
Abstract
This study aimed to model the height of trees and volumetric production of eucalypts trees on the agrosilvopastoral systems (AGP) of Zona da Mata Mineira region, Brazil, using artificial neural network (ANN) and regression models to determine the best alternative. The data was obtained from five systems with different spatial arrangements (8 × 3 m, 10 × 3 m, 11 × 3 m, 12 × 3 m, 12 × 2 m, and 12 × 4 m), ages (5.5, 6.5 and 8 years) and genotypes, of which 122 sample trees were scaled. Hypsometric and volumetric models were adjusted considering no stratification or stratification by the AGP, spatial arrangement, and genotype. A multilayer perceptron ANN was trained using resilient propagation and skip layer training algorithms. The stratification variables used in the regression were used in the ANN as categorical variables. To estimate height of trees were used as continuous variables: diameter at breast height (dbh), dominant height (Dh), and age. To estimate volume were used as continuous variables: dbh, total height, and age. The AGPs’s mean annual increment at 5.5, 6.5 and 8 years of age ranged from 21 to 62 m3 ha−1 year−1. ANN was proven to be an efficient methodology for hypsometric and volumetric estimates of eucalypt in AGP in the study region.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Zona da Mata is located in Minas Gerais, a southeastern region of Brazil, and is predominantly characterized by small rural properties with large conventional livestock activity. However, most of this region is degraded because of intensive use and inadequate soil management (Vale et al. 2004; Souza et al. 2012; de Freitas et al. 2013; Pereira et al. 2018). An alternative for recovering these areas can be the implantation of agrosilvopastoral systems (AGP) or silvopastoral systems (SPS) (Dube et al. 2002; Lacerda et al. 2013; Lana et al. 2018). These systems are characterized by the integration of agriculture, forestry, and animal husbandry at the same place, under a specific spatial and temporal arrangement, enabling ecological and economic interactions between components (Nair 1993).
AGP and SPS have desirable economic and environmental value, and are capable of promoting greater land use efficiency, production diversification, soil conservation, water and biodiversity conservation, and thermal comfort of animals (Magalhães et al. 2007; Ferreiro-Domínguez et al. 2011; Bishaw et al. 2013; Bisseleua et al. 2013; Lemaire et al. 2014; Cordeiro et al. 2018; de Oliveira et al. 2018).
In Brazil, the use of eucalypt species as a tree component in agroforestry systems (AFS) is frequent because of its rapid growth, good adaptation to edaphic and climatic conditions, genetic improvement, and the knowledge about its management (Oliveira Neto et al. 2007; Torres et al. 2016). According to da Silva et al. (2016), this is the most productive genus in terms of even-age forests in Brazil with an average productivity of 36.0 m3 ha−1 year−1 (IBÁ 2019), and has become an economically attractive alternative for smallholders seeking to increase their income through timber production without relying solely on long-term income.
The Program of Fortification for Family Farming (PRONAF Floresta) and the ABC Plan (Low Carbon Agriculture) (Plano 2012) have been driving the diffusion and adoption of AFS in Brazil (Stabile et al. 2012; Oliveira et al. 2016). However, there is little information about forest productivity in these systems. Information on growth stocks and timber production is important for economic analyses to help smallholders with their decisions (Scolforo et al. 2019).
The quantification of growth and yield is performed using forest inventories, where estimates of tree height and volume can be obtained using regression models (Burkhart and Tomé 2012), and/or artificial neural networks (ANNs) (Campos and Leite 2013). Several studies have been conducted to estimate total tree height and volume using ANNs (Diamantopoulou et al. 2009; Diamantopoulou and Milios 2010; Soares et al. 2011; Diamantopoulou 2012; Binoti et al. 2013, 2017; Özçelik et al. 2013; Tavares Júnior et al. 2019).
An ANN can be defined as a computational technique composed of several artificial neurons, which are connected in a specific manner and distributed in parallel layers (Haykin 2009). The dissemination of this technique in the forestry field is associated with some advantages, such as the ability to model nonlinear relationships, the possibility of simultaneously inserting categorical variables, neurobiological analogy, and tolerance to noisy data (Haykin 2001; Che et al. 2018; Tavares Júnior et al. 2019).
Such characteristics can facilitate the modeling of growth and forest yield in AFS. As they are complex and heterogeneous systems whose components are subject to the interactions of several factors (Nair 1993; Brüning et al. 2018), modeling the tree component using regression models can be a complicated task (Binoti et al. 2017), since it requires compliance with statistical premises (Che et al. 2018).
However, a number of studies on ANNs have been carried out with eucalypts monocultures, and most studies on AFS with this species still use regression (Fontan et al. 2011; Müller et al. 2014; Barbosa et al. 2019). Thus, owing to the differences in productive capacity, spatial arrangement, and cultural treatment of AGP, it is important to focus on the prediction of tree height and volume in these systems. The objective of this study is to find the best alternative for estimating tree height and volumetric production of eucalypts trees in AGP using ANN and regression models in four municipalities of Zona da Mata, Minas Gerais.
Materials and methods
Study area characterization
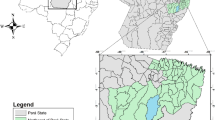
The mesoregion of Zona da Mata (Fig. 1) has a Cwb-type climate, with annual temperature and precipitation averages being approximately 18 °C and 1500 mm, respectively. The topography is characterized by a mountainous terrain with a predominance of deep and drained oxisols, along with high acidity and low natural fertility (Cardoso et al. 2001). Land use in the Zona da Mata region can be characterized by perennial and annual crops and pastures. The pastures occupy approximately 1.2 million hectares in the region under different management conditions (Hott et al. 2016).

Localization of AGP used in the study
The data was collected from five AGPs located in Zona da Mata mineira region (Fig. 1), implanted in no-tillage systems in areas with degraded pastures. The systems were composed of corn (Zea mays) and (Phaseolus vulgaris) in the first year, followed by Brachiaria grass (Urocloa spp.) and the animal component (Bos taurus) inserted after the establishment of an arboreal component (Eucalyptus urophylla × Eucalyptus grandis, Eucalyptus saligna, and Eucalyptus grandis). For all cultures, implantation and maintenance fertilization based on chemical analyses of soil samples and technical fertilization recommendations were performed. Table 1 presents the descriptions of AGPs.
