
Abstract
Uniaxial compressive strength (UCS) of rock is crucial for any type of projects constructed in/on rock mass. The test that is conducted to measure the UCS of rock is expensive, time consuming and having sample restriction. For this reason, the UCS of rock may be estimated using simple rock tests such as point load index (I s(50)), Schmidt hammer (R n) and p-wave velocity (V p) tests. To estimate the UCS of granitic rock as a function of relevant rock properties like R n, p-wave and I s(50), the rock cores were collected from the face of the Pahang–Selangor fresh water tunnel in Malaysia. Afterwards, 124 samples are prepared and tested in accordance with relevant standards and the dataset is obtained. Further an established dataset is used for estimating the UCS of rock via three-nonlinear prediction tools, namely non-linear multiple regression (NLMR), artificial neural network (ANN) and adaptive neuro-fuzzy inference system (ANFIS). After conducting the mentioned models, considering several performance indices including coefficient of determination (R 2), variance account for and root mean squared error and also using simple ranking procedure, the models were examined and the best prediction model was selected. It is concluded that the R 2 equal to 0.951 for testing dataset suggests the superiority of the ANFIS model, while these values are 0.651 and 0.886 for NLMR and ANN techniques, respectively. The results pointed out that the ANFIS model can be used for predicting UCS of rocks with higher capacity in comparison with others. However, the developed model may be useful at a preliminary stage of design; it should be used with caution and only for the specified rock types.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Rock strength plays a significant role in any type of geotechnical projects such as slope and tunnels. The uniaxial compressive strength (UCS) of rock may be estimated directly with standard test method suggested by ISRM (International Society for Rock Mechanics) or ASTM (American Standards for Testing Materials). However, some impeding factors, such as obtaining standard intact rock samples especially in highly jointed faulted rock, exist in determination of UCS directly. Further, performing the direct test to measure the UCS of rock is relatively expensive and time consuming as well [1–3]. Due to that, an estimation of the UCS from simple index tests is economic and easier in present. For these purposes, several prediction methods have been developed and published in the literature [1, 4–10]. Some simple and multiple regression analysis techniques have been used for estimating the UCS of rocks [7, 11, 12].
Several researchers have been developed empirical relations to estimate UCS. New relationships between petrographical and engineering properties of granite were proposed in the study conducted by Tugrul and Zarif [4]. They used simple regression analysis to obtain the relationship between the UCS and other rock properties including sonic velocity, I s(50) and Brazilian tensile strength (BTS). Sharma and Singh [8] introduced empirical equations to estimate the impact strength index, slake durability index and UCS from V p. Yagiz [13] used non-destructive test, p-wave velocity, to estimate UCS, Schmidt hardness, modulus of elasticity, water absorption and effective porosity, slake durability index, saturated and dry density of rock. He stated that there is significant relationship between UCS and p-wave velocity of rocks. D’Andrea et al. [14] suggested a linear regression model for predicting UCS using I s(50). Cargill and Shakoor [15] performed test on five different rocks to evaluate the correlations between UCS and the Schmidt hammer, point load, the slake durability and the Los Angeles abrasion test values. Their results indicate that there is a strong correlation between the UCS and I s(50). Singh and Singh [16] obtained the relationship between I s(50) and UCS of quartzites. Kahraman [17] developed the relationship between UCS and some rock parameters like I s(50), Schmidt hammer, sound velocity tests. Young and Rosenbaum [18] developed a reliable model to control the strength and deformability of sandstone using some mineralogical properties. Kahraman and Gunaydin [19] obtained some correlation between the UCS and I s(50) for igneous, metamorphic and sedimentary rocks via regression analysis. Further, Basu and Kamran [20] examined the point load test on schistose rocks and its applicability for estimating UCS. Singh et al. [11] tested and verified the empirical relation between point load index and UCS for some Indian rocks. Empirical relationships to estimate UCS using P-wave velocity were suggested mainly for coal measure rocks in the studies carried out by Singh and Dubey [21] and Singh et al. [22]. Basu and Aydin [23] recommended an empirical relationship between UCS and point load index for Hong Kong Granite. Sharma et al. [24] established some statistical relationship between Schmidt hammer rebound numbers with impact strength index; slake durability index and p-wave velocity. Table 1 shows some published equations to estimate the UCS of rock.
Various researchers have utilized soft computing methods to estimate UCS [10, 43–48] from some rock index properties including point load, p-wave velocity and Schmidt hammer hardness. Sarkar et al. [49] conducted artificial neural network model to predict the UCS and shear strength of different types of rocks using dynamic wave velocity, I s(50), slake durability index and density. Verma and Singh [50] proposed an ANFIS model for predicting p-wave velocity and they emphasized that neuro-fuzzy method shows a good potential to model complex, nonlinear and multivariate problems. Singh and Verma [51] performed a comparative analysis of intelligent algorithms to correlate strength and petrographic properties of some schistose rocks. Singh et al. [52] also published a comprehensive paper on the prediction of UCS by soft computing methods. Yagiz et al. [53] developed model to estimate uniaxial compressive strength of carbonate rock using slake durability and index properties of rocks. They stated that the slake durability index (I d4), p-wave velocity, density and Schmidt hammer values of rocks may be used for estimating the UCS of rocks. Table 2 presents several recent works on the UCS prediction using soft computing techniques.
