
Abstract
As an effect of changing forest management—away from softwood monocultures to more robust mixed stands—the availability of hardwood on the European timber market increases. Thus, a more diversified spectrum of hardwood products is required between the established uses in furniture and energy production. Glued timber products are a promising option in this respect. One important prerequisite for efficiently producing glued hardwood products is to establish hardwood strength grading. To this end, the current paper explored the potential of microwave scanning, stand-alone or combined with the measurement of dynamic stiffness, to estimate the tension strength of ash, beech, sweet chestnut and oak lamellas. In this preliminary study, combining microwave and dynamic stiffness measurement showed much potential for hardwood strength grading for all four species; for beech and sweet chestnut, coefficients of determination (\({r}^{2}\)) beyond 60% could be achieved, which is on a level with established softwood grading principles. For ash and oak, \({r}^{2}\approx 45\%\) was observed, which is acceptable for machine strength grading. The paper also considered measuring density using microwaves. Such a density measurement was found to be as accurate for hardwoods as for softwoods.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
In forestry, the basic principles of how stands should be managed and cultivated have changed a lot over the last decades. After massive forest devastations in the eighteenth and nineteenth century, spruce (Picea abies) reached a wide spread because of its high growth rates. Industry also adopted to spruce due to the good strength-density-ratio and the easy usability for sawing and gluing. Hardwood species, on the other hand, have almost exclusively been used for furniture; all hardwood material of lower quality was allocated to energy production. On the other hand, spruce monocultures are prone to calamities like storms or bark beetle attacks; climate change increases the risk and severity of such calamities. Thus, the large mono-species spruce stands are now being converted to mixed stands with native tree species of the respective region. The result of this new development has been an increase in hardwood forest and standing volume, predominantly beech and oak, in Germany (BMEL 2016, 2017). In neighbouring countries, additional species have become relevant, for example, sweet chestnut (commonly called “chestnut”) and oak in France (IGN 2014).
The increased availability of hardwoods has become more obvious recently because the new hardwood stands have now grown into stem dimensions suitable for sawing. At this point, the development of new industrial hardwood products with high added value is becoming attractive. Expected benefits include improved overall timber availability for the wood processing industry and a further increase in hardwood growth as targeted in the European forest policies.
Glued timber products, i.e. glued laminated timber (glulam) or cross laminated timber (x-lam), are the most promising future hardwood products for construction. However, three key issues need to be solved. The first issue and the focus of this paper is strength grading of hardwoods, which is much less developed than strength grading of softwoods. The second and third issues are, respectively, adhesives suitable for bonding different hardwood species and European standardization as a basis for producing CE-marked hardwood glulam.
1.1 Softwood strength grading technologies
For softwoods, machine strength grading has seen a big boost over the last twenty years and is now well established in the European sawmilling industry. Technologies include bending machines, X-ray scanning, eigenfrequency or time-of-flight measurement, laser scanning and various types of microwave scanning. In the following, the principles, strengths and weaknesses of each method according to the current state of the art are outlined. As a basis for comparison with the results of the current paper, values for the coefficients of determination (\({r}^{2}\)) are cited whenever available.
Bending machines operate by measuring the physical deflection of the piece and the force required for the deflection. For spruce, Boström (1994) observed \({r}^{2}\) values with bending strength in the range from 40 to 75% depending on machine type and cross-section. Hanhijärvi and Ranta-Maunus (2008) reported spruce bending strength \({r}^{2}\) between 45% and 60%, spruce tension strength \({r}^{2}\) between 55% and 61%, and pine bending strength \({r}^{2}\) between 63% and 72%.
X-ray scanning is used to measure board density; Bacher (2008) reported \({r}^{2}=89\%\) with spruce density. For softwoods, knot density is considerably higher than clear wood density, so that knots can be detected by density measurement. As knots cause grain deviations, which in turn strongly influence strength (Kollmann and Cote 1984; Denzler and Weidenhiller 2015), X-ray scanning can provide good strength estimates. The best \({r}^{2}\) values of X-ray strength estimates with spruce bending, spruce tension and pine bending strength reported in Hanhijärvi and Ranta-Maunus (2008) are 53%, 49% and 69%, respectively. Bacher (2008) achieved \({r}^{2}=52\%\) for spruce tension. Strength limiting factors not directly related to knots or wood density cannot reliably be detected by X-ray board scanning; this includes global grain deviation and top rupture (Denzler and Weidenhiller 2014; Hunger and van de Kuilen 2018).
Dynamic stiffness (Edyn) depends on wood density and the speed of sound in the specimen, where the speed of sound can be calculated from specimen length combined with eigenfrequency or time-of-flight (Gil-Moreno and Ridley-Ellis 2015). Eigenfrequency is measured by exciting longitudinal vibrations by a hammer and then measuring the frequency by a laser interferometer (Viguier et al. 2015); time-of-flight measures the time a stress wave takes to travel through the specimen (Wang 2013). Edyn has high correlations to the stiffness determined by destructive tests \(({r}^{2}\approx 90\%\) for spruce bending and tension and for pine bending tests, as reported by Hanhijärvi and Ranta-Maunus 2008). There are also good correlations to strength. Hanhijärvi and Ranta-Maunus (2008) observed \({r}^{2}\) values of Edyn with spruce bending, spruce tension and pine bending strength of 57%, 58% and 69%, respectively. The results reported by Bacher (2008) and Denzler and Weidenhiller (2015) confirmed these \({r}^{2}\) values. Combining Edyn measurement with X-ray scanning can further improve the correlations; the best \({r}^{2}\) values of such a system with spruce bending, spruce tension and pine bending strength as reported in Hanhijärvi and Ranta-Maunus (2008) were 64%, 64% and 75%, respectively.
