
Abstract
The identification problem of closed-loop or feedback nonlinear systems is a hot topic. Based on the hierarchical identification principle, this paper presents a hierarchical stochastic gradient algorithm and a hierarchical multi-innovation stochastic gradient algorithm for feedback nonlinear systems. The simulation results show that the hierarchical multi-innovation stochastic gradient can more effectively estimate the parameters of the feedback nonlinear systems than the hierarchical stochastic gradient algorithm.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The mathematical models are basic for controller design [40, 41]. System identification is the theory and methods of establishing the mathematical models of systems. In general, the identification algorithm is derived by defining and minimizing a cost function [27–29, 38, 39]. Linear system identification has been mature [5, 7], and nonlinear systems have received extensive attention [6, 20, 24]. Nonlinear phenomena and nonlinear systems are ubiquitous. Almost all systems in real world are nonlinear to a certain degree. Recently, a series of estimation algorithms have been reported for nonlinear systems [22, 23, 34]. There are various forms of nonlinear systems. Bai [1] studied Hammerstein–Wiener systems and proposed an optimal two-stage identification algorithm. Li et al. [14] proposed an observer-based adaptive sliding mode control method for nonlinear Markovian jump systems. Bai and Cai [2] designed the identification scheme for nonlinear parametric Wiener system under Gaussian inputs. Wang and Ding [25] presented the recursive parameter and state estimation algorithm for an input nonlinear state space system using the hierarchical identification principle. Wang and Ding [26] discussed the recursive parameter estimation algorithms and convergence for a class of nonlinear systems with colored noise. Wang and Tang [32] tackled the iterative identification problems for a class of nonlinear systems with colored noises. Recently, a new fault detection design scheme was proposed for interval type-2 Takagi–Sugeno fuzzy systems [13]. Ding et al. [8] proposed recursive least squares parameter estimation for a class of output nonlinear systems based on the model decomposition.
Closed-loop control has received much attention [31]. The closed-loop subspace identification algorithms have been applied to various fields [21]. Wei et al. [36] presented a method for sensor fault diagnosis (detection and isolation) applied to large-scale wind turbine systems. The wind turbine model was built for the wind dynamics based on the closed-loop identification technique. On-line order estimation and parameter identification algorithms were presented for linear stochastic feedback control systems [19].
The multi-innovation identification method is effective for identifying systems [35, 42, 43]. In comparison with the previous algorithms, Mao and Ding [17] introduced a multi-innovation stochastic gradient identification algorithm for Hammerstein controlled autoregressive autoregressive systems based on the filtering technique. The multi-innovation identification method can combine with other identification methods to solve complex problems, such as the least squares algorithm [12], the forgetting gradient algorithm [37].
On the basis of the work in [10], this paper presents a hierarchical stochastic gradient algorithm and a hierarchical multi-innovation stochastic gradient algorithm for closed-loop nonlinear systems. The basic idea is, by means of the hierarchical identification principle, to decompose a feedback nonlinear system into two subsystems and to derive a hierarchical stochastic gradient algorithm. This work differs from the hierarchical least squares algorithms in [22] and the multistage least squares-based iterative estimation for feedback nonlinear systems with moving average noises [10].
This paper is organized as follows. Section 2 derives the identification problem for feedback nonlinear systems. Section 3 describes a hierarchical stochastic gradient algorithm. Section 4 presents a hierarchical multi-innovation stochastic gradient algorithm. Two examples are given in Sect. 5 to illustrate the effectiveness of the proposed algorithms. Finally, concluding remarks are offered in Sect. 6.
2 Problem Description
Let us define some notation. “\(X:=A\)” or “\(A=:X\)” means “A is defined as X”; \(\mathbf I\) represents an identity matrix of appropriate sizes; the superscript T denotes the matrix transpose.

