
Abstract
Parkinson’s disease is caused by tumors, a progressive nervous system disorder that affects development. Stiffness or slow movement is the basic sign of this problem. There is no cure for Parkinson's disease, but some drugs can improve the condition, and sometimes brain surgery can help patients improve their condition. Using machine learning strategies, we developed a priori model to identify patients affected by Parkinson’s disease. By controlling the importance of features, we recognize the most significant indicators of patients who belong to this disease-related estimate. The model-based logic strategies we use include logistic regression (LR), k nearest neighbors (k-NN), support vector classifier (SVC), gradient boosting classifier (GBC), and random forest classifier (RF). The estimated reliability, like the ROC curve and confusion matrix, is five-fold cross-validation. We construct another model that depends on the ensemble method and utilization of majority voting, weighted average, bagging, Ada_boost and Gradient_boosting. The model is also recognized in the five-fold cross-validation and confusion matrix, precision; recall rate and F1 score. The correlation matrix is also drawn to show whether these features are related to each other. Our findings indicate that, compared with different methods, machine learning can provide more reliable clinical outcome assessments for patients with Parkinson’s disease. Among the five algorithms, the higher accuracy fluctuates in the middle of 70–95%. Among them, SVC obtains 93.83% accuracy from the five basic classifiers, and Bagging obtains 73.28% accuracy from the ensemble technique.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Parkinson’s disease (PD) is a neurodegenerative disease that mainly affects neurons that transmit dopamine in specific areas of the brain. PD affects approximately 1% of individuals over 60, and the increases with age. People with PD experience a series of motor and non-motor side effects. These side effects include rigidity, tumor, slow movement, unstable posture, and aggravated steps, for example, freezing of steps, autonomic instability, emotions Problems, restlessness, and psychological deficits [1]. These side effects especially affect and reduce personal satisfaction related to health [2]. PD was first discovered by the English doctor James Parkinson, and its performance is remarkable among mature researchers [3].
In the last many years, some work has been devoted to planning answers to help PD analyze. To this end, a main framework that relies on machine learning programs has been used, which shows promising results. Several researchers have studied machine learning techniques to estimate the accuracy of the classifier and other effective indicators to detect patients with Parkinson's disease regarding the rationality of anti-acoustic estimation, Little et al. [4] proposed that it is better to mix unconventional measures with conventional harmonics to achieve the motion ratio, which can easily isolate the solid phase individual from the PWP. The part support vector machine considers the four characteristics of the harmonic to noise ratio, repetitive cycle density entropy, trend fluctuation analysis and pitch cycle entropy, resulting in an overall classification execution rate of 91.4%. Ene et al. [5] applies the PNN-probabilistic neural network type to classification. Stable search, Monte Carlo search and hybrid tracking are the three types of PNN used for ranking reasons, which are identified by smoothing factors. As a result, although the hybrid search performed better, there was no significant difference between the three strategies viewed by the smoothing factor. Gil et al. [6] evaluated the representation of classifiers constructed by ANN and SVM methods. Through three strategies such as MLP and SVM with two kernel types, they obtain a high-precision confusion matrix on the confusion estimation boundary (such as accuracy, sensitivity, specificity, and true positive and true negative). Finally, they stated that the degree of certainty exceeds 90%. Some limits can reach extremely high accuracy, for example, “sensitivity” and “negative predictive value” are 99.32% and 97.06%, respectively. The classification of Parkinson’s disease is done by several authors. The work done by Das [7] focuses on four classification techniques. Through SAS-based programming, different classifiers have been applied to perceive Parkinson's disease. Recursion, DMNeural, neural network and decision tree are the four independent classifications used. Therefore, the best classification of the neural network is 92.9%. Caglar et al. [8] proposed two kinds of artificial neural networks, namely MLP and RBF network. In addition, an adaptive neuro-fuzzy classifier ANFC with semantic fences is also used. ANFC with voice support gives the best confirmation results, where 99.58% of the data comes from training, and 94.72% of the data set comes from testing. Ramani et al. [9] proposed information mining methods SVM, KNN, random tree, partial least square regression (PLS) and other features to predict the data set of 31 Parkinson’s disease patients (23 of them) biomedical speech estimate. To better characterize the reason, the separation was calculated, the optimal number of algorithms was selected and completed, and a better algorithm was selected. The random tree shapes the classification according to the three average characteristics to obtain a zero error rate. Indira et al. [10] proposed an automatic AI method and distinguished Parkinson's disease from personal speech/voice. They use fuzzy C-means clustering and a method based on pattern recognition to distinguish healthy people from Parkinson’s disease patients. The creator of this article has reached 68.04% accuracy, 75.34% infectivity and 45.83% accuracy. To detect the on/off position of Parkinson's disease patients, Aich et al. [11] conducted experiments using wearable gait signals and four machine learning classifiers (RF, KNN, SVM and NB) as input. About 20 PD subjects are used to evaluate the performance of the classifier. Among all four classifiers, Random Forest performed best with 96.72% accuracy, 97.72% recall rate and 96.92% accuracy. Wang et al. [12], to detect PD patients early, they used 12 machine learning algorithms with integrated technology to compare accuracy. They have adopted 183 healthy people and 401 early patients. The highest accuracy obtained by the classifier is 96.45% on average.
