
Abstract
Due to the accessibility of data with multiple features, many feature determination techniques available in written form. These features promote data with extremely high measurement values. The feature determination strategy provides us with a way to reduce calculation time, improve prediction execution, and have a better understanding of data in machine learning, as well as a way to recognize applications. As pointed out by related works that have been reviewed, in general, existing works only focus on amplifying classification accuracy. For real-world applications, the selected subset of features must be continuous instead. In this research, proposes a sequential feature selection algorithm for detecting death events in heart disease patients during treatment to select the most important features. Several machine learning algorithms (LDA, RF, GBC, DT, SVM, and KNN) are used. In addition, the accuracy obtained by this method (SFS) is compared with the accuracy of the classifier. The confusion matrix, ROC curve, precision, recall rate, and f1-score are also calculated to verify the results obtained by the SFS algorithm. The experimental results show that for Random Forest Classifier_FS, the SFS method reaches 86.67% accuracy.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Cardiovascular failure is a complex clinical disorder, not a disease [1]. It is difficult to distinguish coronary heart disease based on some common risk factors, such as diabetes, high blood pressure, elevated cholesterol, abnormal heart rhythm, and difficulty breathing, such as increased jugular vein weight, pulmonary cracks, and borderline edema caused by underlying diseases [2]. The characteristics of coronary artery disease are complex, so the disease must be treated with caution from now on. Not doing so may affect the heart or cause accidental death. Cardiovascular failure is a real disease associated with high morbidity and mortality [3]. According to statistics from the Society of Cardiology, 26 million adults worldwide suffer from heart failure, and recently 3.6 million people are analyzed each year. 17–45% of patients with heart failure die within the year, and the rest die within 5 years. Management costs determined to have cardiovascular failure account for approximately 1–2% of all healthcare consumption, most of which are related to intermittent clinical confirmation [4]. Expected coronary artery disease depends on performance, especially beating rate, gender, age and many other factors.
Although great progress has been made in understanding the complex pathophysiology of cardiovascular failure, the amount and unpredictability of information and data to be broken down and monitored transforms accurate and effective conclusions of cardiovascular failure and evaluation of useful options into very Effective testing [5]. These elements, plus the beneficial results of early detection of cardiovascular failure, are an explanation for the massive use of AI programs to investigate, foresee and characterize clinical information. Machine learning strategy is a kind of data mining program, these programs have stimulated the enthusiasm of exploring information. The precise sequence of disease stages or etiology or subtypes allows medication and intercession to be communicated in an effective and focused manner, and can evaluate the patient’s disease development [6]. Regardless of whether cardiovascular failure is analyzed at a later stage, data mining strategies may be beneficial, because in this case, the beneficial advantages of intercession and the possibility of endurance are limited because they can predict mortality, dismal and again the danger of admission. Used the information recorded in the subject’s health record, expression segment data, clinical history data, introduction indications, physical assessment results, research facility information, and ECG examination results. This article presents a comprehensive use of AI strategies to solve the aforementioned problems [7]. As shown in Fig. 1.

Heart failure management structure
In the process of recognizing cardiovascular failure, choosing the ideal subset of features is a crucial task. The advantages of choosing trivial features include connection rejection, which reduces the unpredictability of calculations; just as improving the treatment cycle includes finding cardiovascular failure [8]. In any case, the ideal feature subset to be used in the disease prediction and analysis framework is actually still a questionable issue in writing. Existing related works in writing always revolve around selecting a subset of elements to amplify the accuracy of a single/large-scale arrangement.
Literature Review
At the Literary Research Center, most studies show the use of feature determination strategies and other machine learning algorithms, which is a measure to arrange subjects in an expected way or as patients with cardiovascular failure. These techniques are described in Table 1. The fundamental difference between these strategies is determined by identifying the characteristics used to identify cardiovascular failure.
Tools and Techniques
The accompanying section examines each model, instrument, methods, and algorithms used in the inspection, which are of great significance to improving the method proposed in this article.
