
Abstract
The Hyrcanian forests of Iran contain many species-rich communities that can only be maintained through an understanding of the renewal and development of these forests. Located in the Jojadeh section of the Farim forest in northern Iran, individual tree growth of five distinct species [(Oriental beech (Fagus orientalis Lipsky), chestnut-leaved oak (Quercus castaneifolia Coss. ex J.Gay), Persian maple (Acer velutinum Boiss.), common hornbeam (Carpinus betulus L.) and Caucasian alder (Alnus subcordata C.A.Mey.)] were measured on 313 permanent sample plots (0.1 ha) over a 10-year period (2003–2013). In this analysis, various tree-level predictions were investigated using the available data with application of parametric models and two artificial neural networks [i.e., the multilayer perceptron (MLP) and radial basis function (RBF) networks]. Individual tree diameter growth models showed a robust negative relationship with basal area in larger trees, which was relatively consistent across species. A total height model indicated that the examined species did not differ for a given set of covariates. In the survival model, the survival probability of Oriental beech was lower than the other species, while the ingrowth model revealed sapling density of all species increased with greater basal area. The artificial neural network based on the MLP was superior for all models and predicted more accurately than the RBF. Furthermore, the models based on the MLP were also superior to the parametric individual tree models developed using mixed-effect regression. The use of these developed models in forest planning and management is imperative, particularly for uneven-aged stands, but assessment of long-term projection behavior across the contrasting statistical approaches used is warranted despite the general superiority of the nonparametric models.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Hyrcanian forests are the only commercial forests where temperate broad-leaved tree species exist today in Iran. Covering an area of approximately 1.85 million ha, the Hyrcanian forests account for approximately 15% of Iranian forests and 1.1% of the country’s total area. These forests range from sea level up to an elevation of 2800 m and comprise various forest types with no less than 80 woody species (trees and shrubs) (Ahmadi et al. 2020). These forests thus are of significant concern to forest planners and policy makers charged with maintaining the resilience of this important forest ecosystem to support and benefit human livelihoods in the region. Whereas economic planning without consideration for sustaining renewable natural resources can lead to their degradation that can ultimately contribute to the extinction of nations and civilizations (Hatfield and Prueger 2015), decision-makers are no longer solely concerned about economics and do increasingly take a broader, more holistic management perspective (Vanclay 1994).
In forestry, decision-making is the essence of a management plan that includes prescribed activities, a schedule, and control measures aimed at achieving the stated management objectives in a forest area (Bayat et al. 2013). Because multiple forest management objectives often conflict at the landscape scale, a spatial approach to planning uses a modeling technique that adapts spatially explicit stand management objectives to minimize the conflicts at the landscape scale (Baskent and Keles 2005). In addition to high-quality inventory and survey data that describe the current forest condition, both planners and managers thus require a description of the desired future conditions and acceptable alternative future states. To obtain the most reliable information on the likely future state of a forest, planners rely on forecasts from growth and product models that are widely employed in forest management (Bettinger et al. 2005; Weiskittel et al. 2011). The biometrical and mathematical representation of biological processes leads to a growth and yield model. The conversion of growth models into computer programs for forecasting and scenario computation leads to the creation of growth simulators. A model is therefore always the precondition for the development of a simulator, but in contrast, the development of a model does not always lead to a simulator (Pretzsch et al. 2002; Álvarez-González et al. 2009). The development of an even-aged forest stand can be predicted using a stand-level model (Gadow and Hui 1999), while a more detailed approach is often needed for mixed-species or uneven-aged stands (Weiskittel et al. 2011).
Growth and yield models predict the dynamics of forests, including future forest growth and products that enable the study of alternative management options/scenarios and have thus become a key element in sustainable forest management planning (Burkhart 1990; Vanclay 1994; Bayat et al. 2013). For example, sub-models for individual tree diameter/height growth, survival, and ingrowth enabled the predictions of stand density and diameter distributions needed to guide the management of uneven-aged forests in Finland (Pukkala et al. 2009; Pukkala and Kellomäki 2012). Further, harvest intensities were based on height, survival, and growth of the regeneration in uneven mixed softwood stands in Finland to ensure sufficient survival and growth of small spruces (Picea spp.), intolerant birch (Betula spp.) and pine (Pinus spp.) to maintain the species composition of the current selection stands (Eerikainen et al. 2014). Finally, mixed-effects regression models were recently developed to project the distance-independent individual tree growth and yield for uneven-aged forests in northern Iran managed under selection systems (Kalbi et al. 2019). In addition to the mentioned studies, other researches such as Ahmadi et al. (2016, 2020) have developed additional tree-level statistical models for the Hyrcanian forests.
The use of models for better forest management is one of the main factors that justify growth modeling. The developed models predict the growth rate and the factors affecting it, which allows for a better information of the ecosystem. In addition, the future state of the forest can be predicted with these models (Pretzsch et al. 2015; Pretzsch 2009). Accordingly, a correct understanding of the structure of the forest is an essential fact for the optimal management of forest resources. For example, the beech species (Fagus orientalis Lipsky) examined in this analysis covers about one-third of the area and proportionally the standing volume in mixed and relatively pure Hyrcanian forests. Most beech forests are now managed with a new approach to forestry. Accordingly, quantifying forest growth and determining influential factors is one of the most important goals of forest management.
To more fully understand the dynamics of forests, it is often not sufficient to solely model the overall growth of forest stands, but commonly more detailed individual-based modeling approaches are needed that effectively discriminate among several growth components (Vanclay 1994). This is especially true to support uneven-aged forest management in mixed natural stands, and the following set of individual tree growth models is essential: diameter/height growth, tree mortality or survival, and estimates of ingrowth (Trasobares et al. 2004; Bayat et al. 2013). The models can be developed using a variety of statistical techniques, which are further explained below.
The mixed-effects model is a parametric method for addressing hierarchical data. Examples of grouped data are individuals within spatially explicit subgroups, such as sample trees within forest sample plots; observations of a split-plot or a block in a controlled experiment; and repeated measurements of any subjects, such as plants or permanent sample plots. It is quite common that the groups of the data represent only a sample from a population of groups, while general interest is often in making the inference about the entire population of groups. In those situations, the group effects are naturally treated as random variables, which leads to the mixed-effects model, also called mixed or random-effects regression. These mixed models have been extensively used and have now become the standard for growth and yield modeling (Weiskittel et al. 2011). Additional benefits of random group effects over the fixed effects are that the number of observations per group can be small; even one observation per group may be enough for satisfactory estimation accuracy, provided some groups have several observations. As groups get larger, the estimated group effects from the mixed-effects model approach those of the fixed-effects model. Mixed-effects models also enable modeling of variability between groups using fixed predictors that are defined at the group level. Furthermore, prediction is also possible for groups that were not present in the modeling data (Mehtätalo and Lappi 2020). For growth modeling, use of species as hierarchical level in a mixed model has been shown to result in more robust predictions (Kuehne et al. 2020).
