
Abstract
In order for Parkinson’s disease (PD) treatment and examination to be logical, a key requirement is that estimates of disease stage and severity are quantitative, reliable, and repeatable. The PD research in the past 50 years has been overwhelmed by the subjective emotional evaluation of human’s understanding of disease characteristics during clinical visits. The Parkinson’s disease data set contains 23 features and 197 instances, of which 8 patients are sound and 23 patients, are analyzed as PD patients. Relying on chi2 test, extra trees classifier, and correlation matrix as feature extraction strategies and relying on Decision Trees, K-Nearest Neighbors, Random Forests, Bagging, AdaBoosting, and Gradient Boosting as supervised AI calculations for permutation calculations. The calculation is based to obtain higher classifier accuracy, as well as ROC curves accuracy. Three conspicuous component selection strategies allow each of the 23 features to select 10 best performing features. The DT classifier has a higher accuracy of 94.87% in a dataset with 23 attributions, just like a dataset with 11 features. These results are also checked by ROC curve (AUC = 98.7%). This calculation significantly separates PD patients from patients at the individual level, thus ensuring the use of computer-based findings in clinical practice.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Parkinson’s disease (PD) is a dangerous disease that occurs on the earth after Alzheimer’s disease. Countless people around the world have experienced this disease. PD is a reformist and long-term focus sensory system degenerative disorder that seriously affects the elderly [1]. The significant side effects of PD are developmental weakness, such as delayed back development, muscle extension, hindered standing and balance, loss of procedural development, changes in speech, and changes in composition. The undergoing PD has no steady progress in dopamine under the body framework. The sound problem is a potential side effect for PD patients [2]. Such patients have problems with speaking, such as volume level and irregular pronunciation. The sound problems of these issues can be evaluated for early PD analysis. Diagnosing and monitoring PD through speech signals is more accurate and equally powerful. The result information is often used by neurologists to analyze PD through voice recording systems to help patients and get clear opinions. The new symptom model of Parkinson’s infection has been released, and the main model rules for Parkinson’s disease of the Movement Disorder Society have been established. Their goal is to help standardize clinical examinations [3]. The confirmation of Parkinson’s infection is usually guided by certain methods, such as observational evaluation and evaluation of patient clinical records. These strategies, like the abrupt strategies that distinguish PD, are not reliable in terms of accuracy and feasibility. The Medical Foundation announced that the current determination framework has not yet accurately distinguished Parkinson’s disease. To overcome these limitations, we need a reliable technique that can be used to identify and help prevent PD. In this association, part of the AI strategy is critical to the identification, avoidance, and treatment of PD [4].
In order to overcome the aforementioned problems, this article proposes a new coordination strategy based on chi2, extra trees classifier and correlation matrix to select the outline of the appropriate features [5]. These calculations have been used to process a large number of features and rank them as needed. Compared with a separate demonstration, the mixture of the three calculations provides excellent execution [6]. Then, at that time, we used the selected features to train and test six classifiers to predict PD patients. This article describes as follows:
-
First, three calculation methods are proposed for selecting suitable features, that is, the chi2, extra trees classifier, and Correlation matrix, which allocates an appropriate load to each component in the feature set, locates the feature according to the weight, and finally resolves the correlation.
-
Secondly, the presentation of decision tree, K-nearest neighbors, random forest, Bagging, AdaBoosting, and Gradient Boosting has been evaluated using selected features. The results show that compared with the first feature list, DT has created key results based on the features of the chi2, extra trees classifier, and correlation matrix. In addition, ROC curve has been drawn for each selected object, including all the features approved by the result obtained by the classifier.
-
We have conducted extensive investigations on real-world data sets, and the results show that compared with partners, the proposed analysis techniques (including selective classifier-AI classifier) have achieved key results in terms of high accuracy and low computational cost.
