
Abstract
Automotive Industry has an important place all around the world and sales forecasting process supports companies to meet their goals such as sales revenue increase, efficiency improvement, capacity planning and customer care. Traditional methods such as time series and econometrics have been applied by scientists during last decades. However, recently sales forecast problem by means of machine learning techniques are welcomed by data scientists because of increasing power of information technology in both hardware and software aspects. In this research, the hybridization of clustering method, Adaptive network Fuzzy Inference System (ANFIS) and Particle Swarm Optimization (PSO) are developed to forecast annual automotive sales in Iran automotive market. Furthermore, in regard to evaluate the developed model, Artificial Neural Network (ANN) and ARIMA are introduced and comparative analysis in three different scenarios are provided. The results illustrate that proposed method outperforms the rest of techniques and would be more applicable in forecasting problem especially in uns
table macro- environments.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The selling process is an essential part of every business. Consequently, sales forecasting plays a prominent role in finance planning and is an important self-assessment tool for a company. Since managers continually have to monitor the vital pulse of their companies to know how well it is on the right track. Sales forecast analysis could help them in this issue. This can make a difference between surviving and succeeding businesses, and would be a cornerstone of a companies’ budget. Ergo, the future direction of the companies could depend on the accuracy of their sales forecasts. Nowadays, the automotive industry plays an essential role in the world economy. Sales forecast helps the company to achieve its goals, such as increasing sales revenue, improving the efficiency and capacity building. Howsoever, it is still one of the most difficult and complex parts of management science [1, 2].
During the past few decades, when addressing the issue of sales forecasting, traditional methods like time series forecasting such as exponential smoothing, moving average, ARIMA and multivariate regression; have been proposed and widely put in practice to calculate patterns. However, these methods generally do not work when the market is constantly fluctuating [3]. In addition, econometric methods are applicable only when there are sufficient historical observations for the model variables. In these models, using general historical data, the past behavior of the variables is extrapolated and extended to the future. Since, the future relationships between variables are based on their past relationships in econometric methods; the application of these methods requires stability in the response of economic behavior [4].
In recent years, Iran has faced with some sanctions (starting with the automotive industry), so the Iran automotive industry has been in crisis and companies' production was less than the actual capacity. Therefore, the corporates’ roadmaps were not ready for these rapid and disruptive changes because traditional forecast trends were unable to predict these conditions. On the other hand, after the recent US government elections in 2020 and the victory of the Democrats, the Iran market likely experiences a new era and through it, the market grows rapidly. As a result, awareness of strategy is vital in this competitive market. Consequently, a volatile macro environment has led researchers to develop more flexible prediction methodologies, such as computational artificial intelligence. The literature review on this subject reveals that car sales forecast study consists of two types. The first type is the introduction of common and traditional forecasting models for sales forecasting. The second one is a series of studies that use data science-based techniques to predict sales in the automotive industry.
Budget planning plays a critical role in any organization. The key factor to a useful budgeting process is accurate sales forecasting. Predicting the future of a business has consistently been an essential capability of the organization for strategic and tactical business planning [5]. On this account, improving the quality of forecasts is still a prominent question that will come to the mind of any manager [3]. The reason of sales forecasting’s importance is its impact on many of the organization's functions [6]. Sales forecasting can be performed by linear (e.g. ARIMA, ARMA, etc.) and non-linear (e.g. ANN, FIS, etc.) methods. In recent years, many researchers have tried to create a model for sales forecasting. In order to predict sales quantity, many researchers tried to use economic indicators to improve the accuracy of the models.
According to the literature from 2000 to 2021 with the keyword of automotive sales forecasting, 16 papers are found. Most of them not only used sales historical data, but also they considered several explanatory variables in forecasting sales, including the impact of personal income on Car Ownership, GDP, Inflation Rate, Unemployment Rate, Population Density and the Price of Fuel and other variables which is depicted in Table 1.
