
Abstract
Parkinson's disease (PD) is a neurodegenerative disorder that affects the elderly. PD affects the quality of life by causing motor and non-motor disabilities. Traditional PD diagnosis depends on the medical history, a review of symptoms, neurological and physical examinations by a medical specialist. Early detection of PD is a critical step towards providing prompt medical action. In artificial intelligence, computer-assisted methods for PD identification have recently received more attention. The present work focuses on the early detection of PD by logically analyzing time-series data collected during a spiral drawing assessment test of Parkinson’s and normal subjects using digital tablets. A preliminary machine learning approach is taken on static and dynamic drawings tests separately using logistic regression and Support Vector Machine classifier to observe accuracies. It is leveraging a recent novel strategy of employing Restricted Boltzmann machine (RBM) pipelined with multi-layer perceptron model classifier, which provides an accuracy of 95.32% by combining both static and dynamic spiral drawings assessments. The proposed approach is a successful candidate for detecting PD patients. The reported results of cost-effective computer tool-based PD symptom monitoring are helpful in telemedicine applications.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Parkinson’s disease (PD) is a gradually developing neurodegenerative disorder. Patients with early PD symptoms should perhaps be administered to slow the temporal deterioration to prevent the severe complications often observed in the later stages. The available therapeutic possibilities demonstrate no up-front cure for PD; however, therapies do help to alleviate the symptoms. Diagnosis methods primarily depend on medical history, computerized scans and imaging, body movements, sleep patterns, and speech quality. Few symptoms like speech irregularity and handwriting have lately been researched much on the early diagnosis of the disease. PD is a rare neurological motor condition with symptoms that include tremors in the hands, head, legs, face, body swelling, muscle rigidity, postural imbalance, and mobility difficulties (Kuresan et al. 2019; Chou et al. 2020). PD also has non-motor symptoms such as slowing thoughts, dementia, focused attention problems, and speech difficulties (Kuresan et al. 2021). PD was first identified as "shaking palsy" by Dr. James Parkinson (Goetz et al. 2008). Early detection or diagnosis and effectiveness of the treatment by correct and constant evaluation can improve the productive life expectancy of PD patients. The Unified Parkinson’s Rating Scale (UPDRS-III) is typically used to evaluate the stage of PD (Goetz et al. 2008). Clinical treatment and therapy may relieve definitive symptoms, including neuropharmacological and neurosurgical methods. The importance of early diagnosis of the disease in enhancing the quality of life for patients cannot be overstated (Pfeiffer et al. 2004; Johnson et al. 2013).
Human lives have significantly evolved with the steadfast progress in technology. Computer-assisted and artificial intelligence (AI) based systems for diagnosis have been widely accepted in recent years for their use in the pathological realm in healthcare (Schrag et al. 2002; Drotár et al. 2014, 2016). Investigating handwriting and drawing tasks based on spatio-temporal input features is a profound clinical biomarker that leads to monitoring motor signs under consideration and has been applied in practice for over a decade (Danna et al. 2019). PD on the brain's basal ganglia and cortex promotes bradykinesia to micrographic. It leads to cramped and irregular handwriting. Dominant signs related to motor skills are affected because of the spontaneity of the assessments, which causes the kinematic gaps precisely observed in PD patients. A key aspect of handwriting and drawing-based evaluations is the crucial decision of parametric features for attentive implementation and application.
Solid cognitive processing is required to assess motor planning and monitoring hand actions (Impedovo 2019). Specific motor skills accurately executed by normal subjects were disrupted in the case of PD patients (Drotár et al. 2016). Observations of velocity, jerk, pressure, acceleration contribute to this study as informative criteria. Machine/Tablet-based diagnosis has robustness on its own as possible biased results due to clinical data tampering are minimized from both sides, including the examiner and the patients themselves (Cantürk 2021). Dynamic feature analysis of PD patients’ handwriting using automated machine learning (ML) classifiers has played a vital role as a possible and early biomarker because of their high-performance accuracy (Impedovo and Pirlo 2018). Handwriting assessments involve coordination with cognitive planning, which are significant for clinical trials by PD patients (Impedovo et al. 2018). The related literature on spiral drawings for early identification of the PD is discussed in the next section.
2 Related works
Archimedean guided spiral drawing idea on a digital tablet for a similar clinical diagnosis and documenting the dynamic calculations, angular features, and inversion count in direction were explored (Zham et al. 2018). An accurate method is required to differentiate PD patients and control subjects using Spearman’s rank correlation. Discriminating healthy cohorts using an animated spiral test on a tablet using an ergonomic stylus pen was done by Memedi et al. (2015). They proved the potential of such tests by analyzing the motor symptoms by kinematic features and using Multi-Layer Perceptron (MLP) for classification. The digitized spiral analysis is a powerful way to analyze tremors in movement in diseases that affect motor skills (Danna et al. 2019). They observed the spatial and temporal curb changes in their relationship with Parkinson’s symptoms and realized those with the most relevant impact (Monika et al. 2018). The ease of usage and administering such non-invasive procedure with leading domains of action tremor, bradykinesia, rigidity monitored according to the disease’s severity degree asserts how useful and supplemental for motor assessment (Impedovo 2019; Pullman et al. 2008; Miralles et al. 2006).
Digitized spiral drawing-based tests are possible tools to observe precision kinematics irregularities occurring due to the disease during such an assessment. Such spiral drawing analysis opens a window for quantifying kinematic and dynamic related features based on clinical relevance. Brain stimulation effects were also observed and monitored in PD patients and are subjected to further clinical examination (Radmard et al. 2021). Kamble et al. (2021) studied using multiple ML tools on Digitized Spiral Drawings’ impacts and checking through AI-based diagnostic aids. This self-assessment procedure may enable PD patients to collect data at home and send it to the assigned web application server for handling and production (Afonso et al. 2019). The publicly available dataset from UCI ML repository labelled “Parkinson Disease Spiral Drawings Using Digitized Graphics Tablet Data Set” was applied for usage and interpretability (Isenkul and Sarkar 2014; Sakar et al. 2013).
