
Abstract
The area-characteristic, maximum possible earthquake magnitude \(T_M\) is required by the earthquake engineering community, disaster management agencies and the insurance industry. The Gutenberg–Richter law predicts that earthquake magnitudes M follow a truncated exponential distribution. In the geophysical literature, several estimation procedures were proposed, see for instance, Kijko and Singh (Acta Geophys 59(4):674–700, 2011) and the references therein. Estimation of \(T_M\) is of course an extreme value problem to which the classical methods for endpoint estimation could be applied. We argue that recent methods on truncated tails at high levels (Beirlant et al. Extremes 19(3):429–462, 2016; Electron J Stat 11:2026–2065, 2017) constitute a more appropriate setting for this estimation problem. We present upper confidence bounds to quantify uncertainty of the point estimates. We also compare methods from the extreme value and geophysical literature through simulations. Finally, the different methods are applied to the magnitude data for the earthquakes induced by gas extraction in the Groningen province of the Netherlands.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Under the Dutch province of Groningen lies one of the largest gas fields in the world. The reservoir lies at a depth of 3 km in Rotliegend sandstone and contains an estimated 2800 billion cubic metres of gas. Since production started in 1963, around 2000 billion cubic metres of gas has been produced up to 2012 by the NAM (Nederlandse Aardolie Maatschappij), a partnership between Shell and ExxonMobil. As a result of taxes and its participation in NAM, the Dutch government typically receives 70% of the profit from the Groningen Gas Field (GGF), although in some periods this can be even as high as 90% (van der Voort and Vanclay 2015).
Despite the economic advantages of the gas extraction on the Dutch government finances, there is also a serious drawback. Since 1986, anthropogenic (man-made) seismicity is observed in the, otherwise mostly aseismic, northern part of the Netherlands, and especially in the province of Groningen. When the gas is extracted, the porous layer of sandstone, in which it is contained, compacts. Normally, this happens gradually, and the surface subsides without causing any problem. However, when this process happens, e.g. close to fault lines, the sandstone layers can locally compact differently which causes seismic activity (van Eck et al. 2006; van der Voort and Vanclay 2015). Because of this anthropogenic seismicity, houses have been damaged and the NAM has paid around 200 million euro of compensation up to 2014. Moreover, several thousands of houses need to be reinforced to avoid serious damage caused by future potential seismic activity. van Eck et al. (2006) also mention other social impacts of the seismic activity including declining house prices and concerns about breaching of the dykes in the gas field area in case of a large seismic event.
One of the obvious parameters responsible for the damage caused by seismic activity is the magnitude of the seismic event, which is directly linked to the energy released by the seismic event. So far, the largest (local) seismic event magnitude observed in the GGF is \(M=3.6\) which occurred on 16 August 2012 near the village of Huizinge, municipality of Loppersum. A modified Mercalli intensity of VI was observed less than 4 km from the event epicentre (Dost and Kraaijpoel 2013). The event caused significant damage to the infrastructure.
A natural question arises: what is the maximum possible seismic event magnitude \(T_M\) which can be generated by the GGF? Knowledge of this parameter is required by the local authorities, the engineering community, disaster management agencies, environmentalists and the insurance industry. Its value depends on the regional tectonic setting of the area, the presence of active (capable) tectonic faults and, up to certain extent, the production regime. According to a comprehensive study of anthropogenic seismicity since 1929, the largest observed seismic event magnitude caused by oil and gas extraction is 7.3 (Davies et al. 2013). This event and another event of magnitude \(\sim\) 7.0 took place near Gazli in Uzbekistan, in an area that is known to be aseismic. At the Lacq gas field in France, an event of magnitude \(\sim\) 6.0 was recorded (Bardainne et al. 2008). It is uncertain that the events were indeed of anthropogenic origin, but several factors suggest that these are examples of the strongest seismic events related to gas extraction from the gas fields. Seismicity generated by groundwater extraction has a similar character. On 11 May 2011, in Lorca, Spain, extensive groundwater extraction caused the occurrence of a shallow (2–4 km) seismic event of magnitude 5.1, leading to nine casualties and significant damage to infrastructure (González et al. 2012).
The purpose of this research is to assess the maximum possible seismic event magnitude \(T_M\), based on the available seismic event catalogue of anthropogenic seismicity generated by the GGF. Several such estimates for the area have been made by the KNMI (Koninklijk Nederlands Meteorologisch Instituut): 3.3 in 1995, 3.8 in 1998 and 3.9 in 2004. In March 2016, a workshop was held in Amsterdam to provide an estimate for the maximum possible seismic event magnitude, which can be generated by the GGF (see NAM 2016 for an overview of the results). The range of \(T_M\) estimates, provided by the experts, is 3.8–5.0. So far, the epicentres of all occurred seismic events are within the areas of the gas extraction or not more than 500 m outside of the extraction area. This indicates that the observed seismicity can be classified as anthropogenic. However, it cannot be excluded that in the future the stresses generated by the gas extraction will be able to trigger tectonic origin stresses, resulting in significantly stronger events outside of the gas field. As a rule, such events can be significantly stronger than purely induced (see e.g. Gibowicz and Kijko 1994). So far, experts have found no evidence that the Groningen gas fields are capable of triggering significantly stronger seismicity than already observed. However, if such events would occur, experts believe that an event of magnitude at most 7.25 can take place (NAM 2016).