The composition of this paper is as follows. Part 2 introduces machine learning classifiers and ensemble techniques and implementation measures. Part 3 introduces data and its interpretations, part 4. Presents model results and discussion over it. Finally, our work concludes in Part. 5.
Methodology
The machine learning classifier used in our evaluation uses LR, k-NN, SVC, GBC and RF as well as majority voting, weighted average, bagging, Ada_boost, and Gradient_boosting as grouping procedures. These classifiers are completely mainstream classifiers because they are easy to implement and only need to adjust a predetermined number of boundaries. They are depicted below, and we also used the representation estimates: classification accuracy, recall, accuracy, F-measure and area under the curve (AUC). In addition, we also evaluated the relevance of Pearson correlated features, including the feature importance of GBC and RF classifiers.
Machine Learning Classifiers
Logistic Regression (LR)
Logistic regression [13] is a mathematical model whose essential structure uses the calculated capacity to display matched ward variables. In the recurrence check, strategic recurrence or logarithmic recurrence is evaluating the boundaries of the computational model (double recurrence). Numerically, the dual strategy model has a related variable with two potential qualities, for example, valid/falsified, which is spoken by pointer variables, and the two qualities are called “0” and “1” respectively.
Assume that mathematical estimates of 0 and 1 are derived into the two results of the paired variables. If p is the degree of perception that the result is 1, then 1−p is the probability that the result is 0 at that point. The ratio p/ (1−p) are called the odd, and the logarithm is the logarithm of the odd, or simply records the odd. Numerically, the logarithmic odd is determined by
The strategic change is the converse of the logit change. It is composed as
K-nearest neighbours (KNN)
To handle other labels, a supervised algorithm is used, which is supervised and gets a set of label signals [14]. To assign a new point, it finds the nearest point and votes on that point, so it assigns the nearest label in this way. Following distance function are used to evaluate KNN.
Support Vector Classifier (SVC)
There is a supervised machine learning algorithm for classification and regression processes, called support vector machines, for data analysis. Support vector machines can be used for regression, but are mainly used for classification. For each specified coordinate, the value of each feature is also the same in n-dimensional space. These two categories are now characterized by ideal hyperplanes. Individual observations are represented by the coordinates of the support vector [15]. SVM is a more advanced technology that separates the two categories.
The hypothetical function is defined as
Here, The point above or on the hyperplane will be delegated class + 1, and the point underneath the hyperplane will be named class − 1. Processing the (delicate edge) SVM classifier adds up to limiting an outflow of the structure
Gradient Boosting Classifier (GBC)
Gradient boosting is an AI strategy for regression and classification problems. It provides a prediction model in the form of a set of overall prediction models and decision trees. Like other enhancement techniques, it constructs models in a stage-savvy style and summarizes them by allowing arbitrarily distinguishable unfortunate work [16].
Extensive use of “gradient enhancement” follows method 1 to limit target work. In each cycle, we adapt the basic learners to the negative angle of the negative gradient, and continuously increase the expected value, and add it to the incentives emphasized in the past.
where \(L\left(y, F\left(x\right)\right)\mathrm{is a differentiable loss function}\)
Random Forest (RF)
Random Forest classifier is an all-encompassing learning strategy for grouping, relapse, and different undertakings that can be performed with the assistance of choice trees [17]. These choice trees can be built at preparing time, and the yield of this class can be characterization or relapse. With the assistance of this irregular forest, one can address the propensity for over-adjustment to the preparation set.
