
Abstract
The generalized Poisson–XLindley distribution (GPXLD), which is obtained by combining the generalized Poisson distribution and the XLindley distribution based on the Lagrangian probability distribution framework, is a new distribution that we introduce for modeling count datasets. In this study, we also explore some important mathematical aspects of the GPXLD, such as median, mode, and non-central moment. It is shown that the moment of the GPXLD do not exist in some situations and have increasing, decreasing, bathtub and upside-down bathtub shaped hazard rates. For estimating its parameters, the maximum likelihood approach has been presented. A simulation study based on the inverse transformation method is used to evaluate how these estimators perform. In addition, a zero-inflated form of the GPXLD is defined for the case where the datasets contain an excessive amount of zeros. Applications of the GPXLD and zero-inflated GPXLD are described in a number of areas, and they are compared with some other existing distributions.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Count models are used in many theoretical and practical disciplines, including engineering, health, transportation, and insurance. Data science approaches have been used to describe pandemonium behaviour, crop harvesting, business data mining, e-commerce fraud, and other challenges (see Tien 2017). One of the most important uses of statistics is the representation of natural events or different real-world circumstances in a probability function that has a certain probability distribution that fits with those events. In order to express these incidents using a random variable (rv), we must be aware of them. A probability distribution function, which can be discrete, continuous, or mixed, can be used to represent any rv. We provide a mixed count model in this article that is based on the Lagrange expansion mentioned in Jenson (1902).
Poisson distribution is one often used model in the literature for counting data. However, because of its unique characteristics, this distribution is inappropriate for the most of count data, especially when there are issues with overdispersion or underdispersion. The most of count data deviate from the equidispersion of the Poisson distribution. As a result, it restricts the uses for this distribution (see Kusumawati and Wong 1987; Khan et al. 2018). Mixed-Poisson distributions in modeling count datasets have been proposed by researchers as a potential remedy for this problem. For instance, Bhati et al. (2017) created the Poisson-transmuted exponential distribution, a new mixed-Poisson distribution by combining the Poisson distribution with the transmuted exponential distribution. Poisson–Bilal distribution was first introduced by Altun (2020a). Altun et al. (2021) introduced the Poisson–Xgamma distribution (PXGD). Poisson-generalized Lindley distribution (PGLD) was first developed by Altun (2021). An detailed literature overview on mixed-Poisson distributions may be found in Karlis and Xekalaki (2005). Numerous researchers have proposed using generalized distributions to deal with circumstances where many non-homogeneous occurrences and common distributions are unsuccessful in explaining the behavior of their problems. The ability to represent both homogeneous and heterogeneous populations, as well as the fact that they are significantly wider than their usual forms, are characteristics of generalized distributions, see Consul and Jain (1973), Wagh and Kamalja (2017) and Bhattacharyya et al. (2021).
The generalized Poisson distribution (GPD) was created by Consul and Jain (1973) using the Lagrange expansion described in Jenson (1902). The GPD must be more suited to many forms of data with overdispersion or underdispersion than the classical Poisson distribution, which lacks dispersion flexibility. According to Consul and Jain (1973), the variance of the GPD is greater than, equal to, or less than the mean depending on the value of the parameter, whether it is positive, zero, or negative, respectively. Also, they showed that when parameter values increased, so did the variance and mean values, see Khan et al. (2018) and Wagh and Kamalja (2017). Several statistical applications prefer the GPD model, which generalizes the Poisson distribution. The characteristics of the GPD and the potential to represent data with overdispersion or underdispersion as well as the data with equidispersion make it a desirable distribution in distribution theory and a variety of applications, including branching processes, queuing theory, science, ecology, biology, and genetics. Moreover, the GPD takes up the most space and is the most important concept in the theory of Lagrangian distributions.
