
Abstract
The movement that occurs due to landslide is one of the most important issues in the field of geohazard. Determination of the movement of landslide is considered as a problematic task due to the fact that there are many effective parameters on movement of landslide that need to be investigated/observed carefully. In this study, various methods based on artificial intelligence were implemented and developed to evaluate and control this phenomenon. The gene expression programming (GEP) model is one of the newest models in artificial intelligence technique that can build the proper models for solving engineering issues based on the tree expression. Realistic data were used to design these models, where five model inputs including the groundwater surface, antecedent rainfall, infiltration coefficient, shear strength, and slope gradient of the area monitoring were considered as the input data. Many GEP models were constructed based on the most influential factors on GEP and according to two evaluation approaches, the best GEP model was selected. The obtained results of coefficient of determination (R2) for training and testing of GEP were 0.8623 and 0.8594, respectively, which indicate a high a capability of this technique in estimating real values of landslide movements. In optimization section of this study, artificial bee colony, as one of the powerful optimization algorithms was used to minimize risk induced by movement of landslide. According to the obtained results, no movement in landslide can be achieved if values of − 10.5, 400.1, 89.8, 59.65 and 24.95 were reported for groundwater surface, antecedent rainfall, infiltration coefficient, shear strength and slope gradient, respectively.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Ground movement is one of the important topics in landslide researches. Prevention and control of this phenomenon can reduce the risks for facilities and humans [1,2,3,4]. However, the phenomenon of landslide is not easily predictable because of the various parameters affecting it. Important parameters affecting landslide can be referred to the geological and climate conditions according to several scholars such as Crosta and Agliardi [5]. So far, various models for assessing landslide have been developed based on the mechanism that governs this phenomenon [2, 5,6,7,8,9]. In general, these studies can be categorized as statistical models, numerical, physical, and non-linear simulations [10]. Due to the fact that the landslide phenomenon has several complications and the relationship between them is really complex, non-linear models are able to provide better performance than other available techniques. In non-linear and simulation techniques, an indirect assessment will be introduced to predict problems that are complicated in nature [11, 12].
Nowadays, more modern and advanced methods have been introduced in science and engineering fields, among which artificial intelligence techniques can be mentioned [13,14,15,16,17,18]. These intelligent computational methods are able to present various models in different fields of engineering and present appropriate relations and predictions using those models [19]. In civil engineering, artificial intelligence approaches have been employed/proposed for various predictions and optimizations purpose [13, 16, 20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45]. Several intelligent studies have been proposed for solving problems related to landslide [3, 6, 10, 46]. Developing artificial neural networks (ANNs) can provide a solution that increases accuracy level of predictive models [47,48,49,50,51,52]. However, different models on the basis of artificial intelligence can affect the performance of different calculations. One of these new methods, called gene expression programming (GEP), received an excellent capability in solving problems in engineering sciences [53,54,55]. This method, which is a combination of genetic algorithm (GA) and genetic programming (GP), can present/provide a mathematical equation for prediction as well as solving complex problems and increasing accuracy of predictive models [24, 56]. Several researchers highlight the successful application of GEP in various fields of civil engineering such as environmental issues of blasting [39, 57], piling [58], tunneling and rock mechanics [59, 60], concrete technology [61, 62], highway construction [63] and river engineering [64, 65].
The aim of this research is to propose proper models of artificial intelligence for predicting and subsequently optimizing the movement of landslide. To gain prediction models, different data were collected and the effective parameters on ground movement were investigated. Then, using these data, different models of GEP were developed and implemented. Afterward, their performance with ANN networks was investigated for comparison purposes. Eventually, to obtain the minimum risk level, the artificial bee colony (ABC) algorithm was employed and the optimum values were introduced.
2 Methodology
2.1 Data collection
In the present research, various data which have been used for movement determination of landslides in study conducted by Neaupane and Achet [66] were collected and considered. The effective parameters on landslide/slope movement include groundwater surface (m), antecedent rainfall (mm), rainfall intensity (mm/h), infiltration coefficient, shear strength (kN/m2), and slope gradient of the area monitoring (°). It is important to mention that these parameters were selected based on previous researches [46, 66]. These data were used to train and test prediction networks, and values of the movement in landslide were predicted and evaluated using these parameters. Figure 1 shows a map which includes the geology structure/formation of the studied area. The statistical distribution of the utilized data in modelling process is given in Table 1. In the following sections, different models will be developed from these data for predicting landslide movement and their modelling procedures will be explained. The statistical distributions of data are presented in Figs. 2, 3, 4, 5, 6, and 7. More details regarding data collection and study area are available in the original study [66].

