
Abstract
This paper focuses on iterative parameter estimation methods for a nonlinear closed-loop system (i.e., a nonlinear feedback system) with an equation-error model for the open-loop part. By applying negative gradient search, a gradient-based iterative algorithm is constructed. To reduce the computational costs and improve the parameter estimation accuracy, the hierarchical identification principle is employed to derive a hierarchical gradient-based iterative algorithm. A simulation example is provided to test the effectiveness of the proposed algorithms.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
System identification is the theory and method of establishing mathematical models of linear stochastic systems and nonlinear stochastic systems [2, 69, 79]. As most natural systems have nonlinear behaviors, the identification and modeling of nonlinear systems are meaningful [29,30,31,32,33]. Common nonlinear systems include Hammerstein systems, Wiener systems and Wiener-Hammerstein systems. Over the past several decades, a dozen studies have been conducted on identification methods for nonlinear systems. In [1], the estimating function approach was introduced, which can construct estimators that are asymptotically optimal with respect to a specific class of estimators for the identification of nonlinear stochastic dynamical models. Li et al. proposed a linear variable weight particle swarm method for Hammerstein-Wiener nonlinear systems with unknown time delay by utilizing the parallel search ability of the particle swarm optimization and the iterative identification technique [46].
Nonlinear systems can be constructed from dynamical linear subsystems and static nonlinear elements in many different ways, including series, parallel and feedback connections [23, 35, 58]. Here, we focus on a class of nonlinear feedback systems whose forward channels are dynamical linear subsystems and feedback channels are static nonlinearities. Recently, many publications have been devoted to studying the estimation and application of feedback nonlinear systems [20, 21]. For example, Wei et al. derived an overall recursive least squares algorithm and an overall stochastic gradient algorithm to estimate nonlinear feedback systems disturbed by white noise [93]. Based on filtering technology, a linear filter was constructed to convert the colored noise into white noise and a filtering-based multi-innovation stochastic gradient algorithm was obtained deduced for Hammerstein equation-error autoregressive systems [70] by employing the multi-innovation theory [47,48,49,50,51].
In the area of parameter estimation, the iterative technique is an effective tool that has been widely applied to optimize the parameters of the estimated models [41,42,43]. In contrast to recursive algorithms, iterative algorithms use batch data at each iteration and make full use of measurement data, which can improve parameter estimation accuracy [38,39,40]. By combining different search principles, various iterative algorithms can be formed, such as the least squares-based iterative algorithm, the gradient-based iterative algorithm and the Newton iteration algorithm. Several gradient-based iterative algorithms have been studied in previous works [80, 110]. For instance, Fan et al. presented a two-stage auxiliary model gradient-based iterative algorithm for an input nonlinear controlled autoregressive system with variable-gain nonlinearity [18]. Iterative identification is a class of offline identification methods. To track time-varying parameters in real time, Jiang et al. presented a moving data window gradient-based iterative algorithm for a generalized time-varying system with a measurable disturbance vector [36].
To improve the parameter estimation results, hierarchical identification methods were proposed based on the decomposition-coordination principle of large-scale systems [37, 68]. The basic idea is to reduce the scales of the estimated models through decomposition and to perform joint estimation for the models. In [96,97,98,99,100, 102], a separable multi-innovation Newton iterative signal modeling method was derived and implemented to estimate sine multi-frequency signals and periodic signals, in which the measurements are sampled and used dynamically. Wang et al. proposed a two-stage gradient-based iterative algorithm by minimizing two criterion functions for a fractional-order nonlinear system with autoregressive noise [83]. Hu et al. presented a two-stage recursive least squares algorithm for nonlinear feedback systems based on the auxiliary model identification idea and the hierarchical identification principle [27].
The parameter estimation of system models is important for controller design and filter design [112,113,114,115,116]. Some signal processing filters are designed based on parameter estimation algorithms and some self-tuning control and model-based predicted control methods rely on parameter estimation methods [117,118,119,120,121]. The previous works in [104] discussed the multi-innovation gradient-based iterative identification method and the decomposition multi-innovation gradient-based iterative identification methods for nonlinear feedback systems by using the decomposition technique. This paper studies the gradient-based iterative estimation algorithm and the hierarchical gradient-based iterative estimation algorithm to solve the parameter estimation problems of feedback nonlinear systems. The main contributions of this paper are as follows.
-
To make full use of measurement data to estimate the parameters of the nonlinear feedback systems, we utilize the gradient search principle as the optimization strategy and present a gradient-based iterative (GI) algorithm.
-
The system to be identified can be decomposed into two subsystems based on the hierarchical identification principle. Then, a hierarchical gradient-based iterative (H-GI) algorithm is derived to improve the parameter estimation accuracy.
-
The performance of the proposed algorithms is tested by a numerical example, including the computational costs and the parameter estimation accuracy.
In summary, the rest of this paper is organized as follows. Section 2 describes the identification problem for nonlinear feedback systems. A gradient-based iterative algorithm is derived in Sect. 3. Section 4 presents a hierarchical gradient-based iterative algorithm and analyzes the computational costs of the algorithms. Section 5 provides a numerical example for testing the effectiveness of the proposed algorithms. Finally, some concluding remarks are given in Sect. 6.
This paper studies two iterative estimation algorithms to solve parameter estimation problems for nonlinear feedback systems. The proposed iterative identification algorithms for the nonlinear feedback systems can be combined with other techniques and strategies to address parameter estimation problems for different systems and can be applied to other fields, such as information processing and communication.
2 System Description
Let us introduce some symbols used in this paper. The symbol \({\textbf{I}}_n\) stands for an identity matrix of order n; \(\textbf{1}_n\) stands for an n-dimensional column vector whose elements are 1; the superscript \({\textrm{T}}\) stands for vector/matrix transpose; and the norm of a matrix (or a column vector) \({{\varvec{X}}}\) is defined by \(\Vert {\varvec{X}}\Vert ^2:=\textrm{tr}[{\varvec{X}}{\varvec{X}}^{\textrm{T}}]\).
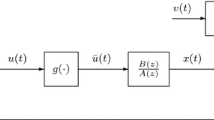
Consider the nonlinear feedback system shown in Fig. 1, where the forward channel is described by a controlled autoregressive (CAR) model:
y(t) is the output of the system, u(t) is the input of the linear part, v(t) is a white noise sequence with zero mean and variance \(\sigma ^2\), and \(y(t)=0\) and \(u(t)=0\) for \(t\leqslant 0\). The feedback channel of the system is a memoryless nonlinear block whose output \(\bar{y}(t)\) can be regarded as a nonlinear function of a known nonlinear basis \({\varvec{h}}:=(h_1,h_2,\cdots ,h_m)\):
where \(q_i\) \((i=1,2,\ldots ,m)\) are the unknown nonlinear coefficients and m is the nonlinear order. The input u(t) of the linear part, the output \(\bar{y}(t)\) of the nonlinear feedback part and the input r(t) of the system have the following relation

The nonlinear feedback CAR system
Define the parameter vectors \({\varvec{a}}\) and \({\varvec{b}}\) of the linear part, and \({\varvec{q}}\) of the nonlinear part as
and define the output information vector \({\varvec{\varphi }}_a(t)\), the input information vector \({\varvec{\varphi }}_b(t)\), and the feedback information matrix \({\varvec{H}}(t)\) as
The parameter identification algorithms proposed in this paper are based on identification model in (4). Many identification methods are derived according to the identification models of the systems [24,25,26, 28, 54, 94, 95, 109], and these methods can be used to estimate the parameters of other linear systems and nonlinear systems [60,61,62,63,64,65,66,67] and can be applied to engineering areas [44, 45, 92, 101, 103,104,105,106] such as information processing and process control systems.
