
Abstract
Blasting operations usually produce significant environmental problems which may cause severe damage to the nearby areas. Air-overpressure (AOp) is one of the most important environmental impacts of blasting operations which needs to be predicted and subsequently controlled to minimize the potential risk of damage. In order to solve AOp problem in Hulu Langat granite quarry site, Malaysia, three non-linear methods namely empirical, artificial neural network (ANN) and a hybrid model of genetic algorithm (GA)–ANN were developed in this study. To do this, 76 blasting operations were investigated and relevant blasting parameters were measured in the site. The most influential parameters on AOp namely maximum charge per delay and the distance from the blast-face were considered as model inputs or predictors. Using the five randomly selected datasets and considering the modeling procedure of each method, 15 models were constructed for all predictive techniques. Several performance indices including coefficient of determination (R 2), root mean square error and variance account for were utilized to check the performance capacity of the predictive methods. Considering these performance indices and using simple ranking method, the best models for AOp prediction were selected. It was found that the GA–ANN technique can provide higher performance capacity in predicting AOp compared to other predictive methods. This is due to the fact that the GA–ANN model can optimize the weights and biases of the network connection for training by ANN. In this study, GA–ANN is introduced as superior model for solving AOp problem in Hulu Langat site.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Blasting refers to the controlled use of explosives for the purpose of breaking down, excavation, or removal of rock. This is the most commonly used technique for rock fragmentation in civil and mining engineering applications, e.g. quarry operations, road and dam constructions, etc. However, blasting has a number of negative side effects on the environment, such as air-overpressure (AOp), ground vibration, flyrock, back-break, and so on (Khandelwal and Kankar 2011; Rezaei et al. 2011; Jahed Armaghani et al. 2015a, b; Shirani Faradonbeh et al. 2015; Hasanipanah et al. 2015), especially if blasting operations are carried out near to residential buildings, factories, etc. or they are not designed appropriately (Kuzu 2008; Chen et al. 2015). AOp resulting from blasting is an undesirable side effect of the use of explosives. This undesirable environmental impact of blasting affects structures and can produce damage when quarrying, which may result in conflict between the quarry management and those who are affected (Konya and Walter 1990; Hopler 1998; Chen et al. 2015).
Several empirical equations have been developed to predict AOp induced by blasting operation (Siskind et al. 1980; Hustrulid 1999; Kuzu et al. 2009; Hajihassani et al. 2014). As a result, these methods are not accurate enough, whereas prediction of AOp values with high degree of accuracy is important to estimate the blasting safety area (Hajihassani et al. 2014). Furthermore, they need to be updated when new blasting parameters are available. Apart from the empirical equations, the use of artificial intelligence (AI) techniques such as artificial neural network (ANN) as quick solutions for engineering problems has recently received attention in field of geotechnical engineering (Khandelwal and Singh 2007; Ceryan et al. 2013; Isik and Ozden 2013; Monjezi et al. 2013; Jahed Armaghani et al. 2014; Maiti and Tiwari 2014; Momeni et al. 2015a; Ghoraba et al. 2015; Hajihassani et al. 2015; Gordan et al. 2015; Jahed Armaghani et al. 2015b, c). Although ANNs can solve complex engineering problems, they have a number of disadvantages; for example, slow learning rate and getting trapped in local minima (Jadav and Panchal 2012; Momeni et al. 2014). As a result, ANN performance can be considerably improved by the use of optimization algorithms such as genetic algorithm (GA) (Bornholdt and Graudenz 1992; Saemi et al. 2007). This study is aimed to solve AOp problem in Hulu Langat quarry site using empirical and intelligent systems namely ANN and hybrid GA–ANN (also called neuro-genetic technique).
Air-overpressure and its prediction methods
The explosion occurs by the shock wave of chemical reaction when the reactive gases pressure reaches the sonic velocity (Baker et al. 1983). The gas pressure velocity quickly rises as the explosive detonation occurs within the blast-hole. Suddenly, surrounding rocks are loaded by the blast-hole pressure, which produces a compressive shock pulse and moves away quickly from the blast-hole. Mainly, the pressure in blasting is indicated by shock and gas mechanisms (Bhandari 1997; Roy 2005).
AOp is produced by large shock waves from explosion point to the free surface. It is refracted horizontally by density variations in the atmosphere. AOp has two atmospheric pressure waves: an audible high frequency sound and sub-audible low frequency (Bhandari 1997). Human ear can detect the minimum sound frequency of 20 Hz, and below this frequency is not hearable. However, sound of more than 20 Hz frequency may cause a concussion for human ear (Kuzu et al. 2009). AOp is measured in Pascal (or in dB) because physically it is a pressure (Kuzu et al. 2009).
In cases where the energy of AOp waves goes above the atmospheric pressure (194.1 dB), surrounding structures may be to some extent damaged (Glasstone and Dolan 1997). The average level and higher spectral frequencies in AOp tend to be higher due to explosions, whereas the AOp amplitude reduces by 6 dB for every doubling of distance from recipient to blast (Stachura et al. 1984). The attenuation range becomes smaller, −3.1 to −10 dB, depending on the differences between the source spectra and propagation conditions. The AOp degree of damage possibility for structures is 180 dB, general window breakage is 171 dB, and occasional window breakage is 151 dB (Kuzu et al. 2009). According to Siskind et al. (1980), as reported by the United States Bureau of Mines (USBM), a value of 134 dB is recommended for AOp limitation. Therefore, many attempts have been made to control AOp values (Kuzu et al. 2009; Rodríguez et al. 2010).