Geology structure of studied area [66]

Statistical distribution of used data (Groundwater surface)

Statistical distribution of used data (antecedent rainfall)

Statistical distribution of used data (infiltration coefficient)

Statistical distribution of used data (shear strength)

Statistical distribution of used data (slope gradient)

Statistical distribution of used data (slope movement)
2.2 Artificial neural network
The concept of neural networks was first introduced in 1950s by the well-known psychologist, Donald Hebb [67], after the introduction of simple learning mechanism. He introduced this method by investigating brain neurons and the effect of learning on them. Since these neurons do not have a specific instruction for data processing, they investigate the relations they obtain between input and output data for learning [68,69,70]. Neural networks function like a biological neuron. In fact, in each neuron, dendrites receive information from the previous neuron, and axons transfer the results to the next section (i.e., next neuron) after an initial processing. Chemical signaling is done through synopses between the cells. The performance of a computational neuron, which is used in neural networks, is similar to a biological neuron (including inputs and outputs). An ANN contains two or more layers, and each layer has a series of neurons. The relation between the layers is associated with the weights constituting a network. These different coefficients in each layer are multiplied by each other and connect to other layers using the functions known as activation functions (see Fig. 8). Two algorithms, i.e., feed-forward multilayer and back-propagation are used in neural networks. Back-propagation is more common and is recommended by different researchers [71,72,73]. Using the pathway of its method in each layer, this algorithm trains the amounts of weights and functions it uses to reach the minimum error in the system. This training process is repeated for a few times so that it can reach the amount determined by the system or termination criterion (see Fig. 9). The back-propagation phase is associated with conditions in which gradient is calculated for non-linear multilayer networks (the networks that are used to solve most of the engineering problems). The sigmoid transfer function receives the input values and presents it as an interval of 0–1 regardless of the initial input interval [50, 51, 68, 74].

The structure of different coefficients in ANN network

The multilayer structure of ANN
2.3 Gene expression programing
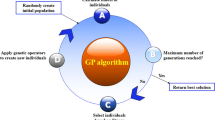
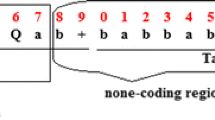
Gene expression programing (GEP) is one of the new methods in artificial intelligence which is, in fact, the developed version of genetic algorithm (GA) and genetic programing (GP). GEP, which presents proper solutions for various problems, is based on different parts [75]. GEP benefits from two main chromosomes, and the expression tree provides solutions for removing the limitations of two older algorithms. The codifications are shown in the form of a string in GEP, which is in fact obtained from Karva programing language and can present a behavior like ETs. One of the interesting functions of GEP is that it can present its own models using mathematical equations. In fact, mathematical equations create relation between independent parameters. Creating models that can provide equations will be very helpful and practical in engineering. Therefore, these methods can be utilized in the place of ANN models in problems. These problems have caused researchers to conduct and develop more work to expand such methods. In GP method, different mathematical functions such as −, +, × and sin are written and implemented for variables so that a mathematical set can be obtained from a combination of them for problem examination. In multigene chromosomes, each gene expresses a sub-ET and consists of a head and a tail. These parts are the areas to which genetic operators are applied to create new solutions. According to Fig. 10, like other EAs, the GEP modeling process begins with the random creation of chromosomes for determined numbers, which follows Karva language (Karva is a symbolic language to introduce chromosomes). These symbolic chromosomes should be then defined as trees with different sizes and shapes [expression trees]. These points are investigated by the functions that are responsible for controlling models and their adaptability. These functions have different types that can be defined by different criteria. Some examples are root mean square error (RMSE), mean absolute error (MAE), and root relative squared error (RRSE). Next, if the termination criterion (in other words, maximum iteration or appropriate fitness value) does not occur, the best chromosomes that have been selected through the Roulette Wheel method for the first process enter the next structure. Afterward, the main genetic operators consisting of mutation, transfer (RIS, IS, and gene transfer), and reconstruction (one point, two points, and gene reconstruction) are applied to the chromosomes based on their proportions, which can be defined using the codes and experts of GP method. This way, the new chromosomes replace the remains, and the process goes on until termination criteria or conditions are reached [76,77,78]. Given the expansion of this method, more information and details about GEP method and the way of its initial implementation can be found in previous studies [79,80,81].