The rest of the paper is divided into seven parts. Section “Literature Review” describes the writing survey. Section “Materials and Methods” introduces the tools and techniques for each model/device/program/calculation used in the discussion, and their importance in advancing the proposed method. The Sect. “Experimental Setup” experiment is arranged to simulation environment and the required boundary and data set depiction. Section “Results and Discussion” discusses the legitimacy and adequacy of the model through decomposition of the results, and finally Sect. “Conclusion” describes the conclusion of work and the scope of future inspections.
Literature Review
In the writing, the suggested PD analysis strategies, obstacles and benefits are summarized in Table 1 for better arrangement, just as the importance of the strategies we proposed. Nonetheless, these technologies are limited in selecting the outline of the appropriate features, and therefore suffer from a lack of PD recognition and proficiency issues.
Das and Tsanas et al. [17, 18], proposed unique artificial intelligence-based techniques that have been created to analyze PD patients. Little et al. [7] proposed a technique for distinguishing Parkinson’s disease using speech signal information. They distinguished between 23 PD patients and 8 able-bodied subjects. SVM is used to characterize Parkinson’s disease and healthy individuals. The accuracy of the proposed strategy was recorded at 91.4%. In another survey [18], 132 features were selected based on the signs of dysphonic discourse. Calculations using specular selection (FS) like LASSO, Relief, MRMR and LLBFS [18]. In addition, the model uses the feature selection calculation to select 10 features from 132 features, which are used for the sequence of Parkinson’s disease and the entity. In contrast, Sakar et al. [8] reported that a large number of voice recordings from 40 subjects were collected, of which 20 were Parkinson’s disease subjects and 20 were non-Parkinson’s subjects. 26 speech signals containing daily pronunciation, words, numbers and vowels were recorded. They used the Praat acoustic inspection program to record the speech [19]. In addition, a theme (LOSO) and S-LOO approval strategy were used to check the presentation of K-NN and SVM classifiers [20]. Exploratory work [7] proposed a strategy that relies on ML calculations, using speech signals to diagnose Parkinson’s disease, conveys the calculations of feature selection, such as help, LLBS, LASSO, and mRMR, and the proposed method achieves excellent results in terms of accuracy. Sakar et al. [8] established an analysis framework using SVM and achieved an accuracy of 92.75%. In addition, Der et al. [9] by using a fluffy-based indirect change strategy combined with SVM, proposed a model for analyzing PD, and an accuracy of 93.47% was achieved. Andre et al. [10] proposed a symptom framework for PD recognition using the backwoods classifier based on the strategy of change and the ideal way. The framework achieved an accuracy of 84.01%. Chai et al. [14] planned another academic project to identify PD. The SVM and mitigation calculations are coordinated with the simplified calculations for bacterial removal, and critical accuracy is achieved. Emarie et al. [19] cultivated a program that uses fluffy theory, K-NN, and PCA to diagnose PD, and achieved an accuracy of 96.07%. Tsanas [18] planned the use of PSO and improved FKNN to find the determination strategy of PD, and obtained an accuracy of 97.47%. To this end, Gok [11] used the results of the Rotation Forest Ensemble (RFE) KNN classifier to propose a PD analysis framework with an accuracy of 98.46%. Along this path, Das [15] studied the scheduling and execution of ANN, strategy recurrence (LR) and (decision tree) DT. Compared with other LRs and DTs, the grouping execution of ANN is very good in terms of accuracy, and an accuracy rate of 92.9% is obtained. A PD discovery framework was proposed in [12], using mRMR to feature certain calculations and complex and respected ANN classifiers. The proposed framework has achieved 98.12% accuracy. Taking into account the writing of the survey, we infer that to effectively derive PD, a very smart judgment framework is required. In the planning of the PD analysis framework, current investigations [21, 22] have used unique grouping calculations, for example, strategy recurrence [23], support vector machines [13], k-NN [23], DT, NB [24] and ANN discovered PD. Among these classifiers, compared with different classifiers, the help vector machine performs very well. In view of the occasional extra features that will affect the performance of the characterization, just like the computational complexity of the model, the grouping execution of the classifier can be improved by selecting the appropriate element determination technology. Notable element selection and boundary improvement calculations include: help, mRMR, LASSO, LLBFS, Genetic-Algorithm (GA), Particle-Swarm Optimization, Whale- Optimization-Algorithm (WO), Natural Product Fly Enhancement (FFO), Differential Flowering Fertilization and Bacterial Elimination and Refinement (BFO) have been used in the feature selection of the existing trial selection outline features.