Data
In AGPs 1 and 2, the diameter and height of all trees were measured (202 and 383, respectively). In the other AGPs, 3 plots of 24 trees were installed for each genotype in the study area. In these plots, the diameters at breast height (cm) (dbh) of all trees and the total height of the first eight trees classified as normal (free from any type of defect and not bifurcated) were measured. The dominant height (Dh) was measured according to Assmann (1970), which is equivalent to the average height of the 100 largest trees in dbh per hectare.
A total of 122 trees were scaled to estimate the volume, using a selective sampling of 3 trees per diametric class, with an amplitude of 2 cm in each class. Measurements of bark diameters were made at heights of 0.1, 0.3, 0.7, 1.0, and 1.3 m, to the height where the bark diameter was approximately 7 cm. In areas where this destructive method could not be used, the trees were scaled standing upright using a Wheeler pentaprism (Campos and Leite 2013). In all cases, scaling was performed using the Smalian formula (Avery and Burkhart 2002). The total number of trees scaled in each area was as follows: 35 (AGP 1), 18 (AGP 2), 50 (AGP 3), 20 (AGP 4), and 16 (AGP 5).
Regression modeling
The data from forest inventory and trees scaled were used to fit the hypsometric and volumetric models.
First, the total height was estimated using the model proposed by Campos et al. (1984) (1), with the dominant height (Dh) based on the average of the tree heights of the three dominant diameters in each plot, or in each planting line in the case of a census, according to Assmann (1970). Then, the model proposed by (Schumacher and Hall 1933) was used for volumetric estimation (2).
where the variables are volume V (m3), tree height H (m), dominant height Dh (m), diameter at 1.30 m height dbh (cm) and \( Ln \) is the neperian logarithm. The parameters of the models are \( \alpha \), \( \beta \) \( \gamma \) and ε a random error such that ε ~ NID (0, σ2).
The model parameters were estimated by the ordinary least squares method using the Gauss–Newton algorithm implemented in “stats” package in R environment (Team 2013). An identity test (Graybill 1976) was applied to evaluate the need for using stratum-specific equations (AGP, spatial arrangement, and genotype). The evaluated hypothesis is as follows:
where k, l, and j indicate AGP, spatial arrangement, and genotype, respectively, and k ≠ k´, l ≠ l´ e j ≠ j´.
At a significance level of 5% with n − 2 degrees of freedom, the F-statistic tests the hypothesis H0: β = [0,1]. If F (H0) < F α (2, n − 2 gl), the hypothesis is not rejected, assuming identical data.
Artificial neural networks
The data from forest inventory and scaled sample tree were also used to train the ANN. The total height and tree volume were estimated using a multilayer perceptron (MLP) ANN. This type of ANN was used as it can universally approximate functions, besides being widely used in modeling the height and volume of eucalypts trees (Binoti et al. 2013; Tavares Júnior et al. 2019). The ANN was trained with different architectures, and using resilient propagation with basic variation RPROD + (Riedmiller and Braun 1993) and skip layer training algorithms. The number of neurons in the hidden layer ranged from 3 to 15, since an excess of neurons in a hidden layer can promote overfitting (Haykin 2001). The tested types of activation functions of the hidden and output layers were logistic, identity, sigmoid, exponential, hyperbolic tangent, and softmax. Thus, all activation functions in the Neuroforest® 4.0 software (Binoti 2012) were tested.
For estimating the total height, we used dbh, dominant height (Dh), and age as continuous variables. For estimating the trees volume, we used dbh, total height, and age as continuous variables. Spatial arrangement, AGP, and genotype were used as categorical input variables to generate estimates of total height and volume of trees. Spatial arrangement, AGP, and genotype were used as categorical input variables to generate estimates of total height and volume of trees. Categorical variables were encoded using binary variable vectors for the artificial neuron calculation to proceed. Continuous variables were normalized linearly at intervals from 0 to 1 using the following transformation (Binoti 2012):
where: x standard is a standardized value; x max and x min are the minimum and maximum values of the variable, respectively; a is the lower limit of standardization (0); and b is the upper limit of standardization.
For the ANN training process, the data obtained from forest inventory and trees scaled were split into two sets, with 70% of data used for ANN training and the remaining 30% for validation, as suggested in some forest modeling studies involving ANN (Binoti et al. 2015; Lacerda et al. 2017). The data for each set was chosen randomly by the software used. To exclude the results because of initial weights, the training was performed five times for each configuration and topology, out of which one was selected based on the statistics and analysis described in Sect. 2.5.
The ANN training was performed using the stopping criteria of 3000 cycles or an average squared error of 0.0001, as suggested by Leal et al. (2015) and Araújo et al. (2016). Thus, ANN training was completed when one of these criteria was satisfied. According to Braga et al. (2000), these stopping criteria are among the most used to determine the moment of ANN training completion.
Method evaluation
The accuracy of the tested methods was based on the root square root mean error (\( RMSE_{\% } \)) (4), correlation between observed and estimated (regression) (\( r_{{y\hat{y}}} \)) (5), and Bias (6). In addition, frequency graphs of percentage relative errors (ER%) and frequency histograms of these errors (7) were also analyzed:
where n denotes number of observations; \( \hat{Y}_{i} \) denotes estimated values; \( Y_{i} \) denotes observed values; and \( Y_m \)—is the average of estimated values.
A summary of the methodology followed in the study is presented in Fig. 2.

Summary of the methodology followed in the study
Results
Regression
No significant difference (p > 0.05) between the general equation adjustment and the stratified equation by AGP to estimate total height was found through the identity test, so the general hypsometric model was adjusted. The \( RMSE_{\% } \) and \( r_{{y\hat{y}}} \) values of the general hypsometric model were 9.06% and 0.8884, respectively (Table 2). For the volumetric models, no significant difference was observed (p > 0.05) between the adjustment of a general or stratified AGP equation. However, owing to the bias presented by the estimates of the general volumetric model, we decided to use specific models for each AGP.
