
Abstract
Desired rock fragmentation is the main goal of the blasting operation in surface mines, civil and tunneling works. Therefore, precise prediction of rock fragmentation is very important to achieve an economically successful outcome. The primary objective of this article is to propose a new model for forecasting the rock fragmentation using adaptive neuro-fuzzy inference system (ANFIS) in combination with particle swarm optimization (PSO). The proposed PSO–ANFIS model has been compared with support vector machines (SVM), ANFIS and nonlinear multiple regression (MR) models. To construct the predictive models, 72 blasting events were investigated, and the values of rock fragmentation as well as five effective parameters on rock fragmentation, i.e., specific charge, stemming, spacing, burden and maximum charge used per delay were measured. Based on several statistical functions [e.g., coefficient of correlation (R 2) and root-mean-square error (RMSE)], it was found that the PSO–ANFIS (with R 2 = 0.89 and RMSE = 1.31) performs better than the SVM (with R 2 = 0.83 and RMSE = 1.66), ANFIS (with R 2 = 0.81 and RMSE = 1.78) and nonlinear MR (with R 2 = 0.57 and RMSE = 3.93) models. Finally, the sensitivity analysis shows that the burden and maximum charge used per delay have the least and the most effects on the rock fragmentation, respectively.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Blasting is the predominant rock fragmentation technique in surface mines and civil works. Only 20–30% of the produced energy is actually used for the desired rock fragmentation and the rest of it goes waste in untoward generation of air blast, flyrock, noise, ground vibration and back-break [1–10]. Aside from these unwanted effects, poor fragmentation is one of the most undesirable consequences of an unsuitable blast design. The optimum rock fragmentation is the primary objective of blasting operation. Fragment size distribution is very important in the overall mining and processing plant economics. As per suggested in many studies [11–16], the influential factors on the rock fragmentation can be grouped into two main categories: (1) properties of rock masses and (2) blast design factors. The properties of rock masses or uncontrollable factors cannot be changed by the explosive engineers, whereas the blast design or controllable factors can be changed by the explosive engineers. The total charge, maximum charge used per delay (MC), stemming (ST), spacing (S), burden (B), sub-drilling, type of explosive material, blast hole depth, blast hole diameter and specific charge (SC) are all controllable factors. A wide range of empirical models have been developed to predict rock fragmentation induced by mine blasting [17–19]. In these empirical models, the rock fragmentation is predicted by using one or two effective parameters such as rock density, compressive strength, blast hole diameter, drilling pattern and explosive characteristics. Since many parameters affect rock fragmentation, the performance predictions of the empirical models are sometimes unreliable. In the recent years, many researchers highlighted the efficiency of artificial intelligence (AI) methods in solving various engineering areas, especially in the field of mining and geotechnical applications [20–24]. In the field of rock fragmentation prediction, these models have been extensively used and developed. Monjezi et al. [25] developed multiple regression (MR) model and artificial neural networks (ANN) to estimate rock fragmentation. In their study, the blast hole diameter, ST, MC, delay between the rows, B to S ratio (B/S) and point load index were selected as the model inputs. The results indicated that the ANN model performs better than the MR. Fuzzy inference system (FIS) and MR for the prediction of rock fragmentation caused by blasting in Gol-E-Gohar iron mine were developed by Monjezi et al. [11]. They used B, S, blast hole depth, specific drilling, ST, MC, rock density and SC as input parameters. Finally, it was found that FIS provided more accurate predictions and had the capacity to generalize. Shi et al. [26] employed support vector machines (SVM), ANN, MR and Kuznetsov methods to estimate rock fragmentation. In their study, the ratio of bench height to B, modulus of elasticity, ratio of ST to B, ratio of B to blast hole diameter, ratio of S to B, block size and SC were utilized as the model inputs. Prediction results show that accuracy of the SVM is higher than that of ANN, MR and Kuznetsov methods. A comprehensive study for forecasting of the rock fragmentation by using adaptive neuro-fuzzy inference system (ANFIS), SVM and Kuz-Ram empirical model was presented by Esmaeili et al. [14]. In their study, S/B, Blastability index, ratio of total delays per number of