
Abstract
Tracking an object in long term is still a great challenge in computer vision. Appearance modeling is one of keys to build a good tracker. Much research attention focuses on building an appearance model by employing special features and learning method, especially online learning. However, one model is not enough to describe all historical appearances of the tracking target during a long term tracking task because of view port exchanging, illuminance varying, camera switching, etc. We propose the Adaptive Multiple Appearance Model (AMAM) framework to maintain not one model but appearance model set to solve this problem. Different appearance representations of the tracking target could be employed and grouped unsupervised and modeled by Dirichlet Process Mixture Model (DPMM) automatically. And tracking result can be selected from candidate targets predicted by trackers based on those appearance models by voting and confidence map. Experimental results on multiple public datasets demonstrate the better performance compared with state-of-the-art methods.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Robust object tracking in a long term is a challenging task in computer vision. There have been many trackers proposed by different researchers [1–3] that employ different types of visual information and learned features to build the appearance models as the base of the tracking, e.g. color histogram in Meanshift, multiple features in particle filter [4], Haar-like in MIL [5], etc.
However, it is still not enough to represent the tracking target with one appearance model, even online updating model or patch dictionary model and so on, while the target in internal and external variations. Internal variation includes pose changing, motion, shape deformation, illumination variation, etc. And External variation includes background changing, covered by foreground objects. Tackle this problem, an appearance model set is needed for describing the historical appearances of tracking target.
Therefore, we propose a novel nonparametric statistical method to model the appearance of the target as combination of multiple appearance models. Each model describes an typical appearance character under specific situation, and clustered by Dirichlet Process Mixture Model (DPMM) [7] framework dynamically unsupervised.

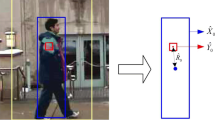
The framework of the adaptive multiple appearance model tracking.
The Framework of our system is shown in Fig. 1. Experimental results on several public datasets show that AMAM tracking system is applicable to multiple camera system and indoor and outdoor climates tracking system, and outperform several state-of- the-art trackers.
The rest of the paper is organized as follows. Section 2 overviews some of the related works. Section 3 describes the proposed AMAM algorithm. We present experimental validation on several public datasets in Sect. 4 and conclude the paper in Sect. 5.
2 Related Works
In long term tracking task, the biggest challenge is drifting problem. Tackle this problem, appearance models tolerance range need to be enhanced. Ensemble tracking [9] and the Multiple Instance Learning boosting method (MIL) [5] using positive sample and negative samples of tracking targets to train classifiers. Semi-online boosting [10] using both unlabeled and labeled tracking candidate target to train classifiers online. Fragment-based tracking [16] coupled with a voting map can accurately track the partially occluded target. However, historical information is ignored when updating classifiers or models. Dictionary learning [15] was employed to using the linear combination to represent the dynamic appearance of the target and handles the occlusion as a sparse noise component. However, spatial and temporal information are lost when algorithm performing. Appearance representation learned by In our model, we build appearance model set to keep the spatial information of tracking target and tracking system could keep the temporal information as well. at the same time, all efficient appearance model can be employed in this framework including sparse coding, dictionary learning and learned target descriptions by deep learning or other machine learning methods.

The procedure of AMAM framework working.
3 The Framework of Adaptive Multiple Appearances Model Tracking
In this section, we describe the common framework of adaptive multiple appearance model. In first, we present the Dirichlet Process Mixture model (DPMM), which are employed to organize the adaptive appearance set. After that, we describe the tracking system based on AMAM framework.
3.1 Dirichlet Process Mixture Model
The Dirichlet process (DP) is parameterized by a base distribution H which has corresponding density \(h (\mathrm {\theta })\), and a positive scaling parameter \(\mathrm {\alpha } > 0\). We denote a DP and suppose we draw a random measure G from a DP, and independently draw N random variables \(\mathrm {\theta }_{n}\) from G, this can be described as follows:


As shown by [8], given N independent observations \(\mathrm {\theta }_{i} \sim G\), the posterior distribution also follows a DP:

where \(n_{1}n_{2}, . . . , n_{r}\) represent the number of observations falling in each of the partitions \(A _{1}A_{2}, . . .A_{r}\) respectively,N is the total number of observations, and \(\mathrm {\delta _{\theta _{i}} }\) represents the delta function at the sample point \(\mathrm {\theta }_{i}\).
3.2 Model Inference
Given N observations \(X= \{{X_{i}}\}^N_{i=1} (X_{i} \in N^d)\), each \(X_{i}=\left\{ {x_{i}}\right\} ^d_{i=1}\) represents a quantized d-dim HOG feature, and \(x_{i}\) is the histogram quantized bin counts, which is a quantized integer. Let \(z_{i}\) indicate the cluster or appearance model, associated with the \(i^{th}\) observation which is represented by quantized HOG feature. As shown in Fig. 1, we would like to infer the number of latent clusters or different appearances underlying those observations, and their parameters \(\mathrm {\theta }_{k}\). Since the exact computation of the posterior is infeasible especially when data size is large, we resort to a variant of MCMC algorithms, namely, the collapsed Gibbs sampler [7] for faster approximate inference.
We choose multinomial distribution \(F(\mathrm {\theta })\) to describe HOG features of observations, and the cluster prior \(H(\mathrm {\lambda })\) is a Dirichlet distribution which is conjugate to \(F(\mathrm {\theta })\). Given fixed cluster assignments \(z_{-i}\) for other observations, the posterior distribution of \(z_{i}\) factors as follows:
The prior \(p\left( z_{i} \vert z_{-i},\alpha \right) \) is given by the Chinese restaurant process (CRP).
The \(\bar{k}\) denotes one of the infinitely many unoccupied clusters or new appearances. \(N_{k}^{-i}\) is the total number of observations in cluster k except observation i.

For the K clusters to which \(z_{-i}\) assigns observations, the likelihood of Eq. (3) is shown as follows:
Because dirichlet distribution \(H(\mathrm {\lambda })\) is conjugate to multinomial distribution \(F (\theta )\), \(\theta = (p_{1}, p_{2}, ..., p_{d})\) and \(\{{X_{i}}\}^N_{i=1} \sim Mult\left( p1, p2, ..., pd\right) \), we can get a closed-form of predictive likelihood expression for each cluster or appearance k as follows:
where \(\lambda ^{'}\) is the posterior of \(\lambda \) and \(\Gamma \) is the gamma function. Similarly, new clusters \(\bar{k}\) are based upon the predictive likelihood implied by the prior hyper parameters \(\lambda \):
where \(A = \sum \limits _{k} \lambda _{k}\) and \(N = \sum \limits _{k} n_{k}\), and where \(n_{k} = \) number of \(x_{i}\)’s with value k. Combining these expressions, we employed Gibbs sampler at Algorithm 1.

3.3 AMAM Tracking
Given the observation set of the target\(X_{1:t} = [X_{1},...,X_{t}]\), where each \(X_{t}\) represents a quantized HOG feature, up to time t, the tracking result \(s_{t}\) can be determined by the Maximum A Posteriori (MAP) estimation, \(\hat{s_{t}} = argmax p \left( s_{t}|X_{1:t}\right) \), where \(p\left( s_{t}|X_{1:t}\right) \) is inferred by the Bayes theorem recursively with
Let \(s_{t} = [l_{x},l_{y},\theta ,s,\alpha ,\phi ]\), where \(l_{x},l_{y},\theta ,s,\alpha ,\phi \) denote x, y translations, rotation angle, scale, aspect ratio, and skew respectively.We apply the affine transformation with those six parameters to model the target motion between two consecutive frames. The state transition is formulated as \(p\left( s_{t}|s_{t-1}\right) = N\left( s_{t};s_{t-1}\sum \right) \), where \(\sum \) is the covariance matrix of six affine parameters.
The observation model \(p\left( X_{t}|s_{t}\right) \) denotes the likelihood of the observation \(X_{t}\) at state \(s_{t}\). The Noisy-OR (NOR) model is adopted for doing this:
where \(H_{k}, k\in \left( 1,2,...,K\right) \) represents the multiple appearance models learned from Algorithm 1.
The equation above has the desired property that if one of the appearance models has a high probability, the resulting probability will be high as well.
Algorithm 2 illustrates the basic flow of our algorithm.
4 Experiments
In our experiments, we employ 10 challenging public tracking datasets selected from [2] and using the same evaluation methods, the center location error and success rate, to verify the performance of our algorithm. The proposed approach is compared with ten state-of-the-art tracking methods. Table 1 shows all the tracking methods we need to evaluate. In addition, we evaluate the proposed tracker against those methods using the source codes provided by the authors and each tracker is running with adjusted parameters for fair evaluation.
4.1 The AMAM Modeling
Figure 2 shows how the AMAM working. These small face images under the main frame shows the appearance instance belong to each appearance model and the historical instances while tracking. The red rectangle in main frame is the tracking result based on the model in red, and the green one is the ground truth. The instances of each appearance models increasing while long term tracking, and the number of appearance models increasing while the inner and inter distance changing based on the DPMM Algorithm 1.