A view of GEP system
2.4 Artificial bee colony
One of the new optimization methods which was developed based on bees group life is the artificial bee colony (ABC) algorithm. This algorithm was first introduced and implemented by Karaboga [82] to optimize complicated science and engineering problems. Three important parts of this algorithm include employed, onlookers, and scouts [83, 84]. In the first stage, searching for food sources is done by two scouts. During these searches, a large number of bees are assumed as onlookers. A type of movement, called waggle dance, is made by the bees to make connections. In this movement, the scouts inform the employed bees of the quality of food sources (problem solutions). In these conditions, different bees can use the obtained information and select the required sources of the beehives. Quality of the presented solution is evaluated based on the amount nectar available as food source.
Different parameters can be effective in ABC algorithm including the number of scout bees (N), amount of food source (M), number of elected food source, number of bees dispatched to the elected food source (Nre), number of bees dispatched to other food source (Nsp), radius of the search area (Ngh), and number of iteration (Imax). With these conditions, the initial solutions (locations of food source) are presented within the defined problem for this algorithm:
where i = 1,…, N and j = 1,…, D area is defined in the equation. Parameters N and D are the amount of food source and number of variables, respectively. In the following, ABC algorithm creates a new solution Vjk within Xk area for every presented solution:
where the two parameters \(\phi_{jk}\) and Xjk represent the uniform distribution of random numbers and the jth solution from among the solutions set of the kth parameter. However, the \(\phi_{jk}\) area and parameter k are randomly selected from domains [1 and − 1] and [1 and N], respectively. Under these conditions, each solution that can solve the problem in a better way will replace the previous one. If the new solution is more adaptable, it will replace the previous one. After that, the scout bee selects a solution per each bee using Eq. 34 and possibility of the calculations. This problem is provided by the onlooker bee, and from among these solutions, the one presenting the most appropriate result will be selected. Figure 11 presents a flowchart of ABC algorithm.

The presented flowchart for ABC algorithm [51]
3 Prediction results
3.1 ANN modeling
As explained in the previous sections, the neural network can solve linear and non-linear engineering problems by presenting appropriate solutions [47, 48, 52, 83]. In this section, neural network models have been presented so that their results can be compared with new GEP models that are implemented in the following. To design the networks, 80 percent of all of data were dedicated to the training section and 20 percent of them were allocated to the testing section. Using this classification, the performance of artificial models can be assessed for predicting movement of landslides.
In general, one of the important criteria used for ANNs is root mean square error (RMSE) which is used for the initial termination criterion of the process of network training. RMSE is obtained from the values that are from the network and measured values. The best value is when RMSE is equal to zero.
where parameters t, Est, Δ, and k are the predicted values, measured values, error, and number of network outputs, respectively. In addition to this criterion, the regression value is also used, which determined the correlation between the predicted and measured values. This criterion is in the best condition when its value is equal to 1, and the closer it gets to zero, the lower prediction ability these models have. To investigate the prediction models developed in this research, these two criteria are employed. The results of the ANN section presented to be compared with the new method have been given in the following. Considering various explanations, a variety of models of ANN have been designed and created so that the solutions obtained from this model can be used to predict movement of landslide. Models of this method have been shown in Figs. 12 and 13. As can be seen, the best performance has been reached when the iteration value is 400 and the number of neurons is set as 10. Investigating the main model developed through this research will be discussed later.