The estimation of \(T_M\) can be done in many different ways. For a review of different methods applicable for the assessment of \(T_M\), see e.g. Kijko and Graham (1998), Kijko (2004), Wheeler (2009), Kijko and Singh (2011), and Vermeulen and Kijko (2017). A comprehensive discussion of \(T_M\) assessment techniques, mainly related and applicable to fluid injection, is provided in Yeck et al. (2015). Unlike Shapiro et al. (2010) and Hallo et al. (2014), Yeck et al. (2015) assumed that the parameters describing the anthropogenic seismic regime (seismic activity rate, the b-value of Gutenberg–Richter and an upper limit of magnitude \(T_M\)) are subject to significant spatial and temporal variation. Especially prone to time-space fluctuation is the value of \(T_M\). Yeck et al. (2015) suggest two different approaches for the assessment of this parameter. The first one is based on the observation (see e.g. McGarr 2014; McGarr et al. 2002; Nicol et al. 2011) that the maximum seismic event magnitude is linearly proportional to the logarithm of the cumulative volume of fluid injected/extraction. However, Yeck et al. (2015) are not answering the question about the saturation of such a time dependence plot. Since fault sizes are limited, and the seismic event magnitude is linked to the fault size, the magnitudes also need to have an upper limit. Based on this simple physical consideration, the \(T_M\) value must reach this certain upper limit. The second approach to assess \(T_M\), which is explored in Yeck et al. (2015), is based on the relationship between the size of the fault rupture and the seismic event magnitude (see e.g. Wells and Coppersmith 1994; Stirling et al. 2013). A similar approach, extended by application of the logic-tree formalism, is suggested in Bommer and van Elk (2017). The drawback of the proposed method is the fact that anthropogenic seismicity often takes place in previously inactive areas with unknown and unmapped faults.
Clearly, assessment of the upper limit of magnitude \(T_M\) can be done using statistical tools, in particular extreme value theory (EVT). In this work, the EVT formalism is applied for assessment of the maximum possible seismic event magnitude in the GGF, by application of two different parameter estimation techniques, as developed in Beirlant et al. (2016), Beirlant et al. (2017). Our work also includes analyses of the confidence bounds of the upper limit of the magnitude distribution. For this purpose, we applied the asymptotic techniques as developed in Beirlant et al. (2016, 2017). Other EVT-based estimators using the moment estimator (Dekkers et al. 1989) or the peaks-over-threshold maximum likelihood (POT-ML) approach have also been applied (see e.g. Beirlant et al. 2004; de Haan and Ferreira 2006). However, comprehensive tests based on simulated data show that moment and POT-ML-based estimators perform worse for truncated distributions than the estimators developed in Beirlant et al. (2016, 2017). For this reason, the moment and the POT-ML endpoint estimators are not discussed in this work. Recently, another endpoint estimator based on EVT was proposed in Fraga Alves et al. (2017). It is, however, not suitable to estimate the endpoint when the distribution is truncated, as is, for example, the case for the Gutenberg–Richter distribution we discuss later. When applying the estimator to simulated data or the GGF data example, which we consider later in this paper, the method of Fraga Alves et al. (2017) yields very volatile estimates. Therefore, it is not included in this paper.
The EVT-based estimators of the upper limit of the earthquake magnitudes, or equivalently the endpoint of the magnitude distribution, have received rather limited attention in the respectable seismological literature. Pisarenko et al. (2008, 2014); Pisarenko and Rodkin (2017); Vermeulen and Kijko (2017) are notable exceptions.
Based on empirical evidence, it is often assumed that earthquake magnitudes follow the so-called Gutenberg–Richter (GR) distribution (Gutenberg and Richter 1956). The original GR magnitude distribution has no upper limit. After right truncation of the GR distribution, or physically speaking, after introducing the upper limit of seismic event magnitude (Hamilton 1967; Page 1968), the cumulative distribution function (CDF) takes the form
where \(t_M > 0\) is the level of completeness of the seismic event catalogue, \(T_M\) is the maximum possible magnitude, i.e. the upper limit (truncation point) of the magnitude distribution, and \(\beta > 0\) the distribution parameter. Note that the Gutenberg–Richter distribution is not only derived empirically. There are several attempts (see e.g. Scholz 1968, 2015; Rundle 1989) to derive the GR relation based on the physical principles of earthquake occurrence or by application of the universal concept of entropy (see e.g. Berril and Davis 1980). Several parametric estimators of \(T_M\) have been derived, which are based on the GR magnitude distribution (see e.g. Pisarenko et al. 1996, 2008; Raschke 2012). Here, we only look at one parametric estimator of \(T_M\): the Kijko–Sellevoll estimator (Kijko and Sellevoll 1989; Kijko 2004). Moreover, we are also analysing a parametric upper confidence bound for \(T_M\) based on the truncated GR distribution (Pisarenko 1991). This technique is applied in Zöller and Holschneider (2016b) to assess the maximum possible seismic event magnitude in the GGF. Note that Bayesian estimators for the maximum earthquake magnitude have also been considered, see e.g. Cornell (1994), Holschneider et al. (2011), and Kijko (2012).
Another parametric model for earthquake magnitudes is the tapered Pareto distribution a.k.a. the modified GR distribution (see e.g. Kagan and Jackson 2000, 2001). However, unlike the truncated GR distribution, this model does not provide an upper bound for the magnitudes, which makes it unrealistic from a physical point of view.
Zöller and Holschneider (2016b) like for example Pisarenko and Rodkin (2017) provide estimates for the maximum expected seismic event magnitude to occur, for different time intervals (time horizons). It is important to note that in our work, we do not try to estimate that quantity, but we only look at estimates for the time-independent maximum possible seismic event magnitude.
In the next section, we discuss the different endpoint estimators that can be applied to estimate the maximum possible seismic magnitude \(T_M\). In Sect. 3, we apply these methods to estimate \(T_M\) for the GGF. Moreover, we also discuss upper confidence bounds for \(T_M\). Afterwards, we compare the performance of the EVT-based estimators with some discussed in Kijko and Singh (2011) using simulations, assuming that the seismic event magnitude is distributed according to the truncated GR distribution.