Kou et al. introduced a model that applied an artificial neural network to learn not only “if–then” rules, but also to detect fuzzy weights. The main variable that they focused was the effect of advertising on sales [7]. In 2009, Bruhl et al. implemented macroeconomic models to forecast the monthly, seasonal, and annual car sales in German Automotive Industry, and the final results demonstrated that the non-linear method was more accurate than the linear one [8]. Shahabuddin implemented an adaptive network-based fuzzy inference system using economic indicators to forecast the number of car sales in Taiwan [9]. Chen et al. provided an efficient method based on a Gray extreme machine learning using Taguchi to estimate sales numbers in the competitive market [10]. Wang et al. developed a forecasting model based on the monthly sales of new cars in Taiwan and compared the results of ANFIS model with ARIMA and ANN as well. They used indicators such as employees' average income, oil price and start of building construction permits, the producer's inventory, the average monthly overtime as the most effective sales forecast variables. The ANFIS model obtained the best results [11]. Ngasoongsong et al. and Gao et al. established a forecasting method based on the econometric model in automobile sales and obtained the stability of the model’s test and the results compared with VAR and ARMA [12, 13]. Muhammad et al. analyzed both short-term and long-term impact of macroeconomic variables in car sales forecasting in the ASEAN countries and concluded that the macroeconomic variables have a long-term correlation with number of automobile sales [14]. Sharma et al. developed an ANN model to forecast car sales in India and illustrated the effects of different macroeconomic variables [15]. Vahabi et al. analyzed the use of genetic algorithm to fit the parameters of the proposed ANFIS model using annual data from Iran’s leading auto manufacturer Saipa Group [16]. Zhang et al. developed a Singular Spectrum Analysis and a Vector Autoregressive model to predict the amount of EV sales in the China Market [17]. Salais-Fierro et al. suggested an integrated fuzzy logic approach (Delphi) and ANN to forecast demand [18]. According to research that has been conducted recently, Jain et al. implemented nine different time series models to forecast the vehicle demand in the Indian car Industry. This study has shown that linear models have less accuracy to estimate sales rather than others [19]. In addition, Hanggara et al. developed a Moving Average approach using sales and production data to prevent surplus car production in the Indonesia Market [20]. Indeed, Arsy et al. proved more accurate results of a Grey model in comparison to Linear and Exponential regression methods in the Automotive Industry [21]. Rožanec et al. implemented an Artificial Intelligence model to B2B discrete demand forecasting in the Automotive Industry. Additionally, they concluded that global Machine Learning methods obtain preferable efficiency than domestic ones [22].
1.1 Statement on the Contributions
According to the literature review, statistical methods such as ARIMA and linear regression have usually been developed by researchers. However, there have been developed several AI-based tools such as ANN and FIS which seem to outperform the results provided by previous models [23,24,25]. The ANN method is applied to train fuzzy inference systems, which leads to the technique of Adaptive Network Fuzzy Inference system (ANFIS). Furthermore, to obtain more accurate results, meta-heuristic algorithms e.g. such as genetic algorithm, particle swarm optimization and harmony search. can be used to adjust the results of the ANFIS. According to the previous researches, a genetic algorithm has been applied to upgrade the results of the ANFIS, which are better than other compared models [9, 26, 27]. Consequently, the main contributions of this paper in regard to the mentioned literature review are as follows:
-
1.
Although the clustering method is applicable in forecasting process, no researchers have considered this issue in the studies. Thanks to clustering process, the range of data would purify and harmonize and as a result, high quality of prediction would be obtained.
-
2.
To the best of our knowledge, there are few researchers have applied meta-heuristics algorithms to optimize the AI methodology and Particle Swarm Optimization algorithm never applied. Hence, in this paper, the PSO algorithm has been used to tune the parameters of membership functions in ANFIS methodology.
-
3.
Vast variety of economic, social and industrial indicators (313 indexes) are considered in the first phase and in the next steps, they are cleaned and filtered.
-
4.
We consider non-linear methodologies such as ANFIS and ANN to handle the high fluctuations of macro environment factors.
Accordingly, regarding the ambiguity of macro environment of Iran, the application of artificial intelligence method especially adaptive network fuzzy inference system adjusted with particle swarm optimization (PSO) after clustering the historical data have been considered. The research method in this prediction problem would be explained in the second part. In the following sections, the findings, discussion and conclusions are illustrated.
2 Research Methodology
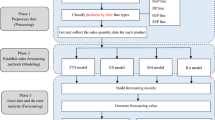
In this research, the sales forecast model in the Iran automotive market is introduced based on a hybrid model of adaptive network fuzzy inference system and particle swarm optimization algorithm. The aim of this system is to predict future annual sales. The process of the developed method is depicted in Fig. 1. The proposed model includes the following steps:
-
1.