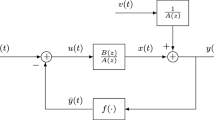
The feedback nonlinear closed-loop system
Consider the following feedback nonlinear stable system in Fig. 1,
where \(r(t)\in {\mathbb {R}}\) is the reference input of the system, \(u(t)\in {\mathbb {R}}\) is the control input of the system, \(\bar{u}(t)\in {\mathbb {R}}\) is the output of the nonlinear block, \(y(t)\in {\mathbb {R}}\) is the system output, \(v(t)\in {\mathbb {R}}\) is a stochastic white noise with zero mean and variance \(\sigma ^2\) and A(z) and B(z) are the polynomials in the shift operator \(z^{-1}\):
Suppose that the nonlinear output \(\bar{u}(t)\) is a linear combination of a known basis \({\varvec{g}}:=(g_1,g_2,\ldots , g_{n_\gamma })\) with unknown coefficients \((\gamma _1, \gamma _2, \ldots , \gamma _{n_\gamma })\) and can be expressed as
Define the parameter vectors \({\varvec{a}}\) and \({\varvec{b}}\) of the linear subsystems and \({\varvec{{\gamma }}}\) of the nonlinear part:
and the information vector and matrix
The right-hand side of (5) contains the product of \({\varvec{b}}\) and \({\varvec{{\gamma }}}\). In order to get the unique parameter estimates, we use the standard constraint on \({\varvec{{\gamma }}}\). In general, assume that the system is stable and \(\Vert {\varvec{{\gamma }}}\Vert =1\) and the first entry of \({\varvec{{\gamma }}}\) is positive, i.e., \(\gamma _1>0\) where the norm of a matrix \({\varvec{X}}\) is defined as \(\Vert {\varvec{X}}\Vert ^2:=\mathrm{tr}[{\varvec{X}}{\varvec{X}}^{\tiny \text{ T }}]\). The method proposed in the paper can be extended to identify the parameters of the system with known controller.
3 The Hierarchical Stochastic Gradient Algorithm
According to the hierarchical identification principle, Eq. (5) can be decomposed into two subsystems, and they contain the parameter vectors \({\varvec{{\gamma }}}\) and \({\varvec{{\theta }}}:=\left[ \begin{array}{c} {\varvec{a}} \\ {\varvec{b}} \end{array} \right] \), respectively.
Define the generalized information vectors \({\varvec{{\phi }}}({\varvec{{\gamma }}},t)\) and \({\varvec{{\psi }}}({\varvec{b}},t)\) and the fictitious output \(y_1(t)\) as
From (5) and (6), we can obtain two subsystems:
Subsystem (7) contains \(n_\gamma \) parameters, and Subsystem (8) contains \(n_a+n_b\) parameters. The vectors \({\varvec{{\gamma }}}\) in \({\varvec{{\phi }}}({\varvec{{\gamma }}},t)\) and \({\varvec{b}}\) in \({\varvec{{\psi }}}({\varvec{b}},t)\) are the associate terms between two subsystems.
Define two criterion functions:
Let \(\hat{{\varvec{{\gamma }}}}(t)\) be the estimate of \({\varvec{{\gamma }}}\) at time t, and \(\hat{{\varvec{{\theta }}}}(t):=\left[ \begin{array}{c} \hat{{\varvec{a}}}(t) \\ \hat{{\varvec{b}}}(t) \end{array} \right] \) be the estimate of \({\varvec{{\theta }}}=\left[ \begin{array}{c} {\varvec{a}} \\ {\varvec{b}} \end{array} \right] \) at time t. Replacing \({\varvec{{\gamma }}}\) with preceding estimate \(\hat{{\varvec{{\gamma }}}}(t-1)\). The gradients of \(J_1({\varvec{{\gamma }}})\) and \(J_2({\varvec{{\theta }}})\) are given by
Using the gradient search and optimizing the criterion functions \(J_1({\varvec{{\gamma }}})\) and \(J_2({\varvec{{\theta }}})\), we can get the following recursive relations:
Furthermore, taking
we can acquire the following stochastic gradient algorithm:
\(\mathrm{sgn}[X]\) is a sign function that extracts the sign of a real number, and we use \(\mathrm{sgn}[\hat{\gamma }_1(t)]\) to stand for the sign of the first element of \(\hat{{\varvec{{\gamma }}}}(t)\) and normalize \(\hat{{\varvec{{\gamma }}}}(t)\) with the first positive element
where the first entry of \({\varvec{{\gamma }}}\) is positive, the initial values \(\Vert \hat{\gamma }(0)\Vert =1\).
Replacing the unknown vectors \({\varvec{a}}\) and \({\varvec{b}}\) in (9) and \({\varvec{{\gamma }}}\) in (12) with their preceding estimates \(\hat{{\varvec{a}}}(t-1)\) and \(\hat{{\varvec{b}}}(t-1)\) and the current estimate \(\hat{{\varvec{{\gamma }}}}(t)\), we can obtain the following hierarchical stochastic gradient algorithm for the feedback nonlinear system (the FN-HSG algorithm for short):
The procedures of computing the parameter estimation vectors \(\hat{{\varvec{{\gamma }}}}(t)\) and \(\hat{{\varvec{{\theta }}}}(t)\) in (15)–(26) are listed in the following.
