
Abstract
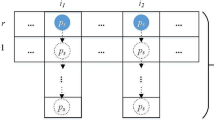
Multiple sequence alignment is a method for comparing two or more DNA or protein sequences. Most multiple sequence alignment methods rely on pairwise alignment and Smith-Waterman algorithm [Needleman and Wunsch, 1970; Smith and Waterman, 1981] to generate an alignment hierarchy. Therefore, as the number of sequences increases, the runtime increases exponentially. To resolve this problem, this paper presents a multiple sequence alignment method using a parallel processing suffix tree algorithm to search for common subsequences at one time without pairwise alignment. The cross-matched subsequences among the searched common subsequences may be generated and those cause inexact-matching. So the procedure of masking cross-matching pairs was suggested in this study. The proposed method, improved STC (Suffix Tree Clustering), is summarized as follows: (1) construction of suffix tree; (2) search and overlap of common subsequences; (3) grouping of subsequence pairs; (4) masking of cross-matching airs; and (5) clustering of gene sequences. The new method was successfully evaluated with 23 genes inMus musculus and 22 genes in three species, clustering nine and eight clusters, respectively.
Article PDF
Similar content being viewed by others


Avoid common mistakes on your manuscript.
References
Chen, J.Y. and Carlis, J.V., “Genomic Data Modeling,”Information Systems,28, 287 (2003).
Choi, S. H. and Manousiouthakis, V., “Global Optimization Methods for Chemical Process Design: Deterministic and Stochastic Approaches,”Korean J. Chem. Eng.,19(2), 227 (2002).
Delcher, A. L., Kasif, S., Fleischmann, R.D., Peterson, J., White, O. and Salzberg, S. L., “Alignment of Whole Genomes,”Nucleic Acids Res.,27(11), 2369 (1999).
Delcher, A. L., Phillippy, A., Carlton J. and Salzberg, S. L., “Fast Algorithms for Large-scale Genome Alignment and Comparison,”Nucleic Acids Res.,30(11), 2478 (2002).
Gusfield, D.,Algorithms on Strings, Trees, and Sequences: Computer Science and Computational Biology, Cambridge University Press, Cambridge, London (1997).
Higgins, D.G., Thompson, J. D. and Gibson, T. J., “Using CLUSTAL for Multiple Sequence Alignments,”Methods Enzymol.,266, 383 (1996).
Higgins, D.G. and Sharp, P.M., “CLUSTAL: A Package for Performing Multiple Sequence Alignment on a Microcomputer,”Gene,73, 237 (1988).
Hon, W. K. and Sadakane, K., “Space-Economical Algorithms for Finding Maximal Unique Matches,”Proceedings of the 13th Annual Symposium on Combinatorial Pattern Matching,144 (2002).
Kalyanaraman, A., Aluru, S. and Kothari, S.,Parallel EST Clustering, HICOMB 2002, 185 (2002).
Kim, D. K., Lee, K. S. and Yang D. R., “Control of pH Neutralization Proess Using Simulation Based Dynamic Programming,”Korean J. Chem. Eng.,21(5), 942 (2004).
Lee, J.M. and Lee, J. H., “Simulation-Based Learning of Cost-To-Go for Control of Nonlinear Processes,”Korean J. Chem. Eng.,21(2), 338 (2004).
McCreight, E., “A Space Economical Suffix Tree Construction Algorithm,”Journal of the ACM,23, 262 (1976).
Miller, R. T., Christoffels, A.G., Gopalakrishnan, C., Burke, J., Ptitsyn, A. A., Broveak, T. R. and Hide, W.A., “A Comprehensive Approach to Clustering of Expressed Human Gene Sequence: The Sequence Tag Alignment and Consensus Knowledge Base,”Genome Research,9, 1143 (1999).
Morgenstern, B., Frech, K., Dress, A. and Werner, T., “DIALIGN: Finding Local Similarities by Multiple Sequence Alignment,”Bioinformatics,14, 290 (1998).
Mount, D.W.,Bioinformatics : Sequence and Genome Analysis, Cold Spring Harbor Laboratory Press (2001).
Needleman, S. B. and Wunsch, C. D., “A General Method Applicable to the Search for Similarities in the Amino Acid Sequences of Two Proteins,”J. Mol. Biol.,48, 443 (1970).
Notredame, C. and Higgins, D.G., “SAGA: Sequence Alignment by Genetic Algorithm,”Nucleic Acids Res.,24, 1515 (1996).
Ostell, J.M., Wheelan, S. J. and Kans, J. A., “The NCBI Data Model,”Methods Biochem. Anal.,43, 19 (2001).
Pearson, W.R. and Miller, W., “Dynamic Programming Algorithm for Biological Sequence Comparison,”Methods Enzymol.,210, 575 (1992).
Phillips, A., Janies, D. and Wheeler, W., “Multiple Sequence Alignment in Phylogenetic Analysis,”Molecular Phylogenetics and Evolution,16, 317 (2000).
Randal, L. S. and Christiansen, T.,Learning Perl, Second Edition, O’Reilly (1997).
Salzberg, S. L., Searls, D. B. and Kasif, S.,Trends Guide to Bioinformatics, Elsevier Science (1998).
Shin, P. K., Koo, J. H. and Lee, W. J., “Modeling of Cell Growth and phoA-Directed Expression of Cloned Genes in Recombinant Escherichia coli,”Korean J. Chem. Eng.,13(1), 82 (1996).
Smith, T. F. and Waterman, M. S., “Identification of Common Molecular Sequences,”J. Mol. Biol.,197, 723 (1981).
Thompson, J. D., Higgins, D.G. and Gibson, T. J., “CLUSTAL W: Improving the Sensitivity of Progressive Multiple Sequence Alignment through Sequence Weighting, Position-specific Gap Penalties and weight Matrix Choice,”Nucleic Acids Res.,22, 4673 (1994).
Tisdall, J.D., Beginning Perl for Bioinformatics, O’REILLY (2001).
Ukkonen, E., “On-line Construction of Suffix Trees,”Algorithmica,14, 249 (1995).
Volfovsky, N., Haas, B. J. and Salzberg, S. L., “A Clustering Method for Repeat Analysis in DNA Sequences,”Genome Biology,2, 1 (2001).
Weiner, P., “Linear Pattern Matching Algorithms,”In Proc. of the 14th IEEE Annual Symposium on Switching and Automata Theory,1 (1973).
Zamir, O., Etzioni, O., Madani, O. and Karp, R.M., “Fast and Intuitive Clustering of Web Documents,”In Proc. of the 3rd International Conference on Knowledge Discovery and Data Mining,287 (1997).
Zamir, O. and Etzioni, O., “Web Document Clustering: A Feasibility Demonstration,”In Proc. of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,46 (1998).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Han, S.I., Lee, S.G., Hou, B.K. et al. A gene clustering method with masking cross-matching fragments using modified suffix tree clustering method. Korean J. Chem. Eng. 22, 345–352 (2005). https://doi.org/10.1007/BF02719409
Received:
Accepted:
Issue Date:
DOI: https://doi.org/10.1007/BF02719409