In identity tests for AGPs 1 and 3, no significant difference was observed between the adjustment of a general volumetric equation and specific equations by spatial arrangement and genotype for the respective AGPs. Therefore, a general volumetric equation was defined for these two areas and specific equations for the others. Table 2 presents the \( RMSE_{\% } \) (6.11–11.96%), Bias (− 0.001 to 0.003), and \( r_{{y\hat{y}}} \) (0.9149–0.9881) statistics for the specific equations, respectively.
Figures 3 and 4 show the plots of relative errors from the height and volume estimates obtained using the equations in Table 2. The frequency distribution of the relative errors in the general hypsometric equation tended to be normal, with 98% frequency of errors concentrated in the error class ± 20% (Fig. 2). Specific volumetric equations also resulted in this tendency, where the frequency of errors ranged from approximately 94–100% in the ± 20% error classes (Fig. 3). Thus, the global hypsometric model and the specific volumetric model by AGP are indicated for eucalypts stands in AGP in the Zona da Mata region of Minas Gerais.

Percentage of cases by relative error class percentage of total height estimates generated by the general hypsometric equation for all AGPs

Percentage of cases by relative error class percentage of volume estimates generated by AGP-specific volumetric equations: a 1, b 2, c 3, d 4, and e 5
Artificial neural networks
Table 3 presents the configuration and statistics of the best selected ANN to estimate the total height and volume for each tested training algorithm. The results of the ANN weights are available as supplementary material.
The ANNs were accurate for both training algorithms. For training data to predict heights, the resilient propagation algorithm (\( RMSE_{\% } \) = 5.32, \( r_{{y\hat{y}}} \) = 0.9545, and Bias = 0.085) was slightly better than the skip layer (\( RMSE_{\% } \) = 5.61, \( r_{{y\hat{y}}} \) = 0.9524, and Bias = 0.082). However, for validation, the statistics were less accurate (\( RMSE_{\% } \) = 10.16, \( r_{{y\hat{y}}} \) = 0.8994, and Bias = 0.098) when using resilient propagation, indicating that the skip layer is better for generalization (\( RMSE_{\% } \) = 8.74, \( r_{{y\hat{y}}} \) = 0.9265 e Bias = 0.096). The same is true for predicting volume, where the skip layer was more accurate in training (\( RMSE_{\% } \) = 7.11, \( r_{{y\hat{y}}} \) = 0.9917, and Bias = 0.0027) and validation (\( RMSE_{\% } \) = 9.11, \( r_{{y\hat{y}}} \) = 0.9847, and Bias = 0.0052) than resilient propagation.
When comparing the results of predicting total height and volume between regression and ANN, it was found that both presented \( r_{{y\hat{y}}} \) values close to 1, and relatively low \( RMSE_{\% } \) and Bias (Table 2). However, despite the satisfactory performance shown by both approaches, the results generated by ANN in some cases were slightly higher. These results are reinforced by the relative error graphs plotted for the total height (Fig. 5) and volume (Fig. 6) estimates, referring to the training and validation data, through the tested training algorithms.

Percentage of cases per relative error class percentage of total height estimates generated by ANN using resilient propagation (a, b) and skip layer (c, d) algorithms, for training (a, c) and validation (b, d) data

Percentage of cases by relative error class percentage of volume estimates generated by ANN using resilient propagation (a, b) and skip layer (c, d) algorithms, for training (a, c) and validation (b, d) data
According to Figs. 5 and 6, the relative errors were normally distributed. This behavior of the training data was similar between the two algorithms. For total height, it was found that while the resilient propagation resulted in the highest frequency of errors (38%) concentrated in the 0% error class during validation, the skip layer was more efficient, concentrating 100% of error frequency between error classes from − 20 to 15%, while resilient propagation resulted in 96% of errors being concentrated within ± 20% error classes during validation.
For estimating volume, it was observed that the skip layer performed better for training and validation data. While resilient propagation originated at 90% of the frequency of errors concentrated in the ± 20% classes, the skip layer resulted in 97% of the frequency of errors concentrated in the same class range.
Figures 7 and 8 present the results regarding the estimates of total height and volume by dominant height class, obtained by regression and ANN applied to the AGP inventory data. Although the performance of regression models was better than that of the ANN, the ANN was able to follow the same trend as those obtained by the regression when the deviations were small and within an acceptable error range.

Plots of the hypsometric relationship by classes (low, medium, and high) of dominant height, with x-axis represented by dbh and y-axis by total estimated height by regression (curves), and predicted by ANN (points) for AGPs: a 1, b 2, c 3, d 4, and e 5

Plots of estimated volume (z axis; m3) by dbh (x-axis; cm) and height (y-axis; m) by dominant height classes (low, medium and high) for the AGPs: a 1, b 2, c 3, d 4, and e 5. Red dots represent estimates by regression, and black dots represent estimates by ANN
Although the volumetric equations were superior, we decided to use ANN to estimate the volume of eucalypts trees in AGP because of its simplified procedures. As follows, owing to the lack of information on AGP productivity in the Zona da Mata region of Minas Gerais, we estimated the volume per hectare and the mean annual increment (MAI) from the recommended methodology, which are presented in Table 4.
AGP 2 presented an MAI from 62 m3 ha−1 year−1 at 8 years, being the most productive system. The other AGP at this age (8 years) presented an MAI of 25.17 m3 ha−1 year−1 (1) and 23.10 m3 ha−1 year−1 (4). The latter was the least productive AGP among the studied systems. The AGP 3 showed an MAI of 23.85 m3 ha−1 year at 5.5 years, while the AGP 5 resulted in an MAI of 24.87 at 6.5 years.