Spiral drawing requires a high level of motor coordination and agility. It is considered a compassionate motor evaluation. For PD, the UPDRS-III is the most commonly used and highly acknowledged grading system. A person's motor skills are impacted in numerous ways by PD, including their ability to speak, write, walk, and coordinate their motions. Due to PD's status as a neurodegenerative motor illness, researchers have suggested a wide range of quantitative measures of motor decline and non-motor biomarkers. In addition to the inconvenience of accompanying the patient to the clinic for a physical examination, diagnosing and monitoring PD is expensive and time-consuming (Kamble et al. 2021). In underdeveloped countries, a clinical invasive procedure is accessible only early, but it has a high risk because of its limited resources. Traditional non-invasive tests such as the handwriting test and spiral drawing pen-paper test were used to evaluate PD in the past. Human skill is required to collect, preserve, and analyze these drawings, which is time-consuming and biased. It is now simpler to acquire drawing samples using digitizing (digital) tablets, which are currently utilized in biological research. The use of graphics tablets allows academics to construct a wide range of image analysis and processing techniques than the pen-and-paper mode.
Serial signatures from pen-and-paper tests for PD screening were originally designed to identify micrographia, which refers to unusually tiny handwriting. Since micrographia, handwriting analysis can be an effective and scalable PD screening method before formal clinical evaluation. The kinematic changes in handwriting may be evaluated long before the emergence of other PD symptoms. A basic circular clock (numbered one to twelve around its diameter) was used for general neurological diseases as an early complicated sketching job. In recent decades, computer tools and analytical methodologies have advanced, making it possible to digitize handwriting analysis and use the kinematic data retrieved from tablets during writing. In this way, tremors, micrographia, and other signs of PD may be detected objectively by medical professionals and researchers (Chandra et al. 2021).
Digital handwriting analysis has a lot of therapeutic advantages for early screening and monitoring. Using a tablet-based tool combined with handwriting comfort allows patients to recognize symptoms and seek medical attention more quickly. Additionally, gathering data aids in the prospective diagnosis made by a medical professional. Because a patient's motor symptoms in PD change over time, physicians may use easily accessible quantitative data on handwriting to follow the disease's development. Because of the impact on a patient's motor function, more thorough monitoring via digital drawing tests may also assist personalized treatment options, innovative medications, and experimental techniques.
In this work, ML models of Support Vector Machines (SVM) and Logistic Regression are used as a pre-evaluation method of assessing the two types of spiral drawings. Then, an automatic RBM based neural network pipeline with MLP is proposed to detect features from the time-series dataset and helps distinguish between PD patients and normal people (Alissa et al. 2021). With the help of mathematical models and interpolation techniques in kinematics, additional spatial and temporal parameter values related to tremors are determined, and significant results are reported (Rastgoo et al. 2021; de Souza et al. 2021).
The present research work is structured as follows: Sect. 1 discusses the background and need of studying a classifier for early detection of PD. Section 2 focuses on the related work for identifying PD using spiral drawing. Section 3 discusses the materials and methods of data sets and the proposed pipeline. In Sect. 4, the static and dynamic test analyses are described. The salient results are discussed in Sect. 5. Section 6 outlines the significant conclusions and summarizes the further works required in the field.
3 Materials and methods
3.1 Dataset description
The spiral sketches for detecting PD were created by hand, using Wacom Cintiq 12WX, a unique graphic tablet/smartphone by 62 people with Parkinson's disease and 15 healthy subjects. The examination took place at the University of Istanbul's Cerrahpasa, Faculty of Medicine's Department of Neurology (Isenkul and Sarkar 2014). The graphics tablet comes with customized software that registers spiral drawings and procures data files (in csv format) according to specific parameters. This cumulative test included three forms of recorded reporting: a static assessment, a dynamic assessment, and a test examining motor stability.
The static version of the test carried the goal of evaluating motor coordination performance and tremor analysis, and disease diagnosis, as shown in Fig. 1. The dynamic test or Dynamic Spiral Assessment Test (DST), in which the same Archimedean spiral popped up and vanished in stipulated time intervals, is depicted in Fig. 1. Patients are required to keep the pen on the red-colored dot at screen’s middle without contact during the third or last test. The first two test sets were taken into consideration and analyzed. The parameter classes directly indicate the person who has (one) or does not have PD (zero). There are 77 instances and seven attributes in the dataset, including kinematic parameters. As input, x, y, z, pressure, grip angle, timestamp, and test ID of each stroke are all delimited as CSV values.

Samples of static and dynamic spiral drawings of Control (left, blue colored) and PD Patients (right, red-colored)
The list of the test IDs is as follows.
-
Test ID: (0) Static Spiral Assessment Test (SST)—Simple drawing on the stated spiral pattern by the subject. The static test plays the precursor form of analysis for experts to segregate the essential kinematic criteria first.
-
Test ID: (1) DST—Pattern keeps blinking based on a specific timer; therefore, subjects must keep drawing. The dynamic evaluation monitors how well the patient responds when the screen flickers and the tablet in the new setting follow the same kinematic criteria as the static assessment.