Remark 1
In Equation (4), there is a cross product between parameter vectors \({\varvec{b}}\) in the linear block and \({\varvec{q}}\) in the nonlinear block, which can be called the bilinear-in-parameter identification model. To identify the parameters of the linear part and the nonlinear part, we can decompose the nonlinear feedback system based on the hierarchical identification principle.
Remark 2
This article considers the feedback nonlinear systems disturbed by white noise. In future research, we will consider identification problems with colored noise, i.e., autoregressive noise, moving average noise, autoregressive moving average noise [19, 34, 111] and so on.
3 The Gradient-Based Iterative Algorithm
Based on negative gradient search, this section derives the GI algorithm for estimating the parameters of a nonlinear feedback system from the measurement data.
Define the information vectors \({\varvec{\varphi }}(t)\) and \({\varvec{\varphi }}_m(t)\) and the parameter vector \({\varvec{\vartheta }}\) as
The identification model for the nonlinear feedback system in (4) is given by
Let L be the data length \((L\gg n)\) and define the stacked output vector \({\varvec{Y}}(L)\), the stacked information matrices \({\varvec{\varPsi }}(L)\), \({\varvec{\varPhi }}_a(L)\), \({\varvec{\varPhi }}_b(L)\) and \({\varvec{\varPhi }}_m(L)\) as
Define the criterion function as
We make the following definitions.
-
(i)
\(k=1,2,3,\cdots \) is the iteration variable.
-
(ii)
\(\hat{{\varvec{\vartheta }}}_k\) is the estimate of the parameter vector \({\varvec{\vartheta }}\) at iteration k.
-
(iii)
\(\mu _{1,k}\) is the iteration step-size.
By means of the negative gradient search, and minimizing the criterion function \(J_1({\varvec{\vartheta }})\) with respect to \({\varvec{\vartheta }}\), we can obtain the iterative relation:
where the information matrices \({\varvec{\varPhi }}_m(L)\) in \({\varvec{\varPsi }}(L)\) are unknown. Because the information vector \({\varvec{\varphi }}_m(t)\) in \({\varvec{\varPhi }}_m(L)\) contains the unknown parameter vector \({\varvec{b}}\), Eq. (7) cannot yield the estimate \(\hat{{\varvec{\vartheta }}}_k\) directly. Our approach is to replace the unknown variable \({\varvec{b}}\) in \({\varvec{\varphi }}_m(t)\) with its estimate \(\hat{{\varvec{b}}}_{k-1}\) at the (\(k-1\))\(\mathrm th\) iteration. The estimate \(\hat{{\varvec{\varphi }}}_{m,k}(t)\) of the information vector \({\varvec{\varphi }}_m(t)\) at iteration k is given by
Replacing \({\varvec{\varPhi }}_m(L)\) and \({\varvec{\varPsi }}_k(L)\) with their estimates \(\hat{{\varvec{\varPhi }}}_{m,k}(L)\) and \(\hat{{\varvec{\varPsi }}}_k(L)\) at k, we have
Utilizing the estimate \(\hat{{\varvec{\varPsi }}}_k(L)\) to replace the information matrix \({\varvec{\varPsi }}(L)\) in (7), we obtain
Equation (8) can be seen as a discrete-time system. To ensure the convergence of \(\hat{{\varvec{\vartheta }}}_k\), all the eigenvalues of matrix \([{\varvec{I}}_n-\mu _{1,k}\hat{{\varvec{\varPsi }}}^{\textrm{T}}_k(L)\hat{{\varvec{\varPsi }}}_k(L)]\) must be in the unit circle. Thus, the step-size \(\mu _{1,k}\) can be conservatively chosen as
From the above derivations, we can summarize the GI algorithm for the nonlinear feedback system as
The steps of computing the parameter estimation vector \(\hat{{\varvec{\vartheta }}}_k\) by the GI algorithm in (9)–(24) are listed as follows.
-
1.
To initialize: let \(k=1\), \(\hat{{\varvec{\vartheta }}}_0=[\hat{a}_{1,0},\ldots ,\hat{a}_{n_a,0}, \hat{b}_{1,0},\ldots ,\hat{b}_{n_b,0}, \hat{q}_{1,0},\ldots ,\hat{q}_{m,0}]^{\textrm{T}}\) be any real vector, \(r(t-j)=1/p_0\) and \(y(t-j)=1/p_0\), \(j=1,2,\ldots ,\max [n_a,n_b]\), \(t=1,2,\ldots ,L\), \(p_0=10^6\). Set the data length L (\(L\gg n\)), the parameter estimation precision \(\varepsilon >0\) and the basis function \(h(\cdot )\).
-
2.
Collect the input and output data r(t) and y(t), \(t=1,2,\ldots ,L\), and form \({\varvec{Y}}(L)\) by (11).
-
3.
Form \({\varvec{H}}(t)\) by (20), form \({\varvec{\varphi }}_a(t)\) and \({\varvec{\varphi }}_b(t)\) by (16) and (17), \(t=1,2,\ldots ,L\).
-
4.
Form \({\varvec{\varPhi }}_a(L)\) and \({\varvec{\varPhi }}_b(L)\) by (13) and (14).
-
5.
Compute \(\hat{{\varvec{\varphi }}}_{m,k}(t)\) by (18), form \(\hat{{\varvec{\varphi }}}_k(t)\) by (19), \(t=1,2,\ldots ,l+L\).
-
6.
Form \(\hat{{\varvec{\varPhi }}}_{m,k}(L)\) by (15), form \(\hat{{\varvec{\varPsi }}}_k(L)\) by (12).
-
7.
Select a large step-size \(\mu _{1,k}\) according to (10), and update the parameter estimation vector \(\hat{{\varvec{\vartheta }}}_k\) by (9).
-
8.
Read out the parameter estimation vectors \(\hat{{\varvec{a}}}_k\), \(\hat{{\varvec{b}}}_k\) and \(\hat{{\varvec{q}}}_k\) from \(\hat{{\varvec{\vartheta }}}_k\) in Eq. (21).
-
9.
Compare \(\hat{{\varvec{\vartheta }}}_k\) with \(\hat{{\varvec{\vartheta }}}_{k-1}\): if \(\Vert \hat{{\varvec{\vartheta }}}_k-\hat{{\varvec{\vartheta }}}_{k-1}\Vert >\varepsilon \), increase k by 1 and go to Step 5; otherwise, output the parameter estimate \(\hat{{\varvec{\vartheta }}}_k\), and terminate this iterative calculation process.