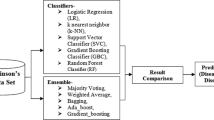
Materials and Methods
The specific details and basic ideas used in the proposed model are described below in Fig. 1. This section proposes six machine learning classifiers and three feature selection methods.

The flowchart describes each step/phase of the method
Machine Learning Classifiers
Decision Tree
There is a classifier whose graphical explicit feature determination is an essential part of the learning cycle: the selection table. The entire question of the study selection table includes selecting the correct credits to be combined. Usually, this is done by estimating the cross-approval execution of the various feature subsets of the form and selecting the best performing subset. Fortunately, the leave-one-out cross-approval is very gentle for this classifier. Obtaining cross-approval errors from the selection list obtained from the preparation information is just a matter of controlling the class check associated with each table entry, because the design of the table will not be changed or erased as occasions increase [25, 26]. To a large extent, the feature space is searched through the pursuit of best priority, because this method is less likely to fall into the largest neighborhood than other methods, such as forward selection.
K-Nearest Neighbor
In order to handle the different marks, a directional calculation is used, which is adjusted and a bunch of name signals are obtained. To assign another point, it finds the nearest point and makes a decision on that point, so it assigns the nearest mark [27, 28]. The following distance work is used to evaluate KNN.
Random Forest
Random forest classifier is a comprehensive learning system for collecting, backing off, and various efforts that can be performed with the help of decision trees. These decision trees can work during planning, and the benefits of this category can be portrayal or retrogressive. With the help of such unpredictable remote areas, people can resolve their affinity for over-adaptation to arrangement sets [29].
At the random forest level, it is completely expected on all trees. The importance of the entire part of each tree is evaluated and isolated by the complete number of trees:
where, RFfii is the significance of highlight I determined from all trees in the Random Forest model. Norm fiij is the standardized element significance for I in tree j. T is the absolute number of trees.
Bagging
The idea of bagging (deciding grouping, average recurrence type problems, and uninterrupted ward income factors) is suitable for prescient information mining space, adding expected orders (predictions) from many models, or models from various learning information of similar types. It is also used to solve the inherent instability of the results, while applying complex models to the index of usually little information. Assuming that the task of information mining is to build a model with a foresighted arrangement, there are usually very few data sets to prepare the model. We can generate sub-examples (with substitutions) from the data set multiple times and apply, for example, tree classifiers (such as CART and CHAID) to progressive examples. In fact, it is common to develop completely different trees for various examples, outlining the instability of the model that is usually obvious with a small number of data sets [30]. One strategy for determining individual predictions (for novel perceptions) is to use all the trees found in various examples and apply some basic democracy: the last feature is a feature that various trees often predict.
AdaBoosting
AdaBoosting or Adaptive Boosting is an AI used for meta-computation. Different learning indicators are usually used to further improve execution efficiency. The benefits of other learning evaluations will be combined into a weighted whole, which is stable with the last benefit of the supported classifiers. AdaBoosting is versatile and can guarantee substitute students who are powerless due to the misclassification of past classifiers [31]. AdaBoosting perceives large amounts of data and one condition. On some issues, over-fitting is not as defensive as other learning measures. Each substitute may be weak, but as long as everyone performs better than any theory, the last model may eventually be severely affected by a strong substitute.
