
Abstract
Soil is a heterogeneous medium and due to this, the parameters on which soil slope stability depends, are having high variability, which makes the analysis a complex problem. To take into account the variability in soil parameters, the current research approach is shifting from deterministic approach to probabilistic approach. This paper describes the application of three soft-computing techniques including multivariate adaptive regression spline (MARS), Gaussian process regression (GPR) and functional network (FN) to study the soil slope reliability based on slope stability. The stability of a soil slope of a given height depends on shear strength parameters c (cohesion), ϕ (angle of shearing resistance) and ϒ (unit weight), which are taken as input variables and Factor of Safety of soil slope (FOS) as the output. Also the model performance was assessed using various performance indices i.e. NS, RMSE, VAF, MAE, RSR, Bias Factor, PI, R2, Adj. R2, MAPE, GPI, LMI, U95, tstat and β. The results of the analyses showed that MARS model outperformed GPR and FN models. Therefore, MARS model can be used as a reliable soft computing technique for analyzing soil slope stability.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Soil slope stability is a major concern nowadays as it plays a major role in the construction of various structure with use of soil e.g. earth dams, embankments and stability of various open pits. Soil is a natural occurring material found on earth, having high variability in its properties due to process of formation. Therefore, it’s very hard to determine the properties of soil with certainty. In spite of various methods e.g. Strength Reduction Method and Limit Equilibrium Method are available to solve or find the solution for stability of soil slope, failure of slopes are occurring in high percentage, as these methods follows the deterministic approach which is highly conservative. And also due to the various errors like the testing error or sampling error there are testing data variability as shown by Phoon (2002). To overcome these limitation of deterministic approach nowadays approach is shifting towards the probabilistic way and to implement the probabilistic approach reliability analysis is used for the slope stability analysis of soil slope. In the reliability analysis various models are being worked out using the soil parameters on which stability of slope depends as input and output of the models are analyzed to find their adaptability to the problem.
In past many researchers have used probabilistic approach in their research work. Researchers have used field and laboratory data values to perform probabilistic analysis to show the uncertainty in soil properties of an embankment (Christian et al. 1994). El-Ramly et al. (2002) showed the probabilistic analysis on the design of slope by using spreadsheet approach based on MCS and also applied the approach using the James Bay hydroelectric project as an example. Wang et al. (2019) showed the probabilistic analysis of post-failure of soil slope using RSPH (random smoothed particle hydrodynamics) and incorporated the slope failure analysis. Liang et al. (1999) performed the reliability analysis on the multi-layer embankment and showed the incorporation of variability in the soil properties. Cheng (2003) showed how to locate the critical failure surface with higher level of precision in short time using annealing method. Babu and Srivastava (2010) conducted the reliability analysis using response surface methodology (RSM) on selected earth dam section. By the use of multi-modal optimisation method (Reale et al. 2015), multiple failure modes were located using various probabilistic models. Earth dams were being analyzed by using ANN model in various conditions e.g. static and dynamic and the model showed good capability of predicting factor of safety of slope (Zeroual et al. 2009). Kumar et al. (2017) used various models like MARS, ANFIS for the reliability analysis of infinite slope and the results showed that the models are reliable for the condition. Gao et al. (2018) developed GPR model for the forecasting of rock fragmentation in mines and also GPR model along with MPMR model were being developed by Samui et al. (2019) to determine the uplift capacity of suction caisson. After reviewing many critical literature, authors found out that in conventional methods of analysis variability in the soil properties parameters are not incorporated. Therefore, the main purpose of present study is to perform reliability analysis of soil slope stability using MARS, GPR and FN soft computing models. In addition, all these models are also tested for reliability analysis of soil slope stability.
Theoretical background of models
Multivariate adaptive regression spline
MARS was developed with an idea that in different sample spaces, all the variables have different level of impact on the response surface. The adaptive in the MARS is basically defines the same i.e. MARS ability to find the dominant variables in each and every sample space region. In MARS there is simple approach to use piecewise polynomials (Splines) is adopted. In order to develop MARS model, it uses basis function. The inputs and output values x and y, respectively, are related using the following equation i.e. Eq. (1):
where \(B_{m} \left( x \right)\), basis function; M, no. of functions; \(a_{o}\) and \(a_{m}\) are the constant and coefficient of the mth function.
