
Abstract
Overdispersion is a phenomenon commonly observed in count time series. Since Poisson distribution is equidispersed, the INteger-valued AutoRegressive (INAR) process with Poisson marginals is not adequate for modelling overdispersed counts. To overcome this problem, in this paper we propose a general class of first-order INAR processes for modelling overdispersed count time series. The proposed INAR(1) processes have marginals belonging to a class of mixed Poisson distributions, which are overdispersed. With this, our class of overdispersed count models have the known negative binomial INAR(1) process as particular case and open the possibility of introducing new INAR(1) processes, such as the Poisson-inverse Gaussian INAR(1) model, which is discussed here with some details. We establish a condition to our class of overdispersed INAR processes is well-defined and study some statistical properties. We propose estimators for the parameters and establish their consistency and asymptotic normality. A small Monte Carlo simulation to evaluate the finite-sample performance of the proposed estimators is presented and one application to a real data set illustrates the usefulness of our proposed overdispersed count processes.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Count time series arise naturally in many practical situations and due to this an increased interest in the modelling of such data have been observed. Some areas where we observe count time series data are economy, medicine, epidemiology, natural and social sciences, just to name a few. For example, in this paper we will deal with monthly counting of sex offences registered in the 21st police car beat in Pittsburgh from January 1990 and ending in December 2001.
The most common way for dealing with this type of data is to consider a ARMA-type model or an INteger-valued AutoRegressive (INAR) process. These models can be seen as parameter-driven and observation-driven models, respectively. We here focus on the observation-driven approach based on the INAR structure.
The Poisson INAR(1) (first-order INAR) model is the most popular INAR process for modelling count time series data. This process is based on the binomial thinning operator; this operator was introduced by Steutel and van Harn (1979). Pionering works on the Poisson INAR (in short PINAR) process are due to McKenzie (1985), Al-Osh and Alzaid (1987) and McKenzie (1988). After these works, some papers have dealt with inferential and forescasting aspects of the PINAR(1) process. For instance, see Freeland and McCabe (2004a), Freeland and McCabe (2004b) and Freeland and McCabe (2005).
An important variant of the PINAR(1) process was considered by Ristić et al. (2009). They introduced an INAR(1) process with geometric marginals by using a negative binomial thinning operator (Aly and Bouzar (1994)). The literature about INAR processes is very rich and the interest in this topic has increased in the last years. Some recent contributions on INAR processes are given by Nastić and Ristić (2012), Jazi et al. (2012), Ristić et al. (2013), Weiß (2013), Weiß and Kim (2013), Meintanis and Karlis (2014), Schweer and Weiß (2014), Andersson and Karlis (2014), Barreto-Souza and Bourguignon (2015), Barreto-Souza (2015), Weiß (2015), Bisaglia and Canale (2016), Nastić et al. (2016a), Nastić et al. (2016b), Nastić et al. (2016c), Yang et al. (2016) and Weiß et al. (2016). For a good review on INAR processes we recommend the papers by McKenzie (2003), Weiß (2008b) and Scotto et al. (2015).
Overdispersion is a phenomenon commonly observed in count time series. Since Poisson distribution is equidispersed, the PINAR process is not adequate for modelling overdispersed counts. Overdispersion can be caused by excess of zeros. In this direction, Jazi et al. (2012) and Barreto-Souza (2015) proposed INAR processes with zero-inflated Poisson innovations and zero-modified geometric marginals, respectively; both models are also able for dealing with underdispersion. Another important work on this issue is due to Schweer and Weiß (2014). They proposed a class of compound Poisson INAR(1) models and in particular obtained an overdispersion testing.
There are many different causes of overdispersion rather than excess of zeros. For example, the non-observation of significant covariates. A common way for treating overdispersion in count data is to use the mixed Poisson distributions, which is obtained by introducing a latent random effect on the mean of a Poisson distribution. For an account on mixed Poisson distributions, we recommend the paper by Karlis and Xekalaki (2005). With this in mind, in this paper we propose a class of overdispersed INAR(1) processes with marginals belonging to a general class of mixed Poisson distributions. With this approach, our class of INAR models includes the known negative binomial INAR(1) process as particular case and open the possibility of introducing new INAR(1) processes, such as the Poisson-inverse Gaussian INAR(1) model.
The paper is organized as follows. In Sect. 2 we define our class of mixed Poisson INAR(1) processes and derive some basic statistical properties. We also establish a condition to our class is well defined. In Sect. 3 we present the Poisson-inverse Gaussian INAR(1) model with some details. We propose estimators for the parameters and establish their consistency and asymptotic normality in Sect. 4. Further, we present a small Monte Carlo simulation to evaluate the finite-sample performance of the proposed estimators. An empirical illustration of our class of overdispersed INAR(1) processes is given in Sect. 5. Concluding remarks and future research are discussed in Sect. 6.