Among them, \({\mathrm{F}}_{\mathrm{t}-1}\left(\mathrm{x}\right)\) is the Boosted classifier, E (F) is the error function, \({\mathrm{F}}_{\mathrm{t}}\left(\mathrm{x}\right)={\mathrm{a}}_{\mathrm{t}}\mathrm{h}(\mathrm{x})\)= frail learner, \(\mathrm{h}\left({\mathrm{x}}_{\mathrm{i}}\right)\) is the test in the learning set, t is the number of iteration, \({\mathrm{\alpha }}_{\mathrm{t}}\) is the distribution coefficient, \({\mathrm{E}}_{\mathrm{t}}\) is the boost result of the classifier.
Gradient Boosting
Gradient boosting is an AI method for recurrence and characterization problems. It gives an expectation model as a bunch of general forecasting models and selection trees. Like other upgrade methods, it builds models in an ingenious way and summarizes them by allowing self-affirmation to be recognizable by appalling work [32].
Extensive use of ‟gradient improvement” follows strategy 1 to limit target work. In each cycle, we adjust the basic students to the negative point of the negative tendency and continue to increase the normal value, and add it to the previously emphasized motivation.
where \(\mathrm{L}\left(\mathrm{y},\mathrm{ F}\left(\mathrm{x}\right)\right)\) is a differentiable loss function.
Feature Selection Method
Suppose we consider the list of capabilities to be processed as x with n features. The feature selection is picking m, out discrete advancement problem n contains the set, that is, m ≤ n (24). Display and execute a classifier that is basically unaffected by features. Therefore, it is fundamentally important to deal with unimportant features from the feature set [33, 34].
Chi2 Test
The χ2 (chi2) test involves determining the calculation of χ2 between each component and the target and selecting the ideal number of features with the best χ2 score using the following equation [35]:
where \({\mathrm{O}}_{i}\,\mathrm{ is\, the \,Observation \,in \,class \,}i.\) Ei is the observations in class i if there was no relationship between the feature and target.
Extra Trees Classifier
For extracting salient features between data set elements by applying the element importance of the model, the model scores each information component and the higher the score, the more components in the income variable [36]. We apply the ET classifier to evaluate the five main features of the data set.
Correlation Matrix
Correlation is an attribute to check whether the characteristics of the data set are associated with the target variable. The relationship may be positive or negative. To a certain extent, if the single meaning of a feature is expanded, it will increase the value of fairness, while if the single meaning of the relevance is expanded, it will reduce the objective value [37]. Through the heat map, it can undoubtedly discover which features are most suitable for the target variable.
Experimental Setup
The data set used in this examination can be accessed online on the UCI machine learning repository [38], which contains the acoustic features of 31 patients. 23 of these patients are experiencing PD. The data set has 197 instances, of which 23 are acoustic features that are separate from the patient. The exploratory meeting aims to discover the features that improve the expected PD performance (see Table 2). The analysis was done on Jupyter Notebook (Anaconda3), Python adapted to 3.8 and 32-bit Windows 7 framework, 4 GB RAM, and Intel® Core™ i3-4600U CPU @ 2.10 GHz 2.70 GHz. The size of the preparation set and test set is 80% and 20%, respectively. In order to evaluate the performance of each classifier, the results have been taken into account for accuracy. Finally, we analyzed the results obtained from the experiment. Table 2 describes the details of the PD patient data set.
Results and Discussion
Pre-preparation methods, for example, deleted missing feature, standard scalar, and min–max scalar have been applied to the data set to successfully prepare and test with the classifier. These factual strategies are the basis for a basic understanding of the data set. The data set has 197 instances and 22 real value features and an output object class. Figure 2 is a correlation matrix, which is a two-dimensional depiction of information, where colors indicate values. The correlation matrix provides a quick visual summary of the data. More complex matrix allows observers to understand complex data sets. In addition, the links between factors indicate that when the value of one variable changes, the other variable usually moves in a certain direction. Understanding this relationship is helpful because we can use the value of one variable to predict the value of another variable.