Discussion
Advantages of modeling approaches
The use of regression models and ANNs can be valuable for forest management in AFS since they can support planning and decision making by smallholders (Campos and Leite 2013; Scolforo et al. 2019). Knowledge about the dynamics of growth and yield of the tree component can help in choosing an AFS design, for example, the spatial arrangement in which the implemented tree component and agricultural culture depends on the purpose (Paula et al. 2013; Barbosa et al. 2019).
Modeling using these tools also makes it possible to determine the best time for carrying out cultural tracts, such as pruning or thinning. These silvicultural treatments, in turn, are carried out to reduce competition between system components, and favor the growth and quality of wood in the tree component (Fontan et al. 2011; Tonini et al. 2019). This type of information is also essential for the management of pasture and agricultural crops since their productivity is associated with the penetration of solar radiation into the system (Paula et al. 2013; Peri et al. 2016). Additionally, diametric distribution modeling is a good strategy for carrying out the interventions mentioned above, as it obtains a higher level of detail of forest stands, thus corroborating a more efficient management of AFS (Binoti et al. 2012; Diamantopoulou et al. 2015). In addition, studies on the shape of a tree stem using these methods provide information on the prediction of wood assortment (Souza et al. 2018; Socha et al. 2020). Wood from AFS can provide greater profitability to smallholders when destined for multi-products, such as sawn wood, energy wood, poles, and firewood (Silveira et al. 2011; Barbosa et al. 2019).
Based on data from continuous forest inventories, it is possible to project growth and yield in the future (Salles et al. 2012; Binoti et al. 2015) and thus, define the technical harvesting or thinning age (Villanova et al. 2018), the financial return from wood (Somarriba et al. 2014; Salles et al. 2019), and its productive potential (Dolácio et al. 2020). In addition, these tools also play an important role in the fulfillment of ecosystem services, as it is possible to predict the carbon and biomass stock (Santi et al. 2017; Zianis et al. 2019), since the arboreal component of AFS has a greater potential for carbon storage (Kay et al. 2019).
Comparison of modeling approaches
In the present study, it was found that the general hypsometric model proposed by Campos et al. (1984) can be used for all AGPs without loss of accuracy. According to Özçelik et al. (2018), models that use variables such as local index, dominant height, and age can often present more accurate estimates than others.
When total height was estimated by ANN, similar results were observed between resilient propagation and skip layer training algorithms. Campos et al. (2016) reported the good performance of resilient propagation in estimating total height in commercial eucalypt stands. In the present study, the skip layer showed a greater accuracy in data validation and a higher sensitivity to noise data, because of a highly heterogeneous system with a wide spatial arrangement (Soares et al. 2017).When comparing the results obtained by ANN using the skip layer algorithm with those obtained by regression, a greater accuracy and normal distribution of errors were observed in the estimates of total height; however, these differences were negligible.
Özçelik et al. (2013) estimated the height of monocultures from Crimean Juniper in Turkey using ANN and nonlinear regression models, and reported them as useful approaches. Despite the good accuracy of regression, the authors reinforce the greater practical applicability of ANN, as they require fewer samples in the field. Binoti et al. (2013) also obtained the same conclusion when estimating the total height of eucalypt monocultures using these methods. These results may indicate interesting possibilities in forest inventories with low data availability and/or financial constraints, commonly observed in the small rural properties of Zona da Mata.
For volumetric models, the model proposed by Schumacher and Hall (1933) presented better performance with greater estimation accuracy, when stratified by AGP. According to Campos and Leite (2013), this model has been widely used in forestry because of its adjustment feature and lower bias. Based on specific equations, it was proven that for the 1 and 3 AGPs, there is no difference between the global volumetric model stratified by spatial arrangement and genotype. These results demonstrate that spatial arrangement and genotype cannot influence the stem shape. However, studies indicate that a spatial planting arrangement can directly affect individual tree volume because of a higher radial growth in low-density planting (Leite et al. 2006; Alcorn et al. 2007; Liziniewicz et al. 2012; Lin et al. 2013; Ferreira et al. 2017).
When estimating the individual volume by ANN, the skip layer was found to be slightly superior in data validation and noise tolerance than resilient propagation. According to Bell et al. (2016), the skip layer makes extra connections directly to the ANN output layer. Some authors believe that these extra connections improve training (Srivastava et al. 2015; Huang et al. 2017). This is suggested as contributing to the greater efficiency of skip layer in this study.
When comparing the results of regressions with those from ANN, the error distribution for volume using regressions was higher than that obtained with ANN, but the estimates generated by the ANN were as accurate as the regressions. According to Campos and Leite (2013), the use of ANN can result in cost savings, because the amount of data for network training may be less than that for regression adjustment. Araújo et al. (2016) estimated the volume of uneven-age forest stands in Minas Gerais, Brazil using skip layer, and showed similar and even superior ANN results than regression. These results are interesting for AFS because of heterogeneous stands, lower density of the trees, and a more likely occurrence of noisy data. Variables such as spatial arrangement, genetic material, soil type, and temperature, among others, can be included in a single ANN, a fact that could make modeling through regression more complex (Görgens et al. 2009; Binoti et al. 2014; Rocha et al. 2018).
Considering that the networks were trained with 70% of the data and based on the obtained results, new studies can be conducted to determine the possibility of reducing the database without any loss of accuracy. Such reduction would only make sense on other occasions when cost, measurement time, and the modeling of total height and volume of trees would occur (Tavares Júnior et al. 2019). Binoti et al. (2014) compared the performance of the model proposed by Schumacher and Hall (1933), and also demonstrated the possibility of cost reduction in forest inventory. Even with a restricted database, ANNs are capable of generating more accurate volumetric estimates than regression (Diamantopoulou and Milios 2010). Moreover, in the case of regression, it is necessary to meet statistical assumptions such as normality, homoscedasticity, multicollinearity, and others (Gujarati and Porter 2011), which is not the case with an ANN.