2 Overview of applied estimators
We now discuss several different types of endpoint estimators: the EVT-based estimators are presented in Sect. 2.1, the non-parametric estimators as discussed in Kijko and Singh (2011) are described in Sect. 2.2 and the parametric Kijko–Sellevoll estimator is presented in Sect. 2.3. We provide only very few details for the estimators already in use for assessment of the upper limit of the seismic event magnitude. More details can be found in Kijko (2004); Kijko and Singh (2011). In all cases where order statistics are used, the ordered sample of magnitudes is denoted as \(M_{1,n} \le \cdots \le M_{n,n}\).
2.1 EVT-based estimators
We consider two EVT-based estimators of the endpoint: the truncated generalised Pareto distribution (GPD) estimator using the framework from Beirlant et al. (2017) and the truncated Pareto estimator of Beirlant et al. (2016).
The methodology for modelling the upper tail of the distribution of a random variable Y relies on the fact that the maximum of independent measurements \(Y_i, \; i=1,\ldots ,n,\) can be approximated by the generalised extreme value distribution: as \(n\rightarrow \infty\),
where \(b_n \in {\mathbb {R}}\), \(a_n >0\) and \(\xi \in {\mathbb {R}}\) are the location, scale and shape parameters, respectively. For \(\xi =0\), \(G_0(y)\) has to be read as \(\exp \left( - \exp (-y)\right)\).
In fact, (1) represents the only possible non-degenerate limits for maxima of independent and identically distributed sequences \(Y_i\). Let \(F_Y (y) = {\mathbb {P}}(Y \le y)\) denote the CDF, \(\bar{F}_Y(y) = 1-F_Y(y)\) the right tail function (RTF) and \(Q_Y (p) = \inf \{y \,|\, F_Y(y) \ge p \}\) (\(0<p<1\)) the quantile function of a random variable Y.
Condition (1) is equivalent to the convergence of the distribution of excesses (or peaks) over high thresholds t to the generalised Pareto distribution (GPD): as t tends to the endpoint of the distribution of Y, then
where \(\sigma _t >0\). The shape parameter \(\xi\) is often called the extreme value index (EVI). The specific case \(\xi >0\) consists of the Pareto-type distributions defined through
The max-domain of attraction (MDA) in case \(\xi =0\) is called the Gumbel domain to which exponentially decreasing tails belong. Finally, the domain corresponding to negative values of the EVI has finite right endpoints.
Right truncation models for X based on a parent variable Y satisfying the above extreme value assumptions are obtained from
for some \(T>0\). The odds of the truncated probability mass under the untruncated distribution Y are denoted by \(D_T = \bar{F}_Y (T)/F_Y(T)\).
Truncation with the threshold \(t=t_n \rightarrow \infty\) is defined through the assumption
which then entails that for \(x\in (0,\kappa )\)
This corresponds to situations where the deviation from the GPD behaviour due to truncation at a high value T will be visible in the data from t on, and the approximation of the peaks-over-threshold (POT) distribution using the limit distribution in (6) appears more appropriate than with a simple GPD.
In the specific case of Pareto-type distributions (i.e. \(\xi >0\)), condition (6) can be simplified to
assuming that \(T/t \rightarrow \rho > 1\).
In practice, one has to choose a certain threshold t. Often, one takes it equal to the \((k+1)\)-th largest observation \(X_{n-k,n}\) and then computes the estimator for many values of k.
2.1.1 Truncated GPD estimator
We can estimate the endpoint of the magnitude distribution using the techniques developed in Beirlant et al. (2017). Its estimator for the truncation point \(T_M\) is based on condition (6) for the variable M where \(\xi\) is the EVI of Y, the parent variable of M, see Table 1. The corresponding estimator for the endpoint is then given by
with \(\hat{\xi }_k\) and \(\hat{\tau }_k\) the estimates for \(\xi\) and \(\tau = \xi /\sigma _t\) obtained by application of the maximum likelihood principle. See Beirlant et al. (2017) for more details on estimation and testing. We will call this estimator the Truncated GPD.
Using Theorem 2 in Beirlant et al. (2017) with \(p=0\), we obtain an approximate \(100(1-\alpha )\%\) upper confidence bound for \(T_M\):
One has to note that in (9), second-order terms have been omitted, and \(\hat{D}_{T,k}\) denote the estimates for the truncation odds \(D_T\), see Beirlant et al. (2017).
2.1.2 Truncated Pareto estimator
The endpoint estimator of Beirlant et al. (2016) is based on condition (7) and is hence only suitable for truncated Pareto-type tails. Since the (truncated) GR magnitude distribution is a truncated exponential distribution, we expect that this estimator cannot be applied to the magnitudes directly. Instead, we use following empirical relationship between the (local) earthquake magnitude M and the energy released by earthquakes (Lay and Wallace 1995)
or reversely
where the energy is expressed in megajoules (MJ). We thus expect the energy to follow a truncated Pareto-type distribution. Therefore, we apply the estimator of Beirlant et al. (2016) to the energy and transform the endpoint back to the magnitudes using (11). By denoting the parent variable of E by \(Y_E\), we have \(E=_d (Y_E \,|\, Y_E<T_E)\), where \(T_E\) is the endpoint for E, see Table 1.
Using the approach of Beirlant et al. (2016) applied to the variable E, the endpoint for the energy is then estimated as
Here \(\hat{\xi }^{Y_E,+}_k\) are the estimates for \(\xi _{Y_E}\), the extreme value index of \(Y_E\). See Beirlant et al. (2016) for more details on estimation and testing. Note that \(\rho\) (see (7)) is estimated by \(E_{n,n}/E_{n-k,n}\).