2 Definition and basic properties
In order to present our class of mixed Poisson INAR(1) processes and make this paper self-contained, we begin this section speaking about mixed Poisson distributions and self-decomposable random variables.
Definition 1
A random variable Y follows a mixed Poisson distribution if satisfies the stochastic representation \(Y|Z=z\sim \text{ Poisson }(\mu z)\), for \(\mu >0\), where Z is some non-negative random variable.
The probability function of a mixed Poisson random variable Y takes the form
for \(y\in \mathbb {N}_0\equiv \{0,1,\ldots \}\), where \(G_\phi (\cdot )\) is the distribution function of Z and \(\phi \) denotes the parameter vector associated to the distribution of Z; we denote \(Y\sim \text{ MP }(\mu ,\phi )\). Let \(\Psi _Z(t)=E(e^{tZ})\) be the moment generating function (mgf) of Z, for t belonging to some interval containing the value zero.
We have that the mgf of Y, say \(\Psi _Y(\cdot )\), can be expressed by
for t belonging some interval containing the value zero. Assume that Z has the finite second moment. Then, the mean and variance of Y are given by \(E(Y)=\mu E(Z)\) and \(\text{ Var }(Y)=\mu \{E(Z)+\mu \text{ Var }(Z)\}\). As we can see, Y is overdispersed for any choice of distribution for Z (with finite second moment).
Definition 2
A random variable X is said to be self-decomposable if, for all \(\alpha \in [0,1)\), there is a random variable \(X_{\alpha }\) independent of X such that the following stochastic representation holds: \(X\mathop {=}\limits ^{d}\alpha X+X_{\alpha }\), where “\(\mathop {=}\limits ^{d}\)” means equality in distribution.
Remark 1
A non-degenerate random variable X that is self-decomposable according Definition 2 is necessarily absolutely continuous.
Definition 3
(Steutel and van Harn (1979)) A random variable X assuming values on \(\mathbb N_0\) is said to be discrete self-decomposable if, for all \(\alpha \in [0,1)\), there is a random variable \(X_{\alpha }\) independent of X such that the following stochastic representation holds: \(X\mathop {=}\limits ^{d}\alpha \circ X+X_{\alpha }\), where \(\circ \) is the thinning operator defined by \(\alpha \circ X=\sum _{i=1}^XB_i\), where \(\{B_i\}_{i=1}^\infty \) is a sequence of iid Bernoulli random variables with \(P(B_1=1)=1-P(B_1=0)=\alpha \) and \(\alpha \circ 0\equiv 0\).
In what follows, we present some results that will be important to define our class of overdispersed INAR processes.
Proposition 1
Let \(Y\sim \text{ MP }(\mu ,\phi )\). Then, \(\alpha \circ Y\sim \text{ MP }(\alpha \mu ,\phi )\), for \(\alpha \in [0,1)\).
Proof
Using the fact that \(\alpha \circ Y|Z=z\) follows a Poisson distribution with parameter \(\alpha \mu z\), we obtain that
that is the mgf of a \(\text{ MP } (\alpha \mu ,\phi )\) random variable. \(\square \)
Proposition 2
Let Z be a non-negative self-decomposable random variable according Def. 2 with mgf \(\Psi _Z(\cdot )\) and \(\Psi (\cdot )\) be a function defined as
for t belonging some interval containing the value 0. Then \(\Psi (t)\) is a proper mgf for all \(\alpha \in [0,1)\). Moreover, this is a mgf of a mixed Poisson distribution.
Proof
Since Z is self-decomposable, there is a random variable \(Z_\alpha \) independent of Z such that \(Z\mathop {=}\limits ^{d} \alpha Z+Z_\alpha \). Hence, we have that the function \(\Psi _Z(t)/\Psi _Z(\alpha t)\) is a proper mgf for all \(\alpha \in [0,1)\); this function is the mgf of \(Z_\alpha \). Let W be a random variable with this mgf. We now show that the function (1) is a mgf of mixed Poisson random variable, denoted by \(\epsilon \), which satisfies the following stochastic representation: \(\epsilon |W=w\sim \text{ Poisson }(\mu w)\), with W as defined above. It follows that
so proving the desired result. \(\square \)
With the results above, we now are ready to define our class of mixed Poisson INAR(1) processes as follows.
Definition 4
We said that a sequence \(\{X_n\}_{n=0}^\infty \) is a Mixed Poisson INAR(1) process, named in short by \(\text{ MPINAR }(1)\) process, if \(X_n\sim \text{ MP }(\mu ,\phi )\) for all n and if it admits the following stochastic representation:
for \(n\ge 1\), with \(\{\epsilon _n\}_{n=1}^\infty \) being a sequence of iid random variables and \(\epsilon _n\) independent of \(X_j\), for \(j<n\), for all n.