Correlation matrix of PD dataset
Result Based on Feature Selection
In this section, the test results of feature selection calculation chi2, extra tree classifiers, and correlation matrix have been explained and discussed in detail. No element is selected in any feature selection algorithm: MDVP:Jitter (%), MDVP:RAP, MDVP:PPQ, and Jitter:DDP and RPDE. Subsequently, these characteristics have little effect on the confirmation of PD.
The features selected by chi2 calculation are shown in Table 3.
The features selected by the extra tree classifier are shown in Fig. 3.

Feature selected by Extra Trees Classifier
In addition, the characteristics of the correlation matrix selection are represented in Table 4 and Fig. 4, respectively.

Highly correlated features by correlation matrix
After applying the three feature selection techniques, 10 best features and one output class are selected from each method mentioned in Tables 3 and 4 and Figs. 3 and 4.
Root Mean Square Error (RMSE) play an important role in the performance of classifiers. It is defined as the values predicted by a classifier and the values actually observed. The values of RSME for training and testing datasets are similar if we have developed the good classifier; in other case if the RMSE values are much higher in testing of data than training data the classifier developed is not good. The RMSE values is calculated using the formula
Chi2, extra tree classifiers, and correlation matrix have been used for effective training and testing of the classifier DT, KNN, RF, Bagging, AdaBoosting, and Gradient Boosting. Thus the experimental results of feature selected by chi2, extra tree classifiers, and correlation matrix with classifiers are reported in Table 5. The experimental results show that the classifier classification performances is same for classifier DT which is 94.87% on reduced feature sets as well as the full feature set. While on the other hand the classifiers (KNN %accuracy = 82.05 for without feature Selection & chi2 feature selection & Extra trees classifier, RF accuracy = 92.30% for without feature Selection & chi2 feature selection, Bagging accuracy = 92.30% for without feature Selection, AdaBoosting accuracy = 89.74% for Correlation matrix, Gradient Boosting accuracy = 94.87% for chi2 feature selection & Correlation matrix) have the higher performance accuracy.
Based on these statistical results, we conclude that DT is significantly better than other peers in accuracy, so the proposed method is suitable for PD identification. Therefore, using chi2, extra tree classifiers, and correlation matrix FS algorithms and classifiers (DT, KNN, RF, Bagging, AdaBoosting, and Gradient Boosting) to select more appropriate features helps the model effectively diagnose PD. The features selected by the proposed FS algorithm include MDVP:Fo (Hz), MDVP:Fhi (Hz), MDVP:Flo (Hz), MDVP:Jitter (Abs), MDVP:Shimmer, MDVP:Shimmer (dB), Shimmer:APQ3, Shimmer:APQ5, MDVP:APQ, Shimmer:DDA, NHR, HNR, DFA, spread2, D2, and PPE. In short, the proposed method can be used to detect PD, especially in the early detection of PD. Figure 5 represents the performance of classifiers with and without feature selection.

Presentation of performance of classifiers
Result Based on ROC Curve
ROC curve were assessed to each set and subset of PD patients to recognize affectability (true positive rate) against the investigation group. Region under the ROC curve (AUC) was assessed to gauge how well the classifiers can recognize a dataset with full features and with diminished features between the investigation groups [38,39,40,41]. Figure 6 shows the area under the classifier performance measurement curve.

Area Under the Classifier (AUC) performance measurement curve. a Represents ROC curve with 23 features, b Represents chi2 feature selection (11 features), c Represents extra trees classifier feature selection (11 features), d Represents correlation matrix feature selection (11 features)
By analyzing the ROC curve, the gradient boosting classifier has a higher performance accuracy of 98.7%, with 11 features reduced by chi2 method.
The results obtained in this paper shows highest performance as compared to other papers. The comparison has been made in following Table 6.