Laser scanning is based on the tracheid effect, i.e. on the observation that laser light is scattered more along wood fibres than perpendicular to wood fibres, so that a point laser directed on the specimen surface produces an ellipse image on the surface (Nyström 2003). Laser scanning can therefore directly measure grain deviation on the specimen surface; from the eccentricity of the ellipse, one can also obtain information about the diving angle of the wood fibres (Viguier et al. 2015). Viguier et al. (2015) used this information to calculate strength profiles for spruce boards; their models obtained \({r}^{2}\) values of more than 60% for bending strength and 70% for tension strength, which could be improved to 78% for tension by including Edyn. Olsson et al. (2013) derived estimates of local stiffness variation in combination with an Edyn measurement; their model achieved \({r}^{2}\) values of up to 71% with spruce bending strength. Information about the interior of the specimen cannot be measured directly by laser scanning; Kandler et al. (2016) presented a method to infer knot geometry from surface grain deviation. Strength predictors based on 3D knot geometry were reported to achieve \({r}^{2}>80\%\) for spruce bending and tension (Lukacevic et al. 2015).
Microwaves interact with timber in an anisotropic manner. The interaction depends on the distribution of water and density in the timber (Torgovnikov 1993). Therefore, microwaves can detect information about the internal structure of wood: density distribution, moisture content distribution and grain angle information (Schajer and Orhan 2005; Aichholzer et al. 2013; Denzler et al. 2013, 2014). Boström (1994) reported spruce bending strength \({r}^{2}\) values in a range from 34 to 55%, depending on cross-section; the used grading machine was a combination of gamma radiation (for density) and microwaves (for moisture content and grain deviation). Combining microwave grain angle measurements with Edyn, Denzler and Weidenhiller (2015) found \({r}^{2}\) values of up to 69% with spruce tension strength.
1.2 Hardwood strength grading technology
In contrast to the large amount of literature on softwood strength grading, results on hardwood strength grading are more limited. Diebold et al. (2000) reported tests including beech and oak specimens in addition to several softwood species. They concluded that machine strength grading was feasible for all considered species and that knot information was useful for all examined scanning combinations. Ehrhart et al. (2016) found only a low \({r}^{2}=22\%\) between Edyn and tensile strength for beech. Knot information was identified as relevant for beech strength grading, even though there were relatively few knots in the timber. Knot-free timber also showed high strength variations, where main influencing factors were obvious grain deviation, discolouration and wavelike annual ring patterns (Ehrhart et al. 2016). For green oak timber, Kretschmann and Green (1999) observed an \({r}^{2}=32\%\) between Edyn and bending strength. Vega et al. (2012) reported up to \({r}^{2}=17\%\) between Edyn and bending strength for chestnut; by adding specimen length and a visual knot variable, \({r}^{2}\) could be increased to 33%. Nocetti et al. (2016) found a slightly better coefficient of determination (\({r}^{2}=24\%\)) between Edyn and bending strength for chestnut; this was sufficient to derive settings according to EN 14081-2 (2012). Van de Kuilen and Torno (2014) found \(r=0.44\) (i.e. \({r}^{2}=19\%\)) between Edyn and tensile strength for ash which they attributed to different measurement lengths for Edyn (5 m) and tensile strength (0.2 m).
Concerning grain deviation, several approaches have already been tested on hardwoods. For red oak, black cherry and black walnut, Zhou and Shen (2003) demonstrated that the tracheid effect is less effective in measuring grain deviation. They explained this by anatomical differences between softwoods and hardwoods—smaller and shorter fibrous cells in comparison to softwood tracheid cells. They proposed a different evaluation method of the laser ellipse images on the wood surface to improve measurement precision. For oak, Daval et al. (2015) even stated that grain deviation was not measurable using the tracheid effect; they suggested measuring the elliptical shape of heat conduction instead of laser light scattering. As heating the wood surface requires some time, industrial processing rates are still out of reach for this method (Daval et al. 2015). Schlotzhauer et al. (2018) compared laser scanning, microwave scanning and electrical field strength measurement with manual reference measurements for ash, basswood, beech, birch, maple, oak and spruce. No system was capable of determining grain angle for ash; laser scanning failed on oak, confirming the observations by Zhou and Shen (2003) and Daval et al. (2015), but correlated well with the reference measurements on knot-free samples of basswood, beech, maple and oak. Microwave scanning worked well for maple, oak and spruce but had little correlation with the reference measurements on the other species. Electrical field strength measurements worked well on beech, oak and spruce, less well on birch and maple and failed on basswood (Schlotzhauer et al. 2018). Ehrhart et al. (2018) observed that for beech, the spindles formed by the medullary rays were a good indicator of the strength-relevant grain deviation. They developed an automatic image analysis to calculate grain deviation from the spindle pattern and confirmed good correspondence with fracture patterns. They judged their method to be readily implementable in state-of-the-art strength grading machines and expected that it would also work for other species with similar anatomical structures, like for example oak.
Nocetti et al. (2016) noted that automatically measuring knots on chestnut is more difficult than on softwoods and that knots have a rather low influence on chestnut bending strength.
In view of the large number of tropical hardwood species, which could be used for structural purposes, species-independent timber grading would be of interest (Firmanti et al. 2005; Ravenshorst 2015). Firmanti et al. (2005) studied the prediction of bending strength by MOE from flatwise bending. On a dataset of 1094 specimens of uniform size, they achieved \({r}^{2}=55\%\) but found that including species information would allow for \({r}^{2}\) values in the range from 60 to 71%. Ravenshorst (2015) developed an approach based on density and Edyn. According to his research, clear wood bending strength depends on density but not on species. He assumed that the main strength reducing factors are knots and global grain deviation, and that for each species, one of those factors dominates the other. This necessitated two strength models, one for each strength-reducing factor. He achieved \({r}^{2}=52\%\) for a weighted nonlinear regression of bending strength based on density and Edyn on a dataset of 2218 specimens from 24 tropical hardwood species (Ravenshorst 2015).
Şahin Kol and Yalçın (2015) measured dielectric properties of small specimens of fir and oak using microwaves. With bending strength, they found \({r}^{2}\) values of up to 46% for fir and up to 78% for oak.
1.3 Aim of the current paper
To sum up, there is a wealth of literature on softwood strength grading. The virtue of combining several scanning technologies has been emphasized by many authors. For hardwoods, much less is known. Most hardwood strength models to date only use Edyn, although the relevance of other parameters like knots or grain deviation has been recognized. The current paper aims to improve on the current strength models, combining grain deviation measurement by microwave scanning with Edyn measurement. Four European hardwood species are considered in this preliminary study: ash (Fraxinus excelsior L.), beech (Fagus sylvatica L.), chestnut (Castanea sativa Mill.), and oak (Quercus robur L., Quercus petraea (MATT.) LIEBL).
