
Abstract
Here, we consider numerical methods for stationary mean-field games (MFG) and investigate two classes of algorithms. The first one is a gradient-flow method based on the variational characterization of certain MFG. The second one uses monotonicity properties of MFG. We illustrate our methods with various examples, including one-dimensional periodic MFG, congestion problems, and higher-dimensional models.
Similar content being viewed by others
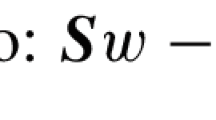

Avoid common mistakes on your manuscript.
1 Introduction
Mean-field games (MFG) model problems with a large number of rational agents interacting noncooperatively [39–43]. Much progress has been achieved in the mathematical theory of MFG for time-dependent problems [13, 23–25, 27, 31, 34, 47, 48] and for stationary problems [22, 28, 32, 33, 46, 50] (also see the recent surveys [7, 11, 35]). Yet, in the absence of explicit solutions, the efficient simulation of MFG is important to many applications. Consequently, researchers have studied numerical algorithms in various cases, including continuous state problems [1–5, 8–10, 14, 36–38] and finite state problems [29, 30]. Here, we develop numerical methods for (continuous state) stationary MFG using variational and monotonicity methods.
Certain MFG, called variational MFG, are Euler–Lagrange equations of integral functionals. These MFG are instances of a wider class of problems—monotonic MFG. In the context of numerical methods, the variational structure of MFG was explored in [2]. Moreover, monotonicity properties are critical for the convergence of the methods in [1, 3, 4]. Recently, variational and monotonicity methods were used to prove the existence of weak solutions to MFG in [12, 13, 18, 44, 49].
Here, our main contributions are two computational approaches for MFG. For variational MFG, we build an approximating method using a gradient flow approach. This technique gives a simple and efficient algorithm. Nevertheless, the class of variational MFG is somewhat restricted. Monotonic MFG encompass a wider range of problems that include variational MFG as a particular case. In these games, the MFG equations involve a monotone nonlinear operator. We use the monotonicity to build a flow that is a contraction in \(L^2\) and whose fixed points solve the MFG.
To keep the presentation elementary, we develop our methods for the one-dimensional MFG:
To streamline the discussion, we study (1.1) with periodic boundary conditions. Thus, the variable x takes values in the one-dimensional torus, \({\mathbb {T}}\). The potential, V, and the drift, b, are given real-valued periodic functions. The unknowns are u, m, and \({\overline{H}}\), where \(u\) and \(m \) are real-valued periodic functions satisfying \(m> 0\), and where \({\overline{H}}\) is a constant. The role of \(\overline{H}\) is to allow for m to satisfy \(\int _{{\mathbb {T}}} m\,\mathrm{d}x=1\). Furthermore, since adding an arbitrary constant to u does not change (1.1), we require
The system (1.1) is one of the simplest MFG models. However, its structure is quite rich and illustrates our techniques well. Our methods extend in a straightforward way to other models, including higher-dimensional problems. In particular, in Sect. 4, we discuss applications to a one-dimensional congestion model and to a two-dimensional MFG.
We end this introduction with a brief outline of our work. In Sect. 2, we examine various properties of (1.1). These properties motivate the ideas used in Sect. 3 to build numerical methods. Next, in Sect. 4, we discuss the implementation of our approaches and present their numerical simulations. We conclude this work in Sect. 5 with some final remarks.
2 Elementary Properties
We begin this section by constructing explicit solutions to (1.1). These are of particular importance for the validation and comparison of the numerical methods presented in Sect. 3. Next, we discuss the variational structure of (1.1) and show that (1.1) is equivalent to the Euler–Lagrange equation of a suitable functional. Because of this, we introduce a gradient flow approximation and examine some of its elementary properties. Finally, we explain how (1.1) can be seen as a monotone operator. This operator induces a flow that is a contraction in \(L^2\) and whose stationary points are solutions to (1.1).
2.1 Explicit Solutions
Here, we build explicit solutions to (1.1). For simplicity, we assume that V and b are \(C^\infty \) functions. Moreover, we identify \({\mathbb {T}}\) with the interval \([0,1]\).
Due to the one-dimensional nature of (1.1), if \(\int _{\mathbb {T}}b\,\mathrm{d}x=0\), we have the following explicit solution
Suppose that \(b=\psi _x\) for some \(C^\infty \) and periodic function \(\psi :{\mathbb {T}}\rightarrow {\mathbb {R}}\) with \(\int _{{\mathbb {T}}} \psi \,\mathrm{d}x=0\). For
the triplet \((u,m, \overline{H})\) solves (1.1). If \(\int _{\mathbb {T}}b\,\mathrm{d}x\ne 0\), we are not aware of any closed-form solution.
Next, we consider the congestion model
Remarkably, the previous equation has the same solutions as (1.1) with \(b=0\). Namely, for \(u(x)=0\), \(m(x)=\frac{e^{V(x)}}{\int _{{\mathbb {T}}} e^{V(y)} \,\mathrm{d}y}\), and \(\overline{H} = \ln \left( \int _{{\mathbb {T}}} e^{V(y)} \,\mathrm{d}y\right) \), the triplet \((u,m, \overline{H})\) solves (2.1). Thus, this model is particularly convenient for the validation of the numerical methods. However, we stress that our methods are valid for general congestion models satisfying monotonicity conditions.
2.2 Euler–Lagrange Equation
We begin by showing that (1.1) is equivalent to the Euler–Lagrange equation of the integral functional