Knots used to connect data points, MARS characterizes data using regressions or by finding it globally (Friedman 1991; Abraham and Steinberg 2001). For getting continues output, the basis function in the adjacent domain intersect at the knot. MARS uses bended regression in place of conventional regressions, to connect x properly between subgroups and between spline. The no. of knots should be 3–4 times the no. of \(B_{m} \left( x \right)\) of MARS model (Sharda et al. 2008). To avoid over-fitting adequate data in subgroup is ensured by the model using shortest distance between the knots (Sephton 2001; Adamowski et al. 2012).
Two segmented truncated power functions separated by a knot location used for the formation of spline basis functions for MARS. The expression for the truncated function to the left and right are as follows:
Here q is power to which spline is raised and t is knot location.
For developing MARS model two steps are followed.
Forward step: In this step, \(B_{m} \left( x \right)\) functions are defined with the help of Eq. (1). But, due to large no. of basis functions there is over fitting problem.
Backward step: \(B_{m} \left( x \right)\) basis functions are selected based on the generalized cross-validation (GCV) statistic which was calculated using the Craven and Wahba method (Craven and Wahba 1978):
where N is the no. of data objects, C(B) is factor of penalty:
where d is the penalty each function defined in the model.
Gaussian process regression (GPR)
A Gaussian process (GP) is a nonparametric model used for probabilistic analysis, in which observations are defined within a domain of continuous range (Grbić et al. 2013). This model is applicable to both types of problems i.e. regression having non-linear behavior (Williams 1997) and classification (Williams and Barber 1998). GPR is defined using its mean and covariance. The mean function is generally taken equal to zero, as it encodes central tendency of the function (Zhang et al. 2016). The covariance function is having the information of structure of the function which is needed for our defined problem. In this study, ϒ, ϕ and c are taken as input variables and FOS as output of GPR. So, x = [ϒ, ϕ, c] and y = [FOS].
GPR uses the following connecting equation between the inputs and the output:
It is assumed that Gaussian noise (\(\varepsilon\)) is independent and having a distribution with mean = 0 and variance = \(\sigma_{n}^{2}\).
Expression for evaluating output for the new input is:
where \(y_{N + 1}\) is target variable and \(x_{N + 1}\) is new input.
The KN+1 and other parameters are related by the Eq. (8) and yN+1 follows the Gaussian distribution:
Covariance between the training inputs and test input is given by k(xN+1) and test input auto-covariance is expressed as k1(xN+1). The covariance (kernel) function is a critical component in a Gaussian process regression. In this study radial basis function is adopted as covariance function to develop the GPR model.
Functional network (FN)
Artificial neural networks are inspired by the working of brain i.e. to learn from the behavior and then reproduce a system accordingly as per the field. Artificial neural networks works by using the neurons (Armaghani et al. 2020) to form a neural network which gives output as per the inputs provided.
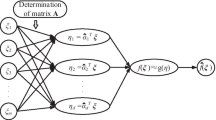
Functional network (FN) (Castillo et al. 1999) is a recently developed useful extension of artificial neural networks, FN in order to develop structure of the network for its working uses the domain background knowledge and also the knowledge of data provided. In FN various arbitrary neural functions were used and also used in the form of multiple argument (Fig. 1).

The basis functions and knot location in the MARS model
In Functional network system of functional equations are formed by the help of the arrangement of the neurons in the neural network, which provides outputs in various formats. The most important step in functional network is the procedure of learning (Castillo et al. 2000) using the domain background knowledge and also the knowledge of data provided. There are generally two types of learning:
-
i.
Structural learning—In this initial knowledge of system background and the properties of the system are used for the design.
-
ii.
Parametric learning—In this neurons are linked in the network with the parameters with the help of the data available.
Layers included in the formation of functional network model:
-
1.
Storing units
-
(i)
Input layer—layer which takes input data x1, x2, x3 etc. as an input for the model.
-
(ii)
Middle layers—layers which evaluate the input from previous layer and provide output for the next layer, f4, f5.
-
(iii)
Output storing units’ layer—output data f6 are stored in this layer.
-
(i)
-
2.
Layers consists of neuron—A neuron being a computing unit uses the input from the previous layer to provide an output set for the next layer. Layer consisting computing units, f1, f2, f3.