2 Materials and methods
The material for the study was collected in the context of the WoodWisdom-Net project European hardwoods for the building sector (see also the acknowledgements). In this project, data were gathered beginning at the stand, including tree, log and board information. The calculations in the present paper are solely based on the board information. However, the information from which tree each board came was used for splitting the data into training and test series (Sect. 2.7).
2.1 Roundwood samples
The key data of the roundwood samples are summarized in Table 1. The sample of ash (Fraxinus excelsior L.) roundwood came from a regular cutting in a mixed deciduous forest close to the city of Freiburg in south-western Germany. The beech (Fagus sylvatica L.) trees were sampled from thinnings of three beech stands in growth trial plots located in the north-eastern part of the Swabian Jura in southern Germany. For oak, eight trees were felled in a 102-year old pure oak stand in northern Baden-Württemberg. For this site, the oak species is not known, but only the genus Quercus ssp. However, with respect to the wood structure and the intrinsic mechanical wood properties of the two indigenous oak species in question, Quercus petraea (MATT.) LIEBL and Quercus robur L., it can be assumed that there would be no differences in the mechanical wood properties for both species. The roundwood of chestnut (Castanea sativa MILL.) originated from a 36-years old pure stand in the west of Baden-Württemberg.
2.2 Board samples
The logs were sawn into a total of 384 rough boards in a sawmill (chestnut, oak) or using a mobile horizontal band saw (ash, beech). Subsequently, all boards were kiln-dried to a target moisture content of 12 ± 2% and then planed on all faces with a four-side planer. Final cross-sections were 25 × 120 mm² (nine oak boards), 30 × 200 mm² (62 ash boards) and 30 × 150 mm² (313 boards of all species). A total number of 116 ash, 86 beech, 97 chestnut and 85 oak boards were obtained.
Due to resource limitations, the preliminary study on the potential of microwave measurements for hardwood boards was restricted to about half of the available material and to one cross-section. From the ash, beech, chestnut and oak boards of cross-section 30 × 150 mm², 38, 42, 45 and 46 specimens were selected, respectively. The aim was to pick 20 defect-free specimens with low grain deviation and 20 specimens with high grain deviation.
2.3 Measurements on boards
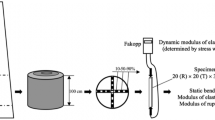
After drying and planing, the eigenfrequency (f) was measured with a Microtec ViScan machine. The board density value (ρ) required for calculating Edyn from f was calculated from weight and board dimensions. Edyn and ρ were corrected to a moisture content of 12% according to EN 384 (2010).
The test span for the tensile tests was 9 times the larger cross-sectional dimension, in this case 9 × 150 mm = 1350 mm (EN 408 2012). Within the test span, all knots of a diameter equal to or larger than 5 mm were recorded manually and used to calculate the maximum total knot area ratio (tKAR) over a sliding range of 150 mm. In other words, for any range of 150 mm within the test span, all knots within that range were projected to the cross-section of the piece. The total knot area ratio is the ratio of the area of this knot projection to the area of the cross-section. The largest of all these total knot area ratios for the different ranges of 150 mm within the test span of a single piece of timber was defined as the piece’s tKAR.
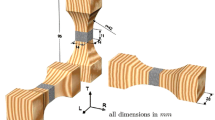
The test span was also scanned with the microwave scanner described in Sect. 2.4. The measurement was taken on a grid of 12.5 × 12.5 mm² cells. This resulted in 108 grid columns along the length of the board and 12 grid rows across the width of the board (Fig. 1).

Layout of microwave measurements. a of the whole board, only the test span was measured; broken line delineates the detail shown in b; b Detail of a; microwave measurements were arranged in rows and columns of height/width 12.5 mm
Tensile strength was measured according to EN 408 (2012). Required correction factors according to EN 384 (2010) regarding moisture content and width were applied. During the tensile strength tests, one board each from the selected ash, beech and oak boards and two from the selected chestnut boards had to be excluded due to failure in the clamping section. Thus, 37, 41, 43 and 45 boards of ash, beech, chestnut and oak respectively remained in the analysis, in total 166 boards.
2.4 The microwave scanner
The microwave scanner used is a prototype constructed by TU Wien (Denzler et al. 2013; Denzler and Weidenhiller 2015). It consists of an array of 28 transmitter antennas of 12.5 mm width each located perpendicular to the feed direction of the timber (which is fed in lengthwise) and three receiver antennas, which are placed in a way that one measures transmission perpendicular to the wood surface, and the other two sensors measure transmission at 45° degree angles to the wood surface. The scanner is set up to capture measurements on a grid of 12.5 by 12.5 mm² cells on the larger face of the timber (width), whereas the information across the smaller cross-sectional dimension of the timber (thickness) is averaged for each cell.
The basic parameters obtained from the microwave receiver antennas are damping (energy loss through dissipation within the timber) and phase-shift (change in the location of “hills” and “valleys” of the waveline), both in fibre direction and perpendicular to the fibre direction (Schajer and Orhan 2005). To obtain damping and phase-shift, microwaves are sent from transmitter antennas through the timber and measured by receiver antennas.
The following parameters are calculated for each cell: damping and phase-shift along (\({att}_{\text{u}}\) and \({{\Phi }}_{\text{u}}\)) and perpendicular (\({att}_{\text{v}}\) and \({{\Phi }}_{\text{v}}\)) to the grain (Schajer and Orhan 2005; Denzler et al. 2014), fibre orientation projected to the larger face of the timber (horizontal angle ϑ; Schajer and Orhan 2005; Aichholzer et al. 2013; Denzler et al. 2013), and fibre orientation projected to the smaller face of the timber (diving angle ω; Koppensteiner et al. 2017).