The idea of this work is based on the mixture of the GPD and XLindley distribution (XLD) using Lagrangian expansion given in Jenson (1902). Chouia and Zeghdoudi (2021) developed the XLD by mixing the exponential and Lindley distributions. This work is motivated by the following: XLD is simple and easy to apply. However, in general it is applicable to try out simpler distributions than more complicated ones; the XLD can be used quite effectively in analyzing many real lifetime data set: application to Ebola, Corona and Nipah virus and gives adequate fits too many datasets. For more details see Chouia and Zeghdoudi (2021).
Several disciplines, including agriculture, biology, ecology, engineering, epidemiology, sociology, etc., frequently use count data with extra zeros. Examples of such data include the number of women over 80 who pass away each day (see Hasselblad 1969), the number of fetal movements per second (Leroux and Puterman 2011), the number of HIV-positive patients (Van den Broek 1995), and the number of ambulances call for illnesses brought on by the heat (Bassil et al. 2011), the number of health services visits during a follow-up time (Feng 2021). To explain count data with excess zeros, a number of zero-inflated models, such as the zero-inflated Poisson distribution (ZIPD), the zero-inflated negative binomial distribution, and many others, have been studied in the literature (see Wagh and Kamalja 2018). In several areas, zero-inflated models are becoming more and more common. We also develop the zero-inflated GPXLD and give it the name zero-inflated GPXLD (ZIGPXLD) in this article.
The following is how the rest of the article is sorted. The detailed description of the Lagrange expansion and XLD are covered in Sect. 2. The definition and some of its special cases are discussed in Sect. 3. Some mathematical properties, and other details are presented in Sect. 4. In Sect. 5, the maximum likelihood estimation technique is defined to estimate the unknown parameters of the new distribution. The performance of the GPXLD parameters for the maximum likelihood estimation is also studied using simulation technique in the Sect. 6. A zero-inflated model with respect to the new distribution is discussed in Sect. 7. The applications and the empirical studies based on the new model concerning two real datasets are conducted in Sect. 8. Then, Sect. 9 finishes with the decisive concluding words.
2 Some Preliminaries
In this section, we define the XLD and give some mathematical background on the generalized Lagrangian family.
2.1 Generalized Lagrangian Family (GLF)
Let g(z) and h(z) be two analytic function of z, which are successively differentiable in \([-1,1]\) such that \(g(1)=h(1)=1,\) and \(g(0)\ne {0}.\) Lagrange considered the inversion of the Lagrange transformation \(u=\frac{z}{g(z)},\) and expressed it as a power series of u. Jenson (1902) defined the Lagrange expansion to be:
where \(D^{r}=\frac{\partial ^{r}}{\partial {z^{r}}}\) and \(h^{\prime }(z)=\frac{\partial {h(z)}}{\partial {z}}.\)
If every term in the series (1) is non-negative, the series turns into a probability generating function (pgf) in u and gives the pmf of the discrete GLF, which is as follows:
Using the Lagrange expansion described in (1), Consul and Shenton (1972) defined and studied the discrete GLF. For more references on the discrete GLF, see Consul and Famoye (2006).
Using Li et al. (2006), it is possible to obtain the Lagrangian probability model by relaxing the assumption that \(g(1)=h(1)=1.\) With this relaxation, we create the novel discrete mixture distribution based on the pmf of the discrete GLF given in (2).
2.2 The XLindley Distribution
A rv T follows a XLD, denoted as \(X\sim XLD(\theta ),\) if its probability density function (pdf) is given by
Now, the cumulative density function (cdf) of the XLD is given as
with \(t>0\) and \(\theta >0.\)
The rth distributional moment \((\mu _{r})\) associated with the XLD is given by
We have employed the gamma function defined by \(\Gamma (m)=\int _{0}^{\infty }t^{m-1}e^{-t}dt,\) with the relation \(\Gamma (m)=(m-1)!\) for any positive integer m.
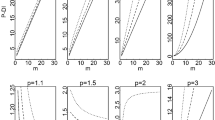
The graphical depiction of the pdf of the XLD is shown in the plots in Fig. 1. To learn more about the XLD, see Chouia and Zeghdoudi (2021).