defined for \(u\in D(J)= W^{2,2}({\mathbb {T}}) \cap L^2_0({\mathbb {T}})\), where \( L^2_0({\mathbb {T}})= \{u\in L^2({\mathbb {T}}): u \text { satisfies }\)(1.2)}.
Remark 2.1
(On the domain of J ) As proved in [16] (see [17, 19, 22, 27, 28, 46] for related problems), (1.1) admits a \(C^\infty \) solution. By a simple convexity argument, this solution is the unique minimizer of
Thus, the minimizers of J in \(\{ v\in W^{1,2}({\mathbb {T}}) :\, \int _{\mathbb {T}}v\,\mathrm{d}x= 0\}\) are also minimizers of J in \(\{ v\in W^{2,2}({\mathbb {T}}) :\, \int _{\mathbb {T}}v\,\mathrm{d}x= 0\}\). Hence, the domain of J is not too restrictive, and, due to this choice, our arguments are substantially simplified. In particular, because we are in the one-dimensional setting, \(W^{2,2}({\mathbb {T}}) \subset W^{1,\infty }({\mathbb {T}})\).
We also observe that \(L^2_0({\mathbb {T}})\) endowed with the \(L^2({\mathbb {T}})\)-inner product is a Hilbert space.
Lemma 2.2
For \({\overline{H}}=0\), (1.1) is equivalent to the Euler–Lagrange equation of J.
Proof
Let \(u\in W^{2,2}({\mathbb {T}})\cap L^2_0({\mathbb {T}})\). We say that u is a critical point of J if
for all \(v\in W^{2,2}({\mathbb {T}}) \cap L^2_0({\mathbb {T}})\). Fix any such v. For all \(\varepsilon \in {\mathbb {R}}\), we have that
Define m by
Then, it follows that
Since \(v\in W^{2,2}({\mathbb {T}})\) is an arbitrary function with zero mean, we conclude that u is a critical point of J if, and only if, (m, u) satisfies (1.1). \(\square \)
As mentioned in Remark 2.1, the functional J defined by (2.2) admits a unique minimizer. Moreover, since J is convex, any solution to the associated Euler–Lagrange equation is a minimizer. By (2.3), we have \(m> 0\). In MFG, it is usual to require
To normalize m, we multiply m by a suitable constant and introduce the parameter \({\overline{H}}\), which leads us to (1.1).
2.3 Monotonicity Conditions
Let H be a Hilbert space with the inner product \(\langle \cdot , \cdot \rangle _H\). A map \(A:D(A)\subset H\rightarrow H\) is a monotone operator if
for all \(w, \tilde{w}\in D(A)\).
In the Hilbert space \(L^2({\mathbb {T}})\times L^2({\mathbb {T}})\), we define
with \(D(A) = \{ (m,u) \in W^{1,2}({\mathbb {T}}) \times W^{2,2}({\mathbb {T}}): \, \inf _{\mathbb {T}}m >0\}\). Observe that \(A\) maps \(D(A)\) into \(L^2({\mathbb {T}})\times L^2({\mathbb {T}})\) because \(W^{1,2}({\mathbb {T}})\) is continuously embedded in \(L^\infty ({\mathbb {T}})\).
The condition \(\inf _{\mathbb {T}}m>0\) in the definition of D(A) is due to the singularity of \(\ln m\). With a non-singular coupling term the condition would become \(\inf _{\mathbb {T}}m\geqslant 0\). However, the proof that a smooth weak solution is a solution requires the condition \(m>0\) (see, e.g., Remark 3.8 for a similar argument).
Lemma 2.3
The operator A given by (2.4) is a monotone operator in \(L^2({\mathbb {T}})\times L^2({\mathbb {T}})\).
Proof
Let (m, u), \((\theta , v)\in D(A)\subset L^2({\mathbb {T}})\times L^2({\mathbb {T}})\). We have
where we used integration by parts. Because \(\ln (\cdot )\) is an increasing function and because \(\theta , m>0\), the conclusion follows. \(\square \)
As observed in [41, 43], the monotonicity of A implies the uniqueness of the solutions. Here, we use the monotonicity to construct a flow that approximates solutions of (1.1).
2.4 Weak Solutions Induced by Monotonicity
Denote by \(\langle \cdot , \cdot \rangle _{{\mathcal {D}}\times {\mathcal {D}}'}\) the duality pairing in the sense of distributions. We say that a triplet \((m, u, {\overline{H}})\in {\mathcal {D}}'\times {\mathcal {D}}' \times \mathbb {R}\) is a weak solution induced by monotonicity (or, for brevity, weak solution) of (1.1) if
for all \((\theta , v)\in {\mathcal {D}}\times {\mathcal {D}}\) satisfying \(\inf _{\mathbb {T}}\theta >0\) and \(\int _{{\mathbb {T}}} \theta \,\mathrm{d}x=1\).
2.5 Continuous Gradient Flow
Next, we introduce the gradient flow of the energy (2.2) with respect to the \(L^2({\mathbb {T}})\)-inner product. First, we extend J in (2.2) to the whole space \(L^2_0({\mathbb {T}})\) by setting \(J[u]=+\infty \) if \(u \in L^2_0({\mathbb {T}}) \backslash W^{2,2}({\mathbb {T}})\). We will not relabel this extension.
The functional \(J: L^2_0({\mathbb {T}}) \rightarrow [0,+\infty ]\) is proper, convex, and lower semicontinuous in \(L^2_0({\mathbb {T}})\). The subdifferential of J is the map \(\partial J: L^2_0({\mathbb {T}})\rightarrow 2^{L^2_0({\mathbb {T}})}\) defined for \(u\in L^2_0({\mathbb {T}})\) by
The domain of \(\partial J\), \(D(\partial J)\), is the set of all \(u\in L^2_0({\mathbb {T}})\) such that \(\partial J[u] \not = \emptyset \).
The gradient flow with respect to the \(L^2({\mathbb {T}})\)-inner product and energy J is
where \(\varvec{u}: [0,+\infty ) \rightarrow L^2_0({\mathbb {T}})\). As we will see next, (2.5) is equivalent to
where \(\varvec{m}(t)\) is given by (2.3) with u replaced by \(\varvec{u}(t)\). Moreover, if the solution \(\varvec{u}\) to (2.6) is regular enough, then
Proposition 2.4
We have \(D(\partial J) = W^{2,2}({\mathbb {T}}) \cap L^2_0({\mathbb {T}})\) and, for \(u\in D(\partial J)\), \(\partial J[u] = -\big (m (u_x+b(x))\big )_x\), where m is given by (2.3).
Proof
By [15, Thm. 1 in §9.6.1], \(D(\partial J) \subset D(J)=\{u\in L^2_0({\mathbb {T}}):\, J[u]<+\infty \}= W^{2,2}({\mathbb {T}}) \cap L^2_0({\mathbb {T}})\).
Conversely, fix \(u\in W^{2,2}({\mathbb {T}}) \cap L^2_0({\mathbb {T}})\), let m be given by (2.3), and set \(v= -\big (m (u_x+b(x))\big )_x\). Then, \(v\in L^2_0({\mathbb {T}})\) by the embedding \(W^{2,2}({\mathbb {T}}) \subset W^{1,\infty }({\mathbb {T}})\) and by the periodicity of \(u\), \(m\), and \(b\). Moreover, using the convexity of the exponential function, the integration by parts formula, and the conditions \(m>0\) and \(\frac{w_x^2}{2} - \frac{u_x^2}{2} \geqslant u_xw_x - u_x^2\), for each \(w\in W^{2,2}({\mathbb {T}}) \cap L^2_0({\mathbb {T}})\), we obtain