2.5 Preparation of microwave data for the density models
Microwave attenuation and phase-shift correlate to timber density ρ and moisture content (Schajer and Orhan 2005; Denzler et al. 2014). In this paper, we only talk about inferring density, but the approach to inferring moisture content is very similar. Wood density can be inferred from attenuation and phase-shift by means of multivariate regression models; separate models may need to be derived for each wood species (Schajer and Orhan 2006). To apply the model to timber specimens of different thicknesses, thickness needs to be included into the regression (Denzler et al. 2014). In the present paper, focus was put on one thickness. While it is possible to determine density distributions across the timber surface (which might be interesting for detecting knots), the focus was on determining the average density of the entire board. As a basis for the regression model for average wood density, average values of damping and phase-shift along the grain (\({att}_{\text{u}}\) and \({{\Phi }}_{\text{u}}\)) and perpendicular to the grain (\({att}_{\text{v}}\) and \({{\Phi }}_{\text{v}}\)) were calculated.
2.6 Preparation of microwave data for the strength models
Tension strength is determined by the weakest section of the board, which in turn is often characterized by strong grain deviation (i.e. deviation of the fibre orientation from the axial direction of the board). For both horizontal angles ϑ and diving angles ω, three types of grain deviation were considered: global grain deviation, local grain deviation, and local changes in grain deviation.
Global grain deviation of a board was calculated as average ϑ or ω over all rows and columns (Fig. 1) resulting in two values per board. The calculation was repeated using only the central eight of the twelve rows, resulting in two further values per board.
For local grain deviation, moving averages were calculated over blocks of c columns and 8 or 12 rows, where c ranged from three to twenty columns. The local grain deviation value for each combination of some c, 8 or 12 rows and ϑ or ω was calculated as the maximum over the absolute value of the moving average. Per board, \(18\times 2\times 2=72\) values for local grain deviation were thus obtained.
For local changes in grain deviation, the moving averages were again taken, but now absolute differences between neighbouring blocks of c columns and 8 or 12 rows were calculated pairwise. Taking the maximum over the pairwise absolute differences resulted in 72 values of local change in grain deviation per board.
2.7 Splitting of the data in training and test series
Aiming at as good an independent verification as possible of the models developed in this paper, the dataset was split into a training series and a test series. The models were developed based on the training series, while the test series was used for verification.
To achieve a test series, which is maximally independent from the training series, it was decided to either assign all boards from one tree to the training series or assign all to the test series. Additionally, the training series should be representative of the entire available data. The test series performance of the models could thus be taken as a first estimate of how good such models could be if they were trained on a fully representative dataset instead of on the data of the present preliminary study.
Therefore, the sum of the absolute differences between training series and test series of the following quantities were calculated: mean strength, standard deviation of strength, mean density, standard deviation of density, proportion of boards with knots in the test span. From all possible assignments of trees to training series or test series, the one assignment was chosen, which minimized this sum of absolute differences.
2.8 Construction of regression models
Linear multivariate regression models were derived using SPSS 20 (Anon. 2011; stepwise regression with default parameters: enter variables at a significance level of 5%, remove variables at a significance level of 10%). Models were derived separately for each species, using only the training series. Sometimes it happened that the output of a regression equation for a board was negative. Such values were forced to zero.
For the density models, four variables were available: \({att}_{\text{u}}\), \({{\Phi }}_{\text{u}}\), \({att}_{\text{v}}\) and \({{\Phi }}_{\text{v}}\) (see 2.5). Unless only a model with one variable was produced by SPSS, the model with two variables was selected, expecting that one would be information along the grain (\({att}_{\text{u}}\) or \({{\Phi }}_{\text{u}}\)), and the other would be information perpendicular to the grain. Models with a larger number of variables were avoided on the assumptions that one information from each direction should be sufficient and that models with more variables risked overfitting the training dataset.
For the strength models, 152 variables were available. Stepwise regression produces a sequence of increasingly complex models; in this case, up to six variables could be entered at a significance level of 5%. To avoid overfitting, a model with more than three variables was never selected, and models were also excluded where some grain deviation variable had a positive coefficient, i.e. increasing grain deviation would increase the strength estimate. This usually occurred for the second grain deviation variable of a group where the first had a negative coefficient. Due to the correlations between the grain deviation variables in a group, such a combination of a negative and a positive coefficient effectively meant that fitting was done to random noise.
To facilitate discussion, the 152 variables were assigned to one of several groups, each with its own variable group symbol (Table 2). Three classes of models (eρk, m, me) were examined. A model in a certain model class was allowed to include variables from certain variable groups, but not from others (Table 2). In the following paragraphs, the model classes are explained in detail.
As a baseline for the microwave-based strength models, regression models were calculated depending on Edyn, ρ and tKAR, similarly to modern strength grading machines for softwood, like the GoldenEye 706 from Microtec (Bacher 2008). These models form the model class “eρk”.
Model class “m” comprised strength models purely based on microwave variables. 148 grain deviation variables were available (\(4+72+72\); see previous section and Table 2). One further microwave-based regression variable was included: the board density value from the above-mentioned density models, leading to a total of 149 variables.
Finally, the potential of a combined machine was explored by combining the microwave variables with Edyn (model class “me”).
Each regression model provided an estimate of a board’s tension strength; this estimate will be called an Indicating Property (IP) value for the board (see EN 14081-2 2012). When such IP values were plotted against the corresponding tension strength values \({f}_{t}\) in a scatterplot, it was often noticed that this point cloud had a curved shape. This is an indicator that the true relationship between the independent variables and \({f}_{\text{t}}\) is nonlinear. To account for this aspect, linear regression was tested on \(\text{log}{f}_{\text{t}}\) instead of \({f}_{\text{t}}\). If such an exponential model better fits the relationship, it will allow for better strength predictions on new data.
The models were then applied to the test series. As a rough measure of model performance, the coefficients of determination (\({r}^{2}\)) of the models on the training series (\({r}_{\text{training}}^{2}\)) and the test series (\({r}_{\text{test}}^{2}\)) were compared. There are three possibilities how \({r}_{\text{training}}^{2}\) and \({r}_{\text{test}}^{2}\) can relate to each other: First, they can be approximately equal. This is taken as an indication that the corresponding model contains only variables, which really relate to strength. Second, \({r}_{\text{training}}^{2}\) can be much larger than \({r}_{\text{test}}^{2}\). In this case, the model derivation process has probably overfit the model to random noise present in the training series. Third, \({r}_{\text{training}}^{2}\) can be much lower than \({r}_{\text{test}}^{2}\). This was hard to interpret; it was primarily attributed to the small sample size of the present dataset. Such high \({r}_{\text{test}}^{2}\) values were read as “optimistic” and the lower \({r}_{\text{training}}^{2}\) value was considered as the more realistic estimate of the corresponding model performance. Generally, \({r}^{2}\) values are susceptible to outliers in the data, which is especially noticeable in small datasets.