Remark 2
Proposition 2 gives us that the self-decomposability of Z is a sufficient condition to the MPINAR(1) process is well-defined. In fact, this condition also is necessary. Forst (1979) (see also Alamatsaz (1983)) showed that a mixed Poisson random variable is discrete self-decomposable if and only if its associated random effect (denoted in this paper by Z) is self-decomposable (in the sense of Def. 2). Therefore, in order to define an INAR process with mixed Poisson marginals, it is sufficient and necessary to restrict to the cases where Z (the random effect) is self-decomposable.
An INAR(1) process \(\{X_n\}_{n=0}^\infty \) satisfying (2) has 1-step transition probabilities given by
for \(k,l\in \mathbb N\). Further, the autocorrelation function is given by \(\rho (k)=\alpha ^k\). For more general properties on INAR processes, see Weiß (2008a).
The following result will be important to establish the asymptotic properties of the estimators which will be proposed in the Sect. 4.
Proposition 3
Let \(\{X_n\}_{n=0}^\infty \) be a mixed Poisson INAR(1) process. If \(E(X_n)<\infty \), then it is a geometrically ergodic, irreducible and aperiodic Markov chain.
Proof
The Markovian property of \(\{X_n\}_{n=0}^\infty \) follows from (2). We now argue that \(P(\epsilon _n=k)>0\) for all \(k\in \mathbb N\). This and (3) implies that the MPINAR(1) processes are irreducible Markov chains.
Since \(\{X_n\}_{n=0}^\infty \) is a MPINAR(1) process, we have that the random latent effect Z is an absolutely continuous random variable (see Remarks 1 and 2). With this, we have that W defined in proof of Proposition 2 is an absolutely continuous random variable. Denote by \(f(\cdot )\) its density function. Further, from proof of Proposition 2 we have that the innovations \(\epsilon _n\) satisfies the stochastic representation \(\epsilon _n|W=w\sim \text{ Poisson }(\mu w)\). Therefore, we have that \(P(\epsilon _n=k)=\int _0^\infty \frac{e^{-\mu w}(\mu w)^k}{k!}f(w)dw>0\). The aperiodicity of \(\{X_n\}_{n=0}^\infty \) follows from the fact (due to the above arguments) \(p_{k,k}>0\) for all \(k\in \mathbb N\).
Now, since \(E(X_n)<\infty \), we obtain that \(E(\epsilon _n)<\infty \). With this, by following the same steps of proof of Theorem 3.4.1 from Schweer and Weiß (2014), we conclude that \(\{X_n\}_{n=0}^\infty \) is geometrically ergodic. \(\square \)
We now discuss about the joint and conditional mgfs and moments. Using standard manipulations, it can be checked that the conditional and joint mgfs are given by
and
respectively, where t belongs some interval containing the value 0 in both cases.
Remark 3
From now on, we assume that \(E(Z)=1\) and \(Var(Z)=\phi ^{-1}\). The condition \(E(Z)=1\) is commonly adopted in mixed Poisson distributions in order to avoid non-identifiability problems.
The conditional mean and variance of \(X_n\) given \(X_{n-1}\) are respectively
and
We now define the jump process by \(J_n=X_n-X_{n-1}\), for \(n\ge 2\). This process is generally used for diagnostic checking of fitted INAR models. For instance, see Weiß (2008b, 2009). The mgf of \(J_n\) can be obtained from (4). More specifically, we have that \(\Psi _{J_n}(t)\equiv E(\exp \{tJ_n\})=\Psi _{X_n,X_{n-1}}(t,-t)\). From this, in particular, we obtain the two first moments of \(J_n\), that are \(E(J_n)=0\) and \(E(J_n^2)=2\mu (1-\alpha )(1+\mu \phi ^{-1})\).
In the subsequent section we introduce and study the Poisson-inverse Gaussian INAR(1) process with some details. Another process that belongs to our class of overdispersed INAR(1) models is the negative binomial INAR(1) process. This model is already known in the literature (under a different parametrization) and therefore we do not present it here; for instance, see McKenzie (1986) and Ristić et al. (2012). We call attention that the Poisson INAR(1) process is obtained as a limiting case of our proposed class by taking \(\phi \rightarrow \infty \).
3 Poisson inverse-Gaussian INAR(1) process
We now present a particular model of our class that yet is unknown in the literature. Let Z be a random variable with inverse Gaussian distribution with mean 1 and dispersion parameter \(\phi >0\). More specifically, assume that the moment generating function of Z is given by
for \(t<\phi /2\).
Let X be a discrete random variable following a Poisson inverse-Gaussian (PIG) distribution with parameters \(\mu >0\) and \(\phi >0\). It is well known that X satisfies the following stochastic representation \(X|Z=z\sim \text{ Poisson }(\mu z)\), where Z is defined above. We denote \(X\sim \text{ PIG }(\mu ,\phi )\). The moment generating function of X is given by
for \(t<\log (1+\phi /(2\mu ))\). The mean and variance of X are \(E(X)=\mu \) and \(\text{ Var }(X)=\mu (1+\phi ^{-1}\mu )\), respectively.
