
Abstract
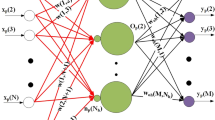
Training multilayer neural networks is typically carried out using gradient descent techniques. Ever since the brilliant backpropagation (BP), the first gradient-based algorithm proposed by Rumelhart et al., novel training algorithms have appeared to become better several facets of the learning process for feed-forward neural networks. Learning speed is one of these. In this paper, a learning algorithm that applies linear-least-squares is presented. We offer the theoretical basis for the method and its performance is illustrated by its application to several examples in which it is compared with other learning algorithms and well known data sets. Results show that the new algorithm upgrades the learning speed of several backpropagation algorithms, while preserving good optimization accuracy. Due to its performance and low computational cost it is an interesting alternative, even for second order methods, particularly when dealing large networks and training sets.
Access provided by Autonomous University of Puebla. Download to read the full chapter text
Chapter PDF
Similar content being viewed by others

Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
References
Rumelhart, D.E., Hinton, G.E., William, R.J.: Learning representations of back-propagation errors. Nature 323, 533–536 (1986)
Vogl, T.P., Mangis, J.K., Rigler, A.K., Zink, W.T., Alkon, D.L.: Accelerating the convergence of back-propagation method. Biological Cybernetics 59, 257–263 (1988)
Jacobs, R.A.: Increased rates of convergence through learning rate adaptation. Neural Networks 1(4), 295–308 (1988)
LeCun, Y., Bottou, L., Orr, G.B., Müller, K.-R.: Efficient BackProp. In: Orr, G.B., Müller, K.-R. (eds.) Neural Networks: Tricks of the Trade. LNCS, vol. 1524, Springer, Heidelberg (1998)
Hagan, M.T., Menhaj, M.: Training feedforward networks with the Marquardt algorithm. IEEE Transactions on Neural Networks 5(6), 989–993 (1994)
Beale, E.M.L.: A derivation of conjugate gradients. In: Lootsma, F.A. (ed.) Numerical methods for nonlinear optimization, pp. 39–43. Academic Press, London (1972)
Biegler-König, F., Bärmann, F.: A Learning Algorithm for Multilayered Neural Networks Based on Linear Least-Squares Problems. Neural Networks 6, 127–131 (1993)
Yam, J.Y.F., Chow, T.W.S, Leung, C.T.: A New method in determining the initial weights of feedforward neural networks. Neurocomputing 16(1), 23–32 (1997)
Bishop, C.M.: Neural Networks for Pattern Recognition. Oxford University Press, New York (1995)
Castillo, E., Fontenla-Romero, O., Alonso Betanzos, A., Guijarro-Berdiñas, B.: A global optimum approach for one-layer neural networks. Neural Computation 14(6), 1429–1449 (2002)
Fontenla-Romero, O., Erdogmus, D., Principe, J.C., Alonso-Betanzos, A., Castillo, E.: Linear least-squares based methods for neural networks learning. In: Kaynak, O., Alpaydın, E., Oja, E., Xu, L. (eds.) ICANN 2003 and ICONIP 2003. LNCS, vol. 2714, pp. 84–91. Springer, Heidelberg (2003)
Erdogmus, D., Fontenla-Romero, O., Principe, J.C., Alonso-Betanzos, A., Castillo, E.: Linear-Least-Squares Initialization of Multilayer Perceptrons Through Backpropagation of the Desired Response. IEEE Transactions on Neural Networks 16(2), 325–337 (2005)
Nguyen, D., Widrow, B.: Improving the learning speed of 2-layer neural networks by choosing initial values of the adaptive weights. In: Proceedings of the International Joint Conference on Neural Networks, vol. 3, pp. 21–26 (1990)
Author information
Authors and Affiliations
Editor information
Rights and permissions
Copyright information
© 2007 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Guijarro-Berdiñas, B., Fontenla-Romero, O., Pérez-Sánchez, B., Fraguela, P. (2007). A Linear Learning Method for Multilayer Perceptrons Using Least-Squares. In: Yin, H., Tino, P., Corchado, E., Byrne, W., Yao, X. (eds) Intelligent Data Engineering and Automated Learning - IDEAL 2007. IDEAL 2007. Lecture Notes in Computer Science, vol 4881. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-77226-2_38
Download citation
DOI: https://doi.org/10.1007/978-3-540-77226-2_38
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-77225-5
Online ISBN: 978-3-540-77226-2
eBook Packages: Computer ScienceComputer Science (R0)