Feature Selection Algorithms
Feature selection is a comprehensive consideration in AI. In general, including selection techniques can be divided into two categories, specifically, including method-based and channel-based methods. Generally, compared with the channel-based method and the channel-based method with higher computational overhead, the coverage-based method can provide more ideal arrangements. Coverage-based methods include sequential forward feature selection (SFS), sequential backward feature selection (SBS), etc. For feature selection in our framework, we use the sequential FS algorithm, and the algorithm selects important features [16].
Due to the iterative idea of algorithms, these algorithms are called continuous algorithms. The Sequential Feature Selection (SFS) algorithm starts with an unfilled set and includes an element in the initial step, which provides the most compelling incentive for the target work. Starting from the second step, the remaining features are specifically added to the current subset, and the new subset is evaluated [17]. Redefine the loop until the necessary numbers of functions are included. This is a naive SFS calculation because it does not indicate the dependencies between functions. The Sequential Backward Selection (SBS) algorithm can be established like SFS, but the calculation starts from the overall arrangement of factors and eliminates each component in turn. The withdrawal of the latter has the least impact on the performance of the indicator [18].
Machine Learning Classifiers
To classify heart disease patients and healthy individuals, an AI classification algorithm is used. This article briefly discusses some well-known classification algorithms and their assumptions.
Linear Discriminant Analysis (LDA)
When the variation covariance grid of all populations is homogeneous, LDA is used. In LDA, our selection principle depends on the linear score function, which is the population element represented by each μi in our g group and the set difference covariance frame [19]. The characteristics of the linear score function are
where \({d}_{i0}=-\frac{1}{2}{\upmu }_{i}^{{{\prime}}}{\sum }^{-1}{\upmu }_{i}\), \({d}_{ij}={\upmu }_{\mathrm{i}}^{{{\prime}}}{\sum }^{-1}j\mathrm{th\, element}\), \({d}_{i}^{L}\left(X\right) \mathrm{is\, a \,linear\, discriment\, function}.\)
The linear scoring function is a function of unknown parameters μi and Σ. Therefore, we must estimate their values from the training data.
Random Forest (RF).
Random forest builds many individual selection trees during preparation. Summarization of the expectations of all trees makes the final prediction; the method of sorting or the average expectation of recurrence. Because they use various results to reach the final conclusion, they are called “ensemble method”. To select important features, it is normal on all trees at the “random forest” level [20]. The overall importance of components in each tree is determined and isolated by the total number of trees:
where \({\mathrm{RFfi}}_{i}\mathrm{ is }i\mathrm{ calculated from all trees in the Random Forest model}\), \({\mathrm{norm}fi}_{ij} \mathrm{is normalized feature importance for }i\mathrm{ in tree }j\), T is number of trees.
Decision Tree Classifier
Decision trees are standardized AI calculations. The decision tree shape is just a tree in which each hub is a leaf hub or selection hub. The technique of selecting trees is fundamental and effective for making decisions. The decision tree contains interconnected internal and external hubs [21]. The internal hub is the dynamic part that determines the selection, and is the part, where the child hub can access the following hubs. Then, the leaf hub no longer has a child hub, and is related to the name.
Gradient Boosting Classifier
Gradient boosting is an AI strategy for regression and classification problems. It provides a prediction model in the form of a set of overall prediction models and decision trees. Like other enhancement techniques, it constructs models in a stage-savvy style and summarizes them by allowing arbitrarily distinguishable unfortunate work [22].
Extensive use of “gradient enhancement” follows method 1 to limit target work. In each cycle, we adapt the basic learners to the negative angle of the negative gradient, and continuously increase the expected value, and add it to the incentives emphasized in the past:
where \(\mathrm{L}\left(y, F\left(x\right)\right) \mathrm{is a differentiable loss function}\).
K-Nearest Neighbor
K-NN is a standardized learning order calculation. K-NN calculates class names that can predict other information; K-NN uses new contributions for its data source testing in preparation. If the new information is the same, the examples in the training set are the same [23]. K-NN group execution is unacceptable. Let (x, y) be the ability to perceive and learn h: x⟶y, the goal is that given perception x, h(x) can determine y.
Support Vector Machine
SVM is commonly used for AI characterization calculations for deployment. SVM utilizes one of the largest marginal methods, which have become unpredictable secondary programming problems [24]. Due to the advantages of SVM in grouping, different applications usually use it.