Performance of ANN prediction model for training

Performance of ANN prediction model for testing
3.2 GEP modeling
After obtaining the results of ANN network, GEP prediction models are implemented in this stage. The used data are similar to those of the previous stage. The purpose is to determine/estimate the movement values in landslides. The values and way of implementing them until obtaining the results of GEP models as well as presenting the relations will be in mathematical route. The process used in this research for implementing GEP is as follows:
- 1.
In the first step, the fitness function is selected as a criterion for each chromosome’s merit occurrence. RMSE is the common fitness function that is used in modeling process of GEP. However, based on the problem’s conditions, different modes can be used for investigating the models’ performance more accurately. Hence, each chromosomes’ fitness is determined as follows:
$${\text{RMSE}}^{\prime } = \frac{1}{{1 + {\text{RMSE}}}} \times 1000.$$(6) - 2.
The second step is to allocate two important sections called the set of terminals (T) and functions (F) to the chromosomes’ structure, which creates a mixture of them. The independent variables (parameters of Table 1) are considered as the terminal set, and the function set is usually defined according to the main core of the problem. In the current study, trigonometry and mathematical functions have been used as follows:
$$F = \left\{ { + , - , \times ,/,{\text{Sin}},{\text{Cos}},{\text{ArcTan}},\tanh ,{\text{sqrt}}} \right\}.$$(7) - 3.
In the third step, structural parameters of GEP (i.e., head size, number of genes, and number of chromosomes) have to be introduced and applied to the system. The number of gene parameter is introduced for ET subsections specified for each chromosome. According to Ferreira’s investigation [78, 80, 81] and some other studies, the best way to obtain proper values for structural parameters of GEP is the method of trial and error. In other words, the analysis starts with the increasing values of abovementioned parameters of GEP, and then the prediction of GEP models’ performance is checked in both training and testing phases. This way, several GEP models are designed and implemented with different parameters for predicting compressive strength of composite columns. Finally, after executing these processes several times, values of the number of chromosomes, head size, and number of genes are found to be 40, 5, and 3, respectively, for this section.
- 4.
The fourth step is to select the rates of genetic operators. In this step, assuming the proposed values by previous researchers ([78, 80, 81]), some other GEP models are created using the trial and error method. The obtained values of GEP parameters are presented in Table 2.
Table 2 GEP model parameters - 5.
In the final step, defining the linking function for connecting the created genes is required. There are various linking functions such as subtraction (−), addition (+), division (÷), and multiplication (×). In the present study, addition of different sections has been used to connect sub-ETs because it provides a better connection in comparison with other functions.
To evaluate the prediction performance of GEP models, R2 was used as well as RMSE values. These functions were selected because they had been used by different researchers for artificial networks and identified to be an appropriate criterion. Several parameters of the GEP model were examined in this section to determine its impact on the performance of models. One of the most important parameters of GEP model is the number of generations. Figure 14 shows their changes in predicting landslide movements. The effect of gene and size of head parameters on the performance of the GEP model is shown in Figs. 15 and 16.

The changes result of generation in predicting landslide movements

The effects of number of genes in predicting landslide movements

The effects of size of head in predicting landslide movements
According to the results presented in these figures, generation, gene and size of head parameters were considered as 3500, 5 and 5, respectively. Eventually, after the aforementioned implementation, the results of five different models are presented in Table 3. Two different scoring techniques were used to select superior models. The first technique is based on the sum of scores for sections of training and testing. In this way, if R2 achieves the high value, the higher score is given and vice versa. The same process will be applied for RMSE. If the amount of RMSE is lower, it will get a higher score. The same two parameters were also used for the second scoring technique. In this technique, if the parameter is more suitable, the more color (red) assign it. At the end, model number 4 was chosen as the selected model based on two scoring techniques.
According to Fig. 17, the expression tree of each gene of model 4 has been presented in which d(0) = groundwater surface, d(1) = antecedent rainfall, d(2) = infiltration coefficient, d(3) = shear strength and d(4) = slope gradient. In addition to the variables, several constant values are obtained as shown in Table 4. All functions and terminal sets have been illustrated in the circles. To extract mathematical equations, reading the circles from left to right and top to bottom is recommended. After extracting the equation of each gene, the final predicting model of GEP is obtained by adding all of model 4. Figures 18 and 19 show the results of model 4 for training and testing sections, respectively. As presented, GEP model can provide high level of accuracy level for prediction of landslide movement.

The tree expression of model 4

The GEP result of model 4 for training section

The GEP result of model 4 for testing section
4 Optimization process
To examine ABC algorithm, which is used in this research for minimizing movement values in landslides, the selected functions were employed. Here, two functions are presented according to Figs. 20 and 21 as follows. The minimum values of these functions in the mentioned intervals are 0 and − 5, respectively. Figures 20 and 21 illustrate the three-dimensional graph of these two functions in the specific interval. These figures demonstrate results obtained through ABC algorithm, which is for these two figures. As can be seen, the written code of this algorithm can identify the minimums well. That is why this code can be run for this research’s conditions obtained in the previous section.

The three-dimensional graph of sample 1

The three-dimensional graph of sample 2
To optimize the movement values, the previous section’s prediction models were used. As it was mentioned, the best model of the previous section is model 4 of GEP. This model is considered as a function. Different models of ABC algorithm were designed, each of which was executed by adjusting the parameters of the optimization algorithm.
After a set of analyses were carried out, the most appropriate parameters of ABC algorithm were obtained. The best parameters that can deliver well the performance of ABC algorithm for optimizing this problem have been achieved in Table 5.
Using the results of the best model, the optimum parameters that can provide movement were determined. The best cost function is presented in Fig. 22 for this problem. The proposed parameters are given in Table 6. It should be noted that the changes in these parameters are assumed to be the values considered for modeling (Table 1). As can be seen, in cases where optimization has been done, appropriate minimum value has been gained in performance of the problem. As an example, optimum values of − 10.5, 400.1, 89.8, 59.65 and 24.95 for groundwater surface, antecedent rainfall, infiltration coefficient, shear strength and slope gradient, respectively, will cause no movement (or movement of zero) in landslide. So, different patterns of designing can be applied under various conditions and the best performance can be reached. In this way, the risks of landslide can be controlled.