After comparing \({r}_{\text{training}}^{2}\) and \({r}_{\text{test}}^{2}\) for each model, variables were manually added or removed from some of the models and the coefficients on the training series were recalculated. For models with overfitting (\({r}_{\text{training}}^{2}\) much larger than \({r}_{\text{test}}^{2}\)), it was attempted to remove variables. For models with low \({r}_{\text{training}}^{2}\) and cases where no model for the combined machine (model class “me”) could be derived, the inclusion of additional variables to an existing model was tested.
Due to the small sample size, the uncertainty in the \({r}^{2}\) estimates is especially relevant. Therefore, bootstrapped confidence intervals around the coefficients of determination of the final density and strength models were calculated. The bootstrapping procedure was implemented using the package “boot” (Canty and Ripley 2017) in the statistics software R (R Core Team 2018).
3 Results
3.1 Overall strength data
Table 3 summarizes the board characteristics on the split data per species between training series and test series. The differences in sample size between training and test series are due to the specific mode of splitting in training and test series, which always included all pieces cut from one tree either in training or in test (cf. Sect. 2.7). Figure 2 shows the distribution of the basic test data, comparing the values of the training series and the test series.

Distribution of a tensile strength, b Edyn and c density; separated for species and series. N = 88; 78 (training; test)
3.2 Density
Multivariate regression on the training series resulted in the following density models for the four species:
Figure 3 shows scatterplots of density measured per microwave technology versus reference wood density ρ. The \({r}_{\text{training}}^{2}\) values are always larger than the \({r}_{\text{test}}^{2}\) values. In the case of beech, the \({r}_{\text{test}}^{2}\) value drops to zero; for the other species, the \({r}_{\text{test}}^{2}\) value remains above 60%. Confidence intervals for the \({r}^{2}\) values are shown in Fig. 5b.

Density calculated from microwave measurements versus board density ρ, by species and training/test, including regression lines and coefficients of determination (in %) both for training and test series
3.3 Tension strength
Table 4 summarises the matrix of all models for tension strength. The first row for each species (in bold) describes the model which was derived by the automated variable selection process in SPSS; any further rows list manually modified models.
The automatic variable selection process produced models in model class “me” only for ash and chestnut (both linear and exponential); for beech and oak, the “me” models provided no significant improvement over the “m” models.
For each species and model class of both linear and exponential models, the model with the best performance was identified and marked with an asterisk (Table 4). The manual modifications and arguments for best performance are further elaborated in the discussion below.
Figure 4 shows the correlation between the linear strength models (IP on horizontal axis) and tension strength obtained by destructive testing (\({f}_{t}\)) for the models with the best performance per species and model class. Confidence intervals for the \({r}^{2}\) values are shown in Fig. 5a.


4 Discussion
As desired, the split in training and test series achieved similar distributions of density and strength between the two series (Fig. 2a, c). Regarding Edyn (Fig. 2b), there are differences between training and test for ash and beech: + 1.6 kN/mm² respectively − 1.2 kN/mm² in the mean value (Table 3). Such differences are possible because it was only striven for equal distribution of strength and density (cf. section 2.7). The presence of such differences indicates that the training and test series are indeed independent of one another. For ash, the coefficient of variation (CoV) of Edyn for the training series is far higher than any other CoV of Edyn, but the CoV for the test series is the lowest (Table 3). To a lesser degree, this pattern of high training CoV and low test CoV can also be observed for ash tensile strength. These differences in CoV might influence the \({r}_{\text{training}}^{2}\) and \({r}_{\text{test}}^{2}\) values of the ash strength models.
Density measurement per microwave technology (Fig. 3) works well for all species. The \({r}^{2}\) values remain mostly high for the test series. The exception of beech where \({r}_{\text{test}}^{2}=0\%\) can be explained by the narrow range of wood density values; but even for beech all microwave measurements are within ± 7% of the board density ρ, and the average difference between the two measurement methods per specimen is less than 1 kg/m³.
The 95% confidence intervals for the \({r}^{2}\) values are rather wide, which shows that confirmation by a larger sample is required. The most extreme case is ash with \({r}_{\text{test}}^{2}\) between 3% and 77%. In the ash test sample there is only one specimen with \(\rho <650\) kg/m³ while in the ash training sample there are five such specimens—this accounts for the large uncertainty about the \({r}_{\text{test}}^{2}\) value.
For spruce, Lundgren et al. (2007) observed \({r}_{\text{test}}^{2}=77\%\) between microwave phase data and density; similar values were reported by Denzler et al. (2014). Possibly, similar \({r}^{2}\) values could be achieved for hardwood density measurements. To obtain generally applicable models for microwave density measurement for these four hardwood species, it will be important to include the relevant range of board thickness and moisture content as well as the full range of board density values observed in practice. The present study indicates that there would be merit in such an extended study.
While the density models work similarly well for each species except for beech (where the spread of the lab density values is not sufficient), there are wide differences in the performance of the strength models between the four species.
The linear and exponential models of class “eρk” work well for beech and chestnut (Table 4; Fig. 4). They lead to \({r}_{\text{test}}^{2}\) values of 60% and more, comparable to coefficients of determination for softwood strength models (Hanhijärvi and Ranta-Maunus 2008; Denzler and Weidenhiller 2015). The oak “eρk” models have rather low coefficients of determination of about 30%, but they are similar for training and test series. These models are based only on tKAR, while for the other species the “eρk” models always include Edyn. Manual inclusion of Edyn in the linear oak model results in a somewhat higher value \({r}_{\text{training}}^{2}=33\text{\%}\) and \({r}_{\text{test}}^{2}=54\text{\%}\), so such a manual addition seems justified. The same applies to the exponential oak model (Table 4). On the contrary, the “eρk” models for ash show distinct overfitting (\({r}_{\text{training/test}}^{2}=76\text{\%}/2\text{\%}\) for the linear and \({r}_{\text{training/test}}^{2}=78\text{\%}/3\%\) for the exponential model). Removing ρ from these models considerably reduces the differences between \({r}_{\text{training}}^{2}\) and \({r}_{\text{test}}^{2}\) both for the linear and the exponential model.
