
Abstract
The agroforestry systems (AFS) in the Amazon stand out in the national and international scenario due to the possibility of cultivating tropical forest species of high commercial value as the Brazilian mahogany, concomitantly, has sought to use more robust approaches to quantifying timber volume that does not require the same assumptions as traditional approaches. In this context, this study aimed to develop volumetric equations, by traditional approaches, by mixed modeling, and by machine learning techniques, that accurately estimate the commercial volume of Brazilian mahogany trees in an AFS in Amazon as well as verify whether there are differences in the estimates of these approaches by univariate analysis. For that, 108 trees were sampled in 36 circular plots of 500 m2 to estimate the commercial volume. Volumetric equations were developed from the fit of the Schumacher and Hall volumetric model and Kozak taper, by nonlinear regression, from the application of nonlinear mixed modeling in the most precise traditional model and training of artificial neural network (ANN) and supporting vector machines. The analysis of variance indicated that there was no significant difference between the mean values estimated by the equations developed by the different approaches tested in the inventoried individual data. Nevertheless, it is recommended to use the equation generated by ANN to perform estimations in other populations, because it presented more precise estimates in the test set.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Agroforestry systems are the use of agricultural and forestry species in the same area and are becoming common in tropical regions, because they are able to maintain biodiversity levels between natural forests and purely agricultural uses, by increasing connectivity or sustaining biodiversity in fragmented forest landscapes, using concepts of nutrient cycling, increased fertility, and soil moisture, thus increasing crop yields (Ribaski et al. 2001; Haggar et al. 2019).
In these tropical regions, Amazon rainforest has suffered losses due mainly to deforestation, which has already reached 20% of its original area (Aguiar et al. 2016) and climate change, which causes decreasing in forest resilience, affecting its exuberant biodiversity (Hilker et al. 2014) and pose a threat to many endangered flora species (Sakuragui et al. 2013), being agroforestry systems an appropriate way to use of forest products.
Among these endangered species, we highlight the Swietenia macrophylla King (Brazilian mahogany) which is a shade-tolerant species found in the dryland forests of Brazilian Amazon, with low population density and has been widely exploited in recent decades due to the high commercial value of its timber. The intense exploration and of Brazilian mahogany in natural areas have grown significantly over the years (Souza et al. 2008; Rocha et al. 2016; Milagres and Machado 2016) which makes necessary the creation of legislation for management and exploitation of species.
Nowadays, the way management is practiced makes it more difficult to explore the species in natural forests, as they need a better ecological and silvicultural understanding (Free et al. 2017). The diametric variation of Brazilian mahogany in natural forests in Brazil was from 31 to 121 cm and with an increment in the basal area of 63.1 cm2 year−1 (Cunha et al. 2016). In the Chiquibul Forest reserve located in Belize, the diametric variation of species was 30–60 cm, where the increment in diameter over 10 years was increased by approximately 40% with the cut of lianas. In Indonesia, Brazilian mahogany was the species that showed very slow growth in agroforestry systems getting only 40 cm at 40 years, approximately (Sabastian et al. 2018).
For these reasons, it is important to study the development of Brazilian mahogany in integrated systems with other plant and animal species as an alternative way to use the species (Viégas et al. 2012; Sabastian et al. 2018; Silva et al. 2018a), beyond an excellent long-term production strategy (Santos et al. 2019) due current difficulty of exploring mahogany in natural forest areas.
However, the success of Brazilian mahogany cultivation depends on, beyond appropriate silvicultural practices (Silva et al. 2017), accurate methods for estimating the volume of timber available and improving decision making in the management of the species. The volume equations are among the most traditional estimation methods, requiring normality and independence residues for their estimates (Fernandes et al. 2017), which is not suitable for many data that present structures of more complex variances, such as multiple measures in the same individual, spatial and temporal correlation, hierarchical and nested data (Zuur et al. 2009), demanding the use of more robust methods (Binoti et al. 2016).
Among the most robust methods stand out the mixed-effects modeling, which allows to include random effects and variances structures (Pinheiro and Bates 2000) and machine learning techniques such as artificial neural networks, and support vector machines, which present promising and generally more accurate results in the estimation of wood volume when compared to traditional methods (García Nieto et al. 2012; Bhering et al. 2015; Vahedi 2016). That technique makes possible to include variables that are generally not used in traditional regression fits (Binoti et al. 2014a, b; Araújo Júnior et al. 2019).
Therefore, this research aimed to develop equations that estimate the commercial volume of Brazilian mahogany trees in agroforest systems using traditional nonlinear approaches, mixed nonlinear modeling, and machine learning techniques, as well as comparing the averages of estimates of these approaches by univariate analysis of variance.
Materials and methods
Study area and data collection
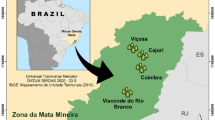
Data on the execution of the study were obtained in the western region of Tomé-Açu municipality, Pará State, Brazil, (02° 29′ 14″ and 02° 30′ 03″ S; 48° 23′ 10″ and 48° 22′ 22″ W), 45 m de altitude (Fig. 1). The climate of the region is Af, rainfall accumulated throughout the year is 2500 mm, without dry season, and the average annual temperature is 26 °C (Alvares et al. 2013). Soil is a dystrophic yellow latosol, according to the Brazilian System of Soil Classification (Santos et al. 2013) which equates to the Xanthic Ferralsol of Food and Agriculture Organization of the United Nations.

