
Abstract
The uniaxial compressive strength (UCS) is considered as a significant parameter related to rock material in design of geotechnical structures connected to the rock mass. Determining UCS values in laboratory is costly and time consuming, hence, its indirect determination through use of rock index tests is of a great interest and advantage. This study presents a prediction process of the UCS values through the use of three non-destructive tests i.e., p-wave velocity, Schmidt hammer and density. This process was done by developing an intelligent predictive technique namely the group method of data handling (GMDH). Before constructing intelligence system, a series of experimental equations were proposed using three non-destructive tests. The results showed that there is a need to propose new model with taking advantages of all three non-destructive tests results. Then, several GMDH models were built through the use of various parametric studies on the most effective GMDH factors. For comparison purposes, an artificial neural network (ANN) was also modelled to predict rock strength. The obtained results of the ANN and GMDH were assessed based on system error and coefficient of determination values. The results confirmed that the proposed GMDH model is an applicable, powerful, and practical intelligence system that is able to provide an acceptable accuracy level for predicting rock strength.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Strength and deformation of rock materials are identified as the most important parameters in any construction project connected to the rock mass. The International Society for Rock Mechanics (ISRM) has proposed the unconfined compression test (UCT) standardized to measure the rock elasticity (Young’s modulus, E), and rock strength (uniaxial compressive strength, UCS) [1]. This test is difficult, time consuming, and costly to determine the laboratory-based characteristics [2, 3]. Due to these imitations, indirect tests and methods are of a great importance and interest in literature. Many scholars (e.g., [4,5,6]) tried to establish a relationship between UCS/E and other rock index tests such as p-wave velocity, Schmidt hammer, physical-based and point load which are easy, simple and cheap to conduct compared to the UCT test.
Literature is consisted of many studies investigating how to relate the rock strength and deformation with the other rock index tests which can be conducted in laboratory. These studies are normally carried out by collecting block samples from the sites or projects, transferring them to laboratory and conducting relevant tests in laboratory. Then, preparing a database comprising of simple tests values together with UCS or E values and making empirical relationships for predicting UCS and E using simple tests results. Many researchers proposed empirical equations for predicting rock strength and deformation using single rock index tests such as p-wave velocity, Schmidt hammer, and porosity [5, 7,8,9,10,11,12,13,14,15,16,17,18]. A side from prediction of UCS and E using single rock index tests, several investigations have been conducted to establish a multiple regression equation for predicting UCS or E using more than one rock index test (at least a combination of two tests) [19,20,21,22,23,24]. However, as reported by Beiki et al. [11] and Armaghani et al. [3], these empirical and multiple regression equations are not able to provide an acceptable level of accuracy where a high actuary level for prediction of rock strength and deformation is required for real geotechnical engineering projects. In addition, the mentioned equations cannot be practically used for the same rock type in other projects [11]. Therefore, the application of empirical and multiple regression equations is not reliable enough when a new available database is different from the original one. This is due to the fact that there is a need to update the equations based on new available database [7, 20]. It seems that some new computational techniques are needed to adapt a high level of accuracy for estimating rock strength and deformation.
A part from empirical and multiple regression equations/models, the successful and efficient application of machine learning (ML) and artificial intelligent (AI) techniques has been reported by some other researchers to forecast rock strength and deformation parameters [10, 25,26,27,28,29,30]. Furthermore, these techniques (ML and AI) have been widely used and applied in other fields related to civil and mining engineering [31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48]. To predict UCS, Meulenkamp and Grima [49] utilized artificial neural network (ANN) using 194 datasets of different types of rock, including limestone, sandstone, and dolomitic stone. The inputs to their model were set to be the Equotip hardness readings, rock type, porosity, density, and grain size. Their findings showed that the developed ANN is a successful tool in estimating UCS. In another project, Gokceoglu and Zorlu [2] attempted to estimate rock strength and deformation in problematic rocks adopting a fuzzy logic method together with the regression techniques. Their input parameters were tensile strength, point load index, p-wave velocity, and block punch index of 82 specimens. They concluded that their fuzzy logic model is more reliable compared to regression analysis. To predict rock strength and deformation, Dehghan et al. [19] applied a feed forward ANN and regression analysis to 30 specimens of travertine. The input of their model were porosity, point load index, Schmidt hammer, and p-wave velocity. Their results also confirmed the high capacity of ANN in doing the predictive tasks defined in their study. In another study, an adoptive neuro-fuzzy inference system (ANFIS) predictive model was used and proposed by Singh et al. [50] for the purpose of predicting rock deformation values and their authors showed that their ANFIS model is a better model compared to ANN and fuzzy logic. A regression tree (RT) predictive technique was developed by Liang et al. [51] to evaluate and estimate strength of sedimentary rock type with low UCS results and successfully indicated that their regression tree model is a good predictor for this type of rock. Table 1 shows some of the previous studies of UCS and E prediction using simple regression, multiple regression and ML/AI models. In this table, model inputs, predictive models, and prediction accuracy (based on coefficient of determination, R2) of the models are presented. According to this table, R2 ranges of (0.39–0.78), (0.58–0.77) and (0.66–0.91) are reported in previous studies for simple regression, multiple regression and ML/AI predictive models, respectively in predicting strength and deformation of rock material. Table 1 confirm better prediction capacity of multiple regression over simple ones and better prediction capacity of ML/AI models over multiple regression predictive models.