The microwave models (model class “m”) have lower \({r}_{\text{test}}^{2}\) than the “eρk” models—only the oak models come close. Forcing a diving angle (variable group ω) into the oak models gives a consistent improvement both in training and test so that the oak “m” models perform as well or better than the “eρk” models if one considers both \({r}_{\text{training}}^{2}\) and \({r}_{\text{test}}^{2}\).
The automatically derived ash models and exponential chestnut model of model class “m” show clear signs of overfitting. Removing the ω variable from the exponential chestnut model leads to a single variable model with low but consistent \({r}_{\text{training/test}}^{2}=36\text{\%}/31\text{\%}\), which is similar to the corresponding linear model. On the other hand, removing a variable from the exponential ash model gives no improvement. The automatically derived linear ash model has only one variable and still looks like overfitting; adding a variable does not improve the model performance.
The models of model class “m” for beech also have a markedly lower \({r}_{\text{test}}^{2}\) than \({r}_{\text{training}}^{2}\) that appears like overfitting, but removing a variable does not change this. Still, the \({r}_{\text{test}}^{2}\) values are the highest of all “m” models, in particular for the exponential model (\({r}_{\text{test}}^{2}=51\%\) is comparable to \({r}^{2}\) values of softwood strength models).
Combining microwave variables and Edyn (model class “me”) leads to the best model for ash found in this study (\({r}_{\text{test}}^{2}=47\%\)). For chestnut, the exponential “me” model even leads to \({r}^{2}\) values around 66% both for training and test, which comes close to the \({r}^{2}\) of the “eρk” model (\({r}_{\text{training}}^{2}=70\%\); the optimistic \({r}_{\text{test}}^{2}=93\%\) is disregarded).
Manual inclusion of Edyn into the beech models leads to competitive \({r}_{\text{test}}^{2}\) values, especially for the exponential model (\({r}_{\text{test}}^{2}=64\%\)). As the difference between \({r}_{\text{test}}^{2}\) and \({r}_{\text{training}}^{2}\) is high for these manually adjusted “me” models, one might consider removing the ω variable—this reduces the difference for the linear model, but not for the exponential model.
For oak, the manual inclusion of Edyn into the models does not improve the \({r}^{2}\) values over those of the “m” models—\({r}_{\text{test}}^{2}\) remains around 45% for the linear and the exponential model.
The widths of the confidence intervals for the \({r}^{2}\) values and especially the \({r}_{\text{test}}^{2}\) values (Fig. 5a) emphasize the smallness of the available dataset. In a small dataset, a single data point can have a large influence on the resulting model and \({r}^{2}\) value. Additional tests with a larger number of specimens are recommended.
Comparison with results from other studies focuses on pure Edyn models (not shown in Figs. 4, 5; Table 4). Between Edyn and ash tension strength, van de Kuilen and Torno (2014) achieved \({r}^{2}=19\%\)—on the present data, it was found \({r}_{\text{training/test}}^{2}=43\text{\%}/0\text{\%}\) between Edyn and tension strength, and \({r}^{2}=24\%\) if it wasn`t split in training and test. So, the same overall strength of correlation was found. For beech, Ehrhart et al. (2016) reported \({r}^{2}=22\%\) between Edyn and tension strength compared to \({r}_{\text{training/test}}^{2}=62\text{\%}/57\text{\%}\) on the present data—the reason for this is unclear.
For chestnut and oak, only models relating Edyn with bending strength, with \({r}^{2}=24\%\) for chestnut (Nocetti et al. 2016) and \({r}^{2}=32\%\) for oak (Kretschmann and Green 1999) were found. The present data yielded a much stronger relationship between Edyn and tension strength for chestnut (\({r}_{\text{training/test}}^{2}=50\text{\%}/80\text{\%})\). For oak, this overall value is on the same level (\({r}^{2}=33\%\)) as Kretschmann and Green (1999), with an uneven distribution between training and test (\({r}_{\text{training/test}}^{2}=18\text{\%}/48\text{\%})\). Despite this uneven distribution, the difference between \({r}_{\text{training}}^{2}\) and \({r}_{\text{test}}^{2}\) is small for the oak “m” and “me” models (Fig. 5a).
Can exponential models (linear regression with the dependent variable \(\text{log}{f}_{t}\)) better fit the strength data than the linear models? A look at the linear models in Fig. 4 confirms that many of the relationships have a curved tendency, in particular for chestnut and oak, but also for beech. The relationship between IP and \({f}_{t}\) for ash appears more linear, although it is difficult to tell because of the widely scattering data points. On the other hand, there is no recognizable curved tendency in the exponential beech models and the exponential “eρk” and “me” models for chestnut. For the oak models and the chestnut “m” model, the curved tendency remains despite the exponential model structure.
Looking at the \({r}^{2}\) values (Table 4; Fig. 5a), one sees some improvements in the \({r}_{\text{test}}^{2}\) values (all beech models, chestnut “eρk” and “me” models) from linear to exponential models. These improvements are gradual; comparing the two corresponding parts of Table 4 respectively Fig. 5a, one finds that between linear and exponential models there are many similarities: of model variable structure, \({r}^{2}\) values and of \({r}^{2}\) confidence interval widths. The widths of the confidence intervals (Fig. 5a) also mean that the size of the present dataset is not sufficient to identify performance differences between linear and exponential models.
5 Conclusion
This preliminary study emphasized the potential of microwave scanning with respect to hardwood strength grading, in particular in combination with a dynamic stiffness measurement (Edyn). Such a combination led to good results for all four species; especially the exponential models for beech and chestnut were competitive with coefficients of determination well over 60%. As the observed correlations between Edyn and tension strength for these two species were higher in the present research than in previous studies, some further validation is recommended.