Various pdf shapes of the XLD for different parameter values
3 The Generalized Poisson–XLindley Distribution
The following theorem from Li et al. (2008) is used with the Lagrangian probability model to generate the novel mixture of the XLD:
Theorem 3.1
Let \(g(z)>0\) and \(h(z)>0\) (for all \(z>0\)) be analytic functions such that \(g(0)\ne {0},\) \(\biggl \{D^{x-1}\left[ \left( g(z)\right) ^{x}h^{\prime }(z)\right] \biggr \}_{z=0}{\ge {0}},\) and \(h(0)\ge {0},\) where \(D=\frac{\partial }{\partial {z}}\) is a derivative operator. If the series
converges uniformly on any closed and bounded interval, then a rv X has a unform mixture of Lagrangian probability model with the pmf
Proof
Proof is given in Li et al. (2008) and hence omitted. \(\square\)
Theorem 3.2
Let g(t) and h(t) satisfy the conditions in Theorem 3.1and let f(t) be a pdf for some continuous rv T, then the pmf of X, a continuous mixture of Lagrangian probability model, is given by
Proof
Proof is given in Li et al. (2008) and hence omitted. \(\square\)
Proposition 3.1
Assume that X follows the new mixture GPXLD with \(\lambda >0,\) \(0<\rho <1\) and \(\theta >0,\) then the pmf of X is given by
This distribution is denoted as GPXLD\((\lambda ,\rho ,\theta ),\) and one can note \(X\sim {GPXLD(\lambda ,\rho ,\theta )}\) to inform that X follows the GPXLD with parameters \(\lambda ,\) \(\rho\) and \(\theta .\)
Proof
Let \(g(z)=e^{\rho {z}}\) and \(h(z)=e^{\lambda {z}},\) where \(0<\rho <1\) and \(\lambda >0.\) Under the transformation \(z=ue^{\rho {z}}\) and using the Lagrange expansion given in (1), we have
substituting \(z=t,\) we get
which implies
when \(t = 1\) the above formulation reduces to the GPD given in Consul and Jain (1973).
Therefore, by Theorem 3.1, we have a uniform mixture of GPD as:
where \(x=0,1,2,\ldots .\)
Clearly, g(t) and h(t) generate a Lagrangian probability model, which satisfies the conditions given in Theorem 3.1. More generally, assuming that the conditions given in Theorem 3.1 hold, and by letting the variable t to be a continuous rv from the XLD with pdf,
By using Theorem 3.2, the pmf of the proposed new mixture model is obtained as follows:
Hence the proof. \(\square\)
Proposition 3.2
If \(\rho =0,\) the GPD reduces to the Poisson distribution. On doing this, we obtain the Poisson mixture of XLD with parameters \(\lambda\) and \(\theta .\)
Proof
Hence the proof. \(\square\)
Figure 2 display the graphical representation of the pmf of the GPXLD for different parameter values of \(\lambda ,\) \(\rho\) and \(\theta .\)
The hrf of the GPXLD is obtained by substituting the pmf of the GPXLD in the following equation
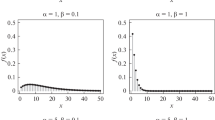
From (7), it is clear that determining the closed form expression of the hrf is more intricate, although, in order to determine the shape of the hrf, we sketch its graph. Figure 3 demonstrates the following facts about the shapes of the hrf of the GPXLD, indicating that the GPXLD has all of the typical shapes, such as decreasing, upside-down bathtub and increasing shapes for varying parameter values.

Various shapes of pmf of the GPXLD for different parameter values

Various shapes of hrf of the GPXLD for different parameter values
4 Mathematical Properties
In this section, different structural properties of the GPXLD have been evaluated. These include median, mode, non-central moment, etc.
4.1 Median
Let X be a rv following the GPMED. Then the median of X is defined by the smaller integer m in \(\left\{ 0,1,2,\ldots \right\} .\) By the definition, m is the smallest integer in \(\left\{ 0,1,2,\ldots \right\}\) such that \(P(X\le {m})\ge {\frac{1}{2}},\)
which is equivalent to the desired result.