Productivity
The productivity values found in the studied AGPs, and a high value of MAI (62.41 m3 ha−1 year−1) observed in the AGP 2 system at 8 years of age indicate a good adaptation of genetic material associated with adequate silvicultural treatments. According to Fontan et al. (2011), good management and right silvicultural treatments can affect the productivity of eucalypt stands in AFS. Salles et al. (2012) studied an AGP with eucalypt clones in a spatial arrangement of 10 × 4 m in northwestern Minas Gerais, and found an MAI of 24.17 m3 ha−1 year−1 at 8 years of age. This value is lower than that observed for AGP 2 (62.41 m3 ha−1 year−1) and AGP 1 (25.17 m3 ha−1 year−1). Such results can be justified by the differences in productive capacity between sites and adaptation of genetic materials (Ogut et al. 2014; Kim et al. 2015), as well as silvicultural treatments.
The low productivity in the AGP 4 (23.10 m3 ha−1 ano−1 MAI) can be attributed to a high late replanting rate (Trindade et al. 2012; Pereira Filho et al. 2020) and a significant occurrence of bifurcated trees. The MAI values at 5.5 and 6.5 years, observed in AGP 3 (23.85 m3 ha−1 year−1) and AGP 5 (22.21 m3 ha−1 year−1), are lower than those found by Kruschewsky et al. (2007) (MAI of 29.33 m3 ha−1 year−1 at 5.5 years) and Lemos-Junior et al. (2016) (43.32 m3 ha−1 year−1 at the age of 6). Both studies are on eucalypt systems, with the first AGP being in a spatial arrangement 10 × 2 m in the northwest of Minas Gerais, and the second being a silvopastoral system in a 3 × 2 + 14 m spatial arrangement in triple rosin in the southeastern region of Goiás State. These results show the influence of spatial arrangement (Khan and Chaudhry 2007; Zhao et al. 2011) associated with the quality of site (Clutter et al. 1983; van Laar and Akça 2007; Resende et al. 2018) on tree productivity in AFS.
Conclusions
In the present study, we found that MLN-type ANNs, using the skip layer training algorithm, were more efficient in estimating the height and volume of eucalypt trees in AGPs in the Zona Mata region, Minas Gerais, and can be recommended for this purpose. Regression models and ANN are decision support tools widely used in forestry enterprises, and they can also assist small holders in AGP management.
Although the traditional regression models have a good accuracy, the ANNs also presented some advantages that facilitated the modeling of height and volume of trees in AGP. Our study is important, because it allows us to infer that ANN can be used with noisy data, which is common in low-density stands. Thus, the skip layer training algorithm can be recommended for this purpose because of its greater tolerance to this type of data. Furthermore, the addition of categorical variables in ANN facilitates the modeling process, as it allows the inclusion of variables that can influence the growth of the tree component. This fact makes modeling through regression more complex, which in some cases requires the division of the database into strata, and the subsequent execution of statistical tests. From the estimates of the ANN training, the MAI of the studied AGPs was obtained, which ranged from 23.10 to 62 m3 ha−1 year−1 at 8 years of age, 24.87 m3 ha−1 year−1 at 6.5 years of age, and 23.84 m3 ha−1 ano−1 at 5.5 years of age.
Finally, we suggest that future studies involve ANNs to verify the possibility of reducing a database while maintaining the same precision obtained with the classic regression models.
References
Alcorn PJ, Pyttel P, Bauhus J et al (2007) Effects of initial planting density on branch development in 4-year-old plantation grown Eucalypt pilularis and Eucalyptus cloeziana trees. For Ecol Manag 252:41–51
Araújo ACSC, Binoti MLMS, Leite HG, Binoti DHB et al (2016) Artificial Neural Networks with Skip Layer Connections to estimate the volume of forest formations in the state of Minas Gerais. Aust J Basic Appl Sci 10:71–79
Assmann E (1970) The principles of forest yield study. Pergamon Press, Oxford p, p 506
Avery TE, Burkhart HE (2002) Forest measurements, 5th edn. Waveland Press Inc, Long Grove, IL
Barbosa RA, dos Reis GG, Reis MGF et al (2019) Growth, yield and economic analysis of an eucalypt-soybean consortium: effect of the distance between trees within the row. Revista Árvore. https://doi.org/10.1590/1806-90882019000200002
Bell S, Zitnick CL, Bala K, Girshick R (2016) Inside-outside net: detecting objects in context with skip pooling and recurrent neural networks. In: 2016 IEEE conference on computer vision and pattern recognition (CVPR). IEEE, Las Vegas, NV, USA, pp 2874–2883
Binoti MLMS (2012) Emprego de redes neurais artificiais em mensuração e manejo florestal. Universidade Federal de Viçosa, Viçosa
Binoti DHB, Binoti MLMDS, Leite HG et al (2012) Descrição da distribuição diamétrica de sistemas agrossilvipastoris utilizando as funções Weibull e Hiperbólica. Revista Árvore 36:349–356
Binoti MLMS, Binoti DHB, Leite HG (2013) Aplicação de redes neurais artificiais para estimação da altura de povoamentos equiâneos de eucalipto. Revista Árvore 37:639–645
Binoti MLMS, Binoti DHB, Leite HG et al (2014) Redes neurais artificiais para estimação do volume de árvores. Rev Árvore 38:283–288. https://doi.org/10.1590/S0100-67622014000200008
Binoti MLMS, Leite HG, Binoti DHB et al (2015) Prognose em nível de povoamento de clones de eucalipto empregando redes neurais artificiais. Cerne 21:97–105. https://doi.org/10.1590/01047760201521011153