Identifying the factors of macro environment and industry: In this step, after searching data and related information, a dataset has been gathered including 313 variables. Then, external factors and effective variables on economy sector, especially the automotive market, have been identified using the existing knowledge in the literature and experts survey (seven experts in automotive industry and universities by deep interview technique). It is noted that no selection was made at this step, and the goal is to have an acceptable and available number of economic parameters so that the next steps can be done with the desired accuracy and comprehensiveness.
-
2.
Extracting the historical data of the determined factors and creating a spreadsheet of data from sources such as the Central Bank of Iran, the Statistics Center of Iran, Economist and Business Monitor International.
-
3.
Data processing and cleaning process: Due to the irrelevance and lack of some data in some years, some factors are removed and other defects such as outliers are eliminated or amended by means of interpolation method.
-
4.
In order to implement the forecasting model in a couple of scenarios, the existing data are clustered so that the years that have common behaviors based on the identified economic factors, are in a same cluster. In the next stages, all forecasting methodologies are executed for each determined cluster in addition to the total data.
-
5.
The resulted clustering is verified based on the opinion of experts before the implementation of the model. In this regard, the obtained clusters are compared with the macro environment of previous years to confirm the rightness of the clusters.
-
6.
In order to select the most relevant external factors or characteristics with the amount of sales according to the available data, Pearson correlation coefficient and stepwise regression method have been applied. It is obvious that the output of this stage would be applied as an input in annual car sales forecast methods.
-
7.
Training the adaptive network fuzzy inference system model and adjustment of its parameters using particle swarm optimization based on 70% of the whole data.
-
8.
Performing test and validation of forecasting model based on 30% of data and extracting deviation indicators such as RMSE and accuracy index.
-
9.
Based on past studies in the literature review and experts’ interviews, variables which are more effective in car sales are extracted. Some variables are considered, such as population size, GDP in dollars, minimum income in dollars, urban household size, rural household size, oil production, car sales, consumer price index, inflation rate, stock index, household income in dollars, Gini coefficient, Liquidity volume, bank interest rate, unemployment rate, export and import value in dollars [9, 13, 14].

The schematic view of modeling procedure
In this paper, the annual data of each input variable from 1990 to 2020 along with the data related to the annual car sales as an output variable were collected and cleaned. Next phase, the clustering process is performed to identify the years that have similar behavior based on the collected variables. The clustering algorithm places information that has near and similar properties into a common category called a cluster. In other words, clustering means segmenting data into meaningful groups or clusters so that the contents of each cluster have the same characteristics but at the same time are different from other objects in other clusters.
To cluster the data, two-step clustering method by SPSS Modeler are applied. The historical data was examined and two clusters were obtained in the years 1990–2000 and 2001–2020. It is crystal clear that each cluster has the same behavior based on the fluctuations of input and output variables, and the clusters show dissimilar behaviors concerning each other and have the maximum distance. In the next stage, a stepwise regression method has been implemented by MATLAB software to select the most appropriate and related prediction variables. This step should be done for all three scenarios: Scenario 1: Total data (years 1990 to 2020), Scenario 2: The first cluster (1990–2000) and Scenario 3: The second cluster (2001–2020).
Figure 2 illustrates the output of the stepwise regression method in Scenario 1. The variables of average household income, dollar value, imports in dollar, urban population, rural population and number of urban households are recognized as the effective variables in car sales and in Table 2 output of three scenarios based on stepwise regression method has been brought.

The output of stepwise regression in scenario 1 by MATLAB
After the determination of the input variables, which affect the annual vehicle sales, the forecasting process based on the ANFIS tuned by the PSO algorithm is performed in three scenarios. To make a comparison and evaluate the proposed model, back-propagation artificial neural network and ARIMA models are executed by MATLAB.
Jang introduced the fuzzy inference system by training a fuzzy inference system within an adapted neural network [28]. The structure of the adaptive neural network consists of some nodes in various layers that are interconnected. A fuzzy inference system is a framework based on fuzzy theory and fuzzy IF–THEN rules. ANFIS is the Sugeno-type fuzzy system in that its rules and the optimal values of its parameters are determined using a series of available training data from the relevant process. The back-propagation algorithm and its combination with the least-squares method sets the parameters of the membership functions of this system.
This model of neuro-fuzzy technique is a combination of fuzzy inference system and artificial neural network that can interpret and analyze any sort of information (numerical, linguistic and logical) and make the ability to self-organize, self-learn and self-regulate as well as quality development of making predictions and obtaining more precise results [28, 29].