Transforming the estimated endpoints for the energy gives the following endpoint estimates for the magnitudes:
We denote this estimator by Truncated Pareto.
Using the asymptotic results in Beirlant et al. (2016), an approximate \(100(1-\alpha )\%\) upper confidence bound for \(T_E\) can be constructed. Application of Theorem 2 in Beirlant et al. (2016), after omitting second-order terms again, gives the following approximate \(100(1-\alpha )\%\) upper confidence bound for \(T_E\):
Here \(\hat{D}^{E,+}_{T,k}\) are the truncated Pareto estimates for the truncation odds \(D_T^E= \bar{F}_{Y_E} (T_E)/F_{Y_E}(T_E)\), see Beirlant et al. (2016). This upper bound can then be transformed back to the magnitude level as before to get an approximate \(100(1-\alpha )\%\) upper confidence bound for \(T_M\):
2.2 Non-parametric estimators
The next estimators are all based on the fact that
see Kijko and Singh (2011). Hence, \(T_M\) can be estimated by
with \(\Delta\) an estimator for \(\int _{t_M}^{T_M} F_M^n(m) \, dm\).
2.2.1 Non-parametric with Gaussian kernel
The CDF in (15) can be estimated using a Gaussian kernel. The estimator for the endpoint is then obtained as the iterative solution of the equation
with
and \(\Phi\) the standard normal CDF. The bandwidth h is chosen using unbiased cross-validation. We denote this estimator by N-P-G. For more details, we refer to Kijko et al. (2001) and Equations 28 and 29 in Kijko and Singh (2011).
2.2.2 Non-parametric based on order statistics
Cooke (1979) proposes to approximate the CDF in (15) with the empirical CDF. The corresponding endpoint estimator, see Equation 33 in Kijko and Singh (2011), is given by
We denote this estimator by N-P-OS.
Cooke (1979) also constructed an approximate \(100(1-\alpha )\%\) upper confidence bound for \(T_M\):
where the parameter \(\nu\) is determined by
for every constant \(c>0\).
Note that \(\nu =1\) for upper truncated distributions which can be proved by application of the mean value theorem. Since it is often assumed that magnitude data come from an upper truncated distribution, e.g. the truncated Gutenberg–Richter distribution, we use \(\nu =1\) in the remainder.
2.2.3 Few largest observations
Later, Cooke (1980) proposed a simple estimator that only uses the maximum and the \((k+1)\)-th largest magnitude. This estimator, see Equation 38 in Kijko and Singh (2011), is equal to
We denote this estimator by FL.
2.2.4 Extended FL
The previous estimator only uses two observations. It can be extended as
see Equation 40 in Kijko and Singh (2011). We denote this estimator by EFL.
2.2.5 Robson–Whitlock
Robson and Whitlock (1964) propose the following simple estimator:
see Equation 42 in Kijko and Singh (2011). We denote this estimator by R–W.
Another approximate \(100(1-\alpha )\%\) upper confidence bound for \(T_M\) was derived in Robson and Whitlock (1964):
Note that this corresponds to the upper confidence bound (18) of Cooke (1979) (with \(\nu =1\)).
2.2.6 Robson–Whitlock–Cooke
The previous estimator can be improved, in terms of MSE, as shown in Cooke (1979). The improved estimator is obtained as
see Equation 46 in Kijko and Singh (2011). As before, we take \(\nu\) equal to 1. We denote this estimator by R–W–C. Note that this estimator corresponds to the FL estimator for \(k=2\).
2.3 Parametric estimator: Kijko–Sellevoll
Kijko and Sellevoll (1989) introduced the equation (see Equation 13 in Kijko and Singh (2011))
with
and \(E_1(z)=\int _z^{\infty } \exp (-s)/s\,{\text {d}}s\) the exponential integral function. Since these expressions depend on \(T_M\), we obtain \(T_M\) using an iterative procedure. The parameter \(\beta\) is estimated based on the truncated Gutenberg–Richter law using maximum likelihood, see Page (1968) and Chapter 12 in Gibowicz and Kijko (1994). It is estimated iteratively using the equation
where \(\overline{M}_n=1/n\sum _{i=1}^n M_i\) is the sample mean of \(M_1,\ldots ,M_n\). Using a Taylor expansion, this becomes
where \(\hat{\beta }_0 = \frac{1}{\overline{M}_n- t_M}\) is the Aki–Utsu (Aki 1965; Utsu 1965) estimator for \(\beta\). This approach does not use iterations and is thus preferred for computational reasons. In each iteration step (for \(T_M\)), we first update the estimate of \(\beta\) using (25) and then improve the estimate of \(T_M\). We denote this estimator of the maximum magnitude by K–S. Note that of all discussed estimators, this is the only one that uses the truncated Gutenberg–Richter law directly.
Based on the truncated Gutenberg–Richter law, a parametric \(100(1-\alpha )\%\) upper confidence bound for \(T_M\) can be constructed (see Equation 19 in Pisarenko (1991)):
where we estimate \(\beta\) using the K–S method. Holschneider et al. (2011), Zöller and Holschneider (2016a) noted that the upper confidence bound as defined in Pisarenko (1991) is infinite if the maximum observed seismic event magnitude is larger than \(t_M-\frac{1}{\beta }\ln (1-\alpha ^{1/n})\). For the GGF magnitude data, this happens when \(\alpha \le 0.061\). Therefore, we consider \(\alpha =0.1\) in the data example and the simulations. A comprehensive discussion on this subject, including a condition on the existence of Pisarenko’s original \(T_M\) estimator, can be found in Vermeulen and Kijko (2017).