rows, blast hole depth, ST and SC were input parameters. Several statistical functions, such as coefficient of correlation (R 2), were used to compare the predictive models. The results showed that ANFIS can be introduced as an acceptable model for forecasting of the rock fragmentation, and its results were more precise than SVM and Kuz-Ram models. R 2 of ANFIS model was obtained as 0.89, whereas the R 2 of SVM and Kuz-Ram models were obtained as 0.83 and 0.38, respectively. Shams et al. [15] constructed FIS and MR models to estimate rock fragmentation in the Sarcheshmeh copper mine, using 185 dataset. They used B, S, ST, SC and Schmidt hammer rebound number as model inputs. They concluded that the predictions by FIS were better in comparison with MR. In the other study of AI methods, Karami and Afiuni-Zadeh [13] established MRA, radial basis function (RBF) and ANFIS to estimate rock fragmentation. Based on their results, it was observed that ANFIS shows a better prediction capability than RBF and MRA models. In the other study, dimensional analysis (DA) and Kuz–Ram models were employed for forecasting of the rock fragmentation by Bakhtavar et al. [27]. Finally, it was demonstrated that the DA model is more suitable for rock fragmentation estimation in comparison with the Kuz–Ram model. In the recent years, many attempts have been done to highlight evolutionary algorithms for the prediction aims in the field of mining engineering (such as [28–31]). The results revealed that such algorithms are useful to increase the performance of ANN model itself. In the present article, a novel hybrid of PSO and ANFIS were developed to estimate the rock fragmentation. The proposed PSO–ANFIS model has been compared with SVM, ANFIS and MR models. The sensitivity analysis was also performed to identify the most effective parameters on the rock fragmentation. The remnant of this paper is formed as follows: The studied case is explained in Sect. 2. The proposed PSO–ANFIS model is explained in Sect. 3. In Sect. 4, the performance capacity of the PSO–ANFIS model has been checked. Afterward, the sensitivity analysis has been performed and explained in Sect. 5. Finally, the conclusion has been presented in Sect. 6.
2 Case study
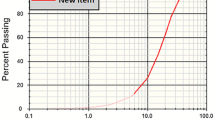
The case study was carried out in Shur river dam area which is situated in the south of province Kerman, Iran, between 30°1′48″ latitudes and 55°51′47″ longitudes. The Shur river dam is the tallest asphaltic concrete core dam in Iran, located in the adjacency of Rafsanjan city and Sarchemeh copper mine. In order to construct the Shur river dam, two mines, i.e., main and second mines, were extracted using drilling and blasting method. In this regard, Wagon Drill Machine and ammonium nitrate fuel oil (ANFO) were used in drilling and blasting processes, respectively. Moreover, the blast holes were stemmed by fine gravel. As suggested by many researchers [11, 13–15], proper rock fragmentation has a vital role on the costs of drilling and blasting. Therefore, precise prediction of rock fragmentation is very crucial. By reviewing the previous investigations [11, 13–16], B, S, ST, MC and SC were the most influential parameters on rock fragmentation and widely used as input parameters in many studies. Hence, the mentioned parameters were selected and used for prediction of rock fragmentation in the current research work. In total, 72 blasting events were considered, and the values of rock fragmentation (D80), S, B, ST, MC and SC were measured. To determine the D80 values, image processing technique, due to its low cost and quickly utilized, was considered. In this regard, digital images with the help of Split Desktop software were used to analyze the size distributions of the fragmented rocks. Figure 1 shows a sample size distribution curve obtained via the Split Desktop software. In order to construct the PSO–ANFIS and MLR methods, the available datasets were split into two sets: training and testing sets. In this paper, 80 and 20% of the total datasets were used as training and testing aims, as recommended by Swingler [32]. In the other words, 58 datasets were used to construct the models, while the remained 14 datasets were used to testify the predicting performance of the models. Table 1 shows the range of parameters used in this research. In addition, Fig. 2 illustrates the frequency distributions of the B, S, ST, SC, MC and rock fragmentation.

Sample of a size distribution curve obtained using Split Desktop software

Frequency histograms of the measured parameters in this study
3 Development of PSO–ANFIS to Predict Rock Fragmentation
In this section, firstly, PSO and ANFIS models are shortly described. Then, the development of PSO–ANFIS model for the prediction of rock fragmentation is explained.