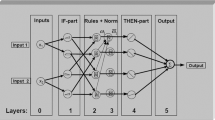
Figure 3 shows a general architecture of an ANFIS system with two X and Y inputs and one output. Basically, five layers are used in the construction of this system. Each layer of this system consists of several nodes, which are described by the function of node. Two rules might be created for a Sugeno fuzzy inference system:

General architecture of neural fuzzy inference system
Here X, Y is the input of the fuzzy inference system. A1, B1 are the fuzzy set of f (x, y) first-order polynomials that represent the output of the first-order Sugeno fuzzy inference system.
The adaptive network fuzzy inference system is a flexible and learnable network that is quite similar to the fuzzy inference system. Layer 1, in this layer inputs, pass through membership functions. The membership functions can be any suitable parametric function, but in most cases, Gaussian and bell functions are used.
Which \(\,\left\{ {a_{i} ,b_{i} ,c_{i} } \right\}\) are a set of parameters. The parameters of this layer are known as the initial parameters. Layer 2, the output of this layer is the multiplication of the input signals, which are actually equivalent to the “if” rules.
Layer 3, the output of this layer is the normalized layer of the previous one.
Layer 4 is called the defuzzification layer. The weighted values of the rules in each node are calculated based on the following formula. Values are obtained by first-order polynomials.
Layer 5: The output of this layer is actually the overall output of the system.
2.1 Particle Swarm Optimization
Particle Swarm Optimization (PSO) is one of the population-based and agent-based parallel search algorithms that starts with a group of random answers and then updates the particle location to find the optimal solution [30]. Each particle is denoted multidimensionally by two vectors x and ν, which represent the position and velocity of the i-th particle, respectively, at every stage of the population movement, the location of each particle is updated by two values. The first value is the best experience that the particle itself has ever had, and the second one is the best experience of all particles. In each iteration, the algorithm updates the new velocity and position of the particle-based on Eqs. (7) and (8) after finding the two better values.
In Eq. (8), w is the coefficient of inertia, which decreases linearly and is usually between zero and one. C1 and C2 are learning or acceleration coefficients. The condition for termination is the convergence to a certain extent or stopping after a certain number of iterations. Equation (7) updates the current position vector of the particle with respect to its new velocity as well. In this research, Particle Swarm Optimization methodology is applied as an algorithm to optimize member functions of ANFIS. The main advantage of PSO is that it declines computation time for a specified topology.
To evaluate the efficiency of forecasting methods, an error evaluation criterion should be applied. There are various evaluation criteria in this field, and two different criteria have been selected. The mean square error (MSE) is a quantity for estimating and comparing the predicted value, and defined in terms of the expectation of squared error as depicted in Eq. 9.
where fi and yi represent the predicted and real values of output, respectively. The root of mean square error (RMSE) is a measure of the value predicted by a model and its observed value is quantitative and defined as the root mean square error, Eq. 10. MSE is a differentiable function that facilitates carrying out mathematical operations. Thus, in numerous models, RMSE is applied as a default index to calculate loss Function despite being harder to interpret than MSE. Furthermore, it illustrated that the RMSE is not enigmatic in its meaning at all and could be the best measure to evaluate the accuracy of forecasting models [31]. Consequently, in this paper, the RMSE indicator has been selected to evaluate the proposed forecasting methodologies alongside the accuracy index. It is worth mentioning that the accuracy index is an ad-hoc indicator based on dividing the average output error of each model by the average annual car sales in the Iran auto market existing in the test data.
2.2 Back-Propagation Artificial Neural Network
A back-propagation network is a multilayer network with a nonlinear stimulus function and is applied to approximate functions, find the relationship between input and output and categorize inputs according to the methods specified by the designer. A back-propagation network with a sigmoid layer and a linear output layer can estimate any function with finite connection points. Thus, Fig. 4 shows the structure of a backpropagation neural network, which illustrates how the elements that make up the network are located and combined.

The structure of the multilayer backpropagation Artificial Neural Network
2.3 ARIMA
Autoregressive Integrated Moving Average Model is a combination of Autoregressive (AR) process and Moving Average process and provides a composite model of the time series. A simple form of ARIMA model as a linear process is depicted below:
The xt is the stationary variable, c is constant, φi is autocorrelation coefficient and \(\in_{t}\), the residuals.
θi are the weight assigned to the prior values.
3 Empirical Result
As the first method, Sugeno-based adaptive network fuzzy inference system with Gaussian membership functions is developed. The parameters of this system include epoch = 250, initial step size = 0.01, decrease rate = 0.9 and increase rate = 1.1.