-
3.
Direction links—These are used to connect layer from each other in a right form to get a functional network. These directed links are used to show the direction of flow of information. The intermediate functions work based on the structure of the network. Example x7 = f4 (x4, x5, x6) as in Fig. 2.

Network diagram of functional network
Model development
In this study, a 15 m high c–ϕ soil slope with side slope 1:1 described as an example by Cho (2010) used for our reliability analysis of soil slope stability using MARS, GPR and FN soft computing models. Details of c–ϕ soil slope is shown in Fig. 3. In the probabilistic analysis, the variation in parameter is considered for cohesion (c), angle of shear resistance (ϕo) and unit weight (γ). The coefficient of variation for cohesion, angle of shear resistance and unit weight is taken as 0.3, 0.2 and 0.03, respectively, and mean value as 10, 30 and 20, respectively.

Cross section of typical c–ϕ soil slope
For determining the factor of safety (FOS) of c–ϕ soil slope using Morgenstern-Price method is used using the GeoStudio 2016 software. The factor of safety (FOS) of c–ϕ soil slope depends on the parameters γ (unit weight), c (cohesion of soil) and ϕ (angle of shear resistance), which are taken as input variables and factor of safety (FOS) of slope as result. The permissible range of γ, c and ϕ are used to get 100 data set and corresponding 100 data set of factor of safety (FOS) using GeoStudio 2016 software. For using these data set in MATLAB for the MARS, GPR and FN models need to be normalized as given by Eq. (9):
where \(X_{{{\text{nor}}}} = {\text{ normalised value}}\), \(X = {\text{ value of parameter}}\), \(X_{{{\text{min}}{.}}} = {\text{ min}}.{\text{ value}}\), \(X_{{{\text{max}}{.}}} = {\text{ max}}.{\text{ value}}\).
The data set are used as input to the models in the normalized form and corresponding predicted output of models are obtained. The actual observed FOS and predicted FOS values which are obtained using models are tested using various fitness parameters to compare and find the best models on their prediction capability.
Performance parameters
Models performance are assessed using the following parameters:
Nash–Sutcliffe efficiency (NS) (Jain and Sudheer 2008) shows the prediction capability of the model which is maximum if its value comes equal to 1:
Root mean square error (RMSE) (Kisi et al. 2013) calculate the prediction error for the shows the error in prediction of the target value:
Variance account factor (VAF) (Grima and Babuška 1999; Gokceoglu 2002; Yılmaz and Yuksek 2008) value used to exhibit the performance of each and the ideal value for VAF equal to 100 for the best performance:
R2 (Coefficient of determination) (Babu and Srivastava 2007) is a parameter which shows that how much the model have incorporated the variability in the soil properties, along with Adj. R2 (adjusted Coefficient of determination) value and the values of both parameter need to close to 1 and to each other also:
Performance index (PI) (Kung et al. 2007) shows how well each model is performing while predicting the target values:
Bias factor (Prasomphan and Machine 2013) value indicates whether the model’s estimation is over or under as per the factor value is greater or less than 1, respectively:
RSR (Moriasi et al. 2007) shows the accuracy in prediction and if RSR is closer to 0 prediction is good:
Normalized mean bias error (NMBE) (Srinivasulu and Jain 2006) value gives the percentage of biasness of predicted value from the mean in normalized format:
MAPE (mean absolute percentage error) (Armstrong and Collopy 1992) parameter value indicate the good amount of accuracy in prediction if it comes in closer to zero:
Relative percentage difference (RPD) (Ray et al. 2020) value indicates the how the model is performing based on the values and corresponding performances given in Table1:
Willmott’s Index for agreement (WI). (Willmott 1981, 1982, 1984) value varies between 0 and 1 and the index value indicates the error in prediction of targeted values:
Mean bias error (MBE) and mean absolute error (MAE). Raventos-Duran et al. (2010) both the values are error calculator, and values closer to 0 indicates good model with lesser error:
Legate and McCabe’s Index (LMI). Legates and McCabe (1999, 2013) shows the level of divergence in prediction by the model from the actual data:
Expanded uncertainty (U95). Gueymard (2014), Behar et al. (2015) shows the short-term performance of the models in prediction:
t-statistic (Stone 1993) is a tool to indicate the performance of the models:
Global performance indicator (GPI) (Viscarra et al. 2006) incorporate all the parameters to access the performance using single parameter:
Reliability index (β) value for each model defines the model performance based on the reliability analysis (USACE 1997):
Here, di = actual observed data of ith point and yi = predicted data of ith point, dmean = mean value observed data, SD = standard deviation, \(\mu_{{\text{F}}}\) is mean value of factor of safety of soil slope and \(\sigma_{{\text{F}}}\) is standard deviations of factor of safety of soil slope under consideration.