The probability function of X can be expressed by
for \(k=0,1,\ldots \), where \(\mathcal K_\lambda (t)=\frac{1}{2}\int _0^\infty u^{\lambda -1}\exp \bigg \{-\frac{t}{2}\bigg (u+\frac{1}{u}\bigg )\bigg \}du\) is the modified Bessel function of third kind, which can be computed in softwares such as R program, Maple and Mathematica.
We have that the inverse-Gaussian distribution is self-decomposable; for instance, Pillai and Satheesh (1992) and Abraham and Balakrishna (2002). With this and using Proposition 2, we obtain that the Poisson inverse-Gaussian distribution is discrete self-decomposable. Hence, we can define our INAR process with PIG marginals as follows.
Definition 5
We said that a sequence \(\{X_n\}_{n=0}^\infty \) is a Poisson-inverse Gaussian INAR(1) process, named in short by \(\text{ PIG }\text{ INAR }(1)\) process, if \(X_n\sim \text{ PIG }(\mu ,\phi )\) for all n and if it admits the stochastic dynamics given in Definition 4.
The mgf of the innovations is given by
for \(t<\log (1+\phi /(2\mu ))\). The first four cumulants of the innovations are
and
We are naturally interested in the distribution of the innovations since we need to simulate the \(\epsilon _n\)’s in order to construct simulated trajectories and to study the finite-sample behaviour of the estimators we will propose. On the other hand, it is very difficult to obtain an explicit form for the probability function of the innovations.
More specifically, our innovations satisfy the following stochastic representation: \(\epsilon |W=w\sim \text{ Poisson }(\mu w)\), where W has the distribution of an innovation of an inverse-Gaussian AR(1) process [see Pillai and Satheesh (1992); Abraham and Balakrishna (2002)], which has not explicit density function. Therefore, we do not have an explicit form for the probability function of our innovations \(\epsilon _n\).
To overcome this problem, we use a method for generating random variables based on the moment generating function given by Ridout (2009). With this, we generate observations of the distribution of W and use the above stochastic representation for generating from the distribution of the innovations.
4 Estimation and asymptotic properties
We discuss here estimation methods of the parameter vector \(\theta \equiv (\mu ,\alpha ,\phi )^\top \) and establish consistency and asymptotic normality. We begin with the conditional least squares (CLS) method. The function we need to minimize in order to find the conditional least squares estimator for \(\theta \) is given by
where n is the sample size of the count time series. The above estimating equation does not depend on \(\phi \) and therefore an alternative method to estimate it is necessary; this point will be discussed in the sequence. By solving the nonlinear system of equations \(\left( \partial Q(\theta )/\partial \mu ,\partial Q(\theta )/\partial \alpha \right) ^\top =(0,0)^\top \), we get
and
The above estimators based on the CLS method estimation assume the same form as the corresponding ones in the Poisson INAR(1) process; see Al-Osh and Alzaid (1987) and Freeland and McCabe (2005).
The additional equation for estimating \(\phi \) is based on the \(Q^*\) function given by
where \(\theta ^*=({\widehat{\mu }}_{cls},{\widehat{\alpha }}_{cls},\phi )^\top \), \(g(\mu ,\alpha ,x)=(\alpha x+\mu (1-\alpha ))^2+\alpha (1-\alpha )x\) and \(h(\mu ,\alpha )=\mu ^2(1-\alpha ^2)\).
The above method we using here, that is, by using two conditional least squares equations, it is known as two-step CLS estimation and was introduced by Karlsen and Tjostheim (1988). Solving the equation \(\partial Q^*(\theta ^*)/\partial \phi =0\), we get
We obtain now the Yule-Walker estimators. Since \(E(X_t)=\mu \), \(\text{ Var }(X_t)=\mu (1+\mu /\phi )\) and \(\text{ corr }(X_{t-1},X_t)=\alpha \), we get the following Yule-Walker estimators:
and
where \(\bar{X}_n=\frac{1}{n}\sum \nolimits _{t=1}^nX_t\) is the sample mean and \(S^2_n=\dfrac{1}{n}\sum \nolimits _{t=1}^nX_t^2-\bar{X}_n^2\) is the sample variance.