In addition to mixed-effects regression techniques, artificial neural network (ANN) is a form of artificial intelligence (AI) and is used for a wide range of complex multivariate problems in various fields, including communication memory, optimization, prediction, diagnosis, control, and forestry (Nandy et al. 2017; Da Rocha et al. 2018; Vieira et al. 2018; Zhu et al. 2018; Zhou et al. 2019). ANNs form a subset of AI whose structure and function generally mimic the human brain and consist of a number of simple structural components with complex connections, analogous to neurons in the brain (Strobl and Forte 2007;). ANNs have recently gained increased traction in forestry with applications in the mapping of forest structure (Ingram et al. 2005), predicting site index (Aertsen et al. 2010), estimating forest growth and yield (Ashraf et al. 2013), modeling tree diameter and height (Reis et al. 2016; Vieira et al. 2018), determining volume and biomass of individual trees (Pereira et al. 2019), predicting the probability of tree survival (Bayat et al. 2019a), and estimation of tree heights (Bayat et al. 2020).
Few studies have investigated how well traditional parametric mixed-effects compare to AI/ANN-based growth and yield models. A recent study comparing the estimation of volume and biomass of individual trees of different species in the Brazilian central savanna derived using both approaches clearly demonstrated the great potential of AI techniques compared to mixed models and underscored the utility of ANN-based models to handle manifold information to accurately predict tree-level attributes (Pereira et al. 2019). However, nonparametric methods like ANN may have important limitations for application in a regional forest growth and yield modeling context, namely inability to extrapolate beyond the fitting data, potential inconsistency with biological expectations, and more difficult transferability to other potential users. To our knowledge, no comprehensive study has compared the tree-level growth and yield results from parametric mixed-effects regression models to those from ANNs to date, particularly in uneven-aged and mixed forests like those in the Hyrcanian forests of Iran.
ANNs used in this study consisted of two architectures that are commonly used for solving difficult engineering problems (Walling et al. 2001; Zhu et al. 2007; Bayat et al. 2020): the feedforward multilayer perceptron (MLP) and the radial base function (RBF) networks. Both methods give robust estimates (Reis et al. 2018; Van Dao et al. 2020) and are able to approximate a variety of nonlinear functions (Benali et al. 2019). The number of layers and neurons in each hidden layer is of great importance in designing the network. The number of neurons in the input and output layers is equal to the number of input and output variables under investigation. The challenging task is to determine the number of hidden layers and the number of neurons in each hidden layer. The ANNs in this study were trained with back-propagation algorithms that used 70% of input–output data records for model training and the remainder for model evaluation (Benali et al. 2019).
To manage mixed uneven-aged forests with the selection system, reliable predictive models of diameter/height growth, survival/mortality rates of trees, and ingrowth of regeneration are needed to guide harvest intensities and residual basal areas to ensure a sustainable development of trees through the diameter distribution. In this study, we have two primary objectives, which are: (1) parameterize various individual tree growth submodels using mixed models and ANN and (2) determine which approach provided the best model accuracy based on a comprehensive model assessment. The primary goal was an accurate and appropriate method for predicting diameter/height growth, survival /mortality rates of trees, and ingrowth of regeneration for the most important and economically valuable species in the forests of northern Iran.
Materials and methods
Study area
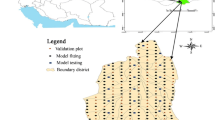
This study was carried out in the Jojadeh district, which is one of five sections covered by forestry development projects in the Farim forest. The Jojadeh section is located on the southern part of the Sari, the capital city of the Mazandaran province on the slopes of the northern Alborz Mountains in the Dodangeh district (Fig. 1). The section covers an area of 3550.2 ha with minimum and maximum altitudes of 782 and 1750 m, respectively. The climate of this forest is classified as humid with an annual rainfall of 832.9 mm and an average annual temperature of 11.2 °C. This forest is composed of an uneven-aged and mixed forest, and in most parts has at least three stories. The primary species of this section are Oriental beech (Fagus orientalis Lipsky), chestnut-leaved oak (Quercus castaneifolia Coss. ex J.Gay), Persian maple (Acer velutinum Boiss.), common hornbeam (Carpinus betulus L.) and Caucasian alder (Alnus subcordata C.A.Mey.) (Hamidi et al. 2019). These primary species often occur together in a variety of mixtures and forest types throughout the region.

Overview of the study area in northern Iran and approximate location of plots used in this analysis. Variations in color indicate different elevations (m, AMSL; see legend). (Color figure online)
Study method
The data used for modeling were obtained from two enumeration periods with fixed sample plots. In 2003, 313 circular permanent sample plots (0.1 ha) were systematically laid out using an inventory grid (200 m × 150 m) in the Jojadeh district. After locating the plot centers in the field, the slope of each plot was determined, and the radius of the sample plot was slope corrected. In each plot, the center was permanently monumented and each tree within the plot received a number that was painted at breast height (1.3 m). The DGPS device (RTK model with an accuracy of approximately 1–5 cm (RMS)) was used to record the position of all sample plots (Bettinger et al. 2019; Hamidi et al. 2020). The DBH of all live trees with a diameter > 12.5 cm was measured using a caliper and recorded by species. The basal area (BA) and basal area larger (BAL) are two important competitive factors that were used in this study, which are obtained from the following formulas, respectively.
where BA is basal area in m2, DBH is diameter, and π = 3.14.
where DBHj > DBHi (i.e., all trees larger than subject tree i), DBH is measured in meters and TFj is a tree factor, i.e., the number of trees represented by jth tree in a hectare derived from area (Pokharel and Dech 2012).
In order to record physiographic factors, in each sample plot, first the slope was recorded using the Sunto slope gauge and the aspect determined with a compass, while the altitude and its geographical position were assessed with the GPS device. In order for the trees that were measured at the beginning of the period to be measured again at the end of the period and to determine the number of trees that have exceeded the count limit, the trees in the sample plots in the forest must be marked in some way. One method of marking the center of the sample plot and trees that have exceeded the count limit is to mark the location of the diameter measurement against the breast in the first period, which was done in the research area. Each tree was marked with a specific symbol and recorded in the relevant forms. At the end of the period, the sample plots were recovered and the measurements were calculated as at the beginning of the period. Measurements were re-taken after 10 years in 2013, and the mortality of any previously tallied tree and ingrowth of trees beyond the diameter threshold were noted. Finally, the amount of forest growth models was calculated in region forest.