Results and discussion
Reliability analysis of soil slope stability on the considered section done using three soft computing models MARS, GPR and FN by normalizing all the data set value, then dividing them in training and testing data and use them as input and FOS as an output for all the three models. After the predicted values of FOS are obtained from the models, the actual and predicted values are being represented using graph between the actual values and predicted values of FOS of soil slope for both training and testing data values of MARS, GPR and FN models as shown in Figs. 4, 5, 6, respectively. Graphs plots of all the models shows the prediction done by the models are satisfactory, as the all values of both the training and testing data are close to the line depicting actual equal to the predicted value. On comparing the three models, it can be said that MARS model performance is good as the values are more closer to the actual equals to predicted line.

MARS model performance for training and testing dataset

GPR model performance for training and testing dataset

FN model performance for training and testing dataset
All the models are tested using various fitness parameters NS, RMSE, VAF, MAE, RSR, Bias factor, PI, R2, Adj. R2, MAPE, GPI, LMI, U95, tstat and β as mentioned in Table 2. In the Table 2 values of each parameter are mentioned for all the three models MARS, GPR and FN. The value of NS shows that all models prediction power is high as the values of NS are closer to 1. The RMSE and VAF values shows that the MARS model performed good in predicting values of FOS of soil slope as compared to other models, as the prediction error of MARS model is less among the three models. The R2 and Adj. R2 values for all the three model are closer to each other and also closer to 1, but values for MARS model are closest to 1 among the models which shows that the MARS model have included most of the soil parameter variability. On comparing the models based on the values of Bias factor, MAPE, NMBE (%), RSR and PI values, MARS model’s prediction capability is high and also the predicted values are least biased from the actual values of factor of safety of soil slope. WI, MAE, MBE and LMI values for all the three models shows that the models are very less deviated from the actual values of FOS. The RPD value of models shows that the MARS model is good (Table 1) i.e. works accurately among the three models. All the models MARS, GPR and FN performed good as U95 and t-stat values are very small. MARS model is having high accuracy in predicting the FOS of soil slope as GPI value is lowest among the three models. Figure 7 shows the β values for FOSM (first order second moment), FOSM (MARS), FOSM (GPR) and FOSM (FN). The reliability index (β) of all three models MARS, GPR and FN (USACE 1997; Baecher and Christian 2003) shows that the models performance is comparable as shown in Fig. 7. After the development of all the models the advantage of MARS model is that it gives an expression (Eq. 29) as an output result for the dataset for the calculation of factor of safety of soil slope stability using Eq. (1) in which y = FOS, M = 9, a0 = 0.00112 and Bm(x) and am detail in Table 3:

Reliability index (β) bar chart for MARS, GPR and FN Model
Taylor diagram (Taylor 2001) is a statistical summary to know the best match model in terms of standard deviation (SD), RMSE and correlation coefficient. The Taylor curves in Fig. 8 combines together all i.e. standard deviation (SD), RMSE and correlation coefficient together to find the most accurate model. Taylor diagram gives a graphical framework that shows the suitability of variables by the different types models based on the reference data. As per, the training Taylor diagram result (Fig. 8), MARS model shows the best results, and the testing Taylor diagram also MARS model values are closer to the observed actual values. In summary, it indicates that there is a good agreement between the actual and the model results for MARS model.

Taylor diagram a training and b testing plotted for MARS, GPR and FN Model
ROC curve (Fawcett 2006) plot for MARS, GPR and FN for the training and testing is shown in Fig. 9 from which AUC (area under curve) value of all three models are calculated and AUC values are shown in Table 4. AUC values from the Table 4 shows that its value for MARS model is highest among the three models, which indicates MARS model is having very high classification accuracy among MARS, GPR and FN models.