3.1 PSO
Kennedy and Eberhart [33] introduced PSO as an evolutionary optimization algorithm. In the PSO model, an amount of particles are put into the search area of the N-dimensional moot point. Each swarm (or particle) demonstrates a possible solution and appraises the objective function at its current location. In the PSO, the next place of particles is specified by merging their current locations with some accidental perturbations. Finally, the swarms move close to the optimum fitness function [34, 35]. The PSO has some advantages, namely [36–38]:
-
1.
PSO is a fast and easy algorithm to understand and implement.
-
2.
PSO is an efficient optimization technique to maintain the diversity of the swarm.
-
3.
PSO has fewer parameters.
The PSO consists of a swarm of particles that search for the best position, including the best global (g best) and personal (p best) positions [39].
The velocity and position of a particle during its moving process can be formulated as follows:
-
\(Rand_{1}\) and \(Rand_{2}\) represent the positive random numbers in (0,1)
-
\(P_{\text{best}}\) (personal best) and \(G_{\text{best}}\) (global best) are the personal best position of particle and the best particle among all of the particles, respectively.
-
\(C_{1}\) and \(C_{2}\) are learning factors.
-
\(X\) and \(V\) represent current position and velocity of particles, respectively.
-
\(X_{\text{new}}\) and \(V_{\text{new}}\) represent new position and velocity of particles, respectively.
-
\(w\) represents the inertial weight coefficient.
The PSO can be found in many studies (e.g., [40, 41]). The PSO has been most widely studied on and applied to solve the real-world problems, so far [42–46]. In the field of mining and geotechnical engineering, the results indicate the reliability of the PSO for prediction aims. For instance, Gordan et al. [47] applied PSO to design/optimize the ANN for the prediction of seismic slope stability. Based on their results, PSO was introduced as a powerful tool to design the ANN, and the performance predictions of the PSO–ANN were better than ANN. In the other study, Hasanipanah et al. [48] developed PSO–ANN for the prediction of maximum surface settlement induced by tunneling at Karaj subway, Iran. Finally, it was concluded that PSO–ANN model simulates the surface settlement more reliably than ANN model.
3.2 ANFIS
ANFIS is an AI method applied for solving complex and highly nonlinear problems. The method was first introduced by Jang [49]. Since ANFIS combines both ANN and FIS, it is capable of handling complex and nonlinear problems in a single framework. The ANFIS architecture with two inputs and five layers is shown in Fig. 3. In this architecture, the Takagi–Sugeno fuzzy type is used as FIS. To describe the procedure of ANFIS, it is assumed that the FIS under consideration consists of one output (O) and two inputs (k, j). The fuzzy rules can be typically reported as follows: [50]:
where \(k\) and \(j\) can be considered as the inputs. \(a_{1} ,s_{1} ,l_{1} , a_{2} ,s_{2} ,l_{2}\) are the function parameters of output (O) or the consequent parameters. Also, \(Z_{1 } , Z_{2 } , U_{1 } , U_{2 }\) are the membership functions for inputs (\(k\) and \(j\)). As shown in Fig. 3, an ANFIS with five layers, two inputs and one output can be explained in the following lines [51, 52]:

An ANFIS architecture
Layer 1 (fuzzification layer): All nodes are considered as an adaptive node.
-
\(n\) is the number of fuzzy sets for each model input.
-
\(k\) and \(j\) are set as input nodes.
-
\(\mu U_{i} \left( j \right)\) and \(\mu Z_{i} \left( k \right)\) are the membership functions.
-
\(Z\) and \(U\) are the linguistic labels.
Layer 2 (product layer): Calculation of the firing strength.
The output node \(\omega_{i}\) represents the firing strength of a rule.
Layer 3 (normalized layer): In this layer, the ratio of firing strength of the \(i\) th rule to the sum of firing strengths of all rules is calculated.
Layer 4 (defuzzification layer): Each node is an adjustable node with the following node function:
In which \(w_{i}\) is output of the third layer or normalized firing strength. Also, {p i , q i , r i } are parameters sets of the node \(i\).
Layer 5 (output layer): System output is generated through sum of the incoming signals.
