| ||\ell (x)_t^*-\ell (x)_t||<\eta \}\) and the negative samples are extracted according to \(X^N=\{x|\psi>||\ell (x)_t^*-\ell (x)_t||>\omega \}\). All the positive and negative samples are used to update P-DPAM and N-DPAM, respectively. Since the number of clusters in N-DPAM grows fast, we remove the cluster that is not updated for a certain number of frames.
4.2 Image features
Image features, e.g., color and texture, that are sufficiently robust to changes are very important for appearance models. In general, using Gabor filter-based texture feature in tracking gives good results, but is computationally expensive. On the other hand, simple and fast-to-compute texture features (e.g., SIFT) do not provide accurate tracking results, especially in viewpoint change situations [47]. In the literature, global (from the entire bounding box of the object) and local (dividing the bounding box into subregions) Hue-Saturation-Value (HSV) color histograms are widely used as image descriptors in tracking systems due to their robustness and simplicity [48, 49]. Following these practices, in our system we define the target appearance as the composition of both global and local color histograms. As discussed in [50], human cognition about color is mainly based on hue (H), then saturation (S) and finally value (V). Thus, we used 24 H channels, 12 S channels and 4 V channels. We chose a low bin number of V channel to reduce the influence of illumination changes [51–53]. So, a 40-bin [\(H=24, S=12, V=4\)] global HSV color feature is extracted from the entire bounding box of the target. In addition, the target is divided into 16 equal-size sub-windows, and a 40-bin local color histogram is obtained from each. Thus, the final feature vector contains 17 40-bin HSV histograms.
5 Experiments
We evaluated our appearance model (DPAM) and tracking system on several challenging image sequences from PETS 2006 [54], AVSS 2007 [55], ViSOR [56] datasets and publicly available video sequences [57]. These are challenging videos with multiple occlusions, pose variations, illumination and scaling changes.
Our tracking system is compared with several state-of-the-art trackers, i.e., tracking-learning-detection (TLD) [21], multiple instance learning (MIL) [22], visual tracking decomposition (VTD) [40], locality sensitive histogram (LSH) [37] and distribution field (DF) [38]. Specifically, TLD used positive and negative samples to train a online binary classifier; MIL used multiple instance learning to build a discriminative tracker; VTD applied both observation and motion models; LSH employed locality sensitive histogram to update the appearance model; and DF used distribution fields to represent targets and images in tracking.

Comparing clustering results between GMM, Kotz and DPAM
In our comparison, either the binary or source codes for TLD, MIL, VTL, LSH and DF are obtained from their authors. The same initialization and default parameter settings are used in our evaluation. For our system, \(\eta \) (range of positive samples), \(\psi \) and \(\omega \) (range of negative samples), \(\gamma \) (target search radius) and \(\zeta \) (confidence threshold) are set to 1, 20, 5, 20 and 0.95, respectively, and used for all the video datasets evaluated in our experiments. These are the common parameters for any detection-based tracking algorithms. The values are typically selected based on the size of the target and the resolution of the video.
Our tracking system is implemented using OpenCV and C++ language on a machine that has a Quad (2.83 and 3.01 GHz) processor and 4GB RAM. The performance of tracking is evaluated by using the mean center location errors between the tracking results and the ground truth. The center location error was computed for all the frames in which a method was able to return a target location. That is, full occlusion frames, when detected by an algorithm, will be excluded.