3 Estimation of the maximum possible seismic event magnitude generated by the GGF
In this section, we attempt to estimate the maximum possible seismic event magnitude which can be generated by gas extraction in the GGF. The database of the seismicity of anthropogenic origin in the area is downloaded from the website of the KNMI: https://www.knmi.nl/kennis-en-datacentrum/dataset/aardbevingscatalogus. The database contains (local) magnitudes M of seismic events of anthropogenic origin in the Netherlands. We only consider events from the database that are located within the rectangle determined by (53.1\(^\circ\)N, 6.5\(^\circ\)E), (53.1\(^\circ\)N, 7\(^\circ\)E), (53.5\(^\circ\) N, 7\(^\circ\)E) and (53.5\(^\circ\)N, 6.5\(^\circ\)E), see Fig. 1a. The selected area is almost the same as the area that was considered in Zöller and Holschneider (2016b). The extracted database contains 286 seismic events with magnitudes at least 1.5, which have been recorded between December 1986 and 31 December 2016. The events, together with the boundaries of the selected area and approximate contours of the whole GGF (green), are shown in Fig. 1b. A plot of the magnitudes of the selected events is shown in Fig. 1c. The dataset was tested for serial correlation, and no significant correlation could be detected. Moreover, comparing the analysis using all earthquakes (as is done in this section) with the analysis using only more recent earthquakes did not indicate non-stationarity in the data which is also confirmed in Fig. 1c.

Locations of anthropogenic seismicity in a the Netherlands and b Groningen between December 1986 and 31 December 2016 with magnitudes at least 1.5, and c magnitude plot of anthropogenic seismicity in the considered area with magnitudes at least 1.5

Groningen gas field anthropogenic seismicity: a Pareto QQ-plot of energy data, b exponential QQ-plot of magnitude data, c mean excess plot of magnitude data and d exponential QQ-plot of magnitude data with fit based on the \(k=125\) largest magnitudes

GGF anthropogenic seismicity: a estimates of \(\xi\) (full line) and \(\xi _{Y_E}\) (dashed line), b estimates of the truncation odds \(D_T\), cP-values of a test for truncation based on the truncated GPD and dP-values of a test for truncation based on the truncated Pareto
The magnitudes in the database are rounded to one decimal digit, and hence, there are several ties in the dataset. Therefore, we smoothed the data by adding independent uniform random numbers within the range [− 0.05, 0.05] to all magnitudes that occur more than once. This ensures that all observations are unique. We then retain the 250 magnitudes larger than or equal to \(t_M=1.5\). The choice of 1.5 as threshold in the Groningen case is standard in the geological literature, see e.g. Dost et al. (2013). The exponential QQ-plot in Fig. 2b indicates that an exponential distribution is indeed suitable for the magnitudes, but the bending off at the largest observations suggests a possible upper truncated tail. The same behaviour is seen in the mean excess plot (see e.g. Chapter 1 in Beirlant et al. 2004) in Fig. 2c: the first horizontal part suggests that the data come from an exponential-like distribution, whereas the downward trend at the end indicates an upper truncation point. Note that the Pareto QQ-plot of the energy in Fig. 2a suggests that the energy follows a truncated Pareto distribution as discussed in Sect. 2.1.2. When applying the truncated GPD estimator to the magnitudes, a value of \(\xi\) around 0 is found suggesting again an exponential-like distribution, see Fig. 3a. The parameter \(\xi _{Y_E}\) is estimated by the truncated Pareto estimator to be around 1.8. The estimators for \(D_T\) based on the truncated GPD and truncated Pareto estimators for \(\xi\) and \(\xi _{Y_E}\), respectively, suggest that the truncation odds are around 1% see Fig. 3b. Next, we test (directly and via the energy) whether the data come indeed from an upper truncated distribution. Under the null hypotheses of both tests, the data come from an unbounded, hence not upper truncated, distribution. The P-values of a test for truncation based on the truncated GPD (Beirlant et al. 2017) in Fig. 3c indicate, for larger values of k, that the magnitude data come from an upper truncated distribution. Similarly, P-values of a test for truncation based on the truncated Pareto (Aban et al. 2006; Beirlant et al. 2016) in Fig. 3d indicate that, for values of k above 75, the distribution of the energy is upper truncated. Note that the significance level of the tests, 10%, is indicated by the horizontal lines in Fig. 3c and d. Finally, the fit provided by the truncated GPD with \(k=125\), and hence \(\hat{\xi }_{125}\approx 0\), models the data well, see Fig. 2d. All these elements suggest that the truncated Gutenberg–Richter distribution, i.e. a doubly truncated exponential distribution, might indeed be a suitable model for the GGF magnitude data.
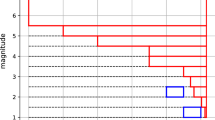
Next, we compute all discussed estimates for the maximum possible earthquake magnitude (Fig. 4a). For estimators where no value of k needs to be chosen, the dot indicates how many observations are used: 2 or n. All estimators suggest that the endpoint lies between 3.61 and 3.80 on the Richter scale. Note, however, that for the estimators of the endpoint based on EVT, we need to look at larger values of k where a more stable pattern emerges as the test for truncation was only significant for \(k\ge 75\). For k around 125, the EVT-based methods estimate the endpoint around 3.76. Note that the EVT estimates for \(k=n\) are close to the estimates of the N-P-G and K–S methods which use all n observations above 1.5. All other methods lead to estimates for the endpoint that are lower than the EVT results.
Additionally, we look at 90% upper confidence bounds for the endpoint as discussed above. The endpoint estimators are given by the full orange (Truncated GPD), dashed blue (Truncated Pareto), purple long dashed (N-P-OS) and grey dash-dotted (K–S) lines in Fig. 4b. The corresponding 90% upper bounds are added as dash-dotted lines in the same colour. The upper bounds using the truncated GPD (9) and truncated Pareto (14) take values of 4.04 and 3.98, respectively, for \(k=125\). The 90% upper bound (18) takes a value of 4.50, and the parametric 90% upper bound (26) is equal to 4.32 (grey point). Note that the latter two confidence bounds are based on n magnitudes and should hence be compared with the EVT-based upper bounds for \(k=n\) (4.03 and 4.04).