At the "random forest" level, it is normal on all trees. The importance of the entire component of each tree is estimated and divided by the total number of trees:
where RFfii is the significance of highlight I determined from all trees in the Random Forest model; Norm fiij is the standardized element significance for I in tree j; T is the absolute number of trees.
Ensemble Techniques
The ensemble itself is a supervised learning calculation because it tends to be prepared and then used to make predictions. In any case, this kind of speculation is not really included in the theoretical space of the model that made it. In principle, this adaptability can allow them to overfit the training data instead of a separate model, but in fact, certain ensemble techniques usually reduce the problems caused by overfitting the training data. Generally, evaluating the predictions of ensemble requires more calculations than evaluating the expectations of the overall model. In a sense, ensemble learning can be considered as a way to make up for weak learning calculations by playing a large number of additional calculations. Again, the choice is to do a lot of extra learning on a non-ensemble framework.
It has been observed that when there is a significant difference between the models, ensemble usually produce better results. Therefore, many ensemble strategies hope to increase diversity among their combined models. Although it may not be instinctive, more arbitrary calculations (decision trees) can be used to create more solid ensemble than conscious calculations (decision trees that reduce entropy). In any case, it turns out that using a variety of powerful learning algorithms is more attractive than using methods designed to promote model development [18].
This article uses five types of ensemble algorithms: majority voting, weighted average, bagging, Ada_boost and gradient_boosting to enhance the model we developed. Another purpose is to compare the model with machine learning classifiers.
Feature Importance
Feature importance implies a strategy for assigning scores to include features in an a priori model that demonstrates the overall importance of each element when making expectations.
Feature importance scores can be determined for questions including predictive mathematical value (called recurrence) and questions including predicted class names (called order) [19].
These scores are very valuable and can be used within a certain range of situations through prescient demonstration questions, such as:
-
For better understanding of information.
-
For better understanding the model.
-
To reduce the number of information features.
The feature importance score can bring knowledge into the data set. The overall score can reflect which characteristics are usually related to the goal, and vice versa. This may have been decrypted by the administrator and can be used as a reason for more or unique information in social activities.
The feature significance score can give an idea of the model. The feature significance score is determined by the prior model suitable for the data set. Evaluating the significance score can give you an idea of the specific model and what highlights are most important to the model when making expectations, and the least important. This is a model conversion that can be performed for those models that provide assistance [20].
Feature importance can be used to improve the prior model. This can be achieved using the significance score to select the feature to be erased (lowest score) or to keep the feature (highest score). This is a feature selection that can eliminate display difficulties, speed up the presentation cycle (erasing features is called dimensionality reduction), and improve the display of the model again and again.
Pearson Correlation Matrix
The Pearson correlation coefficient is the covariance separated by the standard deviation results of the two factors. The types of definitions include “product moments”, that is, the mean value of the results of the mean balance irregular factors; therefore, the modifier item comes second in the name [21].
Pearson’s connection coefficient is usually represented by the Greek letter ρ (rho) when applied to the public, and may be referred to as the coefficient of public relations or the coefficient of public Pearson’s relations (X, Y), then the equation of ρ is:
where cov is the covariance. σx is the standard deviation of X. σy is the standard deviation of Y.
Confusion Matrix
To verify the accuracy of the classifier, the description of validation is as follows:
To check the performance of the classifier, different performance evaluation metrics are used in this exploration. We use the confusion matrix to accurately place each perception in the test set in a box. Given that there are two rest categories, it is a 2 × 2 network. In addition, it gives two correct predictions of the classifier and two non-benchmark predictions [22]. Table 1 shows the confusion matrix.
From the confusion matrix, we draw the following conclusions:
TP: The expected yield is significantly positive (TP). We infer that the characteristics of patients with heart disease have been accurately characterized, and the patients have heart disease.
TN: The expected output is a significant negative value (TN). We believe that the subject is healthy and correctly characterized.
FP: Expected to be a false positive (FP) yield. We assume that a subject is incorrectly characterized as having heart disease (a level 1 error).
FN: The expected yield is false negative (FN). We believe that the diagnosis of heart disease is incorrect because the subject does not have heart disease.