Because \(w\in W^{2,2}({\mathbb {T}}) \cap L^2_0({\mathbb {T}})\) is arbitrary and because \(J=+\infty \) in \(L^2_0({\mathbb {T}}) \backslash W^{2,2}({\mathbb {T}})\), we obtain \(v=-(m (u_x+b(x)))_x \in \partial J[u]\). Because \(u\in W^{2,2}({\mathbb {T}}) \cap L^2_0({\mathbb {T}})\) is also arbitrary, we get \(D(\partial J) \supset W^{2,2}({\mathbb {T}}) \cap L^2_0({\mathbb {T}})\).
To conclude the proof, we show that for \(u\in D(\partial J)\), the function \(-\big (m (u_x+b(x))\big )_x\) with m given by (2.3) is the unique element of \( \partial J[u] \). Let \(\bar{v}\in \partial J[u] \). Then, for all \(\varepsilon >0\) and \(w\in W^{2,2}({\mathbb {T}}) \cap L^2_0({\mathbb {T}})\), we have
Letting \(\varepsilon \rightarrow 0^+\) and arguing as in the proof of Lemma 2.2, we obtain
Because \(w\in W^{2,2}({\mathbb {T}}) \cap L^2_0({\mathbb {T}})\) is arbitrary, it follows that \(\bar{v}= -\big (m (u_x+b(x))\big )_x\). \(\square \)
The following result about solutions to the gradient flow (2.6) holds by [15, Thm. 3 in §9.6.2] and by the fact that \(W^{2,2}({\mathbb {T}}) \cap L^2_0({\mathbb {T}})\) is dense in \(L^2_0({\mathbb {T}})\).
Theorem 2.5
For each \(u\in W^{2,2}({\mathbb {T}}) \cap L^2_0({\mathbb {T}})\), there exists a unique function \(\varvec{u} \in C([0,+\infty );L^2_0({\mathbb {T}}))\), with \(\dot{\varvec{u}} \in L^\infty (0,+\infty ;L^2_0({\mathbb {T}}))\), such that
-
(i)
\(\varvec{u}(0) =u,\)
-
(ii)
\(\varvec{u}(t) \in W^{2,2}({\mathbb {T}}) \cap L^2_0({\mathbb {T}})\) for each \(t>0\),
-
(iii)
\(\dot{\varvec{u}}(t) = \big (\varvec{m}(t) ((\varvec{u}(t))_x+ b(x))\big )_x\) for a.e. \(t\geqslant 0\), where \(\varvec{m}(t)\) is given by (2.3) with u replaced by \(\varvec{u}(t)\).
2.6 Monotonic Flow
Because the operator A is monotone, the flow
is a contraction in \(L^2({\mathbb {T}}) \times L^2({\mathbb {T}})\). That is, if \((\varvec{m},\varvec{u})\) and \((\tilde{\varvec{m}}, \tilde{\varvec{u}})\) solve (2.7), then
provided that for each \(t \geqslant 0\), \((\varvec{m}(t),\varvec{u}(t))\), \((\tilde{\varvec{m}}(t), \tilde{\varvec{u}}(t)) \in D(A)\). The flow (2.7) has two undesirable features. First, it does not preserve probabilities; second, the flow may not preserve the condition \(\varvec{m}>0\). To conserve probability, we modify (2.7) through
where \({\overline{H}}(t)\) is such that \(\frac{\mathrm{d}}{\mathrm{d}t} \int _{\mathbb {T}}\varvec{m}\,\mathrm{d}x=0\). A straightforward computation shows that (2.8) is still a contraction in \(L^2({\mathbb {T}}) \times L^2({\mathbb {T}})\). More precisely, if \((\varvec{m},\varvec{u})\) and \((\tilde{\varvec{m}}, \tilde{\varvec{u}})\) solve (2.8) and satisfy \((\varvec{m}(t),\varvec{u}(t))\), \((\tilde{\varvec{m}}(t), \tilde{\varvec{u}}(t)) \in D(A)\) for all \(t\geqslant 0\), \(\int _{\mathbb {T}}\varvec{m}(0)\,\mathrm{d}x=1\), and \(\int _{\mathbb {T}}\tilde{\varvec{m}}(0)\,\mathrm{d}x=1\), then
Furthermore, thanks to the nonlinearity \(\ln (\cdot )\), positivity holds for the discretization of (2.8) that we develop in the next section. Therefore, the discrete analog of (2.8) is a contracting flow that preserves probability and positivity. Then, as \(t\rightarrow \infty \), the solutions approximate (1.1).
3 Discrete Setting
Here, we discuss the numerical approximation of (1.1). We use a monotone scheme for the Hamilton–Jacobi equation. For the Fokker–Planck equation, we consider the adjoint of the linearization of the discrete Hamilton–Jacobi equation. This technique preserves both the gradient structure and the monotonicity properties of the original problem.
3.1 Discretization of the Hamilton–Jacobi Operator
We consider N equidistributed points on [0, 1], \(x_i=\frac{i}{N}\), \(i\in \{1,...,N\}\), and corresponding values of the approximation to u given by the vector \(u=(u_1, ..., u_N)\in {\mathbb {R}}^N\). We set \(h=\frac{1}{N}\). To incorporate the periodic conditions, we use the periodicity convention \(u_0=u_N\) and \(u_{N+1}= u_1\). For each \(i\in \{1,...,N\}\), let \(\psi _i: \mathbb {R}^N\rightarrow \mathbb {R}^2\) be given by
for \(u\in \mathbb {R}^N\). To discretize the operator
we use a monotone finite difference scheme, see [6]. This scheme is built as follows. We consider a function \(F:{\mathbb {R}}\times {\mathbb {R}}\times {\mathbb {T}}\rightarrow {\mathbb {R}}\) satisfying the following four conditions.
-
1.
F(p, q, x) is jointly convex in (p, q).
-
2.
The functions \(p\mapsto F(p, q, x)\) for fixed (q, x) and \(q\mapsto F(p, q, x)\) for fixed (p, x) are increasing.
-
3.
\(F(-p, p, x)=\frac{p^2}{2}+b(x)p+V(x)\).
-
4.
There exists a positive constant, \(c\), such that
$$\begin{aligned} F(-p, q, x) + F(q', p, x') \geqslant - \frac{1}{c} + c\,p^2. \end{aligned}$$(3.1)
An example of such a function may be found in Sect. 4 below. Next, we set
Let \(G:\mathbb {R}^N\rightarrow \mathbb {R}^N\) be the function defined for \(u\in \mathbb {R}^N\) by
Then, G(u) is a finite difference scheme for the Hamilton–Jacobi operator \(\frac{u_x^2}{2}+V(x)+b(x)u_x\).
Remark 3.1
In the higher-dimensional case, the Hamilton–Jacobi operator can be discretized with a similar monotone scheme. See [45] for a systematic study of convergent monotone difference schemes for elliptic and parabolic equations.
3.2 The Variational Formulation
Here, we study the following discrete version, \(\phi :\mathbb {R}^N \rightarrow \mathbb {R}\), of the functional (2.2):
where \(G_i\) is given by (3.3).
Lemma 3.2
The function \(\phi \) given by (3.4) is convex.
Proof