We summarised the obtained estimates and 90% confidence bounds for the maximum possible earthquake magnitude in Table 2. Note that for the estimators where k needs to be chosen, we indicate the chosen value of k in the last column. Fixed values of k, e.g. 2 for the R–W estimator, are indicated in the last column in italics.

GGF anthropogenic seismicity: a estimates of the maximum possible earthquake magnitude \(T_M\) and b 90% upper confidence bounds for \(T_M\)
4 Simulations
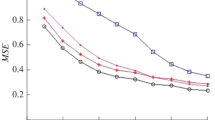
The performance of the nine applied estimators of the upper limit of the magnitude distribution was tested using simulations. We generated 5000 magnitude samples of size 250 from the truncated Gutenberg–Richter distribution with level of completeness \(t_M = 1.5\), rate parameter \(\beta = 2.1203\) and three different endpoints: \(T_M = 3.75\), 4.0 and 4.5. The parameter \(\beta\) was estimated from the GGF data by application of (25) (Gibowicz and Kijko 1994). Note that these endpoints correspond to the 99.2, 99.5 and 99.8% quantiles of the shifted exponential distribution with \(\beta = 2.1203\) and level of completeness \(t_M = 1.5\). For each of these simulations, we plot the relative mean, the relative mean squared error (MSE) and the coverage percentage of the upper confidence bounds over the 5000 simulations. These plots are found in “Appendix”.
The simulations show that the truncated GPD and truncated Pareto estimators have the lowest bias, over all three considered truncation points. However, their MSE is among the highest which indicates that these estimators have the largest variances. As expected, the bias and MSE of all nine analysed estimators increase when the endpoint gets larger. For simulations with endpoint 3.75 and 4.0 (which seem to be realistic scenarios), on average, the EVT estimators slightly overestimate the true endpoint. When \(T_M = 4.5\), all estimates of \(T_M\), except K–S, are on average too low.
The coverage percentages of the upper confidence bounds are defined as the percentage of times that the obtained upper bounds are larger than the true endpoint. In theory, these percentages should be equal to 90%. When the endpoint gets larger, the observed coverage percentages decrease. The coverage percentage for the upper bound (18) of Cooke (1979) is closer to 90% than the ones for the upper bounds of the EVT-based estimators. The performance of the first two EVT-based estimators is rather similar with a slight advantage for the truncated Pareto. Since second-order bias terms were not taken into account for the upper bounds (9) and (14), developing bias reduced methods can improve these upper bounds. The parametric upper confidence bound (26), which uses all \(n=250\) observations, performs similarly to the one using the truncated Pareto for k large when the endpoint is 3.75. For higher endpoints, this upper confidence bound performs much worse than the other ones.
It is important to note that the parametric K–S estimator is designed specifically for the truncated Gutenberg–Richter distribution, which we consider in these simulations, whereas the EVT-based estimators are also suitable for other upper truncated distributions. The good performance of the EVT-based estimators on different upper truncated distributions, e.g. a truncated lognormal distribution, is shown through simulations in Beirlant et al. (2016, 2017).
5 Conclusions
In our work, we investigated the performance of nine different estimators of the endpoint of the distribution and applied it to the estimation of the maximum possible seismic event magnitude generated by gas production in the Groningen gas field. The analysis includes a comparison of EVT-based estimators, non-parametric estimators and a parametric estimator. Since the available database contains only a few large magnitude events, all estimates provide the assessment of the upper limit of magnitude with significant uncertainty. The quantification of the uncertainty is a problem on its own, which requires careful consideration and effort, not less than the assessment of the upper limit of magnitude itself.
Based on the application of the nine different techniques, the maximum possible anthropogenic origin seismic event magnitude in the Groningen gas field is estimated to be in the range 3.61–3.80. The 90% upper confidence bounds vary from 3.85 to 4.50. In addition, the extreme value analysis in Sect. 3 suggests that the widely used truncated Gutenberg–Richter distribution might indeed be appropriate to model the distribution of seismic event magnitudes in the Groningen gas field. However, the EVT-based and non-parametric estimators do not require knowledge of the magnitude distribution, which gives them more flexibility compared to their parametric counterparts.
Based on simulations from the truncated GR distribution, it is clear that the EVT-based methods perform well when estimating the endpoint. It is important to note that these methods usually provide an assessment with a positive bias, which means that, on average, the true endpoint is overestimated, whereas the other estimators (except K–S and N-P-G), on average, are too low. The upper confidence bounds based on these two estimators are sharper than the other ones. However, the simulations point out that they are too sharp indicating the need for bias reduction.
In general, the presence of bias is not an obstacle leading to disqualification of any of the applied endpoint assessment procedures. It would be very useful to study the bias in detail. If we knew the bias, it could be used to correct the endpoint estimator (Lasocki and Urban 2011) and potentially lead to improvement in any of the discussed procedures. Moreover, if additional, independent high-quality information is available, the Bayesian formalism provides a powerful tool, capable of both improving the endpoint estimates and providing a more reliable assessment of its confidence bounds.
Overall, we can conclude that the EVT-based estimators of Beirlant et al. (2016, 2017) are a valuable addition to the already existing methods for estimation of the area-characteristic, maximum possible seismic event magnitude.