Accuracy of the classifiers: Accuracy shows the whole performance of the classification system is as follows:
\({\text{Classification}}\;{\text{Accuracy}} = \frac{{{\text{True}}\;{\text{Positive}}\left( {TP} \right) + {\text{True}}\;{\text{Negative}}\left( {{\text{TN}}} \right)}}{{{\text{True}}\;{\text{Positive}}\left( {{\text{TP}}} \right) + {\text{True}}\;{\text{Negative}}\left( {{\text{TN}}} \right) + {\text{False}}\;{\text{Positive}}\left( {{\text{FP}}} \right) + {\text{False}}\;{\text{Negative}}\left( {{\text{FN}}} \right)}}*100\)Precision: Precision is the ratio of the positive observations that is accurately expected.
Recall (sensitivity): Recall is the ratio of the positive perceptions accurately expected to all the perceptions in the real class-Yes.
F1 score: F1 score is the weighted normal of Precision and Recall. Therefore, this score considers both false positives and false negatives.
ROC curve: The beneficiary’s optimistic curve analyze the expected capabilities of the AI classifier used for grouping. ROC inspection is a portrayal based on graphics, which considers “correct rate” and “error rate”. AI calculates the “positive rate” in the grouping result. AUC depicts the ROC of a classifier. The larger the estimated value of AUC, the more feasible the display of the classifier [23].
To make the test results more satisfactory, the k-fold cross-approval was used in this work. Specifically, we accepted a fivefold cross-validation, in which the first example was randomly assigned to five sub-samples of equivalent size. Keep a single sub-sample as validation information for testing the model, and use the remaining nine sub-samples as training information. Next, the cross-validation measures were remixed multiple times, and each of the ten sub-samples was used exactly once for approval. At each repetition place, each arrangement execution measure will be processed. Therefore, it was determined that its related normal direction and standard deviation exceeded ten repetitions.
Experimental Setup
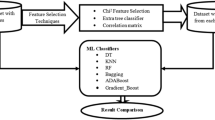
In this work, we have a distinctive purpose. We use the machine learning classifier and ensemble technology on information to arrange the subject as Parkinson’s or non-Parkinson. This does not use human judgment in measurement. Despite the fact that there are obvious human judgments, there are important features to be recorded. The reason is that machine learning should be able to choose to find the proper blend of features without anyone else. Following Fig. 1 shows the overall structure of the model that is implementing to analyze.

Overall structure of compilation
Dataset
We used the dataset used also by to conduct comparative performance analysis of different classifiers in distinguishing between healthy and PD patients based on measurements. The PD data set is taken from the UCI machine learning repository [24]. The dataset contains 26 features (linear and time frequency based) computed from voice records of 20 PD (6 female, 14 male) patients and 20 healthy control (10 female, 10 male) subjects. The 26 voice features, column 1 as subject id, column 28 as UPDRS (Unified Parkinson’s Disease Rating Scale) and column 29 as target feature are presented in Table 2.
Experimental Results & Discussion
Following the tenfold cross-validation convention, all classifiers are prepared using each of the 26 estimated values to produce impressively powerful results. We use Python™ 3.7 programming to display all classification tasks. For each representation, the spread across classifiers is excellent.
The excitation range of the correlation coefficient is − 1 to + 1. The larger the absolute estimate of the coefficient, the stronger the connection between the variables.
For Pearson correlation, flat estimate 1 proves the ideal straight line relationship. A relation close to 0 indicates that there is no direct relation between the factors. The indication of the coefficient illustrates the course of the relationship. If these two factors increase or decrease together as a whole, the coefficient is positive and the line that speaks to the relation will slope upward. When a variable generally increases with different decreases, the coefficient is negative and the line opposite to the connection slopes down [25].
In the following Fig. 2, the features f12, f14, f15, f16, f18, f20 and f22 are positively correlated while f2, f3, f5,…, f12, f13, f17, f22 and f23 are negatively correlated to the target variable.

Pearson correlation of features
Feature importance is also a key factor for deciding the priori model that demonstrates the overall importance of each element when making expectations [26]. This importance of features are evaluated using existing machine learning classifiers gradient boosting classifier as well as random forest classifier as shown in Figs. 3 and 4, respectively.

Important features extracted by GBC

Important features extracted by RF
In Figs. 3 and 4, we can easily see that the features f1 to f6 are very important features and have powerful predictive capabilities.
According to Fig. 5 and Table 3, SVC has the highest accuracy (93.83%) among all five machine learning classifiers. RF won the second place with 89.72% accuracy and k-NN with 84.93% accuracy, and the third place. Similarly, in the ensemble technique, bagging ranks first among the five algorithms with an accuracy rate of 73.28%. Further Gradient_boosting and weighted average are ranked second and third with 72.60% and 71.23% accuracy, respectively.