In this study, several modeling techniques have been used for estimating the uniaxial compressive strength of rocks using various rock properties including Schmidt hardness, p-wave velocity and point load index of rocks. Furthermore, developed models have been discussed and the best model has been chosen to be used for engineering practices.
2 Data source and structure
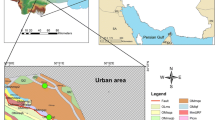
The Pahang–Selangor fresh water tunnel in Malaysia has been investigated to obtain the rock cores to gain the research goals. The tunnel that is crossed under the main mountain range between Pahang and Selangor states is constructed to transfer the fresh water from Pahang state to Selangor and Kuala Lumpur states in the Country. The tunnel is 44.6 km long with a diameter of 5.2 m and a longitudinal gradient of 1/1900. The tunnel is designed to operate under free flow conditions with the maximum 27.6 m3/s of fresh water discharge. 35 km of the tunnel was excavated using three different tunnel boring machines (TBMs), while the remaining tunnel was excavated using the drilling and blasting method. The mentioned TBMs were used to excavate different ground conditions, i.e., mixed ground, very hard ground and blocky ground in Pahang–Selangor fresh water tunnel. Geological map of tunnel site and sampling point along the tunnel is given in Fig. 1. The geological units include granite, metamorphic and some sedimentary rocks as seen in the geological map; however, the most of the rock which is excavated with TBMs and blasting method is composed of granite. To obtain the goal of the study, geotechnical investigation is conducted along the tunnel, and 124 granite block samples were taken from the face of the tunnel in different TBMs site to perform the planned rock testing program. These blocks were taken to the laboratory and the samples were prepared according to the International Society for Rock Mechanics [64]. In this study, representative rock blocks having no defect and discontinuities were collected from site to conduct laboratory tests as much as can be.

Geological map around the tunnel
Afterwards, laboratory tests including Schmidt hammer rebound number (R n), point load index (I s(50)), p-wave velocity (V p) and UCS were carried out on those samples. If the samples were failed along the fractures or any defects, then this test result was extracted and not counted in the dataset since it may not characterize the intact rock strength. Results of the laboratory tests conducted in this study are shown in Table 3. As a result, the established datasets have been used for developing several models by performing different techniques and, then, introduced models are compared to each other for choosing the best model among them.
3 Model constructions
To predict the uniaxial compressive strength of rocks, several methods including simple regression, non-linear multiple regression (NLMR), artificial neural network (ANN) and adaptive neuro-fuzzy inference system (ANFIS) have been utilized herein. The following sections describe modeling procedure of the aforementioned methods to predict the UCS of intact rock like granite. For this purpose, developed data set including R n, I s(50), and V p for 124 samples is used as inputs for purposed models. Afterward, estimated UCS values are compared with actual UCS values obtained from laboratory study.
3.1 Simple regression model and input selection
In this study, first of all, simple regression analyses were conducted to examine the weight of each parameter as input for purposed models. Relevant rock properties that were measured in the laboratory were analyzed to obtain new empirical relations to predict the UCS. In this regard, some equation types such as linear, exponential, power and logarithmic were examined for each predictor as tabulated in Table 4. In this table, values of R 2 were considered to evaluate the capacity performances of the developed empirical equations. In addition, selected equations for each predictor model are highlighted. As result, the best relationship was obtained as exponential, linear and power between the UCS and other rock properties including R n, I s(50), and V p, respectively. The obtained relationships between measured variables and the UCS of rock are given in Figs. 2, 3 and 4. The results revealed that the relationships between the relevant variables and the UCS are statistically meaningful and acceptable. Although gained results are relatively acceptable for predicting UCS, the multiple linear regression analysis was also performed to obtain the best estimation.

Proposed equation for UCS prediction using Schmidt hammer rebound number

Proposed equation for UCS prediction using point load index

Proposed equation for UCS prediction using p-wave velocity
3.2 Non-linear multiple regression model
Multiple regression techniques can be applied to obtain the best-fit equation when more than one input parameter was needed. In common, the objective of this estimation method is to develop a relationship between more than one inputs and outputs. There are two types of multiple regressions, namely linear and non-linear. Using linear multiple regression (LMR) technique, a linear relationship can be achieved between inputs and output parameters, while non-linear multiple regression (NLMR) is an approach to obtain a non-linear relationship between relevant parameters. Many researchers proposed both NLMR and LMR equations for predicting UCS of rock using different rock index properties [1, 10, 42, 48, 65, 66]. In the present study, considering the simple regression analysis, the NLMR equations were introduced and the process was performed via iteration algorithm. The NLMR models were constructed using statistical software package of SPSS version 16 [67] herein. For this purpose, all datasets were normalized using the following equation:
where X min is the minimum value of the measured parameter, X max is the maximum value of the measured parameter, X and X norm are the measured and normalized values in the dataset, respectively. Furthermore, five different datasets were selected randomly for training and testing to develop non-linear models.