Many factors affect AOp like maximum charge per delay, burden and spacing, detonator accuracy, stemming, charge depth, weak strata, overcharging, atmospheric conditions, and conditions arisen from secondary blasting (Siskind et al. 1980; Dowding 2000; Rodríguez et al. 2010). Richards (2010) stated that in open pit blasting, there is a direction of maximum AOp which is close to the perpendicular line to the bench. Though, blasting-induced AOp cannot be easily predicted since, in different cases, the same blast design may generate different results.
Several empirical models have been proposed to predict AOp using its influential parameters. The use of the cube-root scaled distance (SD) factor is a common-used technique to predict AOp resulting from blasting. The relationship between the SD and the two parameters namely explosive charge weight per delay and distance from the blast-face is formulated as below:
in which D denotes the distance (m or ft) and W is the explosive charge weight (kg or lb) and SD is the scaled distance factor (m kg−0.33 or ft lb−0.33). A site-specific AOp attenuation formula can be developed when statistical analysis techniques (i.e., least squares regression analysis) are applied to the representative AOp data (White and Farnfield 1993; Cengiz 2008). The generalized predictor equation for the prediction of AOp is given as follows (Siskind et al. 1980):
where AOp is air-overpressure, H and β are the site factors. The site factor values, H and β, for some blasting conditions are tabulated in Table 1. AOp which is obtained using the parameters in Table 1, is expressed in terms of Pa or dB.
Using both rock material and free air properties, some numerical models introduced and linked to Autodyn2D in the study conducted by Wu and Hao (2005) to make a simulation of AOp and ground shock induced by surface explosions. A semi-empirical method was developed by Rodríguez et al. (2007) to predict AOp generated by blasting works outside a tunnel. The performance of their method was evaluated with several tests and it was shown capable of being used under various conditions. Kuzu et al. (2009) introduced an empirical equation for predicting AOp. They considered two critical parameters of AOp, i.e., the weight of explosive materials and the distance from the blast-face to monitoring point in their model. They analyzed 98 AOp readings recorded from the quarry blasting operations in different conditions and concluded that their proposed equation could predict AOp with a reasonable accuracy. Using the data recorded from two quarries, Segarra et al. (2010) proposed a new AOp predictive equation. The AOp measurements and blasting data were extracted from a total of 122 records of 40 rock blasting operations with low to very low strength. After all, they achieved an empirical equation with 32 % accuracy.
In addition to the above-mentioned empirical methods, numerous studies have been predicted AOp using soft computing techniques. Khandelwal and Singh (2005) proposed an ANN model using distance from the blast-face to monitoring point for the prediction of AOp. They compared the performance of ANN with that of the multi-variate regression analysis (MVRA) and USBM predictor and proved the superiority of their proposed model over MVRA and USBM in terms of estimation accuracy. Considering the distance from the blast-face to the monitoring point and the maximum charge per delay, Mohamed (2011) applied ANN and a fuzzy inference system (FIS) to the prediction of AOp. He made a comparison between the results obtained from the predictive models and the values of regression analyses and observed field data. The ANN and fuzzy models were shown more accurate compared to the regression analysis. Using a total of 75 datasets related to three mines in India and the technique of support vector machine (SVM), Khandelwal and Kankar (2011) attempted to predict AOp. The AOp values obtained from the SVM technique were compared to those of a generalized predictor equation. They concluded that the AOp values predicted by SVM are much closer to the actual values compared to those obtained from the generalized predictor equation. In order to predict AOp using two intelligent systems namely neuro-fuzzy (ANFIS) and ANN, 166 blasting operations were investigated by Jahed Armaghani et al. (2015a) and the most effective parameters on AOp were measured. At the end of this study, they mentioned that when higher accuracy of AOp prediction is needed ANFIS model would be the proper alternative compared to ANN technique. Hajihassani et al. (2015) utilized and developed a combination of the particle swarm optimization and ANN to predict air and ground vibrations of blasting and introduced PSO-ANN as an applicable and accurate tool for estimating air and ground vibrations induced by blasting. Table 2 shows several investigations of AOp prediction and their performances using soft computing techniques.