Performance Metrics
To check the performance of the classifier, different performance evaluation metrics are used in this exploration.
Correlation Matrix
The correlation matrix is a table indicating correlation coefficients between factors. Each cell in the table shows the correlation between the two factors. The correlation matrix is used to aggregate information, as a contribution to further developed research, and as a symptom for cutting-edge examinations [25].
The correlation matrix is “square”, and similar factors appear in lines and segments. The 1.00 line from the upper left corner to the lower right corner is the corners in principle, which shows that each factor in each situation is closely connected with itself. The grid is balanced, and a similar relationship appears on the main tilt, which is the same representation of the tilt under the principle tilt.
Correlation with Target Variable
When performing any machine learning task, feature determination is one of the most important advancements. An element, if a data set should appear; only one part is processed. When we get any data set, not every segment will really affect the yield variable. We are very likely to include these unnecessary features in the model. This provides the need for feature determination.
It can be said that embedded technology is iterative. It can handle each cycle of model preparation and measurement, and carefully separate those functions that contribute the most to the preparation for specific emphasis [26]. The regularization strategy is the most commonly used installation technique, which penalizes components within a given coefficient limit.
Here, we will include the use of lasso regularization features. On occasions when the element is not important, the lasso penalizes sets its coefficient to 0. This eliminates the feature with coefficient = 0 and adopts the remaining features.
Validation Accuracy Metrics
To verify the accuracy of the classifier, the description of validation is as follows:
To check the performance of the classifier, different performance evaluation metrics are used in this exploration. We use the confusion matrix to accurately place each perception in the test set in a box. Given that there are two rest categories, it is a 2 × 2 network. In addition, it gives two correct predictions of the classifier and two non-benchmark predictions. Table 2 shows the confusion matrix [27].
From the confusion matrix, we draw the following conclusions:
TP The expected yield is significantly positive (TP). We infer that the characteristics of patients with heart disease have been accurately characterized, and the patients have heart disease.
TN The expected output is a significant negative value (TN). We believe that the subject is healthy and correctly characterized.
FP Expected to be a false positive (FP) yield. We assume that a subject is incorrectly characterized as having heart disease (a level 1 error).
FN The expected yield is false negative (FN). We believe that the diagnosis of heart disease is incorrect, because the subject does not have heart disease.
Accuracy of the classifiers Accuracy shows the whole performance of the classification system is as follows:
Precision Precision is the ratio of the positive observations that is accurately expected:
Recall (sensitivity) Recall is the ratio of the positive perceptions accurately expected to all the perceptions in the real class-yes.
F1 score F1 score is the weighted normal of Precision and Recall. Therefore, this score considers both false positives and false negatives.
ROC and AUC The beneficiary’s optimistic curve analyze the expected capabilities of the AI classifier used for grouping. ROC inspection is a portrayal based on graphics, which considers “correct rate” and “error rate”. AI calculates the “positive rate” in the grouping result. AUC depicts the ROC of a classifier. The larger the estimated value of AUC, the more feasible the display of the classifier [28].
Experimental Methodology
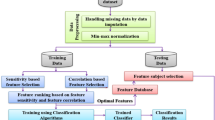
The proposed framework has been created with the plan to differentiate patients who are died due to heart disease. In proposed model we tried to display various machine learning models that fully determine the distribution and selected features of the heart disease data set. For feature selection, SFS is used to select important features and try to display classifiers on these selected features. The well-known machine learning classifiers LDA, RF, DT, GBC, K-NN and SVM are used in the framework to process model approval and execution evaluation metrics. Figure 2 shows the experimental framework for prediction of death cases due to heart disease.

System framework for predicting death from heart disease
The strategy of the proposed framework is divided into five stages, including:
Data set preprocessing, feature selection, cross-validation methods, machine learning classifiers and classifier representation evaluation techniques.
Experimental Setup
The following subsections briefly discuss the research materials and methods of the paper. All calculations are performed in Python 3.7 on Intel(R) Core™i3-1800CPU @ 2.93 GHz PC.