Binoti DHB, Duarte PJ, Silva MLM da et al (2017) Estimation of height of Eucalyptus trees with neuroevolution of Augmenting Topologies (NEAT). Revista Árvore 41
Bishaw Z, Struik PC, Van Gastel AJG (2013) Farmer’s seed sources and seed quality: 2. Seed health. Int J Plant Prod 7:637–657
Bisseleua HBD, Fotio D, Yede ADM, Vidal S (2013) Shade tree diversity, cocoa pest damage, yield compensating inputs and farmers’ net returns in West Africa. PLoS ONE 8:e56115
Braga AP, Carvalho APLF, Ludemir TB (2000) Redes Neurais Artificiais: Teoria e Aplicações. LTC - Livros Técnicos e Científicos Editora S.A
Brüning LZ, Krieger M, Meneses-Pelayo E et al (2018) Land-use heterogeneity by small-scale agriculture promotes amphibian diversity in montane agroforestry systems of northeast Colombia. Agr Ecosyst Environ 264:15–23
Burkhart HE, Tomé M (2012) Modeling forest trees and stands. Springer, Berlin
Campos JCC, Leite HG (2013) Mensuração Florestal: Perguntas E Respostas. Atual. E Ampl. Viçosa, Mg: Editora Ufv
Campos JCC, Ribeiro J, Paula Neto F (1984) Inventário florestal nacional, reflorestamento: Minas Gerais. IBDF, Brasília
Campos BPF, da Silva GF, Binoti DHB et al (2016) Predição da altura total de árvores em plantios de diferentes espécies por meio de redes neurais artificiais. Pesquisa Florestal Brasileira 36:375–385
Cardoso IM, Guijt I, Franco FS et al (2001) Continual learning for agroforestry system design: university, NGO and farmer partnership in Minas Gerais, Brazil. Agric Syst 69:235–257
Che S, Tan X, Xiang C et al (2018) Stand basal area modelling for Chinese fir plantations using an artificial neural network model. J For Res 30:1641–1649
Clutter JL, Fortson JC, Pienaar LV et al (1983) Timber management: a quantitative approach. Wiley, London
Cordeiro AAC, Coelho SD, Ramos NC, Meira-Neto JAA (2018) Agroforestry systems reduce invasive species richness and diversity in the surroundings of protected areas. Agrofor Syst 92:1495–1505
da Silva R, Hakamada R, Bazani J et al (2016) Fertilization response, light use, and growth efficiency in eucalyptus plantations across soil and climate gradients in Brazil. Forests 7:117. https://doi.org/10.3390/f7060117
de Freitas ECS, de Oliveira Neto SN, da Fonseca DM et al (2013) Deposição de serapilheira e de nutrientes no solo em sistema agrossilvipastoril com eucalipto e acácia. Revista Árvore 37:409–417
Diamantopoulou MJ (2012) Assessing a reliable modeling approach of features of trees through neural network models for sustainable forests. Sustain Comput Inform Syst 2:190–197
Diamantopoulou MJ, Milios E (2010) Modelling total volume of dominant pine trees in reforestations via multivariate analysis and artificial neural network models. Biosyst Eng 105:306–315
Diamantopoulou MJ, Milios E, Doganos D, Bistinas I (2009) Artificial neural network modeling for reforestation design through the dominant trees bole-volume estimation. Nat Resour Model 22:511–543
Diamantopoulou MJ, Özçelik R, Crecente-Campo F et al (2015) Estimation of Weibull function parameters for modelling tree diameter distribution using least squares and artificial neural networks methods. Biosyst Eng 133:33–45. https://doi.org/10.1016/j.biosystemseng.2015.02.013
Do Vale R, Couto L, da Silva M et al (2004) Análise da viabilidade econômica de um sistema silvipastoril com eucalipto para a Zona da Mata de Minas Gerais. Agrossilvicultura 1:2
Dolácio CJF, Oliveira RS, Nakajima NY et al (2020) Integration of principal component analysis and artificial neural network to modeling productive capacity of eucalypt stands from biophysical attributes. For Ecol Manag 460:117862
Dube F, Couto L, da Silva M et al (2002) A simulation model for evaluating technical and economic aspects of an industrial eucalyptus-based agroforestry system in Minas Gerais, Brazil. Agrofor Syst 55:73–80
Ferreira AD, Serra AP, Laura VA et al (2017) Influência de arranjos espaciais sobre as características silviculturais de três clones de eucalipto em sistemas de integração lavoura-pecuária-floresta
Ferreiro-Domínguez N, Rigueiro-Rodríguez A, Mosquera-Losada MR (2011) Response to sewage sludge fertilisation in a Quercus rubra L. silvopastoral system: soil, plant biodiversity and tree and pasture production. Agric Ecosyst Environ 141:49–57
Fontan IC, Reis GG, Reis MG et al (2011) Growth of pruned eucalypt clone in an agroforestry system in southeastern Brazil. Agrofor Syst 83:121
Görgens EB, Leite HG, Santos HN et al (2009) Estimação do volume de árvores utilizando redes neurais artificiais. Revista Árvore 33:1141–1147
Graybill FA (1976) Theory and application of the linear model, vol 183. Duxbury press, North Scituate, MA
Gujarati DN, Porter DC (2011) Econometria Básica-5. Amgh Editora
Haykin S (2001) Redes neurais: princípios e prática, 2nd edn. Bookman, Porto Alegre
Haykin S (2009) Neural networks and learning machines, 3rd edn. Prentice Hall, New Jersey
Hott MC, De Carvalho LMT, Antunes MAH et al (2016) Vegetative growth of grasslands based on hyper-temporal NDVI data from the Modis sensor. Pesqui Agropecu Bras 51:858–868. https://doi.org/10.1590/S0100-204X2016000700009
Huang G, Liu Z, van der Maaten L, Weinberger KQ (2017) Densely connected convolutional networks, pp 4700–4708
IBÁ (2019) Relatório Anual. O setor Brasileiro de àrvores. https://iba.org/datafiles/publicacoes/relatorios/iba-relatorioanual2019.pdf