Graphical representation of the performance
As we can see in Fig. 5 and Table 3, the SVC classifier obtains the highest accuracy, and in the ensemble technique, the bagging algorithm. Now, to verify these values, we implemented other metrics such as ROC curve, confusion matrix, precision, recall, and F1 score. In Fig. 6, (a) represents the ROC curve, and (b) represents the confusion matrix. Both index values are obtained through SVC, and the accuracy of the ROC curve is 99% relative to 93.83%.

a ROC curve and b confusion matrix by SVC
Again in Fig. 7, (a) represents the metric value, and (b) represents the confusion matrix. The images obtained by the ensemble algorithm bagging and verify the value obtained in Table 2.

a precision, recall and f1-score, b confusion matrix by bagging
Our outcomes show that the SVC is the best machine learning classifier for grouping PD patients and bagging calculation got the highest accuracy in ensemble method, since it acquired the most elevated score in all exhibition measures aside from accuracy and F-measure. In any case, it accomplished the second best F-measure. Researcher in [27] used relapse models in following of PD advancement dependent on MAE, MSE and coefficient of relationship. They found that SVC help vector classifier beat both multilayer perceptron neural network and general relapse neural network in recognizing healthy and PD patients. Along these lines, both our examination and the investigation in [27] show proof of the appropriateness of the SVC in demonstrating vocal features for PD recognition and checking. Also, the example size is adequately enormous and that we utilized five-cross validation which is a dependable procedure broadly utilized for abstaining from overfitting.
We studied the feasibility of five machine learning classifiers and five ensemble methods. As our results shown in Table 3 and Fig. 5 indicate, SVC and bagging are inherently better than the different classifiers we analyzed. This is an important achievement in the CAD framework plan for clinical application, because clinicians usually worry about whether the patient affected by PD or healthy, so they need to use the most reasonable classifier. It is fascinating that the most significant AUC is obtained by the SVC classifier, which is a representation method that depends on a mixture of influencing and clarity.
Our findings recognize that SVC is more attractive than other AI classifiers considered in this work to separate PD patients from healthy people. Some key points can be used to illustrate the advantages of SVM as an AI classifier. Initially, it depends on the auxiliary hazard minimization standards and the structure of the superior classifier, so that negative and positive situations can be isolated. This can be perfected by expanding the space between the class and the hyperplane using nonlinear bits. In addition, the streamlined results of the SVC classifier are on a global scale. These attractive features add to the achievements of SVM in planned PD estimation.
Conclusion
This examination applies the classification of AI and ensemble methods to tasks that rely on some measurements to identify voice objects and PD patients. We considered exhibitions on the following topics: linear regression (LR), k nearest neighbors (k-NN), support vector classifier (SVC), gradient boosting classifier (GBC) and random forest classifier (RF) and majority voting, Weighted average, bagging, Ada_boost and Gradient_boosting as ensemble method. Support vector classifiers and bagging show better execution ideas than different classifiers. The results obtained by popular classifiers are compared, and the results are verified by measures such as accuracy, recall and F1. To further improve the display effect of SVC and other AI classifiers, future work will consider feature selection.
References
Sethi K. Levodopa unresponsive symptoms in Parkinson disease. Movement Disord. 2008;23(S3):S521–33.
Perez-Lloret S, Negre-Pages L, Damier P, Delval A, Derkinderen P, Destée A, et al. Prevalence, determinants, and effect on quality of life of freezing of gait in Parkinson disease. JAMA Neurol. 2014;71(7):884–90.
Parkinson J. An essay on the shaking palsy. J Neuropsychiatry Clin Neurosci. 2002;14(2):223–36.
Little M, McSharry P, Hunter E, Spielman J, Ramig L. Suitability of dysphonia measurements for telemonitoring of Parkinson’s disease. Nat Prec. 2008. https://doi.org/10.1038/npre.2008.2298.1.
Ene M. Neural network-based approach to discriminate healthy people from those with Parkinson’s disease. Ann Univ Craiova-Math Comput Sci Ser. 2008;35:112–6.
Gil D, Manuel DJ. Diagnosing Parkinson by using artificial neural networks and support vector machines. Glob J Comput Sci Technol. 2009;9(4):63–71.
Das R. A comparison of multiple classification methods for diagnosis of Parkinson disease. Expert Syst Appl. 2010;37(2):1568–72.