-
1.
Let \(t=1\), give the data length \(L_e\), and set the initial values \(\Vert \hat{{\varvec{{\gamma }}}}(0)\Vert =1\) with \(\hat{\gamma }_1(0)>0\), \(\hat{{\varvec{{\theta }}}}(0)=\left[ \begin{array}{c} \hat{{\varvec{a}}}(0) \\ \hat{{\varvec{b}}}(0) \end{array} \right] =\mathbf{1}_{n_a+n_b}/p_0\), \(r_1(0)=1\), \(r_2(0)=1\).
-
2.
Collect the input–output data r(t) and y(t), and compute \(r_1(t)\) using (17).
-
3.
Form \({\varvec{{\varphi }}}_y(t)\) using (18), \({\varvec{G}}(t)\) using (20), and compute \({\varvec{{\psi }}}(\hat{{\varvec{b}}}(t-1),t)\) using (19).
-
4.
Update the estimate \(\hat{{\varvec{{\gamma }}}}(t)\) using (15), and normalize \(\hat{{\varvec{{\gamma }}}}(t)\) using (25).
-
5.
Compute \(r_2(t)\) using (22), and form \({\varvec{{\phi }}}(\hat{{\varvec{{\gamma }}}}(t),t)\) using (24).
-
6.
Update the estimate \(\hat{{\varvec{{\theta }}}}(t)\) using (21).
-
7.
If \(t<L_e\), increase t by 1 and go to Step 2. Otherwise, terminate the procedure and obtain the parameter estimates.
The flowchart of computing the parameter estimates \(\hat{{\varvec{{\gamma }}}}(t)\) and \(\hat{{\varvec{{\theta }}}}(t)\) is shown in Fig. 2.

The flowchart for computing the parameter estimates
4 The Hierarchical Multi-Innovation Stochastic Gradient Algorithm
In order to improve the convergence rate and parameter estimation accuracy of the FN-HSG algorithm, based on the algorithm in (15)–(26), according to the multi-innovation identification theory, we expand the scalar innovations \(e_1(t)=y(t)-{\varvec{{\varphi }}}^{\tiny \text{ T }}_y(t)\hat{{\varvec{a}}}(t-1)-{\varvec{{\psi }}}^{\tiny \text{ T }}(\hat{{\varvec{b}}}(t-1), t)\hat{{\varvec{{\gamma }}}}(t-1)\) in (16) and \(e_2(t)=y(t)-{\varvec{{\phi }}}^{\tiny \text{ T }}(\hat{{\varvec{{\gamma }}}}(t),t)\hat{{\varvec{{\theta }}}}(t-1)\) in (22) to the innovation vectors:
where p denotes the innovation length.
Define the stacked output vector \({\varvec{Y}}(p,t)\) and the information matrices, \(\hat{{\varvec{\varPsi }}}(p,t)\) and \(\hat{{\varvec{\varPhi }}}(p,t)\) as
Then, Eqs. (27) and (28) can be expressed as
Equations (15) and (21) can be rewritten as
We can drive the hierarchical multi-innovation stochastic gradient algorithm for feedback nonlinear systems (the FN-HMISG for short) as follows:
The procedures of computing the parameter estimation vectors \(\hat{{\varvec{{\gamma }}}}(t)\) and \(\hat{{\varvec{{\theta }}}}(t)\) in (29)–(43) are listed in the following.
-
1.
Let \(t=1\), give the data length \(L_e\), and set the initial values \(\Vert \hat{{\varvec{{\gamma }}}}(0)\Vert =1\) with \(\hat{\gamma }_1(0)>0\), \(\hat{{\varvec{{\theta }}}}(0)=\left[ \begin{array}{c} \hat{{\varvec{a}}}(0) \\ \hat{{\varvec{b}}}(0) \end{array} \right] =\mathbf{1}_{n_a+n_b}/p_0\), \(r_1(0)=1\), \(r_2(0)=1\).
-
2.
Collect the input–output data r(t) and y(t), and form \({\varvec{Y}}(p,t)\), \({\varvec{{\varphi }}}_y(t)\) and \({\varvec{G}}(t)\) using (36), (38) and (40).
-
3.