3.2 Proposed work
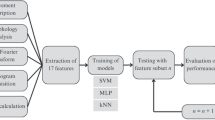
The proposed work includes feature analysis and evaluation of static and dynamic drawing tests and applying Logistic Regression classifier and SVM classifiers on these tests separately and contrasting the outcomes. A fresh approach to applying the RBM pipeline, an unsupervised learning strategy in which the RBM neural network and MLP derive features in the pipeline to distinguish the findings into Parkinson's patient and control patient categories. The unsupervised learning technique involves static and dynamic features extracted from control features and PD features, respectively, and achieved an accuracy of 96%. Feature extraction is performed using Bernoulli RBM, and classification is done by using MLP Pipeline. The traditional RBM is based on some apparent visible random variables and unknown variables (for example, film genres or other internal features). The role of training is to figure out how these two sets of variables are related. Figure 2 depicts the process model's fundamental flow diagram.

Proposed detection system for PD using Digitized Spiral Drawings
Existing methods include deep Recurrent Neural Networks on the same dataset with a test accuracy of 89% (Gallicchio et al. 2018). Deep recurrent neural networks on such a small dataset led to heavyweight usage requiring higher computational cost for strategic implementation in a time-series of input data. Ensemble learning algorithms that involve bagging (Random Forest) and boosting (AdaBoost and XGBoost) to neglect bias in the dataset have been used in the past. However, these oversights deviant behavior in the dataset contains fine information for the cohorts' usage and classification. Among these ensemble algorithms, AdaBoost algorithms work best as the classifier and feature selection by genetic algorithm achieves an accuracy of 96% (Lamba et al. 2021). Random forest classifier on newly derived mathematical and geometric features was separately tested on dynamic and static drawings with 96% and 97% accuracy, respectively (Chandra et al. 2021).
These comparison studies led to developing an algorithm that chooses characteristics from both the SST and DST drawings, combining and classifying the PD and normal populations. The central prominence of this work lies in the worthy use of RBM for critically analyzing the essential characteristics in the time-series data. This is a low-cost, fast and efficient method used to get results on time with high efficiency. The advantage of shallow neural networks is that they are an alternative to the heavy-weighted deep neural network for a small or limited training dataset. In the case of complex representation of feature inputs, the filtering method used by these networks are put to notable use. Since these shallow neural networks are trained task-specific, i.e., categorizing the spiral drawings into PD and regular cohorts, they can be manipulated for other similar time-series spiral drawing databases without training from scratch.
3.3 Static and dynamic test analysis
A fixed spiral design was supplied to the patients in the SST and DST drawings, which were used to evaluate the existing model of tablet-based spiral drawings in distinguishing between PD patients and healthy controls. First, the raw data is analyzed to identify the kinematic aspects (speed, acceleration, jerk, and curvature). The derivatives of the spline-interpolated functions were used to get the needed kinematic data. The subject's drawing's curvature was also taken into consideration. The spiral designs' polar metrics were also estimated. As the distance from the spiral center was obtained for each data point, the associated radius and the point's related angle from the x-axis were computed. The rising edge, the primary signal, and the falling edge are all different components of the pressure signal that are evaluated.
3.4 Input feature outcomes
Figure 3 represents the variations of normal and PD subjects concerning the fundamental features like curvature, velocity, acceleration, jerk, and pressure. These fundamental characteristics were displayed on the axes for graphical review on sample individuals (including 15 normal and 62 PD patients). Interpolation plots the curves and evaluates the findings busing the generated features' X and Y coordinates. This comparison assessment was performed to differentiate between the two cohorts and insights into the dataset. The parameters were derived using SciPy package’s (a Python library) interpolation module (Dhanalakshmi and Chakrapani 2016). The deviations observed, which were based mainly on significant disruptions (tremors in movement) in PD cases compared to normal subjects, were implied through these above five parameters plotting. This tracking necessitated the examination of additional parameters for research.

Comparison of velocity, acceleration, jerk, and curvature of normal and Parkinson’s subjects based on different cohort’s parametric values calculated on x and y coordinates
3.4.1 Pressure
Archimedean spiral designs' pressure signals from various datasets exhibit a three-component structure. Additionally, this split facilitates analysis of the major signals by removing the influence of significant low-end outliers at the boundaries, thereby revealing how the participants begin and conclude the drawing. A rising or falling edge ends by tracing how many consecutive points increase or decrease at a given time (for falling edge). Additionally, these points were found by employing criteria for the ratio of pressure readings at different periods in time to indicate a substantial rise or decrease in pressure. A significant decrease in pressure at the beginning, the falling edge starts, while the flattening out of pressure from areas of pressure rise begins the primary signal.
3.4.2 Curvature and features based on linear regression
An Archimedean spiral has an increasing curvature from beginning to finish because its curvature deviates from a straight line in the clockwise direction. The curvature of this spiral begins at a negative. The Archimedean spiral's characteristics and the Archimedean spiral's design encourage linear regression modeling.
The equation may describe an Archimedean spiral in polar coordinates (r, θ). Spiral loops' distances are controlled by the coefficients a and b, inversely proportional. Curved trajectories have a velocity proportional to their curvature radius (v = ar, where v is the velocity and r is the radius). Furthermore, this equation demonstrates that velocity and time are generally proportional since the radius is exactly proportional to time in a drawing. There is an inverse relationship between pressure and spiral radius and velocity when a person draws an Archimedean spiral from inside. Comparing the R-squared and sums of squared residuals metric results between patients and controls, the patients may draw greater unpredictability and predictability than the controls.
3.4.3 Velocity and curvature—inverse proportional relationship
As previously stated, because of the inverse relationship between radius and curvature, velocity is inversely proportional to curvature. We used the following equation to understand better the link between velocity and curvature: v = a + b/k. The R-squared value, equation coefficients a and b, and regression model sums of squared residuals are used as features. Using default settings, the models were constructed using Scipy’s (v1.6.3) curve fit function.