4.2 Mode
Let X be a rv following the GPXLD. Then, the mode of X, denoted by \(x_{m},\) exists in \(\left\{ 0,1,2,\ldots \right\} ,\) and lies in the case:
We must find the integer \(x=x_{m}\) for which f(x) has the greatest value. That is, we aim to solve \(f(x)\ge {f(x-1)}\) and \(f(x)\ge {f(x+1)}.\) First, note that f(x) can also be written as:
where
Obviously, \(f(x)\ge {f(x-1)}\) implies that
Also, \(f(x)\ge {f(x+1)}\) implies that
By combining (9) and (10), we get (11).
4.3 rth Order Non-central Moment
The rth non-central moment \(\mu _{r}^{\prime }=E(X^{r})\) of the rv X from the pmf given in (5) is:
and
Then
Jenson (1902) showed that the Lagrange expansion could be written as
Taking first derivative of (15) partially with respect to t, we have
which implies that
Taking the second derivative of (17), we get
On multiplying both sides by \(f(t)t\left[ h(t)g(t)D^{1}\left( \frac{t}{g(t)}\right) \right] ^{-1},\) we get
Therefore,
In the similar method, the \(r\)th order non-central moment of X is given by,
where \(W_{1}(t)=D\left\{ \log {h(t)}\left[ D\log \left( \frac{t}{g(t)}\right) \right] ^{-1}\right\} ,W_{2}(t)=L(t)D\left\{ W_{1}(t)\right\} ,\) \(\ldots ,W_{r}(t)=L(t)D\left( W_{r-1}(t)\right) ,\) where
It is important to observe that the integral part is incomplete gamma distribution and consequently the mean and variance of the GPXLD do not exist as in the case of quasi-negative binomial distribution, see Li et al. (2011).
4.4 Mean and Variance
Using (18), the mean (\(\mu _{x}\)) of the GPXLD is derived as follows:
Analogously, using (18) the variance \((\sigma ^{2}_{x})\) can derived as follows:
It is important to point out that, unlike in the case of a quasi-negative binomial distribution, the integral part of the GPXLD is an incomplete gamma distribution, which means that the mean and variance do not exist, see Li et al. (2011).
5 Estimation
Here, we employ the method of maximum likelihood (ML) to estimate the GPXLD’s unknown parameters.
Let \(X_1,X_2,\ldots ,X_n\) be n independently and identically distributed (iid) from the GPXLD\((\lambda ,\rho ,\theta )\) (consequently, using the pmf from (6)), and \(x_1,x_2,\ldots ,x_n\) be n observations. Following that, the appropriate likelihood function is provided by
The log-likelihood function is given by
The ML estimate (MLE) of the parameter vector \({\Theta }=(\lambda , \rho ,\theta ),\) say \({\hat{\Theta }}=({\hat{\lambda }}, {\hat{\rho }},{\hat{\theta }}),\) is obtained by the solutions of the likelihood equations \(\frac{\partial {{\mathcal {L}}_{n}}}{\partial \lambda }=0,\) \(\frac{\partial {{\mathcal {L}}_{n}}}{\partial \rho }=0,\) and \(\frac{\partial {{\mathcal {L}}_{n}}}{\partial \theta }=0\) with respect to \(\lambda ,\) \(\rho\) and \(\theta .\) With these notations, \({\hat{\lambda }},\) \({\hat{\rho }}\) and \({\hat{\theta }}\) are also called MLEs of \(\lambda ,\) \(\rho\) and \(\theta ,\) respectively.
and
The likelihood equations have analytical solutions that cannot be found. Despite so, when employing the L-BFGS-B technique, the MLEs can still be determined numerically by maximizing the log-likelihood function offered in (19) using the best approach available in the R programming language.
6 Simulation Study
We do a brief simulation exercise in this part to assess how well the estimates derived using the ML estimation approach perform in random samples. Here, we simulate a GPXLD random sample using the inverse transformation method (see Ross 2013). The inverse transform algorithm used to create the GPXLD rv is as follows:
-
Step 1: Generate a random number from uniform U(0, 1) distribution.