Data Set
The “Heart Failure Clinical Record Data Set 2020” is used by different researchers [29] and can be obtained from the online information mining archives of UCI machine learning. This data set was used in this inspection study to plan a heart failure framework based on machine learning. The example size of the UCI heart failure data set is 299 patients, has 13 features, and has no missing values. More appropriate autonomous information functions and target yield markers are extracted and used to diagnose heart failure. There are two categories of objective class to classify patient's death or alive from heart failure during the follow-up period. Therefore, the extracted data set has 299 * 13 feature matrices. Table 2 gives the total data and descriptions of 299 cases of 13 features of the data set.
Data Preprocessing
The preprocessing of information is essential for effectively describing information and machine learning classifiers, and it should be prepared and tried in a feasible way. Preprocessing methods (for example, elimination of missing quality, standard scalar and MinMax scalar) have been applied to the data set and can be used in the classifier [30]. The standard scalar guarantees that the mean of each element is 0, the variance is 1, and the coefficients of all elements are similar. Similarly, in MinMax Scalar, the ultimate goal of shift information is that all functions are in the range of 0–1.
Cross Validation
In k-fold cross validation, the information collection is divided into k equal-sized parts, where k – 1 collection is used to prepare the classifier, and the rest is used to check the performance in each progress [31]. The approval cycle has been renamed k times, the classifier to execute according to the k results. For CV, various estimates of k are selected. In our analysis, we use k = 5, because its display is acceptable. In the fivefold CV measurement, 70% of the information is used for training and 30% of the information is used for testing reasons. For the overlap of each loop, the loop is redefined multiple times, and all the conditions in the training and test strings are arbitrarily divided into the entire data set before determining to prepare and test the new set for the new loop. Finally, at the end of the fivefold measurement, the midpoint of all demonstration measurements will be processed.
Results and Discussion
This part of the article includes a discussion of classification models and results (from other perspectives). First, we checked the representations of various machine learning calculations, such as linear feature analysis, random forest, decision tree, gradient boosting classifier, k-nearest neighbor and support vector machine for the complete function of the heart failure clinical record data set. Second, we use element selection to calculate SFS to determine important features. In the third category, exhibitions are considered selected features. Similarly, the k-cross-validation strategy is used. To check the classifier of the exhibition, execution evaluation measures are applied. All functions are standardized before being applied to the classifier.
Result of Image Analysis
In this experiment, those people include who have had a heart attack and died or survived during follow-up [32]. Figure 3 is a collection of those attributes that contain binary values, 1 or 0 (with or without). In this category, the attributes of anemia, diabetes, hypertension, sex, smoking, and death event included.
-
Anemia (hemoglobin): People without anemia are less likely to die than people with severe anemia.
-
Diabetes (if the patient has diabetes): According to Fig. 3, diabetes is not a major risk for people who are already in cardiac attack.
-
High blood pressure (hypertension): Patients with hypertension have a high risk of death.
-
Sex (woman or man): Compared with female patients (0), male patients (1) have a higher risk of death.
-
Smoking (patient smokes or not): As shown in this experiment, smoking has a small effect on the number of deaths.
-
Death event (if the patient deceased during the follow-up period): During the follow-up period, there were fewer deaths than survivors.

Attributes with Boolean values
Figure 4 shows an attribute with a continuous value, under which age, creatinine phosphokinase, ejection fraction, platelets, serum creatinine, serum sodium, and time belongs.
-
Age (years): In Fig. 4, most patients died at the age of 60 during the follow-up period, and the age range of (60–80) is more dangerous for heart disease patients.
-
Creatinine phosphokinase (level of the CPK enzyme in the blood): The range of CPK enzyme levels (0–2000) is more dangerous, because more people die in this range.
-
Ejection fraction (percentage of blood leaving the heart at each contraction): The percentage of ejection fraction ranging from 20 to 40 is very fatal. More people died under this range.
-
Platelets (platelets in the blood): People died during the follow-up period, whose blood contained platelets (200,000–400,000).
-
Serum creatinine (level of serum creatinine in the blood): The dangerous level of serum creatinine is (0–2), at which most people died.
-
Serum sodium (level of serum sodium in the blood): The fatal level is (130–140).
-
Time (follow-up period in days): For a patient who is already at risk (heart attack), the follow-up period (i.e., 0–100 days) is the most important to whether he/she will survive in the future.