Data
A total of 4832 trees of which 2878 were Oriental beech, 838 common hornbeam, 187 oak, 417 Caucasian alder, 80 Persian maple, and 432 Other trees were predominantly Acer cappadocicum, Tilia spp., Ulmus minor, Ulmus glabra, Fraxinus excelsior, and Zelkova carpinifolia. All of these observations across the five primary species were available for modeling diameter growth. Height was modeled using 626 pairs of diameter and height, while a total of 5852 and 1340 trees were used for survival and regeneration modeling, respectively.
Due to the uneven structure of most stands in this forest, the thickest and closest tree to the center of the plot were selected for measurement, which was accomplished using a Sunto clinometer and calculated from the following formula (Eq. 3):
where H: the height of the tree (m), d: the horizontal distance to the tree (m), tan α and tan β: The slope of the tip and the bend of the tree, respectively, are relative to the horizontal surface (%).
Modeling approaches
For modeling the 10-year diameter increment (DBH2013-DBH2003) in this study, the following parameters were included in the model: (1) tree size (DBH); (2) competition [total basal area (BA) and basal area of trees larger than the subject tree (BAL) as well as its transformation, ln(BAL)]. BAL has been suggested as a proxy for the ability of trees to compete for light (Schwinning and Weiner 1998). Other studies have posited that tree competitive position, determined using BAL or modifications of BAL, may be the strongest predictors of diameter growth in both even-aged (Adame et al. 2008; Uzoh and Oliver 2008) and uneven-aged stands (Pukkala et al. 2009); and (3) physiographic factors including slope, aspect, altitude and transformation of these variables with natural log-transformed diameter growth as the dependent variable (Vanclay 1994), linear mixed-effect regression was used to model the diameter increment following Lhotkaa and Loewenstein (2011) that incorporated species as the random variable (Kuehne et al. 2020).
Due to errors in tree height measurements associated with the first inventory, only a static total height model associated with the second inventory could be developed. The static height models were developed based on the relationship between tree height and DBH from 626 trees (i.e., the largest diameter and nearest tree to the center in each sample plot). Twenty alternative nonlinear DBH to height model types were fitted and evaluated in this study from which 11 models were two-parameter and nine were three-parameter models.
The mortality model was based on the number of trees that survived or died between 2003 and 2013 and modeled by species using logistic regression. The explanatory variables evaluated were tree size (DBH and different derivatives) and competition factors (BA, BAL, N); only significant variables (p < 0.05) were retained in the final model (Eq. 4):
where Pi represents the possibility of tree mortality for threshold i, b0–bn are parameters to be estimated and x(1)–x(n) are descriptive variables.
The regeneration/ingrowth model used the number of trees that exceeded the diameter threshold of 12.5 cm DBH as the response variable and that was regressed against stand total basal area. Based on the data availability and desired use in future projections, some additional explanatory variables for predicting the number of ingrowth trees per hectare were selected: (1) total basal area (m2 ha–1); (2) number of trees per ha; (3) average DBH of each plot; (4) physiographic factors; and (5) transformations of basal area (m2 ha–1). These were all used in a Poisson generalized linear model (GLM) (Eq. 5).
The systematic linear predictor is a multiplication of a parameter vector β and an explanatory variable design matrix X (Li et al. 2011). All computations and modeling were done employing the R software using the lme and nlme packages (Pinheiro et al. 2020) similar to Bayat et al. (2020).
Artificial neural network (ANN)
Prior to training, all input and output data were normalized (Nagy et al. 2002). The ANN structure was iteratively altered by changing the number of hidden nodes. The structure that produced the least amount of error (difference between modeled and observed values) was selected for further testing at a later stage. All calculations were analyzed in STATISTICA software.
Model evaluation
Common criteria for assessing the goodness of fit of model predictions are the coefficient of determination (R2), the root-mean-squared error (RMSE), the relative RMSE, BIAS, and relative BIAS (Lumbres et al. 2016; Bayat et al. 2019b). An important advantage of the relative RMSE (in %) is that it enables comparisons among predictions produced by different models (Pulido-Calvo et al. 2007; Janizadeh et al. 2019). So to the above evaluation metrics, the mortality was evaluated with the Nagelkerke R-square criteria, Chi-square (Hann et al. 2003), Hosmer–Lemeshow test (Padilla et al. 2010) and ROC subsurface levels (Lei et al. 2004).
where esti and obsi are the ith estimate and observation, respectively, and n is the number of observations. For evaluation, we performed cross-validation by randomly selecting 70% of the data as the training dataset and 30% as the evaluation dataset.
Results
The data covered a wide range of conditions typical for the region with the descriptive statistics given in Table 1.
Individual tree diameter growth model
The diameter growth of most trees ranged between 0 and 8 cm in the 10-year period. A linear mixed-effect model was employed for modeling of the diameter growth, and the best performing model is presented in Eq. 10:
where Id is the diameter growth in a 10-year period; uj ~ N(0,σu2) represents the random effect species; DBH is the diameter at breast height (cm); DBH squared (cm), BA is the stand basal area (m2 ha−1); BAL is the basal area of larger trees in the plot when compared to the subject tree (m2 ha−1). The variance and standard deviation for the random factor of species were 1.79 and 2.83, respectively. Results also showed that the correlation between growth rate and BAL was negative, i.e., the diameter growth decreased with an increase in this index. The RMSE, bias, and R2 were 1.11, 0.12, and 0.20, respectively.
Results of five MLP- and RBF-based ANNs showed that the RBF-based models gave better results and the superior MLP-based model resulted in an RMSE of 0.06 cm, indicating that the predicted average diameter growth is close to the measured diameter growth (Table 2). In Table 2, only the models with high accuracy are given, while all ANNs fitted are given in the Supplemental Materials (Table S1 and S2). Also, Fig. 2 shows the relationship between the actual and predicted diameter growth for all species by the parametric (mixed-effect regression) and nonparametric methods (ANN).

Graphical presentation of measured and predicted tree diameter growth by the parametric [mixed-effect regression (red line)] and nonparametric methods [ANN (black line)]. (Color figure online)
Individual tree height growth model
The following individual tree data were used to fit tree height models using tree diameter as the main predictor (Table 3). The best obtained height model is shown in Eq. 11:
where H is the tree height and dij is the diameter at the breast height of the tree, BA is the stand basal area (m2 ha−1); BAL is the basal area of the larger trees in the plots (m2 ha−1) and e ~ N (0,σu2) represents the residuals. In addition, modeling was performed for all species separately, but a better model was achieved when all species were combined and species was treated as a random factor. Residual standard error, RMSE, RMSE %, bias, bias %, and R2 were 4.10 m, 4.91 m, 18.45, 0.15 m, 0.27%, and 73%, respectively (Fig. 3).