The idea behind using some datasets for testing is to check the performance capacity of each model to select the best one. Swingler [68] and Looney [69] suggested that the 20 and 25 % of the all datasets can be used for testing. Also, Nelson and Illingworth [70] stated that the 20 to 30 % of the whole datasets may be used for testing. Considering these suggestions in the literature, 20 % of the database was selected randomly for testing, whereas the remaining 80 % of data were used for training the constructed models. Random data selection for purposed models was performed utilizing the ANN code written by authors. Using the constructed datasets, five NLMR equations have been proposed as listed in Table 5. In these models, Schmidt hardness, point load index and p-wave velocity parameters were utilized as inputs and then the UCS of rock was estimated as function of the mentioned rock properties. While the regression coefficients (R 2) of training dataset that used for modeling were various from 0.747 and 0.789, testing datasets have regression coefficients ranges from 0.471 to 0.706 as in Table 5.
3.3 ANN model
Artificial neural network (ANN) is a soft computing technique inspired by the human-brain information process. A typical ANN consists of three main constituents, namely learning rule, network architecture, and transfer function [71]. There are two major types of ANN: recurrent and feed-forward. Shahin et al. [72] stated that if there is no time-dependent parameter in the ANN, the feed-forward (FF) ANN can be employed. The multi-layer perceptron (MLP) neural network is one of the most well-known FF-ANNs [73]. MLP consists of several nodes or neurons in three layers (input, hidden and output) linked to each other by weights. Du et al. [74] and Kalinli et al. [75] reported on the high efficiency of MLP-ANNs in approximating various functions in high-dimensional spaces. Nevertheless, the ANN needs to be trained before interpreting the results. Among many kinds of learning algorithms to train MLP-FF, the back-propagation (BP) is the most extensively utilized algorithm (Dreyfus, 2005). In a BP-ANN, the imported data in the input layer start to propagate to hidden neurons through connection weights [76]. The input from each neuron in the previous layer, I i, is multiplied by an adjustable connection or weight, W ij . At each node, the sum of the weighted input signals is computed and then this value is added to a threshold value known as the bias value, B ij (Eq. 2). To create the output of the neuron, the combined input, J i , is passed through a non-linear transfer function f (J j ), such as a sigmoidal function (Eq. 3). However, in general, the output of each neuron provides the input to the next layer neuron. This procedure is continued until the output is generated. To achieve the error, the created output is checked against the desired output. The BP training can change the weights between the neurons iteratively in a way that minimizes the root mean square error (RMSE) of the system. More details of the BP algorithm can be seen in the classic artificial intelligence books [77].
In ANN modeling procedure, the same datasets of the NLMR analyses were utilized. The parameters of ANN such as momentum coefficient and learning rate play an important role in the performance capacity of the ANN models. A brief review of the previous studies is required to determine the values of these parameters. If the selected learning rate is small, the training rate will be slow. Because minor changes to weights can be occurred when small values of learning rate are implemented [6, 78]. In addition, fluctuations may happen in the results of training phase caused using large values of learning rate [6, 65]. Different learning rate values have been proposed by several authors. Learning rates of 0.05 and 0.5 were suggested in the studies conducted by Jahed Armaghani et al. [42] and Choobbasti et al. [79], respectively. Yilmaz and Yuksek [56], Erzin and Cetin [80] and Momeni et al. [81] recommended the value of 0.01 for learning rate, while this value was suggested as 0.1 in the study conducted by Yagiz et al. [65]. Apart from learning rate, a steadying effect can be observed by momentum coefficient [82]. Various values have been recommended for momentum coefficient such as 0.95 by Yagiz et al. [65], 0.9 by Jahed Armaghani et al. [42], 0.0–1.0 by Hassoun [83] and Fu [84], 0.4–0.9 by Wyhthoff [85] and close to 1.0 by Henseler [86]. According to the above discussion, it seems that different values of learning rates and the momentum coefficients can be utilized to solve the engineering problems. To determine the proper learning rate and momentum coefficient, a series of sensitivity analyses were performed in this study. Considering the provided information by various researchers and the trial-and-error procedure performed in this study, values of 0.05 and 0.9 were chosen for learning rate and the momentum coefficient, respectively.
Besides, performance of ANN models also depends strongly on the suggested architecture of the network as mentioned in the studies conducted by Hush [87] and Kanellopoulas and Wilkinson [88]. Therefore, determination of the optimal architecture is required to design an ANN model. The network architecture is defined as the number of hidden layer(s) and the number of nodes in each hidden layer(s). According to various researchers (e.g., [89–91]) and considering the results of several studies (e.g., [92, 93]), one hidden layer can solve any complex function in a network. Hence, one hidden layer was chosen to construct the ANN models. In addition, determining neuron number(s) in the hidden layer is the most critical task of the ANN architecture as highlighted in the studies conducted by Sonmez et al. [6] and Sonmez and Gokceoglu [94]. Table 6 presents some proposed equations for determination of number of neuron by several scholars. As mentioned earlier, R n, I s(50), and V p were used as input parameters in the analyses of this study. Based on Table 6, considering three neurons in input layer (N i) and one neuron in output layer (N o), the numbers of neurons that should be used in the hidden layer are in the range of 1 and 7.
To determine the optimum number of neurons in the hidden layer, using 5 randomly selected datasets, 35 ANN models were constructed using one hidden layer and number of hidden neurons of 1 to 7 as shown in Table 7. According to Table 7, considering average R 2 value of both training and testing datasets, model no. 5 with hidden neurons of 5 outperforms the other models. Hence, five was selected as number of hidden neurons in constructing ANN models. It should be noted that only results of R 2 are considered as performance criteria to select the best model. Performance indices of all models with 5 hidden neurons for training and testing datasets are presented in Table 9. Suggested ANN structure in this study is illustrated in Fig. 5. More discussions regarding the selection of the best ANN model to predict UCS will be given in results and discussion section.