Attributes with continuous values
The correlation matrix in Fig. 5 represents the relationship between attributes. The higher the positive value toward 1, the feature is highly correlated, while the negative value represents the negative correlation between features, that is, if one feature increases, other features will decrease, and vice versa [33]. If the value is 0, there is no association between the attributes. In the figure below, age, serum creatinine, gender, and smoking are highly correlated with death events, while ejection fraction, serum sodium and time are negatively correlated with target variables.

Correlation matrix
The correlation with the target variable is another measure of feature importance. In Fig. 6, the two characteristics of gender and smoking have a low correlation with the target, while the other variables have a strong correlation with the target variable.

Correlation with target variable
Result of Classifiers (Fivefold Cross Validation) with All Features (n = 13) and with Selected Features (SFS)
In this inspection, all features of the data set are focused on six machine learning classifiers through fivefold cross-validation technology. In the fivefold CV, 70% was used to train the classifier and only 30% was tested. Finally, the normal measurement result of the fivefold technique is obtained. In addition, various boundary evaluations have passed the classifier. Table 3 lists the fivefold cross-validation results of six full-featured classifiers and the results of sequential feature selection.
In Table 3, the random forest classifier with feature selection shows good performance with an accuracy of 86.67%. The next number is the “random forest” classifier and the “gradient start” classifier, their accuracy in all functions is equal to 85.56%. If we distinguish between classifiers with and without feature selection, the classifiers RandomForestClassifier_FS, LinearDiscriminantAnalysis_sfs,KNeighborsClassifier_sfs, radientBoostingClassifier_sfs, Therefore, the descending accuracy of RandomForestClassifier_sfs and DecisionTreeClassifier_sfs are 86.67%, 82.22%, 80.00%, 77.78%, 75.56% and 74.44%, respectively. On the other hand, the classifiers without feature selection, RandomForestClassifier, GradientBoostingClassifier, SVM_rbf, LinearDiscriminantAnalysis, SVC_linear, DecisionTreeClassifier, SVC_poly, KNeighborsClassifier have a descending accuracy are 85.56%, 85.56%, 84.44%, 82.22%, 82.22%, 78.89%, 77.78% and 76.67%, respectively. Except for the random forest classifier with feature selection, only random forest and gradient boosting have good invisibility for all features, but at least.
Figure 7 shows the performance of different classifiers on the training and test data sets in the same order.

Performance of the classifiers with and without SFS
Results of Validation Metrics
To compile and verify the results from the six classifiers, we have Table 4. In this table, it consists of different classifiers with selected important features. By observing the table, all six classifiers and their selected features have two prominent features: ejection_fraction and serum_cretinine.
Precision, recall, and f1-score have the usual meanings, and these values validate the results obtained by the classifier. The confusion matrix shows the predictions of TP, FN, TN and FP for different classifiers of patient deaths during follow-up period.
The ROC curve is the area under true positive rate and the false positive rate. Here the ROC_AUC curve drawn under fivefold cross validation. In different fold, it has different results. To eliminate this confusion, the average accuracy is also calculated. The average accuracy of the higher ROC_AUC obtained by the GBC classifier is 74%.
Conclusion
In this study, a prediction system based on hybrid intelligent machine learning was proposed to diagnose deaths during follow-up. The system was tested on the heart failure clinical record data set. Six well-known classifiers (such as LDA, RF, GBC, DT, SVM and KNN) are used together with the feature selection algorithm SFS to select important features. The system uses K-fold cross-validation method for verification. To check the performance of the classifier, different evaluation indicators are also used. The feature selection algorithm selects important features. These features can improve the classification accuracy, precision, recall, f1-score and ROC_AUC curve performance of the classifier, and reduce the calculation time of the algorithm. When selecting RandomForestClassifier_FS with fivefold cross validation by FS algorithm SFS, its best accuracy is 86.67%. Due to the good performance of RandomForestClassifier_FS with SFS, it is a better prediction system in terms of accuracy. However, the random forest classifier and the gradient boost classifier followed closely, and performed better in terms of accuracy, both of which were 85.56%. In Table 4, the average ROC_AUC, GBC results have a higher accuracy of 74%. As shown in Table 4, feature selection algorithms should be used before classification to improve the classification accuracy of the classifier. Using feature selection (SFS), we obtained two important features (ejection_fraction and serum_cretinine) from which death events can be predicted. Therefore, the FS algorithm can reduce the calculation time and improve the classification accuracy of the classifier. The FS algorithm selects important features related to distinguishing death events from healthy people.