Regression model of diameter-height by the parametric [mixed-effect regression (red line)] and nonparametric methods [ANN (black line)]. (Color figure online)
Of the ANN models evaluated for tree height, the MLP-based ANN that contained seven hidden layers was the superior model that resulted in an RMSE of 4.81 m (Table 4). In Table 4, only the models with high accuracy are given, while the results of all ANN are given in the Supplemental Materials (Table S3 and S4). However, predictions using the best ANN and mixed model were nearly identical across the range of tree sizes examined (Fig. 3).
Individual tree survival growth (mortality) model
In the mortality model, we considered the survival of trees to be a one and dead trees are a zero with a binary logistic regression used to estimate the survival model. Equation 12 is the individual tree survival growth (mortality) model
The results of the neural network show that the MLP-based network of tree survival had an RMSE of 0.28 and a bias of 0.011 and performed better than the RBF-based network (Table 5, Fig. 4). In Table 5, only the models with high accuracy are presented, while all of neural network determined are given in the Supplemental Materials (Table S5 and S6).

Model of survival by the parametric [mixed-effect regression (red line)] and nonparametric methods [ANN (black line)] with observed probabilities by 5 cm diameter class
Evaluation results of survival model are given in Table 6, which suggest that the ANN was slightly better in terms of ROC and R2. The better performance achieved for the ANN was primarily at the ends of the distribution in terms of smaller and larger trees (Fig. 4).
Ingrowth model
The average rate of ingrowth (number of trees that passed the diameter threshold of 12.5 cm) over a 10-year period was 42.8 ± 6.4 (mean ± SD) trees per ha, which was unequally distributed among the different species (Table 7). The average diameter of ingrowth trees in the 10-year period was 17.1 ± 2.21 cm. Equation 13 shows the ingrowth model:
where IN is the ingrowth of a 10-year period (number of trees that passed the diameter class of 12.5 cm) mDBH is the stand-level mean diameter at breast height (cm), BA is the total basal area (m2 ha−1), BA2 is the squared basal area (m2 ha−1) of each plot, and BAFagus is the basal area (m2 ha−1) of Fagus species.
The results of the ANN show that the MLP-based network of ingrowth had an RMSE of 0.54 trees per ha, a bias of 0.027 trees per ha, and performed better than RBF-based network (Tables 8; Fig. 5). In Table 8, only the models with high accuracy are given, while the performance of all determined ANNs is provided in the Supplemental Materials (Table S7 and S8). However, predictions of ingrowth using both ANN and mixed-effects were relatively similar across a range of basal areas (Fig. 5).

Predictions of the mixed-effects ingrowth model [Eq. 11; number of trees passed the diameter class of 12.5 cm) (red line)] and nonparametric methods [ANN (black line)] over total stand-level basal area (m2 ha−1) with observed values
Comparison of modeling approach
A general comparison of the R2 and RMSEs from the parametric (mixed-effects) and nonparametric (ANN) prediction methods indicated that the ANN resulted in the best performance in this analysis (Table 9). For R2, the % improvement by ANN ranged from 3.1 to 157.1%, while % improvement for RMSE was between 10.0 and 94.9%. The largest improvements were primarily observed for the diameter increment model. However, as noted above, many of the predictions using either ANN or mixed-effects were generally consistent across the range of the data and both well aligned with observed trends.
Discussion
Evaluation of the structure and dynamics of natural forests helps to determine the possibility of optimal forest management in achieving a desirable structure so that the implementation of appropriate silviculture operations in the stands under management can help to preserve the biological diversity and sustainability of forests (Ashraf et al. 2013; Zhao et al. 2019). Forest structure and composition are very imperative factors for assessing forest health and sustainability. Hyrcanian forests also have a variety of functions that require an integrated and comprehensive management such as wood production, biodiversity, aesthetics, recreation and habitat. It appears that uneven-aged and mixed species management is an efficient and efficacious way of attaining these varying goals (Bourque and Bayat 2015; Yang et al. 2019). However, lack of suitable decision-support tools for the proper implementation of uneven management in mixed broad-leaved forests has delayed the scientific and efficient implementation of this technique (Bourque et al. 2019).
In this study, some models have been presented that can be employed in forest management. The models for uneven-aged, mixed forest presented in this study include individual tree diameter growth, height, and survival (mortality) as well as ingrowth. According to the results, the individual tree diameter growth had a robust performance across the species examined (Eq. 10). Results of a sensitivity analysis indicated that the most important independent variables used in the best model for diameter growth was the logarithm of DBH. Stand basal area and BAL were used to account for competition. BAL is the most common tool for quantifying one-sided competition because it is an absolute value, a simple calculation, and correlates well with the growth rate (Vanclay 1994; Weiskittel et al. 2011; Kweon and Comeau 2019; Kuehne et al. 2020).
Results also showed that increased competition greatly reduced diameter growth across the species examined. In addition, the ANN based on the multilayer perceptron network (MLP) provided a better fit to the data than the RBF-based ANN (Tab 2; Fig. 3). The results of the ANN sensitivity analysis showed in both cases that DBH and stand basal area were the most influential variables whose effects were further modified by physiographic factors in the form of altitude, slope, and aspect. The parametric model for diameter growth indicated that highest growth was observed on northwest aspects (300–340°), but declined as the slope steepened. Weiskittel et al. (2007) found a similar influence of altitude, slope, and aspect on individual tree diameter growth of species in the US Pacific Northwest.
In this study, the static technique was employed for modeling height growth. The descriptive statistics of trees’ DBH and height indicated that observations were selected from a wide range of values (12.5–138 cm for DBH and 8.0–40.5 m for height; Table 3). This suggests that nearly the full range of tree diameter and height for this area were considered. In the height model, species had no effect on the model, which was obtained when the model was fitted for all species separately and the difference was not statistically significant. The developed mixed effect regression height models from our work expressed tree height as a function of DBH and the best model we produced resulted in a RMSE value equal to 18.5%, which was noticeably lower in the present study than reported by Trasobares et al. (2004), where it ranged from 21 to 24%. This high accuracy is important as height models are needed for predicting tree volume. For the ANN method, the R2 and RMSE % values were lower than the parametric method, which were 0.79 and 18.2%, respectively. The MLP network had higher accuracy than RBF network. In addition, the important variable in this model included diameter, basal area, and basal area in larger trees.
The mortality of individual trees is an important event in the development of a forest stand and has significant applications in forest growth and product modeling (Bourque et al. 2019). In determining the survival model (mortality), despite the predictive difficulties of mortality at the stand level, there are many equations for estimating it at the tree level, and the logistic regression was used in this study similar to several previous studies (e.g., Hann et al. 2003; Monserud and Sterba 1999). Guan and Gertner (1991) in their assessment of using ANN and the logistic function showed the former was an effective technique for tree mortality modeling, which other studies have also found (King et al. 2000; Metcalf et al. 2009). However, when the model is used on independent data, the difference between logistic regression and other fitting methods may be less obvious. As a result, logistic regression is generally appropriate due to its simplicity, robustness, and easy application for many practical purposes of mortality modeling (Yagi and Primicerio 2014).