With respect to above discussion, this study is aimed to develop a prediction process of UCS through experimental equations as well as AI/ML techniques. First, an experimental database with three non-destructive tests i.e., Schmidt hammer, density and p-wave velocity and one destructive test i.e., UCT is provided and established. Then, based on different relationships of these tests results with UCS values, three empirical equations are introduced. Afterwards, AI/ML techniques namely ANN and group method of data handling (GMDH) are applied and proposed to predict rock strength values and finally, their results will be compared to each other for selecting the best AI/ML model in this study.
2 Materials and Methods
2.1 Artificial Neural Network (ANN)
Artificial Neural Network (ANN) refers to a computational system simulating the principles of the human beings’ neural system in a way to configure an artificial system. The ANN-based models typically make use of input training patterns for the purpose of developing accurate predictions regarding the automatic relationships between input and output data, which makes a big difference between this system and any other system working in this field [33]. In an attempt to imitate a biological brain, an ANN utilizes the artificial neurons as fundamental units in a way to process data in a parallel behavior. As a pioneering study making attempt to model the neural network, McCulloch and Walter [62] constructed a binary decision unit and succeeded to model effectively the artificial neurons’ behaviors. In their system, any artificial node was assigned with the total weight of input signals; then, activation function was applied to these signals. This way, they could obtain an output of a higher accuracy level. ANN was described by Ch and Mathur [63] as a network of interlocked nodes that exist in extraordinarily paralleled layers of computational systems. Based on their findings, the neurons connection patterns affect the behaviors and class of these networks.
From a structural perspective, the ANN functions fall into two main groups: feed-forward and feedback. Among the feed-forward multilayer networks with highest popularity, multilayer perceptron (MLP) is the one that processes the available data through the use of activation functions within consecutive layers [64]. In addition, back-propagation (BP), which is known as a learning algorithm, was introduced by Simpson [65]. BP makes use of a learning procedure-based gradient in order to help the network to learn. BP that is consisted of a twofold training cycle (a forward and a backward stage) is capable of delivering acceptable results, especially for those nets that contain feed-forward multilayer [66]. Other scholars in more complementary investigations have given more explanations in regard to the operation of each stage [67, 68]. As demonstrated by these researchers, during one stage, input signals move forwards and transmit error signal for each node that exists in the output layer; after that, the resultant error rates are moved backwards. This way, the weights and biases of network are modified. In general, each neuron’s output is generated through applying a number of activation functions to inputs. Then, the outputs will be transmitted to the neurons existing within subsequent layer as inputs. Principally, the activation function type is determined depending on complexity of the problem in hand. For that reason, in case of nonlinear problems, sigmoid transfer functions such as log or tangent sigmoid can be effectively used. A mathematical model of an artificial neuron is shown in Fig. 1.

A schematic diagram for an artificial node j
2.2 Group Method of Data Handling (GMDH)
In the GMDH algorithm, some sets of neurons are planned in various layers in each of which a quadratic polynomial connects various neuron pairs to each other so that they can produce new neurons in the next layer. This way, inputs can be mapped to outputs. As generally define, the identification problem discusses how to explore a function \(\hat{f}\) approximately applicable in place of the actual function, f, in order to estimate the output \(\hat{y}\) for a certain input vector \(X = \left( {x_{1} ,x_{2} ,x_{3} , \ldots ,x_{n} } \right)\) which is very close to its actual output y. Therefore, given M number of multi-inputs and single-output data pairs:
At present, a neural network designed based on GMDH can be built to predict the output values ŷ for any given input vector \(X = \left( {x_{i1} ,x_{i2} ,x_{i3} , \ldots ,x_{in} } \right)\), that is:
One of the most important challenges in this process is to identify a GMDH-type neural network with the capacity of minimizing the square of difference between the estimated output and the actual one, that is:
With the help of a complex discrete form of the Volterra functional series, the general connections between input factors and the output can be expressed as follows:
It is also possible to express this comprehensive form of mathematical description:
In neural networks of the GMDH type, there are two core concepts: the parametric and the structural identification problems. A GMDH model with 3 input parameters X1, X2 and X3 is shown in Fig. 2.

A GMDH model with three input parameters X1, X2 and X3
During designing GMDH, it is important to note that all polynomials of the neurons existing within each layer of the network are comparable and similar procedures are needed in designing a network. In fact, the essential structure of the GMDH network is the second-order polynomial that was first proposed by Ivakhnenko [69]. In general, in designing the self-organized systems, various types of polynomial, i.e., quadratic, tri-quadratic, bilinear, and the 3rd order, are employed. Compared to the quadratic type of polynomial, more complicated networks are constructed using the tri-quadratic and the 3rd order polynomial. A less complex structure is produced by the bilinear polynomial. The quadratic polynomial involves six weighting coefficients applicable effectively to solving various problems that may arise in engineering fields [70]. As confirmed frequently in literature, selecting a single polynomial from among different types greatly depends upon two parameters: the complexity of the polynomial type and the minimum error of objective function. In literature, many studies [71,72,73] have provided more details regarding the GMDH technique.
2.3 Study Area and Laboratory Tests
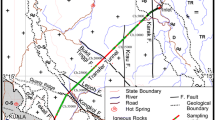
In the present study, all rock samples were collected from a tunnel constructed to transfer water from Pahang to Selangor states, in Malaysia (Fig. 3). The tunnel has crossed beneath the mountain ranges between these two states, with the height of 100–1400 m. The main rock type is granite with rock strength ranging between 80 and 200 MPa. The excavation of three parts of the tunnel with 11.7 km, 11.7 km, and 11.3 km lengths, was performed using three tunnel boring machines (TBMs), TBM 1, TBM 2, and TBM 3, respectively. A number of 100 granite block samples were collected from different TBMs to be applied to the development of models for the prediction of the UCS values. This is worth noting that through coring and cutting, the end parts of the samples were flattened to be perpendicular to the sample axis, while the sides were softened and polished to be off-cracks, veins, fissures, and other flaws in a way to prevent any unfavourable alteration to real rock specimens.