3.4.4 Mean and standard deviation
For the first and second-order derivatives of radius for time and theta to time, we looked at the polar features of the Archimedean spiral. Data pre-processing was used to determine the radius and theta signals. The radius is the distance from the spiral's center and the theta is the angle from the horizontal polar axis. The spline fitted functions of these data signals were used to compute the derivatives, which show the rate of change at each data point in the smoothed and truncated graphic. For example, the mean and standard deviations of the rates of change values reveal the subject's drawing stability. Drawings should show larger rates of change (more mean values) and greater variety (higher standard deviation) in their rates of change.
3.4.5 Acceleration and jerk
The velocity change divided by the time elapsed gives us the average acceleration. A jerk occurs when the rate of acceleration changes over some time. The components of jerk are:
-
Over time, the change in X coordinate is used to compute the magnitude of horizontal.
-
The mean vertical displacement (change in Y coordinate) throughout the complete time length is used to compute the amount of vertical velocity.
-
The average change in horizontal velocity over time is the magnitude of the horizontal acceleration.
-
The mean change in velocity in the vertical direction over time is vertical acceleration.
-
The horizontal jerk's magnitude is the average change in horizontal acceleration during the experiment.
-
The mean change in vertical acceleration over time is used to calculate the magnitude of the vertical jerk.
3.5 Feature Extraction
Every instance includes temporal and spatial characteristics dependent on arithmetic statistics from the consolidated data collection (Monika et al. 2018; Júnior et al. 2020). The temporal characteristics apply to how long it took for the subjects to complete each test (in seconds). The five spatial mapping attributes given in the dataset include x, y, z (coordinates), pressure, and the grip angle in the two main- tests out of the seven attributes. From the provided inputs, other parameters were calculated and enlisted in Table 1. These parameters were calculated using a kinematic mathematical model using interpolation techniques. First, we extract features for Static Drawings, Test ID = 0, then for Dynamic Drawings, Test ID = 1.
3.6 Feature analysis
A feature selection procedure using Select K-Best is a univariate method where the features are so chosen in the data that contribute most to the target variable. Selecting features according to the ‘K’ highest score according to the chi-squared test function (this eliminates the features that most likely are not aligning with the regular class and, therefore, are not valuable for classification). Fitting it into X and Y column sets where X applies for feature columns (for instance, peak velocity, standard acceleration), and Y for a category of patients (control and Parkinson’s subject). The significance of each feature with the resulting score attribute is listed in Table 2.
The Pearson's correlation coefficient focusing on the data's rank is Spearman's rank correlation (Zham et al. 2018). This correlation is plotted on a heatmap taking the dataset features in absolute values. The heat map summarizes the strength and direction (0.2–0.9 scale) of a relationship between the training data features. Figure 4 shows the correlation of all the features extracted using heatmap.

Heatmap for the features based on correlation coefficients rank. The dark color in the diagonal represents the correlation of each parameter by itself. The values closer to 1 indicate positive correlation while values are closer to -1; the relationship is similar but inverse. A value of zero value signifies no correlation
3.7 Machine learning models
As a preliminary evaluation method for static and drawings test cases, two ML classifiers were used below, conducted by Scikit-learn, a python package module. To separately analyze the feature results, both the static (SST) and dynamic (DST) assessment tests, Logistic Regression (LR), and SVM was used as the supervised learning algorithm. The results are interpreted using Receiver Operating Characteristic (ROC) curves. The two algorithms were chosen because of their ease of implementation and effectiveness in binary classification involving small datasets (Barui et al. 2018, Eskidere and Hanilcia 2012).
3.8 Restricted Boltzmann machine (RBM) Idea and interpretability
RBM is a probabilistic energy-based deep learning model. The input nodes are represented by a visible layer, while the hidden nodes are represented by a hidden layer in a basic RBM structure (Pedregosa et al. 2011). All the units are binary and stochastic, which is the true nature of an RBM model. The RBM's hidden nodes intuitively assisted in internal feature identification and selection of control and Parkinson's parametric values needed in any combined filtering approach. Energy is coexistent with the model in each stage of training and is initialized and assessed by the weights linking the visible layers and synapses in the hidden nodes (of layers) and biases. At every step of RBM training, these weights and biases are improved so that the model achieves its minimum energy at last. The energy function given below assesses the efficiency of the joint work carried out:
The biases are \(b_{i}\) and \(c_{j}\), while the \(v_{i}\) and \(h_{j}\) are the binary states of the visible unit i and hidden unit j and \(w_{ij}\) is the weight vector.
The energy term describes the model's joint likelihood for the function inputs \(v\) and \(h\). \(Z\) in the denominator may be defined as the normalized distribution based on the provided sample data from the mean value. Because of the given bipartite arrangement, effective block Gibbs-sampling can be used for inference, which is discussed later in this section. The sigmoid activation operation of the provided input determines the conditional probability distribution of each unit. This acts as the firing function for neurons to get activated.
As a consequence of the shortage of hidden variable connections, the conditional probabilities \(P\left( {v_{i} = 1{|}h} \right)\) and \(P\left( {h_{i} = 1{|}v} \right)\) factorise well.
The logistic sigmoid function is denoted by \(\sigma\):
Thus, the RBM may be a stochastic neural network, with nodes and edges reflecting neurons and synaptic communications.
3.9 Training the RBM model
The spiral drawings data is separated into training and validation targets, taking 70% of the instances to train the RBM. The remainder is used to validate the data and thus analyze its results. Direct sampling of a stochastic process is complex due to our lack of knowledge of the underlying mechanics that create that stochastic process over time. When direct sampling does not yield flexible results, Gibbs-sampling (a Markov Chain Monte Carlo algorithm) extracts and analyzes the series of observations. Contrastive Divergence (CD) is a way to train ML algorithms that rely on Markov chains for data sampling. It is started with the Markov chain with a training example, from a distribution expected to be close to desired. As a result, there is no need to wait for the chain to converge. After just K measures of Gibbs-sampling, samples are collected in ten steps. As per the method, the chain should be stopped following a certain number of iterations, k, sometimes just one.