Artificial neural network
Artificial neural networks (ANNs) which were developed by McCulloch and Pitts (1943), are composed of large numbers of neurons, while a neuron is a simplification of a biological neuron. Depending on problem to be solved, different numbers of neurons can be utilized. There are various ways to connect the neurons in order to create an ANN model. Feed-forward (FF)–back-propagation (BP) is the most commonly used ANN type in a wide range of science and engineering as reported by many researchers (e.g., Simpson 1990; Dreyfus 2005; Momeni et al. 2015b). The multi-layer perceptron (MLP) neural network is one of the most well-known FF-ANNs (Haykin 1999). MLP includes several nodes or neurons in three layers (input, hidden and output) which are linked to each other by weights. Normally, the number of hidden layers and number of neurons in hidden layers are obtained using trial-and-error procedure (Baheer 2000; Poulton 2002). In ANN, initially, a desired weight in the range of (0, 1) is assigned to each input parameter. Then, each input is multiplied by the weight and summation of these amounts is assigned to the hidden layer(s). The obtained value is summed with bias (neuron weight) which is normally equal to one. In the next round, another weight is assigned to the obtained value and the cycle is reached to the next layer (output layer). Summation of all obtained values from each layer is the last step of ANN modeling and after that the training procedure is completed and the system is ready to testing (or checking). In a FF–BP algorithm, the signals flow from input layer to the output layer, called forward pass, then the achieved value(s) from the system is compared to the actual one and the error is computed by the network. The obtained error is propagated back through the network to update the individual weights, called backward pass. In the mentioned process, errors of both training and testing datasets are decreased. FF–BP procedure is repeated until the error is converged to a level defined by a cost function such as mean square error (MSE) and root mean squared error (RMSE) (Simpson 1990; Garrett 1994). However, a database comprising of sufficient number of datasets is needed to construct a suitable ANN model.
Genetic algorithm
GA which was developed by Holland (1975) is a stochastic search algorithm and optimization technique. This algorithm mimics the natural selection mechanism and the biological species evolution. The stochastic optimization is a technique where the solution space is searched through the generation of potential solutions using a random number generator. To advance, GA only needs an evaluation of objective function value for each decision variable. This is because the stochastic-based technique of GA does not need any specific information for guiding the search (Chipperfield et al. 2006). However, GA is not capable of assuring constant optimization response times. Additionally, the difference between the longest and shortest optimization response time is much larger in GAs compared to that of traditional gradient methods. This property of GAs limits its use in real-time applications (Simpson et al. 1994).
Generally, in GA, there are populations of individuals that are known as candidate solutions; each individual gradually converges over time to an optimal solution. Each candidate solution is denoted by a linear string that consists of chromosomes represented by 0 and 1 s. Total solutions form the population size and each iteration of optimization process is known as a generation. There are two termination conditions for the GA optimization process, namely meeting the desired fitness or defining some stopping criteria such as maximum number of generations.
In GA, three basic genetic operators, namely reproduction, cross-over, and mutation should be performed. Reproduction is a process through which the best chromosomes are chosen based on their scaled values considering the given criteria of fitness. Then the selected chromosomes are directly transferred to the next generation. Through the cross-over operator, offsprings (new individuals) are produced through combining particular parts of individuals (parent). Recombination is done through several ways, including single-point cross-over and two-point cross-over. Nevertheless, during the process of cross-over, a random cross-over point and two parents are chosen. The creation of the first offspring is through the combination of the left side genes of the first parent with the right side genes of the second parent. To form the second offspring, an inverse procedure is repeated (Momeni et al. 2014). Mutation is a process during which a random change occurs in elements (allele) of a chromosome. On the other hand, in binary systems, mutation refers to flipping the values of a bit where 1 becomes 0 and 0 becomes 1.
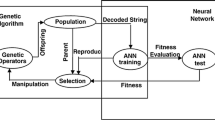
As mentioned earlier, two drawbacks of ANNs are getting trapped in local minima and having a slow rate of learning (Lee et al. 1991). As shown by recently conducted studies, GA can efficiently improve the ANN performance and remove its drawbacks (Majdi and Beiki 2010; TingXiang et al. 2012; Rashidian and Hassanlourad 2013). The most frequently cited advantage of GAs is the capability of these algorithms in escaping from being trapped in a local optimum (Chambers 2010). In study conducted by Chambers (2010), it was mentioned that with the use of a GA or at least a hybrid GA, an appropriate objective function can be freely selected. Indeed, the multidirectional search algorithm that is incorporated in GA helps ANN models to converge towards a global minimum, which leads to the improvement of the prediction capability of ANNs (Rajasekaran and Vijayalakshmi Pai 2007). In other words, in GA–ANN, the model is trained with GA rather than the common BP algorithm. It can be concluded that the network connection weights and biases are optimized with GA instead of random generation. Several researchers have attempted to enhance the performance quality and generalization capabilities of ANNs through the use of GA algorithm (e.g. Monjezi et al. 2012; Aghajanloo et al. 2013; Momeni et al. 2014). A hybrid GA–ANN algorithm is displayed in Fig. 1.

Combination of GA–ANN (Saemi et al. 2007)
Site investigation and data collection
This study was conducted at Hulu Langat quarry site in Selangor state, Malaysia. Geographically, the quarry lies at a latitude of 3°7′0″N and a longitude of 101°49′1″E and is located in the south of Selangor. This quarry is composed of granitic rocks with the capacity to produce large amounts (between 280,000 and 360,000 tons per month) of aggregate. Blasting is carried out 8 to 10 times per month, depending on the weather conditions. According to ISRM (2007) suggested method, the mass weathering grade is mainly classified into grades III to V, and rock mass strength is between 40 and 70 MPa. All blasting operations are conducted using blast-hole diameter of 89 mm. Ammonium nitrate and fuel oil (ANFO) and dynamite were used as the main explosive material and for initiation, respectively. The blast-holes were stemmed using fine gravels.