The successful application of ANFIS model in the field of mining and geotechnical engineering has addressed in many studies [7, 14, 16]. For instance, Jahed Armaghani et al. [53] employed ANFIS to estimate ground vibration. Based on their result, ANFIS can be introduced as a reliable tool for the prediction aims in this field.
3.3 Hybrid PSO–ANFIS
In order to estimate rock fragmentation with high level of accuracy, a combined model based on ANFIS and PSO is developed in the presented study. In the other words, PSO is used to train the ANFIS and select the optimal values of the ANFIS parameters. In order to develop the PSO–ANFIS, the optimum PSO parameters can be determined based on several parametric studies. Maximum number of iterations, maximum number of particles, cognitive acceleration (C 1) and social acceleration (C 2), initial inertia weight (W min) and final inertia weight (W max) are the main PSO parameters. In the first step of PSO–ANFIS modeling, the effective factors on rock fragmentation, i.e., SC, ST, S, B and MC, were set as input factors, and D80 was set as output factor. Consequently, the form of a fuzzy if–then rule for rule \(i\) may be stated as:
where \(A_{i}\) to \(E_{i}\) are fuzzy set labels for input parameters. Also, \(p_{i}\), …, \(y_{i}\) are linear consequent parameters of fuzzy rule \(i\). In the second step, the available data were split into training and testing sets. In the current paper, 58 and 14 datasets were used to train and test PSO–ANFIS model, respectively. Afterward, all datasets were normalized in the range of (0,1) in order to simplify the design procedure as follows:
where \(X_{n}\) and \(X\) are the normalized and measured values, respectively. Also, the minimum and maximum of measured dataset are \(X_{\hbox{min} }\) and \(X_{\hbox{max} }\), respectively. In order to construct the PSO–ANFIS model, a code was written in the MATLAB environment. In the PSO–ANFIS model, the PSO helps hybrid system to have closer relationships between the inputs and the output of model. The proposed hybrid model can predict more accurate results for the nonlinear systems and consequently improve the forecast accuracy. In the present study, root-mean-square error (RMSE) and the Gaussian were used as fitness and membership functions, respectively, as recommended by many studies (e.g., [48, 53]). Note that, a predictive model with lower RMSE values is of advantage. In the modeling, linguistic variables include low (L), medium (M) and high (H) were used for the input parameters. As mentioned above, the most important task in the modeling is the proper selection of PSO parameters. In order to assess the optimum values of the PSO parameters, trial-and-error method was applied in the present paper. The obtained results indicated that the values of 40, 500, 2, 2, 0.9 and 0.5 for the maximum number of particles, maximum number of iterations, C 1, C 2, W min and W max, respectively, were the best among other utilized values. Figure 4 shows the scatter plots of rock fragmentation (D80) predicted by the PSO–ANFIS for both training and testing datasets. Here, it is observed that (from Fig. 4) the predicted values using the PSO–ANFIS model are in excellent agreement with the measures data, which demonstrates the reliability of the PSO–ANFIS model.