Fix \(\lambda \in (0,1)\) and u, \(v\in {\mathbb {R}}^N\). Because each \(F_i\) is convex, because the exponential is an increasing convex function, and because \(h>0\), we have
which completes the proof. \(\square \)
Lemma 3.3
Let \(\phi \) be given by (3.4). Let \({\mathcal {L}}^*_u:\mathbb {R}^N\rightarrow \mathbb {R}^N\) represent the adjoint operator of the linearized operator \({\mathcal {L}}_u :\mathbb {R}^N\rightarrow \mathbb {R}^N\) of the function G at \(u\in \mathbb {R}^N\). A vector \(u\in \mathbb {R}^N\) is a critical point of \(\phi \) if and only if there exists \(\tilde{m}\in \mathbb {R}_+^N\) such that the pair \((\tilde{m},u)\) satisfies
for all \(i\in \{1,...,N\}\).
Proof
The proof is similar to the one for Lemma 2.2. \(\square \)
Remark 3.4
We observe that for \(w\in \mathbb {R}^N\) and \(i\in \{1,...,N\}\), we have
Simple computations show that \({\mathcal {L}}_u^* w\) is a consistent finite difference scheme for the Fokker–Planck equation.
3.3 The Discretized Operator
Motivated by the previous discussion, we discretize (1.1) through the finite difference operator
where \(\ln m = (\ln m_1, ... , \ln m_N)\) and where G is given by (3.3). Accordingly, the analog to (1.1) becomes
where we highlighted the dependence on \(N\) and where \(\varvec{\iota }=(1, ..., 1)\in \mathbb {R}^N\). In (3.6), the unknowns are the vector \(u^N\), the discrete probability density \(m^N\), normalized to \(h \sum _{i=1}^N m_i^N=1\), and the effective Hamiltonian \({\overline{H}}^N\).
We are interested in two main points. The first is the existence and approximation of solutions to (3.6). The second is the convergence of these solutions to solutions of (1.1). The first issue will be examined by gradient flow techniques and by monotonicity methods. The second issue is a consequence of a modified Minty method.
3.4 Existence of Solutions
Here, we prove the existence of solutions to (3.6). Our proof uses ideas similar to those of the direct method of the calculus of variations.
Proposition 3.5
Let \(\phi \) be as in (3.4). Then, there exists \(u^N\in {\mathbb {R}}^N\) with \(\sum _{i=1}^N u_i^N=0\) that minimizes \(\phi \). Moreover,
for some positive constant \(C\) independent of h. In addition, there exist \(m^N\in \mathbb {R}^N\) with \(h\sum _{i=1}^N m_i^N = 1\) and \(\overline{H}^N \in \mathbb {R}^N\) such that the triplet \((u^N, m^N, \overline{H}^N)\) satisfies (3.6).
Proof
To simplify the notation, we will drop the explicit dependence on \(N\) of \(u^N\) and \(m^N\). Accordingly, we simply write \(u\) and \(m\).
As in the direct method of the calculus of variations, we select a minimizing sequence, \((u^k)_{k\in \mathbb {N}} \subset {\mathbb {R}}^N\), for \(\phi \) satisfying
Then, there exists a positive constant, C, independent of k and \(h\) such that \(\sup _{k\in \mathbb {N}}\phi (u^k)\leqslant C\). Using Jensen’s inequality, for all \(k\in \mathbb {N}\), we have that
where \(\tilde{C}\) is positive constant that is independent of k and \(h\). This estimate together with (3.1)–(3.3) implies that
for some positive constant \(\bar{C}\) that is independent of k and \(h\). By a telescoping series argument combined with the Cauchy inequality, for all \(l,m\in \{1,...,N\}\), we have
The previous bound combined with (3.8) yields
By compactness and by extracting a subsequence if necessary, there exists \(u\in {\mathbb {R}}^N\) with \(\sum _{i=1}^N u_i=0\) such that \(u^k\rightarrow u\) in \(\mathbb {R}^N\). The continuity of \(\phi \) implies that u is a minimizer of \(\phi \). Furthermore, (3.7) holds.
Finally, by Lemma 3.3, we have
for \(\tilde{m}_i=e^{G_i(u)}\). By selecting \({\overline{H}}^N\) conveniently and by setting \(m_i=e^{-{\overline{H}}^N}\tilde{m}_i\), we obtain \(h\sum _{i=1}^{N} m_i=1\). Moreover, the triplet \((u,m, \overline{H}^N) \) satisfies (3.6). \(\square \)
Remark 3.6
The proof of the previous proposition gives an \(\ell ^\infty \) bound for \(u_i\), not just the \(\ell ^2\) bound in (3.7). However, the technique used in the proof is one-dimensional since it is similar to the proof of the one-dimensional Morrey’s theorem. As stated in the proposition, inequality (3.7) is a discrete version of the Poincaré inequality; this inequality holds in any dimension. Finally, for our purposes, (3.7) is sufficient.
3.5 Monotonicity Properties
Next, we prove that the operator \(A^N\) is monotone.
Lemma 3.7
The operator \(A^N\) given by (3.5) is monotone in \(\mathbb {R}^N \times \mathbb {R}^N\). More precisely, for all (m, u), \((\theta ,v) \in \mathbb {R}_+^N \times \mathbb {R}^N\),
Proof
Fix (m, u), \((\theta ,v) \in \mathbb {R}_+^N \times \mathbb {R}^N\). Using the definition of \(A^N\) and the fact that \(\ln (\cdot )\) is increasing, we obtain
Moreover, by the periodicity convention, we have that
So, the estimate
follows from the convexity of each \(F_i\) and from the positivity of each \(m_i\). Similarly,
which concludes the proof. \(\square \)
Remark 3.8
Because the operator \(A^N\) is monotone, \((u^N, m^N, {\overline{H}}^N)\) with \(m^N\in \mathbb {R}^N_+\) solves (3.6) if and only if the condition
holds for every \((v, \theta )\in \mathbb {R}^N \times \mathbb {R}^N_+\). In fact, if \((u^N, m^N, {\overline{H}}^N)\) solves (3.6), then clearly (3.11) holds (with “\(\geqslant \)” replaced by “=”). Conversely, let \((\tilde{v}, \tilde{\theta })\in \mathbb {R}^N\times \mathbb {R}^N\) be arbitrary, and for \(\delta >0\), define \((v,\theta ):= (u^N+\delta \tilde{v}, m^N + \delta \tilde{\theta })\). Because \(m^N\in \mathbb {R}^N_+\), we have \(( v, \theta )\in \mathbb {R}^N\times \mathbb {R}^N_+\) for all sufficiently small \(\delta >0\); thus, (3.11) yields
Letting \(\delta \rightarrow 0^+\), we obtain