Water transfer tunnel location in Malaysia
After preparing the rock samples, three non-destructive simple index tests i.e., Schmidt hammer, p-wave velocity (or ultrasonic) and dry density were planned and conducted on the samples. The Schmidt hammer test, also known as rebound test was carried out to determine the surface hardness of rock samples. This test is one of the most popular non-destructive testing methods which is used as indicator of the strength of the rock samples. It is because of its relatively low cost and simple operating procedures. According to ISRM [1], Schmidt hammer tests were conducted 10 times and average of these 10 values were considered as Schmidt hammer rebound (Rn) values. Since the Rn is affected by the orientation of the hammer, therefore hammer position used is in vertically downward direction only. Figure 4 shows a Schmidt hammer test conducted on a sample collected from face of TBM 2.

A conducted test of Schmidt hammer on a sample collected from face of TBM 2
Ultrasonic velocity test is considered as a non-destructive indirect test of the rock. The purpose of this test is to estimate state of compactness of a rock sample. This test verifies propagation velocity of primary wave through material texture of the rock. According to ISRM [1], ultrasonic velocity tests were carried out four times on rock samples in which their ends were flat and perpendicular to the sample axis. Then, their average values were considered as p-wave velocity (Vp) values in our database. An equipment used to conduct Vp values is shown in Fig. 5.

Equipment used to conduct Vp values in this study
In addition to Schmidt hammer and p-wave velocity tests, a physical non-destructive test, i.e., density was conducted on the samples. The density tests were carried out in order to evaluate rock compactness degree of the obtained samples and then, dry density (DD) values were recorded from each conducted test. The last conducted test for establishing a good database for analysis was UCT. This test is able to assess compressive strength of rock under uniaxial loading. UCS values of the rock samples were determined according to ISRM [1] procedure.
2.4 Database
After doing all mentioned tests, 86 series of data samples were established as our database to predict UCS values of granitic rock samples. In this database, results of three non-destructive tests i.e., Rn, DD and Vp were set as input variable while UCS results of the samples were fixed as output variable. In other word, based on the models used in this research, UCS is a function of three parameters i.e., Rn, DD and Vp. The results of these non-destructive tests against their UCS values are displayed in Fig. 6. Additionally, Table 2 shows some statistical information of the tests results in this study. According to this table, different ranges of (4108-7943 m/s), (40–61), (2.4–2.77 g/cm3) and (50.2–211.9 MPa) were achieved in laboratory for Vp, Rn, DD, and UCS tests, respectively. The established database with 86 data samples were used for modeling process of this study.

The results of three non-destructive tests against their UCS values
2.5 Study Framework
Figure 7 presents various steps of this study to propose a GMDH predictive model from start to end. The present study was started by reviewing available literature in field of rock strength estimation. Afterwards, a suitable and relevant geotechnical project (water transfer tunnel) was selected for rock block sample collections. After sample collection, the planned experimental programs were conducted on the samples and a proper database was prepared to do the required analysis. In the analysis and modeling part, first, through simple regression analysis, three experimental equations were proposed to predict UCS using three non-destructive tests. Then, two predictive models of ANN and GMDH were built to forecast UCS values of rock samples using a combination of all three input variables. Eventually, the built predictive models were assessed using popular performance indices and the best one among these two models was chosen for estimation of the UCS values.

Study framework
3 Modeling of Rock Strength
As mentioned before, this section presents modeling procedure of the granitic rock strength through the use of three non-destructive tests i.e., DD, Vp and Rn. The first modeling section is related to analyzing of simple regression. In the second section, the ANN model is built to predict rock strength using multi-input parameters (i.e., all three tests results). In the last section, GMDH predictive model will be constructed in details based on its effective factors to predict rock strength.
3.1 Analysis of Simple Regression
In this research, to establish experimental relations between predictors (Rn, Vp, and DD) and the rock strength values, the simple regression analysis was employed. The relationship between the independent variables and UCS of the samples was analysed. After that, the simple regression was used to suggest some linear, exponential, power, and logarithmic equations (see Table 3). Therefore, these equation types were examined in this study to introduce new empirical equations for UCS prediction. The empirical equations were assessed through making comparisons between R2 results. To calculate R2, the following equation was used:
where \(x_{imeas}\) and \(x_{ipred} \user2{ }\) stand for the measured and predicted values, respectively, and \(\overline{x}\user2{ }\) signifies the average measured values. R2 in a perfect predictive model equals 1. The R2 value ranging from 0.6 to 0.7 for the empirical equations shows that there are a good relationships between non-destructive tests and UCS values. More precisely, based on R2 values presented in Table 3, linear, logarithmic, and linear were obtained as the best models for Rn, Vp, and DD, respectively, in the prediction of the UCS value. The introduced empirical equations with the use of Rn, Vp, and DD, are expressed in Eqs. (7–9), respectively.