5.1 Evaluation of clustering results
In this section, we show the clustering performance of DPAM by comparing it with the Gaussian mixture model (GMM) and the mixture model of Kotz-type distributions (Kotz) using the expectation maximization (EM) algorithm. In both cases, EM starts from some initial estimate of model parameters and then proceeds to iteratively update them until finding the maximum likelihood. More specifically, GMM is a parametric probability density function represented as a weighted sum of Gaussian component densities. Kotz-type distribution has fatter tail regions compared to Gaussian distribution [58]. While Gaussian distribution is powerful in modeling rare tail events, which often represents data with low noise, Kotz-type distribution can be more amenable for modeling more frequent tail events and thus may be more suitable for noisy data. The most general form of Kotz-type distribution is given by,
where \(c_p=\frac{s{\varGamma }({2}/{p})}{\pi ^{\frac{p}{2}} {\varGamma }({2N+p-2}/{2s})}r^{{2N+p-2}/{2s}}.\) In Kotz-type distributions, N, s and r are tuning parameters to modulate tail events, and p represents the dimension of the data. In practice, a number of special cases appeared in the literature, such as in [59–62], in which N is routinely set to 1 for mathematical convenience. Since s and r are a pair of covariates, we simply fix s at 1 and try a couple of different values of r around \(\frac{1}{2}\), the Gaussian case, to examine the fat tail events and to demonstrate its impact on our results.
As a base for comparison, we used Davies–Bouldin index (DBI):
where N is the number of clusters, \(c_k\) is the centroid of the kth cluster, \(M_k\) is the average distance between all instances in kth cluster and its centroid, and \(d(c_i,c_j)\) is the distance between the ith and jth cluster centroids. The clustering method that produces the smallest DBI value is considered the best.
Figure 3 summarizes the comparison, in which three image sequences from PETS 2006, ViSOR and AVSS 2007 are used. As the number of clusters needs to be specified in GMM and Kotz, we run it with different number of clusters. Then, we run DPAM on the same image sequences where the number of clusters is automatically determined. Clearly, DPAM gives a higher performance in all three image sequences.
5.2 Tracking results
In this section, we evaluated our tracker on matchmarking videos [57] and compared it with TLD, VTD, MIL, LSH and DF. The quantitative results are summarized in Table 1 and Fig. 4. Overall, our system provides the most accurate and robust tracking with average speed 20 fps on the 320 \(\times \) 270 frame size.
Comparative tracking results of selected frames are presented in Fig. 5. Specifically, in Sylvester and David videos, the tracking results for the target under lighting, scale and pose changes are presented. Our tracker achieves the best performance compared with all other tracking systems. TLD and LSH provide the second best performance on David video, and MIL provides the second best performance on Sylvester video. Our system tracks the whole target in all video frames with high accuracy and robustness.

The center location error plots

Comparative tracking results of selected frames. The tracking results by TLD, VTD, MIL, LSH, DF and ours are represented by cyan, blue, green, magenta, white and red rectangles, respectively (color figure online)
In Face Occluded 1 video, the main challenges are severe partial occlusion and appearance changes. DF achieved the second best performance on Face Occluded video because it is specifically designed to handle occlusion via distribution fields to represent targets and images in tracking. MIL achieved the third best performance on the video because it depends on patches during tracking. This highlights the advantages of using a dynamic appearance model. Obviously, our system tracked the target accurately in all situations and provides the most accurate and robust results.
In Tiger 1, Sylvester, David, Tiger 2 and Coke Can videos, the main challenges are appearance and pose changes, fast motion and frequent severe occlusions. In all videos, our system provides the best performance comparing with other systems because our tracker has the ability to create a new cluster for abrupt appearance or pose changes. In addition, our system keeps a target’s previous appearance, which helps re-detect it after full or severe occlusion.
In Dollar video, two objects have exactly the same appearance and thus present a big challenge to track the right one. In Surfer video, the target is small and there is a pose and lighting changes. In Twinning video, the object appearance is changed totally. Again, our tracker achieved excellent tracking results on these three videos. The robustness of our system is clearly shown. TLD provides good performance on Surfer, but gets bad results when we have a big appearance change, i.e., in Twinning and Dollar videos. MIL provides similar performance as ours on Twinning video, and LSH provides the second best performance on Dollar Video.