Because \((\tilde{v}, \tilde{\theta })\in \mathbb {R}^N\times \mathbb {R}^N\) is arbitrary, we conclude that \((u^N, m^N, {\overline{H}}^N)\) solves (3.6).
Definition 3.9
We say that \(A^N\) is strictly monotone if (3.9) holds with strict inequality whenever (m, u), \((\theta ,v) \in \mathbb {R}_+^N \times \mathbb {R}^N\) satisfy \(v\ne u\) and \(\sum _{i=1}^{N} v=\sum _{i=1}^{N} u\).
3.6 Uniform Estimates
Estimates that do not depend on N play a major role in establishing the convergence of solutions of (3.6) to (1.1). Here, we prove elementary energy estimates that are sufficient to show convergence.
Proposition 3.10
Let \((u^N,m^N, {\overline{H}}^N)\) solve (3.6). Further assume that \(\sum _{i=1}^{N} u^N_i=0\). Then, there exists a positive constant, C, independent of N such that
and
Proof
By Lemma 3.3, we have that \(\phi (u^N) \leqslant C\), where \(C= \phi (0)\). Then, arguing as in the proof of Proposition 3.5, we obtain the \(\ell ^2\) bound in (3.12).
The bound for \({\overline{H}}^N\) is proven in two steps. First, we have
by Jensen’s inequality. Because \(G_i\) is bounded from below, we obtain
for some constant \(C\geqslant 0\) independent of N. Second, for each \(i\in \{1,..., N\}\), we multiply the ith equation in (3.6) by \(m_i\) and the \((N+i)\)th equation by \(-u_i\). Adding the resulting expressions and summing over i, we get
by Jensen’s inequality. By the concavity of \(G_i(u)\), we have
Hence, \({\overline{H}}^N\leqslant C\) for some constant \(C>0\) independent of N. \(\square \)
3.7 Convergence
Here, we show the convergence of solutions of (3.6) to weak solutions of (1.1).
Proposition 3.11
For \(N\in {\mathbb {N}}\), let \((u^N,m^N, {\overline{H}}^N)\in {\mathbb {R}}^N\times {\mathbb {R}}^N\times \mathbb {R}\) be a solution of (3.6). Denote by \(\bar{u}^N\) the step function in [0, 1] that takes the value \(u^N_i\) in the interval \(\left[ \frac{i-1}{N}, \frac{i}{N}\right] \) for \(1\leqslant i\leqslant N\). Similarly, \(\bar{m}^N\) is the step function associated with \(m^N\). Then, up to a (not relabeled) subsequence, \({\overline{H}}^N\rightarrow {\overline{H}}\) in \({\mathbb {R}}\), \(\bar{u}^N\rightharpoonup \bar{u}\) in \(L^2([0,1])\), and \(\bar{m}^N\rightharpoonup \bar{m}\) in \(\mathcal {P}([0,1])\). Moreover, \((\bar{m}, \bar{u}, {\overline{H}})\) is a weak solution of (1.1).
Proof
According to Proposition 3.10, \(|{\overline{H}}^N|\) and \(\Vert \bar{u}^N\Vert _{L^2([0,1])}\) are uniformly bounded with respect to \(N\). Moreover, \(\Vert \bar{m}^N\Vert _{L^1([0,1])}=1\) by construction. Therefore, there exist \({\overline{H}}\in {\mathbb {R}}\), \(\bar{u} \in L^2([0,1])\), and \(\bar{m}\in \mathcal {P}([0,1])\) such that \({\overline{H}}^N\rightarrow {\overline{H}}\) in \({\mathbb {R}}\), \(\bar{u}^N\rightharpoonup \bar{u}\) in \(L^2([0,1])\), and \(\bar{m}^N\rightharpoonup \bar{m}\) in \(\mathcal {P}([0,1])\), up to a (not relabeled) subsequence.
Select \(v, \theta \in C^\infty ({\mathbb {T}})\) satisfying \(\theta > 0\) and \(\int _{\mathbb {T}}\theta \,\mathrm{d}x=1\). Set \(v^N_i=v\left( \frac{i}{N}\right) \) and \(\theta ^N_i=\theta \left( \frac{i}{N}\right) \). Then, by Remark 3.8,
The proposition follows by letting \(N\rightarrow \infty \) in this last expression. \(\square \)
3.8 A Discrete Gradient Flow
To approximate (3.6), we consider two approaches. Here, we discuss a gradient-flow approximation.. Later, we examine a monotonicity-based method.
The discrete-time gradient flow is
where \(\tilde{\varvec{m}}_i=e^{G_i(\varvec{u})}\). Because \(\phi \) is convex, \(\phi (\varvec{u}(t))\) is decreasing. Moreover, the proof of proposition 3.5 shows that \(\phi \) is coercive on the set \(\sum _{i=1}^N \varvec{u}_i=0\). Note that (3.13) satisfies
Consequently, \(\varvec{u}(t)\) is bounded and converges to a critical point of \(\phi \). Finally, we obtain a solution to (3.6) by normalizing \( \tilde{\varvec{m}}_i\).
3.9 Dynamic Approximation
We can use the monotonicity of \(A^N\) to build a contracting flow in \(L^2\) whose fixed points satisfy (3.6). This flow is
where \({\overline{H}}^N(t)\) is such that the total mass is preserved; that is,
Due to the logarithmic nonlinearity, \(\varvec{m}(t) > 0\) for all t. We further observe that
Moreover, if \((\bar{m}^N, \bar{u}^N, {\overline{H}}^N)\) is a solution of (3.6), then the monotonicity of \(A^N\) implies that
Furthermore, if strong monotonicity holds (see Definition 3.9), the preceding inequality is strict if \((\varvec{m}, \varvec{u})\ne (m^N, u^N)\). In this case, \((\varvec{m}(t), \varvec{u}(t))\) is globally bounded and converges to \((m^N, u^N)\). Finally, this implies that \({\overline{H}}(t)\) converges to \({\overline{H}}^N\).
4 Numerical Results
Here, we discuss the implementation of our numerical methods, the corresponding results, and some extensions.
In our numerical examples, we construct F as follows. First, we build
and
We set
Then, \(F_i\) is given by (3.2).
We implemented our algorithms in MATLAB and Mathematica with no significant differences in performance or numerical results. We present here the computations performed with the Mathematica code. To solve the ordinary differential equations, we used the built-in Mathematica ODE solver with the stiff backward difference formula (BDF) discretization of variable order.
4.1 Gradient Flow
For the gradient flow, we took \(u(x,0)=0.2 \cos (2 \pi x)\) as the initial condition for u. We used \(N=100\). We set \(b=0\) and \(V(x)=\sin (2 \pi x)\). Figures 1 and 2 feature the evolution of u and \(m\), respectively, for \(0\leqslant t\leqslant 1\). We can observe a fast convergence to the stationary solution \(u=0\). Figure 3 illustrates the behavior of m at equally spaced times and compares it to the exact solution (in black).