The best cost of ABC for optimization the problem
5 Conclusions
Assessing and controlling the risks that occur due to landslide is one of the most important discussions in this field. For this reason, this research used new intelligent methods to predict and propose different models for this value. The data used in this research were collected from several real-case studies. These data included parameters of the groundwater surface, antecedent rainfall, infiltration coefficient, shear strength, and slope gradient. The neural networks and new model (GEP) were used for prediction. The GEP model was implemented and developed with different conditions to predict movement of landslide. Each model finally ended in an equation. To investigate the performance of this new model, ANN networks were also implemented in a developed way. The models were compared with each other, and the best model was selected for optimization. The best model (with R2 = 0.8623 and 0.8594 for training and testing section), which was developed through GEP method, was combined with ABC optimization algorithm, and the optimum conditions for specifying movement in landslide were applied. The optimum parameters allow engineers to reach the best performance for decrease the movement of landslides. Finally, the results showed that the ABC algorithm can control the risk level of landslide movements according to their effective parameters.
References
Helmstetter A, Sornette D, Grasso J, et al (2004) Slider block friction model for landslides: application to Vaiont and La Clapiere landslides. J Geophys Res Solid Earth. https://doi.org/10.1029/2002JB002160
Corominas J, Moya J, Ledesma A et al (2005) Prediction of ground displacements and velocities from groundwater level changes at the Vallcebre landslide (Eastern Pyrenees, Spain). Landslides 2:83–96
Gao W, Feng X (2004) Study on displacement predication of landslide based on grey system and evolutionary neural network. Rock Soil Mech 25:514–517
Sornette D, Helmstetter A, Andersen JV et al (2004) Towards landslide predictions: two case studies. Phys A Stat Mech Appl 338:605–632
Crosta GB, Agliardi F (2002) How to obtain alert velocity thresholds for large rockslides. Phys Chem Earth A/B/C 27:1557–1565
Lu P, Rosenbaum MS (2003) Artificial neural networks and grey systems for the prediction of slope stability. Nat Hazards 30:383–398
Jibson RW (2007) Regression models for estimating coseismic landslide displacement. Eng Geol 91:209–218
Mufundirwa A, Fujii Y, Kodama J (2010) A new practical method for prediction of geomechanical failure-time. Int J Rock Mech Min Sci 47:1079–1090
Feng X-T, Zhao H, Li S (2004) Modeling non-linear displacement time series of geo-materials using evolutionary support vector machines. Int J Rock Mech Min Sci 41:1087–1107
Li X, Kong J, Wang Z (2012) Landslide displacement prediction based on combining method with optimal weight. Nat Hazards 61:635–646
Armaghani DJ, Mohamad ET, Narayanasamy MS et al (2017) Development of hybrid intelligent models for predicting TBM penetration rate in hard rock condition. Tunn Undergr Sp Technol 63:29–43. https://doi.org/10.1016/j.tust.2016.12.009
Mohamad ET, Armaghani DJ, Momeni E et al (2016) Rock strength estimation: a PSO-based BP approach. Neural Comput Appl. https://doi.org/10.1007/s00521-016-2728-3
Shi X, Zhou J, Wu B et al (2012) Support vector machines approach to mean particle size of rock fragmentation due to bench blasting prediction. Trans Nonferrous Met Soc China 22:432–441
Zhou J, Li X, Mitri HS (2018) Evaluation method of rockburst: state-of-the-art literature review. Tunn Undergr Sp Technol 81:632–659
Shi XZ, Zhou J, Dong L et al (2010) Application of unascertained measurement model to prediction of classification of rockburst intensity. Chin J Rock Mech Eng 29:2720–2726
Jian Z, Shi X, Huang R et al (2016) Feasibility of stochastic gradient boosting approach for predicting rockburst damage in burst-prone mines. Trans Nonferrous Met Soc China 26:1938–1945
Zhou J, Aghili N, Ghaleini EN et al (2019) A Monte Carlo simulation approach for effective assessment of flyrock based on intelligent system of neural network. Eng Comput. https://doi.org/10.1007/s00366-019-00726-z
Ghaleini EN, Koopialipoor M, Momenzadeh M et al (2018) A combination of artificial bee colony and neural network for approximating the safety factor of retaining walls. Eng Comput 35(2):647–658