Representative frames from different clusters of DPAM in Tiger 1 video. Different appearance changes are shown: view angle (54), scale (96), occlusion (120), appearance (165) and illumination (306) changes. The tracking results by TLD, VTD, MIL, LSH, DF and DPAM are represented by cyan, blue, green, magenta, white and red rectangles, respectively (color figure online)
5.3 A case study
In this section, we take a closer look at the tracking results of Tiger 1 video to clearly illustrate the advantage of DPAM. The video has 353 frames and many appearance changes due to heavy occlusion, scale change, 3D-rotation and uneven illumination. Figure 6 shows representative frames of the target appearance changes: view angle (frame 54), scale (frame 96), occlusion (frame 120), appearance (frame 165) and illumination (frame 306). These changes, in turn, produce many clusters in P-DPAM. Some representative frames in these clusters are shown in Fig. 6. Since determining the number of clusters in advance is generally not possible, DPAM provides a general model for tracking by growing dynamically with the complexity of the video.
MIL, VTD, LSH and DF all lost the target (the center location error is higher than 30) for the first time between frames 108 and 150 (frame 120 is used to show the tracking results), where the target changed its appearance (scale and rotation) during occlusion. TLD first lost the target on frame 165. The loss of tracking attributes to a couple of reasons. First, because of the fast appearance changes, KLT in TLD failed to track the target. Second, these methods do not keep the target’s previous appearance. Their tracking mainly depends on the online updating of the corresponding classifier. In frame 165, background is added to the target box by TLD, leading to the misdetection in the subsequent frames. On the other hand, DPAM can handled sudden appearance changes by quickly creating a new cluster in P-DPAM. In addition, P-DPAM explicitly keeps all the previous appearances of the target, which are used effectively for target detection. The percentages of correctly tracked frames are 46, 40, 70, 60, 55 and 100 % for LTD, MIL, VTD, LSH, DF and DPAM, respectively.
In our experiments, DPAM successfully tracks all the objects for the full length of each video sequence, which none of other trackers can achieve. Even when other methods track the target successfully, our method significantly improves the tracking accuracy, evidenced by the lowest average center location errors shown in Table 1.
6 Conclusion
In this paper, we propose a novel Dirichlet process-based appearance model (DPAM) to handle target appearance changes during tracking. DPAM differs from the traditional Dirichlet process by explicitly introducing a new model variable v, which categorizes the negative and positive target instances into different models and dynamically clusters them based on visual similarity. DPAM provides an infinite nonparametric mixture of distributions that can grow automatically with the complexity of the appearance data. In addition, prior off-line training or specifying the number of mixture components (clusters or parameters) is not required. Our tracking system with DPAM achieves superior performance when compared with several state-of-the-art trackers.
In the future, we plan to employ our model to more complicated tracking problems, e.g., multiple object tracking and deformable object tracking. Specifically, DPAM can be modified to have a model for the background and an individual model for each target to handle the target appearance changes. In this case, the number of DPAM models will grow automatically regarding the number of new targets, and the number of clusters in each model will grow regarding the target appearance changes.
References
Isard M, MacCormick J (2001) Bramble: a bayesian multiple-blob tracker. In: IEEE international conference on computer vision, pp 34–41
Birchfield S (1998) Elliptical head tracking using intensity gradients and color histograms. In: IEEE international conference on computer vision and pattern recognition, pp 232–237
Lepetit V, Fua P (2006) Keypoint recognition using randomized trees. IEEE Trans Pattern Anal Mach Intell 28:1465–1479
Branson K, Belongie S (2005) Tracking multiple mouse contours (without too many samples). In: IEEE international conference on computer vision and pattern recognition, pp 1039–1046