Suggested structure of the ANN model
3.4 ANFIS model
ANFIS was developed by Jang [100] based on the Takagi–Sugeno fuzzy inference system (FIS). ANFIS is constructed by a set of if–then fuzzy rules with proper membership functions to produce the required output from the input data. As a universal predictor, ANFIS has the capability of estimating any real continuous functions [101]. In general, an FIS is established based on five functioning blocks:
-
Several if–then fuzzy rules
-
A database to define the membership functions
-
A decision-making element to conduct the inference operations on the rules
-
A fuzzification interface to convert the inputs utilizing linguistic values
-
A defuzzification interface to convert the fuzzy results into an output.
An ANFIS model offers the advantages of both ANN and FIS principles and presents all their benefits in a single framework. An adaptive ANN model involves numbers of nodes connected by directional links, where each node is designated using a node function with fixed or changeable parameters. In these networks, the ANN is employed to determine the unknown relationship between the parameters when the FIS is initialized. This process is called “adaptive”. An adaptive ANN model which involves premise and consequent parts is shown in Fig. 6a, which equates to an FIS (Fig. 6b).

a Sugeno fuzzy model with two rules, b equivalent ANFIS architecture [101]
To describe the modeling procedure through an ANFIS model, it is supposed that the FIS under consideration is composed of two inputs (x, y) and one output (f) and the rule base includes a two fuzzy rule set “if–then” as below:
-
Rule I: if x is A 1 and y is B 1, then f 1 = p 1 x + q 1 y + r 1
-
Rule II: if x is A 2 and y is B 2, then f 2 = p 2 x + q 2 y + r 2
where p i , q i , and r i are the consequent parameters to be settled. According to Jang [100] and Jang et al. [101], an ANFIS model with two inputs, one output, five layers and two rules (see Fig. 6b) can be described as follows:
Layer 1: Each node i in layer 1 produces a membership grade of a linguistic label. For instance, the node function of the ith node is:
in which Q 1 i and x are the membership function and input to node i, respectively. A i is the linguistic label related to node i and σ 1, v i , b i are parameters that make changes in the form of the membership functions. The existing parameters in this layer are related to the premise part, as shown in Fig. 6a.
Layer 2: Each node in layer 2 computes the firing strength of each rule through multiplication:
Layer 3: The ratio of firing strength of the ith rule to the sum of firing strengths of all rules is obtained in this layer.
Layer 4: Every node i in this layer is a node function whereas W i is the output of layer 3. Parameters of this layer are related to the consequent part.
Layer 5: The incoming signals are summed in this layer and form the overall output.
To develop an ANFIS model for prediction of the UCS of rock, results of three index tests including R n, I s(50), and V p were utilized as input parameters. Accordingly, the results of UCS tests were set as the output parameter. The modeling was conducted over a database consisting of 124 datasets. In ANFIS technique, similar to ANN modeling, the best architecture should be determined. To this aim, using a trial-and-error procedure, several ANFIS models were constructed to determine the number of fuzzy rules. The Gaussian, as a well-known membership function in fuzzy systems, was employed for this model [42]. Eventually, each input parameter with 4 fuzzy rules outperforms the other ANFIS models. Therefore, 64 fuzzy rules (4 × 4 × 4) show the best performance for UCS prediction of the rock. In determining the number of fuzzy rules, the results of RMSE were only considered. The linguistic variables for input parameters were set to very low (VL), low (L), high (H) and very high (VH). In this step, considering the suggested ANFIS structure and using randomly selected datasets, five ANFIS models were constructed as shown in Table 9. In addition, these models were checked using the data assigned for testing datasets. Figures 7, 8 and 9 show the normalized membership functions of the input parameters for the ANFIS model. For this model, the RMSE results were not decreased after epoch number of 17. The presented membership functions were assigned after training the system. Furthermore, for the output, a linear type of membership function was utilized. Table 8 shows ANFIS parameters and their values used in the modeling. It should be mentioned that all ANN and ANFIS models in this study were constructed using MatLab version 7.14.0.739 [102].

Membership functions assigned for Schmidt hammer rebound number

Membership functions assigned for point load index

Membership functions assigned for p-wave velocity
4 Results of models performances
From simple regression results, it was found that the models with multi-input parameters may predict UCS with higher degree of accuracy. Therefore, various non-linear techniques namely NLMR, ANN and ANFIS were developed to predict UCS of rocks obtained from the face of the Pahang–Selangor fresh water tunnel in Malaysia. During the modeling process of this study, all 124 datasets were randomly selected to 5 different datasets including training and testing for development of non-linear models. Some performance indices including R 2, variance account for (VAF) and RMSE were computed to check the capacity performance of all predictive models:
where y, y′ and \(\tilde{y}\) are the measured, predicted and mean of the y values, respectively, N is the total number of data and P is the number of predictors. Theoretically, the model will be excellent if the R 2 is one, VAF is 100 and RMSE is zero. Results of models performance indices (R 2, RMSE and VAF) for all randomly selected datasets based on training and testing are presented in Table 9. High performances of the training datasets indicate that the learning process of the predictive models is successful if those of testing datasets reveal that the models generalization ability is satisfactory. As seen in Table 9, selecting the best model for the UCS prediction is quite difficult. To overcome this difficulty, a simple ranking procedure suggested by Zorlu et al. [55] was used to select the best models. A ranking value was calculated and assigned for each training and testing dataset separately (Table 9). Total ranking of training and testing datasets for three non-linear models is shown in Table 10. According to this table, models 2 and 3 exhibited the best performances of UCS prediction for NLMR and ANN techniques, respectively, while model 3 yielded the best results among ANFIS models. When considering both training and testing datasets, the prediction performances of the ANFIS models are higher than those of ANN and NLMR models. The NLMR equation for model 2 is given as follows:
Utilizing the NLMR, ANN and ANFIS methods, the developed relationship between the estimated UCS of granitic rocks and the measured one is given in Figs. 10, 11 and 12 respectively. It is shown that the best prediction model is obtained using the ANFIS technique with regression coefficient of 0.951 and 0.956 for testing and training data in comparison with others including NLMR and ANN as shown in figures.