ROC curve plot for training and testing values of models
Anderson–Darling (A–D) is a statistical test (Anderson and Darling 1952) used to evaluate which whether the model follows the normal distribution or not and also to know the whether the given data is from the same probability distribution or not. Anderson–Darling (A–D) test provides P-value (shown in Table 5), which are greater than 0.05 for all the models MARS, GPR and FN, that shows all the three models works as normal distribution. Among all the three models MARS model follow closest to the normal distribution trend.
Conclusions
In this article, reliability analysis of soil slope stability was studied using MARS, GPR and FN models. An example of soil slope has been taken to show the procedure of working of the MARS, GPR and FN models. All these models were comprehensively analyzed and compared based on various performance parameters. Values of reliability index of all the models show that models’ prediction capability of factor of safety for the soil slope stability is good. All the models performed satisfactorily, but among three models MARS model outperformed based on the various performance parameters like NS, RMSE, VAF, MAE, RSR, Bias Factor etc. The training and testing data were also accumulated up while graphing Taylor and ROC curves. The results from ROC curve, the largest value of area under curve (AUC) was obtained for MARS model, followed by GPR and FN model. Models were also tested using Anderson–Darling (A–D) statistical test which shows that MARS model followed the closest to normal distribution trend among the models. The developed MARS model is having additional advantage as it provides an equation for determination of factor of safety for soil slope stability analysis. Therefore, it can be concluded that MARS model can be used as reliable tool for the reliability analysis for the prediction of factor of safety of soil slope.
References
Abraham A, Steinberg D (2001) Is neural network a reliable forecaster on earth? A MARS query! In: Lecture notes in computer science (including subseries lecture notes in artificial intelligence and lecture notes in bioinformatics). Springer, pp 679–686
Adamowski J, Chan HF, Prasher SO, Ozga-Zielinski B, Sliusarieva A (2012) Comparison of multiple linear and nonlinear regression, autoregressive integrated moving average, artificial neural network, and wavelet artificial neural network methods for urban water demand forecasting in Montreal, Canada. Wiley Online Libr. https://doi.org/10.1029/2010WR009945
Anderson TW, Darling DA (1952) Asymptotic theory of certain, goodness of fit criteria based on stochastic processes. Ann Math Stat 23:193–212. https://doi.org/10.1214/aoms/1177729437
Armaghani DJ, Mirzaei F, Shariati M, Trung NT, Shariati M, Trnavac D (2020) Hybrid ann-based techniques in predicting cohesion of sandy-soil combined with fiber. Geomech Eng 20:191–205. https://doi.org/10.12989/gae.2020.20.3.191
Armstrong JS, Collopy F (1992) Error measures for generalizing about forecasting methods: empirical comparisons. Int J Forecast 8:69–80. https://doi.org/10.1016/0169-2070(92)90008-W
Babu GLS, Srivastava A (2007) Reliability analysis of allowable pressure on shallow foundation using response surface method. Comput Geotech 34:187–194. https://doi.org/10.1016/j.compgeo.2006.11.002
Babu GLS, Srivastava A (2010) Reliability analysis of earth dams. J Geotech Geoenviron Eng 136:995–998. https://doi.org/10.1061/(asce)gt.1943-5606.0000313
Baecher GB, Christian JT (2003) Reliability and statistics in geotechnical engineering. J Wiley
Behar O, Khellaf A, Mohammedi K (2015) Comparison of solar radiation models and their validation under Algerian climate—the case of direct irradiance. Energy Convers Manag 98:236–251. https://doi.org/10.1016/j.enconman.2015.03.067
Castillo E, Cobo A, Gutiérrez JM, Pruneda E (1999) Working with differential, functional and difference equations using functional networks. Appl Math Model 23:89–107. https://doi.org/10.1016/S0307-904X(98)10074-4