Density measurement by microwaves promises to work equally well for hardwoods as for softwoods and could be an alternative to density measurement by X-ray scanning. So, microwave scanning proves to be a versatile tool for assessing strength and density with one technology also for hardwoods. Like for softwoods, assessing moisture content should be possible as well; for this, a dataset with a wider range of moisture content values is required. A commercial implementation, especially for hardwoods, seems viable.
Generally, it seems that the (tension) strength of ash and oak is more difficult to model than the strength of beech and chestnut, or that the former depends more strongly on other characteristics, which were not part of this analysis. Due to the preliminary nature of this study here with a limited number of specimens, all results should be interpreted with care; a further study with a larger sample is recommended.
References
Aichholzer A, Arthaber H, Schuberth C, Mayer H (2013) Non-destructive evaluation of grain angle, moisture content and density of spruce with microwaves. Eur J Wood Prod 71(6):779–786. https://doi.org/10.1007/s00107-013-0740-1
Anon (2011) IBM SPSS statistics 20 algorithms. http://public.dhe.ibm.com/software/analytics/spss/documentation/statistics/20.0/en/client/Manuals/IBM_SPSS_Statistics_Algorithms.pdf. Accessed 25 Jan 2019
Bacher M (2008) Comparison of different machine strength grading principles. In: Gard WF, van de Kuilen JG (eds) End user’s needs for wood material and products. In: Proceedings of the conference in COST E53 quality control for wood and wood products, pp 183–193 http://www.coste53.net/downloads/Delft/Presentations/COSTE53-Conference_Delft_Bacher.pdf. Accessed 25 Jan 2019
BMEL (2016) Ergebnisse der Bundeswaldinventur 2012 (Results of the federal forest inventory 2012) (In German), Berlin. https://www.bmel.de/SharedDocs/Downloads/Broschueren/Wald-Rohholzpotential-40Jahre.pdf. Accessed 21 Jan 2019
BMEL (2017) Wald und Rohholzpotenzial der nächsten 40 Jahre: Ausgewählte Ergebnisse der Waldentwicklungs- und Holzaufkommensmodellierung 2013 bis 2052 (Forest and raw material potential for the next 40 years: selected results of modelling forest development and timber production 2013–2052) (In German), Berlin. https://www.bmel.de/SharedDocs/Downloads/Broschueren/ErgebnisseBWI2012.pdf. Accessed 21 Jan 2019
Boström L (1994) Machine strength grading. Comparison of four different systems. SP Report nr. (1994:49). http://www.diva-portal.org/smash/get/diva2:961864/FULLTEXT01.pdf. Accessed 25 Jan 2019
Canty A, Ripley BD (2017) boot: Bootstrap R (S-Plus) Functions. R package version 1.3–20. https://cran.r-project.org/web/packages/boot/. Accessed 25 Jan 2019
Daval V, Pot G, Belkacemi M, Meriaudeau F, Collet R (2015) Automatic measurement of wood fiber orientation and knot detection using an optical system based on heating conduction. Opt Express 23(26):33529–33539. https://doi.org/10.1364/OE.23.033529
Denzler JK, Weidenhiller A (2014) New perspectives in machine strength grading: or how to identify a top rupture. In: Aicher S, Reinhardt H, Garrecht H (eds) Materials and joints in timber structures, vol 9. Springer, Netherlands, pp 761–771
Denzler JK, Weidenhiller A (2015) Microwave scanning as an additional grading principle for sawn timber. Eur J Wood Prod 73(4):423–431. https://doi.org/10.1007/s00107-015-0906-0
Denzler JK, Koppensteiner J, Arthaber H (2013) Grain angle detection on local scale using microwave transmission. Int Wood Prod J 4(2):68–74. https://doi.org/10.1179/2042645313Y.0000000030
Denzler JK, Lux C, Arthaber H (2014) Contactless moisture content and density evaluation of sawn timber using microwave transmission. Int Wood Prod J 5(4):200–206. https://doi.org/10.1179/2042645314Y.0000000066
Diebold R, Schleifer A, Glos P (2000) Machine grading of structural sawn timber from various softwood and hardwood species. In: Proceedings of the 12th International Symposium on Nondestructive Testing of Wood University of Western Hungary, Sopron, 13–15 September 2000
Ehrhart T, Fink G, Steiger R, Frangi A (2016) Experimental investigation of tensile strength and stiffness indicators regarding European Beech timber. In: Eberhardsteiner J, Winter W, Fadai A (eds) WCTE 2016 e-book (Proceedings of the 2016 world conference on timber engineering, 22–25 August 2016, Vienna, Austria), pp 600–607 (ISBN 9783903024359)
Ehrhart T, Steiger R, Frangi A (2018) A non-contact method for the determination of fibre direction of European beech wood (Fagus sylvatica L.). Eur J Wood Prod 76(3):925–935. https://doi.org/10.1007/s00107-017-1279-3
EN 14081-2 (2012) Timber structures—strength graded structural timber with rectangular cross section. Part 2: machine grading—additional requirements for initial type testing (EN 14081-2:2010 + A1:2012-11). https://shop.austrian-standards.at/action/en/public/details/462133/OENORM_EN_14081-2_2013_01_15. Accessed 25 Jan 2019
EN 384 (2010) Structural timber—determination of characteristic values of mechanical properties and density. https://shop.austrian-standards.at/action/en/public/details/362300/OENORM_EN_384_2010_05_15. Accessed 25 Jan 2019
EN 408 (2012) Timber structures—structural timber and glued laminated timber—determination of some physical and mechanical properties (EN 408:2010 + A1:2012-07). https://shop.austrian-standards.at/action/en/public/details/448783/DIN_EN_408_2012_10. Accessed 25 Jan 2019
Firmanti A, Bachtiar ET, Surjokusumo S, Komatsu K, Kawai S (2005) Mechanical stress grading of tropical timbers without regard to species. J Wood Sci 51(4):339–347. https://doi.org/10.1007/s10086-004-0661-z