Results of the developed survival model showed that trees with a diameter of 20 to 150 cm had the highest survival (Fig. 4). With an increase in competition (BAL), tree survival rate decreased rapidly. According to the analysis, beech trees also had a lower survival probability than others. Assessment and validation of tree mortality models were difficult because of its discontinuous and discrete nature (Hann et al. 2006). According to our results, ANN was able to better estimate survival probability and to identify the predictors that contribute the most. ANN uses nonlinear network connections and allows an analysis that explores the efficacy of all input variables at the same time, which may lead to an improved quality of the results. In this study, the validation of models was determined using Nagelkerke R2 and its value was 0.40 (Table 6). According to studies, this parameter represents a good fit of the model if the value is between 0.2 and 0.4 (Wilson and Oliver 2005). In this study, the validity of the model was further assessed using Hosmer–Lemeshow test and its value was 0.092. Given the fact that the value of this parameter is greater than 0.05, the model obtained is valid (Pukkala and Kellomäki 2012). In addition, the other criterion was ROC, which was 0.81 and indicates relatively robust predictions. The correct prediction of the survival model was 92% if 0.5 was used as a threshold for survival. In this model, the diameter and basal area and their transformations were among the factors that had a high impact on the model, respectively, while the physiographic factors in this model had no effect.
Models of ingrowth predict the development of trees from the sapling stage instead of predicting seedling development or trying to evaluate the variety of factors that influence the process of forest stand rejuvenation (Ma et al. 2019). One of the benefits of this approach is that the time needed for establishment of regeneration in the stand after the reduction of stand density due to harvesting allows it to be more realistic (Gould et al. 20062007). Regarding the results, the ingrowth model was generally reasonable and was more reliable than other models (Fig. 5). The ANN showed that MLP approach had highest accuracy and lowest bias (Table 8). Ingrowth increased with the basal area of stand, which is a similar finding to results of Trasobares et al. (2004) who showed that the basal area had a major role in regeneration modeling. In this study, the ANN trial-and-error procedure showed that depending on the input variables, four to ten hidden layers resulted in the best performance. However, the number of neurons on the hidden layer varied based on the number of input variables. Some researchers have suggested that the number of neurons on the hidden layer should be more than twice that of the input neurons (Liu et al. 2013; Zhu et al. 2018). Although other researchers found that the number of hidden layers and their neurons is totally dependent on the size of the data, which always leads to a trial and error procedure or application of optimization techniques (Karaboga and Kaya 2018).
Considering the potential of ANN in forest measurements and modeling, studies like Vendruscolo et al. (2017), Çatal and Saplioğlu (2018), Reis et al. (2018), Sanquetta et al. (2018) and Vieira et al. (2018) have found that they generally perform better than regression models, while they can be estimated with higher speeds and result in more precise models. Thereby, in order to minimize the errors in growth models estimation in uneven-aged forest, such as the Hyrcanian forest, the use of neuron network techniques is very important, (Aertsen et al. 2010; Breiman 2001; Cano et al. 2017; Görgens et al. 2015; Ozçelik et al. 2013, 2010; Reis et al. 2018; Siminski 2017; Simões and Shaw 2007). In particular, ANNs represent powerful methods for data analysis that can enhance estimation skill (Xu et al. 2014). However, it is important to recognize many potential limitations of nonparametric methods like ANN as they may over fit the data, cannot extrapolate beyond the available training data, and do not guarantee biologically plausible behavior. Consequently, the assessment and evaluation of long-term growth projections from both parametric and nonparametric is needed. This is important as improved model fit statistics like R2 and RMSE does not necessitate better long-term (25 + years) growth projections (e.g., Russell et al. 2011), which underscores the need and importance of robust model forms that might be challenging for nonparametric approaches to ensure.
Conclusion
Growth and yield models for mixed and uneven forests have a very important role in sustainable management. Today, a logical solution cannot be achieved in many planning and policy formulation processes without modeling and simulation. Consequently, this study was aimed at providing a growth model for the primary species in the Hyrcanian forest in order to determine the best condition and the most important factors for their growth that can be used in forest management. In this study, tree-level diameter growth, height, and survival as well as stand-level ingrowth were developed using mixed effects and artificial neural networks. Individual tree growth models are needed in order to determined suitable management regimes for the uneven- aged and mixed Hyrcanian forests.
Results showed the MLP model was more accurate than RBF and we found the ANN approach relatively easy to use and powerful as they significantly outperformed the traditional approaches for predicting diameter growth, height, survival, and ingrowth. Overall, results indicated that growth and yield model performance was consistent with expectations, and that the general fit to the validation data was acceptable. The results also indicated that the models performed relatively well in terms of amount of the variation explained (36–99%). Therefore, they seem quite suitable for predicting tree growth and survival in uneven-aged hardwood stand types in the region where the study area was situated.
According to the general findings, ANNs were capable of accurately and robustly predicting the different tree-level variables needed for effective forest modeling. Therefore, ANN can likely be considered a very promising alternative technique when sufficient data are available for analysis. It is suggested that the artificial neural network method be used in other forest areas to maximize the available accuracy in future studies. In addition, it is important to compare long-term projections using ANNs with actual field data to ensure robust model behavior and performance that is well aligned with biological expectations. Ultimately, the best approach for growth and yield modeling might be the hybridization of parametric and nonparametric methods like ANN that can fully capitalize on the advantages of each method. In general, long-term data collected in the forest with permanent sample plots are one of the most important sources for evaluating growth and yield models. It is suggested that these models be developed for other forests using permanent sample plot data.