Castillo E, Gutiérrez JM, Cobo A, Castillo C (2000) Some learning methods in functional networks
Cheng Y (2003) Location of critical failure surface and some further studies on slope stability analysis. Comput Geotech 30:255–267
Cho SE (2010) Probabilistic assessment of slope stability that considers the spatial variability of soil properties. J Geotech Geoenviron Eng 136:975–984. https://doi.org/10.1061/(ASCE)GT.1943-5606.0000309
Christian JT, Ladd CC, Baecher GB (1994) Reliability applied to slope stability analysis. J Geotech Eng 120:2180–2207. https://doi.org/10.1061/(ASCE)0733-9410(1994)120:12(2180)
Craven P, Wahba G (1978) Smoothing noisy data with spline functions—estimating the correct degree of smoothing by the method of generalized cross-validation. Numer Math 31:377–403. https://doi.org/10.1007/BF01404567
El-Ramly H, Morgenstern NR, Cruden DM (2002) Probabilistic slope stability analysis for practice. Can Geotech J 39:665–683. https://doi.org/10.1139/t02-034
Fawcett T (2006) An introduction to ROC analysis. Pattern Recognit Lett 27:861–874. https://doi.org/10.1016/J.PATREC.2005.10.010
Friedman J (1991) Multivariate adaptive regression splines. JSTOR 19:1–67
Gao W, Karbasi M, Hasanipanah M, Zhang X, Guo J (2018) Developing GPR model for forecasting the rock fragmentation in surface mines. Eng Comput 34:339–345. https://doi.org/10.1007/s00366-017-0544-8
Grima MA, Babuška R (1999) Fuzzy model for the prediction of unconfined compressive strength of rock samples. Int J Rock Mech Min Sci 36:339–349. https://doi.org/10.1016/S0148-9062(99)00007-8
Gokceoglu C (2002) A fuzzy triangular chart to predict the uniaxial compressive strength of Ankara agglomerates from their petrographic composition. Eng Geol 66:39–51
Grbić R, Kurtagić D, Slišković D (2013) Stream water temperature prediction based on Gaussian process regression. Expert Syst Appl Elsevier 40:7407–7414
Gueymard C (2014) A review of validation methodologies and statistical performance indicators for modeled solar radiation data: towards a better bankability of solar projects. Renew Sustain Energy Rev 39:1024–1034
Jain SK, Sudheer KP (2008) Fitting of hydrologic models: a close look at the nash-sutcliffe index. J Hydrol Eng 13:981–986. https://doi.org/10.1061/(ASCE)1084-0699(2008)13:10(981)
Kisi O, Shiri J, Tombul M (2013) Modeling rainfall-runoff process using soft computing techniques. Comput Geosci 51:108–117. https://doi.org/10.1016/j.cageo.2012.07.001
Kumar R, Samui P, Kumari S (2017) Reliability analysis of infinite slope using metamodels. Geotech Geol Eng. https://doi.org/10.1007/s10706-017-0160-9
Kung GT, Juang CH, Hsiao EC, Hashash YM (2007) Simplified model for wall deflection and ground-surface settlement caused by braced excavation in clays. J Geotech Geoenviron Eng 133:731–747. https://doi.org/10.1061/(ASCE)1090-0241(2007)133:6(731)
Legates DR, McCabe GJ (1999) Evaluating the use of “goodness-of-fit” measures in hydrologic and hydroclimatic model validation. Water Resour Res 35:233–241. https://doi.org/10.1029/1998WR900018
Legates DR, McCabe GJ (2013) A refined index of model performance: a rejoinder. Int J Climatol 33:1053–1056. https://doi.org/10.1002/joc.3487
Liang R, Nusier O, Malkawi A (1999) A reliability based approach for evaluating the slope stability of embankment dams. Eng Geol 54:271–285
Moriasi DN, Arnold JG, Van Liew MW, Bingner RL, Harmel RD, Veith TL (2007) Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans ASABE 50:885–900. https://doi.org/10.13031/2013.23153
Phoon KK (2002) Potential application of reliability-based design to geotechnical engineering. In: Proceedings of 4th Colombian Geotechnical Seminar, Medellin, pp 1–22
Prasomphan S, Machine SM (2013) Generating prediction map for geostatistical data based on an adaptive neural network using only nearest neighbors. Int J Mach Learn Comput 2013:3