Location map of study municipality
Data were measured on Brazilian mahogany trees at 17 years of age, implanted in a 14.65 ha agroforestry system at an 8 × 6 meter spacing. The standing tree was sampled in 36 circular plots of 500 m2, systematically allocated and equidistant in 50 m. The diameter with bark at 1.3 m height (dbhwb), in centimeters, and commercial height (hc), in meters, defined by the first bifurcation, of all trees on the plots were measured and three trees per plot (a total of 108 individuals) were standing scaled to compute the commercial volume by Smalian’s formula (Table 1). These trees represented a diametric distribution of the agroforestry system and ensure sample sufficiency determined by the method proposed by Cochran (1965), considering a sampling error equal to or less than 1%.
The agroforestry system was implemented with scaling species over time, considering the years since the beginning of project: primarily was cultivated the Piper nigrum (kingdom pepper) species during the first 3 years; then Swietenia macrophylla (Brazilian mahogany) and Coco nucifera (coconut) species were implemented from the second and third year, respectively, and, after 9 years was implanted Theobroma cacao (cocoa) species to benefit itself from the shadow of Brazilian mahogany. Individuals from kingdom pepper, coconut, and cocoa were implemented under the spacings of 2.5 m × 2.5 m, 5 m × 7.5 m and 3 m × 3.5 m, respectively.
Volume modeling
The volumetric model of Schumacher and Hall (1933) and the taper model of Kozak et al. (1969) were fitted by nonlinear regression (Eqs. 1, 2, respectively). The first model was fitted for direct estimation of commercial volume and the second to describe the profile of stem, using the “nls” function of the R 3.4.4 software (R Core Team 2018) and, later, the commercial volume was estimated using a numerical integration process (Eq. 3), with the “function”, “integrate”, and “mapply” functions.
\(\hat{v}_{\text{c}}\) is the commercial estimated volume (m3); β0, β1, and β2 were the parameters to be estimated; dbhwb is the diameter with bark at 1.3 m height (cm); hc is commercial height (m); ɛi is the random error (m3); h1 is the lower height measured (m); h the height whose dwb was measured (m); and π is the pi value.
A nonlinear mixed-effects model was applied only in Schumacher and Hall model (Eq. 4), whose criterion for selection was the highest precision in the commercial volume estimation. Moreover, its structure with mixed effects for volume estimation is represented in Eq. 5, where the vector “β” represents the fixed effects common to all individuals and the vector “b” is the random effects specific for each individual for believing that it would increase the volume estimates precision
\(\hat{v}_{\text{c}}\) is the estimated commercial volume (m3); \(\varnothing_{0}\), \(\varnothing_{1}\) and \(\varnothing_{2}\) are the parameters to be estimated; dbhwb is the diameter with bark at 1.3 m height (cm); hc is the commercial height (m), and ɛi the random error (m3).
Given that b ~ N (0, σ2); e ε ~ N (0, σ2I).
The “nlme” function of the “nlme” package (Pinheiro et al. 2018) implemented in software R 3.4.4 was used for mixed-effects modeling, where it was estimated the parameters of fixed-effects and covariance parameters associated with parameters of random effects, more detailed explanation on mixed-effects modeling could be found in the work of Yang et al. (2009).
Artificial neural networks (ANN) and support vector machines (SVM) also were fitted to estimate commercial volume, following the assumptions presented in Haykin (2009) for ANN and Steinwart and Christmann (2008) for SVM. The ANN used in this study was multilayer perceptron type with three layers and feedforward architecture. The input layer consisted of two neurons, dbhwb and hc, in the hidden layer the number of neurons was varied from one to five, and at the output layer, only one neuron was used, referring to vc.
Justified by the simplicity of implementation and interpretation, the hyperbolic tangent function was used as the activation function at the hidden layer and the linear function at output layer. Supervised training was used with the error backpropagation algorithm associated with a descending gradient method. In this algorithm, the error associated with each pair of neurons of the input and output layers is calculated and retro-propagated to fit synaptically and bias weights, aiming to reduce the estimation error (Collazo et al. 2016).
SVM is a system based on mathematical optimization derived from statistical learning (Binoti et al. 2016). It was used to map the training data in high-dimensional spaces, using a kernel function, and then, a linear regression was used to find an optimal hyperplane with a maximum margin of data separation (Sheta et al. 2015; Vapnik 1999). Therefore, were used different values for the cost (C), gamma (γ), and epsilon (ϵ), totaling 2541 trained SVM configurations, resulting from the combination of 21 different values for C (range 90–110, jumps: 1), 11 for γ (range 0.02–0.03, jumps: 0.001), and 11 for ϵ (range 0–0.1, jumps: 0.01), besides radial base function (Eq. 6), only used in the kernel. To optimize the SVM issue (Drucker et al. 1996), the objective error function of type I was used (Eq. 7)
Subject the following restrictions:
where γ is the gamma value; Min is the minimization; w is the coefficient vector; C is the cost value; ξ −i , ξ +i are the gap variables for errors below and above the ε; i is the training case; N is the total number of cases trained; Φ (xi) is the kernel function used; b is the error; yi is the output values; and ϵ is the epsilon value.