Kay S, Graves A, Palma J, Moreno G et al (2019) Agroforestry is paying off—economic evaluation of ecosystem services in European landscapes with and without agroforestry systems. Ecosyst Serv 36:10. https://doi.org/10.1016/j.ecoser.2019.100896
Khan GS, Chaudhry AK (2007) Effect of spacing and plant density on the growth of poplar (Populus deltoides) trees under agro-forestry system
Kim TJ, Bullock BP, Stape JL (2015) Effects of silvicultural treatments on temporal variations of spatial autocorrelation in Eucalyptus plantations in Brazil. For Ecol Manag 358:90–97. https://doi.org/10.1016/j.foreco.2015.09.004
Kruschewsky GC, Macedo RLG, Venturin N, de Oliveira TK (2007) Arranjo estrutural e dinâmica de crescimento de Eucalyptus spp., em sistema agrossilvipastoril no cerrado. Cerne 13:360–367
Lacerda F, Miranda I, Kato OR et al (2013) Weed dynamics during the change of a degraded pasture to agroforestry system. Agrofor Syst 87:909–916
Lacerda THS, Cabacinha CD, Araújo Júnior CA et al (2017) Artificial neural networks for estimating tree volume in the Brazilian savanna. Cerne 23:483–491
Lana ÂMQ, Lana RMQ, Lemes EM et al (2018) Influence of native or exotic trees on soil fertility in decades of silvopastoral system at the Brazilian savannah biome. Agrofor Syst 92:415–424. https://doi.org/10.1007/s10457-016-9998-8
Leal FA, Miguel EP, Matricardi EAT et al (2015) Redes neurais artificiais na estimativa de volume em um plantio de eucalipto em função de fotografias hemisféricas e número de árvores. Revista Brasileira de Biometria 33:233–249
Leite HG, Nogueira GS, Moreira AM (2006) Efeito do espaçamento e da idade sobre variáveis de povoamentos de Pinus taeda L. Revista Árvore 30:603–612. https://doi.org/10.1590/S0100-67622006000400013
Lemaire G, Franzluebbers A, de Carvalho PCF, Dedieu B (2014) Integrated crop–livestock systems: strategies to achieve synergy between agricultural production and environmental quality. Agr Ecosyst Environ 190:4–8. https://doi.org/10.1016/j.agee.2013.08.009
Lemos-Junior JM, Souza KR, Guimaraes LE et al (2016) Volumetric models for Eucalyptus grandis × urophylla in a crop-livestock-forest integration (CLFI) system in the Brazilian cerrado. Afr J Agric Res 11:1336–1343
Lin Y, Yang H, Ivković M et al (2013) Effect of genotype by spacing interaction on radiata pine genetic parameters for height and diameter growth. For Ecol Manag 304:204–211. https://doi.org/10.1016/j.foreco.2013.05.015
Liziniewicz M, Ekö PM, Agestam E (2012) Effect of spacing on 23-year-old lodgepole pine (Pinus contorta Dougl. var. latifolia) in southern Sweden. Scand J For Res 27:361–371
Magalhães WM, Macedo RLG, Venturin N et al (2007) Desempenho silvicultural de clones e espécies/procedências de Eucalyptus na região noroeste de Minas Gerais. Cerne 13:368–375
Müller MD, Salles TT, Paciullo DSC, Al Et (2014) Equações de altura, volume e afilamento para eucalipto e acácia estabelecidos em sistema silvipastoril. Floresta 44:473–484. https://doi.org/10.5380/rf.v44i3.33149
Nair PKR (1993) An introduction to agroforestry. Springer, Berlin
Ogut F, Maltecca C, Whetten R et al (2014) Genetic analysis of diallel progeny test data using factor analytic linear mixed models. For Sci 60:119–127. https://doi.org/10.5849/forsci.12-108
Oliveira Neto SN, Reis GG, Reis MGF (2007) Eucalipto: as questões ambientais e seu potencial para Sistemas agrossilvipastoris. In: Fernandes EM, Pacuillo DS, Castro CRT, Müller MD, Arcuri PB, Carneiro JC (eds) Sistemas agrossilvipastoris na América do Sul: desafios e potencialidades. Embrapa Gado de Leite, Juiz de Fora, pp 245–282
Oliveira CH, Reis GG, Reis MG et al (2016) Dynamics of eucalypt clones canopy and Brachiaria brizantha production in silvopastoral systems with different spatial arrangements. Agrofor Syst 90:1077–1088
Oliveira CC, Alves FV, de Almeida RG et al (2018) Thermal comfort indices assessed in integrated production systems in the Brazilian savannah. Agrofor Syst 92:1659–1672
Özçelik R, Diamantopoulou MJ, Crecente-Campo F, Eler U (2013) Estimating Crimean juniper tree height using nonlinear regression and artificial neural network models. For Ecol Manag 306:52–60
Pereira Filho GM, Jacovine LAG, Schettini BLS (2020) Influence of the replanting age on yield and growth of eucalypt clonal stands. Revista Árvore 44
Pereira LF, Ferreira CFC, Guimarães RMF (2018) Manejo, qualidade e dinâmica da degradação de pastagens na Mata Atlântica de Minas Gerais-Brasil. Nativa Sinop 6:370–379
Peri PL, Hansen NE, Bahamonde HA et al (2016) Silvopastoral systems under native forest in Patagonia Argentina. In: Silvopastoral systems in Southern South America. Springer, Cham, pp 117–168. https://doi.org/10.1007/978-3-319-24109-8_6
Plano ABC (2012) Plano Setorial de Mitigação e de Adaptação às Mudanças Climáticas para a Consolidação de uma Economia de Baixa Emissão de Carbono na Agricultura. Brasília
Resende RT, Soares AA, Forrester DI et al (2018) Environmental uniformity, site quality and tree competition interact to determine stand productivity of clonal Eucalyptus. For Ecol Manag 410:76–83
Riedmiller M, Braun H (1993) A direct adaptive method for faster backpropagation learning: The RPROP algorithm. In: IEEE international conference on neural networks. IEEE, pp 586–591
Rocha SJSS, Torres CMME, Jacovine LAG et al (2018) Artificial neural networks: modeling tree survival and mortality in the Atlantic Forest biome in Brazil. Sci Total Environ 645:655–661