Gil-Moreno D, Ridley-Ellis DJ (2015) Comparing usefulness of acoustic measurements on standing trees for segregation by timber stiffness. In: Ross RJ, Gonçalves R, Wang X (eds) Proceedings: 19th international nondestructive testing and evaluation of wood symposium, pp 378–385. https://www.napier.ac.uk/research-and-innovation/research-search/outputs/comparing-usefulness-of-acoustic-measurements-on-standing-trees-for-segregation-by-timber-1. Accessed 25 Jan 2019
Hanhijärvi A, Ranta-Maunus A (2008) Development of strength grading of timber using combined measurement techniques. Report of the Combigrade-project—phase 2. https://www.vtt.fi/inf/pdf/publications/2008/P686.pdf. Accessed 25 Jan 2019 (ISBN 978-951-38-7106-2)
Hunger F, van de Kuilen JG (2018) Slope of grain measurement: a tool to improve machine strength grading by detecting top ruptures. Wood Sci Technol 52(3):821–838. https://doi.org/10.1007/s00226-018-1000-7
IGN (2014) Résultats d’inventaire forestier—Résultats standards (campagnes 2009 à 2013) (standardized results of the forest inventory (campaigns 2009–2013)): Tome national version régions administratives, Saint-Mandé, France (In French). https://inventaire-forestier.ign.fr/IMG/pdf/RS_0913_FR_RA.pdf. Accessed 25 Jan 2019
Kandler G, Lukacevic M, Füssl J (2016) An algorithm for the geometric reconstruction of knots within timber boards based on fibre angle measurements. Constr Build Mater 124:945–960. https://doi.org/10.1016/j.conbuildmat.2016.08.001
Kollmann F, Cote WA Jr (1984) Principles of wood science and technology, reprint. Springer, Berlin
Koppensteiner J, Denzler JK, Weidenhiller A, Arthaber H, Leder N (2017) Method and apparatus for estimating the projection on a reference plane of the direction of extension of the fibres of a portion of a wooden plank (EP2829876 (B1))
Kretschmann DE, Green DW (1999) Mechanical grading of oak timbers. J Mater Civ Eng 11(2):91–97. https://doi.org/10.1061/(ASCE)0899-1561(1999)11:2(91)
Lukacevic M, Füssl J, Eberhardsteiner J (2015) Discussion of common and new indicating properties for the strength grading of wooden boards. Wood Sci Technol 49(3):551–576. https://doi.org/10.1007/s00226-015-0712-1
Lundgren N, Brännström M, Hagman O, Oja J (2007) Predicting the strength of norway spruce by microwave scanning: a comparison with other scanning techniques. Wood Fiber Sci 39(1):167–172
Nocetti M, Brunetti M, Bacher M (2016) Efficiency of the machine grading of chestnut structural timber: prediction of strength classes by dry and wet measurements. Mater Struct 49(11):4439–4450. https://doi.org/10.1617/s11527-016-0799-3
Nyström J (2003) Automatic measurement of fiber orientation in softwoods by using the tracheid effect. Comput Electron Agric 41(1–3):91–99. https://doi.org/10.1016/S0168-1699(03)00045-0
Olsson A, Oscarsson J, Serrano E, Källsner B, Johansson M, Enquist B (2013) Prediction of timber bending strength and in-member cross-sectional stiffness variation on the basis of local wood fibre orientation. Eur J Wood Prod 71(3):319–333. https://doi.org/10.1007/s00107-013-0684-5
R Core Team (2018) R: A Language and Environment for Statistical Computing. https://www.R-project.org/. Accessed 25 Jan 2019
Ravenshorst GJP (2015) Species independent strength grading of structural timber. Dissertation Thesis, Technische Universiteit Delft
Şahin Kol H, Yalçın İ (2015) Predicting wood strength using dielectric parameters. BioResour. https://doi.org/10.15376/biores.10.4.6496-6511
Schajer GS, Orhan FB (2005) Microwave non-destructive testing of wood and similar orthotropic materials. Subsurf Sens Technol Appl 6(4):293–313. https://doi.org/10.1007/s11220-005-0014-z
Schajer GS, Orhan FB (2006) Measurement of wood grain angle, moisture content and density using microwaves. Holz Roh Werkst 64(6):483–490. https://doi.org/10.1007/s00107-006-0109-9
Schlotzhauer P, Wilhelms F, Lux C, Bollmus S (2018) Comparison of three systems for automatic grain angle determination on European hardwood for construction use. Eur J Wood Prod 76(3):911–923. https://doi.org/10.1007/s00107-018-1286-z
Torgovnikov GI (1993) Dielectric properties of wood and wood-based materials. Springer series in wood science. Springer-Verlag, Berlin
van de Kuilen JG, Torno S (2014) Materialkennwerte von Eschenholz für den Einsatz in Brettschichtholz: Schlussbericht zum Vorhaben [Material characteristics of ash timber for use in glue laminated timber: final report], Munich
Vega A, Dieste A, Guaita M, Majada J, Baño V (2012) Modelling of the mechanical properties of Castanea sativa Mill. structural timber by a combination of non-destructive variables and visual grading parameters. Eur J Wood Prod 70(6):839–844. https://doi.org/10.1007/s00107-012-0626-7
Viguier J, Jehl A, Collet R, Bleron L, Meriaudeau F (2015) Improving strength grading of timber by grain angle measurement and mechanical modeling. Wood Mater Sci Eng 10(1):145–156. https://doi.org/10.1080/17480272.2014.951071
Wang X (2013) Acoustic measurements on trees and logs: a review and analysis. Wood Sci Technol 47(5):965–975. https://doi.org/10.1007/s00226-013-0552-9
Zhou J, Shen J (2003) Ellipse detection and phase demodulation for wood grain orientation measurement based on the tracheid effect. Opt Lasers Eng 39(1):73–89. https://doi.org/10.1016/S0143-8166(02)00041-6
Acknowledgements
This study was conducted in the scope of the WoodWisdom-Net project European hardwoods for the building sector (EU Hardwoods) which was financed by Fachagentur Nachwachsende Rohstoffe e.V. (FNR) under grant number 22004114 in Germany and Bundesministerium für Land- und Forstwirtschaft, Umwelt und Wasserwirtschaft (BMLFUW) under grant number 101003 in Austria.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Weidenhiller, A., Linsenmann, P., Lux, C. et al. Potential of microwave scanning for determining density and tension strength of four European hardwood species. Eur. J. Wood Prod. 77, 235–247 (2019). https://doi.org/10.1007/s00107-019-01387-x
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00107-019-01387-x