The steps followed in the Gibbs-sampling process in RBM are as follows:
-
The probability p (h = 1|v) and values of the hidden nodes by looking at the first sample of visible nodes were calculated. There are 77 elements in this vector, which represents the first sample's hidden layer values.
-
The likelihood p (v = 1|h) and values of the visible nodes are determined using the sample of hidden nodes generated in the first step. As a result, the visible layer values forming the 2nd sample of visible nodes are represented by a vector of size 200. Steps 1 and 2 are replicated according to the number of iterations specified in this study. Step 1 produces Gibbs samples of hidden layers of visible layer nodes.
-
Gibbs-Sampling is the 10-step CD algorithm where the above 1 and 2 stages are applied ten times.
The RBM is trained using Gibbs-sampling with this 10-Steps method for feature extracting needs of the model. The RBM model structure consists of the following components: There are 77 visible nodes (control and Parkinson's) and 200 nodes (based on computational cost and training) for the 77 patients.
-
A (77*200)—dimensional weight matrix is randomly initialized using a Standard Normal Distribution with a mean of zero and an SD of 1.
-
The likelihood bias, p (h = 1|v), is initialized at random using the Standard Normal Distribution (with Mean of zero and SD of 1) as a vector of size 77.
-
The bias for the probability, p (v = 1|h), is randomly initialized according to Standard Normal Distribution (with a mean of zero and SD of 1) as a vector of size 200.
-
An MLP network is linked into the pipeline after the Bernoulli RBM network. The MLP architecture is a layered feedforward neural network with non-linear components (neurons) organized in successive layers and information flowing unidirectionally from the input to output layer via the hidden layer (s). This MLP network uses a logistic sigmoid function to activate the last layer as a supervised model in the fine-tuning problem. An unsupervised-generative model extracts the input distribution for obtaining the essential underlying characteristics within the data.
-
Both sets of hyper-parameters (for the RBM and the MLP-classifier) are calibrated independently, implying that the RBM model is trained unsupervised while the classifier is trained supervised. This is consistent with the essence of the supervised activity and ensures that the Bernoulli RBM's extracted parameters can be helpful for classification.
-
By leveraging the labels learned, this coupled pipeline of Bernoulli RBMs stacked with MLP act in a supervised learning manner to obtain a model for classifying our necessary inputs (as an acceptable binary-data classification model in a supervised manner).
4 Results and discussion
4.1 Implementation
The experiments are carried out through Google Colaboratory with an NVIDIA GPU-enabled server. The evaluation metrics were executed using the Sklearn-learn toolkit, a python framework. The multivariable dataset of inputs of Digitized Spiral Drawings was passed on to the proposed model (RBM). At first, SVM and LR models were also checked for simpler insights.
4.2 Comparison of static vs. dynamic drawings
The notable variation in the kinematic parameters for PD subject was observed and compared with the normal subject. The x and y coordinate axes of the velocity parameter for the 77 sample patients were averaged to suitably compare the results. The velocity comparison for both PD and normal in bar-chart format is shown in Fig. 5a, b. In the dynamic assessment test for spiral drawings-DST, the spiral curve patterns blinked in a specified time, where subjects had to continue plotting while it kept blinking. In the SST, subjects draw in the given spiral pattern with no hindrance; the performance analysis shows that dynamic test slows the test taker by about 19.99%. A sample report is depicted in Fig. 5c. These show the tremors are finely characterized and evident in the dynamic assessment test in the same amount of time as the Static Assessment Test, exhibiting its efficiency.

a Velocity comparison of normal subjects, b velocity comparison of Parkinson’s subjects, c comparison of static and dynamic spiral drawing
4.3 Evaluation metrics
First, ML models are used to identify Parkinson’s subjects and normal subjects for test purposes. Later, a combined feature extraction and prediction model pipeline (of RBM and MLP) is applied on both the drawing tests together. Since the dataset is highly imbalanced, the model’s performance is checked using parameters like accuracy, precision, recall, Matthews Correlation Coefficient (MCC), ROC graph, and area under the ROC Curve (AUC).
Precision is a statistical metric that measures how many optimistic results were accurate. It is determined by dividing the cumulative count of true positives and false positives by the number of true positives.
where, TP is the True Positives; FP is the False Positives.
Recall is a statistical metric that measures how many accurate optimistic predictions from all possible positive predictions. Among all conceivable optimistic forecasts, the recall statistic counts the number of correctly predicted positive outcomes that were accurate. True positives and false negatives are counted and divided by the total value of true positives (e.g., it is the true positive rate).
where, FN is the False Negatives.
Accuracy may be defined as the proportional ratio of the correctly classified samples.
where, TN is the True Negatives; FP = False Positives.
F1-score is the harmonic average of statistical measures of Precision and Recall, and it provides a more accurate estimate of wrongly graded cases than the Accuracy Metric.
A precision-recall curve (PR-Curve) is a graphical analysis of the Precision and Recall (on y-axis and x-axis, respectively) for various probability thresholds. A horizontal line on the plot representing a no-skill classifier would have a precision proportional to the number of positive examples in the dataset. It would be 0.5 for a balanced dataset. The PR-Curve is an effective diagnostic for imbalanced binary classification models since it focuses on the minority class. MCC is a statistical metric that signifies a high score only if the predictions have achieved good results (true positives, false negatives, true negatives, and false positives), proportional to the dataset's positive and negative components size. This is specifically suited for binary classification problems (Chicco 2020).