Caglar MF, Cetisli B, Toprak IB. Automatic recognition of Parkinson’s disease from sustained phonation tests using ANN and adaptive neuro-fuzzy classifier. J Eng Sci Des. 2010;1(2):59–64.
Geetha Ramani R, Sivagami G. Parkinson Disease Classification using Data Mining Algorithms. Int J Comput Appl (0975–8887). 2011;32(9):17–22.
Rustempasic I, Can M. Diagnosis of Parkinson’s disease using Fuzzy C-means clustering and pattern recognition. SouthEast Eur J Soft Comput. 2013. https://doi.org/10.21533/scjournal.v2i1.44.
Aich S, Youn J, Chakraborty S, Pradhan PM, Park JH, Park S, Park J. A supervised machine learning approach to detect the on/off state in Parkinson’s disease using wearable based gait signals. Diagnostics. 2020;10(6):421.
Wang W, Lee J, Harrou F, Sun Y. Early detection of Parkinson’s disease using deep learning and machine learning. IEEE Access. 2020;8:147635–46.
Tolles J, Meurer WJ. Logistic regression relating patient characteristics to outcomes. JAMA. 2016;316(5):533–4. https://doi.org/10.1001/jama.2016.7653.
Sutton O. Introduction to k nearest neighbour classification and condensed nearest neighbour data reduction. Leicester: University lectures University of Leicester; 2012. p. 1–10.
Chaurasia V, Pal S. Applications of machine learning techniques to predict diagnostic breast cancer. SN Comput Sci. 2020;1(5):1–11.
Chakrabarty N, Kundu T, Dandapat S, Sarkar A, Kole DK. Flight arrival delay prediction using gradient boosting classifier. In: Emerging technologies in data mining and information security. Singapore: Springer; 2019. p. 651–9.
Shi T, Horvath S. Unsupervised learning with random forest predictors. J Comput Graph Stat. 2006;15(1):118–38.
Chaurasia V, Pal S. Skin diseases prediction: binary classification machine learning and multi model ensemble techniques. Res J Pharm Technol. 2019;12(8):3829–32.
Altmann A, Toloşi L, Sander O, Lengauer T. Permutation importance: a corrected feature importance measure. Bioinformatics. 2010;26(10):1340–7.
Zheng H, Yuan J, Chen L. Short-term load forecasting using EMD-LSTM neural networks with a Xgboost algorithm for feature importance evaluation. Energies. 2017;10(8):1168.
Kijsipongse E, Suriya U, Ngamphiw C, Tongsima S.. Efficient large pearson correlation matrix computing using hybrid mpi/cuda. In: 2011 eighth international joint conference on computer science and software engineering (JCSSE). New York: IEEE; 2011. p. 237–241.
Lewis HG, Brown M. A generalized confusion matrix for assessing area estimates from remotely sensed data. Int J Remote Sens. 2001;22(16):3223–35.
Hajian-Tilaki K. Receiver operating characteristic (ROC) curve analysis for medical diagnostic test evaluation. Caspian J Intern Med. 2013;4(2):627.
Erdogdu Sakar B, Isenkul M, Sakar CO, Sertbas A, Gurgen F, Delil S, Apaydin H, Kursun O. Collection and analysis of a parkinson speech dataset with multiple types of sound recordings. IEEE J Biomed Health Inf. 2013;17(4):828–34.
Benesty J, Chen J, Huang Y, Cohen I. Pearson correlation coefficient. In: Noise reduction in speech processing. Berlin: Springer; 2009. p. 1–4.
Hooker S, Erhan D, Kindermans PJ, Kim B. Evaluating feature importance estimates; 2018. arXiv preprint. http://arxiv.org/abs/1806.10758.
Eskidere Ö, Ertaş F, Hanilçi C. A comparison of regression methods for remote tracking of Parkinson’s disease progression. Expert Syst Appl. 2012;39(5):5523–8.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
Authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the topical collection “Computational Biology and Biomedical Informatics” guest edited by Dhruba Kr Bhattacharyya, Sushmita Mitra and Jugal Kr Kalita.
Rights and permissions
About this article

Cite this article
Yadav, S., Singh, M.K. Hybrid Machine Learning Classifier and Ensemble Techniques to Detect Parkinson’s Disease Patients. SN COMPUT. SCI. 2, 189 (2021). https://doi.org/10.1007/s42979-021-00587-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42979-021-00587-8