Measured versus predicted values of rock fragmentation, PSO–ANFIS model
4 Evaluation of the proposed PSO–ANFIS model
In the present research work, PSO–ANFIS model is proposed to estimate D80 induced by blasting operations in Shur river dam region, Iran. For comparison aims, SVM, ANFIS and MR models were also developed. SVM is a machine learning theory frame and general way, established on a set of finite samples [54]. The performance of SVM depends greatly on the combination of several parameters. They are capacity parameter \(C\), \(\varepsilon\) of \(\varepsilon\)-insensitive loss function. In this study, trial-and-error method was used, and based on obtained results, the values of 0.1 and 1 were selected as the optimum values for the \(\varepsilon\) and \(C\), respectively. The SVM model can be found in many studies (e.g., [55–57]). Apart from SVM, the ANFIS model was also used for the prediction of D80. In this study, various ANFIS models were designed using a trial-and-error procedure in order to determine the fuzzy rules No. in forecasting D80. In the ANFIS modeling, the linguistic variables of low (L), medium (M) and high (H) were performed for input parameters. Also, Gaussian was selected as the membership function. In order to develop the SVM and ANFIS models in the present study, the same training and testing datasets considering in PSO–ANFIS model were used. In this regard, 72 blasting operations were considered, and the most influential factors on the rock fragmentation including B, S, ST, SC and MC were measured. The mentioned parameters were used as model inputs, while D80 was used as the output parameter. In the PSO–ANFIS, ANFIS and SVM models, 58 datasets were used as training models, and the remained 14 datasets were used as testing the models. It should be mentioned that MATLAB 2013b was used to construct PSO–ANFIS, ANFIS and SVM models. Apart from the mentioned AI models, MR was also utilized for D80 prediction. MR is a widely used method for solving different engineering problems, especially in prediction aims. MR can be applied to obtain the best-fit equation when there is more than one input variable. In the present study, nonlinear MR model was used for the prediction of D80. To construct the nonlinear MR model, the same datasets performed in the modeling of PSO–ANFIS, ANFIS and SVM models were used. Considering the 58 datasets, Eq. (14) was constructed by using SPSS v16 software [58]:
In the second step, the performance of the constructed nonlinear MR model can be evaluated using testing datasets (14 datasets). For controlling and subsequently checking the performance capacity of the utilized models, several statistical criteria including RMSE, R 2, variance account for (VAF), median absolute error (MEDAE) and nash and sutcliffe (NS) were computed:
In which \(n\), \(x_{p}\), \(x_{i}\) are the number of datasets, the predicted and measured rock fragmentation values, respectively. The values of 1, 0, 100%, 0 and 1 for the R 2, RMSE, VAF, MEDAE and NS demonstrate that there is perfect agreement between all the measured and predicted values. Table 2 reports the results of these criteria in the present study. Figures 5, 6 and 7 also depict the scatter plots of rock fragmentation (D80) predicted by the ANFIS, SVM and nonlinear MR models, respectively, for both training and testing datasets. As shown in Table 2 and Figs. 4, 5, 6 and 7, the PSO–ANFIS model can predict D80 better than ANFIS, SVM and nonlinear MR models. Furthermore, Fig. 8 illustrates a comparison of the predicted D80 values by all predictive models and the measured D80, using only testing datasets. The results demonstrate that predictions through PSO–ANFIS model are more acceptable in comparison with ANFIS, SVM and nonlinear MR models.

Measured versus predicted values of rock fragmentation, ANFIS model

Measured versus predicted values of rock fragmentation, SVM model

Measured versus predicted values of rock fragmentation, nonlinear MR model

A comparison of the predicted D80 values by predictive models and the measured D80
5 Sensitivity analysis
In order to identify the most influential factors on the rock fragmentation, a sensitivity analysis was performed in the present paper. For this work, the cosine amplitude method which was introduced by Yang and Zang [59] is used for sensitivity analysis, using the following equation:
In which \(x_{j}\) and \(x_{i}\) the elements of data pairs, which denote the output and input datasets, respectively. Figure 9 illustrates how sensitive is the result of rock fragmentation to the input parameters. Rock fragmentation is sensitive to, in descendent order, MC, SC, ST, S and B. Therefore, MC was the most effective parameter on the rock fragmentation based on available datasets in the present research work.

Effect of input parameters on the rock fragmentation
6 Conclusion
Generally speaking, the primary objective of the blasting is the desired rock fragmentation. Nevertheless, the poor fragmentation is one of the most undesirable consequences of an unsuitable blast design. The main goal of this work is to estimate rock fragmentation produced by blasting at Shur river dam region, Iran. For this aim, a new combination of ANFIS and PSO is proposed in this research. In addition, the PSO–ANFIS model has been compared with ANFIS, SVM and nonlinear MR models. In this regard, 72 blasting operations were considered, and the most influential factors on the rock fragmentation including B, S, ST, SC and MC were measured. The mentioned parameters were used as model inputs, while D80 was used as model output. In the modeling, all datasets were classified to training and testing datasets. In the current paper, 58 and 14 datasets were used for training and testing aims, respectively. In order to examine the accuracy of rock fragmentation predictions by PSO–ANFIS, ANFIS, SVM and nonlinear MR models, five statistical indices including R 2, RMSE, VAF, MEDAE and NS have been used. Comparing the values predicted by the models indicated that the performance of the proposed PSO–ANFIS model was better than the SVM, ANFIS and nonlinear MR models. Results showed that R 2 values in the PSO–ANFIS, SVM, ANFIS and nonlinear MR models were 0.938, 0.9, 0.88 and 0.64, respectively, at training stage and 0.89, 0.83, 0.81 and 0.57, respectively, at test stage. As a conclusion, PSO–ANFIS can be used as a reliable and acceptable model in the field of rock fragmentation prediction. Based on sensitivity analysis, it was also found that the MC was the most effective parameters on the rock fragmentation in this case study.