ROC-AUC score is discussed here. AUC is a measure of separability, while ROC is a probability curve. This curve addresses how well the model can differentiate between different groups of people. The model is better at predicting 0 classes like 0 and 1 classes as 1 when the AUC is higher. For example, the more accurate the model is in determining whether a patient has or does not have an illness, the higher the AUC. A good model has an AUC close to 1, which indicates a high degree of separation. AUC is close to zero for a lousy model, which indicates that it has the poorest capacity to separate. It indicates that the outcome is being mirrored in reality. It predicts 0 s as 1 s and 1 s as 0 s. There is no class separation capability when AUC is 0.5, suggesting that the model is inadequate. ROC-AUC graphs for static and dynamic implementing LR and SVM classifier are shown in Figs. 6a, b and 7a, b, respectively. False positives have a larger x-axis value than true negatives on a ROC curve. However, the higher the y-axis value is, the greater the frequency of true positives. As a result, the ability to balance false positives and false negatives in determining the threshold value. The analysis through these AUC graphs confirms that SVM has more significant performance potential than LR for similar multivariate problems. Consequently, the positive class in the sample was better classified using SVM.

ROC: a LR, b SVM

ROC: a LR, b SVM
4.3.1 Static drawings
Performing LR and SVM in the set with (40% split for test data), given below are the AUC graphs.
4.3.2 Dynamic drawings
Performing LR and SVM on Dynamic drawings dataset, where we split 40% of the data for testing, given below are the AUC graphs. Sensitivity and specificity are high and low at point A. This signifies that all positive class points have been properly categorized, while all negative class points have been wrongly classified. True positive rate is equal to the false positive rate at any position along the blue line. A positive classification error rate is less than or equal to a negative classification error rate, and hence any points above this line represent a positive classification error rate. Point B has a greater specificity while having the same sensitivity as point A. In other words, the amount of class points wrongly assigned to the negative category is smaller than it was before. This suggests that the new threshold is superior to the old one. For the identical specificity between C and D, the Sensitivity at C is greater than at D. The classifier predicted a larger number of positive class points for the same number of erroneously categorized negative class points. As a result, point C's cut-off is preferable to point D's. Point E is the point at which specificity peaks. This means that the model has not detected any False Positives. The model can appropriately classify all the negative class points.
4.4 RBM and MLP pipeline
In Table 3, a comparison of LR, SVM is analyzed for static and dynamic data separately. A fusion of RBM and MLP for a combined static and dynamic drawing dataset is analyzed. Although the accuracy of the fusion of RBM and MLP is not entirely sufficient on its own, given the imbalanced status of the dataset, it proves to be a promising candidate for a multivariate characterized problem because of its stochastic processing nature. It is to be noted that in the case of imbalanced binary classification problems, like this case, one or two evaluation metrics like recall or F1-score may provide misleading outcomes. It is necessary to record other reliable statistical measures like MCC, AUC, or PR-Curve. This way, the model can be further used by more exemplary parameter tuning as a relevant representation. A fusion of RBM with MLP gives an accuracy of 95.32%, and the ROC curve is shown in Fig. 8 for a combined static and dynamic spiral drawings dataset.

ROC for a fusion of RBM and MLP
Combined handwriting and Archimedean spiral evaluations using ML classifiers like Random Forests, SVM, and K-Nearest Neighbors considering kinematic and pressure-based factors produced an accuracy of 76.5% (Rios-Urrego et al. 2019). SVM and Random Forests with kinematic feature sets were 80.64% and 86.92% accurate, respectively (Lamba et al. 2021). These comparable results suggest fine-tuned ML and deep learning models with a better chance of preventing bias when predicting results with higher accuracy from sparse datasets (Pereira et al. 2018). Although the results provided are on par with the literature, the model's low computing cost, simplicity, and flexibility in training make it unique and comparable for analysis and prediction, even with limitations such as an imbalanced dataset.
4.5 Limitations of the study
In RBM, training is more challenging since the energy gradient function is harder to compute and implement considering the complexities of various time-series datasets. RBMs employ the CD-k method, which is less well-known than backpropagation. The adjustment of weights is difficult compared to other algorithms. Moreover, it has been observed that while RBMs with a more significant number of hidden layers allow for faster convergence during learning, this does not invariably translate into superior performance on the test set in all cases. As a result, the demanding affirmative approach for developing an RBM model that can extract and classify various versions of time-series-based spiral tests is still underway. Further study is required on deep learning algorithms that have been identified for improved accuracy. PD specialists might benefit from using measures other than specificity and sensitivity in their diagnosis.
5 Conclusions
Using spiral drawings, the work focuses on identifying the Parkinson’s subject from the normal subject. Considering spatio-temporal factors, identifying the elements that contribute most disruption in motor symptoms in Parkinson’s patients was examined using Pearson’s correlation coefficient rank. The time-series dataset of 62 PD patients and 15 healthy people was analyzed using two assessment tests. The efficiency of both the tests for scientifically and quantitatively examining PD patients’ and healthy cohorts' motor skills was documented. Two ML algorithms—LR and SVM classifier are used to measure and analyze the two tests, static and dynamic spiral drawings. The significant findings are provided as follows.
-
For the combined static and dynamic drawings assessment, a novel method using a neural network pipeline of RBM with MLP layer was applied, which achieved an accuracy of 95.32%.
-
By increasing the instances in a similar imbalanced dataset, the accuracy can be increased even further. The above time-series dataset could be fed into deep recurrent neural networks for better potential diagnosis.
-
In the later stages of PD, handwriting assessments become formidably challenging to reproduce because of different old age factors. Spiral Tests can objectively play the role of a straightforward and non-invasive technique for procedural examinations.