Subsequently, the ANFIS is tuned by the PSO to adjust the parameters of fuzzy membership functions. The parameters of the ANFIS is extracted and stored in the vector P. The aim of implementing the meta-heuristic algorithm is to find the best parameters in order to reduce the Root Mean Squared Error (RMSE).
The parameters of the particle swarm optimization are C1 = 1, C2 = 2 and w = 1. The maximum iteration is 3000, the number of population is 100 and the values of r1 and r2 are random numbers between zero and one. The second method is a back-propagation artificial neural network. In this method, the number of hidden layers is 2 and the number of epochs is varied in the range of 2 to 5 and the best output is applied in the model. Finally, the third method is ARIMA as a traditional linear regression model. All three methods are executed by MATLAB.
Based on the proposed methods for forecasting annual car sales in the Iran automotive market in three scenarios, the results of comparisons are shown in Fig. 5 and Table 3. %70 of the data set in each scenario is used for training and %30 for testing.

Testing output by hybrid ANFIS and PSO in three scenario
4 Discussion and Conclusion
As shown in Table 3 and Fig. 6, the model outputs are illustrated based on an adaptive network fuzzy inference system tuned by particle swarm optimization, artificial neural network and ARIMA in three different scenarios. It considers that the accuracy of all models in scenario 1 is higher than in other scenarios. The reason for this is the existence of more adequate historical data in scenario 1 rather than other scenarios. Because more data have been used to train the artificial neural network, adaptive network fuzzy inference system and ARIMA. Therefore, in this case, the ANFIS-PSO model can forecast the annual sales of the car with 98% accuracy.

The comparison between the accuracy of two proposed methods in three different scenarios
Another achievement of this research is the superiority of the adaptive network fuzzy inference system tuned by the particle swarm optimization over the other techniques, which in all three scenarios had an average accuracy of 96.3%, while the average accuracy of the artificial neural network and ARIMA were 88.7% and 78.3% sequentially.
By the way, an accurate annual sales prediction seems essential for any company to increase market share and provide essential production capacity. Regarding the results, the proposed technique demonstrated its ability to assist the managers not only in the determination of future demand but also toward making critical decisions in capacity planning, material procurement, and budget planning, and etc. In future research, there are several areas to improve the forecasting process in this problem. Firstly, it is worth trying to gather more detailed historical data in monthly or daily rather than annually. Because this change would promote the accuracy of the forecasting model and training process. Secondly, our model does not account for the qualitative variables such as political conditions. However, considering this sort of variable would be an important contribution to the forecasting process. Finally, other meta-heuristic and heuristic algorithms could be applied for tuning ANFIS or FIS models.
References
Chang, P.-C., Liu, C.-H., Fan, C.-Y.: Data clustering and fuzzy neural network for sales forecasting A case study in printed circuit board industry. Knowledge-Based Sys. 22.5, 344–355 (2009)
Abu-Eisheh, S.A., Mannering, F.L.: Forecasting automobile demand for economies in transition: A dynamic simultaneous-equation system approach. Transp. Plan. Technol. 25(4), 311–331 (2002)
Lawrence, M., O’Connor, M.: Sales forecasting updates: how good are they in practice? Int. J. Forecast. 16(3), 369–382 (2000)
Suganthi, L., Anand, A.: Samuel, Energy models for demand forecasting—A review. Renew. Sustain. Energy Rev. 16(2), 1223–1240 (2012)
Fildes, R., Hastings, R.: The organization and improvement of market forecasting. Journal of the Operational Research Society 45(1), 1–16 (1994)
Mentzer, J.T., Bienstock, C.C.: Sales forecasting management: understanding the techniques, systems and management of the sales forecasting process. SAGE Publications, Incorporated (1998)
Kuo, R.J., Wu, P., Wang, C.P.: An intelligent sales forecasting system through integration of artificial neural networks and fuzzy neural networks with fuzzy weight elimination. Neural Netw. 157, 909–925 (2002)