-
Step 2: \(i=0,\) \(p=\frac{\theta ^{2}\left[ (2+\theta )(\theta +\lambda )+1\right] }{(1+\theta )^{2}(\theta +\lambda )^{2}},\) \(F=p.\)
-
Step 3: If \(U<F,\) set \(X=i,\) and stop.
-
Step 4: \(p=p\times \frac{\left( \lambda +\rho (i+1)\right) ^{i}(\theta +\lambda +\rho {i})^{i+2}}{\left( \theta +\lambda +\rho (i+1)\right) ^{i+3}(\lambda +\rho {i})^{i-1}}\times \frac{\left( (2+\theta )(\theta +\rho (i+1)+\lambda )+i+2\right) }{\left( (2+\theta )(\theta +\rho {i}+\lambda )+i+1\right) },\) \(F=F+p,\) \(i=i+1.\)
-
Step 5: Go to Step 3.
where p is the probability that \(X=i,\) and F is the probability that X is less than or equal to i.
The iteration process is repeated for \(N=1000\) times. The specification of the parameter values is as follows:
-
(i)
\(\lambda =0.98, \rho =0.51\) and \(\theta =0.01.\)
-
(ii)
\(\lambda =0.70,\rho =0.16,\theta =0.28.\)
-
(iii)
\(\lambda =0.14,\rho =0.24,\theta =0.75.\)
Thus, we computed the average of the mean square error (MSE), and average absolute bias using the MLEs.
The average absolute bias of the simulated estimates equals \(\frac{1}{1000}\sum _{i=1}^{1000}|{\hat{d}}_{i}-d|\) and the average MSE of the simulated estimates equals \(\frac{1}{1000}\sum _{i=1}^{1000}({\hat{d}}_{i}-d)^2,\) in which i is the number of iterations, \(d\in \left\{ \lambda ,\rho ,\theta \right\}\) and \({\hat{d}}\) is the estimate of d.
Table 1 provides a summary of the study for the samples of sizes 50, 125, 500, and 1000. As the sample size increases, it can be seen that the MSE in both cases of the parameter sets is in decreasing order, and the MLEs of the parameters go closer to their original parameter values, indicating the consistency property of the MLEs.
7 Zero-Inflated GPXLD
Long or heavy tail properties and an excessive amount of zeros are frequent characteristics of overdispersed count data. The negative binomial distribution (NBD) or GPD are often used distributions to fit data with long or heavy tails. These distributions, however, might not be able to accurately fit the proportion of zeros in the case of an excessive number of zeros. As a result of clustering, the situation with excessive zeros frequently occurs (see Johnson et al. 2005). In this article, we present the definition and some important properties of the zero-inflated version of the new proposed model GPXLD, known as zero-inflated generalized Poisson XLindley distribution (ZIGPXLD).
Definition 7.1
Let \(\psi\) be a rv degenerate at the point zero and let X follows GPXLD\((\lambda ,\rho ,\theta ).\) Assume that \(\psi\) and X are statistically independent. Then a discrete rv Y is said to follow the zero inflated GPXLD or in short the ZIGPXLD if its pmf has the following form.
in which \(\omega \in {[0,1]},\) \(\lambda >0,\) \(0<\rho <1\) and \(\theta >0.\)
Clearly, when \(\omega =0,\) the ZIGPXLD reduces to the GPXLD\((\lambda ,\rho ,\theta )\) with pmf given in (20). Next, we present certain properties of the ZIGPXLD through the following results.
By definition, the pgf of the ZIGPXLD with pmf given in (20) is
The corresponding mean and variance of the ZIGPXLD is as follows:
and
The likelihood function of the ZIGPXLD based on n observations, say \((x_{1},x_{2},\ldots ,x_{n})\) is:
The log-likelihood function of the equation given in (21) can be expressed as follows:
The estimates of the parameters in the non-linear equation given in (22) can be obtained by numerical optimization using “optim” or “nlm” functions in the R software, see R Core Team (2021).
8 Applications in Real Life Study
The goal of this section is to show how important the GPXLD and the ZIGPXLD are empirically.