References
Adame P, Hynynen J, Cañellas I, del Río M (2008) Individual-tree diameter growth model for rebollo oak (Querscus pyrenaica Willd.) coppices. For Ecol Manag 255:1011–1022
Aertsen W, Kint V, Van Orshoven J, Özkan K, Muys B (2010) Comparison and ranking of different modelling techniques for prediction of site index in Mediterranean mountain forests. Ecol Model 221(8):1119–1130
Ahmadi K, Alavi SJ (2016) Generalized height-diameter models for Fagus orientalis Lipsky in Hyrcanian forest, Iran. J For Sci 62(9):413–421
Ahmadi K, Alavi SJ, Zahedi Amiri G, Hosseini SM, Serra-Diaz MJ, Svenning JC (2020) Patterns of density and structure of natural populations of Taxus baccata in the Hyrcanian forests of Iran. Nordic J Bot 38(3):1–10. https://doi.org/10.1111/njb.02598
Álvarez-González JG, Zingg A, Gadow K (2009) Estimating growth in beech forests—a study based on longterm experiments in Switzerland. Ann For Sci 67:307
Ashraf MI, Zhao Z, Bourque CPA, MacLean DA, Meng FR (2013) Integrating biophysical controls in forest growth and yield predictions with artificial intelligence technology. Can J For Res 43(12):1162–1171
Baskent EZ, Keles S (2005) Spatial forest planning: a review. Ecol Model 188:145–173
Bayat M, Pukkala T, Namiranian M, Zobeiri M (2013) Productivity and optimal management of the uneven-aged hardwood forests of Hyrcania. Eur J Forest Res 132(5–6):851–864
Bayat M, Namiranian M, Zobeiri M, Omid M, Pukkala T (2014) Growth and yield models for uneven–aged and mixed broadleaf forest (Case study: Gorazbon District in Kheyroud Forest, North of Iran). Iran J For Pop Res 22(1):39–50
Bayat M, Ghorbanpour M, Zare R, Jaafari A, Pham BT (2019)a Application of artificial neural networks for predicting tree survival and mortality in the Hyrcanian forest of Iran. Comput Electron Agric 164:104929
Bayat M, Noi PT, Zare R, Bui DT (2019b) A semi-empirical approach based on genetic programming for the study of biophysical controls on diameter-growth of Fagus orientalis in Northern Iran. Remote Sens 11:1680
Bayat M, Bettinger P, Heidari S, Henareh Khalyani A, Jourgholami M, Hamidi SK (2020) Estimation of tree heights in an uneven-aged, mixed forest in northern Iran using artificial intelligence and empirical models. Forests 11:324
Benali L, Notton G, Fouilloy A, Voyant C, Dizene R (2019) Solar radiation forecasting using artificial neural network and random forest methods: application to normal beam, horizontal diffuse and global components. Renew Energy 132:871–884
Bettinger P, Gratez D, Sessions J (2005) A density-dependent stand-level optimization approach for deriving management prescriptions for Interior Northwest (USA) landscapes. For Ecol Manag 217(2–3):171–186
Bettinger P, Merry K, Bayat M, Tomaštík J (2019) GNSS use in forestry—a multi-national survey from Iran, Slovakia and southern USA. Comput Electron Agric 158:369–383
Bourque CPA, Bayat M (2015) Landscape variation in tree species richness in Northern Iran forests. PLoS ONE 10(4):e0121172
Bourque CPA, Bayat M, Zhang C (2019) An assessment of height–diameter growth variation in an unmanaged Fagus orientalis-dominated forest. Eur J For Res 138(4):607–621
Breiman L (2001) Random forests. Mach Learn 45:5–32
Burkhart HE (1990) Status and future of growth and yield models. In: Proceedings of a symposium on state-of the methodology of forest inventory. USDA forest service, PNW GTR, vol 283. pp 409–414
Cañadas-L Á, Andrade-Candell J, Manuel Domínguez-A J, Molina-H C, Schnabel-D O, Vargas-Hernández J, Wehenkel Ch (2018) Growth and yield models for teak planted as living fences in coastal Ecuador. Forests 9:55
Cano G, Garcia-Rodriguez J, Garcia-Garcia A, Perez-Sanchez H, Benediktsson JA, Thapa A, Barr A (2017) Automatic selection of moleculardescriptors using random forest: application to drug discovery. Expert Syst Appl 72:151–159. https://doi.org/10.1016/j.eswa.2016.12.008
Çatal Y, Saplioğlu K (2018) Comparison of adaptive neuro-fuzzy inference system, artificial neural networks and non-linear regression for bark volume estimation in Brutian pine (Pinus brutia ten.). Appl Ecol Environ Res 16(2):2015–2027
Da Rocha SJSS, Torres CMME, Jacovine LAG, Leite HG, Gelcer EM, Neves KM, Zanuncio JC (2018) Artificial neural networks: MODELING tree survival and mortality in the Atlantic forest biome in Brazil. Sci Total Environ 645:655–661
Eerikainen K, Valkonen S, Saksa T (2014) Ingrowth, survival and height growth of small trees in uneven-aged Picea abies stands in southern Finland. For Ecosyst 1:5
Eslami A (2017) Determination the structure of oriental beech, Fagus orientalis Lipsky stands (case study: Asalem watershed forests, north of Iran). Caspian J Environ Sci 15(1):57–66
Flewelling JW, de Jong R (1994) Considerations in simultaneous curve fitting for repeated height-diameter measurements. Can J For Res 24:1408–1414
Gadow KV, Hui GY (1999) Modelling forest development. Kluwer Academic Publishers, Dordrecht
Gould PJ, Steiner KC, Mcdill ME, Finley JC (2006) Modeling seed-origin oak regeneration in the central appalachians. Canad J For Res 36:833-844.