R 2 of measured and predicted values of UCS for training and testing datasets using NLMR technique

R 2 of measured and predicted values of UCS for training and testing datasets using ANN technique

R 2 of measured and predicted values of UCS for training and testing datasets using ANFIS technique
5 Conclusions
To develop the purposed models, laboratory tests were performed on the rocks obtained from the face of the Pahang–Selangor fresh water tunnel in Malaysia herein. The dataset composed of Schmidt hammer rebound number, point load index, p-wave velocity and UCS properties of granitic rocks. Based on the dataset, several non-linear prediction models were developed for estimating the UCS of granitic rocks. The simple relationship between the UCS and input variables including R n, I s(50) and V p is acceptable and obtained regression coefficients between the UCS and each variable are acceptable. Afterward, non-linear multiple regression model, the ANN and ANFIS techniques were employed for developing the best accurate predictor for estimating the UCS of rocks. Further, the developed models are compared to each other for choosing the best model one. For selecting the best model, obtained regression coefficient and total rank for each model were computed and compared. As considering the testing datasets, the prediction performance of the ANFIS models (R 2 = 0.951) is higher than those of the ANN model (R 2 = 0.886) and NLMR (R 2 = 0.651). Also, considering the training datasets, similar results were also obtained (R 2 = 0.766; 0.867; 0.956, respectively). Further, it is found that the ANFIS model gives best result in comparison with other models according to the total rank method as discussed previously. As a result, it is concluded that each developed model can be used for predicting the UCS of granitic rocks; however, the most accurate result can be obtained using the ANFIS model; however, it is obvious that developed models should be used for similar type of rocks and it is open to be developed.
References
Gokceoglu C, Zorlu K (2004) A fuzzy model to predict the uniaxial compressive strength and the modulus of elasticity of a problematic rock. Eng Appl Artif Intell 17:61–72
Minaeian B, Ahangari K (2013) Estimation of uniaxial compressive strength based on P-wave and Schmidt hammer rebound using statistical method. Arab J Geosci 6:1925–1931
Kahraman S (2014) The determination of uniaxial compressive strength from point load strength for pyroclastic rocks. Eng Geol 170:33–42
Tugrul A, Zarif IH (1999) Correlation of mineralogical and textural characteristics with engineering properties of selected granitic rocks from Turkey. Eng Geol 51:303–317
Sonmez H, Tuncay E, Gokceoglu C (2004) Models to predict the uniaxial compressive strength and the modulus of elasticity for Ankara agglomerate. Int J Rock Mech Min Sci 41(5):717–729
Sonmez H, Gokceoglu C, Nefeslioglu HA, Kayabasi A (2006) Estimation of rock modulus: for intact rocks with an artificial neural network and for rock masses with a new empirical equation. Int J Rock Mech Min Sci 43:224–235
Kahraman S, Gunaydin O, Fener M (2005) The effect of porosity on the relation between uniaxial compressive strength and point load index. Int J Rock Mech Min Sci 42(4):584–589
Sharma PK, Singh TN (2008) A correlation between P-wave velocity, impact strength index, slake durability index and uniaxial compressive strength. Bull Eng Geol Environ 67:17–22
Yagiz S (2009) Predicting uniaxial compressive strength, modulus of elasticity and index properties of rocks using the Schmidt hammer. Bull Eng Geol Environ 68(1):55–63
Yesiloglu-Gultekin N, Gokceoglu C, Sezer EA (2013) Prediction of uniaxial compressive strength of granitic rocks by various nonlinear tools and comparison of their performances. Int J Rock Mech Min Sci 62:113–122
Singh TN, Kainthola A, Venkatesh A (2012) Correlation between point load index and uniaxial compressive strength for different rock types. Rock Mech Rock Eng 45:259–264
Monjezi M, Khoshalan HA, Razifard M (2012) A neuro-genetic network for predicting uniaxial compressive strength of rocks. Geotech Geol Eng 30(4):1053–1062
Yagiz S (2011) P-wave velocity test for assessment of geotechnical properties of some rock materials. Bull Mater Sci 34(4):947–953
D’Andrea DV, Fisher RL, Fogelson DE (1964) Prediction of compression strength from other rock properties. Colo Sch Mines Q 59(4B):623–640
Cargill JS, Shakoor A (1990) Evaluation of empirical methods for measuring the uniaxial compressive strength of rock. Int J Rock Mech Min Sci 27:495–503
Singh VK, Singh DP (1993) Correlation between point load index and compressive strength for quartzite rocks. Geotech Geol Eng 11:269–272
Kahraman S (2001) Evaluation of simple methods for assessing the uniaxial compressive strength of rock. Int J Rock Mech Min Sci 38:981–994