The correlations between Rn, Vp, DD, and UCS are displayed in Fig. 8. In case of these predictors, the R2 results of 0.705, 0.643, and 0.648, respectively, were obtained, which are acceptable and meaningful. It gets more important when considering that such results were achieved on the basis of only a single predictor. According to Table 1, the results obtaine by simple regression equations in this study are better than many of previous investigations like Armaghani et al. [54], Liang et al. [51], Entwisle et al. [15] and Bejarbaneh et al. [59]. However, to estimate the rock strength with higher precision, all of the model predictors can be applied to the development of multi-inputs intelligent techniques, i.e., ANN and GMDH in the present paper.

Scatter plots of model predictors with UCS values, a Rn-UCS, b Vp-UCS and c DD-UCS
3.2 ANN Modeling
This section describe details regarding ANN model development for prediction of the rock strength. As the initial step of AI/ML modeling process, the data was separated into model development data samples or training data samples and model assessment data samples or testing data samples. According to previous investigations [33, 74], the authors decided to use a combination of 80–20% for training and testing purposes in this study. Caudill [75] maintained that for mapping any continuous problem, a network with I inputs requires to be consisted of 2I + 1 hidden neurons (nodes) as the maximum limit. In this study, the trial-and-error method was used to determine the optimum network geometry, where the networks contain one hidden layer comprising 1 to 2I + 1 (or 7 in this study) hidden nodes. Therefore, different ANNs were constructed using 1–7 hidden nodes, and they were trained for 500 training epochs. In this trial-and-error procedure, the training tasks were functioned with the use of different variables of learning rates and momentum terms. In addition, in this procedure, results of R2 and RMSE were considered and determined as assessment indices in both train and test phases. After evaluating all ANN models, the lowest system error and highest R2 received by an ANN model with 5 hidden node66s. Meaning that the proposed ANN model for solving UCS problem, has a structure with 3 model inputs, 5 hidden nodes and one model output which is UCS. The structure of the developed ANN is shown in Fig. 9. A complete discussion regarding the obtained results of ANN will be given later.

The structure of the developed ANN to forecast rock strength
3.3 GMDH Modeling
To design a GMDH model for predicting rock strength based on three non-destructive tests, there is a need for taking into account the key parameters, i.e., the number of GMDH layers, the number of neurons, and the selection pressure. With the help of the selection pressure, the system will be capable of selecting the optimal fits at each step and transferring them to subsequent layers. This process is repeated until the termination criteria, namely the achievement of desired system error, is met. Therefore, a parametric research (through the trial-and-error method) was conducted examining the effects of this parameter. Based on the obtained results, the optimal value for the selection pressure was 70%. In consequence, for the rest of the modelling process, this value was used. To design another efficient parameter i.e., the number of layers in the GMDH model, there was a need for another parametric investigation. To do this, considering the recommendations given by a number of researchers in literature (e.g., [58, 72, 73]), possible numbers of layers were fixed at values between 2 and 10. Afterward, nine GMDH models were built for the aim of estimating the rock strength values. Figure 10 presents their results on the basis of the R2 of training, testing and all (combination of train and test) datasets. Note that this parametric study was conducted using 4 neurons and the selection pressure was set as 70%. Ranges of train, test and all datasets results are (R2 = 0.774 and R2 = 0.835), (R2 = 0.629 and R2 = 0.871) and (R2 = 0.767 and R2 = 0.841), respectively. Considering results of testing and all datasets, the GMDH model holding 9 layers outperformed the other GMDH models. The results of 0.871 and 0.841 were attained in case of the testing and all datasets, respectively.

Train, test and all datasets results related to different number of layers in predicting rock strength
At the last step of the GMDH modelling, it is necessary to determine the number of neurons through another parametric study. Therefore, a review was done on the studies carried out previously (e.g., [72, 73]); then, values between 2 and 20, with incremental step 2, were fixed as the neuron number in the parametric investigation. The obtained results of GMDH models based on R2 for the training, testing and all phases are shown in Fig. 11. As can be seen in this figure, the GMDH model comprising of 6 neurons, outperformed the other models. The mentioned GMDH model received better performance prediction regarding all phases presented in Fig. 11. The R2 results of 0.860, 0.877 and 0.863, for training, testing and all phases of the proposed GMDH model, respectively, showed that GMDH can be used as a powerful and practical technique for predicting rock strength (UCS). Hence, this model was selected as the best GMDH model introducing in this study for forecasting rock strength. Remember that in the developed GMDH model, the number of layers, number of neurons, and the selection pressure were fixed at 9, 6, and 70%, respectively. In the following, the selected GMDH model based on its performance is elaborated.

Train, test and all datasets results related to different number of neurons
4 Model Assessment
After developing a predictive model, a typical action is to assess the models on the basis of their performance. In this study, a quantitative evaluation of the developed models has been conducted through the implementation of several performance indices including R2, RMSE, mean square error (MSE), error mean and error StD. These indices have been used for evaluation purposes of many intelligence relevant studies [31, 76, 77]. The equations of MSE, RMSE, E-mean, and E-StD are presented as follows:
in which \(y_{{i\left( {Model} \right)}}\) denotes predicted UCS value for each observation \(\left( {i = 1,2,.., M} \right)\), \(y_{{i\left( {Actual} \right)}}\) is measured UCS value, M is the number of observations, \(E_{{i\left( {Model} \right)}}\) indicates the error value between the measured UCS value and predicted one for each data point and \(\overline{E}_{Model}\) is the mean value of \(E_{{i\left( {Model} \right)}}\). From theoretical perspective, a prediction model is recognized as completely efficient if its obtained results show RMSE = 0, MSE = 0, R2 = 1, E-mean = 0, and E-StD = 0.