Configurations of the SVM were fitted by using dbhwb and hc as input variables and vc as the output. During the training of ANN and SVM, the k-fold cross-validation method was used to avoid overfitting (Jung 2018), with four and ten folds, respectively. Both trainings were performed with functions “h2o.deeplearning” and “svm” functions of the “h2o” (The H2O.ai Team 2017) and “e1071” (Meyer et al. 2017) packages present in the software R 3.4.4.
Statistical analysis
The approaches were compared without bias using data proportionally partitioned by diametric classes (Fig. 2), arranged by the formula proposed by Sturges (1926). For that, were they used approximately 67% and 33% of the data for the fit and test sets, respectively. The goodness-of-fit made by the different approaches in both sets were evaluated by Pearson’s linear correlation coefficient \(\left( {r_{{y\hat{y}}} } \right)\), by the root-mean-square error (RMSE), in percentage, and by standardized residual scatterplot, beyond of Chi-square test (χ2) at the 5% level of significance, used only for test set. Additionally, univariate analysis of variance with a randomized block experimental design was performed to compare the averages of the estimates made by the different approaches tested. In this analysis, we used the approaches that presented adherence by χ2 as treatments repeated ten times in 36 blocks (inventory plots).

Number of trees used for fit and test of the approaches according to the different diametric classes
The use of each plot as a block was based on the explanation of Winer (1962), which explained about single-factor experiments with repeated measures in the same elements. This author cites that one of the primary purposes of experiments in which the same individual is observed under each of the treatments is to provide control over differences between them, in this case, on the plots. As a result, each plot served as its control and the variability attributable to differences between them was eliminated from the experimental error.
Variances of treatments were evaluated for their homogeneity by Bartlett’s test (Bartlett 1937). Once they showed heterogeneous variances, the original values were transformed by Box and Cox’s method (Box and Cox 1964), so that were tested the effects of treatments through Fisher’s test; when it revealed significant differences in at least one of averages, Scott–Knott’s test was used at the 5% level of significance to compare the treatments. In software R 3.4.4, were conducted analyses with the functions “bartlett.test”, “boxcox”, “aov”, and “SK” of packages “stats”, “MASS” (Venables and Riplay 2002), and “ScottKnott” (Jelihovschi et al. 2014).
Results
All parameters of the nonlinear equations and the mixed nonlinear equation displayed a significance of less than 5%, and all the approaches had a Pearson’s coefficient of correlation greater than 0.99, and RMSE values were less than 7.0%, when evaluating the estimations of the fit set (Table 2).
Nonlinear equation of Schumacher and Hall with mixed effects stood out due to better fitting the variability of separate trees for fit since it showed higher \(r_{{y\hat{y}}}\) and lower RMSE; however, Kozak’s nonlinear taper model exhibited the worst fit statistics. In the test sets, measurements indicated less precision with lower \(r_{{y\hat{y}}}\) and higher RMSE, since were used different data sets, on the other hand, the Chi-square test showed adherence between the estimated and observed commercial volumes by all evaluated approaches. Like what happened in the fit, Kozak’s nonlinear taper model presented lower \(r_{{y\hat{y}}}\) and higher RMSE; however, the ANN showed higher \(r_{{y\hat{y}}}\) and lower RMSE.
All approaches showed most of the standardized residue well distributed and ranged between -3 and 3 (Fig. 3). However, residuals from the fit set had a smaller amplitude in the distribution compared to the residuals in the test estimates.

Residual distribution of vc estimated by the evaluated approaches
Residual dispersions of approaches were similarly distributed over most of the amplitude of estimates, except for the Kozak’s nonlinear taper model, corroborating with the fit statistics. However, estimations made on data observed in fit set by Schumacher and Hall equation fitted with mixed-effects modeling tended to underestimate the vc of trees with lowest observed values, and, on the other hand, ANN overestimated them.
It is also observed that the residues of these two approaches showed a more homogeneous distribution in all amplitudes of data estimated for the trees of the test. Because of that and considering test set the most important modeling process for increasing credibility and confidence, the equation generated by ANN with two neurons at the input layer, four neurons at the hidden layer and one neuron at the output layer was considered the most accurate, nevertheless it should be noted that estimates of other approaches provided good precisions. With the weights and bias obtained in the training of the best ANN, Eqs. 8–11 provide the outputs of four neurons in the hidden layer, and vc can be estimated using Eq. 12
where \(\varnothing_{1,2,3,4}\) are the outputs of hidden neurons; dbhwb is the diameter with bark measured at 1.3 m height (cm); hc is the commercial height (m); and \(\hat{v}_{\text{c}}\) is the estimated commercial volume (m3).
Volumes estimated by different approaches showed heterogeneous variances (K = 14.01; pvalue = 0.007), requiring data transformation to homogenize variances and test the effects of treatments by Fisher’s test. The homogenization of variances was affected when using the 0.5050 value in the Box and Cox formula (K = 7.40; pvalue = 0.116). The univariate analysis with the estimated values of commercial volume indicated that there was no significant difference among averages of the estimated commercial volumes by the different approaches (Fcal. = 0.99, pvalue = 0.409), but there was a difference between the plots (Fcal. = 14.75, pvalue < 0.01). The estimated minimum and maximum values were 0.0001 m3 and 0.6383 m3, respectively, with a mean of 0.1748 m3 per tree (Fig. 4), divided into interquartile ranges of 0.1029; 0.1587 and 0.2385 m3 to 25%, 50%, and 75%, respectively.