8.1 Presentation
To show the usage of the proposed model, we utilize two real life data applications in this paper: the first is the number of suicides data set given in Kadhum and Abdulah (2021), which is used to compare the data modeling ability of the GPXLD over some competitive distributions, and the second is the COVID-19 pandemic data set given in El-morshedy et al. (2021), which is used to compare the data modeling ability of the ZIGPXLD over the ZIPD.
We consider the negative log-likelihood \((-\log \text{L}),\) \(\chi ^{2},\) the criteria like Akaike information criterion (AIC), Bayesian information criterion (BIC) and corrected Akaike information criterion (AICc). The better distribution corresponds to the lesser \(\chi ^{2},\) AIC, BIC and AICc values.
\(\text{AIC}=2k-2\,\log \text{L},\) \(\text{BIC}=k\,\log \,\text{n}-2\,\log \text{L}\) and \({\mathrm{AICc}}= \text{AIC}+\frac{2k(k+1)}{n-k-1},\)
where k is the number of parameters in the statistical model, n is the sample size and \(\log \text{L}\) is the maximized value of the log-likelihood function under the considered model.
Also, a graphical technique based on the total time on test (TTT) is used to determine the hrf of the datasets. If the empirical TTT plot is convex, concave, convex then concave, and concave then convex, then the form of associated hrf is decreasing, increasing, bathtub shape, upside-down bathtub shape, respectively (see Aarset 1987). We use the RStudio software for numerical evaluations of these datasets.
8.2 Number of Suicides Data Set
The first real data set is the number of accident suicides in the city of Baghdad between 2017–2020 period as accident data are rare and random events (see Kadhum and Abdulah 2021). Table 2 shows the descriptive measures of this data, which include sample size n, minimum (min), first quartile \((Q_{1}),\) median (Md), third quartile \((Q_{3}),\) maximum (max), and interquartile range (IQR). The empirical index of dispersion (ID) of the data is equal to 0.9958. As a result, our model employed to describe the current data set is capable of dealing with underdispersion. To demonstrate the GPXLD’s potential benefit, the following distributions are considered for comparison.
-
The new Poisson weighted exponential distribution (NPWED) proposed by Altun (2020b), and defined by the following pmf:
$$\begin{aligned} p_{1}(x)=\alpha (1+\theta )(1+\alpha +\alpha {\theta })^{-x-1},\quad x=0,1,2\ldots , \end{aligned}$$with \(\theta >0\) and \(\alpha >0.\)
-
The PXGD proposed by Bilal et al. (2020), and defined by the following pmf:
$$\begin{aligned} p_{2}(x)=\frac{\theta ^{2}}{2(1+\theta )^{x+4}}\biggl \{2(1+\theta )^{2}+\theta (x+1)(x+2)\biggr \},\quad x=0,1,2\ldots , \end{aligned}$$with \(\theta >0.\)
-
The NBD proposed by Consul and Famoye (2006), and defined by the following pmf:
$$\begin{aligned} p_{3}(x)=\frac{\lambda }{\lambda +x}\left( {\begin{array}{c}\lambda +x\\ x\end{array}}\right) \,\rho ^{x}(1-\rho )^{\lambda },\quad x=0,1,2\ldots , \end{aligned}$$with \(\lambda >0\) and \(0<\rho <1.\)
-
The discrete Lindley distribution (DLD) given in Bilal et al. (2020), and defined by the following pmf:
$$\begin{aligned} p_{4}(x)=\frac{\rho ^{x}}{1+\lambda }\,\biggl \{\lambda (1-2\rho )+(1-\rho )(1-\lambda {x})\biggr \} x,\quad x=0,1,2\ldots , \end{aligned}$$with \(\lambda >0\) and \(0<\rho <1.\)
-
The PGLD proposed by Altun (2021), and defined by the following pmf:
$$\begin{aligned} p_{5}(x)=\frac{1}{(\theta +1)^{x+2}}\biggl \{\theta ^{2}+\frac{\theta ^{\alpha }(\theta +1)^{1-\alpha }\Gamma (x+\alpha )}{\Gamma (\alpha )\Gamma (x+1)}\biggr \},\quad x=0,1,2\ldots , \end{aligned}$$with \(\theta >0\) and \(\alpha >0.\)
In addition, Fig. 4 shows an empirical TTT plot of the data and it reveals an increasing hrf.