We perform now a small Monte Carlo simulation in order to study the finite-sample behaviour of the proposed estimators and to compare the CLS and Yule-Walker estimation methods. We generate the PIGINAR(1) process, which was introduced and studied with some details in the previous section, under four configurations. In the Configurations I, II, III and IV we set \((\mu ,\alpha ,\phi )=(0.5,0.7,0.2)\), \((\mu ,\alpha ,\phi )=(2,0.5,1)\), \((\mu ,\alpha ,\phi )=(1,0.25,0.5)\) and \((\mu ,\alpha ,\phi )=(0.5,0.1,1.5)\), respectively. We consider the sample sizes \(n=100,200,300,400,500,1000\) and the number of loops of the Monte Carlo simulation equals to 10000.
The results based on the Configurations I, II, III and IV are presented in Tables 1, 2, 3 and 4, respectively. These tables give us the empirical mean of the estimates of the parameters and also the standard errors.
Looking at these tables, we see that the bias and standard error of the estimates of the parameters decreases as the sample size increases for all cases considered, as expected. We also observe that the parameters \(\mu \) and \(\alpha \) are in general well estimated and that the CLS and Yule-Walker estimators yield very similar results for these parameters. The explanation for this is that \((\widehat{\mu }_{cls},\widehat{\alpha }_{cls})\) and \((\widehat{\mu }_{yw},\widehat{\alpha }_{yw})\) are asymptotically equivalent. More specifically, we have that \((\widehat{\mu }_{cls}-\widehat{\mu }_{yw},\widehat{\alpha }_{cls}-\widehat{\alpha }_{yw})=o_p(n^{-1/2})\). This can be checked by following the same steps that in Proof of Theorem 3 by Freeland and McCabe (2005). We now concentrate our attention to the estimation of the parameter \(\phi \). Under the Configurations II (\(\phi =1\)) and III (\(\phi =0.5\)), we observe that the estimators \(\widehat{\phi }_{cls}\) and \(\widehat{\phi }_{yw}\) yield similar results with a slightly advantage for the Yule-Walker estimator that presents smaller bias and standard error with respect to the CLS estimator. Now, with respect to the Configurations I (\(\phi =0.2\)) and IV (\(\phi =1.5\)), we see that there is a considerable bias under both CLS and Yule-Walker estimation methods for estimating \(\phi \) with \(n=100,200,300\). Anyway, this bias is smaller under the Yule-Walker approach. We also see that the standard error of the Yule-Walker estimator is smaller than that one based on the CLS estimation. For \(n\ge 400\), both methods work similarly. Overall, we see that the Yule-Walker estimation method works better that the CLS one for our mixed Poisson INAR(1) process considered. With this, we suggest the use of the Yule-Walker approach. This method will be considered in our application to a real dataset.
We establish now the consistency and asymptotic normality of the estimators (5), (6) and (7).
Proposition 4
Assume that \(E(X_n^4)<\infty \). Then, the estimators \({\widehat{\mu }}_{yw}\), \(\widehat{\phi }_{yw}\) and \({\widehat{\alpha }}_{yw}\) are strongly consistent for \(\mu \), \(\phi \) and \(\alpha \) respectively and satisfy the asymptotic normality
as \(n\rightarrow \infty \), where
and \(\Sigma \) being a \(3\times 3\) symmetric matrix with entries given by
and
Proof
Since \(E(X_n)<\infty \) by assumption, it follows from Proposition 3 that the stationary process \(\{X_n\}_{n=0}^\infty \) is ergodic. With this, we can apply the Law of Large Numbers for stationary and ergodic processes to obtain the strong consistency of the estimators; for instance, see Proposition 7.1 by Hamilton (1994).
In order to show the asymptotic normality of the estimators, we define \(Y_n=\sum \nolimits _{t=1}^n X_t\), \(Z_n=\sum \nolimits _{t=1}^n X_t^2\) and \(W_n=\sum \nolimits _{t=1}^n X_{t-1}X_t\), for \(n\ge 1\). Note that the estimators \(({\widehat{\mu }}_{yw},\widehat{\phi }_{yw},{\widehat{\alpha }}_{yw})\) are asymptotically equivalent to \(g(Y_n/n,Z_n/n,W_n/n)\), where \(g(y,z,w)=\left( y,\dfrac{y}{z-y^2-y},\dfrac{w-y^2}{z-y^2}\right) \), for \((y,z,w)\in \mathbb R^+\), \(z\ne y(y+1)\) and \(z\ne y^2\).