References
Singh TN, Singh V (2005) An intelligent approach to prediction and control ground vibration in mines. Geotech Geolog Eng 23:249–262
Singh TN, Verma AK (2010) Sensitivity of total charge and maximum charge per delay on ground vibration. Geomat Nat Hazards Risk 1(3):259–272
Faradonbeh RS, Armaghani DJ, Majid MA, Tahir MM, Murlidhar BR, Monjezi M, Wong HM (2016) Prediction of ground vibration due to quarry blasting based on gene expression programming: a new model for peak particle velocity prediction. Int J Environ Sci Technol. doi:10.1007/s13762-016-0979-2
Khandelwal M, Singh TN (2013) Application of an expert system to predict maximum explosive charge used per delay in surface mining. Rock Mech Rock Eng 46(6):1551–1558
Trivedi R, Singh TN, Raina AK (2014) Prediction of blast-induced flyrock in Indian limestone mines using neural networks. J Rock Mech Geotech Eng 6:447–454
Trivedi R, Singh TN, Gupta NI (2015) Prediction of blast induced flyrock in opencast mines using ANN and ANFIS. Geotech Geol Eng 33:875–891
Trivedi R, Singh TN, Raina AK (2016) Simultaneous prediction of blast-induced flyrock and fragmentation in opencast limestone mines using back propagation neural network. Int J Min Miner Eng 7(3):237–252
Amiri M, Bakhshandeh Amnieh H, Hasanipanah M, Mohammad Khanli L (2016) A new combination of artificial neural network and K-nearest neighbors models to predict blast-induced ground vibration and air-overpressure. Eng Comput. doi:10.1007/s00366-016-0442-5
Dindarloo SR (2015) Prediction of blast-induced ground vibrations via genetic programming. Int J Min Sci Technol 25:1011–1015
Dindarloo SR (2015) Peak particle velocity prediction using support vector machines: a surface blasting case study. J South Afr Inst Min Metall 115:637–643
Monjezi M, Rezaei M, Yazdian Varjani A (2009) Prediction of rock fragmentation due to blasting in Gol-E-Gohar iron mine using fuzzy logic. Int J Rock Mech Min Sci 46:1273–1280
Bahrami A, Monjezi M, Goshtasbi K, Ghazvinian A (2011) Prediction of rock fragmentation due to blasting using artificial neural network. Eng Comput 27:177–181
Karami A, Afiuni-Zadeh S (2013) Sizing of rock fragmentation modeling due to bench blasting using adaptive neuro fuzzy inference system (ANFIS). Int J Min Sci Technol 23(6):809–813
Esmaeili M, Salimi A, Drebenstedt C, Abbaszadeh M, Aghajani Bazzazi A (2014) Application of PCA, SVR, and ANFIS for modeling of rock fragmentation. Arab J Geosci. doi:10.1007/s12517-014-1677-3
Shams S, Monjezi M, Johari Majd V, Jahed Armaghani D (2015) Application of fuzzy inference system for prediction of rock fragmentation induced by blasting. Arab J Geosci. doi:10.1007/s12517-015-1952-y
Hasanipanah M, Jahed Armaghani D, Monjezi M, Shams S (2016) Risk assessment and prediction of rock fragmentation produced by blasting operation: a rock engineering system. Environ Earth Sci 75(9):1–12
Mishnaevsky JR, Schmauder S (1996) Analysis of rock fragmentation with the use of the theory of fuzzy sets. In: Barla (ed) Proceedings of the Eurock 96:735–740
Roy PP, Dhar BB (1996) Fragmentation analyzing scale—a new tool for breakage assessment. Proceedings 5th International Symposium on Rock Fragmentation by blasting-FRAGBLAST 5, Balkema, Rotterdam
Morin AM, Ficarazzo F (2006) Monte Carlo simulation as a tool to predict blasting fragmentation based on the Kuz–Ram model. Comput Geosci 32:352–359
Verma AK, Singh TN (2011) Intelligent systems for ground vibration measurement: a comparative study. Eng Comput 27(3):225–233
Singh R, Kainthola A, Singh TN (2012) Estimation of elastic constant of rocks using an ANFIS approach. Appl Soft Comput 12(1):40–45