Rabunal JR, Puertas J (2006) Hybrid system with artificial neural networks and evolutionary computation in civil engineering. In: Artificial neural networks in real-life applications. IGI Global, pp 166–187
Wang M, Shi X, Zhou J (2018) Charge design scheme optimization for ring blasting based on the developed Scaled Heelan model. Int J Rock Mech Min Sci 110:199–209
Hasanipanah M, Jahed Armaghani D, Khamesi H et al (2016) Several non-linear models in estimating air-overpressure resulting from mine blasting. Eng Comput. https://doi.org/10.1007/s00366-015-0425-y
Hasanipanah M, Golzar SB, Larki IA et al (2017) Estimation of blast-induced ground vibration through a soft computing framework. Eng Comput. https://doi.org/10.1007/s00366-017-0508-z
Hasanipanah M, Monjezi M, Shahnazar A et al (2015) Feasibility of indirect determination of blast induced ground vibration based on support vector machine. Meas J Int Meas Confed. https://doi.org/10.1016/j.measurement.2015.07.019
Faradonbeh RS, Hasanipanah M, Amnieh HB et al (2018) Development of GP and GEP models to estimate an environmental issue induced by blasting operation. Environ Monit Assess 190:351
Chahnasir ES, Zandi Y, Shariati M et al (2018) Application of support vector machine with firefly algorithm for investigation of the factors affecting the shear strength of angle shear connectors. Smart Struct Syst 22:413–424
Safa M, Shariati M, Ibrahim Z et al (2016) Potential of adaptive neuro fuzzy inference system for evaluating the factors affecting steel-concrete composite beam’s shear strength. Steel Compos Struct 21:679–688
Shariat M, Shariati M, Madadi A, Wakil K (2018) Computational Lagrangian Multiplier Method by using for optimization and sensitivity analysis of rectangular reinforced concrete beams. Steel Compos Struct 29:243–256
Mansouri I, Shariati M, Safa M et al (2017) Analysis of influential factors for predicting the shear strength of a V-shaped angle shear connector in composite beams using an adaptive neuro-fuzzy technique. J Intell Manuf 30(3):1247–1257
Rezaei M, Majdi A, Monjezi M (2014) An intelligent approach to predict unconfined compressive strength of rock surrounding access tunnels in longwall coal mining. Neural Comput Appl 24(1):233–241
Das SK, Samui P, Sabat AK (2011) Prediction of field hydraulic conductivity of clay liners using an artificial neural network and support vector machine. Int J Geomech 12:606–611
Samui P, Kim D (2013) Least square support vector machine and multivariate adaptive regression spline for modeling lateral load capacity of piles. Neural Comput Appl 23:1123–1127
Samui P (2012) Determination of ultimate capacity of driven piles in cohesionless soil: a multivariate adaptive regression spline approach. Int J Numer Anal Methods Geomech 36:1434–1439
Mohammadhassani M, Nezamabadi-Pour H, Suhatril M, Shariati M (2014) An evolutionary fuzzy modelling approach and comparison of different methods for shear strength prediction of high-strength concrete beams without stirrups. Smart Struct Syst Int J 14:785–809
Toghroli A, Mohammadhassani M, Suhatril M et al (2014) Prediction of shear capacity of channel shear connectors using the ANFIS model. Steel Compos Struct 17:623–639
Armaghani DJ, Hajihassani M, Mohamad ET et al (2014) Blasting-induced flyrock and ground vibration prediction through an expert artificial neural network based on particle swarm optimization. Arab J Geosci 7:5383–5396
Jahed Armaghani D, Tonnizam Mohamad E, Hajihassani M et al (2016) Application of several non-linear prediction tools for estimating uniaxial compressive strength of granitic rocks and comparison of their performances. Eng Comput. https://doi.org/10.1007/s00366-015-0410-5
Jahed Armaghani D, Hasanipanah M, Mahdiyar A et al (2016) Airblast prediction through a hybrid genetic algorithm-ANN model. Neural Comput Appl. https://doi.org/10.1007/s00521-016-2598-8
Shams S, Monjezi M, Majd VJ, Armaghani DJ (2015) Application of fuzzy inference system for prediction of rock fragmentation induced by blasting. Arab J Geosci 8:10819–10832
Shirani Faradonbeh R, Jahed Armaghani D, Abd Majid MZ et al (2016) Prediction of ground vibration due to quarry blasting based on gene expression programming: a new model for peak particle velocity prediction. Int J Environ Sci Technol. https://doi.org/10.1007/s13762-016-0979-2