By using the Central Limit Theorem for stationary and ergodic processes (see Chapter 7 from Anderson (1971)), we obtain that \(\sqrt{n}\{(Y_n/n,Z_n/n,W_n/n)-(\mu ,\mu ^2+\kappa _2,\mu ^2+\alpha \kappa _2)\}\mathop {\longrightarrow }\limits ^{d} N(0,\Sigma )\) as \(n\rightarrow \infty \), where \(\mu =E(X_n)\), \(\kappa _2=\text{ Var }(X_n)\) and \(\Sigma \) is some asymptotic covariance matrix. With the results above and by applying the Delta Method with the function \(g(\cdot ,\cdot ,\cdot )\) as defined above, we obtain that \(\sqrt{n}\{({\widehat{\mu }}_{yw},\widehat{\phi }_{yw},{\widehat{\alpha }}_{yw})-(\mu ,\phi ,\alpha )\}\mathop {\longrightarrow }\limits ^{d} N(0,B\Sigma B^\top )\), where \(B=\partial g(\theta )/\partial \theta \). The point that remains to be proven is the form of the covariance matrix \(\Sigma \), which is done in the Appendix. \(\square \)
5 Empirical illustration
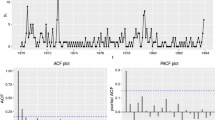
In this section we illustrate the usefulness of the proposed class of mixed Poisson INAR(1) processes. We consider a sex offence count time series data, which can be found at site www.forecastingprinciples.com. For this count time series, an observation corresponds to a monthly count of sex offences reported in the 21st police car beat in Pittsburgh. These data contain 144 observations starting in January 1990 and ending in December 2001 and was firstly used by Ristić et al. (2009). The plots of the data and the associated ACF and PACF are presented in Fig. 1. From these plots, we see that the first sample autocorrelation is more significant than the other and there exists a cutoff after lag 1 in the partial autocorrelations. These facts indicate that an INAR process of order 1 can be suitable for modelling the monthly count of sex offences.

Plots of the monthly count of sex offences reported in the 21st police car beat in Pittsburgh from January 1990 up to December 2001 and the associated ACF and PACF
We begin this application performing an overdispersion test proposed by Schweer and Weiß (2014), which the test statistic is based on the empirical index of dispersion \(\widehat{I}_d\equiv S_n^2/\bar{X}_n\). The null hypothesis is \(H_0{\text {:}}\, X_1,\ldots ,X_n\)come from a Poisson INAR(1) process against the alternative hypothesis \(H_1{\text {:}}\, X_1,\ldots ,X_n\)come from an overdispersed INAR(1) process. For the count time series considered here, we have that \(\widehat{I}_d=1.7394\). The associated p-value is \(2.55\times 10^{-12}\), that is, by using any usual significance level (for instance at 5%) we reject the null hypothesis in favor of the alternative hypothesis that states that an overdispersed INAR(1) process is more adequate for modelling this count data.
In Table 5 we present the estimates of the parameters based on the Yule-Walker estimation method given in Sect. 4. We also present in this table the associated standard errors and confidence intervals for the parameters with significance level at 5%. We consider the PIGINAR(1) and NBINAR(1) (negative binomial) processes and call attention that the estimates of the parameters are the same in both case since the estimation depends only on the first moments that are equal for these models. We see that the standard error for the estimates of \(\mu \) are equal for both models (as expected) and that the standard errors of the estimates of \(\alpha \) and \(\phi \) are smaller under the negative binomial assumption with respect to the PIG-based model.
We also fit a Poisson INAR(1) process and compare with our fitted mixed Poisson INAR(1) processes. In Table 6 we provide some empirical and estimated quantities based on the Poisson, negative binomial and Poisson-inverse Gaussian INAR(1) models. We consider the following quantities: mean, variance, skewness, kurtosis, index of dispersion (ratio of the variance to the mean), probability of zero and the first higher-order moment, denoted by \(\kappa _1\), \(\kappa _2\), skew., kurt., \(I_d\), \(p_0\) and \(\mu (1)\), respectively.
From the results presented in Table 6, it is very clear that the Poisson INAR(1) process is not adequate for modelling the monthly count of sex offences considered here. On the other hand, we observe a good agreement among the empirical quantities and the estimated quantities based on our mixed Poisson INAR(1) processes, with a slight advantage of the PIGINAR(1) process over the NBINAR(1) process.
We now discuss the goodness-of-fit of the models based on the residuals \(R_t\equiv X_t-\widehat{E}(X_t|X_{t-1})=X_t-{\widehat{\alpha }}_{yw} X_{t-1}-{\widehat{\mu }}_{yw}(1-{\widehat{\alpha }}_{yw})\) and on the jumps \(J_t\) defined in the final of Sect. 2, for \(t=2,\ldots ,n\). In the Fig. 2, we present the ACF of the residuals based on the MPINAR(1) process. This figure indicates that the residuals \(R_2,\ldots ,R_n\) are not correlated, so our fitted models seem to have captured well the dependence of the count time series. In this figure we also plot the jumps against the time with \(\pm 3\sigma _J\) bounds chosen as benchmark chart, where \(\sigma _J=\sqrt{\text{ Var }(J_t)}\); this graphic is also known in the literature as Shewhart control chart and was proposed by Weiß (2009) as a diagnostic checking of fitted INAR(1) models. We plot the bounds based on our mixed Poisson INAR processes and also the corresponding to the Poisson INAR process. We see that the bounds based on the mixed INAR process accommodate adequately the points (around 97% of them) in contrast with the benchmark chart related to the Poisson INAR process, where many points are out of the bounds (around 16% of them).