Yu G, Hu Z, Lu H, Li W (2011) Robust object tracking with occlusion handle. Neural Comput Appl 20:1027–1034
Wang N, Wang J, Yeung D-Y (2013) Online robust non-negative dictionary learning for visual tracking. In: IEEE international conference on computer vision, pp 657–664
Chen D, Yuan Z, Wu Y, Zhang G, Zheng N (2013) Constructing adaptive complex cells for robust visual tracking. In: IEEE international conference on computer vision, pp 1113–1120
Grabner H, Leistner C, Bischof H (2008) Semi-supervised on-line boosting for robust tracking. In: European conference on computer vision, pp 234–247
Wang X, Hua G, Han T (2010) Discriminative tracking by metric learning. In: European conference on computer vision, pp 200–214
Li A, Tang F, Guo Y, Tao H (2010) Discriminative nonorthogonal binary subspace tracking. In: European conference on computer vision, pp 258–271
Lefort R, Fablet R, Boucher J (2010) Weakly supervised classification of objects in images using soft random forests. In: European conference on computer vision, pp 185–198
Liu R, Cheng J, Lu H (2009) A robust boosting tracker with minimum error bound in a co-training framework. In: IEEE international conference on computer vision, pp 1459–1466
Santner J, Leistner C, Saffari A, Pock T, Bischof H (2010) Prost: parallel robust online simple tracking. In: IEEE international conference on computer vision and pattern recognition, pp 723–730
Lu H, Zhou Q, Wang D, Xiang R (2011) A co-training framework for visual tracking with multiple instance learning. In: IEEE international conference on automatic face & gesture recognition and workshops, pp 539–544
Dinh T, Medioni G (2011) Co-training framework of generative and discriminative trackers with partial occlusion handling. In: IEEE workshop on applications of computer vision, pp 642–649
Avidan S (2004) Support vector tracking. IEEE Trans Pattern Anal Mach Intell 26:1064–1072
Lepetit V, Lagger P, Fua P (2005) Randomized trees for real-time keypoint recognition. In: IEEE international conference on computer vision and pattern recognition, pp 775–781
Lim J, Ross D, Lin R, Yang M (2004) Incremental learning for visual tracking. In: Advances in neural information processing systems, pp 793–800
Avidan S (2007) Ensemble tracking. IEEE Trans Pattern Anal Mach Intell 29:261–271
Grabner H, Bischof H (2006) On-line boosting and vision. In: IEEE international conference on computer vision and pattern recognition, pp 260–267
Kalal Z, Matas J, Mikolajczyk K (2010) Pn learning: bootstrapping binary classifiers by structural constraints. In: IEEE international conference on computer vision and pattern recognition, pp 49–56
Babenko B, Yang M, Belongie S (2009) Visual tracking with online multiple instance learning. In: IEEE conference on computer vision and pattern recognition, pp 983–990
Williams O, Blake A, Cipolla R (2005) Sparse bayesian learning for efficient visual tracking. IEEE Trans Pattern Anal Mach Intell 27:1292–1304
Aeschliman C, Park J, Kak A (2010) A probabilistic framework for joint segmentation and tracking. In: IEEE international conference on computer vision and pattern recognition, pp 1371–1378
Collins R, Liu Y, Leordeanu M (2005) Online selection of discriminative tracking features. IEEE Trans Pattern Anal Mach Intell 27:1631–1643
Comaniciu D, Ramesh V, Meer P (2003) Kernel-based object tracking. IEEE Trans Pattern Anal Mach Intell 25:564–577
Mei X, Ling H (2009) Robust visual tracking using l 1 minimization. In: IEEE international conference on computer vision, pp 1436–1443
Hager G, Belhumeur P (1998) Efficient region tracking with parametric models of geometry and illumination. IEEE Trans Pattern Anal Mach Intell 20:1025–1039
Black M, Jepson A (1998) Eigentracking: robust matching and tracking of articulated objects using a view-based representation. Int J Comput Vis 26:63–84
Comaniciu D, Ramesh V, Meer P (2000) Real-time tracking of non-rigid objects using mean shift. In: IEEE international conference on computer vision and pattern recognition, pp 142–149
Adam A, Rivlin E, Shimshoni I (2006) Robust fragments-based tracking using the integral histogram. In: IEEE international conference on computer vision and pattern recognition, pp 798–805
Jepson A, Fleet D, El-Maraghi T (2003) Robust online appearance models for visual tracking. IEEE Trans Pattern Anal Mach Intell 25:1296–1311