Table 4 presents the obtained results of performance indices for the developed ANN and GMDH models for training, testing and all datasets. Based on this table, all the proposed models have done their defined predictive tasks acceptably; though, the GMDH model shows a tangibly higher precision compared to the developed ANN model regarding the performance indexes. The R2 results of testing datasets (or model evaluation) were obtained as 0.829 and 0.877 for ANN and GMDH predictive techniques in the rock strength estimation. In addition, taking into consideration the results of all datasets, it was found that the proposed GMDH model can provide higher performance prediction regarding all indexes. For example, E-StD, MSE and R2 values of (0.0985, 0.0096 and 0.823) and (0.0898, 0.008 and 0.863) which were obtained for ANN and GMDH, respectively, confirme higher accuracy level of the GMDH model. Furthermore, Figs. 12 and 13 show a comparison of the measured and predicted UCS results obtained by ANN and GMDH models for training and testing datasets together with their system error results, respectively. From these 2 figures, it was found that the UCS values predicted by GMDH are closer to their actual values compared to the predicted UCS values by ANN predictive model. It is worth noting that the results obtained in this study are better than the previous ML/AI predictive models presented in Table 1. For example, GMDH results are more accurate compared to FIS, ANFIS, ANN, GA, RT and ICA-ANN models which were conducted by Gokceoglu and Zorlu [2], Singh et al. [50], Bejarbaneh et al. [59], Beiki et al. [11], Liang et al. [51], and Armaghani et al. [3], respectively. Of course, some of studies in Table 1 are better than results of GMDH predictive model proposed in this study such as Fang et al. [29]. Probably, it is due to the fact that they used other rock index tests which are destructive while the present study utilized three non-destructive tests as model inputs. From the above discussion, it can be concluded that the GMDH model proposed in this study is an accurate, applicable and powerful method in field of rock strength prediction.

Target and output values of UCS together with errors obtained by ANN model, a training and b testing datasets

Target and output values of UCS together with errors obtained by GMDH model, a training and b testing datasets
5 Conclusions
This study aimed to establish a database for UCS prediction based on three non-destructive tests i.e., Rn, DD and Vp. According to these non-destructive tests, three experimental equations with suitable accuracy level were proposed to predict rock strength. The results of these experimental equations were in the range of 0.6–0.7 in terms of R2 which revealed that there is a need to develop multi-inputs models in order to take advantages of all tests results together with powerful prediction level of AI models i.e., ANN and GMDH. Having plan of prediction of the UCS values with ANN and GMDH models, the most important factors influencing these AI techniques were investigated. Then, ANN and GMDH models were constructed based on several parametric investigations in order to get higher performance prediction for rock strength estimation. The results of these AI techniques showed that they are able to receive higher accuracy level compared to experimental equations using single input. Among these two AI models, it was found that by developing a GMDH technique, we are able to get closer UCS values to their measured ones in laboratory compared to UCS values predicted by ANN technique. Considering results of all data samples, MSE values of (0.0096, and 0.008) and R2 values of (0.823 and 0.863) were obtained for the ANN and GMDH models, respectively, which confirm that the GMDH model can predict UCS values more accurately compared to other implemented technique. The results of this study revealed that the GMDH can be introduced and used as a powerful, applicable and practical predictive model in estimating rock strength values for the design of relevant geotechnical projects with similar rock conditions.
References
Ulusay, R., Hudson, J.A., ISRM: The complete ISRM suggested methods for rock characterization, testing and monitoring: 1974–2006, Comm. Test. Methods. Int. Soc. Rock Mech. Compil. Arranged by ISRM Turkish Natl. Group, Ankara, Turkey. 628 (n.d.).
Gokceoglu, C., Zorlu, K.: A fuzzy model to predict the uniaxial compressive strength and the modulus of elasticity of a problematic rock. Eng. Appl. Artif. Intell. 17, 61–72 (2004)
Armaghani, D.J., Mohamad, E.T., Momeni, E., Monjezi, M., Narayanasamy, M.S.: Prediction of the strength and elasticity modulus of granite through an expert artificial neural network. Arab. J. Geosci. 9, 48 (2016)
Diamantis, K., Gartzos, E., Migiros, G.: Study on uniaxial compressive strength, point load strength index, dynamic and physical properties of serpentinites from Central Greece: test results and empirical relations. Eng. Geol. 108, 199–207 (2009)