The curiosity of this exploratory work is building a discovery framework that can foresee the moment of death events. The framework utilizes SFS calculations, six classifiers, a cross-approval strategy and execution evaluation metrics. Through the strategy of machine learning to plan the choice of an decision support network, the analysis of heart disease will be more reasonable. In addition, some non related features reduce the performance of the model and extend the calculation time. Therefore, another creative element of this research is to use in feature determination calculations to select the best features. These best features can reduce the execution time of the classification model and improve the classification accuracy. Later, we will conduct more inspections using other features (including feature selection and simplified procedures) to build these exhibits of prerequisite classifiers for determining heart disease.
References
Towbin JA, Bowles NE. The failing heart. Nature. 2002;415(6868):227–33.
Ponikowski P, Voors AA, Anker SD, Bueno H, Cleland JG, Coats AJ, et al. 2016 ESC Guidelines for the diagnosis and treatment of acute and chronic heart failure: the Task Force for the diagnosis and treatment of acute and chronic heart failure of the European Society of Cardiology (ESC) Developed with the special contribution of the Heart Failure Association (HFA) of the ESC. Eur Heart J. 2016;37(27):2129–200.
Aljaaf AJ, Al-Jumeily D, Hussain AJ, Dawson T, Fergus P, Al-Jumaily M. Predicting the likelihood of heart failure with a multi level risk assessment using decision tree. In: 2015 Third International Conference on Technological Advances in Electrical, Electronics and Computer Engineering (TAEECE); 2015. p. 101–106. IEEE.
Cowie MR. The heart failure epidemic: a UK perspective. Echo Res Pract. 2017;4(1):R15–20.
Dokken BB. The pathophysiology of cardiovascular disease and diabetes: beyond blood pressure and lipids. Diabetes Spectrum. 2008;21(3):160–5.
Liu M, Jiang Y, Wedow R, Li Y, Brazel DM, Chen F, et al. Association studies of up to 1.2 million individuals yield new insights into the genetic etiology of tobacco and alcohol use. Nat Genetics. 2019;51(2):237–44.
Kadkhoda M, Jahani H. Problem-solving capacities of spiritual intelligence for artificial intelligence. Procedia-Soc Behav Sci. 2012;32:170–5.
Shilaskar S, Ghatol A. Feature selection for medical diagnosis: evaluation for cardiovascular diseases. Expert Syst Appl. 2013;40(10):4146–53.
Kumar D, Carvalho P, Antunes M, Paiva RP, Henriques J. Heart murmur classification with feature selection. In: 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology; 2010. p. 4566–4569. IEEE.
Mokeddem S, Atmani B, Mokaddem M. Supervised feature selection for diagnosis of coronary artery disease based on genetic algorithm. arXiv preprint. 2013; arXiv:1305.6046
Haq AU, Li J, Memon MH, Memon MH, Khan J, Marium SM. Heart disease prediction system using model of machine learning and sequential backward selection algorithm for features selection. In: 2019 IEEE 5th International Conference for Convergence in Technology (I2CT); 2019. p. 1–4. IEEE.
Khemphila A, Boonjing V. Heart disease classification using neural network and feature selection. In: 2011 21st International Conference on Systems Engineering; 2011. p. 406–409. IEEE.
Usman AM, Yusof UK, Naim S. Cuckoo inspired algorithms for feature selection in heart disease prediction. Int J Adv Intell Inf. 2018;4(2):95–106.
Javeed A, Rizvi SS, Zhou S, Riaz R, Khan SU, Kwon SJ. Heart risk failure prediction using a novel feature selection method for feature refinement and neural network for classification. Mobile Inf Syst. 2020. https://doi.org/10.1155/2020/8843115
Yadav DC, Pal S. Prediction of heart disease using feature selection and random forest ensemble method. Int J Pharmaceutical Res. 2020;12(4):56–66.