Gradient flow: u

Gradient flow: m

Gradient flow: m numeric for \(0\leqslant t\leqslant 0.1\) versus exact (black line)
4.2 Monotonic Flow
Here, we present the numerical results for the monotonic flow. We set, as before, \(b=0\) and \(V(x)=\sin (2 \pi x)\). We used \(u(x,0)=0.2 \cos (2 \pi x)\) and \(m(x,0)=1+0.2 \cos (2 \pi x)\) as initial conditions for u and m, respectively. As previously, we used \(N=100\). Figures 4 and 5 depict the convergence to stationary solutions for \(0\leqslant t\leqslant 10\). Figure 6 shows the comparison of the values of m at equally spaced times with the stationary solution. Finally, Figs. 7 and 8 illustrate the solution (u, m) for the case \(b(x)=\cos ^2(2 \pi x)\).

Monotonic flow: u

Monotonic flow: m

Monotonic flow: m numerical versus exact (black line) for \(t=0, 1,\ldots , 10\)

Monotonic flow: u with \(b=\cos ^2(2 \pi x)\)

Monotonic flow: m with \(b=\cos ^2(2 \pi x)\)
In Table 1, we show the error in m and u in \(L^\infty \) and the CPU time for the preceding problem at \(T=100\); that is, we compute \(\max _i|m(x_i)-m^N_i|\) and \(\max _i|u(x_i)-u^N_i|\). We note that the error is extremely small because of the particular form of the solution. Here, the exact solution \(u=0\) is also the exact numerical solution. We also observe that the CPU times increase substantially. Thus, as suggested to the authors by Y. Achdou, we consider the alternative monotone discretization
The corresponding results (also for \(T=100\)) are shown in Table 2. To get a better sense of the convergence of the algorithm, we considered this last discretization for the case
and \(V(x)=\sin ( 2\pi x)\), \(u(x,0)=0.2 \cos (2 \pi x)\), and \(m(x,0)=1+0.2 \cos (2 \pi x)\) as before. The estimated errors are plotted in Table 3 and correspond to the difference between the solution computed with N nodes and the solution computed with 2N nodes. We see that the error decreases roughly linearly in \(\frac{1}{N}\) as one would expect since the monotone discretization of the Hamilton–Jacobi equation is first-order accurate.