Remark 3
The parameter estimation methods proposed in this paper can be combined with other estimation approaches to study parameter estimation problems for linear stochastic systems and nonlinear stochastic systems, and they can be applied to engineering application systems, such as atomic force microscope cantilever modeling, heat exchange processes, and the identification by microwave crystal detectors.
4 The Hierarchical Gradient-Based Iterative Algorithm
Inspired by the hierarchical identification principle, we employ the H-GI algorithm for nonlinear feedback systems to improve parameter estimation accuracy. The feedback nonlinear system in (4) is decomposed into two subsystems, which contain the parameter vectors \({\varvec{{\theta }}}_{1}:=[{\varvec{a}}^{\textrm{T}},{\varvec{b}}^{\textrm{T}}]^{\textrm{T}}\in {\mathbb {R}}^{n_a+n_b}\) and \({\varvec{{\theta }}}_m:={\varvec{q}}\in {\mathbb {R}}^m\).
Define the system information vectors \({\varvec{\varphi }}_{1}(t)\) and \({\varvec{\varphi }}_m(t)\), and the intermediate variable \(y_m\) as
Eq. (4) can be equivalently written as
Let L be the data length \((L \gg n)\) and define the stacked output vectors \({\varvec{Y}}(L)\) and \({\varvec{Y}}_m(L)\), the stacked information matrices \({\varvec{\varPhi }}_{1}(L)\), \({\varvec{\varPhi }}_m(L)\), \({\varvec{\varPhi }}_a(L)\) and \({\varvec{\varPhi }}_b(L)\) as
Define two criterion functions,
Using negative gradient search and the definitions of \({\varvec{Y}}(L)\) and \({\varvec{Y}}_m(L)\), and minimizing the criterion functions \(J_2({\varvec{{\theta }}}_{1})\) and \(J_3({\varvec{{\theta }}}_m)\) with respect to \({\varvec{{\theta }}}_{1}\) and \({\varvec{{\theta }}}_m\), we can obtain the iterative relations:
where \(\mu _{2,k}>0\) and \(\mu _{3,k}>0\) are iterative step-sizes and Eqs. (27)–(28) can be seen as two discrete-time systems. To ensure the convergences of \(\hat{{\varvec{{\theta }}}}_{1,k}\) and \(\hat{{\varvec{{\theta }}}}_{m,k}\), all the eigenvalues of matrices \([{\varvec{I}}_{n_a+n_b}-\mu _{2,k}{\varvec{\varPhi }}^{\textrm{T}}_{1}(L) {\varvec{\varPhi }}_{1}(L)]\) and \([{\varvec{I}}_{m}-\mu _{3,k}{\varvec{\varPhi }}^{\textrm{T}}_m(L){\varvec{\varPhi }}_m(L)]\) must be in the unit circle, that is to say \(\mu _{2,k}\) and \(\mu _{3,k}\) should satisfy \(-{\varvec{I}}_{n_a+n_b}\leqslant {\varvec{I}}_{n_a+n_b}-\mu _{2,k}{\varvec{\varPhi }}^{\textrm{T}}_{1}(L) {\varvec{\varPhi }}_{1}(L)\leqslant {\varvec{I}}_{n_a+n_b}\) and \(-{\varvec{I}}_{m}\leqslant {\varvec{I}}_{m}-\mu _{3,k}{\varvec{\varPhi }}^{\textrm{T}}_m(L){\varvec{\varPhi }}_m(L)\leqslant {\varvec{I}}_{m}\), and the conservative choices of \(\mu _{2,k}\) and \(\mu _{3,k}\) are
where \(\lambda _{\max }[{\varvec{X}}]\) denotes the maximum eigenvalue of the square matrix \({\varvec{X}}\). The right-hand sides of (27)–(28) contain the unknown parameter vectors \({\varvec{{\theta }}}_{1}\), \({\varvec{{\theta }}}_m\) and the unknown information matrices \({\varvec{\varPhi }}_{1}(L)\) and \({\varvec{\varPhi }}_m(L)\), so we cannot directly compute the estimates \(\hat{{\varvec{{\theta }}}}_{1,k}\) and \(\hat{{\varvec{{\theta }}}}_{m,k}\). The solution is to replace \({\varvec{\varPhi }}_{1}(L)\) in (27) with their estimates \(\hat{{\varvec{\varPhi }}}_{1,k}(L)\), and to replace \({\varvec{\varPhi }}_m(L)\), \({\varvec{a}}\) and \({\varvec{b}}\) in (28) with their estimates \(\hat{{\varvec{\varPhi }}}_{m,k}(L)\), \(\hat{{\varvec{a}}}_k\) and \(\hat{{\varvec{b}}}_k\). We can summarize the H-GI algorithm for the nonlinear feedback system as
The methods proposed in this paper can combine some statistical tools and strategies [84,85,86,87] and identification algorithms [59, 81, 82, 89,90,91] to study the parameter estimation algorithms of other linear and nonlinear stochastic systems and can be applied to other fields [13,14,15,16,17, 52,53,54,55,56,57] such as paper-making and chemical engineering systems. The steps of computing the parameter estimation vectors \(\hat{{\varvec{{\theta }}}}_{1,k}\) and \(\hat{{\varvec{{\theta }}}}_{m,k}\) by the H-GI algorithm in (29)–(47) are listed as follows.
-
1.
To initialize: let \(k=1\), \(\hat{{\varvec{{\theta }}}}_{1,0} =[\hat{a}_{1,0},\ldots ,\hat{a}_{n_a,0}, \hat{b}_{1,0},\ldots ,\hat{b}_{n_b,0}]^{\textrm{T}}\), \(\hat{{\varvec{{\theta }}}}_{m,0} =[\hat{q}_{1,0},\ldots ,\hat{q}_{m,0}]^{\textrm{T}}\) be any real vector, \(r(t-j)=1/p_0\) and \(y(t-j)=1/p_0\), \(j=1,2,\ldots ,\max [n_a,n_b]\), \(t=1,2,\ldots ,L\), \(p_0=10^6\). Set the data length L (\(L\gg n\)), the parameter estimation precision \(\varepsilon >0\) and the basis function \(h(\cdot )\).
-
2.
Collect the input and output data r(t) and y(t), \(t=1,2,\ldots ,L\), and form \({\varvec{Y}}(L)\) by (33).
-
3.
Form \({\varvec{H}}(t)\) by (42), and form \({\varvec{\varphi }}_a(t)\) and \({\varvec{\varphi }}_b(t)\) by (40) and (41), \(t=1,2,\ldots ,L\).
-
4.
Compute \(\hat{{\varvec{\varphi }}}_{1,k}(t)\) and \(\hat{{\varvec{\varphi }}}_{m,k}(t)\) by (38) and (39), \(t=1,2,\ldots ,L\).
-
5.