Salles TT, Leite HG, de Oliveira Neto SN et al (2012) Modelo de Clutter na modelagem de crescimento e produção de eucalipto em sistemas de integração lavoura-pecuária-floresta. Pesquisa Agropecuária Brasileira 47:253–260
Salles TT, Nogueira DA, Beijo LA et al (2019) Bayesian approach and extreme value theory in economic analysis of forestry projects. For Policy Econ 105:64–71. https://doi.org/10.1016/j.forpol.2019.05.021
Santi E, Paloscia S, Pettinato S et al (2017) The potential of multifrequency SAR images for estimating forest biomass in Mediterranean areas. Remote Sens Environ 200:63–73. https://doi.org/10.1016/j.rse.2017.07.038
Schumacher FX, Hall FS (1933) Logarithmic expression of timber-tree volume. J Agric Res 47:719–734
Scolforo HF, McTague JP, Burkhart H et al (2019) Eucalyptus growth and yield system: linking individual-tree and stand-level growth models in clonal Eucalypt plantations in Brazil. For Ecol Manag 432:1–16. https://doi.org/10.1016/j.foreco.2018.08.04
Silveira DP, Leite HG, Silveira VDP et al (2011) Classification of eucalyptus trees for poles in agroforestry system. Revista Árvore 35:875–882. https://doi.org/10.1590/S0100-67622011000500013
Soares FAA, Flôres EL, Cabacinha CD et al (2011) Recursive diameter prediction and volume calculation of eucalyptus trees using Multilayer Perceptron Networks. Comput Electron Agric 78:19–27
Soares AAV, Leite HG, Cruz JP, Forrester DI (2017) Development of stand structural heterogeneity and growth dominance in thinned Eucalyptus stands in Brazil. For Ecol Manag 384:339–346. https://doi.org/10.1016/j.foreco.2016.11.010
Socha J, Netzel P, Cywicka D (2020) Stem taper approximation by artificial neural network and a regression set models. Forests 11:79. https://doi.org/10.3390/f11010079
Somarriba EC, Suárez-Islas A, Calero-Borge W et al (2014) Cocoa–timber agroforestry systems: theobroma cacao–Cordia alliodora in Central America. Agrofor Syst 88:1001–1019
Souza HN, de Goede RG, Brussaard L et al (2012) Protective shade, tree diversity and soil properties in coffee agroforestry systems in the Atlantic Rainforest biome. Agric Ecosyst Environ 146:179–196
Souza GSA, Cosenza DN, Araújo ACSC et al (2018) Evaluation of non-linear taper equations for predicting the diameter of eucalyptus trees. Revista Árvore 42:1
Srivastava RK, Greff K, Schmidhuber J (2015) Training very deep networks. In: Advances in neural information processing systems, pp 2377–2385
Stabile MCC, Azevedo A, Nepstad D (2012) Brazil’s “Low Carbon Agriculture Program”: barriers to implementation. Amazon Environmental Research Institute (IPAM), Belém
Tavares Júnior IS, da Rocha JEC, Ebling ÂA et al (2019) Artificial neural networks and linear regression reduce sample intensity to predict the commercial volume of eucalyptus clones. Forests 10:268. https://doi.org/10.3390/f1003026
R Core Team (2013) R: a language and environment for statistical computing. Vienna, Austria, 2011. http://www.R-project.org
Tonini H, Magalhães CADS, Faria Neto ALD (2019) Technical thinning age of eucalyptus trees grown in crop-forest integration systems. Pesquisa Agropecuária Brasileira 54
Torres CMME, Oliveira AC, Pereira BLC et al (2016) Estimativas da produção e propriedades da madeira de eucalipto em Sistemas Agroflorestais. Sci For Sci 44:137–148. https://doi.org/10.18671/scifor.v44n109.13
Trindade C, Jacovine L, Rezende J, Sartorio M (2012) Gestão e controle da qualidade na atividade florestal. Viçosa: Editora UFV 2
van Laar A, Akça A (2007) Forest mensuration. Springer, Berlin
Villanova PH, Jacovine LAG, Torres CEMM et al (2018) Accumulation of carbon and age of thinning of the tree component in agroforestry systems. Braz J Agric Sci 13:1–16
Zhao D, Kane M, Borders BE (2011) Growth responses to planting density and management intensity in loblolly pine plantations in the southeastern USA Lower Coastal Plain. Ann For Sci 68:625–635. https://doi.org/10.1007/s13595-011-0045-7
Zianis D, Pantera A, Papadopoulos A, Losada MRM (2019) Bayesian and classical biomass allometries for open grown valonian oaks (Q. ithaburensis subs. macrolepis L.) in a silvopastoral system. Agrofor Syst 93:241–253. https://doi.org/10.1007/s10457-016-0060-7
Acknowledgements
We acknowledge Conselho Nacional de Desenvolvimento Cientifico e Tecnológico (CNPq) for funding the research. To Agronomist Rogério Jacinto Gomes, to Professor Lino Roberto Ferreira, coordinators of the Forest Integration Zone-Farming-Livestock-Forest Circuit (Partnership EMATER-MG/Universidade Federal De Viçosa). To farmers for the availability of field demonstration units for data collection. To Amana Obolari, Bruno Schettini, Ricardo Pena, Maria Tereza Nunes, and Cristina Nolasco for their assistance in data collection. We would like to thank Editage (www.editage.com) for English language editing.
Author information
Authors and Affiliations
Contributions
Conceptualization, S.S., S. N. O. N. and H. G. L.; Formal analysis, S.S., R. R. O. N., G. S. A. S., S. N. O. N. and H. G. L.; Methodology, S. S.;S.N.O. N. and H. G. L; Writing-original draft S. S.; Writing-review and editing, S. S., S. N. O. N., R. R. O.N., A. E. M. A., H. G. L.; G. S. A. S.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Silva, S., de Oliveira Neto, S.N., Leite, H.G. et al. Productivity estimate using regression and artificial neural networks in small familiar areas with agrosilvopastoral systems. Agroforest Syst 94, 2081–2097 (2020). https://doi.org/10.1007/s10457-020-00526-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10457-020-00526-1