Three tracking video sequences with all tracking result from the all trackers. The bounding boxes in red are our results.
4.2 Tracking System
Figure 3 shows how the AMAM tracking results based on 2. Bounding boxes in red are our results. We can find that our tracker can track the target very well while most of the other tracker are drifting.
In order to measure the performance of tracking result, we employed two traditional measurement operator. One is the center error (CE), and the other is coverage rate (CR).

Tracking result compare with the recent appeared 10 trackers listed in Table 1 by coverage rate (a) and center error (b) and measurement operators in public datasets.
The center error is defined as the average Euclidean distance between the center locations of the tracked targets and the manually labeled ground truths, for calculating precision plot. In a general way, the overall performance of one sequence depends on the average center location error over all the frames of one sequence, but when the tracker loses the target, we will only get the random output location and the average error value which may not measure the tracking performance correctly [5]. Therefore, we use the precision plot to measure the overall tracking performance. It shows the percentage of frames whose estimated location is within the given threshold distance of the ground truth. Figure 4(b) shows result in our experiment. Since the smaller is better, our AMAM tracker performs good in those public testing videos.
The coverage rate is defined as the bounding box overlapping rate between the tracking target and the ground truth. A higher score means the tracking result is closer to ground truth. The formula of calculating score is \(score = \frac{area(ROI_{T}\cap ROI_{G})}{area(ROI_{T}\cup ROI_{G})}\) while the formula of calculating average score is \(avrScore = \frac{\sum \limits ^{frameLength}_{1}score}{frameLength}\).
In Table 2, we compare the performance of trackers in each testing dataset with the same testing result shown in Fig. 4. We selected the best performed tracker and the second tracker in each testing data both based on CR and CE operators. We also calculate the differences between them for tracking accuracy measuring. In Table 3, we also import the variation and average CR to measure the robustness and accuracy. Since the inhumations, backgrounds and targets are different at all, if the tracker performing stable with low variation, the tracker can be considered robustness.
From the Table 2, we find that our AMAM Tracker is outperform in 8 testing videos. The differences between best and our tracker in CR and CE are less than 1.4 % and 1 pixel in the rest 2 testing videos.
From the Table 3, the variation of our tracker in all videos is 0.002, extremely lower than others both in average and individual.The ACR of our AMAM tracker in all testing videos is 19 % higher than others. That means our tracker can perform more robust and more accurate than others.
5 Conclusion
This paper tackled the drifting problem in tracking and proposed an Adaptive Multiple Appearance Model framework for long term robust tracking. We simply employed HOG to build the basic appearance representation of the tracking target in experiment but all efficient representation of visual objects could be joint in our algorithm framework. Historical appearance descriptions could be employed and grouped unsupervised and modeled by Dirichlet Process Mixture Model automatically. And tracking result can be selected from candidate targets predicted by trackers based on those appearance models by voting and confidence map. Experiment in several public datasets shows that, our tracker has low variation (less than 0.002) and high tracking performance (19 % better than other 10 trackers in average) when compared with the state-of-the-art methods.
References
Li, X., Hu, W., Shen, C., et al.: A survey of appearance models in visual object tracking. ACM Trans. Intell. Syst. Technol. (TIST) 4(4), 58:1–58:48 (2013)