Form \({\varvec{{\psi }}}(\hat{{\varvec{b}}}(t-1),t)\), \({\varvec{\varPhi }}_y(p,t)\) and \(\hat{{\varvec{\varPsi }}}(p,t)\) using (35), (37) and (39).
-
4.
Compute \(r_1(t)\) and \({\varvec{E}}_1(p,t)\) using (30) and (31).
-
5.
Update the estimate \(\hat{{\varvec{{\gamma }}}}(t)\) using (29).
-
6.
Form \(\hat{{\varvec{\varPhi }}}(p,t)\) and \({\varvec{{\phi }}}(\hat{{\varvec{{\gamma }}}}(t),t)\) using (41) and (42), and compute \(r_2(t)\) and \({\varvec{E}}_2(p,t)\) using (33) and (34).
-
7.
Update the estimate \(\hat{{\varvec{{\theta }}}}(t)\) using (32).
-
8.
If \(t<L_e\), increase t by 1 and go to Step 2. Otherwise, terminate the procedure and obtain the parameter estimates.
Equations (29)–(43) form the FN-HMISG algorithm for the feedback nonlinear system. Obviously, when \(p=1\), the FN-HMISG algorithm reduces into the FN-HSG algorithm.

The FN-HMISG parameter estimation errors \(\sigma \) versus t (\(\sigma ^2=0.30^2\))
5 Examples
In this section, two examples are given to test the FN-HMISG algorithm.
Example 1
Consider the following nonlinear system:
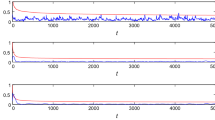
In simulation, the input r(t) is taken as uncorrelated stochastic sequence with zero mean and v(t) as a white noise sequence zero and variance \(\sigma ^2=0.30^2\). Take the data length \(L_e=4000\) and \(\Vert {\varvec{{\gamma }}}\Vert ^2=\gamma _1^2+\gamma _2^2=1\). Applying the FN-HMISG algorithm to estimate the parameters of this nonlinear system, the parameter estimates and their errors are shown in Table 1 with \(p=1\), \(p=2\), \(p=5\) and \(p=7\). The estimation errors \(\delta :=\Vert \hat{{\varvec{{\vartheta }}}}(t)-{\varvec{{\vartheta }}}\Vert /\Vert {\varvec{{\vartheta }}}\Vert \) versus t are shown in Fig. 3.
Furthermore, using the Monte Carlo simulations with 20 sets of noise realizations, the parameter estimates and the variances of the FN-HMISG algorithm are shown in Table 2 with \(\sigma ^2=0.30^2\), \(p=7\) and \(L_e=4000\). From Table 2, we can see that the average values of the parameter estimates are very close to the true parameters.

The FN-HMISG parameter estimation errors \(\sigma \) versus t (\(\sigma ^2=0.30^2\))
Example 2
Consider the following nonlinear system:
The simulation conditions are similar to those in Example 1. We apply the FN-HMISG algorithm to estimate the parameters of this nonlinear system, the parameter estimates and their errors are shown in Table 3 with \(p=1\), \(p=2\), \(p=4\) and \(p=8\), and the estimation errors \(\delta \) versus t are shown in Fig. 4.
From Tables 1 and 3 and Figs. 3 and 4, we can draw the following conclusions.
-
1.
The parameter estimation errors given by the FN-HMISG algorithm are becoming smaller with the innovation length p increasing.
-
2.
The proposed FN-HMISG algorithm becomes more accurate as the data length t increases.
-
3.
The parameter estimates of the FN-HMISG algorithm with \(p > 1\) converge faster to their true values than the parameter estimates of the FN-HSG algorithm.
-
4.
These results confirm that the FN-HMISG algorithm with \(p > 1\) can estimate the parameters more accurately than the FN-HSG algorithm.
6 Conclusions
This paper proposes a hierarchical stochastic gradient algorithm and a hierarchical multi-innovation stochastic gradient algorithm for feedback nonlinear systems. The simulation results indicate that the multi-innovation stochastic gradient algorithm can improve the parameter estimation accuracy compared with the stochastic gradient algorithm. The method used in this paper can be extended to study the identification problems of nonlinear control systems with colored noise [15, 16] and applied to hybrid switching-impulsive dynamical networks [11] or applied to other fields [3, 4, 9, 18, 30, 33].