Young Y, Rosenbaum SM (2002) The artificial neural network as a tool for assessing geotechnical properties. Geotech Geol Eng 20:149–168
Kahraman S, Gunaydin O (2009) The effect of rock classes on the relation between uniaxial compressive strength and point load index. Bull Eng Geol Environ 68(3):345–353
Basu A, Kamran M (2010) Point load test on schistose rocks and its applicability in predicting uniaxial compressive strength. Int J Rock Mech Min Sci 47:823–828
Singh TN, Dubey RK (2000) A study of transmission velocity of primary wave (P-wave) in Coal Measures sandstone. J Sci Ind Res 59:482–486
Singh TN, Kanchan R, Saigal K, Verma AK (2004) Prediction of P-wave velocity and anisotropic properties of rock using artificial neural networks technique. J Sci Ind Res 63(1):32–38
Basu A, Aydin A (2006) Predicting uniaxial compressive strength by point load test: significance of cone penetration. Rock Mech Rock Eng 39(5):483–490
Sharma PK, Khandelwal M, Singh TN (2011) A correlation between Schmidt hammer rebound numbers with impact strength index, slake durability index and P-wave velocity. Int J Earth Sci (Geol Rundsch) 100:189–195
Aufmuth RE (1973) A systematic determination of engineering criteria for rocks. Bull Assoc Eng Geol 11:235–245
Singh RN, Hassani FP, Elkington PAS (1983) The application of strength and deformation index testing to the stability assessment of coal measures excavations. In: Proceeding of 24th US symposium on rock mechanics. Texas A and M University AEG, Balkema, Rotterdam, pp 599–609
Sachpazis CI (1990) Correlating Schmidt hardness with compressive strength and Young’s modulus of carbonate rocks. Bull Int Assoc Eng Geol 42:75–83
Xu S, Grasso P, Mahtab A (1990) Use of Schmidt hammer for estimating mechanical properties of weak rock. In: Proceeding of 6th international IAEG Congress, Balkema, Rotterdam, pp 511–519
Yasar E, Erdogan Y (2004) Estimation of rock physiomechanical properties using hardness methods. Eng Geol 71:281–288
Kilic A, Teymen A (2008) Determination of mechanical properties of rocks using simple methods. Bull Eng Geol Environ 67(2):237–244
Sulukcu S, Ulusay R (2001) Evaluation of the block punch index test with particular reference to the size effect, failure mechanism and its effectiveness in predicting rock strength. Int J Rock Mech Min Sci 38:1091–1111
Tsiambaos G, Sabatakakis N (2004) Considerations on strength of intact sedimentary rocks. Eng Geol 72:261–273
Yilmaz I, Yuksek AG (2008) An example of artificial neural network (ANN) application for indirect estimation of rock parameters. Rock Mech Rock Eng 41(5):781–795
Diamantis K, Gartzos E, Migiros G (2009) Study on uniaxial compressive strength, point load strength index, dynamic and physical properties of serpentinites from Central Greece: test results and empirical relations. Eng Geol 108:199–207
Mishra DA, Basu A (2012) Use of the block punch test to predict the compressive and tensile strengths of rocks. Int J Rock Mech Min Sci 51:119–127
Kohno M, Maeda H (2012) Relationship between point load strength index and uniaxial compressive strength of hydrothermally altered soft rocks. Int J Rock Mech Min Sci 50:147–157
Moradian ZA, Behnia M (2009) Predicting the uniaxial compressive strength and static Young’s modulus of intact sedimentary rocks using the ultrasonic test. Int J Geomech 9:1–14
Khandelwal M (2013) Correlating P-wave velocity with the physico-mechanical properties of different rocks. Pure Appl Geophys 170:507–514
Khandelwal M, Singh TN (2009) Correlating static properties of coal measures rocks with P-wave velocity. Int J Coal Geol 79:55–60
Entwisle DC, Hobbs RN, Jones LD, Gunn D, Raines MG (2005) The relationship between effective porosity, uniaxial compressive strength and sonic velocity of intact Borrowdale volcanic group core samples from Sella field. Geotech Geol Eng 23:793–809
Tonnizam Mohamad E, Jahed Armaghani D, Momeni E, Alavi Nezhad Khalil Abad SV (2014) Prediction of the unconfined compressive strength of soft rocks: a PSO-based ANN approach. Bull Eng Geol Environ. doi:10.1007/s10064-014-0638-0
Jahed Armaghani D, Tonnizam Mohamad E, Momeni E, Narayanasamy MS, Mohd Amin MF (2014) An adaptive neuro-fuzzy inference system for predicting unconfined compressive strength and Young’s modulus: a study on Main Range granite. Bull Eng Geol Environ. doi:10.1007/s10064-014-0687-4
Gokceoglu C (2002) A fuzzy triangular chart to predict the uniaxial compressive strength of the Ankara agglomerates from their petrographic composition. Eng Geol 66(1–2):39–51
Karakus M, Tutmez B (2006) Fuzzy and multiple regression modelling for evaluation of intact rock strength based on point load, Schmidt hammer and sonic velocity. Rock Mech Rock Eng 39(1):45–57
Tiryaki B (2008) Predicting intact rock strength for mechanical excavation using multivariate statistics, artificial neural networks, and regression trees. Eng Geol 99:51–60