Conclusion
This research aims to solve the problem of speech performance execution in Parkinson’s disease using feature elimination and the execution of multiple classifiers. Parkinson’s disease is a dangerous human disease, and different people all over the world have experienced this disease. In this way, a reliable method is needed to fully confirm PD. In this article, we propose a reliable technique that uses appropriate AI to confirm the approach of Parkinson’s disease. In particular, DT, KNN, RF, Bagging, AdaBoosting, and Gradient Boosting have been applied to grouping of Parkinson’s disease and sound subjects. Chi2, extra tree classifiers, and merging techniques based on correlation matrix have been accepted for the selection of relevant features. In addition, the K-fold cross-validation strategy has been used to determine the ideal value of the super boundary of the best model. In addition, evaluation measurements have been used to evaluate the presentation of the proposed model. The test results show that the DT group effectively evaluated PD and physical subjects. The high presentation of our strategy is due to the feature selection that determines the high enough features of the calculation. In terms of accuracy, the proposed strategy achieved amazing results and achieved 94.87% accuracy and AUC (%98.7). In addition, the suggested strategy can be easily used in medical service associations. In future work, since deep neural tissue will naturally select appropriate features for characterization and artificial intelligence calculations need to include selection calculations, in future work, deep neural work methods will be used to sort Parkinson’s disease and entities. The proposed strategy will be applied to other data sets to identify comparative types of diseases. Treatment and recuperation after a given illness are of the utmost importance. In this way, we will gradually reduce infection and apply it for recuperation in future.
Data Availability
The data set used in this exploration work can be found on UCI machine learning repository.
References
S.Y. Lim, S.H. Fox, A.E. Lang, Overview of the extranigral aspects of Parkinson disease. Arch. Neurol. 66(2), 167–172 (2009)
S. Perez-Lloret, M.V. Rey, A. Pavy-Le Traon, O. Rascol, Emerging drugs for autonomic dysfunction in Parkinson’s disease. Expert Opin. Emerg. Drugs 18(1), 39–53 (2013)
K. Seppi, D. Weintraub, M. Coelho, S. Perez-Lloret, S.H. Fox, R. Katzenschlager et al., The Movement Disorder Society evidence-based medicine review update: treatments for the non-motor symptoms of Parkinson’s disease. Movement Dis. 26(S3), S42–S80 (2011)
K.H. Yu, A.L. Beam, I.S. Kohane, Artificial intelligence in healthcare. Nat. Biomed. Eng. 2(10), 719–731 (2018)
L. Ma, T. Fu, T. Blaschke, M. Li, D. Tiede, Z. Zhou et al., Evaluation of feature selection methods for object-based land cover mapping of unmanned aerial vehicle imagery using random forest and support vector machine classifiers. ISPRS Int. J. Geo-Inform. 6(2), 51 (2017)
A.D. Macleod, I. Dalen, O.B. Tysnes, J.P. Larsen, C.E. Counsell, Development and validation of prognostic survival models in newly diagnosed Parkinson’s disease. Mov. Disord. 33(1), 108–116 (2018)
M. Little, P. McSharry, E. Hunter, J. Spielman, L. Ramig, Suitability of dysphonia measurements for telemonitoring of Parkinson’s disease. Nature Precedings (2008). https://doi.org/10.1038/npre.2008.2298.1
C.O. Sakar, O. Kursun, Telediagnosis of Parkinson’s disease using measurements of dysphonia. J. Med. Syst. 34(4), 591–599 (2010)
D.C. Li, C.W. Liu, S.C. Hu, A fuzzy-based data transformation for feature extraction to increase classification performance with small medical data sets. Artif. Intell. Med. 52(1), 45–52 (2011)
Spadoto, A. A., Guido, R. C., Carnevali, F. L., Pagnin, A. F., Falcão, A. X., & Papa, J. P. (2011). Improving Parkinson's disease identification through evolutionary-based feature selection. In 2011 Annual International Conference of the IEEE Engineering in Medicine and Biology Society (pp. 7857–7860). Ieee.