Total time on test (TTT) plot for the suicides data set
According to Table 3, the GPXLD’s \(\chi ^{2},\) AIC, BIC and AICc values are lower than those of the other distributions under consideration. Therefore, the proposed model is the best choice for modeling the provided data set.

Total time on test (TTT) plot for the COVID-19 pandemic datasets
8.3 COVID-19 Pandemic Data Set
Second, we make use of the dataset of daily new cases of COVID-19 disease-related death in Armenia. The data are available at https://www.worldometers.info/coronavirus/country/armenia/ accessed on the 10 September 2020 and are also studied by El-morshedy et al. (2021). They contain the daily new COVID cases between 15 February 2020 and 4 October 2020. Likewise, this data indicates overdispersion problem with ID 4.4822. As a result, our model employed to describe the current data set is capable of dealing with overdispersion. Table 4 shows the descriptive measures of this data, which include n, min, \(Q_{1},\) Md, \(Q_{3},\) max, and IQR. It illustrates that the best fit is the ZIGPXLD, followed by the ZIPD.
In addition, Fig. 5 shows an empirical TTT plot of the data and it reveals an decreasing hrf.
According to Table 5, the ZIGPXLD’s AIC, BIC and AICc values are lower than those of the other distributions under consideration. Therefore, the proposed zero-inflated model is the best choice for modeling the provided data set.
9 Conclusion
In this work, the mixed count model is proposed, known as GPXLD. We show that its special case is the Poisson mixture of the XLD. In particular, we derive some mathematical properties of the GPXLD. The estimation procedure for parameters is also implemented by the maximum likelihood method. Also, we proposed zero-inflated version of the GPXLD, known as ZIGPXLD. The two proposed distributions are applied to two real datasets and it is compared with some important competitive distributions. The comparison results of the minus log-likelihood, AIC, BIC and AICc values for distributions show that the best fit model is the GPXLD and ZIGPXLD. In conclusion, the GPXLD is a flexible model that can be an alternative way to model count data with too many zeros. If the INAR(1) process of the GPXLD and a bivariate version of the GPXLD are created, the direction of this research may change. This work requires considerable revisions and examinations, which we will leave to additional research.
References
Aarset MV (1987) How to identify a bathtub hazard rate. IEEE Trans Reliab 36(1):106–108
Altun E (2020a) A new one-parameter discrete distribution with associated regression and integer-valued autoregressive models. Math Slovaca 70(4):979–994
Altun E (2020b) A new generalization of geometric distribution with properties and applications. Commun Stat Simul Comput 49(3):793–807. https://doi.org/10.1080/03610918.2019.1639739
Altun E (2021) A new two-parameter discrete Poisson-generalized Lindley distribution with properties and applications to healthcare data set. Comput Stat 36(4):1613–9658
Altun E, Cordeiro GM, Ristíc MM (2021) An one-parameter compounding discrete distribution. J Appl Stat 49(8):0266–4763. https://doi.org/10.1080/02664763.2021.1884846
Bassil KL, Cole DC, Moineddin R, Lou W, Craig AM, Schwartz B, Rea E (2011) The relationship between temperature and ambulance response calls for heat-related illness in Toronto, Ontario, 2005. J Epidemiol Community Health 65(9):829–31
Bhati D, Kumawat P, Gómez-Déniz E (2017) A new count model generated from mixed Poisson transmuted exponential family with an application to health care data. Commun Stat Theory Methods 46(22):11060–11076
Bhattacharyya B, Biswas R, Sujatha K, Chiphang DY (2021) Linear regression model to study the effects of weather variables on crop yield in Manipur state. Int J Agric Stat Sci 17(1):317–320