References
E.W. Bai, An optimal two-stage identification algorithm for Hammerstein–Wiener nonlinear systems. Automatica 34(3), 333–338 (1998)
E. Bai, Z. Cai, How nonlinear parametric Wiener system identification is under Gaussian inputs? IEEE Trans. Automat. Control 57(3), 738–742 (2012)
X. Cao, D.Q. Zhu, S.X. Yang, Multi-AUV target search based on bioinspired neurodynamics model in 3-D underwater environments. IEEE Trans. Neural Netw. Learn. Syst. (2016). doi:10.1109/TNNLS.2015.2482501
Z.Z. Chu, D.Q. Zhu, S.X. Yang, Observer-based adaptive neural network trajectory tracking control for remotely operated Vehicle. IEEE Trans. Neural Netw. Learn. Syst. (2016). doi:10.1109/TNNLS.2016.2544786
F. Ding, X.M. Liu, Y. Gu, An auxiliary model based least squares algorithm for a dual-rate state space system with time-delay using the data filtering. J. Franklin Inst. 353(2), 398–408 (2016)
F. Ding, X.M. Liu, M.M. Liu, The recursive least squares identification algorithm for a class of Wiener nonlinear systems. J. Franklin Inst. 353(7), 1518–1526 (2016)
F. Ding, X.M. Liu, X.Y. Ma, Kalman state filtering based least squares iterative parameter estimation for observer canonical state space systems using decomposition. J. Comput. Appl. Math. 301, 135–143 (2016)
F. Ding, X.H. Wang, Q.J. Chen, Y.S. Xiao, Recursive least squares parameter estimation for a class of output nonlinear systems based on the model decomposition. Circuits Syst. Signal Process. 35(9), 3323–3338 (2016)
L. Feng, M.H. Wu, Q.X. Li et al., Array factor forming for image reconstruction of one-dimensional nonuniform aperture synthesis radiometers. IEEE Geosci. Remote Sens. Lett. 13(2), 237–241 (2016)
P.P. Hu, F. Ding, Multistage least squares based iterative estimation for feedback nonlinear systems with moving average noises using the hierarchical identification principle. Nonlinear Dyn. 73(1–2), 583–592 (2013)
Y. Ji, X.M. Liu, Unified synchronization criteria for hybrid switching-impulsive dynamical networks. Circuits Syst. Signal Process. 34(5), 1499–1517 (2015)
Q.B. Jin, Z. Wang, X.P. Liu, Auxiliary model-based interval-varying multi-innovation least squares identification for multivariable OE-like systems with scarce measurements. J. Process Control 35(11), 154–168 (2015)
H. Li, Y. Gao, P. Shi, H.K. Lam, Observer-based fault detection for nonlinear systems with sensor fault and limited communication capacity. IEEE Trans. Automat. Control (2016). doi:10.1109/TAC.2015.2503566
H. Li, P. Shi, D. Yao, L. Wu, Observer-based adaptive sliding mode control for nonlinear Markovian jump systems. Automatica 64, 133–142 (2016)
H. Li, Y. Shi, W. Yan, On neighbor information utilization in distributed receding horizon control for consensus-seeking. IEEE Trans. Cybern. (2016). doi:10.1109/TCYB.2015.2459719
H. Li, Y. Shi, W. Yan, Distributed receding horizon control of constrained nonlinear vehicle formations with guaranteed \(\gamma \)-gain stability. Automatica 68, 148–154 (2016)
Y.W. Mao, F. Ding, Multi-innovation stochastic gradient identification for Hammerstein controlled autoregressive autoregressive systems based on the filtering technique. Nonlinear Dyn. 79(3), 1745–1755 (2015)
J. Pan, X.H. Yang, H.F. Cai, B.X. Mu, Image noise smoothing using a modified Kalman filter. Neurocomputing 173, 1625–1629 (2016)
R.Y. Ruan, C.L. Yang, H.X. Chen, B. Li, On-line order estimation and parameter identification for linear stochastic feedback control systems. Automatica 39(2), 243–253 (2003)
C. Sun, F.L. Wang, X.Q. He, Robust fault estimation for takagi-sugeno nonlinear systems with time-varying state delay. Circuits Syst. Signal Process. 34(2), 641–661 (2015)
J. van Wingerden, M. Verhaegen, Subspace identification of bilinear and LPV systems for open-and closed-loop data. Automatica 45(2), 372–381 (2009)
D.Q. Wang, Hierarchical parameter estimation for a class of MIMO Hammerstein systems based on the reframed models. Appl. Math. Lett. 57, 13–19 (2016)