Further, the efficiency of deep learning methods can be leveraged for supervised diagnosis and tracking the progress of PD. The study reveals how spiral tests and accurate assessments can result in even more widespread usage in clinical trials. Rather than concatenating resources, it is essential to analyze epistemological approaches for creating hierarchical representations. Conclusively, deep learning-assisted PD diagnosis brings hope and promise to improve clinical decision-making by developing new biomarkers to detect PD early in the disease course.
Data availability
The dataset is acquired for access from the publicly available UCI ML Repository https://archive.ics.uci.edu/ml/datasets/Parkinson+Disease+Spiral+Drawings+Using+Digitized+Graphics+Tablet#
References
Afonso LCS, Rosa GH, Pereira CR, Weber SAT, Hook C, Albuquerque VHC, Papa JP (2019) A Recurrence plot-based approach for Parkinson’s disease identification. Future Gener Comput Syst 94:282–292. https://doi.org/10.1016/j.future.2018.11.054
Alissa M, Lones MA, Cosgrove J, Alty JE, Jamieson S, Smith SL, Vallejo M (2021) Parkinson’s disease diagnosis using convolutional neural networks and figure-copying tasks. Neural Comput Appl. https://doi.org/10.1007/s00521-021-06469-7
Barui S, Latha S, Sammiappan D, Muthu P (2018) SVM pixel classification on colour image segmentation. J Phys: Conf Ser 1000:012110. https://doi.org/10.1088/1742-6596/1000/1/012110
Cantürk I (2021) Fuzzy recurrence plot-based analysis of dynamic and static spiral tests of Parkinson’s disease patients. Neural Comput Appl 33:349–360. https://doi.org/10.1007/s00521-020-05014-2
Chandra J, Siva M, Zisheng S, Richard D, Raymond L, Irina T, Dignity B, Daniel S, Sammer M, Soham B, Alexander C, Anushka B, Sreekar M, Daniel ZP (2021) Screening of Parkinson’s disease using geometric features extracted from spiral drawings. Brain Sci 11(10):1297. https://doi.org/10.3390/brainsci11101297
Chicco D (2020) Jurman G (2020) The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom 21:6. https://doi.org/10.1186/s12864-019-6413-7
Chou C, Chou S, Chen YC, Yang CJ (2020) Using machine learning methods to detect physical conditions with postural balance. J Ambient Intell Human Comput. https://doi.org/10.1007/s12652-020-02261-y
Danna J, Velay JL, Eusebio A, Delor LV, Witjas T, Azulay JP, Pinto S (2019) Digitalized spiral drawing in Parkinson’s disease: a tool for evaluating beyond the written trace. Hum Mov Sci 65:S0167-9457. https://doi.org/10.1016/j.humov.2018.08.003
de Souza RWR, Silva DS, Passos LA, Roder M, Santana MC, Pinheiro PR, de Albuquerque VHC (2021) Computer-assisted Parkinsons disease diagnosis using fuzzy optimum-path forest and restricted boltzmann machines. Comput Biol Med. https://doi.org/10.1016/j.compbiomed.2021.104260
Dhanalakshmi S, Chakrapani V (2016) Classification of carotid artery abnormalities in ultrasound images using an artificial neural classifier. Int Arab J Inf Technol 13(6A):756–762
Drotár P, Mekyska J, Rektorova I, Masarova L, Smekal Z, Zanduy MF (2014) Analysis of in-air movement in handwriting: a novel marker for Parkinson’s disease. Comput Methods Programs Biomed 117(3):405–411. https://doi.org/10.1016/j.cmpb.2014.08.007
Drotár P, Mekyska J, Masarova L, Smekal Z, Zanduy MF (2016) Evaluation of handwriting kinematics and pressure for differential diagnosis of Parkinson’s disease. Artif Intell Med 67:39–46. https://doi.org/10.1016/j.artmed.2016.01.004
Eskidere Ö, Hanilcia C (2012) A comparison of regression methods for remote tracking of Parkinson’s disease progression. Expert Syst Appl 39(5):5523–5528. https://doi.org/10.1016/j.eswa.2011.11.067
Gallicchio C, Micheli A, Pedrelli L (2018) Deep echo state networks for diagnosis of parkinson's disease. In: Paper presented at the ESANN 2018—Proceedings, European Symposium on artificial neural networks, computational intelligence and machine learning, pp 397–402. ISBN 978-287587047-6
Goetz CG, Tilley BC, Shaftman SR, Stebbins GT, Fahn S et al (2008) Movement disorder society-sponsored revision of the unified Parkinson’s disease rating scale (MDS-UPDRS): scale presentation and clinometric testing results. Mov Disord 23(15):2129–2170. https://doi.org/10.1002/mds.22340
Impedovo D (2019) Velocity-based signal features for the assessment of parkinsonian handwriting. IEEE Signal Process Lett 26(4):632–636. https://doi.org/10.1109/LSP.2019.2902936
Impedovo D, Pirlo G (2018) Dynamic handwriting analysis for the assessment of neurodegenerative diseases: a pattern recognition perspective. IEEE Rev Biomed Eng 12:209–220. https://doi.org/10.1109/RBME.2018.2840679
Impedovo D, Pirlo G, Vessio G (2018) Dynamic handwriting analysis for supporting earlier Parkinson’s disease diagnosis. Information 9(7):247. https://doi.org/10.3390/info9100247
Isenkul ME, Sarkar BE (2014) Improved spiral test using digitized graphics tablet for monitoring Parkinson's disease. In: The 2nd International Conference on e-Health and Telemedicine (ICEHTM-2014), pp 171–175. https://doi.org/10.13140/RG.2.1.1898.6005