Form \(\hat{{\varvec{\varPhi }}}_{1,k}(L)\) and \(\hat{{\varvec{\varPhi }}}_{m,k}(L)\) by (34) and (35).
-
6.
Select the large step-sizes \(\mu _{2,k}\) and \(\mu _{3,k}\)according to (30) and (32), and update the parameter estimation vectors \(\hat{{\varvec{{\theta }}}}_{1,k}\) and \(\hat{{\varvec{{\theta }}}}_{m,k}\) by (29) and (31).
-
7.
Read out the parameter estimation vectors \(\hat{{\varvec{a}}}_k\) and \(\hat{{\varvec{b}}}_k\) from \(\hat{{\varvec{{\theta }}}}_{1,k}\) in (43), and \(\hat{{\varvec{q}}}_k\) from \(\hat{{\varvec{{\theta }}}}_{m,k}\) in (44).
-
8.
If \(\Vert \hat{{\varvec{{\theta }}}}_{1,k}-\hat{{\varvec{{\theta }}}}_{1,k-1}\Vert +\Vert \hat{{\varvec{{\theta }}}}_{m,k}-\hat{{\varvec{{\theta }}}}_{m,k-1}\Vert >\varepsilon \), increase k by 1 and go to step 4; otherwise, output the parameter estimates \(\hat{{\varvec{{\theta }}}}_{1,k}\) and \(\hat{{\varvec{{\theta }}}}_{m,k}\), terminate this iterative calculation process.
Remark 4
Previous works presented an overall recursive least squares algorithm and an overall stochastic gradient algorithm to estimate the nonlinear feedback systems disturbed by white noise [93] and proposed a two-stage recursive least squares algorithm for nonlinear feedback systems based on auxiliary model identification [27]. In contrast to the recursive algorithms proposed in [93] and [27], this paper proposes an iterative estimation method for nonlinear feedback systems and introduces the hierarchical principle to reduce the calculation costs and to improve the identification accuracy.
The computational cost for an identification algorithm can be evaluated by the number of floating point operation (flops for short). An addition or multiplication counts as a flop. The computational costs for each iteration of the GI and H-GI algorithms are listed in Tables 1, 2. The total numbers of flops of these two algorithms are \(N_1:=2n^2L+4nL+2L+2mn_b-n^2-m\) and \(N_2:=4L(n_a+n_b+m)+4L+2(n_a+n_b)L+2m^2L+2(n_a+n_b)^2L+2mn_b-m^2-(n_a+n_b)^2-m\), respectively. The difference between the computation loads of these two algorithms at each iteration is \(N_1-N_2=2L((n_a+n_b)(2m-1)-1)+(n_a+n_b)^2+m^2>0\), thus, the H-GI algorithm has less computation load than the GI algorithm.
5 The Simulation Example
Consider the following nonlinear feedback system:
The parameters to be identified are
The simulation of the algorithms in this paper is performed in MATLAB. In the simulation, we set the input and output data and noise as follows.

The GI parameter estimation errors \(\delta \) versus k with different \(\sigma ^2\)

The H-GI parameter estimation errors \(\delta \) versus k with different \(\sigma ^2\)

The GI estimation errors \(\delta _i\) under different \(\sigma ^2\)

The H-GI estimation errors \(\delta _i\) under different \(\sigma ^2\)
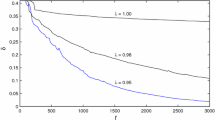
Take the noise variances \(\sigma ^2=1.00^2\), \(\sigma ^2=2.00^2\) and \(\sigma ^2=3.00^2\), respectively, and apply the GI and H-GI algorithms to estimate the parameters of this example system. The parameter estimates and the corresponding errors are given in Tables 3, 4, and the parameter estimation errors \(\delta :=\parallel \hat{{\varvec{\vartheta }}}_k-{\varvec{\vartheta }}\parallel /\parallel {\varvec{\vartheta }}\parallel \) versus k are shown in Figs. 2, 3. In addition, to show the estimation results of each parameter under each algorithm more clearly, define \(\delta _i:=| \hat{\vartheta }_{i,k}-\vartheta _i|/|\vartheta _i|\). Hence, under different noise variances \(\sigma ^2\), the estimation errors \(\delta _i\) of each parameter at \(k=200\) as shown in Figs. 4, 5.
Apply the H-GI algorithm with the noise variance \(\sigma ^2=1.00^2\) and the data lengths \(L=1000\), \(L=2000\) and \(L=3000\) to identify this example system, respectively. The parameter estimates and the corresponding errors are shown in Table 5, and the parameter estimation errors \(\delta \) versus k are shown in Fig. 6.
Taking the noise variance \(\sigma ^2=1.00^2\), the parameter estimation errors \(\delta \) versus k with different algorithms are plotted in Fig. 7. The GI and H-GI estimates of the parameters \(a_1\), \(a_2\), \(b_1\), \(b_2\), \(q_1\) and \(q_2\) versus k are shown in Figs. 8, 9.

The H-GI parameter estimation errors \(\delta \) versus k with different data length L (\(\sigma ^2=1.00^2\))

The GI and H-GI estimation errors \(\delta \) versus k (\(\sigma ^2=1.00^2\))

The GI parameter estimates versus k (\(\sigma ^2=1.00^2\)). Asterisk: the parameter estimates, Circle: the true values

The H-GI parameter estimates versus k (\(\sigma ^2=1.00^2\)). Asterisk: the parameter estimates, Circle: the true values
For model validation, we use the remaining \(L_r=200\) observations from \(t=L_e+1\) to \(t=L_e+L_r\) and the models predicted by the GI and H-GI algorithms with \(\sigma ^2=1.00^2\). The predicted outputs \(\hat{y}_i(t)\) (\(i=1,2\)), the actual outputs y(t) and their errors are plotted in Figs. 10, 11.
The predicted outputs are
Use the GI estimates in Table 3 with the noise variance \(\sigma ^2=1.00^2\) and \(k=200\) to construct the GI estimated model:
Use the H-GI estimates in Table 4 with the noise variance \(\sigma ^2=1.00^2\) and \(k=200\) to construct the H-GI estimated model:
To evaluate the prediction performance, we define and compute the root-mean-square errors (RMSEs):

The predicted outputs \(\hat{y}_1(t)\), the actual outputs y(t) and their errors versus t based on the GI estimates

The predicted outputs \(\hat{y}_2(t)\), the actual outputs y(t) and their errors versus t based on the H-GI estimates
From Tables 3, 4, 5 and Figs. 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, we can draw the following conclusions.
-
Throughout the entire simulation process, shown in Tables 3, 4 and Figs. 2, 3, 4, 5, we find that the parameter estimation errors of the GI and H-GI algorithms decrease as the iteration number k increases, and the estimation accuracy improves as the noise level reduces. However, the H-GI algorithm yields more exact estimates than the GI algorithm under the same iteration and noise variance—see Fig. 7.
-
For the same noise variance, the parameter estimation errors of the H-GI algorithm become smaller as the data length L and iteration k increase—see Table 5 and Fig. 6.