Kahraman, S., Gunaydin, O., Fener, M.: The effect of porosity on the relation between uniaxial compressive strength and point load index. Int. J. Rock Mech. Min. Sci. 42, 584–589 (2005)
Mohamad, E.T., Armaghani, D.J., Momeni, E., Abad, S.V.: Prediction of the unconfined compressive strength of soft rocks: a PSO-based ANN approach. Bull. Eng. Geol. Environ. 74, 745–757 (2014). https://doi.org/10.1007/s10064-014-0638-0
Yilmaz, I., Yuksek, G.: Prediction of the strength and elasticity modulus of gypsum using multiple regression, ANN, and ANFIS models. Int. J. Rock Mech. Min. Sci. 46, 803–810 (2009)
Fener, M.: The effect of rock sample dimension on the P-wave velocity. J. Nondestruct. Eval. 30, 99–105 (2011)
Qiuyue, F., Guocheng, X., Xiaopeng, G.: Ultrasonic nondestructive evaluation of porosity size and location of spot welding based on wavelet packet analysis. J. Nondestruct. Eval. 39, 7 (2020). https://doi.org/10.1007/s10921-019-0650-1
Momeni, E., Nazir, R., Armaghani, D.J., Mohamad, E.T.: Prediction of unconfined compressive strength of rocks: a review paper. J. Teknol. 77, 43–50 (2015)
Beiki, M., Majdi, A., Givshad, A.: Application of genetic programming to predict the uniaxial compressive strength and elastic modulus of carbonate rocks. J. Rock Mech. Min. 63, 159–169 (2013)
Nazir, R., Momeni, E., Armaghani, D.J., Amin, M.F.M.: Prediction of unconfined compressive strength of limestone rock samples using l-type schmidt hammer. Electron. J. Geotech. Eng. 18, 1767–1775 (2013)
Tuğrul, A., Zarif, I.H.: Correlation of mineralogical and textural characteristics with engineering properties of selected granitic rocks from Turkey. Eng. Geol. 51, 303–317 (1999)
Khandelwal, M.: Correlating P-wave velocity with the physico-mechanical properties of different rocks. Pure Appl. Geophys. 170, 507–514 (2013)
Entwisle, D.C., Hobbs, P.R.N., Jones, L.D., Gunn, D., Raines, M.G.: The relationships between effective porosity, uniaxial compressive strength and sonic velocity of intact Borrowdale Volcanic Group core samples from Sellafield. Geotech. Geol. Eng. 23, 793–809 (2005)
Li, D., Wong, L.N.Y.: Point load test on meta-sedimentary rocks and correlation to UCS and BTS. Rock Mech. Rock Eng. 46, 889–896 (2013)
Selçuk, L., Yabalak, E.: Evaluation of the ratio between uniaxial compressive strength and Schmidt hammer rebound number and its effectiveness in predicting rock strength. Nondestruct. Test. Eval. 30, 1–12 (2015)
Jiang, H., Han, J., Li, Y., Yilmaz, E., Sun, Q., Liu, J.: Relationship between ultrasonic pulse velocity and uniaxial compressive strength for cemented paste backfill with alkali-activated slag. Nondestruct. Test. Eval. (2019). https://doi.org/10.1080/10589759.2019.1679140
Dehghan, S., Sattari, G.H., Chelgani, S.C., Aliabadi, M.A.: Prediction of uniaxial compressive strength and modulus of elasticity for Travertine samples using regression and artificial neural networks. Min. Sci. Technol. 20, 41–46 (2010)
Jahed Armaghani, D., Mohd Amin, M.F., Yagiz, S., Faradonbeh, R.S., Abdullah, R.A.: Prediction of the uniaxial compressive strength of sandstone using various modeling techniques. Int. J. Rock Mech. Min. Sci. 85, 174–186 (2016). https://doi.org/10.1016/j.ijrmms.2016.03.018
Armaghani, D.J., Mohamad, E.T., Hajihassani, M., Yagiz, S., Motaghedi, H.: Application of several non-linear prediction tools for estimating uniaxial compressive strength of granitic rocks and comparison of their performances. Eng. Comput. 32, 189–206 (2016)
Rezaei, M., Majdi, A., Monjezi, M.: An intelligent approach to predict unconfined compressive strength of rock surrounding access tunnels in longwall coal mining. Neural Comput. Appl. 24, 233–241 (2014)
Yang, H.Q., Zeng, Y.Y., Lan, Y.F., Zhou, X.P.: Analysis of the excavation damaged zone around a tunnel accounting for geostress and unloading. Int. J. Rock Mech. Min. Sci. 69, 59–66 (2014)
Yang, H.Q., Li, Z., Jie, T.Q., Zhang, Z.Q.: Effects of joints on the cutting behavior of disc cutter running on the jointed rock mass. Tunn. Undergr. Sp. Technol. 81, 112–120 (2018)
Mohamad, E.T., Armaghani, D.J., Momeni, E., Yazdavar, A.H., Ebrahimi, M.: Rock strength estimation: a PSO-based BP approach. Neural Comput. Appl. 30, 1635–1646 (2018)
Momeni, E., Armaghani, D.J., Hajihassani, M., Amin, M.F.M.: Prediction of uniaxial compressive strength of rock samples using hybrid particle swarm optimization-based artificial neural networks. Measurement 60, 50–63 (2015)
Zorlu, K., Gokceoglu, C., Ocakoglu, F., Nefeslioglu, H.A., Acikalin, S.: Prediction of uniaxial compressive strength of sandstones using petrography-based models. Eng. Geol. 96, 141–158 (2008)
Rabbani, E., Sharif, F., Koolivand Salooki, M., Moradzadeh, A.: Application of neural network technique for prediction of uniaxial compressive strength using reservoir formation properties. Int. J. Rock Mech. Min. Sci. 56, 100–111 (2012)