Wu, Y., Lim, J., Yang, M.: Online object tracking: a benchmark. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2411–2418 (2013)
Smeulders, A., Chu, D., Cucchiara, R.: Visual tracking: an experimental survey. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 36(7), 1442–1468 (2014)
Wang, H., Suter, D., Schindler, K.: Effective appearance model and similarity measure for particle filtering and visual tracking. In: Proceedings of European Conference Computer Vision (ECCV) (2006)
Babenko, B., Yang, M., Belongie, S.: Robust object tracking with online multiple instance learning. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 33(8), 1619–1632 (2011)
Wang, N., Yeung, D.: Learning a deep compact image representation for visual tracking. In: Proceedings of the NIPS, (5192), pp. 809–817 (2013)
Neal, R.M.: Markov chain sampling methods for Dirichlet process mixture models. J. Comput. Graph. Stat. 9, 249–265 (2000)
Ferguson, T.: A Bayesian analysis of some nonparametric problems. Ann. Stat. 1(2), 209–230 (1973)
Avidan, S.: Ensemble tracking. IEEE Trans. Pattern Anal. Mach. Intell. 29(2), 261–271 (2007). IEEE society
Grabner, H., Bischof, H.: On-line boosting and vision. In: Proceedings of Computer Vision and Pattern Recognition, 1, pp. 260–267 (2006)
Stenger, B., Woodley, T., Cipolla, R.: Learning to track with multiple observers. In: Proceedings of Computer Vision and Pattern Recognition, pp. 2647–2654 (2009)
Yu, Q., Dinh, T.B., Medioni, G.: Online tracking and reacquisition using co-trained generative and discriminative trackers. In: ECCV (2008)
Gao, Y., Ji, R., Zhang, L., Hauptmann, A.: Symbiotic tracker ensemble toward a unified tracking framework. IEEE Trans. Circuits Syst. Video Technol. (TCSVT) 24(7), 1122–1131 (2014)
Zhang, L., Gao, Y., Hauptmann, A., Ji, R., Ding, G., Super, B.: Symbiotic black-box tracker. In: Proceedings of the Advances on Multimedia modeling (MMM), pp. 126–137 (2012)
Wang, N., Wang, J., Yeung, D.: Online robust non-negative dictionary learning for visual tracking. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV 2013), pp. 657–664 (2013)
Adam, A., Rivlin, E., Shimshoni, I.: Robust fragments-based tracking using the integral histogram. In: Proceedings of the CVPR (2006)
Oron, S., Bar-Hillel, A., Levi, D., Avidan, S.: Locally orderless tracking. In: CVPR (2012)
Ross, D., Lim, J., Lin, R., Yang, M.: Incremental learning for robust visual tracking. IJCV 77(1), 125–141 (2008)
Jia, X., Lu, H., Yang, M.: Visual tracking via adaptive structural local sparse appearance model. In: CVPR (2012)
Bao, C., Wu, Y., Ling, H., Ji, H.: Real time robust L1 tracker using accelerated proximal gradient approach. In: CVPR (2012)
Zhang, T., Ghanem, B., Liu, S., Ahuja, N.: Robust visual tracking via multi-task sparse learning. In: CVPR (2012)
Kwon, J., Lee, K.M.: Visual tracking decomposition. In: CVPR (2010)
Grabner, H., Grabner, M., Bischof, H.: Real-time tracking via online boosting. In: BMVC (2006)
Kalal, Z., Matas, J., Mikolajczyk, K.: P-N learning: bootstrapping binary classifiers by structural constraints. In: CVPR (2010)
Hare, S., Saffari, A., Torr, P.H.S.: Struck: structured output tracking with kernels. In: ICCV(2011)
Acknowledgments
This material is based upon work supported by the Key Technologies Research and Development Program of China Foundation under Grants No. 2012BAH38F01-5. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the Key Technologies Research and Development Program of China Foundation.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
Tang, S., Zhang, L., Chi, J., Wang, Z., Ding, G. (2015). Adaptive Multiple Appearances Model Framework for Long-Term Robust Tracking. In: Ho, YS., Sang, J., Ro, Y., Kim, J., Wu, F. (eds) Advances in Multimedia Information Processing -- PCM 2015. PCM 2015. Lecture Notes in Computer Science(), vol 9314. Springer, Cham. https://doi.org/10.1007/978-3-319-24075-6_16
Download citation
DOI: https://doi.org/10.1007/978-3-319-24075-6_16
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-24074-9
Online ISBN: 978-3-319-24075-6
eBook Packages: Computer ScienceComputer Science (R0)