-
For sufficiently large data length, the parameter estimates of the GI and H-GI algorithms gradually approach the true values with the increase of the iteration k, which verifies the effectiveness of the GI and H-GI algorithms—see Figs. 8, 9.
-
The predicted outputs of the GI and H-GI algorithms verge on the true values and the differences between them are small—see Figs. 10,11. This shows that the estimated models based on the GI and H-GI algorithms have good prediction performance and can acquire the dynamics of the feedback nonlinear systems well.
6 Conclusions
This paper studies the parameter identification problem for nonlinear feedback system. By negative gradient search, a GI algorithm is derived for estimating the unknown parameters. Inspired by the hierarchical identification principle, the nonlinear feedback system is decomposed into two subsystems and an H-GI algorithm is proposed for the nonlinear feedback system. Compared with the GI algorithm, the H-GI algorithm has a higher computational efficiency and a comparable parameter estimation accuracy. The simulation results demonstrate the performance of the proposed algorithms. The approaches presented in this paper can be extended to investigate the modeling and optimization of some production and process systems [22, 88, 107, 108] and can be applied to other control and schedule areas [3,4,5,6,7,8,9,10,11,12] such as information processing systems and transportation communication systems [71,72,73,74,75,76,77,78] and so on.
Data availability statement
All data generated or analyzed during this study are included in this article.
References
M.R.H. Abdalmoaty, H. Hjalmarsson, Identification of stochastic nonlinear models using optimal estimating functions. Automatica 119, 109055 (2020)
V. Bezzubov, A. Bobtsov, D. Efimov, R. Ortega, N. Nikolaev, Adaptive state observation of linear time-varying systems with delayed measurements and unknown parameters. Int. J. Robust Nonlinear Control 33(2), 1203–1213 (2023)
Y. Cao, Y. An, S. Su et al., A statistical study of railway safety in China and Japan 1990–2020. Accid. Anal. Prevent. 175, 106764 (2022)
Y. Cao, Y.S. Ji, Y.K. Sun, S. Su, The fault diagnosis of a switch machine based on deep random forest fusion. IEEE Intell. Transp. Syst. Mag. 15(1), 437–452 (2023)
Y. Cao, L.C. Ma, S. Xiao et al., Standard analysis for transfer delay in CTCS-3. Chinese J. Electron. 26(5), 1057–1063 (2017)
Y. Cao, Y.K. Sun, G. Xie, P. Li, A sound-based fault diagnosis method for railway point machines based on two-stage feature selection strategy and ensemble classifier. IEEE Trans. Intell. Transp. Syst. 23(8), 12074–12083 (2022)
Y. Cao, Y.K. Sun, G. Xie, T. Wen, Fault diagnosis of train plug door based on a hybrid criterion for IMFs selection and fractional wavelet package energy entropy. IEEE Trans. Veh. Technol. 68(8), 7544–7551 (2019)
Y. Cao, Z. Wang, F. Liu, P. Li, G. Xie, Bio-inspired speed curve optimization and sliding mode tracking control for subway trains. IEEE Trans. Veh. Technol. 68(7), 6331–6342 (2019)
Y. Cao, J.K. Wen, A. Hobiny, P. Li, T. Wen, Parameter-varying artificial potential field control of virtual coupling system with nonlinear dynamics. Fractals 30(2), 2240099 (2022)
Y. Cao, J.K. Wen, L.C. Ma, Tracking and collision avoidance of virtual coupling train control system. Alex. Eng. J. 60(2), 2115–2125 (2021)
Y. Cao, Y.R. Yang, L.C. Ma et al., Research on virtual coupled train control method based on GPC & VAPF. Chinese J. Electron. 31(5), 897–905 (2022)
Y. Cao, Z.X. Zhang, F.L. Cheng, S. Su, Trajectory optimization for high-speed trains via a mixed integer linear programming approach. IEEE Trans. Intell. Transp. Syst. 23(10), 17666–17676 (2022)
T. Cui, Moving data window-based partially-coupled estimation approach for modeling a dynamical system involving unmeasurable states. ISA Trans. 128, 437–452 (2022)
F. Ding, Least squares parameter estimation and multi-innovation least squares methods for linear fitting problems from noisy data. J. Comput. Appl. Math. 426, 115107 (2023)
F. Ding, H. Ma, J. Pan, E.F. Yang, Hierarchical gradient- and least squares-based iterative algorithms for input nonlinear output-error systems using the key term separation. J. Franklin Inst. 358(9), 5113–5135 (2021)
F. Ding, L. Xu, X. Zhang, Y.H. Zhou, Filtered auxiliary model recursive generalized extended parameter estimation methods for Box-Jenkins systems by means of the filtering identification idea. Int. J. Robust Nonlinear Control 33(10), 5510–5535 (2023)
J.L. Ding, W.H. Zhang, Finite-time adaptive control for nonlinear systems with uncertain parameters based on the command filters. Int. J. Adapt. Control Signal Process. 35(9), 1754–1767 (2021)
Y.M. Fan, X.M. Liu, Two-stage auxiliary model gradient-based iterative algorithm for the input nonlinear controlled autoregressive system with variable-gain nonlinearity. Int. J. Robust Nonlinear Control 30(14), 5492–5509 (2020)
Y.M. Fan, X.M. Liu, Auxiliary model-based multi-innovation recursive identification algorithms for an input nonlinear controlled autoregressive moving average system with variable-gain nonlinearity. Int. J. Adapt. Control Signal Process. 36(3), 521–540 (2022)
R. Goel, T. Garg, S.B. Roy, Closed-Loop reference model based distributed MRAC using cooperative initial excitation and distributed reference input estimation. IEEE Trans. Control Net. Syst. 9(1), 37–49 (2021)
R. Goel, S.B. Roy, Closed-loop reference model based distributed model reference adaptive control for multi-agent systems. IEEE Control Syst. Lett. 5(5), 1837–1842 (2021)
Y. Gu, Q.M. Zhu, H. Nouri, Identification and U-control of a state-space system with time-delay. Int. J. Adapt. Control Signal Process. 36(1), 138–154 (2022)
C.S. Hemsi, C.M. Panazio, Sparse estimation technique for digital pre-distortion of impedance-mismatched power amplifiers. Circuits Syst. Signal Process. 40(8), 3727–3755 (2021)
J. Hou, F. Chen, P. Li et al., Gray-box parsimonious subspace identification of Hammerstein-type systems. IEEE Trans. Ind. Electron. 68(10), 9941–9951 (2021)
J. Hou, H. Su, C. Yu et al., Bias-correction errors-in-variables Hammerstein model identification. IEEE Trans. Ind. Electron. 70(7), 7268–7279 (2023)