Variation of vc estimated by different models. ANN is the artificial neural network; KNL is nonlinear Kozak; SHNL is the nonlinear Schumacher and Hall; SHNLM is the mixed nonlinear Schumacher and Hall; and SVM is the support vector machine
Discussion
Equations developed using traditional approaches were viable for estimates of the commercial volume of Brazilian mahogany trees, as well as equations developed with nonlinear mixed-effects approaches, ANN, and SVM, because they all presented accurate estimates of commercial volume. All parameters estimated by traditional methods and mixed effects were significant, which ensures higher accuracy, the better possibility of use in other works with agroforestry system that presents structural characteristics similar to that used in this research, and no multicollinearity among the independent variables used in the fit (Sileshi 2014; Silva and Santana 2014; Siqueira et al. 2017).
The Schumacher and Hall model is used worldwide to model the individual volumetric production of forest species in natural environments (Akindele and LeMay 2006; Gimenez et al. 2015, 2017) or in a monoculture system (Shiver and Brister 1992; Silva et al. 2009; Schikowski et al. 2018) because it was developed to explain the functional relationship of the volume of trees with the variables that are easily measured in the field as diameter at 1.3 m above ground and height. The fit of this model in the original or logarithmic form usually presents significant parameters and good accuracy, as also observed in the present study and Ribeiro et al. (2014) with three species in the National Forest of Tapajós and Cysneiros et al. (2017) with 32 commercial species from the Amazon in Concession forest.
Mixed-effects modeling can generate equations that accurately estimate significantly higher than the precision of equations generated by the least-square method (Crecente-Campo et al. 2010; Gouveia et al. 2015; Sharma et al. 2017) because mixed modeling adds the estimated random parameters to the fixed value of the parameters before estimating. Contrary to this statement, Miguel et al. (2013) suggested that fixed-effects models should be used when calibration data are not available, even comparing with the use of mixed effects.
Randomness generates different parameters for each subsample (Ercanli et al. 2015; Fu et al. 2015; Sharma et al. 2018), that in this research are individuals, even if implanted in a single site and the accuracy of these parameters is influenced by the number of subsamples, with a direct relationship with the quantity used (Fu et al. 2013, 2017). Based on the above, we believe that the parameters estimated in this research are consistent since were used 108 individuals for their estimates. The use of random effects variance components in the fit of the Schumacher and Hall model also increased the accuracy of estimates in the fit set of this study, but there was no gain in accuracy when test set estimates were analyzed.
The use of ANN to estimate the volume of trees has been already reported; however, all studies are not comparable to ours, because they have not worked specifically with Brazilian mahogany in agroforestry systems or natural environmental conditions. Many studies used ANN to model the volume of species of genus Eucalyptus (Soares et al. 2011; Silva et al. 2018b; Tavares Júnior et al. 2019), of species of genus Pinus (Diamantopoulou 2005; Diamantopoulou and Milios 2010; Çatal and Saplioğlu 2018), of other species in natural environments or implanted in a monoculture system (Özçelik et al. 2010; Sanquetta et al. 2015, 2017), and this study is the first to train and test an ANN for estimation of the commercial volume of species in an agroforestry system.
In comparative studies with other approaches, the ANN was also more efficient in estimating the commercial volume of trees in the National Forest of Tapajós (Ribeiro et al. 2016) and the estimation of stem form of Araucaria angustifólia (Martins et al. 2017), for example. The ANN superiority about the other approaches is mainly due to the parallel processing of neurons, a noise tolerance, and the high capacity of learning by modeling the complex nonlinear interactions that exist between variables (Zou et al. 2008; Egrioglu et al. 2014; Reis et al. 2018).
The experimental design used was efficient to reduce the experimental error, but it was not enough to identify differences between the averages of estimates made by the approaches. Only results similar to this were found in studies comparing average values of volumes estimated by different approaches via analysis of variance, for example, Correia et al. (2017) compared the volume of wood estimated in ombrophilous dense forest on the coast of Santa Catarina by form factor with the volume estimated by volumetric equation and Lanssanova et al. (2018) compared volumetric estimates obtained by form factor, volumetric models, and taper model for commercial species of the Amazon Forest and found no significant differences.
Nevertheless, it was found that the amplitude of the estimates made by ANN was the smallest when comparing the amplitudes of other approaches and a low value signifies that equation should be sound and effective for estimate the response variable and that the estimates presented lower variance, justifying why the choice of this method as the most accurate. The use of more accurately approach, even if they show a small gain in accuracy, would impact considerable differences in the production of agroforestry system with a large area, for example.
Conclusion
The equation fitted with mixed effects in the Schumacher and Hall model for the estimation of the commercial volume is more accurate than the fitted of traditional form, considering only the fixed effects; however, the artificial neural network presented greater precision, especially in the test data.
No significant differences were found between the averages of the commercial volume estimated by the different methods in the analysis of variance indicating that using the simplest equation, such as the Schumacher and Hall nonlinear equation, can be used to estimate the commercial volume of Brazilian mahogany in agroforestry systems. However, we indicate the use of ANN with two input neurons, four at the hidden layer, and one at the output layer because presented the highest precision.
This is the first study to develop equations for estimating the commercial volume of Brazilian mahogany in an agroforestry system in the Amazon, and the equations can be used and tested in other agroforestry systems and serve as a basis for the management of the species in the Brazilian Amazon.