Since the blasting operations in Hulu Langat quarry site are conducted close to residential areas, AOp is an important blasting environmental impact in this quarry. The nearest building to the mentioned quarry site is about 300 m (see Fig. 2). By conducting blasting operations in Hulu Langat quarry, sometimes, AOp causes damage to surrounding residential area, especially on the building’s windows. Therefore, AOp is a significant problem in this site.

Residential area which is located near Hulu Langat granite quarry site
During data collection, 76 blasting operations were investigated and parameters including hole depth, maximum charge per delay, burden, spacing, stemming length, powder factor, and distance from the blast-face were measured (see Table 3). The range of powder factors in these operations was observed between 0.5 and 0.9 kg/m3. The minimum and maximum measured stemming length was 2 and 3.5 m, respectively. Minimum value for burden to spacing ratio was measured as 0.4 while the maximum value of this ratio was obtained as 0.85. In each blast, AOp was recorded using a VibraZEB seismograph. The AOp values were monitored using linear L type microphones connected to the AOp channels. A range of AOp values from 88 dB (7.25 × 10−5 psi or 0.5 Pa) to 148 dB (0.0725 psi or 500 Pa) can be recorded by VibraZEB. The microphones have an operating frequency response from 2 to 250 Hz, which is adequate for measuring AOp accurately in the frequency range critical for structures and human hearing. All AOp values were recorded in front of the quarry bench. Considering location of the nearest building, the distance between the monitoring point and the blast-face was set in the range of 150–720 m.
According to Tables 1 and 2, the most-utilized input parameters for prediction of AOp are maximum charge per delay and distance from the blast-face. Therefore, in the present study, only results of maximum charge per delay and distance from the blast-face obtained from 76 blasting operations were used to develop AOp predictive models.
Prediction of AOp using non-linear techniques
In order to predict AOp, three non-linear techniques namely empirical equation suggested by Siskind et al. (1980), ANN and GA–ANN were applied in this study. In these models, maximum charge per delay and distance from the blast-face were considered as predictors or model inputs. The following sections describe modeling procedure of the aforementioned methods to predict AOp. Subsequently, to demonstrate the ability of these methods, the measured values of AOp were compared with the corresponding predicted values of AOp.
Power equation suggested by USBM
Previously, several scholars suggested some empirical equations for prediction of AOp using the suggested method of USBM (see Eq. 2 and Table 1). In this study, an attempt was made to develop an empirical equation for estimation AOp using two predictors including maximum charge per delay and distance from the blast-face. To do this, based on the suggestions in the literature (Zorlu et al. 2008; Yagiz et al. 2009), considering all 76 datasets, 5 different sets were selected (to training and testing datasets) randomly for choosing the most precise equation. Random data selection for purposed models was performed utilizing the ANN code written by authors. In the studies conducted by Swingler (1996) and Looney (1996), testing dataset was recommended as 20 and 25 % of whole dataset, respectively, while a range of 20–30 % of whole data was suggested for testing in the study by Nelson and Illingworth (1990). Therefore, in the present study, 20 % (15 datasets) of whole datasets (76 datasets) was selected randomly as testing datasets, whereas the remaining 61 datasets were used to develop the models. Using the selected datasets, five power equations (based on Eq. 2) were proposed to predict AOp as listed in Table 4. In construction of these equations, results of maximum charge per delay and distance from the blast-face were used to calculate the SD values. The statistical software package of SPSS version 16 (SPSS 2007) was used to construct and analyze the empirical equations. As shown in Table 4, when considering only model development datasets, R 2 of the proposed empirical equations vary between 0.602 and 0.684. However, the R 2 values are in the range of 0.501 and 0.782 when testing datasets are taken into consideration. More information regarding selection of the best equation will be given later.
ANN modeling
In ANN modeling procedure of this study, the same datasets performed in the analyses of empirical equation were applied. As a first step of ANN modeling, all data should be normalized using the following equation:
where X norm, X min and X max represent the normalized, minimum and maximum values of the measured parameter, respectively, and X is the measured value.
The performance of ANN models depends strongly on the suggested architecture of the network as mentioned in the studies by Hush (1989) and Kanellopoulas and Wilkinson (1997). Therefore, determination of the optimal architecture is required to design an ANN model. The network architecture is defined as the number of hidden layer(s) and the number of neurons in each hidden layer(s). According to various researchers (e.g., Hecht-Nielsen 1987; Hornik et al. 1989), one hidden layer can solve any complex function in a network. Hence, in this study, one hidden layer was chosen to construct the ANN models. In addition, determining neuron number(s) in the hidden layer is the most critical task in the ANN architecture as stated by Sonmez et al. (2006). Table 5 tabulates some equations related to determination of number of neuron proposed by several scholars. Based on this table and considering 2 neurons in input layer (N i) and one neuron in output layer (N o), the number of neurons which should be used in the hidden layer is in the range of 1 and 6.
In order to determine the optimum number of neurons in the hidden layer, using only one dataset of all five datasets, several ANN models were constructed considering one hidden layer and number of hidden neurons in the range of 1–6 (see Table 6). It should be noted that, in constructing these models, the results of R 2 were only consider to select the optimum number of hidden node. According to Table 6, considering average R 2 values of both training and testing datasets, model No. 5 with hidden neurons of 5 outperforms the other ANN models. Hence, 5 was selected as optimum number of hidden neuron in constructing ANN models of this study. Levenberg–Marquardt (LM) back-propagation learning algorithm was used in ANN modeling. Study by Hagan and Menhaj (1994) suggests the efficiency of this algorithm compared to other conventional gradient descent techniques. Using the suggested ANN structure (2 × 5 × 1) and five different randomly selected datasets, five ANN models were trained. The testing datasets were also simulated for each train and their results will be discussed later. More details regarding LM algorithm can be seen in the study carried out by Hagan and Menhaj (1994). Suggested ANN structure for solving AOp problem is displayed Fig. 3.