Sample autocorrelation function (ACF) of the residuals and jumps against time with bounds based on the mixed Poisson INAR(1) and Poisson INAR(1) processes
As suggested by one referee, we also use the standardized Pearson residual (for instance, see Harvey and Fernandes (1989) and Jung and Tremayne (2011))
for \(t=2,\ldots ,n\), in order to check the variance, which should be close to 1. According to Harvey and Fernandes (1989), a sample variance greater than 1 indicates overdispersion with respect to the model that is being considered. We compute the sample variance of the standardized Pearson Residual and obtain that it is equal to 0.9539, so giving evidence that our mixed Poisson INAR(1) processes have captured with success the overdispersion of the count time series considered.
With the results and discussion presented above, we conclude that the INAR process based on the Poisson assumption is not adequate for modelling the present count time series data and that the mixed Poisson INAR processes provide an adequate approach.
6 Conclusions and future research
A common way for treating overdispersion in count data is to use the mixed Poisson distributions, which is obtained by introducing a latent random effect on the mean of a Poisson distribution. With this motivation, we introduced a class of INAR(1) processes with mixed Poisson marginals. We established a condition to our class is well-defined and discussed statistical properties. The INAR(1) process with Poisson-inverse Gaussian marginals was introduced and presented with some details. We discussed estimation of the parameters and gave conditions to have consistency and asymptotic normality of the estimators. Simulated results showed that the estimators work well for the scenarios considered. An empirical example illustrated the importance in considering our overdispersed INAR processes for analyzing count time series data.
Possible points of future research are: (a) multivariate extension of our mixed Poisson INAR(1) process; (b) to define and study a mixed Poisson INAR process of p-order; (c) to explore more particular cases of our class of overdispersed INAR processes such as an INAR model with Poisson-log normal marginals.
References
Abraham B, Balakrishna N (2002) Inverse gaussian autoregressive models. J Time Ser Anal 20:605–618
Alamatsaz MH (1983) Completeness and self-decomposability of mixtures. Ann Inst Stat Math 35:355–363
Aly EEAA, Bouzar N (1994) Explicit stationary distributions for some galton-watson processes with immigration. Stoch Models 10:499–517
Al-Osh MA, Alzaid AA (1987) First-order integer valued autoregressive (INAR(1)) process. J Time Ser Anal 8:261–275
Anderson TW (1971) The statistical analysis of time series. Wiley, New York
Andersson J, Karlis D (2014) A parametric time series model with covariates for integers in \(\mathbb{Z}\). Stat Model 14:135–156
Barreto-Souza W (2015) Zero-modified geometric INAR(1) process for modelling count time series with deflation or inflation of zeros. J Time Ser Anal 36:839–852
Barreto-Souza W, Bourguignon M (2015) A skew INAR(1) process on \(\mathbb{Z}\). Adv Stat Anal 99:189–208
Bisaglia L, Canale A (2016) Bayesian nonparametric forecasting for INAR models. Comput Stat Data Anal 100:70–78
Forst G (1979) A characterization of self-decomposable probabilities in the half-line. Zeit Wahrscheinlichkeitsth 49:349–352
Freeland RK, McCabe BPM (2004a) Analysis of low count time series data by Poisson autoregression. J Time Ser Anal 25:701–722
Freeland RK, McCabe BPM (2004b) Forecasting discrete valued low count time series. Int J Forecast 20:427–434
Freeland RK, McCabe BPM (2005) Asymptotic properties of CLS estimators in the Poisson AR(1) model. Stat Prob Lett 73:147–153
Hamilton JD (1994) Time series analysis. Princeton University Press, Princeton
Harvey AC, Fernandes C (1989) Time series models for count or qualitative observations. J Bus Econ Stat 7:407–417
Jazi MA, Jones G, Lai CD (2012) First-order integer valued processes with zero inflated poisson innovations. J Time Ser Anal 33:954–963
Jung RC, Tremayne AR (2011) Useful models for time series of counts or simply wrong ones? Adv Stat Anal 95:59–91
Karlis D, Xekalaki E (2005) Mixed Poisson distributions. Int Stat Rev 73:35–58
Karlsen H, Tjostheim D (1988) Consistent estimates for the NEAR(2) and NLAR(2) time series models. J R Stat Soc Ser B 50:313–320
McKenzie E (1985) Some simple models for discrete variate time series. Water Resour Bull 21:645–650