Johnson SJ, Diener MD, Kaltenboeck A, Birnbaum HG, Sidserowf AD (2013) An economic model of Parkinson’s disease: implications for slowing progression in the United States. Mov Disord 28(3):319–326. https://doi.org/10.1002/mds.25328
Júnior EP, Dermiro ILD, Magaia N, Maia FM, Hassan MM, Albuquerque VHC, Fornitino G (2020) intelligent sensory pen for aiding in the diagnosis of Parkinson’s disease from dynamic handwriting analysis. Sensors 20:5840. https://doi.org/10.3390/s20205840
Kamble M, Srivastava P, Jain M (2021) Digitized spiral drawing classification for Parkinson’s disease diagnosis. Meas Sens 16:147. https://doi.org/10.1016/j.measen.2021.100047
Kuresan H, Samiappan D, Masunda S (2019) Fusion of WPT and MFCC feature extraction in Parkinson’s disease diagnosis. Technol Health Care. https://doi.org/10.3233/THC-181306
Kuresan H, Samiappan D, Ghosh S, Gupta AS (2021) Early diagnosis of Parkinson’s disease based on non-motor symptoms: a descriptive and factor analysis. J Ambient Intell Human Comput. https://doi.org/10.1007/s12652-021-02944-0
Lamba R, Gulati T, Al-Dhlan KA, Jain A (2021) A systematic approach to diagnose Parkinson’s disease through kinematic features extracted from handwritten drawings. J Reliab Intell Environ 7:253–262. https://doi.org/10.1007/s40860-021-00130-9
Memedi M, Sadiko A, Grosnik V, ZabkarJ MM, Bergquist F, Johansson A, Haubenberger D, Nyholm D (2015) Automatic spiral analysis for objective assessment of motor symptoms in Parkinson’s disease. Sensors 15(9):23727–23744. https://doi.org/10.3390/s150923727
Miralles F, Torangi S, Espino A (2006) Quantification of the drawing of an Archimedes spiral through the analysis of its digitized picture. J Neurosci Methods 152:18–31. https://doi.org/10.1016/j.jneumeth.2005.08.007
Monika R, Dhanalakshmi S, Sreejith S (2018) Coefficient random permutation based compressed sensing for medical image compression. Lecture Notes Electric Eng 443:529–536. https://doi.org/10.1007/978-981-10-4765-7_56
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B et al (2011) Scikit-learn: machine learning in python. J Mach Learn Res 12(85):2825–2830
Pereira CR, Pereira DR, Rosa GH, Albuquerque VHC, Weber SAT, Hook C, Papa JP (2018) Handwritten dynamics assessment through convolutional neural networks: an application to Parkinson’s disease identification. Artif Intell Med 87:67–77. https://doi.org/10.1016/j.artmed.2018.04.001
Pfeiffer RF, Wszolek ZK, Ebadi M (2004) Parkinson’s disease, 1st edn. CRC Press. https://doi.org/10.1201/9780203508596
Pullman MPH, Stanley BSK, Floyd BAA (2008) Validity of spiral analysis in Early Parkinson’s disease. Mov Disord 23(4):531–537. https://doi.org/10.1002/mds.21874
Radmard S, Ortega RA, Ford B, Arroyave NV, Makhann GM, Sheth SA, Winfeild L, Luciano MS, Pullman RS (2021) Using computerized spiral analysis to evaluate deep brain stimulation outcomes in Parkinson disease. Clin Neurol Neurosurg 208:106878. https://doi.org/10.1016/j.clineuro.2021.106878
Rastgoo R, Kiani K, Escalera S (2021) Real-time isolated hand sign language recognition using deep networks and SVD. J Ambient Intell Humaniz Comput. https://doi.org/10.1007/s12652-021-02920-8
Rios-Urrego CD, Vásquez-Correa JC, Vargas-Bonilla JF, Nöth E, Lopera F, Orozco-Arroyave JR (2019) Analysis and evaluation of handwriting in patients with parkinson’s disease using kinematic, geometrical, and non-linear features. Comput Methods Programs Biomed 173(2019):43–52. https://doi.org/10.1016/j.cmpb.2019.03.005
Sakar BE, Isenkul ME, Sarkar CO, Sertbas A, Gurgen F, Delil S, Apaydin H, Kursun O (2013) Collection and analysis of a parkinson speech dataset with multiple types of sound recordings. IEEE J Biomedical Health Inform 17(4):828–834. https://doi.org/10.1109/JBHI.2013.2245674
Schrag A, Shlomo YB, Quinn N (2002) How valid is the clinical diagnosis of Parkinson’s disease in the community? J Neurol Neurosurg Psychiatry 73(5):529–534. https://doi.org/10.1136/jnnp.73.5.529
Zham P, Arjunan SP, Raghav S, Kumar DK (2018) Efficacy of guided spiral drawing in the classification of Parkinson’s disease. IEEE J Biomed Health Inf 22(5):1648–1652. https://doi.org/10.1109/JBHI.2017.2762008
Acknowledgements
The authors are grateful to SRM Institute of Science and Technology, Kattankulathur, Chennai, India, for providing the required research facilities.
Funding
No funding was received for this research work.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare no conflicts of interest.
Ethical approval
Ethical clearance is obtained from SRM Medical College Hospital and Research Center, India. Ethics Clearance Number: 1739/IEC/2019.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Thakur, M., Dhanalakshmi, S., Kuresan, H. et al. Automated restricted Boltzmann machine classifier for early diagnosis of Parkinson’s disease using digitized spiral drawings. J Ambient Intell Human Comput 14, 175–189 (2023). https://doi.org/10.1007/s12652-022-04361-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12652-022-04361-3