Suggested ANN structure for solving AOp problem
GA–ANN modeling
In order to develop GA–ANN model for prediction of AOp, the most influential GA parameters should be determined. For this purpose, several parametric investigations were carried out to find optimum GA parameters. In the GA–ANN modeling, the mutation probability was set to 25 % of the population size; whereas the recombination percentage was fixed at 9 % and value of 1 % was applied in the study conducted by Momeni et al. (2014). The single-point cross-over was used with possibility of 70 %. Numerous selection methods have been proposed in the literatures regarding cross-over operation; however, the tournament selection method was employed to generate two offspring from two parents Momeni et al. (2014). It should be mentioned that the mutation probability and cross-over possibility were determined using trial-and-error method.
Finding the best population size is the next step of GA–ANN modeling. In this regard, several GA–ANN models were built with various population sizes ranging from 25 to 600 as shown in Table 7. In these models, the suggested ANN architecture (2 × 5 × 1) and maximum generation of 50 were used. According to Table 7, considering the results of both training and testing datasets, among all 14 models, model No. 5 with population size of 150 can provide better network performance. Therefore, population size = 150 was selected in the GA–ANN modeling of this study.
Determination of maximum number of generation is the next step of hybrid GA–ANN modeling procedure. Another parametric study was conducted to investigate the effect of maximum number of generation on the network’s performance. The number of generation was set to be 500 to determine the optimum number of generation. To do this, 14 models presented in Table 7 were constructed again using the mentioned maximum generation number (500). Figure 4 shows the importance of the number of generation to the network performance for AOp prediction. As indicated in this figure, there is no changes in the network performance (RMSE) after generation number = 300. Hence, the optimum number of generation was set to be 300 in design of GA–ANN models. It is worth mentioning that in determining number of generation, the other mentioned network parameters were kept constant.

The effect of the number of generation on the network performance
In the last step of GA–ANN modeling, using the suggested ANN structure (2 × 5 × 1), same different randomly selected datasets, and obtained GA parameters, five GA–ANN models were trained. In addition, similar to two other predictive methods, the testing datasets were also used in each train. The relevant results of training and testing datasets of GA–ANN models as well as their discussion will be given in the following section.
Results and discussion
In this research, three non-linear techniques, i.e., power equation, ANN and GA–ANN were developed to predict AOp obtained from the granite quarry site in Malaysia. During the modeling process of this study, all 76 datasets were randomly selected to five different datasets (training and testing) for development of the non-linear models. In order to evaluate the prediction performance of the developed models, several performance indices including R 2, variance account for (VAF) and root mean square error (RMSE) were considered and calculated.
where
where y, \(y^{{\prime }}\) and \(\tilde{y}\) are the measured, predicted and mean of the y values, respectively, and N is the total number of data. Moreover, \((y - \bar{y})\) and \((y - \bar{y})^{2}\) are deviation from the mean and squared deviation from the mean, respectively. Theoretically, the model will be excellent if the VAF = 100, RMSE = zero and R 2 = 1. Results of models performance (power equation, ANN and GA–ANN) indices (R 2, RMSE and VAF) for all randomly selected datasets based on training and testing are presented in Table 8. As it can be seen in Table 8, selecting the best model for AOp prediction is too difficult. To overcome this difficulty, a simple ranking procedure suggested by Zorlu et al. (2008) and applied by Yagiz et al. (2009) was used to select the best models. A ranking value was calculated and assigned for each training and testing dataset separately (see Table 8). It is worth noting that the RMES results of ANN and GA–ANN techniques were obtained for normalized datasets whereas, these values were achieved in modeling of empirical models using the original (not normalized) datasets. This is due to limitation to make a power relationship for AOp prediction. Total ranking of training and testing datasets for three non-linear models is shown in Table 9. According to this table, model No. 5 exhibited the best performance of AOp prediction for empirical method, while models No. 2 and 4 yielded the best results in predicting AOp for ANN and GA–ANN techniques, respectively. When considering both training and testing datasets, the prediction performances of the GA–ANN models are higher than those of empirical and ANN models. The selected power equation (model No. 5) is shown in the following equation:
The graphs of predicted AOp using the empirical, ANN and GA–ANN techniques against the measured AOp for training and testing datasets are shown in Figs. 5, 6 and 7, respectively. As shown in these figures, the GA–ANN model can perform better in the prediction of AOp in comparison to other predictive models. Based on these figures, the R 2 equal to 0.974 for testing dataset suggests the superiority of the GA–ANN technique in predicting AOp, while these values are 0.782 and 0.902 for empirical and ANN models, respectively. It is worth mentioning that the performance capacity of the GA–ANN model is higher than the performance capacities of the other techniques implemented by previous scholars (see Table 2). This shows the capability of the GA–ANN technique in predicting AOp induced by blasting.