References
Aban IB, Meerschaert MM, Panorska AK (2006) Parameter estimation for the truncated Pareto distribution. J Am Stat As 101(473):270–277
Aki K (1965) Maximum likelihood estimate of \(b\) in the formula \(\log (n) = a - bm\) and its confidence limits. Bull Earthq Res Inst Tokyo Univ 43(2):237–239
Bardainne T, Dubos-Sallée N, Sénéchal G, Gaillot P, Perroud H (2008) Analysis of the induced seismicity of the Lacq gas field (Southwestern France) and model of deformation. Geophys J Int 172(3):1151–1162
Beirlant J, Goegebeur Y, Teugels J, Segers J (2004) Statistics of extremes: theory and applications. Wiley, Chichester
Beirlant J, Fraga Alves MI, Gomes MI (2016) Tail fitting for truncated and non-truncated Pareto-type distributions. Extremes 19(3):429–462
Beirlant J, Fraga Alves I, Reynkens T (2017) Fitting tails affected by truncation. Electron J Stat 11:2026–2065
Berril JB, Davis RO (1980) Maximum entropy and the magnitude distribution. Bull Seismol Soc Am 70(5):1823–1831
Bommer JJ, van Elk J (2017) Comment on “The maximum possible and the maximum expected earthquake magnitude for production-induced earthquakes at the gas field in Groningen, The Netherlands” by Gert Zöller and Matthias Holschneider. Bull Seismol Soc Am 107(3):1564–1567
Cooke P (1979) Statistical inference for bounds of random variables. Biometrika 66(2):367–374
Cooke P (1980) Optimal linear estimation of bounds of random variables. Biometrika 67(1):257–258
Cornell CA (1994) Statistical analysis of maximum magnitudes. In: Schneider JF (ed) The earthquakes of stable continental regions. vol 1, Assessment of Large Earthquake Potential, EPRI, pp 5–1–5–27
Davies R, Foulger G, Bindley A, Styles P (2013) Induced seismicity and hydraulic fracturing for the recovery of hydrocarbons. Mar Pet Geol 45:171–185
de Haan L, Ferreira A (2006) Extreme value theory: an introduction. Springer, Berlin
Dekkers ALM, Einmahl JHJ, de Haan L (1989) A moment estimator for the index of an extreme-value distribution. Ann Stat 17(4):1795–1832
Dost B, Kraaijpoel D (2013) The August 16, 2012 Earthquake Near Huizinge (Groningen). https://www.rijksoverheid.nl/documenten/rapporten/2013/01/15/the-august-16-2012-earthquake-near-huizinge-groningen. KNMI report. Last Accessed on 25 Apr 2017
Dost B, Caccavale M, van Eck T, Kraaijpoel D (2013) Report on the Expected PGV and PGA Values for Induced Earthquakes in the Groningen Area. https://www.rijksoverheid.nl/documenten/rapporten/2014/01/17/rapport-verwachte-maximale-magnitude-van-aardbevingen-in-groningen. KNMI report. Last Accessed on 21 Feb 2017
Fraga Alves I, Neves C, Rosário P (2017) A general estimator for the right endpoint with an application to supercentenarian women’s records. Extremes 20(1):199–237
Gibowicz S, Kijko A (1994) An introduction to mining seismology. Academic Press, Cambridge
González PJ, Tiampo KF, Palano M, Cannavò F, Fernández J (2012) The 2011 Lorca earthquake slip distribution controlled by groundwater crustal unloading. Nat Geosci 5:821–825
Gutenberg B, Richter CF (1956) Earthquake magnitude, intensity, energy and acceleration. Bull Seismol Soc Am 46(2):105–145
Hallo M, Oprsal I, Eisner L, Ali MY (2014) Prediction of magnitude of the largest potentially induced seismic event. J Seismol 18(3):421–431
Hamilton RM (1967) Mean magnitude of an earthquake sequence. Bull Seismol Soc Am 57(5):1115–1116
Holschneider M, Zöller G, Hainzl S (2011) Estimation of the maximum possible magnitude in the framework of the doubly truncated Gutenberg-Richter model. Bull Seismol Soc Am 101(4):1649–1659
Kagan YY, Jackson DD (2000) Probabilistic forecasting of earthquakes. Geophys J Int 143(2):438–453
Kagan YY, Schoenberg F (2001) Estimation of the upper cutoff parameter for the tapered Pareto distribution. J Appl Probab 38(A):158–175
Kijko A (2004) Estimation of the maximum earthquake magnitude \(m_{max}\). Pure Appl Geophys 161(8):1655–1681
Kijko A (2012) On Bayesian procedure for maximum earthquake magnitude estimation. Res Geophys 2(1):46–51
Kijko A, Graham G (1998) Parametric-historic procedure for probabilistic seismic hazard analysis part I: estimation of maximum regional magnitude \(m_{max}\). Pure Appl Geophys 152(3):413–442
Kijko A, Sellevoll M (1989) Estimation of earthquake hazard parameters from incomplete data files. Part I. Utilization of extreme and complete catalogs with different threshold magnitudes. Bull Seism Soc Am 79(3):645–654
Kijko A, Singh M (2011) Statistical tools for maximum possible earthquake estimation. Acta Geophys 59(4):674–700
Kijko A, Lasocki S, Graham G (2001) Non-parametric seismic hazard in mines. Pure Appl Geophys 158(9):1655–1675
Lasocki S, Urban P (2011) Bias, variance and computational properties of Kijko’s estimators of the upper limit of magnitude distribution, \(M_{max}\). Acta Geophys 59(4):659–673
Lay T, Wallace T (1995) Modern global seismology. Academic Press, London
McGarr A (1976) Seismic moments and volume changes. J Geophys Res 81:1487–1494
McGarr A (2014) Maximum magnitude earthquakes induced by fluid injection. J Geophys Res: Solid Earth 119(2):1008–1019