McKenzie E (1986) Autoregressive moving-average processes with negative binomial and geometric marginal distributions. Adv Appl Probab 18:679–705
McKenzie E (1988) Some ARMA models for dependent sequences of Poisson counts. Adv Appl Probab 20:822–835
McKenzie E (2003) Discrete variate time series. In: Rao CR, Shanbhag DN (eds) Handbook of statistics. Elsevier, Amsterdam, pp 573–606
Meintanis SG, Karlis D (2014) Validation tests for the innovation distribution in INAR time series models. Comput Stat 29:1221–1241
Nastić AS, Ristić MM (2012) Some geometric mixed integer-valued autoregressive (INAR) models. Stat Probab Lett 82:805–811
Nastić AS, Ristić MM, Djordjević MS (2016a) An INAR model with discrete Laplace marginal distributions. Braz J Probab Stat 30:107–126
Nastić AS, Laketa PN, Ristić MM (2016b) Random environment integer-valued autoregressive process. J Time Ser Anal 37:267–287
Nastić AS, Ristić MM, Janjić AD (2016c) A mixed thinning based geometric INAR(1) model. Filomat
Pillai RN, Satheesh S (1992) \(\alpha \)-inverse Gaussian distributions. Sankhya A 54:288–290
Ridout MS (2009) Generating random numbers from a distribution specified by its Laplace transform. Stat Comput 19:439–450
Ristić MM, Nastić AS, Ilić AVM (2013) A geometric time series model with dependent Bernoulli counting series. J Time Ser Anal 34:466–476
Ristić MM, Bakouch HS, Nastić AS (2009) A new geometric first-order integer-valued autoregressive (NGINAR(1)) process. J Stat Plan Inference 139:2218–2226
Ristić MM, Nastić AS, Bakouch HS (2012) Estimation in an integer-valued autoregressive process with negative binomial marginals (NBINAR(1)). Commun Stat 41:606–618
Schweer S, Weiß CH (2014) Compound Poisson INAR(1) processes: stochastic properties and testing for overdispersion. Comput Stat Data Anal 77:267–284
Scotto MG, Weiß CH, Gouveia S (2015) Thinning-based models in the analysis of integer-valued time series: a review. Stat Model 15:590–618
Steutel FW, van Harn K (1979) Discrete analogues of self-decomposability and stability. Ann Probab 7:893–899
Weiß CH (2008a) Thinning operations for modeling time series of counts-a survey. Adv Stat Anal 92:319–341
Weiß CH (2008b) Serial dependence and regression of Poisson INARMA models. J Stat Plan Inference 138:2975–2990
Weiß CH (2009) Controlling jumps in correlated processes of Poisson counts. Appl Stoch Models Bus Ind 25:551–564
Weiß CH (2013) Integer-valued autoregressive models for counts showing underdispersion. J Appl Stat 40:1931–1948
Weiß CH (2015) A Poisson INAR(1) model with serially dependent innovations. Metrika 78:829–851
Weiß CH, Homburg A, Puig P (2016) Testing for zero inflation and overdispersion in INAR(1) models. Stat Pap
Weiß CH, Kim HY (2013) Binomial AR(1) processes: moments, cumulants, and estimation. Statistics 47:494–510
Yang K, Wang D, Jia B, Li H (2016) An integer-valued threshold autoregressive process based on negative binomial thinning. Stat Pap
Acknowledgements
I thank the two anonymous referees and the Associated Editor for their useful suggestions and comments that led to an improved version of this article. I also thank the financial support from CNPq (Brazil) and FAPEMIG (Brazil).
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
We here derive the asymptotic covariance matrix of the weak convergence given in Proposition 4. For this, we will use joint moments, which are defined by
where \(0\le s_1\le \ldots \le s_r\) and r belongs to \(\mathbb N\). Expressions of joint moments up to fourth order for INAR(1) processes were obtained by Schweer and Weiß (2014) (Theorem 3.3.1). We will use these expressions for computing the desired asymptotic covariance matrix.
Let \(Y_n\), \(Z_n\) and \(W_n\) be as defined in Sect. 4 and define \(g_n(i,j)=n{-}i{-}\frac{\alpha ^j}{1-\alpha ^j}\big (1-\alpha ^{j(n-i)}\big )\), for \(i,j\in \mathbb N\). Using joint moments and their expressions given in Theorem 3.3.1 from Schweer and Weiß (2014), after some manipulations we obtain that
and
where \(\mu =E(X_n)\), \(\kappa _j=E((X_n-\mu )^j)\) and \(\mu _j=E(X_n^j)\), for \(j=2,3,4\).
Let \(\Sigma _n\) be the covariance matrix with the above terms. Hence, it follows that the covariance matrix \(\Sigma \) of the Proposition 4 can be obtained by \(\Sigma =\displaystyle \lim _{n\rightarrow \infty }\Sigma _n/n\).
Rights and permissions
About this article

Cite this article
Barreto-Souza, W. Mixed Poisson INAR(1) processes. Stat Papers 60, 2119–2139 (2019). https://doi.org/10.1007/s00362-017-0912-x
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00362-017-0912-x