Raventos-Duran T, Camredon M, Valorso R, Mouchel-Vallon C, Aumont B (2010) Structure-activity relationships to estimate the effective Henry’s law constants of organics of atmospheric interest. Atmos Chem Phys 10:7643–7654. https://doi.org/10.5194/acp-10-7643-2010
Ray R, Kumar D, Samui P, Roy LB, Goh ATC, Zhang W (2020) Application of soft computing techniques for shallow foundation reliability in geotechnical engineering. Geosci Front 12:375–383. https://doi.org/10.1016/j.gsf.2020.05.003
Reale C, Xue J, Pan Z, Gavin K (2015) Deterministic and probabilistic multi-modal analysis of slope stability. Comput Geotech 66:172–179
Samui P, Kim D, Jagan J, Roy SS (2019) Determination of uplift capacity of suction caisson using Gaussian process regression, minimax probability machine regression and extreme learning machine. Iran J Sci Technol Trans Civ Eng 43:651–657. https://doi.org/10.1007/s40996-018-0155-7
Sephton P (2001) Forecasting recessions: can we do better on mars. Fed Reserv Bank St Louis Rev 83:39–49
Sharda VN, Prasher SO, Patel RM, Ojasvi PR, Prakash C (2008) Performance of multivariate adaptive regression splines (MARS) in predicting runoff in mid-Himalayan micro-watersheds with limited data. Hydrol Sci J 53:1165–1175. https://doi.org/10.1623/hysj.53.6.1165
Srinivasulu S, Jain A (2006) A comparative analysis of training methods for artificial neural network rainfall–runoff models. Appl Soft Comput 6:295–306. https://doi.org/10.1016/j.asoc.2005.02.002
Stone RJ (1993) Improved statistical procedure for the evaluation of solar radiation estimation models. Sol Energy 51:289–291. https://doi.org/10.1016/0038-092X(93)90124-7
Taylor KE (2001) Summarizing multiple aspects of model performance in a single diagram. J Geophys Res Atmos 106:7183–7192. https://doi.org/10.1029/2000JD900719
USACE (1997) Risk-based analysis in geotechnical engineering for support of planning studies, engineering and design. Dept Army, USACE Washington, DC
Viscarra RA, McGlynn RN, McBratney AB (2006) Determining the composition of mineral-organic mixes using UV–vis–NIR diffuse reflectance spectroscopy. Geoderma 137:70–82. https://doi.org/10.1016/j.geoderma.2006.07.004
Wang Y, Qin Z, Liu X, Li L (2019) Probabilistic analysis of post-failure behavior of soil slopes using random smoothed particle hydrodynamics. Eng Geol 261:105266. https://doi.org/10.1016/j.enggeo.2019.105266
Williams CKI (1997) Regression with gaussian processes, pp 378–382
Williams CKI, Barber D (1998) Bayesian classification with Gaussian processes. IEEE Trans Pattern Anal Mach Intell 20:1342–1351. https://doi.org/10.1109/34.735807
Willmott CJ (1981) On the validation of models. Phys Geogr 2:184–194. https://doi.org/10.1080/02723646.1981.10642213
Willmott CJ (1982) Some comments on the evaluation of model performance. Bull Am Meteorol Soc 63:1309–1313. https://doi.org/10.1175/1520-0477(1982)063%3c1309:SCOTEO%3e2.0.CO;2
Willmott CJ (1984) On the evaluation of model performance in physical geography. In: Spatial statistics and models. Springer, Netherlands, Dordrecht, pp 443–460
Yılmaz I, Yuksek AG (2008) An example of artificial neural network (ANN) application for indirect estimation of rock parameters. Rock Mech Rock Eng 41:781–795. https://doi.org/10.1007/s00603-007-0138-7
Zeroual A, Fourar A, Djeddou M (2009) Predictive modeling of static and seismic stability of small homogeneous earth dams using artificial neural network. Arab J Geosci. https://doi.org/10.1007/s12517-018-4162-6
Zhang C, Wei H, Zhao X, Liu T, Zhang K (2016) A Gaussian process regression based hybrid approach for short-term wind speed prediction. Energy Convers Manag 126:1084–1092. https://doi.org/10.1016/j.enconman.2016.08.086
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Ray, R., Choudhary, S.S. & Roy, L.B. Reliability analysis of soil slope stability using MARS, GPR and FN soft computing techniques. Model. Earth Syst. Environ. 8, 2347–2357 (2022). https://doi.org/10.1007/s40808-021-01238-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40808-021-01238-w