Mohamad ET, Faradonbeh RS, Armaghani DJ et al (2017) An optimized ANN model based on genetic algorithm for predicting ripping production. Neural Comput Appl 28:393–406
Zhou J, Li X, Mitri HS (2016) Classification of rockburst in underground projects: comparison of ten supervised learning methods. J Comput Civ Eng 30:4016003
Wang M, Shi X, Zhou J, Qiu X (2018) Multi-planar detection optimization algorithm for the interval charging structure of large-diameter longhole blasting design based on rock fragmentation aspects. Eng Optim 50:2177–2191
Zhou J, Li X, Shi X (2012) Long-term prediction model of rockburst in underground openings using heuristic algorithms and support vector machines. Saf Sci 50:629–644
Zhou J, Shi X, Du K et al (2016) Feasibility of random-forest approach for prediction of ground settlements induced by the construction of a shield-driven tunnel. Int J Geomech 17:4016129
Zhou J, Li E, Wang M et al (2019) Feasibility of stochastic gradient boosting approach for evaluating seismic liquefaction potential based on SPT and CPT Case Histories. J Perform Constr Facil 33:4019024
Li XZ, Kong JM (2014) Application of GA–SVM method with parameter optimization for landslide development prediction. Nat Hazards Earth Syst Sci 14:525–533
Koopialipoor M, Fahimifar A, Ghaleini EN et al (2019) Development of a new hybrid ANN for solving a geotechnical problem related to tunnel boring machine performance. Eng Comput. https://doi.org/10.1007/s00366-019-00701-8
Koopialipoor M, Murlidhar BR, Hedayat A et al (2019) The use of new intelligent techniques in designing retaining walls. Eng Comput. https://doi.org/10.1007/s00366-018-00700-1
Hasanipanah M, Armaghani DJ, Amnieh HB et al (2018) A risk-based technique to analyze flyrock results through rock engineering system. Geotech Geol Eng 36:2247–2260
Liao X, Khandelwal M, Yang H et al (2019) Effects of a proper feature selection on prediction and optimization of drilling rate using intelligent techniques. Eng Comput. https://doi.org/10.1007/s00366-019-00711-6
Zhao Y, Noorbakhsh A, Koopialipoor M et al (2019) A new methodology for optimization and prediction of rate of penetration during drilling operations. Eng Comput. https://doi.org/10.1007/s00366-019-00715-2
Koopialipoor M, Nikouei SS, Marto A, Fahimifar A, Armaghani DJ, Mohamad ET (2018) Predicting tunnel boring machine performance through a new model based on the group method of data handling. Bull Eng Geol Environ. https://doi.org/10.1007/s10064-018-1349-8
Jahed Armaghani D, Safari V, Fahimifar A et al (2017) Uniaxial compressive strength prediction through a new technique based on gene expression programming. Neural Comput Appl. https://doi.org/10.1007/s00521-017-2939-2
Faradonbeh RS, Armaghani DJ, Monjezi M, Mohamad ET (2016) Genetic programming and gene expression programming for flyrock assessment due to mine blasting. Int J Rock Mech Min Sci 88:254–264
Armaghani DJ, Faradonbeh RS, Momeni E et al (2018) Performance prediction of tunnel boring machine through developing a gene expression programming equation. Eng Comput 34:129–141
Faradonbeh RS, Jahed Armaghani D, Monjezi M (2016) Development of a new model for predicting flyrock distance in quarry blasting: a genetic programming technique. Bull Eng Geol Environ. https://doi.org/10.1007/s10064-016-0872-8
Faradonbeh RS, Armaghani DJ, Monjezi M, Mohamad ET (2016) Genetic programming and gene expression programming for flyrock assessment due to mine blasting. Int J Rock Mech Min Sci. https://doi.org/10.1016/j.ijrmms.2016.07.028
Armaghani DJ, Faradonbeh RS, Rezaei H et al (2016) Settlement prediction of the rock-socketed piles through a new technique based on gene expression programming. Neural Comput Appl. https://doi.org/10.1007/s00521-016-2618-8
Jahed Armaghani D, Faradonbeh RS, Momeni E et al (2017) Performance prediction of tunnel boring machine through developing a gene expression programming equation. Eng Comput. https://doi.org/10.1007/s00366-017-0526-x
Armaghani DJ, Safari V, Fahimifar A et al (2017) Uniaxial compressive strength prediction through a new technique based on gene expression programming. Neural Comput Appl 30(11):3523–3532
Saad S, Malik H (2018) Gene expression programming (GEP) based intelligent model for high performance concrete comprehensive strength analysis. J Intell Fuzzy Syst 35(5):5403–5418. https://doi.org/10.3233/JIFS-169822