References
Aguiar APD, Vieira ICG, Assis TO, Dalla-Nora EL, Toledo PM, Santos-Junior RAO, Batistella M, Coelho AS, Savaget EK, Aragão LEOC, Nobre CA, Ometto JPH (2016) Land use change emission scenarios: anticipating a forest transition process in the Brazilian Amazon. Glob Change Biol 22:1821–1840. https://doi.org/10.1111/gcb.13134
Akindele SO, LeMay VM (2006) Development of tree volume equations for common timber species in the tropical rain forest area of Nigeria. For Ecol Manag 226:41–48. https://doi.org/10.1016/j.foreco.2006.01.022
Alvares CA, Stape JL, Sentelhas PC, Gonçalves JLM, Sparovek G (2013) Köppen’s climate classification map for Brazil. Meteorol Z 22:711–728. https://doi.org/10.1127/0941-2948/2013/0507
Araújo Júnior CA, Souza PDD, Assis ALD, Cabacinha CD, Leite HG, Soares CPB, Castro RVO (2019) Artificial neural networks, quantile regression, and linear regression for site index prediction in the presence of outliers. Pesqui Agropecu Bras 54:e00078. https://doi.org/10.1590/S1678-3921.pab2019.v54.00078
Bartlett MS (1937) Properties of sufficiency and statistical tests. Proc R Soc Lond 160:268–282. https://doi.org/10.1098/rspa.1937.0109
Bhering LL, Cruz CD, Peixoto LA, Rosado AM, Laviola BG, Nascimento M (2015) Application of neural networks to predict volume in Eucalyptus. Crop Breed Appl Biotechnol 15:125–131. https://doi.org/10.1590/1984-70332015v15n3a23
Binoti DHB, Binoti MLMS, Leite HG (2014a) Configuração de redes neurais artificiais para estimação do volume de árvores. Rev Ciência da Madeira 5:58–67. https://doi.org/10.12953/2177-6830.v05n01a06
Binoti MLMS, Binoti DHB, Leite HG, Lages S, Garcia R, Ferreira MZ et al (2014b) Redes neurais artificiais para estimação do volume de árvores. Rev Árvore 38:283–288. https://doi.org/10.1590/S0100-67622014000200008
Binoti DHB, Binoti MLMS, Leite HG, Andrade AV, Nogueira GS, Romarco ML et al (2016) Support vector machine to estimate volume of eucalypt trees. Rev Árvore 40:689–693. https://doi.org/10.1590/0100-67622016000400012
Box GEP, Cox DR (1964) An analysis of transformations. J R Soc 26:211–252
Çatal Y, Saplioğlu K (2018) Comparison of adaptive neuro-fuzzy inference system, artificial neural networks and non-linear regression for bark volume estimation in Brutian pine (Pinus brutia Ten.). Appl Ecol Environ Res 16:2015–2027. https://doi.org/10.15666/aeer/1602_20152027
Cochran WG (1965) Sampling techniques. Fundo de Cultura, Rio de Janeiro
Collazo RA, Pessôa LAM, Bahiense L, Pereira BB, Reis AF, Silva NS (2016) A comparative study between artificial neural network and support vector machine for acute coronary syndrome prognosis. Pesqui Oper 6:321–343. https://doi.org/10.1590/0101-7438.2016.036.02.0321
Correia J, Fantini A, Piazza G (2017) Equações volumétricas e fator de forma e de casca para florestas secundárias do litoral de Santa Catarina. Floresta e Ambiente 24:e20150237. https://doi.org/10.1590/2179-8087.023715
Crecente-Campo F, Tomé M, Soares P, Diéguez-Aranda U (2010) A generalized nonlinear mixed-effects height–diameter model for Eucalyptus globulus L. in northwestern Spain. For Ecol Manag 259:943–952. https://doi.org/10.1016/j.foreco.2009.11.036
Cunha TA, Finger CAG, Hasenauer H (2016) Tree basal area increment models for Cedrela, Amburana, Copaifera and Swietenia growing in the Amazon rain forests. For Ecol Manag 365:174–183. https://doi.org/10.1016/j.foreco.2015.12.031
Cysneiros VC, Pelissari AL, Machado SA, Figueiredo-Filho A, Souza L (2017) Modelos genéricos e específicos para estimativa do volume comercial em uma floresta sob concessão na Amazônia. Sci Forest 45:295–304. https://doi.org/10.18671/scifor.v45n114.06
Diamantopoulou MJ (2005) Artificial neural networks as an alternative tool in pine bark volume estimation. Comput Electron Agric 48:235–244. https://doi.org/10.1016/j.compag.2005.04.002
Diamantopoulou MJ, Milios E (2010) Modelling total volume of dominant pine trees in reforestations via multivariate analysis and artificial neural network models. Biosyst Eng 105:306–315. https://doi.org/10.1016/j.biosystemseng.2009.11.010
Drucker H, Burges CJC, Kaufman L, Smola A, Vapnik V (1996) Support vector regression machines. In: Mozer M, Jordan MI, Petsche T (eds) Advances in neural information processing systems, vol 9. Neural Information Processing Systems Foundation, Inc. https://papers.nips.cc/book/advances-in-neural-information-processing-systems-9-1996. Accessed 28 Jan 2019
Egrioglu E, Yolcu U, Aladag CH, Bas E (2014) Recurrent multiplicative neuron model artificial neural network for non-linear time series forecasting. Proc Soc Behav Sci 109:1094–1100. https://doi.org/10.1016/j.sbspro.2013.12.593