Congestion model: u
4.3 Application to Congestion Problems
Our methods are not restricted to (1.1) nor to one-dimensional problems. Here, we consider the congestion problem (2.1) and present the corresponding numerical results. We examine higher-dimensional problems in the next section.
The congestion problem (2.1) satisfies the monotonicity condition (see [32]). Moreover, this problem admits the same explicit solution as (1.1) with \(b=0\). We chose \(V(x)=\sin (2 \pi x)\), for comparison.
We took the same initial conditions as in the previous section and set \(N=100\). We present the evolution of u and m in Figs. 9 and 10, respectively. In Fig. 11, we superimpose the exact solution, m, on the numerical values of m at equally spaced times. Finally, in Figs. 12 and 13, we consider the quartic mean-field game with congestion

Congestion model: m

Congestion model: m numerical versus exact (black line) for \(t=0, 1,\ldots , 10\)

Quartic congestion model: u

Quartic congestion model: m
4.4 A Singular MFG
The logarithmic coupling in the MFG studied so far prevents m to vanish. However, m can vanish in many cases. The following example, taken from [26] (also see [20, 21]), illustrates this behavior. Consider the MFG
The solution of the preceding problem is \(m=(3\sin (2\pi x)-{\overline{H}})^+\), where \({\overline{H}}\) is determined by the condition
and u is a viscosity solution of
Here, the monotone flow fails to preserve the positivity of m. Thus, we introduce a regularized version of the monotone flow for which the set \(m\geqslant 0\) is invariant. This regularized flow is obtained by discretizing the following continuous flow
where \(\lambda \) is a regularization parameter. The results corresponding to \(\lambda =100\) are shown in Fig. 14 (the evolution of m) and Fig. 15 (comparison between exact and numerical solution).

Evolution of m for the modified monotone flow at \(T=100\) for the singular MFG

Comparison between numerical (blue) and exact (dashed) solution for the singular MFG (Color figure online)
4.5 Higher-Dimensional Examples
As a last example, we consider the following two-dimensional version of (1.1):
with \(W(x,y)=\sin (2 \pi x)+\sin (2 \pi y)\). Because \(W(x,y)=V(x)+V(y)\) for \(V(x)=\sin (2 \pi x)\), the solution to (4.1) takes the form \(w(x,y)=u(x)+u(y)\) and \(\theta (x,y)=m(x)+m(y)\), where (u, m) solves (1.1) with \(b=0\).
We chose \(w(x,y,0)=0.4 \cos (x+ 2 y)\), \(\theta (x,y,0)=1+0.3 \cos (x- 3 y)\), and \(N=20\). Figure 16 illustrates \(\theta \) at \(T=50\). The numerical errors for \(\theta \) and w are shown in Figs. 17 and 18, respectively.

Two-dimensional problem: numeric \(\theta \) at \(T=50\)