Aval SBB, Ketabdari H, Gharebaghi SA (2017) Estimating shear strength of short rectangular reinforced concrete columns using nonlinear regression and gene expression programming. Structures 12:13–23
Yi LU, Xiangyun LUO, Zhang H (2011) A gene expression programming algorithm for highway construction cost prediction problems. J Transp Syst Eng Inf Technol 11:85–92
Azamathulla HM (2013) Gene-expression programming to predict friction factor for Southern Italian rivers. Neural Comput Appl 23:1421–1426
Azamathulla HM, Cuan YC, Ghani AA, Chang CK (2013) Suspended sediment load prediction of river systems: GEP approach. Arab J Geosci 6:3469–3480
Neaupane KM, Achet SH (2004) Use of backpropagation neural network for landslide monitoring: a case study in the higher Himalaya. Eng Geol 74:213–226
Hebb DO (1955) Drives and the CNS (conceptual nervous system). Psychol Rev 62:243
Koopialipoor M, Fallah A, Armaghani DJ et al (2018) Three hybrid intelligent models in estimating flyrock distance resulting from blasting. Eng Comput. https://doi.org/10.1007/s00366-018-0596-4
Koopialipoor M, Armaghani DJ, Haghighi M, Ghaleini EN (2017) A neuro-genetic predictive model to approximate overbreak induced by drilling and blasting operation in tunnels. Bull Eng Geol Environ. https://doi.org/10.1007/s10064-017-1116-2
Koopialipoor M, Ghaleini EN, Tootoonchi H et al (2019) Developing a new intelligent technique to predict overbreak in tunnels using an artificial bee colony-based ANN. Environ Earth Sci 78:165. https://doi.org/10.1007/s12665-019-8163-x
Momeni E, Nazir R, Armaghani DJ, Maizir H (2015) Application of artificial neural network for predicting shaft and tip resistances of concrete piles. Earth Sci Res J 19:85–93
Mohamad ET, Armaghani DJ, Hajihassani M et al (2013) A simulation approach to predict blasting-induced flyrock and size of thrown rocks. Electron J Geotech Eng 18(B):365–374
Tonnizam Mohamad E, Hajihassani M, Jahed Armaghani D, Marto A (2012) Simulation of blasting-induced air overpressure by means of Artificial Neural Networks. Int Rev Model Simulations 5:2501–2506
Koopialipoor M, Armaghani DJ, Hedayat A et al (2018) Applying various hybrid intelligent systems to evaluate and predict slope stability under static and dynamic conditions. Soft Comput. https://doi.org/10.1007/s00500-018-3253-3
Ferreira C (2001) Algorithm for solving gene expression programming: a new adaptive problems. Complex Syst 13:87–129
Khandelwal M, Armaghani DJ, Faradonbeh RS et al (2016) A new model based on gene expression programming to estimate air flow in a single rock joint. Environ Earth Sci 75:739
Keshavarz A, Mehramiri M (2015) New gene expression programming models for normalized shear modulus and damping ratio of sands. Eng Appl Artif Intell 45:464–472
Khandelwal M, Faradonbeh RS, Monjezi M et al (2017) Function development for appraising brittleness of intact rocks using genetic programming and non-linear multiple regression models. Eng Comput 33:13–21
Zidan A (2015) Cellular automata for population growth prediction: Tripoli-Libya case. Doctoral dissertation, Brunel University London
Brownlee J (2011) Clever algorithms: nature-inspired programming recipes. Jason Brownlee
Ferreira C (2006) Gene expression programming: mathematical modeling by an artificial intelligence. Springer, Berlin
Karaboga D (2005) An idea based on honey bee swarm for numerical optimization. Technical report-tr06, Erciyes university, engineering faculty, computer engineering department
Koopialipoor M, Ghaleini EN, Haghighi M et al (2018) Overbreak prediction and optimization in tunnel using neural network and bee colony techniques. Eng Comput. https://doi.org/10.1007/s00366-018-0658-7
Gordan B, Koopialipoor M, Clementking A et al (2018) Estimating and optimizing safety factors of retaining wall through neural network and bee colony techniques. Eng Comput. https://doi.org/10.1007/s00366-018-0642-2
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Luo, Z., Luo, Z., Qin, Y. et al. Developing new tree expression programing and artificial bee colony technique for prediction and optimization of landslide movement. Engineering with Computers 36, 1117–1134 (2020). https://doi.org/10.1007/s00366-019-00754-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00366-019-00754-9