Measured and predicted AOp values by empirical model for training and testing datasets

Measured and predicted AOp values by ANN model for training and testing datasets

Measured and predicted AOp values by GA–ANN model for training and testing datasets
Conclusions
In the present study, an attempt was made for estimating AOp induced by quarry blasting using empirical, ANN and GA–ANN methods. This was accomplished using the blasting data obtained from 76 blasting operations at Hulu Langat granite quarry site, Malaysia. The most influential parameters on AOp namely maximum charge per delay and the distance from the blast-face were considered as input parameters, whereas the values of measured AOp were set as output of the system. Using the five randomly selected datasets and considering the modeling procedure of each model, 15 models were constructed for all predictive techniques. Considering some model performance indices including R 2, RMSE and VAF and using simple ranking method, the best models were selected among all created models. The results indicated that the GA–ANN approach outperforms the other predictive techniques. The R 2 equal to 0.974 for testing dataset suggests the superiority of the GA–ANN technique in predicting AOp, while these values are 0.782 and 0.902 for empirical and ANN methods, respectively. Although all proposed models in this study are applicable for solving AOp problem in Hulu Langat granite quarry site, they can be used depending on the condition. When high accuracy of AOp prediction is required, the GA–ANN model would be the proper alternative as it can optimize the weights and biases of the network connection to train by ANN.
References
Aghajanloo MB, Sabziparvar AA, Talaee PH (2013) Artificial neural network–genetic algorithm for estimation of crop evapotranspiration in a semi-arid region of Iran. Neural Comput Appl 23(5):1387–1393
Baheer I (2000) Selection of methodology for modeling hysteresis behavior of soils using neural networks. J Comput Aided Civil Infrastruct Eng 5(6):445–463
Baker WE, Cox PA, Kulesz JJ, Strehlow RA, Westine PS (1983) Explosion hazards and evaluation. Elsevier Science, Amsterdam
Bhandari S (1997) Engineering rock blasting operations. A.A. Balkema, Rotterdam
Bornholdt S, Graudenz D (1992) General asymmetric neural networks and structure design by genetic algorithms. Neural Networks 5:327–334
Cengiz K (2008) The importance of site-specific characters in prediction models for blast-induced ground vibrations. Soil Dyn Earthq Eng 28:405–414
Ceryan N, Okkan U, Kesimal A (2013) Prediction of unconfined compressive strength of carbonate rocks using artificial neural networks. Environ Earth Sci 68(3):807–819
Chambers LD (2010) Practical handbook of genetic algorithms: complex coding systems. CRC Press, Boca Raton
Chen S, Zhang Z, Wu J (2015) Human comfort evaluation criteria for blast planning. Environ Earth Sci 74:2919–2923
Chipperfield A, Fleming P, Pohlheim H et al (2006) Genetic algorithm toolbox for use with MATLAB user’s guide, version 1.2. University of Sheffield
Dowding CH (2000) Construction vibrations. In: Dowding CH (ed) pp 204–207
Dreyfus G (2005) Neural networks: methodology and application. Springer, Berlin
Garrett J (1994) Where and why artificial neural networks are applicable in civil engineering. J Comput Civil Eng 8:129–130
Ghoraba S, Monjezi M, Talebi N, Moghadam MR, Jahed Armaghani D (2015) Prediction of ground vibration caused by blasting operations through a neural network approach: a case study of Gol-E-Gohar Iron Mine, Iran. J Zhejiang Univ Sci A. doi:10.1631/jzus.A1400252
Glasstone S, Dolan PJ (1997) The effects of nuclear weapons. US Department of Defense and Energy Research, Washington
Gordan B, Jahed Armaghani D, Hajihassani M, Monjezi M (2015) Prediction of seismic slope stability through combination of particle swarm optimization and neural network. Eng Comput. doi:10.1007/s00366-015-0400-7
Hagan MT, Menhaj MB (1994) Training feed forward networks with the Marquardt algorithm. IEEE Trans Neural Networks 5:861–867
Hajihassani M, Jahed Armaghani D, Sohaei H, Mohamad ET, Marto A (2014) Prediction of airblast-overpressure induced by blasting using a hybrid artificial neural network and particle swarm optimization. Appl Acoust 80:57–67
Hajihassani M, Jahed Armaghani D, Monjezi M, Mohamad ET, Marto A (2015) Blast-induced air and ground vibration prediction: a particle swarm optimization-based artificial neural network approach. Environ Earth Sci 74:2799–2817
Hasanipanah M, Monjezi M, Shahnazar A, Jahed Armaghani D, Farazmand A (2015) Feasibility of indirect determination of blast induced ground vibration based on support vector machine. Measurement 75:289–297
Haykin S (1999) Neural networks, 2nd edn. Prentice-Hall, Englewood Cliffs
Hecht-Nielsen R (1987) Kolmogorov’s mapping neural network existence theorem. In: Proceedings of the first IEEE international conference on neural networks, San Diego, CA, USA, pp 11–14