Baykasoğlu A, Güllü H, Çanakçı H, Özbakır L (2008) Prediction of compressive and tensile strength of limestone via genetic programming. Expert Syst Appl 35(1–2):111–123
Cevik A, Akcapınar-Sezer E, Cabalar AF, Gokceoglu C (2011) Modeling of the uniaxial compressive strength of some clay-bearing rocks using neural network. Appl Soft Comput 11:2587–2594
Dehghan S, Sattari Gh, Chehreh Chelgani S, Aliabadi MA (2010) Prediction of uniaxial compressive strength and modulus of elasticity for Travertine samples using regression and artificial neural networks. Min Sci Technol 20:41–46
Sarkar K, Tiwary A, Singh TN (2010) Estimation of strength parameters of rock using artificial neural networks. Bull Eng Geol Environ 69:599–606
Verma AK, Singh TN (2013) A neuro-fuzzy approach for prediction of longitudinal wave velocity. Neural Comput Appl 22(7–9):1685–1693
Singh TN, Verma AK (2012) Comparative analysis of intelligent algorithms to correlate strength and petrographic properties of some schistose rocks. Eng Comput 28:1–12
Singh R, Vishal V, Singh TN, Ranjith PG (2012) A comparative study of generalized regression neural network approach and adaptive neuro-fuzzy inference systems for prediction of unconfined compressive strength of rocks. Neural Comput Appl 23(2):499–506
Yagiz S, Sezer EA, Gokceoglu C (2012) Artificial neural networks and nonlinear regression techniques to assess the influence of slake durability cycles on the prediction of uniaxial compressive strength and modulus of elasticity for carbonate rocks. Int J Numer Anal Methods 36:1636–1650
Meulenkamp F, Grima MA (1999) Application of neural networks for the prediction of the unconfined compressive strength (UCS) from Equotip hardness. Int J Rock Mech Min Sci 36(1):29–39
Zorlu K, Gokceoglu C, Ocakoglu F, Nefeslioglu HA, Acikalin S (2008) Prediction of uniaxial compressive strength of sandstones using petrography-based models. Eng Geol 96(3–4):141–158
Yilmaz I, Yuksek G (2009) Prediction of the strength and elasticity modulus of gypsum using multiple regression, ANN, and ANFIS models. Int J Rock Mech Min Sci 46(4):803–810
Rabbani E, Sharif F, Koolivand Salooki M, Moradzadeh A (2012) Application of neural network technique for prediction of uniaxial compressive strength using reservoir formation properties. Int J Rock Mech Min Sci 56:100–111
Rezaei M, Majdi A, Monjezi M (2012) An intelligent approach to predict unconfined compressive strength of rock surrounding access tunnels in longwall coal mining. Neural Comput Appl 24(1):233–241
Ceryan N, Okkan U, Kesimal A (2012) Prediction of unconfined compressive strength of carbonate rocks using artificial neural networks. Environ Earth Sci 68(3):807–819
Beiki M, Majdi A, Givshad AD (2013) Application of genetic programming to predict the uniaxial compressive strength and elastic modulus of carbonate rocks. Int J Rock Mech Min Sci 63:159–169
Mishra DA, Basu A (2013) Estimation of uniaxial compressive strength of rock materials by index tests using regression analysis and fuzzy inference system. Eng Geol 160:54–68
Torabi-Kaveh M, Naseri F, Saneie S, Sarshari B (2014) Application of artificial neural networks and multivariate statistics to predict UCS and E using physical properties of Asmari limestones. Arab J Geosci. doi:10.1007/s12517-014-1331-0
Momeni E, Jahed Armaghani D, Hajihassani M, Amin MFM (2015) Prediction of uniaxial compressive strength of rock samples using hybrid particle swarm optimization-based artificial neural networks. Measurement 60:50–63
ISRM (2007) The complete ISRM suggested methods for rock characterization, testing and monitoring: 1974–2006. In: Ulusay R, Hudson JA (eds) Suggested methods prepared by the commission on testing methods, international society for rock mechanics. ISRM Turkish National Group, Ankara, Turkey
Yagiz S, Gokceoglu C, Sezer E, Iplikci S (2009) Application of two non-linear prediction tools to the estimation of tunnel boring machine performance. Eng Appl Artif Intell 22(4):808–814
Yagiz S, Gokceoglu C (2010) Application of fuzzy inference system and nonlinear regression models for predicting rock brittleness. Expert Sys Appl 37(3):2265–2272
SPSS Inc (2007) SPSS for Windows (Version 160). SPSS Inc, Chicago
Swingler K (1996) Applying neural networks: a practical guide. Academic Press, New York
Looney CG (1996) Advances in feed-forward neural networks: demystifying knowledge acquiring black boxes. IEEE Trans Knowl Data Eng 8(2):211–226
Nelson M, Illingworth WT (1990) A practical guide to neural nets. Addison-Wesley, Reading
Simpson PK (1990) Artificial neural system: foundation, paradigms, applications and implementations. Pergamon, New York
Shahin MA, Maier HR, Jaksa MB (2002) Predicting settlement of shallow foundations using neural networks. J Geotech Geoenviron Eng 128(9):785–793
Haykin S (1999) Neural networks, 2nd edn. Prentice-Hall, Englewood Cliffs
Du KL, Lai AKY, Cheng KKM, Swamy MNS (2002) Neural methods for antenna array signal processing: a review. Signal Process 82:547–561