McGarr A, Simpson D, Seeber L (2002) Case histories of induced and triggered seismicity. In: Lee WHK, Kanamori H, Jennings PC, Kisslinger C (eds) International handbook of earthquake and engineering seismology. Academic Press, Cambridge, pp 647–661
NAM (2016) Groningen seismic hazard and risk assessment: report on Mmax expert workshop. http://feitenencijfers.namplatform.nl/download/rapport/cef44262-323a-4a34-afa8-24a5afa521d5?open=true. Last Accessed on 21 Feb 2017
Nicol A, Carne R, Gerstenberger M, Christophersen A (2011) Induced seismicity and its implications for CO\(_2\) storage risk. Energy Proced 4:3699–3706
Page R (1968) Aftershocks and microaftershocks of the great Alaska earthquake of 1964. Bull Seismol Soc Am 58(3):1131–1168
Pisarenko VF (1991) Statistical evaluation of maximum possible magnitude. Izvestiya Earth Phys 27(3):757–763
Pisarenko VF, Rodkin MV (2017) The estimation of probability of extreme events for small samples. Pure Appl Geophys 174(4):1547–1560
Pisarenko VF, Lyubushin AA, Lysenko VB, Golubeva TV (1996) Statistical estimation of seismic hazard parameters: maximum possible magnitude and related parameters. Bull Seismol Soc Am 86(3):691–700
Pisarenko VF, Sornette A, Sornette D, Rodkin MV (2008) New approach to the characterization of \(m_{\max }\) and of the tail of the distribution of earthquake magnitudes. Pure Appl Geophys 165(5):847–888
Pisarenko VF, Sornette A, Sornette D, Rodkin MV (2014) Characterization of the tail of the distribution of earthquake magnitudes by combining the GEV and GPD descriptions of extreme value theory. Pure Appl Geophys 171(8):1599–1624
Raschke M (2012) Inference for the truncated exponential distribution. Stoch Environ Res Risk Assess 26(1):127–138
Robson DS, Whitlock JH (1964) Estimation of a truncation point. Biometrika 51(1–2):33–39
Rundle JB (1989) Derivation of the complete Gutenberg-Richter magnitude-frequency relation using the principle of scale invariance. J Geophys Res: Solid Earth 94(B9):12337–12342
Scholz CH (1968) The frequency-magnitude relation of microfracturing in rock and its relation to earthquakes. Bull Seismol Soc Am 58(1):399–415
Scholz CH (2015) On the stress dependence of the earthquake \(b\) value. Geophys Res Lett 42(5):1399–1402
Shapiro SA, Dinske C, Langenbruch C, Wenzel F (2010) Seismogenic index and magnitude probability of earthquakes induced during reservoir fluid stimulations. Lead Edge 29(3):304–309
Stirling M, Goded T, Berryman K, Litchfield N (2013) Selection of earthquake scaling relationships for seismic-hazard analysis. Bull Seismol Soc Am 103(6):2993–3011
Utsu T (1965) A method for determining the value of \(b\) in a formula \(\log n = a - bm\) showing the magnitude-frequency relation for earthquakes. Geophys Bull Hokkaido Univ 13:99–103
van der Voort N, Vanclay F (2015) Social impacts of earthquakes caused by gas extraction in the province of Groningen, The Netherlands. Environ Impact Assess Rev 50:1–15
van Eck T, Goutbeek F, Haak H, Dost B (2006) Seismic hazard due to small-magnitude, shallow-source, induced earthquakes in The Netherlands. Eng Geol 87(1–2):105–121
Vermeulen P, Kijko A (2017) More statistical tools for maximum possible earthquake magnitude estimation. Acta Geophys 65(4):579–587
Wells DL, Coppersmith KJ (1994) New empirical relationships among magnitude, rupture length, rupture width, rupture area, and surface displacement. Bull Seismol Soc Am 84(4):974–1002
Wheeler RL (2009) Methods of Mmax estimation east of the Rocky Mountains. U.S. Geological Survey Open-File Report 2009-1018
Yeck WL, Block LV, Wood CK, King VM (2015) Maximum magnitude estimations of induced earthquakes at Paradox Valley, Colorado, from cumulative injection volume and geometry of seismicity clusters. Geophys J Int 200(1):322–336
Zöller G, Holschneider M (2016a) The earthquake history in a fault zone tells us almost nothing about \(m_{\max }\). Seismol Res Lett 87(1):132–137
Zöller G, Holschneider M (2016b) The maximum possible and the maximum expected earthquake magnitude for production-induced earthquakes at the gas field in Groningen. The Netherlands. Bull Seismol Soc Am 106(6):2917–2921
Author information
Authors and Affiliations
Corresponding author
Appendix: Simulation results
Appendix: Simulation results

\(GR(\beta =2.1203, t_M=1.5, T_M=3.75)\): relative means of endpoint estimates (top), relative MSE of endpoint estimates (middle) and coverage percentage of 90% upper confidence bounds for the endpoint (bottom)

\(GR(\beta =2.1203, t_M=1.5, T_M=4)\): relative means of endpoint estimates (top), relative MSE of endpoint estimates (middle) and coverage percentage of 90% upper confidence bounds for the endpoint (bottom)

\(GR(\beta =2.1203, t_M=1.5, T_M=4.5)\): relative means of endpoint estimates (top), relative MSE of endpoint estimates (middle) and coverage percentage of 90% upper confidence bounds for the endpoint (bottom)
Rights and permissions
About this article

Cite this article
Beirlant, J., Kijko, A., Reynkens, T. et al. Estimating the maximum possible earthquake magnitude using extreme value methodology: the Groningen case. Nat Hazards 98, 1091–1113 (2019). https://doi.org/10.1007/s11069-017-3162-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-017-3162-2