Fang, Q., Bejarbaneh, B.Y., Vatandoust, M., Armaghani, D.J., Murlidhar, B.R., Mohamad, E.T.: Strength evaluation of granite block samples with different predictive models. Eng. Comput. (2019). https://doi.org/10.1007/s00366-019-00872-4
Koopialipoor, M., Noorbakhsh, A., Noroozi Ghaleini, E., Jahed Armaghani, D., Yagiz, S.: A new approach for estimation of rock brittleness based on non-destructive tests. Nondestruct. Test. Eval. 1, 22 (2019). https://doi.org/10.1080/10589759.2019.1623214
Harandizadeh, H., Armaghani, D.J., Mohamad, E.T.: Development of fuzzy-GMDH model optimized by GSA to predict rock tensile strength based on experimental datasets. Neural Comput. Appl. (2020). https://doi.org/10.1007/s00521-020-04803-z
Armaghani, D.J., Mohamad, E.T., Narayanasamy, M.S., Narita, N., Yagiz, S.: Development of hybrid intelligent models for predicting TBM penetration rate in hard rock condition. Tunn. Undergr. Sp. Technol. 63, 29–43 (2017). https://doi.org/10.1016/j.tust.2016.12.009
Armaghani, D.J., Koopialipoor, M., Marto, A., Yagiz, S.: Application of several optimization techniques for estimating TBM advance rate in granitic rocks. J. Rock Mech. Geotech. Eng. (2019). https://doi.org/10.1016/j.jrmge.2019.01.002
Li, E., Zhou, J., Shi, X., Armaghani, D.J., Yu, Z., Chen, X., Huang, P.: Developing a hybrid model of salp swarm algorithm-based support vector machine to predict the strength of fiber-reinforced cemented paste backfill. Eng. Comput. (2020). https://doi.org/10.1007/s00366-020-01014-x
Sun, D., Lonbani, M., Askarian, B., Armaghani, D.J., Tarinejad, R., Pham, B.T., Van Huynh, V.: Investigating the applications of machine learning techniques to predict the rock brittleness index. Appl. Sci. 10, 1691 (2020)
Zhou, J., Li, X., Mitri, H.S.: Comparative performance of six supervised learning methods for the development of models of hard rock pillar stability prediction. Nat. Hazards. 79, 291–316 (2015)
Zhou, J., Shi, X., Li, X.: Utilizing gradient boosted machine for the prediction of damage to residential structures owing to blasting vibrations of open pit mining. J. Vib. Control. 22, 3986–3997 (2016)
Wang, M., Shi, X., Zhou, J., Qiu, X.: Multi-planar detection optimization algorithm for the interval charging structure of large-diameter longhole blasting design based on rock fragmentation aspects. Eng. Optim. 50, 2177–2191 (2018)
Zhou, J., Li, E., Yang, S., Wang, M., Shi, X., Yao, S., Mitri, H.S.: Slope stability prediction for circular mode failure using gradient boosting machine approach based on an updated database of case histories. Saf. Sci. 118, 505–518 (2019)
Zhou, J., Li, X., Mitri, H.S.: Evaluation method of rockburst: State-of-the-art literature review. Tunn. Undergr. Sp. Technol. 81, 632–659 (2018)
Armaghani, P.G., Asteris, D.J.: A comparative study of ANN and ANFIS models for the prediction of cement-based mortar materials compressive strength. Neural Comput. Appl. 20, 20 (2020). https://doi.org/10.1007/s00521-020-05244-4
Apostolopoulou, M., Asteris, P.G., Armaghani, D.J., Douvika, M.G., Lourenço, P.B., Cavaleri, L., Bakolas, A., Moropoulou, A.: Mapping and holistic design of natural hydraulic lime mortars. Cem. Concr. Res. 136, 106167 (2020)
Chin, R.J., Lai, S.H., Ibrahim, S., Wan Jaafar, W.Z., Elshafie, A.: Rheological wall slip velocity prediction model based on artificial neural network. J. Exp. Theor. Artif. Intell. 31, 659–676 (2019)
Yaseen, Z.M., Karami, H., Ehteram, M., Mohd, N.S., Mousavi, S.F., Hin, L.S., Kisi, O., Farzin, S., Kim, S., El-Shafie, A.: Optimization of reservoir operation using new hybrid algorithm. KSCE J. Civ. Eng. 22, 4668–4680 (2018)
Yang, H.Q., Xing, S.G., Wang, Q., Li, Z.: Model test on the entrainment phenomenon and energy conversion mechanism of flow-like landslides. Eng. Geol. 239, 119–125 (2018)
Liu, B., Yang, H., Karekal, S.: Effect of water content on argillization of mudstone during the tunnelling process. Rock Mech. Rock Eng. (2019). https://doi.org/10.1007/s00603-019-01947-w
Yagiz, A.C., Ghasemi, S., Adoko, E.: Prediction of rock brittleness using genetic algorithm and particle swarm optimization techniques. Geotech. Geol. Eng. 36, 3767–3777 (2018)
Marto, A., Hajihassani, M., Momeni, E.: Bearing Capacity of Shallow Foundation’s Prediction through Hybrid Artificial Neural Networks. Appl. Mech. Mater 567, 681–686 (2014)
Meulenkamp, F., Grima, M.: Application of neural networks for the prediction of the unconfined compressive strength (UCS) from Equotip hardness. Int. J. Rock Mech. 36, 29–39 (1999)
Singh, R., Kainthola, A., Singh, T.N.: Estimation of elastic constant of rocks using an ANFIS approach. Appl. Soft Comput. 12, 40–45 (2012)
Liang, M., Mohamad, E.T., Faradonbeh, R.S., Jahed Armaghani, D., Ghoraba, S.: Rock strength assessment based on regression tree technique. Eng. Comput. 32, 343–354 (2016). https://doi.org/10.1007/s00366-015-0429-7
Kahraman, S.: Evaluation of simple methods for assessing the uniaxial compressive strength of rock. Int. J. Rock Mech. Min. Sci. 38, 981–994 (2001)