J. Hou, H. Su, C.P. Yu et al., Consistent subspace identification of errors-in-variables Hammerstein systems. IEEE Trans. Syst. Man Cybern. Syst. 53(4), 2292–2303 (2023)
P.P. Hu, F. Ding, J. Sheng, Auxiliary model based least squares parameter estimation algorithm for feedback nonlinear systems using the hierarchical identification principle. J. Frankl. Inst. 350(10), 3248–3259 (2013)
C. Hu, Y. Ji, C.Q. Ma, Joint two-stage multi-innovation recursive least squares parameter and fractional-order estimation algorithm for the fractional-order input nonlinear output-error autoregressive model. Int. J. Adapt. Control Signal Process. 37(7), 1650–1670 (2023)
G. Huang, A. Liu, M.J. Zhao, Two-stage adaptive and compressed CSI feedback for FDD massive MIMO. IEEE Trans. Veh. Technol. 70(9), 9602–9606 (2021)
Y. Ji, A.N. Jiang, Filtering-based accelerated estimation approach for generalized time-varying systems with disturbances and colored noises. IEEE Trans. Circuits Syst. II Express Briefs. 70(1), 206–210 (2023)
Y. Ji, X.K. Jiang, L.J. Wan, Hierarchical least squares parameter estimation algorithm for two-input Hammerstein finite impulse response systems. J. Frankl. Inst. 357(8), 5019–5032 (2020)
Y. Ji, Z. Kang, Three-stage forgetting factor stochastic gradient parameter estimation methods for a class of nonlinear systems. Int. J. Robust Nonlinear Control 31(3), 971–987 (2021)
Y. Ji, Z. Kang, X.M. Liu, The data filtering based multiple-stage Levenberg-Marquardt algorithm for Hammerstein nonlinear systems. Int. J. Robust Nonlinear Control 31(15), 7007–7025 (2021)
Y. Ji, Z. Kang, C. Zhang, Two-stage gradient-based recursive estimation for nonlinear models by using the data filtering. Int. J. Control Autom. Syst. 19(8), 2706–2715 (2021)
Y. Ji, C. Zhang, Z. Kang, T. Yu, Parameter estimation for block-oriented nonlinear systems using the key term separation. Int. J. Robust Nonlinear Control 30(9), 3727–3752 (2020)
A.N. Jiang, Y. Ji, L.J. Wan, Iterative parameter identification algorithms for the generalized time-varying system with a measurable disturbance vector. Int. J. Robust Nonlinear Control 32(6), 3527–3548 (2020)
Z. Kang, Y. Ji, X.M. Liu, Hierarchical recursive least squares algorithms for Hammerstein nonlinear autoregressive output-error systems. Int. J. Adapt. Control Signal Process. 35(11), 2276–2295 (2021)
J.M. Li, A novel nonlinear optimization method for fitting a noisy Gaussian activation function. Int. J. Adapt. Control Signal Process. 36(3), 690–707 (2022)
M.H. Li, X.M. Liu, Maximum likelihood hierarchical least squares-based iterative identification for dual-rate stochastic systems. Int. J. Adapt. Control Signal Process. 35(2), 240–261 (2021)
M.H. Li, X.M. Liu, Iterative identification methods for a class of bilinear systems by using the particle filtering technique. Int. J. Adapt. Control Signal Process. 35(10), 2056–2074 (2021)
M.H. Li, X.M. Liu, Particle filtering-based iterative identification methods for a class of nonlinear systems with interval-varying measurements. Int. J. Control Autom. Syst. 20(7), 2239–2248 (2022)
M.H. Li, X.M. Liu, The filtering-based maximum likelihood iterative estimation algorithms for a special class of nonlinear systems with autoregressive moving average noise using the hierarchical identification principle. Int. J. Adapt. Control Signal Process. 33(7), 1189–1211 (2019)
L.W. Li, F.X. Wang, H.L. Zhang, X.M. Ren, Adaptive model recovery scheme for multivariable system using error correction learning. IEEE Trans. Instrum. Meas. 70, 3108569 (2021)
L.H. Li, G.C. Yang, Y. Li et al., Abnormal sitting posture recognition based on multi-scale spatiotemporal features of skeleton graph. Eng. Appl. Artif. Intell. 123, 106374 (2023)
Y. Li, G. Yang, Z. Su, Y. Wang, Human activity recognition based on multienvironment sensor data. Inf. Fusion 91, 47–63 (2023)
J.H. Li, T.C. Zong, G.P. Lu, Parameter identification of Hammerstein-Wiener nonlinear systems with unknown time delay based on the linear variable weight particle swarm optimization. ISA Trans. 120, 89–98 (2022)
Q.L. Liu, Recursive least squares estimation methods for a class of nonlinear systems based on non-uniform sampling. Int. J. Adapt. Control Signal Process. 35(8), 1612–1632 (2021)
Q.L. Liu, Gradient-based recursive parameter estimation for a periodically nonuniformly sampled-data Hammerstein-Wiener system based on the key-term separation. Int. J. Adapt. Control Signal Process. 35(10), 1970–1989 (2021)
S.Y. Liu, Hierarchical principle-based iterative parameter estimation algorithm for dual-frequency signals. Circuits Syst Signal Process. 38(7), 3251–3268 (2019)
X.M. Liu, Y.M. Fan, Maximum likelihood extended gradient-based estimation algorithms for the input nonlinear controlled autoregressive moving average system with variable-gain nonlinearity. Int. J. Robust Nonlinear Control 31(9), 4017–4036 (2021)
H.B. Liu, J.W. Wang, Y. Ji, Maximum likelihood recursive generalized extended least squares estimation methods for a bilinear-parameter systems with ARMA noise based on the over-parameterization model. Int. J. Control Autom. Syst. 20(8), 2606–2615 (2022)
P. Ma, New gradient based identification methods for multivariate pseudo-linear systems using the multi-innovation and the data filtering. J. Franklin Inst. 354(3), 1568–1583 (2017)
J.X. Ma, Filtering-based multistage recursive identification algorithm for an input nonlinear output-error autoregressive system by using the key term separation technique. Circuits Syst. Signal Process. 36(2), 577–599 (2017)
H. Ma, J. Pan, W. Ding, Partially-coupled least squares based iterative parameter estimation for multi-variable output-error-like autoregressive moving average systems. IET Control Theory Appl. 13(18), 3040–3051 (2019)
P. Ma, L. Wang, Filtering-based recursive least squares estimation approaches for multivariate equation-error systems by using the multiinnovation theory. Int. J. Adapt. Control Signal Process. 35(9), 1898–1915 (2021)
J.X. Ma, W.L. Xiong, J. Chen, Hierarchical identification for multivariate Hammerstein systems by using the modified Kalman filter. IET Control Theory Appl. 11(6), 857–869 (2017)
Y.W. Mao, C. Xu, J. Chen, Y. Pu, Q.Y. Hu, Auxiliary model-based iterative estimation algorithms for nonlinear systems using the covariance matrix adaptation strategy. Circuits Syst. Signal Process. 41(12), 6750–6773 (2022)