Gould PJ, Fei S, Steiner KC (2007) Modeling sprout-origin oak regeneration in the central Appalachians. Can J For Res 37:170–177
Görgens EB, Montaghi A, Rodriguez LCE (2015) A performance comparison of machine learning methods to estimate the fast-growing forest plantation yield based on laser scanning metrics. Comput Electron Agric 116:221–227. https://doi.org/10.1016/j.compag.2015.07.004
Guan BT, Gertner G (1991) Modeling red pine tree survival with an artificial neural network. For Sci 37:1429–1440
Hamidi K, FallahHosseini Yekani ABMSA (2019) Investigating the diameter and height models of beech trees in uneven age forest of northern Iran (case study: forest Farim). Iran For Ecol 3(11):373–386
Hamidi K, Zenner EK, Bayat M, Fallah A (2020) Analysis of plot-level volume increment models developed from machine learning methods applied to an uneven-aged mixed forest. Ann For Sci (in press)
Hann DW, Marshall DD, Hanus ML (2003) Equation for predicting height- to- crown base, 5-year diameter growth rate, 5-year height growth rate, 5-year mortality rate, and maximum size-density trajectory for Douglas-fir and western hemlock in the coastal region of the Pacific Northwest. Research Contribution 40, Oregon State University, College of Forestry Research Laboratory, Corvallis
Hann DW, Marshall DD, Hanus ML (2006) Reanalysis of the SMC-ORGANON equations for diameter-growth rate, height–growth rate, and mortality rate of Douglas-fir. Research Contribution 49. Oregon State University, Forest Research Laboratory, Corvallis
Härkönen S, Mäkinen A, Tokola T, Rasinmäki J, Kalliovirta J (2010) Evaluation of forest growth simulators with NFI permanent sample plot data from Finland. For Ecol Manag 259:573–589
Hatfield J, Prueger J (2015) Temperature extremes: effect on plant growth and development. Weather Clim Extremes 10:4–10
Ingram JC, Dawson TP, Whittaker RJ (2005) Mapping tropical forest structure in southeastern Madagascar using remote sensing and artificial neural networks. Remote Sens Environ 94(4):491–507
Janizadeh S, Avand M, Jaafari A, Phong TV, Bayat M, Ahmadisharaf E, Prakash I, Pham BT, Lee S (2019) Prediction success of machine learning methods for flash flood susceptibility mapping in the Tafresh Watershed. Iran Sustain 11(19):5426
Kalbi S, Fallah A, Shataee Sh, Bettinger P, Yousefpour R (2019) Growth and yield models for uneven-aged forest stands managed under a selection system in northern Iran. Eurasian J For Sci 7(3):321–333
Karaboga D, Kaya E (2019) Adaptive network based fuzzy inference system (ANFIS) training approaches: a comprehensive survey. Artif Intell Rev 52(4):2263–2293
King SL, Bennett KP, List S (2000) Modeling catastrophic individual tree morality using logistic regression, neural network and support vector machine. Comput Electron Agric 27:401–406
Kuehne C, Russell MB, Weiskittel AR, Kershaw JA Jr (2020) Comparing strategies for representing individual-tree secondary growth in mixed-species stands in the Acadian forest region. For Ecol Manag 459:117823
Kweon D, Comeau PG (2019) Relationships between tree survival, stand structure and age in trembling aspen dominated stands. For Ecol Manag 438:114–122
Lei YC, Zhang SY (2004) Feature and partial derivatives of Bertalanffy–Richards growth model in forestry. Nonlinear Analy Model Control 9(1):65–73
Li R, Weiskittel AR, Kershaw JA Jr (2011) Modeling annualized occurrence, frequency, and composition of ingrowth using mixed-effects zero-inflated models and permanent plots in the Acadian Forest Region of North America. Can J For Res 41(10):2077–2089
Ling J (2010) Dynamics and management of Alaska boreal forest: an all aged multi-species matrix growth model. For Ecol Manag 260:491–501
Liu, Y., Starzyk JA, Zhu Z (2007) Optimizing number of hidden neurons in neural networks. In: Proceedings of the IASTED Internationalconference on artificial intelligence and applications (AIA ’07), pp. 121–126.
Lhotkaa JM, Loewenstein EF (2011) An individual-tree diameter growth model for managed uneven-aged oak-shortleaf pine stands in theOzark Highlands of Missouri, USA. For Ecol Manag 261:770–778
Lumbres IRC, Abino CA, Pampolina MN, Calora GF Jr, Lee YJ (2016) Comparison of stem taper models for the four tropical tree species in Mount Makiling, Philippines. J Mt Sci 13:536–545
Ma P, Hana X, Lina Y, Moore J, Guo Y, Yue M (2019) Exploring the relative importance of biotic and abiotic factors that alter the self-thinning rule: Insights from individual-based modelling and machine learning. Ecol Model 397:16–24
Mehtätalo L, Lappi J (2020) Biometry for forestry and environmental data with examples in R. Taylor & Francis, London
Metcalf C, James E, Clark S, Clark A (2009) Tree growth inference and prediction when the point of measurement changes: Modelling around buttresses in tropical forests. J Trop Ecol 25:1–12
Monserud RA, Sterba H (1999) Modeling individual tree mortality for Austrian forest species. For Ecol Manag 113:109–123
Nagy HM, Watanabe K, Hirano M (2002) Prediction of sediment load concentration in rivers using artificial neural network model. J Hydraul Eng 128:588–595
Nandy S, Singh R, Ghosh S, Watham T, Kushwaha SPS, Kumar AS, Dadhwal VK (2017) Neural network-based modelling for forest biomass assessment. Carbon Manag 8(4):305–317
Ozçelik R, Diamantopoulou JM, Brooks JR, Wiant HV (2010) Estimating tree bole volume using artificial neural network models for four species in Turkey. J Environ Manag 91:742–753
Özçelik R, Diamantopoulou MJ, Crecente-Campo F, Eler F (2013) Estimating Crimean juniper tree height using nonlinear regression and artificial neural network models. For Ecol Manag 306:52–60
Padilla M, Vidala B, Sánchez J, Francisco I (2010) Land-use changes and carbon sequestration through the twentieth century in a Mediterranean mountain ecosystem: implications for land management. J Environ Manag 91:2688–2695
Pereira MSJ, da Marques SML, da Ferreira SE, da Fernandes S, de Ribeiro M, Cabacinha A, Santos JS, Vieira GC, Felix de Almeida MN, Fernandes MR (2019) Computational techniques applied to volume and biomass estimation of trees in Brazilian savanna. J Environ Manag 249:109368. https://doi.org/10.1016/j.jenvman.2019.109368
Pinheiro J, Bates D, DebRoy S, Sarkar D, and R Core Team (2020) nlme: linear and nonlinear mixed effects models. R package version 3.1-148. https://CRAN.R-project.org/package=nlme.