Bilal AP, Tariq RJ, Hassan SB (2020) Poisson Xgamma distribution: a discrete model for count data analysis. Model Assist Stat Appl 15:139–159. https://doi.org/10.3233/MAS-200484
Chouia S, Zeghdoudi H (2021) The XLindley distribution: properties and application. J Stat Theory Appl 20:318–327. https://doi.org/10.2991/jsta.d.210607.001
Consul PC, Famoye F (2006) Lagrangian probability distributions. Birkháuser, New York
Consul PC, Jain GC (1973) A generalization of the Poisson distribution. Technometrics 15:791–799
Consul PC, Shenton LR (1972) Use of Lagrange expansion for generating generalized probability distributions. SIAM J Appl Math 23:239–248
El-morshedy M, Altun E, Eliwa M (2021) A new statistical approach to model the counts of novel coronavirus cases. Math Sci. https://doi.org/10.1007/s40096-021-00390-9
Feng CX (2021) A comparison of zero-inflated and hurdle models for modeling zero-inflated count data. J Stat Distrib Appl 8(8):2195–5832
Hasselblad V (1969) Estimation of finite mixtures of distributions from the exponential family. J Am Stat Assoc 64(328):1459–71. https://doi.org/10.1080/01621459.1969.10501071
Jenson J (1902) Sur une identité d́ Abel et sur d́autres formules analogues. Acta Math 26:307–318
Johnson NL, Kemp AW, Kotz S (2005) Univariate discrete distributions. Wiley, New York
Kadhum MK, Abdulah EK (2021) Statistical computation and application with generalized Poisson distribution. Int J Agric Stat Sci 17(1):1401–1405
Karlis D, Xekalaki E (2005) Mixed Poisson distributions. Int Stat Rev 73:35–58
Khan MTF, Adnan MAS, Hossain MF, Albalawi A (2018) Generalized Poisson and geometric distributions an alternative approach. J Stat Theory Appl 17(3):478–490
Kusumawati A, Wong YD (1987) The applications of generalized Poisson distribution in accident data analysis. J East Asia Soc Transp Stud 11:2189–2208
Leroux BG, Puterman ML (2011) Maximum-penalized-likelihood estimation for independent and Markov-dependent mixture models. Biometrics 48(2):545–58
Li S, Famoye F, Lee C (2006) On some extensions of the Lagrangian probability distributions. Far East J Theor Stat 18:25–41
Li S, Famoye F, Lee C (2008) On certain mixture distributions based on Lagrangian probability models. J Probab Stat Sci 6:91–100
Li S, Yang F, Famoye F, Lee C, Blacka D (2011) Quasi-negative binomial distribution: properties and applications. Comput Stat Data Anal 55:2363–2371
R. R Core Team (2021) A Language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/. Accessed 6 Sept 2021
Ross S (2013) Simulation, 5th edn. Academic Press, Cambridge. https://doi.org/10.1016/B978-0-12-415825-2.00001-2
Tien J (2017) Internet of things, real-time decision making, and artificial intelligence. Ann Data Sci 4(2):149–178
Van den Broek J (1995) A score test for zero inflation in a Poisson distribution. Biometrics 51(2):738–743
Wagh YS, Kamalja KK (2017) Comparison of methods of estimation for parameters of generalized Poisson distribution through simulation study. Commun Stat Simul Comput 46(5):4098–4112
Wagh YS, Kamalja KK (2018) Zero-inflated models and estimation in zero-inflated Poisson distribution. Commun Stat Simul Comput 47(8):106–108
Funding
Research work is supported by Govt. of Kerala.
Author information
Authors and Affiliations
Contributions
Both the authors, M. Monisha and D. S. Shibu, contributed equally to this work.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Monisha, M., Shibu, D.S. On Discrete Mixture of XLindley Distribution Using Lagrangian Probability Model: Properties and Applications in Count Data with Excess Zeros. J Indian Soc Probab Stat 24, 419–441 (2023). https://doi.org/10.1007/s41096-023-00160-x
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41096-023-00160-x