Holland J (1975) Adaptation in natural and artificial systems. The University of Michigan Press, Ann Arbor
Hopler RB (1998) Blasters’ handbook. International Society of Explosives Engineers
Hornik K, Stinchcombe M, White H (1989) Multilayer feedforward networks are universal approximators. Neural Networks 2:359–366
Hush DR (1989) Classification with neural networks: a performance analysis. In: Proceedings of the IEEE international conference on systems engineering. Dayton, OH, USA, pp 277–280
Hustrulid WA (1999) Blasting principles for open pit mining: general design concepts. Balkema, Amsterdam
Isik F, Ozden G (2013) Estimating compaction parameters of fine-and coarse-grained soils by means of artificial neural networks. Environ Earth Sci 69(7):2287–2297
ISRM (2007) In: Ulusay and Hudson (eds) The complete ISRM suggested methods for rock characterization, testing and monitoring: 1974–2006. Suggested methods prepared by the commission on testing methods, International Society for Rock Mechanics
Jadav K, Panchal M (2012) Optimizing weights of artificial neural networks using genetic algorithms. Int J Adv Res Comput Sci Electron Eng 1:47–51
Jahed Armaghani D, Tonnizam Mohamad E, Momeni E, Narayanasamy MS, Mohd Amin MF (2014) An adaptive neuro-fuzzy inference system for predicting unconfined compressive strength and Young’s modulus: a study on Main Range granite. Bull Eng Geol Environ. doi:10.1007/s10064-014-0687-4
Jahed Armaghani D, Hajihassani M, Monjezi M, Mohamad ET, Marto A, Moghaddam MR (2015a) Application of two intelligent systems in predicting environmental impacts of quarry blasting. Arab J Geosci. doi:10.1007/s12517-015-1908-2
Jahed Armaghani D, Momeni E, Alavi Nezhad Khalil Abad SV, Khandelwal M (2015b) Feasibility of ANFIS model for prediction of ground vibrations resulting from quarry blasting. Environ Earth Sci 74:2845–2860
Jahed Armaghani D, Mohamad ET, Hajihassani M, Yagiz S, Motaghedi H (2015c) Application of several non-linear prediction tools for estimating uniaxial compressive strength of granitic rocks and comparison of their performances. Eng Comp. doi:10.1007/s00366-015-0410-5
Kaastra I, Boyd M (1996) Designing a neural network for forecasting financial and economic time series. Neurocomputing 10:215–236
Kanellopoulas I, Wilkinson GG (1997) Strategies and best practice for neural network image classification. Int J Remote Sens 18:711–725
Khandelwal M, Kankar PK (2011) Prediction of blast-induced air overpressure using support vector machine. Arab J Geosci 4:427–433
Khandelwal M, Singh TN (2005) Prediction of blast induced air overpressure in opencast mine. Noise Vib Control Worldw 36:7–16
Khandelwal M, Singh TN (2007) Evaluation of blast-induced ground vibration predictors. Soil Dyn Earthq Eng 27:116–125
Konya CJ, Walter EJ (1990) Surface blast design. Prentice Hall, Englewood Cliffs
Kuzu C (2008) The importance of site-specific characters in prediction models for blast-induced ground vibrations. Soil Dyn Earthq Eng 28:405–414
Kuzu C, Fisne A, Ercelebi SG (2009) Operational and geological parameters in the assessing blast induced airblast-overpressure in quarries. Appl Acoust 70:404–411
Lee Y, Oh SH, Kim MW (1991) The effect of initial weights on premature saturation in back-propagation learning, In: Proceedings of the international joint conference on neural networks, pp 765–770
Looney CG (1996) Advances in feed-forward neural networks: demystifying knowledge acquiring black boxes. IEEE Trans Knowl Data Eng 8(2):211–226
Maiti S, Tiwari RK (2014) A comparative study of artificial neural networks, Bayesian neural networks and adaptive neuro-fuzzy inference system in groundwater level prediction. Environ Earth Sci 71(7):3147–3160
Majdi A, Beiki M (2010) Evolving neural network using a genetic algorithm for predicting the deformation modulus of rock masses. Int J Rock Mech Min Sci 47:246–253
Masters T (1994) Practical neural network recipes in C++. Academic Press, Boston
McCulloch WarrenS, Pitts Walter (1943) A logical calculus of the ideas immanent in nervous activity. Bull Math Biophys 5:115–133
Mohamed MT (2011) Performance of fuzzy logic and artificial neural network in prediction of ground and air vibrations. Int J Rock Mech Min Sci 48:845–851
Momeni E, Nazir R, Jahed Armaghani D, Maizir H (2014) Prediction of pile bearing capacity using a hybrid genetic algorithm-based ANN. Measurement 57:122–131
Momeni E, Jahed Armaghani D, Hajihassani M, Amin MFM (2015a) Prediction of uniaxial compressive strength of rock samples using hybrid particle swarm optimization-based artificial neural networks. Measurement 60:50–63
Momeni E, Nazir R, Jahed Armaghani D, Maizir H (2015b) Application of artificial neural network for predicting shaft and tip resistances of concrete piles. Earth Sci Res J 19(1):85–93
Monjezi M, Khoshalan HA, Varjani AY (2012) Prediction of flyrock and backbreak in open pit blasting operation: a neuro-genetic approach. Arab J Geosci 5(3):441–448