Two-dimensional problem: \(\theta \) numerical error

Two-dimensional problem: w numerical error
5 Final Remarks
Here, we developed two numerical methods to approximate solutions of stationary mean-field games. We addressed the convergence of a discrete version of (1.1), and the convergence to weak solutions through a monotonicity argument. Our techniques generalize to discretized systems that are monotonic, and that admit uniform bounds with respect to the discretization parameter.
In the cases we considered, our methods approximate well the exact solutions. While the gradient flow is considerably faster than the monotonic flow, this last method applies to a wider class of problems.
We selected a simple model for illustration purposes. In our numerical examples, however, we illustrated the convergence of the schemes in higher-dimensional problems and congestion MFG problems. Furthermore, our results can be easily extended to related problems—higher-dimensional cases, second-order MFG, or non-local (monotonic) problems. Additionally, our methods provide a natural guide for two future research directions. The first is the development of a general theory of convergence for monotone schemes and the extension of our methods to mildly non-monotonic MFG. The second is the study of time-dependent MFG. This last direction is particularly relevant since the coupled structure of MFG and the initial-terminal conditions that are usually imposed make these problems very challenging from the numerical point of view.
References
Achdou Y (2013) Finite difference methods for mean field games. In: Hamilton-Jacobi equations: approximations, numerical analysis and applications. Lecture notes in mathematics, vol 2074. Springer, Heidelberg, pp. 1–47. doi:10.1007/978-3-642-36433-4_1
Achdou Y, Camilli F, Capuzzo-Dolcetta I (2012) Mean field games: numerical methods for the planning problem. SIAM J Control Optim 50(1):77–109
Achdou Y, Capuzzo-Dolcetta I (2010) Mean field games: numerical methods. SIAM J Numer Anal 48(3):1136–1162
Achdou Y, Perez V (2012) Iterative strategies for solving linearized discrete mean field games systems. Netw Heterog Media 7(2):197–217
Achdou Y, Porretta A (2016) Convergence of a finite difference scheme to weak solutions of the system of partial differential equations arising in mean field games. SIAM J Numer Anal 54(1):161–186. doi:10.1137/15M1015455
Barles G, Souganidis PE (1991) Convergence of approximation schemes for fully nonlinear second order equations. Asymptot Anal 4(3):271–283
Bensoussan A, Frehse J, Yam P (2013) Mean field games and mean field type control theory. Springer Briefs in Mathematics. Springer, New York
Cacace S, Camilli F (2016) Ergodic problems for Hamilton-Jacobi equations: yet another but efficient numerical method (preprint)
Camilli F, Festa A, Schieborn D (2013) An approximation scheme for a Hamilton–Jacobi equation defined on a network. Appl Numer Math 73:33–47
Camilli F, Silva F (2012) A semi-discrete approximation for a first order mean field game problem. Netw Heterog Media 7(2):263–277
Cardaliaguet P (2011) Notes on mean-field games
Cardaliaguet P, Graber PJ (2015) Mean field games systems of first order. ESAIM Control Optim Calc Var 21(3):690–722
Cardaliaguet P, Graber PJ, Porretta A, Tonon D (2015) Second order mean field games with degenerate diffusion and local coupling. NoDEA Nonlinear Differ Equ Appl 22(5):1287–1317
Carlini E, Silva FJ (2014) A fully discrete semi-Lagrangian scheme for a first order mean field game problem. SIAM J Numer Anal 52(1):45–67
Evans LC (1998) Partial differential equations. Graduate Studies in Mathematics. American Mathematical Society, Providence
Evans LC (2003) Some new PDE methods for weak KAM theory. Calc Var Partial Differ Equ 17(2):159–177
Evans LC (2009) Further PDE methods for weak KAM theory. Calc Var Partial Differ Equ 35(4):435–462
Ferreira R, Gomes D (2016) Existence of weak solutions for stationary mean-field games through weak solutions (preprint)
Gomes D, Iturriaga R, Sánchez-Morgado H, Yu Y (2010) Mather measures selected by an approximation scheme. Proc Am Math Soc 138(10):3591–3601
Gomes D, Nurbekyan L, Prazeres M (2016) Explicit solutions of one-dimensional, first-order, stationary mean-field games with congestion. Proceeding of IEEE-CDC (to appear)
Gomes D, Nurbekyan L, Prazeres M (2016) One-dimensional, stationary mean-field games with a local coupling (preprint)
Gomes D, Patrizi S, Voskanyan V (2014) On the existence of classical solutions for stationary extended mean field games. Nonlinear Anal 99:49–79
Gomes D, Pimentel E (2016) Local regularity for mean-field games in the whole space. Minimax Theory Appl 1(1):65–82
Gomes D, Pimentel E, Sánchez-Morgado H (2016) Time-dependent mean-field games in the superquadratic case. ESAIM Control Optim Calc Var 22(2):562–580. doi:10.1051/cocv/2015029
Gomes D, Pimentel E, Sánchez-Morgado H (2015) Time-dependent mean-field games in the subquadratic case. Commun Partial Differ Equ 40(1):40–76
Gomes D, Pimentel E, Voskanyan V (2016) Regularity theory for mean-field game systems. Springer, Berlin, p x \(+\) 118. doi:10.1007/978-3-319-38934-9
Gomes D, Pires GE, Sánchez-Morgado H (2012) A-priori estimates for stationary mean-field games. Netw Heterog Media 7(2):303–314
Gomes D, Sánchez Morgado H (2014) A stochastic Evans-Aronsson problem. Trans Am Math Soc 366(2):903–929
Gomes D, Velho RM, Wolfram M-T (2014) Dual two-state mean-field games. In: Proceedings CDC 2014
Gomes D, Velho RM, Wolfram M-T (2014) Socio-economic applications of finite state mean field games. Philos Trans R Soc Lond Ser A Math Phys Eng Sci 372(2028):20130405, 18
Gomes D, Voskanyan V (2015) Short-time existence of solutions for mean-field games with congestion. J Lond Math Soc 92(3):778–799. doi:10.1112/jlms/jdv052
Gomes DA, Mitake H (2015) Existence for stationary mean-field games with congestion and quadratic Hamiltonians. NoDEA Nonlinear Differ Equ Appl 22(6):1897–1910
Gomes DA, Patrizi S (2015) Obstacle mean-field game problem. Interfaces Free Bound 17(1):55–68
Gomes DA, Pimentel E (2015) Time-dependent mean-field games with logarithmic nonlinearities. SIAM J Math Anal 47(5):3798–3812
Gomes DA, Saúde J (2014) Mean field games models—a brief survey. Dyn Games Appl 4(2):110–154
Guéant O (2012) Mean field games equations with quadratic Hamiltonian: a specific approach. Math Models Methods Appl Sci 22(9):1250022, 37
Guéant O (2012) Mean field games with a quadratic Hamiltonian: a constructive scheme. In: Advances in dynamic games, vol 12 of Ann Int Soc Dyn Games. Birkhäuser/Springer, New York, pp 229–241
Guéant O (2012) New numerical methods for mean field games with quadratic costs. Netw Heterog Media 7(2):315–336
Huang M, Caines PE, Malhamé RP (2007) Large-population cost-coupled LQG problems with nonuniform agents: individual-mass behavior and decentralized \(\epsilon \)-Nash equilibria. IEEE Trans Automat Control 52(9):1560–1571
Huang M, Malhamé RP, Caines PE (2006) Large population stochastic dynamic games: closed-loop McKean–Vlasov systems and the Nash certainty equivalence principle. Commun Inf Syst 6(3):221–251
Lasry J-M, Lions P-L (2006) Jeux à champ moyen. I. Le cas stationnaire. C R Math Acad Sci Paris 343(9):619–625
Lasry J-M, Lions P-L (2006) Jeux à champ moyen. II. Horizon fini et contrôle optimal. C R Math Acad Sci Paris 343(10):679–684
Lasry J-M, Lions P-L (2007) Mean field games. Jpn J Math 2(1):229–260
Mészáros AR, Silva FJ (2015) A variational approach to second order mean field games with density constraints: the stationary case. J Math Pures Appl (9) 104(6):1135–1159
Oberman AM (2006) Convergent difference schemes for degenerate elliptic and parabolic equations: Hamilton–Jacobi equations and free boundary problems. SIAM J Numer Anal 44(2):879–895 (electronic)
Pimentel E, Voskanyan V (2016) Regularity for second-order stationary mean-field games. Indiana Univ Math J (to appear)
Porretta A (2015) Weak solutions to Fokker–Planck equations and mean field games. Arch Ration Mech Anal 216(1):1–62
Porretta Alessio (2014) On the planning problem for the mean field games system. Dyn Games Appl 4(2):231–256
Santambrogio F (2012) A modest proposal for MFG with density constraints. Netw Heterog Media 7(2):337–347
Voskanyan VK (2013) Some estimates for stationary extended mean field games. Dokl Nats Akad Nauk Armen 113(1):30–36
Author information
Authors and Affiliations
Corresponding author
Additional information
The authors were partially supported by King Abdullah University of Science and Technology baseline and start-up funds and by KAUST SRI, Center for Uncertainty Quantification in Computational Science and Engineering.
Rights and permissions
About this article

Cite this article
Almulla, N., Ferreira, R. & Gomes, D. Two Numerical Approaches to Stationary Mean-Field Games. Dyn Games Appl 7, 657–682 (2017). https://doi.org/10.1007/s13235-016-0203-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13235-016-0203-5