Brühl, Bernhard, et al., (2009) A sales forecast model for the german automobile market based on time series analysis and data mining methods, Industrial Conference on Data Mining, Springer
Shahabuddin, S.: Forecasting automobile sales. Manag. Res. News 32(7), 670–682 (2009)
Chen, F.L., Ou, T.Y.: Sales forecasting system based on Gray extreme learning machine with Taguchi method in retail industry. Expert Syst. Appl. 38(3), 1336–1345 (2011)
Wang, F.-K., Chang, K.-K., Tzeng, C.-W.: Using adaptive network-based fuzzy inference system to forecast automobile sales. Expert Syst. Appl. 38(8), 10587–10593 (2011)
Gao, J., et al.: Chinese automobile sales forecasting using economic indicators and typical domestic brand automobile sales data A method based on econometric model. Adv Mech Engin 102, 1–11 (2018)
Sa-Ngasoongsong, A., et al.: Multi-step sales forecasting in automotive industry based on structural relationship identification. Int J Prod Econ 1402, 875–887 (2012)
Muhammad, F., Hussin, M.Y.M., Razak, A.A.: Automobile sales and macroeconomic variables A pooled mean group analysis for ASEAN countries. IOSR J Business and Management 21, 15–21 (2012)
Sharma, R., Sinha, A.K.: Sales forecast of an automobile industry.". Int J Comput Appl 53(12), 25–28 (2012)
Vahabi, A.: Shahrooz Seyyedi Hosseininia, and Mahmood Alborzi, A sales forecasting model in automotive industry using Adaptive Neuro-Fuzzy Inference System (ANFIS) and Genetic Algorithm (GA). Inter J Adv Comp Sci Appl (IJACSA) 7(11), 24–30 (2016)
Zhang, Y., et al.: Forecasting electric vehicles sales with univariate and multivariate time series models: The case of China. PLoS ONE 12(5), 176 (2017)
Salais-Fierro, T.E., et al.: Demand prediction using a soft-computing approach: a case study of automotive industry. Appl Sci 10(3), 829 (2020)
Jain, Piyush and Parv Arora, Analysis of Time Series Forecasting Techniques for Indian Automotive Industry, Jetir 8(7) (2021)
Hanggara Fuad Dwi., (2021) Forecasting Car Demand in Indonesia with Moving Average Method. Journal of Engineering Science and Technology Management (JES-TM) 1(1): 1–6
Arsy, F.A.: Demand forecasting of toyota avanza cars in indonesia: grey systems approach. Inter J Grey Sys 1(1), 38–47 (2021)
Rožanec, J.M., et al.: Automotive OEM demand forecasting A comparative study of forecasting algorithms and strategies. Appl. Sci. 11(15), 67–87 (2021)
Chow, T.W.S., Leung, C.-T.: Non-linear autoregressive integrated neural network model for short-term load forecasting. IEE Proc-Gener, Transm Distrib 143(5), 500–506 (1996)
Law, R., Norman, Au.: A neural network model to forecast Japanese demand for travel to Hong Kong. Tour. Manage. 20(1), 89–97 (1999)
Luxhøj, J.T., Riis, J.O., Stensballe, B.: A hybrid econometric—neural network modeling approach for sales forecasting. Int. J. Prod. Econ. 43(2–3), 175–192 (1996)
Wei, L.-Y.: A GA-weighted ANFIS model based on multiple stock market volatility causality for TAIEX forecasting. Appl. Soft Comput. 13(2), 911–920 (2013)
Kampouropoulos, Konstantinos, et al., A methodology for energy prediction and optimization of a system based on the energy hub concept using particle swarms, SAAEI (2012)
Jang, J-SR. (1993) ANFIS: adaptive-network-based fuzzy inference system, IEEE transactions on systems, man, and cybernetics 23(3): 665–685
Dwivedi, A., Niranjan, M., Sahu, K.: A business intelligence technique for forecasting the automobile sales using Adaptive Intelligent Systems (ANFIS and ANN). International J Computer Appl 74(9), 7–13 (2013)
Clerc, M., Kennedy, J.: The particle swarm-explosion, stability, and convergence in a multidimensional complex space. IEEE Trans. Evol. Comput. 6(1), 58–73 (2002)
Chai, T., Draxler, R.R.: Root mean square error (RMSE) or mean absolute error (MAE)?–Arguments against avoiding RMSE in the literature. Geosci Model Dev 7(3), 1247–1250 (2014)
Author information
Authors and Affiliations
Corresponding author
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Hasheminejad, S.A., Shabaab, M. & Javadinarab, N. Developing Cluster-Based Adaptive Network Fuzzy Inference System Tuned by Particle Swarm Optimization to Forecast Annual Automotive Sales: A Case Study in Iran Market. Int. J. Fuzzy Syst. 24, 2719–2728 (2022). https://doi.org/10.1007/s40815-022-01263-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40815-022-01263-6