Verma AK, Singh TN (2013) A neuro-fuzzy approach for prediction of longitudinal wave velocity. Neural Comput Appl 22(7–8):1685–1693
Verma AK, Singh TN (2013) Comparative study of cognitive systems for ground vibration measurements. Neural Comput Appl 22(1):341–350
Singh J, Verma AK, Banka H, Singh TN, Maheshwar S (2016) A study of soft computing models for prediction of longitudinal wave velocity. Arab J Geosci 9(3):1–11
Monjezi M, Bahrami A, Yazdian Varjani A (2010) Simultaneous prediction of fragmentation and flyrock in blasting operation using artificial neural networks. Int J Rock Mech Min Sci 47(3):476–480
Shi XZ, Zhou J, Wu B, Huang D, Wei W (2012) Support vector machines approach to mean particle size of rock fragmentation due to bench blasting prediction. Trans Nonferrous Met Soc China 22:432–441
Bakhtavar E, Khoshrou H, Badroddin M (2015) Using dimensional-regression analysis to predict the mean particle size of fragmentation by blasting at the Sungun copper mine. Arab J Geosci 8:2111–2120
Hajihassani M, Jahed Armaghani D, Marto A, Tonnizam Mohamad E (2014) Ground vibration prediction in quarry blasting through an artificial neural network optimized by imperialist competitive algorithm. Bull Eng Geol Environ. doi:10.1007/s10064-014-0657-x
Fouladgar N, Hasanipanah M, Bakhshandeh Amnieh H (2016) Application of cuckoo search algorithm to estimate peak particle velocity in mine blasting. Eng Comput. doi:10.1007/s00366-016-0463-0
Hasanipanah M, Shahnazar A, Bakhshandeh Amnieh H, Jahed Armaghani D (2016) Prediction of air-overpressure caused by mine blasting using a new hybrid PSO–SVR model. Eng Comput. doi:10.1007/s00366-016-0453-2
Jahed Armaghani D, Hasanipanah M, Tonnizam Mohamad E (2016) A combination of the ICA-ANN model to predict air-overpressure resulting from blasting. Eng Comput 32(1):155–171
Swingler K (1996) Applying neural networks: a practical guide. Academic Press, New York
Kennedy J, Eberhart RC (1995) Particle swarm optimization, In: Proceedings of IEEE international conference on neural networks, Perth, Australia, pp 1942–1948
Eberhart RC, Shi Y (2001) Particle swarm optimization: developments, applications and resources. In: Proceedings of IEEE international conference on evolutionary computation, pp 81–86
Mendes R, Cortes P, Rocha M, Neves J (2002) Particle swarms for feed forward neural net training. In: Proceedings of IEEE international joint conference on neural networks, Honolulu, HI, USA, 12–17 May 2002, pp 1895–1899
Zhang JR, Zhang J, Lok TM, Lyu MR (2007) A hybrid particle swarm optimization–back-propagation algorithm for feedforward neural network training. Appl Math Comput 185(2):1026–1037
Hajihassani M, JahedArmaghani D, Sohaei H, Tonnizam Mohamad E, Marto A (2014) prediction of airblast-overpressure induced by blasting using a hybrid artificial neural network and particle swarm optimization. Appl Acoust 80:57–67
Jahed Armaghani D, Hajihassani M, Yazdani Bejarbaneh B, Marto A, Tonnizam Mohamad E (2014) Indirect measure of shale shear strength parameters by means of rock index tests through an optimized artificial neural network. Measurement 55:487–498
Momeni E, Jahed Armaghani D, Hajihassani M, Amin MFM (2015) Prediction of uniaxial compressive strength of rock samples using hybrid particle swarm optimization-based artificial neural networks. Measurement 60:50–63
Yagiz S, Gokceoglu C, Sezer E, Iplikci S (2009) Application of two non-linear prediction tools to the estimation of tunnel boring machine performance. Eng Appl Artif Intell 22:808–814
Kalatehjari R, Ali N, Kholghifard M, Hajihassani M (2014) The effects of method of generating circular slip surfaces on determining the critical slip surface by particle swarm optimization. Arab J Geosci 7(4):1529–1539