Ercanli I, Gunlu A, Başkent EZ (2015) Mixed effect models for predicting breast height diameter from stump diameter of Oriental beech in Göldağ. Sci Agric 72:245–251. https://doi.org/10.1590/0103-9016-2014-0225
Fernandes AMV, Gama JRV, Rode R, Melo LO (2017) Equações volumétricas para Carapa guianensis Aubl. e Swietenia macrophylla King em sistema silvipastoril na Amazônia. Rev Nativa 1:73–77. https://doi.org/10.5935/2318-7670.v05n01a12
Free CM, Grogan J, Schulze MD, Landis RM, Brienen RJ (2017) Current Brazilian forest management guidelines are unsustainable for Swietenia, Cedrela, Amburana, and Copaifera: a response to da Cunha and colleagues. For Ecol Manag 386:81–83. https://doi.org/10.1016/j.foreco.2016.09.031
Fu L, Sun H, Sharma RP, Lei Y, Zhang H, Tang S (2013) Nonlinear mixed-effects crown width models for individual trees of Chinese fir (Cunninghamia lanceolata) in south-central China. For Ecol Manag 302:210–220. https://doi.org/10.1016/j.foreco.2013.03.036
Fu L, Zhang H, Lu J, Lou M, Wang G (2015) Multilevel nonlinear mixed-effect crown ratio models for individual trees of Mongolian Oak (Quercus mongolica) in Northeast China. PLoS ONE 10:e0133294. https://doi.org/10.1371/journal.pone.0133294
Fu L, Sharma RP, Hao K, Tang S (2017) A generalized interregional nonlinear mixed-effects crown width model for Prince Rupprecht larch in northern China. For Ecol Manag 389:364–373. https://doi.org/10.1016/j.foreco.2016.12.034
García Nieto PJ, Torres JM, Fernández MA, Galán CO (2012) Support vector machines and neural networks used to evaluate paper manufactured using Eucalyptus globulus. Appl Math Model 36:6137–6145. https://doi.org/10.1016/j.apm.2012.02.016
Gimenez BO, Danieli FE, Oliveira CKA, Santos J, Higuchi N (2015) Volume equations for merchantable timber species of Southern Roraima State. Sci Forest 43:291–301
Gimenez BO, Santos LT, Gebara J, Celes CHS, Durgante FM, Lima AJN et al (2017) Tree climbing techniques and volume equations for Eschweilera (Matá-Matá), a hyperdominant genus in the Amazon Forest. Forests 8:154–164. https://doi.org/10.3390/f8050154
Gouveia JF, Silva JAA, Ferreira RLC, Gadelha FHL, Lima Filho LMA (2015) Modelos volumétricos mistos em clones de Eucalyptus no polo gesseiro do Araripe, Pernambuco. Floresta 45:587–598. https://doi.org/10.5380/rf.v45i3.36844
Haggar J, Pons D, Saenz L, Vides M (2019) Contribution of agroforestry systems to sustaining biodiversity in fragmented forest landscapes. Agric Ecosyst Environ 283:106567. https://doi.org/10.1016/j.agee.2019.06.006
Haykin S (2009) Neural networks and learning machines. Prentice Hall, Pearson
Hilker T, Lyapustin AI, Tucker CJ, Hall FG, Myneni RB, Wang Y, Bi J, Moura YM, Sellers PJ (2014) Vegetation dynamics and rainfall sensitivity of the Amazon. Proc Natl Acad Sci 111:16041–16046. https://doi.org/10.1073/pnas.1404870111
Jelihovschi EG, Faria JC, Allaman IB (2014) ScottKnott: a package for performing the Scott–Knott clustering algorithm in R. Trends Appl Comput Math 15:3–17. https://doi.org/10.5540/tema.2014.015.01.0003
Jung Y (2018) Multiple predicting k-fold cross-validation for model selection. J Nonparametric Stat 30:197–215. https://doi.org/10.1080/10485252.2017.1404598
Kozak A, Munro DD, Smith JHG (1969) Taper functions and their application in forest inventory. For Chronic 45:278–283
Lanssanova LR, Silva FA, Schons CT, Pereira ACS (2018) Comparação entre diferentes métodos para estimativa volumétrica de espécies comerciais da Amazônia. BIOFIX Sci J 3:109–115. https://doi.org/10.5380/biofix.v3i1.57489
Martins APM, Debastiani AB, Pelissari AL, Machado AS, Sanquetta CR (2017) Estimativa do afilamento do fuste de araucária utilizando técnicas de inteligência artificial. Floresta e Ambiente 24:e20160234. https://doi.org/10.1590/2179-8087.023416
Meyer D, Dimitriadou E, Hornik K, Weingessel A, Leisch F (2017) e1071: Misc functions of the department of statistics, probability theory group (formerly: E1071), TU Wien. https://CRAN.R-project.org/package=e1071. Accessed 28 Jan 2019
Miguel S, Guzmán G, Pukkala T (2013) A comparison of fixed- and mixed-effects modeling in tree growth and yield prediction of an indigenous neotropical species (Centrolobium tomentosum) in a plantation system. For Ecol Manag 291:249–258. https://doi.org/10.1016/j.foreco.2012.11.026
Milagres VAC, Machado ELM (2016) Potential distribution modeling of useful Brazilian trees with economic importance. J Agric Sci Technol 6:400–410. https://doi.org/10.17265/2161-6264/2016.06.005