M. Gök, An ensemble of k-nearest neighbours algorithm for detection of Parkinson’s disease. Int. J. Syst. Sci. 46(6), 1108–1112 (2015)
M. Peker, B. Sen, D. Delen, Computer-aided diagnosis of Parkinson’s disease using complex-valued neural networks and mRMR feature selection algorithm. J. Healthcare Eng. 6(3), 281–302 (2015)
L. Naranjo, C.J. Perez, J. Martin, Y. Campos-Roca, A two-stage variable selection and classification approach for Parkinson’s disease detection by using voice recording replications. Comput. Methods Programs Biomed. 142, 147–156 (2017)
Z. Cai, J. Gu, H.L. Chen, A new hybrid intelligent framework for predicting Parkinson’s disease. IEEE Access 5, 17188–17200 (2017)
A.U. Haq, J.P. Li, M.H. Memon, A. Malik, T. Ahmad, A. Ali et al., Feature selection based on L1-norm support vector machine and effective recognition system for Parkinson’s disease using voice recordings. IEEE Access 7, 37718–37734 (2019)
S. Yadav, M.K. Singh, Hybrid machine learning classifier and ensemble techniques to detect Parkinson’s disease patients. SN Computer Sci. 2(3), 1–10 (2021)
R. Das, A comparison of multiple classification methods for diagnosis of Parkinson disease. Expert Syst. Appl. 37(2), 1568–1572 (2010)
A. Tsanas, M.A. Little, P.E. McSharry, L.O. Ramig, Nonlinear speech analysis algorithms mapped to a standard metric achieve clinically useful quantification of average Parkinson’s disease symptom severity. J. R. Soc. Interface 8(59), 842–855 (2011)
J. Howell, When technology is too hot, too cold or just right. Emerg. Learn. Design J. 5(1), 2 (2017)
C.W. Hsu, C.J. Lin, A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 13(2), 415–425 (2002)
H.L. Chen, G. Wang, C. Ma, Z.N. Cai, W.B. Liu, S.J. Wang, An efficient hybrid kernel extreme learning machine approach for early diagnosis of Parkinson’s disease. Neurocomputing 184, 131–144 (2016)
N. Singh, V. Pillay, Y.E. Choonara, Advances in the treatment of Parkinson’s disease. Prog. Neurobiol. 81(1), 29–44 (2007)
X. Wu, V. Kumar, J.R. Quinlan, J. Ghosh, Q. Yang, H. Motoda et al., Top 10 algorithms in data mining. Knowl. Inform. Syst. 14(1), 1–37 (2008)
F. Pernkopf, Bayesian network classifiers versus selective k-NN classifier. Pattern Recogn. 38(1), 1–10 (2005)
V. Chaurasia, S. Pal, Applications of machine learning techniques to predict diagnostic breast cancer. SN Comput. Sci. 1(5), 1–11 (2020)
M.K. Pandey, M.K. Singh, S. Pal, B.B. Tiwari, Prediction of phishing websites using stacked ensemble method and hybrid features selection method. SN Comput. Sci. 3(6), 488 (2022)
Z. Soumaya, B.D. Taoufiq, N. Benayad, B. Achraf, A. Ammoumou, A hybrid method for the diagnosis and classifying parkinson’s patients based on time–frequency domain properties and K-nearest neighbor. J. Med. Sig. Sensors 10(1), 60 (2020)
R. Aggrawal, S. Pal, Sequential feature selection and machine learning algorithm-based patient’s death events prediction and diagnosis in heart disease. SN Comput. Sci. 1(6), 344 (2020)
H. Byeon, Best early-onset Parkinson dementia predictor using ensemble learning among Parkinson’s symptoms, rapid eye movement sleep disorder, and neuropsychological profile. World J. Psychiatr. 10(11), 245 (2020)
A.K. Tiwari, Machine learning based approaches for prediction of Parkinson’s disease. Mach. Learn Appl. 3(2), 33–39 (2016)
L. Ali, C. Zhu, N.A. Golilarz, A. Javeed, M. Zhou, Y. Liu, Reliable Parkinson’s disease detection by analyzing handwritten drawings: construction of an unbiased cascaded learning system based on feature selection and adaptive boosting model. IEEE Access 7, 116480–116489 (2019)