Monjezi M, Hasanipanah M, Khandelwal M (2013) Evaluation and prediction of blast-induced ground vibration at Shur River Dam, Iran, by artificial neural network. Neural Comput Appl 22:1637–1643
Nelson M, Illingworth WT (1990) A practical guide to neural nets. Addison-Wesley, Reading
Paola JD (1994) Neural network classification of multispectral imagery. MSc thesis, The University of Arizona, USA
Poulton MM (2002) Neural networks as an intelligence amplification tool: a review of applications. J Geophys 67(3):979–993
Rajasekaran S, Vijayalakshmi Pai GA (2007) Neural networks, fuzzy logic, and genetic algorithms, synthesis and applications. Prentice-Hall of India, New Delhi
Rashidian V, Hassanlourad M (2013) Predicting the shear behavior of cemented and uncemented carbonate sands using a genetic algorithm-based artificial neural network. Geotech Geol Eng 2:1–18
Rezaei M, Monjezi M, Varjani AY (2011) Development of a fuzzy model to predict flyrock in surface mining. Safe Sci 49(2):298–305
Richards AB (2010) Elliptical airblast overpressure model. Min Technol 119(4):205–211
Ripley BD (1993) Statistical aspects of neural networks. In: Barndoff-Neilsen OE, Jensen JL, Kendall WS (eds) Networks and chaos-statistical and probabilistic aspects. Chapman & Hall, London, pp 40–123
Rodríguez R, Toraño J, Menéndez M (2007) Prediction of the airblast wave effects near a tunnel advanced by drilling and blasting. Tunn Undergr Sp Technol 22:241–251
Rodríguez R, Lombardía C, Torno S (2010) Prediction of the air wave due to blasting inside tunnels: approximation to a ‘phonometric curve’. Tunn Undergr Sp Technol 25:483–489
Roy PP (2005) Rock blasting effects and operations. A.A. Balkema, India
Saemi M, Ahmadi M, Varjani AY (2007) Design of neural networks using genetic algorithm for the permeability estimation of the reservoir. J Petrol Sci Eng 59:97–105
Segarra P, Domingo JF, López LM, Sanchidrián JA, Ortega MF (2010) Prediction of near field overpressure from quarry blasting. Appl Acoust 71:1169–1176
Shirani Faradonbeh R, Monjezi M, Jahed Armaghani D (2015) Genetic programing and non-linear multiple regression techniques to predict backbreak in blasting operation. Eng Comput. doi:10.1007/s00366-015-0404-3
Simpson P (1990) Artificial neural system: foundation, paradigms, applications and implementations. Pergamon, New York
Simpson AR, Dandy GC, Murphy LJ (1994) Genetic algorithms compared to other techniques for pipe optimization. J Water Res PL-ASCE 120:423–443
Siskind DE, Stachura VJ, Stagg MS, Koop JW (1980) In: Siskind DE (ed) Structure response and damage produced by airblast from surface mining. United States Bureau of Mines
Sonmez H, Gokceoglu C, Nefeslioglu HA, Kayabasi A (2006) Estimation of rock modulus: for intact rocks with an artificial neural network and for rock masses with a new empirical equation. Int J Rock Mech Min Sci 43:224–235
SPSS Inc. (2007) SPSS for Windows (Version 16.0). SPSS Inc., Chicago
Stachura VJ, Siskind DE, Kopp JW (1984) Airheast and ground vibration generation and propagation from contour mine blasting. U.S. Dept. of the Interior, Bureau of Mines
Swingler K (1996) Applying neural networks: a practical guide. Academic Press, New York
TingXiang L, ShuWen Z, QuanYuan W et al. (2012) Research of agricultural land classification and evaluation based on genetic algorithm optimized neural network model. In: Wu Y (ed) Software engineering and knowledge engineering: theory and practice. Springer, Berlin, pp 465–471
Tonnizam Mohamad E, Hajihassani M, Jahed Armaghani D, Marto A (2012) Simulation of blasting-induced air overpressure by means of artificial neural networks. Int Rev Modell Simul 5:2501–2506
Wang C (1994) A theory of generalization in learning machines with neural application. PhD thesis, The University of Pennsylvania, USA
White TJ, Farnfield RA (1993) Computers and blasting. Trans Inst Min Metall Sec 102:A150–A151
Wu C, Hao H (2005) Modelling of simultaneous ground shock and air blast pressure on nearby structures from surface explosions. Int J Impact Eng 31:699–717
Yagiz S, Gokceoglu C, Sezer E, Iplikci S (2009) Application of two non-linear prediction tools to the estimation of tunnel boring machine performance. Eng Appl Artif Intel 22(4):808–814
Zorlu K, Gokceoglu C, Ocakoglu F, Nefeslioglu HA, Acikalin S (2008) Prediction of uniaxial compressive strength of sandstones using petrography-based models. Eng Geol 96(3):141–158
Acknowledgments
The authors would like to extend their appreciation to the Government of Malaysia and Universiti Teknologi Malaysia for the FRGS Grant No. 4F406 and for providing the required facilities that made this research possible. Also, the authors are grateful to the reviewers for their constructive comments.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Tonnizam Mohamad, E., Jahed Armaghani, D., Hasanipanah, M. et al. Estimation of air-overpressure produced by blasting operation through a neuro-genetic technique. Environ Earth Sci 75, 174 (2016). https://doi.org/10.1007/s12665-015-4983-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12665-015-4983-5