Özçelik R, Diamantopoulou MJ, Brooks JR, Wiant HV Jr (2010) Estimating tree bole volume using artificial neural network models for four species in Turkey. J Environ Manag 91:742–753. https://doi.org/10.1016/j.jenvman.2009.10.002
Pinheiro J, Bates D (2000) Mixed-effects models in S and S-PLUS. Springer, New York
Pinheiro J, Bates D, Debroy S, Sarkar D, R Core Team (2018) Nlme: linear and nonlinear mixed effects models. https://CRAN.R-project.org/package=nlme. Accessed 15 Jan 2019
R Core Team (2018) R: a language and environment for statistical computing. R Foundation for Statistical Computing, Vienna
Reis LP, Souza AL, Reis PCM, Mazzei L, Soares CPB, Torres CMME et al (2018) Estimation of mortality and survival of individual trees after harvesting wood using artificial neural networks in the amazon rain forest. Ecol Eng 112:140–147. https://doi.org/10.1016/j.ecoleng.2017.12.014
Ribaski J, Montoya LJ, Rodigheri HR (2001) Sistemas Agroflorestais: aspectos ambientais e socioeconômicos. Inf Agropecu 22:61–67. https://www.alice.cnptia.embrapa.br/handle/doc/305995. Accessed 14 July 2019
Ribeiro RBS, Gama JRV, Melo LO (2014) Seccionamento para cubagem e escolha de equações de volume para a Floresta Nacional do Tapajós. Cerne 20:605–612. https://doi.org/10.1590/01047760201420041400
Ribeiro RBS, Gama JRV, Souza AL, Leite HG, Soares CPB, Silva GF (2016) Methods to estimate the volume of stems and branches in the Tapajós National Forest. Rev Árvore 40:81–88. https://doi.org/10.1590/0100-67622016000100009
Rocha JECD, Bentes A, Noronha NC, Gama MAP, Carvalho EJM, Silva AR, Santos CRCD (2016) Organic matter and physical-hydric quality of an oxisol under eucalypt planting and abandoned pasture. Cerne 22:381–388. https://doi.org/10.1590/01047760201622042224
Sabastian GE, Kanowski P, Williams E, Roshetko JM (2018) Tree diameter performance in relation to site quality in smallholder timber production systems in Gunungkidul, Indonesia. Agrofor Syst 92:103–115. https://doi.org/10.1007/s10457-016-0018-9
Sakuragui CM, Calazans LSB, Vaz Stéfano M, Valente ASM, Maurenza D, Kutschenko DC, Prieto PV, Penedo TSA (2013) Meliaceae. In: Martinelli G, Moraes MA (eds) Livro vermelho da flora do Brasil, 1st edn. Instituto de Pesquisas Jardim Botânico do Rio de Janeiro, Rio de Janeiro, pp 697–701. http://www.terrabrasilis.org.br/ecotecadigital/index.php/estantes/pesquisa/2180-livro-vermelho-da-flora-do-brasil. Accessed 10 July 2019
Sanquetta CR, Inoue MN, Corte APD, Netto SL, Mognon F, Wojciechowski J et al (2015) Modeling the apparent volume of bamboo culms from Brazilian plantation. Afr J Agric Res 10:3977–3986. https://doi.org/10.5897/AJAR2014.9176
Sanquetta CR, Piva LRO, Wojciechowski J, Corte APD, Schikowski AB (2017) Volume estimation of Cryptomeria japonica logs in southern Brazil using artificial intelligence models. South For 80:29–36. https://doi.org/10.2989/20702620.2016.1263013
Santos HG, Jacomine PKT, Anjos LHC, Oliveira VA, Lumbreras JF, Coelho MR et al (2013) Sistema brasileiro de classificação de solos. Embrapa, Brasília
Santos PZF, Crouzeilles R, Sansevero JBB (2019) Can agroforestry systems enhance biodiversity and ecosystem service provision in agricultural landscapes? A meta-analysis for the Brazilian Atlantic Forest. For Ecol Manag 433:140–145. https://doi.org/10.1016/j.foreco.2018.10.064
Schikowski AB, Corte APD, Ruza MS, Sanquetta CR, Montaño RANR (2018) Modeling of stem form and volume through machine learning. An Acad Bras Ciênc 90:3389–3401. https://doi.org/10.1590/0001-3765201820170569
Schumacher FX, Hall FS (1933) Logarithmic expression of timber-tree volume. J Agric Res 47:719–734
Sharma RP, Bílek L, Vacek Z, Vacek S (2017) Modelling crown width–diameter relationship for Scots pine in the central Europe. Trees 31:1875–1889. https://doi.org/10.1007/s00468-017-1593-8
Sharma RP, Vacek Z, Vacek S (2018) Generalized nonlinear mixed-effects individual tree crown ratio models for Norway spruce and European beech. Forests 9:555. https://doi.org/10.3390/f9090555
Sheta AF, Ahmed SEM, Faris H (2015) A comparison between regression, artificial neural networks and support vector machines for predicting stock market index. Int J Adv Res Artif Intell 4:55–63. https://doi.org/10.14569/IJARAI.2015.040710
Shiver BD, Brister GH (1992) Tree and stand volume functions for Eucalyptus saligna. For Ecol Manag 47:211–223. https://doi.org/10.1016/0378-1127(92)90275-E
Sileshi GW (2014) A critical review of forest biomass estimation models, common mistakes and corrective measures. For Ecol Manag 329:237–254. https://doi.org/10.1016/j.foreco.2014.06.026