S. Marzougui, S. Bedoui, A. Atitallah, K. Abderrahim, Parameter and state estimation of nonlinear fractional-order model using Luenberger observer. Circuits Syst. Signal Process. 41(10), 5366–5391 (2022)
X. Meng, Y. Ji, J. Wang, Iterative parameter estimation for photovoltaic cell models by using the hierarchical principle. Int. J. Control Autom. Syst. 20(8), 2583–2593 (2022)
J. Pan, Q. Chen, J. Xiong, G. Chen, A novel quadruple-boost nine-level switched capacitor inverter. J. Electr. Eng. Technol. 18(1), 467–480 (2023)
J. Pan, X. Jiang, X.K. Wan, W. Ding, A filtering based multi-innovation extended stochastic gradient algorithm for multivariable control systems. Int. J. Control Autom. Syst. 15(3), 1189–1197 (2017)
J. Pan, W. Li, H.P. Zhang, Control algorithms of magnetic suspension systems based on the improved double exponential reaching law of sliding mode control. Int. J. Control Autom. Syst. 16(6), 2878–2887 (2018)
J. Pan, Y.Q. Liu, J. Shu, Gradient-based parameter estimation for an exponential nonlinear autoregressive time-series model by using the multi-innovation. Int. J. Control Autom. Syst. 21(1), 140–150 (2023)
J. Pan, S.D. Liu, J. Shu, X.K. Wan, Hierarchical recursive least squares estimation algorithm for secondorder Volterra nonlinear systems. Int. J. Control Autom. Syst. 20(12), 3940–3950 (2022)
J. Pan, H. Ma, X. Zhang et al., Recursive coupled projection algorithms for multivariable output-error-like systems with coloured noises. IET Signal Process. 14(7), 455–466 (2020)
J. Pan, B. Shao, J.X. Xiong, Q. Zhang, Attitude control of quadrotor UAVs based on adaptive sliding mode. Int. J. Control Autom. Syst. 21(8), 2698–2707 (2023)
J. Pan, H. Zhang, H. Guo, S. Liu, Y. Liu, Multivariable CAR-like system identification with multi-innovation gradient and least squares algorithms. Int. J. Control Autom. Syst. 21(5), 1455–1464 (2023)
Y. Pu, Y.J. Rong, J. Chen, Y.W. Mao, Accelerated identification algorithms for exponential nonlinear models: two-stage method and particle swarm optimization method. Circuits Syst. Signal Process. 41(5), 2636–2652 (2022)
F. Shahriari, M.M. Arefi, H. Luo, S. Yin, Multistage parameter estimation algorithms for identification of bilinear systems. Nonlinear Dyn. 110(3), 2635–2655 (2022)
B.B. Shen, F. Ding, L. Xu, T. Hayat, Data filtering based multi-innovation gradient identification methods for feedback nonlinear systems. Int. J. Control Autom. Syst. 16(5), 2225–2234 (2018)
S. Su, J. She, K. Li et al., A nonlinear safety equilibrium spacing based model predictive control for virtually coupled train set over gradient terrains. IEEE Trans. Transp. Electrif. 8(2), 2810–2824 (2022)
S. Su, T. Tang, J. Xun et al., Design of running grades for energy-efficient train regulation: a case study for Beijing Yizhuang line. IEEE Intell. Transp. Syst. Mag. 13(2), 189–200 (2021)
S. Su, X. Wang, Y. Cao, J.T. Yin, An energy-efficient train operation approach by integrating the metro timetabling and eco-driving. IEEE Trans. Intell. Transp. Syst. 21(10), 4252–4268 (2020)
S. Su, X. Wang, T. Tang et al., Energy-efficient operation by cooperative control among trains: a multi-agent reinforcement learning approach. Control Eng. Pract. 116, 104901 (2021)
S. Su, Q. Zhu, J. Liu et al., Eco-driving of trains with a data-driven iterative learning approach. IEEE Trans. Ind. Inf. (2023). https://doi.org/10.1109/TII.2022.3195888
Y.K. Sun, Y. Cao, P. Li, Contactless fault diagnosis for railway point machines based on multi-scale fractional wavelet packet energy entropy and synchronous optimization strategy. IEEE Trans. Veh. Technol. 71(6), 5906–5914 (2022)
Y.K. Sun, Y. Cao, L.C. Ma, A fault diagnosis method for train plug doors via sound signals. IEEE Intell. Transp. Syst. Mag. 13(3), 107–117 (2021)
Y.K. Sun, Y. Cao, G. Xie, T. Wen, Sound based fault diagnosis for RPMs based on multi-scale fractional permutation entropy and two-scale algorithm. IEEE Trans. Veh. Technol. 70(11), 11184–11192 (2021)
S.S. Tabatabaei, M. Tavakoli, H.A. Talebi, A finite-time adaptive order estimation approach for non-integer order nonlinear systems. ISA Trans. 127, 383–394 (2022)
J.W. Wang, Y. Ji, C. Zhang, Iterative parameter and order identification for fractional-order nonlinear finite impulse response systems using the key term separation. Int. J. Adapt. Control Signal Process. 35(8), 1562–1577 (2021)
X.H. Wang, Modified particle filtering-based robust estimation for a networked control system corrupted by impulsive noise. Int. J. Robust Nonlinear Control 32(2), 830–850 (2022)
Y.J. Wang, Recursive parameter estimation algorithm for multivariate output-error systems. J. Franklin Inst. 355(12), 5163–5181 (2018)
J.W. Wang, Y. Ji, X. Zhang, L. Xu, Two-stage gradient-based iterative algorithms for the fractional-order nonlinear systems by using the hierarchical identification principle. Int. J. Adapt. Control Signal Process. 36(7), 1778–1796 (2022)
H. Wang, G. Ke, J. Pan, Q. Su, Modeling, dynamical analysis and numerical simulation of a new 3D cubic Lorenz-like system. Sci. Rep. 13, 6671 (2023)
H. Wang, G. Ke, J. Pan, F. Hu, H. Fan, Q. Su, Two pairs of heteroclinic orbits coined in a new sub-quadratic Lorenz-like system. Eur. Phys. J. B 96(3), 28 (2023)
H. Wang, G. Ke, J. Pan, Q. Su, Conjoined Lorenz-like attractors coined. Miskolc Math. Note (2023)
H. Wang, G. Ke, J. Pan, Q. Su, G. Dong, H. Fan, Revealing the true and pseudo-singularly degenerate heteroclinic cycles. Indian J. Phys. (2023). https://doi.org/10.1007/s12648-023-02689-w
X. Wang, S. Su, Y. Cao, X.L. Wang, Robust control for dynamic train regulation in fully automatic operation system under uncertain wireless transmissions. IEEE Trans. Intell. Transp. Syst. 23(11), 20721–20734 (2022)
Y.J. Wang, S.H. Tang, M.Q. Deng, Modeling nonlinear systems using the tensor network B-spline and the multi-innovation identification theory. Int. J. Robust Nonlinear Control 32(13), 7304–7318 (2022)
Y.J. Wang, S.H. Tang, X.B. Gu, Parameter estimation for nonlinear Volterra systems by using the multi-innovation identification theory and tensor decomposition. J. Franklin Inst. 359(2), 1782–1802 (2022)