D.Q. Wang, F. Ding, Parameter estimation algorithms for multivariable Hammerstein CARMA systems. Inf. Sci. 355–356(10), 237–248 (2016)
Y.J. Wang, F. Ding, Recursive least squares algorithm and gradient algorithm for Hammerstein–Wiener systems using the data filtering. Nonlinear Dyn. 84(2), 1045–1053 (2016)
X.H. Wang, F. Ding, Recursive parameter and state estimation for an input nonlinear state space system using the hierarchical identification principle. Signal Process. 117, 208–218 (2015)
Y.J. Wang, F. Ding, Recursive parameter estimation algorithms and convergence for a class of nonlinear systems with colored noise. Circuits Syst. Signal Process. 35(10), 3461–3481 (2016)
Y.J. Wang, F. Ding, Novel data filtering based parameter identification for multiple-input multiple-output systems using the auxiliary model. Automatica 71, 308–313 (2016)
Y.J. Wang, F. Ding, The filtering based iterative identification for multivariable systems. IET Control Theory Appl. 10(8), 894–902 (2016)
Y.J. Wang, F. Ding, The auxiliary model based hierarchical gradient algorithms and convergence analysis using the filtering technique. Signal Process. 128, 212–221 (2016)
T.Z. Wang, J. Qi, H. Xu et al., Fault diagnosis method based on FFT-RPCA-SVM for cascaded-multilevel inverter. ISA Trans. 60, 156–163 (2016)
J. Wang, A. Sano, D. Shook, T. Chen, B. Huang, A blind approach to closed-loop identification of Hammerstein systems. Int. J. Control 80(2), 302–313 (2007)
C. Wang, T. Tang, Several gradient-based iterative estimation algorithms for a class of nonlinear systems using the filtering technique. Nonlinear Dyn. 77(3), 769–780 (2014)
T.Z. Wang, H. Wu, M.Q. Ni et al., An adaptive confidence limit for periodic non-steady conditions fault detection. Mech. Syst. Signal Process. 72–73, 328–345 (2016)
D.Q. Wang, W. Zhang, Improved least squares identification algorithm for multivariable Hammerstein systems. J. Franklin Inst. 352(11), 5292–5307 (2015)
C. Wang, L. Zhu, Parameter identification of a class of nonlinear systems based on the multi-innovation identification theory. J. Franklin Inst. 352(10), 4624–4637 (2015)
X.K. Wei, M. Verhaegen, T. van Engelen, Sensor fault detection and isolation for wind turbines based on subspace identification and Kalman filter techniques. Int. J. Adapt. Control Signal Process. 24(8), 687–707 (2010)
D.H. Wu, Y.Y. Li, Fault diagnosis of variable pitch for wind turbines based on the multi-innovation forgetting gradient identification algorithm. Nonlinear Dyn. 79(3), 2069–2077 (2014)
L. Xu, The damping iterative parameter identification method for dynamical systems based on the sine signal measurement. Signal Process. 120, 660–667 (2016)
L. Xu, Application of the Newton iteration algorithm to the parameter estimation for dynamical systems. J. Comput. Appl. Math. 288, 33–43 (2015)
L. Xu, A proportional differential control method for a time-delay system using the Taylor expansion approximation. Appl. Math. Comput. 236, 391–399 (2014)
L. Xu, L. Chen, W.L. Xiong, Parameter estimation and controller design for dynamic systems from the step responses based on the Newton iteration. Nonlinear Dyn. 79(3), 2155–2163 (2015)
L. Xu, F. Ding, Recursive least squares and multi-innovation stochastic gradient parameter estimation methods for signal modeling. Circuits Syst. Signal Process (2017). doi:10.1007/s00034-016-0378-4
G. Zhang, X. Zhang, H. Pang, Multi-innovation auto-constructed least squares identification for 4 DOF ship manoeuvring modelling with full-scale trial data. ISA Trans. 58, 186–195 (2015)
Acknowledgments
This work was supported by the National Natural Science Foundation of China (No. 61273194) and the 111 Project (B12018).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Shen, B., Ding, F., Alsaedi, A. et al. Gradient-Based Recursive Identification Methods for Input Nonlinear Equation Error Closed-Loop Systems. Circuits Syst Signal Process 36, 2166–2183 (2017). https://doi.org/10.1007/s00034-016-0394-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-016-0394-4