Silva EN, Santana AC (2014) Modelos de regressão para estimação do volume de árvores comerciais, em florestas de Paragominas. Rev Ceres 61:631–636. https://doi.org/10.1590/0034-737X201461050005
Silva MLM, Binoti DHB, Gleriani JM, Leite HG (2009) Ajuste do modelo de Schumacher e Hall e aplicação de redes neurais artificiais para estimar volume de árvores de eucalipto. Rev Árvore 33:1133–1139. https://doi.org/10.1590/S0100-67622009000600015
Silva GR, Viegas IJM, Silva Júnior ML, Gama MAP, Okumura RS, Frazão DAC, Matos GSB, Souza Junior JC, Lima EV, Galvao JR (2017) Growth and mineral nutrition of mahogany (‘Swietenia macrophylla’) seedlings subjected to lime in yellow Alic latosol. Aust J Crop Sci 11:1297–1303. https://search.informit.com.au/documentSummary;dn=404794058619857;res=IELHSS. Accessed 13 July 2019
Silva EC, Gama JRV, Rode R, Coelho ALM (2018a) Tree species growth in a silvipastoral system in Amazon. Afr J Agric Res 13:95–103. https://doi.org/10.5897/AJAR2017.12736
Silva EM Jr, Maia RD, Cabacinha CD (2018b) Bee-inspired RBF network for volume estimation of individual trees. Comput Electron Agric 152:401–408. https://doi.org/10.1016/j.compag.2018.07.036
Siqueira LS, Amaral HF, Correia LF (2017) O efeito do risco de informação assimétrica sobre o retorno de ações negociadas na BM&FBOVESPA. Rev Contab Finanç 28:425–444. https://doi.org/10.1590/1808-057x201705230
Soares FAAMN, Flôres EL, Cabacinha CD, Carrijo GA, Veiga ACP (2011) Recursive diameter prediction and volume calculation of eucalyptus trees using multilayer perceptron networks. Comput Electron Agric 78:19–27. https://doi.org/10.1016/j.compag.2011.05.008
Souza CR, Azevedo CP, Rossi L (2008) Desempenho de espécies florestais para uso múltiplo na Amazônia. Sci Forest 36:7–14. https://www.ipef.br/publicacoes/scientia/nr77/cap01.pdf. Accessed 14 July 2019
Steinwart I, Christmann A (2008) Support vector machines. Springer, New York. https://doi.org/10.1007/978-0-387-77242-4
Sturges HA (1926) The choice of a class interval. J Am Stat Assoc 21:65–66
Tavares Júnior IS, Rocha JEC, Ebling ÂA, Chaves AS, Zanuncio JC, Farias AA et al (2019) Artificial neural networks and linear regression reduce sample intensity to predict the commercial volume of Eucalyptus clones. Forests 10:268. https://doi.org/10.3390/f10030268
The H2O.ai Team (2017) h2o: r interface for H2O. https://CRAN.R-project.org/package=h2o. Accessed 25 Jan 2019
Vahedi AA (2016) Artificial neural network application in comparison with modeling allometric equations for predicting above-ground biomass in the Hyrcanian mixed-beech forests of Iran. Biomass Bioenerg 88:66–76. https://doi.org/10.1016/j.biombioe.2016.03.020
Vapnik VN (1999) An overview of statistical learning theory. IEEE Trans Neural Netw 10:988–999
Venables WN, Riplay BD (2002) Modern applied statistics with S. Springer, New York. https://doi.org/10.1007/978-0-387-21706-2
Viégas IDJM, Lobato ADS, Rodrigues MDS, Cunha RLM, Frazão DAC, Neto CFO, Conceição HEO, Guedes EMS, Alves GAR, Silva SP (2012) Visual symptoms and growth parameters linked to deficiency of macronutrients in young Swietenia macrophylla plants. J Food Agric Environ 10:937–940. https://pdfs.semanticscholar.org/e31d/e295df34145de52199f189b7d30d5263cbd3.pdf?_ga=2.78494036.1570760350.1566330979-1966975036.1566330979. Accessed 14 July 2019
Winer BJ (1962) Single-factor experiments having repeated measures on the same elements. In: Winer BJ (ed) Statistical principles in experimental design. McGraw-Hill, New York
Yang Y, Huang S, Trincado G, Meng SX (2009) Nonlinear mixed-effects modeling of variable-exponent taper equations for lodgepole pine in Alberta, Canada. Eur J Forest Res 128:415–429. https://doi.org/10.1007/s10342-009-0286-2
Zou J, Han Y, So SS (2008) Overview of artificial neural networks. In: Livingstone DJ (ed) Artificial neural networks: methods in molecular biology. Humana Press, New York. https://doi.org/10.1007/978-1-60327-101-1_2
Zuur AF, Ieno EN, Walker NJ, Saveliev AA, Smith GM (2009) Mixed effects models and extensions in ecology with R. Springer, New York. https://doi.org/10.1007/978-0-387-87458-6
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Dolácio, C.J.F., de Oliveira, T.W.G., Oliveira, R.S. et al. Different approaches for modeling Swietenia macrophylla commercial volume in an Amazon agroforestry system. Agroforest Syst 94, 1011–1022 (2020). https://doi.org/10.1007/s10457-019-00468-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10457-019-00468-3