Moradian, Z.A., Behnia, M.: Predicting the uniaxial compressive strength and static Young’s modulus of intact sedimentary rocks using the ultrasonic test. Int. J. Geomech. 9, 14–19 (2009)
Armaghani, D.J., Mohamad, E.T., Momeni, E., Narayanasamy, M.S.: An adaptive neuro-fuzzy inference system for predicting unconfined compressive strength and Young’s modulus: a study on Main Range granite. Bull. Eng. Geol. Environ. 74, 1301–1319 (2015)
Sachpazis, C.I.: Correlating Schmidt hardness with compressive strength and Young’s modulus of carbonate rocks. Bull. Int. Assoc. Eng. Geol. 42, 75–83 (1990)
Çobanoğlu, İ, Çelik, S.B.: Estimation of uniaxial compressive strength from point load strength, Schmidt hardness and P-wave velocity. Bull. Eng. Geol. Environ. 67, 491–498 (2008)
Lashkaripour, G.R.: Predicting mechanical properties of mudrock from index parameters. Bull. Eng. Geol. Environ. 61, 73–77 (2002)
Armaghani, P., Momeni, D.J., Asteris, E.: Application of group method of data handling technique in assessing deformation of rock mass. Metaheuristic. Comput. Appl. 1, 1–18 (2020)
Bejarbaneh, B.Y., Bejarbaneh, E.Y., Fahimifar, A., Armaghani, D.J., Majid, M.Z.A.: Intelligent modelling of sandstone deformation behaviour using fuzzy logic and neural network systems. Bull. Eng. Geol. Environ. 77, 345–361 (2018)
Yesiloglu-Gultekin, N., Gokceoglu, C., Sezer, E.A.: Prediction of uniaxial compressive strength of granitic rocks by various nonlinear tools and comparison of their performances. Int. J. Rock Mech. Min. Sci. (2013). https://doi.org/10.1016/j.ijrmms.2013.05.005
Monjezi, M., Khoshalan, H., Razifard, M.: A neuro-genetic network for predicting uniaxial compressive strength of rocks. Geotech. Geol. Eng. 30, 1053–1062 (2012)
McCulloch, W.S., Pitts, W.: A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 5, 115–133 (1943)
Ch, S., Mathur, S.: Particle swarm optimization trained neural network for aquifer parameter estimation. KSCE J. Civ. Eng. 16, 298–307 (2012)
Asteris, P.G., Apostolopoulou, M., Skentou, A.D., Moropoulou, A.: Application of artificial neural networks for the prediction of the compressive strength of cement-based mortars. Comput. Concr. 24, 329–345 (2019)
Simpson, P.K.: Artificial Neural Systems: Foundations, Paradigms, Applications, and Implementations. Pergamon, Oxford (1990)
Basheer, I.A., Hajmeer, M.: Artificial neural networks: fundamentals, computing, design, and application. J. Microbiol. Methods. 43, 3–31 (2000)
Mohandes, M.A.: Modeling global solar radiation using Particle Swarm Optimization (PSO). Sol. Energy. 86, 3137–3145 (2012)
Ahmadi, M.A., Shadizadeh, S.R.: New approach for prediction of asphaltene precipitation due to natural depletion by using evolutionary algorithm concept. Fuel 102, 716–723 (2012)
Ivakhnenko, A.G.: The group method of data of handling; a rival of the method of stochastic approximation. Sov. Autom. Control. 13, 43–55 (1968)
Najafzadeh, M., Barani, G.-A.: Comparison of group method of data handling based genetic programming and back propagation systems to predict scour depth around bridge piers. Sci. Iran. 18, 1207–1213 (2011)
Najafzadeh, M., Barani, G.-A., Azamathulla, H.M.: GMDH to predict scour depth around a pier in cohesive soils. Appl. Ocean Res. 40, 35–41 (2013)
Koopialipoor, M., Nikouei, S.S., Marto, A., Fahimifar, A., Armaghani, D.J., Mohamad, E.T.: Predicting tunnel boring machine performance through a new model based on the group method of data handling. Bull. Eng. Geol. Environ. 78, 3799–3813 (2018)
Li, D., Moghaddam, M.R., Monjezi, M., Jahed Armaghani, D., Mehrdanesh, A.: Development of a group method of data handling technique to forecast iron ore price. Appl. Sci. 10, 2364 (2020)
Momeni, E., Armaghani, D.J., Fatemi, S.A., Nazir, R.: Prediction of bearing capacity of thin-walled foundation: a simulation approach. Eng. Comput. 34, 319–327 (2018)
Caudill, M.: Neural networks primer, Part III. AI Expert 3, 53–59 (1988)
Armaghani, D.J., Asteris, P.G., Fatemi, S.A., Hasanipanah, M., Tarinejad, R., Rashid, A.S.A., Van Huynh, V.: On the use of neuro-swarm system to forecast the pile settlement. Appl. Sci. 10, 1904 (2020)
Armaghani, D.J., Mirzaei, F., Shariati, M., Trung, N.T., Shariati, M., Trnavac, D.: Hybrid ANN-based techniques in predicting cohesion of sandy-soil combined with fiber. Geomech. Eng. 20, 191–205 (2020)
Acknowledgements
The first author would like to acknowledge the financial support from the Joint Funds of the National Natural Science Foundation of China (No. U1934211).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflicts of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Li, D., Armaghani, D.J., Zhou, J. et al. A GMDH Predictive Model to Predict Rock Material Strength Using Three Non-destructive Tests. J Nondestruct Eval 39, 81 (2020). https://doi.org/10.1007/s10921-020-00725-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10921-020-00725-x