Feng XT, Chen BR, Yang C, Zhou H, Ding X (2006) Identification of visco-elastic models for rocks using genetic programming coupled with the modified particle swarm optimization algorithm. Int J Rock Mech Min Sci 43:789–801
Yagiz S, Karahan H (2011) Prediction of hard rock TBM penetration rate using particle swarm optimization. Int J Rock Mech Min Sci 48(3):427–433
Babanouri N, Karimi Nasab S, Sarafrazi S (2013) A hybrid particle swarm optimization and multi-layer perceptron algorithm for bivariate fractal analysis of rock fractures roughness. Int J Rock Mech Min Sci 60:66–74
Li L, Zhong D, Zhang C (2013) Determination of blasting vibration parameters using particle swarm optimization. In: Proceedings of the 3rd international conference on information science and technology (ICIST 2013), Yangzhou, China, pp 326–329
Khan A, Niemann-Delius C (2014) Application of particle swarm optimization to the open pit mine scheduling problem. In: Proceedings of the 12th international symposium continuous surface mining (ISCSM 2014), Aachen, Germany, pp 195–212
Gordan B, Jahed Armaghani D, Hajihassani M, Monjezi M (2015) Prediction of seismic slope stability through combination of particle swarm optimization and neural network. Eng Comput. doi:10.1007/s00366-015-0400-7
Hasanipanah M, Noorian-Bidgoli M, Jahed Armaghani D, Khamesi H (2016) Feasibility of PSO-ANN model for predicting surface settlement caused by tunneling. Eng Comput. doi:10.1007/s00366-016-0447-0
Jang JSR (1993) ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans Syst Man Cybern 23:665–685
Mahapatra S, Daniel R, Narayan Dey D, Kumar Nayak S (2015) Induction motor control using PSO–ANFIS. Proc Comput Sci 48:754–769
Jang RJS, Sun CT, Mizutani E (1997) Neuro-fuzzy and soft computing. Prentice-Hall, Upper Saddle River, p 614
Iphar M, Yavuz M, Ak H (2008) Prediction of ground vibrations resulting from the blasting operations in an open-pit mine by adaptive neuro fuzzy inference system. Environ Geol 56:97–107
Jahed Armaghani D, Momeni E, Abad SVANK, Khandelwal M (2015) Feasibility of ANFIS model for prediction of ground vibrations resulting from quarry blasting. Environ Earth Sci 74(4):2845–2860
Vapnik VN (1998) Statistical learning theory. Wiley, New York
Khandelwal M, Kankar PK (2011) Prediction of blast-induced air overpressure using support vector machine. Arab J Geosci 4:427–433
Amini H, Gholami R, Monjezi M, Torabi SR, Zadhesh J (2012) Evaluation of flyrock phenomenon due to blasting operation by support vector machine. Neural Comput Appl 21:2077–2085
Khandelwal M, Monjezi M (2013) Prediction of backbreak in open-pit blasting operations using the machine learning method. Rock Mech Rock Eng 46:389–396
SPSS Inc (2007) SPSS for windows (version 16.0). SPSS Inc, Chicago
Yang Y, Zang O (1997) A hierarchical analysis for rock engineering using artificial neural networks. Rock Mech Rock Eng 30:207–222
Acknowledgements
The authors would like to extend their appreciation to manager, engineers and personnel of Shur river dam, especially Mr. Alireza Farazmand, for providing the needed information and facilities that made this research possible.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Rights and permissions
About this article

Cite this article
Hasanipanah, M., Amnieh, H.B., Arab, H. et al. Feasibility of PSO–ANFIS model to estimate rock fragmentation produced by mine blasting. Neural Comput & Applic 30, 1015–1024 (2018). https://doi.org/10.1007/s00521-016-2746-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-016-2746-1