Y.J. Wang, L. Yang, An efficient recursive identification algorithm for multilinear systems based on tensor decomposition. Int. J. Robust Nonlinear Control 31(16), 7920–7936 (2021)
Y. Wang, G. Yang, Arrhythmia classification algorithm based on multi-head self-attention mechanism. Biomed. Signal Process. Control 79, 104206 (2023)
C. Wei, Overall recursive least squares and overall stochastic gradient algorithms and their convergence for feedback nonlinear controlled autoregressive systems. Int. J. Robust Nonlinear Control 32(9), 5534–5554 (2022)
J.X. Xiong, J. Pan, G.Y. Chen et al., Sliding mode dual-channel disturbance rejection attitude control for a quadrotor. IEEE Trans. Ind. Electron. 69(10), 10489–10499 (2022)
H. Xu, Joint parameter and time-delay estimation for a class of nonlinear time-series models. IEEE Signal Process. Lett. 29, 947–951 (2022)
L. Xu, Separable multi-innovation Newton iterative modeling algorithm for multi-frequency signals based on the sliding measurement window. Circuits Syst. Signal Process. 41(2), 805–830 (2022)
L. Xu, Parameter estimation for nonlinear functions related to system responses. Int. J. Control Autom. Syst. 21(6), 1780–1792 (2023)
L. Xu, Separable Newton recursive estimation method through system responses based on dynamically discrete measurements with increasing data length. Int. J. Control Autom. Syst. 20(2), 432–443 (2022)
L. Xu, Hierarchical recursive signal modeling for multi-frequency signals based on discrete measured data. Int. J. Adapt. Control Signal Process. 35(5), 676–693 (2021)
L. Xu, Separable synthesis estimation methods and convergence analysis for multivariable systems. J. Comput. Appl. Math. 427, 115104 (2023)
C. Xu, Y. Qin, H. Su, Observer-based dynamic event-triggered bipartite consensus of discrete-time multi-agent systems. IEEE Trans. Circuits Syst. II: Express Briefs 70(3), 1054–1058 (2023)
L. Xu, G.L. Song, A recursive parameter estimation algorithm for modeling signals with multi-frequencies. Circuits Syst. Signal Process. 39(8), 4198–4224 (2020)
C. Xu, H. Xu, Z.H. Guan, Y. Ge, Observer-based dynamic event-triggered semi-global bipartite consensus of linear multi-agent systems with input saturation. IEEE Trans. Cybern. 53(5), 3139–3152 (2023)
D. Yang, F. Ding, Multi-innovation gradient-based iterative identification methods for feedback nonlinear systems by using the decomposition technique. Int. J. Robust Nonlinear Control 33(13), 7755–7773 (2023)
G. Yang, S. Li, L. He, Short-term prediction method of blood glucose based on temporal multi-head attention mechanism for diabetic patients. Biomed. Signal Process. Control 82, 104552 (2023)
G. Yang, S. Yang, K. Luo, S. La, L. He, Y. Li, Detection of non-suicidal self-injury based on spatiotemporal features of indoor activities. IET Biometrics 12, 91–101 (2023)
J. You, C. Yu, J. Sun, J. Chen, Generalized maximum entropy based identification of graphical ARMA models. Automatica 141, 110319 (2022)
C. Yu, Y. Li, H. Fang, J. Chen, System identification approach for inverse optimal control of finite-horizon linear quadratic regulators. Automatica 129, 109636 (2021)
X. Zhang, Hierarchical parameter and state estimation for bilinear systems. Int. J. Syst. Sci. 51(2), 275–290 (2020)
C. Zhang, H.B. Liu, Y. Ji, Gradient parameter estimation of a class of nonlinear systems based on the maximum likelihood principle. Int. J. Control Autom. Syst. 20(5), 1393–1404 (2022)
E.L. Zhang, R. Pintelon, Identification of dynamic errors-in-variables systems with quasi-stationary input and colored noise. Automatica 123, 109344 (2021)
T.Y. Zhang, S.Y. Zhao, X.L. Luan, F. Liu, Bayesian inference for state-space models with student-t mixture distributions. IEEE Trans. Cybern. 53(7), 4435–4445 (2023)
S.Y. Zhao, B. Huang, Trial-and-error or avoiding a guess? Initialization of the Kalman filter. Automatica 121, 109184 (2020)
S.Y. Zhao, B. Huang, C.H. Zhao, Online probabilistic estimation of sensor faulty signal in industrial processes and its applications. IEEE Trans. Ind. Electron. 68(9), 8858–8862 (2021)
S.Y. Zhao, K. Li, C. Ahn, B. Huang, F. Liu, Tuning-free Bayesian estimation algorithms for faulty sensor signals in state-space. IEEE Trans. Ind. Electron. 70(1), 921–929 (2023)
S.Y. Zhao, Y.S. Shmaliy, C.K. Ahn, F. Liu, Self-tuning unbiased finite impulse response filtering algorithm for processes with unknown measurement noise covariance. IEEE Trans. Control Syst. Technol. 29(3), 1372–1379 (2021)
S.Y. Zhao, Y.S. Shmaliy, C.K. Ahn, L.J. Luo, An improved iterative FIR state estimator and its applications. IEEE Trans. Ind. Inf. 16(2), 1003–1012 (2020)
S.Y. Zhao, Y.S. Shmaliy, C.K. Ahn, C.H. Zhao, Probabilistic monitoring of correlated sensors for nonlinear processes in state space. IEEE Trans. Ind. Electron. 67(3), 2294–2303 (2020)
S.Y. Zhao, Y.S. Shmaliy, J.A. Andrade-Lucio, F. Liu, Multipass optimal FIR filtering for processes with unknown initial states and temporary mismatches. IEEE Trans. Ind. Inf. 17(8), 5360–5368 (2021)
S.Y. Zhao, Y.S. Shmaliy, F. Liu, Batch optimal FIR smoothing: increasing state informativity in nonwhite measurement noise environments. IEEE Trans. Ind. Inf. 19(5), 6993–7001 (2023)
S.Y. Zhao, J.F. Wang, Y.S. Shmaliy, F. Liu, Discrete time q-lag maximum likelihood FIR smoothing and iterative recursive algorithm. IEEE Trans. Signal Process. 69, 6342–6354 (2021)
Acknowledgements
This work was supported by the National Natural Science Foundation of China (No. 62273167, 62076110), the 111 Project (B23008), the Natural Science Foundation of Shanghai (No. 22ZR1445300) and the Academic Research Fund (Applied Technology) Project (CFK201808) of Changzhou Vocational Institute of Textile and Garment and the Fundamental Research Funds for the Central Universities under Grant (JUSRP221027).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflicts of interest
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Yang, D., Liu, Y., Ding, F. et al. Hierarchical Gradient-Based Iterative Parameter Estimation Algorithms for a Nonlinear Feedback System Based on the Hierarchical Identification Principle. Circuits Syst Signal Process 43, 124–151 (2024). https://doi.org/10.1007/s00034-023-02477-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-023-02477-1