Gunasundari S, Janakiraman S. A hybrid PSO-SFS-SBS algorithm in feature selection for liver cancer data. In: Power Electronics and Renewable Energy Systems. New Delhi: Springer; 2015. p. 1369–76.
Yan K, Ma L, Dai Y, Shen W, Ji Z, Xie D. Cost-sensitive and sequential feature selection for chiller fault detection and diagnosis. Int J Refrig. 2018;86:401–9.
Ruan F, Qi J, Yan C, Tang H, Zhang T, Li H. Quantitative detection of harmful elements in alloy steel by LIBS technique and sequential backward selection-random forest (SBS-RF). J Anal Atom Spectrom. 2017;32(11):2194–9.
Chaurasia V, Pal S. Skin diseases prediction: binary classification machine learning and multi model ensemble techniques. Res J Pharmacy Technol. 2019;12(8):3829–32.
Chaurasia V, Pal S. Applications of machine learning techniques to predict diagnostic breast cancer. SN Comput Sci. 2020;1(5):1–11.
Safavian SR, Landgrebe D. A survey of decision tree classifier methodology. IEEE Trans Syst Man Cybernet. 1991;21(3):660–74.
Son J, Jung I, Park K, Han B Tracking-by-segmentation with online gradient boosting decision tree. In: Proceedings of the IEEE International Conference on Computer Vision; 2015. p. 3056–3064.
Keller JM, Gray MR, Givens JA. A fuzzy k-nearest neighbor algorithm. IEEE Trans Syst Man Cybernet. 1985;4:580–5.
Vishwanathan SVM, Murty MN. SSVM: a simple SVM algorithm. In: Proceedings of the 2002 International Joint Conference on Neural Networks. IJCNN'02 (Cat. No. 02CH37290) Vol. 3; 2002. p. 2393–2398. IEEE.
Higham NJ. Computing the nearest correlation matrix—a problem from finance. IMA J Numerical Anal. 2002;22(3):329–43.
McColl KA, Vogelzang J, Konings AG, Entekhabi D, Piles M, Stoffelen A. Extended triple collocation: estimating errors and correlation coefficients with respect to an unknown target. Geophys Res Lett. 2014;41(17):6229–36.
Oberkampf WL, Barone MF. Measures of agreement between computation and experiment: validation metrics. J Comput Phys. 2006;217(1):5–36.
Pritom AI, Munshi MAR, Sabab SA, Shihab S. Predicting breast cancer recurrence using effective classification and feature selection technique. In: 2016 19th International Conference on Computer and Information Technology (ICCIT); 2016. p. 310–314. IEEE
Chapman B, DeVore AD, Mentz RJ, Metra M. Clinical profiles in acute heart failure: an urgent need for a new approach. ESC Heart Failure. 2019;6(3):464–74.
Shaheen H, Agarwal S, Ranjan P. MinMaxScaler binary PSO for feature selection. In: First International Conference on Sustainable Technologies for Computational Intelligence. Singapore: Springer; 2020. p. 705–16.
Chaurasia V, Pal S, Tiwari BB. Chronic Kidney disease: a predictive model using decision tree. Int J Eng Res Technol. 2018;11(11):1781–94.
Tantimongcolwat T, Naenna T, Isarankura-Na-Ayudhya C, Embrechts MJ, Prachayasittikul V. Identification of ischemic heart disease via machine learning analysis on magnetocardiograms. Comput Biol Med. 2008;38(7):817–25.
Rebonato R, Jäckel P. The most general methodology to create a valid correlation matrix for risk management and option pricing purposes. Available at SSRN 1969689. 2011.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors declared that they have interest of conflict.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the topical collection “Advances in Computational Approaches for Artificial Intelligence, Image Processing, IoT and Cloud Applications” guest edited by Bhanu Prakash K N and M. Shivakumar.
Rights and permissions
About this article

Cite this article
Aggrawal, R., Pal, S. Sequential Feature Selection and Machine Learning Algorithm-Based Patient’s Death Events Prediction and Diagnosis in Heart Disease. SN COMPUT. SCI. 1, 344 (2020). https://doi.org/10.1007/s42979-020-00370-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42979-020-00370-1