I. Karabayir, S.M. Goldman, S. Pappu, O. Akbilgic, Gradient boosting for Parkinson’s disease diagnosis from voice recordings. BMC Med. Inform. Decis. Mak. 20(1), 1–7 (2020)
V. Chaurasia, S. Pal, Stacking-based ensemble framework and feature selection technique for the detection of breast cancer. SN Computer Sci. 2(2), 1–13 (2021)
V. Chaurasia, A. Chaurasia, Novel method of characterization of heart disease prediction using sequential feature selection-based ensemble technique. Biomed. Mater. Dev. (2023). https://doi.org/10.1007/s44174-022-00060-x
V. Chaurasia, S. Pal, Data mining techniques: to predict and resolve breast cancer survivability. Int. J. Comput. Sci. Mobile Computing IJCSMC 3(1), 10–22 (2014)
Chaibub Neto, E. L. I. A. S., Bot, B. M., Perumal, T., Omberg, L., Guinney, J., Kellen, M., et al. (2016). Personalized hypothesis tests for detecting medication response in Parkinson disease patients using iPhone Sensor data. In Biocomputing 2016: Proceedings of the Pacific Symposium (pp. 273–284).
A. Zhan, S. Mohan, C. Tarolli, R.B. Schneider, J.L. Adams, S. Sharma et al., Using smartphones and machine learning to quantify Parkinson disease severity: the mobile Parkinson disease score. JAMA Neurol. 75(7), 876–880 (2018)
https://archive.ics.uci.edu/ml/datasets/parkinsons Accessed 4 July 2021
Yadav, D. C., & Pal, S. (2022). Measure the superior functionality of machine intelligence in brain tumor disease prediction. In Artificial Intelligence-Based Brain-Computer Interface (pp. 353–368). Academic Press, London.
D.C. Yadav, S. Pal, An ensemble approach for classification and prediction of diabetes mellitus disease, in Emerging trends in data driven computing and communications. ed. by R. Mathur, C.P. Gupta, V. Katewa, D. SinghJat, N. Yadav (Springer, Singapore, 2021), pp. 225–235
S. Pal, Chronic kidney disease prediction using machine learning techniques. Biomed. Mater. Dev. (2022). https://doi.org/10.1007/s44174-022-00027-y
A. Li, C. Li, Detecting parkinson’s disease through gait measures using machine learning. Diagnostics 12(10), 2404 (2022)
D. Trabassi, M. Serrao, T. Varrecchia, A. Ranavolo, G. Coppola, R. De Icco et al., Machine learning approach to support the detection of Parkinson’s disease in IMU-based Gait analysis. Sensors 22(10), 3700 (2022)
Mamun, M., Mahmud, M. I., Hossain, M. I., Islam, A. M., Ahammed, M. S., & Uddin, M. M. (2022, October). Vocal Feature Guided Detection of Parkinson’s Disease Using Machine Learning Algorithms. In 2022 IEEE 13th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON) (pp. 0566–0572). IEEE.
M. Thakur, S. Dhanalakshmi, H. Kuresan et al., Automated restricted Boltzmann machine classifier for early diagnosis of Parkinson’s disease using digitized spiral drawings. J. Ambient Intell. Human Comput. 14, 175–189 (2023). https://doi.org/10.1007/s12652-022-04361-3
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors have no affiliation with any organization with a direct or indirect financial interest in the subject matter discussed in the manuscript.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Yadav, S., Singh, M.K. & Pal, S. Artificial Intelligence Model for Parkinson Disease Detection Using Machine Learning Algorithms. Biomedical Materials & Devices 1, 899–911 (2023). https://doi.org/10.1007/s44174-023-00068-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s44174-023-00068-x