Kalinli A, Acar MC, Gunduz Z (2011) New approaches to determine the ultimate bearing capacity of shallow foundations based on artificial neural networks and ant colony optimization. Eng Geol 117:29–38
Kuo RJ, Wang YC, Tien FC (2010) Integration of artificial neural network and MADA methods for green supplier selection. J Clean Prod 18(12):1161–1170
Fausett LV (1994) Fundamentals of neural networks: architecture, algorithms and applications. Prentice-Hall, Englewood Cliffs
Engelbrecht AP (2007) Computational intelligence: an introduction. Wiley, New York
Choobbasti AJ, Farrokhzad F, Barari A (2009) Prediction of slope stability using artificial neural network (case study: Noabad, Mazandaran, Iran). Arab J Geosci 2(4):311–319
Erzin Y, Cetin T (2013) The prediction of the critical factor of safety of homogeneous finite slopes using neural networks and multiple regressions. Comput Geosci 51:305–313
Momeni E, Nazir R, Jahed Armaghani D, Maizir H (2014) Prediction of pile bearing capacity using a hybrid genetic algorithm-based ANN. Measurement 57:122–131
Negnevitsky M (2002) Artificial intelligence: a guide to intelligent systems. Addison-Wesley, England
Hassoun MH (1995) Fundamentals of artificial neural networks. MIT Press, Cambridge
Fu L (1995) Neural networks in computer intelligence. McGraw-Hill, New York
Wyhthoff BJ (1993) Backpropagation neural networks: a tutorial. Chemom Intell Lab Syst 18:115–155
Henseler J (1995) Backpropagation. In: Braspenning PJ et al (eds) Artificial neural networks, an introduction to ANN theory and practice., Lecture notes in computer scienceSpringer, Berlin, pp 37–66
Hush DR (1989) Classification with neural networks: a performance analysis. In: Proceedings of the IEEE international conference on systems engineering, Dayton, OH, USA, pp 277–280
Kanellopoulas I, Wilkinson GG (1997) Strategies and best practice for neural network image classification. Int J Remote Sens 18:711–725
Hecht-Nielsen R (1987) Kolmogorov’s mapping neural network existence theorem. In: Proceedings of the first IEEE international conference on neural networks, San Diego, CA, USA, pp 11–14
Hornik K, Stinchcombe M, White H (1989) Multilayer feedforward networks are universal approximators. Neural Netw 2:359–366
Baheer I (2000) Selection of methodology for modeling hysteresis behavior of soils using neural networks. J Comput Aid Civil Infrastruct Eng 5(6):445–463
Hajihassani M, Jahed Armaghani D, Sohaei H, Mohamad ET, Marto A (2014) Prediction of airblast-overpressure induced by blasting using a hybrid artificial neural network and particle swarm optimization. Appl Acoust 80:57–67
Jahed Armaghani D, Hajihassani M, Mohamad ET, Marto A, Noorani SA (2014) Blasting-induced flyrock and ground vibration prediction through an expert artificial neural network based on particle swarm optimization. Arab J Geosci 7:5383–5396
Sonmez H, Gokceoglu C (2008) Discussion on the paper by H. Gullu and E. Ercelebi, “A neural network approach for attenuation relationships: an application using strong ground motion data from Turkey. Eng Geol 97:91–93
Ripley BD (1993) Statistical aspects of neural networks. In: Barndoff-Neilsen OE, Jensen JL, Kendall WS (eds) Networks and chaos-statistical and probabilistic aspects. Chapman & Hall, London, pp 40–123
Paola JD (1994) Neural network classification of multispectral imagery. MSc thesis, The University of Arizona, USA
Wang C (1994) A theory of generalization in learning machines with neural application. PhD thesis, The University of Pennsylvania, USA
Masters T (1994) Practical neural network recipes in C++. Academic Press, Boston
Kaastra I, Boyd M (1996) Designing a neural network for forecasting financial and economic time series. Neurocomputing 10:215–236
Jang RJS (1993) ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans Syst Man Cybern 23:665–685
Jang RJS, Sun CT, Mizutani E (1997) Neuro-fuzzy and soft computing. Prentice-Hall, Upper Saddle River
Demuth H, Beale M, Hagan M (2009) MATLAB Version 7.14.0.739; Neural network toolbox for use with Matlab. The Mathworks
Acknowledgments
The authors would like to extend their sincere gratitude to the Pahang–Selangor fresh water tunnel project team, especially to Ir. Dr. Zulkeflee Nordin, Ir. Arshad, the contractor and consultant groups for facilitating this study. Further, the authors wish to express their appreciation to Universiti Teknologi Malaysia for supporting this research.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Jahed Armaghani, D., Tonnizam Mohamad, E., Hajihassani, M. et al. Application of several non-linear prediction tools for estimating uniaxial compressive strength of granitic rocks and comparison of their performances. Engineering with Computers 32, 189–206 (2016). https://doi.org/10.1007/s00366-015-0410-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00366-015-0410-5