Matthews L, Ishikawa T, Baker S (2004) The template update problem. IEEE Trans Pattern Anal Mach Intell 6:810–815
Ross D, Lim J, Lin R, Yang M (2008) Incremental learning for robust visual tracking. Int J Comput Vis 77:125–141
Zhou H, Yuan Y, Shi C (2009) Object tracking using sift features and mean shift. Comput Vis Image Underst 113:345–352
Godec M, Roth P, Bischof H (2013) Hough-based tracking of non-rigid objects. Comput Vis Image Underst 117:1245–1256
He S, Yang Q, Lau R, Wang J, Yang M (2013) Visual tracking via locality sensitive histograms. In: IEEE international conference on computer vision and pattern recognition, pp 2427–2434
Lara L, Learned-Miller E (2012) Distribution fields for tracking. In: IEEE international conference on computer vision and pattern recognition, pp 1910–1917
Yu T, Dinh TB, Medioni G (2008) Online tracking and reacquisition using co-trained generative and discriminative trackers. In: European conference on computer vision, pp 678–691
Kwon J, Lee KM (2010) Visual tracking decomposition. In: IEEE international conference on computer vision and pattern recognition, pp 1269–1276
Kim T, Woodley T, Stenger B, Cipolla R (2010) Online multiple classifier boosting for object tracking. In: IEEE international conference on computer vision and pattern recognition, pp 1–6
Liu B, Yang L, Huang J, Meer P, Gong L, Kulikowski C (2010) Robust and fast collaborative tracking with two stage sparse optimization. In: European conference on computer vision, pp 624–637
Han Z, Ye Q, Jiao J (2011) Combined feature evaluation for adaptive visual object tracking. Comput Vis Image Underst 115:69–80
Cherian A, Morellas V, Papanikolopoulos N, Bedros S (2011) Dirichlet process mixture models on symmetric positive definite matrices for appearance clustering in video surveillance applications. In: IEEE international conference on computer vision and pattern recognition, pp 3417–3424
Ferguson T (1973) A bayesian analysis of some nonparametric problems. Ann Stat 1:209–230
Aldous D (1985) Exchangeability and related topics. École d’Été de Probabilités de Saint-Flour, pp 1–198
Ramisa A, Vasudevan S, Aldavert D, Toledo R, de Mantaras RL (2009) Evaluation of the sift object recognition method in mobile robots. In: International conference of the catalan association for artificial intelligence, pp 56–73
Yu S-I, Yang Y, Hauptmann A (2013) Harry potter’s marauder’s map: localizing and tracking multiple persons-of-interest by nonnegative discretization. In: IEEE conference on computer vision and pattern recognition, pp 3714–3720
Lee D-Y, Sim J-Y, Kim C-S (2014) Visual tracking using pertinent patch selection and masking. In: IEEE conference on computer vision and pattern recognition, pp 3486–3493
Jain YK, Yadav R (2014) Content-based image retrieval approach using three features color, texture and shape. Int J Comput Appl 97(17):1–8
Nummiaro K, Koller-Meier E, Van Gool L (2003) Color features for tracking non-rigid objects. ACTA Autom Sin 29(3):345–355
Wang J, Yagi Y (2006) Integrating shape and color features for adaptive real-time object tracking. In: IEEE international conference on robotics and biomimetics, pp 1–6
Ogul B, Temizel A (2013) Person re-identification by combining features in a learning based framework. In: International conference on imaging for crime detection and prevention, pp 1–5
Plungpongpun K, Naik D (2008) Multivariate analysis of variance using a kotz type distribution. Proc World Congr Eng 2:2–4
Fang K, Kotz S, Ng K (1998) Symmetric multivariate and related distributions. Chapman & Hall, London
Gómez E, Gomez-Viilegas M, Marin J (1998) A multivariate generalization of the power exponential family of distributions. Commun Stat Theory Methods 27(3):589–600
Johnson ME (2013) Multivariate statistical simulation: a guide to selecting and generating continuous multivariate distributions. Wiley, Hoboken
Naik DN, Plungpongpun K (2006) A kotz-type distribution for multivariate statistical inference. In: Advances in distribution theory, order statistics, and inference, pp 111–124
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Almomani, R., Dong, M. & Zhu, D. Object tracking via Dirichlet process-based appearance models. Neural Comput & Applic 28, 867–879 (2017). https://doi.org/10.1007/s00521-016-2280-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-016-2280-1