Pokharel B, Dech J (2012) Mixed-effects basal area increment models for tree species in the boreal forest of Ontario, Canada using an ecological land classification approach to incorporate site effects. Forestry 85(2):254–270
Pretzsch H (2009) Forest dynamics, growth and yield. From measurement to model. Springer, Heidelberg
Pretzsch H, Biber P, Dursky J, Gadow KV, Hasenauer H, Kändler G, Kenk G, Kublin E, Nagel J, Pukkala T, Skovsgaard JP, Sodtke R, Sterba H (2002) Recommendations for standardized documentation and further development of forest growth simulators. Forstwissenschaftliches Centralblatt 121:138–151
Pretzsch H, del Río M, Ammer C, Avdagic A, Barbeito I, Bielak K, Brazaitis G, Coll L, Dirnberger G, Drössler L, Fabrika M, Forrester DI, Godvod K, Heym M, Hurt M (2015) Growth and yield of mixed versus pure stands of Scots pine (Pinus sylvestris L.) and European beech (Fagus sylvatica L.) analysed along a productivity gradient through Europe. Eur J For Res 134:927–947
Pukkala T, Kellomäki S (2012) Anticipatory vs. adaptive optimization of stand management when tree growth and timber prices are stochastic. Forestry 85(4):463–472
Pukkala T, Lähde E, Laiho O (2009) Growth and yield models for uneven aged stand in Finland. For Ecol Manag 258:207–216
Pulido-Calvo I, Montesi Nos P, Roldan J, Ruiz-Navarro F (2007) Linear regressions and neural approaches to water demand forecasting in irrigation districts with telemetry systems. Biosyst Eng 97(2):283–293
Reis LP, de Souza AL, Mazzei L, dos Reis PCM, Leite HG, Soares CPB, Ruschel AR (2016) Prognosis on the diameter of individualtrees on the eastern region of the amazon using artificial neural networks. For Ecol Manag 382:161–167
Reis LP, de Souza AL, dos Reis PCM, Mazzei L, Soares CPB, Torres CMME, da Silva LF, Ruschel AR, Rêgo LJS, Leite HG (2018) Estimation of mortality and survival of individual trees after harvesting wood using artificial neural networks in the Amazon rain forest. Ecol Eng 112:140–147
Russell MB, Weiskittel AR, Kershaw JA (2011) Assessing model performance in forecasting long-term individual tree diameter versus basal area increment for the primary Acadian species. Can J For Res 41:2267–2275
Sáncheza CAL, Varela JG, Doradoa FC, Alboreca AR, Soalleiro RR, Gonzalez JGA, Rodriguez FS (2003) A height–diameter model for Pinus radiata D. Don in Galicia (North-west Spain). Ann For Sci 60:237–245
Sanquetta CR, Wojciechowski J, Dalla Corte AP, Behling A, Péllico Netto S, Rodrigues AL, Sanquetta MNI (2015) Comparison of datamining and allometric model in estimation of tree biomass. BMC Bioinformatics 16:247. https://doi.org/10.1186/s12859-015-0662-5
Schumacher FX (1939) A new growth curve and its application to timber yield studies. J For 37:819–820
Schwinning S, Weiner J (1998) Mechanisms determining the degree of size asymmetry in competition among plants. Oecologia 113:447–455
Sharma M, Zhang SY (2004) Height–diameter models using stand characteristics for Pinus banksiana and Picea mariana. Scand J For Res 19:442–451
Silva JPM, da Silva MLM, da Silva EF, da Silva GF, de Mendonça AR, Cabacinha CD, Araújo EF, Santos JS, Vieira GC, de Almeida MNF, de Moura Fernandes MR (2019) Computational techniques applied to volume and biomass estimation of trees in Brazilian savanna. J Environ Manag 249(1):109368
Simões MG, Shaw IS (2007) Controle E modelagem fuzzy, 2nd edn. Edgard Blucher, São Paulo
Siminski K (2017) Interval type-2 neuro-fuzzy system with implication-based inference mechanism. Expert Syst Appl. 79:140–152. https://doi.org/10.1016/j.eswa.2017.02.046
Sirkia S, Heinonen J, Miina J, Eerikainen K (2014) Subject-specific prediction using a nonlinear mixed model: consequences of different approaches. For Sci 61(2):205–212
Stonkova TV (2016) A dynamic whole-stand growth model, derived from allometric relationships. Silva Fennica 50:1406
Strobl RO, Forte F (2007) Artificial neural network exploration of the influential factors in drainage network derivation. Hydrol Process 21:2965–2978
Trasobares A, Pukkala T (2004) Using past growth to improve individual-tree diameter growth models for uneven-aged mixtures Pinus sylvestris L. and Pinus nigra Arn. in Catalonia, north-east Spain. Ann For Sci 61:409–417
Uzoh FCC, Oliver WW (2008) Individual tree diameter increment model for managed even-aged stands of ponderosa pine throughout the western United States using a multilevel linear mixed effects model. For Ecol Manag 256:438–445
Van Dao D, Jaafari A, Bayat M, Mafi-Gholami D, Qi C, Moayedi H, Van Phong T, Ly HB, Le TT, Trinh PT, Luu C (2020) A spatially explicit deep learning neural network model for the prediction of landslide susceptibility. CATENA 188:104451
Vanclay JK (1991) Aggregating tree species to develop diameter increment equations for tropical rain forests. For Ecol Manag 42:143–168
Vanclay JK (1994) Modelling forest growth and yield: application to mixed tropical forests. CAB international, Wallingford
Vendruscolo DGS, Chaves AGS, Medeiros RA, Da Silva RS, Souza HS, Drescher R, Leite HG (2017) Height estimative of Tectona grandis L. f. trees using regression and artificial neural networks. Nativa Pesquisas Agrárias e Ambientais 5(1):52–58
Vieira GC, de Mendonça AR, da Silva GF, Zanetti SS, da Silva MM, dos Santos AR (2018) Prognoses of diameter and height of trees of eucalyptus using artificial intelligence. Sci Total Environ 619:1473–1481
Walling DE, Collins AL, Sichingabula HA, Leeks GJL (2001) Integrated assessment of catchment suspended sediment budgets: a Zambian example. Land Degrad Dev 12:387–415
Weiskittel AR, Garber SM, Johnson GP, Maguire DA, Monserud RA (2007) Annualized diameter and height growth equations for Pacific Northwest plantation-grown Douglas-fir, western hemlock, and red alder. For Ecol Manag 250:266–278
Weiskittel AR, Hann DW, Kershaw JA Jr, Vanclay JK (2011) Forest growth and yield modeling. Wiley, New York
Wilson JS, Oliver CD (2000) Stability and density management in Douglas-fir plantations. Canadian J For Res 30:910–920
Xu H, Sun Y, Wang X, Li Y (2014) Height-diameter models of Chinese fir (Cunninghamia lanceolata) based on nonlinear mixed-effects models in Southeast China. Adv J Food Sci Technol 6(4):445–452
Yagi A, Primicerio M (2014) A modified forest kinematic model. Vietnam J Math Appl 12:107–118
Yang M, Cai T, Ju C et al (2019) Evaluating spatial structure of a mixed broad-leaved/Korean pine forest based on neighborhood relationships in Mudanfeng National Nature Reserve China. J For Res 30(4):1375–1381
Zhao J, He C, Qi C et al (2019) Biomass increment and mortality losses in tropical secondary forests of Hainan, China. J For Res 30:647–655. https://doi.org/10.1007/s11676-018-0624-7
Zhou R, Wu D, Zhou R, Fang L, Zheng X, Lou X (2019) Estimation of DBH at forest stand level based on multi-parameters and generalized regression neural network. Forests 10:778
Zhu XX, Zhou LY (2007) Suspended sediment flux modeling with artificial neural network: An example of the Longchuanjiang River in the Upper Yangtze Catchment, China. Geomorphology 84:111–125
Zhu AX, Miao Y, Wang R, Zhu T, Deng Y, Liu J, Hong H (2018) A comparative study of an expert knowledge-based model and two data-driven models for landslide susceptibility mapping. CATENA 166:317–327
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no competing interests.
Additional information
Communicated by Thomas Knoke.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Hamidi, S.K., Weiskittel, A., Bayat, M. et al. Development of individual tree growth and yield model across multiple contrasting species using nonparametric and parametric methods in the Hyrcanian forests of northern Iran. Eur J Forest Res 140, 421–434 (2021). https://doi.org/10.1007/s10342-020-01340-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10342-020-01340-1